Embed Size (px)
DESCRIPTION
Programming the Origin2000 with OpenMP: Part II. William Magro Kuck & Associates, Inc. Outline. A Simple OpenMP Example Analysis and Adaptation Debugging Performance Tuning Advanced Topics. x. y. 1. n. A Simple Example. dotprod.f. real*8 function ddot(n,x,y) integer n - PowerPoint PPT Presentation
Citation preview

Programming the Origin2000 with OpenMP: Part II
William MagroKuck & Associates, Inc.

ALLIANCE ’98
Outline
A Simple OpenMP ExampleAnalysis and AdaptationDebuggingPerformance TuningAdvanced Topics

ALLIANCE ’98
A Simple Example
real*8 function ddot(n,x,y)
integer n
real*8 x(n), y(n)
ddot = 0.0
!$omp parallel do private(i)
!$omp& reduction(+:ddot)
do i=1,n
ddot = ddot + x(i)*y(i)
enddo
return
end
dotprod.f
xy
1 n

ALLIANCE ’98
A Less Simple Example
real*8 function ddot(n,x,y)
integer n
real*8 x(n), y(n), ddot1
!$omp parallel private(ddot1)
ddot1 = 0.0
!$omp do private(i)
do i=1,n
ddot1 = ddot1 + x(i)*y(i)
enddo
!$omp end do nowait
!$omp atomic
ddot = ddot + ddot1
!$omp end parallel
dotprod2.f
xy
1 n
ddot1 ddot1 ddot1
ddot
ddot1 ddot1 ddot1

ALLIANCE ’98
Analysis and Adaptation
Thread-safetyAutomatic ParallelizationFinding Parallel OpportunitiesClassifying DataA Different Approach

ALLIANCE ’98
Thread-safety
Confirm code works with -automatic in serial f77 -automatic -DEBUG:trap_uninitialized=ON <source files>
a.out
Synchronize access to static data logical function overflows
integer count
save count
data /count/0/
overflows = .false.
!$omp critical
count = count + 1
if (count .gt. 10) overflows = .true.
!$omp end critical

ALLIANCE ’98
Power Fortran Accelerator Detects parallelism Implements parallelism
Using PFAmodule swap MIPSpro MIPSpro.beta721
f77 -pfa <source files>
PFA options to try -IPA enables interprocedural
analysis -OPT:roundoff=3 enables reductions
Automatic Parallelization

