Embed Size (px)
Citation preview

1
Minggu 1: Pengantar Database
Database Istilah database secara umum bisa diartikan sebagai suatu kumpulan data yang saling berhubungan (Elmasri & Navathe, 1994). Istilah data bisa dipakai baik untuk tunggal maupun jamak, karena sudah umum dalam dunia database. Dalam bahasa Inggris sehari-hari, data hanya dipakai untuk jamak; datum dipakai untuk tunggal. Database memiliki karakteristik sebagai berikut: • Database dipakai untuk merepresentasikan aspek-aspek dari dunia nyata. • Database memiliki sekumpulan data yang teratur dan memiliki arti jelas. Data
sembarang tidak boleh disebut database. • Database didesain, dibuat, dan diisi dengan data untuk suatu tujuan tertentu dan
pemakai tertentu. Suatu database bisa berskala kecil maupun sangat besar dengan kompleksitas yang bervariasi. Berikut ini adalah beberapa definisi database yang banyak dipakai: Elmasri & Navathe (1994)
• A database is a collection of related data. (p. 2) Kroenke (1995)
• A database is a self-describing collection of integrated records. (pp. 13-16) Date (1995)
• A database consists of some collection of persistent data that is used by the application systems of some given enterprise.
Todd & Keller (1995) • A database is a collection of files that store information needed by an
application or a user. DBMS (Database Management System) DBMS adalah sekumpulan program untuk mendefinisikan, membuat dan memanipulasi database untuk berbagai macam aplikasi. • Mendefinisikan: membuat spesifikasi tipe dan struktur data, termasuk batasan-
batasan jenis data yang boleh disimpan di database. • Membuat: proses menyimpan data pada media penyimpan yang dikontrol oleh
DBMS. • Memanipulasi: mencari data (query), memodifikasi data (update), dan membuat
laporan (report). Karakteristik suatu DBMS adalah: • mampu untuk mengatur / mengurus data dalam jumlah sangat banyak. • memiliki fasilitas untuk mengakses data yang sangat banyak tersebut secara
efisien. • memiliki fasilitas untuk mengakses data yang sangat banyak tersebut secara
concurrent. ⇒ contoh: bank dan ATM-nya.

2
• memiliki fasilitas untuk mengakses data yang sangat banyak tersebut secara aman. ⇒ contoh: dua orang mengedit file yang sama dalam suatu jaringan komputer.
Orang yang terakhir menyimpan file tersebut yang ‘menang’. Bandingkan contoh tersebut dengan dua orang yang mengambil uang dari ATM dari account yang sama pada waktu yang sama. Siapapun dari dua orang tersebut yang terakhir melakukan transaksi akan mendapatkan saldo terakhir yang tidak sesuai dengan yang diharapkan (sudah dikurangi oleh transaksi yang satunya).
Sistem Database Suatu sistem database adalah gabungan dari database dan software untuk memanipulasi database tersebut.
Users/Programmers DATABASE SYSTEM
Application Programs/Queries DBMS SOFTWARE
Software to Process Queries/Programs
Software to Access Stored Data
Stored Database Stored Definition Database (Meta-Data)
Figure 1.1: Suatu lingkungan sistem database yang disederhanakan Desain Database Proses desain dari database adalah bagian paling penting dalam suatu pengembangan sistem informasi. Dalam suatu sistem informasi, database adalah komponen yang paling berpengaruh pada unjuk kerja (performance) dari sistem. Tahap-tahap suatu pengembangan sistem: • Problem definition • Feasibility Study

3
• Analysis • Design • Implementation • Maintenance Tahap-tahap desain dari database: • Semantic (or Data) Modeling • Relational Database Design • Logical Design • Physical Design Beberapa istilah dalam database Table File yang dipakai untuk menyimpan data yang berhubungan. Suatu
table memiliki beberapa record (baris), dimana tiap record dibagi menjadi beberapa field (kolom). Tiap baris memiliki jumlah kolom yang sama.
Record Dikenal juga dengan istilah row atau tuple. Suatu record berisi
informasi tentang item tertentu. Misalnya, suatu record dalam table Pegawai berisi informasi tentang salah satu pegawai. Jika table tersebut berisi 20.000 record, artinya, perusahaan tersebut memiliki 20.000 pegawai.
Field Dikenal juga dengan istilah column atau attributes. Suatu field berisi
sebagian informasi dari suatu record. Misalnya, record dalam table Pegawai bisa berisi field-field seperti: nama, alamat, kota, kode-pos, dll.
Domain Dipakai untuk merepresentasikan isi dari field yang diijinkan.
Misalnya, field jenis kelamin dalam table Pegawai memiliki dua domain, yaitu Laki dan Perempuan. Setiap field dalam suatu table pasti memiliki domain. Banyak field yang bisa memiliki domain yang sama. Dengan menggunakan domain, sistem database bisa mendeteksi pengisian data yang salah pada saat mencari / mengisi data.
Primary Key Dipakai untuk mengidentifikasi suatu record dalam suatu table.
Misalnya, field Nomor-Pegawai adalah primary key dalam table Pegawai. Tiap table dalam suatu relational database harus memiliki paling sedikit satu Primary Key. Primary key tambahan dikenal juga dengan nama Alternate Keys atau Candidate Keys.
Foreign Keys Jika suatu Primary Key dari suatu table dipakai sebagai Non-primary
key field dari table lain, maka, ia disebut sebagai Foreign Key. Referensi Todd, B. & Kellen, V. 1995, Delphi, a developer’s guide, M&T Books.

4
Minggu 2: Entity Relationship Modeling Pemodelan data (Data Modeling / Data Analysis) adalah teknik untuk memahami suatu permasalahan dan kompleksitasnya dan juga untuk mendapatkan informasi yang dibutuhkan untuk memecahkan masalah tersebut dengan cara
1. Entity Relationship Modeling
melihat permasalahan tersebut dari sudut pandang DATA. Beberapa teknik pemodelan data
Pertama kali diperkenalkan oleh Chen, P. (1976). Data model yang paling sering dipakai dalam mendesain aplikasi database secara konseptual, dengan fokus pada data yang hendak disimpan.
2. Semantic Object Modeling
Menggunakan konsep class dan subclass dalam data modeling. 3. The NIAM (Nijssen Information Analysis Method)
Model ini berdasarkan pada deskripsi data yang sesungguhnya. Model ini adalah model data konseptual yang memiliki notasi lengkap untuk merepresentasikan data.
4. Binary Data Modeling
Adalah suatu data model berorientasi grafik dimana titik-titiknya (nodes) adalah suatu atribut atomik (sederhana) dan garis-garisnya (arcs) merepresentasikan tipe relasi biner antara dua atribut.
5. Object-oriented Modeling
Teknik pemodelan yang berdasarkan konsep yang berorientasi pada objek (object-oriented) dan cocok untuk aplikasi yang menggunakan bahasa dan database yang berorientasi pada objek.
Dari bermacam-macam teknik pemodelan data tersebut, ER modeling adalah yang paling populer selama 2 dekade terakhir, meskipun akhir-akhir ini mulai muncul metode lain yang bisa merepresentasikan lebih banyak informasi, yaitu Semantic Object Modeling dan Object-Oriented Modeling. Apa yang ada dalam sistem biasanya direpresentasikan dalam bentuk elemen-elemen (entity) dari permasalahan, karakteristiknya (attribute) dan hubungan (relationship) antar elemen-elemen tersebut. Tahap-tahap E.R. Modeling 1. Mempelajari input 2. Merancang model konseptual dalam pikiran kita 3. Merepresentasikan model tersebut dengan menggunakan diagram yang memakai
notasi ER modeling.
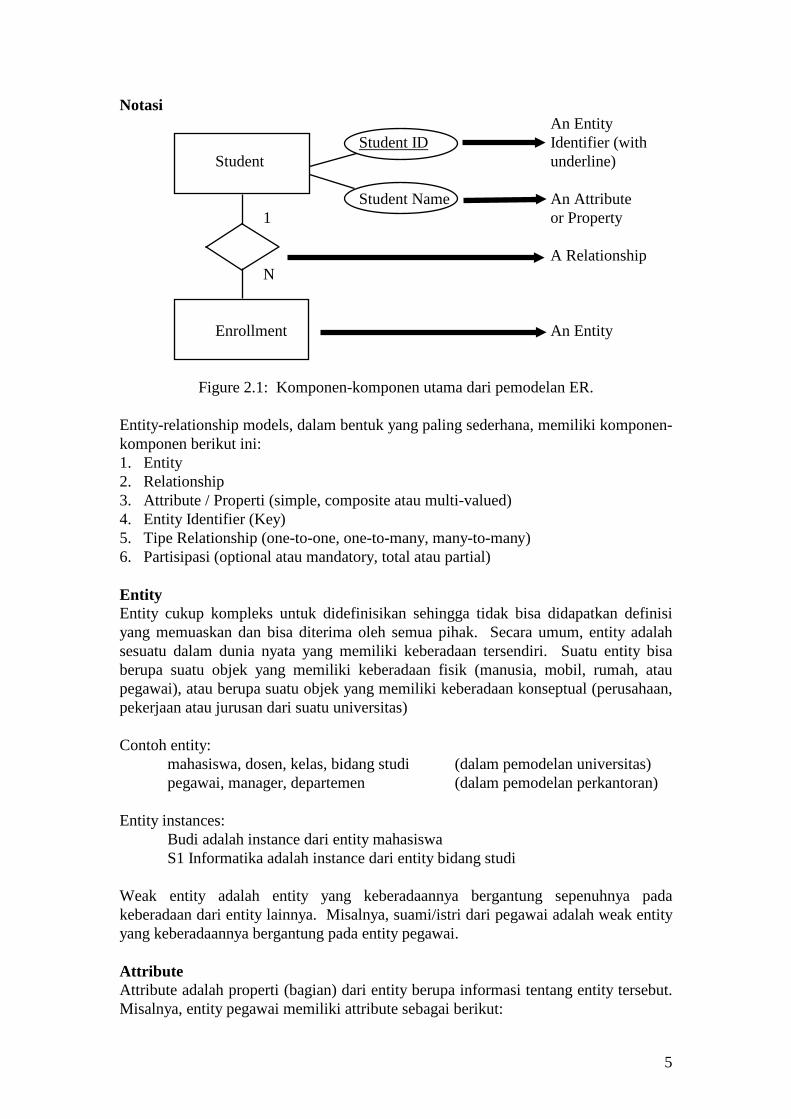
5
Notasi An Entity Student ID Student underline)
Identifier (with
Student Name An Attribute 1 or Property A Relationship N Enrollment An Entity
Figure 2.1: Komponen-komponen utama dari pemodelan ER. Entity-relationship models, dalam bentuk yang paling sederhana, memiliki komponen-komponen berikut ini: 1. Entity 2. Relationship 3. Attribute / Properti (simple, composite atau multi-valued) 4. Entity Identifier (Key) 5. Tipe Relationship (one-to-one, one-to-many, many-to-many) 6. Partisipasi (optional atau mandatory, total atau partial) Entity Entity cukup kompleks untuk didefinisikan sehingga tidak bisa didapatkan definisi yang memuaskan dan bisa diterima oleh semua pihak. Secara umum, entity adalah sesuatu dalam dunia nyata yang memiliki keberadaan tersendiri. Suatu entity bisa berupa suatu objek yang memiliki keberadaan fisik (manusia, mobil, rumah, atau pegawai), atau berupa suatu objek yang memiliki keberadaan konseptual (perusahaan, pekerjaan atau jurusan dari suatu universitas) Contoh entity: mahasiswa, dosen, kelas, bidang studi (dalam pemodelan universitas) pegawai, manager, departemen (dalam pemodelan perkantoran) Entity instances: Budi adalah instance dari entity mahasiswa S1 Informatika adalah instance dari entity bidang studi Weak entity adalah entity yang keberadaannya bergantung sepenuhnya pada keberadaan dari entity lainnya. Misalnya, suami/istri dari pegawai adalah weak entity yang keberadaannya bergantung pada entity pegawai. Attribute Attribute adalah properti (bagian) dari entity berupa informasi tentang entity tersebut. Misalnya, entity pegawai memiliki attribute sebagai berikut:

