Embed Size (px)
Citation preview

Automatic Foreground Extraction of HeadShoulder Images
Jin Wang1, Yiting Ying2, Yanwen Guo2,3, and Qunsheng Peng2
1 Xuzhou Normal University, Xuzhou, China2 State Key Lab of CAD&CG, Zhejiang University, Hangzhou 310027, China
3 School of Computer Science and Technology, Shandong University,Jinan 250100, China
Abstract. Most existing techniques of foreground extracting work onlyin interactive mode. This paper introduces a novel algorithm of auto-matic foreground extraction for special object, and verifies its effective-ness with head shoulder images. The main contribution of our idea is tomake the most use of the prior knowledge to constrain the processing offoreground extraction. For human head shoulder images, we first detectface and a few facial features, which helps to estimate an approximatemask covering the interesting region. The algorithm then extracts thehard edge of foreground from the specified area using an iterative graphcut method incorporated with an improved Gaussian Mixture Model.To generate accurate soft edges, a Bayes matting is applied. The wholeprocess is fully automatic. Experimental results demonstrate that ouralgorithm is both robust and efficient.
1 Introduction
Foreground extraction is a long lasting topic in computer vision and graphics.Early research focused on fast and precise interactive segmentation tools. In-telligent Scissors [6], Snakes [4] and Level sets [5] are several typical methods,which present hard edges. Then, matting techniques were developed to get softedges with a transparent alpha mask. Poission [9] and Bayes [8] matting arethe two representative algorithms. Recently, researchers attempt to enhance theautomatization [1], [2], [3]. In [3], an intuitive user interface is suggested, butis still complex for some images. [2] present the up-to-date technique on im-age cutout, which only requires the user to draw a rectangle surrounding thedesired object. Fully automatic foreground extraction is still a big challenge to-day. It seems impossible to develop a universal algorithm to recognize the shapeof interested object out of complex background, because objects in the worldvary greatly. We must take the knowledge of the foreground objects into ac-count. Fortunately, many objects have their certain characteristics which helpto locate those objects’ outline. Many detection techniques for special objects,such as car, face, text, etc., have been proposed. Those detection results willfacilitate automatic image segmentation. Based on above analysis, we presenta novel framework for fully automatic foreground extraction of special objects.
H.-P. Seidel, T. Nishita, and Q. Peng (Eds.): CGI 2006, LNCS 4035, pp. 385–396, 2006.c© Springer-Verlag Berlin Heidelberg 2006

386 J. Wang et al.
Our paper focuses on making the most use of prior knowledge to select moreprecise sample set of the background and foreground, remove unwanted piecesand retrieve lost patches.
Our algorithm has three stages. First, we locate some obvious features on theobject and get its probable outline by the prior knowledge of the object. Withthese information, we secondly apply an iterative Graph cut algorithm basedon improved Gauss Mixture Model (GMM) to estimate the foreground over themask and generate the hard edges. Thirdly, along a narrow strip around the hardedges, Bayesian matting is used to refine the cutout boundary and generate thefinal soft edges.
Human face and body are the most familiar things in our life, whose extractionis significant and meaningful. So we choose the head shoulder images as examplesto validate our algorithm. Its prior knowledge can be represented as facial organ,which can be obtained with face detection and features locating.
The main contribution of this paper is that we introduce a novel, robustalgorithm to extract foreground automatically for special objects, in which wemake full use of the prior knowledge as strong constraint. This work is of greatsignificance for those embedding devices without interactive tools, such as digitalcameras and mobile phones.
2 Related Work
For automatic image cutout, there are few achievements up to now. We will de-scribe briefly and compare several representative interactive image cutout tech-niques, which focus on presenting convenient interactions. In addition, GMMwill be addressed briefly which will be improved in the next section.
