Embed Size (px)
Citation preview

Peer-to-Peer Services
Lintao Liu
5/26/03

Papers
YAPPERS: A Peer-to-Peer Lookup Service over Arbitrary Topology• Stanford University
Associative Search in Peer-to-Peer Network: Harnessing Latent Semantics• AT&T Research Lab & Tel Aviv Univ.
Cooperative Peer Groups in NICE• Univ. of Maryland

YAPPERS: A P2P Lookup Service over Arbitrary Topology Motivation:
• Gnutella-style Systems• work on arbitrary topology, flood for query• Robust but inefficient• Support for partial query, good for popular resources
• DHT-based Systems• Efficient lookup but expensive maintenance• By nature, no support for partial query
Solution: Hybrid System• Operate on arbitrary topology• Provide DHT-like search efficiency

Design Goals
Impose no constraints on topology• No underlying structure for the overlay network
Optimize for partial lookups for popular keys• Observation: Many users are satisfied with partial lookup
Contact only nodes that can contribute to the search results • no blind flooding
Minimize the effect of topology changes• Maintenance overhead is independent of system size

Query Model:
<key, value> pair TotalLookup(N, k):
• Return all values associated with k
• Query initiates from Node N
PartialLookup(N, k, n):• Return n values associated with k
• If total available < n, return all available

Basic Idea:
Keyspace is partitioned into a small number of buckets. Each bucket corresponds to a color.
Each node is assigned a color.• # of buckets = # of colors
Each node sends the <key, value> pairs to the node with the same color as the key within its Immediate Neighborhood.• IN(N): All nodes within h hops from Node N.
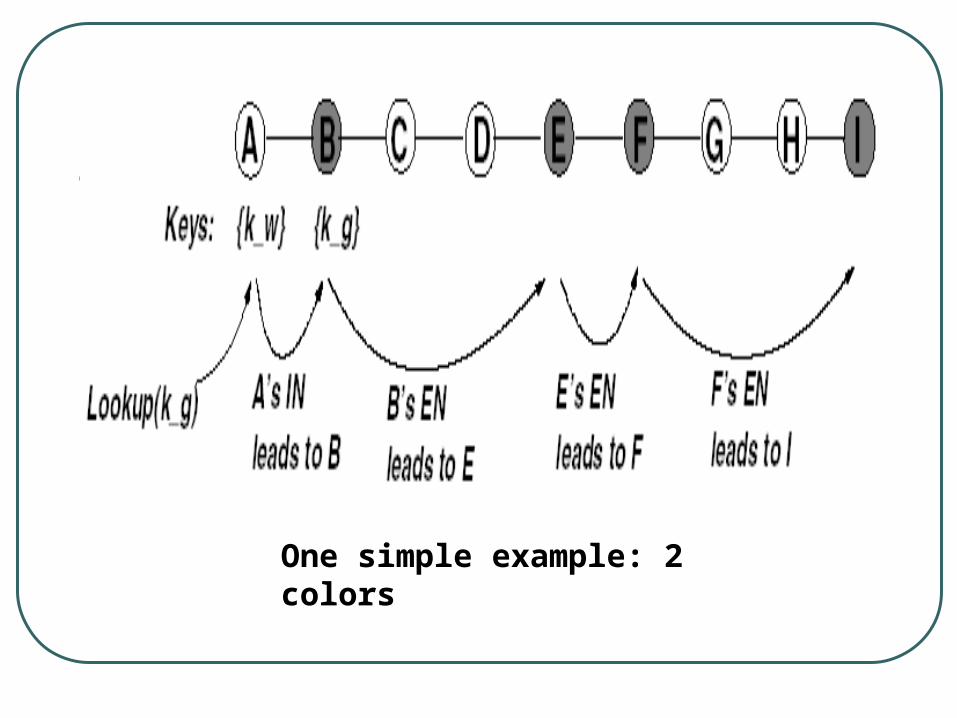
One simple example: 2 colors

Immediate Neighborhood
Different node has different IN set. Two problems:
• Consistency: same node should get the same color in different IN set.
• Stability: same node is always assigned with the same color even it leaves/joins.
Solution: • Hashing the IP address => color

More…
When node X is inserting <key, value>• Multiple nodes in IN(X) have the same color?
• No node in IN(X) has the same color as key k? Solution:
• P1: randomly select one
• P2: Backup scheme: Node with next color• Primary color (unique) & Secondary color (zero or more)
Problems coming with this solution:• No longer consistent and stable
• The effect is isolated within the Immediate neighborhood

