Embed Size (px)
Citation preview

Peer-to-Peer Systems
Chapter 25

What is Peer-to-Peer (P2P)?
• Napster?
• Gnutella?
• Most people think of P2P as music sharing
What is a peer?
• Contrasted with Client-Server model
• Servers are centrally maintained and administered
• Client has fewer resources than a server
What is a peer?
• A peer’s resources are similar to the resources of the other participants
• P2P – peers communicating directly with other peers and sharing resources

P2P ConceptsClient-client as opposed to client-serverFile sharing: I get a copy from someone, and now make it available for others to
download---copies are/workload is spread outAdvantages: Scalable, stable, self-repairing
Process: A peer joins the system when a user starts the application, contributes some resources while
making use of the resources provided by others, and leaves the system when the user exits the application.
Session: One such join-participate-leave cycleChurn: The independent arrival and departure by thousands—or millions— of
peers creates the collective effect we call churn. The user-driven dynamics of peer participation must be taken intoaccount in both the design and evaluation of any P2P application. For example,
the distribution of session lengthcan affect the overlay structure, the resiliency of theoverlay, and the selection of key design parameters.

Types of clients
• Based on the client behavior, there are three types of clients:
• True clients (not active participants; take but don’t give; short duration of stay)
• Peers: Clients that stay long enough and well-connected enough to participate actively (Take and give)
• Servers (Give, but don’t take)
• Safe vs. probabilistic protocols• Mostly logarithmic order of performance/cost

Levels of P2P-ness
• P2P as a mindset– Slashdot
• P2P as a model– Gnutella
• P2P as an implementation choice– Application-layer multicast
• P2P as an inherent property– Ad-hoc networks

P2P Goals/Benefits
• Cost sharing
• Resource aggregation
• Improved scalability/reliability
• Increased autonomy
• Anonymity/privacy
• Dynamism
• Ad-hoc communication

P2P File Sharing
• Content exchange– Gnutella
• File systems– Oceanstore
• Filtering/mining– Opencola

P2P File Sharing Benefits
• Cost sharing
• Resource aggregation
• Improved scalability/reliability
• Anonymity/privacy
• Dynamism
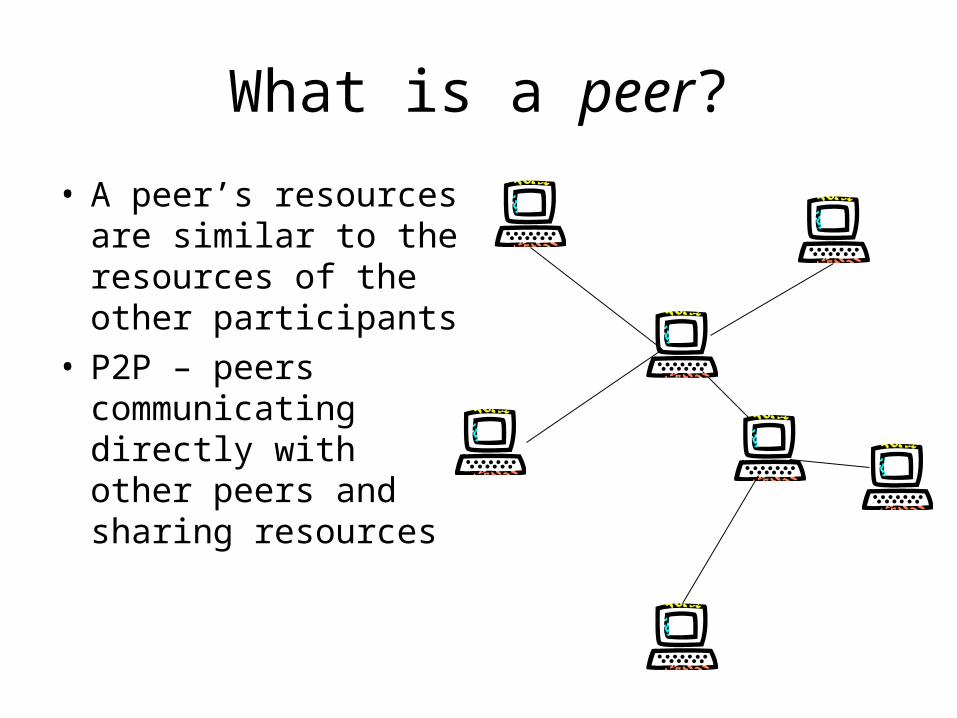
P2P Application Taxonomy
P2P Systems
Distributed ComputingSETI@home
File SharingGnutella
CollaborationJabber
PlatformsJXTA

Management/Placement Challenges
• Per-node state
• Bandwidth usage
• Search time
• Fault tolerance/resiliency