Image Cutout. Several early image segmentation methods have been appliedin commercial products, such as Snakes [4], Level sets [5] and Intelligent Scissors[6], all of which are interactive tools. Users first define an initial contour. Thendriven by different forms of energy minimization, these contours can be refinedand snapped to the image edges iteratively. The main disadvantage of abovemethods is that the final segmentation result depends on the initialization heav-ily, especially in camouflage. Excessive interaction also limits their application.
Recently, a powerful image segmentation technique Graph cut [1] is presented.Graph cut poses image cutout as a binary labelling problem, which means thateach pixel p belongs to either foreground or background. Define Lp as the trans-parency of p. If p belongs to foreground, denote it as Lp = 1; otherwise Lp = 0.Guided by the observed foreground and background greylevel histograms, thesolution L, i.e. a segmentation, can be obtained by minimizing a Gibbs energyE(L) with the form:
E(L) = U(p, Lp) + V (p, Lp) (1)
where the first term represents penalty energy for pixel labelling and the lat-ter term is the smoothing term indicating the interaction between neighboringpixels. Usually U(p, Lp) and V (p, Lp) can be defined as follows:

Automatic Foreground Extraction of Head Shoulder Images 387
U(p, Lp) = λ ·∑
p∈P
−lnh(p; Lp), (2)
V (p, Lp) =∑
(p,q)∈N
e− (Ip−Iq)2
2σ2 ·|Lp − Lq|dist(p, q)
(3)
in which λ is a weight between the penalty energy and the smoothing term,(p, q) ∈ N means p, q are neighboring pixels, h is the color distribution, Ip isthe grey value of pixel p, σ is a constant and dist(p, q) is the Euclidean distancebetween p and q. Minimization of E(L) is done by using a standard minimumcut algorithm. More details about the Graph cut algorithm can be found in [1].
GrabCut [2] extended Boykov’s algorithm on several aspects to improve the effi-ciency and reduce user interaction. Firstly, it replaces color histograms with GMMto achieve more accurate color sampling. Secondly, it adopts an iterative Graphcut procedure to substitute for the one-shot minimum cut estimation. It requiresonly a rectangle surrounding the desired object for foreground extraction, whichis the most automatic algorithm for foreground extraction up to now. However,the algorithm is not robust enough since it samples background and foregroundin a imprecise region, so further interactions are still needed in many cases.
Lazy Snapping [3] is another fine Graph cut based cutout algorithm. It sepa-rates coarse and fine scale processing, making object specification and detailedadjustment easy. In the coarse process, the image is clustered adaptively andGraph cut is applied to these clusters to generate an initial segmentation fast.While in the fine process, a set of user interface tools is designed to provideflexible control and editing. To obtain satisfactory results, usually the exigentinteraction is also unavoidable.
Above approaches mainly focus on the hard segmentation, which can notget smooth edge information, whose results can not be composed with anotherimage smoothly. Some work has been addressed in the soft segmentation [7],[8], [9], which endows the pixel around the boundary with continuous alphavalues. Usually, for these approaches, a user-supplied trimap T = {TF ; TU ; TB}is needed, where TF is the user specified foreground, TB is background and TU isthe the unknown region whose alpha values are to be solved. Bayes matting [8]models the color distributions with oriented Gaussian covariance, and relies on aBayesian approach to solve the matting problem. Poisson matting [9] formulatesthe problem as solving Poisson equations with the matte gradient field.
Gaussian Mixture Model (GMM). GMM is a type of probability densitycomposing of a set of Gaussian models. The GMM with K Gaussian models is:
p(ω|x) =K∑
k=1
αkG(x; μk, σk) (4)
where α1, ..., αk is the mixing proportions satisfying ΣKk=1αk = 1, μk, σk is the
mean value and covariance of kth Gaussian model. A commonly used approachfor determining the parameters of GMM is the Expectation-Maximization(EM)algorithm [10].

388 J. Wang et al.
3 Head Shoulder Cutout Algorithm
The process of automatically extracting foreground of head shoulder picturesis divided into three steps: make a rough mask with the face detection andfeature location techniques; extract the hard edges of the foreground with theconstraints of the mask by Graph cut; refine the result and generate soft edgeswith matting.
