Embed Size (px)
Citation preview

PENGANTAR SPSS
Saptawati Bardosono

PendahuluanPada saat merancang usulan penelitian, maka
pengolahan datanya sudah harus direncanakan pula:
1) Teknik pengolahan data meliputi: editing, coding, entry dan cleaning serta analisis
2) Tabel, grafik atau ringkasan angka2 yang akan dihasilkan
Masalah yang sering timbul: Model analisis muncul setelah data terkumpul

EditingDilakukan pemeriksaan seluruh kuesioner atau seluruh
formulir isian setelah data terkumpul, apakah:1) Dapat dibaca 2) Semua pertanyaan terisi (lengkap)3) Terdapat ketidakserasian antara jawaban yang
satu dengan yang lainnya (konsisten)4) Terdapat kesalahan2 lain yang dapat mengganggu
pengolahan data selanjutnya (akurat)

EditingKegiatan editing dapat dilakukan dengan cara:1) Editing lapangan, dimana supervisor
mengadakan pengecekan ulang terhadap beberapa pertanyaan penting biasanya kepada 10% responden segera setelah data terkumpul semuanya
2) Editing menyeluruh, dilakukan secara menyeluruh terhadap jawaban responden, sehingga dapat diperoleh konsistensi jawaban

EditingYang sering terjadi misalnya1) Jawaban tidak tepat dikolom yang tersedia2) Salah menulis jawaban pertanyaan, misalnya
data kelamin diisi di kolom jawaban umur3) Umur diisi 25 tahun tetapi di jumlah anak
diisi 104) Salah menggunakan unit ukuran
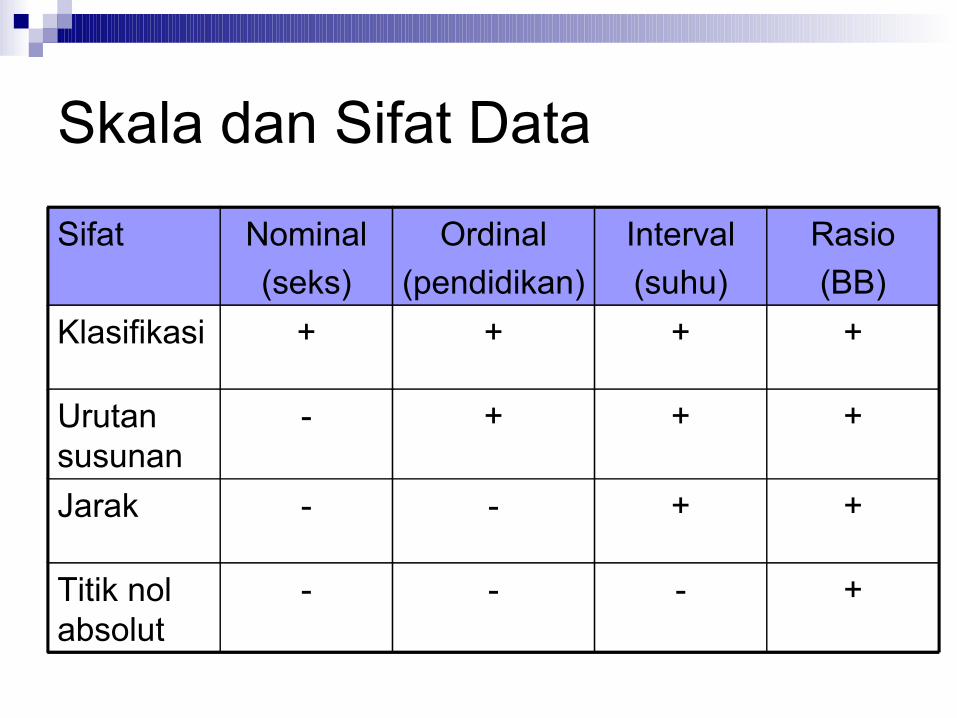
Skala dan Sifat Data
Sifat Nominal(seks)
Ordinal(pendidikan)
Interval(suhu)
Rasio(BB)
Klasifikasi + + + +
Urutan susunan
- + + +
Jarak - - + +
Titik nol absolut
- - - +

KodingMemberi angka2 atau kode2 tertentu yang telah
disepakati terhadap jawaban2 pertanyaan dalam kuesioner, sehingga memudahkan pada saat memasukkan data ke komputer
Misalnya untuk variabel pendidikan:1) Tidak sekolah2) SD3) SMP4) SMA5) PT

KodingPersyaratan dalam koding:1) Kesesuaian, variabel harus sesuai dengan tujuan2) Klasifikasi, perlu dibuat kategorisasi untuk
pengelompokkan jawaban sesuai rujukan/ alasan tertentu, misal: pendapatan
3) Jawaban tidak mendua, pilihan jawaban yang tersedia harus jelas definisi operasionalnya
4) Harus tersedia buku definisi variabel

Data EntryMenyiapkan lembar kerja yang berisi variabel2
dalam kuesioner secara lengkap (program SPSS, Stata, Epi-Info, dll)
Masukkan data jawaban kuesioner sesuai kode yang telah ditentukan untuk masing-masing variable sehingga menjadi suatu data dasar
Siapkan file khusus untuk menyimpan data dasar tersebut yang tidak boleh dianalisis. Untuk melakukan analisis data maka gunakan file khusus

Data Cleaning Merupakan analisis data awal, dimana dilakukan
penggolongan, pengurutan dan penyederhanaan data, sehingga mudah dibaca dan diinterpretasi
Untuk data nominal dan ordinal, dibuat tabulasi distribusi frekuensi untuk setiap variabel
Untuk data interval/rasio, dianalisis nilai tengah dan tes normalitas datanya

Data CleaningTabel distribusi frekuensi untuk:1) Deskripsi ciri-ciri atau karakteristik dari
suatu variabel2) Mempelajari distribusi dari variabel pokok3) Memilih klasifikasi2 pokok untuk tabulasi
silang

Data CleaningTabel silang, yaitu teknik untuk membandingkan atau
melihat hubungan antara dua variabel atau lebih:1) Dihitung persentase responden untuk setiap
kelompok2) Variabel bebas pada baris (faktor risiko)3) Variabel terikat pada kolom (penyakit)Selanjutnya, data siap dianalisis untuk membuktikan
hipotesis penelitian dengan analisis statistik bivariat dan multivariat

SPSS(statistical program for social sciences)
Tampilan layar SPSS ada 2: Sebagai lembar kerja seperti Excel, dBase
= data view Sebagai definisi operasional
= variable viewDengan menu2 yang mudah dijalankan
Data view
Variabel Variabel Variabel dst
1
2
dst
Variabel viewName Type Width Decimals Label Values dst
1
2
dst

Penggunaan SPSS
Menyiapkan sarana untuk data entry (penyusunan lembar kerja)
Membantu data cleaning (analisis awal) Analisis statistik untuk membuktikan
hipotesis Analisis statistik untuk penyajian data

Latihan Penggunaan SPSS
1. Menyiapkan sarana untuk data entry (penyusunan lembar kerja)
2. Membantu data cleaning (analisis awal)3. Analisis statistik untuk membuktikan
hipotesis4. Analisis statistik untuk penyajian data

Menyiapkan sarana untuk data entry (penyusunan lembar kerja)
Data latihan – dietstudy: File – open – data – pilih file - open Lihat data view: jumlah kasus Lihat variabel view: jumlah variabel Buat code book variable: utilities – file info

Menyiapkan sarana untuk data entry: penyusunan lembar kerja
Menyiapkan data dasar – latihan membuat data dasar: Lokasi penelitian Tanggal pengambilan data Nama ibu Tanggal lahir Berat badan Tinggi badan Tingkat pendidikan ibu Jenis pekerjaan ibu Pengetahuan ibu tentang gizi seimbang
Data entry – latihan

Analisis data: data cleaning
Analisis univariat (deskriptif, frekuensi, explore)
Uji normalitas data (KS, histogram) Analisis bivariat (crosstab)
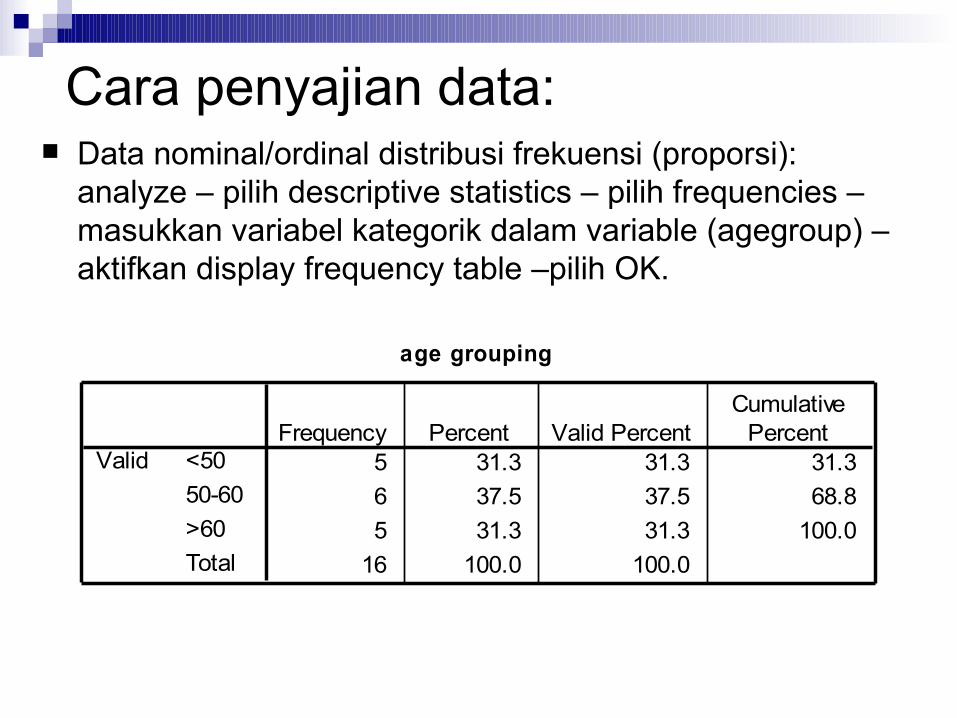
Cara penyajian data: Data nominal/ordinal distribusi frekuensi (proporsi):
analyze – pilih descriptive statistics – pilih frequencies – masukkan variabel kategorik dalam variable (agegroup) – aktifkan display frequency table –pilih OK.
age grouping
5 31.3 31.3 31.36 37.5 37.5 68.85 31.3 31.3 100.0
16 100.0 100.0
<5050-60>60Total
ValidFrequency Percent Valid Percent
CumulativePercent

Cara penyajian data:
Data interval/rasio:Distribusi normal: mean ± SDDistribusi tidak normal: median (min-maks)

Distribusi normal?
1. Signifikansi KS >0,05
2. Signifikansi SW >0,05
3. Nilai kerampingan dan kemiringan
4. Histogram dalam area kurva normal