ALLIANCE ’98
Basic Compiler Transformations
Work variable privatization:
DO I=1,N x = ... . . . y(I) = xENDDO
!$omp parallel do!$omp& private(x) DO I=1,N x = ... . . . y(I) = x ENDDO
ALLIANCE ’98
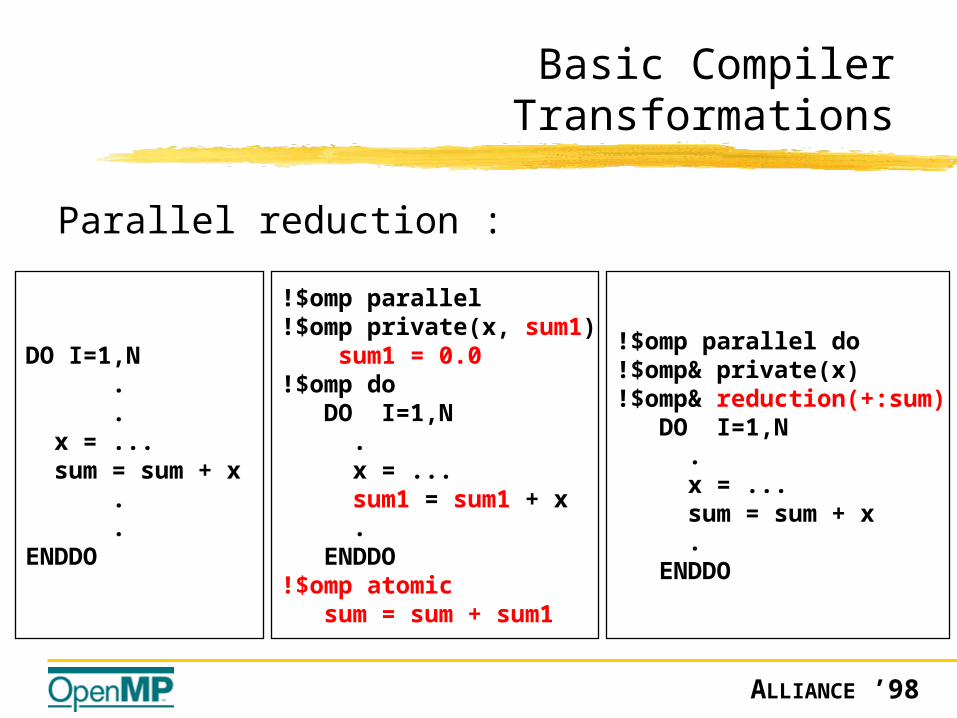
Basic Compiler Transformations
Parallel reduction :
DO I=1,N . . x = ... sum = sum + x . .ENDDO
!$omp parallel!$omp private(x, sum1) sum1 = 0.0!$omp do DO I=1,N . x = ... sum1 = sum1 + x . ENDDO!$omp atomic sum = sum + sum1
!$omp parallel do!$omp& private(x)!$omp& reduction(+:sum) DO I=1,N . x = ... sum = sum + x . ENDDO
ALLIANCE ’98
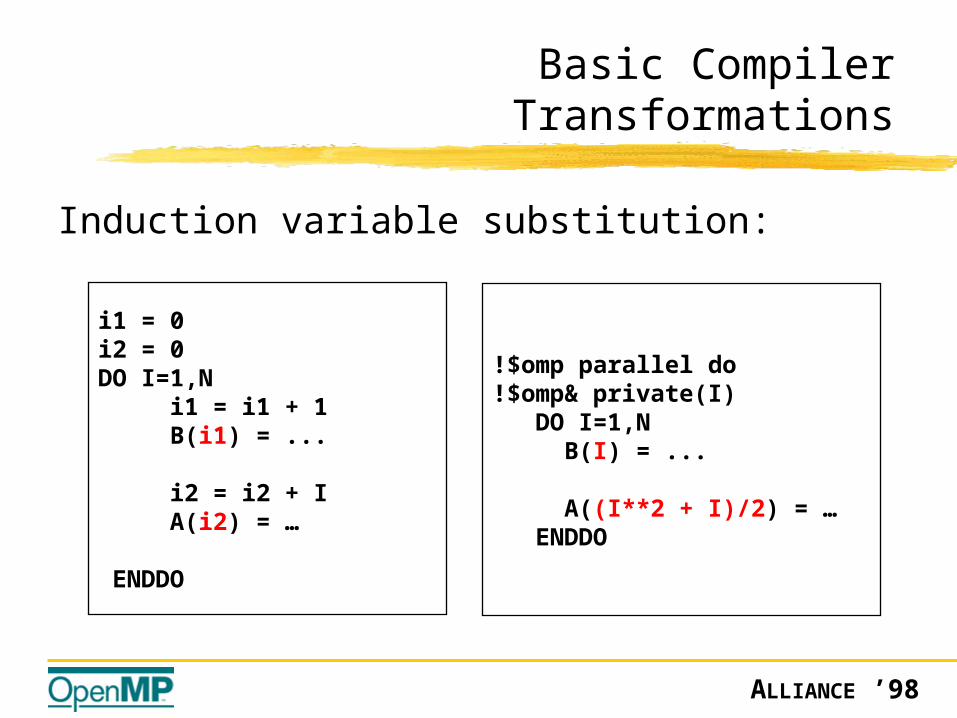
Basic Compiler Transformations
Induction variable substitution:
i1 = 0i2 = 0DO I=1,N i1 = i1 + 1 B(i1) = ... i2 = i2 + I A(i2) = …
ENDDO
!$omp parallel do!$omp& private(I) DO I=1,N B(I) = ...
A((I**2 + I)/2) = … ENDDO

ALLIANCE ’98
Automatic Limitations
IPA is slow for large codesWithout IPA, only small loops go parallelAnalysis must be repeated with each
compileCan’t parallelize data dependent
algorithmsResults usually don’t scale

ALLIANCE ’98
Compiler Listing
Generate listing with ‘-pfa keep’f77 -pfa keep <source files>
The listing gives many useful clues: Loop optimization tables Data dependencies Explanations about applied transformations Optimization summary Transformed OpenMP source code
Use listing to help write OpenMP version Workshop MPF presents listing graphically