3.1 Face and Feature Detection
Face and facial feature detection have been studied for many years, with manytechniques proposed [15], [16], [18]. A detailed comparison and survey on facedetection algorithms can be found in [15]. Among the face detection methods,learning-based algorithms have demonstrated excellent results. Recently, P. Viola[18] presented an efficient and robust method with AdaBoost and integral image.We adopt an improved Adaboost algorithm to search the face candidate in headshoulder image.
In order to enhance the detection ratio and performance of Adaboost algo-rithm, we make two improvements. First, an adaptive Gauss mixture skin colormodel is employed to ignore those non-skin regions, and canny filter is used toreduce those chaos regions. Second, in Adaboost algorithm, when the numberof features exceeds 200, the distribution of face and non face classes in Harr-likefeatures space almost completely overlap in later stages of the cascade training.In order to solve this problem, PCA feature is introduced in the later stages ofcascaded training. Adaboost with PCA can get much higher detection ratio thanthat without PCA at the same false alarm ratio.
Further, we also employ Adaboost algorithm to locate eye corners and mouthcorners based on the detected face, and apply VPF [13] algorithm to locate jawand jowl feature points. The whole process abides to the idea of LFA [14], whichenhances the efficiency and increases detection ratio. In general, we detect 9feature points: eye corners, mouth corners, left/right jowl and jaw.
3.2 Face Mask
With the help of the the detected face and features, we create a mask to definethe region of interest in the image, which indicates the approximate position ofthe head and shoulder. This mask will strongly constrain the whole Graph cutprocess to emphasize foreground, remove fractional pieces and unwanted patches,and retrieve the lost foreground.
Candide is a wire-frame face model to define a basic facial structure, which hasbeen popular in video coding research for many years [19]. The new variant ofthis model is also compliant to MPEG-4 Face Animation. We adopt the frontalprojection of Candide to assist in constructing the face mask, as shown in Fig.1.The green points denote the detected features and the blue ones are estimatedwith Candide. The region surrounded by the pink polygon demonstrates theapproximate face area and the half ellipse adhering to the face mask denotes theshoulder position. Besides, the proportions of all parts are also fixed.

Automatic Foreground Extraction of Head Shoulder Images 389
In Fig.1, the area covered by face mask and the half ellipse is deemed asthe estimated initial foreground served for the further Graph cut, while therest region is the background. Obviously, this initial samples selection of back-ground/foreground is more accurate than previous semi-automatic approaches.
Fig. 1. The head and shoulder mask. The green points are automatically detected andthe blue ones are estimated with Candide model; Some length proportions are alsolabeled, wherein h, w represent the length and width of the face respectively.
3.3 Color Distribution
GMM is a widely used model for the description of color distribution. Based onthat, we propose a new model, named multi-GMM, to achieve more robust effect.