Nilai kemiringan dan kerampingan
Nilai kemiringan (skewness) dan nilai
kerampingan (kurtosis) digunakan untuk
menentukan distribusi normal/simetris dari
data bergantung dari bentuk kurva distribusi
data
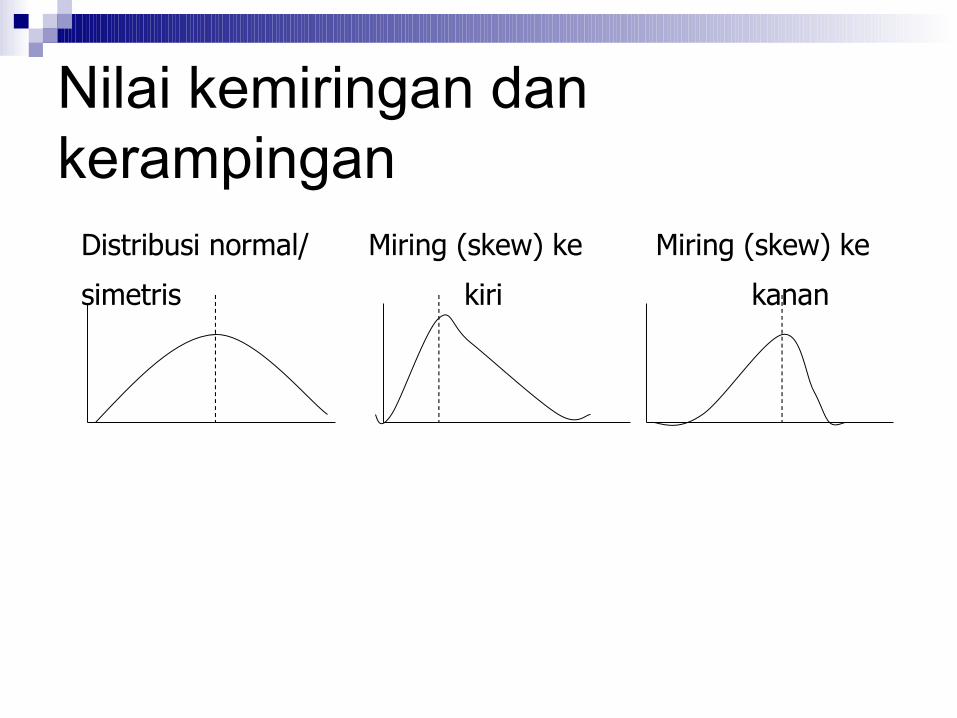
Nilai kemiringan dan kerampingan
Distribusi normal/ Miring (skew) ke Miring (skew) ke
simetris kiri kanan

Nilai kemiringan dan kerampinganContoh:
Bila diketahui skewness -0,316 dan standard error skewness 0,254 maka rasio skewness = -0,316/0,254 = -1,244
Dengan kurtosis 0,284 dan standard error kurtosis 0,503 maka rasio kurtosis = 0,284/0,503 = 0,564
Sehingga rasio skewness dan kurtosis keduanya berada di antara interval angka -2 dan +2 atau distribusi data normal atau simetris
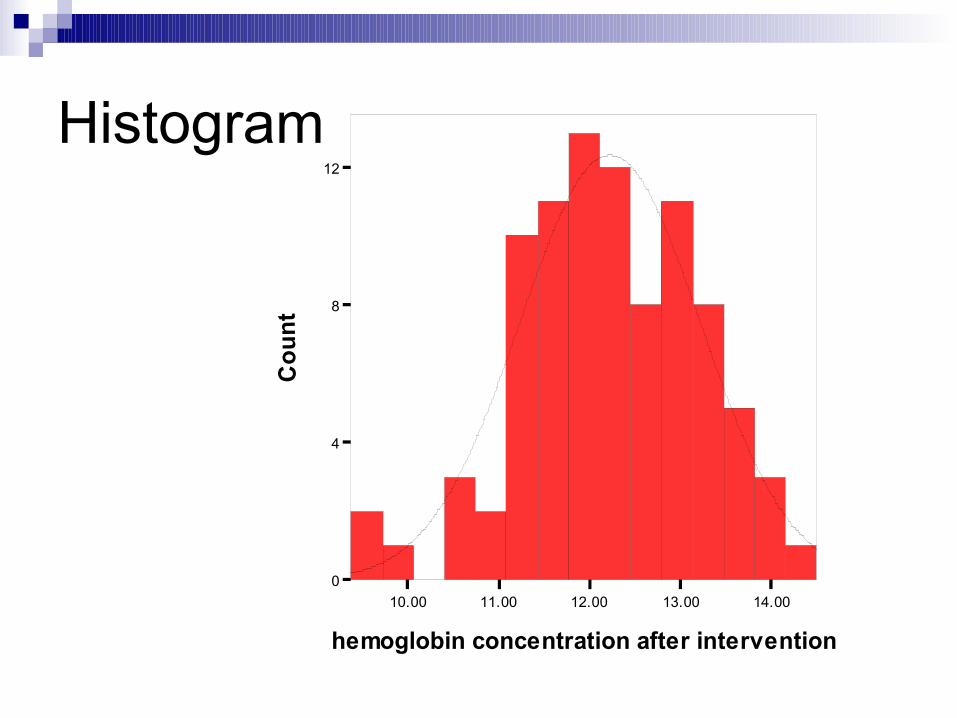
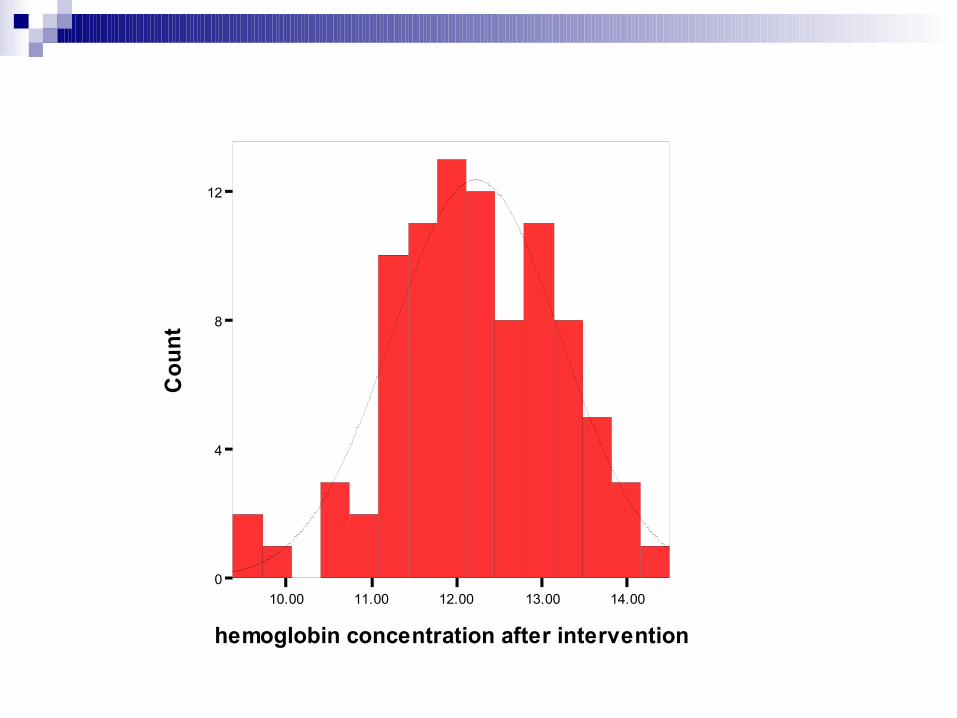
Histogram
10.00 11.00 12.00 13.00 14.00
hemoglobin concentration after intervention
0
4
8
12
Cou
nt

Histogram:
Bentuk kurva simetris Mean = median = mode Kiri = kanan = 50%

Uji normalitas data:
analyze – pilih descriptive statistics – pilih explore – masukkan variabel rasio dalam dependent list (wgt0) – pada pilihan display pilih plots – klik plots – pilih normality plots with test (non-aktifkan yang lainnya) – pilih continue – pilih OK. Perhatikan tampilan tabel test of normality

Uji Kolmogorov-Smirnov (KS) dan Shapiro-Wilk (SW)
Tests of Normality
.15616
.200*
.93816
.320
StatisticdfSig.StatisticdfSig.
Kolmogorov-Smirnov
a
Shapiro-Wilk
Cholesterol
This is a lower bound of the true significance.*.
Lilliefors Significance Correctiona.
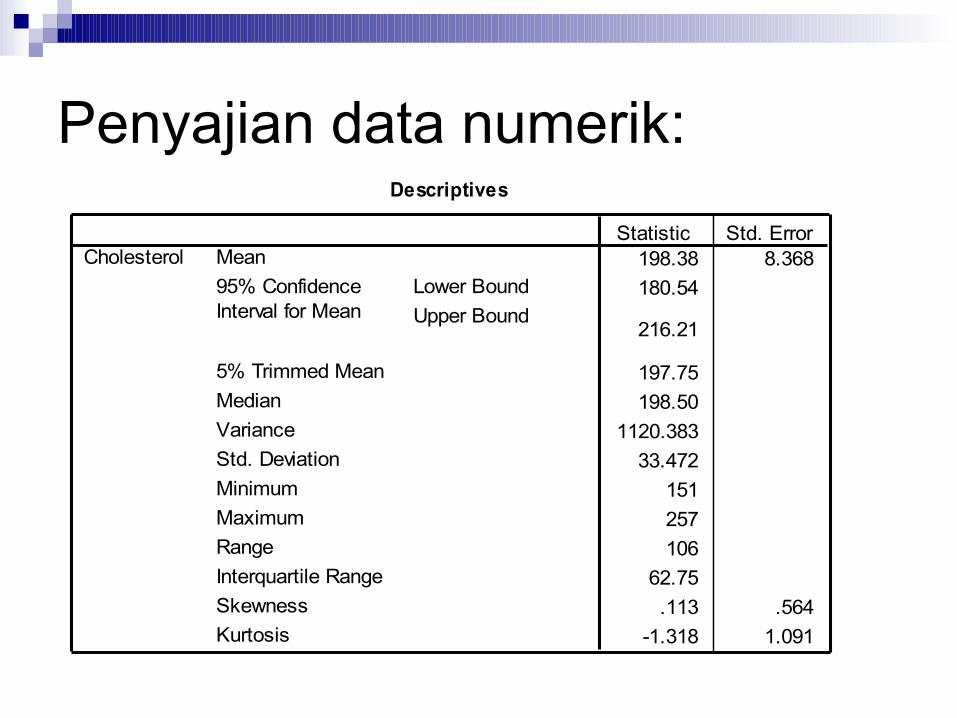
Penyajian data numerik:Descriptives
198.38 8.368180.54
216.21
197.75198.50
1120.38333.472
151257106
62.75.113 .564
-1.318 1.091
MeanLower BoundUpper Bound
95% ConfidenceInterval for Mean
5% Trimmed MeanMedianVarianceStd. DeviationMinimumMaximumRangeInterquartile RangeSkewnessKurtosis
CholesterolStatistic Std. Error

