Embed Size (px)
DESCRIPTION
Mining Frequent Patterns without Candidate Generation. Problem. Frequent Pattern Mining. Given a transaction database DB and a minimum support threshold ξ , find all frequent patterns (item sets) with support no less than ξ. Input:. DB:. TIDItems bought - PowerPoint PPT Presentation
Citation preview

Mining Frequent Patterns Mining Frequent Patterns without Candidate Generationwithout Candidate Generation

2
Frequent Pattern MiningFrequent Pattern MiningGiven a transaction database DB and a minimum support threshold ξ, find all frequent patterns (item sets) with support no less than ξ.
Problem
TID Items bought 100 {f, a, c, d, g, i, m, p}200 {a, b, c, f, l, m, o}
300 {b, f, h, j, o}
400 {b, c, k, s, p}
500 {a, f, c, e, l, p, m, n}
DB:
Minimum support: ξ =3
Input:
Output: all frequent patterns, i.e., f, a, …, fa, fac, fam, …
Problem: How to efficiently find all frequent patterns?

3
OutlineOutline• Review:
– Apriori-like methods• Overview:
– FP-tree based mining method• FP-tree:
– Construction, structure and advantages• FP-growth:
– FP-tree conditional pattern bases conditional FP-tree frequent patterns
• Experiments• Discussion:
– Improvement of FP-growth• Conclusion

4
• The core of the Apriori algorithm:– Use frequent (k – 1)-itemsets (Lk-1) to generate candidates of
frequent k-itemsets Ck
– Scan database and count each pattern in Ck , get frequent k-itemsets ( Lk ) .
• E.g.,
Review
TID Items bought 100 {f, a, c, d, g, i, m, p}200 {a, b, c, f, l, m, o}
300 {b, f, h, j, o}
400 {b, c, k, s, p}
500 {a, f, c, e, l, p, m, n}
Apriori iteration C1 f,a,c,d,g,i,m,p,l,o,h,j,k,s,b,e,nL1 f, a, c, m, b, p
C2 fa, fc, fm, fp, ac, am, …bpL2 fa, fc, fm, …
…
AprioriApriori

5
Performance Performance Bottlenecks of AprioriBottlenecks of Apriori
• The bottleneck of Apriori: candidate generation– Huge candidate sets:
• 104 frequent 1-itemset will generate 107 candidate 2-itemsets
• To discover a frequent pattern of size 100, e.g., {a1, a2, …, a100}, one needs to generate 2100 1030 candidates.
– Multiple scans of database
Review

6
ObservationsObservations• Perform one scan of DB to identify the sets of frequent items• Avoid repeatedly scanning DB by using some compact
structure.
E.g., 1) merge transactions having identical frequent item sets; 2) merge the shared prefix among different frequent item sets.
Overview: FP-tree based method
TID Items bought 100 {f, a, c, d, g, i, m, p}200 {f, a, c, d, g, i, m, p}300 {f, a, c, d, e, f, g, h}
TID Items bought N1 {f, a, c, d, g, i, m, p}: 2
300 {f, a, c, d, e, f, g, h}
TID Items bought N1 {i, m, p} : 1
{f, a, c, d, g} : 2
N2 {e, f, g, h}: 1
1)
2)

7
• Compress a large database into a compact, Frequent-Pattern tree (FP-tree) structure– highly condensed, but complete for frequent pattern mining
– avoid costly database scans
• Develop an efficient, FP-tree-based frequent pattern mining method (FP-growth)– A divide-and-conquer methodology: decompose mining tasks
into smaller ones
– Avoid candidate generation: sub-database test only.
IdeasIdeas
Overview: FP-tree based method

FP-tree: Design and Construction

9
Construct FP-treeConstruct FP-tree2 Steps:
1. Scan the transaction DB once, find frequent 1-itemsets (single item patterns) and order them into a list L in frequency descending order.
e.g., L=[f:4, c:4, a:3, b:3, m:3, p:3}
2. Scan DB again, construct FP-tree by processing each transaction in L order.
FP-tree

