Embed Size (px)
Citation preview

Parallel Programming on Computational Grids

Outline
• Grids
• Application-level tools for grids
• Parallel programming on grids
• Case study: Ibis

Grids
• Seamless integration of geographically distributed computers,databases, instruments– The name is an analogy with power grids
• Highly active research area– Global Grid Forum– Globus middleware– Many European projects
• e.g. Gridlab: Grid Application Toolkit and Testbed– VL-e (Virtual laboratory for e-Science) project– ….

Why Grids?• New distributed applications that use data or instruments across multiple administrative
domains and that need much CPU power– Computer-enhanced instruments– Collaborative engineering– Browsing of remote datasets – Use of remote software– Data-intensive computing– Very large-scale simulation– Large-scale parameter studies

Web, Grids and e-Science
• Web is about exchanging information
• Grid is about sharing resources– Computers, data bases, instruments
• e-Science supports experimental science by providing avirtual laboratory on top of Grids– Support for visualization, workflows, data management,
security, authentication, high-performance computing

The big picture
Managementof comm. & computing
Managementof comm. & computing
Managementof comm. & computing
Potential Generic
partPotential Generic
part
Potential Generic
part
Application Application Application
Virtual Laboratory Application oriented services
GridsHarness distributed resources

Applications
• e-Science experiments generate much data, that often is distributed and that need much (parallel) processing– high-resolution imaging: ~ 1 GByte per measurement– Bio-informatics queries: 500 GByte per database– Satellite world imagery: ~ 5 TByte/year– Current particle physics: 1 PByte per year– LHC physics (2007): 10-30 PByte per year

Grid programming
• The goal of a grid is to make resource sharing very easy (transparent)
• Practice: grid programming is very difficult– Finding resources, running applications, dealing with heterogeneity and security, etc.
• Grid middleware (Globus Toolkit) makes this somewhat easier, but is still low-level and changes frequently
• Need application-level tools

Application-level tools
• Builds on grid software infrastructure
• Isolates users from dynamics of the grid hardware infrastructure
• Generic (broad classes of applications)
• Easy-to-use

Taxonomy of existing application-level tools
• Grid programming models– RPC– Task parallelism– Message passing– Java programming
• Grid application execution environments– Parameter sweeps– Workflow– Portals

Remote Procedure Call (RPC)
• GridRPC: specialize RPC-style (client/server) programming for grids– Allows coarse-grain task parallelism & remote access– Extended with resource discovery, scheduling, etc.
• Example: NetSolve– Solves numerical problems on a grid
• Current development: use web technology (WSDL, SOAP) for grid services
• Web and grid technology are merging

Task parallelism
• Many systems for task parallelism (master-worker, replicated workers) exist for the grid
• Examples– MW (master-worker)– Satin: divide&conquer (hierarchical master-worker)

Message passing
• Several MPI implementations exist for the grid
• PACX MPI (Stutgart):– Runs on heterogeneous systems
• MagPIe (Thilo Kielmann):– Optimizes MPI’s collective communication
for hierarchical wide-area systems
• MPICH-G2:– Similar to PACX and MagPIe, implemented on Globus

Java programming
• Java uses bytecode and is very portable– ``Write once, run anywhere’’
• Can be used to handle heterogeneity
• Many systems now have Java interfaces:– Globus (Globus Java Commodity Grid)– MPI (MPIJava, MPJ, …)– Gridlab Application Toolkit (Java GAT)
• Ibis is a Java-centric grid programming system

Parameter sweep applications
• Computations what are mostly independent– E.g. run same simulation many times with different parameters
• Can tolerate high network latencies, can easily be made fault-tolerant
• Many systems use this type of trivial parallelism to harness idle desktops– APST, SETI@home, Entropia, XtremWeb

Workflow applications
• Link and compose diverse software tools and data formats– Connect modules and data-filters
• Results in coarse-grain, dataflow-like parallelism thatcan be run efficiently on a grid
• Several workflow management systems exist– E.g. Virtual Lab Amsterdam (predecessor VL-e)

Portals
• Graphical interfaces to the grid
• Often application-specific
• Also portals for resource brokering, file transfers, etc.