Analisis data: data cleaning
Analisis bivariat (crosstab) Analyze – pilih descriptive statistics – pilih
crosstab – pada row masukkan data kategorik variabel bebas (gender) – pada column(s) masukkan data kategorik variabel terikat (cholstat)– pada display aktifkan clustered bar chart - pilih OK. Perhatikan outputnya
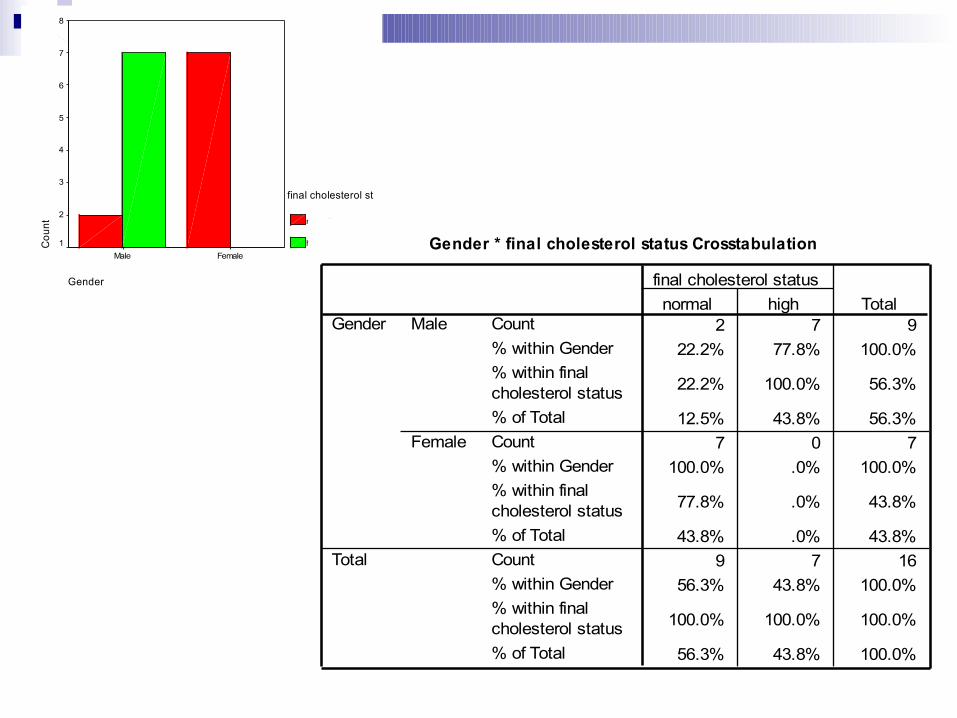
Gender
FemaleMale
Cou
nt
8
7
6
5
4
3
2
1
final cholesterol st
normal
high Gender * final cholesterol status Crosstabulation
2 7 922.2% 77.8% 100.0%
22.2% 100.0% 56.3%
12.5% 43.8% 56.3%7 0 7
100.0% .0% 100.0%
77.8% .0% 43.8%
43.8% .0% 43.8%9 7 16
56.3% 43.8% 100.0%
100.0% 100.0% 100.0%
56.3% 43.8% 100.0%
Count% within Gender% within finalcholesterol status% of TotalCount% within Gender% within finalcholesterol status% of TotalCount% within Gender% within finalcholesterol status% of Total
Male
Female
Gender
Total
normal highfinal cholesterol status
Total

Analisis data: untuk membuktikan hipotesis
Analisis bivariat crosstab, korelasi, uji T dua sampel bebas dan berpasangan)
Analisis multivariat (ANOVA, regresi ganda)

Analisis data: untuk membuktikan hipotesis
Analisis bivariat crosstab: Analyze – pilih crosstab – pada row
masukkan variabel bebas (gender) – pada column(s) masukkan variabel terikat (cholstat) – pilih statistics – klik continue – OK. Perhatikan hasilnya.
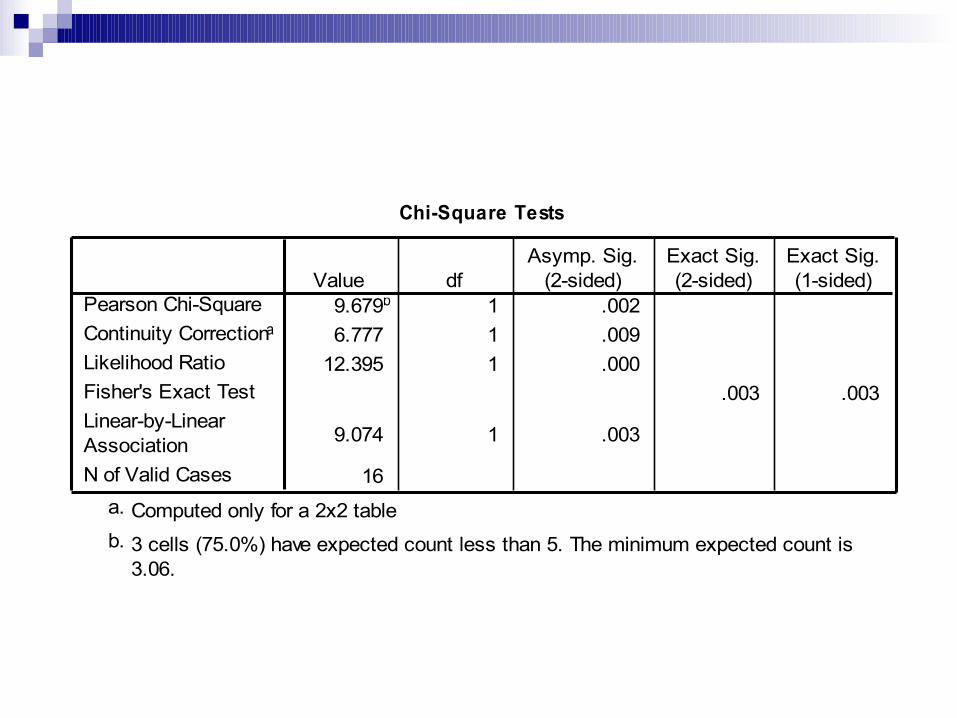
Chi-Square Tests
9.679b 1 .0026.777 1 .009
12.395 1 .000.003 .003
9.074 1 .003
16
Pearson Chi-SquareContinuity Correctiona
Likelihood RatioFisher's Exact TestLinear-by-LinearAssociationN of Valid Cases
Value dfAsymp. Sig.
(2-sided)Exact Sig.(2-sided)
Exact Sig.(1-sided)
Computed only for a 2x2 tablea.
3 cells (75.0%) have expected count less than 5. The minimum expected count is3.06.
b.
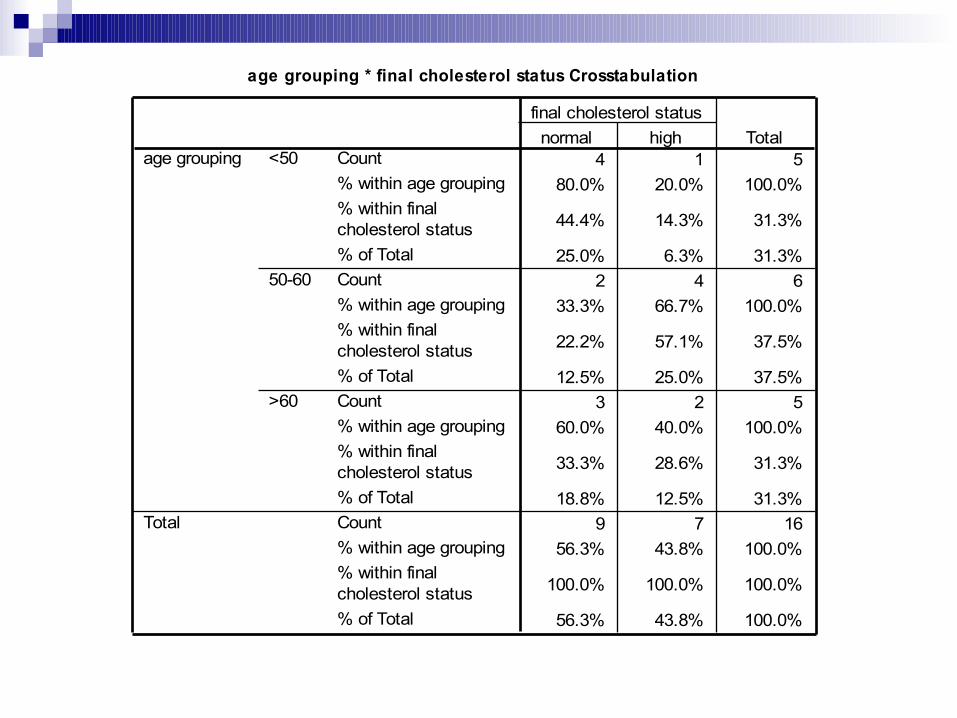
age grouping * final cholesterol status Crosstabulation
4 1 580.0% 20.0% 100.0%
44.4% 14.3% 31.3%
25.0% 6.3% 31.3%2 4 6
33.3% 66.7% 100.0%
22.2% 57.1% 37.5%
12.5% 25.0% 37.5%3 2 5
60.0% 40.0% 100.0%
33.3% 28.6% 31.3%
18.8% 12.5% 31.3%9 7 16
56.3% 43.8% 100.0%
100.0% 100.0% 100.0%
56.3% 43.8% 100.0%
Count% within age grouping% within finalcholesterol status% of TotalCount% within age grouping% within finalcholesterol status% of TotalCount% within age grouping% within finalcholesterol status% of TotalCount% within age grouping% within finalcholesterol status% of Total
<50
50-60
>60
age grouping
Total
normal highfinal cholesterol status
Total

Uji KS 2 sampel tidak berpasangan
Chi-Square Tests
2.455a 2 .2932.558 2 .278
.381 1 .537
16
Pearson Chi-SquareLikelihood RatioLinear-by-LinearAssociationN of Valid Cases
Value dfAsymp. Sig.
(2-sided)
6 cells (100.0%) have expected count less than 5. Theminimum expected count is 2.19.
a.
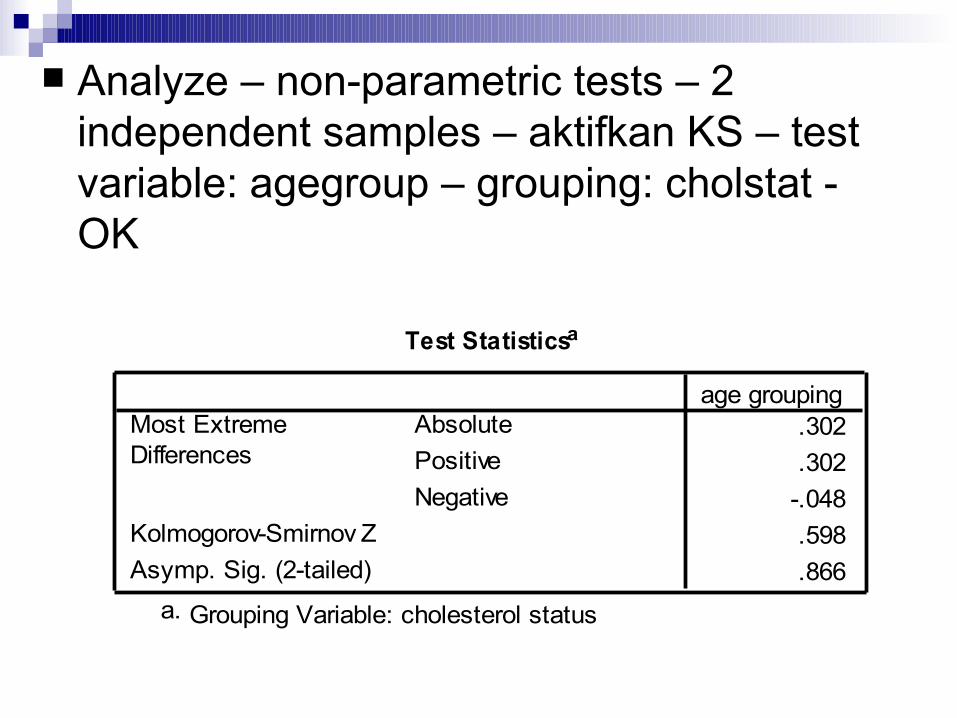
Analyze – non-parametric tests – 2 independent samples – aktifkan KS – test variable: agegroup – grouping: cholstat - OK
Test Statisticsa
.302
.302-.048.598.866
AbsolutePositiveNegative
Most ExtremeDifferences
Kolmogorov-Smirnov ZAsymp. Sig. (2-tailed)
age grouping
Grouping Variable: cholesterol statusa.

