Embed Size (px)
Citation preview

Priprema i čišćenje podataka
Zagreb, 23.03.2016. Lada Banić, vodeći konzultant
Marko Štajcer, direktor Inovacija i razvoja
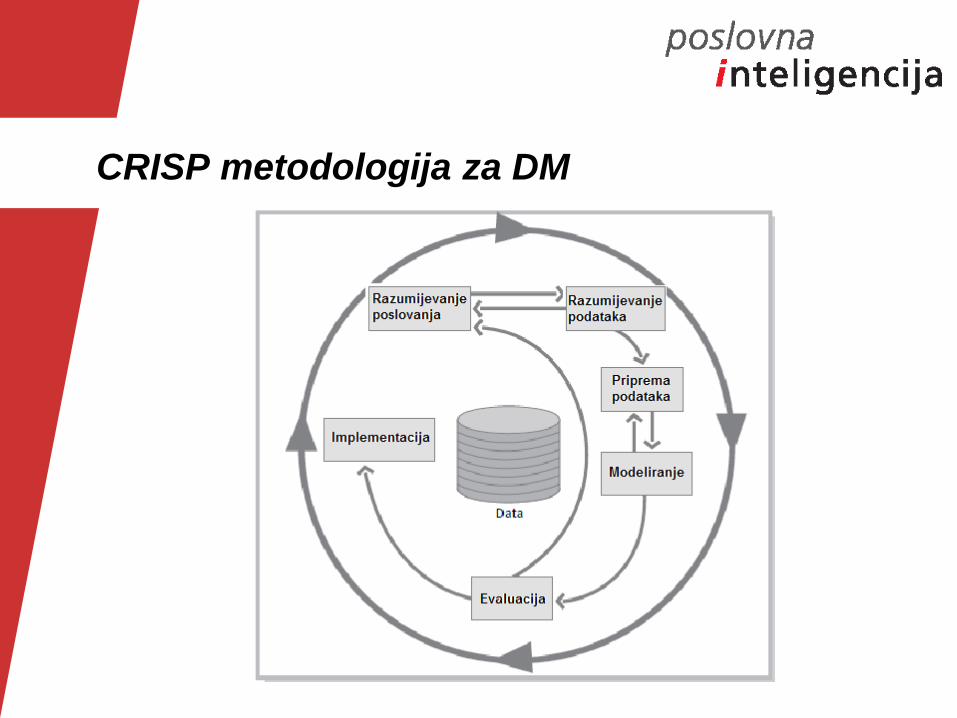
CRISP metodologija za DM

CRISP metodologija za DM

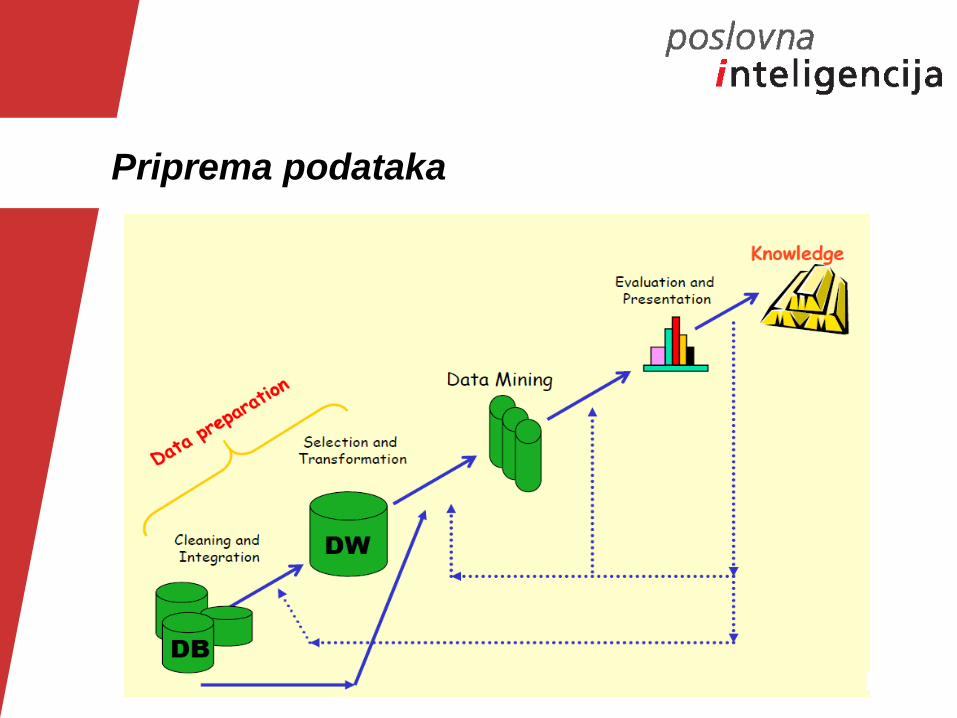
Priprema podataka
Podaci su „prljavi”
nepotpuni:
atributima nedostaju vrijednosti
nedostaju atributi koji bi bili interesantni za analizu
podaci su agregirani (nedostaju detaljni podaci)
šum u vrijednostima pojedinih atributa
podaci sadrže outliere
podaci sadrže greške
nekonzistentnost podataka
Podaci sadrže razlike u kodovima ili nazivima

Priprema podataka
Ako podaci nisu kvalitetni ne možemo
očekivati kvalitetne rezultate
Kvalitetne odluke moraju biti bazirane na
kvalitetnim rezultatima
Priprema podataka

Tipovi podataka
Nominalni podaci
ID korisnika, imena osoba
Categorijski podaci
boja očiju, poštanski brojevi
Ordinalni podaci
Ocjena proizvoda 1-10, veličine: XS, S, M, L, XL etc.
Intervalni podaci
datumi
primanja
trajanja

Osnovni zadaci pripreme podataka
Diskretizacija podataka
posebno važno kod numeričkih podataka
Čišćenje podataka
popunjavanje praznih vrijednosti atributa
identifikacija outliera i ekstrema
rješavanje nekonzistentnosti
pretvaranje podataka u standardni oblik (datumi)
Integracija podataka
Povezivanje podataka iz različitih izvora
Transformacija podataka
normalizacija
agregacija