Outline
• Grids
• Application-level tools for grids
• Parallel programming on grids
• Case study: Ibis

Distributed supercomputing
• Parallel processing on geographically distributed computing systems (grids)• Examples:
– SETI@home ( ), RSA-155, Entropia, Cactus
• Currently limited to trivially parallel applications
• Questions:– Can we generalize this to more HPC applications?– What high-level programming support is needed?

Grids versus supercomputers
• Performance/scalability– Speedups on geographically distributed systems?
• Heterogeneity– Different types of processors, operating systems, etc.– Different networks (Ethernet, Myrinet, WANs)
• General grid issues– Resource management, co-allocation, firewalls, security, authorization, accounting, ….

Approaches
• Performance/scalability– Exploit hierarchical structure of grids
(previous project: Albatross)
• Heterogeneity– Use Java + JVM (Java Virtual Machine) technology
• General grid issues– Studied in many grid projects: VL-e, GridLab, GGF

• Grids usually are hierarchical– Collections of clusters, supercomputers– Fast local links, slow wide-area links
• Can optimize algorithms to exploit this hierarchy
– Minimize wide-area communication
• Successful for many applications– Did many experiments on a homogeneous wide-area test bed (DAS)
Speedups on a grid?

Example: N-body simulation
• Much wide-area communication– Each node needs info about remote bodies
CPU 1
CPU 2
CPU 1
CPU 2
Amsterdam Delft

Trivial optimization
Amsterdam Delft
CPU 1
CPU 2
CPU 1
CPU 2

Wide-area optimizations
• Message combining on wide-area links• Latency hiding on wide-area links• Collective operations for wide-area systems
– Broadcast, reduction, all-to-all exchange
• Load balancing
Conclusions:– Many applications can be optimized to run efficiently on a hierarchical wide-area system– Need better programming support

The Ibis system
• High-level & efficient programming support for distributed supercomputing on heterogeneous grids
• Use Java-centric approach + JVM technology – Inherently more portable than native compilation
• “Write once, run anywhere ”– Requires entire system to be written in pure Java
• Optimized special-case solutions with native code– E.g. native communication libraries

Ibis programming support
• Ibis provides– Remote Method Invocation (RMI)– Replicated objects (RepMI) - as in Orca– Group/collective communication (GMI) - as in MPI– Divide & conquer (Satin) - as in Cilk
• All integrated in a clean, object-oriented way into Java, using special “marker” interfaces– Invoking native library (e.g. MPI) would give up
Java’s “run anywhere” portability

Compiling/optimizing programs
source
• Optimizations are done by bytecode rewriting– E.g. compiler-generated serialization (as in Manta)
Javacompiler
bytecoderewriter JVM
JVM
JVM
source bytecodebytecode

Satin: a parallel divide-and-conquer system on top of Ibis
• Divide-and-conquer is inherently hierarchical
• More general than master/worker
• Satin: Cilk-like primitives (spawn/sync) in Java
• New load balancing algorithm (CRS)– Cluster-aware random work stealing
fib(1) fib(0) fib(0)
fib(0)
fib(4)
fib(1)
fib(2)
fib(3)
fib(3)
fib(5)
fib(1) fib(1)
fib(1)
fib(2) fib(2)cpu 2
cpu 1cpu 3
cpu 1

Example
interface FibInter {public int fib(long n);
}
class Fib implements FibInter { int fib (int n) {
if (n < 2) return n;return fib(n-1) + fib(n-2);
}}
Single-threaded Java

Java + divide&conquer
Exampleinterface FibInter extends ibis.satin.Spawnable {
public int fib(long n);}
class Fib extends ibis.satin.SatinObject implements FibInter { public int fib (int n) {
if (n < 2) return n;int x = fib (n - 1);int y = fib (n - 2);sync();return x + y;
}} GridLab testbed

Ibis implementation
• Want to exploit Java’s “run everywhere” property, but– That requires 100% pure Java implementation,
no single line of native code– Hard to use native communication (e.g. Myrinet) or native compiler/runtime system
• Ibis approach:– Reasonably efficient pure Java solution (for any JVM)– Optimized solutions with native code for special cases

Ibis design

Status and current research
• Programming models- ProActive (mobility)- Satin (divide&conquer)
• Applications- Jem3D (ProActive)- Barnes-Hut, satisfiability solver (Satin)- Spectrometry, sequence alignment (RMI)
• Communication- WAN-communication, performance-awareness