Analisis data: untuk membuktikan hipotesis
Korelasi: Analyze – pilih correlate – pilih bivariate –
masukkan dua variabel numerik – pilih Pearson – pilih two tailed – aktifkan flag significant correlation – pilih option – aktifkan exclude case pairwise – OK. Perhatikan hasilnya

Analisis data: untuk membuktikan hipotesis
Korelasi: Analyze – pilih correlate – pilih bivariate –
masukkan dua variabel numerik – pilih Spearman – pilih two tailed – aktifkan flag significant correlation – pilih option – aktifkan exclude case pairwise – OK. Perhatikan hasilnya
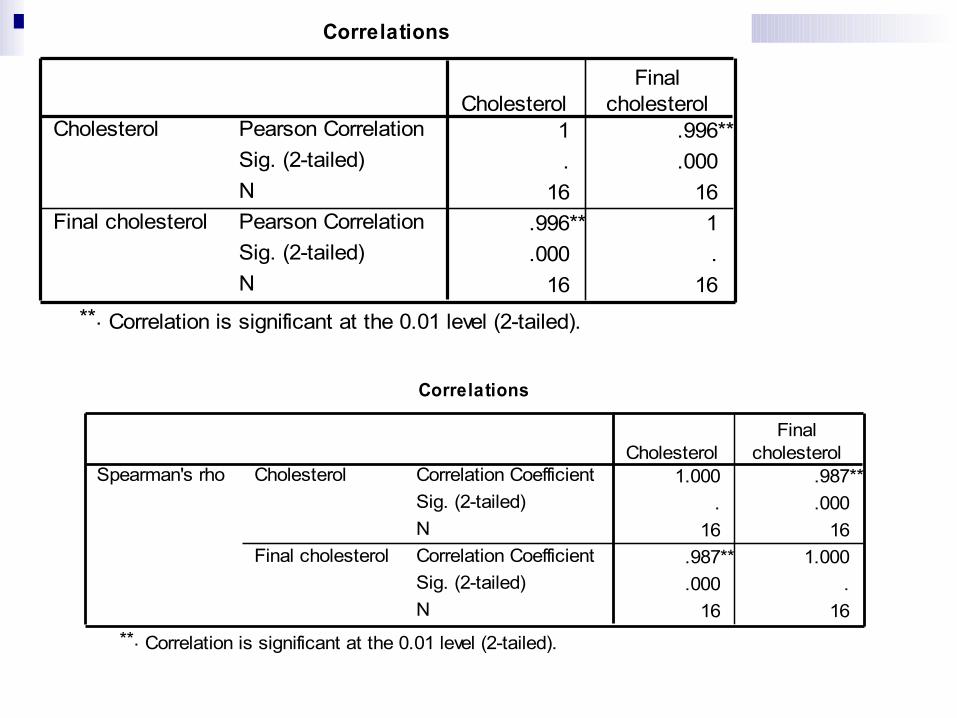
Correlations
1 .996**. .000
16 16.996** 1.000 .
16 16
Pearson CorrelationSig. (2-tailed)NPearson CorrelationSig. (2-tailed)N
Cholesterol
Final cholesterol
CholesterolFinal
cholesterol
Correlation is significant at the 0.01 level (2-tailed).**.
Correlations
1.000 .987**. .000
16 16.987** 1.000.000 .
16 16
Correlation CoefficientSig. (2-tailed)NCorrelation CoefficientSig. (2-tailed)N
Cholesterol
Final cholesterol
Spearman's rhoCholesterol
Finalcholesterol
Correlation is significant at the 0.01 level (2-tailed).**.

Persamaan regresi:
Graph – interactive – scatter plot – sumbu X = variabel bebas (wgt0) – sumbu Y = variabel terikat (wgt3) – fit – regression – include constant in equation – fit lines for total - OK
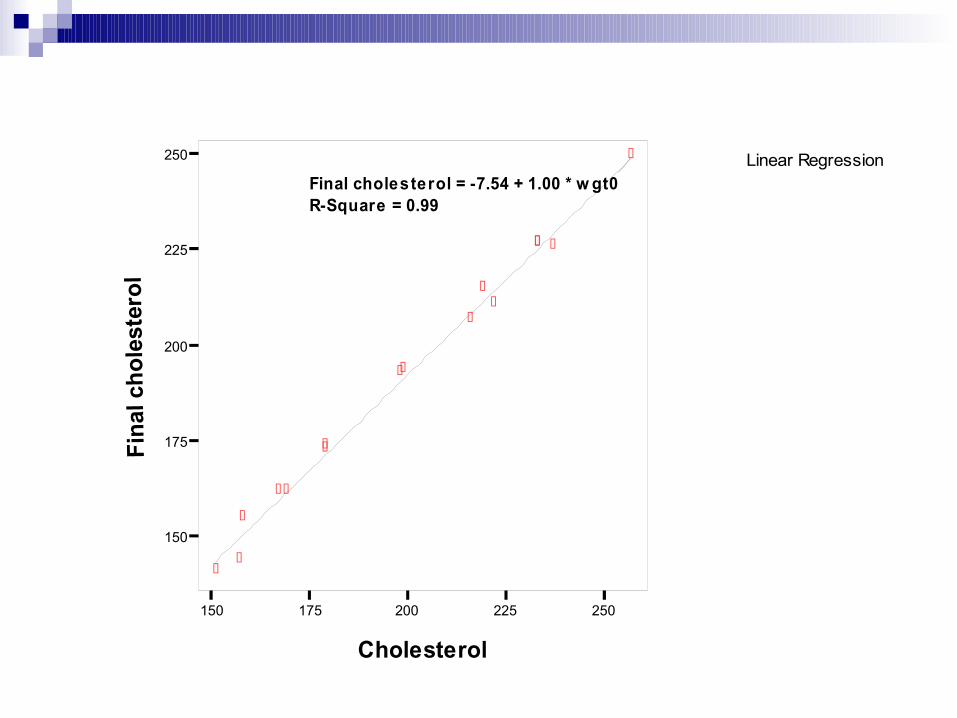
Linear Regression
150 175 200 225 250
Cholesterol
150
175
200
225
250Fi
nal c
hole
ster
ol
Final cholesterol = -7.54 + 1.00 * w gt0R-Square = 0.99

Analisis data: untuk membuktikan hipotesis
Uji T dua sampel bebas: Analyze – pilih compare means – pilih
independent samples t-test – pada test variable(s) pilih variabel numerik (wgt0) – pada grouping variable masukkan variabel 2 kategorik (gender) – pada define group masukkan 1 untuk group 0 dan 2 untuk group 1 – pilih continue – pada option aktifkan tingkat kepercayaan 95% dan exclude cases analysis by analysis – pilih continue dan OK. Perhatikan hasilnya
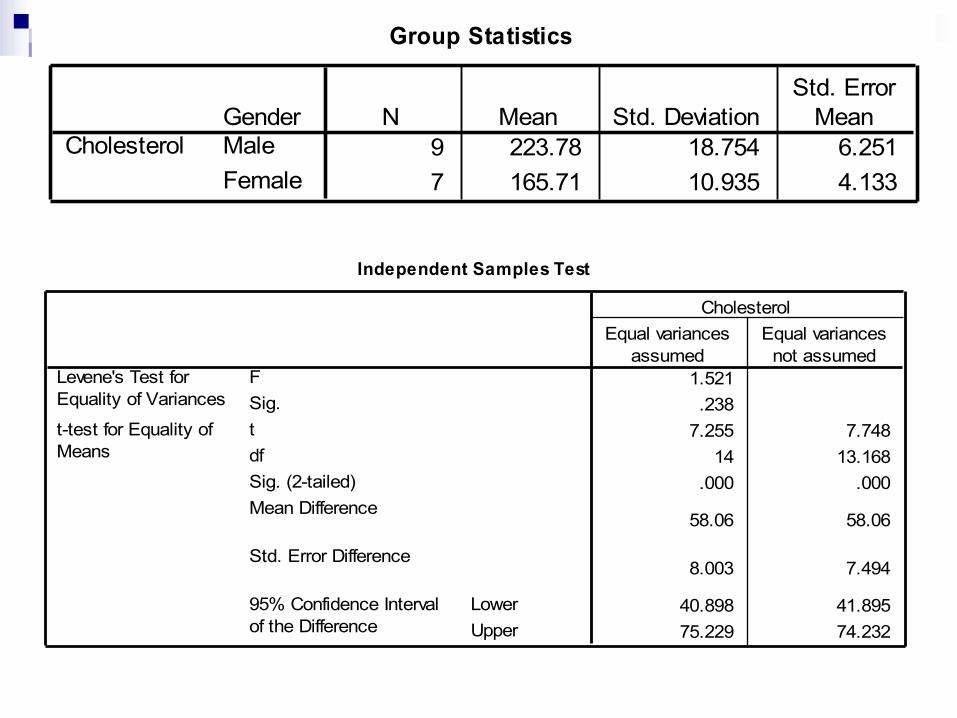
Group Statistics
9 223.78 18.754 6.2517 165.71 10.935 4.133
GenderMaleFemale
CholesterolN Mean Std. Deviation
Std. ErrorMean
Independent Samples Test
1.521.238
7.255 7.74814 13.168
.000 .000
58.06 58.06
8.003 7.494
40.898 41.89575.229 74.232
FSig.
Levene's Test forEquality of Variances
tdfSig. (2-tailed)Mean Difference
Std. Error Difference
LowerUpper
95% Confidence Intervalof the Difference
t-test for Equality ofMeans
Equal variancesassumed
Equal variancesnot assumed
Cholesterol

Non-parametrik – Mann Whitney:
Analyze – non-parametric tests – 2 independent samples - pada test variable(s) pilih variabel numerik (wgt0) – pada grouping variable masukkan variabel 2 kategorik (gender) – pada define group masukkan 1 untuk group 0 dan 2 untuk group 1 – pilih continue – pada test type aktifkan Mann Whitney –OK. Perhatikan hasilnya
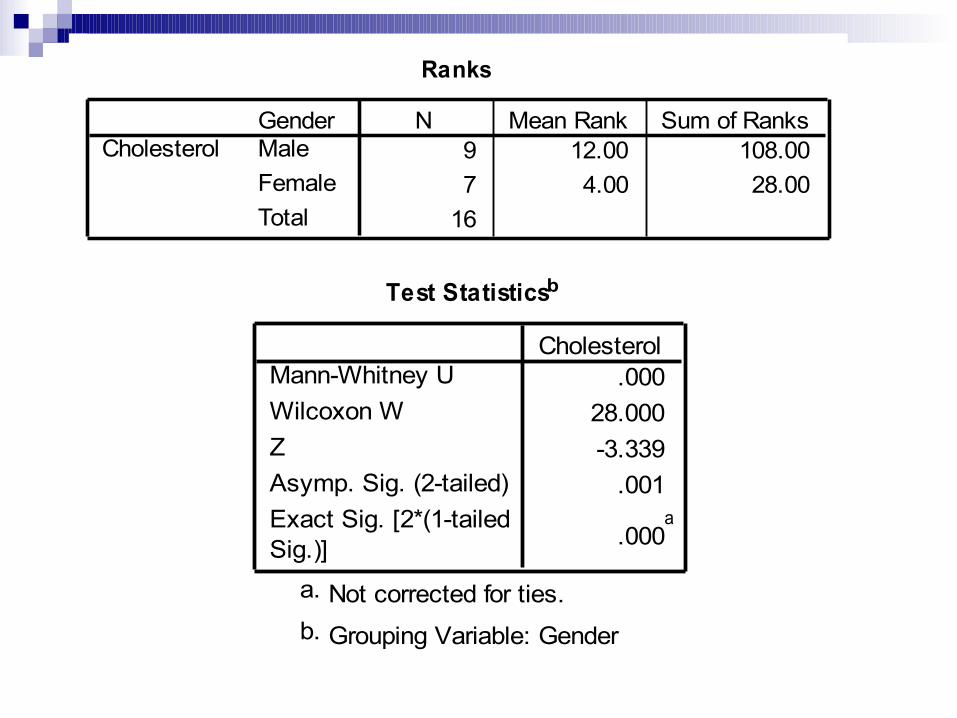
Ranks
9 12.00 108.007 4.00 28.00
16
GenderMaleFemaleTotal
CholesterolN Mean Rank Sum of Ranks
Test Statisticsb
.00028.000-3.339
.001
.000a
Mann-Whitney UWilcoxon WZAsymp. Sig. (2-tailed)Exact Sig. [2*(1-tailedSig.)]
Cholesterol
Not corrected for ties.a.
Grouping Variable: Genderb.