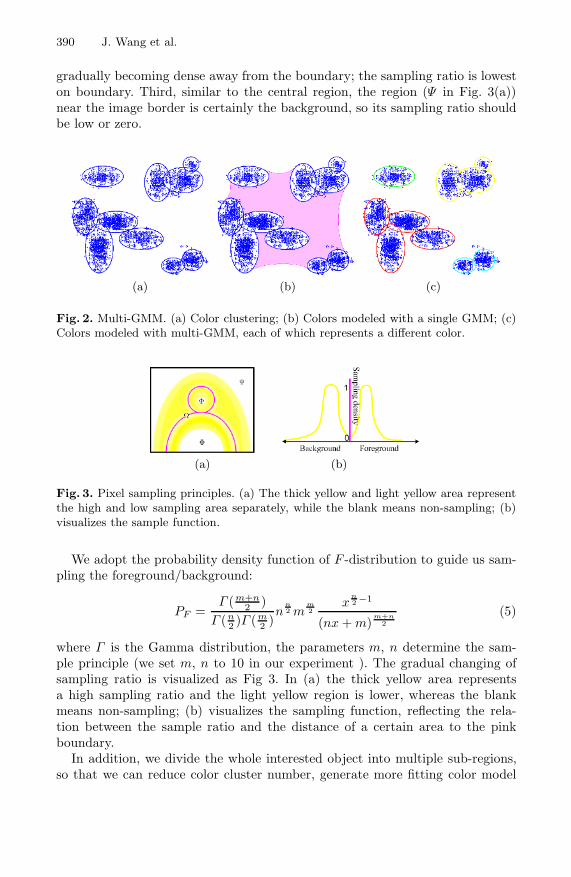
When colors in an image are complicated, a single GMM doesn’t fit well.As is shown in Fig. 2(b), if we model all the colors with a single GMM, it issignificantly inaccurate in the pink region. This would further lead to a poor cutbetween the foreground and background. In such case, we split the model into 4separate GMMs, as show in Fig. 2 (c), according to the distances between eachGaussians. In our algorithm, we use this multi-GMM to model the foregroundand background color distributions. We firstly employ the algorithm in [17] todetermine the proper number of color clusters. Secondly, we group the clustersinto multi-GMM. For the initialization of each GMM, we use LBG [22] algorithm,which generates more precise initial value compared to the splitter [20] and k-means [21] methods. Then we apply EM algorithm [11] to get our GMMs.
Sampling all pixels within the mask to construct the multi-GMM is not neces-sary and results in great mistake since the mask is just a rough estimation of thehead shoulder position. To reduce the affection of above problem and decreasethe computational complexity for constructing multi-GMM, we adopt the sam-pling principles as follows. First, in general cases, the central area of the maskand half ellipse should belong to foreground doubtlessly, which is deemed asforeground without sampling (Φ in Fig. 3 (a)). This area is almost worthless forthe segmentation. On the contrary, it may bring some false cut patches. More-over, sampling this region costs a lot to construct the color model. Second, theregion near the boundary of the mask and half ellipse is the unknown area (Ω inFig. 3 (a)). The narrow strip near the boundary will be sampled sparsely while
390 J. Wang et al.
gradually becoming dense away from the boundary; the sampling ratio is loweston boundary. Third, similar to the central region, the region (Ψ in Fig. 3(a))near the image border is certainly the background, so its sampling ratio shouldbe low or zero.
(a) (b) (c)
Fig. 2. Multi-GMM. (a) Color clustering; (b) Colors modeled with a single GMM; (c)Colors modeled with multi-GMM, each of which represents a different color.
(a) (b)
Fig. 3. Pixel sampling principles. (a) The thick yellow and light yellow area representthe high and low sampling area separately, while the blank means non-sampling; (b)visualizes the sample function.
We adopt the probability density function of F -distribution to guide us sam-pling the foreground/background:
PF =Γ (m+n
2 )Γ (n
2 )Γ (m2 )
nn2 m
m2
xn2 −1
(nx + m)m+n
2
(5)
where Γ is the Gamma distribution, the parameters m, n determine the sam-ple principle (we set m, n to 10 in our experiment ). The gradual changing ofsampling ratio is visualized as Fig 3. In (a) the thick yellow area representsa high sampling ratio and the light yellow region is lower, whereas the blankmeans non-sampling; (b) visualizes the sampling function, reflecting the rela-tion between the sample ratio and the distance of a certain area to the pinkboundary.
In addition, we divide the whole interested object into multiple sub-regions,so that we can reduce color cluster number, generate more fitting color model

Automatic Foreground Extraction of Head Shoulder Images 391
and speed up as well. For head shoulder photos, we divide them into two sub-regions of head and shoulder, in which shoulder mask can be adaptively createdbased on the head clustered result. While for other special objects, we can dividedifferent number of sub-regions according to its physical structure.
3.4 Image Cutout
With the multi-GMM obtained, an improved Graph cut algorithm is employedto cut out the head and shoulder from the pictures.
