Embed Size (px)
Citation preview

Operating Systems & Middleware Group Research activities
Prof. Dr. Andreas Polze

OSM Group: Teaching
■ Operating system foundations and principles
□ Operating systems I + II (Bachelor)
□ Server operating systems (Master)
□ History of operating systems (Master)
■ Middleware and distributed systems
□ Component programming and middleware (Bachelor)
□ Middleware and distributed systems (Master)
□ Embedded operating systems (Master)
■ Programming Parallel and Distributed systems (Master)
■ Dependable systems (Master)
■ Operating the cloud
■ …
2

OSM Group: Research
■ “Extending the reach of middleware”
□ Operating systems
◊ New concepts for new hardware paradigms
(NUMA, Intel SCC, IBM Power platform, GPU accelerators)
◊ Cloud-based teaching concepts
□ Middleware and embedded systems
◊ Predictable behavior in unpredictable environments
◊ Telemedicine in rural areas
□ Programming models for hybrid parallelism
◊ CPU vs. Xeon Phi vs. NVidia Tesla vs. cluster
■ Dependable systems based on imprecise knowledge
■ Operation of the HPI FutureSOC Lab
3

EU-Projekte
□ Adaptive Services Grid
□ Leonardo Da Vinci
Deutsche Post IT-Solutions
□ AOP
□ Eingebettete Systeme
Microsoft / Microsoft Research
□ Micro.NET, Phoenix
□ Windows Research Kernel
□ Curriculum Research Kit
Hewlett-Packard, IBM
□ Server Computing Summit
Industry Cooperation
Bachelorprojekte
– DaimlerChrysler Research
– Siemens AG
– Beckhoff
– Software AG
Fontane-Projekt
– BMBF

