Embed Size (px)
Citation preview

Performance and Overhead in a Hybrid Reconfigurable Computer
O. D. Fidanci1, D. Poznanovic2, K. Gaj3, T. El-Ghazawi1, N. Alexandridis1
1George Washington University, 2SRC Computers Inc.,
3George Mason University
http://cpe02.gmu.edu/rcm/

Features of General-Purpose Reconfigurable Computers
composed of traditional microprocessors and
Field Programmable Gate Arrays (FPGAs)
closely integrated with each other
programming does not require knowledge of
hardware design
permit run-time reconfiguration of FPGAs

Hardware Architecture and
Programming Modelof SRC-6E
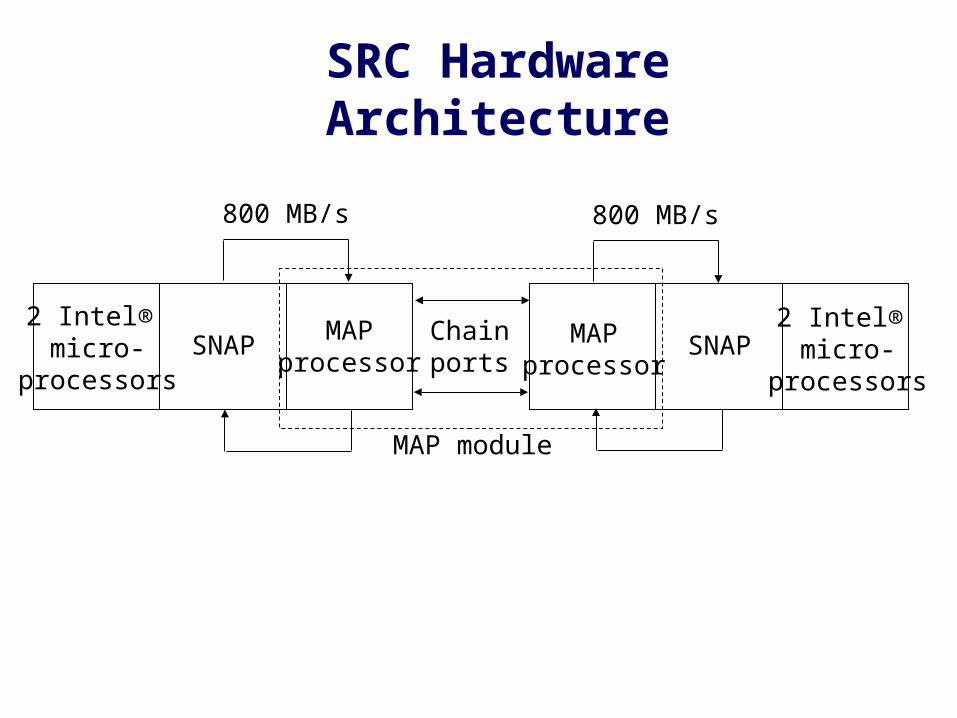
SRC Hardware Architecture
2 Intel® micro-
processorsSNAP
MAPprocessor
2 Intel® micro-
processorsSNAP
Chainports
800 MB/s 800 MB/s
MAPprocessor
MAP module
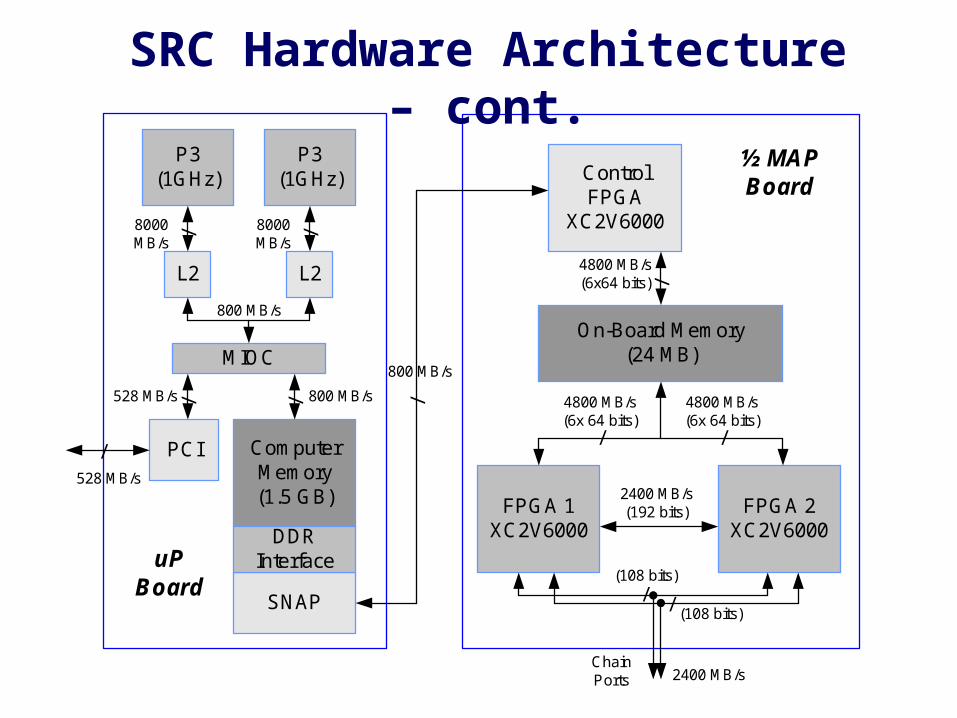
SNAP
ComputerMemory(1.5 GB)
P3(1GHz)
P3(1GHz)
/ /8000MB/s
8000MB/s
MIOC
L2L2
800 MB/s
// 800 MB/s528 MB/s
DDRInterface
PCI
ControlFPGA
XC2V6000
800 MB/s
On-Board Memory(24 MB)
/4800 MB/s(6x64 bits)
FPGA 1XC2V6000
FPGA 2XC2V6000
/
4800 MB/s(6x 64 bits)
/
4800 MB/s(6x 64 bits)
2400 MB/s(192 bits)
/
/ /
(108 bits)
ChainPorts 2400 MB/s
(108 bits)
/
528 MB/s
½ MAPBoard
uPBoard
SRC Hardware Architecture – cont.
