Embed Size (px)
Citation preview

Probabilistic (Average-Case) Analysis and Randomized
Algorithms• Two different approaches
– Probabilistic analysis of a deterministic algorithm– Randomized algorithm
• Example Problems/Algorithms– Hiring problem (Chapter 5)– Sorting/Quicksort (Chapter 7)
• Tools from probability theory– Indicator variables– Linearity of expectation

Probabilistic (Average-Case) Analysis
• Algorithm is deterministic; for a fixed input, it will run the same every time
• Analysis Technique– Assume a probability distribution for your inputs
– Analyze item of interest over probability distribution
• Caveats– Specific inputs may have much worse performance
– If distribution is wrong, analysis may give misleading picture

Randomized Algorithm
• “Randomize” the algorithm; for a fixed input, it will run differently depending on the result of random “coin tosses”
• Randomization examples/techniques– Randomize the order that candidates arrive– Randomly select a pivot element– Randomly select from a collection of deterministic
algorithms• Key points
– Works well with high probability on every inputs– May fail on every input with low probability

Common Tools
• Indicator variables– Suppose we want to study random variable X that
represents a composite of many random events
– Define a collection of “indicator” variables Xi that focus on individual events; typically X = Xi
• Linearity of expectations– Let X, Y, and Z be random variables s.t. X = Y + Z
– Then E[X] = E[Y+Z] = E[Y] + E[Z]
• Recurrence Relations

Hiring Problem
• Input– A sequence of n candidates for a position– Each has a distinct quality rating that we can determine in an
interview
• Algorithm– Current = 0;– For k = 1 to n
• If candidate(k) is better than Current, hire(k) and Current = k;
• Cost:– Number of hires
• Worst-case cost is n

Analyze Hiring Problem
• Assume a probability distribution– Each of the n! permutations is equally likely
• Analyze item of interest over probability distribution– Define random variables
• Let X = random variable corresponding to # of hires• Let Xi = “indicator variable” that ith interviewed candidate is hired
– Value 0 if not hired, 1 if hired
• X = i = 1 to n Xi
– E[Xi] = ? • Explain why:
– E[X] = E[i = 1 to n Xi] = i = 1 to n E[Xi] = ?• Key observation: linearity of expectations

Alternative analysis
• Analyze item of interest over probability distribution– Let Xi = indicator random variable that the ith
best candidate is hired• 0 if not hired, 1 if hired
– Questions• Relationship of X to Xi?• E[Xi] = ? • i = 1 to n E[Xi] = ?

Questions
• What is the probability you will hire n times?• What is the probability you will hire exactly
twice?• Biased Coin
– Suppose you want to output 0 with probability ½ and 1 with probability ½
– You have a coin that outputs 1 with probability p and 0 with probability 1-p for some unknown 0 < p < 1
– Can you use this coin to output 0 and 1 fairly?– What is the expected running time to produce the fair
output as a function of p?