5
Operating Systems -
Projects & Labs
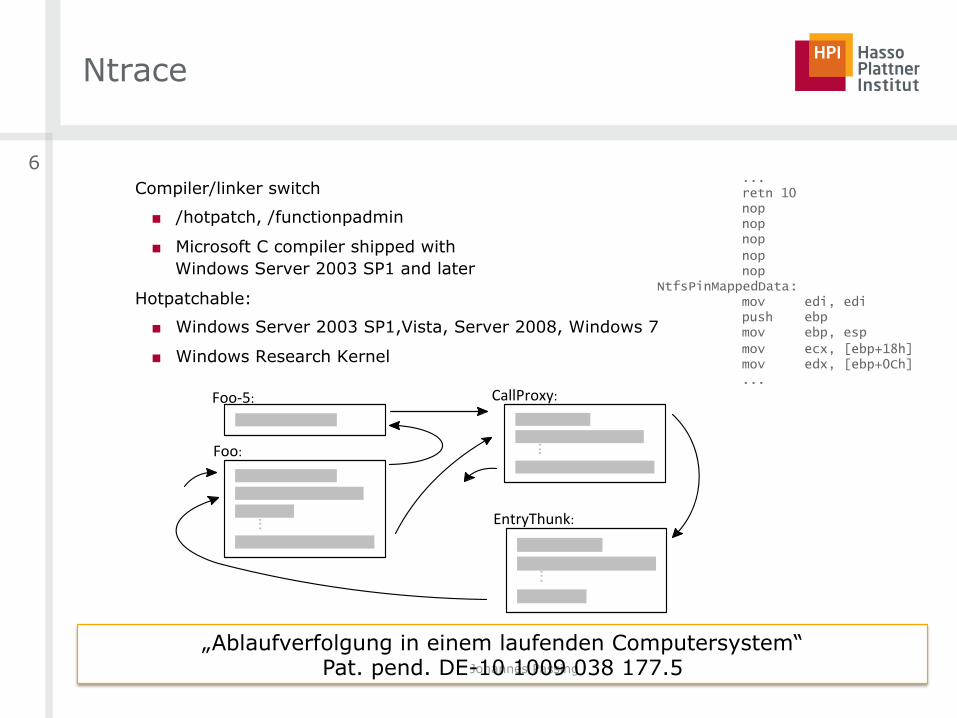
Ntrace
6
Johannes Passing 27.01.13
Foo-5: CallProxy:
. . .
. . .
EntryThunk:
Foo:
. . .
„Ablaufverfolgung in einem laufenden Computersystem“ Pat. pend. DE-10 1009 038 177.5
... retn 10 nop nop nop
nop nop
NtfsPinMappedData: mov edi, edi push ebp mov ebp, esp
mov ecx, [ebp+18h] mov edx, [ebp+0Ch] ...
Compiler/linker switch
■ /hotpatch, /functionpadmin
■ Microsoft C compiler shipped with
Windows Server 2003 SP1 and later
Hotpatchable:
■ Windows Server 2003 SP1,Vista, Server 2008, Windows 7
■ Windows Research Kernel
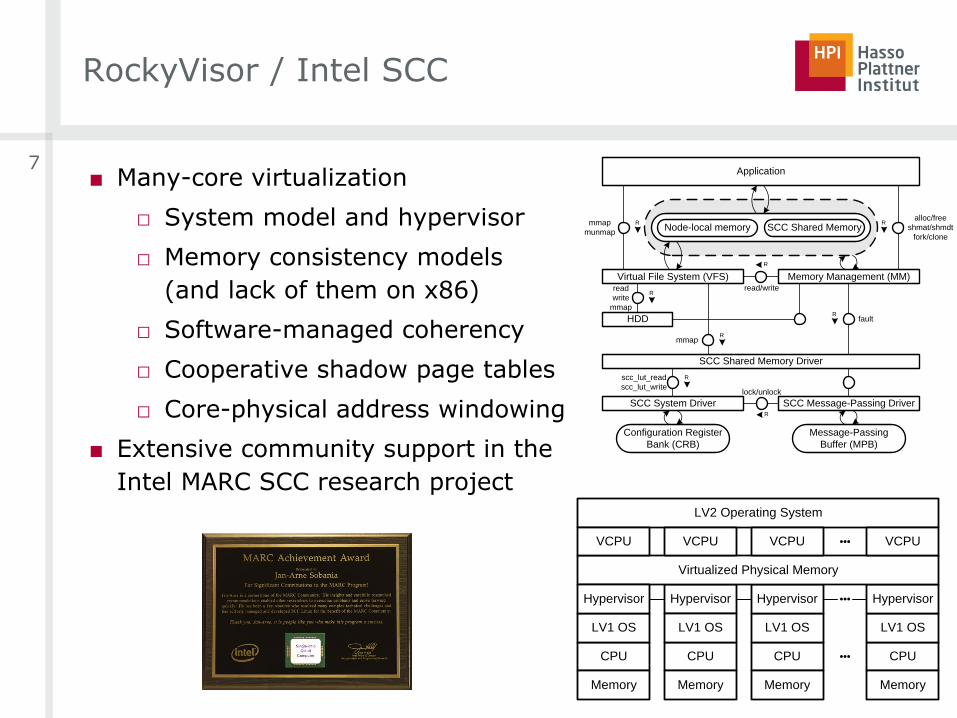
RockyVisor / Intel SCC
■ Many-core virtualization
□ System model and hypervisor
□ Memory consistency models
(and lack of them on x86)
□ Software-managed coherency
□ Cooperative shadow page tables
□ Core-physical address windowing
■ Extensive community support in the
Intel MARC SCC research project
7 Application
Virtual File System (VFS)
HDD
Rread
write
mmap
Memory Management (MM)
R
read/write
Ralloc/free
shmat/shmdt
fork/cloneNode-local memory SCC Shared Memory
Rmmap
munmap
SCC Shared Memory Driver
SCC System Driver
Configuration Register
Bank (CRB)
Message-Passing
Buffer (MPB)
Rfault
SCC Message-Passing DriverR
lock/unlock
Rscc_lut_read
scc_lut_write
Rmmap
CPU CPU CPU CPU
LV1 OS LV1 OS LV1 OS
Hypervisor Hypervisor Hypervisor
Virtualized Physical Memory
LV2 Operating System
VCPU VCPU VCPU VCPU
Memory Memory Memory
Hypervisor
LV1 OS
Memory
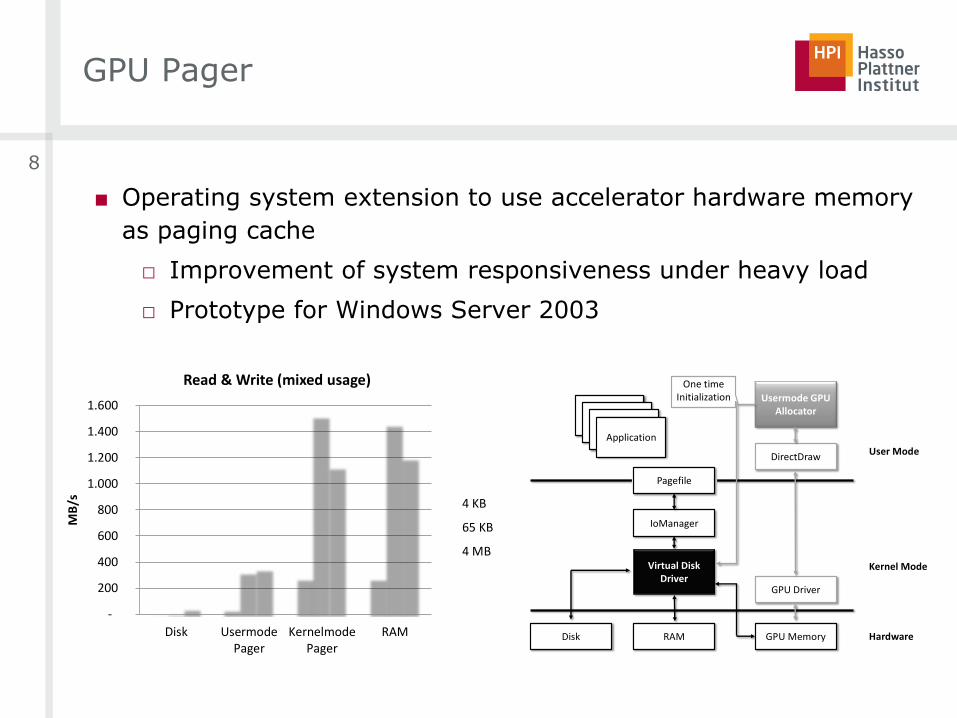
GPU Pager
■ Operating system extension to use accelerator hardware memory
as paging cache
□ Improvement of system responsiveness under heavy load
□ Prototype for Windows Server 2003
8
5
Name Descr iption CPU GPU Memory Disk Operating System
A Dell OptiPlex Intel P4 Nvidia Quadro NVS 295 Windows Server 2003 SP2GX620 3,2 Ghz 256 MB GDDR3 2 GB DDR2 500 GB HDD 32 bit
B Gigabyte Intel Core i7-2600K Nvidia GeForce GTX 460 Mushkin PC3-10666 Intel Rapid Storage Windows 7 Ultimate SP1GA-P67A-UD4 3,7 Ghz 1023 MB GDDR5 8 GB DDR3 64 GB SSD 64 bit
C MSI Intel Core 2 Duo E8500 Nvidia GeForce GTX 275 OCZ2P10002G ST31000524AS Windows 7 Ultimate SP1P45 Neo2 3,17 Ghz 896 MB GDDR3 8 GB DDR2 1 TB 7200 RPM 64 bit
D Acer Aspire Intel Core i7-2620M Nvidia GeForce GT 540M Samsung Corsair Force 3 Windows 7 Ultimate SP13830TG 2,7 Ghz 2 GB GDDR3 8 GB DDR3 240 GB SSD 64 bit
TABLE ITEST SYSTEMS
Application Application
Application Application
Usermode GPU Allocator
DirectDraw
GPU Driver
GPU Memory RAM Disk
Kernel Mode
User Mode
Hardware
Virtual Disk Driver
IoManager
Pagefile
One time Initialization
Fig. 7. The architecture of the Kernel Mode version of the GPU-basedPaging Cache.
each of the GPU paging cache approaches. The page sizes
were chosen according to the typical defaults in modern 32bit
and 64bit operating systems. We determined these defaults by
monitoring our experiment system with different workloads.
The results are shown in Figure ?? and Figure ??.
Vielausfhrlicher-welcheSys-teme,welcheWork-load
Vielausfhrlicher-welcheSys-teme,welcheWork-load 4KB
57%
8KB 10%
65KB 16%
Other 17%
Read requests to pagefile
Fig. 8. Write(left) and read(right) activity on the pagefile
WassolldieFormel?WasistdieSchrit-tweitebeiderSumme?
WassolldieFormel?WasistdieSchrit-tweitebeiderSumme?
bandwidth =1
RTT
RTT = RTTR ead + RTTW r i t e
RTTR ead =
1M BX
i = 4K B
Pr opabi l i tyR ead(i )
B andwidthR ead(i )
1 MB 95%
Other 5%
Write requests to pagefile
Fig. 9. Write(left) and read(right) activity on the pagefile
RTTW r i t e =
1M BX
i = 4K B
Pr opabi l i tyW r i t e(i )
B andwidthW r i t e(i )
As a baseline, we compared our caching solution with a
disk-only mode (all read requests are passed through) and
with a memory-only mode, where a RAM disk acted as stable
paging storage. Stimmtdasso?
Stimmtdasso?
Figure ?? shows the results of the experiments. The results
clearly show that both the user mode and the kernel mode
version outperform the disk-based paging mechanisms, as it is
used in unmodified Windows systems. Additional experiments
with SSD disks showed the same effect, since even SSD drives
demand some I/O overhead in comparison to a page read
served from the GPU-based cache. As expected, the kernel
mode version performs much better due to the avoidance of
frequent mode changes.
ReadfrKernel-Varianteistdochgarnichtlangsam?
ReadfrKernel-Varianteistdochgarnichtlangsam?
The performance of our fastest version is roughly as good
as a RAM-based paging device. However, such device does