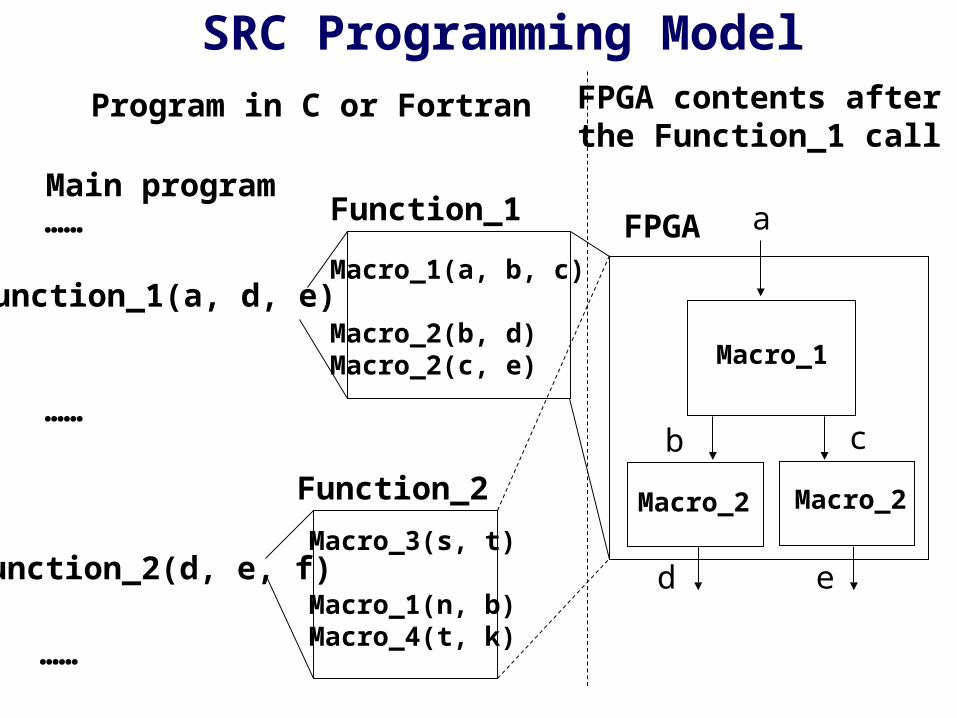
Main program
Function_1(a, d, e)
Function_2(d, e, f)
Function_1
Function_2
Macro_1(a, b, c)
Macro_2(b, d)Macro_2(c, e)
Macro_3(s, t)
Macro_1(n, b)Macro_4(t, k)
FPGA……
……
……
Macro_1
Macro_2 Macro_2
a
b c
d e
FPGA contents afterthe Function_1 call
Program in C or Fortran
SRC Programming Model
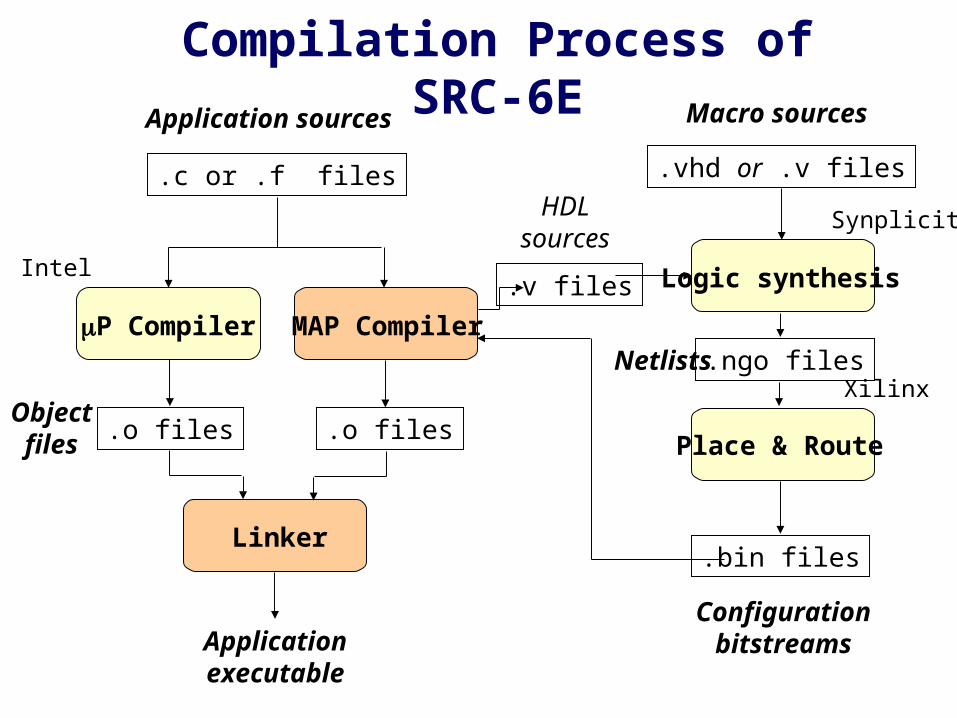
Objectfiles
Application sources Macro sources
MAP CompilerP Compiler
Logic synthesis
Place & Route