Podaci koji nedostaju
Osnovni koraci za analizu podataka koji nedostaju:
Identifikacija uzoraka/razloga zašto podaci nedostaju ili nisu
pravilno zapisani
Razumijeti distribuciju podataka koji nedostaju
Odlučiti o najboljoj metodi za rješavanje problema podataka
koji nedostaju

Mehanizmi podataka koji nedostaju
Podaci koji nedostaju su u potpunosti nasumični (MCAR)
Vrijednosti koje nedostaju (y) ne ovise niti o x niti o y
Podaci koji nedostaju su nasumični (MAR)
Vrijednosti koje nedostaju (y) ovise o x ali ne o y
Podaci koji nedostaju nisu nasumični (NMAR)
Vjerojatnost da će podatak nedostajati ovisi o varijabli u kojoj
podatak nedostaje

Nadopunjavanje podataka koji nedostaju
Koristiti znanja o podacima koji nedostaju
Zašto podaci nedostaju
Distribucija podataka koji nedostaju
Mogućnosti rješavanja problema nedostajućih podataka
Brisanje zapisa
brisanje liste, brisanje parova
Metoda nadopune
supstitucija vrijednostima Mean ili Mode, metoda s dummy
varijablom, regresija
Popunjavanje vrijednosti bazirano na modelu
najveća vjerojatnost, popunjavanje višestrukim vrijednostima
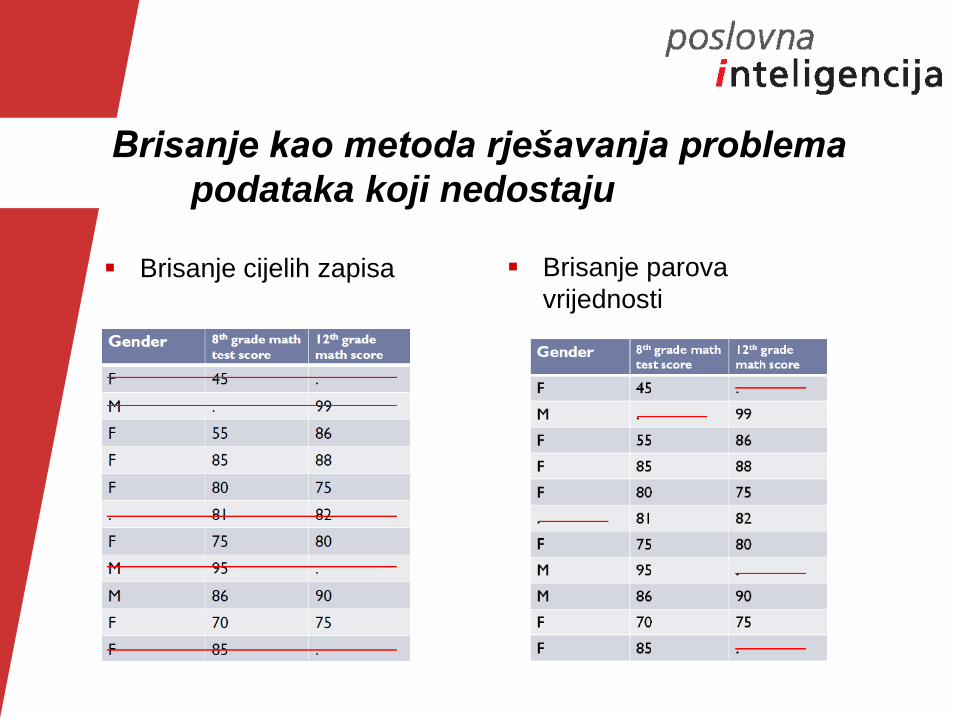
Brisanje kao metoda rješavanja problema
podataka koji nedostaju
Brisanje cijelih zapisa Brisanje parova
vrijednosti
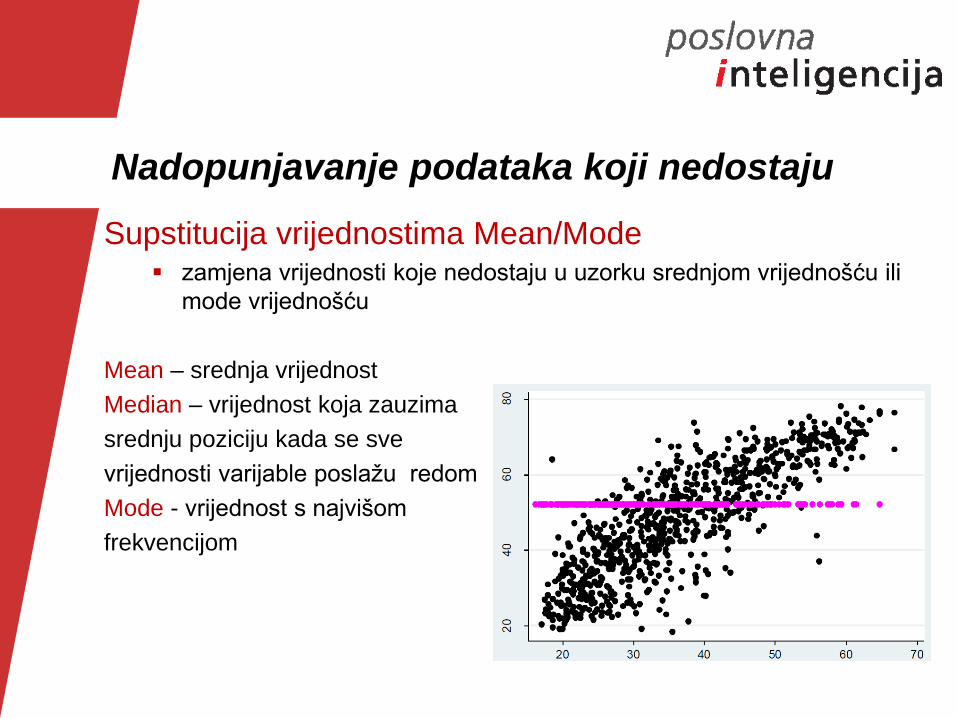
Nadopunjavanje podataka koji nedostaju
Supstitucija vrijednostima Mean/Mode zamjena vrijednosti koje nedostaju u uzorku srednjom vrijednošću ili
mode vrijednošću
Mean – srednja vrijednost
Median – vrijednost koja zauzima
srednju poziciju kada se sve
vrijednosti varijable poslažu redom
Mode - vrijednost s najvišom
frekvencijom