Analisis data: untuk membuktikan hipotesis
Uji T dua sampel berpasangan): Analyze – pilih compare means – pilih paired
samples t-test – pada paired variable(s) masukkan variabel numerik sebelum intervensi (wgt0) dan variabel numerik sesudah intervensi (wgt4) - pada option aktifkan tingkat kepercayaan 95% dan exclude cases analysis by analysis – pilih continue dan OK. Perhatikan hasilnya
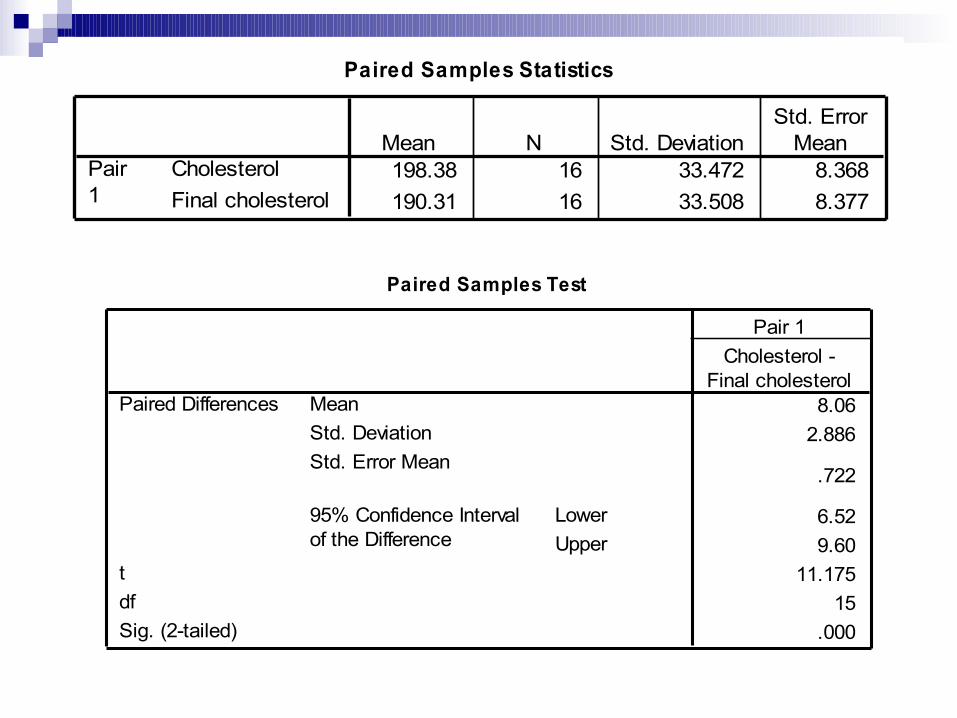
Paired Samples Statistics
198.38 16 33.472 8.368190.31 16 33.508 8.377
CholesterolFinal cholesterol
Pair1
Mean N Std. DeviationStd. Error
Mean
Paired Samples Test
8.062.886
.722
6.529.60
11.17515
.000
MeanStd. DeviationStd. Error Mean
LowerUpper
95% Confidence Intervalof the Difference
Paired Differences
tdfSig. (2-tailed)
Cholesterol -Final cholesterol
Pair 1

Analisis data: untuk membuktikan hipotesis
Uji T dua sampel berpasangan): Analyze – pilih non-parametric tests – pilih
2 related samples – pilih variabel numerik wgt0 dan variabel numerik wgt4 - dan OK. Perhatikan hasilnya
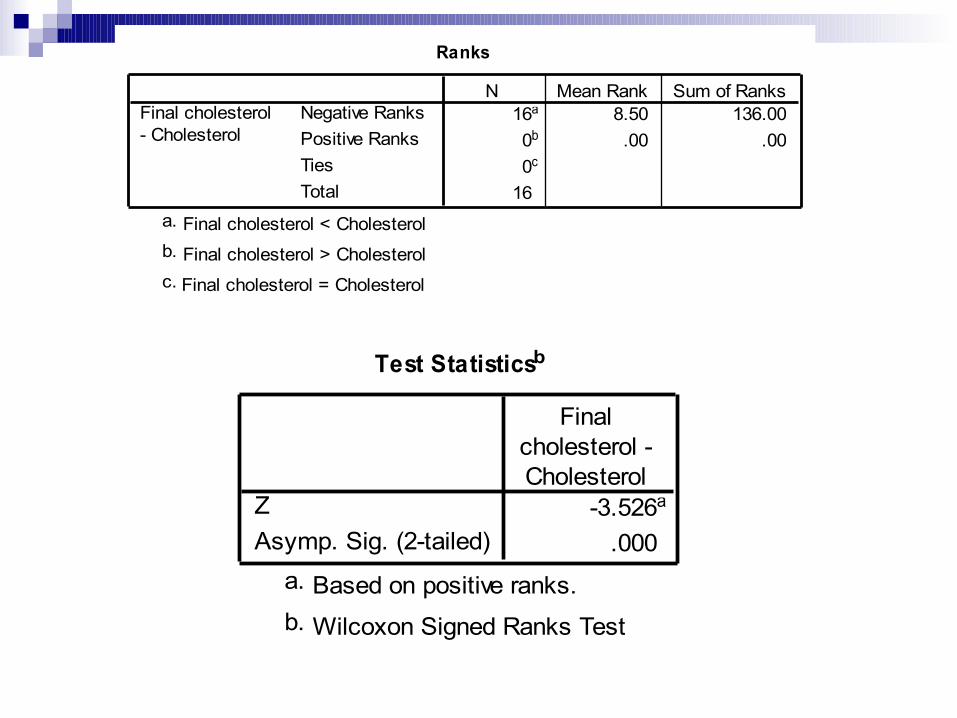
Ranks
16a 8.50 136.000b .00 .000c
16
Negative RanksPositive RanksTiesTotal
Final cholesterol- Cholesterol
N Mean Rank Sum of Ranks
Final cholesterol < Cholesterola.
Final cholesterol > Cholesterolb.
Final cholesterol = Cholesterolc.
Test Statisticsb
-3.526a
.000ZAsymp. Sig. (2-tailed)
Finalcholesterol -Cholesterol
Based on positive ranks.a.
Wilcoxon Signed Ranks Testb.

Analisis data: untuk membuktikan hipotesis
Analisis multivariat (ANOVA): Analyze – pilih compare means – pilih one-way
anova – pada dependent list pilih variabel numerik (wgt0) – pada faktor pilih variabel lebih 2 kategorik (agegroup) – pada option aktifkan descriptive dan homogeneity of variance – pilih continue – pada post-hoc pilih bonferroni – pilih continue dan OK. Perhatikan hasilnya
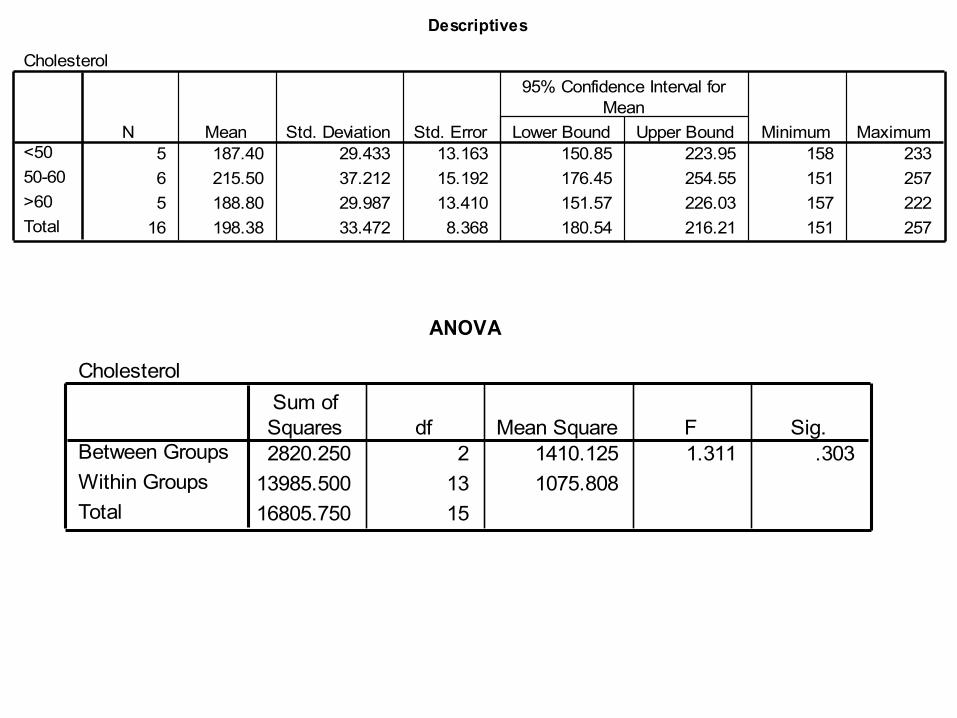
Descriptives
Cholesterol
5 187.40 29.433 13.163 150.85 223.95 158 2336 215.50 37.212 15.192 176.45 254.55 151 2575 188.80 29.987 13.410 151.57 226.03 157 222
16 198.38 33.472 8.368 180.54 216.21 151 257
<5050-60>60Total
N Mean Std. Deviation Std. Error Lower Bound Upper Bound
95% Confidence Interval forMean
Minimum Maximum
ANOVA
Cholesterol
2820.250 2 1410.125 1.311 .30313985.500 13 1075.80816805.750 15
Between GroupsWithin GroupsTotal
Sum ofSquares df Mean Square F Sig.
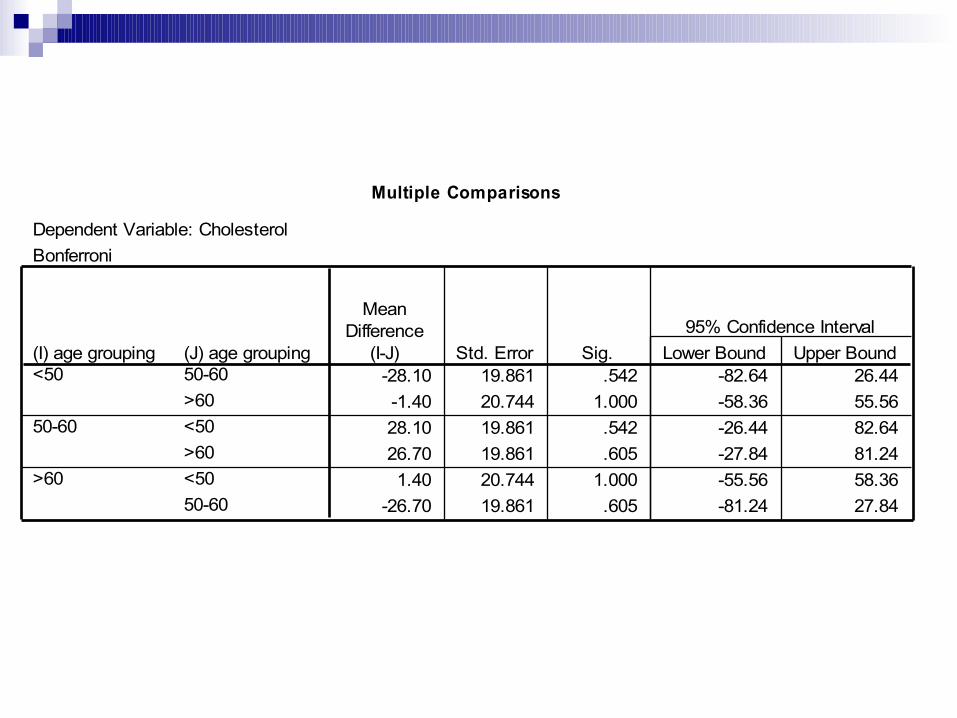
Multiple Comparisons
Dependent Variable: CholesterolBonferroni
-28.10 19.861 .542 -82.64 26.44-1.40 20.744 1.000 -58.36 55.5628.10 19.861 .542 -26.44 82.6426.70 19.861 .605 -27.84 81.241.40 20.744 1.000 -55.56 58.36
-26.70 19.861 .605 -81.24 27.84
(J) age grouping50-60>60<50>60<5050-60
(I) age grouping<50
50-60
>60
MeanDifference
(I-J) Std. Error Sig. Lower Bound Upper Bound95% Confidence Interval