Extended Neighborhood
IN(A): Immediate Neighborhood F(A): Frontier of Node A
• All nodes that are directly connected to IN(A), but not in IN(A)
EN(A): Extended Neighborhood• The union of IN(v) where v is in F(A)
• Actually EN(A) includes all nodes within 2h + 1 hops
Each node needs to maintain these three set of nodes for query.
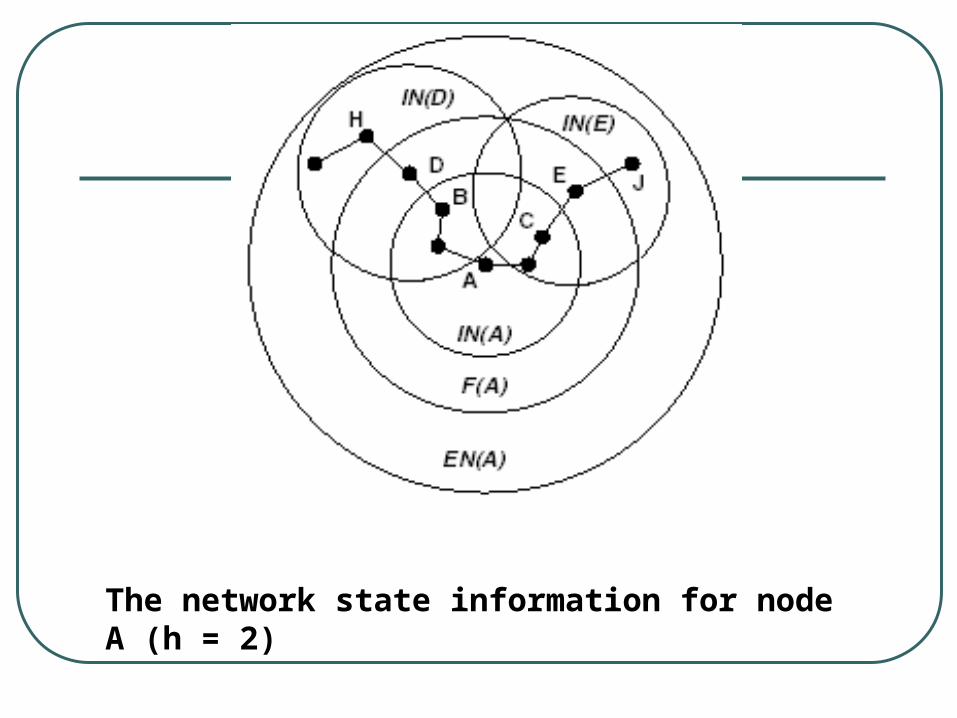
The network state information for node A (h = 2)

Searching with Extended Neighborhood
Node A wants to look up a key k of color C(k), it picks a node B with C(k) in IN(A)• If multiple nodes, randomly pick one
• If none, pick the backup node
B, using its EN(B), sends the request to all nodes which are in color C(k).
The other nodes do the same thing as B. Duplicate Message problem:
• Each node caches the unique query identifier.

More on Extended Neighborhood
All <key, value> pairs are stored among IN(X). (h hops from node X)
Why each node needs to keep an EN(X)? Advantage:
• The forwarding node is chosen based on local knowledge
• Completeness: a query (C(k)) message can reach all nodes in C(k) without touching any nodes in other colors (Not including backup node)

Maintaining Topology
Edge Deletion: X-Y• Deletion message needs to be propagated to all
nodes that have X and Y in their EN set
• Necessary Adjustment:
• Change IN, F, EN sets
• Move <key, value> pairs if X/Y is in IN(A)
Edge Insertion:• Insertion message needs to include the neighbor info
• So other nodes can update their IN and EN sets

Maintaining Topology Node Departure:
• a node X with w edges is leaving
• Just like w edge deletion
• Neighbors of X initiates the propagation Node Arrival: X joins the network
• Ask its new neighbors for their current topology view
• Build its own extended neighborhood
• Insert w edges.