6
Nama Alamat Jenis kelamin NIP (Nomor Induk Pegawai) Contoh attribute diatas adalah attribute biasa. Selain itu, ada beberapa jenis attribute lainnya, yaitu: • Composite attribute
•
, yaitu attribute yang dibentuk dari gabungan beberapa attribute lainnya. Misalnya: attribute alamat, berasal dari gabungan attribute jalan, kota dan kode pos. Multi-value attribute
Identifier (key) adalah attribute khusus yang secara unique bisa dipakai untuk mengidentifikasi suatu instance dari entity. Misalnya: NIP adalah key untuk entity pegawai NRP adalah key untuk entity mahasiswa Relationship Relationship dipakai untuk menghubungkan dua entity atau lebih dengan arti tertentu. Misalnya: Mahasiswa Budi
, yaitu attribute yang memiliki beberapa value (nilai) untuk tiap instance dari entity. Misalnya: gelar (Ir, drs, SH, ...), seseorang bisa memiliki beberapa gelar sekaligus.
masuk jurusan bidang studi S1 Informatika Pegawai Tono bekerja pada
1. Sederhana
perusahaan X Degree (derajat) dari relationship adalah jumlah entity yang berpartisipasi dalam relationship tersebut. Degree ini bisa berupa unary (satu entity), binary (dua entity) , ternary (tiga entity), ... Relationship binary adalah yang paling umum dipakai. Cardinality dari relationship dipakai untuk mengidentifikasi struktur dari relationship. Misalnya: One to one (1:1) One to many (1:N) Many to many (N:M) Keuntungan pemodelan ER
2. Mampu merepresentasikan inti dari apa yang dibutuhkan untuk membuat suatu desain database yang baik.
Kerugian pemodelan ER 1. Hasilnya bisa berupa beberapa alternatif model, tergantung bagaimana para
analis/desainer memahami sistem. 2. Notasi dari ER modeling masih banyak variasi (kurang standard)
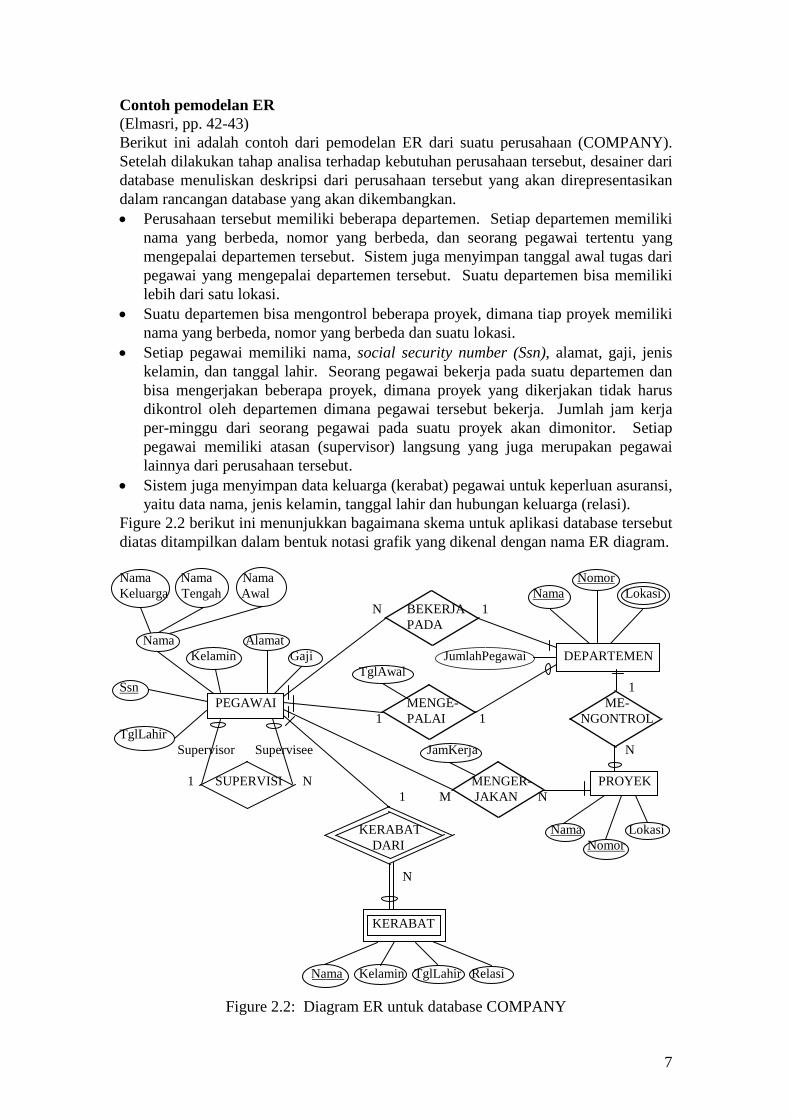
7
Contoh pemodelan ER (Elmasri, pp. 42-43) Berikut ini adalah contoh dari pemodelan ER dari suatu perusahaan (COMPANY). Setelah dilakukan tahap analisa terhadap kebutuhan perusahaan tersebut, desainer dari database menuliskan deskripsi dari perusahaan tersebut yang akan direpresentasikan dalam rancangan database yang akan dikembangkan. • Perusahaan tersebut memiliki beberapa departemen. Setiap departemen memiliki
nama yang berbeda, nomor yang berbeda, dan seorang pegawai tertentu yang mengepalai departemen tersebut. Sistem juga menyimpan tanggal awal tugas dari pegawai yang mengepalai departemen tersebut. Suatu departemen bisa memiliki lebih dari satu lokasi.
• Suatu departemen bisa mengontrol beberapa proyek, dimana tiap proyek memiliki nama yang berbeda, nomor yang berbeda dan suatu lokasi.
• Setiap pegawai memiliki nama, social security number (Ssn), alamat, gaji, jenis kelamin, dan tanggal lahir. Seorang pegawai bekerja pada suatu departemen dan bisa mengerjakan beberapa proyek, dimana proyek yang dikerjakan tidak harus dikontrol oleh departemen dimana pegawai tersebut bekerja. Jumlah jam kerja per-minggu dari seorang pegawai pada suatu proyek akan dimonitor. Setiap pegawai memiliki atasan (supervisor) langsung yang juga merupakan pegawai lainnya dari perusahaan tersebut.
• Sistem juga menyimpan data keluarga (kerabat) pegawai untuk keperluan asuransi, yaitu data nama, jenis kelamin, tanggal lahir dan hubungan keluarga (relasi).
Figure 2.2 berikut ini menunjukkan bagaimana skema untuk aplikasi database tersebut diatas ditampilkan dalam bentuk notasi grafik yang dikenal dengan nama ER diagram. Nama Nama Nama Nomor Keluarga Tengah Awal Nama
TglAwal
Lokasi N BEKERJA 1 PADA Nama Alamat Kelamin Gaji JumlahPegawai DEPARTEMEN
Ssn 1 PEGAWAI MENGE- ME- 1 PALAI 1 NGONTROL TglLahir Supervisor Supervisee JamKerja N 1 SUPERVISI N MENGER- PROYEK 1 M JAKAN N KERABAT Nama Lokasi DARI Nomor
N KERABAT Nama Kelamin TglLahir Relasi
Figure 2.2: Diagram ER untuk database COMPANY
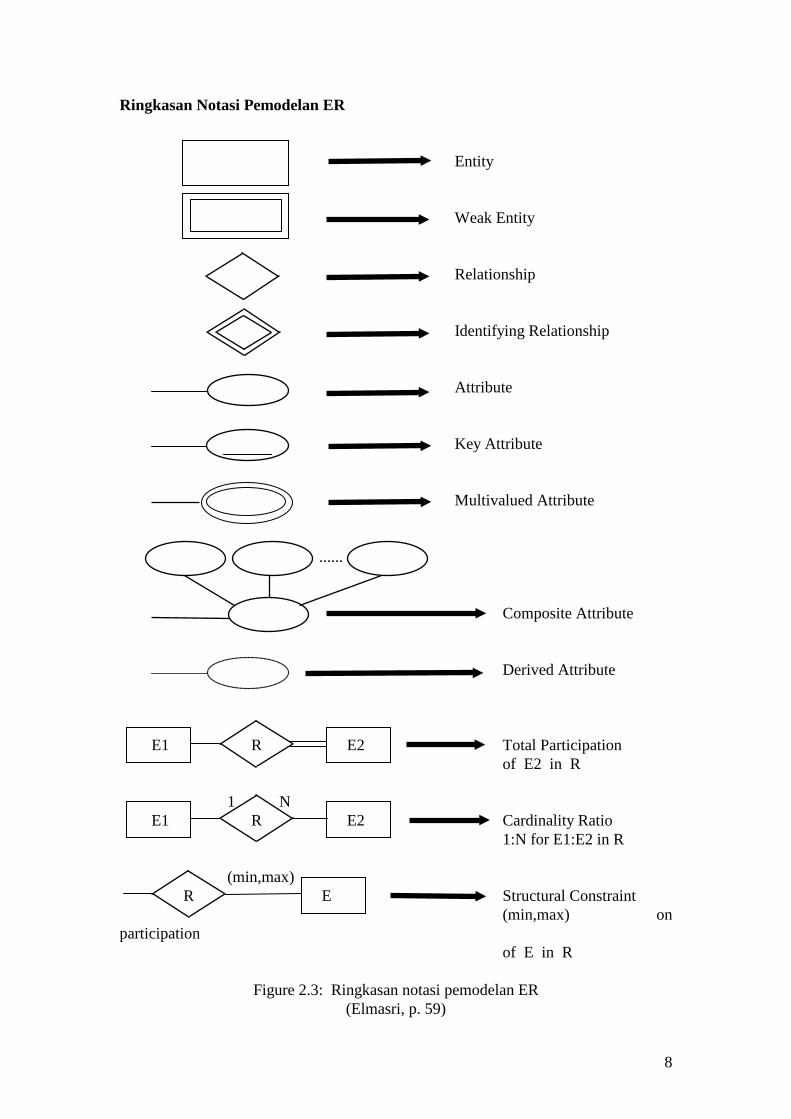
8
Ringkasan Notasi Pemodelan ER Entity Weak Entity Relationship Identifying Relationship Attribute Key Attribute Multivalued Attribute ...... Composite Attribute Derived Attribute E1 R E2 Total Participation of E2 in R 1 N E1 R E2 Cardinality Ratio 1:N for E1:E2 in R (min,max) R E Structural Constraint (min,max) on participation of E in R
Figure 2.3: Ringkasan notasi pemodelan ER (Elmasri, p. 59)