Challenges
• How to make the system flexible enough– Run seamlessly on different hardware / protocols
• Make the pure-Java solution efficient enough– Need fast local communication even
for grid applications
• Special-case optimizations

Fast communication in pure Java
• Manta system [ACM TOPLAS Nov. 2001]
– RMI at RPC speed, but using native compiler & RTS
• Ibis does similar optimizations, but in pure Java– Compiler-generated serialization at bytecode level
• 5-9x faster than using runtime type inspection
– Reduce copying overhead• Zero-copy native implementation for primitive arrays• Pure-Java requires type-conversion (=copy) to bytes
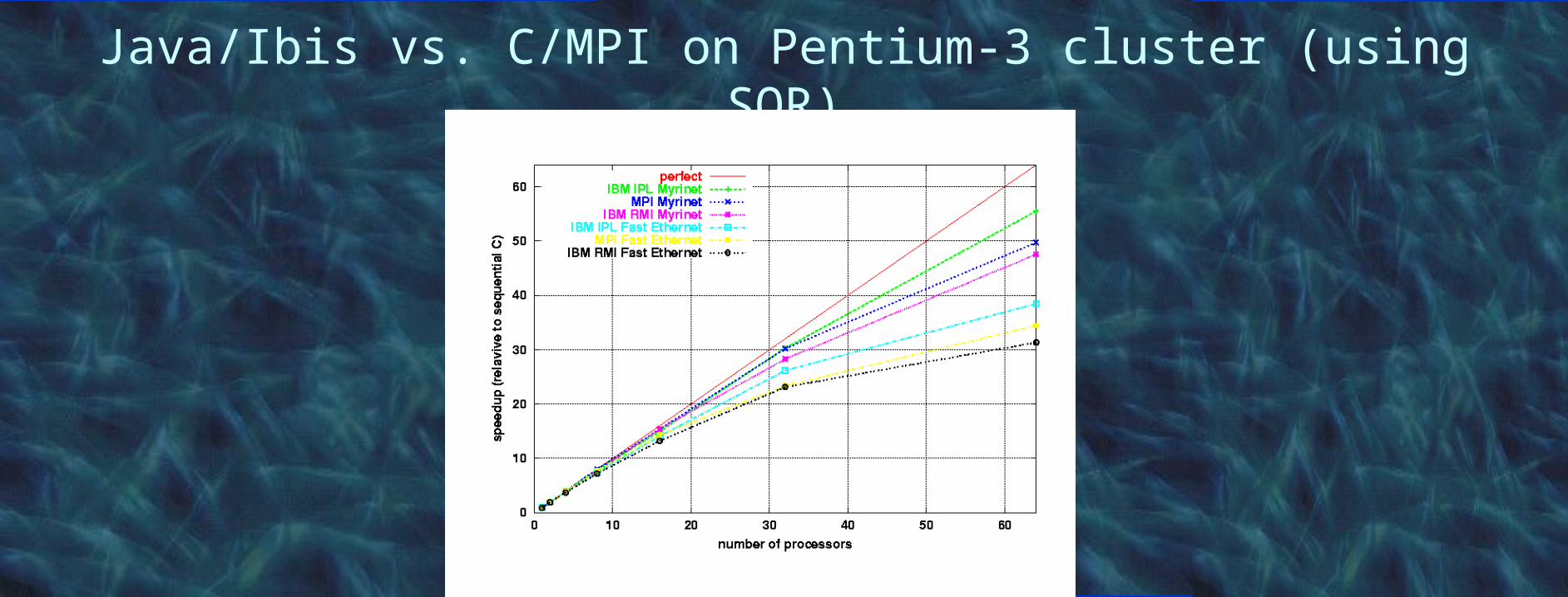
Java/Ibis vs. C/MPI on Pentium-3 cluster (using SOR)

Grid experiences with Ibis
• Using Satin divide-and-conquer system– Implemented with Ibis in pure Java, using TCP/IP
• Application measurements on– DAS-2 (homogeneous)– Testbed from EC GridLab project (heterogeneous)– Grid’5000 (France) – N Queens challenge

