Embed Size (px)
Citation preview

Metadata Extraction @ ODU
for
DTICPresentation to Senior Management
May 16, 2007
Kurt Maly, Steve Zeil, Mohammad Zubair{maly, zeil, zubair} @cs.odu.edu

Outline Metadata Extraction Project
System overview Demo Current status
Why ODU Research, new technology, Inexpensive, Maintenance
(Department commitment) Why DTIC as Lead
Amortize development cost, Expand template set (helpful in future too), Consistent with DTIC strategic mission
Required enhancements

ODU Metadata Extraction System Input: pdf documents
processed through OCR (Optical Character Recognition) Output: metadata in XML format
easily processed for uploading into DTIC databases
(demo: 1st document)

System Overview
Processing has two main branches: Documents with forms (RDPs) Documents without forms
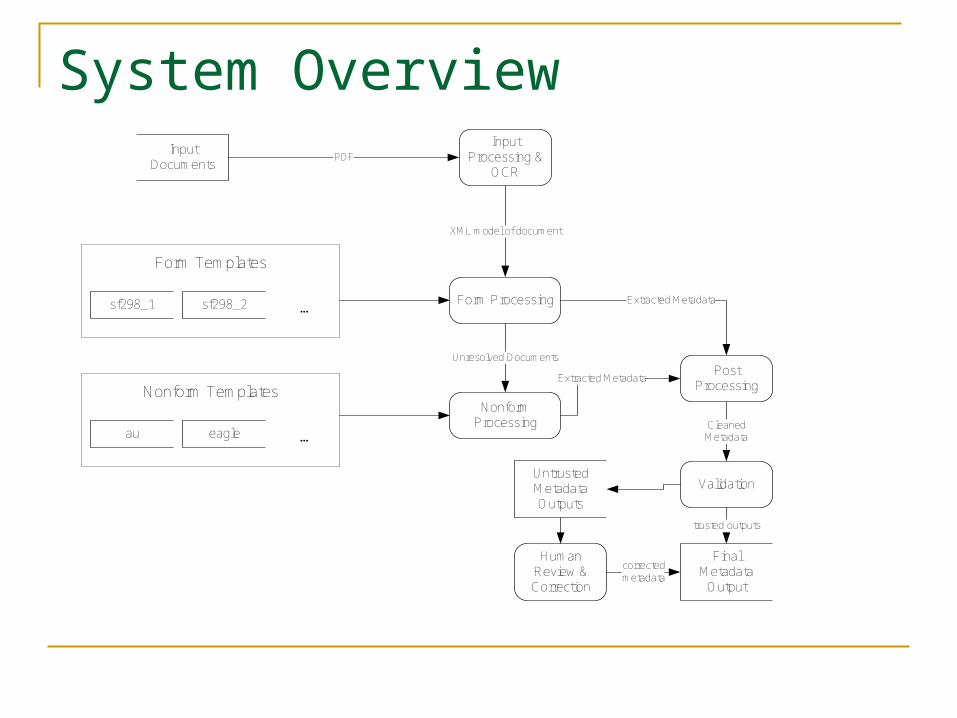
System OverviewInput
Documents
Input Processing &
OCR
Form Processing
Final Metadata
Output
XML model of document
Unresolved Documents
Extracted Metadata
CleanedMetadata
sf298_1 sf298_2 ...
Form Templates
au eagle ...
Nonform Templates
Post Processing
Nonform Processing
Extracted Metadata
Validation
trusted outputs
Untrusted Metadata Outputs
Human Review & Correction
correctedmetadata

Demo
(additional documents)

Documents With RDP Forms
Status Extracts high-quality metadata for 7 variants of SF-298 and
1 less common RDP form Tested on over 9000 (unclassified) DTIC documents
Major needs: Validation & standardization of output

Documents Without Forms
Status Extracts moderate-quality metadata for 10
common document layouts Tested on over 600 (unclassified) DTIC
documents Major needs:
Validation & standardization of output Extraction Engine Enhancements Expansion of template set to cover most common
document layouts

