Embed Size (px)
Citation preview


Nucleic acids• Informational macromolecule
• Deoxyribonucleic acid (DNA) is the genetic material
• Ribonucleic acid (RNA)
– Messenger RNA (mRNA) carries information from DNA to the
ribosomes
– Ribosomal RNA (rRNA) and transfer RNA (tRNA) are involved
in protein synthesis
– RNAs involved in regulation of gene expression and processing
and transport of RNAs and proteins

Nucleic acids• DNA and RNA are polymers of
nucleotides• Nucleotides consist of
– Purine and pyrimidine bases• Purines: adenine (A) and guanine (G)• Pyrimidines: cytosine (C) and
thymine(T) • RNA has uracil (U) in place of thymine
– 5 C sugar (5’ phosphorylated)• D-Ribose (RNA)• D-2’deoxyrobose (DNA)
– Phosphate: 1-3 phosphate at 5’C of sugar

Nitrogenous bases
• Structures are meaningful• Reactive centers?

Base pairing: Hydrogen bonding
Hydrogen bonding btw complementary bases is the basis for double stranded DNA structure

Adenosine
Adenosine monophosphate (AMP)
Adenosine diphosphate (ADP)
Adenosine triphosphate (ATP)
Backbone• Sugar phosphodiester forms
the backbone• Ribose for RNA• 2’-deoxyribose for DNA• Nucleoside=covalent bonding
of C1 of sugar and a base• Naming: Guanosine,
Adenosine, cytidine and Thymidine, Uridine
• Nucelotide= Nuceloside+5’phosphate (1-3)
• Naming: – Adenosine monophosphate
(AMP)– Adenosine diphosphate (ADP) – Adenosine triphosphate (ATP)
• Can you name the others?

Phosphodiester bond formation
• DNA polymerases catalyze the rxn• uses complementary dNTPs• dehydration reaction between
• 3’-OH of new strand and• 5’-phosphate of incoming dNTP• synthesis is 5’3’
• covalent bond is called phosphodiester• there is always a 5’-phosphate and a 3’-OH that gives the DNA its polar sense (5’3’) • complementary strands are anti-parallel

Phosphodiester bond formation
• DNA polymerases catalyze the rxn• uses complementary dNTPs• dehydration reaction between
• 3’-OH of new strand and• 5’-phosphate of incoming dNTP• synthesis is 5’3’
• covalent bond is called phosphodiester• there is always a 5’-phosphate and a 3’-OH that gives the DNA its polar sense (5’3’) • complementary strands are anti-parallel

DNA is an antiparallel helix
• Geometry of bases and their spacial arrangement to form H-bond cause helix structure of dDNA• In B-form right handed dDNA• pairing bases stack in the centre• backbone intertwined• creates minor and major grooves• 0.34 nm (3.4 A) rise per base pair• one full helix turn houses 10 nucleotides
34 A
Major groove
20 A

Central dogma• Complementary base pairing allows one strand of DNA to
act as a template for synthesis of a complementary DNA or RNA strand
• DNA is transcribed to pass genetic information to RNA
• The information in RNA is present in a triplet code where every three bases stands for one of the 20 amino acids
• Translation: mRNA codes for protein
• This flow of information from DNA to protein is called “central dogma” in cell biology
Information flow: DNAmRNAProtein

Central dogma and mutations
• The DNA contains the instructions for the sequence of amino acids in each protein
• The order of amino acids in a protein determines its shape and function• Errors or faults, ie mutations, in the DNA can change the amino acid
sequence and function of the encoded protein• Sickle cell anaemia is due to one nucleotide change affecting
hemoglobin reduced O2 carrying capacity
GAGGUG

ProteinsProteins• Proteins are the most diverse of all macromolecules• Each cell contains several thousand different proteins• Proteins direct virtually all activities of the cell• Functions of proteins include:
Enzymes Structural components (e.g. keratin, collagen) Motility (e.g. actin) Regulatory (e.g. transcription factors) Transport (e.g. Na+-K+-ATPase) Receptors (e.g. insulin receptors) Transport and storage of small molecules (e.g. O2)
Transmit information between cells (protein hormones), Defense against infection (antibodies)

Amino acidsAmino acids
• Polymers of 20 different amino acids. • Each amino acid consists of the α carbon bonded to a
carboxyl group (COO−), an amino group (NH3+), a
hydrogen, and a distinctive side chain (R)

Amino acidsAmino acids
• Amino acids are grouped based on characteristics of the side chains:– Nonpolar side chains– Polar side chains– Side chains with charged basic groups– Acidic side chains terminating in carboxyl
groups

Nonpolar amino acidesNonpolar amino acides
• 10 aa have nonpolar R-groups (hydrophobic)• Simplest is glycine (R=H)• 2 contain S and two have cyclic side chains• Nonpolar aa tend to be burried in the hydrophobic core of proteins

Polar amino acidesPolar amino acides
• 5 aa have polar R-groups; either –OH or NH2 (hydrophilic)• Partial charge; H-bond formation with water• Polar aa tend to appear on the surface of proteins

Charged amino acidsCharged amino acids
• 3 aa have positively charged NH2 groups (basic)• Full charge; H-bond and ionic bond• Like Polar aa tend to appear on the surface of proteins• Might take part in catalytic core of enzymes