Approaches
• Centralized
• Flooding
• Document Routing
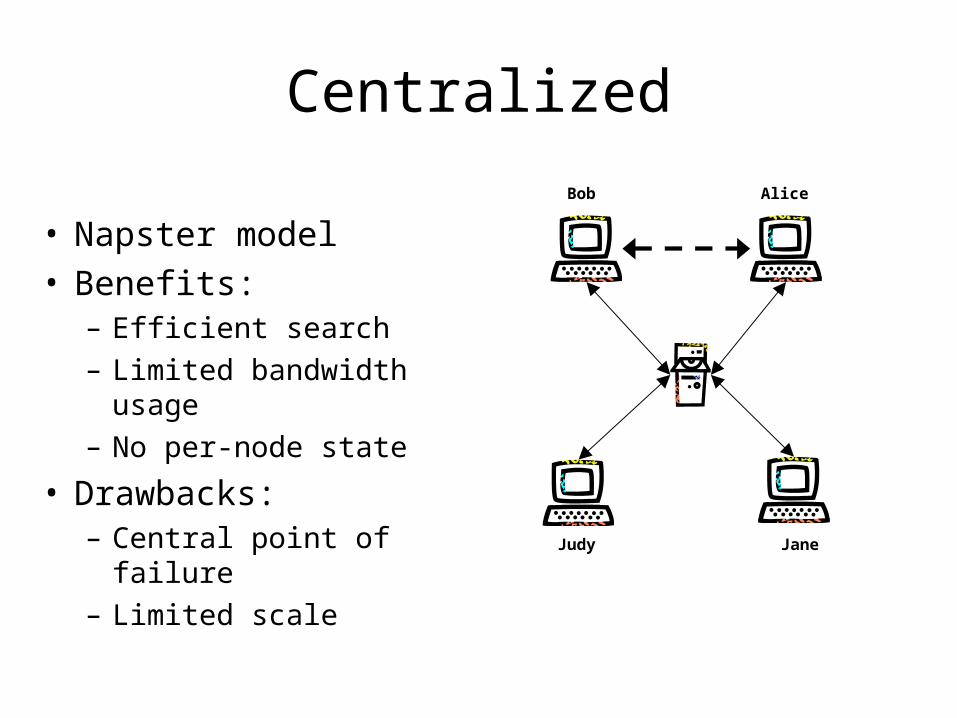
Centralized
• Napster model• Benefits:
– Efficient search– Limited bandwidth
usage– No per-node state
• Drawbacks:– Central point of failure– Limited scale
Bob Alice
JaneJudy
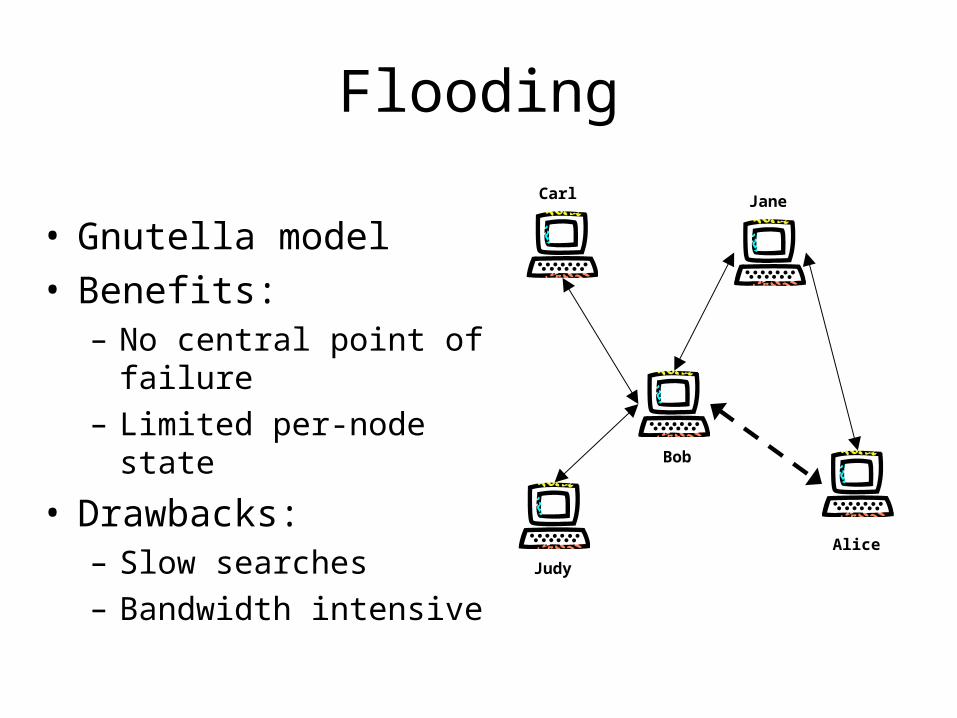
Flooding
• Gnutella model• Benefits:
– No central point of failure– Limited per-node state
• Drawbacks:– Slow searches– Bandwidth intensive
Bob
Alice
Jane
Judy
Carl
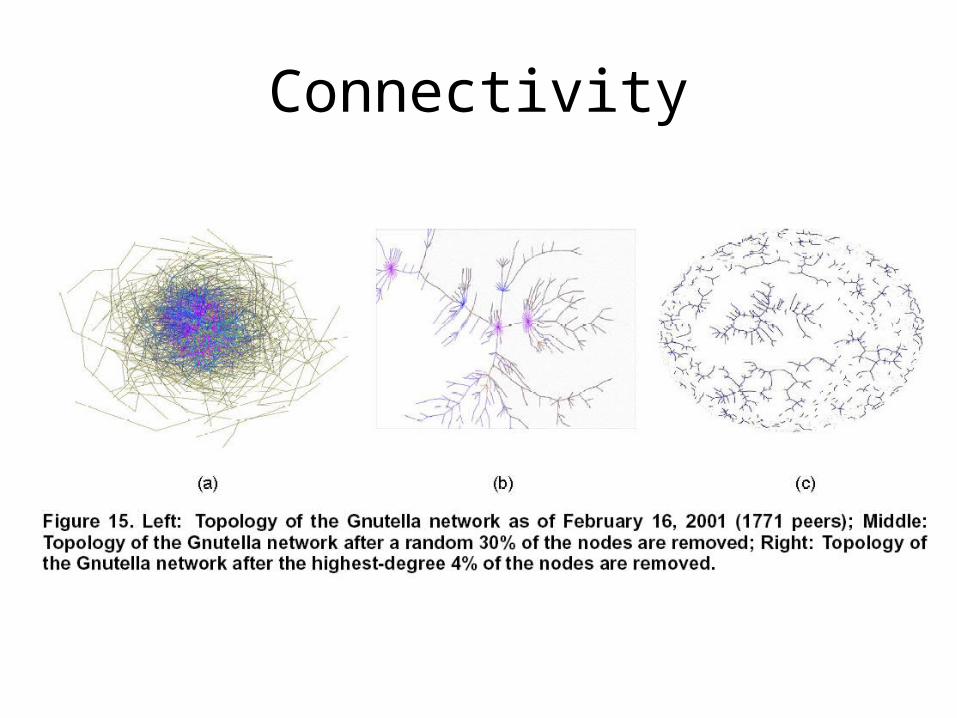
Connectivity