Status
Completely Automated Software for: Drop in pdf file Process and produce output metadata in XML format
Easy (less than 5 minutes) installation process
Default set of templates for: RDP containing documents Non-form documents
Statistical models of DTIC collection(800,000 documents) and NASA collection (30,000 documents) Phrase dictionaries: personal authors, corporate authors Length and English word presence for title and abstract Structure of dates, report numbers

StatusMetadata Extraction Results for 98 documents that were randomly selected from the DTIC Collection
* Notes1. Accuracy is defined as successful completion of the extractor with
reasonable metadata values extracted2. “Reasonable” implies that values could be automatically processed (see
required enhancements) into standard format3. Accuracy for documents without RDP could be enhanced with additional
templates, (see required enhancements)
Document Type
Number of documents
Number of templates used
Accuracy *
With RDP 50 9 100%
Without RDP 50 11 66%
Overall 100 14 83%

Why - software from ODU
Research, new technology ODU digital library research group is world class and has made
many contributions to advancing field. $2.5M funding in last five years from various agencies National Science Foundation, Andrew Mellon Foundation, Los Alamos, Sandia National Laboratory, Air Force Research Laboratory, NASA Langley, DTIC, and IBM
State of art in automated metadata extraction is good for homogenous collection but not effective for large, evolving, heterogeneous collections (such as DTIC’s)
Need for new methods, techniques and processes

Why - software from ODU
Inexpensive (relatively) ODU is university with low overhead (43%)
Universities can use students and pay them assistantships rather than fulltime salaries
Department adds matching tuition waivers for research assistants which is big incentives for students to apply for research work
Faculty are among best in field, require partial funding.

Why - software from ODU
Long term software maintenance through department Department commits continuity independent of faculty
on projects
Department will find and assign faculty and student who can become conversant with code and maintain it (not evolve it)
Likely that there would be other faculty who are interested in evolving code for appropriate funding

Why – DTIC as Lead Agency
Amortize Development Cost We are working with NASA and plan to get on
GPO board soon. NASA gave us partial funding to investigate the applicability of our approach for their collection.

Why – DTIC as Lead Agency
Cross Fertilization DTIC has distinctive requirements that can benefit from
enhancing the metadata extraction technology for other agencies (for example richer template set)
Heterogeneity: DTIC collects documents… of many different types from an unusually large number of sources with minimal format restrictions
Evolution:DTIC collection spans time frame in which submission formats change from typewritten to word processed,
scanned to electronic asserts minimal control over layouts & formats

Why – DTIC as Lead Agency
Consistent with DTIC Strategic Mission DTIC is largest organization with most diverse
collection and has stature to disseminate to other government agencies

Required Enhancements – Priority 1 Enhance portability Standardized output Template creation (initial release), Text PDF input MS Word input

Required Enhancements – Priority 2 PrimeOCR input Multipage metadata Template Creation (enhanced release) Template Creation Tool

Required Enhancements – Priority 3 Human intervention software

Time Line
May 2007 to September 2007 Add flexibility to code Enable the current product to produce standardized
output Create new templates that will cover the Larger
Contributors Investigate different approaches to handle text pdf
documents and finalize the design?

Time Line
October 2007 to September 2008 Validate the extraction according to the DTIC provided Cataloging
document . Module that would allow the functional user to create a new template that
would easily integrate into the extraction software. Create new templates that will cover the Larger Contributors of DTIC Create a module that converts Prime OCR into IDM Create the code necessary to enable the non-form documents to be able
to extract the metadata from more than one single page Implement the support for the text pdf as finalized in the first part Implement support for Word documents Create the code necessary to display the scoring on validation at the
documents level (for workers) and collection level (managers)

Extra slides

Sample RDP

Sample RDP (cont.)