9
Latihan Kembangkan suatu ER diagram lengkap (entity, relationship, key, attributes, tipe relationship, partisipasi) untuk sistem berikut ini: 1. Suatu pabrik memiliki 15 bengkel. Satu bengkel berisi 30 mesin dimana tiap
mesin membutuhkan skill tertentu untuk mengoperasikannya. Mesin yang berbeda bisa saja membutuhkan skill yang sama. Pabrik itu mempekerjakan 500 operator, dimana tiap operator bisa memiliki 2 sampai 8 skill. Suatu skill bisa dikuasai oleh beberapa operator (bisa saja tidak ada operator yang mampu menguasainya).
2. Sebuah bank memiliki banyak cabang, dan tiap cabang memiliki banyak account dan loan. Customer dari bank bisa juga sekaligus memiliki account dan loan pada cabang yang sama. Tiap customer paling sedikit harus memiliki satu account, dan paling banyak memiliki 2 loan pada suatu waktu. Suatu cabang maksimum mengeluarkan 1000 loan.
Referensi Elmasri, chapter 3, pp. 39-68. Kroenke, chapter 4, pp. 97-121.

10
Minggu 3: Relational Database Pengantar Relational Model diperkenalkan oleh Codd pada tahun 1970. Riset dan pengembangan relational model yang paling banyak dilakukan oleh IBM di San Jose (Almaden) Research Centre. Pada tahun 1980-an, IBM memperkenal dua produk relational DBMS, yaitu: SQL/DS for DOS/VSE (1981) dan DB2 for MVS (1983). Produk relational DBMS lain yang cukup terkenal adalah INGRES yang dikembangkan oleh University of California, Berkeley, pada awal 1970-an dan dikomersialkan pada akhir 1970-an. Selain itu, ada pula Oracle, Sybase, RDB, Informix, Unify, dll. Selain produk-produk RDBMS diatas, relational data model juga diimplementasikan pada platform PC pada tahun 1980-an, misalnya: Paradox, OS/2 Database Manager, dBase, FoxBase, FoxPro, Watcom SQL, Sybase SQL Server, dan yang akhir-akhir ini Microsoft Access. Awalnya, produk-produk ini hanya bisa untuk single-user, tetapi akhir-akhir ini mereka juga menawarkan arsitektur database client-server dan mulai mendukung standard Microsoft Open Database Connectivity (ODBC). Properti dari Relation • Tidak diperbolehkan adanya record yang sama (duplicate records). Tiap table
harus memiliki primary key. • Record tidak urut (dari awal sampai akhir record). • Attribute juga tidak urut (dari kiri ke kanan) • Semua value dari attribute adalah atomic value. Relational Keys Sekumpulan attribute (misalkan disimbolkan dengan K) dari suatu relation R, disebut relational key jika dan hanya jika (iff) memenuhi persyaratan berikut ini: • Uniqueness
Setiap saat, tidak boleh ada lebih dari satu record dari R yang memiliki nilai K yang sama.
• Irreducibility atau minimality Jika K adalah attribute composite, maka tidak boleh ada komponen dari K yang bisa dihilangkan tanpa merusak uniqueness dari relation R.
The Entity Integrity Rule Entity Integrity Rule adalah aturan dalam relational database yang mengharuskan tiap komponen dari suatu relational key(s) untuk memiliki value (tidak boleh kosong/null). The Referential Integrity Rule Referential Integrity Rule adalah aturan dalam Relational Database untuk selalu melakukan validasi pada foreign key dari suatu table (Foreign key harus selalu valid).

11
Foreign Key Rules Dalam proses update data, jika terdapat data yang tidak memenuhi referential integrity rule, maka yang harus dilakukan adalah: • Pada saat Insert. Proses insert harus ditolak. • Pada saat Delete. Proses delete harus ditolak atau di cascade. • Pada saat Modify. Proses modify harus ditolak atau di cascade. Cascade artinya proses update harus dilakukan pada semua record dari semua table dimana terdapat relational key dan foreign key yang bersangkutan. Functional Dependence (FD) Suatu attribute Y dari relation R disebut functionally dependent pada attribute X dari R jika dan hanya jika (if and only if / iff) tiap value X dari R setiap saat hanya berasosiasi dengan satu value Y dari R. Dengan kata lain, X adalah determinant dari Y. Sedangkan Y adalah dependant dari X. X dan Y bisa berupa composite attribute (attribute yang terdiri dari kumpulan beberapa attribute lainnya). Misalkan, S# determines SNAME, STATUS, CITY. Terdapat tiga notasi untuk menunjukkan functional dependencies dari relation tersebut. 1. In Line S# → SNAME, S# → STATUS, S# → CITY 2. Functional Dependence (FD) Diagrams SNAME S# STATUS CITY 3. Notasi Elmasri dan Navathe S# SNAME STATUS CITY Dalam contoh ini, tiap S# hanya memiliki satu SNAME, satu STATUS dan satu CITY. Relationship ini sudah baku. Jika value dari field tidak diketahui, maka boleh diisi NULL, tetapi tetap hanya ada satu value untuk tiap field. Jika Determinant berupa composite attribute, maka terdapat dua jenis dependencies: 1. Fully Functional Dependencies Dependant tergantung pada semua attribute dari determinant. 2. Partly Functional Dependencies Dependant tergantung pada sebagian attribute dari determinant.

12
Minggu 4: Konversi ER ke relational model Proses konversi dari ER diagram ke relational model bisa dilakukan dengan mengikuti enam ketentuan berikut ini untuk menghindari relation yang non-homogeneous. Many to Many (1) One to Many (2) One to Many (3) a1 A a2 n c1 m B b1 b2 R1(a1, a2) R2(b1, b2) R3(a1, b1, c1)
a1 A a2 1 c1 n B b1 b2 R1(a1, a2) R2(b1, b2) R3(a1, b1, c1)
a1 A a2 1 c1 n B b1 b2 R1(a1, a2) R2(b1, b2, c1, a1)
One to One (4) One to One (5) One to One (6) a1 A a2 1 c1 1 B b1 b2 R1(a1, a2) R2(b1, b2) R3(a1, b1, c1)
a1 A a2 1 c1 1 B b1 b2 R1(a1, a2, c1, b1) R2(b1, b2)
a1 A a2 1 c1 1 B b1 b2 R1(a1, b1, a2, b2, c1)
Figure 4.1: Aturan Konversi dari ER diagram ke Relational Model Petunjuk desain Database Relational 1. Relation harus didesain sedemikian rupa sehingga mudah untuk dimengerti.
Attribute-attribute dari entity dan relationship tidak boleh digabungkan menjadi satu relation.
2. Relation yang dihasilkan harus dalam bentuk BCNF sehingga masalah insert, delete, update, integrity dan redundancy bisa diminimalkan.
3. Sebisa mungkin, relation harus homogeneous, sehingga null values bisa dihindari. 4. Relation harus didesain sedemikian rupa sehingga bisa ditambahkan attribute
seperti primary atau foreign keys. Dengan kata lain, relation tersebut dibuat dengan memenuhi decomposition rule, sehingga bisa dipastikan proses lossless decomposition

