Embed Size (px)
Citation preview

1043
Recent studies on cardiovascular biology have been trans-formed by growing applications of Omics technolo-
gies.1–5 For example, large-scale proteomic investigations have discovered the protein anatomy and dynamics of indi-vidual cardiac organelles as well as new principles of cardiac regulations in forms of widespread post-translational modifi-cations. Numerous other large-scale data sets are now being generated, which enable investigators to ask more complex biological questions.
Efficient bioinformatics resources are vital for connecting these increasingly voluminous and diversified data to experts of various disciplines to formulate new biological insights.6,7 However, at this moment, the data are often distributed in forms that are not readily accessible, and as a result, they are often of limited value to researchers outside a particular area of ex-pertise. Furthermore, efficient use of these data sets has been impeded by inconsistent annotation guidelines. Addressing these challenges, therefore, requires new computational tools
New Methods in Cardiovascular Biology
© 2013 American Heart Association, Inc.
Circulation Research is available at http://circres.ahajournals.org DOI: 10.1161/CIRCRESAHA.113.301151
Rationale: Omics sciences enable a systems-level perspective in characterizing cardiovascular biology. Integration of diverse proteomics data via a computational strategy will catalyze the assembly of contextualized knowledge, foster discoveries through multidisciplinary investigations, and minimize unnecessary redundancy in research efforts.
Objective: The goal of this project is to develop a consolidated cardiac proteome knowledgebase with novel bioinformatics pipeline and Web portals, thereby serving as a new resource to advance cardiovascular biology and medicine.
Methods and Results: We created Cardiac Organellar Protein Atlas Knowledgebase (COPaKB; www.HeartProteome.org), a centralized platform of high-quality cardiac proteomic data, bioinformatics tools, and relevant cardiovascular phenotypes. Currently, COPaKB features 8 organellar modules, comprising 4203 LC-MS/MS experiments from human, mouse, drosophila, and Caenorhabditis elegans, as well as expression images of 10 924 proteins in human myocardium. In addition, the Java-coded bioinformatics tools provided by COPaKB enable cardiovascular investigators in all disciplines to retrieve and analyze pertinent organellar protein properties of interest.
Conclusions: COPaKB provides an innovative and interactive resource that connects research interests with the new biological discoveries in protein sciences. With an array of intuitive tools in this unified Web server, nonproteomics investigators can conveniently collaborate with proteomics specialists to dissect the molecular signatures of cardiovascular phenotypes. (Circ Res. 2013;113:1043-1053.)
Key Words: computational biology ■ COPaKB ■ mitochondria ■ Omics science ■ organelles ■ proteomics ■ translational medical research
Original received February 9, 2013; revision received August 19, 2013; accepted August 21, 2013. In July 2013, the average time from submission to first decision for all original research papers submitted to Circulation Research was 13.24 days.
From the NHLBI Proteomics Center at UCLA/NHLBI Proteomics Program (N.C.Z., Ha.L., M.P.Y.L., R.C.J., C.S.K., N.D., A.K.K., J.H.C., I.Z., D.L., J.O., T.X., J.W., H.D., M.U., J.R.Y., R.A., H.H., P.P.), and Departments of Physiology and Medicine/CVRL (N.C.Z., Ha.L., Hu.L., M.P.Y.L., C.S.K., A.K.K., J.H.C., I.Z., D.L., D.M., J.W., P.P), UCLA School of Medicine, Los Angeles, CA; College of Biomedical Engineering and Instrumentation, Zhejiang University, the Key Laboratory for Biomedical Engineering of Ministry of Education, Hangzhou, China (Ha.L., N.D., H.D., P.P.); Shanghai Institute of Cardiovascular Diseases, Zhongshan Hospital, Fudan University, Shanghai, China (Hu.L., J.G., P.P.); EMBL Outstation European Bioinformatics Institute, Wellcome Trust Genome Campus, Hinxton, Cambridge, United Kingdom (R.C.J., R.A., H.H.); Science for Life Laboratory, the Royal Institute of Technology (KTH), Stockholm, Sweden (J.O., M.U.); Department of Chemistry, Fudan University, Shanghai, China (C.F., H.-j.L.); Department of Chemical Physiology, the Scripps Research Institute (TSRI), La Jolla, CA (T.X., J.R.Y.).
*These authors contributed equally to this study.The online-only Data Supplement is available with this article at http://circres.ahajournals.org/lookup/suppl/doi:10.1161/CIRCRESAHA.
113.301151-/DC1.Correspondence to PeiPei Ping, or Nobel C. Zong, UCLA School of Medicine, 675 Charles E. Young Dr S, MRL Building Suite 1–609, Los Angeles,
CA 90095. E-mail [email protected] or [email protected]
Integration of Cardiac Proteome Biology and Medicine by a Specialized Knowledgebase
Nobel C. Zong,* Haomin Li,* Hua Li,* Maggie P.Y. Lam, Rafael C. Jimenez, Christina S. Kim, Ning Deng, Allen K. Kim, Jeong Ho Choi, Ivette Zelaya, David Liem, David Meyer,
Jacob Odeberg, Caiyun Fang, Hao-jie Lu, Tao Xu, James Weiss, Huilong Duan, Mathias Uhlen, John R. Yates III, Rolf Apweiler, Junbo Ge, Henning Hermjakob, Peipei Ping
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from
by guest on A
pril 16, 2018http://circres.ahajournals.org/
Dow
nloaded from
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from
by guest on A
pril 16, 2018http://circres.ahajournals.org/
Dow
nloaded from
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from
by guest on A
pril 16, 2018http://circres.ahajournals.org/
Dow
nloaded from
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from
by guest on A
pril 16, 2018http://circres.ahajournals.org/
Dow
nloaded from
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from
by guest on A
pril 16, 2018http://circres.ahajournals.org/
Dow
nloaded from
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from
by guest on A
pril 16, 2018http://circres.ahajournals.org/
Dow
nloaded from
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from
by guest on A
pril 16, 2018http://circres.ahajournals.org/
Dow
nloaded from
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from
by guest on A
pril 16, 2018http://circres.ahajournals.org/
Dow
nloaded from
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from
by guest on A
pril 16, 2018http://circres.ahajournals.org/
Dow
nloaded from
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from
by guest on A
pril 16, 2018http://circres.ahajournals.org/
Dow
nloaded from
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from
by guest on A
pril 16, 2018http://circres.ahajournals.org/
Dow
nloaded from
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from
by guest on A
pril 16, 2018http://circres.ahajournals.org/
Dow
nloaded from
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from

