Embed Size (px)
Citation preview

1
Obsah
Obsah .................................................................................................................................. 11 Úvod................................................................................................................................ 32 Základní pojmy počtu pravděpodobnosti........................................................................ 7
2.1 Základní statistické pojmy ....................................................................................... 72.2 Funkce náhodných veličin ....................................................................................... 82.3 Charakteristiky náhodných veličin ........................................................................ 102.4 Některá rozdělení pravděpodobnosti ..................................................................... 122.5 Základy matematické statistiky.............................................................................. 16
3 Základy teorie chyb....................................................................................................... 233.1 Náhodné chyby ...................................................................................................... 23Příklad........................................................................................................................... 263.2 Systematické chyby ............................................................................................... 283.3 Úplná chyba ........................................................................................................... 323.4 Chyby nepřímo měřených veličin.......................................................................... 333.5 Výsledek měření .................................................................................................... 37
4 Nejistoty měření............................................................................................................ 394.1 Zavedení nejistot měření........................................................................................ 394.2 Stanovení standardních nejistot při přímém měření .............................................. 404.3 Stanovení standardních nejistot při nepřímém měření........................................... 424.4 Výsledek měření .................................................................................................... 46
5 Vyrovnání funkční závislosti ........................................................................................ 485.1 Metoda nejmenších čtverců (MNČ)....................................................................... 485.2 Skupinová metoda.................................................................................................. 51
6 Měřicí metody a měřicí přístroje................................................................................... 536.1 Rozdělení měřicích metod ..................................................................................... 536.2 Metoda lineární interpolace ................................................................................... 546.3 Parametry měřicích přístrojů.................................................................................. 55
7 Literatura....................................................................................................................... 59Výsledky kontrolních otázek ........................................................................................ 61


3
1 Úvod
Všechny přírodní vědy mají teoretické a experimentální discipliny. Mezi těmitodisciplinami existují těsné vazby – experimentální discipliny potvrzují či vyvracejí závěryteoretických disciplin anebo experimenty poskytují výsledky, jejichž zdůvodnění azobecnění je úkolem disciplin teoretických. Tyto vazby se realizují kvantitativnímivýsledky experimentů neboli výsledky určitých měření. Je zřejmé, že měření realizovanáv rámci různých vědních oborů (fyziky, chemie, biologie atd.) mají své specifickévlastnosti dané odlišnostmi jednotlivých oborů, ale současně mají i řadu společných rysů.Úkolem této studijní opory je seznámení se s těmito společnými základy měřenív přírodních vědách a se zákonitostmi, kterými se řídí.Problematika měření nabývá stále větší důležitosti a to nejen v přírodních vědách, ale iv praktickém životě. Stále častější aplikace elektronických měřících systémů spolus využíváním počítačů rozšiřují možnosti měření a výsledkem je množící se objemvýsledků. Je však nezbytné umět tyto výsledky posuzovat kriticky a především umětkvantitativně vyhodnotit shodu naměřených výsledků se skutečnou hodnotou měřenéveličiny, tj. vyhodnotit chybu měření. Tato znalost je důležitá jak ve vědníchdisciplinách, tak v praktickém životě (např. shoda či neshoda údajů měřidel spotřebyenergií se skutečností může mít závažné ekonomické důsledky).Tuto úvodní kapitolu věnujeme definicím a objasnění základních pojmů, které budemev celé opoře používat:Jako měření označujeme empirickou (experimentální) činnost, jejímž výsledkem jeurčení hodnoty nějaké fyzikální veličiny. Považujeme za užitečné připomenout, že termínfyzikální veličina má dvojí význam: označuje jednak abstraktní pojem (např. hmotnostv obecném smyslu), jednak jeho konkrétní realizaci (např. hmotnost určitého tělesa), přiníž fyzikální veličina nabývá zcela určité hodnoty. Tato vlastnost fyzikálních veličin seprojevuje tím, že každá veličina se vyjadřuje součinem číselné hodnoty její velikosti ajejí jednotky :
{ } [ ].A A A= , (1.1)
kde A je značka veličiny a { }A značka její číselné hodnoty vyjádřené v jednotce [ ]A .
Jednotka fyzikální veličiny je zvolená veličina specifikovaná jako referenční veličina.Soubor jednotek vytvořený tak, že pro zvolené základní veličiny jsou stanovené jejichzákladní jednotky a z nich se odvozují jednotky ostatních veličin, se nazývá soustavajednotek. V České republice je zákonem stanovena povinnost používat jednotkysoustavy SI s určitými výjimkami, které jsou uvedeny v normě ČSN ISO 1000. Skutečná hodnota veličiny je hodnota, kterou měřená veličina nabývá za podmínekexistujících v okamžiku, kdy je měřena. Skutečná hodnota je hodnota ideální, protože veskutečnosti nemůže být přesně zjištěna. Rozdíl hodnoty x zjištěné měřením fyzikálníveličiny a její skutečné hodnoty x0 se nazývá chyba měření e
0e x x= − . (1.2)

4
Takto definovaná chyba měření se nazývá také absolutní chyba, zatímco poměrabsolutní chyby a skutečné hodnoty se nazývá relativní chyba er
0
r
ee
x= . (1.3)
Chyby měření jsou vyvolávány různými příčinami, ale ty jsou v podstatě dvojího druhu.Některé působí při daném měření soustavně, tzn. že při opakování měření za stejnýchpodmínek ovlivňují jeho výsledek pravidelným způsobem, takže způsobují chybustejného znaménka a přibližně i stejné velikosti. Chyby měření vyvolané těmito vlivy senazývají chyby systematické. Patří mezi ně chyba měřidla, chyba metody, chybyrůzných údajů používaných při měření atd. Podrobněji o chybách systematickýchpojednáme v odstavci 3.2. Výsledek měření je zpravidla zatížen také chybami měřenívyvolanými nepravidelnými, proměnnými vlivy, které jsou prakticky nekontrolovatelnéa způsobují, že při opakování téhož měření za stejných podmínek nedostáváme přesněstejné výsledky. Chyby tohoto druhu tedy mají v podstatě náhodný charakter, pokládámeje za náhodné veličiny a nazýváme je náhodné chyby. Náhodnými chybami se budemezabývat v odstavci 3.1. Na celkové chybě měření se podílejí jak chyby náhodné, takchyby systematické. Proto chybu měření e často označujeme jako úplnou chybu měření.V mnoha případech však můžeme s ohledem na velikosti jednotlivých chyb jednu ztěchto chyb vůči druhé zanedbat a převažující chybu považovat za úplnou chybu měření.Zvláštním případem chyby měření jsou chyby hrubé. Vznikají např. nesprávnýmpostupem při měření, nesprávným odečtením naměřené hodnoty, náhlým působenímsilného vnějšího vlivu, poškozením měřidla apod. Údaj zatížený hrubou chybou zesouboru měření vždy vylučujeme.Zatím jsme se uvažovali taková měření, kde hodnota naměřené veličiny je přímovýsledkem měření. Nazýváme ji proto přímo měřenou veličinou. Jestliže veličinu nelzeměřit přímo, ale její hodnotu určujeme ze vztahu, ve kterém vystupují dvě nebo vícepřímo měřených veličin, hovoříme o určení nepřímo měřené veličiny. Pro nepřímoměřenou veličinu musíme rovněž stanovit nebo odhadnout chybu. Tato chyba bude mítstejné vlastnosti jako chyba přímo měřené veličiny, tj. bude se skládat ze složkysystematické a náhodné. Její velikost bude záviset na hodnotách chyb jednotlivých přímoměřených veličin a na tvaru funkce, která vyjadřuje závislost nepřímo měřené veličinyna veličinách měřených přímo. O chybách nepřímo měřených veličin pojednáváodstavec 3.4.
Nové požadavky přírodních věd, techniky i ekonomiky si vyžádaly i nový pohled nahodnocení přesnosti měření. Tento nový přístup se odráží i v nových dokumentech, kteréjsou od počátku 90. let postupně přijímány ve všech vyspělých zemích světa. Přesnostměření se vyjadřuje pomocí nejistoty měření. Pojem nejistoty není omezen jen navýsledek měření, ale vztahuje se i na měřidla, použité konstanty, korekce apod.Podrobněji se o nejistotách zmíníme v kapitole 4.

5
Hodnota fyzikální veličiny zjištěná měřením se liší odskutečné hodnoty této fyzikální veličiny. Rozdíl mezi hodnotou zjištěnouměřením a skutečnou hodnotou se nazývá absolutní chyba měření. Relativníchyba měření je poměr absolutní chyby měření a skutečné hodnoty fyzikálníveličiny. Podle zdroje chyb měření rozlišujeme chyby náhodné a chybysystematické. Nový přístup k hodnocení přesnosti měření vyžadujevyhodnocení nejistoty měření.
Doposud jsme se zabývali problematikou měření v případě určení jedné hodnoty určitéfyzikální veličiny za daných podmínek. Existuje však daleko širší disciplína souvisejícís měřením, která se nazývá regresní analýza. Zabývá se případy, kdy je třeba vyšetřiturčitou závislost mezi fyzikálními veličinami, například ověřit platnost určitéhofyzikálního zákona. V jednoduším případě můžeme s dostatečnou pravděpodobnostípředpokládat, že tuto závislost známe, např. ve formě obecně uznávaného fyzikálníhozákona. Naše úloha v tomto případě spočívá v určení konstant, které v tomto zákoněvystupují. Jako příklad uveďme měření elektrického odporu z Ohmova zákona. Jedná-lise o měření elektrického odporu kovového rezistoru při běžných proudech a napětích,Ohmův zákon stanoví lineární závislost mezi napětím na rezistoru a proudem, který jímprotéká. Konstantou úměrnosti je neznámá hodnota jeho elektrického odporu. Pokud byměření nebylo zatíženo chybou, stačila by pro určení odporu jediná dvojice naměřenýchhodnot napětí a proudu. Potlačení chyb měření ale vyžaduje měření opakovat a provyhodnocení souboru naměřených hodnot se používají metody regresní analýzy, kterépopíšeme v kapitole 5.V praxi se často setkáváme s případy, kdy konkrétní tvar funkce popisující závislostmezi veličinami neznáme. Jako příklad uveďme závislost termoelektrického napětí natermočlánku na rozdílu teplot mezi oběma konci termočlánku. Tato závislost je obecněnelineární, nahrazujeme ji polynomem a naší úlohou je určit stupeň tohoto polynomu akonstanty, které v něm vystupují. Úlohy tohoto typu jsou podstatně náročnější a jejichobtížnost přesahuje rámec tohoto úvodního textu.Text této opory je uzavřen kapitolou stručně pojednávající o metodách měření a oobecných vlastnostech měřicích přístrojů. Cílem této kapitoly je seznámení se základníterminologií používanou v oboru měření. Soupis použité odborné literatury současněpodává potenciálním zájemcům informaci o zdrojích hlubších poznatků v oboru měření.


7
2 Základní pojmy počtu pravděpodobnosti
Jak jsme uvedli v předcházející kapitole, je z experimentální praxe známé, že měřenímurčité fyzikální veličiny opakovaným za stálých podmínek a se stejnými přístrojizískáváme soubor hodnot, které se od sebe do určité míry liší. Je to důsledek náhodnýchvlivů ovlivňujících výsledek měření, a takto vzniklé odchylky od správné hodnotyoznačujeme jako náhodné chyby. Příčiny jejich vzniku jsou v některých případechneznámé, v některých případech jsou sice známé, ale z principiálních důvodů je nelzeodstranit a pro jednotlivá měření ani nelze předvídat míru jejich uplatnění. Tyto chybyjsou proto charakterizovány náhodným výskytem jejich hodnot. To znamená, že tytohodnoty se nedají stanovit předem, ale dá se předvídat výskyt určitých hodnots příslušnou pravděpodobností.
Existence náhodných chyb vyvolává potřebu řešení dvouproblémů:
- jakým způsobem určit ze souboru vzájemně odlišných naměřenýchhodnot výsledek měření, který se nejvíce blíží správné hodnotě měřenéveličiny,
- jakým způsobem charakterizovat odchylku výsledku měření od správnéhodnoty, tj. jak určit velikost náhodné chyby (velikost nejistoty typu A– kapitola 5) zjištěného výsledku opakovaných měření.
K řešení těchto problémů přistupujeme tak, že na soubory naměřených hodnot pohlížímejako na soubory náhodných veličin a pro vyhodnocení měření a analýzu náhodnýchchyb používáme metody počtu pravděpodobnosti a metody matematické statistiky. Jetřeba si uvědomit, že náhodné chyby se jako náhodné veličiny řídí statistickýmizákonitostmi umožňujícími jen určité pravděpodobnostní výroky o výskytu jejich hodnot.Podobně o výsledcích měření určovaných z těchto souborů lze vyslovit pouzepravděpodobnostní výroky o jejich přiblížení správné hodnotě měřené veličiny. Je protonutné, abychom se seznámili s některými základními pojmy a zákony matematickéstatistiky.
2.1 Základní statistické pojmy
Údaje o hodnotě spojitě proměnné veličiny se získávají měřením (např. měřenímteploty, hustoty apod.), údaje o hodnotě nespojité (diskrétní) veličiny se získávajíčítáním (např. určením počtu částic emitovaných zdrojem ionizujícího záření). Souborytakto zjištěných náhodných kvantitativních údajů se nazývají statistické soubory.Náhodnou veličinu označujeme velkým písmenem (např. X, Y..), jednotlivé hodnoty zestatistického souboru malými písmeny ( např. xi, yj…), celkový počet hodnot vestatistickém souboru symbolem n. Počet případů, v nichž se určitá hodnota xi vyskytne

