Embed Size (px)
Citation preview

ComputingDOI 10.1007/s00607-013-0367-4
Performance of CPU/GPU compiler directiveson ISO/TTI kernels
Sayan Ghosh · Terrence Liao · Henri Calandra ·Barbara M. Chapman
Received: 20 March 2013 / Accepted: 29 October 2013© Springer-Verlag Wien 2013
Abstract GPUs are slowly becoming ubiquitous devices in High Performance Com-puting, as their capabilities to enhance the performance per watt of compute inten-sive algorithms as compared to multicore CPUs have been identified. The primaryshortcoming of a GPU is usability, since vendor specific APIs are quite different fromexisting programming languages, and it requires a substantial knowledge of the deviceand programming interface to optimize applications. Hence, lately a growing numberof higher level programming models are targeting GPUs to alleviate this problem. Theultimate goal for a high-level model is to expose an easy-to-use interface for the userto offload compute intensive portions of code (kernels) to the GPU, and tune the codeaccording to the target accelerator to maximize overall performance with a reduceddevelopment effort. In this paper, we share our experiences of three of the notablehigh-level directive based GPU programming models—PGI, CAPS and OpenACC(from CAPS and PGI) on an Nvidia M2090 GPU. We analyze their performance andprogrammability against Isotropic (ISO)/Tilted Transversely Isotropic (TTI) finite dif-ference kernels, which are primary components in the Reverse Time Migration (RTM)application used by oil and gas exploration for seismic imaging of the sub-surface.
S. Ghosh (B) · B. M. ChapmanDepartment of Computer Science, University of Houston, Houston, TX, USAe-mail: [email protected]
B. M. Chapmane-mail: [email protected]
T. LiaoTOTAL E&P R&T USA, LLC, Houston, TX, USAe-mail: [email protected]
H. CalandraTOTAL E&P, Pau, Francee-mail: [email protected]
123

S. Ghosh et al.
When ported to a single GPU using the mentioned directives, we observe an average1.5–1.8x improvement in performance for both ISO and TTI kernels, when comparedwith optimized multi-threaded CPU implementations using OpenMP.
Keywords RTM · ISO · TTI · OpenMP · GPU · OpenACC · Performance ·Accelerator directives · Finite difference discretization
Mathematics Subject Classification 68U99
1 Introduction
The highly parallel structure of a GPU makes them more effective against generalpurpose CPUs for parallel algorithms. However, writing code in low level vendorspecific APIs (such as CUDA and Brooks for Nvidia and ATI GPUs) might be chal-lenging since it requires a bottom-up re-design of an existing application, which mightrequire significant time and effort. Alternatively, directive-based approaches [7,8,12]are gaining popularity, because of their simplicity and portability across many plat-forms (write once, deploy many). The most computationally intensive portion of areverse time migration (RTM) application is the section for solving the wave equationusing finite difference schemes. Bihan et al. [5], have discussed an RTM use case usingCAPS HMPP directives on Nvidia GPUs, and they have shown that performance ona single Nvidia S1070 GPU was found to be approximately 4x better than 8 IntelHarpertown CPU cores. In this paper, we compare OpenMP multithreaded cache-blocked CPU implementation, with that of GPU implementations using directives ofOpenACC, PGI and HMPP for two finite difference kernels—ISO and TTI in Fortran2003. These two kernels exhibit completely different characteristics; ISO kernel istoward memory bound, whereas the TTI is shifted towards compute bound.
Since the underlying compiler would translate the pragma embedded user code,according to the specified target hardware architecture, the performance of applica-tions greatly depends on (a) compiler flags that were passed to the front-end and (b)the version of native compiler (CUDA NVCC 4.x in our case). The version of NVCCcompiler also plays a role in performance differences, since the compiler front-enduntil CUDA 4.0 was Open64 compiler based, and the latest ones use low level vir-tual machine (LLVM) compiler front-end. As such, we observed radically differentperformances for some experiments when we tried different combinations of NVCCversion and compilation options. As the primary bottleneck for a GPU is the host todevice data transfer latency, porting an application to a GPU is beneficial only if com-putation supersedes the data communication efforts. Through our experiments on TTIand ISO finite difference kernels, we analyze the performance of PGI, CAPS HMPPand OpenACC accelerator directives w.r.t multithreaded CPU implementation.
In a nutshell, we observe reasonable speedup in our experiments (Table 1 liststhe acceleration factor with respect to cache-blocked OpenMP-parallelized version ofthe TTI/ISO kernel), which validates the efficacy of using high-level models to portapplications on GPUs.
Table 2 contains the information about our evaluation platform/testbed. In this paperwe use the term GPU and accelerator interchangeably.