13
Contoh Konversi ER Diagram ke Relational Model Dengan menggunakan contoh ER diagram pada figure 2.2 tentang Database COMPANY dan penerapan aturan konversi ER ke relational model, maka dihasilkan relational model dari Database COMPANY sebagai berikut: • PEGAWAI(SsnPeg, Nama, Alamat, JenisKelamin, TglLahir, Gaji, NamaDep) • SUPERVISI(SsnSupervisor, SsnSupervisee) • DEPARTEMEN(NamaDep, NomorDep, Lokasi, Jumlah, SsnKepala, TglAwal) • PROYEK(NamaProyek, NomorProyek, Lokasi, NamaDep) • MENGERJAKAN(NamaProyek, SsnPeg) • KERABAT(NamaKerabat, JenisKelamin, TglLahir, Relasi, SsnPeg) Pada relasi PEGAWAI, terdapat ForeignKey NamaDep yang berasal dari relasi DEPARTEMEN. ForeignKey ini didapatkan dari konversi relasi 1:N dengan total participation dari PEGAWAI (Aturan Konversi nomor 3). Relasi SUPERVISI adalah relasi yang dihasilkan dari recursive relationship dari Entity PEGAWAI, dimana seorang pegawai bisa menjadi supervisor dari beberapa pegawai lainnya, dan tiap pegawai hanya memiliki satu supervisor langsung, kecuali pegawai dengan pangkat tertinggi (Aturan Konversi nomor 2). Relasi DEPARTEMEN memiliki ForeignKey SsnKepala yang berasal dari relasi PEGAWAI. ForeignKey ini didapatkan dari konversi relasi 1:1 dengan total participation dari DEPARTEMEN (Aturan Konversi nomor 5). Pada relasi PROYEK, terdapat ForeignKey NamaDep yang berasal dari relasi DEPARTEMEN. ForeignKey ini didapatkan dari konversi relasi 1:N dengan total participation dari PROYEK (Aturan Konversi nomor 3). Relasi MENGERJAKAN adalah relasi yang dihasilkan dari relasi N:M antara entity PEGAWAI dan entity PROYEK (Aturan Konversi nomor 1). Relasi KERABAT memiliki ForeignKey SsnPeg yang berasal dari relasi PEGAWAI. ForeignKey ini didapatkan dari konversi relasi 1:N dengan total participation dari KERABAT (Aturan Konversi nomor 3). Latihan • Konversikan ER diagram yang dihasilkan dari latihan soal nomor 1 dan 2 dari
bahan kuliah minggu ke-2 ke dalam bentuk relational model dengan menggunakan ke-enam aturan konversi!

14
Minggu 5: Normalisasi Pengantar Pengertian tentang teori relational database sangat penting untuk membangun suatu aplikasi database yang baik. Teori tersebut harus diaplikasikan pada saat mendesain table-table yang hendak dipakai. Pada saat mendesain suatu aplikasi, banyak pertanyaan yang muncul. Misalnya, berapa banyak table yang harus dipakai? Field-field apa saja yang harus ada dalam table-table tersebut? Relationship apa yang diperlukan antar table tersebut? Proses untuk menjawab semua pertanyaan tersebut itulah yang dinamakan database normalization. First Normal Form First normal form saat ini bisa juga dikatakan sebagai bagian dari definisi formal dari suatu relation. Intinya, 1NF ini tidak mengijinkan multivalued attributes, composite attributes, dan kombinasinya. Domain dari attribute-attribute-nya hanya boleh berisi atomic value saja. Misalnya, suatu field seperti Alamat yang berisi nama jalan, nama kota dan kode-pos dalam satu field tidak boleh disebut 1NF, karena, field tersebut berisi tiga value yang berbeda: jalan, kota dan kode-pos, yang seharusnya dipisah menjadi tiga field yang berbeda. Definisi: Suatu relation R disebut 1NF jika dan hanya jika semua value attribute-nya adalah atomic value, dan non-key attributes-nya (jika ada) tidak FFD pada relational key(s). Second Normal Form Definisi: Suatu relation R disebut 2NF jika dan hanya jika non-key attributes-nya (jika ada) FFD pada relational key(s), dan terdapat saling ketergantungan (dependencies) antar non-key attributes tersebut. Third Normal Form Definisi: Suatu relation R disebut 3NF jika dan hanya jika non-key attributes-nya: • Tidak ada saling ketergantungan (Mutually Independent) • FFD pada relational key(s) dan • ada determinant yang bukan relational key(s)

15
BOYCE-CODD Normal Form (BCNF) Definisi: Suatu relation R disebut BCNF jika dan hanya jika non-key attributes-nya: • Tidak ada saling ketergantungan (Mutually Independent) • FFD pada relational key(s) dan • semua determinant adalah relational key(s) Langkah-langkah untuk menentukan Normal Form Tertinggi (Highest NF) dari suatu relation 1. Tentukan semua functional dependencies antar attribute dalam suatu relation. 2. Tentukan semua relation key(s) dari relation tersebut. 3. Tentukan key dan non-key attributes. 4. Apakah semua non-key attributes FFD pada tiap relation key?
Jika TIDAK, maka relation berada dalam 1NF. STOP. Jika YA, maka relation sedikitnya berada dalam 2NF. Lanjut ke Step 5.
5. Apakah terdapat functional dependencies antar non-key attributes? Jika YA, maka relation berada dalam 2NF. STOP. Jika TIDAK, maka relation sedikitnya berada dalam 3NF. Lanjut ke Step 6.
6. Jika relation hanya memiliki SATU relation key, maka relation sudah dalam BCNF. Jika relation memiliki lebih dari satu relation key, lanjutkan ke Step 7.
7. Apakah semua determinant yang ditentukan pada Step 1 adalah relation key? Jika YA, maka relation berada dalam BCNF. Jika TIDAK, maka relation hanya berada dalam 3NF.
Kesimpulan Proses normalisasi dari suatu database sebenarnya adalah proses untuk mencari dan menghilangkan semua data yang redundant (berlebihan / tidak perlu). Selama proses ini, biasanya jumlah field dalam table akan berkurang, dan jumlah table dalam aplikasi akan bertambah. Ini adalah indikator yang baik. Jangan kuatir dengan jumlah table yang terus bertambah. Suatu desain relational database yang baik biasanya memiliki banyak table yang sederhana. Latihan A. Tentukan relational key(s), normal form dan alasannya untuk relation-relation
berikut ini. Gunakan intuisi anda untuk mengubah relation tersebut ke BCNF jika relation tersebut belum BCNF. Gambarlah FD diagram terlebih dahulu untuk tiap relation berikut ini.
1. BRANCH (Bran_Id, City_In, Company_Id, Main_Product) Brand_Id → City_In

16
Brand_Id → Company_Id Company_Id → Main_Product 2. TUTORIAL (Unit_Id, Tut_No, Time, Place, Duration, Level) Unit_Id, Tut_No → Time, Place Time, Place → Unit_Id, Tut_No Unit_Id, Tut_No → Duration Unit_Id → Level Note: Tutorials supporting the same unit have the same duration 3. PESTY_FRUIT (Pest_Id, Season, Degree, Fruid_Id, Acidity, Colour) Pest_Id → Season Fruit_Id → Acidity, Colour Pest_Id, Fruit_Id → Degree Note: Degree has the domain of ‘mild’, ‘moderate’, ‘severe’, etc. 4. TAXI_DRIVER (Driver_No, Age, Reg_No, Make, Model) Driver_No → Age, Reg_No Reg_No → Driver_No, Make, Model Note: Different Makes of taxi are never the same model 5. ALL (U_Id, U_Name, Stream, Rating, Sem_No, Budget, Stud_Id, Status, Grade) U_Id → U_Name, Stream U_Name → U_Id Sem_No → Budget Stud_Id → Status U_Id, Sem_No → Rating U_Id, Sem_No, Stud_Id → Grade B. Untuk tiap relation berikut ini, tentukan relational key(s), highest NF dan alasannya. 1. R(A,B,C); AB → C, C → A 2. R(A,B,C,D); A → C, C → A, AB → D 3. R(A,B,C,D,E); BD → AE, AB → C 4. R(S,T,U,V,W); SU → T, ST → UV, UV → W 5. R(A,B,C,D,E,F,G); ABC → DE, DE → CF, F → EG, G → F 6. R(A,B,C,D,S,T,U,V); S → T, T → S, D → B, B → A, A → C, DT → V, V → U, U → V

17
Minggu 6: Relational Algorithms (1) Functional Dependency Inference Rules Inference Rules untuk Functional Dependencies dipakai untuk mengetahui functional dependencies lainnya yang tidak dituliskan secara eksplisit. Rules yang dipakai sebenarnya juga merupakan dasar dari manipulasi-manipulasi lainnya. Menurut konvensi, terdapat 6 inference rules yang dipakai. Tiga rules yang terakhir bisa didapatkan dari tiga rules yang pertama. Tiga rules yang pertama bisa dibuktikan dari definisi dari FD. Misalkan, X, Y, Z dan W adalah kumpulan attribute dari suatu database. Ke-enam rules tersebut adalah: 1. Reflexive rule If Y is a subset of X, then X → Y 2. Augmentation rule If X → Y, then XZ → Y 3. Transitive rule If X → Y and Y → Z, then X → Z 4. Decomposition rule If X → YZ, then X → Y and X → Z 5. Union rule If X → Y and X → Z, then X → YZ 6. Pseudotransitive rule If X → Y and WY → Z, then WX → Z Rule nomor 1 adalah dasar dari Functional Dependencies. Ke-enam inference rules ini bisa dipakai untuk mendapatkan FD lain yang belum diketahui dalam suatu database. The Membership Algorithm Algoritma ini dipakai untuk menjawab pertanyaan: Apakan suatu FD bisa diwakili oleh sekumpulan FD lainnya? Suatu sistem database bisa menjadi sangat kompleks dalam waktu singkat, sehingga masalah desain relational database tidak bisa diselesaikan dengan mudah. Algoritma berikut ini adalah algoritma dasar yang sangat berguna. Misalkan F adalah kumpulan dari FD, T adalah variable untuk menyimpan elemen data, X → A adalah FD tertentu dalam F, dan Y → B adalah FD yang hendak diperiksa apakah bisa diwakili oleh kumpulan FD tersebut atau tidak. Algoritma membership adalah sebagai berikut: T := Y; repeat for each FD if X → A has X, but not in A, in T add A to T remove this FD from F until (T contains B) or (a scan of all F produces no change in F) or (F is empty) Jika T berisi B, maka Y → B bisa diwakili dari kumpulan FD yang ada.

