Embed Size (px)
Citation preview

Metody Deep Learning

Autoencoders
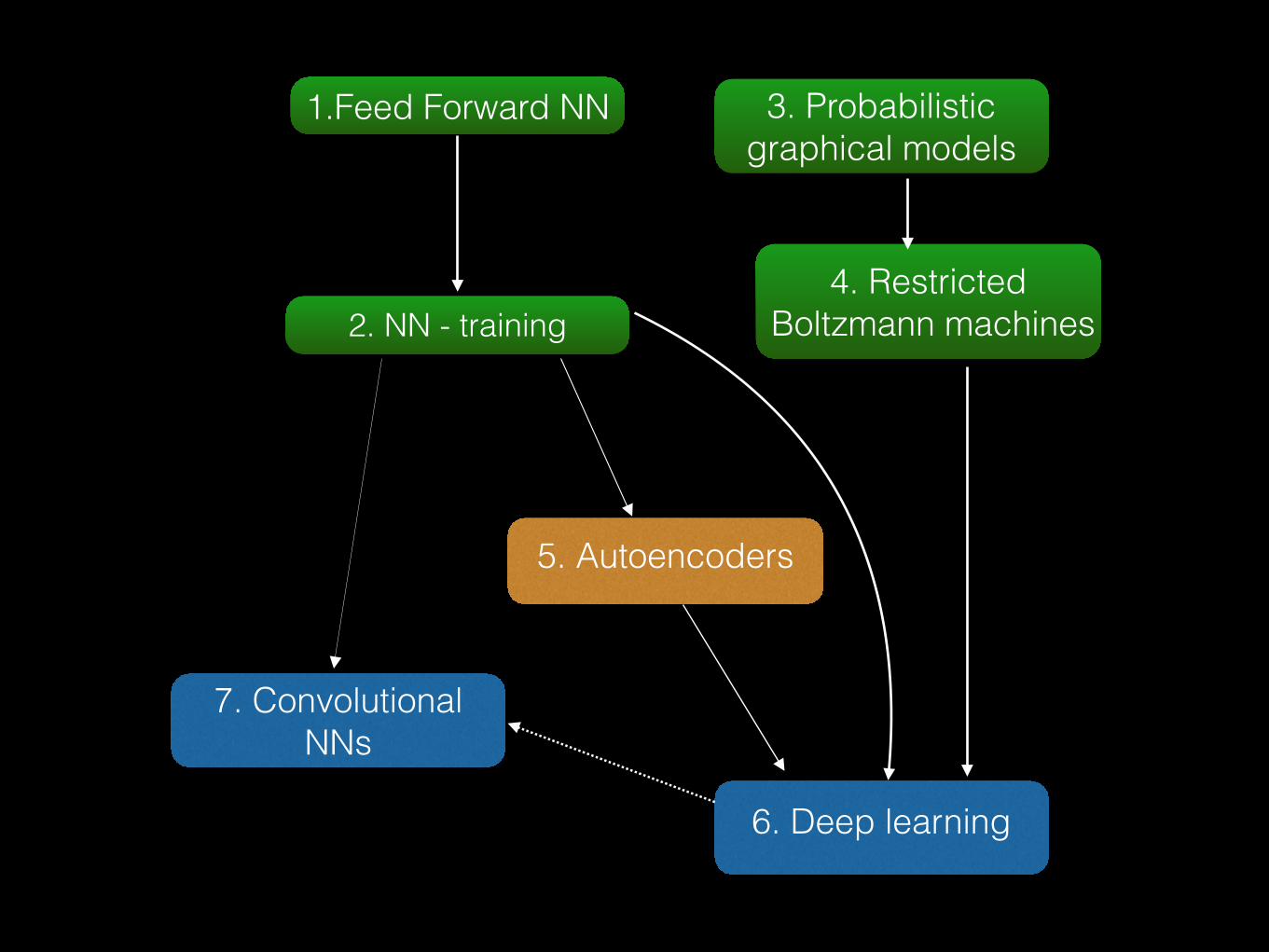
1.Feed Forward NN
2. NN - training
3. Probabilistic graphical models
4. Restricted Boltzmann machines
5. Autoencoders
6. Deep learning
7. Convolutional NNs
Dlaczego?

