Embed Size (px)
Citation preview

CoMeT Collegium Medicorum Theatri
Annual Meeting
2011
May 16-17
AVFA Advanced Voice Function Assessment
COST Action 2103
International Workshop 2011
May 15-16
PPrrooggrraamm
CCOOSSTT AAccttiioonn 22110033 // CCooMMeeTT 22001111
OOrrggaanniizzeedd bbyy tthhee
DDeeppaarrttmmeenntt ooff PPhhoonniiaattrriiccss aanndd PPeeddiiaattrriicc AAuuddiioollooggyy
CChhaaiirr:: PPrrooff.. KKaattrriinn NNeeuummaannnn,, MMDD
GGooeetthhee--UUnniivveerrssiittyy ooff FFrraannkkffuurrtt // MMaaiinn
TThheeooddoorr--SStteerrnn--KKaaii 77,, HHoouussee 77AA
DD--6600559900 FFrraannkkffuurrtt // MMaaiinn,, GGeerrmmaannyy
TTeell ++4499 6699 66330011 66336699
FFaaxx ++4499 6699 66330011 55000022
MMoobbiillee ++4499 116600 99777700 55559900
ee--mmaaiill KKaattrriinn..NNeeuummaannnn@@eemm..uunnii--ffrraannkkffuurrtt..ddee

2
Dear colleagues and friends of the fields of voice science, voice therapy, and performing arts,
It is my pleasure and a special honour to welcome you to the International AVFA Workshop 2011,
organized by the COST Action 2103 “Advanced Voice Function Assessment”, held together with
the 2011 Annual Meeting of the Collegium Medicorum Theatri – CoMeT.
The COST Action 2103 "Advance Voice Function Assessment" (http://www.cost2103.eu/) is a
joint initiative of voice and speech processing teams of engineers and physicists and of the European
Laryngological Research Group (ELRG) under the umbrella of COST (European Cooperation in
Science and Technology), with 17 countries participating. Its main objective is to create a European
network of voice experts by bringing together research institutions, universities, and companies
involved in signal processing and voice disorders with the aim of gaining new insights, through
interdisciplinary cooperation, into basic research problems as well as clinical/therapeutic
applications. Its aim is the development of objective and clinically useful methods for the
investigation of voice quality and for the prevention and treatment of occupational voice disorders in
professional speakers. This objective requires an understanding of the relationship between
biomedical changes at the level of vocal folds and alterations of the acoustical voice signal, which in
turn asks for objective voice assessment. Hence, the Action combines previously unexploited
techniques with new theoretical developments to improve the assessment of voice for the various
European languages, to refine existing voice production models, and to improve models of
pathological processes.
CoMeT is composed of doctors, scientists, voice coaches, and voice pathologists from different
regions of the world, who are connected with major theaters, operas, or conservatories, or who have
demonstrated special dedication to the physiology and pathology of the voices of singers and actors.
CoMeT strives for the scientific investigation of the physiology and pathology of the voice of singers
and actors, clinical studies on these professional voice users, the exchange of knowledge and ideas
among the members in this field, the facilitation of the referral of a singer or actor to a well qualified
specialist in another city where the artist is scheduled to perform and the development of educational
activities related to the vocal problems of singers and actors.
Because of the overlap of the issues of both COST Action 2103 and CoMeT, we will perform a
shared event with oral presentations, roundtables, and workshops. Moreover, in a special session we
want to present the main issues of our research in an easy understandable way to students and local
professionals.
The topics of our event are
- Signal processing and acoustic voice analysis
- Perceptual voice analysis
- Modelling of the voice
- Assessment of voice disorders
- Physiology and pathophysiology of the singer´s and speaker´s voice
- Special voice problems in singers and actors
- Evidence-based vocal medicine
- Voice therapy
- Phonosurgery
- Vocal training and pedagogy for voice professionals

3
COST Action 2103
Program Committee
Katrin Neumann, University Frankfurt/M
Philippe H. Dejonckere, University of Utrecht
Yannis Stylianou, University of Crete
Malte Kob, Hochschule für Musik, Detmold
Scientific Committee Markus GUGATSCHKA, Austria
Martin HAGMUELLER, Austria
Jean SCHOENTGEN, Belgium
Thierry DUTOIT, Belgium
Mieke MOERMAN, Belgium
Jaromir HORACEK, Czech Republic
Jean SVEC, Czech Republic
Niels RASMUSSEN, Denmark
Mette F. PEDERSEN, Denmark
Laura LEHTO, Finland
Paavo ALKU, Finland
Anne-Maria LAUKKANEN, Finland
Olivier ROSEC, France
Antoine GIOVANNI, France
Katrin NEUMANN, Germany
Malte KOB, Germany
Ioanis BIZAKIS, Greece
Peter MURPHY, Ireland
Ailbhe NICHASAIDE, Ireland
Christer GOHL, Ireland
John FENTON, Ireland
Richard REILLY, Ireland
Giovanna CANTARELLA, Italy
Claudia MANFREDI, Italy
Irma VERDONCK , Netherlands
Luis CALDAS DE OLIVEIRA, Portugal
Jerneja ZGANEC GROS, Slovenia
Bojan PETEK, Slovenia
Sten TERNSTRöM, Sweden
Maria SöDERSTEN, Sweden
Krzysztof IZDEBSKI, USA
David M. HOWARD, UK
Adrian FOURCIN, UK
Eric GOODYER, UK
Julian MCGLASHAN, UK
CoMeT
President
Prof. John S. Rubin, M.D.
15 Smith Close
London SE16 5PB, UK
Tel: +44 207 232 1653
Fax: +44 207 232 0311
e-mail: [email protected]
Secretary Europe Dr. Josef Schlömicher-Thier, MD
Kleinköstendorf 65
A-5203 Köstendorf, Austria
Secretary outside Europe Prof. Robert F. Orlikoff, PhD
West Virginia University, P. O. Box 6122,
Morgantown, WV 26505, USA
Treasurer Dr. Matthias H. J. Weikert, MD
Heitzerstraße 19
D-93049 Regensburg, Germany

4
Registration
Registration fees (for each of the two events):
Students: 30 €
Speech therapists and singing teachers: 180 €
Full rate: 230 €
Accompanying persons: 100 €
Conference dinner: 60 €
Ticket for Verdi Requiem : 35 / 42 €
Attendance at the COST Workshop is free for members of the COST Action
2103.
Venue
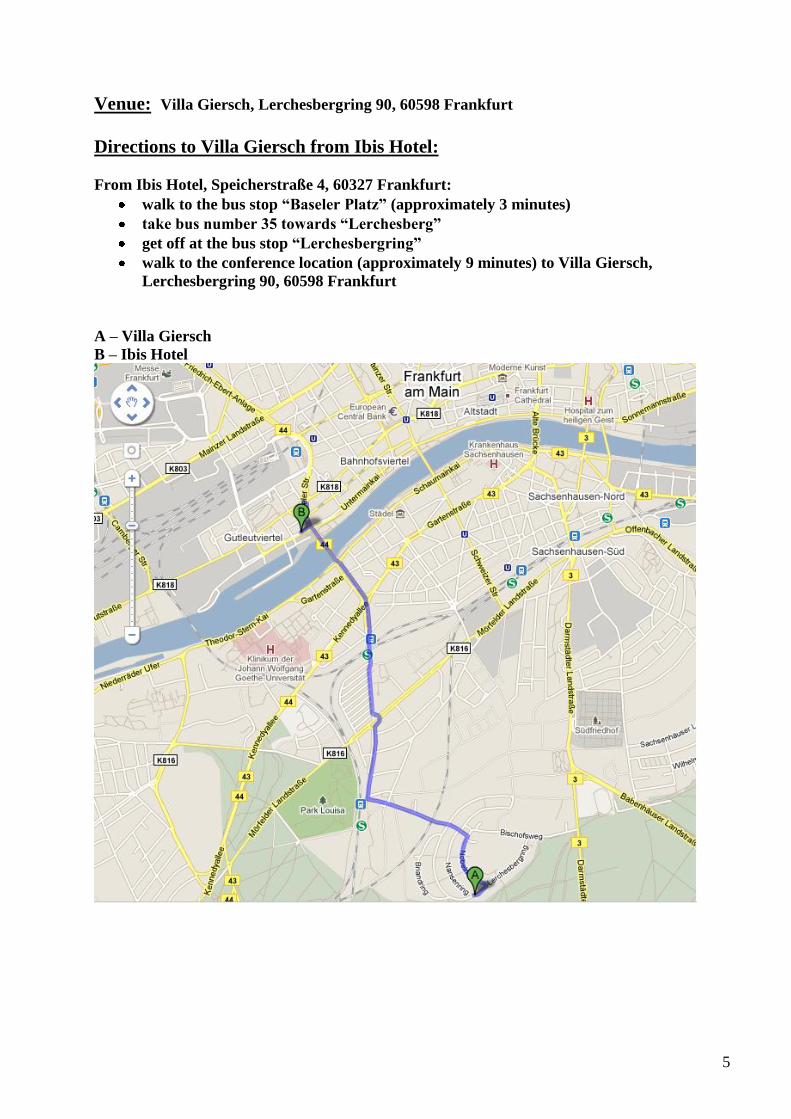
Villa Giersch, Lerchesberg 90, 60598 Frankfurt am Main
Accommodation
Ibis Hotel Frankfurt Centrum
For any requests, please contact: Jutta Göring
Department of Phoniatrics and Pediatric Audiology
ENT Dept., Goethe-University of Frankfurt / Main
Theodor-Stern-Kai 7, House 7A
D-60590 Frankfurt / Main, Germany
Tel +49 69 6301 6369
Fax +49 69 6301 5002
e-mail [email protected]
5
Venue: Villa Giersch, Lerchesbergring 90, 60598 Frankfurt
Directions to Villa Giersch from Ibis Hotel:
From Ibis Hotel, Speicherstraße 4, 60327 Frankfurt:
walk to the bus stop “Baseler Platz” (approximately 3 minutes)
take bus number 35 towards “Lerchesberg”
get off at the bus stop “Lerchesbergring”
walk to the conference location (approximately 9 minutes) to Villa Giersch,
Lerchesbergring 90, 60598 Frankfurt
A – Villa Giersch
B – Ibis Hotel

6
From Ibis Hotel to “Baseler Platz” From “Lerchesbergring“ to Villa Giersch
Our event will be accompanied by pianist Tobias Hartlieb.
Tobias Hartlieb studied piano at the University of Music Hamburg with
Volker Banfield. He continued his studies with a scholarship of Rotary
International at the renowned Indiana University Bloomington, USA.
Leonard Hokanson, Menahem Pressler and Elisabeth Wright under which he
studied Lied, chamber music and pianoforte, count to his teachers. Tobias Hartlieb was
distinguished several times with prices and scholarships, among them the 1st price at "Jugend
musiziert", the 1st price at the international Johannes Brahms Wettbewerb, Austria, a scholarship
of the Max Kade Foundation, New York.
As a pianist he appeared furthermore at the Karajan Academy of the Berlin Philharmonic
Orchestra, at the state opera Nuremberg (opera Late Night), the Nuremberg Symphony Orchestra,
the Hamburg Symphony Orchestra, with the Bavarian Chamber Orchestra Bad Brückenau as well
as with the Ensemble Kontraste Nuremberg. Recordings at the Bavarian Broadcasting and NDR as
well as CD recordings with chamber music and art song display his artistic activity.
Tobias Hartlieb is a lecturer in piano and chamber music at the University of Music Frankfurt /
Main.