For a clear description, we define the pink curve C in Fig. 3 (a) as the contourconsisting of the outer edge of the face mask and its adhering half ellipse. Werepresent the sampled pixel set out of C as Pb, the interior set as Pf . Obviously,for the pixel belonging to Pb , the farther from C, the more probable it isbackground. The same for the sampled pixel of Pf . This fact is imposed inGraph cut by appending prior weight function to the penalty energy term of theGraph cut objective function.
For a pixel p, dis(p) denotes the Euclidean distance from p to C. If p belongsto Pf , define D(p) = dis(p) as the distance from p to the contour; otherwise,define a negative D(p) = −dis(p) as its oriented distance to C. We adopt anormalized function W (p, Lp) as the prior coefficient with the form:
W (p, Lp) =
{1√2π
∫ p
−∞ e−x22 dx + 1
2 , Lp = 01 , Lp = 1.
The Gibbs energy of (1) is modified as:
E(L) = W (p, Lp)U(p, Lp, Gp) + V (p, Lp) (6)
where W (p, Lp) acts as the intensity to emphasize the constraint of prior knowl-edge and is valued as the displacement of the distribution function of the stan-dard normal distribution for Lp = 0. It takes effect on the background energyor foreground energy. For background energy, if p belongs to Pf , its backgroundenergy is reduced, otherwise increased.
U(p, Lp, Gp) derived from U(p, Lp) of (1) is the new penalty energy incorpo-rated with GMM by substituting the pixel’s weighted Gaussian distributions:Gp for the color distribution in monochrome image. It can be formulated as:
U(p, Lp, Gp) = λ ·∑
p∈P
[−ln(n⊙
i=1
αi(p)li∑
j=1
βijG(p, μij , σij))] (7)
in which λ inherited from (1). n represents the number of GMM and li means thenumber of Gaussians contained in ith GMM. The symbol
⊙represents whether
p belongs to ith GMM. In our color multi-GMM distribution, each pixel p onlybelongs to a GMM in general, assumed as kth (k ∈ [1, n]), then αk(p) is set to 1,others set to zero. βj is the coefficient of jth Gaussian’s probability weight amongith GMM and is computed by dividing the sample number in jth Gaussian bythe pixel number contained in ith GMM.

392 J. Wang et al.
We adopt an iterative method to solve E(L). It starts with minimizing E(L)with the standard minimal cut algorithm, and regards the cutout result asthe initial estimation of the foreground/background for the next iteration. Af-ter every iteration, the multi-GMM is applied again to model the color dataof the new estimated foreground/background. Since after every iteration theestimated foreground/background becomes more accurate, the iteration isconvergent.
For each iteration with our new form of Gibbs energy, the pixels on estimatedforeground/background is resampled and clustered by LBG algorithm, then EMoptimization is performed. The rules for computing W (p, Lp) holds unchanged,so the distance D(p) for every sample is computed only once.
3.5 Matting
Image matting used to generate soft edges, and is especially useful for transparentobjects, such as hair and feathers. We perform Bayesian matting along the hardedges generated with above Graph cut. The unknown area of trimap is generatedby dilating along the hard edges with a constant width (we set 12 pixels in ourexperiments), while interior and exterior strip regions are labeled as foregroundand background separately.
Note that, to enhance the efficiency of our algorithm, Graph cut can be im-plemented on the down-sampled image, whereas the matting algorithm is per-formed on the original image, which doesn’t basically affect the last results inprinciple.
4 Experimental Results
We have tested our algorithm with 263 normal upright head shoulder pictureswith over 70% success ratio on an Intel Pentium IV 2.4GHz PC with 512MBmain memory under the Windows XP operating system. The detection costs 1-2seconds, cutout stage costs 1-3 seconds and matting takes 1-3 seconds.
Fig. 4(b), (e) show the poor cutout results without the constraint of priorweight function W (p, Lp) while solving the objective function E(L). The reasonlies in that the color distribution of foreground is similar to its nearby back-ground. (c), (f) are the right cutout results by taking the constraint of priorknowledge into account.