Nadopunjavanje podataka koji nedostaju
Definiranje Dummy varijable Kreiranje polja indikatora za vrijednost koja nedostaje
flag s vrijednostima:
1 vrijednost nedostaje
0 vrijednost postoji
Popuniti vrijednosti kojenedostaju konstantom
mean/mode
Uključiti indikator u model
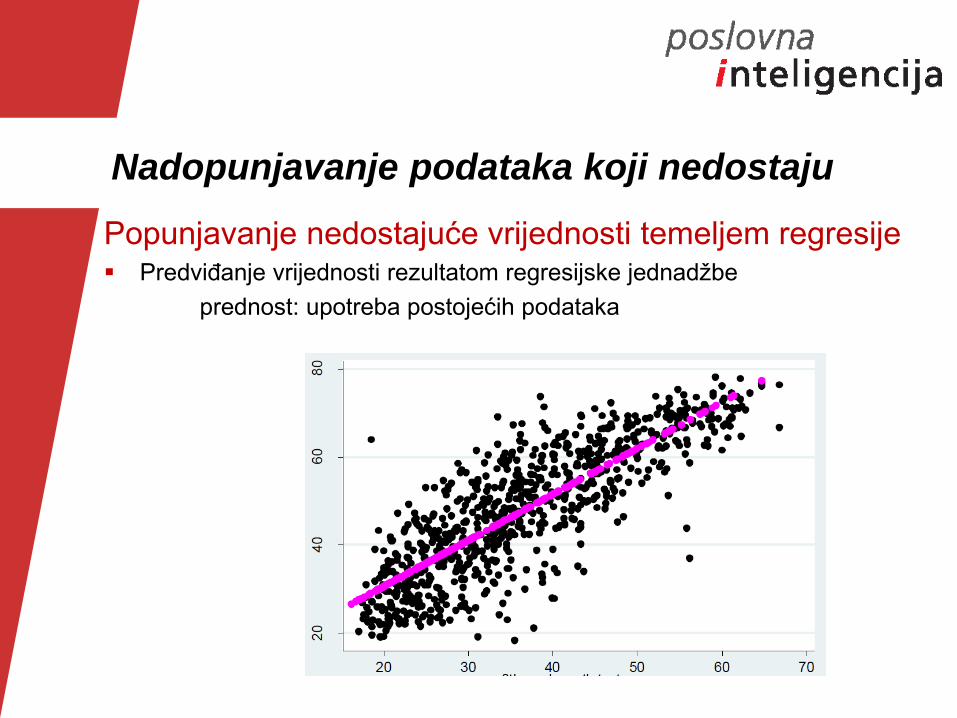
Nadopunjavanje podataka koji nedostaju
Popunjavanje nedostajuće vrijednosti temeljem regresije Predviđanje vrijednosti rezultatom regresijske jednadžbe
prednost: upotreba postojećih podataka

Outlieri i ekstremi
opažanja koja su jako daleko od norme (sredine) za populaciju varijable
Vrijednosti koje izvan raspona -1.5 x IQR to 1.5 x IQR (IQR – inter
quartile range)
Vrijednosti koje su van 5tog do 95tog percentila
Vrijednosti koje su tri ili više standardnih devijacija od sredne vrijednosti
(outlieri između 3 i 5 standardnih devijacija, ekstremi iznad 5
standardnih devijacija od sredine raspodjele)
Mogu ovisiti o razumijevanju poslovanja
Statističke odrednice mogu biti problematične ako se ne radi o normalnoj raspodjeli
već ako je rapospodjela izduljena (skewed) i posebno za male uzorke. Zato su Van
Selst i Jolicoeur 1994 prepremili tablicu sa specifikacijom outliera ovisno o veličini
uzorka, kako bi minimizirali probleme koji se javljaju kod distribucija koje nisu
normalne.

Outlieri i ekstremi
Outleiri mogu značajno utjecati na rezultate analize podataka i statističke
modele. Mnogi su negativni utjecaji:
Povećana greška varijance i smanjuje točnost statističkih testova
Ako outlieri nisu nasumično distribuirani mogu smanjiti normalnost
raspodjele
Također mogu utjecati na osnovne pretpostavke za Regresiju, Anovu
i ostale pretpostavke statističkih modela.