7
Clemens Rech
began playing the guitar at the age of eleven and studied music at the Wiesbaden
Conservatoire, class of Horst Klee, as well as musicology and philosophy at the
Johannes-Gutenberg-University, Mainz. He completed his instrumental
education with Wilfried Halter at the Dr. Hoch´s Conservatoire, Frankfurt, and
attended international master classes by, among others, Wolfgang Lendle and
Prof. Karl Scheit.
Early encounters with the art of Dietrich Fischer-Dieskau and Peter Pears awakened his interest in
song accompaniment and led to a continuing collaboration with singers like the tenor Ralph
Nickles and the soprano Sigrun Haaser (CDs: “Meine Lieder, meine Sänge”; „Meine Liebe,
schläfst Du noch?“). Additionally in recent years the guitarist developed an interest in historically
informed performance, playing Romantic music on 19th
century period instruments.
The soprano Sigrun Haaser has received a training to be a singer at the cathedral
choir of Speyer since the age of seven. Already at an early stage did she sing
smaller parts of sacred music as a sopran soloist. It was at one of these occasions
that the singer of chamber music Mrs. Erika Köth took notice of her; encouraged
and supported her until the start of her voice studies with private lessons. Her
voice study started with Mrs. Prof. Eva-Maria Molnar in Mannheim, followed by
further studies with Prof. Klaus Dieter Kern at the High school of Music in
Karlsruhe, where she received a diploma with distinctions as a concert singer.
Her art career as a singer continued in Karlsruhe with studies of classic songs under Prof. Hartmut
Höll and Mitsuko Shirai.
She took part in numerous master classes for opera and operetta, as well as for the art of songs and
oratorios, for instance under Bernd Weikl (in Austria), Edith Mathis (in Switzerland), Anna
Reynolds (in England), Sena Jurinac and Hilde Zadek (in Vienna), Barbara Schlick (baroque
singing in Karlsruhe) and Charlotte Lehmann with Dr. Huber-Contwig (in Lichtenberg). This
resulted in invitations to song evenings, oratorios, opera- and operetta-engagements during
concerts. During these operetta concerts she displayed a wide repertoire for the various parts in
operettas from Lehar, Johann Strauß and Robert Stolz. In October 2000 she sang one of the main
parts of the only preserved opera “La constanza vince l‟inngano” by Christoph Graupner. Since
October 2000 Sigrun Haaser lectures singing at the University of Würzburg.
Dimiter Ivanov was born in Sofia/Bulgaria and grew up in
Würzburg/Germany. At the age of eight he took his first lessons of violin.
During his studies in Germany (Hochschule für Musik, Würzburg and
Hochschule für Musik Hanns Eisler, Berlin) and the US (Indiana
University/Bloomington) he was a scholarship holder of the “Studienstiftung
des deutschen Volkes” and “Deutsche Stiftung Musikleben”.
Dimiter Ivanov is prize winner in several international violin competitions e.g.
the “Groblizc-Family“ (Krakau/Poland), “Andrea Postacchini“ (Fermo/Italy)

8
“Henryk Szering“ (Mexico) “Johannes Brahms“ (Pörtschach/Austria), “Rodolfo Lipizer“
(Gorizia/Italy) and “Gerhard Taschner“ (Berlin/Germany). He has performed as a soloist in violin
at the “Radio-Sinfonieorchester Krakau“, the “Nürnberger Sinfonikern“, the “Philharmonischer
Orchester Würzburg“ and the “Berlin-Brandenburgischen Sinfonie-Orchester“ as well as the
“Konzerthausorchester Berlin.“
2005-2008 Dimiter Ivanov was the first concertmaster at the “Orchestra del Teatro lirico di
Cagliari“(Sardinia/Italy), since season 2008/09 he continued his work in the same position at the
“Museumsorchester der Oper Frankfurt“. In 2010 he became a member of the stuff of the
“Hochschule für Musik Hanns Eisler”.
Elisa Fenner-Ivanov was born in Berlin/Germany. She received her first
singing lessons by Maria Zahlten-Hall. In 2008 she finished her studies at the
“Hochschule für Musik Hanns Eisler” (Berlin/Germany) and deepened her
Italian repertoire in Cagliari (Sardinia/Italy).
Elisa Fenner-Ivanov performed in several important opera parts e.g. the
Ännchen in "Der Freischütz" (Weber), the Echo in "Ariadne auf Naxos" (R.
Strauss). In the course of the festival "Oper Oder-Spree"(federal state of
Brandenburg) she played the Celidora in "Die Gans von Kairo" (Mozart) and
the Zerlina in “Don Giovanni“(Mozart). She was also involved in the debut
performance of "Mephistopheles"(Boito) as Helena in the Philharmonie, Berlin and as Marie in
„Die verkaufte Braut“(Smetana) at the Schloßtheater Rheinsberg.
She attended within the framework of the “Schleswig-Holstein Musikfestival” and as a scholarship
holder of the “Schubert Stichting Amsterdam“, mastercourses by Rudolf Jansen, Robert Holl, Elly
Ameling and Irwin Gage. As well as by Hector Urbón, Julia Varady, Thomas Quasthoff, Thomas
Heyer, Jutta Schlegel, Willy Decker and Gerd Uecker.
2001 she was awarded with the „Lotte Lehmann-Förderpreis” (Perleberg/Germany). Since March
2009 Gundula Hintz is her vocal coach.
In 2010 Elisa Fenner-Ivanov became a member of the ensemble of the “Kammeroper Köln“ and
started her studies in logopedics at the “Hochschule Fresenius“ (Frankfurt am Main/ Germany).

9
Scientific Program
AVFA Workshop 2011 and CoMeT 2011 Meeting
May 15
AVFA Workshop 2011
8:00-9:00 Registration
9:00-10:00 Keynote speech:
Ingo Titze. The importance of source-filter interaction in speaking and singing
10:00-10:40 Oral presentations Acoustic signal analysis; Chair: Jan G. Svec
Philippe Dejonckere, Jean Schoengen, Claudia Manfredi. Perceptual and computer
performances in cycle-pattern recognition of irregular voices
Claudia Manfredi, Andrea Giordano, Jean Schoentgen, Samia Fraj, Leonardo
Bocchi, Philippe Dejonckere. Validity of jitter measures in non quasi-periodic
voices
10:40-11:00 Coffee break
11:00-12:40 Oral presentations Modeling and acoustic signal analysis; Chair: Claudia
Manfredi
Klára Visci, Viktor Imre. Voice disorder detection on the basis of continuous speech
Jaromír Horáček, Petr Sváček. Numerical simulation of phonation onset:
comparison of finite element glottal flow approximation with a simplified model
Evaldas Vaiciukynas, Atanas Verikas, Adas Gelzinis, Marija Bacauskiene,
Virgilijus Uloza. Exploring fuison of generative and discriminative models for
similarity-based classification of larynx pathology
Jan G. Svec, Hana Sramkova, Tomas Fürst, Svante Granqvist. What is the dynamic
range of human voice?
Fredric Lindström, Marcus Wirebrand, Sten Ternström, Maria Södersten. A
discussion on what type of data a voice usage database should consist of
12:40-13:30 Lunch break
13:30-14:30 Oral presentations Clinical applications; Chair: Philippe Dejonckere
Grażyna Demenko, Magdalena Jastrzębska. Analysis of vocal stress in
conversations to call centers

10
Víctor Osma-Ruiz, Juana María Gutiérrez-Arriola, Juan Ignacio Godino-Llorente,
Janaina Mendes-Laureano, Nicolás Sáenz-Lechón, Rubén Fraile, Julián David
Arias. EntrenaVox, a computer program for voice rehabilitation through games
Mette Pedersen. Highspeed films for evaluation of reflux to help rock popular
singers
Katrin Neumann, Malte Kob, Harald A. Euler1, Tobias Weissgerber, Alexander
Wolff von Gudenberg, Anne-Lise Giraud, Christian Kell. How does the brain
process prosody? An fMRI study with persons who stutter
14:30-15:30 Workshop
Hugo Lycke. Voice classification by phonetography: the „why‟ and the „how‟.
15:30-17:00 MC meeting

11
May 16
AVFA Workshop 2011 and CoMeT 2011 Meeting
8:40-9:00 Opening
9:00-10:00 Keynote speech:
Eckart Altenmüller. Is music the universal „language“ of emotions? The
neurobiology and psychology of aesthetic feelings
10:00-11:10 Oral presentations Assessment of the professionals’ voice; Chair: Tom Harris
Vojtěch Radolf, Anne-Maria Laukkanen, Radan Havlík, Jaromír Horáček. Effects of
a vocal warm-up on the vocal tract setting of a male voice professional. An MRI and
modelling study
Matthias Echternach, Louisa Traser, Bernhard Richter. Tenors‟ vocal tract
configurations in different registers and vowel conditions
Samuli Siltanen, Aku Seppänen, Antti Nissinen, Ville Kolehmainen, Anne-Maria
Laukkanen. Feasibility of electrical impedance tomography for the imaging of the
larynx – preliminary results
Lionel Fawcett. Singing – a dual system
Josef Schlömicher-Thier, Matthias Weikert, Hannes Tropper, Alexandra Pichler,
Silvia Hißmayr. Medical and educational occupational voice care for teacher-
students at the College of Education in Salzburg
11:10-11:30 Coffee break
11:30-13:00 Oral presentations Phonosurgery; Chair: Tadeus Nawka
11:30-11:45 Tadeus Nawka. Introduction to the topic and demonstration of the RADIESSE
Voice system
11:45-12:05 Nobuhiko Isshiki. Phonosurgical procedure and outcome in case of a laryngeal
paresis of an operatic singer
12:05-12:20 Jaechul Bae. Report on his voice recovery as an operatic singer after a laryngeal
paresis and a subsequent phonosurgery
12:20-12:30 Totaro Wajima. Report on the voice recovery of Mr. Jaechul Bae by his producer
12:30-12:45 Giovanna Cantarella, Giovanna Baracca, Stella Forti, Elisabetta Iuffrida, Riccardo
F. Mazzola. Treatment of glottic insufficiency by structural fat grafting
12:45-13:00 Eugenia Chávez. Results of indirect endoscopic surgery in singers
13:00-13:30 Roundtable with the presenters, Tom Harris, and John Rubin. Open discussion on
phonosurgical issues; Chair: John Rubin
13:30-14:20 Lunch break

