Embed Size (px)
Citation preview

Natural Language Processing
Parte 4: Semantica lessicale

Semantica lessicale • Un lessico in genere ha una forma molto strutturata ▫ Memorizza i significati e i possibili usi di ogni parola ▫ Codifica le relazioni fra le parole e i significati
• Un lessema è l’unità minima che viene rappresentata nel lessico ▫ associa il lemma (la forma ortografica scelta per rappresentare la parole)
con una forma simbolica di rappresentazione del significato (il senso) • Un dizionario è una forma di lessico in cui i significati sono espressi tramite
definizioni ed esempi
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
2
son noun a boy or man in relation to either or both of his parents. • a male offspring of an animal. • a male descendant : the sons of Adam. • ( the Son) (in Christian belief) the second person of the Trinity; Christ. • a man considered in relation to his native country or area : one of Nevada's most famous sons. • a man regarded as the product of a particular person, influence, or environment : sons of the French Revolution. • (also my son) used by an elder person as a form of address for a boy or young man : “You're on private land, son.”

Lessici e dizionari • Le definizioni dei dizionari usano altre parole e possono essere
anche circolari
▫ Paradossalmente gli elementi del dizionario non sono vere definizioni sono descrizioni di lessemi fatte con altri lessemi con la speranza che l’utente
del dizionario abbia sufficiente informazione su questi altri termini! questo approccio fallirebbe senza conoscenza a priori derivante dal mondo
esterno tuttavia le descrizioni forniscono una notevole quantità di informazioni sulle
relazioni fra le parole che permettono di eseguire operazioni semantiche
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
3
destro agg. 1. Che, nel corpo umano, sta dalla parte opposta a quella del cuore 2. Che è a destra rispetto a un punto di riferimento più o meno esplicito 3. (fig. )Agile, attivo, sciolto

Relazioni fra lessemi e sensi • Si possono definire molte tipologie fra i lessemi e i loro sensi alcune
delle quali sono importanti per l’elaborazione automatica ▫ Omonimia (Homonymy)
E’ una relazione fra parole che hanno la stessa forma ma significati incorrelati (e la stessa PoS) es. vite (plurale di vita, la pianta, l’oggetto con la filettatura), bank (la banca, la
sponda del fiume) Sono proprietà correlate l’omofonia (stessa pronuncia ma ortografia diversa) e
l’omografia (stessa grafia ma pronuncia diversa pésca/pèsca) E’ una causa di ambiguità per l’interpretazione di una frase e genera più
lessemi con la stessa grafia (vite1, vite2,..) ▫ Polisemia (Polysemy)
Corrisponde al caso di un lessema che ha più significati correlati fra loro Per distinguerla dall’omonimia occorre considerare l’etimologia della parola
(es. collo parte del corpo/collo della bottiglia, banca/banca dati)
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
4

Polisemia/Sinonimia Per i lessemi polisemici occorre definire Un modo per capire quanti e quali sono i significati e se sono effettivamente
distinti (lavoro dei lessicografi) Come sono correlati fra loro i vari significati Come possono essere distinti in modo da interpretare correttamente una parola
in un certo contesto di frase (word sense disambiguation) ▫ Sinonimia (Synonymy)
E’ una relazione fra due diversi lessemi con lo stesso significato (ovvero sono sostituibili in un certo contesto senza modificarne il significato o la correttezza) – es. Ho ricevuto un dono/regalo Non è detto che l’equivalenza valga in tutti i contesti per piccole differenze
semantiche (es. ho donato/regalato una caramella ai bimbi – ho donato una bella cifra all’ente di beneficienza; la tariffa/il prezzo del servizio – il prezzo della casa)
In genere la sostituibilità dipende dall’intersezione dei sensi dei due lessemi e anche da fattori sociali (ciabatta/pantofola)
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
5

Iponimia/Ipernimia • L’iponimia (hyponymy) è una relazione fra due lessemi (o meglio fra
due sensi) tali che uno denota una sottoclasse dell’altro ▫ alano, cane – melo, albero – auto, veicolo ▫ La relazione non è simmetrica
L’elemento più specifico è detto iponimo (hyponym) di quello più generico L’elemento più generale è detto iperonimo (hypernym) di quello più specifico
▫ L’iponimia (ipernimia) è la base per la definizione di una tassonomia (struttura ad albero che definisce relazioni di inclusione in una ontologia di oggetti) anche se non lo è propriamente La definizione di una vera tassonomia richiederebbe maggiore uniformità/
rigore formale nell’interpretazione del concetto di inclusione In ogni caso le relazioni oggetto eredità proprietà dai suoi antenati nella
gerarchia
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
6