Linker
.v files
.bin files
.ngo files
.o files .o files
Applicationexecutable
Configurationbitstreams
HDLsources
Netlists
.c or .f files .vhd or .v files
Compilation Process of SRC-6E
Synplicity
Xilinx
Intel

High-throughput Triple DES encryption
Application Case Study 1
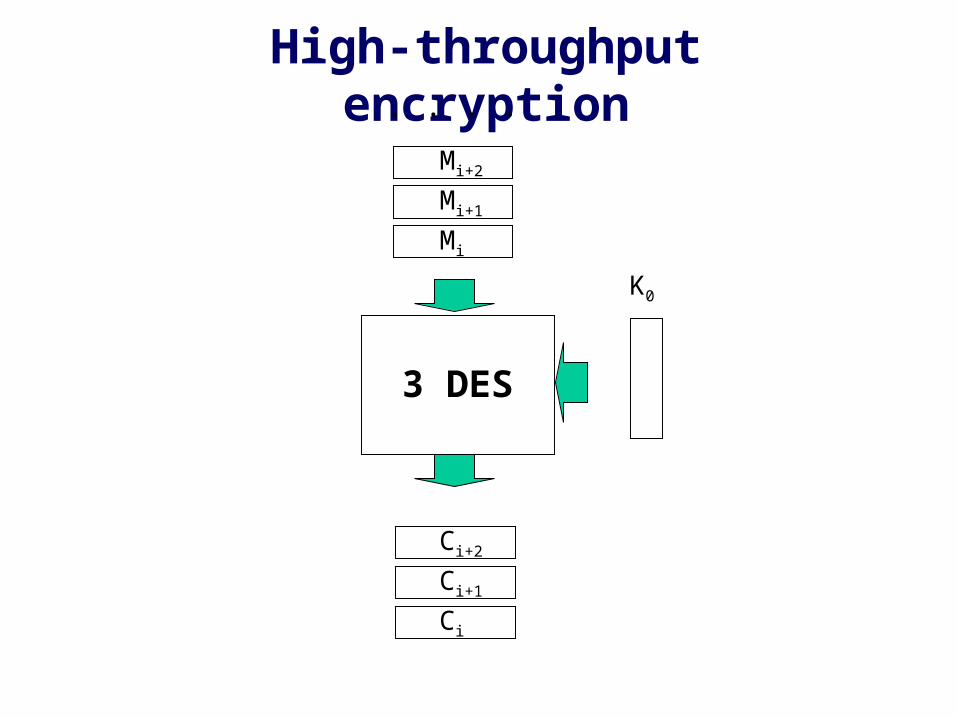
High-throughput encryption
3 DES
Mi
Mi+1
Mi+2
Ci
Ci+1
Ci+2
. . . .
K0
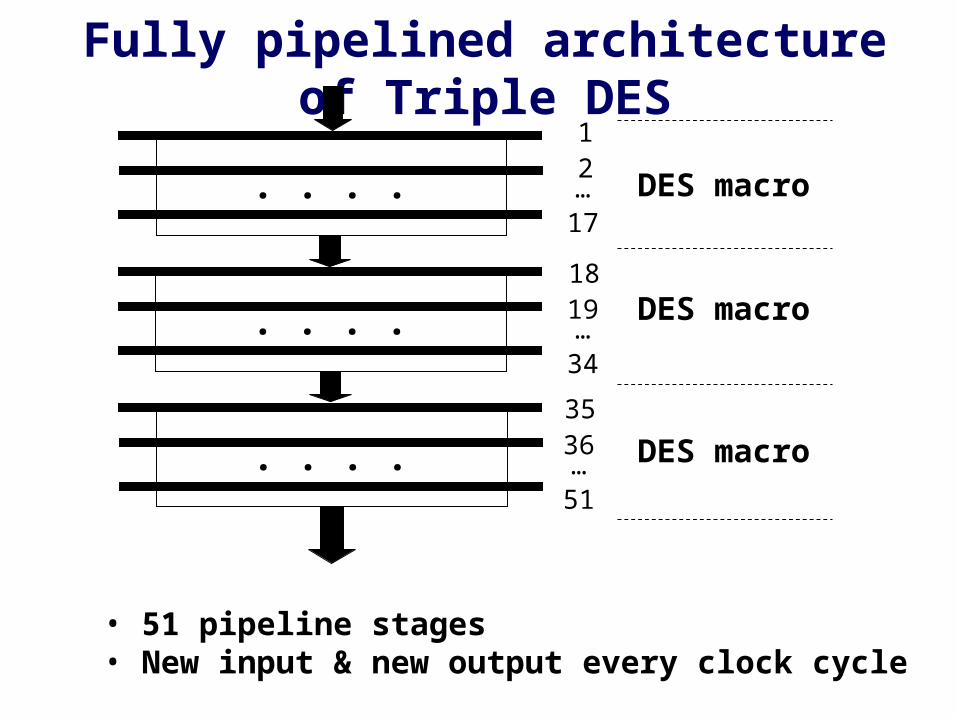
Fully pipelined architecture of Triple DES
. . . .