Napster
• Uses a centralized directory mechanism– To control the selection of peers– To generate other revenue-generating activities
• In addition is has several regional servers• Users first connect to the Napster’s centralized server to
one of the regional servers• Basically, each client system has a Napster proxy that
keeps track of the local shared files and informs the regional server
• Napster uses some heuristic evaluation mechanisms about the reliability of a client before it starts using it as a shared workspace

Gnutella and Kazaa
• Unlike Napster, it is a pure P2P with no centralized component---all peers are completely equal
• Protocol:– Ensures that each user system is concerned with a few Gnutella
nodes– Search for files: if the distance specified is 4, then all machines
within 4 hops of the client will be probed (1st all M/C within 1 hop; then 2 hops; and so on)
– The anycast mechanism becomes extremely costly as system scales up.
• Kaaza also does not have a centralized control (as Gnutella); it uses Plaxton trees.

CAN• Content Addressable Network• Each object is expected to have a unique system wide name or identifier• The name is hashed into a d-tuple--- identifier is converted into a random-
looking number using some cryptographic hash function• In a 2-dimensional CAN the id is hashed to a 2-dimensional tuple: (x,y)• Same scheme is used to convert machine IDs• Recursively subdivide the space of possible d-dimensional identifiers,
storing each object at the node owning the part of the space (zone) that object’s ID falls in.
• When a new node is added, it shares its space with the new node; similarly when a node leaves, its space is owned by a nearby node
• Once a user provides the search key, it is converted to (x,y); the receiving CAN node finds a path from itslef to the node having (x,y) space. If d is the dimensions, and N is the #of nodes, then the number of hops is (d/4)*N1/d
• TO take care of node failures, there will be backups.• Cost is high when there are frequent joins/leaves
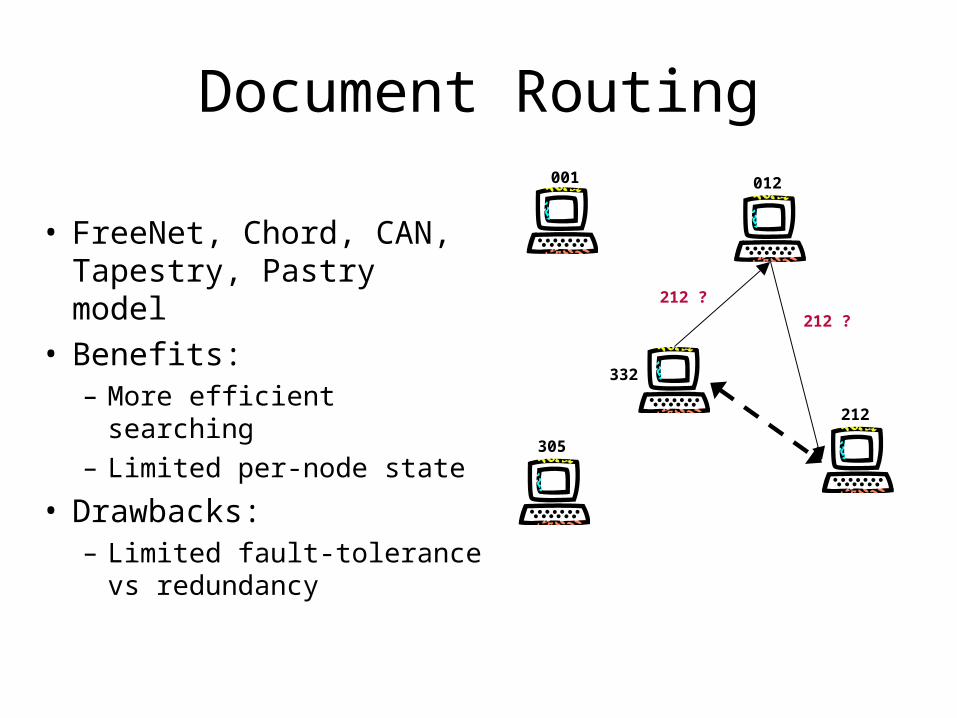
Document Routing
• FreeNet, Chord, CAN, Tapestry, Pastry model
• Benefits:– More efficient searching– Limited per-node state
• Drawbacks:– Limited fault-tolerance vs
redundancy
001 012
212
305
332
212 ?
212 ?