10
Construction ExampleConstruction Example
{}
f:4 c:1
b:1
p:1
b:1c:3
a:3
b:1m:2
p:2 m:1
Header Table
Item frequency head f 4c 4a 3b 3m 3p 3
TID Items bought (ordered) frequent items100 {f, a, c, d, g, i, m, p} {f, c, a, m, p}200 {a, b, c, f, l, m, o} {f, c, a, b, m}300 {b, f, h, j, o} {f, b}400 {b, c, k, s, p} {c, b, p}500 {a, f, c, e, l, p, m, n} {f, c, a, m, p}
FP-tree
L

11
Advantages of the FP-tree StructureAdvantages of the FP-tree Structure
• The most significant advantage of the FP-tree
– Scan the DB only twice.
• Completeness:
– the FP-tree contains all the information related to mining frequent
patterns (given the min_support threshold)
• Compactness:
– The size of the tree is bounded by the occurrences of frequent items
– The height of the tree is bounded by the maximum number of items
in a transaction
FP-tree

FP-growth:Mining Frequent Patterns
Using FP-tree

13
Mining Frequent Patterns Using FP-treeMining Frequent Patterns Using FP-tree
• General idea (divide-and-conquer)
Recursively grow frequent patterns using the FP-tree: looking for shorter ones recursively and then concatenating the suffix:– For each frequent item, construct its conditional pattern
base, and then its conditional FP-tree;– Repeat the process on each newly created conditional
FP-tree until the resulting FP-tree is empty, or it contains only one path (single path will generate all the combinations of its sub-paths, each of which is a frequent pattern)
FP-Growth

14
3 Major Steps3 Major Steps
Starting the processing from the end of list L:
Step 1:
Construct conditional pattern base for each item in the header
table
Step 2
Construct conditional FP-tree from each conditional pattern base
Step 3
Recursively mine conditional FP-trees and grow frequent patterns
obtained so far. If the conditional FP-tree contains a single path,
simply enumerate all the patterns
FP-Growth
15
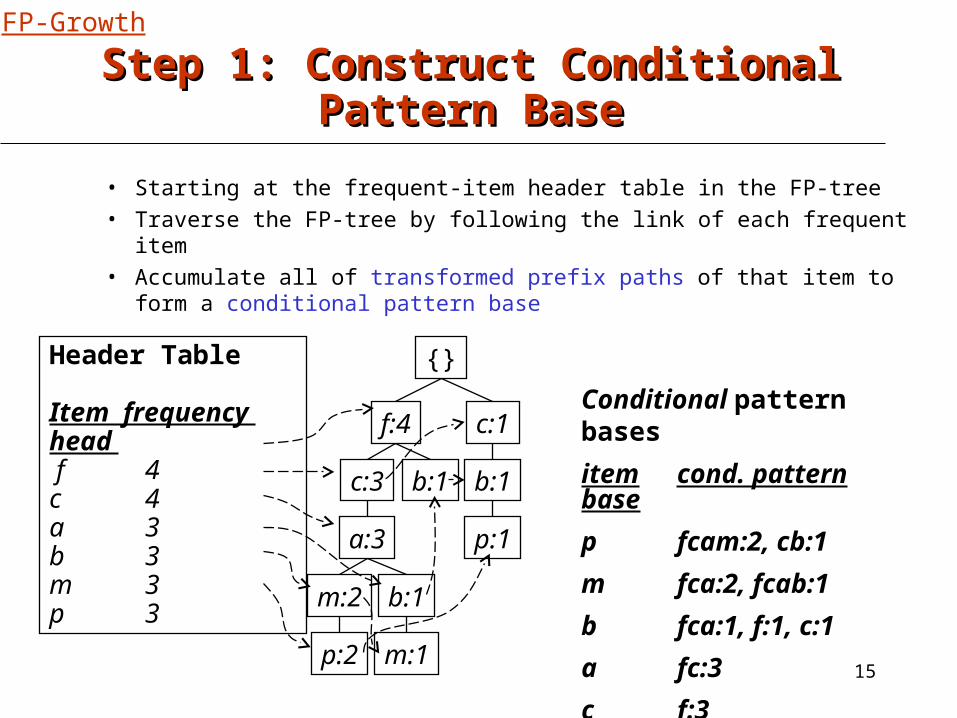
Step 1: Construct Conditional Pattern BaseStep 1: Construct Conditional Pattern Base
• Starting at the frequent-item header table in the FP-tree• Traverse the FP-tree by following the link of each frequent item• Accumulate all of transformed prefix paths of that item to form a
conditional pattern base
Conditional pattern bases
item cond. pattern base
p fcam:2, cb:1
m fca:2, fcab:1
b fca:1, f:1, c:1
a fc:3
c f:3
{}
f:4 c:1
b:1
p:1
b:1c:3
a:3
b:1m:2
p:2 m:1
Header Table
Item frequency head f 4c 4a 3b 3m 3p 3
FP-Growth