Przykład: redukcja wymiarowości - PCA

Przykład: redukcja wymiarowości - DAE
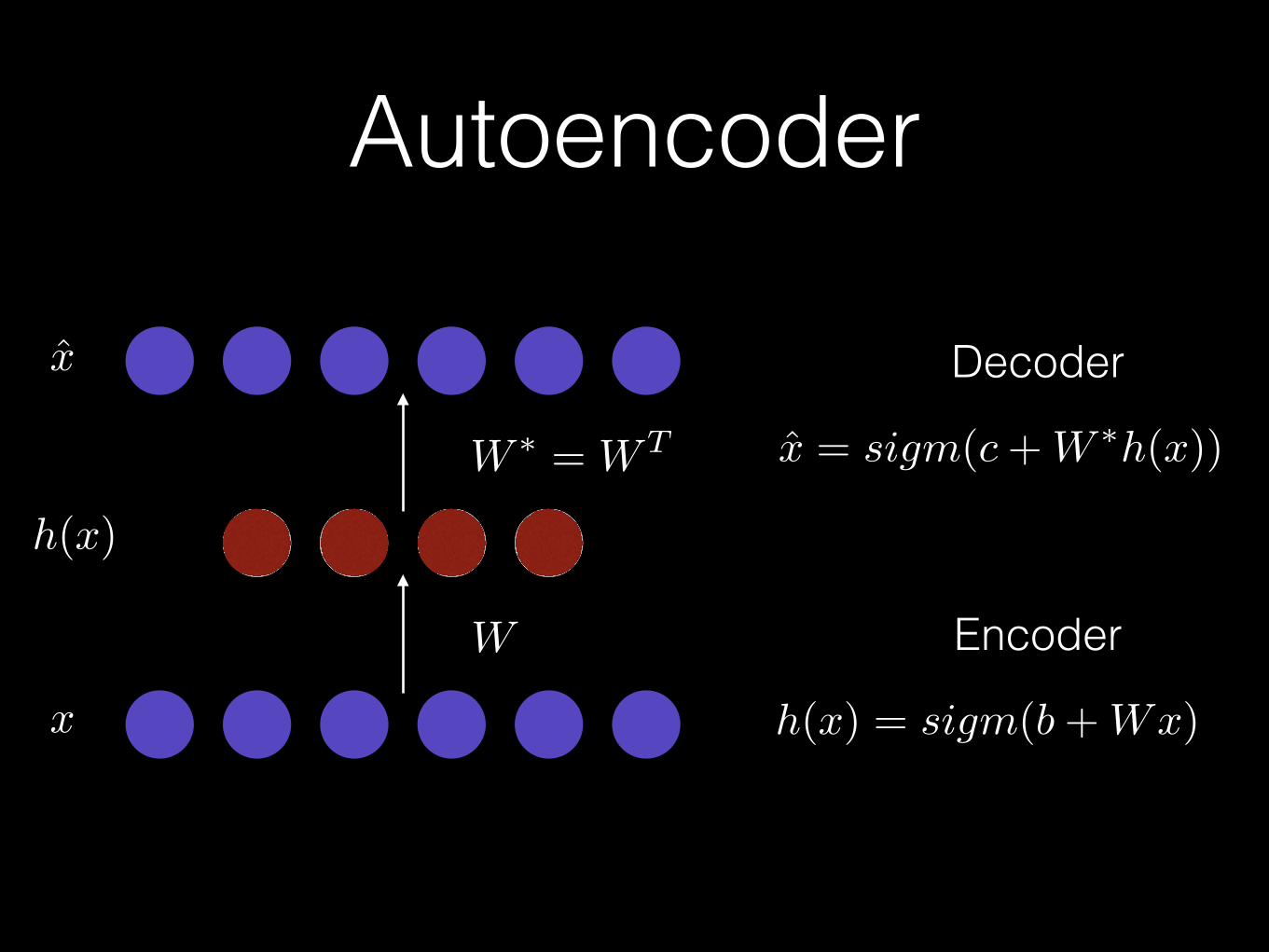
Autoencoder
W
W ⇤ = WT
Decoder
Encoder
x̂ = sigm(c+W
⇤h(x))
h(x) = sigm(b+Wx)x
h(x)
x̂

Loss function• dla danych binarnych
• dla danych liniowych
l(x, x̂) = �X
k
(xk log (x̂k) + (1� xk) log (1� x̂k))
l(x, x̂) =1
2
X
k
(xk � x̂k)2

Trenowanie• możemy minimalizować koszt metodą gradient descent • dla obu przypadków funkcji kosztu gradient względem
aktywacji ma taką samą formę:
Oa(x)l(x, x̂) = x̂� x
• gradienty wag oraz biasów możemy uzyskać propagacją wsteczną