not promise persistency of the paging information (as for
example needed in suspend-to-disk functionality) and demands
dedicate main memory regions. Our solution leverages the
anyway existing additional GPU memory resources and has
no additional overhead in main memory consumption.
Messungenmitreal-worldwork-load?
Messungenmitreal-worldwork-load?
V. CONCLUSION
State-of-the-art computer systems are a combination of
general purpose processors and computational accelerators.
The special class of GPU acceleration devices is meanwhile
commodity in desktop and even server systems.
6
-
200
400
600
800
1.000
1.200
1.400
1.600
1.800
2.000
Disk UsermodePager
KernelmodePager
RAM
MB
/s
Read
4 KB
65 KB
4 MB
-
200
400
600
800
1.000
1.200
1.400
1.600
Disk UsermodePager
KernelmodePager
RAM
MB
/s
Write
4 KB
65 KB
4 MB
-
200
400
600
800
1.000
1.200
1.400
1.600
Disk UsermodePager
KernelmodePager
RAM
MB
/s
Read & Write (mixed usage)
4 KB
65 KB
4 MB
Tested system 1: Dell™ OptiPlex™ GX620 (Intel Pentium 4 3,2 Ghz, 2 GB RA M) NVIDIA Quadro NVS 295 (256 MB GDDR3) MS Windows Server 2003 SP2
Fig. 10. Performance evaluation of the GPU-based Paging cache. (Higher values are better.)
Our GPU paging cache approach leverages non-utilized
GPU memory resources for optimizing the paging perfor-
mance of the operating system. The approach is completely
application-agnostic and needs no major modifications in
the operating system kernel. Our prototypical implementation
has shown the feasibility of the approach, were the paging
performance is improved in comparison to the disk-only-based
original paging mechanism.
Both tested solution strategies, namely the user mode and
the kernel mode version, have their advantages. While the
kernel mode version has the better performance, it lacks
portability and can only utilize a fraction of the available
GPU memory for caching. The user mode version has op-
timal portability for different hardware and can leverage the
complete GPU memory space, but has deal with the overhead
imposed with the permanent changes between user mode and
kernel mode. Ultimately, this leads to a balancing decision
between the performance improvement by more available
cache space, and the performance decrease from the additional
mode switches. The clarification of the relevant independent
variables in this equation demands further research in the
future.
For an optimal solution, it would be necessary to have stable
kernel driver interfaces for GPU devices. This would allow
to leverage the complete GPU memory for kernel activities
without loosing portability. This demand as also identified in
related work, so that there is some hope to get such a stable
kernel GPU API in the future.
Future work also needs to focus on a cache page replace-
ment strategy in this solution, which depends on the available
GPU memory, the current application load and the paging
strategies of the operating system itself.
REFERENCES
[1] M. Russinovich and D. Solomon, Windows Internals, 6th ed. MicrosoftPress Corp., 2012.
[2] Microsoft Developer Network, “Memory Limits for Windows Releases,”http://msdn.microsoft.com/en- us/library/windows/desktop/aa366778\%28v=vs.85\ %29.aspx, Jun. 2012.
[3] M. Russinovich, “Pushing the Limits of Windows: Virtual Memory,”http://blogs.technet.com/b/markrussinovich/archive/2008/11/17/3155406.aspx, Nov. 2008.
[4] Valve Corporation, “Steam Hardware & Software Survey,” http://store.steampowered.com/hwsurvey, 2012.
[5] C. Rossbach, J. Currey, and E. Witchel, “Operating Systems mustsupport GPU abstractions,” in 13th USENIX conference on Hot topicsin operating systems. USENIX Association, 2011, pp. 32–32.
[6] S. Kato, S. Brandt, Y. Ishikawa, and R. Rajkumar, “Operating SystemsChallenges for GPU Resource Management,” in Operating SystemsPlatforms for Embedded Real-Time applications, Jul. 2011.
[7] C. J. Rossbach, J. Currey, M. Silberstein, B. Ray, E. Witchel, T. Wobber,and P. Druschel, “PTask: operating system abstractions to manage GPUsas compute devices,” in Proceedings of the 23rd ACM Symposium onOperating Systems Principles 2011. ACM, 2011, pp. 233–248.
[8] V. Gough, “EncFS Encrypted Filesystem,” http://www.arg0.net/encfs,2010.
[9] Nvidia, NVIDIA CUDA C Programming Guide 3.2, Nov. 2010.
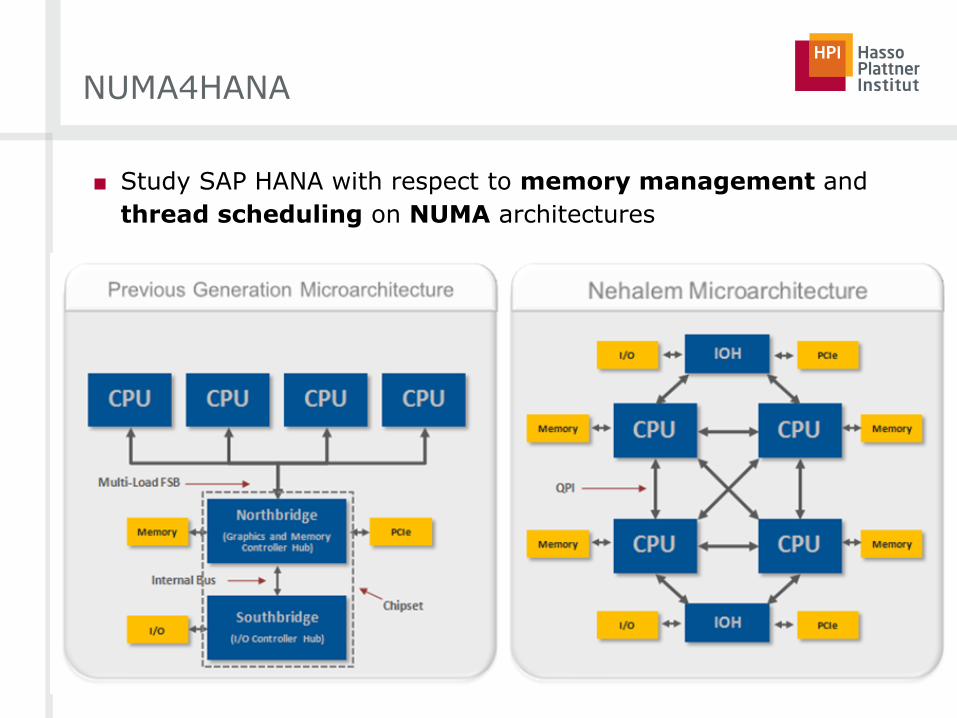
■ Study SAP HANA with respect to memory management and
thread scheduling on NUMA architectures
NUMA4HANA
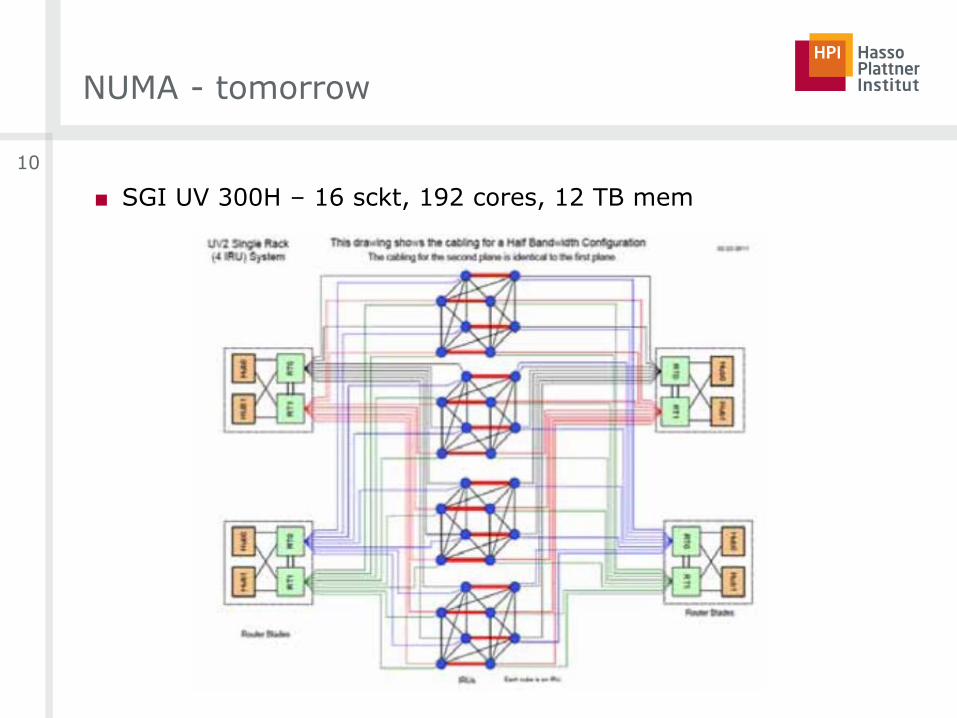
NUMA - tomorrow
■ SGI UV 300H – 16 sckt, 192 cores, 12 TB mem
10