. . . .
. . . .
12
17…
1819
34…
3536
51…
DES macro
DES macro
DES macro
• 51 pipeline stages• New input & new output every clock cycle
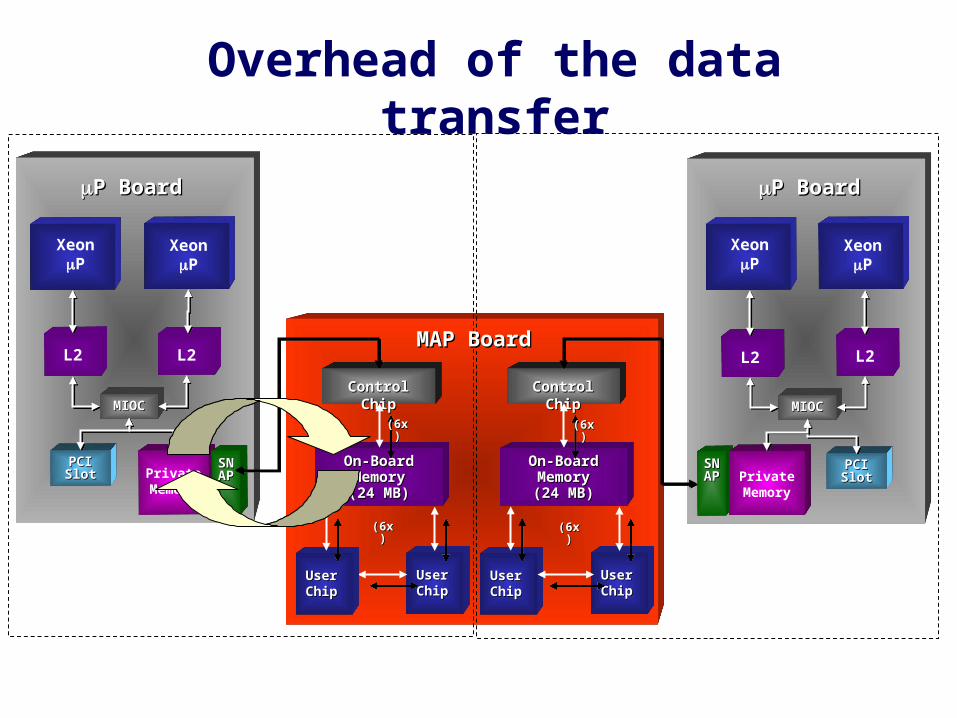
Overhead of the data transfer
L2
MIOCMIOC
L2
PCIPCISlotSlot
SSNNAAPP
PrivateMemory
P BoardP Board
XeonP
L2
PCIPCISlotSlot
MIOCMIOC
PrivateMemory
SSNNAAPP
L2
P BoardP Board
Control ChipControl Chip
On-Board On-Board MemoryMemory(24 MB)(24 MB)
(6x)(6x)
User User ChipChip
User User ChipChip
Control ChipControl Chip
On-Board On-Board MemoryMemory(24 MB)(24 MB)
User User ChipChip
User User ChipChip
XeonP
(6x)(6x)
(6x)(6x)
(6x)(6x)
XeonP
XeonP
MAP BoardMAP Board

Timing Measurements
1. end-to-end execution time: (wall clock time - HLL Level) includes the configuration, data transfer and data processing times
2. w/o configuration time: (wall clock time - HLL Level) excludes the configuration time but includes data transfer and data processing times
3. MAP Time: (clock counter - Hardware Level) only includes data processing time
