Embed Size (px)
Citation preview

Open SourceData PersistenceCreating Order from Chaos
Manuel SilveyraMichael BrewerMegan Kostick
OSCON 2018

2
Lead Architect IBMCode
Austin, TX
twitter.com/manuel_silveyra
github.com/silveyram
developer.ibm.com/code
Manuel Silveyra
3
Software Developer
Austin, TX
twitter.com/mbrewed
github.com/mjbrewer
developer.ibm.com/code
Michael Brewer

4
Software Developer
Seattle, WA
twitter.com/kostickmegan
github.com/kostickm
developer.ibm.com/code
Megan Kostick

Open Source
5
We become members of open source communities
IBM Code / April 4, 2018 / © 2018 IBM Corporation
Provide key contributions to the communities
Communities include Kubernetes, Node.js, Docker, Blockchain, Serverless, and more
Advocacy
6
Official developer advocacy team in IBM
Hundreds of advocates worldwide on the team
Worldwide advocate presence in key cities

Events & Meetups
7
1,000+ events hosted last year
40+ events /week worldwide

8
developer.ibm.com/code
Built by developers for developers

Code, Content, & Outreach
9
140+ code patterns (apps), adding 3/week
100+ Open source projects
Thousands of technical articles and tutorials
Hundreds of hours of technical videos
16 newsletters

IBM Code Infrastructure Team
10
Is responsible for:
§ Development
§ Design
§ Automation
§ DevOps
§ Data gathering
§ Reporting
Our Goals
11
Make it easy for any developer to access our content and code
Make it possible for our developers and advocates to connect with developers outside of IBM
Provide our developers and advocates with the data necessary to drive decisions
Our Problems
12
Data from different sources
Data in different formats
Some data is easily accessible by API
Some data needs to be manually input
Data consistency issues
Data integrity
Data validation
Data correlation
Our Approach
13
Open source software
Automate everything
Abstract the origin of data
Make correlation easy
Data Sources
14
SQL Databases
NoSQL Databases
APIs
Other

Tooling
15
• Docker• Kubernetes• Jenkins• Compose Transporter• JDBC Logstash Importer• SQL/NoSQL Database• Grafana• Nodejs• Angular• ElasticSearch

ElasticSearch and friends
16
• ElasticSearch – Apache 2.0• Uniform data structure• Easy to use API• Fast processing for large data sets• Quick native search functionality• Lightweight set up• Highly Available
• Tools for syncing data between SQL and No SQL database• Compose Transporter – BSD 3-Clause• Dockerized
• JDBC Logstash Importer – Apache 2.0
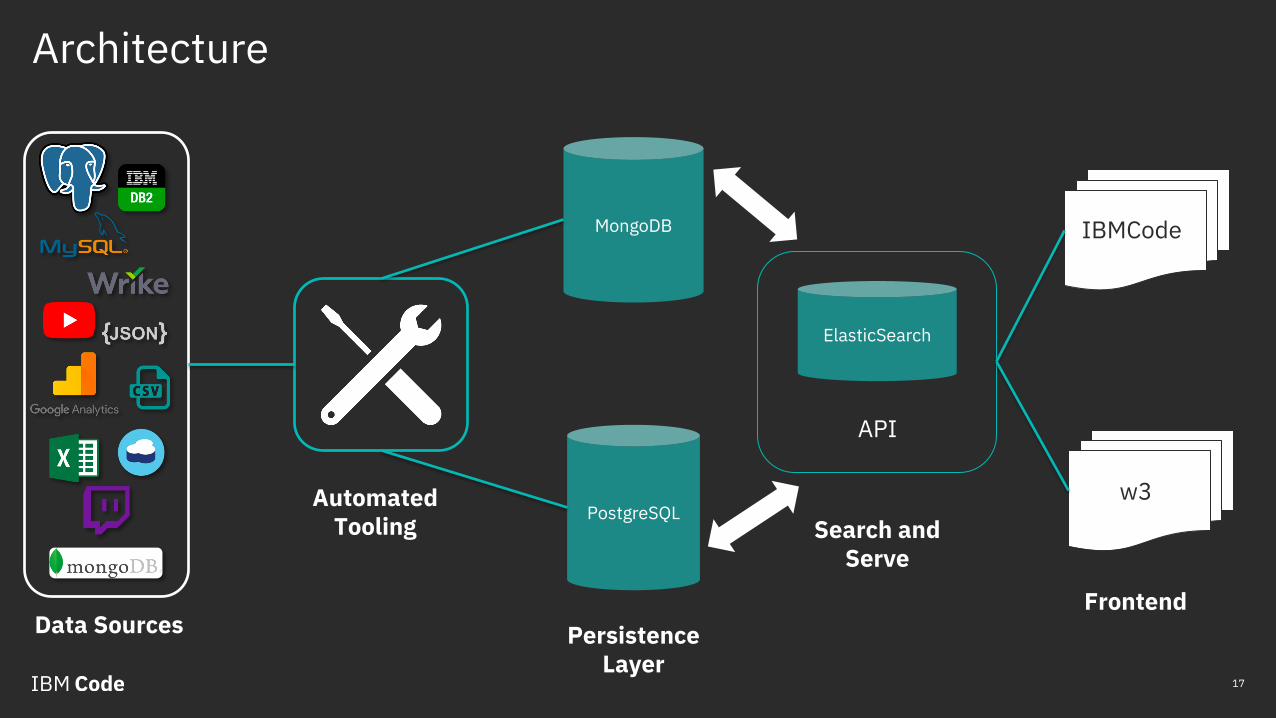
Architecture
17
MongoDB
PostgreSQL
ElasticSearch
IBMCode
w3
API
Data Sources
Automated Tooling
Persistence Layer
Search and Serve
Frontend

Why Open Source?
18
• Experience and past success• Ideology and Community• Flexible architecture• Free and accessible• Open Source Initiative• Tried and true

Challenges faced
19
• Version compatibly• Tools as needed (not always as designed)• Maintaining persistence• Jack of all trades, master of all• Data formatting• Creating a template process

Demo
20

Questions?
21

22

23
STEP 1:
REGISTER FOR THE CHALLENGE
callforcode.org/challenge
LEARN ABOUT THE COMPETITION SCOPE, PRIZES, RULES, AND SCHEDULE
STEP 2:
SIGN UP FOR A FREE IBM CLOUD ACCOUNT
ibm.biz/BecomeIBMcoder
GET AN ACCOUNT GRANTING FREE TIER ACCESS FOR AN UNLIMITED TIME.
STEP 3:
START BUILDING WITH CODE PATTERNS
ibm.biz/callforcodeOSCON
USE CODE PATTERNS IN SIX TECH AREAS TO INSPIRE YOUR SUBMISSION
STEP 4:
ENGAGE WITH THE COMMUNITY
ibmcoders.influitive.com
MEET ADVOCATES, BRAINSTORM IDEAS, FIND A TEAM, HEAR ABOUT UPDATES
How to start solving the world's largest natural disaster challenges through code