NUMA4HANA: Visualizer
■ Goal:
□ Visualize NUMA behavior
◊ Local with collected data to analyze
◊ Local/remote with live data
□ Detect system topology and map to visualization
□ Provide runtime information for programmers to support
NUMA aware development
□ Improve performance by migrate tables to other nodes (later)
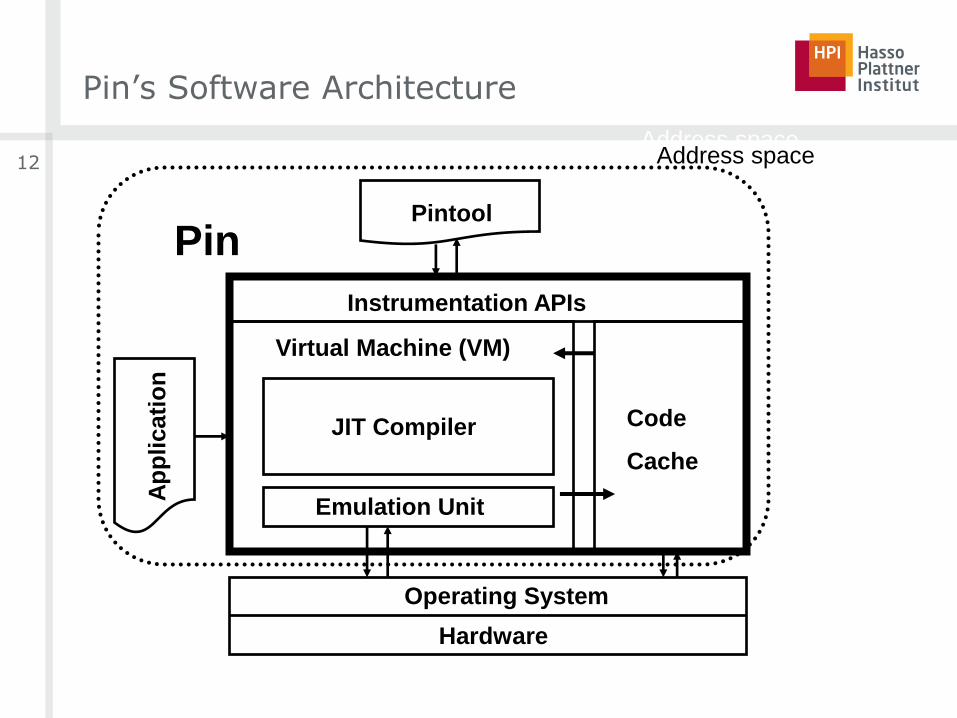
Pin’s Software Architecture
12 Address space
JIT Compiler
Emulation Unit
Virtual Machine (VM)
Code
Cache
Instrumentation APIs
Ap
pli
cati
on
Operating System
Hardware
Pin Pintool
Address space