ALLIANCE ’98
Picking Parallel Loops
Avoid inherently serial loops Time stepping loops Iterative convergence loops
Parallelize at highest level possibleChoose loops with large trip countAlways parallelize in same dimension, if
possibleWorkshop MPF’s static analysis can help

ALLIANCE ’98
Profiling
Use SpeedShop to profile your program Compile normally in serial Select typical data set Profile with ‘ssrun’:
ssrun -ideal <program> <arguments>
ssrun -pcsamp <program> <arguments>
Examine profile with ‘prof’:prof -gprof <program>.ideal.<pid>
Look for routines with: Large combined ‘self’ and ‘child’ time Small invocation count

ALLIANCE ’98
Example Profile self kids called/total parents
index cycles(%) self(%) kids(%) called+self name index
self kids called/total children
[...]
20511398 453309309775 1/1 PSET [4]
[5] 453329821173(100.00%) 20511398( 0.00%) 453309309775(100.00%) 1 RUN [5]
18305495901 149319136904 267589/268116 DCTDX [6]
19503577587 22818946546 527/527 DKZMH [13]
13835415346 24761094596 526/526 DUDTZ [14]
12919215922 24761094596 526/526 DVDTZ [15]
11953815047 25150873141 527/527 DTDTZ [16]
4541238123 24964028293 66920/66920 DPDX [18]
3883200260 24920009235 66802/66803 DFTDX [19]
5749986857 17489462744 527/527 DCDTZ [21]
8874949202 11380650840 526/526 WCONT [24]
10830140377 0 527/527 HYD [30]
3873808360 1583161052 527/527 ADVU [36]
3592836688 1580156951 526/526 ADVV [37]
1852017128 1583161052 527/527 ADVC [39]
1680678888 1583161052 527/527 ADVT [40]
[...]
apsi.profile

ALLIANCE ’98
Multiple Parallel Loops
Nested parallel loops Prefer outermost loop Preserve locality -- chose same index as in other
parallel loops If relative sizes of trip counts are not known
Use NEST() clauseUse IF clause to select best based on dataset
Non nested parallel loops Consider fusing loops Execute code between loops in parallel
Privatize data in redundant calculations

ALLIANCE ’98
Nested Parallel Loops
subroutine copy (imx,jmx,kmx,imp2,jmp2,kmp2,w,ws)
do nv=1,5!$omp do do k = 1,kmx do j = 1,jmx do i = 1,imx ws(i,j,k,nv) = w(i,j,k,nv) end do end do end do!$omp end do nowait end do
!$omp barrier
return end
copy.f

ALLIANCE ’98
Variable Classification
In OpenMP, data is shared by default
OpenMP provides several privatization mechanisms
A correct OpenMP program must have its variables properly classified
!$omp parallel!$omp& PRIVATE(x,y,z)!$omp& FIRSTPRIVATE (q)!$omp& LASTPRIVATE(I)
common /blk/ l,m,n!$omp THREADPRIVATE(/blk/)

ALLIANCE ’98
Shared Variables
Shared is OpenMP defaultMost things are shared
The major arrays Variables whose indices match loop index
!$omp parallel do
do I = 1,N
do J = 1, M
x(I) = x(I) + y(J)
Variables only read in parallel region Variables read, then written, requiring
synchronizationmaxval = max(maxval, currval)

ALLIANCE ’98
Private Variables
Local variables in called routines are automatically private
Common access patterns Work variables written then
read (PRIVATE) Variables read on first
iteration, then written (FIRSTPRIVATE)
Variables read after last iteration (LASTPRIVATE)
program main!$omp parallel call compute!$omp end parallel end
subroutine compute integer i,j,k[...] return end

ALLIANCE ’98
Variable Typing
DIMENSION HELP(NZ),HELPA(NZ),AN(NZ),BN(NZ),CN(NZ) ...[...]!$omp parallel!$omp& default(shared)!$omp& private(help,helpa,i,j,k,dv,topow,nztop,an,bn,cn)!$omp& reduction(+: wwind, wsq) HELP(1)=0.0 HELP(NZ)=0.0 NZTOP=NZ-1!$omp pdo DO 40 I=1,NX DO 30 J=1,NY DO 10 K=2,NZTOP [...]40 CONTINUE!$omp end pdo!$omp end parallel
wcont.fwcont_omp.fdwdz.f