Quicksort Algorithm
• Overview– Choose a pivot element– Partition elements to be sorted based on
partition element– Recursively sort smaller and larger elements
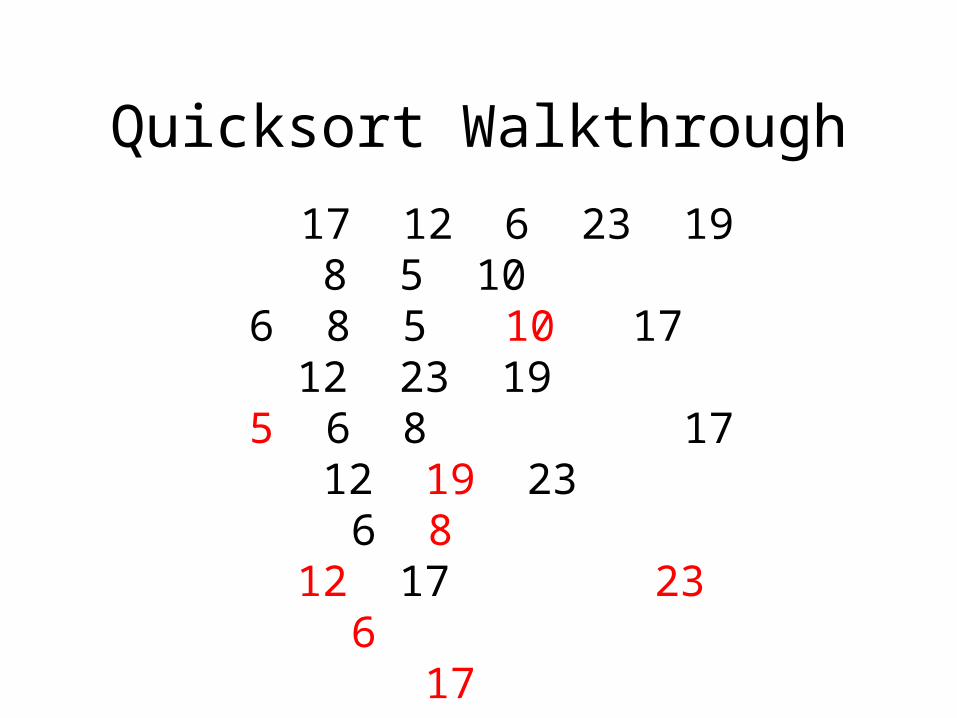
Quicksort Walkthrough
17 12 6 23 19 8 5 106 8 5 10 17 12 23 195 6 8 17 12 19 23 6 8 12 17 23 6 17
5 6 8 10 12 17 19 23

Pseudocode
Sort(A) { Quicksort(A,1,n);}
Quicksort(A, low, high) { if (low < high) { pivotLocation = Partition(A,low,high); Quicksort(A,low, pivotLocation - 1); Quicksort(A, pivotLocation+1, high); }}

Pseudocodeint Partition(A,low,high) { pivot = A[high]; leftwall = low-1; for i = low to high-1 { if (A[i] < pivot) then { leftwall = leftwall+1; swap(A[i],A[leftwall]); } swap(A[high],A[leftwall+1]); } return leftwall+1;}
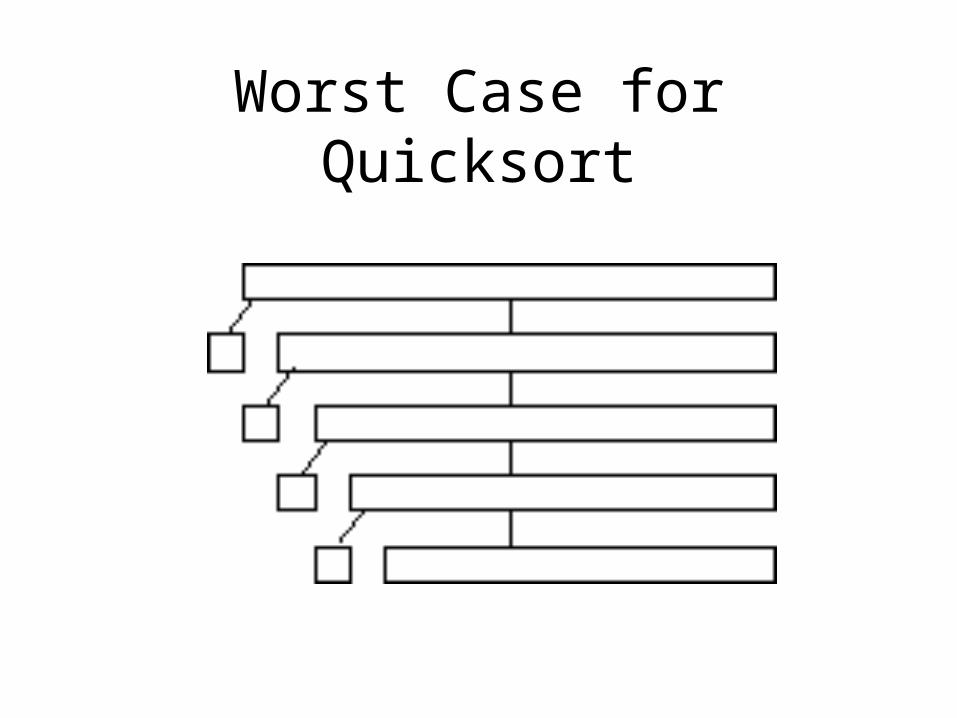
Worst Case for Quicksort

Average Case for Quicksort?