Wordnet • E’ un database lessicale per l’Inglese (sono comunque disponibili
versioni per altre lingue) ▫ Sono rappresentati sostantivi, verbi, aggettivi e avverbi ma non sono
presenti i termini funzionali di classe chiusa (preposizioni, ecc.) ▫ I lessemi sono raggruppati in insiemi di sinonimi cognitivi (synset),
ciascuno dei quali esprime un concetto distinto ▫ A ciascun lessema (forma ortografica unica) è associato un insieme di
sensi (synset) ▫ I synset sono connessi da relazioni concettuali/semantiche e lessicali ▫ Wordnet comprende file lessicografici, un applicativo per trasformare
questi file in un database e una libreria di funzioni di ricerca e navigazione per visualizzare le informazioni del database
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
7
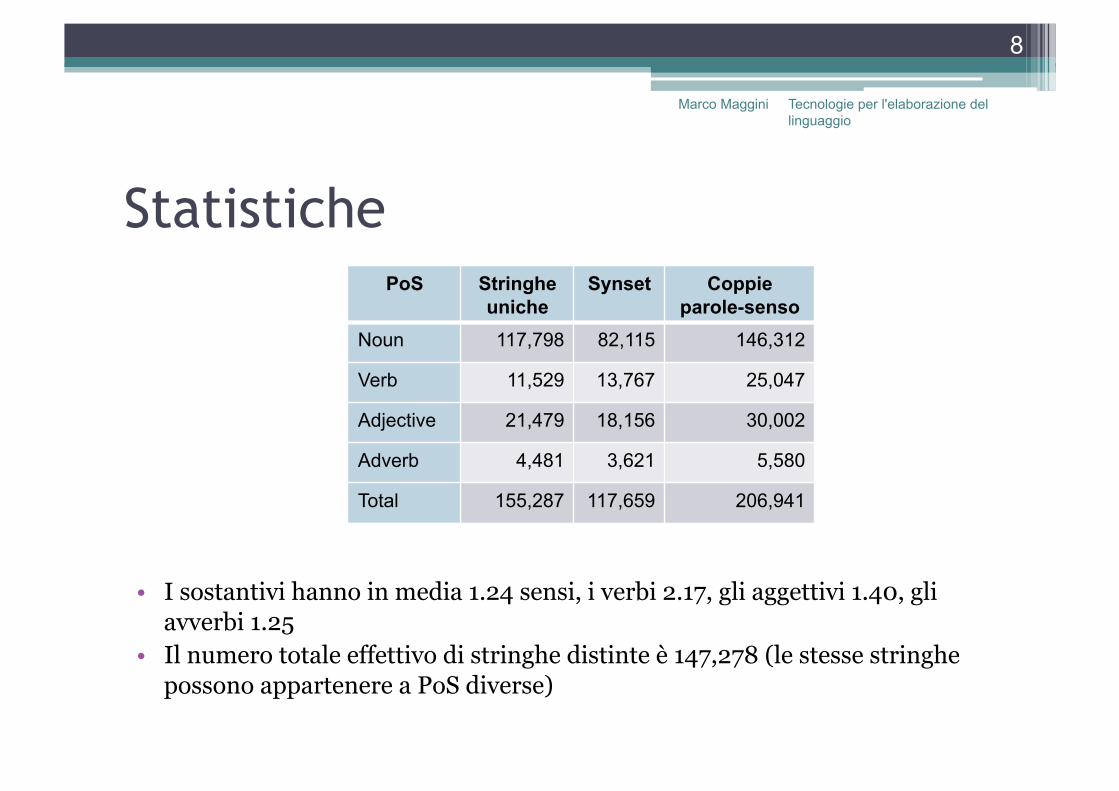
Statistiche PoS Stringhe
uniche Synset Coppie
parole-senso Noun 117,798 82,115 146,312
Verb 11,529 13,767 25,047
Adjective 21,479 18,156 30,002
Adverb 4,481 3,621 5,580
Total 155,287 117,659 206,941
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
8
• I sostantivi hanno in media 1.24 sensi, i verbi 2.17, gli aggettivi 1.40, gli avverbi 1.25
• Il numero totale effettivo di stringhe distinte è 147,278 (le stesse stringhe possono appartenere a PoS diverse)