8
ve statistickém souboru se nazývá absolutní četnost ni, podíl ni / n je relativní četnostf i.
2.2 Funkce náhodných veličin
Jak jsme již uvedli, o chování náhodných veličin lze uvádět pouze pravděpodobnostnívýroky. To znamená, že např. četnost výskytu určité hodnoty náhodné veličiny v danémstatistickém souboru nemůžeme stanovit s jistotou, ale pouze s určitou pravděpodobností.Možnosti výskytu určitých hodnot ve statistickém souboru, tj. přiřazení pravděpodobnostík hodnotám náhodné veličiny, proto popisujeme pomocí rozdělení pravděpodobnosti.Toto rozdělení lze pro spojité i diskrétní veličiny jednoduše popsat pomocí distribu čnífunkce F(x), která je pro náhodnou veličinu X definována tak, že v bodě x0 je F(x0)rovna pravděpodobnosti, že náhodná veličina X nabude hodnoty menší nebo rovné x0. Jetedy
( ) ( )0 0F x P x x= ≤ . (2.1)
Je zřejmé, že distribuční funkce je funkce neklesající a platí pro ní
( ) ( )lim 0 lim 1x x
F x F x→−∞ →∞
= = (2.2)
Pro spojitě proměnné veličiny se chování náhodné veličiny nejčastěji popisuje pomocífunkce nazývané hustota pravděpodobnosti f(x). Ta je definována jako derivacedistribuční funkce F(x) podle x (pokud tato derivace existuje). Platí
( ) ( ) ( )/dF xf x F x
dx= = . (2.3)
Pro objasnění významu obou funkcí uvedeme dva příklady.
Příklad 1: prvním případě se jedná o spojitě proměnnou náhodnou veličinu. Uvažujmenáhodný pokus realizovaný pomocí zařízení podobného ruletě. Tento pokus spočíváv mnohokrát opakovaném roztočení kruhu, v jeho otáčení vlivem setrvačnosti a konečněv jeho samovolném zastavení působením pasivních odporů. Kruh má na svém obvoduznačky dělící obvod v intervalu 0 až 2π , mimo kruh je pevná značka určující, na kterémmístě se kruh zastavil. Protože předpokládáme, že každý úhel při zastavení je stejněmožný (jako by tomu mělo být např. u rulety), představují naměřené hodnoty tohoto úhluspojitou náhodnou veličinu proměnnou v intervalu 0, 2π.Distribuční funkce této náhodné veličiny je pak
( ) (
( )( )
0;220 0
1 2
xF x pro x
F x pro x
F x pro x
ππ
π
= ∈ ⟩
= ≤
= >
(2.4)
9
Hustota pravděpodobnosti náhodné veličiny v tomto příkladu je
( ) ( ) (
( )
120,2
2
0 0 2
xd
dF xf x pro x
d x d x
f x pro x a x
π ππ
π
= = = ∈ ⟩
= ≤ >
(2.5)
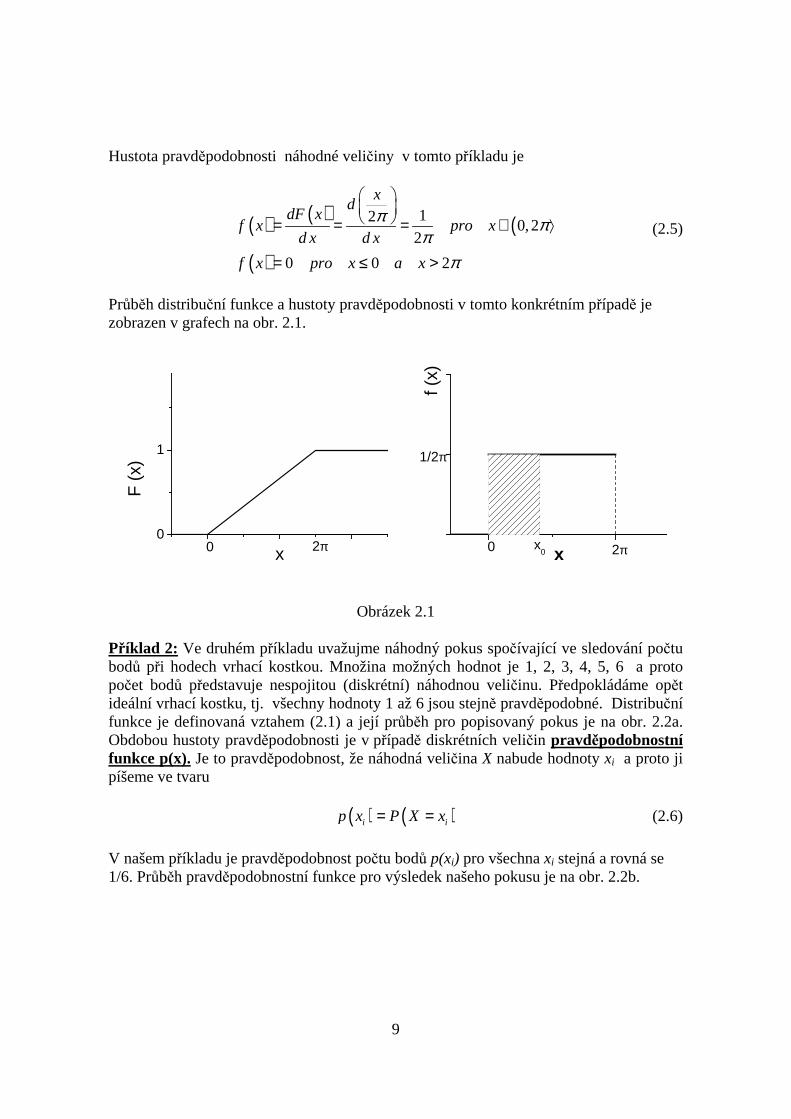
Průběh distribuční funkce a hustoty pravděpodobnosti v tomto konkrétním případě jezobrazen v grafech na obr. 2.1.
0
1
2π0
F (
x)
x
1/2π
2πx00
f (x)
x
Obrázek 2.1
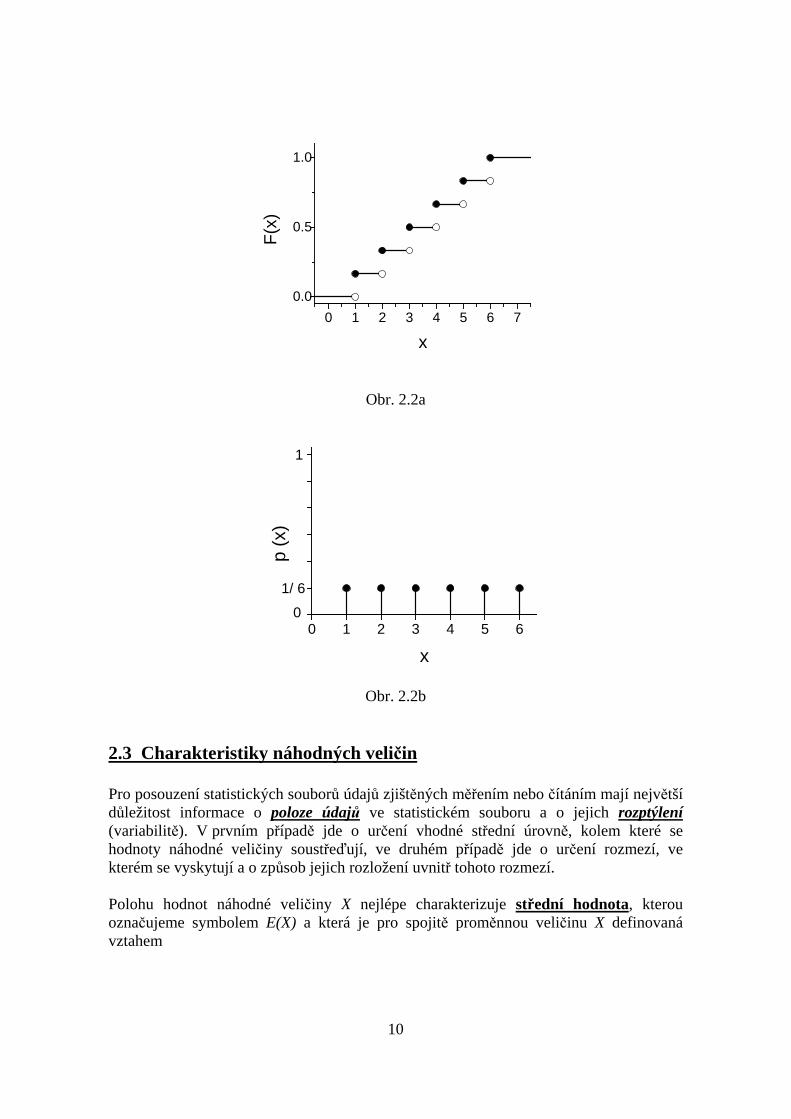
Příklad 2: Ve druhém příkladu uvažujme náhodný pokus spočívající ve sledování počtubodů při hodech vrhací kostkou. Množina možných hodnot je 1, 2, 3, 4, 5, 6 a protopočet bodů představuje nespojitou (diskrétní) náhodnou veličinu. Předpokládáme opětideální vrhací kostku, tj. všechny hodnoty 1 až 6 jsou stejně pravděpodobné. Distribučnífunkce je definovaná vztahem (2.1) a její průběh pro popisovaný pokus je na obr. 2.2a.Obdobou hustoty pravděpodobnosti je v případě diskrétních veličin pravděpodobnostnífunkce p(x). Je to pravděpodobnost, že náhodná veličina X nabude hodnoty xi a proto jipíšeme ve tvaru
( ) ( )i ip x P X x= = (2.6)
V našem příkladu je pravděpodobnost počtu bodů p(xi) pro všechna xi stejná a rovná se1/6. Průběh pravděpodobnostní funkce pro výsledek našeho pokusu je na obr. 2.2b.
10
0 1 2 3 4 5 6 7
0.0
0.5
1.0
F(x
)
x
Obr. 2.2a
Obr. 2.2b
2.3 Charakteristiky náhodných veličin
Pro posouzení statistických souborů údajů zjištěných měřením nebo čítáním mají největšídůležitost informace o poloze údajů ve statistickém souboru a o jejich rozptýlení(variabilitě). V prvním případě jde o určení vhodné střední úrovně, kolem které sehodnoty náhodné veličiny soustřeďují, ve druhém případě jde o určení rozmezí, vekterém se vyskytují a o způsob jejich rozložení uvnitř tohoto rozmezí.
Polohu hodnot náhodné veličiny X nejlépe charakterizuje střední hodnota, kterouoznačujeme symbolem E(X) a která je pro spojitě proměnnou veličinu X definovanávztahem
0 1 2 3 4 5 60
1
1/ 6
p (x
)
x

11
( ) ( )b
a
E X x f x dx=∫ . (2.7)
Symboly a, b v tomto vztahu jsou meze definičního oboru veličiny X.Varianci náhodných veličin nejlépe charakterizuje rozptyl D2, který určujeme ze vztahu
( ) ( ) ( )22b
a
D X x E X f x dx= − ∫ . (2.8)
Rozptýlení hodnot náhodné veličiny často vyjadřujeme kladně vzatou druhouodmocninou z rozptylu, kterou nazýváme směrodatná odchylka σσσσ(X).
( ) ( )2X D Xσ = + (2.9)
V případě diskrétní náhodné veličiny určujeme střední hodnotu náhodné veličiny zevztahu
( ) ( )1
n
i ii
E X x p x=
=∑ (2.10)
a rozptyl, respektive směrodatnou odchylku ze vztahů
( ) ( ) ( )
( ) ( )
22
1
2
n
i ii
D X x E X p x
X D Xσ=
= −
= +
∑ (2.11)
Základními charakteristikami statistického souboru jsou středníhodnota E a rozptyl 2D .Střední hodnota E určuje polohu statistického souboru, rozptyl D2 určujevarianci jednotlivých náhodných veličin ve statistickém souboru okolostřední hodnoty. Častěji se tato variance vyjadřuje pomocí směrodatnéodchylky σ.
Pro další použití pojmů střední hodnota, rozptyl a směrodatná odchylka jsou důležitéjejich obecné vlastnosti, z nichž uvedeme:
1) Jestliže k označuje konstantu, platí ( )E k k= , ( )2 0kσ = , 0σ = . (2.12)

12
2) Náhodná veličina Z je součtem nebo rozdílem náhodných veličin X a Y. Pak platí: Z X Y= ± , ( ) ( ) ( )E Z E X E Y= ± ,
( ) ( ) ( ) ( )2 2 2 2Z X Y X Yσ σ σ σ= + = + . (2.13)
3) Náhodná veličina Z je k – násobkem náhodné veličiny X. Pak platí: Z k X= , ( ) ( ) ( )E Z E k X k E X= = ,
( ) ( ) ( )2 2 2 2Z k X k Xσ σ σ= = . (2.14)
Kontrolní otázky
1. Pro spojitě proměnnou náhodnou veličinu X z Příkladu 1 určete střední hodnotu E(X), rozptyl D2(X) a směrodatnou odchylku σ2(X).2. Pro diskrétní náhodnou veličinu X z Příkladu 2 určete střední hodnotu E(X), rozptyl D2(X) a směrodatnou odchylku σ2(X).
3. Příklad 2. budeme realizovat s vrhací kostkou, která oproti obvykle používané kostce bude mít na stěnách trojnásobek bodů, tj. postupně 3, 6, 9, 12, 15 a 18 bodů. Určete střední hodnotu E(Y), rozptyl D2(Y) a směrodatnou odchylku σ2(Y) náhodné veličiny Y, kterou získáte sledováním vrhů s takovou kostkou.
2.4 Některá rozdělení pravděpodobnosti
Náhodné procesy, jejichž výsledkem jsou statistické soubory náhodných veličin, jsouvelmi rozmanité a tomu také odpovídá velký počet funkcí, které vyjadřují jejich rozdělenípravděpodobnosti. Následující výklad se omezuje na rozdělení pravděpodobnosti, sekterými se nejčastěji můžete setkat v oblasti vyhodnocování fyzikálních měření.
První z nich je rovnoměrné rozdělení pravděpodobnosti. Náhodnou veličinu X lzepopsat rovnoměrným rozdělením, jestliže všechny hodnoty náhodné veličiny X v danémintervalu mají stejnou pravděpodobnost výskytu. Pro rozsah hodnot náhodné veličiny Xvymezený v intervalu a x b≤ ≤ jsou distribuční funkce F(x) a rozdělení hustotypravděpodobnosti f(X) určeny vztahy
( )
( )
( )
0
1
F X x a
x aF X a x b
b aF X x b
= <−= ≤ ≤−
= >
(2.15)

13
( ) 1f X
b a=
− (2.16)
Je zřejmé, že rovnoměrným rozdělením se řídí náhodná veličina z Příkladu 1 v odstavci2.2 a vztahy (2.15) a (2.16) jsou zobecněním vztahů (2.4) a (2.5).
Normální (Gaussovo) rozdělení pravděpodobnosti je nejčastěji používaný modelrozdělení spojité náhodné veličiny a mnoho spojitých náhodných veličin se jím alespoňpřibližně řídí. Náhodné veličiny řídící se tímto rozdělením můžeme charakterizovat jakoveličiny vzniklé složením vlivů, které jsou nezávislé, kterých je větší počet a z nichžkaždá ovlivňuje skutečnou hodnotu náhodné veličiny jen malým příspěvkem. Náhodnáveličina X nabývá hodnot x v intervalu ( ),−∞ + ∞ s hustotou pravděpodobnosti
( )( )2
221
2
x
f x eµ
σ
σ π
−−
= (2.17)
a distribuční funkcí
( )( )2
221
2
yx
F x e dyµ
σ
σ π
−−
−∞
= ∫ . (2.18)
Je patrné, že normální rozdělení má dva parametry ,µ σ . První z nich má význam středníhodnoty souboru, druhým je směrodatná odchylka. Lze proto psát
( )E x µ= (2.19)
( )2 2xσ σ= (2.20)
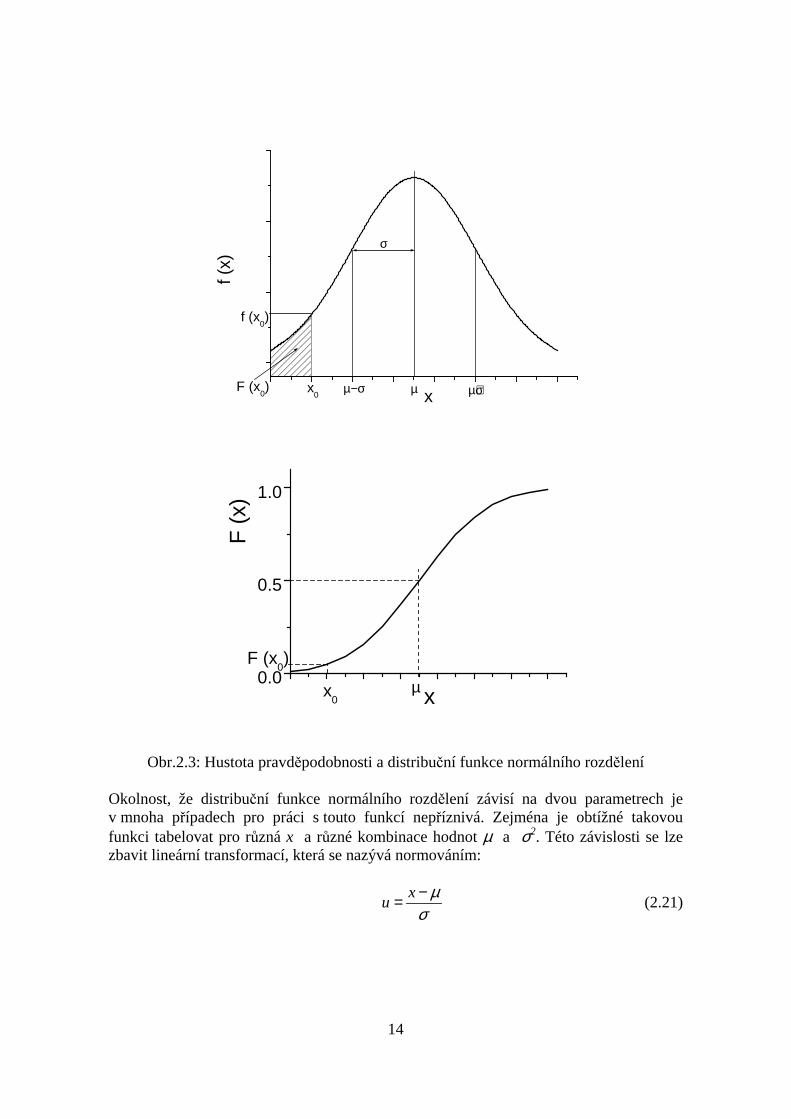
Hustota pravděpodobnosti normální náhodné veličiny spolu s její distribuční funkcí jsouznázorněny na obr. 2.3. Obrázek názorně ukazuje význam parametrů µ a σ.
14
F (x0)
f (x0)
x0 µ+σµ−σ µ
σf (
x)
x
0.0
0.5
1.0
µx0
F (x0)
F (
x)
x
Obr.2.3: Hustota pravděpodobnosti a distribuční funkce normálního rozdělení
Okolnost, že distribuční funkce normálního rozdělení závisí na dvou parametrech jev mnoha případech pro práci s touto funkcí nepříznivá. Zejména je obtížné takovoufunkci tabelovat pro různá x a různé kombinace hodnot µ a σ2. Této závislosti se lzezbavit lineární transformací, která se nazývá normováním:
x
uµ
σ−= (2.21)

15
Náhodná veličina nabývající hodnot u má normované normální rozdělení. Distribučnífunkce F(u) a hustota pravděpodobnosti normovaného normálního rozdělení jsou dányvztahy
( )
( )
2
2
2
2
1
2
1
2
uu
u
F u e du
f u e
π
π
−
−∞
−
=
=
∫ (2.22)
Pro normované normální rozdělení platí
( ) ( )20 1E u D u= = (2.23)
Pro diskrétní náhodné veličiny uvedeme dvě rozdělení. První z nich binomickérozdělení. Toto rozdělení popisuje situaci, kdy náhodný jev nastává s pravděpodobnostíp a kdy n krát nezávisle opakujeme náhodný pokus, při kterém může náhodný jev nastata zkoumáme počet x výskytů jevu v sérii těchto n nezávislých pokusů. Binomickánáhodná veličina X nabývá hodnot 0, 1, 2, …, n. Pravděpodobnostní funkce binomickéhorozdělení je
( ) ( )1n xxn
p x p px
− = −
. (2.24)
Střední hodnota rozdělení a jeho rozptyl nabývají hodnot
( ) ( ) ( )2 1E X n p D X n p p= = − . (2.25)
Druhé rozdělení, se kterým se můžeme při fyzikálních měřeních setkat, je Poissonovorozdělení. Vztahuje se k náhodné veličině,. která vyjadřuje počet výskytů málopravděpodobných (řídkých) jevů za daných podmínek (v určitém časovém intervalu, vevymezené oblasti apod.). Jako příklad můžeme uvést přeměnu atomových jader, kterásplňuje tyto podmínky, protože– přeměna jader se řídí přeměnovým zákonem ( ) ( )0 tN t N e λ−= , kde N(t) je počet dosud
nepřeměněných jader v čase t, N(0) je počáteční počet jader a λ je přeměnová konstanta,– diferencováním tohoto zákona dojdeme ke vztahu prokazujícímu, že počet jader dN přeměněných za krátký časový interval dt je úměrný délce tohoto intervalu,– pravděpodobnost výskytu přeměny je nezávislá na četnosti výskytu přeměny v předcházejícím časovém intervalu stejné délky,– pravděpodobnost přeměny nezávisí na poloze počátku intervalu.
Poissonova náhodná veličina X nabývá hodnot 0, 1, 2, … a její pravděpodobnostní funkceje
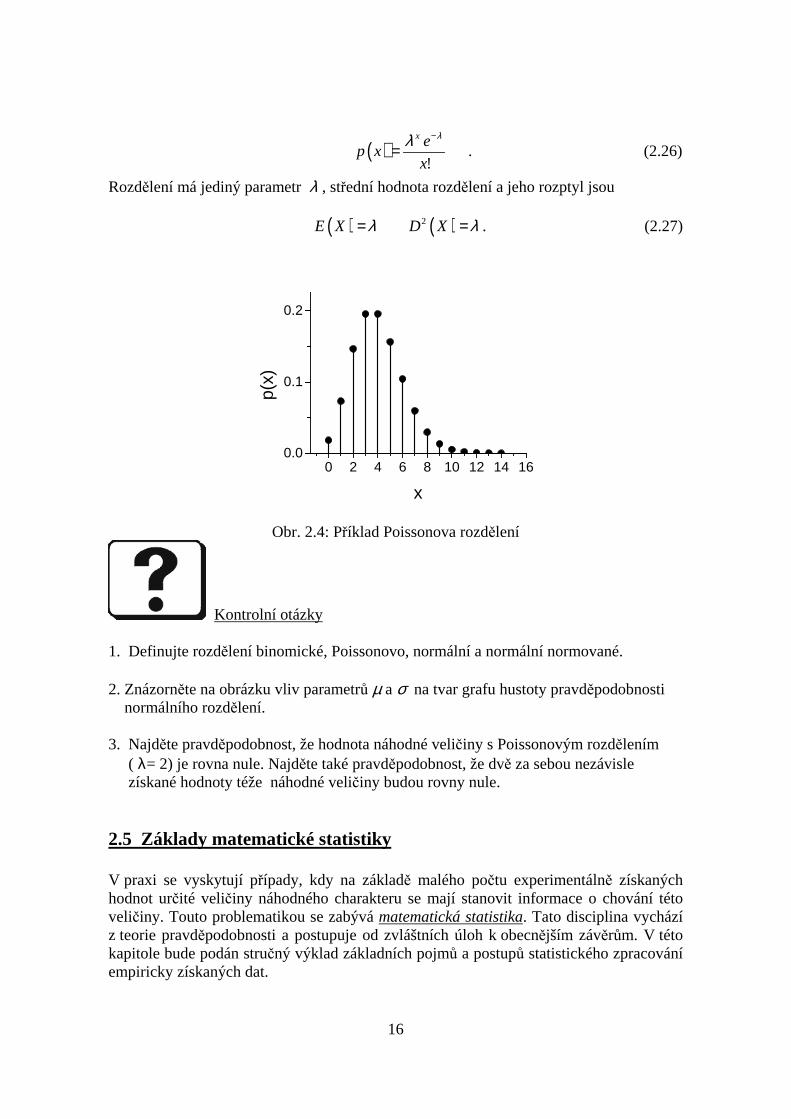
16
( )!
x ep x
x
λλ −
= . (2.26)
Rozdělení má jediný parametr λ , střední hodnota rozdělení a jeho rozptyl jsou
( ) ( )2 .E X D Xλ λ= = (2.27)
0 2 4 6 8 10 12 14 160.0
0.1
0.2
p(x)
x
Obr. 2.4: Příklad Poissonova rozdělení
Kontrolní otázky
1. Definujte rozdělení binomické, Poissonovo, normální a normální normované.
2. Znázorněte na obrázku vliv parametrů µ a σ na tvar grafu hustoty pravděpodobnosti normálního rozdělení.
3. Najděte pravděpodobnost, že hodnota náhodné veličiny s Poissonovým rozdělením ( λ= 2) je rovna nule. Najděte také pravděpodobnost, že dvě za sebou nezávisle získané hodnoty téže náhodné veličiny budou rovny nule.
2.5 Základy matematické statistiky
V praxi se vyskytují případy, kdy na základě malého počtu experimentálně získanýchhodnot určité veličiny náhodného charakteru se mají stanovit informace o chování tétoveličiny. Touto problematikou se zabývá matematická statistika. Tato disciplina vycházíz teorie pravděpodobnosti a postupuje od zvláštních úloh k obecnějším závěrům. V tétokapitole bude podán stručný výklad základních pojmů a postupů statistického zpracováníempiricky získaných dat.