18
The Reduction Algorithm Algoritma ini dipakai untuk menjawab pertanyaan: Bagaimana cara untuk mendapatkan kumpulan FD minimal dari sekumpulan FD yang ada? Algoritma berikut ini dipakai untuk mendapatkan kumpulan FD minimal C, dimana algoritma secara berulang-ulang memeriksa kumpulan FD tersebut untuk mencari FD yang redundant. repeat for each FD in C if f (an element of C) can be inferred from (C - f) using the membership algorithm then delete f from C until a scan of all C produces no change in C. Algoritma ini bisa menghasilkan lebih dari satu jawaban, karena pada tiap tahap, bisa terdapat beberapa pilihan FD, selain itu urutan FD juga bisa membuat perbedaan. Algoritma ini harus diaplikasikan dengan hati-hati untuk menentukan kumpulan FD minimal - yang sering bisa lebih dari satu pilihan. Latihan A. Dari kumpulan FD berikut ini, tentukan apakah Target FD bisa diwakili. 1. AB → E BC → S BCD → T U → T DT → V T → W Target: ABCT → V 2. DE → F C → B AB → C AB → D Target: AC→ F 3. CDT → B AC → D A → S A → T ST → C T → A Target: A → B

19
B. Gunakan reduction algorithm (atau inspection jika mungkin) untuk menentukan semua non-redundant FD dari kumpulan FD berikut ini:
1. A → B A → C A → D B → C B → D C → D 2. AB → D A → C C → D 3. B → C AC → B AC → D AB → D 4. AB → C A → D A → E C → D C → E D → E E → D 5. A → B B → C B → D B → E C → A C → D D → E 6. AB → C AB → D C → E DE → S AB → S D → T S → T

20
Minggu 7: Relational Algorithms (2) The Key Finding Algorithm Algoritma ini dipakai untuk menentukan relational key(s) dari suatu relation. Penentuan key(s) ini amat penting untuk menentukan Normal Form dari suatu relation. Algoritma ini didasarkan pada definisi dari relational key dimana disitu disebutkan, bahwa untuk menjadi key, kumpulan attribute tersebut harus bisa menentukan semua attribute lainnya dalam relation, dan tidak ada bagian dari kumpulan attribute tersebut yang bisa melakukan hal yang sama. Misalkan L adalah kumpulan attribute dalam relation, A adalah attribute dalam L dan C adalah kumpulan FD minimum (algoritma ini bisa dikerjakan lebih cepat pada kumpulan FD minimum). Semua FD dalam C tersebut harus diperiksa tersebut sebelum algoritma ini dikerjakan. Semua FD atau attribute yang redundant harus dihilangkan. repeat for each A in L if the membership algorithm shows that (L-A) → A can be inferred from C, then delete A from L. until no further deletions from L are possible. (L is now a relational key) Algoritma ini juga bisa menghasilkan banyak jawaban, karena urutan data elemen dalam L dan pilihan dari A juga mempengaruhi hasil algoritma. Dengan ketelitian dan kesabaran, semua key akan bisa ditentukan. Lossless Decomposition Berikut ini adalah langkah-langkah yang harus dilakukan untuk menghasilkan suatu kumpulan relation yang sudah BCNF dari relation dalam normal form yang lebih rendah. Dengan mengikuti algoritma ini, yang dikenal dengan decomposition rule, maka proses decomposition disebut lossless, jika tidak, proses decomposition disebut lossy. Ulangi step 1 sampai 3 sampai semua relation menjadi BCNF 1. Tentukan relational key(s). Gunakan key finding algorithm jika perlu. 2. Jika relation bukan BCNF, tentukan satu fully functional determinant yang bukan
relational key. 3. Decompose relation tersebut menjadi dua relation; relation pertama terdiri dari
attribute dari determinant yang dipilih pada step 2 dan attribute yang ditentukan olehnya. Relation kedua terdiri dari attribute dari determinant yang dipilih pada step 1 dan sisa attribute yang tidak ada pada relation pertama.

21
Latihan A. Tentukan key(s) dan highest normal form dari relation-relation berikut ini. 1. R(A,B,C,D) AB → C C → A C → B BC → D 2. R(S,T,U,V,W) ST → V UV → T SU → W 3. R(K,L,M,N) KL → N N → L KN → M 4. R(A,B,C,D) AB → A BCD → B CD → C D → D 5. R(V,W,X,Y,Z) V → X VW → Y X → V 6. R(S,T,U,V,W,X) ST → V UV → X WX → T 7. R(A,B,C,D,E) AB → C C → B CD → E E → D

22
B. Gunakan decomposition rule untuk relation-relation berikut ini supaya menjadi BCNF relations. 1. R(A,B,C,D,E,F) BC → A B → D D → E C → F 2. R(A,B,C,D,E) A → C AB → D CD → E 3. R(A,B,C,D) B → D AB → C C → D 4. R(A,B,C,D,E) AB → C C → B CD → E E → D 5. R(U,V,W,X,Y,Z) U → X V → XY W → Y X → Z Y → Z

23
Minggu 8: SQL (1) Pengantar SQL adalah singkatan dari Structured Query Language, yang dulu dikenal dengan nama Sequel. SQL menjadi standard sejak tahun 1985 dan sudah digunakan oleh banyak DBMS. SQL sangat powerful dan flexible. Perintah SQL dilakukan dalam table dan menghasilkan table pula sebagai outputnya. Data Definition Language (DDL): Create Table, Create Index, Create View, Drop Table, Drop Index, Drop View, Alter Table. Data Manipulation Language (DML): Select, Insert, Delete and Update. Syntax dari Select: Select <attribute list> From <table list> [Where <condition>] [Group by <grouping attribute(s)>] [Having <group condition>] [Order by <attribute list>] Note [....] adalah optional clauses Secara umum, terdapat banyak cara untuk mendapatkan informasi yang sama dalam SQL. Beberapa cara lebih efisien dari cara lainnya. Untuk mendapatkan cara yang paling efisien dalam penggunaan SQL, pemakai harus mengetahui secara mendalam teknik SQL dari suatu produk. Embedded SQL: • Embedded SQL adalah perintah SQL yang dieksekusi dalam suatu host language
environment seperti COBOL, PL/1, C, Ada, Pascal dan sebagainya. • Embedded SQL memiliki dua metode: Preprocessor dan Procedure Call. Oracle
menggunakan preprocessor dengan PL/SQL-nya. • Perintah SQL diawali dengan klausa Exec Sql. • SQL adalah table-oriented language, sedangkan host language yang dipakai adalah
record-oriented language, sehingga dibutuhkan suatu metode untuk mendapatkan record secara individual dengan memakai SQL pada saat mengakses data.
• Solusi yang dipakai adalah dengan menggunakan konsep cursor, yang merupakan suatu pointer yang menunjuk ke suatu record dari table yang sedang diakses.
QBE (Query by Example): • User friendly • Lebih condong sebagai table filling language daripada command language

24
SQL Struktur dasar dari suatu ekspresi SQL terdiri dari tiga klausa, yaitu: select, from dan where. • select dipakai untuk menuliskan attribute yang diinginkan sebagai hasil dari suatu
query (sama dengan operasi project dalam relational algebra). • from dipakai untuk menuliskan nama-nama relation yang dipakai dalam query. • where dipakai untuk menuliskan predicate (seperti syarat dari query) yang terdiri
dari attribute-attribute dari relation yang ada pada klausa from (sama dengan selection predicate dalam relational algebra).
Hasil dari suatu SQL query adalah suatu relation. Berikut ini adalah contoh-contoh query sederhana dengan menggunakan relation yang ada pada halaman terakhir dari bahan kuliah minggu ini. Query: “Tampilkan unit_code dari relation TUTORIAL” select unit_code from tutorial; Output:
unit_code ID527 ID527 ID658 ID658 ID851 ID851 ID999 ID999
Jika duplicate tidak diperbolehkan dalam output, maka bisa dipakai keyword distinct setelah select. Query diatas bisa dituliskan seperti dibawah ini: select distinct unit_code from tutorial; Output:
unit_code ID527 ID658 ID851 ID999
Berikut ini adalah contoh penggunaan keyword where.

25
Query: Tampilkan ID dari full-time (FT) students dari relation STUDENT. select id from student where status = “FT”; Output:
ID 95113000 95113002 96114000
Jika informasi yang dibutuhkan berasal dari beberapa relation, notasi yang dipakai adalah relation-name.attribute-name. Query: Tampilkan ID dan status dari semua student yang terdaftar di unit ID658. select student.id, student.status from student, enrollment where student.id = enrollment.id and enrollment.unit_code = “ID658”; Untuk menjawab suatu query, SQL memiliki dua alternatif yang bisa dipakai, yaitu notasi join (memakai keyword and, or dan not) dan notasi sub-query (memakai keyword in dan not in). Berikut ini adalah alternatif jawaban query diatas dengan menggunakan notasi sub-query: select id, status from student where id in (select id from enrollment where unit_code = “ID658”); Output:
ID status 95113000 FT 96114000 FT 96114001 PT
SQL bisa juga memakai alias dari relation (seperti variabel tuple dalam relational calculus). Suatu variabel tuple dalam SQL harus diasosiasikan dengan suatu relation tertentu. Variabel tuple didefinisikan dalam klausa from. Contoh dari penggunaan variabel tuple adalah sebagai berikut:

26
Query: Tampilkan ID dan status dari semua student yang terdaftar di unit ID658. select S.id, S.status from student S, enrollment T where S.id = T.id and T.unit_code = “ID658”; Latihan Dengan menggunakan relasi STUDENT, ENROLLMENT dan TUTORIAL yang diberikan pada halaman 27, tuliskan perintah SQL dan output yang diharapkan untuk menyelesaikan query-query berikut ini: 1. Tampilkan UnitCode yang Tutornya bernama Dewi. 2. Tampilkan ID dari mahasiswa yang Tutornya bernama Bob. 3. Tampilkan Tutor yang tidak mengajar PartTime Students.
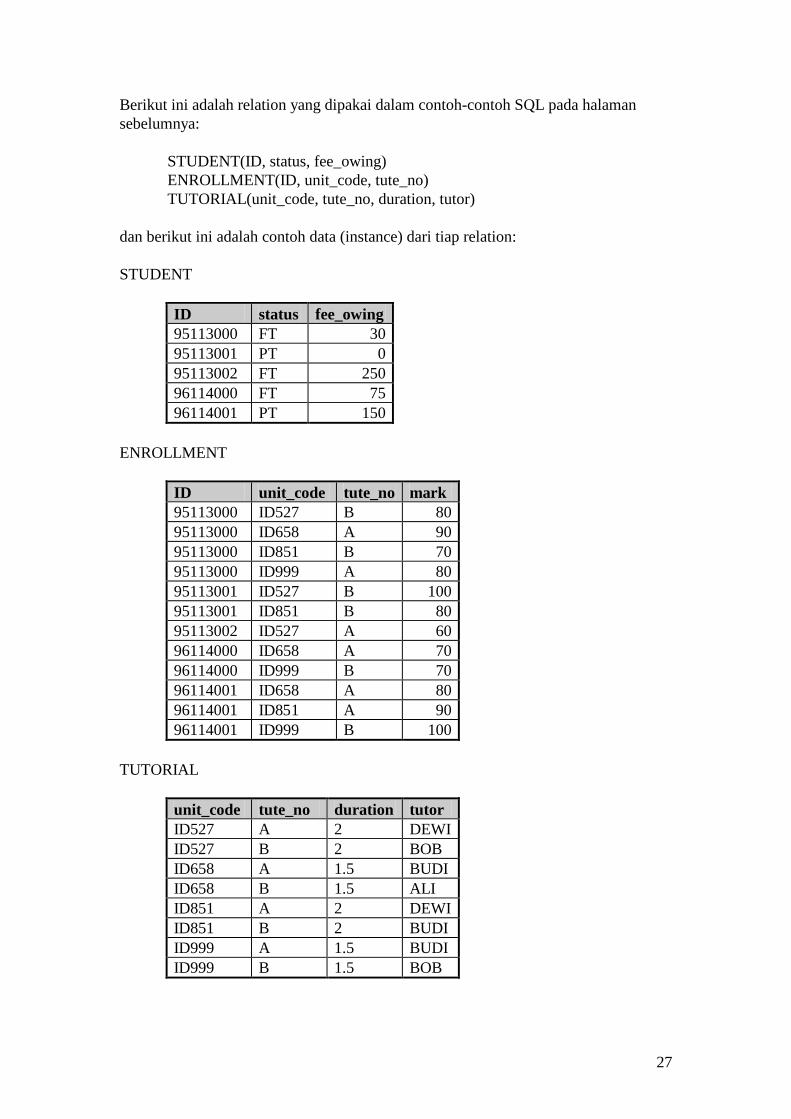
27
Berikut ini adalah relation yang dipakai dalam contoh-contoh SQL pada halaman sebelumnya: STUDENT(ID, status, fee_owing) ENROLLMENT(ID, unit_code, tute_no) TUTORIAL(unit_code, tute_no, duration, tutor) dan berikut ini adalah contoh data (instance) dari tiap relation: STUDENT
ID status fee_owing 95113000 FT 30 95113001 PT 0 95113002 FT 250 96114000 FT 75 96114001 PT 150
ENROLLMENT
ID unit_code tute_no mark 95113000 ID527 B 80 95113000 ID658 A 90 95113000 ID851 B 70 95113000 ID999 A 80 95113001 ID527 B 100 95113001 ID851 B 80 95113002 ID527 A 60 96114000 ID658 A 70 96114000 ID999 B 70 96114001 ID658 A 80 96114001 ID851 A 90 96114001 ID999 B 100
TUTORIAL
unit_code tute_no duration tutor ID527 A 2 DEWI ID527 B 2 BOB ID658 A 1.5 BUDI ID658 B 1.5 ALI ID851 A 2 DEWI ID851 B 2 BUDI ID999 A 1.5 BUDI ID999 B 1.5 BOB

28
Minggu 9: SQL (2) SQL memiliki fasilitas untuk mengurutkan record dari relation yang hendak ditampilkan dengan menggunakan klausa order by. Query: Tampilkan secara urut nama-nama tutor ID527 dari relation TUTORIAL. select tutor from tutorial where unit_code = “ID527” order by tutor; Output:
tutor BOB DEWI
Untuk memenuhi permintaan order by, SQL harus melakukan proses sorting. Proses sorting record yang berjumlah sangat banyak membutuhkan waktu lama, karena itu, perintah order by ini hanya digunakan apabila benar benar perlu. SQL memiliki beberapa fungsi komputasi dari suatu kelompok record dengan menggunakan klausa group by. Attribute yang dituliskan dalam klausa group by dipakai untuk membentuk kelompok record. Record yang memiliki attribute dengan value yang sama akan dikelompokkan dalam satu group. Berikut ini adalah fungsi komputasi yang dimiliki SQL: • average: avg • minimum: min • maximum: max • total: sum • count: count Query: Tampilkan id dan nilai rata-rata dari semua student yang terdaftar: select id, avg(mark) from enrollment group by id; Output:
ID avg(mark) 95113000 80 95113001 90 95113002 60 96114000 70 96114001 90

29
Operasi seperti avg diatas disebut aggregate operations, karena mereka dioperasikan pada gabungan (aggregate) record. Syarat query bisa juga diberlakukan untuk suatu kelompok record. Misalkan, dari query diatas, hanya diinginkan student dengan nilai rata-rata >= 80. Untuk menjawab query tersebut, bisa digunakan klausa having. Predicate (syarat) dari klausa having ini akan dieksekusi setelah group dibentuk, sehingga operator aggregate bisa juga dipakai dalam klausa having ini. Query tersebut bisa diekspresikan dalam SQL sebagai berikut: select id, avg(mark) from enrollment group by id having avg(mark) >= 80; Output:
ID avg(mark) 95113000 80 95113001 90 96114001 90
Operator aggregate count sering dipakai untuk menghitung jumlah record dari suatu relation. Notasi yang dipakai adalah count(*). Berikut ini adalah perintah SQL untuk menghitung jumlah record dari relation STUDENT: select count(*) from student; Output:
count(*) 5
Proses delete record dari suatu relation mudah untuk dilakukan. Permintaan delete diekspresikan dengan cara yang sama dengan query. Bedanya, proses delete bukan menampilkan record yang dihasilkan, tetapi menghapus record dari database. Proses delete akan menghapus suatu record secara keseluruhan, bukan hanya field tertentu. Dalam SQL, proses delete diekspresikan sebagai berikut: delete r where P; P dipakai untuk merepresentasikan suatu predicate dan r merepresentasikan suatu relation. Record t dalam r dimana P(t) memenuhi syarat akan di-delete dari r. Misalkan, untuk men-delete semua enrollment dari student ID 95113001: delete enrollment where id = 95113001;

30
Proses insert data ke suatu relation bisa dilakukan dengan dua cara, yaitu dengan menuliskan value dari record atau menuliskan suatu query yang hasilnya adalah sekumpulan record yang hendak di-insert ke relation. Misalkan, untuk meng-insert student baru ke relation student: insert into student values (96114002, “FT”, 300); Jika dibutuhkan untuk mengubah isi dari field tertentu dari suatu record, digunakan perintah update. Seperti pada perintah insert dan delete, record yang hendak di ubah bisa didapatkan dari hasil suatu query. Misalkan, untuk melakukan proses upgrade nilai (mark) 5 point dari unit_code ID527: update enrollment set mark = mark + 5 where unit_code = “ID527”; Kesimpulan SQL bisa digunakan untuk melakukan proses-proses berikut ini: • Melihat data berdasarkan kriteria tertentu. • Melakukan proses join pada table yang berelasi. • Update, Insert, atau Delete data. • Aktivitas-aktivitas lainnya yang berhubungan dengan data (sort, dll). Keyword dari SQL DML (Data Manipulation Language): • SQL statements: SELECT, UPDATE, INSERT, DELETE. • SQL aggregates: SUM, AVG, MIN, MAX, COUNT. • SQL clauses: FROM, WHERE, ORDER BY, GROUP BY, HAVING. • SQL operators: +, -, *, /, =, <, <=, >, >=, <>, IS NULL, AND, OR, NOT,
|| (String concatenation)