NUMA4HANA
■ Statistics
□ Brief overview of aggregated memory events
□ Detailed replay of system behaviour
□ Filtering and additional Information
□ Memory controller imbalance, average interconnect usage
□ Local access ratio
■ Integration
□ Injection with PIN
□ HANA allocators log and memory statistics
□ Threads, MemOps of certain methods / modules
■ Visualization
□ Perception of Min/Max values, relation to max bandwidth
□ Relation to other parts of app if filtered
■ Machine Topology

NUMA4HANA – Next Steps
Working with HANA performance team (Alexander Böhm‘s group, SAP)
■ OLAP
□ benchBwaOlap.py contains massive aggregation queries of BW customers. The test runs
one query at a time.
□ benchMcKesson3_MUT_MultiProvider_ImoCube.py performs heavy BW OLAP queries,
however, it puts some stress on the system by running several queries in parallel.
■ OLTP
□ benchCpp_soltp-selectInDetail.py -c configVBAK01 -t test03 - sequential SELECT
queries (one at a time) fired against the column store main
□ benchCpp_soltp-selectInDetail.py -c configVBAK01 -t test05 -parallel SELECT queries
(100 threads in parallel issuing the query) fired against the column store main
□ benchCpp_soltp-selectInDetail.py -c configVBAK02 -t test03 - sequential SELECT
queries (one at a time) fired against the row store
□ benchCpp_soltp-selectInDetail.py -c configVBAK02 -t test05 - parallel SELECT queries
(100 threads in parallel issuing the query) fired against the row store
■ Simulator of the SAP SD benchmark with benchLSDSim.py