Distributed ASCI Supercomputer (DAS) 2
VU (72 nodes)UvA (32)
Leiden (32) Delft (32)
GigaPort(1-10 Gb)
Utrecht (32)
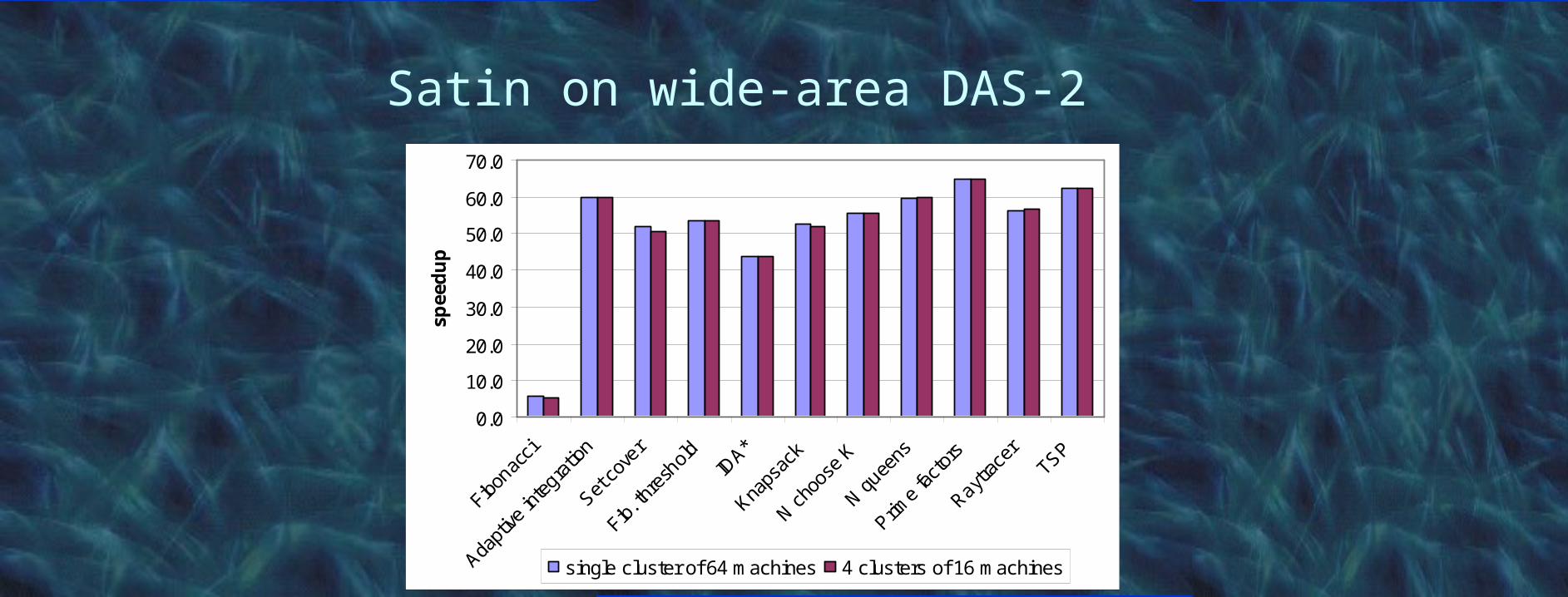
Satin on wide-area DAS-2
0.0
10.0
20.0
30.0
40.0
50.0
60.0
70.0
Fibonac
ci
Adapt
ive in
tegra
tion
Set co
ver
Fib. th
resh
old IDA*
Knaps
ack
N cho
ose
K
N quee
ns
Prime
facto
rs
Raytrac
erTSP
spee
du
p
single cluster of 64 machines 4 clusters of 16 machines

Satin on GridLab
• Heterogeneous European grid testbed
• Implemented Satin/Ibis on GridLab, using TCP
• Source: van Nieuwpoort et al., AGRIDM’03 (Workshop on Adaptive Grid Middleware, New Orleans, Sept. 2003)

GridLab
• Latencies:– 9-200 ms (daytime),
9-66 ms (night)
• Bandwidths:– 9-4000 KB/s

Configuration
Type OS CPU Location CPUs
Cluster Linux
Pentium-3
Amsterdam 8 1
SMP Solaris Sparc Amsterdam 1 2
Cluster Linux Xeon Brno 4 2
SMP Linux Pentium-3 Cardiff 1 2
Origin 3000 Irix MIPS ZIB Berlin 1 16
SMP Unix Alpha Lecce 1 4