17
Základní soubor je soubor všech možných zjistitelných hodnot náhodné veličinys daným rozdělením pravděpodobnosti. Může obsahovat konečný i nekonečný počethodnot. V případě spojitě proměnné náhodné veličiny by rozsah základního souboruměl být nekonečný. Z praktického hlediska ale stačí N tak velké, že další zvyšování N jižnepřináší znatelné změny charakteristik. Rozsah základního souboru diskrétní náhodnéveličiny je dán celkovým počtem možných hodnot této veličiny. Skutečné velikosticharakteristik náhodné veličiny (střední hodnota, rozptyl) jsou určeny ze základníhosouboru.Realizace měření, při kterém je získán soubor naměřených hodnot odpovídající rozsahuzákladního souboru je často v praxi z důvodů technických, časových i ekonomickýchnemožná. K dispozici tedy obvykle máme soubor podstatně menší, který představujeurčitý výběr ze základního souboru. Aby se charakteristiky takového souboru co nejlépeblížily charakteristikám základního souboru, je třeba aby představoval náhodný výběr.Náhodný výběr ze základního souboru je skupina n hodnot náhodné veličiny vybranýchnezávisle na sobě a takovým způsobem, aby všechny hodnoty základního souboru mělystejnou možnost být do tohoto výběru pojaty. Pro náš další výklad je důležité, ženáhodným výběrem může mj. být i souhrn hodnot získaných při opakování měření téževeličiny za stejných podmínek.Počet hodnot náhodného výběru n udává rozsah náhodného výběru .Podobně jako má základní soubor své charakteristiky, můžeme analogickými veličinamicharakterizovat i náhodný výběr a to například výběrovým průměrem, výběrovýmrozptylem, výběrovou směrodatnou odchylkou a výběrovým rozdělenímpravděpodobnosti.Výběrový průměr x náhodného výběru je dán vztahem
1
1 n
ii
x xn =
= ∑ (2.28)
kde xi jsou všechny hodnoty náhodné veličiny X v náhodném výběru.
Výběrový rozptyl s2 je vyjádřen vztahem
( )2 2
1
1( )
1
n
ii
s x x xn =
= −− ∑ (2.29)
a výběrová směrodatná odchylka s je definována kladnou druhou odmocninouz výběrového rozptylu
2 .s s= + (2.30)
I když obvykle pracujeme pouze s jedním výběrovým souborem, musíme si uvědomit, žejde o náhodný výběr a že stejně pravděpodobně bychom mohli pracovat s náhodnýmvýběrem, který by se od původního výběru poněkud lišil. To by se mj. projevilo i tím, žecharakteristiky obou souborů by byly odlišné, i když rozdíly by byly relativně malé.Totéž by platilo i pro další náhodné výběry ze stále stejného základního souboru. Lzetedy vyslovit tvrzení, že výběrové charakteristiky jsou náhodnými veličinami.

18
Například z náhodného výběru rozsahu n odebraného ze základního souboru náhodnéveličiny X se vypočítá výběrový průměr 1x . Odběrem dalšího náhodného výběru z téhož
základního souboru a stejného rozsahu se stanoví výběrový průměr 2x , z dalšího
náhodného výběru 3x atd. Hodnoty těchto výběrových průměrů nebudou stejné a budou
mít náhodný charakter. Výběrový průměr se chová jako náhodná veličina. Stejně sebude chovat výběrový rozptyl s2. Výběrové charakteristiky jsou tedy náhodnýmiveličinami a lze je popsat rozděleními pravděpodobnosti, která se nazývají výběrovározdělení. Je zřejmé, že pro práci s výběrovými soubory je nezbytná znalost toho, jakávýběrová rozdělení jsou přiřazená k jednotlivým výběrovým charakteristikám.Nejvýznamnější výběrová charakteristika je výběrový průměr. Poněkud komplikovanýmpostupem lze dokázat, že platí tvrzení: jestliže náhodná veličina X má normálnírozdělení s parametry µµµµ(x) a σσσσ(x), potom i hodnoty výběrového průměru budourozděleny podle normálního rozdělení pravděpodobnosti s parametry
( ) ( ) ( ), /x x x nµ µ σ σ σ= = = (2.32)
Pokud se náhodná veličina X neřídí normálním rozdělením a pokud její rozdělení nenízásadně odlišné od normálního, pak rozdělení náhodné veličiny u
x
x
xu
µσ−= (2.33)
se blíží normovanému normálnímu rozdělení tím více, čím větší je rozsah náhodnéhovýběru n. V literatuře se uvádí, že rozdělení náhodné veličiny u pravděpodobnostněkonverguje k normálnímu rozdělení pro n větší než 50.Problém stanovení rozdělení hodnot výběrového rozptylu a výběrové směrodatnéodchylky je ještě složitější. Lze dokázat, že tyto dvě náhodné veličiny se řídí rozdělenímχ2 . Rozdělení χχχχ2222 má náhodná veličina daná součtem n kvadrátů náhodných veličin X1,X2…..Xn přičemž každá z nich má normované normální rozdělení. Parametrem rozděleníχ2 je počet stupňů volnosti ν = n − 1 . Střední hodnota a směrodatná odchylka tohotorozdělení jsou
( ) ( )2 2, 2µ χ ν σ χ ν= = . (2.34)
Posledním rozdělením, které se při vyčíslení výsledků uplatní, je rozdělení t(Studentovo): Nechť Y a Z jsou nezávislé náhodné veličiny, přičemž veličina Y mározdělení χ2 a veličina Z má normované normální rozdělení. Pak náhodná veličina t
z
ty
ν
= (2.35)

19
má Studentovo rozdělení. Poměrně složitým postupem popsaným v [1] a vycházejícímze vztahů (2.33) a (2.34) lze dokázat, že veličina
xt n
µσ−=
má Studentovo rozdělení a využít této skutečnosti ke stanovení intervalu spolehlivosti(odstavec 3.1).
Vraťme se nyní k problematice vyhodnocení měření, přesněji k problému kvantifikovánívlivu náhodných chyb na výsledek měření. Soubor výsledků opakovaných měření zastejných podmínek představuje náhodný výběr, jehož rozsah je obvykle podstatně nižšínež je rozsah základního souboru. Stojíme proto před problémem, jak určitcharakteristiky výběrového souboru malého rozsahu tak, aby se co nejlépe blížilycharakteristikám základního souboru a jak vyčíslit odchylky mezi těmitocharakteristikami. Výběrové charakteristiky budeme označovat jako odhady velikostícharakteristik základního souboru. Protože odhad velikosti některé charakteristiky jevyjádřen jediným číslem, je ve statistice obvyklé označovat jej jako bodový odhad. Tytoodhady jsou pochopitelně zatíženy určitou chybou a určení intervalu okolo bodovéhoodhadu, v němž se s určitou pravděpodobností nalézá charakteristika základního souboru,se nazývá intervalový odhad.Odhad charakteristiky budeme volit tak, aby splňoval tyto podmínky:– Je nestranný (nevychýlený): odhad je nestranný, je-li střední hodnota odhadů
vypočítaných z náhodných výběrů rovna velikosti příslušné charakteristikyzákladního souboru,
– je dostatečně vydatný: má nejlepší rozptyl hodnot,– je konzistentní: s rostoucím rozsahem výběrového souboru se blíží charakteristice
základního souboru.Pro bodový odhad střední hodnoty základního souboru vyhovuje těmto podmínkámnejlépe výběrový průměr x (2.28).
Pro bodový odhad rozptylu základního souboru vyhovuje těmto podmínkám nejlépevýběrový rozptyl vypočítaný ze vztahu
( )2 2
1
1( )
1
n
ii
s x x xn =
= −− ∑ (2.36)
a nejlepší bodový odhad směrodatné odchylky základního souboru udává výběrovásměrodatná odchylka, která se stanoví ze vztahu
( ) 2
1
1( )
1
n
ii
s x x xn =
= −− ∑ . (2.37)
Tento odhad směrodatné odchylky se vztahuje k libovolné hodnotě z výběrovéhosouboru. Můžeme ovšem využít vztahu (2.32) a stanovit výběrový odhad směrodatnéodchylky výběrového průměru x

20
( ) ( ) ( )2
1
1
1
n
ii
s x x xn n =
= −− ∑ . (2.38)
Zejména při náhodném výběru malého rozsahu se může bodový odhad střední hodnoty ibodový odhad směrodatné odchylky značně lišit od skutečných hodnot základníhosouboru a proto je třeba bodové odhady doplnit intervalovým odhadem. Matematickástatistika vyvinula metody umožňující stanovit meze intervalu okolo bodového odhadutak, že je známa pravděpodobnost γ s jakou se skutečná hodnota charakteristikyzákladního souboru nalézá v tomto intervalu. Číslo α = 1 – γ se nazývá riziko ,v některých učebnicích se pro tento pojem používá název hladina významnosti.V případě výběrového průměru hodnotíme přesnost tohoto bodového odhadu pomocíveličiny ε nazývanou přesnost odhadu:
( )x xε µ= − . (2.39)
Předpokládáme-li, že střední hodnota ( )xµ základního souboru leží v intervalu okolo
výběrového průměru x s pravděpodobností γ , je splněna nerovnost
( )( )P x xµ ε γ− < = . (2.40)
Pak lze dokázat, že platí
( )( ) ( ) ( )( ), , 1n nP x t s x x x t s xα αµ γ α − < < + = = − (2.41)
kde koeficient tn,α se nazývá Studentův koeficient, určuje se ze Studentova rozdělení ajeho hodnoty jsou tabelovány. Aplikace těchto poznatků na konkrétní případyopakovaného měření jsou popsány v kapitole 3.
Vraťme se nyní k problému vyhodnocení souborů náhodných veličin získaných měřenímfyzikální veličiny ovlivněné náhodnými chybami. Tyto soubory jsou obdoboustatistických souborů a mezi jejich základní charakteristiky také patří poloha a rozptyl(variance).
Základním ukazatelem polohy statistického souboru (x1, x2, …, xn) je aritmetickýprůměr x , který určujeme pomocí vztahu
1
1 n
ii
x xn =
= ∑ . (2.42)

21
Jestliže se ve statistickém souboru vyskytují některé hodnoty vícekrát, tj. je-li v němk různých hodnot x1, x2, …, xk přičemž hodnota xi se vyskytuje s četností ni, lze prourčení průměru statistického souboru ze vztahu (2.42) použít výraz ve tvaru váženéhoaritmetického průměru
1
1 k
i ii
x n xn =
= ∑ (2.43)
Základním ukazatelem rozptýlení hodnot statistického souboru jsou odchylky těchtohodnot od aritmetického průměru. Jako ukazatele rozptýlení ale nemůžeme použít pouzesoučet těchto odchylek, protože z rovnice (2.42) vyplývá, že je roven nule. Platí
1 1
( ) 0n n
i ii i
x x x n x= =
− = − =∑ ∑ . (2.44)
V praxi se nejčastěji používá ukazatel rozptýlení založený na součtu čtverců odchylek odaritmetického průměru. Aby jeho velikost nebyla ovlivněna rozsahem statistickéhosouboru, používá se jako ukazatel průměrný součet čtverců odchylek od aritmetickéhoprůměru, nazývá se rozptyl statistického souboru a značí se s2. Platí
2 2
1
1( )
n
ii
s x xn =
= −∑ . (2.45)
Častěji se ale rozptýlení souboru charakterizuje kladnou druhou odmocninou z rozptylu,která se nazývá směrodatná odchylka statistického souboru s. Je určená vztahem
( )2
1
( )n
ii
i
x xs x
n=
−=∑
. (2.46)
Kontrolní otázky
1. Pro soubor náhodných hodnot (4,8; 5,1; 4,9; 4,4; 4,8; 4,9; 5,0; 4.5; 4,8) určete: a) výběrový průměr, b) výběrový rozptyl, c) výběrovou směrodatnou odchylku.
2. Určitý soubor náhodných hodnot má výběrový průměr x , rozptyl ( )2s x a
směrodatnou odchylku ( )s x . Uveďte hodnoty těchto charakteristik, jestliže se každá
hodnota v tomto souboru a) násobí dvěma, b) dělí čtyřmi.

22
V praxi obvykle není k dispozici základní soubor a pracujemepouze s náhodným výběrem ze základního souboru. Základní charakteristikynáhodného výběru jsou výběrový průměr, výběrový rozptyl a výběrovásměrodatná ochylka. Tyto výběrové charakteristiky jsou odhadycharakteristik základního souboru.Výběrový průměr (2.28) je nejlepším odhadem střední hodnoty základníhosouboru.Nejlepším odhadem rozptylu základního souboru je výběrový rozptyl (2.29).Nejlepším odhadem směrodatné odchylky základního souboru je výběrovásměrodatná odchylka (2.37).

23
3 Základy teorie chyb
3.1 Náhodné chyby
Vzhledem k povaze náhodných chyb můžeme na soubory naměřených hodnot pohlížetjako na soubory náhodných veličin a pro vyhodnocení měření a analýzu náhodných chybpoužívat metody počtu pravděpodobnosti a metody matematické statistiky, tj. používatpoznatky, ke kterým jsme dospěli v kapitole 2. Náhodnou chybu hodnoty x veličiny Xbudeme označovat k(x), relativní náhodnou chybu kr(x).Úkolem tohoto odstavce je stanovit postup, kterým ze souboru hodnot naměřených zastejných podmínek určíme nejpravděpodobnější hodnotu veličiny a velikostnáhodné chyby tohoto výsledku. Budeme přitom předpokládat, že naměřené hodnotypředstavují náhodný výběr ze základního souboru a že rozdělení náhodných hodnotv tomto souboru se blíží normálnímu Gaussovu rozdělení. Tento předpoklad je v souhlases poznatky z praxe o náhodných chybách měřících přístrojů. Mají-li se dobře popisovat ahodnotit náhodné chyby, měly by být známy hodnoty charakteristik základního souboru.Obvykle se ovšem v laboratorní praxi pracuje se soubory naměřených hodnot, jejichžrozsah je podstatně menší než je rozsah základního souboru. Nezbývá tedy nic jiného,než charakteristiky náhodných chyb odhadovat z náhodného výběru. Tím se získávají jenvýběrové charakteristiky a podle nich se pak činí závěry o vlastnostech náhodných chyb.Při těchto odhadech využijeme poznatky uvedené v odstavci 2.5.
Předpokládejme, že opakovaným měřením za stejných podmínek jsme získali soubor nhodnot xi = x1, x2, ..... xn. Prvním úkolem je získat nejsprávnější odhad skutečné hodnotyměřené veličiny. Za předpokladu, že náš soubor představuje náhodný nevychýlený výběrze základního souboru, nabízí se možnost považovat za nejsprávnější tu hodnotu, která sev souboru nejčastěji opakuje. Odpovídá ji maximum v normálním Gaussově rozdělení. Zmatematického vyjádření tohoto rozdělení lze dokázat, že nejsprávnějším odhademskutečné hodnoty je aritmetický pr ůměr x ze všech naměřených hodnot xi, který jsmev odstavci 2.5 označili jako výběrový průměr (2.28):
xx
n
ii
n
= =∑
1 . (3.1)
Dokázat lze i tvrzení, že čím větší je počet měření, tím více se hodnota aritmetickéhoprůměru přiblíží ke skutečné hodnotě měřené veličiny.Velikost náhodné chyby zřejmě souvisí s tím, jak jsou jednotlivé naměřené hodnoty xi
rozptýleny okolo hodnoty aritmetického průměru x . Je zřejmé, že čím přesnějšímměřidlem budeme popisované měření délky provádět, tím méně budou naměřené hodnotyrozptýleny kolem hodnoty aritmetického průměru a křivka rozdělení bude štíhlejší. Protoje základem pro kvantitativní vyjádření velikosti náhodné chyby nejlepší odhadsměrodatné odchylky základního souboru (2.37), který v tomto případě nazývámesměrodatná odchylka s(x) jednoho měření veličiny x, a která je daná vztahem