Adaptacja do wejścia• wybieramy łączny rozkład nad wejściem p(x | µ)
gdzie µ to wektor parametrów tego rozkładu
• wybieramy relację pomiędzy wektorem µ
i ukrytą warstwąh(x)
• użyj jako funkcji kosztu:
l(x) = � log p(x | µ)

Jaka może być warstwa ukryta?
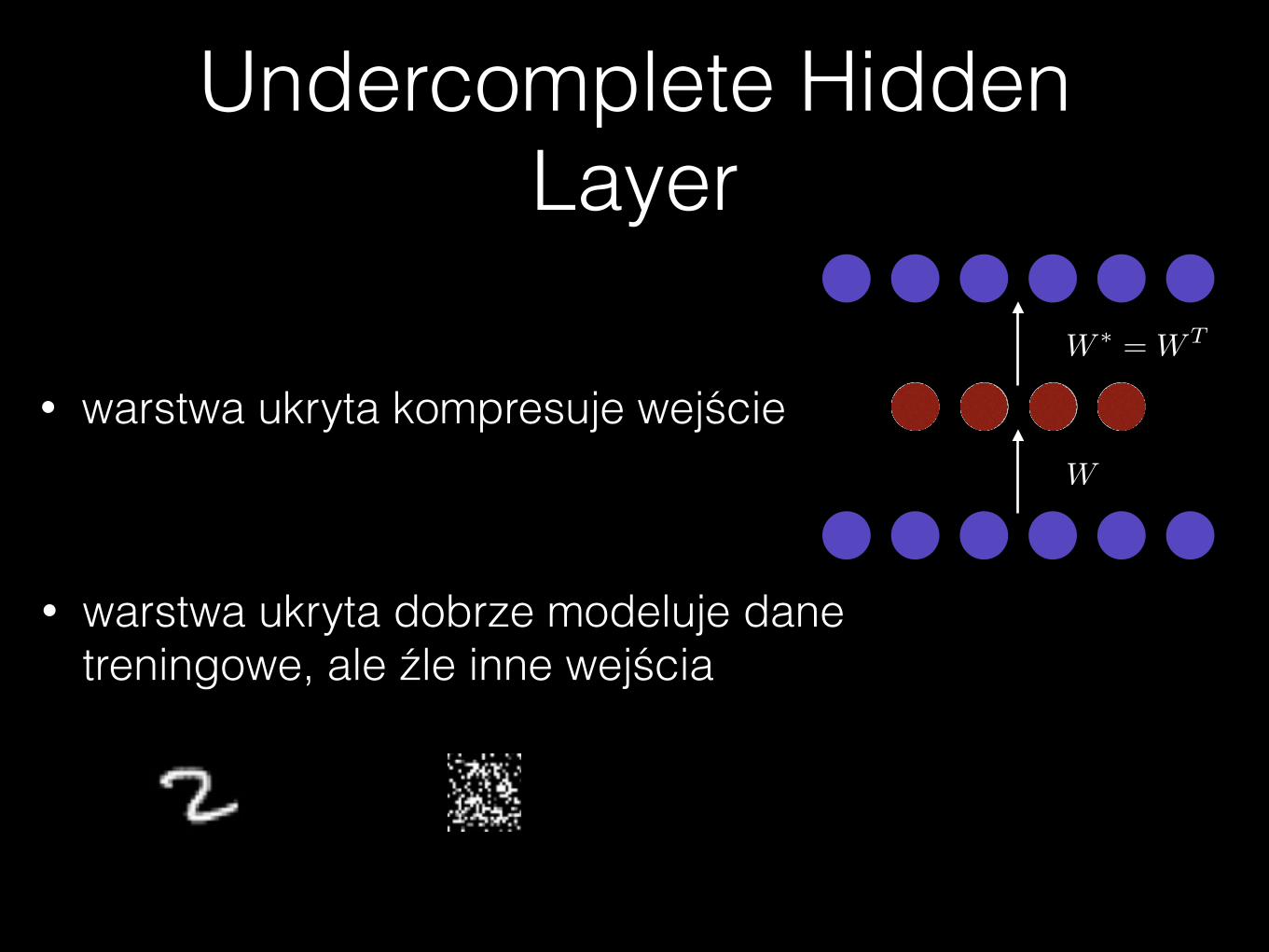
Undercomplete Hidden Layer
• warstwa ukryta kompresuje wejścieW