1044 Circulation Research October 12, 2013
and bioinformatics infrastructures to integrate, analyze, and visualize multidisciplinary data sets.8
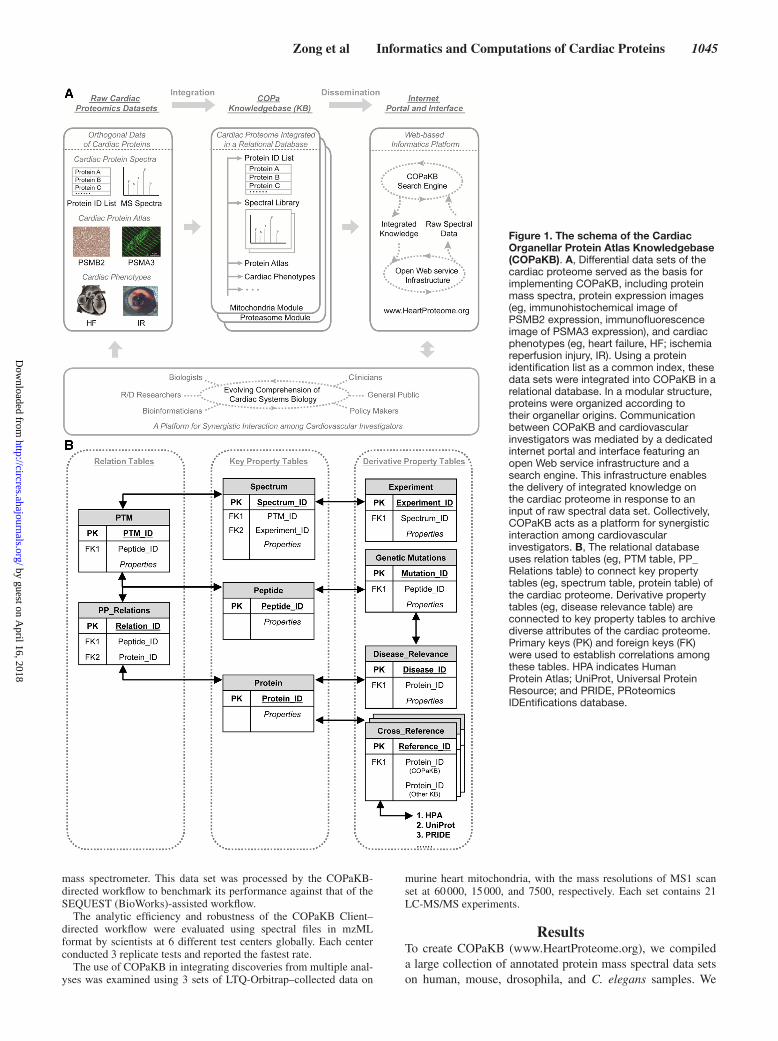
Here, we present the Cardiac Organellar Protein Atlas Knowledgebase (COPaKB), a specialized resource for the cardiovascular community with 3 distinct components. First, it comprises comprehensive spectral libraries of individual cardiac organelles and a search engine for investigators to quickly identify proteins from supplied data sets with high coverage. Second, it contains a curated database and a set of bioinformatics tools to integrate the identified proteins with relevant biomedical attributes (eg, genetic mutations, disease phenotypes) and orthogonal biomolecular properties (eg, protein expression imaging, gene transcription activity; Figure 1). Lastly, COPaKB provides a unified Web portal with a robust Web service infrastructure to allow proteomic data to be efficiently analyzed, distributed, and queried. The Wiki component of the Web portal, in particular, facilitates interactions and collaborations among investigators, support-ing a knowledge-building process in cardiovascular biology and medicine.
A primary benefit of this unified knowledgebase is that it contextualizes and distributes cardiac proteome data within a consistent set of standards. The data sets from multiple studies of different investigators can be combined through COPaKB as the shared reference for effective comparative analyses. Moreover, COPaKB Client is created to enable high-speed analysis of large data sets on a proteome scale. Overall, COPaKB encapsulates carefully curated data, new informatics schema, and an effective Web portal in a complete package. We anticipate this platform will broaden the use of proteomic data for the entire cardiovascular community and help bridge discovery-driven and hypothesis-driven studies.
MethodsConstruction of a Modular Knowledgebase for Cardiovascular Proteome BiologyCOPaKB contains the following components: a relational data-base supporting multiple modules of proteome knowledge, a Wiki interface promoting user input, and a computational toolbox fa-cilitating data analyses (Figure 1). All components are regularly updated and maintained.
Structure and Organization of COPaKBCOPaKB contains a repertoire of protein properties based on their subcellular compartments. The underlying relational database is configured using spectral libraries as a backbone structure. The selection of representative spectra has been based on the cross-correlation score (Xcorr) assigned by ProLuCID.8 An Oracle da-tabase has been used to manage orthogonal proteomic data sets in COPaKB. Known associations between protein function and car-diac diseases were retrieved from Online Mendelian Inheritance in Man Web service9 and from peer-reviewed publications via PubMed
using keyword combinations of protein name, gene symbol, and heart diseases.
Protein expression profiles probed with specific antibodies were integrated from the Human Protein Atlas (HPA; http://www.pro-teinatlas.org).10 The differential expression of gene transcript was integrated from Gene Expression Atlas.11 Gene Ontology (GO) an-notations were obtained using Universal Protein Resource (UniProt)12 and QuickGO services.13 The relationships among different GO terms were delineated using Ontology Lookup Service14 by European Molecular Biology Laboratory - European Bioinformatics Institute. The schema of this relational database is readily expandable to ac-commodate additional forms of knowledge (Figure 1). Each com-ponent of the COPaKB are constantly updated and maintained. The release history is outlined in the COPaKB Website (http://www.HeartProteome.org/copa/ReleaseHistory.aspx).
COPaKB Computational ToolboxWe have implemented the COPaKB Web server on a DELL Precision T7500 workstation. Details on server configuration are documented in the Online Data Supplement.
We developed the COPaKB Client software to enable Web-based data transfer via the Simple Object Access Protocol (SOAP). Details on the coding and application of this program are documented in the Online Data Supplement.
The analysis of proteomic data files from COPaKB users has been supported by a spectral library search engine that we previously developed.15
We processed mass spectral data files to create spectral libraries for COPaKB. Thus far, 10 modules have been configured on multiple replicate analyses (biological and technical), 8 of which are organel-lar modules. They include human heart mitochondria (29 replicates), human heart proteasomes (20 replicates), murine heart mitochondria (34 replicates), murine heart proteasomes (22 replicates), murine heart nucleus (30 replicates), murine heart cytosol (9 replicates), drosophila mitochondria (18 replicates), and Caenorhabditis elegans mitochondria (9 replicates). Two modules are total tissue lysates: hu-man heart lysate (20 replicates) and mouse heart lysate (1 replicate). Details on data source and data processing are documented in the Online Data Supplement.
We created a publicly accessible Website to interface COPaKB with the scientific community. The specific procedures of imple-menting both the Website and its Wiki Web portal (software de-velopment for each component) are described in the Online Data Supplement.
Data Source and Tissue CollectionAs of May 31, 2013, COPaKB hosts 10 modules. The modules of mu-rine heart mitochondria, murine heart proteasome, murine heart cyto-sol, drosophila mitochondria, human heart mitochondria, and human heart proteasome were created using the data collected at UCLA; the modules of murine heart nuclei, murine heart total lysates, C. ele-gans mitochondria, and human heart total lysates were curated from public resources.
Regarding data created at UCLA, all procedures involving mice (ICR strain) were performed in accordance with the Animal Research Committee guidelines at UCLA and the Guide for the Care and Use of Laboratory Animals, published by the National Institutes of Health. Drosophila mitochondria were extracted from the Oregon-R-C strain. The experimental procedures involving human samples were approved by the UCLA Human Subjects Protection Committee and the UCLA Institutional Review Boards. The phenotypes of all samples are documented online at COPaKB Website. Additional in-formation can be found in the Online Data Supplement.
Demonstration of the COPaKB-Assisted Proteomics WorkflowA test data set was downloaded from the Peptide Atlas Repository16 (PAe000353),17 containing a total of 111 raw proteomic data files. In this data set, murine heart mitochondrial proteins were extracted from the female ICR mouse strain and analyzed on a LCQ Deca XP
Nonstandard Abbreviations and Acronyms
COPaKB Cardiac Organellar Protein Atlas Knowledgebase
GO Gene Ontology
HPA Human Protein Atlas
SOAP Simple Object Access Protocol
UniProt Universal Protein Resource
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from
Zong et al Informatics and Computations of Cardiac Proteins 1045
mass spectrometer. This data set was processed by the COPaKB-directed workflow to benchmark its performance against that of the SEQUEST (BioWorks)-assisted workflow.
The analytic efficiency and robustness of the COPaKB Client–directed workflow were evaluated using spectral files in mzML format by scientists at 6 different test centers globally. Each center conducted 3 replicate tests and reported the fastest rate.
The use of COPaKB in integrating discoveries from multiple anal-yses was examined using 3 sets of LTQ-Orbitrap–collected data on
murine heart mitochondria, with the mass resolutions of MS1 scan set at 60 000, 15 000, and 7500, respectively. Each set contains 21 LC-MS/MS experiments.
ResultsTo create COPaKB (www.HeartProteome.org), we compiled a large collection of annotated protein mass spectral data sets on human, mouse, drosophila, and C. elegans samples. We
Figure 1. The schema of the Cardiac Organellar Protein Atlas Knowledgebase (COPaKB). A, Differential data sets of the cardiac proteome served as the basis for implementing COPaKB, including protein mass spectra, protein expression images (eg, immunohistochemical image of PSMB2 expression, immunofluorescence image of PSMA3 expression), and cardiac phenotypes (eg, heart failure, HF; ischemia reperfusion injury, IR). Using a protein identification list as a common index, these data sets were integrated into COPaKB in a relational database. In a modular structure, proteins were organized according to their organellar origins. Communication between COPaKB and cardiovascular investigators was mediated by a dedicated internet portal and interface featuring an open Web service infrastructure and a search engine. This infrastructure enables the delivery of integrated knowledge on the cardiac proteome in response to an input of raw spectral data set. Collectively, COPaKB acts as a platform for synergistic interaction among cardiovascular investigators. B, The relational database uses relation tables (eg, PTM table, PP_Relations table) to connect key property tables (eg, spectrum table, protein table) of the cardiac proteome. Derivative property tables (eg, disease relevance table) are connected to key property tables to archive diverse attributes of the cardiac proteome. Primary keys (PK) and foreign keys (FK) were used to establish correlations among these tables. HPA indicates Human Protein Atlas; UniProt, Universal Protein Resource; and PRIDE, PRoteomics IDEntifications database.
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from

1046 Circulation Research October 12, 2013
integrated these data in a modular structure that parallel the organization of subcellular organelles inside the cardiac cell. The following examples demonstrate the use of COPaKB for efficiently conducting analyses of protein properties.
Assembly of Cardiac Spectral Data SetsMass spectral data sets of proteins were organized into modular fashions based on their subcellular locations. Each module included multiple replicate analyses, which encap-sulate the dynamic range of protein expression. For the hu-man mitochondria module, a total of 6 biological replicates were integrated (Figure 2A); for the human proteasome module, a total of 5 biological replicates were integrated (Figure 2B). Altogether, the human mitochondria mass spec-tral library module was built on 856 LC-MS/MS experiments,
and the human proteasome module incorporated 160 LC-MS/MS experiments.
A total of 41 758 nonredundant mass spectra representing 1398 proteins and 28 031 peptides were compiled for the hu-man mitochondria module. A total of 5668 mass spectra rep-resenting 283 proteins and 3482 peptides were assembled for the human proteasome module; these data include proteasome subunits and their associated proteins. A total of 59 020 mass spectra representing 1619 proteins and 38 421 peptides were organized into the murine mitochondria module. A total of 9442 mass spectra representing 151 proteins and 6409 peptides were collected for the murine proteasome module (Table 1).
The data coverage of knowledgebase modules was evalu-ated by analyzing the cumulative number of protein entries as more replicates were incorporated. For the 4 example modules
Figure 2. Coverage of the four organellar modules in the Cardiac Organellar Protein Atlas Knowledgebase. A, Six biological replicates of human mitochondria preparations were analyzed to construct this spectral library module. A total of 1398 proteins were identified and compiled; the cumulative proteome coverage reached the limits of the LC-MS/MS platform. B, Five biological replicates were analyzed for the human proteasome module to reach a plateau in protein identification with 283 proteins. C, Ten biological replicates were analyzed for the mouse mitochondria module to reach a plateau of 1619 proteins. D, Five biological replicates were analyzed for the mouse proteasome module to reach a plateau of 151 proteins.
Table 1. Cardiovascular Proteome Biology Integrated in a Modular Knowledgebase
Modules* Proteins† Peptides‡ Spectra§ Images║ Diseases#
Human mitochondria 1398 28 031 41 758 822 142
Human proteasomes 283 3482 5668 146 53
Mouse mitochondria 1619 38 421 59 020 189
Mouse proteasomes 151 6409 9409 29
Mouse nuclei 1048 6918 9115
Mouse cytosol 2558 13 983 19 141
Human lysate 21 834 43 086 61 745 9956
Mouse lysate 4247 49 068 69 156
Drosophila mitochondria 1015 13 770 27 185
Caenorhabditis elegans mitochondria 1117 18 291 27 493
*Ten Modules are currently supported by Cardiac Organellar Protein Atlas Knowledgebase. The number of nonredundant entries for proteins, peptides, and spectra were listed in the columns of †Proteins,
‡Peptides, and §Spectra, respectively. ║Images summarizes the number of proteins with an expression profile available in the Human Protein Atlas.#Diseases outlines the number of proteins with regard to certain cardiovascular diseases in publications.
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from