24
( )( )
s x
x x
n
ii
n
=−
−=∑
1
2
1 . (3.2)
.Z hlediska dosažení vyšší přesnosti odhadu skutečné hodnoty měřené veličiny jevýhodnější využít skutečnosti, že opakovaná měření budeme vyhodnocovat pomocíaritmetického průměru a proto pro vyčíslení náhodné chyby použijeme nejlepší odhadsměrodatné odchylky výběrového průměru (2.38), který označíme jako směrodatnouodchylku aritmetického průměru ( )s x , a kterou počítáme ze vztahu
( )( )( )
2
1
1
n
ii
x xs x
n n=
−=
−
∑ . (3.3)
Pro stanovení velikosti náhodné chyby se jako nejjednodušší možnost jeví prohlásit zanáhodnou chybu s(x), resp. ( )s x . Abychom posoudili praktický význam takového kroku,
vraťme se k obr. 2.3. Jednoduchou integrací funkce (2.17) lze ukázat, že plocha podkřivkou normálního rozdělení v intervalech ( ),µ σ µ σ− + představuje asi 68% z celkové
plochy pod touto křivkou. Pak pro dostatečně velká n platí, že
( )( ) ( )( ) 0,68i iP x s x x x s x − < < + = , (3.4)
neboli že pravděpodobnost, že skutečná hodnota x měřené veličiny leží v intervalu
( ) ( )( ),i ix s x x s x− + (3.5)
je 68 %, resp. že riziko, že správná hodnota leží mimo tento interval je 32 %. Obdobnétvrzení platí pro interval okolo hodnoty aritmetického průměru
( ) ( )( ),x s x x s x− + ,
(3.6)
který je ovšem užší, protože platí vztah
( ) ( )s xs x
n= . (3.7)
V řadě případů však je riziko 32% toho, že skutečná hodnota měřené veličiny leží mimointerval daný (3.5) nebo (3.6) nepřijatelně velké a interval je proto nutné nějakýmdefinovaným způsobem rozšířit. Pokud je splněn předpoklad o dostatečně velkém počtu
25
měření n (v praxi stačí 50n ⟩ ), můžeme k tomu využít vlastností normálního rozdělení.Jednoduše lze odvodit, že pro dvakrát rozšířený interval okolo aritmetického průměru xpřibližně platí
( )( ) ( )( )2 2 0,95P x s x x x s x − ⟨ ⟨ + = , (3.8)
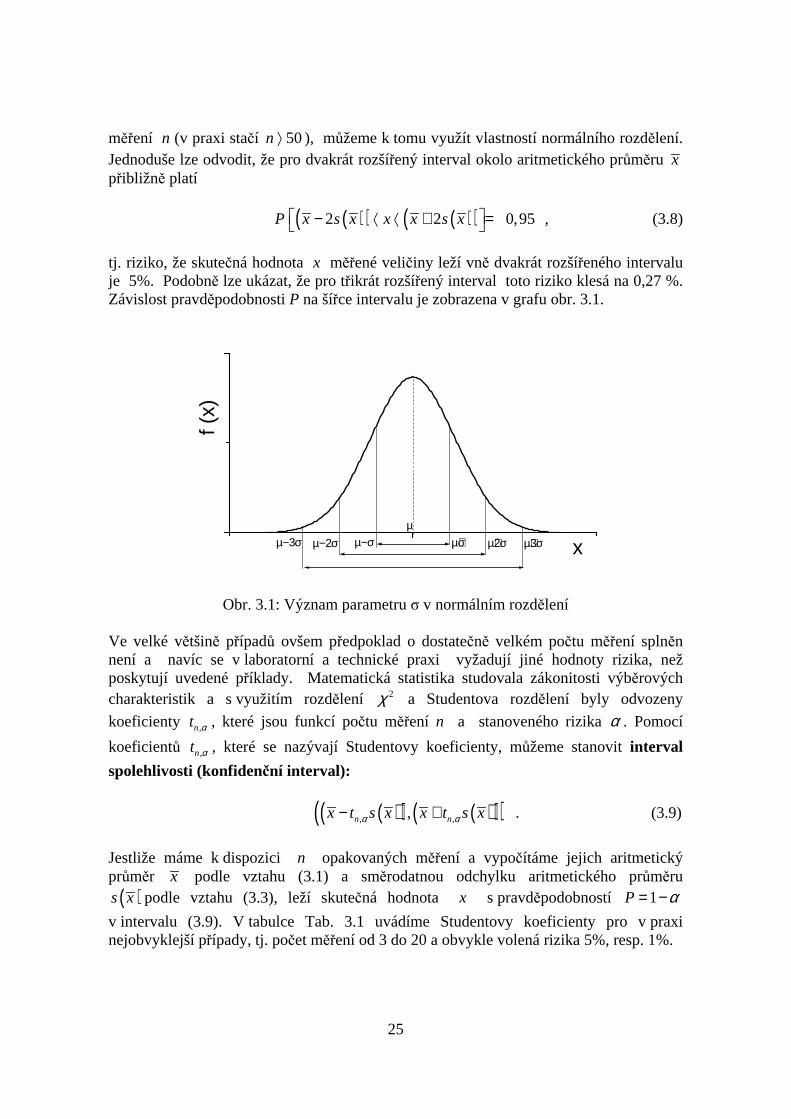
tj. riziko, že skutečná hodnota x měřené veličiny leží vně dvakrát rozšířeného intervaluje 5%. Podobně lze ukázat, že pro třikrát rozšířený interval toto riziko klesá na 0,27 %.Závislost pravděpodobnosti P na šířce intervalu je zobrazena v grafu obr. 3.1.
xµ
µ−2σµ−3σ µ+σ µ+3σµ+2σµ−σ
f (x)
Obr. 3.1: Význam parametru σ v normálním rozdělení
Ve velké většině případů ovšem předpoklad o dostatečně velkém počtu měření splněnnení a navíc se v laboratorní a technické praxi vyžadují jiné hodnoty rizika, nežposkytují uvedené příklady. Matematická statistika studovala zákonitosti výběrovýchcharakteristik a s využitím rozdělení 2χ a Studentova rozdělení byly odvozeny
koeficienty ,nt α , které jsou funkcí počtu měření n a stanoveného rizika α . Pomocí
koeficientů ,nt α , které se nazývají Studentovy koeficienty, můžeme stanovit interval
spolehlivosti (konfidenční interval):
( )( ) ( )( )( ), ,,n nx t s x x t s xα α− + . (3.9)
Jestliže máme k dispozici n opakovaných měření a vypočítáme jejich aritmetickýprůměr x podle vztahu (3.1) a směrodatnou odchylku aritmetického průměru
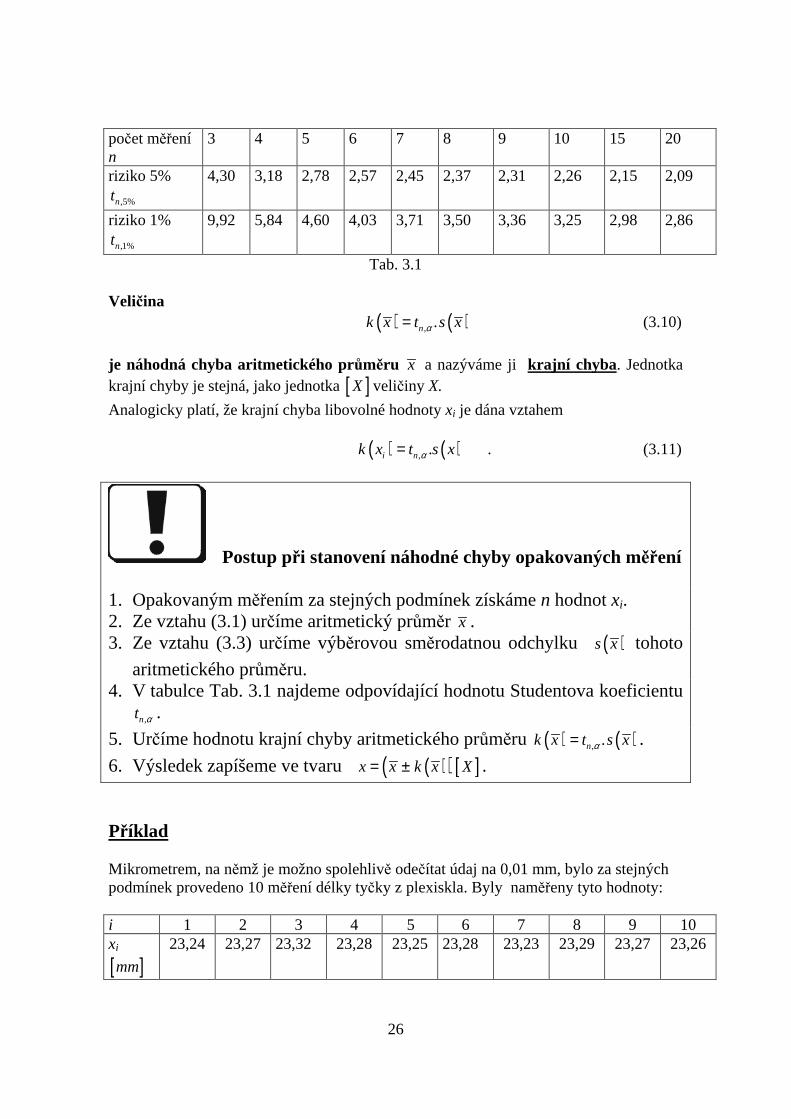
( )s x podle vztahu (3.3), leží skutečná hodnota x s pravděpodobností 1P α= −v intervalu (3.9). V tabulce Tab. 3.1 uvádíme Studentovy koeficienty pro v praxinejobvyklejší případy, tj. počet měření od 3 do 20 a obvykle volená rizika 5%, resp. 1%.
26
počet měřenín
3 4 5 6 7 8 9 10 15 20
riziko 5%
,5%nt4,30 3,18 2,78 2,57 2,45 2,37 2,31 2,26 2,15 2,09
riziko 1%
,1%nt9,92 5,84 4,60 4,03 3,71 3,50 3,36 3,25 2,98 2,86
Tab. 3.1
Veličina ( ) ( ), .nk x t s xα= (3.10)
je náhodná chyba aritmetického průměru x a nazýváme ji krajní chyba. Jednotkakrajní chyby je stejná, jako jednotka [ ]X veličiny X.
Analogicky platí, že krajní chyba libovolné hodnoty xi je dána vztahem
( ) ( ), .i nk x t s xα= . (3.11)
Postup při stanovení náhodné chyby opakovaných měření
1. Opakovaným měřením za stejných podmínek získáme n hodnot xi.2. Ze vztahu (3.1) určíme aritmetický průměr x .3. Ze vztahu (3.3) určíme výběrovou směrodatnou odchylku ( )s x tohoto
aritmetického průměru.4. V tabulce Tab. 3.1 najdeme odpovídající hodnotu Studentova koeficientu
,nt α .
5. Určíme hodnotu krajní chyby aritmetického průměru ( ) ( ), .nk x t s xα= .
6. Výsledek zapíšeme ve tvaru ( )( ) [ ]x x k x X= ± .
Příklad
Mikrometrem, na němž je možno spolehlivě odečítat údaj na 0,01 mm, bylo za stejnýchpodmínek provedeno 10 měření délky tyčky z plexiskla. Byly naměřeny tyto hodnoty:
i 1 2 3 4 5 6 7 8 9 10xi
[ ]mm
23,24 23,27 23,32 23,28 23,25 23,28 23,23 23,29 23,27 23,26

27
1. Aritmetický průměr naměřených hodnot je x = 23,269 mm.2. Výběrová směrodatná odchylka aritmetického průměru je ( )s x = 0,0186 mm.
3. Pro počet měření n = 10 a zvolené riziko α = 5 % je Studentův koeficient t10 , 5% = 2,26.4. Hodnota krajní chyby je aritmetického průměru je ( )k x = 0,0186 mm.
5. Výsledek měření: x = ( 23,269 ± 0,019 ) mm.
Poznámka
Hodnotu chyby uvádíme nanejvýš na dvě platné cifry, tj. do výsledku měření zapisujemehodnotu krajní chyby vypočítanou ze vztahu (3.10) zaokrouhlenou podle tohoto pravidla.Hodnotu výsledku měření zaokrouhlujeme tak, aby poslední platná cifra výsledku byla nastejném desetinném místě, jako poslední platná cifra chyby.
Kontrolní otázky
1. Pro soubor náhodných hodnot z příkladu 1. na str. 17 určete velikost krajní chybyaritmetického průměru pro riziko 1α = %.
2. Napětí na rezistoru, kterým protéká proud, kolísá v důsledku náhodných změn jehoodporu. Měřením byly zjištěny tyto hodnoty napětí:
i 1 2 3 4 5U[ ]V 0,5231 0,5228 0,5233 0,5226 0,5229
Určete nejpravděpodobnější hodnotu napětí U a její krajní chybu ( )k U pro riziko
a ) 5α = %, b) 1α = %.

28
3.2 Systematické chyby
Systematické chyby souvisejí obvykle s použitou metodu či měřícími přístroji nebo sesamotným pozorovatelem. Říkáme, že jsou způsobeny kontrolovatelnými vlivy.
Příklad: V případě vážení na rovnoramenných vahách může systematickou chybuzpůsobovat odchylka od rovnoramennosti vah, odchylka v hmotnosti závaží,nezapočítaná oprava na rozdíl vztlaku závaží a předmětu ve vzduchu apod.
Vzniklé systematické chyby zkreslují výsledek při opakovaném měření konaném zastejných podmínek vždy stejným způsobem, tj. buď výsledek stále zvětšují nebo stálezmenšují. Teoreticky lze kontrolovatelné vlivy zjistit a ohodnotit pomocí přesnějšíchpřístrojů, eventuálně korekční metody, a proto by v principu bylo možné systematickéchyby vyloučit. V praxi je tento požadavek těžko uskutečnitelný a velikost chyb sesnažíme alespoň přibližně odhadnout.Systematickou chybu hodnoty x označujeme m(x). Tato absolutní chyba má častocharakter maximální chyby. Její význam je takový, že chyba, které se při měřeníhodnoty x skutečně dopustíme, je vždy menší nebo nejvýš rovna chybě ( )m x . V
některých případech je výhodnější pracovat s relativní systematickou chybou mr(x)měřené hodnoty.
Hlavní zdroje systematických chyb jsou:
a) omezená přesnost přístrojůJejí příčinu je třeba hledat v nedokonalém a ne zcela přesném provedení měřicíchpřístrojů. Typickým příkladem může být nedokonalost a nepřesnost stupnic. Tyto chybyby bylo možno odstranit nebo alespoň podstatně zmenšit použitím dokonalejších zařízení,ale v praxi by používání velmi přesných přístrojů bylo často nákladné a těžkorealizovatelné. Proto se snažíme v některých případech dosáhnout větší přesnosti, a tímzmenšení systematické chyby, kalibrací přístroje před měřením. Kalibrace spočívá vporovnání údajů přístroje s údaji podstatně přesnějšího měřidla a výsledkem jestanovení hodnoty korekčního faktoru či korekční křivky, pomocí kterých naměřenéhodnoty opravujeme.
Příklad:Mohrovými vážkami byla při teplotě 20 OC naměřena hustota vody s =́ 997 kg.m-3.Tabulková hodnota hustoty vody při této teplotě, což je hodnota naměřená přesnějšímměřením, je s = 998,205 kg.m-3. Opravný koeficient k, kterým musíme násobit každouhodnotu hustoty naměřenou těmito vážkami, je dán vztahem
′=
s
sk .
V našem případě k = 1,0012.
Pro některé sériově vyráběné přístroje výrobce udává jejich největší přípustnou(maximální) chybu m(x). Tak zaručuje, že hodnota veličiny x naměřená přístrojem

29
bude v celém jeho rozsahu mít chybu zpravidla menší, ale nanejvýš rovnou maximálníchybě. Maximální chyba je elektrické ukazovací (ručkové, analogové) měřicípřístroje výrobcem udávána pomocí třídy přesnosti Tp. Údaj o třídě přesnosti jeobvykle uveden v pravém dolním rohu pod stupnicí přístroje a to ve formě čísliceumístěné nad značkou udávající, je-li přístroj určen pro střídavý nebo stejnosměrnýproud. Podle platné normy je třída přesnosti číslo z řady 0,1; 0,2; 0,5; 1; 1,5; 2,5; 5.Největší přípustnou chybu naměřené hodnoty lze pak stanovit ze vztahu
( ) max
1
100 pm x T x= , (3.12)
kde xmax je rozsah přístroje. Největší přípustná chyba je stejná, ať měříme vkterékoliv části rozsahu, zatímco relativní chyba je tím větší, čím menší je měřenáhodnota vzhledem k maximální hodnotě v rozsahu. Proto se s elektrickými měřicímipřístroji snažíme měřit tak, aby výchylka byla pokud možno ve třetí třetině rozsahu.Měříme-li hodnotu právě rovnou hodnotě rozsahu, je relativní chyba měřenéhodnoty nejmenší, a je právě rovna třídě přesnosti vyjádřené v procentech.
Příklad:Měříme s voltmetrem třídy přesnosti Tp = 0,5 na rozsahu 0 - 30 V. Naměřené hodnoty
napětí jsou U1 = 15 V, U2 = 30 V. Maximální chyby vyplývající z třídy přesnostijsou pro obě naměřené hodnoty stejné, protože byly měřeny na jednom rozsahu a jejichvelikosti vypočteme ze vztahu (3.2) ( ) ( )1 2m U m U= = 0,01 . 0,5 . 30 = 0,15 V .
Relativní chyby ( )1rm U = 0,15 / 15 = 0,01 ,
( )2rm U = 0,15 / 30 = 0,005 .
Hodnotu napětí 15 V měříme s relativní chybou 1%, hodnotu 30 V, která je maximálníhodnotou rozsahu 0 - 30 V, měříme s relativní chybou 0,5 %, která je číselně rovnatřídě přesnosti.
U číslicových (digitálních) elektrických měřicích přístrojů má chyba dvě složky:základní chyba je chyba přístroje při měření v referenčních podmínkách (obvykleteplota, vlhkost vzduchu apod.) stanovených výrobcem přístroje a přídavná chyba jechyba vznikající při nedodržení referenčních podmínek. V laboratorních podmínkách seobvykle uplatňuje jen základní chyba. Základní chyba číslicových voltmetrů ačíslicových multimetrů se vyjadřuje dvěma způsoby a chyba se skládá ze dvou složek.
První způsob určení základní chyby: chybou mr(x) v procentech měřené hodnoty x achybou m/
r(x) v procentech rozsahu (maximální hodnoty rozsahu).Druhý způsob určení základní chyby: chybou mr(x) v procentech měřené hodnoty x apočtem kvantizačních kroků N, což je počet jedniček (digitů) nejnižšího místačíslicového zobrazovače na zvoleném rozsahu. Předem je třeba zjistit z rozsahu a počtumíst jeho zobrazovače, jaká hodnota měřené veličiny odpovídá 1 digitu. Tento tvar