Metadata Extracted from Sample RDP (1/3)<metadata templateName="sf298_2">
<ReportDate>18-09-2003</ReportDate>
<DescriptiveNote>Final Report</DescriptiveNote>
<DescriptiveNote>1 April 1996 - 31 August 2003</DescriptiveNote>
<UnclassifiedTitle>VALIDATION OF IONOSPHERIC MODELS</UnclassifiedTitle>
<ContractNumber>F19628-96-C-0039</ContractNumber> <ContractNumber></ContractNumber>
<ProgramElementNumber>61102F</ProgramElementNumber>
<PersonalAuthor>Patricia H. Doherty Leo F. McNamara
Susan H. Delay Neil J. Grossbard</PersonalAuthor>
<ProjectNumber>1010</ProjectNumber>
<TaskNumber>IM</TaskNumber>
<WorkUnitNumber>AC</WorkUnitNumber>
<CorporateAuthor>Boston College / Institute for Scientific Research 140 Commonwealth Avenue Chestnut Hill, MA 02467-3862</CorporateAuthor>

Metadata Extracted from Sample RDP (2/3)<ReportNumber></ReportNumber> <MonitorNameAndAddress>Air Force Research Laboratory 29 Randolph Road
Hanscom AFB, MA 01731-3010</MonitorNameAndAddress> <MonitorAcronym>VSBP</MonitorAcronym> <MonitorSeries>AFRL-VS-TR-2003-1610</MonitorSeries> <DistributionStatement>Approved for public release; distribution
unlimited.</DistributionStatement> <Abstract>This document represents the final report for work performed under the Boston College contract F I9628-96C-0039. This contract was entitled Validation of Ionospheric Models. The objective of this contract was to obtain satellite and ground-based ionospheric measurements from a wide range of geographic locations and to utilize the resulting databases to validate the theoretical ionospheric models that are the basis of the Parameterized Real-time Ionospheric Specification Model (PRISM) and the Ionospheric Forecast Model (IFM). Thus our various efforts can be categorized as either observational databases or modeling studies.</Abstract>

Metadata Extracted from Sample RDP (3/3)<Identifier>Ionosphere, Total Electron Content (TEC), Scintillation, Electron density, Parameterized Real-time Ionospheric Specification Model (PRISM), Ionospheric Forecast Model (IFM), Paramaterized Ionosphere Model (PIM), Global Positioning System
(GPS)</Identifier> <ResponsiblePerson>John Retterer</ResponsiblePerson> <Phone>781-377-3891</Phone> <ReportClassification>U</ReportClassification>
<AbstractClassification>U</AbstractClassification> <AbstractLimitaion>SAR</AbstractLimitaion></metadata>

Non-Form Sample (1/2)

Non-Form Sample (2/2)

Metadata Extracted From the Title Page of the Sample Document
<paper templateid="au"> <identifier>AU/ACSC/012/1999-04</identifier> <CorporateAuthor>AIR COMMAND AND STAFF COLLEGE AIR UNIVERSITY</CorporateAuthor> <UnclassifiedTitle>INTEGRATING COMMERCIAL ELECTRONIC EQUIPMENT TO IMPROVE MILITARY CAPABILITIES </UnclassifiedTitle> <PersonalAuthor>Jeffrey A. Bohler LCDR, USN</PersonalAuthor> <advisor>Advisor: CDR Albert L. St.Clair</advisor> <ReportDate>April 1999</ReportDate></paper>

Enhanced Portability
Relax hard-coded system dependencies Less technical documentation, particularly as
regards operational procedure Improved error logging Priority: 1
duration: 2 mos, impact: easier to operate software,

Standardized Output
WYSIWYG What You See is What You Get
WYG != WYW What You Get is not necessarily What You
Want