15
Middleware and Embedded Systems
- Projects & Labs

InstantLab: The burden of running OS experiments
• Teaching operating systems requires chances for hands-on
experience and demonstrations on live systems
• Providing these experiments is hard:
• Changes of the underlying hardware and software make it hard
to reproduce results
• Considerable set-up work is required
• InstantLab employs Windows Research Kernel (WRK)
• Stripped down Windows Server 2003 sources
• Freely available to academic institutions
Solution
InstantLab 2.0
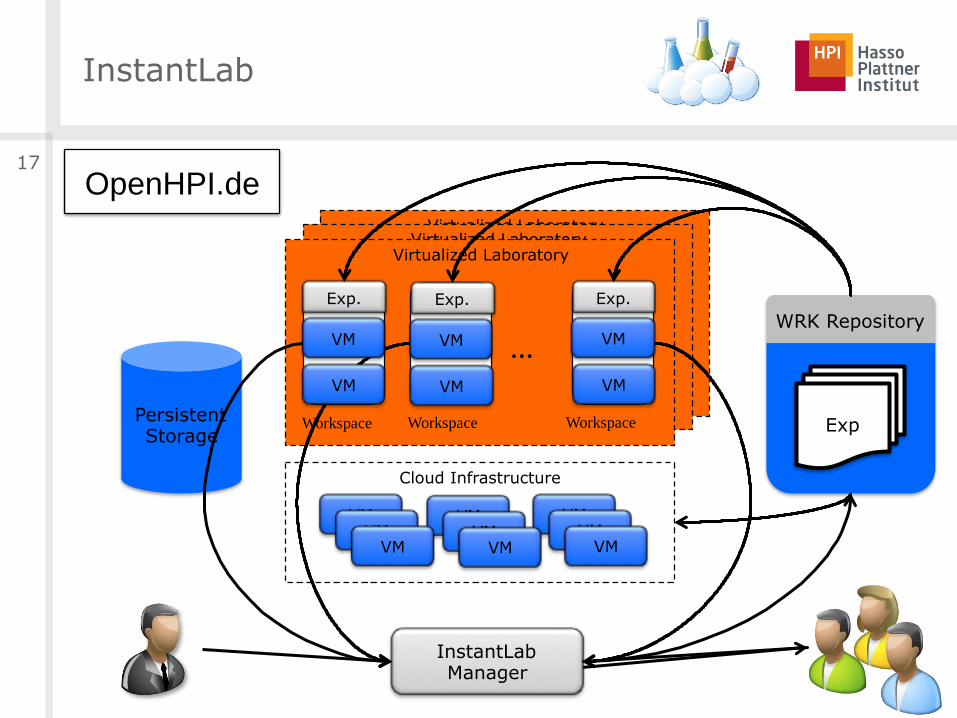
InstantLab
17
WRK Repository
Virtualized Laboratory Virtualized Laboratory
Persistent Storage
InstantLab Manager
Virtualized Laboratory
Workspace Workspace Workspace
...
Cloud Infrastructure
VM VM VM VM VM VM
VM VM VM
Exp
Exp. Exp. Exp.
VM
VM
VM
VM
VM
VM
OpenHPI.de