Problems with basic design Fringe node:
• Those low connectivity node allocates a large number of secondary colors to its high-connectivity neighbors.
Large fan-out:• The forwarding fan-out degree at A is
proportional to the size of F(A)
• This is desirable for partial lookup, but not good for full lookup
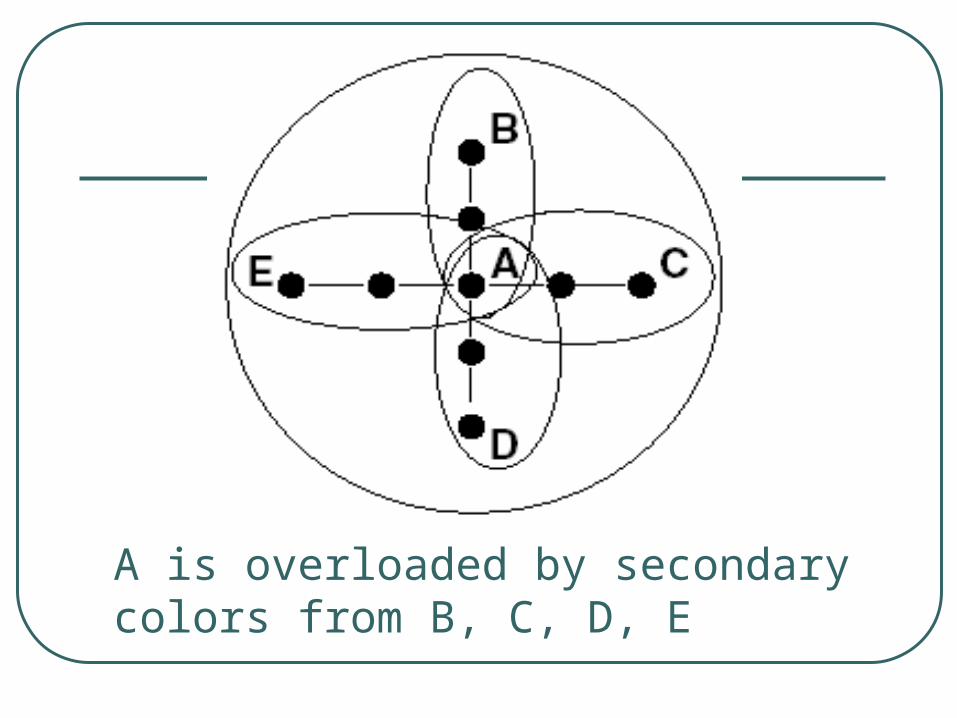
A is overloaded by secondary colors from B, C, D, E

Solutions:
Prune Fringe Nodes:• If the degree of a node is too small, find a proxy node.
Biased Backup Node Assignment:• X assigns a secondary color to y only when
a * |IN(x)| > |IN(y)|
Reducing Forward Fan-out:• Basic idea:
• try backup node,
• try common nodes

Experiment:
H = 2 (1 too small, >2 EN too large) Topology: Gnutella snapshot Exp1: Search Efficiency