16
Properties of Step 1Properties of Step 1
• Node-link property
– For any frequent item ai, all the possible frequent patterns that
contain ai can be obtained by following ai's node-links, starting
from ai's head in the FP-tree header.
• Prefix path property
– To calculate the frequent patterns for a node ai in a path P, only
the prefix sub-path of ai in P need to be accumulated, and its
frequency count should carry the same count as node ai.
FP-Growth

17
Step 2: Construct Conditional FP-treeStep 2: Construct Conditional FP-tree
• For each pattern base– Accumulate the count for each item in the base– Construct the conditional FP-tree for the frequent items of the
pattern base
m-conditional pattern base:
fca:2, fcab:1
{}
f:3
c:3
a:3m-conditional FP-tree
{}
f:4
c:3
a:3
b:1m:2
m:1
Header TableItem frequency head f 4c 4a 3b 3m 3p 3
FP-Growth

18
Conditional Pattern Bases and Conditional Pattern Bases and Conditional FP-TreeConditional FP-Tree
EmptyEmptyf
{(f:3)}|c{(f:3)}c
{(f:3, c:3)}|a{(fc:3)}a
Empty{(fca:1), (f:1), (c:1)}b
{(f:3, c:3, a:3)}|m{(fca:2), (fcab:1)}m
{(c:3)}|p{(fcam:2), (cb:1)}p
Conditional FP-treeConditional pattern baseItem
FP-Growth
order of L

19
Step 3: Recursively mine the Step 3: Recursively mine the conditional FP-treeconditional FP-tree
{}
f:3
c:3
a:3m-conditional FP-tree
Cond. pattern base of “am”: (fc:3)
{}
f:3
c:3am-conditional FP-tree
Cond. pattern base of “cm”: (f:3)
{}
f:3
cm-conditional FP-tree
Cond. pattern base of “cam”: (f:3)
{}
f:3cam-conditional FP-tree
FP-Growth
Cond. pattern base of “fm”: 3
Cond. pattern base of “fam”: 3
Cond. pattern baseof “m”: (fca:3)
add“a”
add“c”
add“f”
add“c”
add“f”
Frequent Pattern
Frequent Pattern
Frequent Pattern
Frequent PatternFrequent Pattern
Frequent Pattern
“fcam”Frequent Pattern

20
Principles of FP-GrowthPrinciples of FP-Growth
• Pattern growth property– Let be a frequent itemset in DB, B be 's conditional pattern
base, and be an itemset in B. Then is a frequent
itemset in DB iff is frequent in B.
• Is “fcabm ” a frequent pattern?– “fcab” is a branch of m's conditional pattern base
– “b” is NOT frequent in transactions containing “fcab ”
– “bm” is NOT a frequent itemset.
FP-Growth

21
Single FP-tree Path GenerationSingle FP-tree Path Generation
• Suppose an FP-tree T has a single path P. The complete set of
frequent pattern of T can be generated by enumeration of all the
combinations of the sub-paths of P{}
f:3
c:3
a:3
m-conditional FP-tree
All frequent patterns concerning m
m,
fm, cm, am,
fcm, fam, cam,
fcam
FP-Growth

22
Efficiency AnalysisEfficiency Analysis
Facts: usually1. FP-tree is much smaller than the size of the DB
2. Pattern base is smaller than original FP-tree
3. Conditional FP-tree is smaller than pattern base
mining process works on a set of usually much smaller pattern bases and conditional FP-trees
Divide-and-conquer and dramatic scale of shrinking
FP-Growth














![Scalable Topical Phrase Mining from Text Corpora[Mining frequent patterns] without candidate generation: a [frequent pattern] tree approach. Title 2. [Frequent pattern mining] : current](https://img.dokumen.tips/doc/110x75/5e9b8030d4570c75907f97b4/scalable-topical-phrase-mining-from-text-mining-frequent-patterns-without-candidate.jpg)