Uji Kruskal-Wallis:
Analyze – non-parametric tests – k independent samples – test variable: wgt0 – grouping: agegroup – define: minimum (1) dan maximum (3) – continue - OK
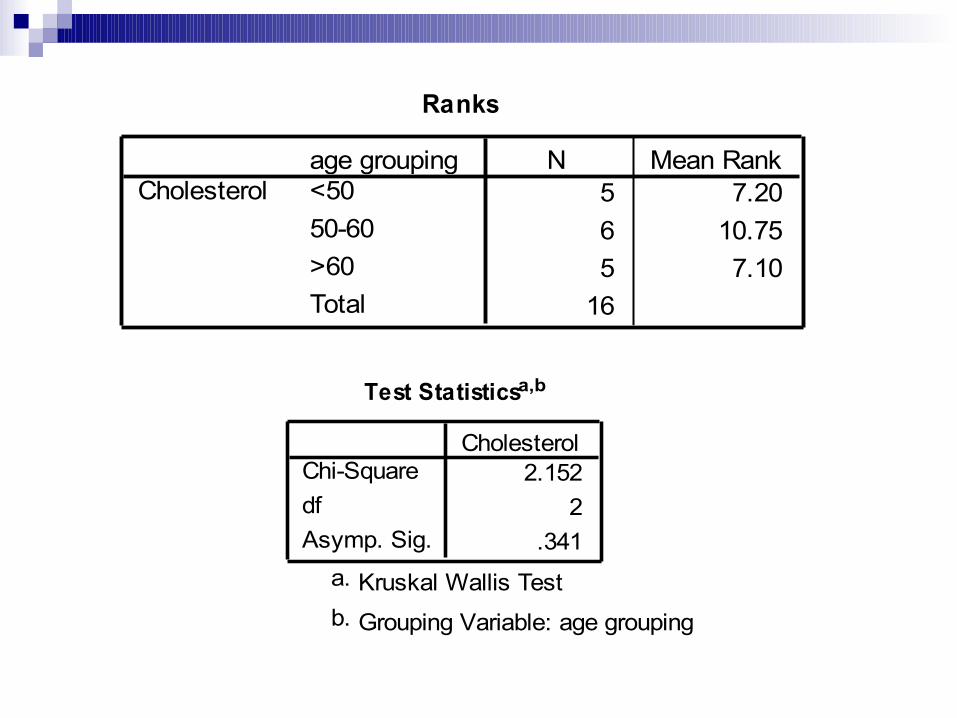
Test Statisticsa,b
2.1522
.341
Chi-SquaredfAsymp. Sig.
Cholesterol
Kruskal Wallis Testa.
Grouping Variable: age groupingb.
Ranks
5 7.206 10.755 7.10
16
age grouping<5050-60>60Total
CholesterolN Mean Rank

REGRESI BERGANDA
Memprediksi besar variabel dependen dengan menggunakan data variabel bebas yang sudah diketahui besarnya

REGRESI BERGANDA
Analyze – regression – linear:Dependent : WGT4 Independent(s): WGT0, TG0, AGECase labels: genderMethod: enterOK

REGRESI BERGANDA
Variables Entered/Removedb
Cholesterol, Age inyears,Triglyceride
a
. Enter
Model1
VariablesEntered
VariablesRemoved Method
All requested variables entered.a.
Dependent Variable: Final cholesterolb.

REGRESI BERGANDA
Model Summary
.997a .994 .992 2.953Model1
R R SquareAdjustedR Square
Std. Error ofthe Estimate
Predictors: (Constant), Cholesterol, Age in years,Triglyceride
a.

REGRESI BERGANDA
ANOVAb
16736.790 3 5578.930 639.737 .000a
104.648 12 8.72116841.438 15
RegressionResidualTotal
Model1
Sum ofSquares df Mean Square F Sig.
Predictors: (Constant), Cholesterol, Age in years, Triglyceridea.
Dependent Variable: Final cholesterolb.
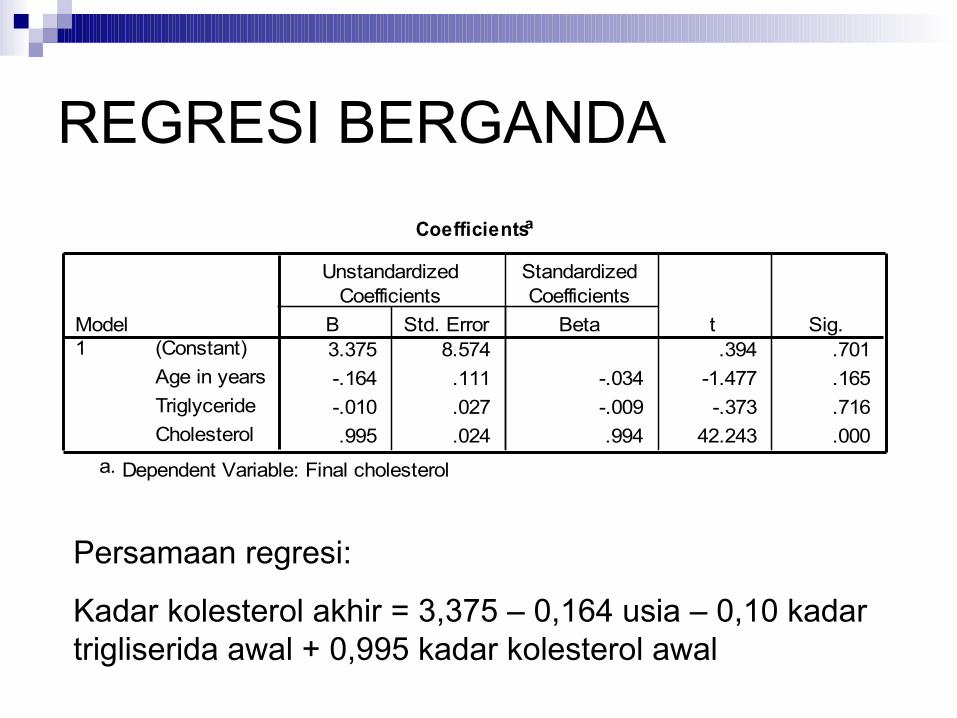
REGRESI BERGANDACoefficientsa
3.375 8.574 .394 .701-.164 .111 -.034 -1.477 .165-.010 .027 -.009 -.373 .716.995 .024 .994 42.243 .000
(Constant)Age in yearsTriglycerideCholesterol
Model1
B Std. Error
UnstandardizedCoefficients
Beta
StandardizedCoefficients
t Sig.
Dependent Variable: Final cholesterola.
Persamaan regresi:
Kadar kolesterol akhir = 3,375 – 0,164 usia – 0,10 kadar trigliserida awal + 0,995 kadar kolesterol awal
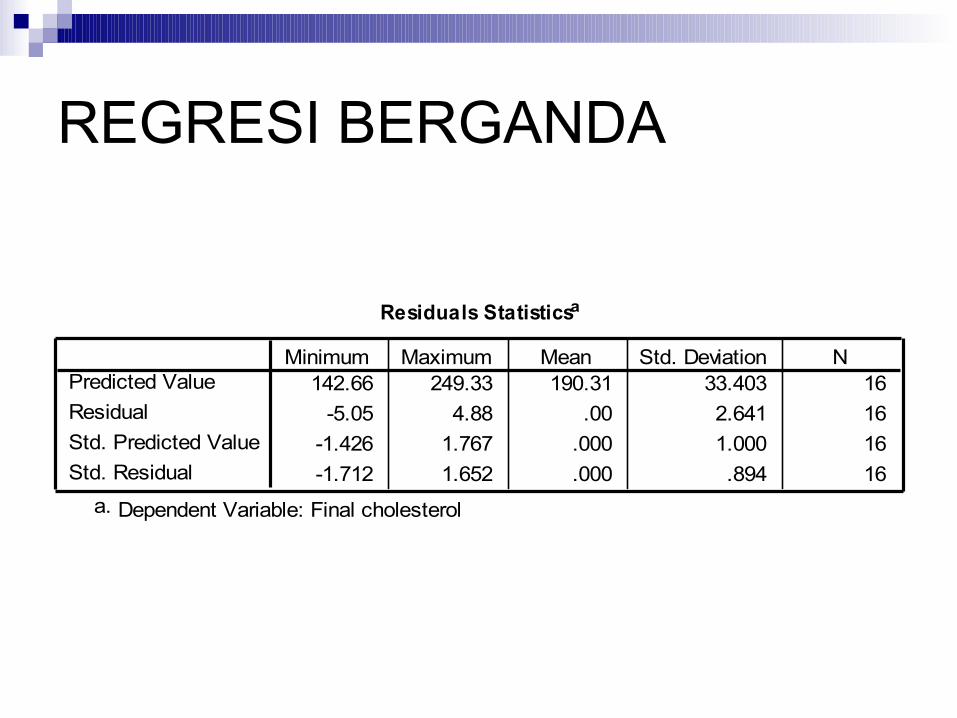
REGRESI BERGANDA
Residuals Statisticsa
142.66 249.33 190.31 33.403 16-5.05 4.88 .00 2.641 16
-1.426 1.767 .000 1.000 16-1.712 1.652 .000 .894 16
Predicted ValueResidualStd. Predicted ValueStd. Residual
Minimum Maximum Mean Std. Deviation N
Dependent Variable: Final cholesterola.
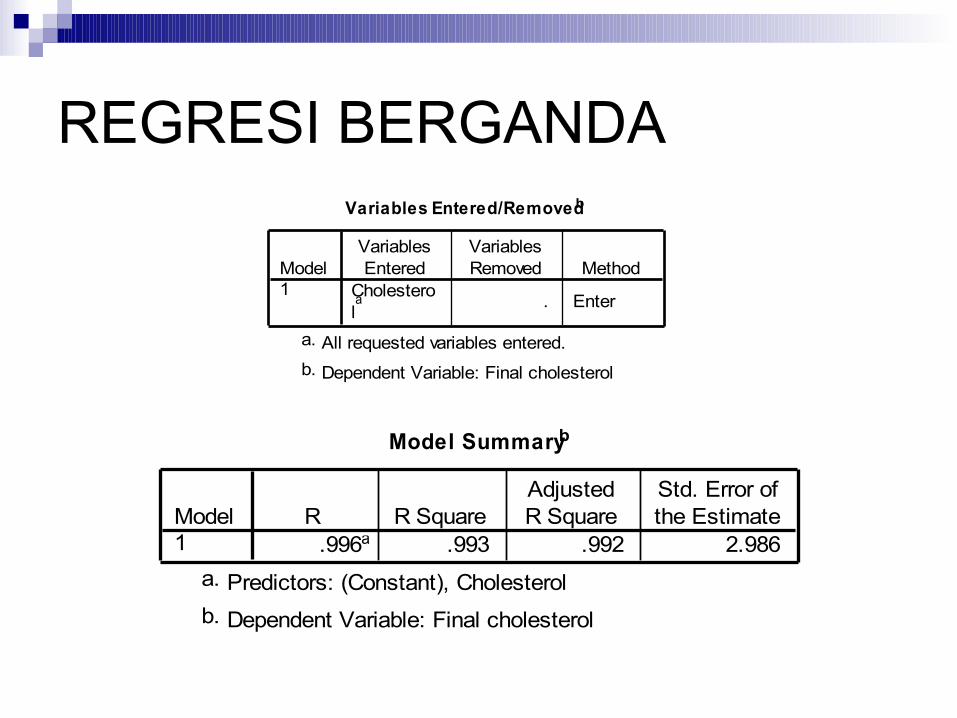
REGRESI BERGANDAVariables Entered/Removedb
Cholesterola . Enter
Model1
VariablesEntered
VariablesRemoved Method
All requested variables entered.a.
Dependent Variable: Final cholesterolb.
Model Summaryb
.996a .993 .992 2.986Model1
R R SquareAdjustedR Square
Std. Error ofthe Estimate
Predictors: (Constant), Cholesterola.
Dependent Variable: Final cholesterolb.

