Embed Size (px)
DESCRIPTION
Learning Patterns in Images. 전산과학과 인공지능연구실 이 재영. Concern learning patterns in images & image sequences using the obtained pattern for interpreting new images Three problem areas semantic interpretation of color image detection of blasting caps in x-ray image - PowerPoint PPT Presentation
Citation preview

Learning Patterns in Images
전산과학과 인공지능연구실이 재영

• Concern– learning patterns in images & image sequences– using the obtained pattern for interpreting new
images
• Three problem areas– semantic interpretation of color image– detection of blasting caps in x-ray image– recognizing actions in video image sequences
=> Image formation processes
=> The choices of representation spaces

Introduction
• Motivation of this research– vision system need learning capabilities for
difficult problems
• Current research on learning in vision– concentrated on neural network
• Symbolic learning– insufficiently explored– potentially very promising research area

Semantic Interpretation of Color Images of Outdoor Scenes
• MIST Methodology– Multi-level Image Sampling and Transformation
– environment for applying diverse machine learning methods to computer vision
– semantically interpret natural scenes
• Three learning programs– AQ15c: learning decision rules from examples

– NN: neural network learning– AQ-NN: multi-strategy learning combining
symbolic and neural network methods

The MIST Methodology• Learning Mode
– builds or updates the Image Knowledge Base• image area attributes => class label• developed by inductive inference from examples by a
trainer
• Interpretation Mode– learned image transformation procedure
• new image => ASI(Annotated Symbolic Image)
– ASIarea <=> class label, annotations(additional information)

Original Image ASI

• Training (Learning Mode)
Description space generation & BK formulation
Event generation: area -> attribute vector
Learning or refinement -> class description
Image interpretation and evaluation
Image Knowledge Base
ASI

• Description space generation & BK formulation– initialized by trainer
• assign class names to area
• define initial description spaces– initial attributes: hue, saturation, gradient, intensity, high
frequency spots, etc…
– procedures for the measurement of attributes
• Event generation– using chosen procedures – sampled areas -> training examples (attribute vector)
• computed by 5x5 windowing operator

• Learning or refinement– applies selected machine learning program to the
training examples– generate a class description (a kind of rule?)
• Image interpretation and evaluation– applying developed descriptions to testing area– generate an Annotated Symbolic Image(ASI)
• area <=> class labeling & annotations
– compare ASI label with test area label• => stop train or continue iteration with ASI as input
– complete class description: a sequence of image transformations that produce final ASI

Interpretation Mode
• procedurenew image
=> apply description
=> majority voting(3x3 window)
=> ASI with annotation(degree of confidence)

Experimental Result
• AQ-NN– AQ
• learn attributional decision rules from example
• used to structure NN architecture
– NN• further optimize the AQ induced descriptions
Learningmethod
Training time Recognition time Accuracy(%)
AQ15c 0.43s 1.000s 94.00
NN 4.38s 0.033s 99.97
AQ-NN 10.93s 0.016s 99.98

Detection of Blasting Caps in X-Ray Images
• Problem– inspect a sequence of images for known objects– but little standardization of the class of objects
• Focus– how vision and learning can be combined to
find blasting caps– relationship between image characteristics and
object functionality
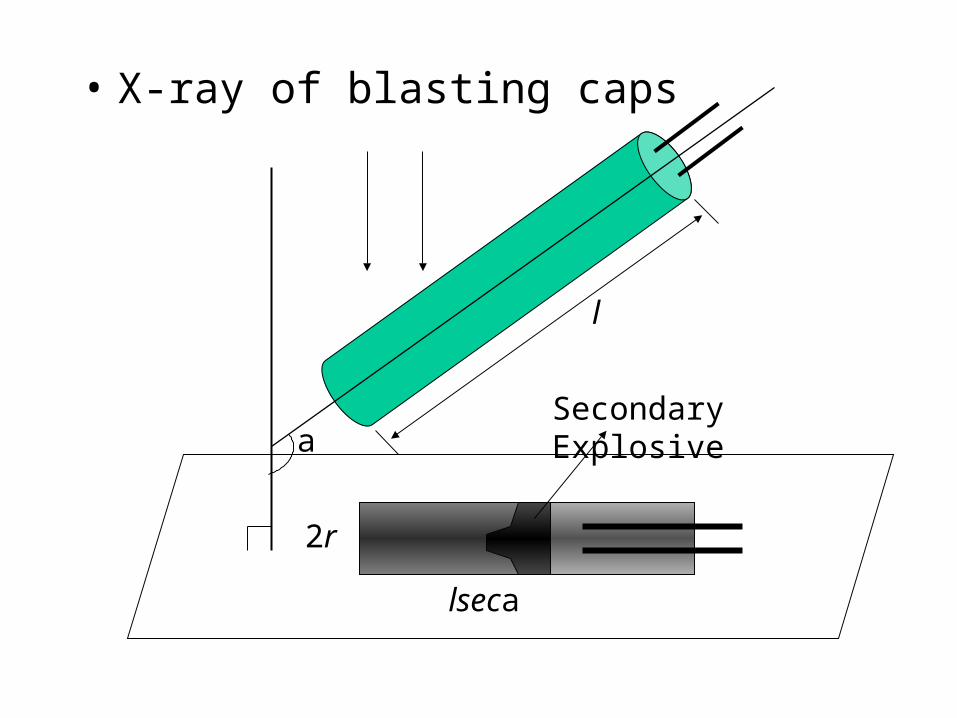
• X-ray of blasting caps
l
a
lseca
2r
Secondary Explosive