Outlieri i ekstremi
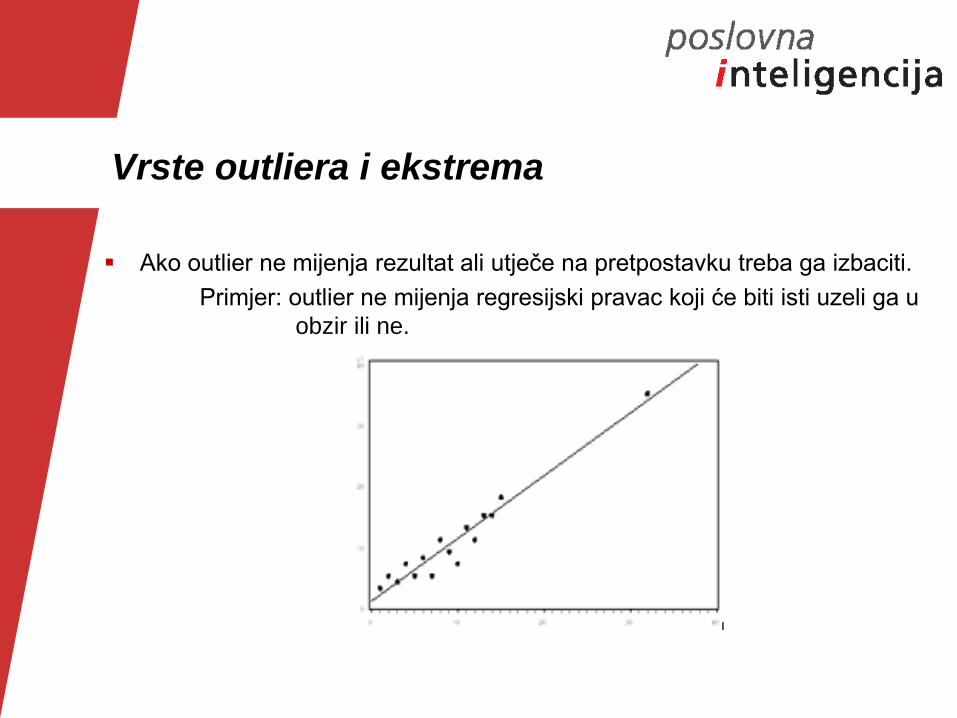
Vrste outliera i ekstrema
Ako outlier ne mijenja rezultat ali utječe na pretpostavku treba ga izbaciti.
Primjer: outlier ne mijenja regresijski pravac koji će biti isti uzeli ga u
obzir ili ne.
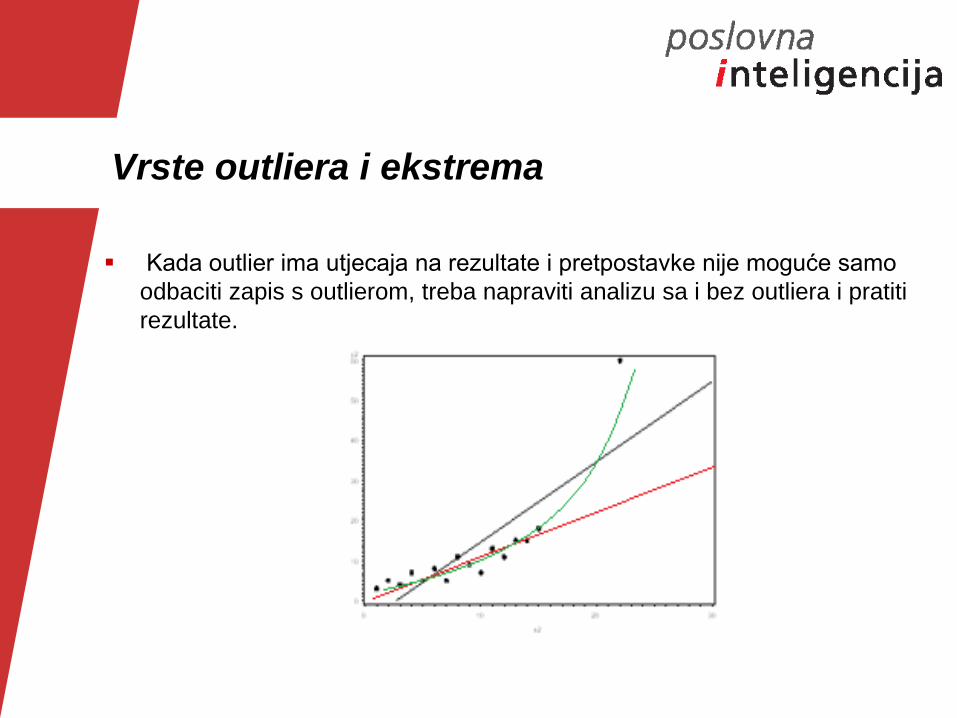
Vrste outliera i ekstrema
Kada outlier ima utjecaja na rezultate i pretpostavke nije moguće samo
odbaciti zapis s outlierom, treba napraviti analizu sa i bez outliera i pratiti
rezultate.

Vrste outliera i ekstrema
Ako outlier kreira pretpostavku, treba ga izbaciti.
Primjer: povezanost x i y osi je kreirana zbog outliera. Bez njega ne
postoji korelacija između x i y osi pa regresijski koeficijent ne
opisuje stvarni utjecaj x na y.

Izvori outliera i ekstrema
Slučajna greška kod unosa
Namjerna ili motivirana greška za nekorektno izvještavanje – kod
ispitanika koji iz bilo kogje razloga ne žele reći istinu (npr. ispitivanje
teenagera o korištenju droga i alkohola)
Outlieri zbog greške u uzorkovanju – moguće je da se prilikom uzimanja
uzorka uzme i nekoliko zapisa koji pripadaju drugoj populaciji
Standardizacije istraživanja ako se ne obraća pažnja na okolinu
Krive pretpostavke o distribuciji podataka bilo da je distribucija izdužena,
bliža asimptoti etc, sezonsko ponašanje i slično – to su legitimni podaci i
njima je mjesto u podacima, ne izbacuje ih se.

Izvori outliera i ekstrema
Veličina uzorka; u normalnoj distribuciji vjerojatnije je da će odabrani
uzorak podataka dolaziti iz gušće naseljenog područja ali kako
povećavamo uzorak ako je njegova populacija odražava raspodjelu iz
koje je izdvojen, vjerojatnost da ćemo obuhvatiti outlier uzorkom postaje
sve veća.
Postoji samo 1% vjerojatnosti da će iz normalne distribucije
podataka biti izvučen outlier, dakle u prosjeku postoji 1%
vjerojatnosti da će uzorka biti 3 standardne devijacije od prosjeka.
Outliers kao fokus istraživanja
teenager sa 100 najboljih prijatelja.

Rješavanje problema outliera
Najveći dio metoda kako riješiti outliere se podudara s metodama koje se
koriste za vrijednosti koje nedostaju i o su:
Uklanjanje takvih zapisa
Transformacija zapisa
Binning
Promatranje takvih zapisa kao zasebnih grupa
Druge statističke metode

Rješavanje problema outliera
Transformacije:
Prirodni logaritam smanjuje varijaciju koja je uzrokovana ekstreminm
vrijednostima.

Priprema podataka
Ako podaci nisu kvalitetni ne možemo
očekivati kvalitetne rezultate
Kvalitetne odluke moraju biti bazirane na
kvalitetnim rezultatima

Izvor podataka
Izvor podataka je Excel datoteka
Sadrži preko 2000 akcija po utakmici
Podatke je ustupila tvrtka 'Once sports‘
Eksport u .xls format iz Once sustava za prikupljanje i
analizu podataka

Primjeri alata za realizaciju rješenja
MySql relacijska baza podataka
http://www.toadworld.com/m/freeware
https://www.mysql.com/products/workbench/
Alat za integraciju podataka
https://marketplace.informatica.com/solutions/pcexpress
https://www.talend.com/products/talend-open-studio
R Studio
https://www.rstudio.com/products/rstudio/
Alat za vizualizaciju podataka
http://www.cytoscape.org/
http://community.pentaho.com/