Document Routing – CAN
• Associate to each node and item a unique id in an d-dimensional space
• Goals– Scales to hundreds of thousands of nodes– Handles rapid arrival and failure of nodes
• Properties – Routing table size O(d)– Guarantees that a file is found in at most d*n1/d steps,
where n is the total number of nodes
Slide modified from another presentation
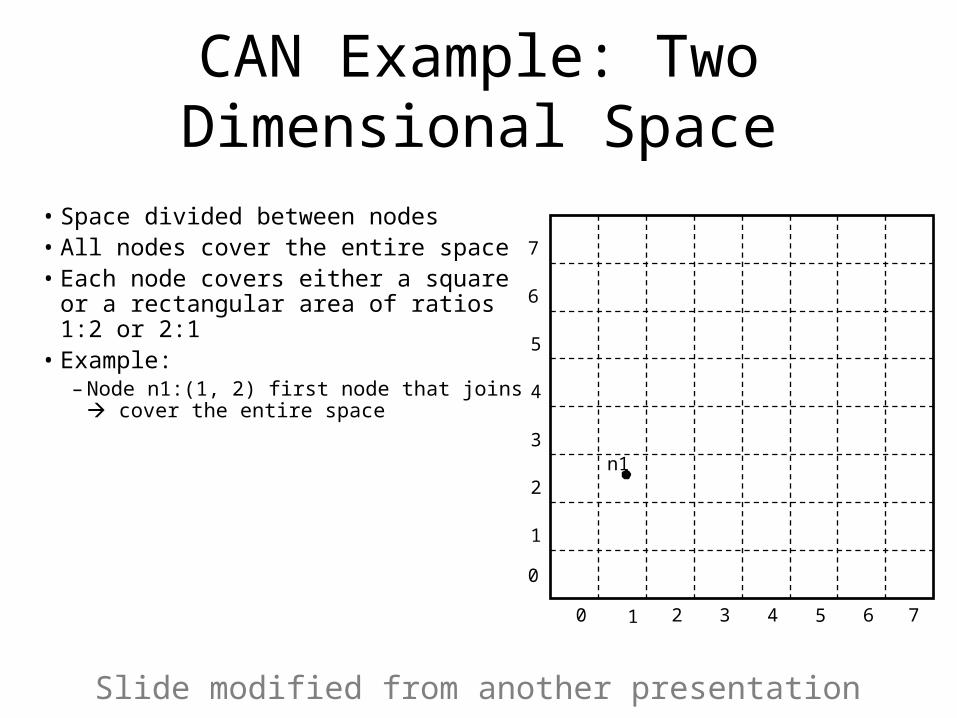
CAN Example: Two Dimensional Space
• Space divided between nodes• All nodes cover the entire space• Each node covers either a square or
a rectangular area of ratios 1:2 or 2:1• Example:
– Node n1:(1, 2) first node that joins cover the entire space
1 2 3 4 5 6 70
1
2
3
4