• Blasting caps– various shape but same functionality– strongest feature
• low intensity blob in the center of a rectangular ribbon of higher intensity
• the intensities of both blob & ribbon are lowest along the axis of the blasting cap and highest along the occluding contour
– blasting caps can be occluded by other objects• airport security scenario
• detect blasting caps in x-ray image of luggage

Methods and experimental results– AQ15c inductive learning system was used to learn
descriptions of blasting caps and non-blasting caps (geometric & intensity features)
• First phase– detect candidate : find low intensity blobs
• Second phase– a flexible matching routine is used to match the
local model to the image characteristics– attempt to fit a local model to ribbon-like features
surrounding the blob

• Test luggage image– contains various objects
• clothes, shoes, calculators, pens, batteries, etc…
• ResultsAverage Predictive Accuracy (%)
Correct 83.51± 1.3OverallIncorrect 16.49± 1.3Correct 85.82± 2.1Blasting CapIncorrect 14.18± 2.1Correct 81.19± 2.4Non-Blasting
Cap Incorrect 18.81± 2.4

Recognizing Actions in Video Image Sequence
• Recognizing the function of objects from its motion– based on characteristics such as shape, physics
and causation– velocity, acceleration, force of impact from
motion => strongly constrain possible function– object(motion) should not be evaluated in
isolation, but in context

• Primitive shapes– stick : a1a2 << a3– strip : a1a2 a2∧ a3 a1∧ a3– plate: a1 a2 >> a3– blob : a1 a2 a3
• Primitive motions (ex. Knife)– stabbing– slicing– chopping

• Inferring object function from primitive motions– object: a collection of primitives
• knife : handle(stick) + blade(strip)
– function depends on object’s motion• in object’s coordinate system &
• in relative to the actee (object it acts on)
direction of motion
the main axis of the object
the surface of the actee
=> determine intended function

– Ex] knife motion• stab: parallel to the main axis of knife &
perpendicular to the surface of the actee
• chop: perpendicular to the main axis & perpendicular to the surface of the actee
• slice: back-and-forth motion parallel to its main axis & parallel to the surface of the actee
• Computing primitive motion– for both actor’s coordinate & actee’s coordinate– using optical flow with shape information(main
axis, center of mass, …)

Parameterizing the Motion of a Stick or Strip
Motion direction

Experiments
• Knife– 25 frames /second for 5 seconds
=> 125 images– sampling
• 11 evenly spaced samples, each composed of 3 consecutive images( 0-2, 10-12, …_
• 33 images for each experiment

Stabbing
time
angle
0
-90

Chopping
time
angle
0
-90

Slicing
time
angle
0
-90

Summary
• Semantic interpretation of color images– apply machine learning to computer vision– AQ-NN
• Detection of blasting caps– analysis of the functional properties of blasting
caps (intensity & geometric features)

• Recognizing actions in video image sequences– understanding of the way an object is being
used by an agent– use combined information
• the shape of the object
• its motion
• its relation to the actee





