ALLIANCE ’98
Synchronization
Reductions Max, min values Global sums, products, etc. Use REDUCTION() clause for scalars
!$omp do reduction(max: ymax)
do i=1,n
y(i) = a*x(i) + y(i)
ymax = max(ymax,y(i))
enddo
Code array reductions by hand
maxpy.f

ALLIANCE ’98
Array Reductions
!$omp parallel private(hist1,i,j,ibin) do i=1,nbins hist1(i) = 0 enddo!$omp do do i=1,m do j=1,m ibin = 1 + data(j,i)*rscale*nbins hist1(ibin) = hist1(ibin) + 1 enddo enddo
!$omp critical do i=1,nbins hist(i) = hist(i) + hist1(i) enddo!$omp end critical!$omp end parallel
histogram.fhistogram.omp.f

ALLIANCE ’98
Building the Parallel Program
Analyze, Insert Directives, and Compile:module swap MIPSpro MIPSpro.beta721
f77 -mp -n32 <optimization flags> <source files>
- or -source /usr/local/apps/KAI/setup.csh
guidef77 -n32 <optimization flags> <source files>
Run multiple times; compare output to serialsetenv OMP_NUM_THREADS 3
setenv OMP_DYNAMIC false
a.out
Debug

ALLIANCE ’98
Correctness and Debugging
OpenMP is easier than MPI, but bugs are still possible
Common Parallel BugsDebugging Approaches

ALLIANCE ’98
Debugging Tips
Check parallel P=1 resultssetenv OMP_NUM_THREADS 1
setenv OMP_DYNAMIC false
a.out
If results differ from serial, check: Uninitialized private data Missing lastprivate clause
If results are same as serial, check for: Unsynchronized access to shared variables Shared variables that should be private Variable size THREADPRIVATE common declarations

ALLIANCE ’98
Parallel Debuggingis Hard
What can go wrong? Incorrectly classified variables
Unsynchronized writes
Data read before written
Uninitialized private data
Failure to update global data
Other race conditions
Timing-dependent bugs
parbugs.f

ALLIANCE ’98
Parallel DebuggingIs Hard
What else can go wrong? Unsynchronized I/O
Thread stack collisionsIncrease with mp_set_slave_stacksize() function or
KMP_STACKSIZE variable
Privatization of improperly declared arrays
Inconsistently declared private common blocks

ALLIANCE ’98
Debugging Options
Print statementsMultithreaded debuggersAutomatic parallel debugger

ALLIANCE ’98
Advantages WYSIWYG Can be useful Can monitor scheduling of iterations on threads
Disadvantages Slow, human-time intensive bug hunting
Tips Include thread ID Checksum shared memory regions Protect I/O with a CRITICAL section
Print Statements

ALLIANCE ’98
Multithreaded Debugger
Advantages Can find causes of deadlock, such as threads
waiting at different barriers
Disadvantages Locates symptom, not cause Hard to reproduce errors, especially those
which are timing-dependent Difficult to relate parallel (MP) library calls
back to original source Human intensive

ALLIANCE ’98
WorkShop Debugger
Graphical User InterfaceUsing the debugger
Add debug symbols with ‘-g’ on compile and link:f77 -g -mp <source files>
- or -guidef77 -g <source files>
Run the debuggersetenv OMP_NUM_THREADS 3
setenv OMP_DYNAMIC false
cvd a.out
Follow threads and try to reproduce the bug

ALLIANCE ’98
Automatic OpenMP Debugger
Advantages Systematically finds parallel bugs
Deadlocks and race conditionsUninitialized dataReuse of PRIVATE data outside parallel regionsMeasures thread stack usage
Uses computer time rather than human time
Disadvantages Data set dependent Requires sequentially consistent program Increased memory usage and CPU time

ALLIANCE ’98
KAI’s Assure
Looks like an OpenMP compilerGenerates an ideal parallel computer
simulationItemizes parallel bugsLocates exact location of bug in sourceIncludes GUI to browse error reports

ALLIANCE ’98
Serial Consistency
Parallel program must have a serial counterpart Algorithm can’t depend on number of threads Code can’t manually assign domains to threads Can’t call omp_get_thread_num() Can’t use OpenMP lock API.
Serial code defines correct behavior Serial code should be well debugged Assure sometimes finds serial bugs as well