12
14:20-15:45 Workshops
Leah Frey-Rubine. Master class „Honing the professional singing voice‟
Olaf Nollmeyer. Singer's/ -speaker's formant in real life
15:45-16:00 Closing of the AVFA 2011 Workshop
16:00-18:00 Special session for students, artists, therapists, and other professionals: Say it
easy ─ how does the voice function? John Rubin, Ingo Titze.
VENUE: University hospital Frankfurt/M, Theodor-Stern-Kai 7, House 22, lecture
room 2
18:00-19:30 CoMeT Annual General Meeting

13
May 17
CoMeT 2011 Meeting
09:00-10:00 Keynote speech:
Malte Kob. The acoustics of over- and undertone singing
10:00-11:00 Oral presentations Voice classification and assessment; Chair: Krzysztof
Izdebski
Hugo Lycke, Wivine Decoster W, Felix I. de Jong. Voice classification in practice:
criteria in contemporary singing education
Hugo Lycke, Wivine Decoster, Anna Ivanova, Marc M. van Hulle, Felix I. de Jong.
The reliability of voice range profile derived parameters in the discrimination of
three basic female voice categories.
Philipp Aichinger, Birgitta Aichstill, Felicitas Feichter, Berit Schneider-Stickler. Towards standardized DSI-measurement in clinical practice
Erkki Bianco. Individual harmonic listening in spectral sounds of the voice
11:00-11:20 Coffee break
11:20-12:50 Oral presentations Special issues of the singers’ and speakers’ voice; Chair:
Katrin Neumann
Krzysztof Izdebski. Phonetotopic organization of phonation. Evidence from
electrophysiology, aerodynamics, acoustics and kinesthetics
Katrin Neumann, Judith Thoma, Tobias Weissgerber, Felix Langenbruch, Jörn
Loviscach, Malte Kob. Female register transitions
Philippe Dejonckere. Actress' formant: does it exist?
Geert Berghs, Felix I. de Jong. Singing voice and ageing
Geert Berghs, Felix I. de Jong. Vibrato and ageing of the voice in professional choir
singers
12:50-13:40 Lunch break
13:40-14:20 Oral presentations Occupational issues; Chair: Berit Schneider-Stickler
13:40-14:00 Sara Harris. Speech therapy for the injured singer
14:00-14:20 Eugenia Chávez. Singers resonance, allergies and environment

14
14:20-15:45 Workshops
Eugen Rabine. Workshop „Double ventile function – breathing and posture in
singing‟
Margaretha Bessel. Workshop „Sing aaaaah, free your voice!‟
15:45-16:00 Closing CoMeT Meeting
Sunday, May 15: AVFA Workshop 2011
Sunday, May 15, 9:00-10:00
Keynote Speech:
The importance of source-filter interaction in speaking and singing
Ingo R. Titze
Executive Director; National Center for Voice and Speech; The University of Utah, lead institution
University of Iowa Foundation Distinguished Professor; Department of Communication Sciences
and Disorders; The University of Iowa
The source-filter theory has been the flagship of speech and voice science for over half a century.
Traditionally, the source (glottal airflow in vocal fold vibration) and the filter (the vocal tract
airway) have been treated independently. One could not affect the other. Recent discoveries
challenge that concept. As in wind instruments, the filter (vocal tract) can have a strong influence
on the source. Specific vowel shapes are matched by specific glottal configurations. This is of
particular importance in characterizing singing styles and voice qualities in speech.
Prof. Dr. Ingo R. Titze:
Prof. Dr. Ingo R. Titze is a University of Iowa Foundation Distinguished
Professor in the Department of Communication Sciences and Disorders and the
School of Music. He also directs the National Center for Voice and Speech,
which is an Institute of the University of Utah in Salt Lake City, with a
companion site at the University of Iowa. The NCVS also collaborates with
many institutions around the country.
Although he was formally educated as a physicist (Ph.D.) and engineer
(M.S.E.E.), Prof. Dr. Titze has applied his scientific knowledge to a lifelong love of clinical voice
and vocal music. Specifically, his research interests include biomechanics of human tissues,
acoustic phonetics, speech science, voice disorders, professional voice production, musical
acoustics, and the computer simulation of voice.
Prof. Dr. Titze has published over 250 articles in scientific and educational journals, authored three
books entitled Principles of Voice Production, The Myoelastic-Aerodynamic Theory of Phonation,
and most recently Fascinations with the Human Voice. He has also co-edited two books in a series
entitled Vocal Fold Physiology. He is currently completing an additional book entitled Vocology.

15
He is an associate editor of the Journal of Singing and has written a bi-monthly column in this
Journal for 20 years.
Prof. Dr. Titze is the father of vocology, a specialty within speech-language pathology. He defined
the word and the specialty as “the science and practice of voice habilitation.” In many ways, it
parallels audiology. The discipline focuses on the sound-producing organ rather than the sound-
receiving organ in terms of prevention and care. A Summer Vocology Institute is ongoing, in
which speech language pathologist, otolaryngologist, speech trainers, and singing teachers can get
intensive, graduate level training in voice.
Most recently, Prof. Dr. Titze has formally begun to address the vocal problems of teachers, which
comprise about 4% of the working population. Because of the many hours of vocal engagement
with students, many teachers fatigue after three to four hours of talking. They don‟t recover from
day to day, or week to week. Research is underway in Prof. Dr. Titze‟s laboratories to study the
effects of long-term vibration on cells and extra-cellular tissues in the vocal folds. Also underway
is the development of therapy techniques to improve the economy of sound production in teachers.
An outgrowth of Prof. Dr. Titze‟s research on voice physiology, biomechanics, and acoustics has
been a singing and speaking robot, Pavarobotti. He has used it widely for creating entertaining
lectures on the human voice. Prof. Dr. Titze and Pavarobotti perform operatic arias together. It is
expected that, in time, this technology will be widely used for assistive devices in speech
communication, in speech training, and in education. The unique feature of his approach is that all
the computer simulations are done on the basis of anatomy and physiology, rather than sound
processing.
Prof. Dr. Titze is a recipient of the William and Harriott Gould Award for laryngeal physiology,
the Jacob Javits Neuroscience Investigation Award, the Claude Pepper Award, the Quintana Award
of the Voice Foundation, and the American Laryngological Award. He is a Fellow of the
Acoustical Society of America, the American Speech Language and Hearing Association, and the
American Laryngological Association. He and his work have been featured in several well-known
television programs, including Innovation, Quantum, and Beyond 2000.
Prof. Dr. Titze has served on a number of national advisory boards and scientific review groups,
including the Scientific Advisory Board of the Voice Foundation, the Division of Research Grants
of the National Institutes of Health, and the Advisory Council of National Institutes on Deafness
and Other Communication Disorders. In addition to his scientific endeavors, Prof. Dr. Titze
continues to be active as a singer, giving several recitals a year in the U.S. and Europe.
His wife, Kathy, is a piano teacher and his daughter is a speech-language pathologist; and his three
sons are all pursuing college degrees.
Sunday, May 15, 10:00
Oral Presentation: Acoustic signal analysis
Perceptual and computer performances in cycle-pattern recognition of irregular
voices

16
Philippe Dejonckere1, 2, 3
, Jean Schoengen2, Claudia Manfredi
4
1 Catholic University of Leuven, Neurosciences, Exp. ORL, Belgium
2 Federal Institute of Occupational Diseases, Brussels, Belgium
3 Utrecht University UMC, The Netherlands. AZU Heidelberglaan 100, F.02.504, NL 3584
CX Utrecht. 4 Department of Electronics and Telecommunications, Università degli Studi di Firenze, Via
S. Marta 3, 50139 Firenze, Italy
Objective measurement of the severity of dysphonia typically requires signal processing algorithms
applied to acoustic recordings. Since Lieberman (1963) introduced the concept of perturbation
analysis in the area of voice, the best-known acoustic parameter in clinical practice is conventional
jitter. However jitter measurements have some critical limitations. According to a widely accepted
guideline, in sustained vowels of dysphonic voices, only perturbation measures less than about 5%
are reliable: this is related to period extraction methods. This limit of 5% deserves critical analysis,
certainly when there are indications that some acoustic analysis programs can be applied to quite
irregular voices such as substitution voices. The present experiment demonstrates that – on signals
of synthesized deviant voices (sustained vowel) with moderate additive noise – different raters are
able to visually identify in a very consistent way the period durations of successive cycles up to
values of about 13% jitter. Furthermore, even for higher values – over 30 % – the jitter %
computed with the period values rated by visual perception is, for some of the raters, very
comparable to the real value. This suggests that improved acoustic programs using more reliable
algorithms could validly transgress the traditional limit of 5% if they demonstrate the
correspondence of their computations with the true jitter values. This is now made possible by
synthesizers generating artificial deviant voices that cannot be distinguished from true dysphonia,
and in which the jitter put in is exactly known.
Sunday, May 15, 10:20
Oral Presentation: Acoustic signal analysis
Validity of jitter measures in non quasi-periodic voices
Claudia Manfredi
1, Andrea Giordano
1, Jean Schoentgen
2, 3, Samia Fraj
2, Leonardo Bocchi
1,
Philippe Dejonckere4, 5, 6
1 Department of Electronics and Telecommunications, Università degli Studi di Firenze, Via S.
Marta 3, 50139 Firenze, Italy 2 L.I.S.T. Faculty of Applied Sciences Université Libre de Bruxelles, CP165/51, 50, Av. F.-D.
Roosevelt, B-1050 Brussels, Belgium 3
National Fund for Scientific Research, Belgium 4 Catholic University of Leuven, Neurosciences, Exp. ORL, Belgium
5 Federal Institute of Occupational Diseases, Brussels, Belgium
6 Utrecht University UMC, The Netherlands. AZU Heidelberglaan 100, F.02.504, NL 3584
CX Utrecht.