Charged amino acidsCharged amino acids
• 2 aa have negatively charged –COO- group (acidic)• Full charge; H-bond and ionic bond• tend to appear on the surface of proteins or enzyme catalytic core

Peptide bond formationPeptide bond formation• Polypeptides: chains of
amino acids joined by peptide bonds
• Number of aa’s varied
• oxytocin – 9 aa,• insulin – 51 aa,
titin (connectin)– 34,350 aa’s
• Average 400-500 aa
• One end of a polypeptide terminates in an α amino group (N terminus)
• other end is an α carboxyl group (C terminus)

Protein structureProtein structure• Sequence of amino acids in a protein is
determined by the order of nucleotide bases in a gene (Primary structure)
• One can deduce aa sequence from the sequence of nucleotides in the gene (or mRNA)
• 3-D conformation is critical to proteins function
• What determines the 3-D structure of proteins?

Protein secondary structureProtein secondary structure
• 3-D structure is a result of interactions between the amino acids• Christian Anfinsen denatured ribonuclease (RNase) by heat
treatment; breaks H-bonds• If the treatment was mild, the proteins would return to their
normal shape at room temperature• This would mean that the information for folding the protein is in
its primary sequence (how could he test?)
Christian B. Anfinsen (1957)
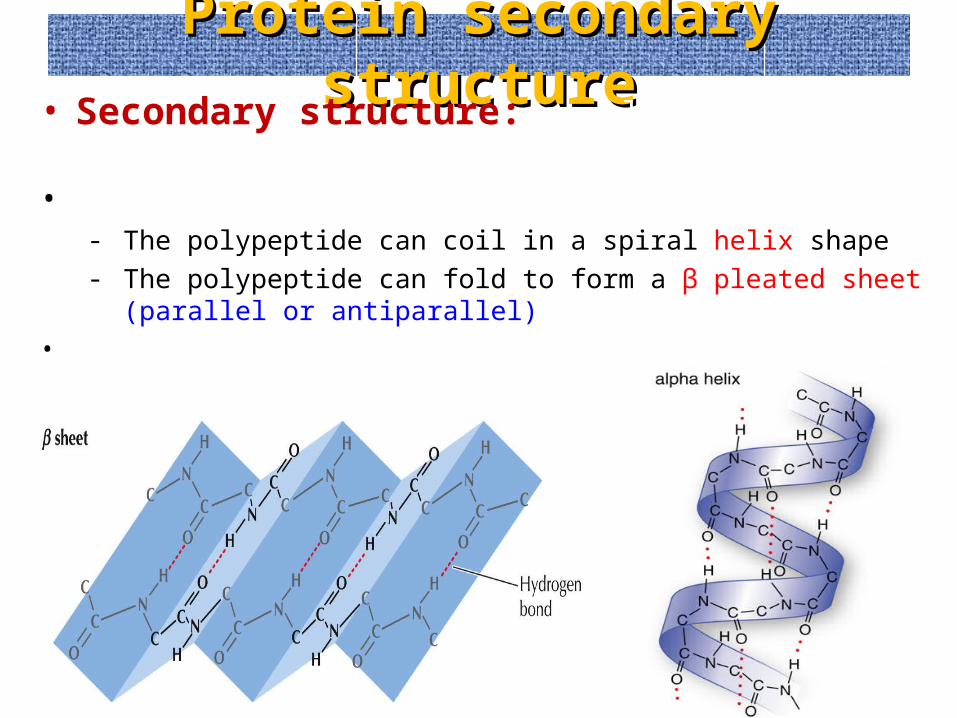
Protein secondary structureProtein secondary structure• Secondary structure: regular arrangement of amino acids
within localized regions• There are 2 types of secondary structure:
- The polypeptide can coil in a spiral helix shape- The polypeptide can fold to form a β pleated sheet (parallel or
antiparallel)• Both are held together by hydrogen bonds between the CO and NH
groups of peptide bonds

Protein Tertiary structureProtein Tertiary structureObservation:Observation:• Similarly disrupting the disulfide
bonds (S-S) using chemical denaturing agents (eg. β-mercaptoethanol) denatures proteins (-SH forms)
• Incubation under oxygen refolded the RNase back to its functional conformation (ie enzyme gained capacity to degrade RNA)
• indicates a higher level of structure important for function that relies on covalent S-S bridge (tertiary structure)

Protein Tertiary structureProtein Tertiary structureRNase
Insulin
• Tertiary structure: folding of secondary structural elements to form a 3-D arrangement
• 2° elements connected by loops and less ordered aa’s
• interactions btw the side chains of amino acids in different regions of protein stabilizes the 3° structure
- Covalent bonds (S-S bridge)- Hydrophobic and hydrophilic
interactions
• In most proteins this results in domains, the basic units of tertiary structure

Protein Quaternary structureProtein Quaternary structure• Quaternary structure
consists of interactions between different polypeptide chains
• In multi-subunit enzymes
• Hemoglobin, for example, is composed of four polypeptide chains

Protein structure: SummaryProtein structure: Summary
Campbell & Reece, 2002

Can you meet these objectives?
• Distinguish among nucleosides, nucleotides and nucleic acids?
• Explain the structure of DNA?• List some functions of proteins in cells?• Describe and distinguish between amino
acids?• Discuss the levels of protein structure and
organization of proteins?





