Relacijska baza podataka
Koncept
Dr. E. F. Codd je postavio model relacijske baze podataka 1970. g. koji
je i danas temelj za RDBMS sustave
Relacijski model se sastoji od skupa objekata ili relacija
Relacija se prikazuje tablicom u kojoj redak odgovara jednoj n-torki,
a stupac jednom atributu (koji poprima vrijednosti iz domene)
Vrijednost jednog atributa su podaci iste vrste ili tipa
Skup vrijednosti jednog atributa naziva se domenom atributa
Broj n-torki naziva se kardinalnost relacije

Relacijska baza podataka

Veza između tablica
Svaki redak u tablici može biti jedinstveno identificiran pomoću
primarnog ključa – Primary key
Logički je moguće povezati više tablica pomoću vanjskog ključa -
Foreign key (FK)
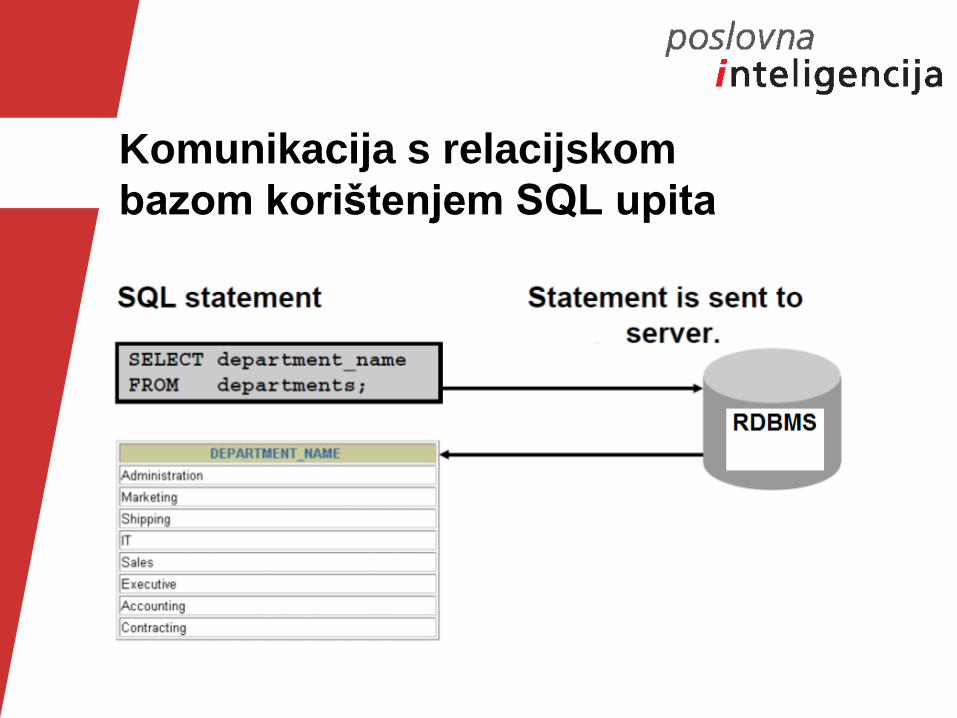
Komunikacija s relacijskom
bazom korištenjem SQL upita

Osnovni SQL upit
SELECT definira koje kolone će se prikazati
FROM definira tablice iz kojih će se dohatiti podaci
WHERE definira uvjet po kojem će se podaci dohvatiti
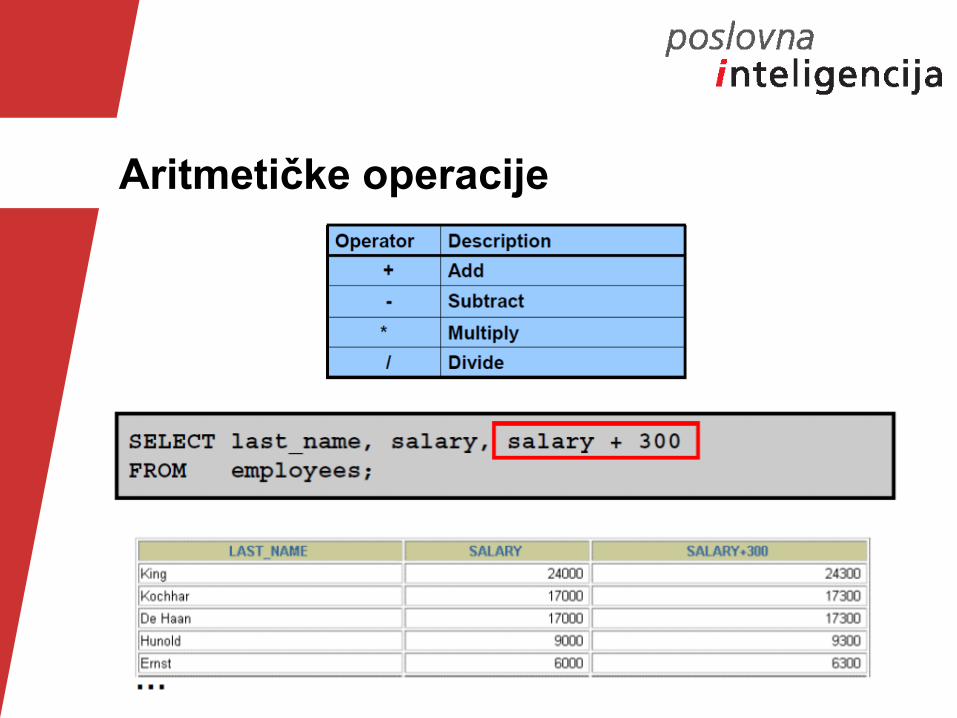
Aritmetičke operacije