Zong et al Informatics and Computations of Cardiac Proteins 1047
(human heart mitochondria, human heart proteasome, murine heart mitochondria, and murine heart proteasome) presented in Figure 2, the coverage of these modules reached plateau when sufficient number of replicates were included.
Data Integration in COPaKBCOPaKB organizes cardiac proteome knowledge in a rela-tional database (Figure 1). The core structure of this database is built on an integrated framework using mass spectrometry data sets, which capture multidimensional molecular features ranging from peptides to proteins. This unique hierarchy structure of the database renders seamless incorporation of diverse properties.
Protein expression image data sets were synchronized with those curated by the HPA10 and compiled into a HPA refer-ence table of COPaKB. Immunofluorescence and immuno-histochemistry images of a total of 10 924 human proteins were included (Table 1). Immunofluorescence images en-list protein expression profiles with subcellular resolution;
immunohistochemistry images assist visualization of the pro-tein expression profiles in different cardiac cell types.
Changes in protein properties associated with cardiovascu-lar pathogenesis were documented by performing a systematic literature search on peer-reviewed sources; a total of 413 non-redundant perturbations were found. In parallel, biomedical data from Online Mendelian Inheritance in Man18 and Gene Expression Atlas19 were incorporated into COPaKB to present the relevance of individual proteins to heart diseases.
Application of COPaKB to Support New Biology in Cardiovascular StudiesThe main utilities and functional outputs of COPaKB are sum-marized in Table 2. Queries may take the format of (1) a pro-tein identifier of interest as Protein Identifier, (2) a particular amino acid sequence of interest as Amino Acid Sequence; (3) any mass spectrometry data files from users as MS Data File(s); or (4) identifiers of existing analyses by any investi-gator team(s) as Analysis of Multiple Data Sets. Specifically,
Table 2. Utilities and Functional Outputs of Cardiac Organellar Protein Atlas Knowledgebase (COPaKB)
Queries* Protein Identifier Amino Acid Sequence MS Data File(s) Analysis of Multiple Data Sets
Query format† Protein name, its gene symbol, or its Universal Protein Resource (UniProt) ID
Full or partial amino acid sequence of a protein, a peptide, or a specific domain
Directory or URL address(es) of existing MS data files on user protein samples
Existing analyses by any investigator team or by different groups
Entry point‡ www.heartproteome.org/copa/ KeywordSearch.aspx?type=1
www.heartproteome.org/copa/KeywordSearch.aspx?type=2
www.heartproteome.org/copa/ MSRUNSearch.aspxor www.heartproteome.org/ copa/COPaKBClient.aspx
www.heartproteome.org/ epiSearch.aspx
Example inputs§
Example 1: Protein name, glycogen synthase kinase-3α28; its gene symbol, GSK3α; or its UniProt ID, P49840
Example 1: TTTLAFKFR Example 1: www.heartproteome.org/sample/human_proteasome_sample.mzML
Example 1: 14455, 14457, 14458
Example 2: Protein name, RAC- α serine/threonine-protein kinase29; its gene symbol, AKT1; or its UniProt ID, P31749
Example 2: GGVTTFVALYDYESRTETDLSF KKGERLQIVN NTEGDWWLAHSLSTGQT GYIPSNYVAPSDS
Example 2: https://dL. dropboxusercontent.com/u/65582675/1Orbi_Mito_B12_A.mzML
Example 2: See Figure 5
Reports by COPaKB║
• Reported cardiac phenotypes• mRNA expression profiles• Interacting partners• Tissue immunohisochemistry
images• Immunocytofluorescence
images• A list of peptides identified with
MS data• Peer-reviewed reports provided
by Information Hyperlinked over Proteins
• A Wiki page for further annotations
• PTM sites identified#• Its protein origin when querying a
peptide or a domain• Expression in organelles• A Wiki page for further annotations
• Protein expression profiles• Interacting partners• PTM sites identified with
MS data• Protein abundance
information• MS spectra of identified
proteins• A unique identifier for each
user sample analysis
• Proteins commonly expressed in multiple samples
• Interacting partners• Protein expression
comparison• Protein abundance
comparison
Example outputs**
www.heartproteome.org/copa/ proteinInfo.aspx?qType=protein% 20ID&qValue=P49840
www.heartproteome.org/copa/PeptideInfo.aspx?qType=Peptide%20Sequence&qValue=TTTLAFKFR
www.heartproteome.org/copa/ Report.aspx?TaskID=14455
www.heartproteome.org/copa/ epiTest.aspx?Tasks=14455,% 2014457,%2014458& Markers=
*Users can query COPaKB using multiple specific inputs.†User-directed queries allow several formats.‡Users can query COPaKB by entering these query requests at a number of sites available in COPaKB.§Users can submit inputs in formats as shown here in the example.║Users receive a report from COPaKB in response to their queries.#Analysis of post-translational modification sites includes phosphorylation, acetylation, ubiquitination, oxidation, and carbamidomethylation.**Users can view examples of outputs as shown via the links listed here.
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from

1048 Circulation Research October 12, 2013
a protein identifier may be a name of a protein; the glyco-gen synthase kinase-3α is shown in Table 2 as an example. Moreover, the protein identifier may also be its gene symbol, for example, GSK3α, or its UniProt ID, for example, P49840. When a query is made, COPaKB will generate reports regard-ing the relevance of this protein in cardiac phenotypes, infor-mation in the literature on its mRNA expression, its interacting protein partners, its immunohistochemistry images in the myo-cardium, and its immunocytofluorescence images in human cells. In addition, COPaKB will also report a list of peptides
identified with corresponding mass spectra data about this pro-tein and all peer-reviewed publications on this protein as docu-mented by Information Hyperlinked over Proteins (iHOP). Furthermore, COPaKB welcomes user inputs to further anno-tate this protein in the format of a Wiki page. An example out-put of this query by COPaKB is presented in Table 2 as www.heartproteome.org/copa/proteinInfo.aspx?qType=protein%20ID&qValue=P49840. In similar fashions, Table 2 details ex-amples highlighting query formats made as Amino Acid Sequence, MS Data File(s), or Analysis of Multiple Data Sets.
Figure 3. Sensitive protein identification via the Cardiac Organellar Protein Atlas Knowledgebase (COPaKB)–mediated Web service. The test data set of the murine mitochondrial proteome containing 111 raw data files was downloaded from the Peptide Atlas Repository16 (PAe000353).17 A, Compared with a database search workflow (SEQUEST), the COPaKB Web service covered 143 shared proteins (78.7%) and an additional 117 identifications (63.9%). The 117 proteins uniquely identified by the COPaKB workflow were categorized according to their Gene Ontology annotations. Among them, 92 proteins had a subcellular location annotation of the mitochondrion with functional implications in metabolism (74), apoptosis (4), transport (3), and unknown (11). Among the 39 proteins identified uniquely with the sequence database search engine, only 7 proteins had a subcellular location annotation of the mitochondrion. B, Mass spectrum corresponding to peptide LFQADNDLPVHLK was identified as belonging to cytochrome c oxidase 7a1 of the mitochondrial electron transport chain complex IV, which was identified by the COPaKB Web service. C, The expression profile of cytochrome b-c1 complex subunit 1 (Q9CZ13) in human myocardium was probed by its specific antibody (ID: HPA002815). This image was automatically retrieved by the COPaKB Web service from the Human Protein Atlas after its identification. D, Immunofluorescence image of this protein with the same antibody provided organellar resolution of protein expression. With the reference of organellar markers, Q9CZ13 was probed to express in mitochondria.
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from

Zong et al Informatics and Computations of Cardiac Proteins 1049
Furthermore, to demonstrate the utility of COPaKB-facilitated analyses, we acquired a test data set of murine mitochondria pro-teins from the Peptide Atlas Repository (PAe000353).17 This test data set was reprocessed using the murine mitochondria module of COPaKB as a reference. In this analysis, we identified a to-tal of 261 proteins with a statistical confidence of 95%. In con-trast, when this test data set was analyzed using the SEQUEST, a commonly used mass spectra search engine, we identified 183 proteins at the same confidence level (Online Table II). Specifically, 78.7% of proteins were commonly identified by the 2 approaches (Figure 3A), whereas COPaKB identified an ad-ditional 64.5% proteins (ie, 117 proteins) that were not covered by the SEQUEST search (Figure 3B). This added protein cover-age significantly expanded the search outcome; the additional 117 proteins include mitochondrial proteins (eg, cytochrome c oxidase 7A1 of the electron transport chain complex IV).
Moreover, an automatic query to the knowledgebase for pro-tein identification was integrated with functional annotations. Among the 117 proteins uniquely identified by COPaKB, 92 proteins (79%) had a GO annotation of the mitochondrion as their primary subcellular location (Figure 3A). Seventy-four out of the 92 mitochondrial proteins (80%) were involved in metabolism, 3 were involved in transport, and 4 were involved
in apoptosis. Furthermore, 199 protein expression images (among the 261 identified proteins) were available in HPA and were automatically retrieved (Figure 3C). According to peer-reviewed publications, 49 of the 261 proteins were involved in the processes of cardiac pathogenesis.
Performance Efficiency of COPaKB WorkflowA reliable delivery of Omics-scale information requires robust Web portals. The traditional Web-based data transfer protocol is limited by its ability to transfer data effectively within a defined timeframe (eg, 60 minutes). To overcome this chal-lenge, a COPaKB Client program was engineered to imple-ment a SOAP-assisted workflow (Figure 4). Its performance efficiency was benchmarked against that of the traditional HTTP-assisted workflow by participating investigators from 6 test centers (Table 3 and Online Table I). In all these tests, large-scale data files were reliably and consistently delivered by the COPaKB Client. In a load test, the COPaKB server was able to process 50 simultaneous search requests without compromising its reliability.
The analytic efficiency of the COPaKB-supported search engine was also benchmarked against that of the SEQUEST. Analysis using COPaKB requires extra time to upload the data
Figure 4. Large-scale spectral analysis over the Web. Cardiac Organellar Protein Atlas Knowledgebase (COPaKB) Client orchestrates segmentation (1) and submission (2) of mass spectral data through the internet to the COPaKB server. Data packets (3) received by the COPaKB server were analyzed using the spectral library as a reference (4). For matched spectra (5), the properties of their corresponding proteins are retrieved from COPaKB automatically (6), which are returned to COPaKB Client (7). By the end of the analysis, COPaKB Client presents a consolidated report (8) outlining the proteome properties encoded in the raw spectral files.
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from