123

OpenMP, PGI, HMPP and OpenACC directives on ISO/TTI kernels
Table 1 Acceleration of TTI and ISO kernels compared with directive based approaches on a GPU againstmulti-threaded OpenMP cache-blocked implementation on an 8-core SMP
Accelerator directives/kernels ISO TTI
CAPS HMPP 1.29 1.76
PGI accelerator 0.85 1.39
OpenACC 1.54 1.73
Table 2 Evaluation platformSoftware/hardware Facets
CPU Two Intel Quad-core Xeon [email protected] GHz, 12 MB L3 Caches,total 8 cores, and 96 GB memory
GPU Two Nvidia Fermi M2090 on CPUplatform with dedicated PCIe2x16per GPU (only one GPU is used inthis study), 512 Compute cores, 6GB GDDR5 memory, ECC:disabled
Compilers Intel Compiler 12.1.5, CAPS HMPPWorkbench 3.2.1, PGI Compiler12.3 / 12.6, Nvidia CUDA 4.0 / 4.2
API and languages OpenMP 3.1, OpenACC 1.0, PGIAccelerator Model v1.3,FORTRAN 2003
The rest of the paper is organized as follows:
– In Sects. 2 and 3, we discuss some of the notable efforts in improving programmabil-ity of heterogeneous devices, and the role of compilers in application optimization.
– In Sects. 4 and 5 we discuss multiple CPU and GPU implementations of ISO andTTI kernels, their evaluation and results.
– Finally, we end with our conclusions in Sect. 6.
2 Programmibility of GPUs
Currently, the dominant programming models used on GPUs could be divided intohigh level-compiler aided programming models, like OpenACC and low-level/librarybased programming models such as CUDA [11] and OpenCL [13]. The OpenCL APIis the first attempt in unifying a platform-independent interface for heterogeneousdevices and accelerators, such as CPU, GPU, DSP and FPGA. However, developingan application with OpenCL requires substantial effort, and possibly re-writing anapplication kernel. The OpenACC API [12] is gaining recognition as an open standardthat is supported by multiple compilers and portable across various accelerators. Itchampions pragma directives like in OpenMP [1] to port application kernel code(mostly nested-loop regions) and associated data to the accelerator. CAPS HMPPdirectives on the other hand are more feature rich, providing users with many optionsto tune code, impacting incremental performance. OpenMPC [9] is an amalgamationof OpenMP API and CUDA specific tunable parameters, that are used to translate
123

S. Ghosh et al.
OpenMP regions to efficient CUDA program. This is however, specific to Nvidia GPUsonly. StarSs programming model [3] provides annotations (similar to OpenMP taskingmodel) which could be used to identify code-blocks to execute them on multiple GPUs(as tasks) on a single node. The users would need to mention the data transfer directionin the annotations, via in, out, inout clauses, in order for the runtime to tracktask dependencies. The StarPU [2] project from INRIA, France offers an OpenCL task-queue like task-based runtime to schedule tasks on CPUs and GPUs (shared as well asdistributed across nodes). The StarPU runtime manages the inter-task dependencies,and optimizes data transfers from local to remote memory.
The PEPPHER project (from leading European universities) [4] provides an auto-tuning framework that analyzes an application for performance critical kernels, andthen performs source-to-source translation for multiple target hardware platforms,according to usage context, performance criteria and statistics from previous applica-tion runs.
Our aim was to inject absolutely minimal, or no changes to the application codeunder test, and hence we evaluated some of the common higher-level directive basedsolutions available for GPUs. We found out that although the directives offer an easyway to port an application to a GPU, substantial analysis needs to be undertaken toidentify and fix performance bottlenecks.
3 Role of compilers in optimization
Performance of an application depends greatly on the optimizations performed bya compiler, which could be influenced by the compilation options or switches thatare passed by the user at compile time. The role of compilers are even critical inhigh-level approaches since the native code is generated by the compiler, according tothe semantics specified by the user. This intermediate high level code is compiled bythe device specific compiler (CUDA NVCC in our case), which translates it to PTX(CUDA assembler source) and optimizes it further before generating the final CUDAbinary (a .cubin file).
3.1 Differences in compute device 1.3 and 2.0
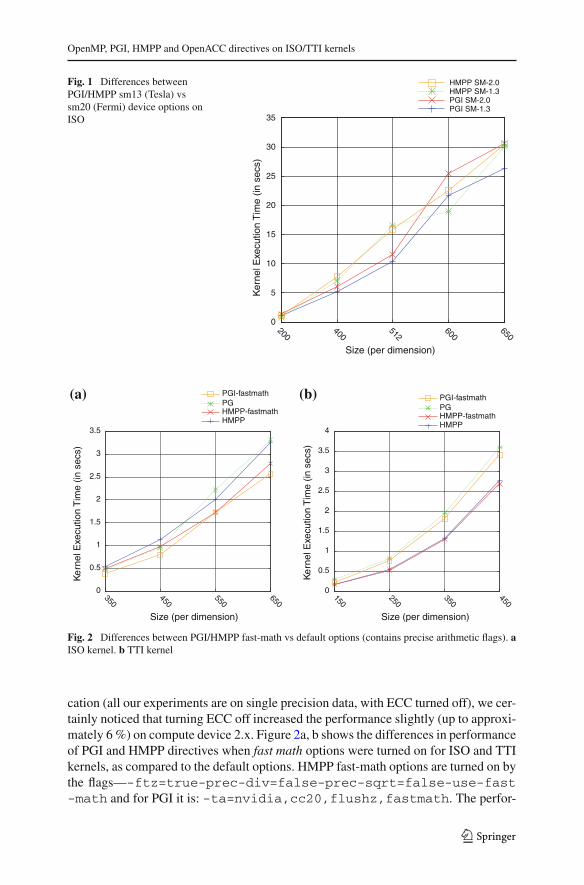
The number of resources vary from one device family to another, and we observedsome divergent results in our test cases upon switching the target devices. Thesedifferences between device families (compute device 1.x vs 2.x) could be primarilydue to numerical precision, since sm_1x devices were known to implement a truncatedfloating point multiply add (FMAD) operation, which made it faster but inaccurate.Figure 1 shows the performance difference between compute device 1.x vs 2.x, usingthe sm13/sm20 compilation option of PGI and HMPP directives.