Fig. 5 demonstrates the iterative process of solving E(L). Here we give thecutout result of the head part step by step as (b), (c) and (d). On the other hand,although the facial detection result (a) is not fully exact inducing inaccuratemask, our algorithm can generate proper cutout (e) as well.
Fig. 6 shows the matting effect of the hair. Fig. 7 presents some other exam-ples. Fig. 8 composes a cutout result with a different background smoothly.
A few of the above pictures are fetched from the papers: [2] and [23]. Wealso selected a few samples from our test library, and submitted them with ourprototype system to the online submission web page, the user can implement itand test the pictures according to the user instruction.

Automatic Foreground Extraction of Head Shoulder Images 393
(a) (b) (c)
(d) (e) (f)
Fig. 4. The constraint of prior knowledge. (a), (d) are the original images; (b), (e) arethe cutout results without the constraint of W (p,Lp), (b) loses a few pieces and (e)generates some unwanted patches; (c) (f) are the results taking account of W (p,Lp).
(a) (b) (c)
(d) (e)
Fig. 5. The process of iteration. (a) The original image with detected feature points;(b), (c) and (d) show the iterative results of head; (e) The last cutout result.

394 J. Wang et al.
(a) (b) (c)
(d) (e)
Fig. 6. Bayes matting. (a) The original image; (b)(c) The cutout matte and result withhard edge; (d)(e) The matting result corresponding to (d).
Fig. 7. Some other results of our algorithm. The upper row shows four original headshoulder pictures and the lower row presents the corresponding cutout results.
(a) (b) (c)
Fig. 8. One cutout and composite example. (a) The original picture; (b) The cutoutresult; (c) The composite result.

Automatic Foreground Extraction of Head Shoulder Images 395
5 Conclusions and Future Work
We have presented a novel approach to automatically extract special object andverified it with head shoulder images. The key point is how to make full useof prior knowledge of the object to estimate the region of interest, model theforeground and background color distributions and implement a robust and rapidGraph cut algorithm. The main advantage of this approach is that it requiresno user interactions.
Although initial experiments generated some encouraging results, our ap-proach is not yet robust enough to handle all cases. One main problem is thatour face detection algorithm has not considered the cases of rotation and vary-ing of lights, which affects the results sometimes. To resolve this problem andabide this tolerance is a future work. Besides, the speed is not fast enough yet.The extraction process costs 2 to 5 seconds in general. Our future works includethe following aspects. The processing, with the GMM construction and Graphcut can be optimized to a real-time speed. We are also doing some research onextraction of the full body. In addition, similar to the head shoulder images, theautomatic extraction of other special objects, such as cars, trees, animals, canbe applied.
Acknowledgements
This research work is supported by The National Basic Research Program ofChina (973 Program) under Grant No. 2002CB312101, NSFC under Grant No.60403038 and Direct Research Grant (No. 2050349).
References
1. Boykov, Y., Jolly, MP. Interactive Graph cuts for Optimal Boundary and RegionSegmentation of Objects in N-D Images. In: IEEE International Conference onComputer Vision, pp 105-112 (2001)
2. Rother, C., Kolmogorov, V., Blake, A. Grabcut - Interactive Foreground ExtractionUsing Iterated Graph cuts. In: ACM SIGGRAPH 2004, pp 309-314 (2004)
3. Li, Y., Sun, J., Tang C., Shum, H. Lazy Snapping. In: ACM SIGGRAPH 2004, pp303-308 (2004)
4. Kass, M., Witkin, A., Terzolpoulos, D. Snakes: Active Contour Models. Interna-tional Journal of Computer Vision, Vol. 2, pp 321-331 (1988)
5. Caselles, V., Kimmel, R., Sapiro, G. Geodesic Active Contours. In: IEEE Interna-tional Conference on Computer Vision, pp 694-699 (1995)
6. Mortensen, EN., and Barrett, WA. Intelligent Scissors for Image Composition. In:ACM SIGGRAPH 95, pp 191-198 (1995)
7. COREL Corporation. Knockout user guide. (2002)8. Chuang, YY., Curless, B., Salesin, D., Szeliski, R. A Bayesian Approach to Digital
Matting. In: IEEE Conference on Computer Vision and Pattern Recognition, pp264-271 (2001)
9. Sun, J., Jia, J., Tang, C., Shum, H. Poisson Matting In: ACM SIGGRAPH 2004,pp 315-321 (2004)