17
Corresponding author:
Claudia Manfredi
Department of Electronics and Telecommunications
Università degli Studi di Firenze
Via S. Marta 3
50139 Firenze, Italy
In this paper the effect of noise on both perceptual and automatic evaluation of the glottal cycle
length in irregular voice signals (sustained vowels) is studied. The reliability of four tools for voice
analysis is compared to visual inspection made by trained clinicians using two measures of voice
signal irregularity: the jitter (J) and the coefficient of variation of the fundamental frequency
(F0CV). The purpose is also to test to what extent of irregularity trained raters are capable to
visually determine the glottal cycle length as compared to devoted software tools.
For a perfect control of the amount of jitter and noise put in, data consist of synthesised sustained
vowels corrupted by increasing jitter and noise.
All the tools give almost reliable measurements up to 15% of jitter, for low or moderate noise,
while only few of them are reliable for higher jitter and noise levels and would thus be suited for
perturbation measures in strongly irregular voice signals.
For low noise levels the results obtained by visual inspection from expert raters are comparable or
even better than those obtained with the analysis tools presented here, but results rapidly
deteriorate with increasing noise. Hence, the use of a robust tool for voice analysis can give a valid
support to clinicians in term of reliability, reproducibility of results and time saving.
Key Words: perceptual and objective voice analysis, jitter, glottal cycle length, coefficient of
variation, synthesised signals, noise.
Sunday, May 15, 11:00
Oral Presentation:
Voice disorder detection on the basis of continuous speech
Klára Vicsi, Viktor Imre
Laboratory of Speech Acoustics, Budapest University of Technology and Economics
Department of Telecommunications and Media Informatics
During vocal diagnostical analyses there were made more examinations in connection with that
question, whether sustained voice, or continuous speech is more effective in distinguishing healthy
voice from pathological voice. While in phoniatrical practice mainly continuous speech is applied
by doctors, we also want to concentrate to the examination of the continuous speech. First a
detailed statistical analyses of acoustical parameters of vowels in continuous speech and sustained
voice databases were examined, and compared the results in case of healthy speech and
pathological ones. Now, in this lecture we present our classification experiments, how it is possible

18
to separate the healthy speech from the pathological one automatically on the base of continuous
speech. It is cleared out, that by a multi-step processing methodology, most of those examples at
which uncertainties occurred at the measurement of the acoustical parameters can be grouped
separately, and in this way, the automatic classification results of the healthy and pathological
voices are improved in a big extent.
Sunday, May 15, 11:20
Oral Presentation:
Numerical simulation of phonation onset: comparison of finite element glottal
flow approximation with a simplified model
Jaromír Horáček
1, Petr Sváček
2
1 Institute of Thermomechanics, Academy of Sciences of the Czech Republic, Dolejškova 5,
Praha 8, Czech Republic, Email address: [email protected], corresponding author 2 Department of Technical Mathematics, Faculty of Mechanical Engineering, Czech
Technical University in Prague, Karlovo nam. 13, Praha 2, 121 35, Czech Republic, Email
address: [email protected]
The phonation onset in biomechanics of voice is an important characteristic of human voice
production. From the point of view of the flow-induced vibrations it means a state of the system
when it is losing the aeroelastic stability, i.e. when the airflow parameters like subglottal pressure
or air flow rate cross a limit value and the system becomes unstable by flutter. Frequency-modal
analyses of a simplified three-mass model of the vocal fold in interaction with a potential flow
separated at the superior edge of the vocal fold showed that the two eigenfrequencies are coupled
when the instability occurs (Horáček and Švec, 2002).
In this contribution the instability threshold is studied in the time domain using the two-
dimensional finite element model of the viscous incompressible flow coupled with two-degrees of
freedom model of the vocal folds. The incompressible Navier-Stokes equations are spatially
discretized with the aid of the stabilized finite element method. The motion of the computational
domain is treated with the aid of Arbitrary Lagrangian Eulerian method. The structure dynamics is
replaced by a kinematically equivalent system with the two degrees of freedom governed by a
system of ordinary differential equations and discretized in time with the aid of an implicit
multistep method and strongly coupled with the flow model. The influence of inlet/outlet boundary
conditions is studied and the numerical analysis is performed and compared to the related results
obtained for the phonation onset by using the simplified flow model.
Horáček, J., and Švec, J. G. (2002). “Aeroelastic model of vocal-fold-shaped vibrating element for
studying the phonation threshold,” J. Fluids Struct. 16(7), 931–955.

19
Sunday, May 15, 11:40
Oral Presentation:
Exploring fuison of generative and discriminative models for similarity-based
classification of larynx pathology
Evaldas Vaiciukynas
1, Atanas Verikas
1, 2, Adas Gelzinis
1, Marija Bacauskiene
1, Virgilijus
Uloza3
1 Department of Electrical & Control Equipment, Kaunas University of Technology
2 Intelligent Systems Laboratory, Halmstad University, Sweden
3 Department of Otolaryngology, Lithuanian University of Health Sciences
In our experiments identification of laryngeal disorders using cepstral parameters of human voice
is researched. Mel-frequency cepstral coefficients (MFCCs) and also some other frequency domain
features, extracted from audio recordings of patient's voice, are further approximated by building
Gaussian mixture model (GMM) for each patient. The effectiveness of similarity-based
classification techniques in categorizing such data into normal voice, nodular, and diffuse vocal
fold lesion classes is explored. Also calibration and fusion of different classifiers is evaluated.
Basic classification with GMM is outperformed by GMM supervector based SVM and also by the
use of distance kernels in GMM-SVM combination. The results indicate that features, modeled
with GMM, and kernel methods, like SVM, exploiting this information, is an interesting fusion of
generative (probabilistic) and discriminative (hyperplane) models for similarity-based
classification.
Sunday, May 15, 12:00
Oral Presentation:
What is the dynamic range of human voice?
Jan G. Svec1, Hana Sramkova
1, Tomas Fürst
2, Svante Granqvist
3
1 Department of Biophysics, Faculty of Science, Palacky University, Olomouc, Czech
Republic 2 Department of Mathematical Analysis and Mathematical Applications, Faculty of Science,
Palacky University, Olomouc, Czech Republic 3 Royal Institute of Technology, Stockholm, Sweden
Email: [email protected], [email protected], [email protected],
The literature on the dynamic range of human voice reveals considerable discrepancies in
published sound levels. Furthermore, different studies use different methods for level
measurement. The purpose of this study was to find the dynamic range of human voice using a
method that is independent from a single specific device.

20
Loudest and softest phonations of 37 subjects (23 women and 14 men) without voice problems
were captured using two microphones (head mounted and stand mounted) calibrated for a standard
distance 30 cm from the mouth and recorded digitally. The sound levels were then obtained using
the specifications according to IEC-standard (standard frequency-weighting filters A, C or Z,
“Fast” time weighting for the soft phonations).
The peak sound pressure levels of the loudest phonations were found 118±5 and 121±4 dB(Z) for
women and men, respectively, with the highest level of 127 dB(Z) at 30 cm. The minimum time-
weighted sound levels for the softest voiced phonations were found 45±4 and 37±5 dB(A) for
women and men, with the lowest level of 31 dB(A) at 30 cm.
These levels appear to be more extreme than those measured previously. The results were used to
derive recommendations on microphone specifications for human voice measurements.
Sunday, May 15, 12:20
Oral Presentation:
A discussion on what type of data a voice usage database should consist of
Fredric Lindström, Marcus Wirebrand, Sten Ternström, Maria Södersten
Our knowledge of how we use our voice in a daily manner is very limited. There is a need for more
studies investigating how factors such as occupation, gender, age, culture, language, etc affect the
voice usage. There is also a need for more research on how voice usage is related to certain voice
problems.
In recent years wearable measurement equipment has made it possible to register voice parameters
such as phonation time or fundamental frequency; allowing larger population voice usage studies.
However, in order to efficiently advance the research field it is important to standardized the data
collecting procedures so that data collected by different research groups can be compared and that
general conclusion can be drawn.
In this presentation we present some database data fields which have been used in different
research projects in Sweden collecting voice usage data from mainly voice patients and pre-school
teachers. Also some preliminary findings are presented and their impacts on required data fields
are discussed.
Sunday, May 15, 13:30
Oral Presentation:
Analysis of vocal stress in conversations to call centers
Grażyna Demenko, Magdalena Jastrzębska

21
[email protected], [email protected]
This paper presents how voice stress is manifested in the acoustic and phonetic structure of the
speech signal. Out of 60 000 of the authentic Police 997 emergency phone calls, 22 000 were
automatically selected, a few hundred of which were chosen for acoustic evaluation, the basis for
selection being a perceptual assessment.
In highly stressful conditions (e.g. panic) a systematic dynamic over-one-octave shift in pitch and
significant increase in speech tempo was observed. In states of depression a systematic down shift
in pitch and significant decrease in speech tempo was observed. Basic statistical measurements for
stressed and neutral speech run over the database showed the relevance of the arousal and potency
dimension in stress processing. In speech produced under fear an upward shift in pitch register was
significant (in comparison to neutral speech), while speech recorded during experiencing anger
was characterized by an increase in F0 range.
Key Words: acoustics of real emotional speech signals, call centers interfaces, emotional speech
Sunday, May 15, 13:45
Oral Presentation:
EntrenaVox, a computer program for voice rehabilitation through games
Víctor Osma-Ruiz
1, Juana María Gutiérrez-Arriola
1, Juan Ignacio Godino-Llorente
1,
Janaina Mendes-Laureano1, Nicolás Sáenz-Lechón
1, Rubén Fraile
2, Julián David Arias
3
1 EUIT Telecomunicación, Universidad Politécnica de Madrid, Ctra de Valencia km. 7, 28031
Madrid, Spain 2 Universidad CEU Cardenal Herrera, Av. Seminario sn, 46113 Moncada, Valencia, Spain.
3 Facultad de Ingeniería Electrónica y Biomédica, Universidad Antonio Nariño, Carrera 3 este No
47-15, Bogotá, Colombia
We have developed a computer program aimed for clinical use to assess, rehabilitate and work on
the aesthetics of voice for people with phonation problems or who have temporarily lost the voice
due to disease or surgery.
The application consists of different PC games built on a patient information system, which allows
the speech therapist to manage and customize the treatments for every patient, adjusting for
example when to start the exercises, the duration and the frequency of each test, the degree of
difficulty, etc. It also provides the ability to visualize the degree of compliance (both qualitatively
and quantitatively) achieved by each patient.
Patients are thus provided with a visual tool in the form of a game that gives an immediate
feedback of the emitted stimuli, allowing them to work different characteristics of the voice. The
features that are the basis for the treatments and that are trained through such games are the
utterance of voiced and voiceless sounds, the fundamental frequency or pitch, and the intensity of
the voice.

22
Oral Presentation:
Sunday, May 15, 14:00
Highspeed films for evaluation of reflux to help rock popular singers
Mette Pedersen
1, Mike Ellingsen
2
1 Ear-Nose-Throat specialist, FRSM, Danish representative COST2103. The Medical Center,
Oestergade 18, 1100 Copenhagen, Denmark, www.mpedersen.org. 2 Nanotechnology student at Copenhagen University, Denmark.
Objective: The objective of the study was to evaluate the use of highspeed films to quantify
swelling in the larynx due to reflux in order to help singers.
Material and methods: It is known that mucus can be regurgitated to the larynx due to reflux.
Highspeed films from Wolf Ltd. have 8000 pictures during a period of two seconds. On highspeed
films the mucus was discovered in the larynx during a period of 0,2 seconds, after which there only
was a slight oedema on the arytenoids region. Especially rock singers tend to have problems with
reflux in their career. Two films are shown of rock singers with reflux.
We have tried to make video scores of the abnormality of the arytenoids region in highspeed
films. In an earlier study, it was shown that acoustical measures were different when scores were
abnormal. In this study we compared visual scores on high speed films a group of patients before
and after treatment for laryngeal reflux with one of three groups receiving either: lifestyle
guidance and no other related medication, lifestyle guidance and 40mg esomeprazole, or
lifestyle guidance combined with 40mg esomeprazole and alginate.
Results and conclusion: Statistically the arytenoids oedema was reduced on highspeed films in all
patients. Due to the fact that online evaluation of the larynx on highspeed films is the correct
visual picture, it is our experience that highspeed films are superior to video stroboscopy for
evaluating reflux in singers.
On high speed films, inter-arytenoids oedema was found to be the basic objective finding in
patients with reflux to the larynx. If the reflux is discovered early and lifestyle changed, the
influence on a singing career is probably minimal.
Reference: (1) Pedersen M, Munck K (2007). A prospective case-control study of jitter%,
shimmer% and Qx%, glottis closure cohesion factor (Spead by Laryngograph Ltd.) and Long
Time Average Spectra. Congress report Models and analysis of vocal emissions for biomedical
applications (MAVEBA); pages 60-4.