Standardized Output (cont.)
Field values to adhere to defined standard: Title in ‘title’ format ala: This is a Title Well Formed Date ala: 28 MAR 2007 Personal authors ala: Leo F. McNamara ;Susan H.
Delay ;Neil J. Grossbard Contract/grant number, corporate authors, distribution
statement,.. Priority: 1
duration: 3 mos, impact: better template selection and metadata ready for
DB insertion Dependency: none

Template Creation (initial release) For RDP relative few (5 templates cover 100% of about 9,000
out of 10,000 in testbed) more needed. For documents without RDP need more (currently have 10
templates covering 600 non-RDP documents) to cover largest DTIC contributors Requires acquiring and exploiting an updated testbed
from last three years documents as they arrived at DTIC need about 5,000 documents
Template set to be enhanced still further in later stages Priority – 1
duration: 4 mos, impact: closer to production stage, dependency: new testbed

Text PDF Input
Current system processes all documents through OCR allows input of documents that arrive as scanned images time consuming source of error
Increasing percentage of new DTIC documents arrive as “native” or “text” PDF
Add processing path to accept text PDF without OCR
Priority: 1 Duration: 6 months

MS Word Input
Could be handled via Word ML or by generating Text PDFs from Word
Need solution imposing minimal additional requirements on operating platform
Priority: 1 Duration: 2 months

Required Enhancements
Desirable (Priority 2) PrimeOCR input Multipage metadata Template Creation Template Creation Tool
Optional (Priority 3) Human intervention software

Current System (Detailed)
Input Documents
Extract 1st & last 5 pages
OCR
Backup
Form Processor
UnresolvedConvert to CleanXML
Omnipage XML
Extract Metadata
Validation Script
Select Best Metadata
Omnipage Clean
Final Form Output
Final Nonform Output
Authority FilePost
Processor
PDFReduced
Original PDF
Omnipage XML
Omnipage XML
Resolved Documents
IDM
IDM
CleanXML
CandidateMetadata
Sets
IDM
Extracted Metadata
PermittedValues
CleanedMetadata
Selected Metadata
Omnipage XML MetaIDM
Resolved
sf298_1 sf298_2 ...
Form Templates
au eagle ...
Nonform Templates

Status – Distribution of Documents
Template TypeNumber of documents
Template 1 (sf298_1) 10
Template 2 (sf298_2) 10
Template 3 (sf298_3) 5
Template 4 (sf298_4) 10
Template 5 (citation) 15
Total 50
Distribution of documents with RDP
Distribution of documents without RDP
Template TypeNumber of documents
Template 1 (arl) 3
Template 2 (crs) 2
Template 3 (headabstr) 2
Template 4 (npsthesis) 9
Template 5 (nsrp) 10
Template 6 (au) 3Template 7 (eagle) 3Template 8 (rand) 2Unresolved 2Total 26

Input Processing
OCR – Omnipage update radically changed XML output Details later
Study of 10188 DTIC documents found none with POINT (Page Of INTerest) pages outside 1st and last 5 suspended efforts at more sophisticated POINT page location
Input Documents
PDF ReducedPDF
Omnipage XML
Extract 1st & last 5 pages
Backup
Original PDF
OCR
Omnipage XML
Omnipage XML

Form Processing
Form Processor
Unresolved
Omnipage XML
Resolved Documents
IDM
Unresolved Documents(IDM)
Omnipage XML MetaIDM
Resolved
sf298_1 sf298_2 ...
Form Templates
Extracted Metadata
Bug fixes and Tuning Omnipage XML converted to IDM
Main form template engine rewritten to work from IDM

Independent Document Model (IDM) Platform independent Document Model Motivation
Dramatic XML Schema Change between Omnipage 14 and 15
Tie the template engine to stable specification Protects from linking directly to specific OCR product Allows us to include statistics for enhanced feature usage
Statistics (i.e. avgDocFontSize, avgPageFontSize, wordCount, avgDocWordCount, etc..)