31
Exercise The questions below refer to the following three relations:
SALESPERSON(Name, Age, Salary) ORDERS(Number, Cust-name, Salesperson-name, Amount) CUSTOMER(Name, City, Industry-type)
An instance of these relations is shown in the next page. Use the data in those tables and show SQL statements to display or modify data as indicated in the following questions: 1. Show the ages and salaries of all salespeople. 2. Show the ages and salaries of all salespeople (duplicates omitted). 3. Show the names of all salespeople less than thirty years old. 4. Show the names of all salespeople having and order with ABERNATHY
CONSTRUCTION. 5. Show the names and salaries of all salespeople not having an order with
ABERNATHY CONSTRUCTION, in ascending order of salary. 6. Compute the number of orders. 7. Compute the number of different customers having an order. 8. Compute the average age of salespersons. 9. Show the name of the oldest salesperson. 10. Compute the number of orders for each salesperson. 11. Compute the number of orders for each salesperson, considering only orders
having an amount exceeding 500. 12. Show the names and ages of salespeople having an order with ABERNATHY
CONSTRUCTION (use subquery). 13. Show the names and ages of salespeople having an order with ABERNATHY
CONSTRUCTION (use join), in descending order of age. 14. Show the age of salespeople having an order with a customer in MEMPHIS (use
subquery), in descending order of age. 15. Show the age of salespeople having an order with a customer in MEMPHIS (use
join). 16. Show the industry type and ages of salesperson of all orders for companies in
MEMPHIS. 17. Show the names of salespeople having two or more orders. 18. Show the names and ages of salespeople having two or more orders. 19. Show the names and ages of salespeople having an order with all customers. 20. Show an SQL statement to insert a new row into CUSTOMER. 21. Show an SQL statement to insert a new name and age into SALESPERSON;
assume salary is undetermined. 22. Show an SQL statement to insert rows into a new table, HIGH-ACHIEVER
(Name, Age), where, to be included, a salesperson must have a salary of at least 100,000.
23. Show an SQL statement to delete customer ABERNATHY CONSTRUCTION. 24. Show an SQL statement to delete all orders for ABERNATHY
CONSTRUCTION. 25. Show an SQL statement to change the salary of salesperson JONES to 45,000. 26. Show an SQL statement to give all salespeople a 10 percent pay increase. 27. Assume salesperson JONES changes name to PARKS. Show SQL statements to
make appropriate changes.
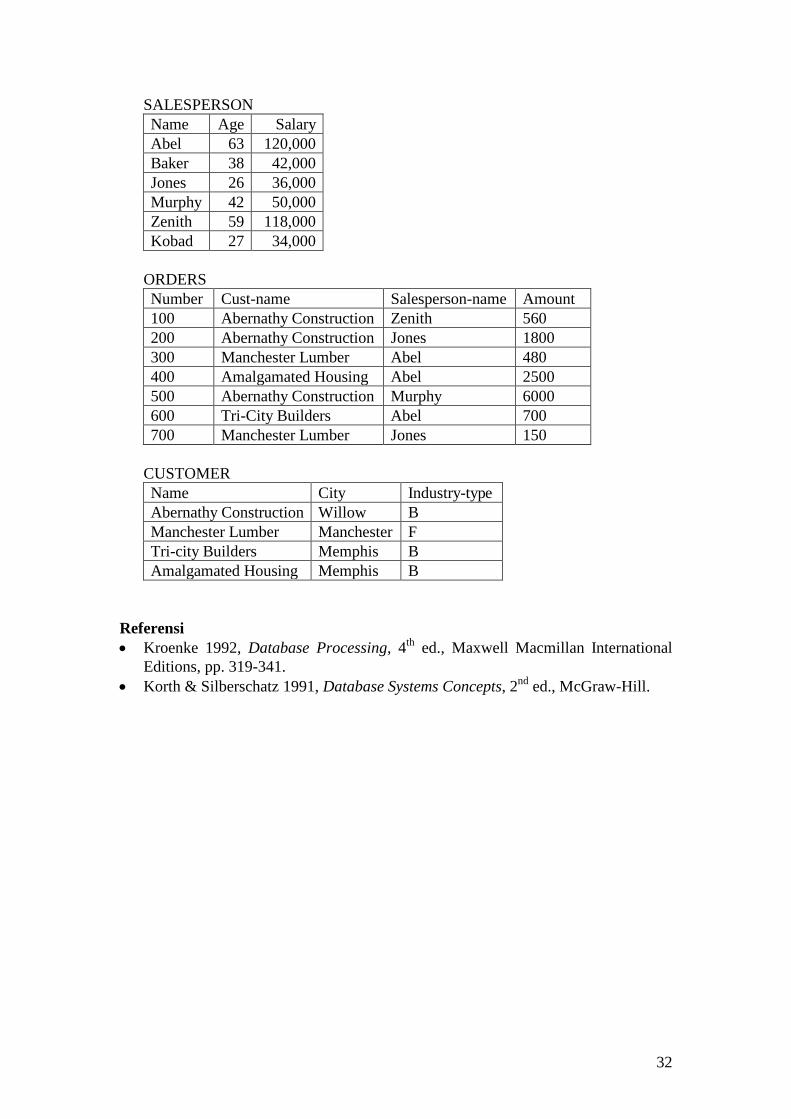
32
SALESPERSON Name Age Salary Abel 63 120,000 Baker 38 42,000 Jones 26 36,000 Murphy 42 50,000 Zenith 59 118,000 Kobad 27 34,000
ORDERS
Number Cust-name Salesperson-name Amount 100 Abernathy Construction Zenith 560 200 Abernathy Construction Jones 1800 300 Manchester Lumber Abel 480 400 Amalgamated Housing Abel 2500 500 Abernathy Construction Murphy 6000 600 Tri-City Builders Abel 700 700 Manchester Lumber Jones 150
CUSTOMER
Name City Industry-type Abernathy Construction Willow B Manchester Lumber Manchester F Tri-city Builders Memphis B Amalgamated Housing Memphis B
Referensi • Kroenke 1992, Database Processing, 4th ed., Maxwell Macmillan International
Editions, pp. 319-341. • Korth & Silberschatz 1991, Database Systems Concepts, 2nd ed., McGraw-Hill.

33
Minggu 12: Pengantar Data Warehousing Pengantar Istilah Data Warehouse pertama kali diperkenalkan oleh W.H. Inmon pada tahun 1992 (Elmasri and Navathe, 2000). W.H. Inmon mendefinisikan Data Warehouse sebagai berikut:
"Data Warehouse is a subject-oriented, integrated, nonvolatile, time-variant collection of data in support of management's decisions."
Data warehouse memungkinkan pengaksesan data untuk analisis yang kompleks, penemuan pengetahuan baru dan pengambilan keputusan. Pada pembahasan awal dalam diktat ini, database didefinisikan sebagai kumpulan dari data yang saling berelasi, dan sistem database adalah gabungan dari database dan software database. Data warehouse juga merupakan kumpulan informasi dan juga sebagai sistem pendukung. Meskipun demikian database dan data warehouse memiliki perbedaan yang jelas. Database tradisional memiliki karakteristik transaksional (relational, object-oriented, network atau hierarchical). Data warehouse memiliki karakteristik unik yang tidak dimiliki oleh database tradisional, yaitu data warehouse ditujukan untuk aplikasi pendukung pengambilan keputusan. Data warehouse dioptimisasi untuk pengambilan / pengaksesan data, bukan untuk pemrosesan transaksi sehari-hari. Data warehouse mendukung beberapa jenis aplikasi seperti OLAP (On-Line Analytical Processing), DSS (Decision Support System) dan Data Mining. OLAP adalah istilah yang dipakai untuk menggambarkan analisis dari data kompleks yang diambil dari data warehouse. DSS dan juga EIS (Executive Information System) dipakai untuk mendukung pengambilan keputusan pada suatu organisasi dengan menggunakan data pada level yang lebih tinggi. Data mining digunakan untuk penemuan pengetahuan baru, yaitu proses pencarian data untuk pengetahuan baru yang sebelumya belum diketahui. Database tradisional mendukung OLTP (On-Line Transaction Processing), yang termasuk penambahan, perubahan dan penghapusan data, dan juga mendukung pengambilan data berdasarkan query tertentu. Database relasional tradisional dioptimisasi untuk memproses query yang hanya menyentuh sebagian kecil dari database dan transaksi yang berhubungan dengan penambahan atau perubahan pada beberapa record per table untuk diproses. Jadi, mereka tidak bisa dioptimisasi untuk OLAP, DSS atau Data Mining. Sebaliknya, data warehouse didisain secara khusus untuk mendukung ekstraksi, pemrosesan dan representasi data secara efisien untuk tujuan analisis dan pengambilan keputusan. Data warehouse umumnya berisi data dalam jumlah yang sangat banyak yang berasal dari berbagai sumber, termasuk database dari data model-data model yang berbeda-beda dan terkadang termasuk file yang berasal dari sistem dan platform independent.
34
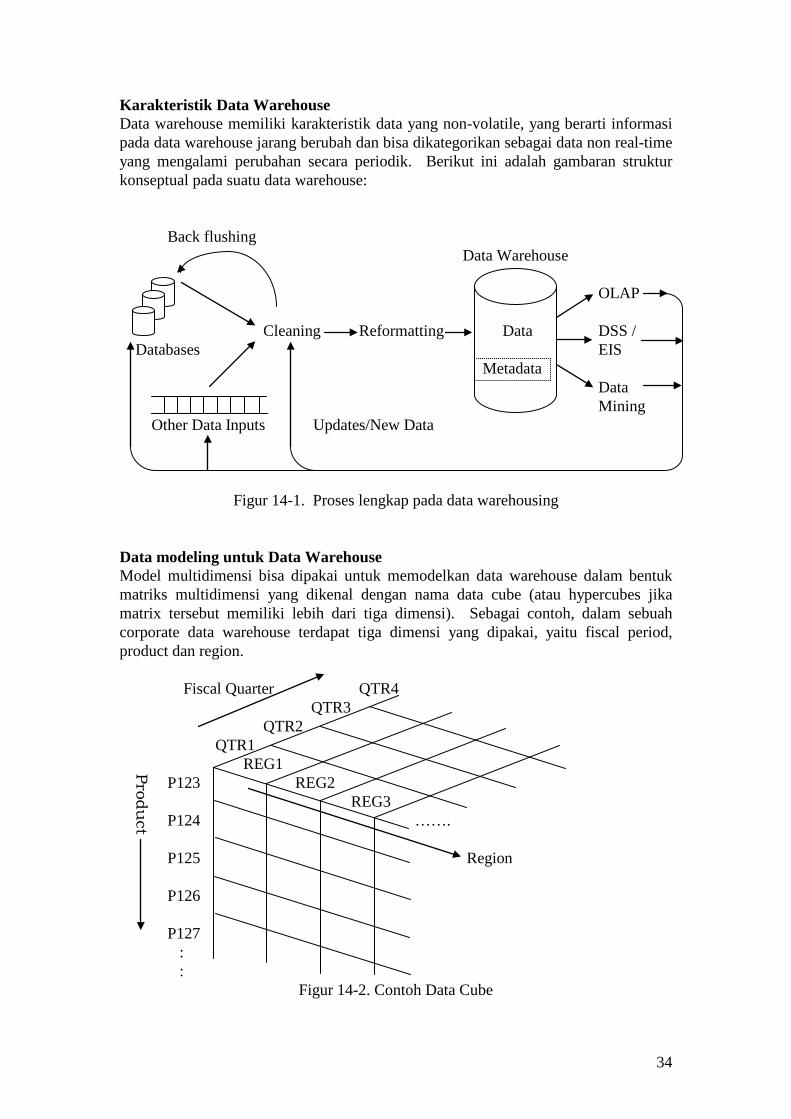
Karakteristik Data Warehouse Data warehouse memiliki karakteristik data yang non-volatile, yang berarti informasi pada data warehouse jarang berubah dan bisa dikategorikan sebagai data non real-time yang mengalami perubahan secara periodik. Berikut ini adalah gambaran struktur konseptual pada suatu data warehouse: Back flushing Data Warehouse OLAP Cleaning Reformatting Data DSS / Databases EIS Metadata Data Mining Other Data Inputs Updates/New Data
Figur 14-1. Proses lengkap pada data warehousing Data modeling untuk Data Warehouse Model multidimensi bisa dipakai untuk memodelkan data warehouse dalam bentuk matriks multidimensi yang dikenal dengan nama data cube (atau hypercubes jika matrix tersebut memiliki lebih dari tiga dimensi). Sebagai contoh, dalam sebuah corporate data warehouse terdapat tiga dimensi yang dipakai, yaitu fiscal period, product dan region. Fiscal Quarter QTR4
QTR3 QTR2 QTR1 REG1 P123 REG2 REG3 P124 …….
P125 Region
P126
P127 : :
Figur 14-2. Contoh Data Cube
Product