23
Sunday, May 15, 14:45
Oral Presentation:
How does the brain process prosody? An fMRI study with persons who stutter
Katrin Neumann1, Malte Kob
2, Harald A. Euler
1, Tobias Weissgerber, Alexander Wolff
von Gudenberg3, Anne-Lise Giraud
4, Christian Kell
5
1Dept. of Phoniatrics and Pediatric Audiology and 5 Dept. of Neurology, University of
Frankfurt am Main, Frankfurt am Main, Germany 2 Erich-Thienhaus-Institute, University of Music, Detmold, Germany
3 Institut der Kasseler Stottertherapie, Bad Emstal, Germany
4 Département d‟Etudes Cognitives, Ecole Normale Supérieure, Paris, France
Introduction: Previous neuroimaging studies on speech prosody have mainly investigated
perceptive aspects (Kotz et al., 2003; Wildgruber et al., 2006). They have shown left-hemispheric
activations during linguistic prosodic tasks and either right-hemispheric or bilateral brain
activations during affective prosodic tasks in the temporal cortex, the peri-sylvian cortex, the
frontal operculum, and in the basal ganglia. All these regions show either abnormal activations or
abnormal morphology in persons who stutter (PWS) compared to non-stuttering control subjects
(PWNS). An effective stuttering therapy should normalize the disturbed speech prosody in PWS.
On the other hand, therapy approaches such as fluency shaping methods exploit prosodic cues for
therapeutic aims for example by practicing special voice onsets and speech bows.
The aim of this study was the examination of the brain activations during speech motor tasks
performed with neutral, linguistic, and affective prosody of PWS before and after an effective
fluency shaping therapy compared with those of PWNS.
Method: An fMRI experiment was performed with 13 male PWS (mean age 27 years, range 18 –
39, mean handedness score 50, SD = 54) before and after an intensive course of the Kassel
Stuttering Therapy and 13 males who had recovered from stuttering spontaneously during speech
production (Kell et al., 2009).
Results: PWNS activated mainly in the left-sided anterior insula, inferior frontal gyrus, and
supramarginal gyrus as well as in the right cerebellum. There were no remarkable activation
differences between affective and linguistic prosodic tasks. PWS were not able to activate this
network before therapy. However, directly after therapy the activation of PWS for affective
prosody already normalized relative to PWNS. Contrasting, a normalization of the activation for
the linguistic prosodic task was not observed at that time but one year after finishing the therapy.
The activation changes were paralleled by a normalization of prosody parameters.
Conclusion: Cerebral activations shown in PWNS reflect the prosodic network in normal speaking
subjects. The described activation changes in PWS may be attributed to local insular and left
inferior frontal trainee effects which are accompanied by subcortical overactivation.
References
Kell CA, Neumann K, von Kriegstein K, Posenenske C, Wolff von Gudenberg A, Euler HA,
Giraud AL (2009) How the brain repairs stuttering. Brain, 132, 2747-2760;
doi:10.1093/brain/awp185.

24
Kotz SA, Meyer M, Alter K, Besson M, D. Yves von Cramon D, Friederici AD (2003) On the
lateralization of emotional prosody: An event-related functional MR investigation. Brain and
Language, 86, 366-376.
Wildgruber D, Ackermann H, Kreifelts B, Ethofer T (2006) Review Cerebral processing of
linguistic and emotional prosody: fMRI studies. Progress in Brain Research, 156, 249-268.
Sunday, May 15, 14:30
Workshop:
Voice classification by phonetography: the ‘why’ and the ‘how’
Hugo Lycke
Lab. Exp. ORL, Dep. Neuroscience, K.U.Leuven (Belgium)
An age-related and gender-specific pattern card of the human voice was elaborated on
phonetographic analysis of intensity related parameters in 632 subjects (422 females and 210 males) with
different background of vocal experience. The age of the female subjects ranged from 8 to 65 years
(mean age 23.8 years). The age of the male subjects ranged from 10 to 76 years (mean age 27.8
years). This referential database enables a basic voice classification of any subject.
The following topics are discussed in this workshop:
1. Introduction: Subject classification and voice classification in voice research and the need for a
basic classification for every human voice.
2. Methodology of voice classification by phonetographic analysis.
3. Workshop participants are invited to cooperate in classifying female and male voices.
4. Discussion: Application of voice classification in the education of speech and the singing
voice and in voice therapy.
Monday, May 16: AVFA Workshop 2011 and CoMeT 2011 Meeting
Monday, May 16, 9:00-10:00
Keynote Speech:
Is music the universal „language“ of emotions? The neurobiology and psychology
of aesthetic feelings
Eckart Altenmüller

25
Institute of Music Physiology and Musicians‟ Medicine, University of Music, Drama and Media,
Hannover, Emmichplatz 1, D-30175 Hannover
Although music is generally acknowledged as a powerful tool for eliciting emotions, little is
known concerning the neurobiological basis of these emotions. We investigated the psychological
and neurobiological basis of strong emotional responses to music (SEM), leading to shivers down
the spine (chills) and changes in heart rate. From previous studies it is known that these SEMs are
accompanied by the activation of a brain network that includes areas involved in reward, emotion
and motivation.
In order to observe distinct acoustical and music structural elements related to chill reactions, in a
series of experiments, on-line emotional self report and psychophysiological data was obtained
while participants were listening to music inducing strong emotions and aesthetic feelings.
Despite of highly individual emotional reactions towards music, some inter-individually constant
characteristics of music eliciting chill responses can be found. Chills were much more frequent in
previously known music and in familiar music stiles. Furthermore, distinct musical events
frequently caused strong emotional responses, especially when violating expectancies.
These results demonstrate that strong emotional responses are not only related to the
psychoacoustic properties of the respective pieces of music, but furthermore to biographical
memories, personality traits and social environments.
Dr. Eckart Altenmüller:
Eckart Altenmüller (b. 1955) holds a Masters degree in Classical flute, and a
MD and PhD degree in Neurology and Neurophysiology. Since 1994 he is
chair and director of the Institute of Music Physiology and Musicians‟
Medicine. He continues research into the neurobiology of emotions and into
movement disorders in musicians as well as motor, auditory and sensory
learning. During the last ten years, he received 18 grants from the German
Research Society (DFG). Since 2005 he is President of the German Society of Music Physiology
and Musicians‟ Medicine and Member of the Göttingen Academy of Sciences.
Monday, May 16, 10:00-10:15
Oral Presentation:
Effects of a vocal warm-up on the vocal tract setting of a male voice professional.
An MRI and modelling study
Vojtěch Radolf
1, Anne-Maria Laukkanen
2, Radan Havlík
3, Jaromír Horáček
1
1 Institute of Thermomechanics, Academy of Sciences of the Czech Republic; Dolejškova
1402/5; 182 00, Prague; CZ, e-mail: [email protected] and e-mail: [email protected] 2 Speech and Voice Research Laboratory, School of Education, University of Tampere; FIN-
33014, Tampere; Finland, e-mail: [email protected]

26
3 AUDIO – Fon Centr. s.r.o.; Obilní trh 4; 602 00, Brno; CZ, e-mail: [email protected]
Vocal warm-up is supposed to improve voicing either through changing the laryngeal or
supralaryngeal setting or by causing beneficial physiological changes (improved blood circulation,
mucus segretion etc.) The present study concerned the possible changes in the vocal tract setting.
Inverse method was used for numerical simulation of acoustic characteristics of a professional
musical actor before and after a vocal warm-up. The geometrical data for a 1D model of the
acoustic cavities of the vocal tract were evaluated from magnetic resonance images (MRI)
registered during sustained phonation of vowels [a:, i:, u:] before and after the warm-up. The
numerically simulated voice signals are compared with acoustic recordings, and the warm-up
related changes in the vocal tract are discussed.
Key Words: Biomechanics of voice, singer‟s and speaker‟s formant cluster, acoustic effects of
vocal exercises
Monday, May 16, 10:15-10:30
Oral Presentation:
Tenors’ vocal tract configurations in different registers and vowel conditions
Matthias Echternach
1, Louisa Traser
2, Bernhard Richter
1
1 Institute of Musicians‟ Medicine, Freiburg University Medical Center, Germany
2 Medical Student, Charite, Berlin, Germany
Objective: The role of the vocal tract in registers is still unclarified. In previous studies, in 10
tenors strong vocal tract modifications were observed reaching high pitches in their stage voice on
vowel /a/. The aim of this study was to analyse the influence of vowel conditions on vocal tract
configurations in register functions.
Material and Methods: Dynamic real time MRI of 8 frames per second was used to analyze the
vocal tract profile in four world wide leading tenors (one oratory/classical song, one light lyrical,
one young dramatic, and one Heldentenor) , who sang on the vowels /a,e,i,o,u, ae/ an ascending
scale between C4 (261Hz) to A4 (440Hz). The scale included in one condition their register
transition from modal register to falsetto and in another condition the continuation of stage voice
above passaggio.
Results: Transitions from modal register to stage voice above passaggio were associated with
stronger modifications of the vocal tract compared to register transitions to falsetto. Magnitude of
vocal tract modifications in register transitions was different in the different vowel conditions and
also differs strongly between the subjects.