W ⇤ = WT
• warstwa ukryta dobrze modeluje dane treningowe, ale źle inne wejścia
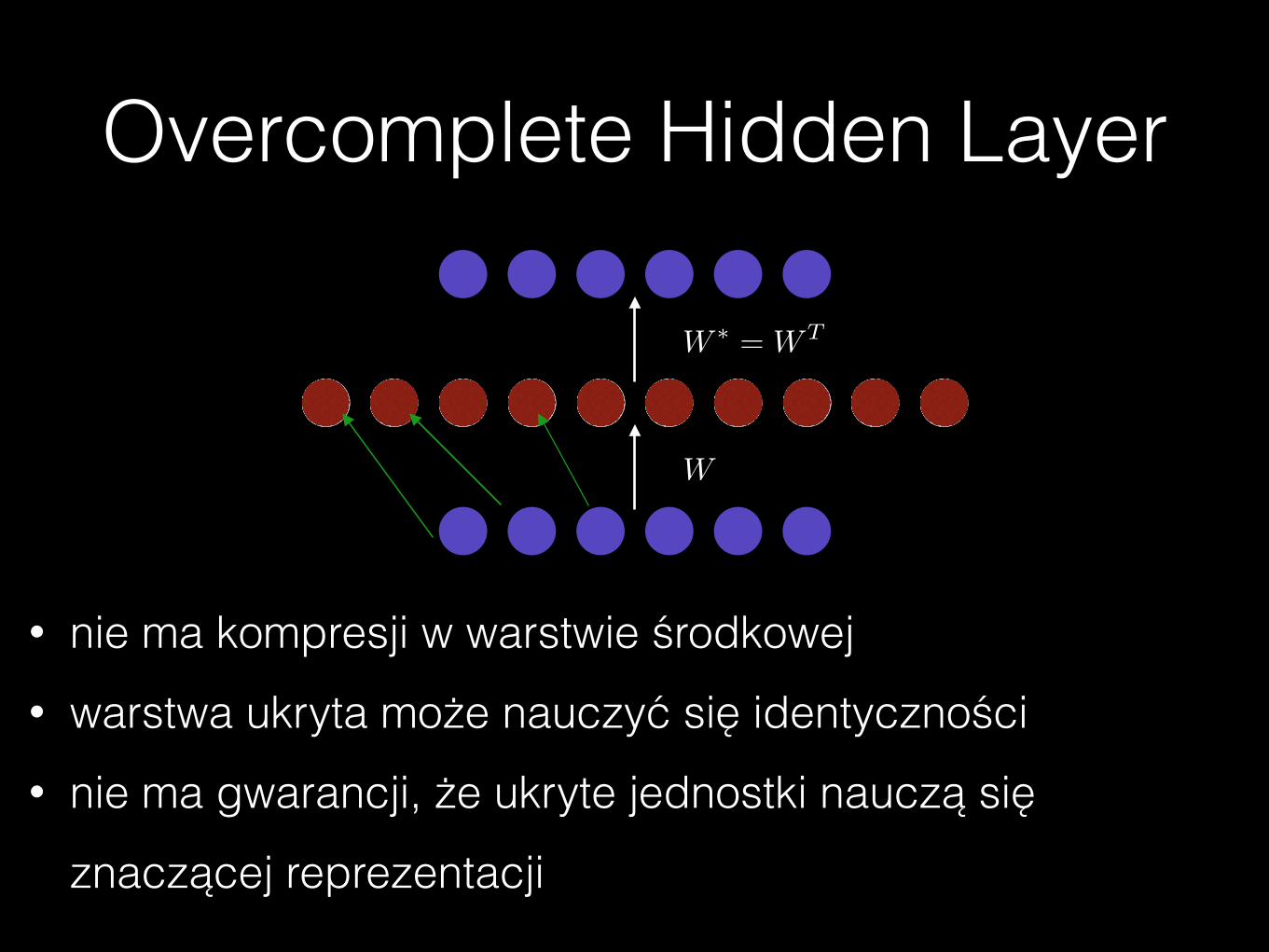
Overcomplete Hidden Layer
W
W ⇤ = WT
• nie ma kompresji w warstwie środkowej • warstwa ukryta może nauczyć się identyczności • nie ma gwarancji, że ukryte jednostki nauczą się
znaczącej reprezentacji

Jak zapobiec uczeniu się identyczności?