3.2 Fast-math compiler option
Only recently GPUs have started to support precise arithmetic operations (with theoption of ECC hardware), and since we do not require extreme precision for our appli-
123
OpenMP, PGI, HMPP and OpenACC directives on ISO/TTI kernels
Fig. 1 Differences betweenPGI/HMPP sm13 (Tesla) vssm20 (Fermi) device options onISO
0
5
10
15
20
25
30
35
200400
512600
650
Ker
nel E
xecu
tion
Tim
e (in
sec
s)
Size (per dimension)
PGI SM-1.3PGI SM-2.0HMPP SM-1.3HMPP SM-2.0
0
0.5
1
1.5
2
2.5
3
3.5
350450
550650
Ke
rnel
Exe
cutio
n T
ime
(in s
ecs)
Size (per dimension)
HMPPHMPP-fastmathPGPGI-fastmath
HMPPHMPP-fastmathPGPGI-fastmath
0
0.5
1
1.5
2
2.5
3
3.5
4
150250
350450
Ke
rnel
Exe
cutio
n T
ime
(in s
ecs)
Size (per dimension)
(a) (b)
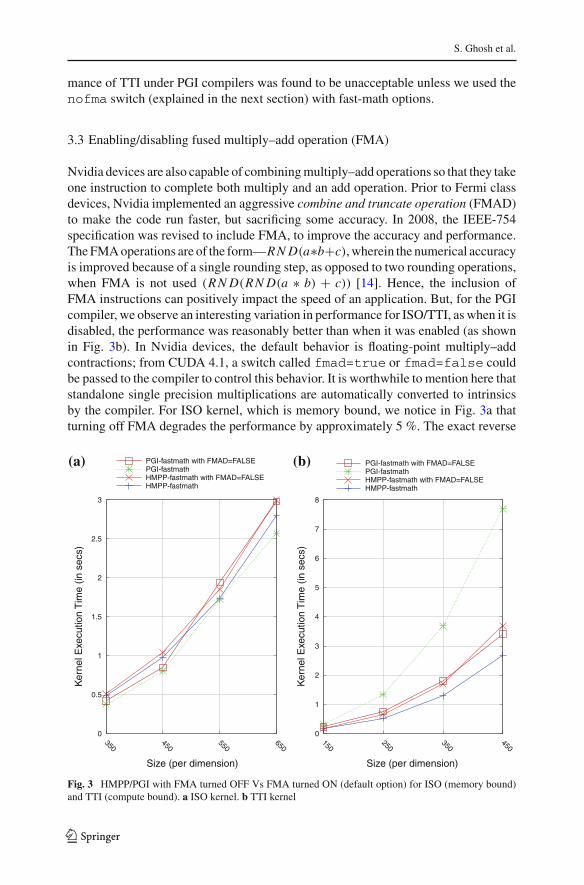
Fig. 2 Differences between PGI/HMPP fast-math vs default options (contains precise arithmetic flags). aISO kernel. b TTI kernel
cation (all our experiments are on single precision data, with ECC turned off), we cer-tainly noticed that turning ECC off increased the performance slightly (up to approxi-mately 6 %) on compute device 2.x. Figure 2a, b shows the differences in performanceof PGI and HMPP directives when fast math options were turned on for ISO and TTIkernels, as compared to the default options. HMPP fast-math options are turned on bythe flags—-ftz=true-prec-div=false-prec-sqrt=false-use-fast-math and for PGI it is: -ta=nvidia,cc20,flushz,fastmath. The perfor-
123
S. Ghosh et al.
mance of TTI under PGI compilers was found to be unacceptable unless we used thenofma switch (explained in the next section) with fast-math options.