30
vyjádření přesnosti se používá zejména v zahraniční literatuře, kde údaj přesnosti mánapř. tvar 0,02% rdg. 2 digits± ± , kde zkratka rdg.(reading) znamená čtená (měřená)hodnota.
Příklad: Dva číslicové voltmetry s maximálním údajem 9999 jsou použity na rozsahu0-10 V a měřený údaj je v obou případech 5,000V. Jejich chyby jsou specifikoványnásledovně:pro první voltmetr: 0,01 % čtení + 0,01 % rozsahu,pro druhý voltmetr: 0,01 % čtení + 2 kvantovací kroky (nebo 0,01% rdg.+ 2 digits).Pro první voltmetr je maximální chyba měřené hodnoty
m(U) = 1.10-4. 5 V + 1.10-4 .10V = 1,5 mV.Pro druhý voltmetr je maximální chyba měřené hodnoty
m(U) =1.10-4. 5 V + 2.10-3V= 2,5 mV.
Jestliže výrobce neudává informace o přesnosti měřidla, musíme sami chybuměřidla odhadnout. Obvykle chybu mx odhadujeme tak, že ji položíme rovnu částinejmenšího dílku na stupnici přístroje, kterou jsme schopni ještě rozlišit. Zpravidla tobývá 1/2 nejmenšího dílku nebo celý dílek. Tento způsob určení chyby m(x) souvisí stím, že optimální hodnota nejmenšího dílku stupnice by měla být výrobcem stanovenatak, abychom mohli na stupnici odečítat hodnoty naměřené veličiny v souladu s citlivostía přesností daného přístroje nebo měřidla. Takto odhadnutou chybu čtení považujemeza největší přípustnou chybu m(x) a opět ji používáme k vyjádření systematické chyby aneurčitosti. Hodnoty maximálních chyb pro nejčastěji užívaná měřidla jsou v Tab.3.2.
b) použitá metodaSystematická chyba vzniká nepřesností, nedokonalostí nebo nevhodností použitéhozpůsobu měření. Například při vážení na vzduchu vzniká systematická chyba určenéhmotnosti jako důsledek nezapočtení různého vztlaku působícího na závaží a váženýpředmět, jestliže mají rozdílné objemy. Tyto chyby lze odstranit nebo potlačit buďzměnou metody nebo vyloučením chyby výpočtem (oprava na vztlak).
měřidlo m(x) váhy praktikantské (0,01 - 0,1) g váhy analytické (0,01 - 0,001)g měřítko pásové (0,5 - 1) mm měřítko posuvné 0,1 mm mikrometr 0,01 mm stopky mechanické 0,3 s teploměry (0,5 - 1) nejmenší dílek Tab. 3.2
c) osobní chybyJednotliví pozorovatelé se obvykle dopouštějí chyb, které souvisejí s různou smyslovoukoordinací a jsou pro ně charakteristické. Uplatňují se např. při měření časovýchintervalů, odečtu při zrcátkové metodě apod. Lze je vyloučit tím, že subjektivní měření

31
nahradíme objektivním, např. časový interval měříme místo stopek pomocí čidlaspojeného s počítačem.
Chyby z uvedených zdrojů se skládají do výsledné systematické chyby. Způsob skládánízávisí na konkrétním měření a nelze jej zcela zobecnit. Často chyba z jednoho zdrojesvoji velikostí řádově převyšuje chyby z ostatních zdrojů a ty můžeme zanedbat. Pokudjsou velikosti systematických chyb z různých zdrojů řádově stejné, lze s dobrou přesnostípovažovat za výslednou systematickou chybu jejich součet. V mnoha případech, zvláštěpři složitějších měřeních, nelze dostatečně určit a ohodnotit zdroje systematických chyb,které se podílejí na nepřesnosti výsledku, a nelze proto provést přesné oceněnísystematických chyb. Vždy se však snažíme alespoň o řádový odhad systematické chyby.
Systematické chyby mohou mít několik různých zdrojů:nedokonalost měřicího přístroje, chybu metody, osobní chyby, případněchyby způsobené dalšími vlivy.Chybu způsobenou nedokonalostí měřicího přístroje obvykle udává výrobcepřístroje. U analogových (ručkových) přístrojů chybu charakterizuje třídapřesnosti, u digitálních přístrojů má chyba dvě složky a její základní hodnotuurčujeme postupem popsaným na str. 25. Chybí-li údaj o přesnosti přístroje,určujeme chybu odhadem (z nejmenšího dílku stupnice apod.).Chybu metody charakterizujeme aditivním nebo multiplikativním faktorem,kterým korigujeme výsledek měření.Chybu osobní započítáváme do výsledné systematické chyby.
Kontrolní otázky
1. Voltmetrem s třídou přesnosti Tp = 0,5 a rozsahem 120 V byl naměřeno napětí U = 80V.Určete systematickou chybu m(U) a relativní systematickou chybu mr(U) tohoto údaje.
2. Digitální ampérmetr s maximálním údajem 9999 byl použit k měření na rozsahu1,0000 Aa měřený údaj byl I = 0,2000 A. Chybu přístroje udává výrobce ve tvaru: 0,2 % čtení +2 digity. Určete systematickou chybu toho údaje.
3. Příkon cca 400 W má být měřen wattmetrem s rozsahem 500 W. Jaká může býtmaximálně třída přesnosti wattmetru, aby relativní chyba údaje nepřesáhla 1,5 % ?

32
3.3 Úplná chyba
Výsledkem hodnocení přesnosti určované veličiny x by mělo být stanovení úplné chybyměření e(x), která, jak jsme zatím konstatovali, je složena ze systematické a náhodnéchyby. Systematickou chybu veličiny jsme v odstavci 3.2 označili m(x) a uvedli jsmezpůsoby jejího stanovení. Náhodnou chybu veličiny při opakovaném měření jsmev odstavci 3.1 charakterizovali směrodatnou odchylkou aritmetického průměru ( )s x ,
obvykle ale krajní chybou ( )k x aritmetického průměru. Úplnou chybu ( )e x
aritmetického průměru veličiny x měřené opakovaně určujeme na základě zákonahromadění chyb ze vztahu
( ) ( ) ( )2 2e x k x m x= + , (3.13)
případně z méně přesného vztahu
( ) ( ) ( )e x k x m x= + . (3.14)
Pro úplnou chybu jedné naměřené hodnoty xi ze souboru naměřených hodnot x1, x2,..xn
veličiny x platí analogický vztah
( ) ( ) ( )ie x k x m x= + (3.15)
Při přípravě, realizaci a vyhodnocení měření určité veličiny je třeba přihlédnout khlavním zdrojům chyb a posoudit, které budou mít rozhodující význam. Ve většinělaboratorních i technických měření obvykle převažuje systematická chyba nad náhodnou,vliv náhodné chyby je tudíž zanedbatelný a měření se provádí pouze jednou, nikoliopakovaně. V takovém případě je ( ) ( )e x m x≈ .
V případě, že měříme přesným přístrojem a systematická chyba je proto velice malá,může být velikost náhodné chyby srovnatelná s velikostí chyby systematické a její vliv napřesnost výsledku nezanedbatelný. Podobná situace může nastat i v případě použití málopřesného přístroje, kdy silné rušivé vlivy mohou způsobovat významné náhodné kolísáníměřených hodnot. V takových případech je třeba provést opakované měření. Čím většípočet měření provedeme, tím podle vztahu (3.3) bude směrodatná odchylka ( )s x a tudíž
i krajní chyba ( )k x menší. Měření opakujeme tolikrát, abychom snížili hodnotu ( )k x
na několik desetin hodnoty systematické chyby m(x). Dosáhneme tak potlačení vlivunáhodné chyby. Pouze v případech, kdy hodnoty systematické a náhodné chyby veličinyjsou řádově stejné, je nutné uvažovat součet obou chyb podle (3.13) nebo (3.14).
Příklad: Měření délky l předmětu bylo prováděno mikrometrem, jehož systematickáchyba je m(l) = 0,01 mm. Z dvaceti naměřených hodnot délky byla krajní chyba
aritmetického průměru ( )k l = 0,01 mm. Velikosti obou chyb jsou srovnatelné a proto

33
úplná chyba stanovené délky je ( ) 0,01 0,01 0,02e l = + = mm. Kdybychom se zabývali
chybou pouze jednoho měření, pak směrodatná odchylka s(l) jednoho měření je podle
vztahu (3.7) ( ) ( )s l s l n= , kde n = 20, přibližně 4,5 krát větší. Ve stejném poměru se
zvětší i krajní chyba jednoho měření ( ) ( )4,5k l k l≈ . Pro jedno měření je ( )k l ≈ 0 045,
mm, tj. přibližně 4,5 krát větší než hodnota systematické chyby mikrometru m(l) = 0,01mm.V tomto případě má proto smysl provádět opakovaná měření. Jestliže chceme snížitpodíl náhodné chyby například pětkrát, je třeba provést 25 měření.
3.4 Chyby nepřímo měřených veličin
Až doposud jsme se uvažovali taková měření, kde hodnota naměřené veličiny je přímovýsledkem měření. Nazýváme ji proto přímo měřenou veličinou. Jestliže určujemehodnotu veličiny ze vztahu, ve kterém vystupují dvě nebo více měřených veličin,hovoříme o určení nepřímo měřené veličiny. Pro nepřímo měřenou veličinu musímerovněž stanovit nebo odhadnout chybu. Tato chyba bude mít stejné vlastnosti jakochyba přímo měřené veličiny, tj. bude se skládat ze složky systematické a náhodné. Jejívelikost bude záviset na hodnotách úplných chyb jednotlivých přímo měřených veličin ana tvaru funkce, která vyjadřuje závislost výsledné nepřímo měřené veličiny najednotlivých veličinách měřených přímo. Tato závislost se vyjadřuje pomocí parciálníchderivací funkce podle těchto veličin. Při určitém zjednodušení lze tvrdit, že parciálníderivace charakterizují citlivost změny funkce na změny jednotlivých veličin.Předpokládejme, že hodnotu veličiny y nelze měřit přímo, ale určujeme ji výpočtemz výsledku měření několika přímo měřených veličin x1, x2, ....xm
. Známe-li tvar funkční
závislosti y = f (x1,x2,...xm) a chyby přímo měřených veličin k(x1), k(x2),..., k(xm), lze
určit úplnou chybu k(y) ze zákona hromadění chyb, který řeší skládání chyb a to buďlineárně nebo kvadraticky. Jednodušší tvar tohoto zákona, kdy se chyby skládají lineárně,má tvar
( ) ( ) ( ) ( )1 21 2
..... mm
f f fe y e x e x e x
x x x
∂ ∂ ∂∂ ∂ ∂
= + + + . 3.16)
Chyby jednotlivých přímo měřených veličin se hromadí lineárně (ve vztahuvystupují první mocniny chyb jednotlivých veličin násobené číselnými hodnotamiderivací). Přitom předpokládáme zcela obecný případ, tj. že některé z veličin mohly býtměřeny opakovaně a některé pouze jednou. Vztah pro lineární hromadění chyb máopodstatnění zejména v případech převažujících systematických chyb a v případěmenšího počtu přímo měřených veličin. V případech, kdy se skládají převážně náhodnéchyby, je výhodné použít alternativní vztah založený na předpokladu kvadratickéhohromadění chyb. Má tvar

34
( ) ( ) ( ) ( )22 2
2 2 21 2
1 2
.... mm
f f fe y e x e x e x
x x x
∂ ∂ ∂∂ ∂ ∂
= + + + . (3.17)
Dále budeme pro zjednodušení důsledně používat lineární tvar zákona hromaděníchyb daný vztahem (3.16).
Příklad: Určení hustoty vzorku hydrostatickou metodou spočívá ve vážení vzorku navzduchu a téhož vzorku ponořeného ve vodě. Hustotu vzorku ρ vypočteme ze vztahu
( )1
Z s
Z Z
δρ δ
−= +
−,
Z ………….. hmotnost závaží vyvažující vzorek na vzduchuZ1………….. hmotnost závaží vyvažující vzorek ponořený ve voděs ……………hustota vodyδ ………….. hustota vzduchu.
Chyby hustoty vody a vzduchu jsou proti chybám e(Z) a e(Z1) zanedbatelné a proto se vevztahu (3.16) uplatní pouze derivace
( )( )
( )( )1
2 211 1
,Z Z
s sZ ZZ Z Z Z
ρ ρδ δ∂ ∂= − = −∂ ∂− −
.
Chybu veličiny ρ určíme ze vztahu
( )( )
( ) ( )( )
( ) ( )112 2
1 1
ZZe s e Z s e Z
Z Z Z Zρ δ δ= − + −
− −
Obecný vzorec (3.16) pro hromadění chyb lze ve speciálních případech funkčníchzávislostí nahradit jednoduššími výrazy pro výpočet chyb nepřímo měřené veličiny:
Nepřímo měřená veličina je součet nebo rozdíl přímo měřených veličin:
( )y f x x ax bx= = ±1 2 1 2, , (3.18)
kde a,b jsou reálná čísla. Z lineárního tvaru zákona hromadění chyb vyplývá, že úplnáchyba veličiny y je
( ) ( ) ( )1 2e y a e x b e x= + . (3.19)

35
Pro prostý součet a rozdíl dvou veličin
( )y f x x x x= = ±1 2 1 2, (3.20)
se (3.16) redukuje na následující vztah
( ) ( ) ( )1 2e y e x e x= + . (3.21)
V případě, kdy určujeme chybu veličiny, která je rovna součtu nebo rozdílu dvouveličin, je její výsledná absolutní chyba tvořena součtem absolutních chyb přímoměřených veličin.Pro zpřesnění výsledku má smysl zpřesňovat měření té veličiny, jejíž absolutníchyba je největší.
Příklad: Určujeme tloušťky stěny dutého válce. Vnější průměr válečku d1 = 12,1 mm,vnitřní průměr d2 = 8,1 mm, rozměry byly změřeny posuvným měřítkem. Chyba údajeposuvného měřítka je pro oba rozměry stejná, m(d1) = m(d2) = 0,1 mm. Označíme-litloušťku stěny x, pak pro ni platí
( )x d d= −1
2 1 2 .
Chyba v určení x je podle vztahu (2.12) rovna
( ) ( ) ( )1 2
1 10,2 0,1
2 2e x e d e d mm= + = = .
Tloušťka stěny x je určena s chybou 0,1 mm. Kdybychom chtěli zpřesnit měření, jetřeba zpřesnit měření obou rozměrů d1 i d2, protože se podílejí na výsledné chybě
rovným dílem.
Nepřímo měřená veličina je součin nebo podíl přímo měřených veličin:
( )y f x x ax xm n= =1 2 1 2, (3.22)
kde a, m, n jsou reálné konstanty. Z lineárního tvaru zákona hromadění chyb vyplývá, žeúplná relativní chyba veličiny y je
( ) ( ) ( )1 2r r re y m e x n e x= + . (3.23)
Pro prostý součin nebo podíl dvou veličin x1, x2 se výraz (3.23) redukuje na vztah
( ) ( ) ( )1 2r r re y e x e x= + . (3.24)

36
V případě, kdy určujeme chybu veličiny, která je rovna součinu nebo podílu dvouveličin, je její výsledná relativní chyba tvořena součtem relativních chyb přímoměřených veličin.Pro zpřesnění výsledku má smysl zpřesňovat měření té veličiny, jejíž relativní chybaje největší nebo s ohledem na (3.23) se ve vztahu (3.22) vyskytuje ve vyšší mocnině.
Příklad: Určujeme chybu elektrického odporu R spotřebiče pro proud I = 100 mA schybou m(I) = 0,5 mA a napětí na spotřebiči U = 200 V s chybou m(U) = 2 V. Protožeodpor R souvisí s proudem I a napětím U vztahem R = U/I, je úplná chyba odporu Rpro jedno měření proudu a napětí
( ) ( )e R m R=a pro relativní chybu podle vztahu (2.17) platí
( ) ( ) ( )r r re R e U e I= + .
Po dosazení dostaneme
( ) 2 0,50,015
200 100re R = + = .
Při výpočtu jsme využili definiční vztah pro relativní chybu veličiny. Relativní chybavelikosti elektrického odporu činí 1,5 %. Z výpočtu vyplývá, že hodnota napětí jezatížena dvakrát větší relativní chybou než hodnota proudu. Zlepšení přesnosti výsledkuby bylo možno dosáhnout např. použitím voltmetru s lepší třídou přesnosti.
Nepřímo měřená veličina je funkcí dvou a více přímoměřených veličin. Chyba nepřímo měřené veličiny závisí na chybách veličinměřených přímo, přičemž míra této závislosti je vyjádřena parciální derivacífunkční závislosti podle příslušné veličiny. Úplná chyba nepřímo měřenéveličiny se počítá z kvadratického zákona hromadění chyb nebo méněpřesněji z lineárního zákona hromadění chyb.Absolutní chyba součtu nebo rozdílu veličin je rovna součtu absolutníchchyb těchto veličin.Relativní chyba součinu nebo podílu veličin je rovna součtu relativních chybtěchto veličin.