35
Pada figur 14-2 terdapat data cube tiga dimensi berisi data penjualan product tiap fiscal quarter dan tiap region penjualan. Setiap sel dalam data cube berisi data untuk product tertentu pada fiscal quarter tertentu dan pada region tertentu. Dengan menambahkan dimensi lainnya, suatu data hypercube bisa dikembangkan, meskipun jika lebih dari tiga dimensi agak sulit divisualisasikan. Dengan model multidimensi ini, query bisa dilakukan pada kombinasi dimensi manapun, tanpa harus melakukan query pada database yang kompleks. Dimensi data yang dipilih bisa diubah sesuai dengan keinginan user. Misalnya pada figur 14-2, dimensi pertama adalah product, kedua adalah region dan ketiga adalah fiscal quarter. Jika dilakukan Rotation (Pivoting), maka, Dimensi Data Cube tersebut bisa diubah menjadi Region (dimensi 1), Fiscal Quarter (dimensi 2) dan Product (dimensi 3). Model Multidimensi memungkinkan user untuk merepresentasikan data dalam bentuk lain yang dikenal dengan nama roll-up display dan drill-down display. Roll-up display dipakai untuk mengelompokkan data pada suatu dimensi (misalnya, menjumlah data mingguan jadi 3 bulanan (quarterly) atau data 3 bulanan menjadi data tahunan). Sebagai contoh, jika dimensi ketiga (fiscal quarter) pada figur 14-2 di roll-up, maka hasil penjualan product tiap region untuk semua quarter akan dijumlah dan ditampilkan dalam matrix berikut ini:
Region
1xx
2xx
3xx
4xx
Figur 14-3. Roll-up Display Sebaliknya, drill-down display dipakai untuk merepresentasikan data dalam bentuk yang lebih detail. Misalnya pada contoh diatas, tiap region dibagi lagi menjadi sub-region, dan product bisa dibagi lagi menjadi beberapa style (misal style A, B, C, …). Region 1 Region 2 SubReg 1 SubReg 2 SubReg 3 SubReg 1 SubReg 2 PROD123 A B C D PROD124 A B C
Figur 14-4. Drill-down Display
Product
36
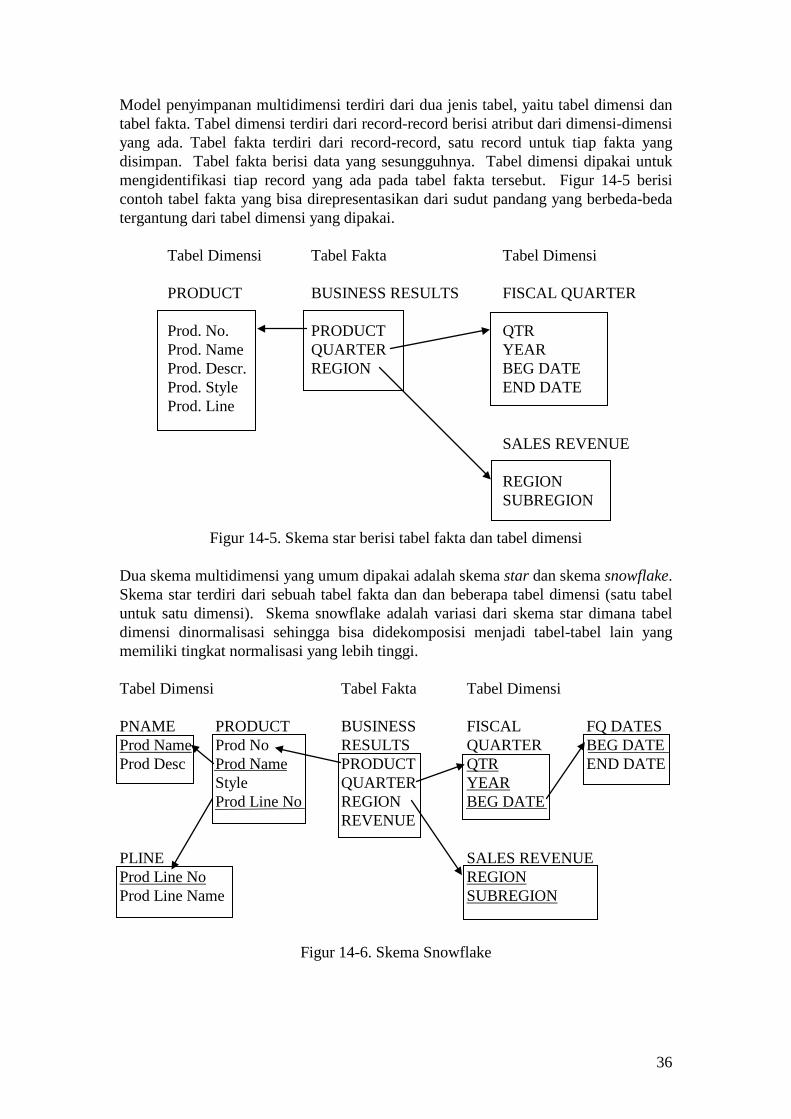
Model penyimpanan multidimensi terdiri dari dua jenis tabel, yaitu tabel dimensi dan tabel fakta. Tabel dimensi terdiri dari record-record berisi atribut dari dimensi-dimensi yang ada. Tabel fakta terdiri dari record-record, satu record untuk tiap fakta yang disimpan. Tabel fakta berisi data yang sesungguhnya. Tabel dimensi dipakai untuk mengidentifikasi tiap record yang ada pada tabel fakta tersebut. Figur 14-5 berisi contoh tabel fakta yang bisa direpresentasikan dari sudut pandang yang berbeda-beda tergantung dari tabel dimensi yang dipakai. Tabel Dimensi Tabel Fakta Tabel Dimensi PRODUCT BUSINESS RESULTS FISCAL QUARTER Prod. No. PRODUCT QTR Prod. Name QUARTER YEAR Prod. Descr. REGION BEG DATE Prod. Style END DATE Prod. Line SALES REVENUE REGION SUBREGION
Figur 14-5. Skema star berisi tabel fakta dan tabel dimensi Dua skema multidimensi yang umum dipakai adalah skema star dan skema snowflake. Skema star terdiri dari sebuah tabel fakta dan dan beberapa tabel dimensi (satu tabel untuk satu dimensi). Skema snowflake adalah variasi dari skema star dimana tabel dimensi dinormalisasi sehingga bisa didekomposisi menjadi tabel-tabel lain yang memiliki tingkat normalisasi yang lebih tinggi. Tabel Dimensi Tabel Fakta Tabel Dimensi PNAME PRODUCT BUSINESS FISCAL FQ DATES Prod Name Prod No RESULTS QUARTER BEG DATE Prod Desc Prod Name PRODUCT QTR END DATE Style QUARTER YEAR Prod Line No REGION BEG DATE REVENUE PLINE SALES REVENUE Prod Line No REGION Prod Line Name SUBREGION
Figur 14-6. Skema Snowflake

37
Jika suatu tabel dimensi dipakai oleh lebih dari satu tabel fakta, maka kumpulan tabel fakta tersebut disebut fact constellation. Figur 14-7 menunjukkan suatu fact constellation dimana dua tabel fakta (business results dan business forecast) menggunakan tabel dimensi yang sama, yaitu tabel product. Fact constellation membatasi kemungkinan query pada warehouse. FACT TABLE 1 DIMENSION TABLE FACT TABLE 2 BUSINESS RESULTS PRODUCT BUSINESS FORECAST PRODUCT Prod. No PRODUCT QUARTER Prod. Name FUTURE QTR REGION Prod. Descr REGION REVENUE Prod. Style PROJECTED REVENUE Prod. Line
Figur 14-7. Fact Constellation Penyimpanan Data Warehouse menggunakan teknik pengindeksan yang mendukung akses berkecepatan tinggi, yaitu pengindeksan bitmap. Dalam pengindeksan bitmap, satu bit vektor akan dibuat untuk tiap domain yang ada pada field yang hendak diindeks. Pengindeksan bitmap sangat cocok untuk field yang memiliki domain yang sedikit. Misalkan, suatu tabel yang berisi 100.000 mobil hendak diindeks dengan menggunakan pengindeksan bitmap pada field car_size. Jika terdapat empat car_size, yaitu economy, compact, midsize, dan fullsize, maka akan terdapat empat buah bit vektor, masing-masing berisi 100.000 bits (12.5 K). Jadi total memori yang dibutuhkan untuk ke empat vektor tersebut adalah 50 K. Pengindeksan bitmap sangat menguntungkan ditinjau dari kecepatan input/outputnya yang tinggi dan hemat memori untuk penyimpanan indeksnya. Pada skema star, data pada tabel dimensi bisa diindeks untuk menghubungkannya dengan tabel fakta dengan menggunakan pengindeksan gabungan (join index). Indeks gabungan adalah indeks tradisional untuk menghubungkan primary key dan foreign key, misalnya untuk menghubungkan value yang ada pada tabel dimensi dengan record-record yang ada pada tabel fakta. Misalkan, tabel fakta Sales berhubungan dengan tabel dimensi City dan tabel dimensi Fiscal Quarter. Jika dibuat indeks gabungan pada tabel City, maka untuk tiap City yang ada akan disimpan ID dari record pada tabel fakta yang berisi City tersebut. Indeks gabungan boleh dibuat untuk banyak dimensi. Referensi Elmasri and Navathe, chapter 26, pp.841-872.






