3.3 Enabling/disabling fused multiply–add operation (FMA)
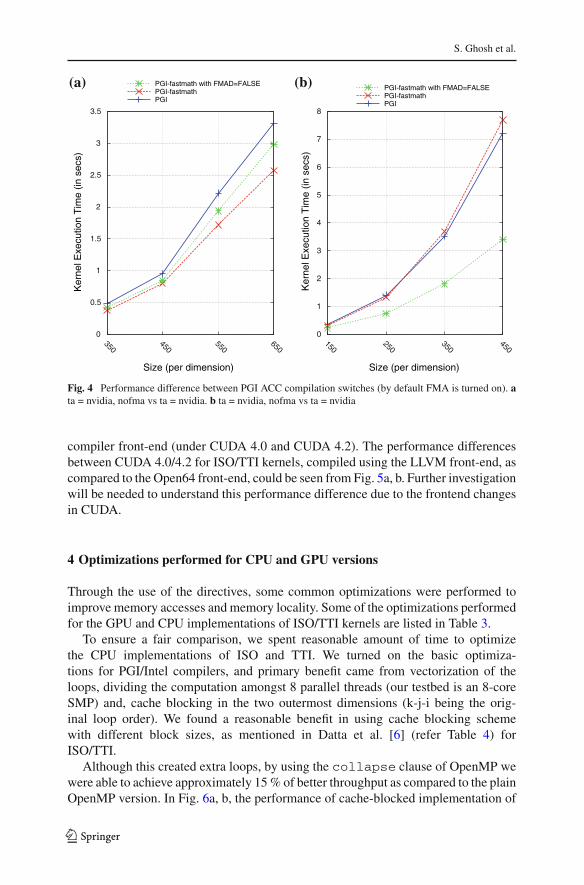
Nvidia devices are also capable of combining multiply–add operations so that they takeone instruction to complete both multiply and an add operation. Prior to Fermi classdevices, Nvidia implemented an aggressive combine and truncate operation (FMAD)to make the code run faster, but sacrificing some accuracy. In 2008, the IEEE-754specification was revised to include FMA, to improve the accuracy and performance.The FMA operations are of the form—RN D(a∗b+c), wherein the numerical accuracyis improved because of a single rounding step, as opposed to two rounding operations,when FMA is not used (RN D(RN D(a ∗ b) + c)) [14]. Hence, the inclusion ofFMA instructions can positively impact the speed of an application. But, for the PGIcompiler, we observe an interesting variation in performance for ISO/TTI, as when it isdisabled, the performance was reasonably better than when it was enabled (as shownin Fig. 3b). In Nvidia devices, the default behavior is floating-point multiply–addcontractions; from CUDA 4.1, a switch called fmad=true or fmad=false couldbe passed to the compiler to control this behavior. It is worthwhile to mention here thatstandalone single precision multiplications are automatically converted to intrinsicsby the compiler. For ISO kernel, which is memory bound, we notice in Fig. 3a thatturning off FMA degrades the performance by approximately 5 %. The exact reverse
0
0.5
1
1.5
2
2.5
3
350450
550650
Ker
nel E
xecu
tion
Tim
e (in
sec
s)
Size (per dimension)
HMPP-fastmathHMPP-fastmath with FMAD=FALSEPGI-fastmathPGI-fastmath with FMAD=FALSE
0
1
2
3
4
5
6
7
8
150250
350450
Ker
nel E
xecu
tion
Tim
e (in
sec
s)
Size (per dimension)
HMPP-fastmathHMPP-fastmath with FMAD=FALSEPGI-fastmathPGI-fastmath with FMAD=FALSE(a) (b)
Fig. 3 HMPP/PGI with FMA turned OFF Vs FMA turned ON (default option) for ISO (memory bound)and TTI (compute bound). a ISO kernel. b TTI kernel
123

OpenMP, PGI, HMPP and OpenACC directives on ISO/TTI kernels
of this behavior is observed for the TTI kernel (Fig. 3b), which is compute intensive,wherein the performance increases by 5 %.
For TTI, it is evident from Fig. 3b, that there is a degradation (approximately 5 %according to our observations) in performance when FMA operations are allowed(which is the default case), versus when it is explicitly turned off.
Use of FMA may increase register pressure slightly, because three source operandsmust be available at the same time. Turning FMA generation on/off may lead to smalldifferences in instruction scheduling and register allocation, which in turn can leadto small performance differences. In the generated code of TTI, we noticed a largenumber of multiplications (less additions), which could be the cause of little benefitfrom the use of FMA. For HMPP, we observe performance degradation (Fig. 3a, b)when FMA is turned off (for both TTI and ISO), which should be the ideal scenario.
3.3.1 Enabling/disabling the “nofma” switch of PGI
We observe substantial differences in throughput of the PGI compiler for ISO/TTIwhen FMA is turned off as opposed to when it is enabled. We analyzed the generatedintermediate GPU code, when nofma was passed, PGI compiler transformed themultiplications to __fmul_rn intrinsic and the number of operations were morethan the base version which had FMA. Intrinsics (like __fmul_rn) are never fusedinto FMA operations, so if the generated code contains intrinsics, it would not befused.