5
6
7
0
n1
Slide modified from another presentation
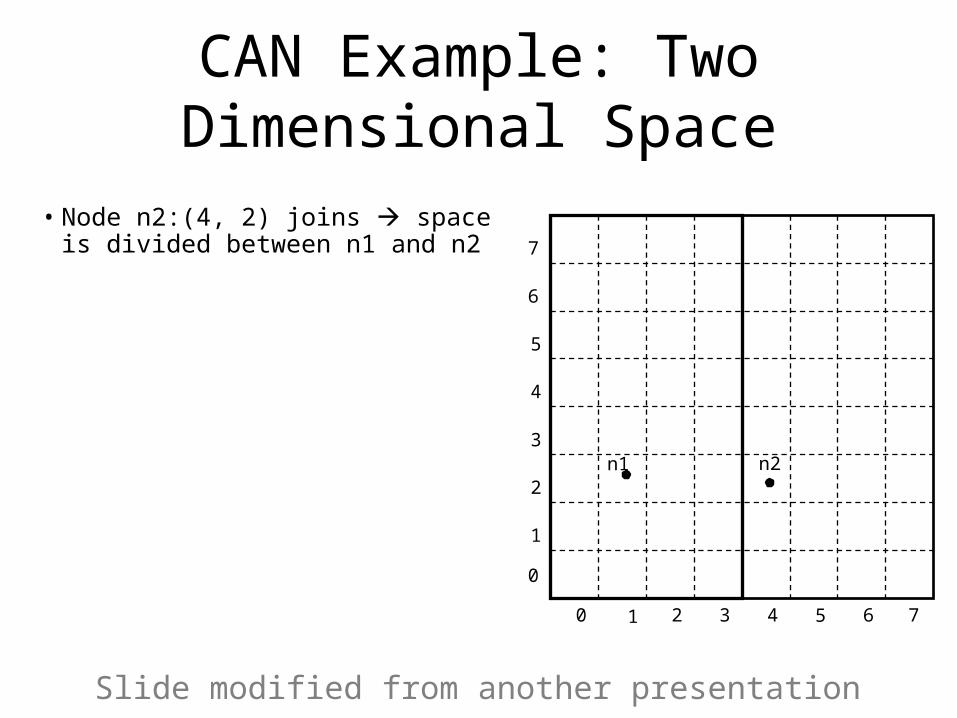
CAN Example: Two Dimensional Space
• Node n2:(4, 2) joins space is divided between n1 and n2
1 2 3 4 5 6 70
1
2
3
4
5
6
7
0
n1 n2
Slide modified from another presentation
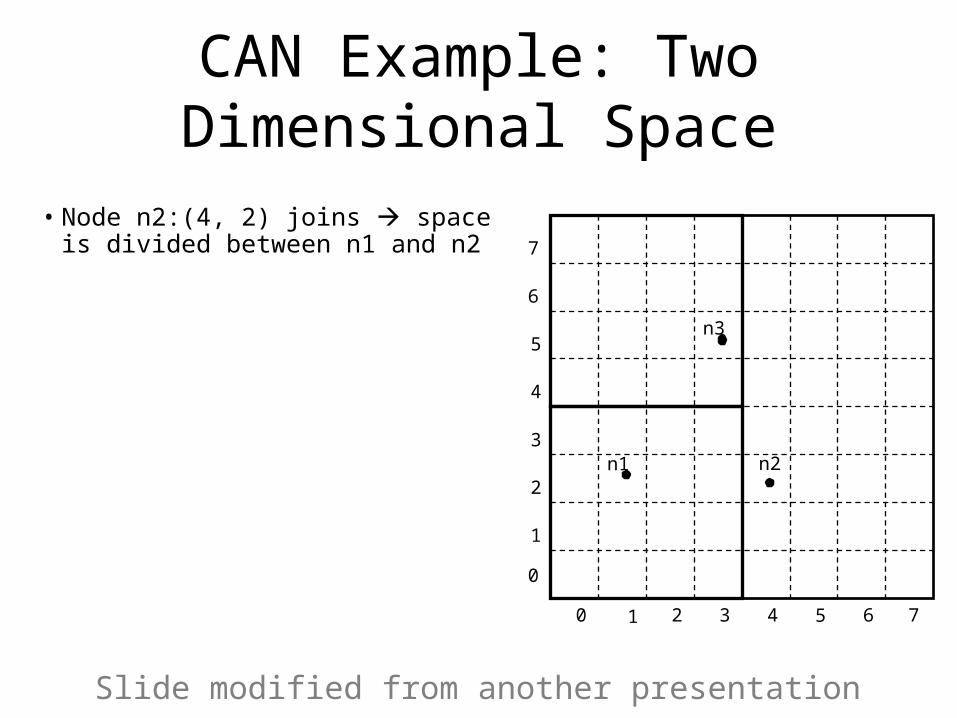
CAN Example: Two Dimensional Space
• Node n2:(4, 2) joins space is divided between n1 and n2
1 2 3 4 5 6 70
1
2
3
4
5
6
7
0
n1 n2
n3
Slide modified from another presentation
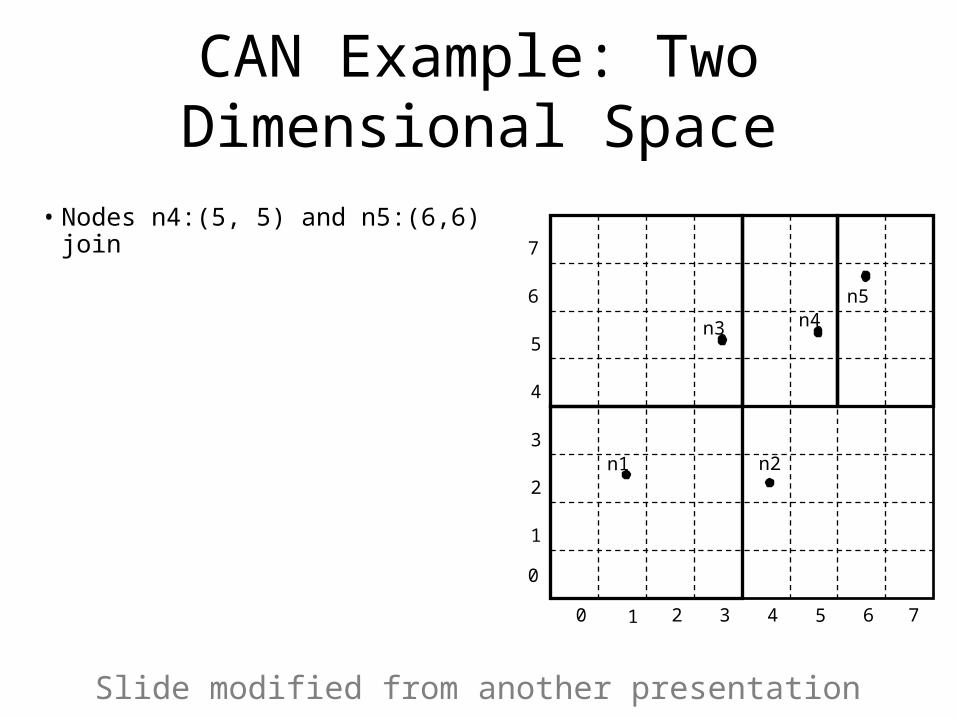
CAN Example: Two Dimensional Space
• Nodes n4:(5, 5) and n5:(6,6) join
1 2 3 4 5 6 70
1
2
3
4
5
6
7
0
n1 n2
n3 n4n5
Slide modified from another presentation