Distribution of colors per node

Fan-out:
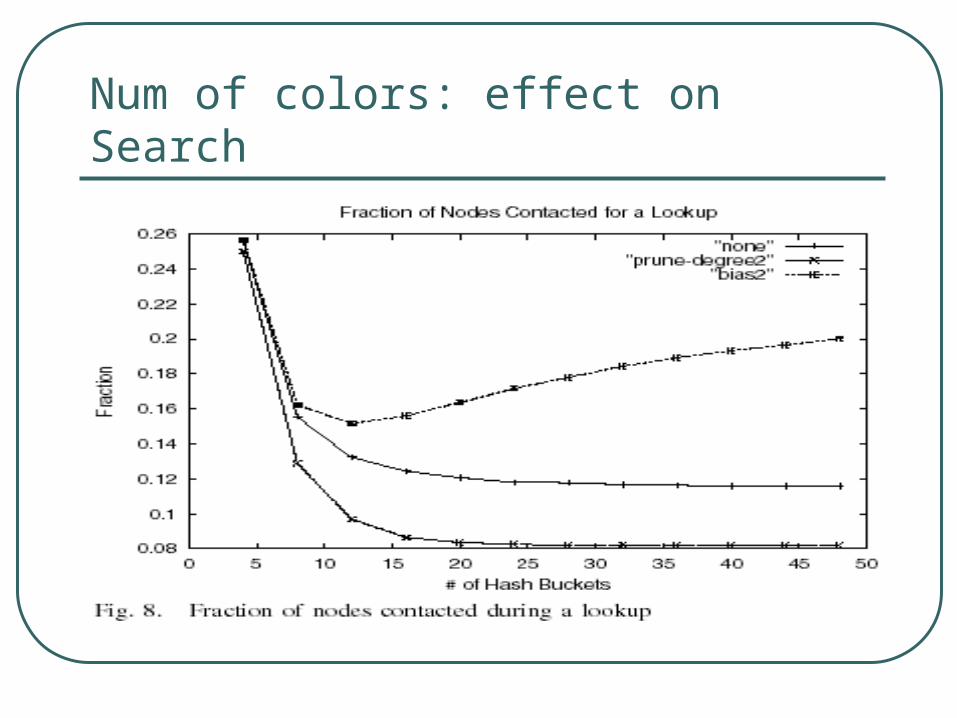
Num of colors: effect on Search
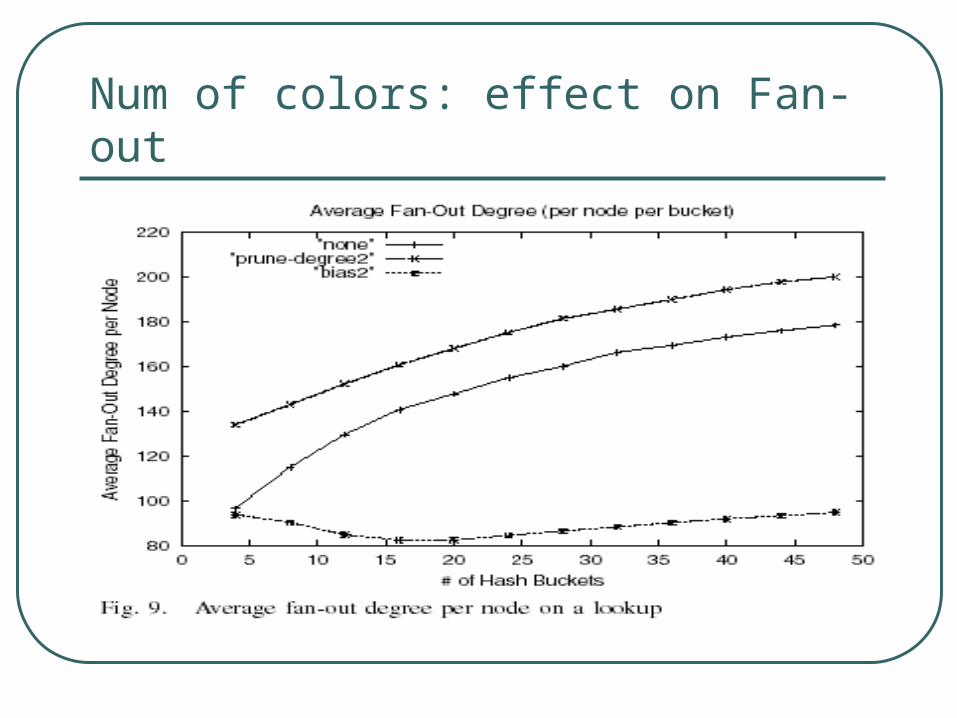
Num of colors: effect on Fan-out

Conclusion and discussion
Each search only disturbs a small fraction of the nodes in the overlay.
No restructure the overlay Each node has only local knowledge
• scalable
Discussion:• Hybrid (unstructured and local DHT) system
• …

Associative Search in P2P networks: Harnessing Latent Semantics
Motivation: • Similar with the previous paper
• Avoid a blind search on unstructured P2P
• Not sensitive to node join/failure
Proposed system: Associative Overlays• Based on unstructured architecture
• Improve the efficiency of locating rare items by “orders of magnitude”.