Generating IDM
Use XSLT 2.0 stylesheets to transform Supporting new OCR schema only requires
generation of new XSLT stylesheet. -- Engine does not change
Chain a series of sheets to add functionality (CleanML)
Schema Specification Available (http://dtic.cs.odu.edu/devzone/IDM_Specification.doc)

IDM Usage
Each incoming XML schema requires specific XSLT 2.0 Stylesheet
Resulting IDM Doc used for “Form Based” templates
IDM transformed into CleanML for “Non-form” templates
CleanML XML Doc
OmniPage 14 XML Doc
OmniPage 15 XML Doc
Other OCR Output XML Doc
IDM XML Doc
Form Based Extraction
Non Form Extraction
docTreeModelCleanML.xsl
docTreeModelOther.xsl
docTreeModelOmni15.xsl
docTreeModelOmni14.xsl

IDM Tool Status
Converters completed to generate IDM from Omnipage 14 and 15 XML Omnipage 15 proved to have numerous errors in its
representation of an OCR’d document Consequently, not recommended
Form-based extraction engine revised to work from IDM Non-form engine still works from our older “CleanXML”
convertor from IDM to CleanXML completed as stop-gap measure
direct use of IDM deferred pending review of other engine modifications
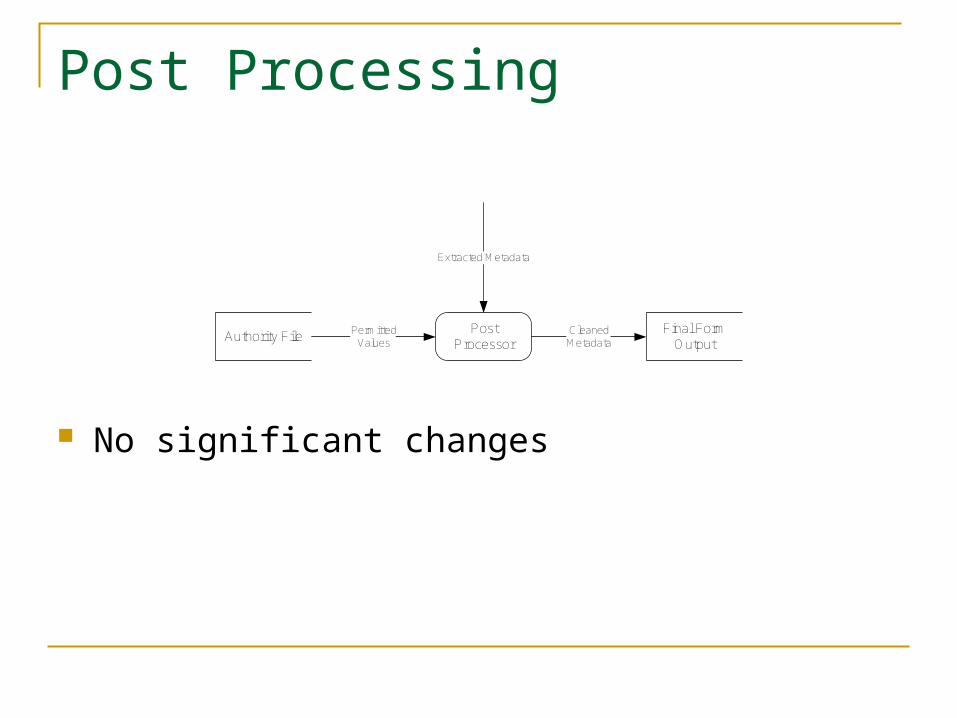
Post Processing
No significant changes
Final Form Output
Authority FilePost
Processor
Extracted Metadata
PermittedValues
CleanedMetadata

Nonform Processing
Bug fixes & tuning Added new
validation component
Post-hoc classification replaces former a
priori classification schemes
Convert to CleanXML
Extract Metadata
Validation Script
Select Best Metadata
Clean
Final Nonform Output
Unresolved Docs(IDM)
CleanXML
CandidateMetadata
Sets
IDM
Selected Metadata
document
document
au eagle ...
Nonform Templates