CAN Example: Two Dimensional Space
• Nodes: n1:(1, 2); n2:(4,2); n3:(3, 5); n4:(5,5);n5:(6,6)
• Items: f1:(2,3); f2:(5,1); f3:(2,1); f4:(7,5);
1 2 3 4 5 6 70
1
2
3
4
5
6
7
0
n1 n2
n3 n4n5
f1
f2
f3
f4
Slide modified from another presentation

CAN Example: Two Dimensional Space
• Each item is stored by the node who owns its mapping in the space
1 2 3 4 5 6 70
1
2
3
4
5
6
7
0
n1 n2
n3 n4n5
f1
f2
f3
f4
Slide modified from another presentation

CAN: Query Example
• Each node knows its neighbors in the d-space
• Forward query to the neighbor that is closest to the query id
• Example: assume n1 queries f4• Can route around some failures
– some failures require local flooding
1 2 3 4 5 6 70
1
2
3
4
5
6
7
0
n1 n2
n3 n4n5
f1
f2
f3
f4
Slide modified from another presentation

CAN: Query Example
• Each node knows its neighbors in the d-space
• Forward query to the neighbor that is closest to the query id
• Example: assume n1 queries f4• Can route around some failures
– some failures require local flooding
1 2 3 4 5 6 70
1
2
3
4
5
6
7
0
n1 n2
n3 n4n5
f1
f2
f3
f4
Slide modified from another presentation

CAN: Query Example
• Each node knows its neighbors in the d-space
• Forward query to the neighbor that is closest to the query id
• Example: assume n1 queries f4• Can route around some failures
– some failures require local flooding
1 2 3 4 5 6 70
1
2
3
4
5
6
7
0
n1 n2
n3 n4n5
f1
f2
f3
f4
Slide modified from another presentation

CAN: Query Example
• Each node knows its neighbors in the d-space
• Forward query to the neighbor that is closest to the query id
• Example: assume n1 queries f4• Can route around some failures
– some failures require local flooding
1 2 3 4 5 6 70
1
2
3
4
5
6
7
0
n1 n2
n3 n4n5
f1
f2
f3
f4
Slide modified from another presentation

CFS and PAST
• Files are replicated prior to storage---copies are stored at adjacent locations in the hashed-id space
• Make use of indexing systems to locate nodes on which they store objects or from which they retrieve copies
• IDs are hashed to a 1-dimensional space• Leaves/Joins result in several file copies---
could be a bottleneck

OceanStore
• Focused on long term archival storage (rather than file sharing)---e.g., digital libraries
• Ensure codes --- class of error-correcting codes that can reconstruct a valid copy of a file given some percentage of copies

Distributed Indexing in P2P
• Two requirements: – A lookup mechanism to track down a node
holding an object– A superimposed file system that knows how to
store and retrieve files
• DNS---a distributed object locator: M/C names to IP addresses
• P2P indexing tools let users store (key, value) pairs---a distributed hash system