REGRESI BERGANDA
ANOVAb
16716.618 1 16716.618 1874.976 .000a
124.819 14 8.91616841.438 15
RegressionResidualTotal
Model1
Sum ofSquares df Mean Square F Sig.
Predictors: (Constant), Cholesterola.
Dependent Variable: Final cholesterolb.

REGRESI BERGANDACoefficientsa
-7.536 4.630 -1.628 .126.997 .023 .996 43.301 .000
(Constant)Cholesterol
Model1
B Std. Error
UnstandardizedCoefficients
Beta
StandardizedCoefficients
t Sig.
Dependent Variable: Final cholesterola.
Persamaan regresi:
Kadar kolesterol akhir = -7,536 + 0,997 kadar kolesterol awal
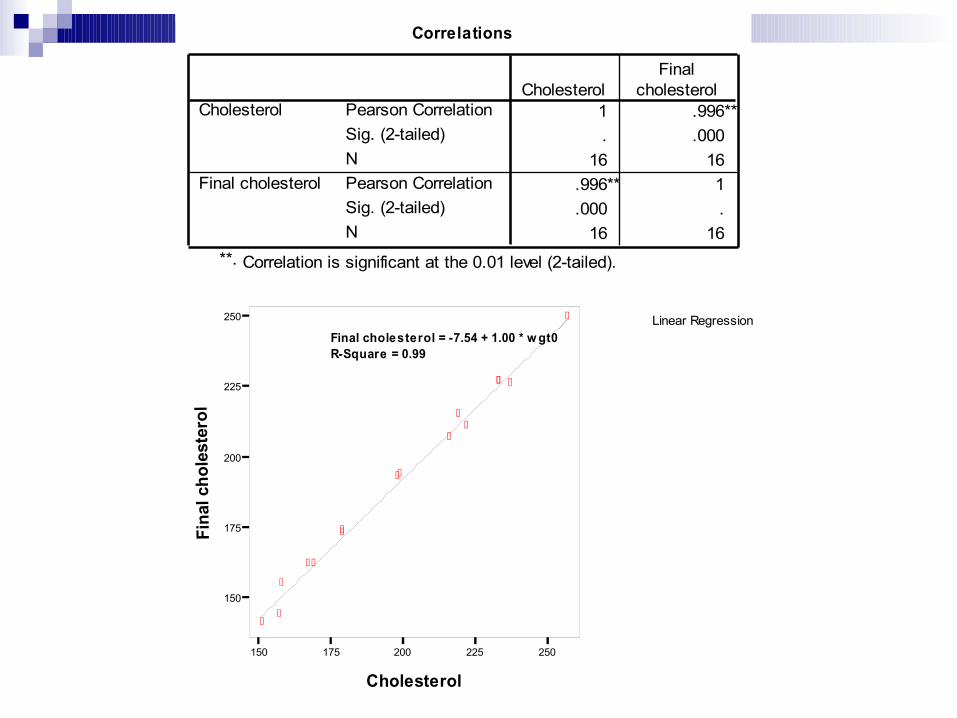
Correlations
1 .996**. .000
16 16.996** 1.000 .
16 16
Pearson CorrelationSig. (2-tailed)NPearson CorrelationSig. (2-tailed)N
Cholesterol
Final cholesterol
CholesterolFinal
cholesterol
Correlation is significant at the 0.01 level (2-tailed).**.
Linear Regression
150 175 200 225 250
Cholesterol
150
175
200
225
250
Fina
l cho
lest
erol
Final cholesterol = -7.54 + 1.00 * w gt0R-Square = 0.99

Uji regresi logistik binari
Ingin memprediksi variabel dependen yang berskala binari (ya=1 dan tidak=0) dengan menggunakan data variabel independen yang sudah diketahui besarnya

Uji regresi logistik binari
Buka SPSS: file – data –dietstudy Analyze – Regression – Binary logistic:
Dependent: cholst0 (status kadar kolesterol awal, 1=tinggi, 0=normal)
Covariates: age dan TG0Options: Homer-Lemeshow goodness of fitOK
Uji regresi logistik binari
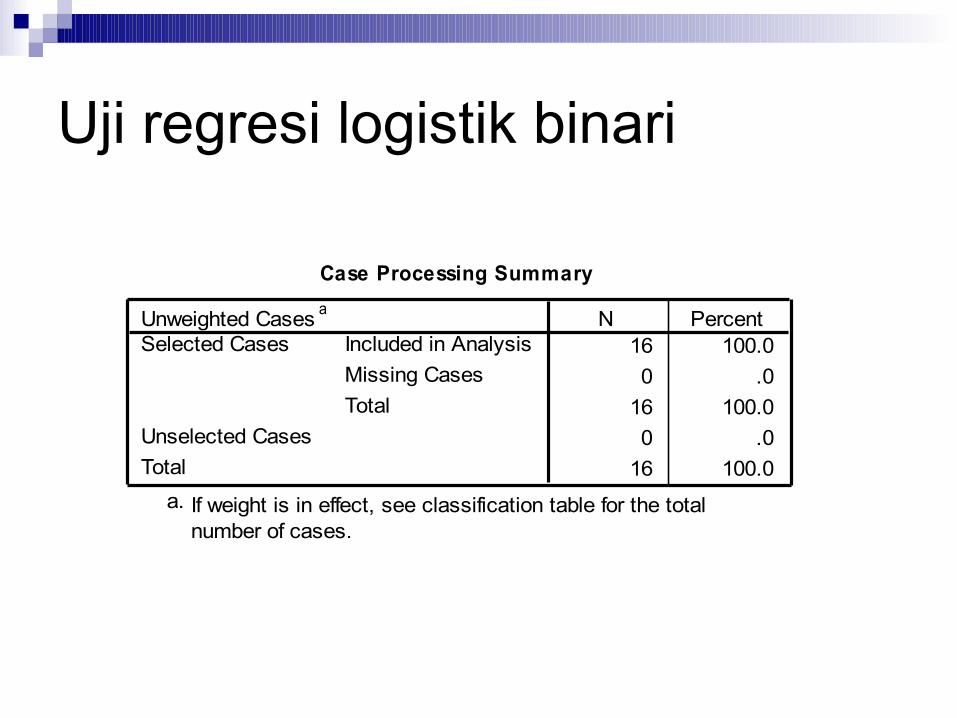
Case Processing Summary
16 100.00 .0
16 100.00 .0
16 100.0
Unweighted Cases a
Included in AnalysisMissing CasesTotal
Selected Cases
Unselected CasesTotal
N Percent
If weight is in effect, see classification table for the totalnumber of cases.
a.

Uji regresi logistik binari
Omnibus Tests of Model Coefficients
1.902 2 .3861.902 2 .3861.902 2 .386
StepBlockModel
Step 1Chi-square df Sig.

Uji regresi logistik binariModel Summary
20.028 .112 .150Step1
-2 Loglikelihood
Cox & SnellR Square
NagelkerkeR Square
Hosmer and Lemeshow Test
9.129 6 .166Step1
Chi-square df Sig.
Uji regresi logistik binari
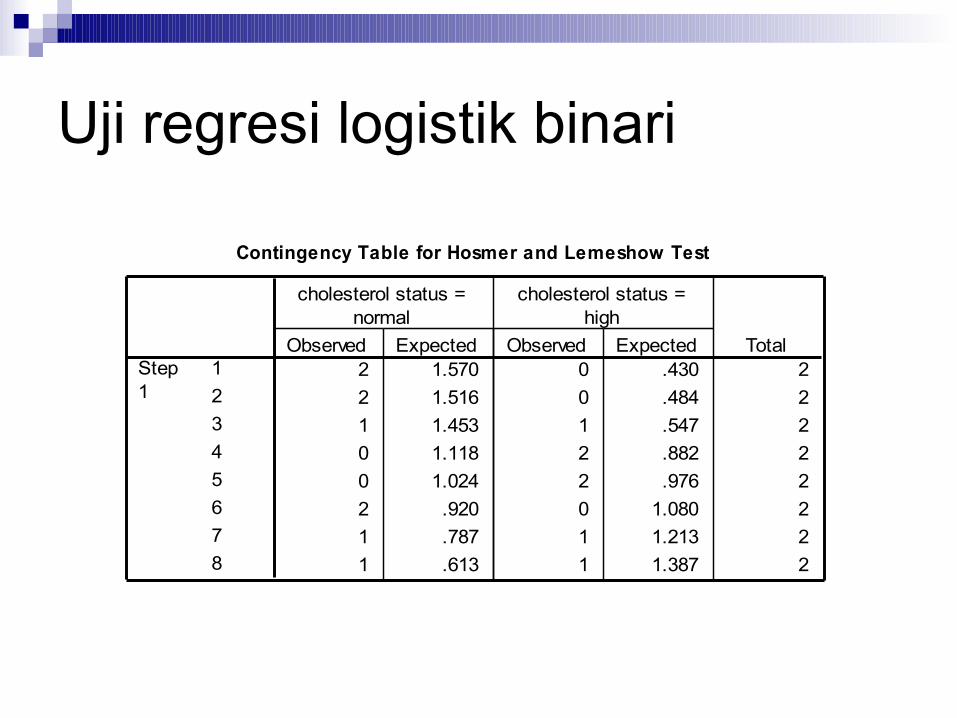
Contingency Table for Hosmer and Lemeshow Test
2 1.570 0 .430 22 1.516 0 .484 21 1.453 1 .547 20 1.118 2 .882 20 1.024 2 .976 22 .920 0 1.080 21 .787 1 1.213 21 .613 1 1.387 2
12345678
Step1
Observed Expected
cholesterol status =normal
Observed Expected
cholesterol status =high
Total

Uji regresi logistik binari
Classification Tablea
5 4 55.64 3 42.9
50.0
Observednormalhigh
cholesterol status
Overall Percentage
Step 1normal highcholesterol status Percentage
Correct
Predicted
The cut value is .500a.