Experiences
• No support for co-allocation yet (done manually)
• Firewall problems everywhere– Currently: use a range of site-specific open ports– Can be solved with TCP splicing
• Java indeed runs anywhere
modulo bugs in (old) JVMs
• Need clever load balancing mechanism (CRS)

Cluster-aware Random Stealing
• Use Cilk’s Random Stealing (RS) inside cluster• When idle
– Send asynchronous wide-area steal message– Do random steals locally, and execute stolen jobs– Only 1 wide-area steal attempt in progress at a time
• Prefetching adapts– More idle nodes more prefetching
• Source: van Nieuwpoort et al., ACM PPoPP’01

Performance on GridLab
• Problem: how to define efficiency on a grid?• Our approach:
– Benchmark each CPU with Raytracer on small input– Normalize CPU speeds (relative to a DAS-2 node)– Our case: 40 CPUs, equivalent to 24.7 DAS-2 nodes– Define:
• T_perfect = sequential time / 24.7• efficiency = T_perfect / actual runtime
– Also compare against single 25-node DAS-2 cluster

Results for Raytracer Time (sec) Efficiency (%)
Night RS 878 62.6
CRS 677 81.3
Day RS 2084 26.4
CRS 693 79.3
1 cluster 580 96.1
sequential
13,564 100
RS = Random Stealing, CRS = Cluster-aware RS

Some statistics
• Variations in execution times:– RS @ day: 0.5 - 1 hour– CRS @ day: less than 20 secs variation
• Internet communication (total):– RS: 11,000 (night) - 150,000 (day) messages
137 (night) - 154 (day) MB– CRS: 10,000 - 11,000 messages
82 - 86 MB

N-Queens Challenge
• How many ways are there to arrange N non-attacking queens on an NxN chessboard ?

Known Solutions• Currently, all solutions up to N=25 are known
• Result N=25 was computed usingthe 'spare time' of 260 machines
• Took 6 months
• Used over 53 cpu-years!
N # Solutions
19 496805784820 3902918888421 31466622271222 269100870164423 2423393768444024 22751417197373625 2207893435808350

N-Queens Challenge
• How many solutions can you calculate in 1 hour, using as many machines as you can get ?
• Part of the PlugTest 2005 held in Sophia Antipolis

Satin & Ibis
• Our submission used a Satin/Ibis application
• Uses Satin (Divide & Conquer) to solve N-Queens recursively
• Satin distributes different parts of the computation over the Grid– Uses Ibis for communication

Satin & Ibis
• Used the Grid 5000 testbed to run– Large testbed distributed over France
• Currently contains some 1500 CPU's
• Will (eventually) contain 5000 CPU's

Largest Satin/Ibis Run
• Our best run used 961 CPUs on 5 clusters for a single application – Largest number of CPUs of all contestants
• Solved N=22 in 25 minutes
• Second place in the contest

Current/future work: VL-e
• VL-e: Virtual Laboratories for e-Science• Large Dutch project (2004-2008):
– 40 M€ (20 M€ BSIK funding from Dutch goverment)
• 20 partners– Academia: Amsterdam, TU Delft, VU, CWI,
NIKHEF, ..– Industry: Philips, IBM, Unilever, CMG, ....

DAS-3
• Next generation grid in the Netherlands (2006)
• Partners:– NWO & NCF (Dutch science foundation)– ASCI– Gigaport-NG/SURFnet: DWDM computer backplane
(dedicated optical group of up to 8 lambdas)– VL-e and MultimediaN BSIK projects
CP
U’s
R
CPU’sR
CPU’s
R
CP
U’s
R
CPU’sR
NOC

StarPlane project
• Application-specific management of optical networks
• Future applications can:– dynamically allocate light paths, of 10 Gbit/sec each
– control topology through the Network Operations Center
• Gives flexible, dynamic, high-bandwidth links
• Research questions:– How to provide this flexibility (across domains)?
– How to integrate optical networks with applications?
• Joint project with Cees de Laat (Univ. of Amsterdam), funded by NWO

Summary
• Parallel computing on Grids (distributed supercomputing) is a challenging and promising research area
• Many grid programming environmenents exist
• Ibis: a Java-centric Grid programming environment– Portable (“run anywhere”) and efficient
• Future work: Virtual Laboratory for e-Science (VL-e), DAS-3, StarPlane





