ALLIANCE ’98
Using Assure
Pick a project database file name: e.g., “buggy.prj”
Compile all source files with “assuref77”:source /usr/local/apps/KAI/setup.csh
assuref77 -WA,-pname=./buggy.prj -c buggy.f
assuref77 -WA,-pname=./buggy.prj buggy.o
Source files in multiple directories must specify same project file
Run with a small, but representative workloada.out
setenv DISPLAY your_machine:0
assureview buggy.prj

ALLIANCE ’98
Assure Tips
Select small, but representative data sets Increase test coverage with multiple data setsNo need to run job to completion (control-c)Get intermediate reports (e.g., every 2 minutes)
setenv KDD_INTERVAL 2m
a.out &
assureview buggy.prj
[ wait a few minutes ]
assureview buggy.prj
Quickly learn about stack usage and call graphsetenv KDD_DELAY 48h

ALLIANCE ’98
A Different Approach to Parallelization
Locate candidate parallel loop(s)Identify obvious shared and private
variablesInsert OpenMP directivesCompile with Assure parallel debuggerRun programView parallel errors with AssureViewUpdate directives
md.fmd.omp.f

ALLIANCE ’98
Parallel Performance
Limiters of Parallel PerformanceDetecting Performance ProblemsFixing Performance Problems