Uji regresi logistik binari
Variables in the Equation
.042 .079 .277 1 .598 1.043
.025 .020 1.527 1 .217 1.025-5.970 5.416 1.215 1 .270 .003
AGETG0Constant
Step1
a
B S.E. Wald df Sig. Exp(B)
Variable(s) entered on step 1: AGE, TG0.a.
Penafsiran dan prediksi:
Status kadar kolesterol = -5,970 + 0,42 usia + 0,025 kadar trigliserida

Analisis data: untuk penyajian data
Hasil analisis statistik Diagram batang (bar) Histogram Boxplot Scatterplot Pie chart dll
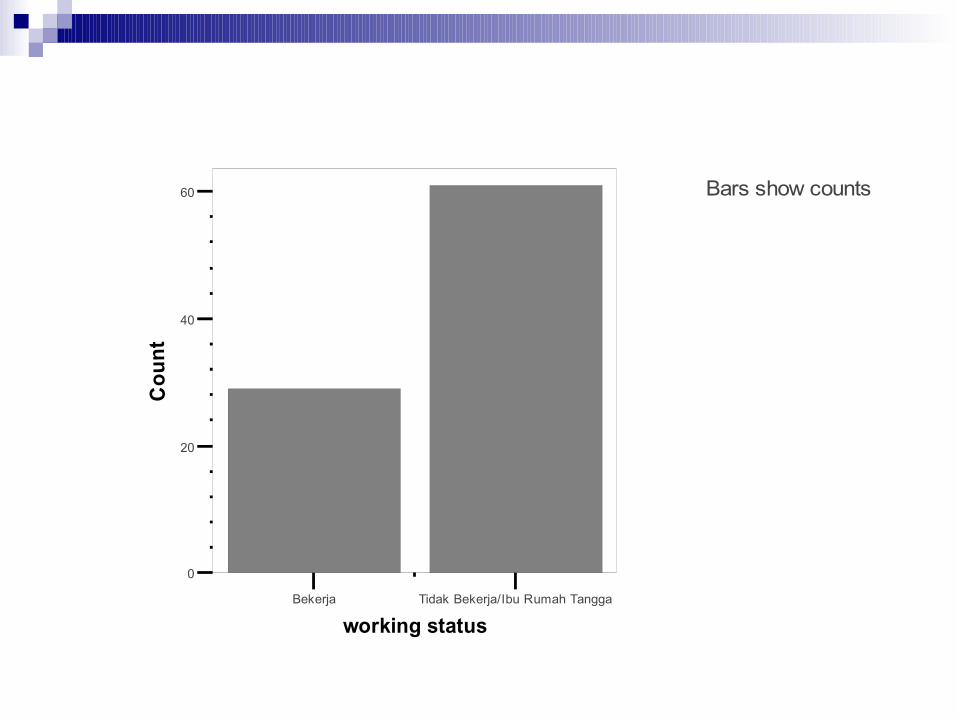
Bars show counts
Bekerja Tidak Bekerja/Ibu Rumah Tangga
working status
0
20
40
60
Cou
nt
10.00 11.00 12.00 13.00 14.00
hemoglobin concentration after intervention
0
4
8
12C
ount
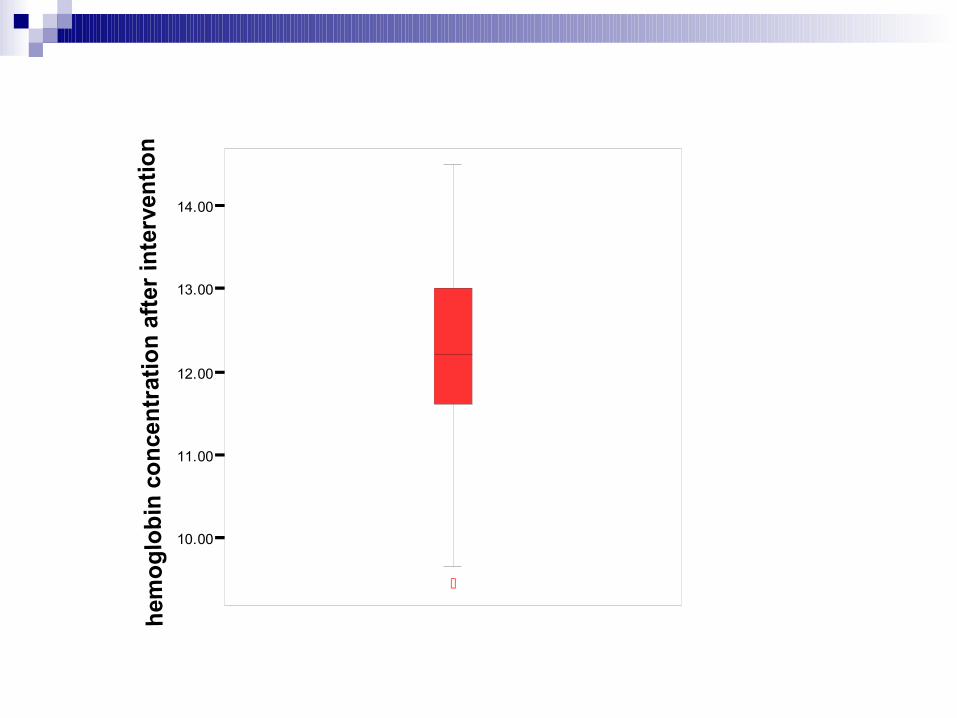
10.00
11.00
12.00
13.00
14.00
hem
oglo
bin
conc
entr
atio
n af
ter i
nter
vent
ion
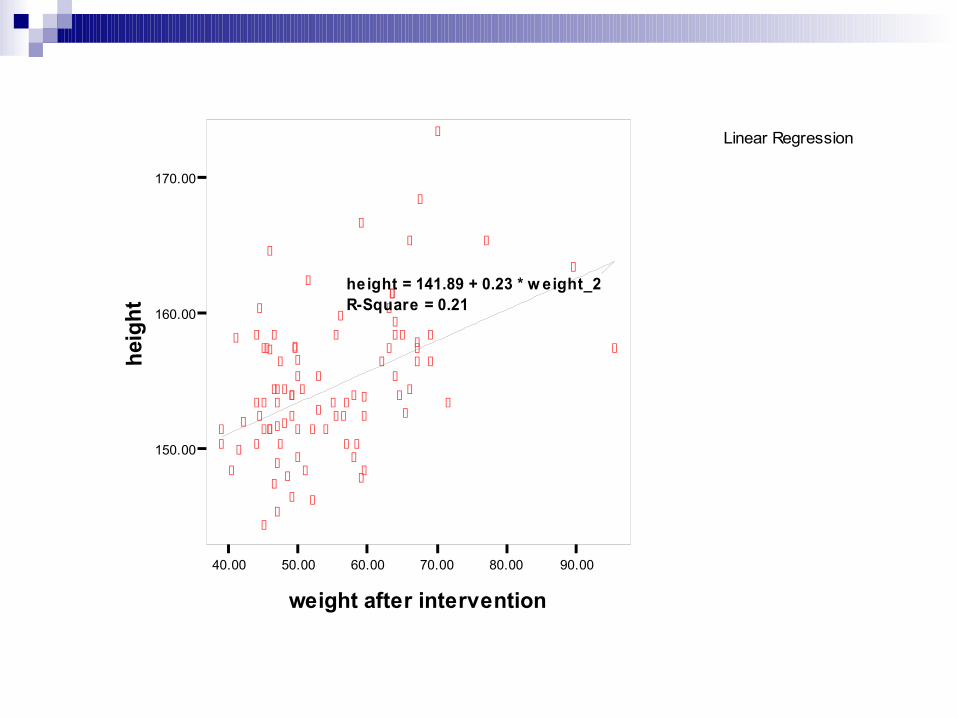
Linear Regression
40.00 50.00 60.00 70.00 80.00 90.00
weight after intervention
150.00
160.00
170.00
heig
ht
height = 141.89 + 0.23 * w eight_2R-Square = 0.21
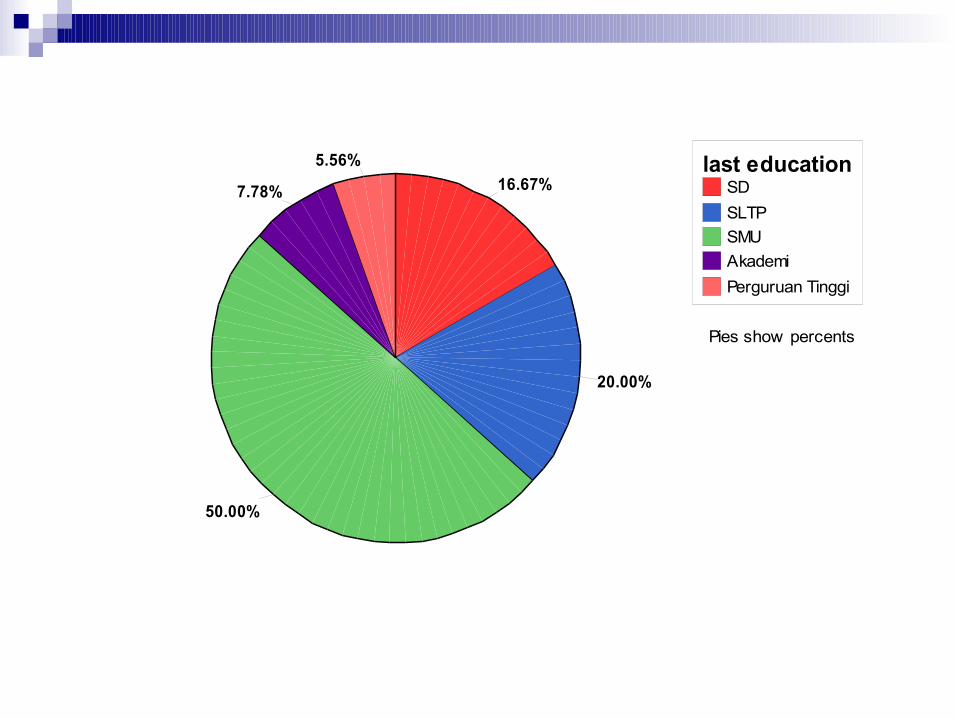
SDSLTPSMUAkademiPerguruan Tinggi
last education
Pies show percents
16.67%
20.00%
50.00%
7.78%
5.56%





