1050 Circulation Research October 12, 2013
onto the knowledgebase server. Despite the required extra time, the COPaKB-supported workflow completed the anal-yses faster than that performed by the SEQUEST-supported workflow. This test was repeated on a personal computer and on a computing cluster of moderate size (7 nodes; Table 4). This enhanced efficiency of COPaKB workflow is accom-plished by a condensed search space within the mass spectral library, a simplified spectral matching algorithm, a strategy of selecting only MS2 spectra for Web-based protein identifica-tion, and the integration of the SOAP protocol.
Platform to Promote New Discoveries Through Collaborative EffortDiscoveries from multiple studies can be integrated in real time via the COPaKB server (Table 2). COPaKB receives the
identifier of each analysis task as input and returns a list of proteins that are identified in each of these analyses. Three test data sets of murine mitochondrial proteins were collected using an LTQ-Orbitrap mass spectrometer with different set-tings of MS1 resolution; they were independently analyzed via COPaKB (Figure 5A). These results were then combined using the murine mitochondria module of COPaKB as a ref-erence. Comparative analysis on these data sets was subse-quently conducted (Figure 5B).
COPaKB relies on inputs from the scientific community. Integration of mass spectrometry–based data sets from various sources necessitates standard operation protocols. COPaKB achieves consistency following the principles established by the Minimum Information about a Proteomics Experiment.20 This guideline describes experimental procedures with
Table 3. Performance of the Cardiac Organellar Protein Atlas Knowledgebase (COPaKB) Web Service Across the Globe
Test Data Set* Centers† SOAP, mm:ss‡ HTTP, mm:ss§Terminal
Bandwidth║
Human mitochondria(LTQ-Orbitrap): 12 197 scans; 1.34 GB (mzML file)
Los Angeles, CA 1:28 3:56 100 Mbps
San Diego, CA 2:53 21:12 1 Gbps
Woods Hole, MA 5:56 29:12 130 Mbps
Ann Arbor, MI 2:45 59:22 144 Mbps
Cambridge, United Kingdom 8:27 46:42 1 Gbps
Shanghai, China 18:25 53:48 100 Mbps
Mouse proteasomes (LTQ-Orbitrap): 17 746 scans; 1.88 GB (mzML file)
Los Angeles, CA 1:17 4:05 100 Mbps
San Diego, CA 5:45 30:24 1 Gbps
Woods Hole, MA 26:45 45:46 130 Mbps
Ann Arbor, MI 4:18 >60 144 Mbps
Cambridge, United Kingdom 14:01 57:21 1 Gbps
Shanghai, China 13:01 >60 100 Mbps
Human mitochondria(LTQ-XL): 20 677 scans; 292 MB (mzML file)
Los Angeles, CA 5:35 6:05 100 Mbps
San Diego, CA 14:37 7:45 1 Gbps
Woods Hole, MA 22:21 10:43 130 Mbps
Ann Arbor, MI 11:15 16:08 144 Mbps
Cambridge, United Kingdom 28:31 12:48 1 Gbps
Shanghai, China 23:10 12:22 100 Mbps
Human proteasomes (LTQ-XL): 20 736 scans; 249 MB (mzML file)
Los Angeles, CA 2:56 3:00 100 Mbps
San Diego, CA 9:09 5:11 1 Gbps
Woods Hole, MA 13:05 7:02 130 Mbps
Ann Arbor, MI 6:52 13:01 144 Mbps
Cambridge, United Kingdom 28:21 10:40 1 Gbps
Shanghai, China 12:00 8:53 100 Mbps
The performance of the COPaKB Web service was validated across 6 test centers around the globe: Los Angeles, San Diego, Woods Hole, Ann Arbor, Cambridge, and Shanghai. Four representative spectral files were used as test data sets, including both Orbitrap-acquired high-resolution mass spectra and LTQ-acquired low-resolution mass spectra. The analytic times were compared between the SOAP workflow and the HTTP workflow. If data upload exceeded the timeout threshold of 60 minutes, the analyses were aborted in the HTTP workflow. Bandwidth of the Web portal at each test center was listed; this contributed to the overall data transfer rate between the clients and the COPaKB server. With high mass resolution data sets, the SOAP Web portal offered a significantly faster analytic rate. This advantage was especially prominent when the overall network bandwidth decreased. The SOAP and HTTP workflows showed comparable efficiency in processing low-resolution data sets. SOAP indicates Simple Object Access Protocol.
*Source and size of each test file.†Location of the 6 test centers.‡Time needed for completing an analysis via a SOAP portal.§Time needed for completing an analysis via a HTTP portal.║Internet bandwidth available at each test center.
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from

Zong et al Informatics and Computations of Cardiac Proteins 1051
sufficient details using controlled vocabularies. The complex-ity of the controlled vocabulary, however, often serves as a double-edged sword; the redundant terminology allows the same experiments to be described in different terms. Using a specialized subset of the data submission utility,21 COPaKB
conducts standardized collection and propagation of pro-teomics data (Online Figure III).
Along with the effort to streamline the knowledgebase with consistent vocabularies, a text-based Wiki component has been created to facilitate communication among investigators. The Wiki component is coupled to each peptide, protein, and spectrum entry of the knowledgebase, welcoming users to add or edit the content relevant to the subject. The open nature of the Wiki component fosters a worldwide collaborative effort (Online Figure IV).
DiscussionOur goal is to create a protein knowledgebase to support the long-term advancement of cardiovascular biology in an infor-matics-driven era. As the continued growth of any bioinfor-matics platform hinges on community support, we designed COPaKB from the grounds up with community participa-tion in mind.
Systems Integration and Software Engineering for COPaKBCOPaKB assembles its individual modules based on pro-tein localizations. Each module consists of orthogonal data sets curated from either a public resource or a large cohort of experiments. The public resources also include UniProt,12 HPA,22 OMIM,9 and Gene Expression Atlas.19 The annotated data sets are integrated using a relational database schema, which offers the investigators easy access to an array of pro-tein properties.
COPaKB operates via an innovative workflow. First, it has the design features to support multidimensional data integration. Specifically, using mass spectrometry–based proteomics data has the benefit that information from dif-ferent disciplines can be synthesized. Second, it carries a new mechanism of conducting data query. Many online proteomics resources exist, including repertoires of 2-di-mensional PAGE images,23 mass spectra,10 and protein ex-pression images.16,21 Retrieving these data from multiple databases remains laborious and requires repetitive mining efforts. COPaKB overcomes these challenges with 2 unique functional features. One is to connect specific interests of individual investigators with vast information hosted in the
Table 4. Comparison of Analytic Efficiency of Cardiac Organellar Protein Atlas Knowledgebase (COPaKB) Client and SEQUEST
Test Data Set*
SEQUEST, mm:ss†COPaKB Client,
mm:ss‡
PC Head Node Cluster; 7 Nodes Cluster; 13 Nodes PC Head Node
Human mitochondria (LTQ-Orbitrap) 21:40 16:39 1:14 0:45 1:35 0:57
Mouse proteasomes (LTQ-Orbitrap) 21:49 19:32 1:15 0:44 2:24 1:15
Human mitochondria (LTQ-XL) 286:00 277:00 12:54 0:29 5:05 2:13
Human proteasomes (LTQ-XL) 263:00 259:00 11:57 0:23 2:39 2:09
The efficiency of spectral analysis via the COPaKB Web service was demonstrated using SEQUEST as a control. Even when Web-based data transfer time was included, COPaKB Client outperformed SEQUEST. COPaKB Client using only 1 node showed an analytic rate comparable to that of SEQUEST running on a cluster of 13 nodes.
*Source of each test file.†Time needed for completing an analysis by SEQUEST.‡Time needed for completing an analysis by COPaKB Client.
Figure 5. Integration of discoveries from multiple analyses. A, Via Cardiac Organellar Protein Atlas Knowledgebase, discoveries from multiple proteomic investigations from discrete research groups can be aligned by specifying the task ID of each analysis. Alternatively, the expression of selected biomarkers in these studies can be probed. B, There were 452 shared protein identities among the tasks 13855, 13878, and 14003. Meanwhile, 627 proteins were detected only in task 13855, 4 proteins only in 14003, and 17 proteins only in 13878.
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from