Structuring Experiments: The UMK Approach
■ U-phase
□ Concentrate on OS concepts
□ Introduce OS interfaces
□ Systems programming
■ M-phase
□ Observe concepts at run-time
□ Introduce monitoring tools
□ System measurements
■ K-phase
□ Discuss kernel implementation
□ Introduce kernel source code (WRK/UNIX)
□ Kernel programming
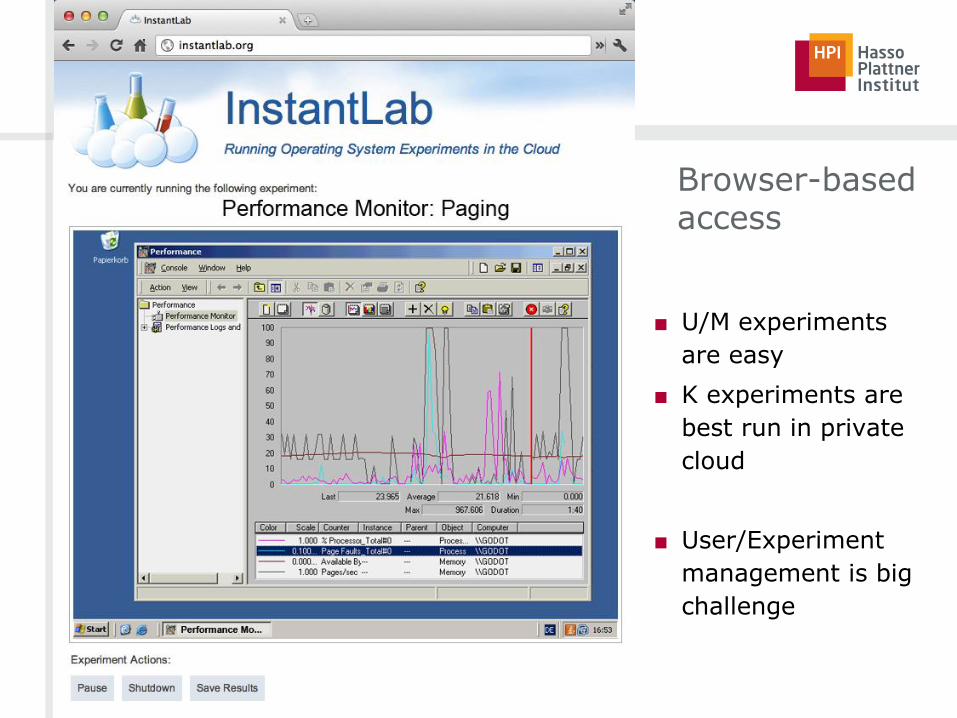
Browser-based access
■ U/M experiments
are easy
■ K experiments are
best run in private
cloud
■ User/Experiment
management is big
challenge
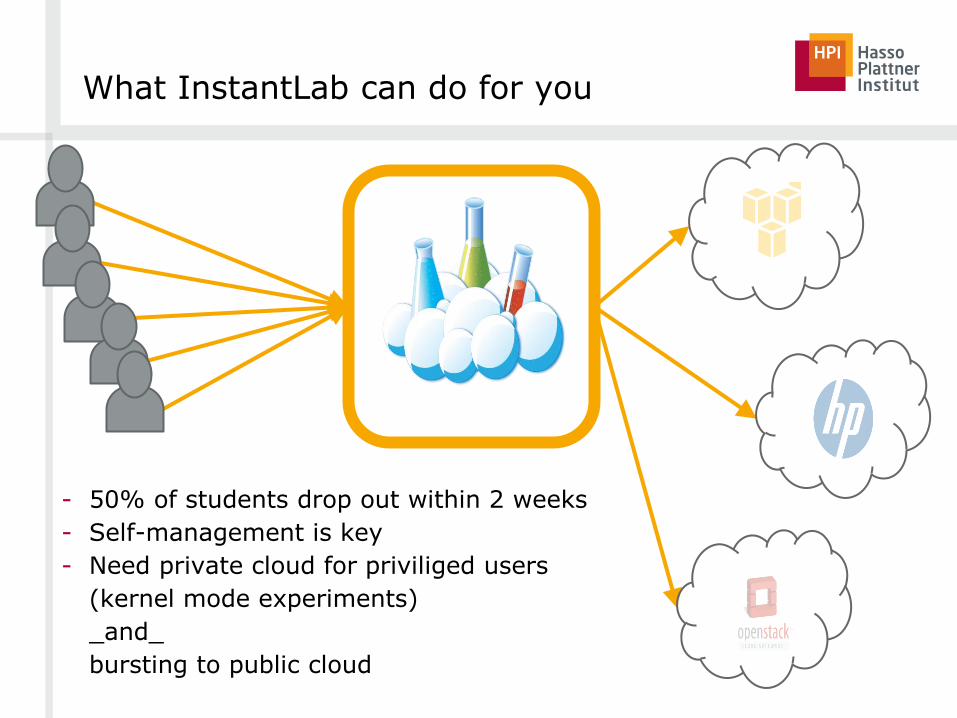
What InstantLab can do for you
- 50% of students drop out within 2 weeks
- Self-management is key
- Need private cloud for priviliged users
(kernel mode experiments)
_and_
bursting to public cloud
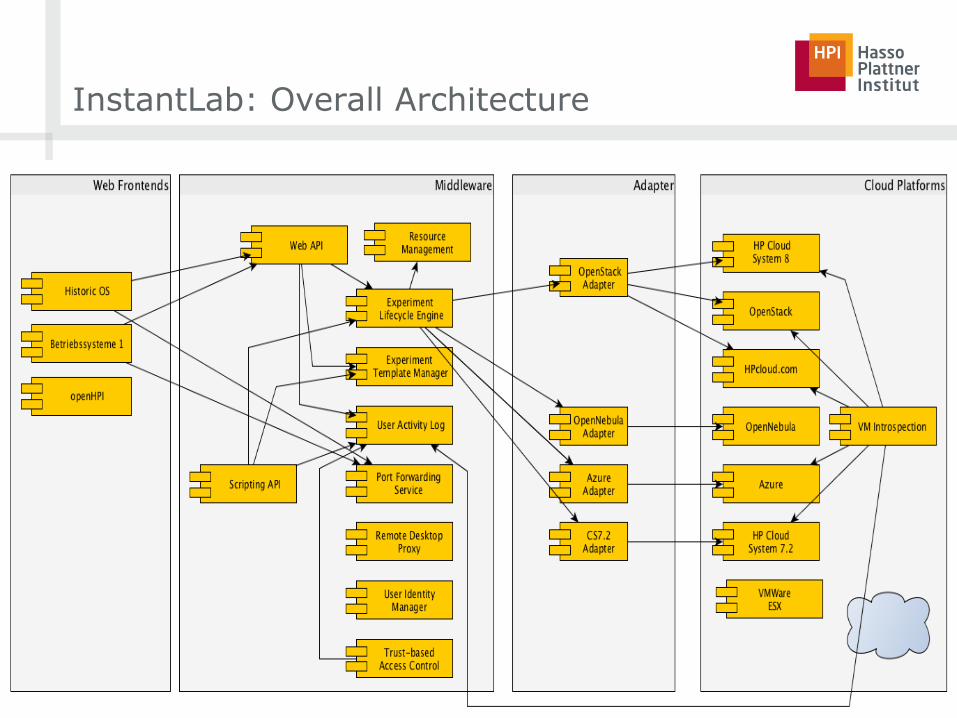
InstantLab: Overall Architecture
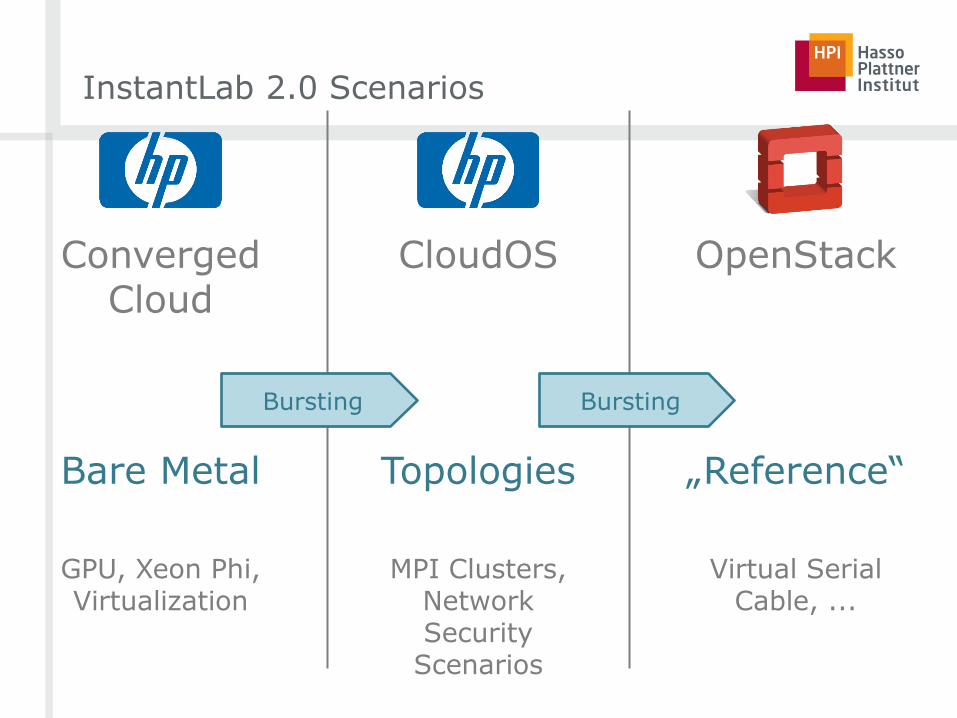
ConvergedCloud
CloudOS OpenStack
Bare Metal Topologies „Reference“
GPU, Xeon Phi, Virtualization
MPI Clusters, Network Security
Scenarios
Virtual Serial Cable, ...
InstantLab 2.0 Scenarios
Bursting Bursting
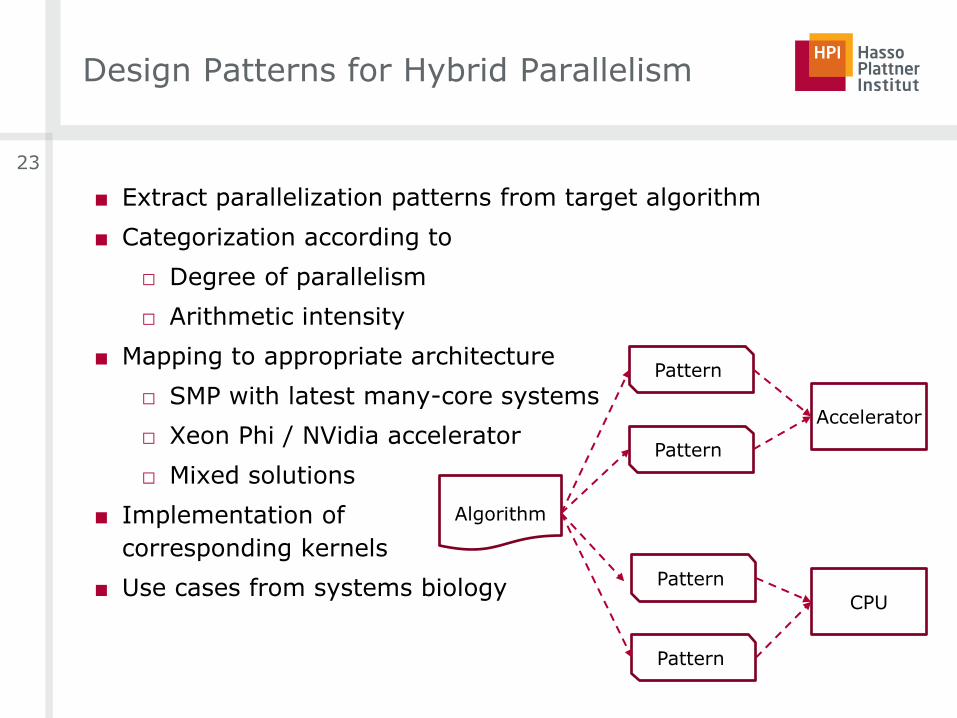
Design Patterns for Hybrid Parallelism
■ Extract parallelization patterns from target algorithm
■ Categorization according to
□ Degree of parallelism
□ Arithmetic intensity
■ Mapping to appropriate architecture
□ SMP with latest many-core systems
□ Xeon Phi / NVidia accelerator
□ Mixed solutions
■ Implementation of
corresponding kernels
■ Use cases from systems biology
23
Pattern
Pattern
Pattern
Pattern
Accelerator
CPU
Algorithm