Intuitive Average Case Analysis
0 n/4 n/2 3n/4 n
Anywhere in the middle half is a decent partition
(3/4)h n = 1 => n = (4/3)h
log(n) = h log(4/3)
h = log(n) / log(4/3) < 2 log(n)

How many steps?
At most 2log(n) decent partitions suffices to sort an array of n elements.
But if we just take arbitrary pivot points, how often will they, in fact, be decent?
Since any number ranked between n/4 and 3n/4 would make a decent pivot, half the pivots on average are decent.
Therefore, on average, we will need 2 x 2log(n) = 4log(n) partitions to guarantee sorting.

Formal Average-case Analysis
• Let X denote the random variable that represents the total number of comparisons performed
• Let indicator variable Xij = the event that the ith smallest element and jth smallest element are compared– 0 if not compared, 1 if compared
• X = i=1 to n-1 j=i+1 to n Xij
• E[X] = i=1 to n-1 j=i+1 to n E[Xij]

Computing E[Xij]
• E[Xij] = probability that i and j are compared
• Observation– All comparisons are between a pivot element and
another element
– If an item k is chosen as pivot where i < k < j, then items i and j will not be compared
• E[Xij] =– Items i or j must be chosen as a pivot before any items
in interval (i..j)

Computing E[X]
E[X] = i=1 to n-1 j=i+1 to n E[Xij]
= i=1 to n-1 j=i+1 to n 2/(j-i+1)
= i=1 to n-1 k=1 to n-i 2/(k+1)
<= i=1 to n-1 2 Hn-i+1
<= i=1 to n-1 2 Hn
= 2 (n-1)Hn

Alternative Average-case Analysis
• Let T(n) denote the average time required to sort an n-element array– “Average” assuming each permutation equally likely
• Write a recurrence relation for T(n)– T(n) =
• Using induction, we can then prove that T(n) = O(n log n)– Requires some simplification and summation
manipulation

Avoiding the worst-case
• Understanding quicksort’s worst-case
• Methods for avoiding it– Pivot strategies– Randomization

Understanding the worst case
A B D F H J KA B D F H JA B D F HA B D FA B D A BA
The worst case occur is a likely case for many applications.

Pivot Strategies
• Use the middle Element of the sub-array as the pivot.
• Use the median element of (first, middle, last) to make sure to avoid any kind of pre-sorting.
What is the worst-case performance for these pivot selection mechanisms?

Randomized Quicksort
• Make chance of worst-case run time equally small for all inputs
• Methods– Choose pivot element randomly from range
[low..high]– Initially permute the array

Hat Check Problem
• N people give their hats to a hat-check person at a restaurant
• The hat-check person returns the hats to the people randomly
• What is the expected number of people who get their own hat back?

Online Hiring Problem
• Input– A sequence of n candidates for a position– Each has a distinct quality rating that we can determine in an interview
• We know total ranking of interviewed candidates, but not with respect to candidates left to interview
– We can hire only once• Online Algorithm Hire(k,n)
– Current = 0;– For j = 1 to k
• If candidate(j) is better than Current, Current = j;– For j = k+1 to n
• If candidate(j) is better than Current, hire(j) and return• Questions:
– What is probability we hire the best qualified candidate given k?– What is best value of k to maximize above probability?

Online Hiring Analysis
• Let Si be the probability that we successfully hire the best qualified candidate AND this candidate was the ith one interviewed
• Let M(j) = the candidate in 1 through j with highest score
• What needs to happen for Si to be true?– Best candidate is in position i: Bi
– No candidate in positions k+1 through i-1 are hired: Oi
– These two quantities are independent, so we can multiply their probabilities to get Si

Computing S
• Bi = 1/n
• Oi = k/(i-1)
• Si = k/(n(i-1))
• S = i>k Si = k/n i>k 1/(i-1) is probability of success
• k/n (Hn – Hk): roughly k/n (ln n – ln k)
• Maximized when k = n/e• Leads to probability of success of 1/e














![Probabilistic Pointer Analysis [PPA]](https://img.dokumen.tips/doc/110x75/56812ab7550346895d8e7c81/probabilistic-pointer-analysis-ppa.jpg)