Three-level timing measurement scheme has been employed:
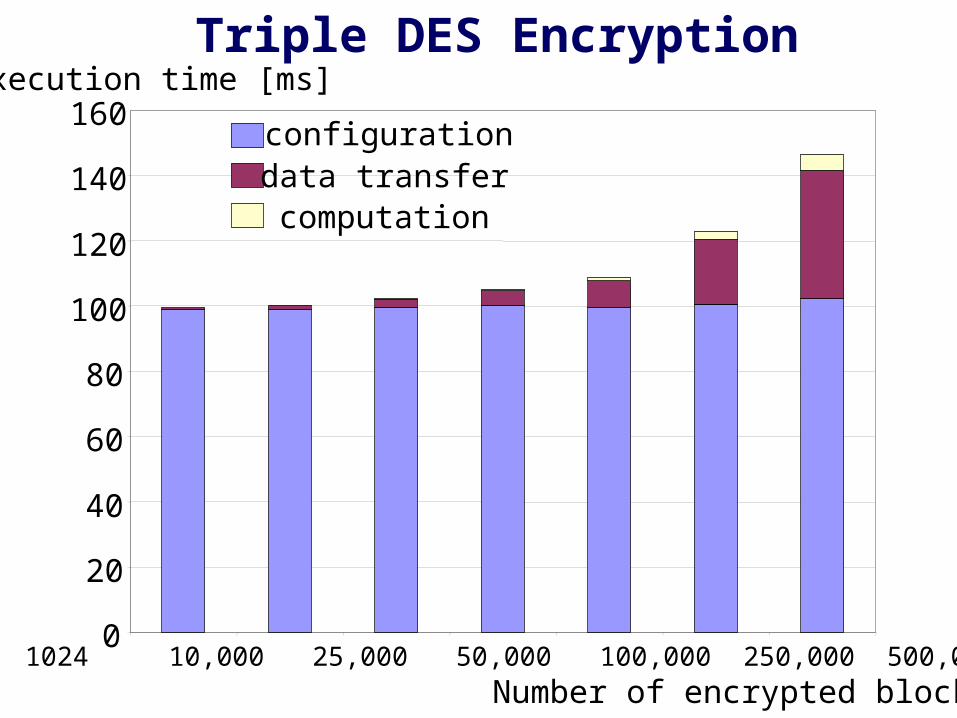
Triple DES Encryption
0
20
40
60
80
100
120
140
160
1024 10,000 25,000 50,000 100,000 250,000 500,000
configurationdata transfercomputation
Execution time [ms]
Number of encrypted blocks

• execution time dominated by - configuration of the MAP FPGA and - data transfer between the System Common Memory and On-Board-Memory
Problems
• configuration time hiding techniques preloading the configuration before execution flip-flopping FPGAs during reconfiguration
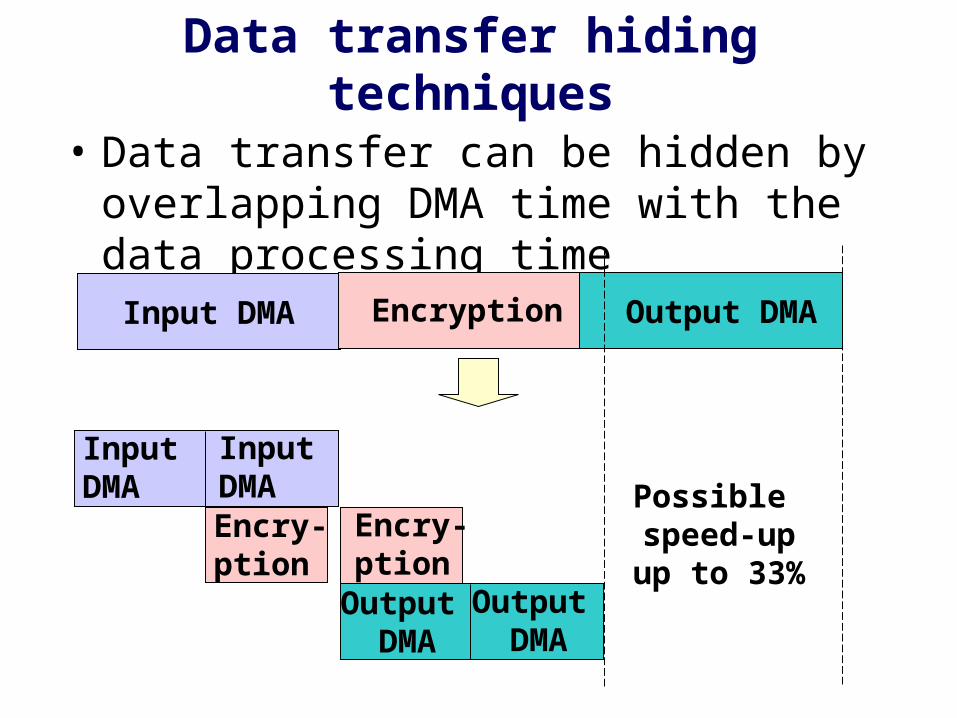
Data transfer hiding techniques
• Data transfer can be hidden by overlapping DMA time with the data processing time
Input DMA Encryption Output DMA
Input DMA
Encry-ption
Output DMA
Input DMA
Encry-ption
Possible speed-up
up to 33%Output DMA

Reference software implementations
Platform:
Software:
Pentium 4, 1.8 GHz, 512 kB cache, 1 GB RAM