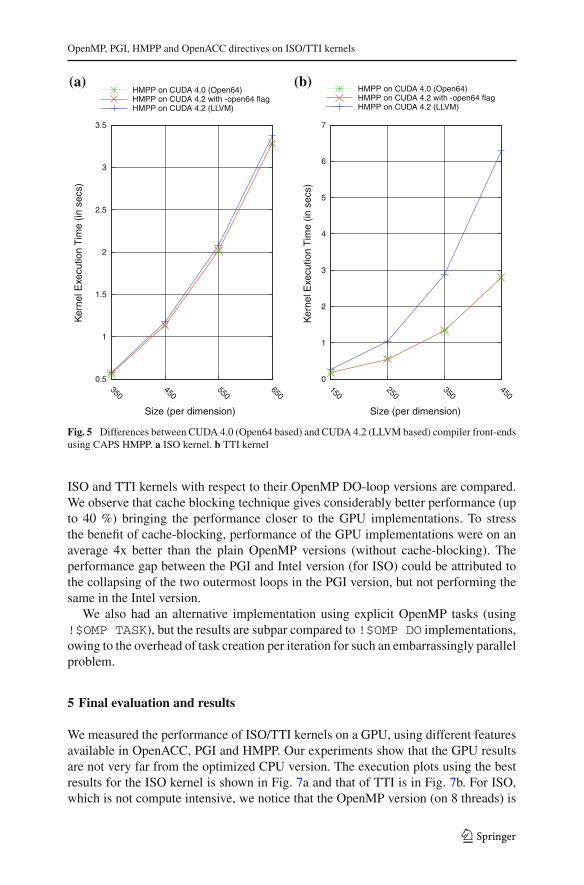
Perhaps the amount of instructions per memory accesses evens out for computebound kernels when there are more instructions, which could not merge into FMAoperations. On the contrary, the same operation was found to negatively affect memorybound problems like ISO. Using Nvidia profiler, we found out that inclusion of nofmaswitch converts the TTI kernel from memory bound to instruction bound. The idealinstructions per byte metric of the testbed GPU is 3.79 (theoretical instruction through-put/theoretical memory throughput). According to our analysis, enabling FMA leads toan instruction throughput of 2.79 (memory bound), whereas disabling it makes it 4.22(greater than the ideal, and hence instruction bound). Figure 4a, b show the differencesin execution time when we passed -ta=nvidia as compared to -ta = nvidia,nofma as a compilation option to the PGI compiler for TTI/ISO kernels.
3.4 LLVM/Open64 compiler front-ends of CUDA and their performances
Nvidia introduced the LLVM compiler front-end from CUDA 4.1, whereas untilCUDA 4.0, Open64 front-end was used. Nvidia claims that the new compiler pro-vides better performance, but in most of our tests the performance of CUDA 4.0exceeded CUDA 4.2, and hence we decided to use CUDA 4.0 for all our experiments.The -open64 compiler switch was added in CUDA 4.1, which could be used to spec-ify the Open64 compiler front-end (no longer the default) as the preferred compiler.We do not observe any marked difference between the performance of CUDA 4.0 andCUDA 4.2 with -open64 flag. On the other hand, the performance of CUDA 4.2using the default LLVM front-end, was found to be subpar as compared to the Open64
123
S. Ghosh et al.
0
0.5
1
1.5
2
2.5
3
3.5
350450
550650
Ker
nel E
xecu
tion
Tim
e (in
sec
s)
Size (per dimension)
PGIPGI-fastmathPGI-fastmath with FMAD=FALSE
0
1
2
3
4
5
6
7
8
150250
350450
Ker
nel E
xecu
tion
Tim
e (in
sec
s)
Size (per dimension)
PGIPGI-fastmathPGI-fastmath with FMAD=FALSE(a) (b)
Fig. 4 Performance difference between PGI ACC compilation switches (by default FMA is turned on). ata = nvidia, nofma vs ta = nvidia. b ta = nvidia, nofma vs ta = nvidia
compiler front-end (under CUDA 4.0 and CUDA 4.2). The performance differencesbetween CUDA 4.0/4.2 for ISO/TTI kernels, compiled using the LLVM front-end, ascompared to the Open64 front-end, could be seen from Fig. 5a, b. Further investigationwill be needed to understand this performance difference due to the frontend changesin CUDA.
4 Optimizations performed for CPU and GPU versions
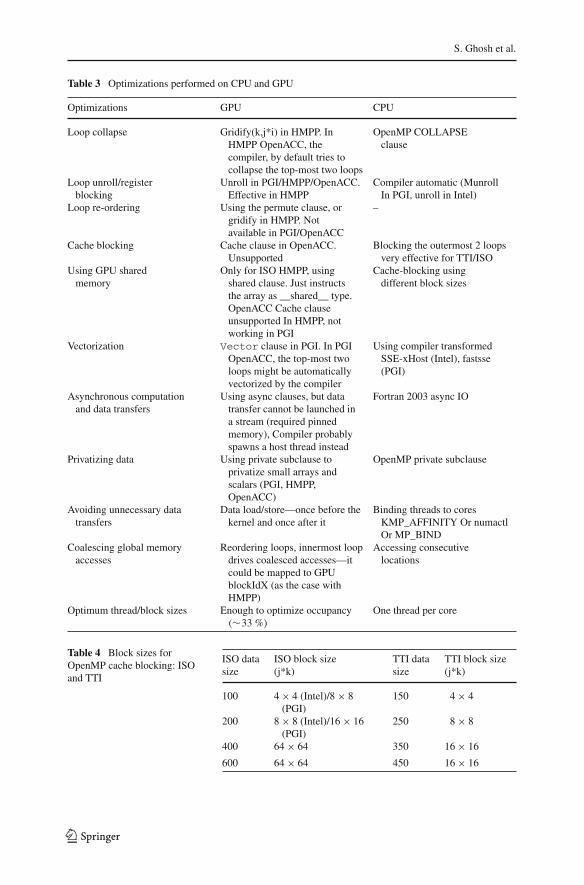
Through the use of the directives, some common optimizations were performed toimprove memory accesses and memory locality. Some of the optimizations performedfor the GPU and CPU implementations of ISO/TTI kernels are listed in Table 3.