Idea: reprezentacja odporna na szum

Denoising autoencoder
W
W ⇤ = WT
x
h(x)
x̂
x̃
p(x̃ | x)
• dodajemy szum do wejścia
• rekonstrukcja obliczana z zaszumionego wejścia
• loss function porównuje rekontrukcję z autentycznym wejściem

Intuicja
x
x
x̃
x̃
x̂ = sigm(c+Wh(x̃))
p(x̃ | x)

• Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Demonising Criterion - Vincent, Larochelle, Lajoie, Bengio Manzagol, 2008
• A Connection Between Score Matching and Denoising Autoencoders - Vincent, 2011
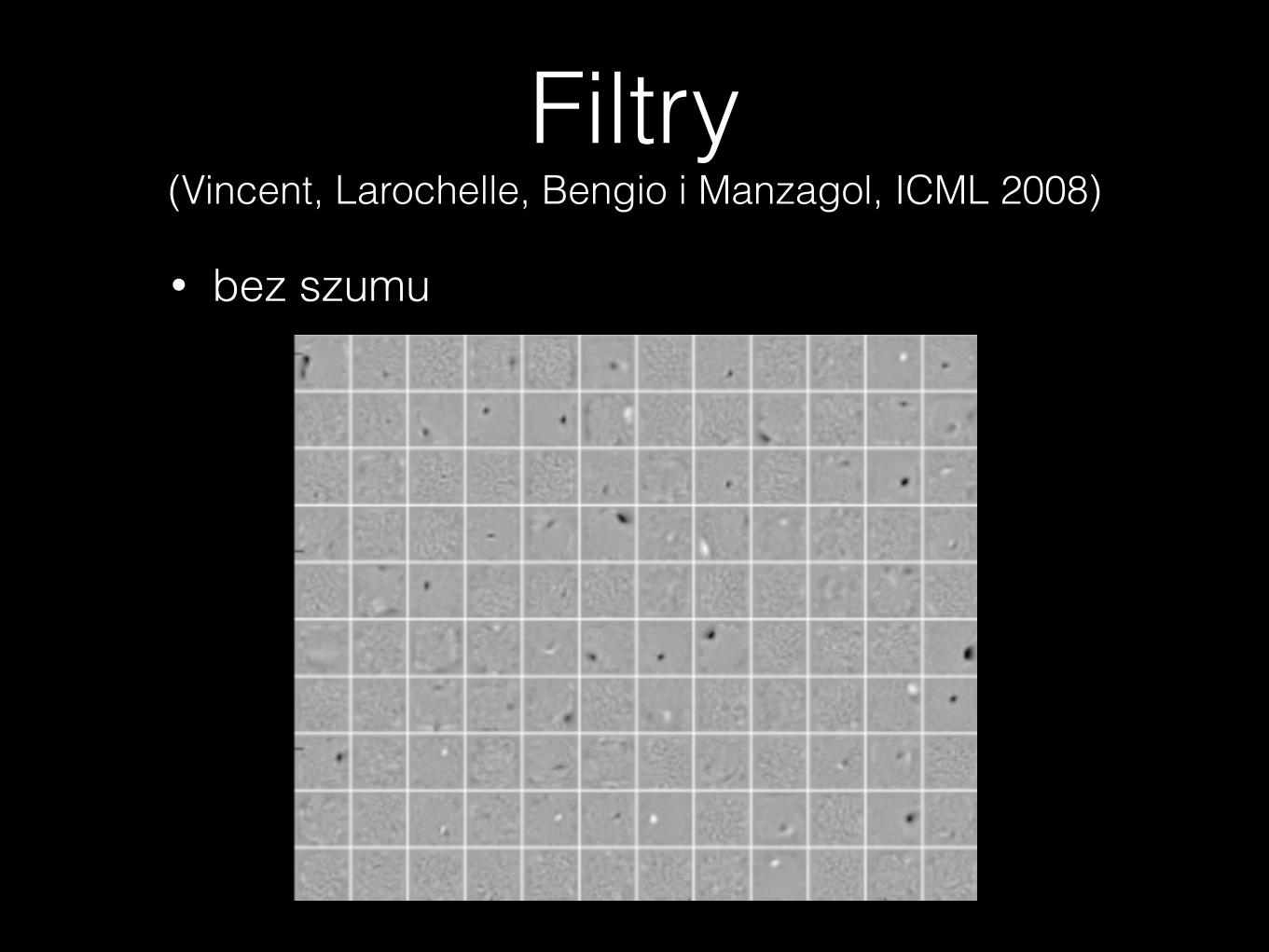