Operatori usporedbu
podataka

Logički operatori
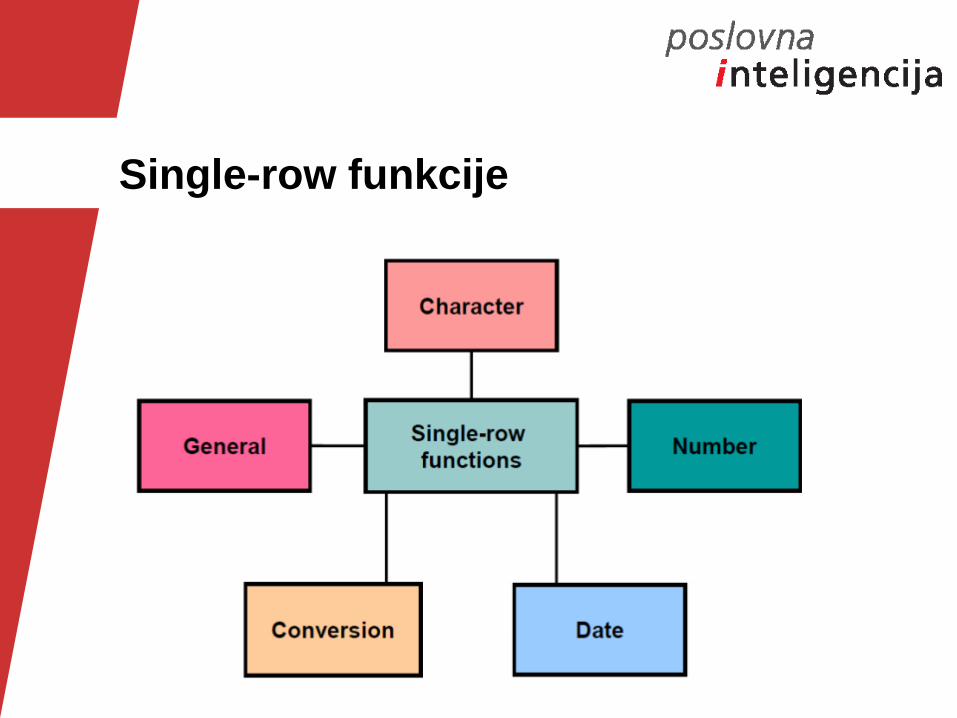
Single-row funkcije
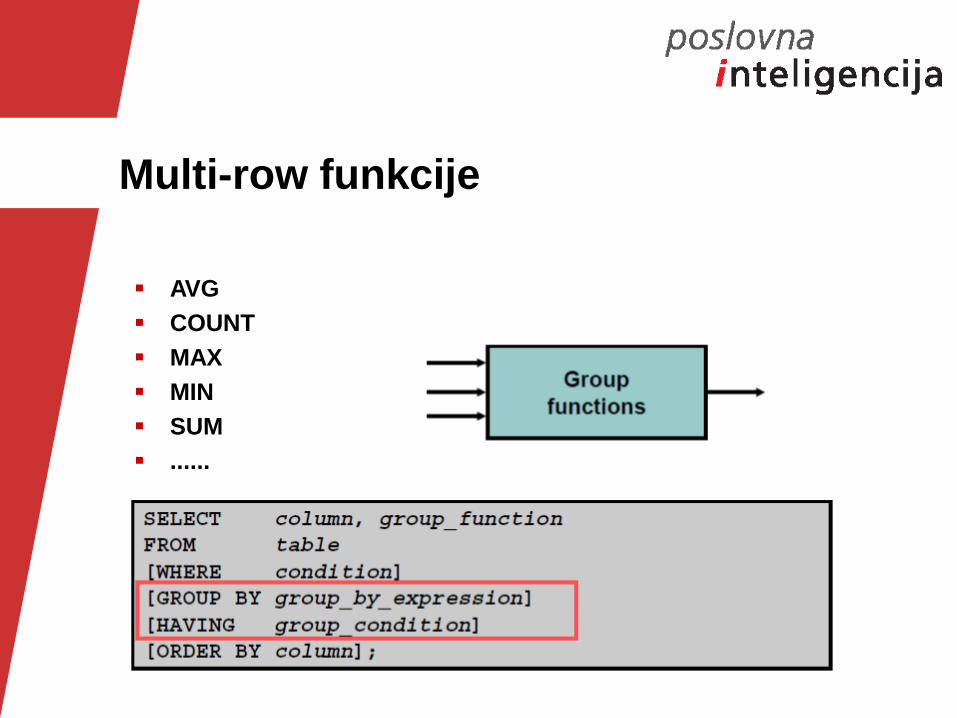
Multi-row funkcije
AVG
COUNT
MAX
MIN
SUM
......