37
Kontrolní otázky:
1. Hustota tělesa ve tvaru koule byla určena jako podíl hmotnosti M a objemu V.Hmotnost M byla určena jedním vážením s chybou m(M) = e(M). Objem byl vypočítánz výsledku n měření poloměru r koule, jejichž výsledkem byl aritmetický průměrpoloměru r a jeho krajní chyba ( )k r . Měřidlo, kterým byl poloměr měřen, mělo
systematickou chybu m(r). Objem koule byl vypočítán ze vztahu 34
3V rπ= . Napište
vztah pro výpočet celkové chyby ( )e ρ hustoty koule.
2. Magnetická indukce v mezeře mezi póly elektromagnetu byla měřena pomocí měřenívýchylky ψ cívky protékané proudem I zavěšené na pružném závěsu. Velikost indukcebyla vypočítána ze vztahu
cos
KB
I
ψψ
= .
Proud I byl změřen s chybou e(I) a úhel výchylky ψ s chybou ( )e ψ . Napište vztah pro
určení chyby e(B).
3.5 Výsledek měření
Z předchozích odstavců vyplývá, že výsledkem měření je nejen hodnota veličiny, alesoučasně i její chyba. Při zpracování měření je proto třeba dodržet určitý postup, kterýshrnujeme do několika bodů.
1) Ke každé přímo měřené veličině xi stanovte nebo alespoň odhadněte jejísystema- tickou chybu m(xi).
2) Je-li některá veličina, označme ji x, měřena opakovaně, stanovte jejíaritmetický průměr x , směrodatnou odchylku ( )s x , případně ( )k x . Posuďte, která z
chyb, náhodná nebo systematická, má rozhodující podíl na výsledné chybě veličiny x.
3) Je-li úkolem měření stanovit nepřímo měřenou veličinu y, použijte provýpočet její chyby buď obecný vztah (3.16) nebo (3.17) nebo některý z konkrétních vztahů (3.19), (3.21), (3.23), (3.24). Přitom za úplné chyby e(xi) jednotlivých

38
přímo měřených veličin xi dosazujte jejich systematické chyby m(xi), eventuálně součet ( ) ( )im x k x+ , pokud některé z nich byly měřeny opakovaně. Výpočet
chyb zjednodušte tak, že ve výpočtu zanedbejte ty členy, které jsou řádově menší než členy ostatní.
Zápis výsledkuPři zápisu výsledné hodnoty veličiny je třeba vždy vyjádřit výslednou hodnotuveličiny ve tvaru ( x ± e (x)) [X]. Symbol [X] označuje jednotku veličiny X.
Příklad: Pásovým měřítkem byla naměřena délka předmětu l = 453 mm. Maximálníchyba tohoto údaje odpovídající jednomu nejmenšímu dílku stupnice je 1 mm, a proto jesprávný zápis výsledku l = ( 0,453 ± 0,001 ) m .
Chyba je v tomto případě vyjádřena jednou platnou cifrou ( jako první platná cifra seoznačuje první nenulová cifra počítaje odleva).
Chyby se zaokrouhlují nejvýš na dvě cifry, a hodnota veličiny se zaokrouhlí tak,aby se řád poslední cifry hodnoty veličiny i chyby shodoval.
Příklad: Měřením byla stanovena vlnová délka světla helium-neonového laseruλ = 632,84 nm s chybou e(λ) = 1, 29 nm. Chybu zaokrouhlíme na dvě platné cifry atomu přizpůsobíme i poslední cifru hodnoty vlnové délky.
Zápis výsledku měření vlnové délky je λ = (632,8 ± 1,3).10-9 m.

39
4 Nejistoty měření
4.1 Zavedení nejistot měření
V 80. letech minulého století si potřeby vědy a techniky stále více vyžadovalyvšestrannější přístup k hodnocení přesnosti měření. Mezinárodní komise formulovalanový přístup, který se formálně projevuje tak, že nehovoříme o chybě měření, ale onejistotě měření. Tento nový přístup nepopírá pojem chyby měření, ale zobecňuje jej.Řada postupů je při vyhodnocení nejistot měření formálně podobná postupům popsanýmv kapitole 3.Zatímco chyba charakterizuje rozdíl naměřené hodnoty od skutečné (pravé) hodnoty,nejistota měření charakterizuje rozsah (interval) hodnot měřené veličiny kolemvýsledku měření, který podle očekávání obsahuje skutečnou hodnotu měřenéveličiny. Nejistota se stanoví nejen pro výsledek měření, ale také pro měřidla,použité konstanty, pro korekce apod.
Základem určování nejistot je statistický přístup a to jak pro chyby náhodné, takchyby systematické. Předpokládá se určité rozdělení pravděpodobnosti, které popisuje,jak se mohou naměřené hodnoty veličiny x odchylovat od skutečné hodnoty. Základnícharakteristikou nejistoty je standardní nejistota označovaná písmenem u, a její mírouje směrodatná odchylka udávané hodnoty veličiny. Standardní nejistota udává rozsahhodnot okolo naměřené (stanovené) hodnoty, ve kterém se s danou pravděpodobnostínachází skutečná hodnota. Standardní nejistoty se podle zdrojů, z kterých vznikají(obdobně jako chyby), dělí na standardní nejistoty typu A a standardní nejistoty typu B.
Standardní nejistoty typu A jsou způsobovány náhodnými vlivy. Stanoví se zopakovaných měření určité hodnoty za stále stejných podmínek na základě statistickéhopřístupu a označují se uA. Nejistoty typu A se zmenšují se zvětšujícím se počtemopakovaných měření.
Standardní nejistoty typu B jsou způsobovány známými a odhadnutelnými příčinamivzniku. Standardní nejistoty typu B se označují uB. Jejich určení vychází z odhadusystematických chyb naměřených hodnot. Mohou pocházet z různých zdrojů, a přiurčitém měření je výsledná standardní nejistota typu B dána odmocninou ze součtukvadrátů nejistot od jednotlivých zdrojů s respektováním korelací (vzájemnýchzávislostí) mezi jednotlivými zdroji nejistot.Protože se stanovení nejistot typu A i B provádí na základě stejného přístupu, je možnéskládat nejistoty typu A a B. Sumací kvadrátů standardní nejistoty typu A a standardnínejistoty typu B se dostane kvadrát kombinované standardní nejistoty. Hodnotí-li sevýsledek měření standardní nejistotou, pak se neuvádějí odděleně nejistoty typu A anejistoty typu B.
2 2 2A Bu u u= + (4.1)

40
Kombinovaná standardní nejistota u udává interval či rozsah hodnot, ve kterém se spoměrně velkou pravděpodobností může vyskytovat skutečná hodnota. V praxi se všakčasto objevuje požadavek na zvýšení pravděpodobnosti (snížení rizika) a toho se dosáhnezvětšením intervalu, který pokrývá nejistota. Proto se zavádí rozšířená standardnínejistota U, která je dána vztahem U k uU= , (4.2)
kde kU je koeficient rozšíření nebo pokrytí. Rozšířená nejistota má být vždy doplněnaúdajem o velikosti kU. Velikost kU se volí 2 až 3. V poslední době se doporučuje volitkU = 2, tj. U = 2 u, což odpovídá pravděpodobnosti 95% pro normální rozdělení.Standardní nejistotu můžeme vyjadřovat v jednotkách měřené veličiny, pak hovoříme oabsolutní standardní nejistotě, nebo poměrem absolutní nejistoty a hodnoty příslušnéveličiny, který nazýváme relativní standardní nejistota. Znaménko ± se dává předčíselnou hodnotu nejistoty v případě, že se připojuje k hodnotě výsledku měření.
4.2 Stanovení standardních nejistot při přímém měření
Podobně jako v případě chyb měření, i v případě nejistot se postup při stanovenístandardních a rozšířených nejistot liší podle toho, zda se jedná o přímé nebo nepříméměření určité veličiny či veličin.
Při přímém měření se měření provádí buď jednou (při většině technických měřeních),nebo opakovaně. Při opakovaném měření se vychází se ze série měření provedených přistále stejných podmínkách a získá se n naměřených hodnot. Při jediném měření by mělabýt zaručena dostatečně malá náhodná chyba, provádí-li se opakované měření, měl by býtpočet měření nejméně 5.
Stanovení standardní nejistoty při přímém měření. Jak jsme již uvedli v odstavci 4.1,výchozí hodnotou při určování nejistot je směrodatná odchylka měřené veličiny. Jestližeopakovaným měřením veličiny X získáme n údajů x1........xn, výsledek měření budearitmetický průměr x daný vztahem (3.1), a standardní nejistota typu A je rovnavýběrové směrodatné odchylce aritmetického průměru
∑=
−−
==n
iixxA xx
nnsu
1
2)()1(
1 . (4.3)
Pokud je počet opakovaných měření menší než 10 a není možné určit kvalifikovanýodhad na základě zkušenosti, lze standardní nejistotu typu A stanovit přibližně na základěvztahu
( )x xu k s x= (4.4)
kde kx je koeficient, jehož velikost závisí na počtu měření tak, že pro počet n < 5 jehohodnota značně vzrůstá (pro n = 4 je jeho hodnota 1,7 a pro n = 3 je to již 2,5).Doporučuje se proto volit počet měření větší než 10, v krajním případě větší než 5.

41
Standardní nejistoty typu B jsou někdy označovány jako systematické nejistoty a vmnoha případech se tak projevují. Jejich určování je založeno jako v případě nejistot typuA na statistickém přístupu. Dříve, než se přistoupí k měření, je třeba najít možné zdrojesystematických chyb (nejistot typu B).
Zdroje nejistot typu B při měření (podobně jako systematické chyby) vznikají v důsledku:- nedokonalosti měřicích přístrojů a měřicí techniky,- použitých měřicích metod,- podmínek při měření,- odečtu naměřené hodnoty (ukazatel naměřené hodnoty se nachází mezi označenými dílky stupnice a jeho polohu určí experimentátor odhadem)- dalších vlivů.
Odhad standardních nejistot typu B od jednotlivých zdrojů nejistot Zi se provádínásledujícím způsobem:- odhadne se pro každý zdroj nejistoty maximální rozsah změn ±∆zmax , velikost
∆zmax se volí taková, aby její překročení bylo málo pravděpodobné (maximálně přípustná chyba nebo nejmenší dílek stupnice).- uváží se, které rozdělení pravděpodobnosti nejlépe vystihuje výskyt hodnot v intervalu ±∆zmax , aby bylo možné z mezní odchylky ∆zmax stanovit směrodatnou odchylku příslušející tomuto typu rozdělení. Je třeba se rozhodnout, jak bude rozdělena pravděpodobnost, se kterou může ovlivňující veličina nabývat jednotlivých hodnot mezi svými krajními mezemi danými ±∆zmax . Nejčastěji se předpokládá rovnoměrné rozdělení, pro které je stejná pravděpodobnost výskytu libovolné hodnoty ležící mezi krajními mezemi. V tomto případě je koeficient χ , sloužící k přepočtu mezní hodnoty
ovlivňující veličiny na směrodatnou odchylku 3χ = . Normální (Gaussovo) rozdělení se volí tehdy, je-li pravděpodobnost malých odchylek značná a velkých odchylek zanedbatelná a koeficient χ = 3.
- určí se nejistoty typu B od jednotlivých zdrojů Zi ze vztahu
uz
zB =∆ max
χ , (4.5)
kde χ udává poměr mezní odchylky ke směrodatné odchylce pro vybraný typ rozdělení.Hodnota χ nabývá obvykle hodnoty 3 , event. 3.- určí se výsledná standardní nejistota typu B veličiny X podle vztahu
2 2,
1j j
n
xB x z zj
u A u=
= ∑ , (4.6)
sčítání se provádí přes všechny zdroje Zi nejistot typu B. Odhadnuté nejistoty odjednotlivých zdrojů se ve vztahu (3.10) násobí koeficienty vypočtenými pomocí

42
funkční závislosti X = f(Z1, Z2,.....Zn). Koeficienty , jx zA (citlivostní koeficienty) se
vypočtou z relací
, jx zj
XA
Z
∂∂
= . (4.7)
Pomocí koeficientů citlivosti , jx zA lze převést jednotlivé složky nejistoty typu B na
jednotky měřené veličiny.Vztah (4.7) platí pouze za určitého předpokladu, a to tehdy, jestliže není vazba (korelace)mezi jednotlivými složkami nejistoty. Není-li tento předpoklad splněn, je třeba použítsložitější postup, který případný zájemce o tuto problematiku najde v příslušné literatuře[6], [7].Kombinovaná standardní nejistota ux se při přímém měření určuje ze vztahu
2 2x xA xBu u u= + . (4.8)
Při dosazování do vztahu (4.8) je vhodné posoudit, jestli některá složka nejistoty nemározhodující význam, a druhou je pak možno zanedbat.Pro demonstraci rozdílu při stanovení úplné chyby a kombinované standardní nejistotyuvedeme příklad analogický příkladu ze závěru odstavce 3.1:Příklad na stanovení nejistoty přímo měřené veličiny: Měření délky l předmětu byloprováděno mikrometrem 20krát. Z naměřených hodnot délky byla určena směrodatná
odchylka aritmetického průměru ( )s l = 0,01 mm. Směrodatná odchylka aritmetického
průměru je podle vztahu (4.3) rovna standardní odchylce ulA typu A. Zdrojem nejistotytypu B je pouze omezená přesnost mikrometru, a proto se pro tento případ měření určí zmaximální chyby mikrometru, která je 0,01 mm Předpokládáme symetrické rozloženíhodnot měřených mikrometrem v intervalu 0,01 mm± , a proto podle vztahu (4.5) je
0,01/ 3mmlBu = . Kombinovaná standardní nejistota je podle vztahu (4.8)
2
2 0,010,01 0,012 mm
3lu
= + =
.
Obě složky nejistot jsou v tomto případě řádově stejně velké, a proto nemůžeme anijednu z nich zanedbat.
4.3 Stanovení standardních nejistot při nepřímém měření
Situace při nepřímém měření je popsána v úvodu odstavce 3.4, tj. hodnotu veličinyurčujeme na základě vztahu, v kterém vystupuje jedna nebo více přímo měřených veličina konstanty.Nechť veličina Y je dána funkční závislostí na jedné nebo několika přímo měřenýchveličinách Xj a konstantách Vh,, u nichž neznáme přesné hodnoty. Platí
Y=f(X1,..X j..Xm.,V1…Vh,....Vp) .

43
Předpokládejme obecný případ, kdy měření se opakuje m - krát a pro i-té měření sezískají hodnoty 1 .....
i mix x přímo měřených veličin X1 …..Xm. Výslednou hodnotu y
stanovíme tak, že dosadíme výběrové aritmetické průměry přímo měřených veličin dofunkční závislostiStandardní nejistotu při nepřímém měření lze stanovit stejným obecným postupem, jako vpřípadě přímo měřené veličiny.
Stanovení standardní nejistoty při nepřímém měření veličiny lze shrnout donásledujících kroků:1. Stanovíme výběrový aritmetický průměr y podle vztahu
1 1( ,.., ... , ,..., ,... )j m h py f x x x V V V= , (4.9)
kde x j je aritmetický (výběrový) průměr j-té přímo měřené veličiny.
2. Stanovíme směrodatné odchylky ( )js x pro jednotlivé opakovaně měřené veličiny Xj
podle vztahu (4.3), které jsou totožné s nejistotami typu A, tj. Ax ju .
3. Výslednou standardní nejistotu uyA typu A určíme na základě nejistot odjednotlivých zdrojů podle vztahu
2 2
1j j
m
yA y y xj
u s A s=
= = ∑ , (4.10)
kde 1 1( .. .. , .. .. )j
j m h py
j
f X X X V V VA
X
∂∂
= jsou převodní koeficienty, jejichž hodnoty se
vypočítají dosazením hodnot x j a Vh do parciálních derivací, a které převádějí
jednotlivé nejistoty do jednotek měřené veličiny. Pro zjednodušení zde předpokládáme,že hodnoty konstant Vh nejsou ovlivněny nejistotami.Jestliže neprovádíme opakované měření, body 1 - 3 odpadají a hodnotu veličiny Ydostaneme dosazením jednou měřených hodnot veličin X1,…Xm a nejistotu typu Anepočítáme.4. Určíme všechny zdroje složek nejistoty typu B.5. Pro každý zdroj nejistoty typu B určíme krajní meze, mezi kterými by se mělanacházet jeho skutečná hodnota.6. Pro každý zdroj nejistoty zjistíme předpokládané rozdělení pravděpodobností výskytujednotlivých hodnot mezi krajními mezemi a podle typu rozdělení jim přiřadíme hodnoty
koeficientu χ ( χ = 3 pro normální rozdělení, χ = 3 pro rovnoměrné rozdělení).7. Podle vztahu (4.6) vypočteme nejistoty typu B od jednotlivých zdrojů.8. Vypočteme výslednou standardní nejistotu uyB typu B podle vztahu
2 2 2 2
1 1j j h h
m l
yB x x B V V Bj h
u A u A u= =
= +∑ ∑ , (4.11)

44
kde ,j hx V
j h
Y YA A
X V
∂ ∂∂
= =∂
jsou převodní koeficienty určené pomocí
parciálních derivací, převádějící nejistoty od jednotlivých zdrojů do jednotek určovanéveličiny.9. S použitím Gaussova kvadratického zákona šíření nejistot určíme kombinovanoustandardní nejistotu uy
2 2y yA yBu u u= + . (4.12)
10. Je-li požadavek na zvýšení pravděpodobnosti (snížení rizika) výskytu skutečnéhodnoty v intervalu (y - Uy), (y - Uy) stanovíme rozšířenou standardní nejistotu Uy,která se zavádí vztahem y y yU k u= , (4.13)
kde kU je koeficient rozšíření nebo pokrytí. Hodnoty koeficientu se obvykle volí od 2 do3, většinou se doporučuje volit kU = 2, aby pro normální rozdělení odpovídalpravděpodobnosti pokrytí cca 95%.
Je zřejmé, že v obecném případě může být správné určení nejistot měření obtížné. Jeužitečné zvážit vliv nejistot jednotlivých přímo měřených veličin a výpočet zjednodušitzanedbáním řádově menších výrazů (kvadrátů nejistot). Podobně jako při určování chybnepřímo měřených veličin, lze odvodit i zjednodušené vzorce pro určování nejistot prosoučty (rozdíly) a součiny (podíly).
Výpočet nejistot pro jednoduché případy nepřímo měřených veličin.Předpokládejme, že hodnotu veličiny Y přímo neměříme, ale určujeme ji pomocíjednou měřených hodnot x1, x2 dvou nepřímo měřených veličin X1, X2. Nejistota uyB jezároveň kombinovanou nejistotou uy, protože hodnoty přímo měřených veličin jsouměřeny pouze jednou. Pro kombinovanou nejistotu uy dostaneme
2 2
2 21 2
1 2y B B
Y Yu u u
X X
∂ ∂∂ ∂
= +
, (4.14)
kde pro přehlednost píšeme BBxBBx uuuu 21 21, ≡≡ .
Nepřímo měřená veličina je lineární kombinace přímo měřených veličin
( ) 2121, bXaXXXfY ±== , (4.15)
kde a,b jsou reálná čísla. Z kvadratického zákona šíření nejistot, vztah vyplývá, žekombinovaná standardní nejistota veličiny Y je
2 2 2 21 2y B Bu a u b u= + . (4.16)