synset • Un synset è un insieme di sinonimi che definiscono un concetto o
accezione di parola ▫ Oltre la metà dei synset (~54%) contiene un solo termine, circa un terzo
(~29%) 2 termini, il ~10% 3 termini ▫ Ai synset (specie a quelli con un solo termine) è associata una glossa di
spiegazione (un synset contiene mediamente ~1.75 termini)
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
9
2 senses of teacher
Sense 1 teacher#1, instructor#1 -- (a person whose occupation is teaching) => educator#1, pedagogue#1, pedagog#1 -- (someone who educates young people)
Sense 2 teacher#2 -- (a personified abstraction that teaches; "books were his teachers"; "experience is a demanding teacher") => abstraction#1, abstract#1 -- (a concept or idea not associated with any specific instance; "he loved her only in the abstract--not in person”)
synset
synset
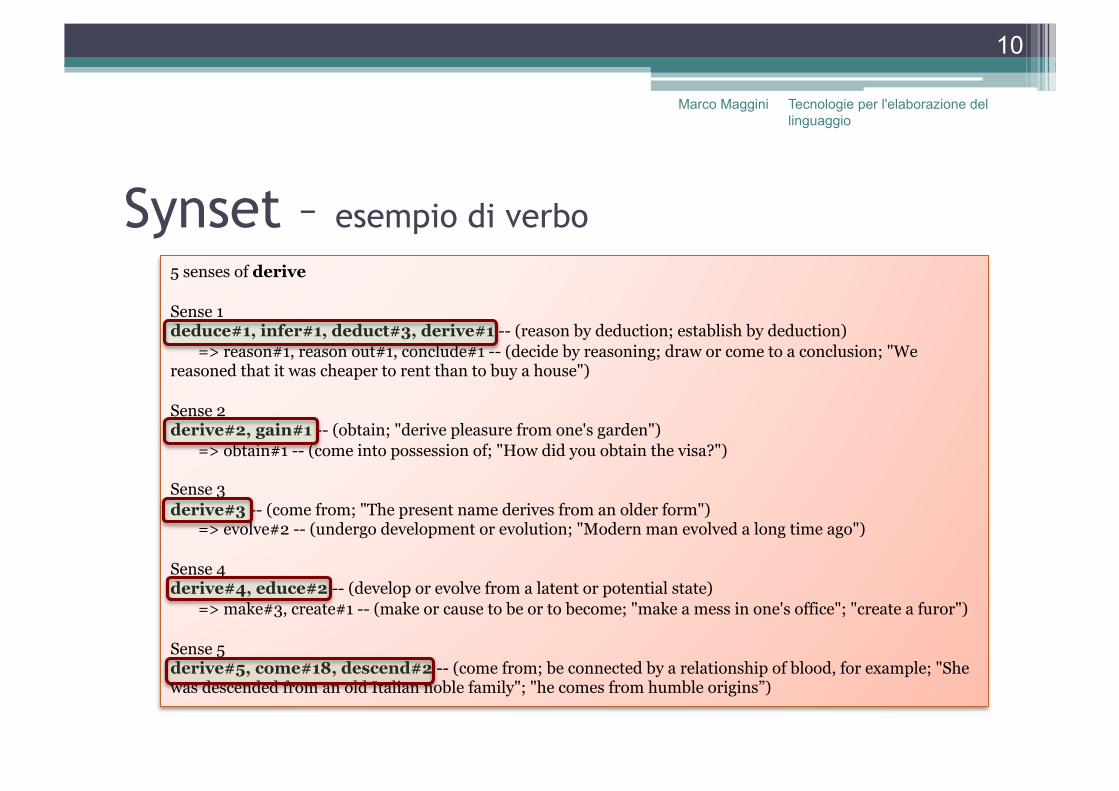
Synset – esempio di verbo
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
10
5 senses of derive
Sense 1 deduce#1, infer#1, deduct#3, derive#1 -- (reason by deduction; establish by deduction) => reason#1, reason out#1, conclude#1 -- (decide by reasoning; draw or come to a conclusion; "We reasoned that it was cheaper to rent than to buy a house")
Sense 2 derive#2, gain#1 -- (obtain; "derive pleasure from one's garden") => obtain#1 -- (come into possession of; "How did you obtain the visa?")
Sense 3 derive#3 -- (come from; "The present name derives from an older form") => evolve#2 -- (undergo development or evolution; "Modern man evolved a long time ago")
Sense 4 derive#4, educe#2 -- (develop or evolve from a latent or potential state) => make#3, create#1 -- (make or cause to be or to become; "make a mess in one's office"; "create a furor")
Sense 5 derive#5, come#18, descend#2 -- (come from; be connected by a relationship of blood, for example; "She was descended from an old Italian noble family"; "he comes from humble origins”)