MySql Workbech – Import
podataka Vizualni alat namijenjem arhitekrima, developerima i administratorima MySql
baze podataka
Omogućava dizajniranje, razvoj, administraciju, konfiguraciju, backup MySql
baze podataka u grafičkom sučelju
Podržane su Windows, Linux i MacOs X platforme
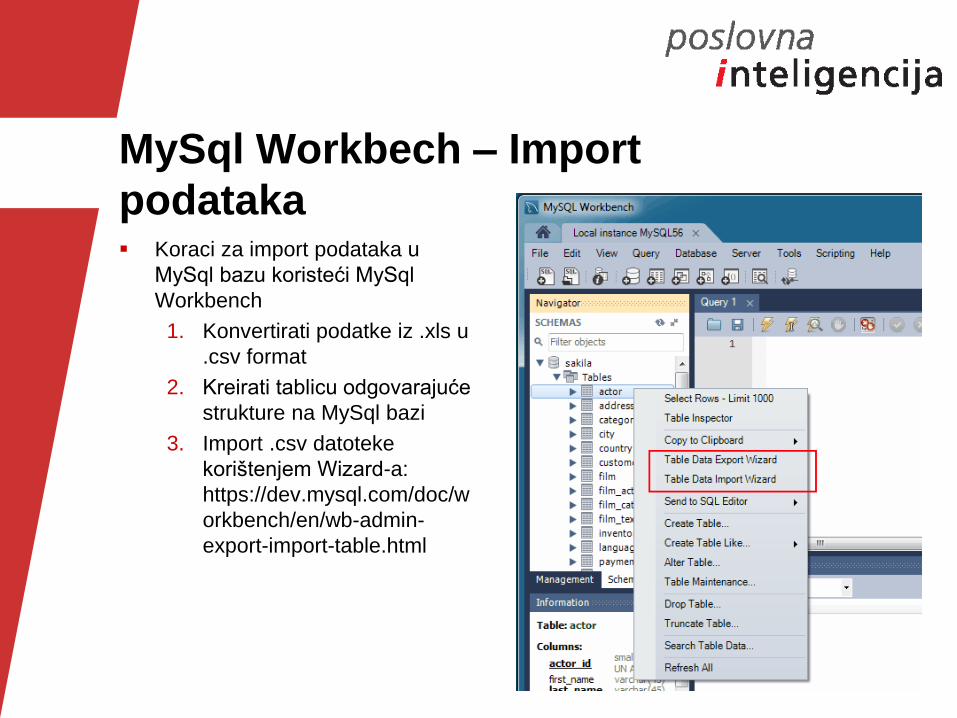
MySql Workbech – Import
podataka Koraci za import podataka u
MySql bazu koristeći MySql
Workbench
1. Konvertirati podatke iz .xls u
.csv format
2. Kreirati tablicu odgovarajuće
strukture na MySql bazi
3. Import .csv datoteke
korištenjem Wizard-a:
https://dev.mysql.com/doc/w
orkbench/en/wb-admin-
export-import-table.html
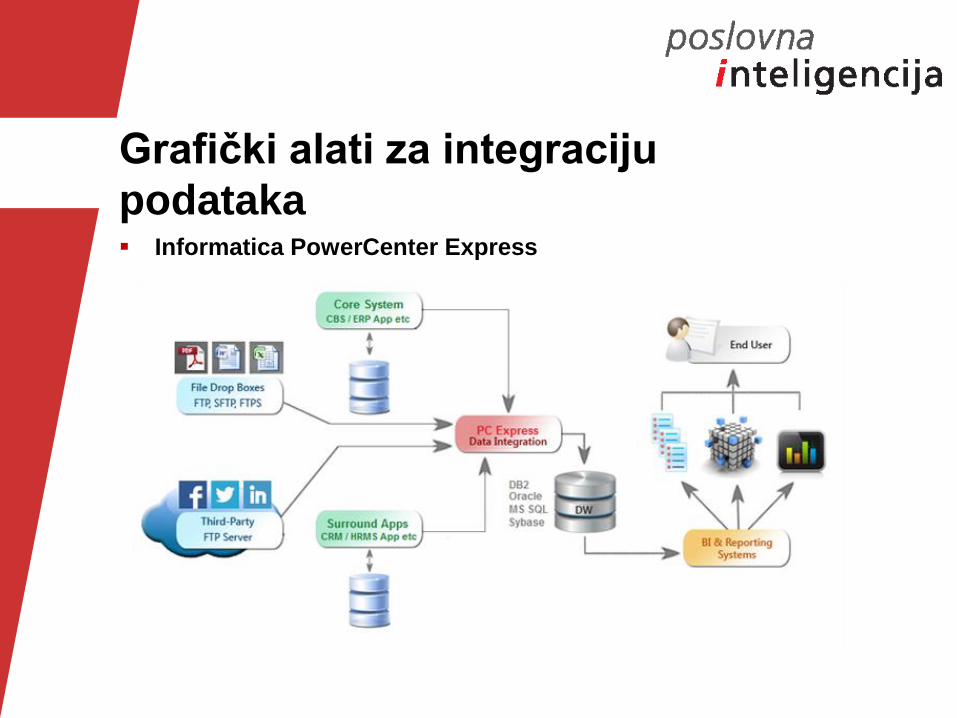
Grafički alati za integraciju
podataka Informatica PowerCenter Express
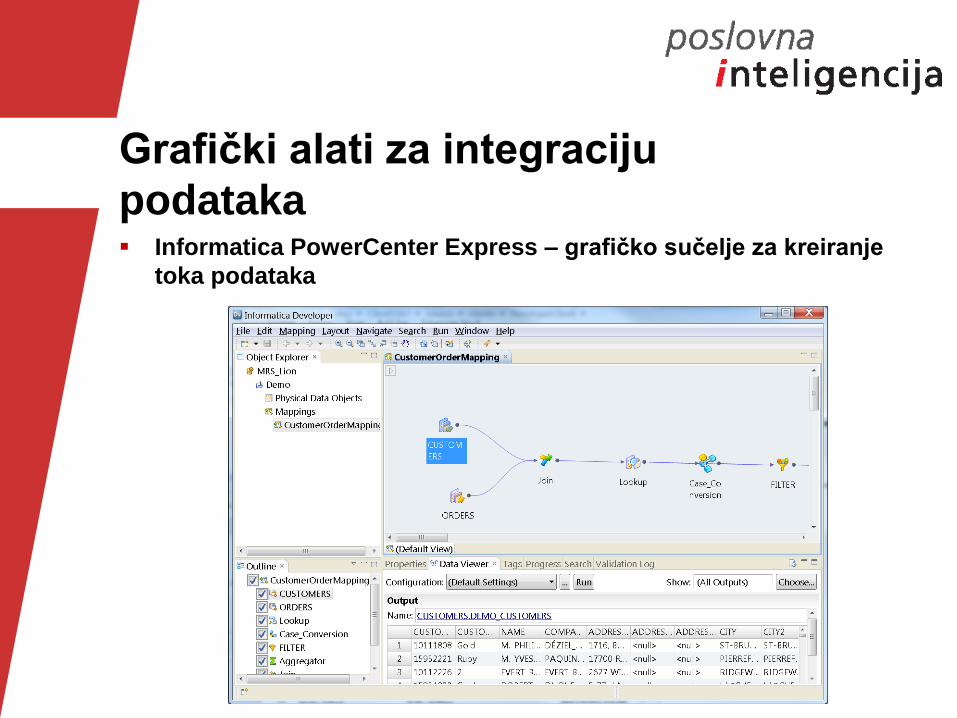
Grafički alati za integraciju
podataka Informatica PowerCenter Express – grafičko sučelje za kreiranje
toka podataka
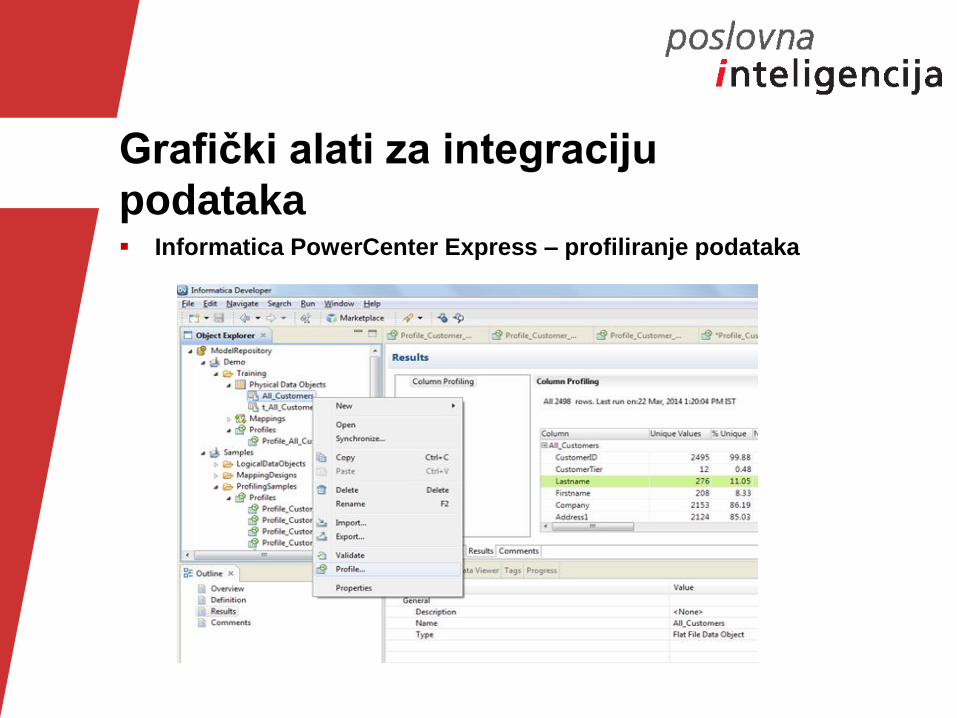
Grafički alati za integraciju
podataka Informatica PowerCenter Express – profiliranje podataka
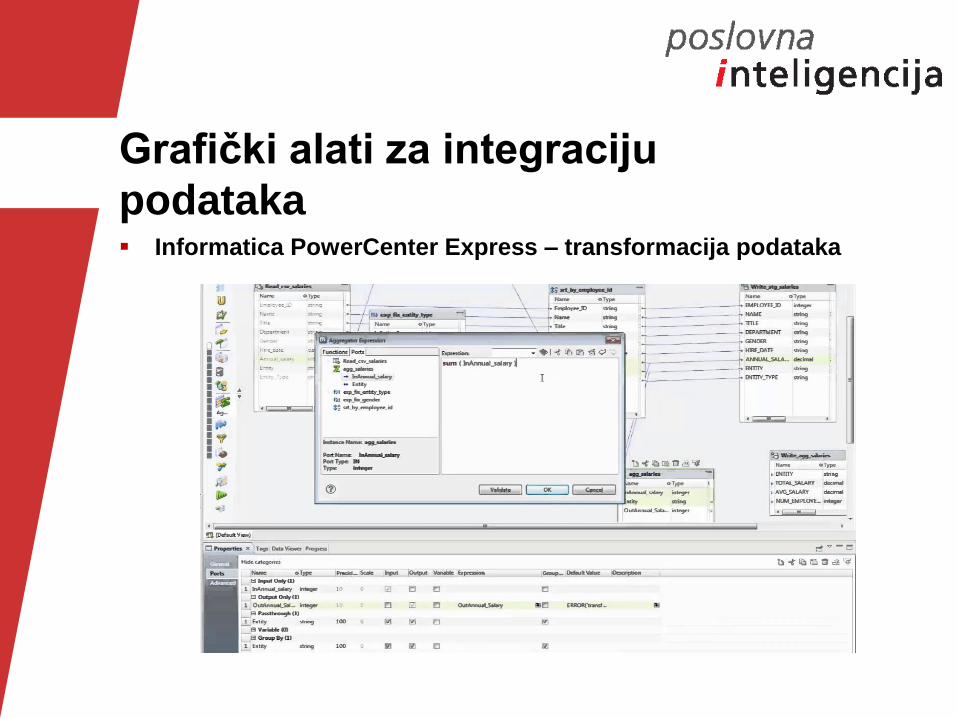
Grafički alati za integraciju
podataka Informatica PowerCenter Express – transformacija podataka