ALLIANCE ’98
Parallel Performance
Limiters of performance Amdahl’s law Load imbalance Synchronization Overheads False sharing
Easy
Hard
Obvious
Subtle
ALLIANCE ’98
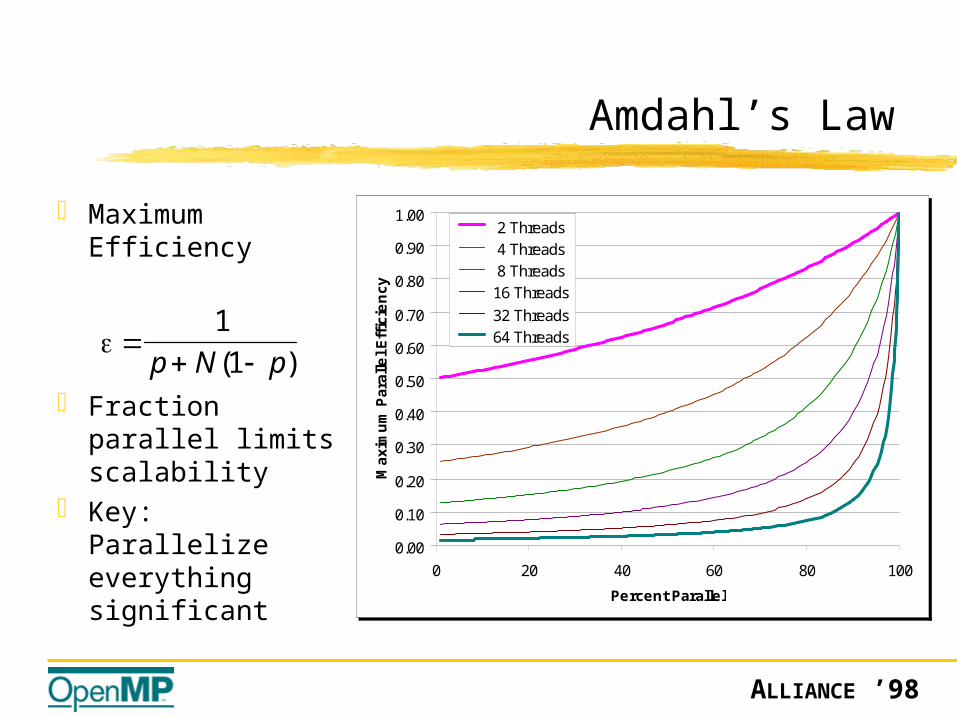
Amdahl’s Law
Maximum Efficiency
Fraction parallel limits scalability
Key: Parallelize everything significant
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
0 20 40 60 80 100
Percent Parallel
Ma
xim
um
Pa
rall
el
Eff
icie
nc
y
2 Threads
4 Threads
8 Threads
16 Threads
32 Threads
64 Threads 1
1p N p( )
ALLIANCE ’98
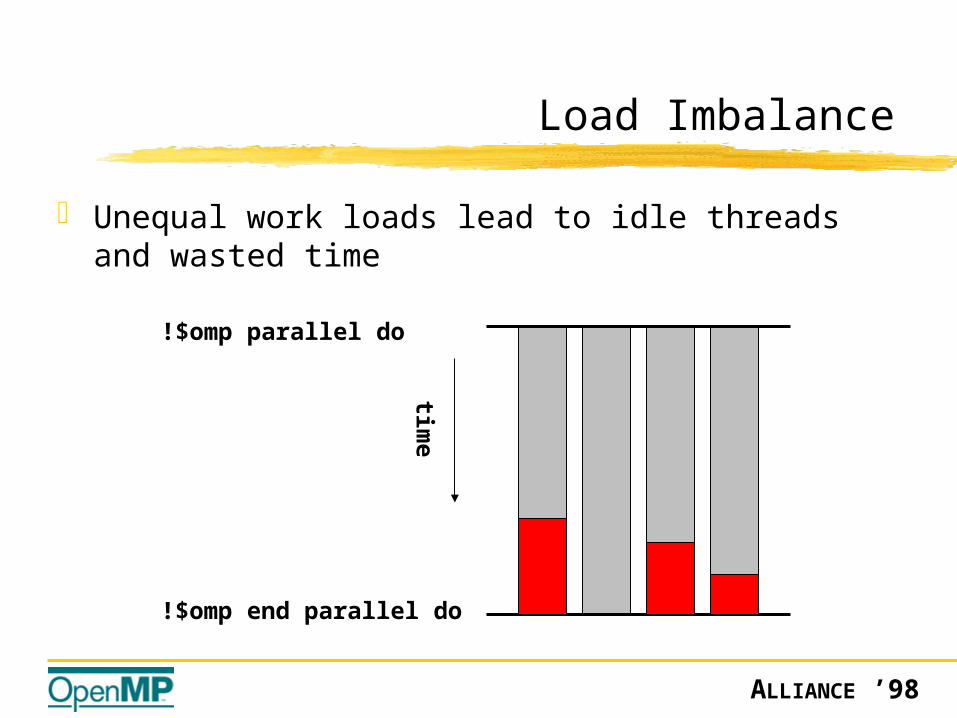
Load Imbalance
Unequal work loads lead to idle threads and wasted time
time
!$omp parallel do
!$omp end parallel do
ALLIANCE ’98
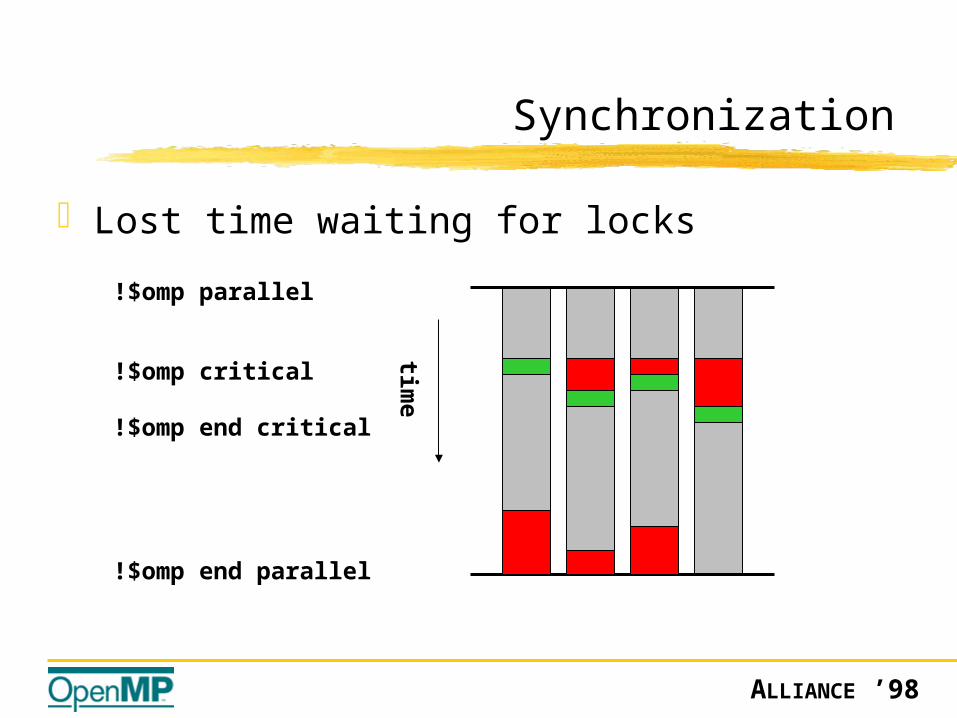
Synchronization
Lost time waiting for locks
time
!$omp parallel
!$omp end parallel
!$omp critical
!$omp end critical