N-Queens with Dynamic Parallelism
■ “Place N queens on a NxN chess board in a way
that no queen attacks another queen”
■ Finding all valid solutions is NP-hard
■ Current solutions traverse search tree
in parallel with backtracking
□ Search tree is highly imbalanced
□ High idle time for some threads
■ Approach: CUDA Dynamic Parallelism
□ Avoid imbalance by spawning sub-tasks as needed
□ Prevent synchronization with the CPU
□ Demands optimization of sub-task spawning
■ Experiments on Xeon CPU vs. NVidia Tesla K20
24

Other Projects
■ Operating systems and middleware
□ Algorithms for dynamic parallelism (Martin Linkhorst)
□ Parallelization of SIFT on Nvidia Tesla K20 (Lysann Schlegel)
□ Virtual Machine Introspection (Florian Westphal)
□ Mainframe experiments (Claudia Dittrich)
■ Dependability with uncertainties
□ Software-implemented lockstep (Michael Grünewald)
□ z/Linux resiliency and fault model (Stefan Richter)
□ Fuzzy logic for dependability analysis (Franz Becker)
25

FutureSOC Lab Bernhard Rabe
■ HPI FutureSOC lab research infrastructure
□ Over 2300 processing elements
□ 30 TB main memory
□ 200 TB storage capacity
□ Easy application process, no fees
■ Partners: Fujitsu, Hewlett Packard, EMC, SAP
■ Started in June 2010
□ 150 researchers from all over
the world
□ More than 50 successful
finalized projects
■ Currently 30 running projects
26

Cooperation with Industry
27





