Validation
Given a set of extracted metadata mark each field with a confidence value indicating how
trustworthy the extracted value is mark the set with a composite confidence score
Fields and Sets with low confidence scores may be referred for additional processing automated post-processing human intervention and correction

Validating Extracted Metadata
Techniques must be independent of the extraction method A validation specification is written for each collection, combining Field-specific validation rules
statistical models derived for each field of text length % of words from English dictionary % of phrases from knowledge base prepared for that
field pattern matching

Sample Validation Specification
Combines results from multiple fields<val:validate collection="dtic"
xmlns:val="jelly:edu.odu.cs.dtic.validation.ValidationTagLibrary">
<val:average>
<val:field name="UnclassifiedTitle">...</val:field>
<val:field name="PersonalAuthor">...</val:field>
<val:field name="CorporateAuthor">...</val:field>
<val:field name="ReportDate">...</val:field>
</val:average>
</val:validate>

Validation Spec: Field Tests
Each field is subjected to one or more tests…<val:field name="PersonalAuthor"> <val:average> <val:length/> <val:max>
<val:phrases length="1"/> <val:phrases length="2"/> <val:phrases length="3"/>
</val:max> </val:average> </val:field><val:field name="ReportDate"> <val:reportFormat/></val:field>...

Sample Input Metadata Set
<metadata>
<UnclassifiedTitle>Thesis Title: The Military Extraterritorial Jurisdiction Act</UnclassifiedTitle>
<PersonalAuthor>Name of Candidate: LCDR Kathleen A. Kerrigan</PersonalAuthor>
<ReportDate>Accepted this 18th day of June 2004 by:</ReportDate>
</metadata>

Sample Validator Output
<metadata confidence="0.522"><UnclassifiedTitle confidence="0.943">Thesis Title: The Military Extraterritorial Jurisdiction Act</UnclassifiedTitle>
<PersonalAuthor confidence="0.622">Name of Candidate: LCDR Kathleen A. Kerrigan</PersonalAuthor>
<ReportDate confidence="0.0" warning="ReportDate field does not match required pattern">Accepted this 18th day of June 2004 by:</ReportDate>
</metadata>