ALLIANCE ’98
Successful loop parallelization requires large loops.
!$OMP PARALLEL DO SCHEDULE(STATIC) startup time ~3500 cycles or 20 micro-seconds on 4 processors ~200,000 cycles or 1 milli-second on 128 processors
Loop time should be large compared to parallel overheads Data size must grow faster than number of threads to maintain parallel efficiency
Parallel Loop Size
Max loop speedup =serial loop execution
serial loop execution+parallel loop startupnumber of processors

ALLIANCE ’98
False Sharing
False sharing occurs when multiple threads repeated write to the same cache line
Use perfex to detect if cache invalidation is a problemperfex -a -y -mp <program> <arguments>
Use SpeedShop to find the location of the problemssrun -dc_hwc <program> <arguments>
ssrun -dsc_hwc <program> <arguments>
false.f

ALLIANCE ’98
Measuring Parallel Performance
Measure wall clock time with ‘timex’setenv OMP_DYNAMIC false
setenv OMP_NUM_THREADS 1
timex a.out
setenv OMP_NUM_THREADS 16
timex a.out
Profilers (speedshop, perfex) Find remaining serial time Identify false sharing
Guide’s instrumented parallel library

ALLIANCE ’98
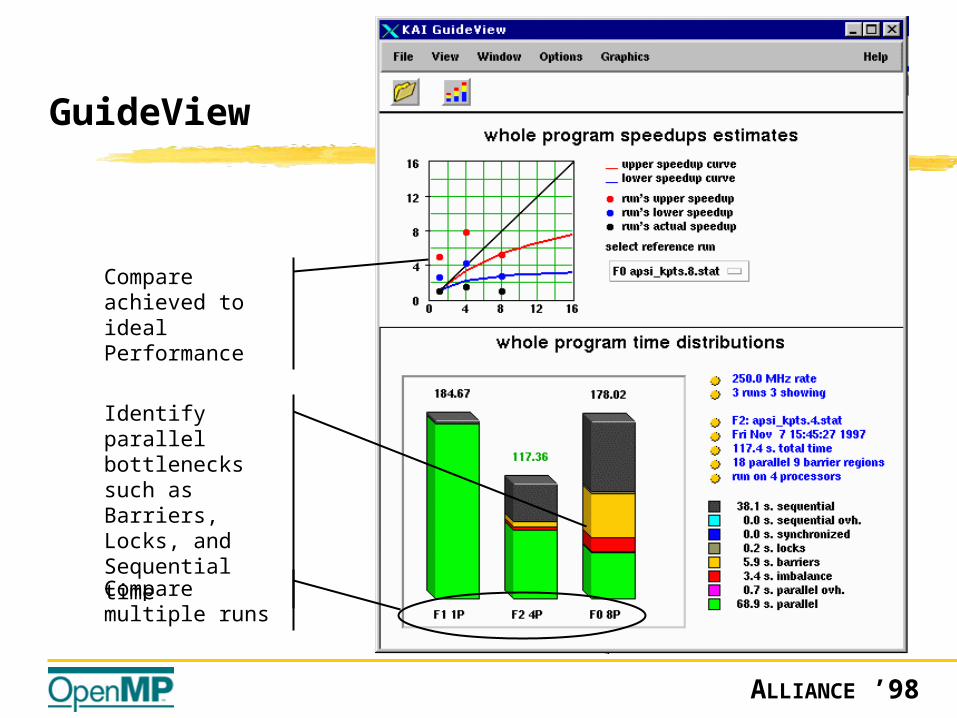
Using GuideView
Compile with Guide OpenMP compiler and normal compile optionssource /usr/local/apps/KAI/setup.csh
guidef77 -c -Ofast=IP27 -n32 -mips4 source.f ...
Link with instrumented libraryguidef77 -WGstats source.o …
Run with real parallel workloadsetenv KMP_STACKSIZE 32M
a.out
View performance reportguideview guide_stats
ALLIANCE ’98
Compare achieved to ideal Performance
GuideView
Identify parallel bottlenecks such as Barriers, Locks, and Sequential time
Compare multiple runs
ALLIANCE ’98
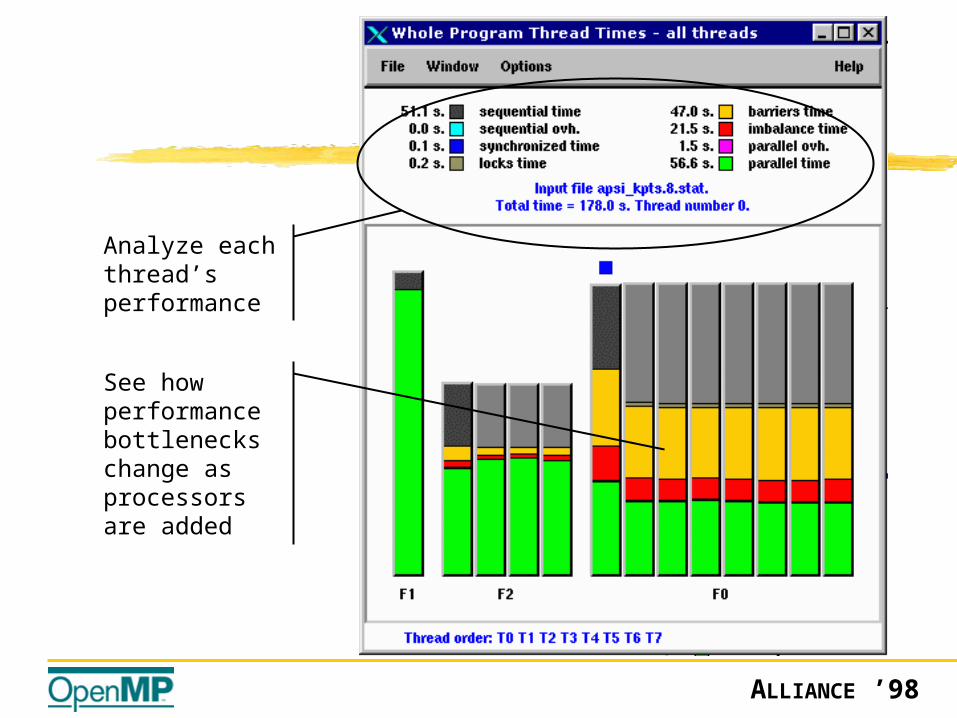
Analyze each thread’s performance
See how performance bottlenecks change as processors are added