To ensure a fair comparison, we spent reasonable amount of time to optimizethe CPU implementations of ISO and TTI. We turned on the basic optimiza-tions for PGI/Intel compilers, and primary benefit came from vectorization of theloops, dividing the computation amongst 8 parallel threads (our testbed is an 8-coreSMP) and, cache blocking in the two outermost dimensions (k-j-i being the orig-inal loop order). We found a reasonable benefit in using cache blocking schemewith different block sizes, as mentioned in Datta et al. [6] (refer Table 4) forISO/TTI.
Although this created extra loops, by using the collapse clause of OpenMP wewere able to achieve approximately 15 % of better throughput as compared to the plainOpenMP version. In Fig. 6a, b, the performance of cache-blocked implementation of
123
OpenMP, PGI, HMPP and OpenACC directives on ISO/TTI kernels
0.5
1
1.5
2
2.5
3
3.5
350450
550650
Ker
nel E
xecu
tion
Tim
e (in
sec
s)
Size (per dimension)
HMPP on CUDA 4.2 (LLVM)HMPP on CUDA 4.2 with -open64 flagHMPP on CUDA 4.0 (Open64)
0
1
2
3
4
5
6
7
150250
350450
Ker
nel E
xecu
tion
Tim
e (in
sec
s)
Size (per dimension)
HMPP on CUDA 4.2 (LLVM)HMPP on CUDA 4.2 with -open64 flagHMPP on CUDA 4.0 (Open64)
(a) (b)
Fig. 5 Differences between CUDA 4.0 (Open64 based) and CUDA 4.2 (LLVM based) compiler front-endsusing CAPS HMPP. a ISO kernel. b TTI kernel
ISO and TTI kernels with respect to their OpenMP DO-loop versions are compared.We observe that cache blocking technique gives considerably better performance (upto 40 %) bringing the performance closer to the GPU implementations. To stressthe benefit of cache-blocking, performance of the GPU implementations were on anaverage 4x better than the plain OpenMP versions (without cache-blocking). Theperformance gap between the PGI and Intel version (for ISO) could be attributed tothe collapsing of the two outermost loops in the PGI version, but not performing thesame in the Intel version.
We also had an alternative implementation using explicit OpenMP tasks (using!$OMP TASK), but the results are subpar compared to !$OMP DO implementations,owing to the overhead of task creation per iteration for such an embarrassingly parallelproblem.
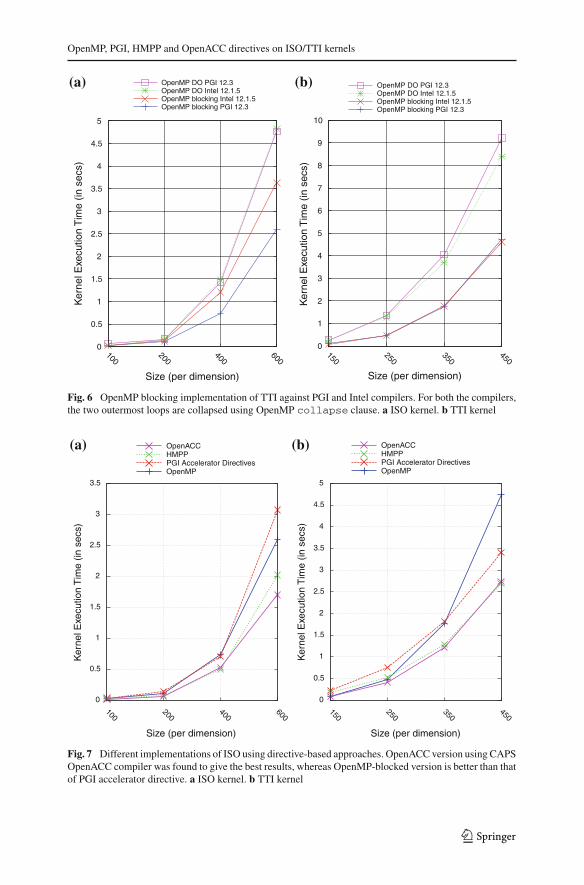
5 Final evaluation and results
We measured the performance of ISO/TTI kernels on a GPU, using different featuresavailable in OpenACC, PGI and HMPP. Our experiments show that the GPU resultsare not very far from the optimized CPU version. The execution plots using the bestresults for the ISO kernel is shown in Fig. 7a and that of TTI is in Fig. 7b. For ISO,which is not compute intensive, we notice that the OpenMP version (on 8 threads) is