Non-optimized: Optimized for encryption(but not for cipher breaking):
Public domain code C only
Intel C++-O3 optimization
Phil Karn’s DES codeC and assembly language withlook-up table precomputations
GNU gcc v. 2.96-O4 optimization
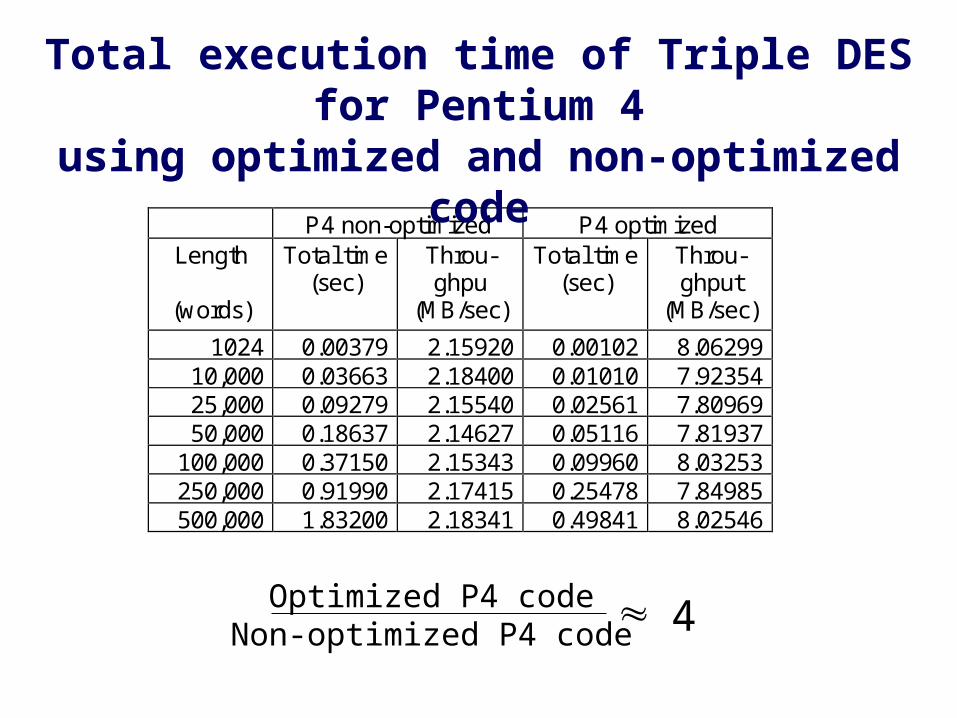
P4 non-optimized P4 optimized Length
(words)
Total time (sec)
Throu-ghpu
(MB/sec)
Total time (sec)
Throu-ghput
(MB/sec)
1024 0.00379 2.15920 0.00102 8.06299 10,000 0.03663 2.18400 0.01010 7.92354 25,000 0.09279 2.15540 0.02561 7.80969 50,000 0.18637 2.14627 0.05116 7.81937
100,000 0.37150 2.15343 0.09960 8.03253 250,000 0.91990 2.17415 0.25478 7.84985 500,000 1.83200 2.18341 0.49841 8.02546
Optimized P4 codeNon-optimized P4 code
Total execution time of Triple DES for Pentium 4using optimized and non-optimized code
4
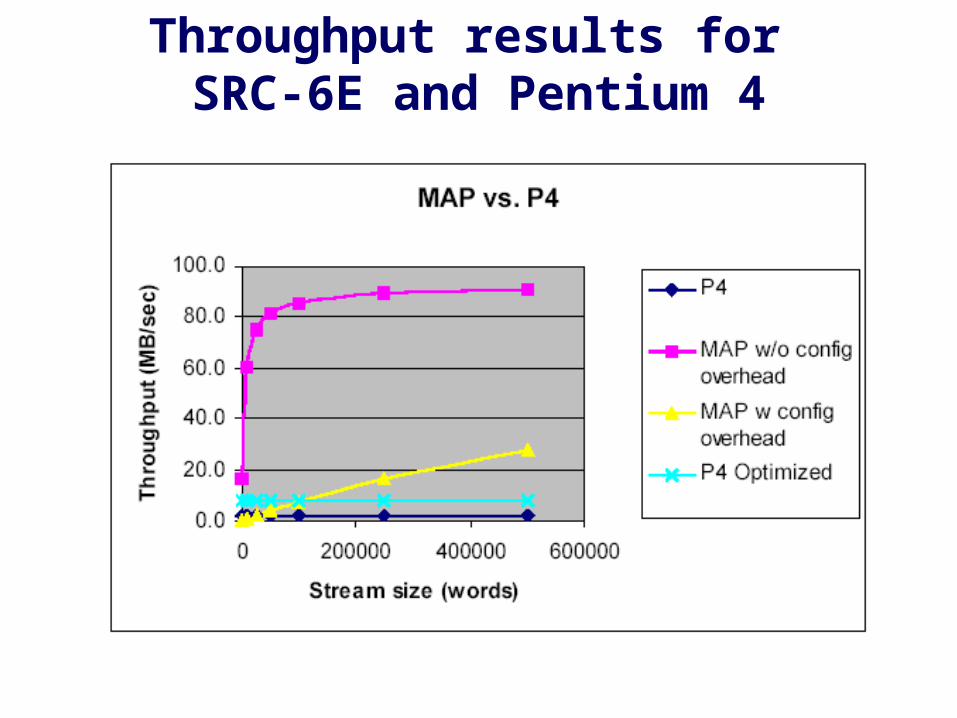
Throughput results for SRC-6E and Pentium 4

SRC-6E vs. Pentium 4speed-up

DES cipher breaking
Application Case Study 2
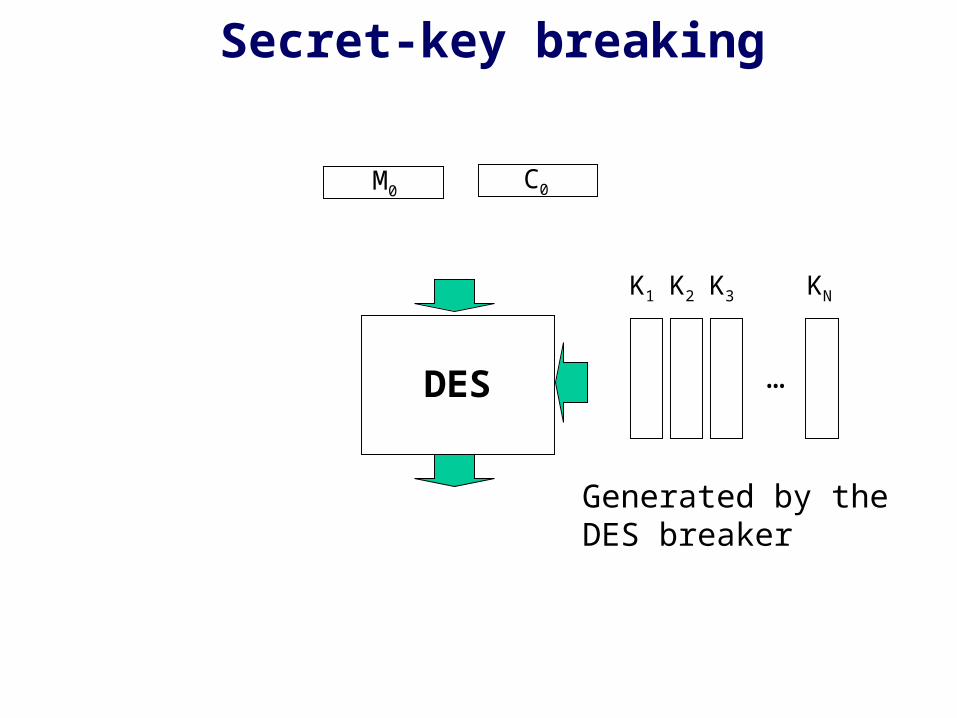