ALLIANCE ’98
Performance Data By Region
Analyze each Parallel region
Find serial regions that are hurt by parallelism
Sort or filter regions to navigate to hotspots

ALLIANCE ’98
Dynamic SchedulingRelieve load imbalanceStatic even scheduling
Equal size iteration chunks Based on runtime loop limits Totally parallel scheduling OpenMP default
Dynamic and Guided scheduling Threads do some work then
get next chunk
!$omp parallel do!$omp& schedule(static)
!$omp parallel do!$omp& schedule(dynamic,8)
!$omp parallel do!$omp& schedule(guided,8)

ALLIANCE ’98
Limiting Parallel Overheads
Merge adjacent parallel regions
When safe, avoid barrier at end of !$omp do
Eliminate small parallel loops
Use IF clause to limit parallelism
Increase problem size
!$omp parallel!$omp& if(imax .gt. 1000)
!$omp do do I=1,100 [...] enddo!$omp end do nowait
!$omp do do I=1,100 [...] enddo!$omp end parallel

ALLIANCE ’98
Advanced Topics
OpenMP can be used with MPI to achieve two-level parallelism
setenv OMP_NUM_THREADS 4
mpirun -np 4 a.out
Data distribution and affinity directivesman mp
Explicit domain decomposition with OpenMP

ALLIANCE ’98
Reference
Speaker contact info Faisal Saied, [email protected], 217-244-9481 Fady Najjar, [email protected], 217-244-4934 Bill Magro, [email protected], 217-398-3284
ssrun, timex, perfex, cvd, cvpav, cvperf, f77, f90 See man pages or “insight” documents
Guide Documentation On modi4: /usr/local/apps/KAI/guide35/docs
Assure Documentation On modi4: /usr/local/apps/KAI/assure35/docs





