Filtry (Vincent, Larochelle, Bengio i Manzagol, ICML 2008)
• bez szumu
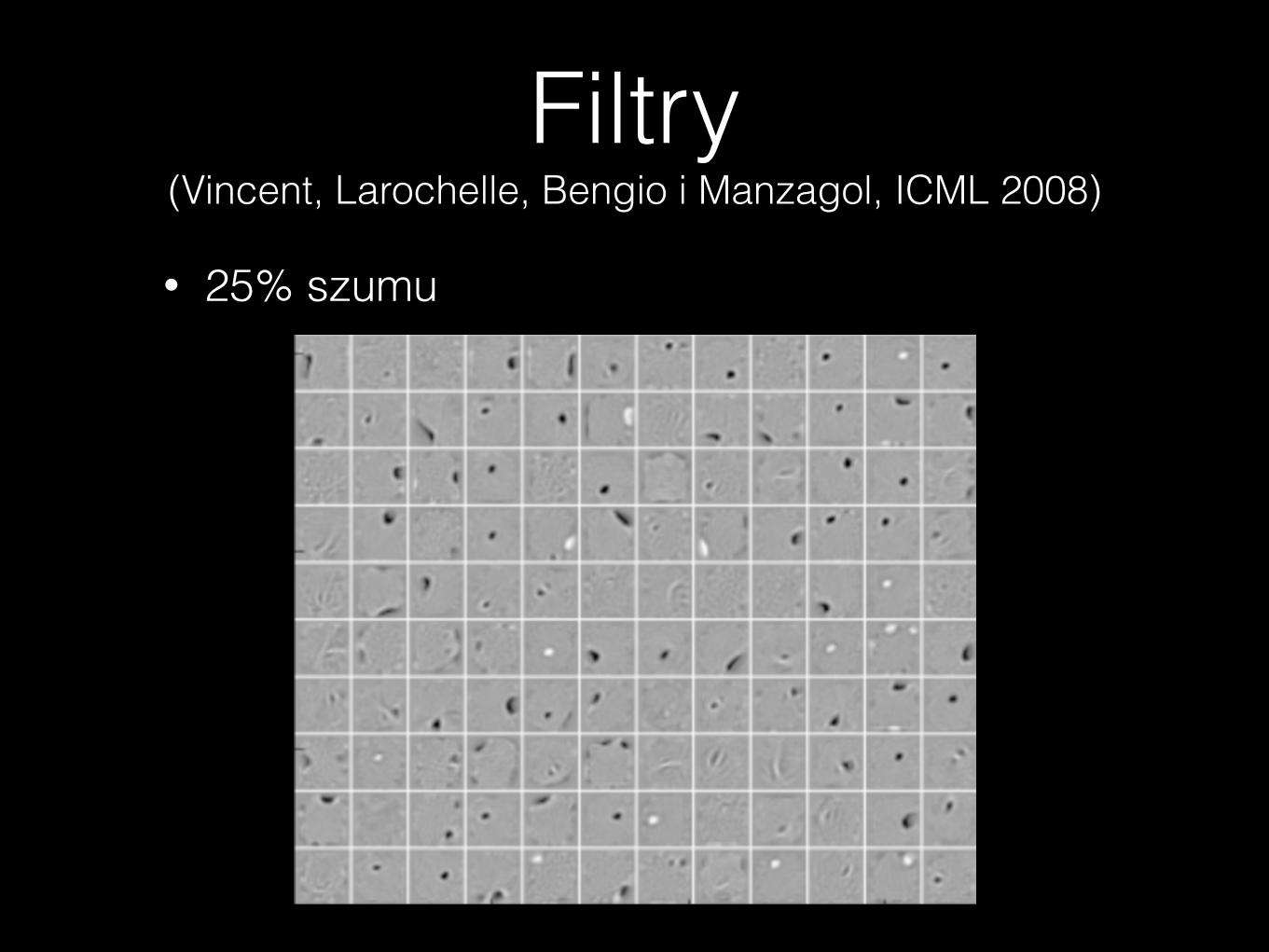
Filtry (Vincent, Larochelle, Bengio i Manzagol, ICML 2008)
• 25% szumu
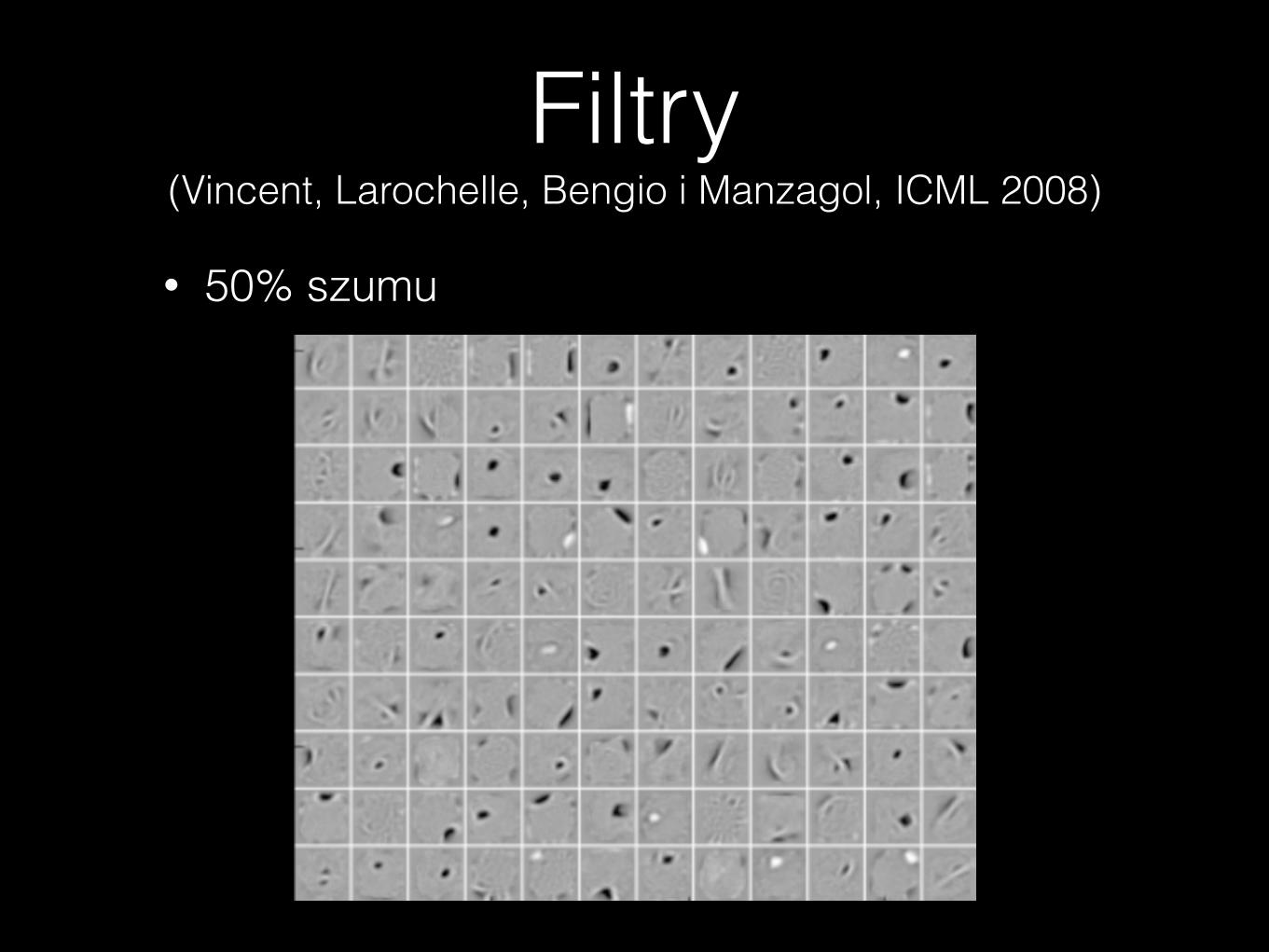
Filtry (Vincent, Larochelle, Bengio i Manzagol, ICML 2008)
• 50% szumu