Basic Idea:
Exploit association inherent in human selections
Steer the search process to peers that are more likely to answer a query
Guide Rule: • A set of peers that satisfy some predicate
• A search message is only flooding inside one specific Guile Rule.
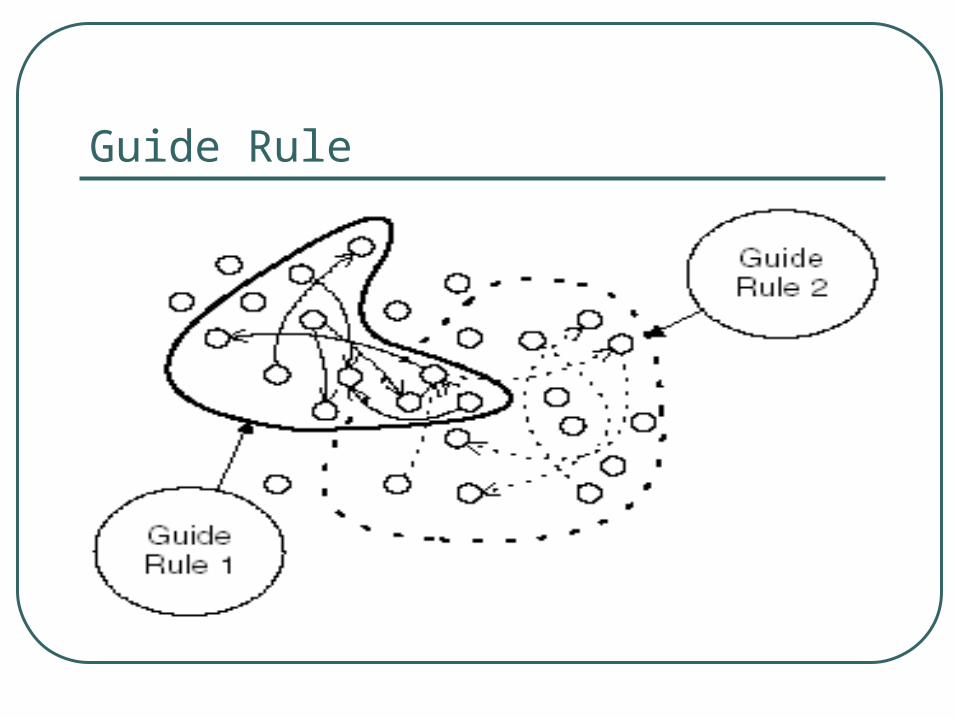
Guide Rule

More on Guile Rule: Peers in one Guile Rule
• Contain data items that are semantically similar.• E.g. Contain documents on philosophy, songs…
Choose a Guile Rule for query message: • “Networking” aspect (connectivity properties…)• “data mining” aspects:
• Tules distill common interests Maintenance:
• Maintain a small list of other peers Possession Rules
• Automatically extracted guide rules from the shared items

Algorithms
RAPIER Algorithm:• Random Possession Rule
• If a node is interested in A, B, C, etc, just randomly choose one and perform a blind search amongst that rule
• More efficient than blink search GAS Algorithm:
• Greedy Guide Rule
• Deciding the order to try different rules
• Each node invokes a query in rules that have been more effective on its past queries.

Conclusion and Discussion
It offers orders of magnitude improvement in the scalability of locating infrequent items
Discussion: • the advantage is generated by classifying unstructured
peers into some loose so-called “Guile Rules”.
• Didn’t understand how they clearly defined these Rules and maintain it.
• A lot of mathematics and data mining stuff

Cooperative Peer Groups in NICE
Trust management in P2P environment Design:
• Reputation information is stored in a completely decentralized manner.
• Efficient identify non-cooperative nodes Basic operation:
• After a transaction between A and B
• A will sign a cookie and send it to B,
• B does the same thing
• Cookies can be dropped as A/B likes.

Trust Graph
Vertex: Nodes If A has a cookie issued by B, we draw an edge from B to
A. The weight of the edge is the value given by B in the cookie (1/0 in this paper)
A can calculate how much A should believe B• Two different ways proposed

Distributed Trust Reference:
A wants to do a transaction with B:• A needs to present some cookies to B that A i
s “good”
• If A has a cookie assigned by B, A just sends it to B.
• If A doesn’t have a cookie from B, so A should collect some related cookies to make B believes that it is “good”.

Distributed Trust Inference:
Detailed Procedures:• A initiates a search for B’s cookies
• Recursively search its neighbors
• This will generate a trust graph starting from B and ending at A.
• A presents all the cookies to B
• B will decide whether A is “good” or not It is A who collects the cookies to
• Avoid DoS attack.

Refinements
Efficient searching• Each node caches the cookies of its neighbors
• When A searches for B’s cookies, A checks whether its neighbors have.
• If no, randomly choose neighbors to forward• This is like flooding: if a neighbor fails, try next
• This random walk is limited to predefined steps.

Refinement:
Negative Cookies:• If A has present B enough cookies to make
sure A is a “good” peer, B can search for “Negative cookies” of A to make sure.
• Search follows the high trust edges out of B
Preference Lists:• Nodes that are highly probably to be “good”
• A will try to do transaction with those nodes.

Conclusion and discussion:
Scalable Resistant to some attack. But many aspects still don’t look very
nice yet.
Discussion??





