27
Monday, May 16, 10:30-10:45
Oral Presentation:
Feasibility of electrical impedance tomography for the imaging of the larynx –
preliminary results
Samuli Siltanen
1, Aku Seppänen
2, 3, Antti Nissinen
2, 3, Ville Kolehmainen
2 and Anne-Maria
Laukkanen3
1 Department of Mathematics and Statistics, University of Helsinki
PO Box 68, 00014 University of Helsinki, Finland 2 Department of Applied Physics, University of Eastern Finland,
FI-70211, Kuopio, Finland 3 Speech and Voice Research Laboratory, School of Education, University of Tampere
Electrical impedance tomography (EIT) is a non-invasive medical imaging method. In EIT, the
three-dimensional (3D) distribution of the electrical conductivity inside a person is reconstructed
on the basis of harmless and painless electrical measurements using electrodes attached to the skin
of the person. Since various tissues have different conductivities, EIT can be used for imaging
anatomical and physiological features. EIT has been applied to several biomedical applications,
including monitoring of ventilation and diagnosing breast cancer. Here, the feasibility of EIT for
the imaging of the larynx is discussed. This can be considered as an extension of electro-
glottography (EGG), a widely used method in speech research. EIT extends EGG by using a
greater number of electrodes and measurement channels. Further, while EGG is based on direct
analysis of the raw measurement signals, EIT involves advanced mathematical modeling for 3D
image reconstruction based on the multi-channel measurement data. The focus of this research is
the possibility of (1) detecting and quantifying vocal loading and (2) measuring the consequences
of vocal loading by monitoring the glottis using EIT. The hypotheses behind this idea is two-fold.
First, the closing speed of the glottis can probably be estimated more accurately by using EIT
instead of EGG; the closing speed is in turn assumed to correlate with impact stress. Second, EIT
may allow precise localization of increased blood flow or chemical changes in glottal structures,
possibly leading to novel measurements of the consequences of vocal loading. Computational
reconstructions of simulated larynx anatomies are presented, suggesting that EIT is a promising
method for functional imaging of the larynx. An encouraging feature of EIT is that the
measurements involve only electrodes on the skin, it is possible in principle to monitor the glottis
during an extended period of minimally disturbed professional voice use.
Key Words: occupational voice loading, non-invasive measurement, imaging, electrical impedance
tomography, ill-posed inverse problem

28
Monday, May 16, 10:45-11:00
Oral Presentation:
Singing – a dual system
Lionel Fawcett
Humans are in every sense “dual beings”, always involved in coordinating two elements which
should, or could, be complementary, but more often than not are antagonistic. The dualism of mind
and matter, of good and evil, of the emotional and the rational, all point to the quintessentially
human contradiction between our need for other people on the one hand, and our individualism on
the other. It is the dialectical process inherent in this contradiction which allows an individual to be
a godlike genius or a despicable criminal. The art of singing is also fundamentally dualistic.
We all have two vocal folds governed by two opposing muscle systems (the cricothyroids
responsible for pitch and the arytenoids responsible for volume), two types of breathing (the
thoracic for air pressure and the abdominal for air flow), and two directions of resonance (the labial
for bright and pharyngeal for dark sounds). The coordination of these opposites produces not just
singing of remarkable tonal and dynamic range, but also vocal agility and stamina and vocal
health. Vocal pedagogy must understand and respect the natural ability of these vocal mechanisms
with their inherent dualism, while at the same time taking account of the emotional and
psychological constitution behind singing as a physical event – in other words both body and soul.
Artistic singing requires functional voice training which is able to diagnose sung sound on the
basis of its acoustical properties and as indicator of the under lying muscular and physical
condition. The sound-orientated development of the natural voice through functional voice training
enables the singer to become conscious of each sound experience and facilitates reflection on the
same in the form of sound experiments. The mere projection of the singing teacher‟s own personal
experience or method is not objective enough and therefore not sufficiently scientific. Sung sound
imparts physical sensations, which by serving as a guide to the teacher‟s critical powers eventually
result in a therapy based on empathy. Pure sound aesthetics, on the other hand, are too personal and
cannot lead to an objective functional assessment of the singing voice, or to a way of improving the
sung sound. Improving the agility and expressive capacity of the vocal apparatus can be achieved
honestly only by a proper understanding of how it works. After all, vocal beauty cannot be an end
in itself, but must serve as a medium for musical expression – which in turn is an expression of
human feeling and passion.
All vocal pedagogy, therefore, grows first and foremost out of the teacher‟s will and ability to
understand the system and to accept its inherent dualism and contradictions. The Italian singing
teachers of the 18th
century had no idea how the voice worked, but they knew how to work the
voice. Their conclusions rested on sound quality, which they described as “chiaroscuro”, providing
us with yet another pointer to the dual system that governs our singing. This “light/dark”
description of vocal sound is indicative of a present day physical and medical definition of singing
long before Manuel Garcia‟s invention of the laryngoscope in 1854.
If we know how the voice works, then we know how to work the voice!

29
Monday, May 16, 11:00-11:10
Oral Presentation:
Medical and educational occupational voice care for teacher-students at the
College of Education in Salzburg
Josef Schlömicher-Thier, Matthias Weikert, Hannes Tropper, Alexandra Pichler, Silvia
Hißmayr
Austrian Voice Institute, Salzburgerstrasse 7, A-5202 Neumarkt, AUSTRIA, Tel.: +43-6216-4030,
Fax: 0043-4030-20, E-Mail: [email protected], Website: www.austrianvoice.at
From February 2002 until November 2009 there were 1300 female and male students attended to
in a workshop format In a retrospective study the voice function screening of the following
parameters of the of 548 female and male students were analyzed by Statistics-Program SPSS
Version 12.01, Coefficient of correlation Spearman and Kolmogorov-Smirnov-Test·
Habitual pitch range of the speaking voice
· Voice range in Semitones
MPT
· Dynamic of the shouting voice
· Voice Handicap Index (VHI)
· R-B-H Scala
· Voice technic habits
· Analysis of acoustic Parameters in a small group
Subjective voice evaluation and voice technic habits:
Voice scanning is a voice precaution project of the Austrian Voice Institute at the College of
Education in Salzburg. The task of the Austrian Voice Institute in this matter is to educate on
basics of voice hygiene and voice physiology in lectures and by organizing workshops.
Furthermore there is a necessity to identify with this “voice scanning” methods students whose
voices are rated diseased to provide a medical and educational occupation-accompanying voice
care for them. Pathological rated voices that need further phoniatrician assistance can be identified,
as well as voice talents, that can be motivated to starting a professional voice career. These project
shows, that an interdisciplinary cooperation between voice teachers and phoniatricians is necessary
before a reliable evaluation of the parameters is possible.
Monday, May 16, 11:30-11:45
Oral Presentation: Phonosurgery
Introduction to the topic and demonstration of the RADIESSE Voice system
Tadeus Nawka

30
Monday, May 16, 11:45-12:05
Oral Presentation: Phonosurgery
Phonosurgical procedure and outcome in case of a laryngeal paresis of an
operatic singer
Nobuhiko Isshiki
Professor emeritus at Kyoto Univ., Japan
A world-famous opera singer, Mr. Jaechul Bae had been operated upon for his left malignant
Struma and neck metastasis. Inevitable section of the superior and inferior laryngeal nerves and the
phrenic nerve resulted in his loss of professional voice. In an attempt to restore the voice, type 1
and 4 Thyroplasties were performed under local anesthesia, while the voice was carefully
monitored as the procedures went on.
How to adjust the tension of the paralyzed vocal fold so that he could produce a wide range of
vocal pitch was a core of surgery and took 4 hours to finish.
At the end of operation, he could sing a hymn he had been so accustomed to singing, so slowly as
if he were searching for and confirming the right musical note. It was so solemn and moving.
I feel this provided only the basis on which he has built an unbelievably magnificent structure.
Worthy of special mention is his incredibly intensive self-training of singing songs.
Monday, May 16, 12:05-12:20
Oral Presentation: Phonosurgery
Report on his voice recovery as an operatic singer after a laryngeal paresis and a
subsequent phonosurgery
Jaechul Bae
I was making my career as an opera singer playing the main tenor‟s roles in numerous operatic
theaters in Europe since 1996. However I had a thyroid cancer 2005 while I was singing in
Saarland State Opera House, and had lost my voice completely by cutting 3 main nerves for
producing voice. Generally it would be impossible to come back again on stage with this situation.
In fact, I was informed by the doctor who operated me for thyroid cancer in Mainz that it would be
like an athlete with only one leg if I wanted to sing again. But I was fortunate to meet the plastic
surgery The Type 1 of Isshiki‟s Operation, and even more I got this operation by Dr. Isshiki
himself in April 2006 in Kyoto.
After 2 years of personal rehabilitation, I have come back on stage as an opera singer. I feel my
voice is coming back 60 % now. I am convinced from my experience that the voice can return even
from the worst situation like mine if we take the right way. I would like to also sing 2 pieces to

31
prove that on this occasion, hoping my presentation could encourage all the people who suffer
from the voice problem.
Monday, May 16, 12:20-12:30
Oral Presentation: Phonosurgery
Report on the voice recovery of Mr. Jaechul Bae by his producer
Totaro Wajima
Presenting the world rare case of Mr. Jaechul Bae as his producer who observed his voice and his
life in these 7 past years, I would like to share the hope and endless possibility of recovering the
voice with all the people who participate in CoMET according to the following theme.
1. The detailed process of recovery of his voice after the plastic surgery by Dr.Isshiki
2. The condition of his current voice – what it has lost, what it has gained.
3. Thankfulness to the development of medical operation -from the producers point of view
4. Duet of Music and Medicine, duet of Korea and Japan
Monday, May 16, 12:30-12:45
Oral Presentation: Phonosurgery
Treatment of glottic insufficency by structural fat grafting
Giovanna Cantarella1, Giovanna Baracca
1, Stella Forti
2, Elisabetta Iuffrida
1, Riccardo F.
Mazzola1, 3
1 Otolaryngology Department and
2 Audiology Unit, Fondazione IRCCS Ca‟ Granda Ospedale Maggiore Policlinico, Milan,
Italy 3
Dipartimento di Scienze Chirurgiche Specialistiche, University of Milan, Italy
Objectives: Aims of this study were to evaluate results of vocal fold structural fat grafting for
glottic insufficiency and to compare the outcomes obtained in unilateral vocal fold paralysis
(UVFP), and in congenital or acquired soft tissue defects in vocal folds.
Design: Prospective study.
Setting: University Hospital.
Patients: Eighty-one consecutive patients with breathy dysphonia in 54 cases (age 16-82 years)
related to UVFP and in 27 (age 16-82 years) to vocal fold iatrogenic scar or sulcus vocalis.