Secret-key breaking
DES
M0 C0
…
K1 K2 K3 KN
Generated by the DES breaker
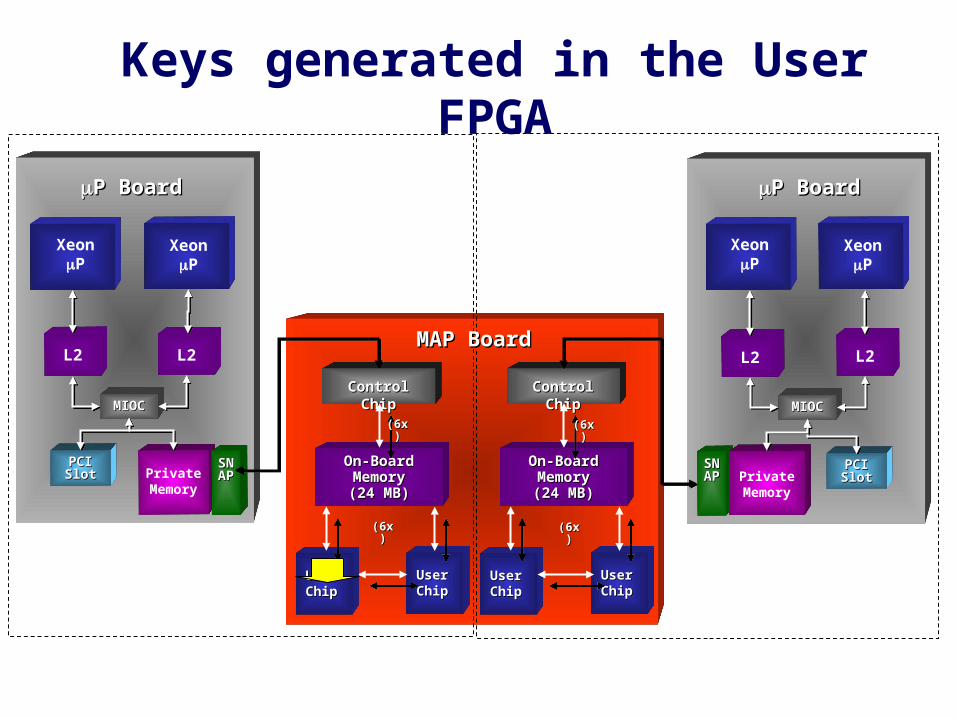
Keys generated in the User FPGA
L2
MIOCMIOC
L2
PCIPCISlotSlot
SSNNAAPP
PrivateMemory
P BoardP Board
XeonP
L2
PCIPCISlotSlot
MIOCMIOC
PrivateMemory
SSNNAAPP
L2
P BoardP Board
Control ChipControl Chip
On-Board On-Board MemoryMemory(24 MB)(24 MB)
(6x)(6x)
User User ChipChip
User User ChipChip
Control ChipControl Chip
On-Board On-Board MemoryMemory(24 MB)(24 MB)
User User ChipChip
User User ChipChip
XeonP
(6x)(6x)
(6x)(6x)
(6x)(6x)
XeonP
XeonP
MAP BoardMAP Board
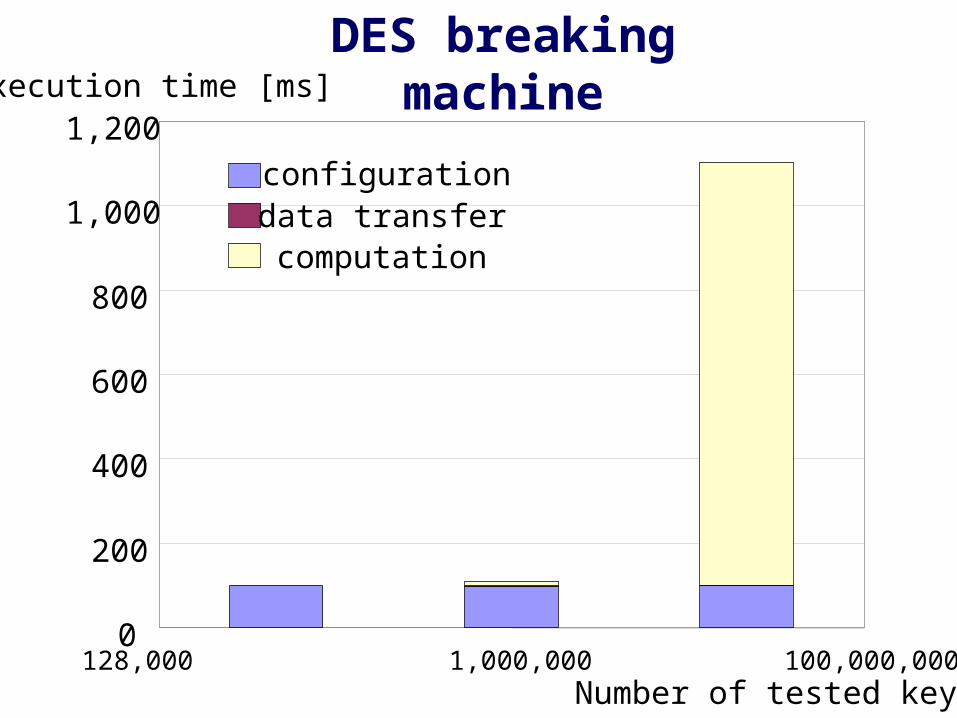
0
200
400
600
800
1,000
1,200
128,000 1,000,000 100,000,000Number of tested keys
Execution time [ms]DES breaking machine
configurationdata transfercomputation
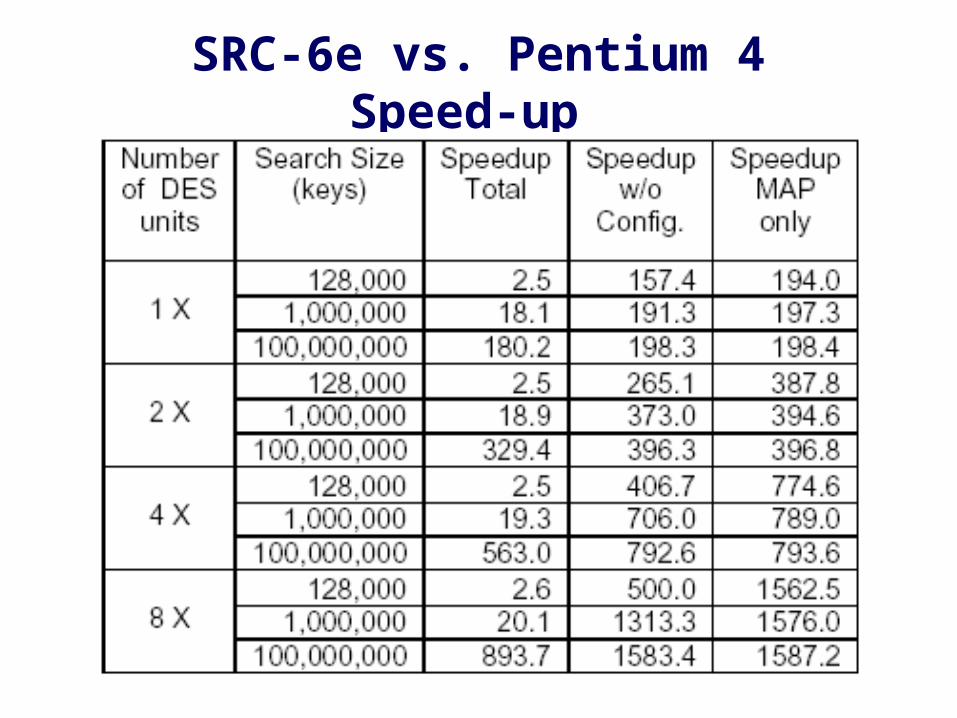
SRC-6e vs. Pentium 4 Speed-up

Conclusions
Two different classes of applications developed
and tested for SRC-6E and Pentium 4 PC
- Triple DES encryption: real-time data streaming
- DES breaking: minimal input/output

Wall-clock speed-ups
3 DES Encryption
Speed-ups without reconfiguration
Conclusions – cont.
DES Breaking
3.4 vs. P4 C code12.5 vs. P4 assembly code
894 vs. P4 C code(larger for real-time input sizes)
11 vs. P4 C code41 vs. P4 assembly code
1583 vs. P4 C code
3 DES Encryption DES Breaking

Informal speed/cost comparison
Cost of the SRC machineCost of PC
100
Speed of the SRC machineSpeed of PC
1600*
* with only one out of four FPGAs used in computations
16 x improved speed/cost ratio

Conclusions: Overheads Reconfiguration time
Data transfer time
Most affected applications:
Minimization techniques:
Most affected applications:
Minimization techniques:
short execution time, large resource requirements,frequent reconfiguration
high speed real-time input/output
• overlapping data transfer with computations
• preloading configuration• flip-flopping among multiple FPGAs





