123
S. Ghosh et al.
Table 3 Optimizations performed on CPU and GPU
Optimizations GPU CPU
Loop collapse Gridify(k,j*i) in HMPP. InHMPP OpenACC, thecompiler, by default tries tocollapse the top-most two loops
OpenMP COLLAPSEclause
Loop unroll/registerblocking
Unroll in PGI/HMPP/OpenACC.Effective in HMPP
Compiler automatic (MunrollIn PGI, unroll in Intel)
Loop re-ordering Using the permute clause, orgridify in HMPP. Notavailable in PGI/OpenACC
–
Cache blocking Cache clause in OpenACC.Unsupported
Blocking the outermost 2 loopsvery effective for TTI/ISO
Using GPU sharedmemory
Only for ISO HMPP, usingshared clause. Just instructsthe array as __shared__ type.OpenACC Cache clauseunsupported In HMPP, notworking in PGI
Cache-blocking usingdifferent block sizes
Vectorization Vector clause in PGI. In PGIOpenACC, the top-most twoloops might be automaticallyvectorized by the compiler
Using compiler transformedSSE-xHost (Intel), fastsse(PGI)
Asynchronous computationand data transfers
Using async clauses, but datatransfer cannot be launched ina stream (required pinnedmemory), Compiler probablyspawns a host thread instead
Fortran 2003 async IO
Privatizing data Using private subclause toprivatize small arrays andscalars (PGI, HMPP,OpenACC)
OpenMP private subclause
Avoiding unnecessary datatransfers
Data load/store—once before thekernel and once after it
Binding threads to coresKMP_AFFINITY Or numactlOr MP_BIND
Coalescing global memoryaccesses
Reordering loops, innermost loopdrives coalesced accesses—itcould be mapped to GPUblockIdX (as the case withHMPP)
Accessing consecutivelocations
Optimum thread/block sizes Enough to optimize occupancy(∼33 %)
One thread per core
Table 4 Block sizes forOpenMP cache blocking: ISOand TTI
ISO datasize
ISO block size(j*k)
TTI datasize
TTI block size(j*k)
100 4 × 4 (Intel)/8 × 8(PGI)
150 4 × 4
200 8 × 8 (Intel)/16 × 16(PGI)
250 8 × 8
400 64 × 64 350 16 × 16
600 64 × 64 450 16 × 16
123
OpenMP, PGI, HMPP and OpenACC directives on ISO/TTI kernels
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
100200
400600
Ker
nel E
xecu
tion
Tim
e (in
sec
s)
Size (per dimension)
OpenMP blocking PGI 12.3OpenMP blocking Intel 12.1.5OpenMP DO Intel 12.1.5OpenMP DO PGI 12.3
0
1
2
3
4
5
6
7
8
9
10
150250
350450
Ker
nel E
xecu
tion
Tim
e (in
sec
s)
Size (per dimension)
OpenMP blocking PGI 12.3OpenMP blocking Intel 12.1.5OpenMP DO Intel 12.1.5OpenMP DO PGI 12.3(a) (b)
Fig. 6 OpenMP blocking implementation of TTI against PGI and Intel compilers. For both the compilers,the two outermost loops are collapsed using OpenMP collapse clause. a ISO kernel. b TTI kernel
0
0.5
1
1.5
2
2.5
3
3.5
100200
400600
Ker
nel E
xecu
tion
Tim
e (in
sec
s)
Size (per dimension)
OpenMPPGI Accelerator DirectivesHMPPOpenACC
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
150250
350450
Ker
nel E
xecu
tion
Tim
e (in
sec
s)
Size (per dimension)
OpenMPPGI Accelerator DirectivesHMPPOpenACC(a) (b)
Fig. 7 Different implementations of ISO using directive-based approaches. OpenACC version using CAPSOpenACC compiler was found to give the best results, whereas OpenMP-blocked version is better than thatof PGI accelerator directive. a ISO kernel. b TTI kernel
123

S. Ghosh et al.
1.2x better than the GPU version (for PGI), suggesting a negative impact when portedto GPUs. The TTI kernel however, maintains on an average a speedup close to 1.5x,as compared to the multi-threaded OpenMP version.
5.1 Understanding performance limiters using Nvidia profiler
To have an idea about the performance of an application on a device, we compare itwith the ideal performance metrics for that particular device. Mostly, profile countershelp us in understanding the limitations in our code, and might be able to provide uswith hints to improve our program. Apart from instructions per byte metric calculatedusing profile counters, the CUDA visual profiler [10] could help in identifying manymore performance limiters. We discuss three profiling cases for the TTI kernel usingdifferent ways to schedule loop-nests on a GPU using HMPP GRIDIFY directive.Figures 8, 9 and, 10 show the profiler results of three different distribution of loopsonto (sequence of the loops in the code for this specific example is: outermost-k, thenj and then the innermost-i) the GPU grid of blocks. The width of the block in thefigures signify the execution times of kernel, which is typically executed over manyiterations.
From the three figures, it is evident that Fig. 10 is the best gridification strategy,which collapses the j and i loops mapping into a 1-D grid-block, which is run by thestrip-mined k-loop. On the other hand, in Fig. 8, the i-loop which drives coalescedmemory accesses would be the innermost loop, and hence would unnecessarily beexecuted by all threads in different blocks, which degrades the performance substan-tially. Loop distribution strategy is a key component in extracting performance foraccelerator directives.