Nomi • I nomi sono organizzati in una gerarchia di specializzazioni (iponimi) e
generalizzazioni (iperonimi) ▫ Nella versione 3.0 è prevista una unica categoria radice {entity} detta
unique beginner mentre nelle versioni precedenti sono definiti più unique beginner (25 nella versione 1.7.1)
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
11
vase#1 -- (an open jar of glass or porcelain used as an ornament or to hold flowers) => jar#1 -- (a vessel (usually cylindrical) with a wide mouth and without handles) => vessel#3 -- (an object used as a container (especially for liquids)) => container#1 -- (any object that can be used to hold things (especially a large metal boxlike object of standardized dimensions that can be loaded from one form of transport to another)) => instrumentality#3, instrumentation#1 -- (an artifact (or system of artifacts) that is instrumental in accomplishing some end) => artifact#1, artefact#1 -- (a man-made object taken as a whole) => whole#2, unit#6 -- (an assemblage of parts that is regarded as a single entity; "how big is that part compared to the whole?"; "the team is a unit") => object#1, physical object#1 -- (a tangible and visible entity; an entity that can cast a shadow; "it was full of rackets, balls and other objects") => physical entity#1 -- (an entity that has physical existence) => entity#1 -- (that which is perceived or known or inferred to have its own distinct existence (living or
nonliving))

Gerarchia dei nomi • Primi tre livelli della gerarchia dei nomi a partire dalla radice unique
beginner {entity} per Wordnet 3.0
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
12

Relazioni in Wordnet – nomi e verbi
• Per i sostantivi sono definite le seguenti relazioni fra i synset ▫ Iperonimia - X è un tipo di Y (alano → cane) ▫ Iponimia – Y è un tipo di X (cane → alano) ▫ Termini coordinati – Y è un termine coordinato a X se X e Y hanno in
comune un iperonimo (alano e mastino) ▫ Olonimia – X è parte di Y (ruota → bicicletta) ▫ Meronimia – Y è parte di X (bicicletta → ruota)
• Per i verbi sono definite le seguenti relazioni fra i synset ▫ Iperonimia – l’attività di X è un tipo di attività Y (vedere → percepire) ▫ Troponimia – l’attività Y esegue X in qualche modo (mangiare →
divorare) ▫ Implicazione (entailment) – Per fare X si deve fare Y (russare→dormire) ▫ Termini coordinati – I termini condividono uno stesso iperonimo
(ascoltare-vedere come casi di percepire)
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
13

Relazioni in Wordnet – aggettivi e avverbi
• Le parole possono essere connesse ad altre parole con relazioni lessicali come l’antonimia (opposti) ▫ buono ⇔ cattivo, scuro ⇔ chiaro
• Per gli aggettivi sono definite le seguenti relazioni ▫ Nomi correlati – (rumoroso → rumore) ▫ Simile a – (rumoroso → sferragliante)
Un parte degli aggettivi (descrittivi) sono organizzati in gruppi che contengono un synset principale (head) e synset satelliti. Ciascun gruppo è organizzato attorno ad una coppia (talvolta tripla) di antonimi che corrispondono ai termini principali. I synset satelliti sono quelli legati dalla relazione “Simile a”.
Gli aggettivi relazionali o pertinenti non hanno invece struttura a gruppo e non hanno antonimi (es. batterico)
• Per gli avverbi sono definite le relazioni ▫ Aggettivo base – (lentamente → lento)
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
14

Esempio - aggettivo descrittivo
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
15
similar to
opposite
related noun
NOISY
QUIET

Word sense disambiguation • La word sense disambiguation (WSD) riguarda il problema di
individuare quale senso di una parola è usato in una data frase ▫ Si applica alle parole con più significati (polisemia) ▫ Richiede un dizionario che elenca i possibili sensi di ogni parola ▫ Si può affrontare su singole parole o congiuntamente su tutte le parole
della frase (si considerano le combinazioni di significati)
▫ Sono stati proposti molti metodi per la WSD (Machine Readable) Dictionary and knowledge-based, Machine Learning
Supervised methods, Semi-supervised and Unsupervised methods
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
16
Ho mangiato un piatto freddo Ho lavato un piatto sporco Hanno servito un piatto freddo