1052 Circulation Research October 12, 2013
knowledgebase; another is to support the analysis of raw data files in an efficient manner. Both features are supported by computational strategies created for COPaKB. These strategies include a spectral library and a search engine that automatically decodes raw spectral data,24–26 subsequently combining them with orthogonal properties of proteins and genes. This computational toolbox provides a new mecha-nism of using biomedical knowledgebase where functional annotations of each protein in the sample are presented in a cohesive context. Accordingly, this built-in bioinformatics pipeline in COPaKB supports investigators to complement their targeted investigation with discovery-based or hypoth-esis-driven approaches.
Finally, COPaKB Client addresses the technical limitations of transferring large data files on a proteome scale. We have engineered this program to use a Web-based SOAP portal to enable robust connections with the COPaKB server, allow-ing reliable access to contextualized properties on proteins of interest.
Building COPaKB Via a Community-Driven ParadigmComprehensive understanding of cardiovascular biology on a proteome scale is a long-term goal that often exceeds the capacity of individual investigators. COPaKB alleviates this limitation by implementing the bioinformatics infrastructure necessary to facilitate effective collaboration. In particular, COPaKB allows real-time integration of analyses on multiple data sets from numerous investigators in parallel. This strategy surmounts technical challenges in long-distance collabora-tions, namely geographic boundaries and platform discrepan-cies. Additionally, the Wiki component in COPaKB supports investigators to communicate and contribute information on individual proteins in a variety of formats (eg, images or text).
Investigator participation is essential to the future growth of a community-driven knowledgebase. Currently, the capac-ity of COPaKB modules is primarily contributed by data sets publicly available. However, the current coverage of COPaKB on several modules is at infant stage. Particularly, this situa-tion applies to the module of mouse heart total lysate. Because the ProteomeXchange consortium27 led by EBI has acceler-ated the supply of raw proteomic data, COPaKB is expected to grow and will cover additional modules on organelles and cells from cardiovascular-relevant model systems. The con-tent of each module will expand with the increasingly avail-able public data.
Despite the rapid development in proteomics science, the gap in translating the new tools to biological applications has widened. This is largely due to limited access to high-end in-strumentation and difficulties to manage large data analyses. The user-friendly workflow of the COPaKB helps nonpro-teomics investigators to benefit directly from the technologi-cal advancement and new data sets. Investigators are no longer restricted amid lacking a direct access to high-end mass spec-trometry. For example, COPaKB documents the parameters (eg, molecular mass and charge state) that are associated with peptides; the institutional proteomic core can then adjust in-strument settings accordingly to improve the detection of their selected proteins. In this scenario, the cost and time in using
the proteomic technologies are optimized. Taken together, COPaKB provides a number of effective workflows to guide cardiovascular investigators from proteomics data to system-atic interpretation of biomedical properties. We are continuing to develop innovative workflows to aid better understanding of protein functions in cardiovascular diseases.
In conclusion, COPaKB is a novel computational platform with its unique bioinformatics pipelines and Web portals, engaging a community effort to build a knowledgebase. As proteome biology has become increasingly integrated into cardiovascular medicine, we envision a growing importance of this new resource.
Sources of FundingThis work was supported, in part, by National Heart, Lung, and Blood Institute Proteomics Center Award HHSN268201000035C, NIH R01 HL063901, an endowment from Theodore C. Laubisch to P.P.; R37HL063901 diversity supplement award to D.M.; and R37HHSN268201000035C diversity supplement award to I.Z.
DisclosuresNone.
References 1. Pazdrak K, Young TW, Straub C, Stafford S, Kurosky A. Priming of eosin-
ophils by GM-CSF is mediated by protein kinase CbetaII-phosphorylated L-plastin. J Immunol. 2011;186:6485–6496.
2. Wang SB, Foster DB, Rucker J, O’Rourke B, Kass DA, Van Eyk JE. Redox regulation of mitochondrial ATP synthase: implications for cardiac resynchronization therapy. Circ Res. 2011;109:750–757.
3. Zhang J, Guy MJ, Norman HS, Chen YC, Xu Q, Dong X, Guner H, Wang S, Kohmoto T, Young KH, Moss RL, Ge Y. Top-down quan-titative proteomics identified phosphorylation of cardiac troponin I as a candidate biomarker for chronic heart failure. J Proteome Res. 2011;10:4054–4065.
4. Théberge R, Infusini G, Tong W, McComb ME, Costello CE. Top-down analysis of small plasma proteins using an LTQ-Orbitrap. Potential for mass spectrometry-based clinical assays for transthyretin and hemoglo-bin. Int J Mass Spectrom. 2011;300:130–142.
5. Lam MP, Lau E, Scruggs SB, Wang D, Kim TY, Liem DA, Zhang J, Ryan CM, Faull KF, Ping P. Site-specific quantitative analysis of cardiac mito-chondrial protein phosphorylation. J Proteomics. 2013;81:15–23.
6. Mazumder R, Natale DA, Julio JA, Yeh LS, Wu CH. Community annota-tion in biology. Biol Direct. 2010;5:12.
7. Chen C, McGarvey PB, Huang H, Wu CH. Protein bioinformatics in-frastructure for the integration and analysis of multiple high-throughput “omics” data. Adv Bioinformatics. 2010:423589.
8. Xu T, Wong CC, Kashina A, Yates JR III. Identification of N-terminally arginylated proteins and peptides by mass spectrometry. Nat Protoc. 2009;4:325–332.
9. McKusick VA. Mendelian Inheritance in Man and its online version, OMIM. Am J Hum Genet. 2007;80:588–604.
10. Uhlen M, Oksvold P, Fagerberg L, Lundberg E, Jonasson K, Forsberg M, Zwahlen M, Kampf C, Wester K, Hober S, Wernerus H, Björling L, Ponten F. Towards a knowledge-based Human Protein Atlas. Nat Biotechnol. 2010;28:1248–1250.
11. Kapushesky M, Adamusiak T, Burdett T, et al. Gene Expression Atlas up-date–a value-added database of microarray and sequencing-based func-tional genomics experiments. Nucleic Acids Res. 2012;40:D1077–D1081.
12. Wu CH, Apweiler R, Bairoch A, et al. The Universal Protein Resource (UniProt): an expanding universe of protein information. Nucleic Acids Res. 2006;34:D187–D191.
13. Binns D, Dimmer E, Huntley R, Barrell D, O’Donovan C, Apweiler R. QuickGO: a web-based tool for Gene Ontology searching. Bioinformatics. 2009;25:3045–3046.
14. Côté R, Reisinger F, Martens L, Barsnes H, Vizcaino JA, Hermjakob H. The Ontology Lookup Service: bigger and better. Nucleic Acids Res. 2010;38:W155–W160.
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from

Zong et al Informatics and Computations of Cardiac Proteins 1053
15. Li H, Zong NC, Liang X, Kim AK, Choi JH, Deng N, Zelaya I, Lam M, Duan H, Ping P. A novel spectral library workflow to enhance protein identifications. J Proteomics. 2013;81:173–184.
16. Desiere F, Deutsch EW, King NL, Nesvizhskii AI, Mallick P, Eng J, Chen S, Eddes J, Loevenich SN, Aebersold R. The PeptideAtlas project. Nucleic Acids Res. 2006;34:D655–D658.
17. Kislinger T, Cox B, Kannan A, Chung C, Hu P, Ignatchenko A, Scott MS, Gramolini AO, Morris Q, Hallett MT, Rossant J, Hughes TR, Frey B, Emili A. Global survey of organ and organelle protein expres-sion in mouse: combined proteomic and transcriptomic profiling. Cell. 2006;125:173–186.
18. Hamosh A, Scott AF, Amberger JS, Bocchini CA, McKusick VA. Online Mendelian Inheritance in Man (OMIM), a knowledgebase of human genes and genetic disorders. Nucleic Acids Res. 2005;33:D514–D517.
19. Kapushesky M, Emam I, Holloway E, Kurnosov P, Zorin A, Malone J, Rustici G, Williams E, Parkinson H, Brazma A. Gene expression atlas at the European bioinformatics institute. Nucleic Acids Res. 2010;38: D690–D698.
20. Taylor CF, Paton NW, Lilley KS, et al. The minimum information about a proteomics experiment (MIAPE). Nat Biotechnol. 2007;25:887–893.
21. Jones P, Côté RG, Cho SY, Klie S, Martens L, Quinn AF, Thorneycroft D, Hermjakob H. PRIDE: new developments and new datasets. Nucleic Acids Res. 2008;36:D878–D883.
22. Pontén F, Jirström K, Uhlen M. The Human Protein Atlas–a tool for pa-thology. J Pathol. 2008;216:387–393.
23. Hoogland C, Mostaguir K, Appel RD, Lisacek F. The World-2DPAGE Constellation to promote and publish gel-based proteomics data through the ExPASy server. J Proteomics. 2008;71:245–248.
24. Yates JR III, Morgan SF, Gatlin CL, Griffin PR, Eng JK. Method to com-pare collision-induced dissociation spectra of peptides: potential for li-brary searching and subtractive analysis. Anal Chem. 1998;70:3557–3565.
25. Lam H, Deutsch EW, Eddes JS, Eng JK, King N, Stein SE, Aebersold R. Development and validation of a spectral library searching method for peptide identification from MS/MS. Proteomics. 2007;7:655–667.
26. Li H, Zong N, Liang X, Kim A, Choi J, Deng N, Zelaya I, Lam M, Duan H, Ping P. A novel spectral library workflow to enhance protein identifica-tions. J Proteomics. 2013;81:173–184.
27. Orchard S, Albar JP, Deutsch EW, Eisenacher M, Binz PA, Martinez-Bartolomé S, Vizcaíno JA, Hermjakob H. From proteomics data represen-tation to public data flow: a report on the HUPO-PSI workshop September 2011, Geneva, Switzerland. Proteomics. 2012;12:351–355.
28. Zhai P, Sadoshima J. Overcoming an energy crisis?: an adaptive role of glycogen synthase kinase-3 inhibition in ischemia/reperfusion. Circ Res. 2008;103:910–913.
29. Shiojima I, Walsh K. Role of Akt signaling in vascular homeostasis and angiogenesis. Circ Res. 2002;90:1243–1250.
What Is Known?
• Proteomics techniques allow for large-scale analysis of global protein expression, but are not commonly accessible because of the need for specialized computational and informatics expertise.
What New Information Does This Article Contribute?
• Cardiac Organellar Protein Atlas Knowledgebase (COPaKB) is a new resource consolidating relevant protein data sets from multiple scientific disciplines and linking protein molecular properties to their functional phenotypes.
• COPaKB features a novel algorithm supporting user-directed protein pathway studies in their specified biological context of interests.
• COPaKB could serve as a centralized Web portal, allowing remote data management, and as an online platform for collaboration among investigators.
Proteomics investigations have received increasing attention in cardiovascular research, but several obstacles remain before effective translation and utilization of proteomic data. These challenges include fragmented data structure, inconsistent data annotations, and, often, investigator inaccessibility to relevant technology platforms. COPaKB was created as a unique resource to facilitate better understanding of proteomic data sets. This platform is a curated relational database of protein molecular and biomedical phenotype properties, interfaced to a Website for public data retrieval. It allows any investigator to process raw proteomic data sets without the need of accessing high-end in-strumentation, and it returns a consistently annotated report of protein properties. The platform also offers a wide range of in-formatics tools for investigators to analyze different studies in parallel and to conduct meta-analyses.
Novelty and Significance
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from

R. Yates III, Rolf Apweiler, Junbo Ge, Henning Hermjakob and Peipei PingOdeberg, Caiyun Fang, Hao-jie Lu, Tao Xu, James Weiss, Huilong Duan, Mathias Uhlen, John
Ning Deng, Allen K. Kim, Jeong Ho Choi, Ivette Zelaya, David Liem, David Meyer, Jacob Nobel C. Zong, Haomin Li, Hua Li, Maggie P.Y. Lam, Rafael C. Jimenez, Christina S. Kim,Integration of Cardiac Proteome Biology and Medicine by a Specialized Knowledgebase
Print ISSN: 0009-7330. Online ISSN: 1524-4571 Copyright © 2013 American Heart Association, Inc. All rights reserved.is published by the American Heart Association, 7272 Greenville Avenue, Dallas, TX 75231Circulation Research
doi: 10.1161/CIRCRESAHA.113.3011512013;113:1043-1053; originally published online August 21, 2013;Circ Res.
http://circres.ahajournals.org/content/113/9/1043World Wide Web at:
The online version of this article, along with updated information and services, is located on the
http://circres.ahajournals.org/content/suppl/2013/08/21/CIRCRESAHA.113.301151.DC1Data Supplement (unedited) at:
http://circres.ahajournals.org//subscriptions/
is online at: Circulation Research Information about subscribing to Subscriptions:
http://www.lww.com/reprints Information about reprints can be found online at: Reprints:
document. Permissions and Rights Question and Answer about this process is available in the
located, click Request Permissions in the middle column of the Web page under Services. Further informationEditorial Office. Once the online version of the published article for which permission is being requested is
can be obtained via RightsLink, a service of the Copyright Clearance Center, not theCirculation Researchin Requests for permissions to reproduce figures, tables, or portions of articles originally publishedPermissions:
by guest on April 16, 2018
http://circres.ahajournals.org/D
ownloaded from

Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S1
SUPPLEMENTAL MATERIALS
TABLE OF CONTENTS
Extended Methods (Pages S2-S4).
Legends of Supplemental Figures (Pages S5-S6).
Supplemental Table:
o Supplemental Table I shows the impact of network bandwidth on the speed of
COPaKB-mediated mass spectral analysis (Page S7).
o Supplemental Table II lists proteins identified from the test dataset (PAe000353)
using COPaKB and SEQUEST (Pages S8-S14).
References (Page S15).
Supplemental Figures:
o Supplemental Figure I outlines the organizational structure of the figures and
tables presented in this manuscript (Page S16).
o Supplemental Figure II illustrates how COPaKB Client mediates data analyses
using web service (Pages S17-S19).
o Supplemental Figure III presents the user interface for the specialized version of
the PRIDE converter (Page S20).
O Supplemental Figure IV provides examples of the wiki components in the COPa
Knowledgebase (Pages S21-S23).

Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S2
EXTENDED METHODS
Construction of a Modular Knowledgebase for Cardiovascular Proteome Biology
COPaKB contains the following components: a relational database that supports multiple modules of proteome knowledge, a Wiki interface that promotes user input, and a computational toolbox that facilitates data analyses (Fig. 1). All components are regularly updated and maintained. Structure and Organization of the COPa Knowledgebase
COPa knowledgebase contains a repertoire of protein properties based on their subcellular compartments. An Oracle database has been used to manage orthogonal proteomic datasets in the COPaKB. Known associations between protein function and cardiac diseases were retrieved from OMIM web service8 and from peer-reviewed publications via PubMed; the search was performed using keyword combinations of protein name, gene symbol and heart diseases.
Protein expression profiles probed with specific antibodies were integrated from the
Human Protein Atlas9. The differential expression of gene transcript was integrated from Gene Expression Atlas10. Gene Ontology (GO) annotations were obtained using UniProt API11 and QuickGO services12. The relationships among different GO terms were described using Ontology Lookup Service13 developed by EMBL-EBI. The schema of this relational database is readily expandable to accommodate additional forms of knowledge (Fig. 1). Each component of the COPaKB are constantly updated and maintained. The release history is outlined in the COPaKB website (Please visit http://www.heartproteome.org/copa/ReleaseHistory.aspx).
COPaKB Computational Toolbox
We have implemented the COPaKB web server on a DELL Precision T7500 workstation. This workstation is equipped with an Intel Xeon four-core CPU X5687 (3.6Hz), 48 GB DDR3 RAM, 2 TB internal hard drive and 1 Gbps network connection.
We developed the COPaKB Client software (Fig. SII) that enables web-based data transfer via the Simple Object Access Protocol (SOAP). The current build of COPaKB Client (V2.0) is coded in Java using the IntelliJ IDEA 11.1 by JetBrains. It functions on Windows, OS X and Linux platforms with Java SE version 7 (32-bit or 64 bit). COPaKB Client accepts MS/MS file input in mzML format, which is the recommended format of the Proteomic Standardization Initiative8. Various MS/MS file types can be converted into the mzML format using the open source utility, ProteoWizard Converter (http://proteowizard.sourceforge.net/)9. A plugin slot is pre-configured in COPaKB Client to be coupled with ProteoWizard Converter (Fig. SIID). COPaKB Client partitions mzML data files into small data packets, which are transferred to the COPaKB web server using the SOAP workflow. Meanwhile, the results are returned to the Client for real-time review. At the end of the analysis, a final report is assembled by COPaKB Client to summarize the discoveries. The analysis of proteomic data files from COPaKB users is supported by a spectral library search engine that we developed10.
We processed mass spectral data files to create spectral libraries. Using the UniProt protein database5 of human (128,974 entries), mouse (99,274 entries), drosophila (37,596 entries) and C. elegans (49,690 entries) species, protein identification was performed on the raw spectral datasets via ProLuCID1 algorithm. The enzyme specificity was set at semi-tryptic specificity. A tolerance of deviation in precursor mass measurements was set at 50 ppm for LTQ-Orbitrap-acquired datasets (mass resolution of 60,000 at m/z 400) and 2 AMU for LTQ-

Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S3
acquired datasets. Tolerance for fragment mass measurements was set at 1 AMU for both cases. Static modification included carboxyamidomethylation of the cysteine residue (+57.02146 Da); differential modifications included oxidation of the methionine residue (+15.9949 Da) and acetylation of the protein’s N-terminus (+42.0106 Da). With reversed sequence database as control, DTASelect11 (V2.0) was applied to control false discovery rate within 1% at the protein level. Thus far, ten modules have been configured upon multiple replicate analyses (biological and technical), eight of which are organellar modules. These include human heart mitochondria (29 replicates), human heart proteasomes (20 replicates), murine heart mitochondria (34 replicates), murine heart proteasomes (22 replicates), murine heart nuclei (30 replicates), murine heart cytosols (9 replicates), drosophila mitochondria (18 replicates), and C. elegans mitochondria (9 replicates). Two other modules are total tissue lysates: human heart lysates (20 replicates) and mouse heart lysates (1 replicate). For each peptide, an annotated spectrum was provided for all possible combinations of charge state and post-translational modification status. The selection of representative spectra was based on the cross-correlation score (Xcorr) assigned by the ProLuCID algorithm.
We created a website of COPaKB as an interface for investigators. Internet Information
Services (IIS v7.5) in Windows 7 (64 bits) was configured to manage this web server. The website was developed in ASP.NET using Microsoft Visual Studio 2010. A wiki component was constructed with LiteWiki (v0.2.1, http://litewiki.codeplex.com/) and FreeTextBox (v3.2, http://www.freetextbox.com/) to accompany each entry within this resource. NeatUpload (v1.3.25, http://neatupload.codeplex.com/) was utilized to enable submission of a raw MS/MS data file to the COPaKB server via a HTTP web portal and subsequent analysis on the server. A threshold for a HTTP-based server connection timeout was set at a maximum of one hour. Data Source and Tissue Collection
As of May 31st 2013, COPaKB hosts ten modules. The modules of murine heart mitochondria, murine heart proteasome, murine heart cytosol, drosophila mitochondria, human heart mitochondria and human heart proteasome were created using the data collected at UCLA; the modules of murine heart nuclei, murine heart total lysates, C. elegans mitochondria, and human heart total lysates were curated from public resources.
Regarding data created at UCLA, all procedures involving animals were performed in accordance with the Animal Research Committee (ARC) guidelines at UCLA and the Guide for the Care and Use of Laboratory Animals, published by the National Institutes of Health. Drosophila samples were taken from flies 1-2 weeks of age. The experimental procedures involving human samples were approved by the UCLA Human Subjects Protection Committee (HSPC) and the UCLA Institutional Review Boards (IRBs). The phenotypes of all samples are documented online at COPaKB website.
Evaluation of the COPaKB-assisted Proteomics Workflow
A test dataset was downloaded from the Peptide Atlas Repository12 (Project ID: PAe000353)13, containing a total of 111 raw proteomic data files. In this dataset, murine heart mitochondrial proteins were extracted from the female ICR mouse strain and analyzed on a LCQ Deca XP mass spectrometer. This dataset was processed by the COPaKB-directed workflow to benchmark its performance against that of the SEQUEST-assisted workflow.
The analytical efficiency and robustness of the COPaKB Client-directed workflow were evaluated using spectral files in mzML format by scientists at six different test centers globally. Each center conducted three replicate tests and reported the fastest rate.

Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S4
The utility of COPaKB in integrating discoveries from multiple analyses was examined using three sets of LTQ-Orbitrap-collected data on murine heart mitochondria, with the mass resolutions of MS1 scan set at 60,000, 15,000, and 7,500, respectively. Each set contains 21 LC-MS/MS experiments.

Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S5
ONLINE SUPPLEMENT FIGURES AND LEGENDS Supplement Figure I. This flowchart shows the organization of figures and tables in this manuscript. It illustrates the overall knowledgebase structure, bioinformatics tools and web portals, as well as benchmark results. The solid line denotes the structural breakdown of the COPaKB framework; the dashed line denotes a benchmark evaluation or a property of a COPaKB component. Supplement Figure II. COPaKB Client mediates the communication between the COPaKB terminals and the COPaKB server. Via a robust SOAP web portal, it processes large-scale raw spectral datasets and returns to the terminals the corresponding integrated proteome properties archived in the COPaKB server. A. The interface of COPaKB Client comprises four sections. The top-left pane contains four buttons: “Open” (to load query files), “Settings” (to define the parameters of spectral analysis), “Search” (to start spectral analysis), and “Save” (to save the results of the analysis). A summary of settings for spectral analysis is listed below these buttons. The center-left pane lists the queue of spectral files to be analyzed. The bottom left pane shows real time progress of the spectral analysis. The content displayed in the right pane is connected to the bottom left pane; the right pane illustrates a match between the library spectrum and the query spectrum selected in the bottom left pane. When the analysis is finished, the bottom left pane displays statistical evaluations, proteins identified, and semi-quantitative assessments of the protein abundances via spectral counting. B. The “Open” dialog box appears after clicking the “Open” button. Multiple spectral files can be selected in one analysis. C. The “Settings” dialog box loads after clicking the “Settings” button. In the “Search Engine” tab, a choice of reference spectral library modules, tolerance of precursor mass deviation, accommodation of systematic shift in fragment ion mass measurements, and threshold for false positive discoveries can be set. D. The “General” tab of the “Settings” dialog box includes settings for the size of transferring each data packet, range of spectra within the files to be analyzed and maximum number of attempts to reconnect to the COPaKB server after a connection failure. The ProteoWizard converter9 may be incorporated here to couple the file format conversion with data analysis. E. During spectral analysis, the “Search” button is changed to “Stop Search” button; clicking on this button stops an ongoing analysis and triggers the presentation of a partial report. In the center-left pane, the spectral file under active analysis is labeled with a bar icon. Real time progress on spectral matching is illustrated in the bottom left pane; the match between a particular query spectrum and its corresponding library spectrum is retrievable in the right pane by selecting the query spectrum in the bottom left pane. The progress of spectral analysis is shown with a grey bar. F. After the analysis is completed, identified proteins and peptides are shown in the bottom-left pane. The right pane lists the original data files, the parameters selected for spectral analysis, and the total number of protein identifications. Score distributions of spectral matches and threshold used to separate target matches and false positive matches are illustrated below. The final portion of the report is a semi-quantitative assessment of protein abundance presented in the form of Normalized Spectral Abundance Factor (NSAF). Supplement Figure III. To facilitate the exchange of mass spectrometry-based proteomics datasets, a specialized submission software was utilized. The software was coded by Proteomics Identifications database (PRIDE)15, which is a core member of the ProteomeXchange consortium. The software uses an enriched set of controlled vocabularies (CVs) that denote cardiovascular parameters to assist investigators with consistent annotation of their individual proteomic datasets.

Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S6
Supplement Figure IV. A wiki component was coupled to each data entry of the COPa Knowledgebase to welcome critiques as well as to allow easy incorporation of biological insights from multidisciplinary perspectives. This utility accommodates free-texts and images as input. A. Properties of Pdha2 and its corresponding wiki section are shown as an example. B. Molecular properties of peptide acetyl-AERGYSFSLTTFSPSGK are shown with its wiki component. C. A mass spectrum of peptide GTTTLAFKFLHGVIVAADSR with its wiki section is shown as an example.

Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S7
ONLINE SUPPLEMENT TABLE AND LEGEND Supplement Table I. Rate of Web-based Spectral Analysis and Network Bandwidth. The rate of web-based, large-scale spectral analysis depends on the network bandwidth between the terminals and the COPaKB server. As the throughput of the client web connection in a test center approached the high end, the rate of analysis plateaued.
Test Datasets SOAP HTTP Terminal
Bandwidth Total Total Upload Matching
Human Mitochondria (Orbi) 12,197 scans
1.34 GB (mzML file)
1:25 min 3:30 min 1:37 min 1:53 min 1 Gbps
1:28 min 3:29 min 2:03 min 1:26 min 100 Mbps
2:31 min 12:10 min 11:32 min 0:48 min 54 Mbps
3:25 min 29:00 min 28:21 min 0:49 min 10 Mbps
Mouse Proteasomes (Orbi) 17,746 scans
1.88 GB (mzML file)
1:17 min 4:05 min 2:40 min 1:25 min 1 Gbps
1:37 min 4:05 min 2:52 min 1:13 min 100 Mbps
3:57 min 18:35 min 17:55 min 0:40 min 54 Mbps
6:48 min 33:36 min 32:47 min 0:49 min 10 Mbps
Human Mitochondria (LTQ) 20,677 scans
292 MB (mzML file)
5:35 min 6:05 min 0:24 min 5:41 min 1 Gbps
6:44 min 6:00 min 0:26 min 5:34 min 100 Mbps
11:11 min 6:08 min 2:43 min 3:25 min 54 Mbps
17:05 min 11:35 min 5:46 min 5:49 min 10 Mbps
Human Proteasomes (LTQ) 20,736 scans
249 MB (mzML file)
2:56 min 3:00 min 0:21 min 2:39 min 1 Gbps
4:04 min 3:00 min 0:22 min 2:38 min 100 Mbps
7:21 min 5:17 min 2:15 min 3:02 min 54 Mbps
11:14 min 7:30 min 5:07 min 2:23 min 10 Mbps

Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S8
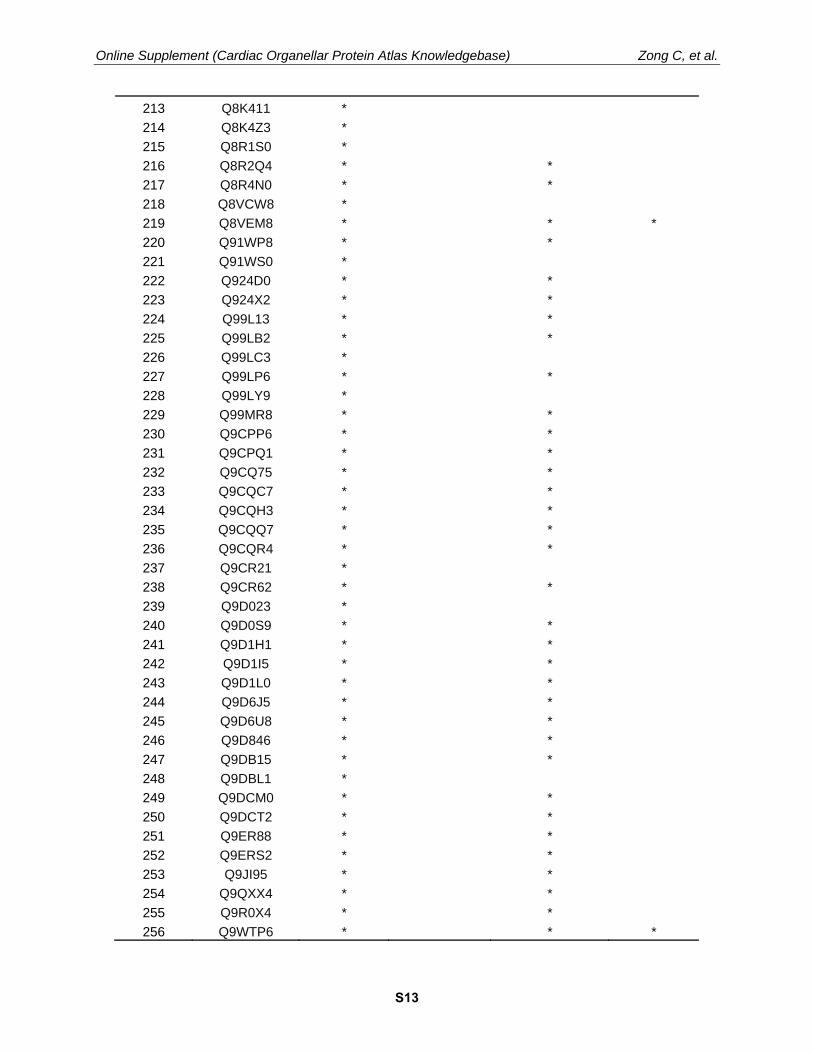
Supplement Table II. Proteins identified from the test dataset (PAe000353). Proteins identified by COPaKB or SEQUEST were denoted by “*” in the corresponding column; their UniProt IDs were provided. Proteins with expression profile (Human protein atlas, http://www.proteinatlas.org/) were denoted with “*” in the HPA Reference column; the proteins were probed with corresponding antibodies in human myocardium. Proteins that are associated with cardiac diseases according to peer-reviewed publications were denoted with “*” in the Diseases column. These attributes are available in COPaKB (www.HeartProteome.org).
Index UniProt ID COPaKB SEQUEST HPA Reference Diseases
1 P09671 * * * *
2 P70404 * * *
3 Q9CY10 * * 4 P68134 * * * *
5 P60710 * * *
6 P47738 * * * 7 Q9CZ13 * * *
8 Q9CZU6 * * *
9 P42125 * * *
10 Q05920 * * *
11 P48962 * * 12 Q99JY0 * * * *
13 O08788 * * *
14 O55137 * * 15 Q99KI0 * * *
16 P20108 * * *
17 Q99KR7 * * 18 P05125 * * * 19 Q07417 * * 20 Q99LC5 * * *
21 P05202 * * *
22 O70468 * * * 23 Q9DB20 * * *
24 P51174 * * *
25 Q9DB77 * * *
26 P50544 * * * *
27 P62631 * * *
28 Q6P8J7 * * 29 Q9DC69 * * *
30 P12787 * * * *
31 Q9DCJ5 * * *
32 Q61425 * * *
33 Q9DCS9 * * * 34 Q921G7 * * *
35 Q9DCW4 * * *
36 Q6P3Z7 * * * *

Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S9
37 Q8VCF0 * * *
38 Q9JK42 * * * *
39 Q60930 * * *
40 Q60932 * * * *
41 Q922B1 * * *
42 Q9WUR9 * * 43 Q8CC88 * * 44 Q91VA7 * * 45 Q91VM9 * * * 46 P07310 * * 47 Q91WD5 * * * 48 P52503 * * 49 P29758 * * *
50 Q02566 * * * *
51 P99029 * * *
52 P97807 * * *
53 Q03265 * * *
54 Q91YT0 * * * *
55 O35459 * * *
56 P00405 * * *
57 P07724 * * *
58 Q9D051 * * *
59 Q9D0K2 * * *
60 Q9D0M3 * * *
61 Q9CQN1 * * *
62 O35658 * * *
63 Q9CR61 * * *
64 Q9CR68 * * *
65 Q9D172 * * 66 P09542 * * * *
67 Q9CQZ5 * *
68 P16332 * * *
69 P38647 * * *
70 Q9D2G2 * * *
71 P45952 * * *
72 Q9QYR9 * * 73 P23927 * * * *
74 Q8BMF4 * * *
75 Q8QZS1 * * *
76 Q8QZT1 * * * *
77 Q8K2C6 * * *
78 Q68FD5 * * *
79 Q9D6J6 * * * *
80 Q8BKZ9 * * *

Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S10
81 Q8BMS1 * * * *
82 Q7TQ48 * * 83 Q8BWT1 * * *
84 P20152 * * *
85 P21550 * * *
86 P11404 * * * *
87 P05201 * * 88 Q8K2B3 * * * * 89 Q9DCX2 * * 90 O70250 * * 91 P04247 * * *
92 Q9Z2I9 * * *
93 Q8BWF0 * * *
94 Q8BFR5 * * *
95 Q9CXT8 * * *
96 Q8BH86 * * 97 Q91VD9 * * 98 P63038 * * * *
99 Q8BMF3 * * *
100 Q922E1 * * *
101 Q64518 * * * *
102 Q8R429 * * * *
103 P24270 * * *
104 Q91VR2 * * 105 Q9CQX8 * * * 106 P02089 * * 107 P54071 * * *
108 E9Q120 * * *
109 P20029 * * * *
110 P43023 * * *
111 P59017 * * *
112 P63017 * * * *
113 P08249 * * *
114 Q91ZA3 * * 115 Q9D6Y7 * * * *
116 P50136 * * *
117 O08749 * * * 118 P35486 * * 119 Q9CQA3 * * * 120 O55143 * * 121 B2RXT3 * * 122 Q7TMF3 * * * 123 Q9CXI0 * * 124 Q9CQ62 * * *

Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S11
125 Q8CHT0 * * *
126 Q9WUM5 * * *
127 Q6PB66 * * *
128 Q60597 * * * *
129 Q9D3D9 * * *
130 Q8BH95 * * *
131 Q9Z2I8 * * 132 Q9D6R2 * * *
133 Q9EQ20 * * *
134 Q1XH17 * * *
135 P56480 * * *
136 Q8CFZ3 * * * *
137 Q8R0F8 * * *
138 Q99NB1 * * 139 Q9JHI5 * * 140 P02088 * * 141 Q505N7 * * *
142 Q01853 * * * *
143 Q60597 * * * *
144 A8DUK7 * * 145 A2AFQ2 * *
146 A2AT64 * * *
147 D3YU05 * *
148 D3YX33 * *
149 D3Z6E4 * *
150 O08749 * *
151 O08756 * *
152 O09161 * * *
153 O35129 * *
154 O55124 * *
155 O55126 *
156 O88696 * * *
157 O88844 * *
158 P00158 * *
159 P04919 * *
160 P08228 * * *
161 P10605 * *
162 P14869 * *
163 P17710 * *
164 P18242 * *
165 P19123 * * *
166 P19536 * *
167 P19783 * *
168 P26443 *

Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S12
169 P26443 * *
170 P34914 * *
171 P41216 * *
172 P43024 *
173 P47934 * *
174 P51667 * * *
175 P52196 * *
176 P52825 * * *
177 P53395 *
178 P56391 * *
179 P56392 *
180 P58771 * * *
181 P62897 * *
182 P67778 * *
183 P68369 * *
184 P85094 * *
185 P97450 * *
186 P99028 * *
187 Q01768 * * *
188 Q06185 * *
189 Q149B8 * *
190 Q2TPA8 *
191 Q3TC72 * *
192 Q3TLP5 * *
193 Q60936 * *
194 Q61001 *
195 Q61554 * *
196 Q62425 *
197 Q6P3A8 * *
198 Q71RI9 * *
199 Q78J03 * *
200 Q80Z21 * *
201 Q8BGC4 * *
202 Q8BH59 * *
203 Q8BIJ6 * *
204 Q8BMS4 * *
205 Q8BTM8 * *
206 Q8CAK1 * *
207 Q8CAQ8 * *
208 Q8CI22 * *
209 Q8JZQ2 * *
210 Q8K0Z7 * *
211 Q8K1Z0 * *
212 Q8K370 *
Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S13
213 Q8K411 *
214 Q8K4Z3 *
215 Q8R1S0 *
216 Q8R2Q4 * *
217 Q8R4N0 * *
218 Q8VCW8 *
219 Q8VEM8 * * *
220 Q91WP8 * *
221 Q91WS0 *
222 Q924D0 * *
223 Q924X2 * *
224 Q99L13 * *
225 Q99LB2 * *
226 Q99LC3 *
227 Q99LP6 * *
228 Q99LY9 *
229 Q99MR8 * *
230 Q9CPP6 * *
231 Q9CPQ1 * *
232 Q9CQ75 * *
233 Q9CQC7 * *
234 Q9CQH3 * *
235 Q9CQQ7 * *
236 Q9CQR4 * *
237 Q9CR21 *
238 Q9CR62 * *
239 Q9D023 *
240 Q9D0S9 * *
241 Q9D1H1 * *
242 Q9D1I5 * *
243 Q9D1L0 * *
244 Q9D6J5 * *
245 Q9D6U8 * *
246 Q9D846 * *
247 Q9DB15 * *
248 Q9DBL1 *
249 Q9DCM0 * *
250 Q9DCT2 * *
251 Q9ER88 * *
252 Q9ERS2 * *
253 Q9JI95 * *
254 Q9QXX4 * *
255 Q9R0X4 * *
256 Q9WTP6 * * *

Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S14
257 Q9WTP7 *
258 Q9WVE4 * *
259 Q9WVL0 * *
260 Q9Z0X1 * * *
261 Q9Z1P6 *
262 Q9CWF2 *
263 A2AMM0 * *
264 Q9D8E6 * *
265 P70670 *
266 Q9CZR8 * *
267 P47955 * *
268 P33622 *
269 P04117 * *
270 Q80X68 *
271 Q02357 * *
272 P14206 * *
273 O89023 * *
274 Q9CQ09 *
275 Q9D1C3 *
276 Q9QYG0 * *
277 P62082 *
278 Q921I1 * *
279 Q8K4F5 * *
280 P11499 * *
281 Q8CIE6 * *
282 Q8BHF5 * *
283 P62702 * *
284 Q07417 * *
285 P97351 *
286 Q9CPY7 * *
287 O88799 *
288 B7ZCC9 * *
289 P26039 * *
290 E9Q223 *
291 Q9EQH3 *
292 P09813 * *
293 Q8VED5 *
294 Q3ZAW8 * *
295 Q80TQ2 * *
296 Q63836 *
297 Q6NXH9 * *
298 Q3V1M1 * *
299 Q67BT3 * *
300 Q9CY58 * *

Online Supplement (Cardiac Organellar Protein Atlas Knowledgebase) Zong C, et al.
S15
REFERENCES 1. Xu T, Wong CC, Kashina A, Yates JR, 3rd. Identification of n-terminally arginylated
proteins and peptides by mass spectrometry. Nat Protoc. 2009;4:325-332 2. McKusick VA. Mendelian inheritance in man and its online version, omim. American
journal of human genetics. 2007;80:588-604 3. Uhlen M, Oksvold P, Fagerberg L, Lundberg E, Jonasson K, Forsberg M, Zwahlen M,
Kampf C, Wester K, Hober S, Wernerus H, Bjorling L, Ponten F. Towards a knowledge-based human protein atlas. Nat Biotechnol. 2010;28:1248-1250
4. Kapushesky M, Adamusiak T, Burdett T, Culhane A, Farne A, Filippov A, Holloway E, Klebanov A, Kryvych N, Kurbatova N, Kurnosov P, Malone J, Melnichuk O, Petryszak R, Pultsin N, Rustici G, Tikhonov A, Travillian RS, Williams E, Zorin A, Parkinson H, Brazma A. Gene expression atlas update--a value-added database of microarray and sequencing-based functional genomics experiments. Nucleic Acids Res. 2012;40:D1077-1081
5. Wu CH, Apweiler R, Bairoch A, Natale DA, Barker WC, Boeckmann B, Ferro S, Gasteiger E, Huang H, Lopez R, Magrane M, Martin MJ, Mazumder R, O'Donovan C, Redaschi N, Suzek B. The universal protein resource (uniprot): An expanding universe of protein information. Nucleic Acids Res. 2006;34:D187-191
6. Binns D, Dimmer E, Huntley R, Barrell D, O'Donovan C, Apweiler R. Quickgo: A web-based tool for gene ontology searching. Bioinformatics. 2009;25:3045-3046
7. Cote R, Reisinger F, Martens L, Barsnes H, Vizcaino JA, Hermjakob H. The ontology lookup service: Bigger and better. Nucleic Acids Res. 2010;38:W155-160
8. Martens L, Chambers M, Sturm M, Kessner D, Levander F, Shofstahl J, Tang WH, Rompp A, Neumann S, Pizarro AD, Montecchi-Palazzi L, Tasman N, Coleman M, Reisinger F, Souda P, Hermjakob H, Binz PA, Deutsch EW. Mzml--a community standard for mass spectrometry data. Mol Cell Proteomics. 2011;10:R110 000133
9. Kessner D, Chambers M, Burke R, Agus D, Mallick P. Proteowizard: Open source software for rapid proteomics tools development. Bioinformatics. 2008;24:2534-2536
10. Li H, Zong NC, Liang X, Kim A, Choi JH, Deng N, Zelaya I, Lam M, Duan H, Ping P. A novel spectral library workflow to enhance protein identifications. J Proteomics. 2013
11. Cociorva D, D LT, Yates JR. Validation of tandem mass spectrometry database search results using dtaselect. Curr Protoc Bioinformatics. 2007;Chapter 13:Unit 13 14
12. Desiere F, Deutsch EW, King NL, Nesvizhskii AI, Mallick P, Eng J, Chen S, Eddes J, Loevenich SN, Aebersold R. The peptideatlas project. Nucleic Acids Res. 2006;34:D655-658
13. Kislinger T, Cox B, Kannan A, Chung C, Hu P, Ignatchenko A, Scott MS, Gramolini AO, Morris Q, Hallett MT, Rossant J, Hughes TR, Frey B, Emili A. Global survey of organ and organelle protein expression in mouse: Combined proteomic and transcriptomic profiling. Cell. 2006;125:173-186
14. Keller A, Nesvizhskii AI, Kolker E, Aebersold R. Empirical statistical model to estimate the accuracy of peptide identifications made by ms/ms and database search. Anal Chem. 2002;74:5383-5392
15. Jones P, Cote RG, Cho SY, Klie S, Martens L, Quinn AF, Thorneycroft D, Hermjakob H. Pride: New developments and new datasets. Nucleic Acids Res. 2008;36:D878-883

Biology- and Organelle-basedModular Structure of COPaKB
Table 1; Figs. 2A, 2B, 2C, 2D
Reliable Assembly of Cardiac Proteome via Organelle-based Spectral Libraries
Figs. 4A, 4B, 4C
Robust Web-based Analyses ofCardiac Proteome Properties across COPaKB
Tables 2, 3; Fig. 3; Suppl. Table I; Suppl. Fig. II
Overview and Schema of Cardiac Organellar Protein Atlas Knowledgebase (COPaKB)
Figs. 1A, 1B
Supplement Figure I
Platform and Portals for Synergistic Interactions among Individual Cardiovascular Investigators
Figs. 5, Suppl. Figs. III, IV
Assembly of Cardiac Proteome Properties
Table 1
Cardiac Protein Spectral Library Modules
Figs. 2A, 2B, 2C, 2D
Specific Recognition of Organellar Proteins
Figs. 4B, 4C
Sensitive Identification of Cardiac Proteins
Figs. 4A, 4B, 4C; Suppl. Table II
Superior Efficiency over Sequence Search
Table 3
Reproducible Global Data Dissemination
Fig.3; Table 2; Suppl. Table I

A
B
Supplement Figure II

C
D
Supplement Figure II

E
F
Supplement Figure II

Supplement Figure III

A
Supplement Figure IV

B
Supplement Figure IV

C
Supplement Figure IV





