Fig. 8 HMPP TTI profile with GRIDIFY(k, j, i) clause—k and j loops gridified, i-loop run by all threadsin a block
Fig. 9 HMPP TTI profile with GRIDIFY(j, i, k) clause—j and i loops gridified, k-loop run by all threadsin a block
123

OpenMP, PGI, HMPP and OpenACC directives on ISO/TTI kernels
Fig. 10 HMPP TTI profile with GRIDIFY(j*i) clause—j and i loops collapsed and gridified, k-loop unrolled(9 times) to exploit GPU ILP. More kernels are scheduled per time unit, improving load balance
6 Conclusions
The closeness of CPU and GPU performance results for ISO/TTI kernels might hintthat the directive approaches would need to improve along with the devices. In ourtest cases, we were not able to exceed more than 1.7x acceleration for the TTI (morecompute intensive) kernel using the accelerator directives as compared to optimizedCPU multi-threaded cache-blocked code. To maximize performance out of a GPUusing the accelerator directives, apart from exploiting the features of a directive, onemight need to study the compilation options as well. Most of the divergent results thatwe observed, were related to using different compilation options. The most interestingone involves turning off FMA, which greatly improved the performance of TTI (for thePGI compiler). Ideally, the opposite should be happening for a compute bound kernel,as we observe for CAPS HMPP. Although all the programming models aim to achievethe same functionality, the performance depends on the underlying compiler. This iswhat we had expected and thus observed in this study. Nevertheless, the directivesoffer a stable approach to reduce efforts in code development, and makes it easier forthe developer to write optimized code with a handful of pragmas. Our evaluation onfinite difference kernels for seismic imaging seems to reassure that the pragma-basedapproach can provide a suitable balance amongst programmability, adaptability andperformance.
Acknowledgments We wish to thank Georges-Emmanuel Moulard of CAPS enterprise, Matthew Col-grove of PGI and, Philippe Thierry of Intel Corp., who helped us immensely by providing answers to ourquestions, and suggesting improvements. This work would not have been possible without their guidance.Finally, we would like to thank TOTAL for granting permission to publish this paper.
References
1. OpenMP ARB (2010) The OpenMP API specification for parallel programming. http://openmp.org/wp/
2. Augonnet C, Thibault S, Namyst R, Wacrenier PA (2011) Starpu: a unified platform for task schedulingon heterogeneous multicore architectures. Concurr Comput Pract Exp 23(2):187–198
123

S. Ghosh et al.
3. Ayguadé E, Badia RM, Igual FD, Labarta J, Mayo R, Quintana-Ortí ES (2009) An extension of thestarss programming model for platforms with multiple gpus. In: Euro-Par 2009 parallel processing,Springer, New York, pp 851–862
4. Benkner S, Pllana S, Traff JL, Tsigas P, Dolinsky U, Augonnet C, Bachmayer B, Kessler C, MoloneyD, Osipov V (2011) Peppher: efficient and productive usage of hybrid computing systems. Micro IEEE31(5):28–41
5. Bihan S, Moulard GE, Dolbeau R, Calandra H, Abdelkhalek R (2009) Directive-based heterogeneousprogramming-a gpu-accelerated rtm use case. In: Proceedings of the 7th international conference oncomputing, communications and control technologies
6. Datta K, Murphy M, Volkov V, Williams S, Carter J, Oliker L, Patterson D, Shalf J, Yelick K (2008)Stencil computation optimization and auto-tuning on state-of-the-art multicore architectures. In: Pro-ceedings of the 2008 ACM/IEEE conference on supercomputing, IEEE Press, New York, p 4
7. Dolbeau R, Bihan S, Bodin F (2007) Hmpp: a hybrid multi-core parallel programming environment.In: Workshop on general purpose processing on graphics processing units (GPGPU 2007)
8. The Portland Group (2010) Pgi accelerator programming model. http://www.pgroup.com/resources/accel.htm
9. Lee S, Eigenmann R (2010) Openmpc: extended openmp programming and tuning for gpus. In: Pro-ceedings of the 2010 ACM/IEEE international conference for high performance computing, network-ing, storage and analysis, IEEE Computer Society, pp 1–11
10. Nvidia (2011) Nvidia cuda visual profiler. http://developer.download.nvidia.com/compute/DevZone/docs/html/C/doc/Compute_Visual_Profiler_User_Guide.pdf
11. CUDA Nvidia (2007) Compute unified device architecture programming guide12. PGI Nvidia, CAPS and Cray (2011) Openacc application programming interface: directives for accel-
erators. http://www.openacc.org13. Stone JE, Gohara D, Shi G (2010) Opencl: a parallel programming standard for heterogeneous com-
puting systems. Comput Sci Eng 12(3):6614. Whitehead N, Fit-Florea A (2011) Precision & performance: floating point and ieee 754 compliance
for nvidia gpus. rn (A + B) 21:1–1874919 424
123













![TTI [LAB.2]](https://img.dokumen.tips/doc/110x75/55cf8e52550346703b90e377/tti-lab2.jpg)