Idea: karanie modelowania wszystkich
danych

Contractive Autoencoder
W
W ⇤ = WT
h(x)
x̂
x̃
• dodajemy składnik do funkcji kosztu,
który penalizuje nieinteresujące nas
rozwiązania • chcemy ekstrachować tylko cechy, które
odzwierciedlają wariacje danych ze
zbioru treningowego • model ma być inwariantny na inne
wariacje

Contractive Autoencoder
l(x, x̂) + � kOx
h(x)k2F
Nowa funkcja kosztu:
Dla binarnych obserwacji:
l(x, x̂) = �X
k
(xk log (x̂k) + (1� xk) log (1� x̂k))
� kOx
h(x)k2F
=X
j
X
k
(@h(x)
j
@x
k
)2
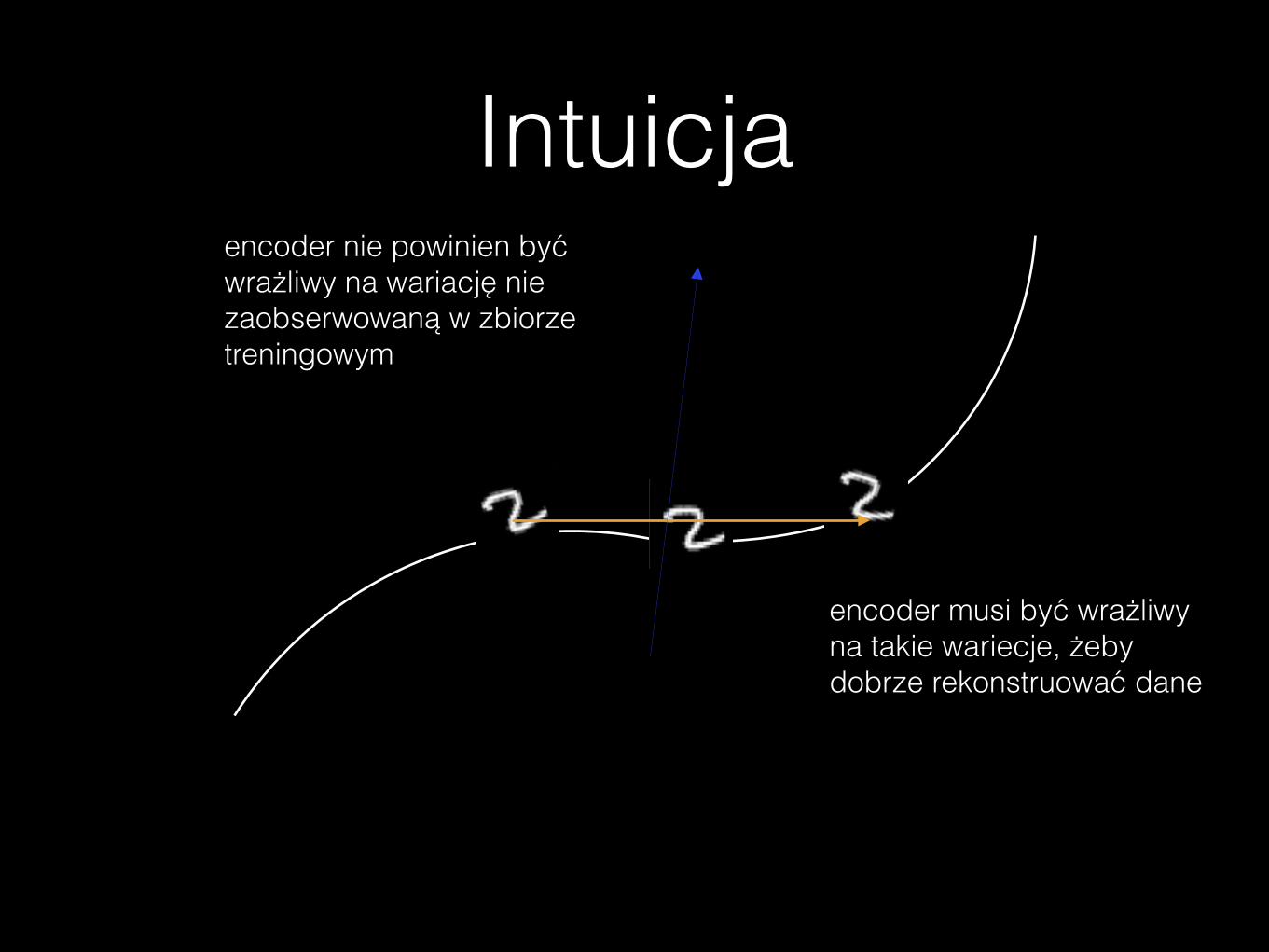
Intuicja
encoder musi być wrażliwy na takie wariecje, żeby dobrze rekonstruować dane
encoder nie powinien być wrażliwy na wariację nie zaobserwowaną w zbiorze treningowym

Contractive Auto-Encoders: Explicit Invariance During Feature Extraction - Rifai, Vincent, Muller,
Glorot, Bengio, 2011






