45
V případě, kdy určujeme nejistotu veličiny, která je rovna součtu nebo rozdílu dvouveličin, je její výsledná nejistota rovna odmocnině součtu kvadrátů nejistot přímoměřených veličin.Pro zpřesnění výsledku má smysl zpřesňovat měření té veličiny, jejíž absolutnínejistota je největší.
Příklad: Určujeme tloušťky stěny dutého válce. Vnější průměr válečku d1 = 12,1 mm,vnitřní průměr d2 = 8,1 mm, rozměry byly změřeny posuvným měřítkem. Chyba údajeposuvného měřítka je pro rozměry stejná, m1 = m2 = 0,1 mm. Předpokládáme-li, žehodnoty jsou v rozmezí ± 01, mm rozloženy rovnoměrně, pak podle vztahu (4.5)
1 2
0,1mm
3B Bu u= = ,
neboť pro rovnoměrné rozdělení hodnot platí, že χ = 3 .Označíme-li tloušťku stěny x, pak pro ni platí
( )x d d= −1
2 1 2 .
Nejistota určení x je podle vztahu (4.16) rovna2 2
2 21 2
1 1 1 0,1 0,10.041mm
4 4 2 3 3x B Bu u u
= + = + =
.
Tloušťka stěny x je určena s nejistotou 0,041 mm. Kdybychom chtěli zpřesnit měření, jetřeba zpřesnit měření obou rozměrů d1 i d2, protože se podílejí na výsledné nejistotě
rovným dílem.
Nepřímo měřená veličina je mocnina přímo měřených veličin
( )y f X X ax xm n= =1 2 1 2, , (4.17)
kde a, m, n jsou reálné konstanty. Z obecného vztahu (4.11) vyplývá, že relativní(poměrná) standardní nejistota typu B veličiny Y je
2 2 2 21 2ry r ru m u n u= + . (4.18)
V případě, kdy určujeme nejistotu veličiny, která je rovna součinu nebo podíludvou veličin, je její relativní nejistota rovna odmocnině ze součtu kvadrátůrelativních nejistot přímo měřených veličin.Pro zpřesnění výsledku má smysl zpřesňovat měření té veličiny, jejíž relativnínejistota je největší nebo se ve vztahu (4.17) vyskytuje ve vyšší mocnině.
Příklad: Určujeme nejistotu elektrického odporu R spotřebiče pro proud I = 100 mAměřený s maximální chybou mI = 0,5 mA a napětí na spotřebiči U = 200 Vs maximální chybou mU = 5 V. Předpokládáme, používáme kvalitní ampérmetr ivoltmetr a proto pro hodnoty napětí a v proudu v rozmezí chyb platí normální rozdělení.Podle vztahu (4.5)

46
0,5 5
mA 0,17mA, 1,7V3 3IB UBu u V= = = =
a relativní nejistoty jsou
u urIB rUB= = = =− −017
1001 7 10
1 7
2008 5 103 3,
, . ,,
, . .
Protože elektrický odpor souvisí s proudem I a napětím U vztahem R = U/I, platí prorelativní standardní nejistotu typu B elektrického odporu R určeného z jednoho měřeníproudu a napětí vztah (4.18)
( ) ( )2 22 2 3 31,7.10 8,5.10 0,0087rR rI rUu u u − −= + = + = .
Při výpočtu jsme využili definiční vztah pro relativní nejistotu. Velikost relativnínejistoty elektrického odporu činí 0,87 %. Z výpočtu vyplývá, že hodnota napětí mápětkrát větší relativní nejistotu než hodnota proudu. Zlepšení přesnosti výsledku by bylomožno dosáhnout např. použitím voltmetru s lepší třídou přesnosti.
4.4 Výsledek měření
Obdobně jako v odstavci 3.5 pro chybu měřené veličiny, můžeme nyní stručně shrnoutpostup při vyhodnocení měření se stanovením nejistot:
V případě přímo měřené veličiny:1) K přímo měřené veličině X stanovte nebo alespoň odhadněte zdroje všechsystematických chyb a uvažte, jakým rozdělením se budou hodnoty v rámci chybyřídit2) Vypočtěte standardní nejistotu typu B podle vztahu (4.6).3) Je-li veličina měřena opakovaně, stanovte její aritmetický průměr x asměrodatnou odchylku ( )s x , která je rovna standardní nejistotě uxA .
4) Stanovte kombinovanou standardní nejistotu podle vztahu (4.8).
V případě nepřímo měřené veličiny:1. V případě, že některé veličiny měříte opakovaně, stanovte výběrový aritmetickýprůměr y dosazením aritmetických průměrů jednotlivých přímo měřených veličinpodle vztahu (4.9).2. Stanovte směrodatné odchylky ( )js x pro jednotlivé opakovaně měřené veličiny
Xj podle vztahu (4.3), které jsou totožné s nejistotami typu A, tj. Ax ju .
3. Výslednou standardní nejistotu uyA typu A ur čete na základě nejistot odjednotlivých zdrojů podle vztahu (4.10).Jestliže neprovádíte opakované měření, body 1 - 3 odpadají.4. Určete všechny zdroje složek nejistoty typu B přímo měřených veličin anepřesnosti konstant.5. Pro každý zdroj nejistoty typu B určete krajní meze, mezi kterými by se mělanacházet jeho skutečná hodnota a zjistěte předpokládané rozdělení

47
pravděpodobností výskytu jednotlivých hodnot mezi krajními mezemi a podle typurozdělení jim přiřaďte hodnoty koeficientu χχχχ ( χ = χ = χ = χ = 3 3 3 3 pro normální rozdělení,χ = 3 pro rovnoměrné rozdělení). Jestliže si nejste jisti výběrem rozdělení,použijte hodnotu 3χ = .6. Podle vztahu (4.6) vypočtěte nejistoty typu B od jednotlivých zdrojů.7 Stanovte výslednou standardní nejistotu uyB typu B podle vztahu (4.11).8. S použitím Gaussova kvadratického zákona šíření nejistot, vztah (4.12) určetekombinovanou standardní nejistotu uy.
9. Je-li požadavek na zvýšení pravděpodobnosti (snížení rizika) výskytu skutečnéhodnoty v intervalu ( ), ( )y yy U y U− + stanovte rozšířenou standardní nejistotu Uy
podle vztahu (4.13).
Výsledek se zapisuje ve stejné formě jako v případě určení úplné chyby měření, tj.
( )yy y u= ± [Y].
Obvykle se respektuje pravidlo neuvádět nejistotu měření na více jak dvě platné cifry.
Kontrolní otázky:
1. Který typ nejistot je odvozen a) z náhodných chyb, b) ze systematických chyb ?
2. Délka hranolku byla měřena jednorázově a to a) posuvným měřítkem (m = 0,05 mm) s výsledkem l / = 13,25 mm, b) mikrometrem (m = 0,02 mm) s výsledkem l // = 13,24 mm. Určete v obou případech standardní nejistotu a zapište výsledek měření.
3. Průměr drátu byl změřen mikrometrem (m = 0,01 mm) a to pětkrát s výsledkem (v mm): 2,12 ; 2,10 ; 2,15 ; 2,14 ; 2,11. Určete plochu S průřezu drátu a její kombinovanou standardní nejistotu uS.

48
5 Vyrovnání funkční závislosti
Jak jsme již vedli v kapitole 1, není měření omezeno pouze na určení jedné hodnoty měřenéveličiny, ale při mnoha laboratorních i technických měřeních vyšetřujeme závislost jednéveličiny na jiné veličině, případně na několika jiných veličinách. Předpokládejme projednoduchost, že veličina y je funkcí pouze jedné veličiny x. Takové měření spočívá v tom, žepro množinu zvolených hodnot nezávisle proměnné x1, x2, .... , xn měřením získámeodpovídající množinu hodnot závisle proměnné y1, y2, .... , yn. Přitom musíme brát v úvahu,že obě množiny představují výsledky měření a jsou proto zatíženy chybami. Ve zcelaobecném případě ani neznáme tvar funkční závislosti
y = f(x)
a výsledkem analýzy naměřených hodnot má být stanovení nejpravděpodobnějšího tvaru tétofunkční závislosti a nejpravděpodobnějších hodnot velikosti konstant, které v ní vystupují.Takové úlohy jsou však značně obtížné a my se v dalším omezíme na případy, kdy je tvarfunkce f známý a výsledkem naší analýzy má být stanovení nejpravděpodobnějších hodnotkonstanty nebo konstant, které v ní vystupují. Chyby naměřených hodnot přitom způsobují, žesoubor naměřených hodnot y1, y2, .... , yn nesplňuje funkční závislost zcela přesně, a proto semusíme zabývat problémem, jak určit optimální hodnoty konstant, aby naměřené hodnoty conejlépe sledovaly očekávanou funkční závislost. Tomuto postupu se říká optimální vyrovnánínaměřených hodnot funkční závislosti a tuto problematiku řeší regresní analýza.
5.1 Metoda nejmenších čtverců (MNČ)
Regresní analýza používá poměrně složité postupy, které se uplatňují v různých oborech.Jejich základem obvykle je minimalizace rozdílů mezi naměřenými hodnotami aodpovídajícími hodnotami teoretickými (vyrovnanými). Seznámíme se s metodouoznačovanou jako metoda nejmenších čtverců (MNČ), která je poměrně jednoduchá, alevelmi často používaná a poskytující výsledky s dostatečnou přesností. Tato metoda je početněsice dost náročná, ale bývá součástí softwarového vybavení počítačů, tabulkových procesorů ivědeckých kalkulátorů.Princip MNČ vyložíme na nejjednoduším případu, kdy naměřené hodnoty yi odpovídajícíhodnotám xi mají ležet na přímce procházející počátkem. Naším úkolem je tedy naměřenéhodnoty co nejlépe vyrovnat lineární závislostí y = a x a určit optimální hodnotu parametrua a dále jeho chybu e(a). Předpokládáme, že nezávisle proměnnou x měříme bez chyby.MNČ je založena na splnění požadavku, aby součet čtverců odchylek naměřenýchhodnot yi pro jednotlivá xi od vyrovnaných hodnot a xi, byl minimální. Parametr apředstavuje neznámou hodnotu, kterou určujeme z požadavku minimalizace rozdílů mezinaměřenými hodnotami a hodnotami vyrovnanými. Musí tedy platit
∆yii
n2
1
==∑ min. , (5.1)
kde ∆yi = yi - a xi a n je počet měření. Pro jednotlivé dvojice hodnot xi, yi můžeme tedy∆yi vyjádřit z rozdílů ∆y1 = y1 - a x1
∆y2 = y2 - a x2
….

49
∆yn = yn - a xn .
Požadavek minima z rovnice (5.1) je splněn tehdy, je-li derivace výrazu na levé straně rovnicepodle parametru a rovna nule.
2
1 0
n
ii
d y
d a=
∆ =∑
. (5.2)
Dosazením za ∆yi2 do rovnice (5.1) dostaneme
y12 - 2 a x1 y1 + a2 x1
2 + + y2
2 - 2 a x2 y2 + a2 x22 +
: (5.3) + yn
2 - 2 a xn yn + a2 xn2 = min.
Pro levou stranu rovnice (5.3) se v odborné literatuře používá termín součet reziduí (SR).Provedením derivace levé strany rovnice (5.3) podle a získáme výraz
- 2 x1 y1 + 2 a x1 2 -
- 2 x2 y2 + 2 a x2 2 -
: - 2 xn yn + 2 a xn
2
a jeho úpravou dále dostaneme
( x12 + x2
2 + ......... + xn2 ) a - ( x1 y1 + x2 y2 + ........ + xn yn ) .
Tento výraz se podle (5.2) rovná nule a pro a tedy platí
ax y
x
i ii
n
ii
n= =
=
∑
∑1
2
1
. (5.4)
Stejný postup bychom mohli použít pro vyrovnání lineární závislosti typu y = a x + b.V tomto případě bychom hledali dva parametry a, b této funkční závislosti z podmínkyminima analogické (5.1), tj. z rovnic
2
1 0
n
ii
y
a=
∂ ∆ =
∂
∑,
2
1 0
n
ii
y
b=
∂ ∆ =
∂
∑ (5.5)
a dospěli bychom ke složitým nepřehledným vztahům. I když aplikaci těchto vztahůzjednodušují vědecké kalkulátory vybavené statistickými funkcemi, doporučujeme k jejichvýpočtu používat tabulkové procesory. Je samozřejmé, že z rovnice (5.4) lze odvodit i vztahpro určení chyby e(a). Pro určení těchto chyb lze s výhodou opět využít tabulkovéprocesory.

50
Příklad: Vyrovnání přímé úměrnosti metodou nejmenších čtverců se s výhodou používánapř. při určení periody nějakého periodického děje. Přitom počet period i odpovídánezávisle proměnné x. Doba kyvu kyvadla byla měřena dvouručičkovými stopkami tak, že měření započalo v časet = 0, dále byl zaznamenáván okamžik průchodu kyvadla rovnovážnou polohou po každémkyvu. Bylo naměřeno celkem 5 hodnot času.
i (pořadové číslo měření) 1 2 3 4 5__________________________________________________________________________
t (naměřený čas v s) 4,1 7,8 12,0 16,2 19,9
Dále předpokládáme, že doba kyvu se s časem nemění, tj. naměřené hodnoty ti by měly ležetna přímce
ti = a i ,kde i odpovídají hodnotám nezávisle proměnné x a ti hodnotám závisle proměnné y vobecné funkční závislosti
y = a x.
Naměřené hodnoty chceme co nejlépevyrovnat přímkou jdoucí počátkem.Závislost naměřených a vyrovnanýchhodnot času na pořadovém čísle měření jena obr. 5.1.
Obr.5.1
Parametr a vypočteme podle vztahu (5.4)
5
15
2
1
2204
55
ii
i
ita
i
=
=
= = =∑
∑ .
Na základě vypočteného a, což je zároveň určená doba kyvu τ = a = 4 s, můžeme stanovitvyrovnané hodnoty ti.
ti (naměřené hodnoty v s) 4,1 7,8 12,0 16,2 19,9__________________________________________________________________________
ai (vyrovnané hodnoty v s) 4 8 12 16 20
0
5
10
15
20
0 2 4 i
t (s)
naměřenéhodnoty
vyrovnanéhodnoty

51
5.2 Skupinová metoda
Pro naměřené hodnoty yi, o kterých předpokládáme, že splňují funkční závislost y = ax jetaké možné provést vyrovnání skupinovou metodou. Tato metoda je založena na grafickémetodě hledání těžiště bodů reprezentující naměřené hodnoty, přičemž předpokládáme, žekaždý z těchto bodů má stejnou statistickou váhu. Z rovnice pro polohu těžiště se snadnoodvodí rovnice
( )y axi ii
n
− ==∑
1
0 , (5.6)
kde n je počet měření. Pro a dostaneme vztah
ay
x
ii
n
ii
n= =
=
∑
∑1
1
. (5.7)
Přitom musíme předpokládat, že všechny body jsou změřeny stejně přesně, přisuzujemestejnou váhu.Vyrovnání lineární závislosti je samozřejmě jednodušší než vyrovnání obecnějších závislostí.Proto se vždy, pokud je to možné, snažíme převést měřenou funkční závislost na lineární,např. vhodnou matematickou úpravou.
Aplikaci skupinové metody si ukážeme na příkladu vyrovnání závislosti, která je sicenelineární, ale kterou lze vhodnou matematickou úpravou linearizovat. Jedná se o měřenízávislosti absorpce elektromagnetického záření na tloušťce absorbující vrstvy
Příklad: Měříme hodnoty veličiny N vyhovující funkční závislosti typu N = N0 exp(-µx),a úkolem je z naměřených dvojic xi, Ni určit hodnotu µ. Závislost převedeme na lineárníúpravou do tvaru
0lnN
xN
µ= ,
což je již rovnice přímky procházející počátkem, protože pro x = 0, je N = N0 a úloha seredukuje na funkční závislost typu y = a x, kde
yN
N= ln 0 a parametr a = µ . Tento parametr určíme dosazením do rovnice (5.4):
0
1
1
lnn
in
ii
N
Na
xµ =
=
= =∑
∑ .

52
Kontrolní otázky
1. Při měření délky vlny stojatého vlnění byly měřeny polohy l i jednotlivých uzlů s cílemurčit vyrovnanou hodnotu vzdálenosti mezi sousedními uzly / 2d λ= . Výsledek měřeníbyl zapsán do tabulky:
i 1 2 3 4 5 6 7 8 9 10 l i[mm] 124 243 370 497 618 741 866 1052 1112 1232
Určete vyrovnanou hodnotu vzdálenosti d mezi sousedními uzlya) metodou nejmenších čtvercůb) skupinovou metodou.
2. Odvoďte obecný výraz pro chybu e(a) vyrovnané hodnoty a ze vztahů (5.4) a (5.7) a to za předpokladu, že hodnoty nezávislé proměnné xi byly naměřeny bez chyby a hodnoty závisle proměnné yi byly změřeny všechny se stejnou chybou ( ) ( ) ( ) ( )1 2 .... ne y e y e y e y= = = = . Určete, která z chyb je menší, případně, která z chyb
má menší relativní hodnotu. Návod: vyjděte ze vztahu (3.19).