Chord• It is a major DHT architecture• Forms a massive virtual ring in which every node in the distributed
system is a member---each owning part of a periphery.• If hash value of a node is h, and the lower value is hL, and the
higher is hH, then the node with h owns objects in the range: hL< k <= h
• E.g., if a,b, c hash to 100, 120, and 175, respectively, then b is responsible for IDs in the range 101-120; c is responsible for 121-175.
• When a new node joins, it computes its hash and then joins at the right place in the ring; then the corresponding range of objects are transferred to it.
• Potential problems---adjacent nodes could be far apart in distance• Statistics: Average path length in an internet is 22 network routers
leading an average length of 10 milliseconds; this further slowed by slow nodes

Chord---cont.
• Two mechanisms in Chord:– Applications that repeatedly access the same object---Chord
nodes cache link information so that after the initial lookup each node on the path remembers (its IP addresses) all nodes on the path for future use.
– When a node joins the Chord system, at hashed location hash(key), it looks up the nodes associated with hash(key)/2, hash(key)/4, hash(key)/8, etc. This is in a circular range.
– It uses a binary search to locate an object resulting in log(N) search time; but this is not good enough---cached pointers help the effort
– Frequent leaves creates dangling pointers—a problem– Churn—frequent joins/leaves---results in several key shuffles---a
problem
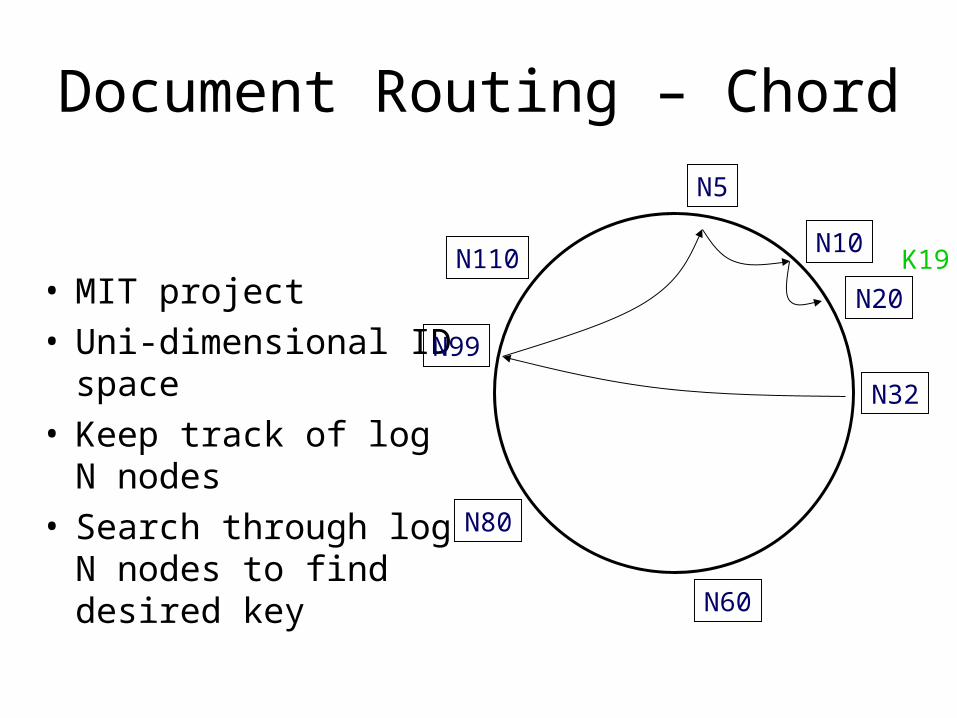
Document Routing – Chord
• MIT project• Uni-dimensional ID
space• Keep track of log N
nodes• Search through log N
nodes to find desired key
N32
N10
N5
N20
N110
N99
N80
N60
K19