32
Intervention: Autologous structural fat grafting into vocal folds. Lipoaspirates were centrifuged at
1200 g for 3' to separate and remove blood, cell debris and the oily layer, and the refined fat was
injected under direct microlaryngoscopy in a multilayered way.
Main outcome measures: Grade, roughness, breathiness, asthenicity and strain (GRBAS)
perceptual evaluation, maximum phonation time (MPT), self-assessed Voice Handicap Index
(VHI), and voice acoustic analysis, considered preoperatively and at 3 and 6 months after fat
grafting.
Results: After surgery, MPT, VHI (all subscales), G and B improved in both groups (p<0.05). In
particular, G and VHI functional subscales decreased more significantly in patients with UVFP
(p<0.05). Conversely acoustic variables improved significantly only in the UVFP group (p<0.005).
From 3 to 6 months postoperatively most considered variables showed a trend to further
improvement.
Conclusions: Vocal fold structural fat grafting is effective in treating glottic insufficiency due to
UVFP or soft tissue defects. Perceptual, acoustic and subjective assessments statistically confirm
that patients with UVFP have a better outcome than those with soft tissue defects.
Monday, May 16, 12:45-13:00
Oral Presentation: Phonosurgery
Results of indirect endoscopic surgery in singers
Eugenia Chávez
Monday, May 16, 13:00-13:30
Roundtable with the presenters, Tom Harris, and John Rubin. Open discussion
on phonosurgical issues. Chair: John Rubin
Monday, May 16, 14:20-15:45
Workshop:
Masterclass ‘Honing the professional singing voice’
Leah Frey-Rubine

33
Monday, May 16, 14:20-15:45
Workshop:
Singer's/ -speaker's formant in real life
Olaf Nollmeyer
Hubertusweg 13, 26133 Oldenburg, ++494414855490, www.stimme-koerper-klang.de
Although the Singer's/Speaker's Formant is considered an asset of high quality voices, it is
commonly used only in evaluating voice qualities in scientific context or in speech therapists
practices rather than playing an open key role in voice training or therapy. Therapists are
commonly more focused on pathological aspects of the voice rather than listening to its potentials.
Teachers of voice in singing and speech tend to think of the sound as something being simply the
result of a (primary) physiological process: its outcome.
Functional voice training, as initiated in Lichtenberg, Germany in the late 1980's on the other hand,
takes into account the manifold ways sound interacts with the physical processes. Glottal
movement is not independent of the sound reflected back on it. A more differentiated concept of
sound – including the two aspects of vowels and the singer's formant -along with a more
differentiated hearing opens ways to new and simple exercises in training and therapy.
This workshop shows ways of putting knowledge of the Singer's Speaker's formant into practice. It
shows how vowel formants and singer's formants can be easily experienced and played with in
many ways helping voices instantly to become richer in sound while being produced with
considerably more ease.
Key Words: Signal processing and acoustic voice analysis, voice professionals, voice therapy,
vocal training
Monday, May 16, 16:00-18:00
Special session for students, artists, therapists, and other professionals:
Say it easy ─ how does the voice function?
John Rubin, Ingo Titze

34
Tuesday, May 17: CoMeT 2011 Meeting
Tuesday, May 17, 9:00-10:00
Keynote Speech:
The acoustics of over- and undertone singing
Malte Kob
Director of studies "Music Transmission" and head of the Erich Thienhaus Institute at the
University of Music Detmold
Singing voice production covers an impressive range of acoustic phenomena that are responsible
for the basic voice properties such as fundamental frequency, formant structure, voice intensity
and radiation efficiency. Less obvious are the conditions that determine the properties of special
singing such as overtone and undertone singing. An investigation of the participating structures and
airways reveals the interaction of resonances that interact such that voice features extend the range
of classic singing in ambitus and sound quality. The presentation reviews current approaches for
measurement and description of these phonation types.
Prof. Dr.-Ing. Malte Kob:
Malte Kob is professor for Theory of Music Transmission at the
University of Music Detmold. He lectures basics of electrical
engineering, informatics science and acoustics as well as advanced
courses in music acoustics and audio signal acquisition and processing.
During his studies at the Technical University and work at the
Physikalisch-Technische Bundesanstalt in Braunschweig he enjoyed
doing jazz and church music. From 1991 he focussed on acoustics with
emphasis on music acoustics and acoustic measurement techniques. In
1999 he joined the ICVPB in Berlin and decided to start his Ph.D. work
on physical modeling of the singing voice at the Institute of Technical
Acoustics in Aachen. In 2001 he started to work on voice analysis and diagnosis at the Department
of Phoniatrics, Pedaudiology and Communication Disorders at the University Hospital Aachen.
Since 2009 he works in Detmold where he continues research in singing voice and music acoustics.
Malte Kob is executive council member of the German Acoustical Society (DEGA) and the
European Acoustics Association (EAA).
Tuesday, May 17, 10:00-10:10
Oral Presentation:
Voice classification in practice: criteria in contemporary singing education
Hugo Lycke
1, Wivine Decoster
1 and Felix I.C.R.S. de Jong
1, 2
1 Centre of Excellence for Voice, Lab. Exp. ORL, K.U.Leuven (Belgium)

35
2 Department of ENT- Head and Neck Surgery, University Hospitals K.U. Leuven, (Belgium).
Objectives: In Classical singing education great emphasis is put upon voice classification but little
is known of how contemporary singing teachers deal with voice classification. The purpose of this
study was to explore how contemporary singing teachers deal with voice classification and which
criteria they use.
Study Design: explorative study using questionnaires.
Methods: One questionnaire was sent to 200 singing teachers via internet and a second
questionnaire to 22 singing teachers of one Classical conservatory and two Musical Theatre
conservatories.
Results: Of the 200 singing teachers, 72 responded (36%). In 61.1% voice classification was
important for at least one reason, while 38.9% did not find voice classification an important issue.
Most used acoustical parameters for voice classification were frequency range/tessitura (56.0%),
voice quality/timbre (56.0%), volume (12.1%) and register transition (9.0%). The 22 conservatory
singing teachers classified their students (n = 165). Frequency range/tessitura, voice quality,
register transition, and volume were the most frequently used criteria. However, each singing
teacher reported a varying individual set of voice classification criteria, depending on the singing
student and on the specialty of the department.
Conclusions: Apparently there is no consensus about the advisability and criteria of voice
classification among singing teachers.
Tuesday, May 17, 10:10-10:20
Oral Presentation:
The reliability of voice range profile derived parameters in the discrimination of
three basic female voice categories
Lycke Hugo1, Decoster Wivine
1, Ivanova Anna
2, Van Hulle Marc M.
3, de Jong, Felix
I.C.R.S.1, 4
1
Lab. Exp. ORL, Dep. Neuroscience, K.U.Leuven (Belgium)
2 Leuven Statistics Research Centre, K.U.Leuven (Belgium)
3 Lab. Neuro- & Psychophysiology, K.U.Leuven (Belgium)
4 Department of ENT – Head and Neck Surgery, University Hospitals K.U.Leuven (Belgium)
Objectives. Assessing whether „clever feature combinations‟ of the voice range profile can be
constructed with which a clear cluster separation between the three basic female voice categories
be found, and whether these findings, in turn, can contribute to resolve the lingering riddle of voice
classification.
Methods. The data obtained by voice range profiling of 206 female conservatory singing students
were studied by cluster analysis based on data points corresponding to the value of more traditional
voice frequency and intensity parameters.

36
Results. Out of 49 features the 3 cluster solution proved to be the most consistent one, across all
single- and combinations of features considered. The clusters were verified to largely correspond to
the three basic female voice categories. The best cluster solutions, when ranking them according to
the R-squared cluster separation metric, contained the feature R4 (R4 – ratio perimeter chest
voice/perimeter total).
Conclusions. „clever feature combinations‟ of the voice range profile led to the identification of 3
clusters that could be successfully linked to the three basic female voice categories. The most
important feature turned out to be the ratio perimeter chest voice/perimeter total. We assert that our
findings can help to resolve the riddle of voice classification.
Tuesday, May 17, 10:20-10:35
Oral Presentation:
Towards standardized DSI-measurement in clinical practice
Philipp Aichinger, Birgitta Aichstill, Felicitas Feichter, Berit Schneider-Stickler
Medical University of Vienna, Währinger Gürtel 18-20, A-1090 Vienna, Austria
The dysphonia severity index (DSI) is an unidimensional quantitative measure that is designed to
measure the overall vocal quality. The index is being used internationally in clinical voice
diagnostics and scientific voice research. In order to evaluate the validity of the DSI in its clinical
application, newly measured data is compared to reference DSI data. Further on, the DSI's test-
retest reliability is evaluated. Therefore, the DSIs of 30 subjects (18 euphonic, 12 dysphonic; 18
female, 12 male; aged between 15 and 66 years) is measured using two commercially available
measurement devices in parallel. The results indicate that different measurement devices measure
different DSI-values, which furthermore do not correspond to DSI reference data. Technical and
methodical aspects of the measurements' reliability and validity are discussed. The necessity to
revise measurement procedures and to define a standardized procedure is shown.
Tuesday, May 17, 10:35-10:50
Oral Presentation:
Individual harmonic listening in spectral sounds of the voice
Erkki Bianco
ENT & Phoniatre, anc. laryngologue de l'opera de paris, Paris, France
Purpose: Provide new acoustic experience of the sounds produced by the voice, isolating the
harmonics one by one with Audiosculpt.

37
HSDI of the vocal cords were recorded during phonation produced by internationally known
singers (male and female from bass to high soprano including countertenors) on a single vowel
using Wolf Gmbh. Germany HSD system, Fourcin & Frokjaer Jensen laryngographs .
When analyzed frame-by-frame, astonishing movements of the vocal cords were noted.
(Specifically, different patterns of vibration in falsetto when sung by barytone or countertenor,
asymmetry of the mucosal wave was present at the beginning of each vocal cord cycle ) It became
important to analyse the sounds produced and to listen to them separating each harmonic with the
audiosculpt system.
Methods: Analysing the recorded sounds: vowels by a baritone, phrases by M.Callas M.Caballe
J.Brel J.Vickers E.Kitt M.Anderson R.Alagna N.Dessay and others with Audiosculpt and listening,
analysing and modifying the harmonics one by one.
Results: When isolated different parts of the sounds can be perceived.
Conclusions: Listening to the harmonics of the vocal signal one by one provides a new perception
of the voice. This allows a new understanding of the quality of the voice and validates the singing
technique called “poussé-tiré” de la voix.
Key Words: HSDI, vocal cycle, audiosculpt, harmonics, perception singing voice, singing
technique, poussé-tiré de la voix, emotion.
Tuesday, May 17, 11:10-11:30
Oral Presentation:
Phonetotopic organization of phonation. Evidence from electrophysiology,
aerodynamics, acoustics and kinestetics
Krzysztof Izdebski
Pacific Voice and Speech Foundation, San Francisco, CA, USA
Purpose: To present neurophysiologic evidence of phonation organization, and to
elaborate on voice pitch pattern predictability as evidence for our understanding of
phonation training and disordered phonation processes.
Method: Data from electromyographic, aerodynamic, kinesthetic and acoustic signals
acquired simultaneously during the production of phonatory ranges, intensities and
reaction times. From these data a model of phonatory organization was constructed,
termed the “phonetotopic model of phonation.”
Results: It was found that human voice pitch production follows a predictable pattern.
This pattern follows phonetotopic organization of all intrinsic and extrinsic laryngeal
muscle activity corresponding to given pitch, intensity and quality targets. Based on this
phonetotopic organization, pattern deviations are predictable and consequently indicative