53
6 Měřicí metody a měřicí přístroje
6.1 Rozdělení měřicích metod
Měřicí metodou rozumíme způsob jakým je možno měřit veličinu. Protože určitou veličinulze obvykle měřit různým způsobem, rozlišujeme různé měřicí metody pro měření jednéveličiny. Volba měřicí metody závisí jednak na povaze samotné veličiny, dále na tom, jaképřístroje nebo zařízení máme k dispozici, jaké máme nároky na přesnost, případně naekonomických omezeních. Metody lze kategorizovat podle různých kritérií.
Podle způsobu určení měřené veličiny se měřicí metody dělí na:Přímé měřicí metody, kdy se výsledek měření získá odečtením údaje jediného přístroje,např. měření proudu pomocí ampérmetru, odečtení délky ze stupnice mikrometru.Nepřímé měřicí metody zahrnují všechny ostatní metody, kdy se výsledek měření získávýpočtem hodnoty funkce jedné nebo několika proměnných. Hodnoty těchto proměnných sezískají pomocí přímých měřicích metod. Příkladem je určení odporu z údaje voltmetru aampérmetru pomocí Ohmova zákona.
Metody absolutní a relativníAbsolutní metoda je taková, která poskytuje hodnotu veličiny v definovaných jednotkách,např. délku v metrech, elektrické napětí ve voltech.Relativní metody jsou metody, které jsou založeny na porovnání hodnoty měřené veličiny shodnotou stanovenou obvykle s vysokou přesností a tu označujeme jako etalon nebo normálveličiny. Jako srovnávací metodu lze uvést vážení na rovnoramenných vahách, kde etalonemjsou hmotnosti závaží (přesná závaží se pravidelně kontrolují). Dalším příkladem je můstkovámetoda pro stanovení elektrického odporu, při které je měřený odpor srovnáván snastavitelnými odpory na přesné odporové dekádě.
Metody substituční a kompenzačníPrincip substituční metody spočívá v porovnávání neznámé hodnoty měřené veličiny seznámými hodnotami té samé veličiny. Jako výsledek měření se bere taková hodnota veličiny,která vyvolává na měřicích přístrojích stejnou odezvu jako určovaná hodnota.Substituční metoda je velice často užívána ve spojení s interpolačním postupem. Namístopracného a často neproveditelného nahrazení měřené hodnoty veličiny přesně stejnou známouhodnotou (pro kterou dostáváme přesně stejnou odezvu na měřicím přístroji) raději zvolímedvě hodnoty, kterým odpovídají na měřicím přístroji dvě výchylky, jedna větší a jedna menší,než kterou dostáváme pro měřenou hodnotu veličiny. Přesněji je tento postup popsánv odstavci 6.2.
Kompenzační metoda je analogická s metodou substituční s tím rozdílem, že účinek měřenéveličiny vyrovnáváme (kompenzujeme) účinkem známé veličiny stejné hodnoty, aleopačného znaménka. Jako příklad můžeme uvést měření hustoty kapalin Mohrovýmivážkami, kde vyrovnáváme moment síly momentem stejně velkým, ale opačného znaménka.
Metoda následných měřeníTato metoda slouží ke zpřesnění výsledku měření a používá se v případech, kdy koncový údajjednoho měření je počátečním údajem následujícího měření.. Jako příklad lze uvést postupné

54
odečítání času dvojručkovými stopkami například po každém kyvu kyvadla, takže výsledkemjsou narůstající hodnoty času. Naměřené hodnoty času je pak vhodné zpracovat jako lineárnífunkční závislost, kde nezávisle proměnou je pořadové číslo měření a závisle proměnouodečítaný čas. Parametr lineární závislosti je v našem případu totožný s hledanou dobou kyvukyvadla. Naměřené hodnoty se zpracují metodou MNČ (odstavec 5.1).
6.2 Metoda lineární interpolace
Při měření vycházejícím ze závislosti y = f(x) se někdy setkáme s následujícím požadavkem:Dvěmi měřeními byly pro blízké hodnoty určeny hodnoty veličiny y1 = f(x1) a y2 = f(x2) a jetřeba určit hodnotu y0 odpovídající hodnotě x0 ležící mezi x1, x2:
1 0 2x x x< < . (6.1)
Příklad: Vážením na praktikantských vahách byla určena hmotnost předmětu pouzepřibližně, protože poloha jazýčku vahadla při vyvážení se lišila od nulové polohy (např. ojeden dílek stupnice). Přesnější vyvážení nebylo možné (např. nebylo k dispozici dostatečněmalé závaží, proces vyvažování by byl příliš zdlouhavý apod.). Určení správné hmotnostipředmětu se řeší početně metodou lineární interpolace ze dvou vyvážení, jednou pro polohujazýčku vlevo, jednou vpravo od nulové polohy.
Metoda lineární interpolace je nejjednodušší početní metoda, která umožňuje určení y. Jejíprincip spočívá v tom, že v intervalu 1 2,x x⟨ ⟩ funkci y = f(x) nahradíme úsečkou spojující
body (x1,y1) a (x2,y2) – obr. 6.1. Z podobnosti trojúhelníků lze odvodit interpolační vzorec vetvaru
( )y yy y
x xx x0 1
2 1
2 10 1= +
−−
− . (6.2)
Takto provedenou interpolaci označujeme jako lineární. Ze vztahu (6.2) vyplývá, že vkartézské soustavě souřadnic body o souřadnicích (x1, y1), (x0, y0), (x2, y2) leží na jednépřímce. Interpolaci můžeme provádět také graficky. Sestrojíme graf přímky určené body(x1, y1), ( x2, y2) a hledáme y0 odpovídající x0.
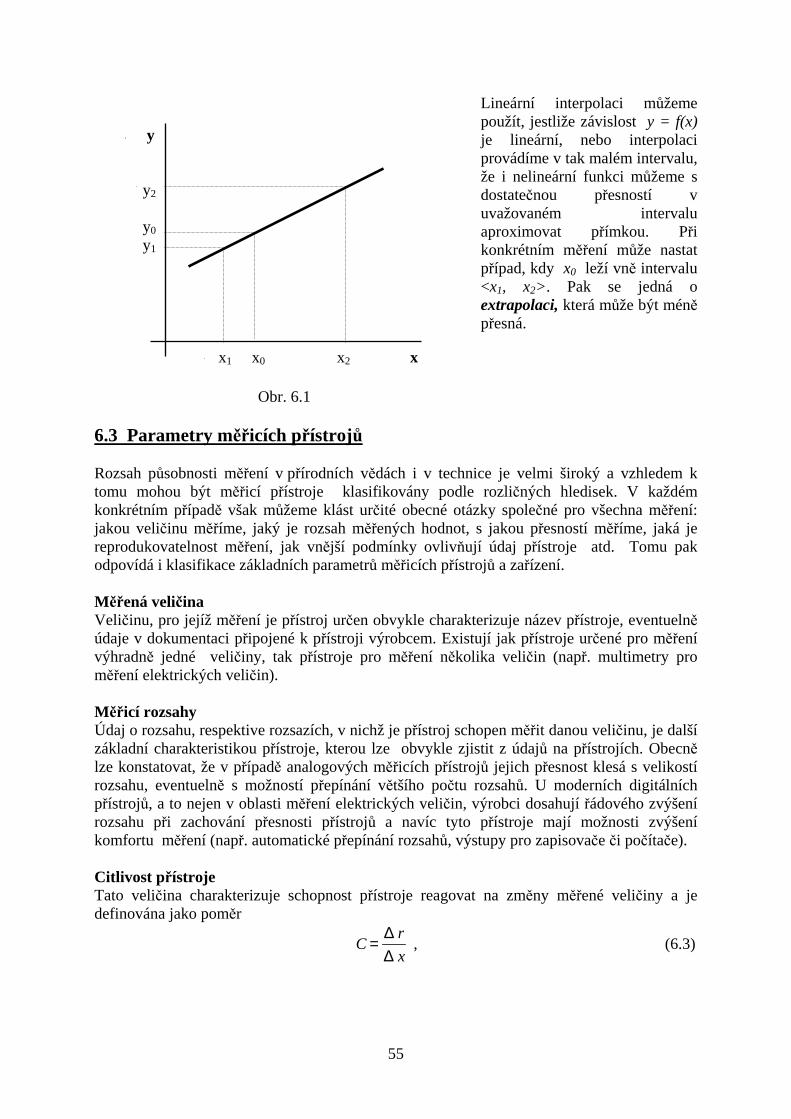
55
Lineární interpolaci můžemepoužít, jestliže závislost y = f(x)je lineární, nebo interpolaciprovádíme v tak malém intervalu,že i nelineární funkci můžeme sdostatečnou přesností vuvažovaném intervaluaproximovat přímkou. Přikonkrétním měření může nastatpřípad, kdy x0 leží vně intervalu<x1, x2> . Pak se jedná oextrapolaci, která může být méněpřesná.
Obr. 6.1
6.3 Parametry měřicích přístrojů
Rozsah působnosti měření v přírodních vědách i v technice je velmi široký a vzhledem ktomu mohou být měřicí přístroje klasifikovány podle rozličných hledisek. V každémkonkrétním případě však můžeme klást určité obecné otázky společné pro všechna měření:jakou veličinu měříme, jaký je rozsah měřených hodnot, s jakou přesností měříme, jaká jereprodukovatelnost měření, jak vnější podmínky ovlivňují údaj přístroje atd. Tomu pakodpovídá i klasifikace základních parametrů měřicích přístrojů a zařízení.
Měřená veličinaVeličinu, pro jejíž měření je přístroj určen obvykle charakterizuje název přístroje, eventuelněúdaje v dokumentaci připojené k přístroji výrobcem. Existují jak přístroje určené pro měřenívýhradně jedné veličiny, tak přístroje pro měření několika veličin (např. multimetry proměření elektrických veličin).
Měřicí rozsahyÚdaj o rozsahu, respektive rozsazích, v nichž je přístroj schopen měřit danou veličinu, je dalšízákladní charakteristikou přístroje, kterou lze obvykle zjistit z údajů na přístrojích. Obecnělze konstatovat, že v případě analogových měřicích přístrojů jejich přesnost klesá s velikostírozsahu, eventuelně s možností přepínání většího počtu rozsahů. U moderních digitálníchpřístrojů, a to nejen v oblasti měření elektrických veličin, výrobci dosahují řádového zvýšenírozsahu při zachování přesnosti přístrojů a navíc tyto přístroje mají možnosti zvýšeníkomfortu měření (např. automatické přepínání rozsahů, výstupy pro zapisovače či počítače).
Citlivost přístrojeTato veličina charakterizuje schopnost přístroje reagovat na změny měřené veličiny a jedefinována jako poměr
Cr
x=
∆∆
, (6.3)
y
y2
y0
y1
x1 x0 x2 x

56
kde ∆r je přírůstek výchylky ukazatele přístroje a ∆x je přírůstek měřené veličiny, který tutozměnu způsobil. Převrácená hodnota citlivosti se nazývá konstanta přístroje K a má významvelikosti změny měřené veličiny při změně polohy ukazatele přístroje o jeden dílek.
Rozlišení (rozlišovací schopnost)Rozlišení je nejmenší změna měřené veličiny, která vyvolá detegovatelnou změnu údajepřístroje (např. dílek nebo polovina dílku stupnice u analogového přístroje nebo změnaposledního místa displeje o jedničku u číslicových přístrojů).
Přesnost přístrojePřesností přístroje rozumíme jeho schopnost udávat hodnotu měřené veličiny s určitounejmenší odchylkou od skutečné hodnoty této veličiny. Problematikou kvantitativníhozhodnocení přesnosti měřicích přístrojů jsme se zabývali v odstavci 3.2.Je třeba zdůraznit, že přesnost a citlivost přístrojů jsou dva naprosto odlišné pojmy, kterénelze zaměňovat. Citlivost přístrojů lze např. zvyšovat za cenu zvýšení odezvy přístroje nazměnu vnějších podmínek, což se ovšem projeví zhoršením reprodukovatelnosti měření, tj.zvýšením rozdílů mezi údaji přístroje při opakovaném měření veličiny téže velikosti a tímzvýšením náhodné složky úplné chyby měření.
Kalibra ční křivkaNemá-li přístroj stupnici kalibrovanou v jednotkách veličiny, kterou chceme měřit, ale pouzev dílcích, je třeba tuto stupnici pomocí několika známých hodnot měřené veličiny okalibrovat.Mezi hodnotami veličiny a odpovídajícím počtem dílků stupnice přístroje je obvykle lineárnízávislost. Jestliže tuto závislost vyjádříme graficky, dostaneme kalibrační křivku. Její významje takový, že pro libovolnou hodnotu výchylky v dílcích umožňuje určit velikost měřenéveličiny. Kalibrační křivka je obvykle součástí dokumentace přístroje dodávané výrobcem.
Přístrojová křivkaV případech, kdy klademe zvýšené nároky na přesnost měření, je třeba mít jistotu, že přístrojměří správně v celém rozsahu či nezměnil svoji citlivost v porovnání s údajem výrobce. Protohodnoty udávané přístrojem je třeba překontrolovat pomocí řady přesně známých hodnotměřené veličiny, tj. řady normálů. Závislost údajů naměřených přístrojem na známýchhodnotách měřené veličiny vyjádřená graficky je přístrojová křivka.
Příklad: Hranolovým spektrometrem určujeme neznámé vlnové délky záření emitovanéhozdrojem světla. Přístroj má stupnici kalibrovanou v nanometrech. Před vlastním měřenímproměříme přístrojovou křivku, tj. porovnáme naměřené hodnoty vlnových délek stabulkovými hodnotami pro několik spektrálních čar (např. výbojek naplněných He, Hg, Neapod.). Křivku, která je lineární, vyrovnáme MNČ. Výsledkem vyrovnání je korekčníkoeficient mezi naměřenými a skutečnými hodnotami vlnové délky včetně určení jeho chyby,eventuelně dva koeficienty, jestliže přímka neprochází počátkem.
V některých případech postačuje určit korekční koeficient pouze na základě měření jednéznámé hodnoty. Příkladem je zjištění toho koeficientu pro Mohrovy vážky na základěporovnání naměřené hodnoty a tabulkové hodnoty hustoty destilované vody při známé teplotě(příklad v odstavci 3.2).

57
Určování rovnovážné polohyU některých typů analogových (ručkových) měřicích přístrojů se setkáváme s tím, žeukazatel (ručka, světelná značka apod.) se okamžitě neustálí, ale vykonává kmitavý pohybokolo rovnovážné polohy n, kterou je třeba stanovit. Obvykle se jedná o tlumené kmity aukazatel by se v této rovnovážné poloze po určité době zastavil. Rovnovážnou polohu lzevšak určit rychleji, z několika po sobě následujících výchylek kmitavého pohybu. Nejčastějizaznamenáváme tři po sobě jdoucí krajní výchylky ukazatele a1, a2, a3 (a1 a a3 jsou na jednéstraně, a2 na opačné straně vzhledem k hledané rovnovážné poloze).Rovnovážnou polohu na stupnici určíme ze vztahu
( )n a a a= + +
12
122 1 3 .
Výchylky a1, a2, a3 i rovnovážná poloha n mohou nabývat kladných i záporných hodnot vzávislosti na volbě nuly na stupnici. Někdy je vhodné stupnici očíslovat, respektivepřečíslovat tak, aby všechny výchylky byly kladné a výpočet n byl bez znaménkovýchkomplikací.
Příklad: Vážíme na praktikantských rovnoramenných vahách, kde stupnice pod jazýčkemvah je číslovaná 0 až 20 dílků. Tři po sobě jdoucí výchylky jazýčku při nezatíženýchvahách jsou a1 = 6, a2 = 14,5, a3 = 7. Určete rovnovážnou polohu vah ( v tomto případě sejedná o nulovou polohu n0).Rovnovážnou polohu určíme ze vztahu (3.2).
( )n0
12
14 512
6 7 10 5= + +
=, ,
Nulová poloha je 10,5 dílků.
Čtení na stupniciČtení na stupnici záleží na způsobu dělení stupnice. Je-li dělení velmi husté, a má-li stupnicedělicí čárky poměrně široké, odhadujeme polohu ukazatele alespoň na polovinu dílkustupnice. Jsou-li však dělicí čárky tenké proti jejich vzdálenostem, mělo by být snahouurčovat polohu ukazatele na desetinu dílku stupnice. Polohu buď odhadujeme nebo v lepšímpřípadě je přístroj opatřen pomocnou stupnicí (vernier čili nonius). Pomocná stupnice jedělena na k dílků (obvykle k = 10), přičemž každý z nich je menší o 1/k nejmenšího dílkuhlavní stupnice. Jestliže posuneme nonius tak, aby počátky obou stupnic splynuly, kryje sek-tý dílek nonia s k-1 dílkem hlavní stupnice (obr.6.2a). Při měření slouží okrajový(počáteční) dílek nonia jako odečítací ryska. Její poloha mezi ryskami hlavní stupnice jeurčena podle toho, která ryska nonia splývá s ryskou hlavní stupnice. Na obr. 6.2b je ukázánpříklad čtení, kdy počáteční ryska nonia je mezi 7 a 8 a čtvrtá ryska nonia splývá s ryskouhlavní stupnice. Proto čtení na stupnici je 7,4.

58
Obr.6.2a Obr.6.2b
0 105 15
0 105
0 105 15
0 105

59
7 Literatura
Tato opora podává úvodní informace z oblasti měření. Její autor opory použil podklady z několikapublikací, jejichž seznam je uveden dále. Pro zájemce o hlubší studium problematiky měření mohoutyto publikace sloužit jako zdroj dalších informací.
[1] Egermayer, F., Dušek, J., Statistika pro techniky, SNTL, Praha, 1984
[2] ČSN ISO 3534-1 „Statistika – slovník, značky“, Český normalizační institut, Praha 1994
[3] Novotný J., Vybrané statě z fyziky (Zpracování experimentálních dat), Vydavatelství ČVUT, Praha, 1994
[4]. Novák, R., Nováková, D., Základy měření a zpracování dat, Vydavatelství ČVUT, Praha, 1999
[5] Vítovec, J., Zpracování naměřených údajů, Česká metrologická společnost, Praha, 1997
[6] „Guide to the Expresion of Uncertainty in Measurement“, ISO, IEC, OIML, CIPM, Paris, 1992[7] TMP 0051-93 „Stanovenie neistôt pri meraniach“, ČSMÚ, Bratislava, 1993


61
Výsledky kontrolních otázek
Odstavec 2.3
1. ( ) (10,2
2f x x π
π= ∈ , E(X) = π, D2(X)=π2/3, σ(x)= 3π /3.
2. ( ) ( ) ( )27 35 35, ,
2 12 12E X D X Xσ= = =
3. ( ) ( ) ( ) ( ) ( ) ( )2 221 105 1053 , 9 , 3
2 4 4E Y E X D Y D X Y Xσ σ= = = = = =
Odstavec 2.4
3. p(0) = 0.135
Odstavec 2.5
1. ( ) ( ) ( )24,8 , 0,005 , 0,071, 0,024x s x s x s x= = = =
2. a) ( ) ( )22 , 4 , 2x s x s x
b) ( ) ( )20,25 , 0,0625 , 0,25x s x s x
Odstavec 3.1
1. ( ) ( )9,1% 0,0806k x t s x= =
2. ( ) 40,52294 , 1,208.10U V s U V−= =
a) ( ) ( )43,26 .10 , 0,55294 0,00033k U V U V−= = ±
b) ( ) ( )45,56.10 , 0,52294 0,00056k U V U V−= = ±
Odstavec 3.2
1. ( ) ( )0,6 , 0,075rm U V m U= =
2. ( ) ( )0.0022 , 0,2000 0,0022m I A I A= = ±
3. ( ) 6 , 1pm P W T= ≤

62
Odstavec 3.3
1. ( ) ( ) ( ) ( )( ) ( ) ( ) ( )3 3r r r
k r m re Me e e M e r
M rρ ρ ρ ρ ρ
+= = + = +
2. ( ) ( ) ( )2 2
cos sin
cos cos
k ke B e I e
I I
ψ ψ ψ ψ ψψ ψ
+= +
Odstavec 4.4
1. a) uA b) uB
2. a) ( )
/ /
/
0,033l l B
m lu u mm= = = b)
( )// //
/
0,013l l B
m lu u mm= = =
3. ( ) 23,543 0,032S mm= ±
Odstavec 5.2
1. a) a = 125,17 mm b) a = 124,64 mm
2. MNČ: ( )( )
( )( )
1 1
2
1 1
n n
i ii i
rn n
i i ii i
e y x e y xe a e a
x x y
= =
= =
= =∑ ∑
∑ ∑
skupinová metoda: ( ) ( ) ( ) ( )
1 1
rn n
i ii i
n e y n e ye a e a
x y= =
= =∑ ∑


![Количество экземпляров п/ пrsmu.ru/fileadmin/templates/DOC/Discipliny/knigoob...3 Акушерство и гинекология [Электронный ресурс]](https://img.dokumen.tips/doc/110x75/601061e6aaf7755cf7724034/-rsmurufileadmintemplatesdocdisciplinyknigoob.jpg)


