Apprendimento supervisionato • La WSD può essere affrontata come un problema di classificazione ▫ il senso corretto è la classe da predire ▫ la parola è rappresentata con un insieme (vettore) di feature in ingresso
al classificatore L’ingresso è di solito costituito da una rappresentazione della parola da
disambiguare (target) e del contesto in cui si trova (un certo numero di parole a sinistra e destra della parola target)
Come feature si possono considerare la parola, la radice della parola, la PoS della parola
▫ Il classificatore può essere stimato con tecniche di apprendimento automatico a partire da un dataset etichettato
▫ Si possono usare diversi modelli per costruire il classificatore (Naïve Bayes, reti neurali, alberi di decisione…)
▫ Il limite degli approcci basati su apprendimento è la scalabilità quando richiedono dati supervisionati
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
17

Naïve Bayes • L’approccio bayesiano ha come obiettivo la massimizzazione della
probabilità del senso s dato il vettore di feature fw che descrive la parola target
▫ con l’ipotesi semplificativa di indipendenza delle componenti del vettore di feature (parole del contesto) è possibile esprimere p(fw|s)
le probabilità p(fj|s) esprimono la statistica relativa alla distribuzione della feature j (es. una data parola) nel contesto del senso s della parola w
p(s) individua la probabilità a priori di ciascun senso della parola
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
18
s = argmaxs∈S
p(s|fw) = argmaxs∈S
p(fw|s)p(s)p(fw)
p(fw|s) =n�
j=1
p(fj |s)

Dictionary-based methods • Un dizionario può fornire informazioni sul contesto legato ai sensi delle
parole (le glosse) ▫ L’algoritmo più semplice è quello di Lesk (1986)
Si calcola la sovrapposizione fra le glosse associate ai vari significati delle parole nella frase
Si sceglie la combinazione di significati che fornisce il massimo livello di sovrapposizione complessiva (complessità è combinatoria nel numero di sensi)
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
19
pine cone
PINE 1. kinds of evergreen tree with needle-shaped leaves 2. waste away through sorrow or illness
CONE 1. solid body which narrows to a point 2. something of this shape whether solid or hollow 3. fruit of certain evergreen trees
pine1 ∩ cone1 = 0
pine1 ∩ cone2 = 0
pine1 ∩ cone3 = 2 pine2 ∩ cone1 = 0
pine2 ∩ cone2 = 0
pine2 ∩ cone3 = 0

Limiti dell’algoritmo di Lesk • L’algoritmo di Lesk permette di ottenere prestazioni del 50-70% ▫ La maggiore limitazione è che dipende dalle glosse/esempi legati ai sensi
delle parole nel dizionario che sono generalmente corte e non forniscono informazione sufficiente per addestrare un classificatore Le parole usate nel contesto e la loro definizione deve avere una
sovrapposizione (condividere il maggior numero di termini) ▫ Si può migliorare la copertura aggiungendo le parole in relazione ma non
contenute nelle glosse del termine target ad esempio le parole delle definizioni che contengono il termine target purché
sia chiaro il senso con cui è usato in quel contesto ▫ Nel calcolo della sovrapposizione/similarità fra i contesti si possono
usare delle misure più flessibili Correlazione con pesi TermFrequency-InverseDocumentFrequency in modo da
dare meno importanza alle parole più comuni
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
20

Word similarity • La sinonimia è una forma stretta di similarità ▫ completa sostituibilità in certi contesti
• Si può definire una similarità fra parole come distanza semantica ▫ Definizione con un Thesaurus (Wordnet)
In un thesaurus le parole (significati) sono collegati fra loro da relazioni La distanza semantica può essere definita in base alla lunghezza del cammino
minimo per arrivare da una parola all’altra usando le relazioni
▫ Difinizione in base alla distribuzione statistica Probabilità di trovare le parole in contesti simili Le parole sono rappresentate come vettori N-dimensionali e la similarità/
distanza è calcolata in questo spazio
Tecnologie per l'elaborazione del linguaggio
Marco Maggini
21
sim(w1, w2) = − log pathlenght(s(w1), s(w2))





