R
programski jezik (okruženje) za statistiku, analizu podataka i grafiku
https://www.r-project.org/
open-source
jednostavan i moćan alat s kvalitetnom grafikom
dodatne funkcionalnosti preko specijaliziranih paketa
vrlo dobra podrška i dokumentacija
velika zajednica korisnika i rastuća popularnost
karakteristična data frame struktura

R & MySQL konekcija
https://cran.r-project.org
R paket RMySQL
> install.packages("RMySQL")
Connection object:
> con = dbConnect(MySQL(), user = 'user',
password = 'password', dbname = 'mydb', host = 'localhost')
> dbListTables(con)
Upiti na bazu: > res = dbSendQuery(con, "select * from akcija order by
ime")
Rezultati upita: > data = dbFetch(res, n = 10)
Zapis rezultata iz R-a u bazu:
> dbWriteTable(con, "ime_tablice", df[,3:10])

R & MySQL konekcija
SQLDF paket za R
https://cran.r-project.org/web/packages/sqldf/sqldf.pdf
omogućava pisanje SQL upita u R-u na data-frame i manipulaciju nad
podacima
Primjer:
pod <- sqldf("select * from res where br_golova>2")

Priprema podataka za SNA
vizualizacije
adjacency
matrix
• edgelist
node1 node2 node3 node4 ...
node1 - 1 1 0
node2 1 - 1 1
node3 0 1 - 0
node4 0 0 1 -
...
node1 node2 weight
382726 494081 5
884463 275550 12
193863 884463 4
275550 884463 7

• Vertices
attribute1 attribute2 attribute3 ...
node1 17 0 Eintracht Frankfurt
node2 18 1 FC Augsburg
node3 12 1 Borussia Dortmund
...
Priprema podataka za SNA
vizualizacije

Alati za vizualizaciju podataka
Pentaho Comunity
Tableau for students, free verzija dostupna za studente
http://www.tableau.com/academic/students
Izvori podataka
ODBC, JDBC
Flat file-ovi, csv
XML
Cytoscape, Gephi – specijalizirani alati za SNA analizu

Cytoscape
open-source platforma za vizualizaciju i analizu velikih mreža
izvorno dizajniran za biološka istraživanja; vizualizaciju gena i molekularnih
interakcija, a kasnije postao generalni alat za vizualizaciju kompleksnih mreža
različitih tipova
dodatne mogućnosti – Apps