Pastry• Basic idea: Construction of a matrix (of size r x logrN) of pointers at each participating
node---r is a radix and N is the size of the network; If N = 165 and r =5, then each matrix is of size 16 x 5.
• Maps keys to a hashed space (like others)• By following the pointers, a request is routed closer and closer to the node owning the
portion of the space that an object belongs to.• Hexadecimal addresses: with r=5, the address has 5 hexadecimals: 65A1FC as in the
example.• Top row has: indices from 0 to F representing the 1st hexadecimal in the hash
address. For 65A1FC, there is a match at 6, so it has another level of index: 0-F representing the 2nd position in the address. For the current node, there is a 2nd level match at 5; so this node is extended to next level from 0-F: once again there is a match at A which is further expanded to the 4th level; This has 0-F in the 4th position, current one matching at F. This is further expanded to 5th level from 0-F (not shown in Figure 25.5). Thus, it has 16 x 5 matrix of pointers to nodes.
• To take care of joins/leaves, Pastry periodically probes each pointer (finger) and repairs broken links when it notices problems
• It uses an application-level multicast (overlay multicast architecture)
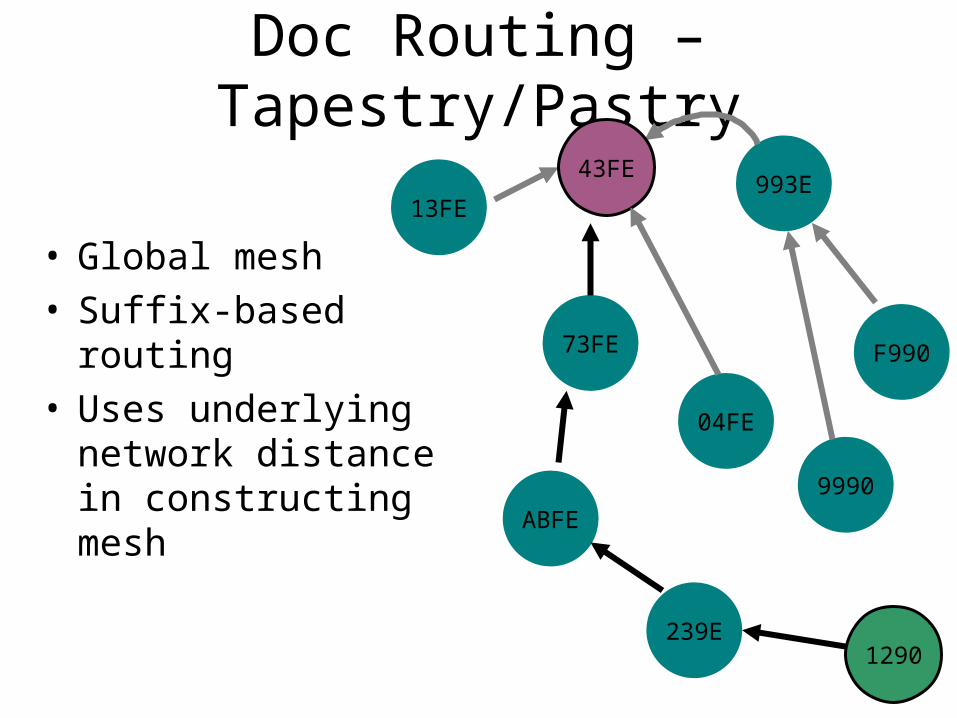
Doc Routing – Tapestry/Pastry
• Global mesh• Suffix-based routing• Uses underlying
network distance in constructing mesh
13FE
ABFE
1290239E
73FE
9990
F990
993E
04FE
43FE

Node Failure Recovery
• Simple failures– know your neighbor’s neighbors– when a node fails, one of its neighbors takes
over its zone
• More complex failure modes– simultaneous failure of multiple adjacent
nodes – scoped flooding to discover neighbors– hopefully, a rare event
Slide modified from another presentation
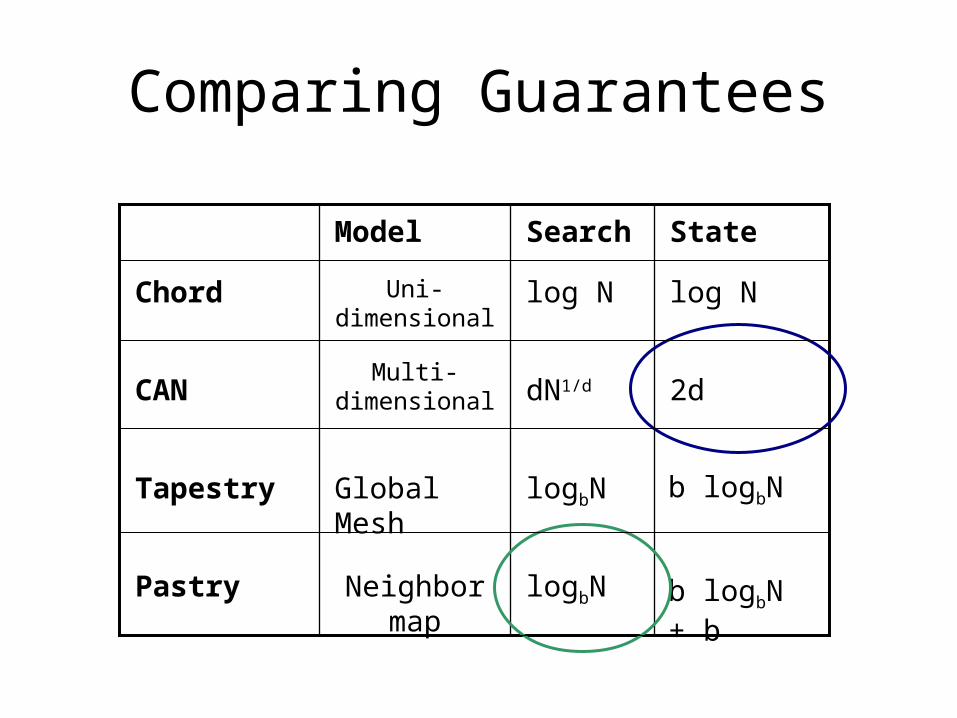
Comparing Guarantees
logbNNeighbor map
Pastry
b logbNlogbNGlobal Mesh
Tapestry
2ddN1/dMulti-dimensional
CAN
log Nlog NUni-dimensional
Chord
StateSearchModel
b logbN + b

Remaining Problems?
• Hard to handle highly dynamic environments
• Usable services
• Methods don’t consider peer characteristics