Classification (a priori)
Classify (select best template)
Final Nonform Output
CleanXML
Extracted Metadata
au eagle ...
Nonform Templates
Unresolved Document
Extract Metadata
selectedtemplate
Previously, we had attempted various schemes for a priori classification x-y trees bin classification
Still investigating some visual recognition
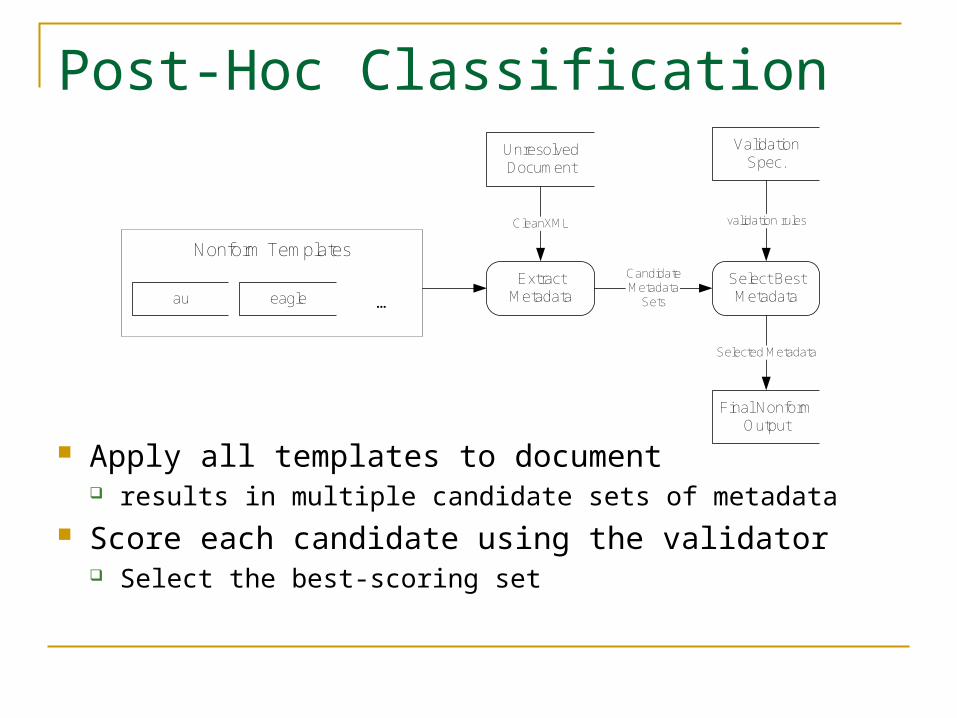
Post-Hoc Classification
Apply all templates to document results in multiple candidate sets of metadata
Score each candidate using the validator Select the best-scoring set
Extract Metadata
Final Nonform Output
CleanXML
Selected Metadata
au eagle ...
Nonform Templates
Unresolved Document
Select Best Metadata
CandidateMetadata
Sets
Validation Spec.
validation rules
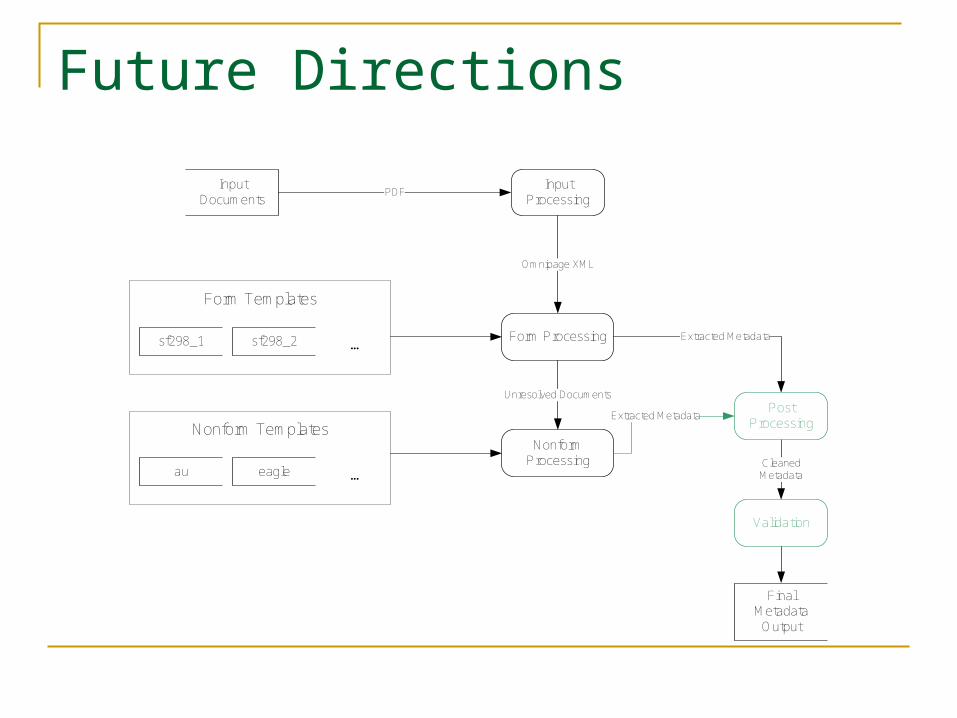
Future Directions
Input Documents
Input Processing
Form Processing
Final Metadata
Output
Omnipage XML
Unresolved Documents
Extracted Metadata
CleanedMetadata
sf298_1 sf298_2 ...
Form Templates
au eagle ...
Nonform Templates
Post Processing
Nonform Processing
Extracted Metadata
Validation





