38
of voice conditions present in the various vocal pathologies and/or during artistic
training.
Therefore, when examining voice production by referring observations to phonetotopic
patterns, an unequivocal description of any phonation is possible. Accordingly, pitfalls or
deficits of phonation production will correspond in an organized fashion to the specific
conditions observed. Depending upon these conditions, phonation patterns will differ
with organic (mucosal), neurologic (motility), traumatic (motility and mobility) and/or
functional dysphonias including malingering, or when the subject is undergoing vocal
training.
Key Words: Phonatory neurophysiology, voice, pitch, intensity, laryngeal muscles,
dysphonias, modeling, vocal training, vocal pathology.
References: Izdebski, K. Clinical Voice Assessment: The Role & Value of the Phonatory
Function Studies. Chapter 29, In Lalwani, A. K. (ed.) Current Diagnosis & Treatment in
OTOLARYNGOLOGY-HEAD & NECK SURGERY, Lange Medical Books/McGraw- Hill, New York, 3rd Edition, 2011
Tuesday, May 17, 11:30-11:50
Oral Presentation:
Female register transitions
Katrin Neumann
1, Judith Thoma
1, Tobias Weissgerber
1, Felix Langenbruch
2, Jörn
Loviscach2, Malte Kob
3
1 Dept. of Phoniatrics and Pediatric Audiology, University of Frankfurt am Main, Frankfurt
am Main, Germany 2 University of Applied Sciences Bielefeld, Bielefeld, Germany
3 Erich-Thienhaus-Institute, University of Music, Detmold, Germany
Objectives: The appropriate performance of register transitions is essential for a classical singer to
smoothly reach all regions of her voice range. The definition of register transitions, however, often
gives reason for discussions among voice professionals. In particular in female singers it seems to
be difficult to define registers precisely in their number and boundaries (Miller, 2000).
Conventional register definitions rely largely on singers' self-reports, and perceptual studies
presumed that expert listeners concurred with such reports. However, singers themselves are
frequently unable to localize their point of transition and to distinguish clearly between registers.
The problem of subjective register distinction is aggravated by the fact that listeners and even
experienced singing teachers cannot distinguish between different registers with certainty,
especially if sung with register equalization. There has thus been and still is a need for objective
criteria for the distinction of vocal registers.
Recently we detected typical frequency patterns of the male upper register transition (Neumann et
al., 2005). The aim of the study presented here was to find changes in the spectral patterns which
characterize the lower female register transition between chest and middle register. The aim of this

39
study was the development of an algorithm to extract patterns of the acoustic signals for an
objectification of female register transitions.
Method: Ten classical singers (14 sopranos, 8 mezzo-sopranos, 6 altos) sung ascending scales of
the vowels [a:], [e:], [i:], [o:], and [u:], five times each. Recordings of the audio and
electroglottographic signals and of an equivalent of the subglottal pressure signal were made and
underwent a subsequent signal analysis which was compared with a perceptive evaluation of the
regions of register transitions. Two first trials for the development of an algorithm have been made
using the register transitions during singing a sustained [a:] by three representatives of each voice
category.
Results: A first algorithm which has recently been developed revealed that a precise identification
of register transitions basing on a single parameter seems to be not very probable (Langenbruch et
al., 2011). There is, however, a clear tendency of the feasibility of some parameters. These
parameters are in particular the spectral centroid of register transitions and the phase information of
the single partial tones related to the phase of the fundamental tone. Because of a timbre change
during the register transition it is suggested to use spectral parameters for its detection. Since, on
the other hand, singers minimize this timbre change an involvement of the phase information
seems to be useful.
Discussion: As suggested earlier the register transition between „chest‟ and „middle‟ registers seem
to be a rather laryngeal phenomenon, seen in the EEG signal, and the transitions between „middle‟
and „head‟ as well as between „head‟ and „flageolet‟ seem to be caused rather by a resonance
adaptation in the vocal tract.
Conclusion: Also for the female singer´s voice there seem to exist typical spectral, phase, and EGG
patterns which allow for a definition of register transitions basing on objective parameters. A
combination of single parameters and the involvement of local minima and maxima may lead to a
higher detection rate as achieved with our first trials. It can be expected that the application of an
automated training of the algorithm basing on a subjective perceptive analysis will further improve
the detection rate.
References:
Miller DG: Registers in singing. Thesis. Groningen, Rijksuniversiteit Groningen, 2000.
Neumann K, Schunda P, Hoth S, Euler HA (2005) The interplay between glottis and vocal tract
during the male passaggio. Folia Phoniat Logoped 57, 308-327.
Langenbruch F, Thoma J, Loviscach J, Neumann K, Kob M (2011) Entwicklung eines
Algorithmus für die Detektion von Registerübergängen. Proceedings der 37. Jahrestagung der
Deutschen Arbeitsgemeinschaft für Akustik. Düsseldorf, 21.-23. März 2011.
Tuesday, May 17, 11:50-12:10
Oral Presentation:
Actress' formant: does it exist?
Philippe Dejonckere
1, 2, 3, H. Stoffels
3

40
1 Catholic University of Leuven, Neurosciences, Exp. ORL, Belgium
2 Federal Institute of Occupational Diseases, Brussels, Belgium
3 Utrecht University UMC, The Netherlands. AZU Heidelberglaan 100, F.02.504, NL 3584
CX Utrecht.
The “singer's formant” is a prominent spectrum envelope peak near 3 kHz, typically found in
voiced sounds produced by classical operatic male singers. According to previous research
(Sundberg & Titze), it is mainly a resonatory phenomenon produced by a clustering of formants 3,
4, and 5.
Work by Weiss & al. (2001) does not support its presence in the soprano voices of trained female
singers. High female voices rather rely upon formant tuning for reaching extra power and
brilliance.
Leino (1993) proposed the term "actor's formant" or "speaker's formant" for a similar – but less
pronounced – acoustic phenomenon in projected voices of male actors. The spoken voice of female
actor‟s should theoretically be suited for applying comparable vocal tract adjustments, but it
remains unclear if actresses actually use the "actor's formant". Actresses – as well as actors –
obviously (can) use a perceptually different timbre when performing, particularly dramatic
passages.
In order to investigate the acoustic specificities of acting voice in females, a pilot study was
conducted with 6 professional – classically trained – actresses. They interpreted a similar highly
„dramatic‟ passage from Euripides‟ tragedy „Medea‟. The LTAS-data were compared with those of
the same passage read by the same subject with a (controlled) louder than normal voice, but
without dramatic interpretation.
Results clearly demonstrate that production and perception of dramatic voice projection is
associated with LTAS-changes, mainly consisting of a relative supplement of spectral power in the
zone of 2,2 to 4,4 KHz. Experiments are going on, but the pilot-study seems to confirm that – at
least in specific acting conditions – professional actresses demonstrate an acoustic phenomenon
similar to the singer‟s and actor‟s formant.
Tuesday, May 17, 12:10-12:20
Oral Presentation:
Singing voice and ageing
Geert Berghs
1 and Felix I.C.R.S.
2, 3
1 Singer, singing teacher, Bussum, The Netherlands
2 Dep. ENT, Head and Neck Surgery, K.U.Leuven, Belgium
3 Centre of Excellence for Voice, Lab. Exp. ORL, K.U.Leuven, Belgium
A professional singer‟s life most commonly starts in adolescence and can carry on over the age of
60. As the years increase, singers may notice a loss of vocal quality, due to ageing.

41
Interindividually, there may be a great difference between age-dependent changes of the voice.
Some singers have to quit professional singing before 50, while others perform well even over the
age of 65. Amongst others, for reasons of employment and prevention it is important to identify the
incidence and severity of vocal problems due to ageing. In this ongoing study, 16 male and 32
female professional choir singers were examined (age between 21 and 60 years). Voice analysis
was carried out by Voice Range Profile (VRP; Voice Profiler 4.0 Spectral) measurements and
acoustic analysis (PRAAT). Additionally, maximum phonation time was determined. The VRP
parameter “highest frequency” was found to correlate rather strongly negatively with age in both
males and females (males, ρ=-0.467, p=0.008; females, ρ=-0.532, p=0.038). This was also found
for “frequency range” (males, ρ=-0.465, p=0.008; females, ρ=-0.507, p=0.045). For the parameters
“lowest frequency”, “lowest intensity”, “highest intensity” and “intensity range” no significant
correlation with age was found. Also for “maximum phonation time” no significant correlation
with age was found. The dysphonia Severity Index correlated negatively with age in both males
and females (males, ρ=-0.560, p=0.024; females, ρ=-0.395, p=0.028). The correlation was more
pronounced in males than in females. These findings indicate parameters for the ageing voice. The
results of ongoing analysis are presented.
Tuesday, May 17, 12:20-12:30
Oral Presentation:
Vibrato and ageing of the voice in professional choir singers
Geert Berghs
1 and Felix I.C.R.S.
2, 3
1 Singer, singing teacher, Bussum, The Netherlands
2 Dep. ENT, Head and Neck Surgery, K.U.Leuven, Belgium
3 Centre of Excellence for Voice, Lab. Exp. ORL, K.U.Leuven, Belgium
Vibrato parameters express vocal quality. Vibrato was correlated with age in this ongoing study,
comprising 16 male and 32 female professional choir singers (age between 21 and 60 years). Voice
analysis was carried out by Voice Range Profile (VRP; Voice Profiler 4.0 Spectral) measurements
and acoustic analysis (PRAAT). From these data, vibrato was analyzed by FoTraceAnalysis. Both
in the males and females Vibrato Amplitude, SD Amplitude, Vibrato Frequency and SD Frequency
were found not to be correlated with age. In spite of the widespread complaints about the vibrato of
elderly singers, this could not be demonstrated in this study. It does correspond, however, with the
information given by 72% of the singers, who had experienced positive developments in their
singing over the years, especially in vibrato control. The results of ongoing analysis are presented.
Tuesday, May 17, 13:40-14:00
Oral Presentation:
Speech therapy for the injured singer
Sara Harris

42
What is an injured singer? This talk will look at the type of problems we see in a UK voice clinic
that can be considered to constitute an “injured singer” and what might lie behind these problems
in terms of aetiology. Possible therapy options that will meet the needs of these singers will be
outlined and illustrated through case studies.
Tuesday, May 17, 14:00-14:20
Oral Presentation:
Singers resonance, allergies and environment
Eugenia Chávez
Tuesday, May 17, 14:20-15:45
Workshop:
Double ventile function – breathing and posture in singing
Eugen Rabine
The Rabine Method for functional vocal pedagogy, vocal therapy and vocal training has its basis in
the „double valve function“ within the larynx and in the functional integrated unity within the
„double valve system“. The double valve system embodies the multifarious interrelated
relationships within the biological, neurological, physiological, psychosomatic and acoustical
reciporcol functions in vocal communication and thereby incorporates information regarding all
aspects of human activities and behaviour. The method in its application concentrates on self
perception, sensorimotoric learning and mental concept development. „How a person thinks is how
he/she will adjust posture, perform movements, produce voice and express himself in physical-
acoustical emotional communication.“
Tuesday, May 17, 14:20-15:45
Workshop:
Sing aaaaah, free your voice!
Margaretha Bessel
Dipl. Gesangspädagogin, Ludwig-Reinheimer-Str. 2, 60439 Frankfurt am Main, Home: +49 –
(0)69 – 978 40 225, Cell: +49 – (0)177 – 78 40 225

43
Content: Group exercises for self-awareness of vocal mechanisms (Free Your Voice Training),
using vowels, consonants, tonality, pitch and volume; Audio examples and functional analysis of
sound qualities; Tune up Your Voice – tools to take home









![Rezensionen für - Audite...Classic Record Collector Summer 2010 (Norbert Hornig - 2010.07.01) Continental Report [ &] On 28 May Dietrich Fischer-Dieskau celebrated his eighty-fifth](https://img.dokumen.tips/doc/110x75/5e9fda0485d8212e5d719537/rezensionen-fr-audite-classic-record-collector-summer-2010-norbert-hornig.jpg)



