396 J. Wang et al.
10. Vasconcelos, N., Lippman, A. Embedded Mixture Modeling for Efficient Probabilis-tic Content-Based Indexing and Retrieval. In: Proc. of SPIE Conf. on MultimediaStorage and Archiving Systems III, Boston, (1998)
11. McLachlan, G., Krishnan, T. The EM Algorithm and Extensions. Wiley Series inProbability and Statisticcs, John Weley & Sons.
12. Lai, ZB., Gao, P., Wang T., et al., Comparison on Bayesian YING-YANG TheoryBased Clustering Number Selection Criterion with Information Theoretical Cri-teria. In: IEEE International Joint Conference on Neural Networks, Anchorage,USA, Vol. 1, pp 725-729 (1985)
13. Geng, X., Zhong, XP., Zhou, XM., Sun, SP., Zhou, ZH. Refining Eye LocationUsing VPF for Face Detection. In: Proc. of the 3rd Conference of Sinobiometrics,Xi’an China, pp 25-28 (2002)
14. Mandel, ED., Penev, PS., Facial Feature Tracking and Pose Estimation in VideoSequences by Factorial Coding of the Low-Dimensional Entropy Manifolds due tothe Partial Symmetrie s of Faces. In: Proc. 25th IEEE Int’l Conf. Acoustics, Speechand Signal Processing (ICASSP 2000), Vol. 4, pp 2345-2348 (2000)
15. Yang, MH., Kriegman, DJ., Ahuja, N. Detecting Faces in Images: A Survey. IEEETransactions on Pattern Analysis and Machine Intelligence, Vol. 24(1), pp 34-58(2002)
16. Chua, TS., Zhao, YL., Kankanhalli, MS. Detection of human faces in a compresseddomain for video stratification. The Visual Computer, Vol. 18, pp 121-133 (2002)
17. Gao, P., Lyu, MR. A Study on Color Space Selection for Determining Image Seg-mentation Region Number. In: Proc. of the 2000 International Conference on Ar-tificail Intelligence, Monte Carlo Resort, Las Vegas, Nevada, USA, June 26-29, Vol3, pp 1127-1132 (2000)
18. Viola, P., Jones, M. Rapid Object Detection using a Boosted Cascade of SimpleFeatures. In: IEEE Conf. on Computer Vision and Pattern Recognition, Kauai,Hawaii, USA, Vol 1, pp 511-518 (2001)
19. Ahlberg, J., Candide-3 – an Updated Parameterized Face. Technical Report LiTH-ISY-R-2326, Linkping University, Sweden, (2001)
20. Senior, A., Hsu, RL., Mottaleb, MA., Jain AK. Face Detection in Color Images.IEEE Computer Society, Vol. 24(5), ISSN:0162-8828, pp 696-706 (2002)
21. MacQueen, JB. Some Methods for classification and Analysis of Multivariate Ob-servations. In: Proc. of 5-th Berkeley Symposium on Mathematical Statistics andProbability, Berkeley, University of California Press, Vol. 1, pp 281-297 (1967)
22. Orchard, MT., Bouman, CA. Color Quantization of Images. IEEE Transactions onSignal Processing, Vol. 39(12), pp 2677-2690 (1991)
23. Chuang, YY., Agarwala, A., Curless, B., Salesin, D., Szeliski, R. Video Matting ofComplex Scenes. In: ACM SIGGRAPH 2004, Vol. 21(3), pp 243-248 (2002)





























