Embed Size (px)
Citation preview

2232 IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY, VOL. 9, NO. 12, DECEMBER 2014
Kernelized Neighborhood Preserving Hashing forSocial-Network-Oriented Digital Fingerprints
Cong Liu, Hefei Ling, Member, IEEE, Fuhao Zou, Lingyu Yan, Yunfei Wang, Hui Feng, and Xinyu Ou
Abstract— Digital fingerprinting is a promising approach toprotect multimedia content from unauthorized redistribution.However, the existing fingerprints are unsuitable for socialnetwork tasks, because they fail to represent the social networkstructure, which incurs inefficient fingerprint coding. In addition,they are infeasible to efficiently trace colluders due to the largescale of social networks. To address these problems, we designa novel fingerprint, which consists of community relationshipcode and user identification code. Aiming to preserving thesocial network structure, we propose a kernelized neighborhoodpreserving hashing method to generate community relationshipcodes. The proposed method assigns similar community rela-tionship codes to users in the same or close communities, whichimproves the anticollusion performance. Because the communityrelationship codes are binary and neighborhood preserving,they can be used for fast indexing and retrieval. To acceleratethe collusion fingerprint tracing, we treat the communityrelationship codes as index keys to construct a hash table andan inverted index table. Based on the tables, we correspondinglypropose an efficient fingerprint detection method. Extensiveexperiments show that the proposed fingerprint is suitable forsocial network tasks and the real colluders can be efficientlyidentified by the proposed fingerprint detection approach.
Index Terms— Multimedia security, social network, digitalfingerprinting, hash-based similarity search, neighborhoodpreserving hashing.
I. INTRODUCTION
W ITH the advance of multimedia and Internet, socialnetwork services (SNS), such as Facebook, Flickr,
YouTube, and Twitter, have become prevalent all over theworld in recent years, resulting in that multimedia contentsshared online increase explosively. For instance, Flickr
Manuscript received August 19, 2013; revised March 20, 2014 andSeptember 13, 2014; accepted September 16, 2014. Date of publicationSeptember 29, 2014; date of current version November 12, 2014. Thiswork was supported in part by the National Science Foundation of Chinaunder Grant 61272409, in part by the Fundamental Research Funds forthe Central Universities, and in part by the Wuhan Youth Science andTechnology Chenguang Program. The associate editor coordinating the reviewof this manuscript and approving it for publication was Prof. Z. Jane Wang.(Corresponding author: Hefei Ling.)
C. Liu is with the Department of Computer Science and Technology,Huazhong University of Science and Technology, Wuhan 430000, China(e-mail: [email protected]).
H. Ling, F. Zou, L. Yan, Y. Wang, and X. Ou are with the Collegeof Computer Science, Huazhong University of Science and Technology,Wuhan 430000, China (e-mail: [email protected]; [email protected];[email protected]; [email protected]; [email protected]).
H. Feng is with the School of Transportation, Wuhan University ofTechnology, Wuhan 430070, China (e-mail: [email protected]).
Color versions of one or more of the figures in this paper are availableonline at http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TIFS.2014.2360583
has collected over 5 billion images and the number increasesby 3 million per day, while another visual content sharingwebsite YouTube receives more than 48 hours of uploadedvideos per minute. SNS gives people a lot of convenience forsharing their photos and video clips. Nevertheless they cannotprevent the unauthorized use of multimedia content, such asillegal duplication, processing and redistribution, which leadsto copyright infringement and privacy leakage. With the pop-ularity of the SNS and the maturity of the P2P technology, theonline distribution of images and videos is obviously speedingup and the scale of the shared content becomes extremelylarge, which makes piracy overrunning. Therefore, it is urgentto protect the shared multimedia content in social networks.
To address this issue, some social network websites employsome classical security mechanisms, such as encryption andaccess control. These methods are available to protect the mul-timedia content during transmission and distribution amongspecified communities and users. Whereas, these methods failto prevent the contents from unauthorized redistribution by theusers. Digital fingerprinting, as an emerging technology, is aneffective technique for copyright tracking. Unique masks, alsoknown as digital fingerprints, are embedded into differentcopies of the same content before distribution. Fingerprintscan be extracted to help identify culprits when an unauthorizedleak is found. By providing evidence to content owners ordigital right enforcement agencies that substantiates the guiltof parties involved in the improper use of content, fingerprint-ing ultimately discourages fraudulent behavior. Consequently,digital fingerprinting is a promising approach for addressingthe aforementioned problem in the social networks.
One potential threat to fingerprinting is collusion, whereby agroup of adversaries combine their individual copies trying toremove the embedded fingerprints. In social network tasks,an adversary is more likely to collude with others in thesame or close communities than others in distant communities.However, this prior knowledge is ignored by the existinganti-collusion fingerprints [1]–[8]. In other words, the finger-print codes neglect the social network structure, which leadsto inefficient fingerprint coding. The group-oriented finger-print (GOF) [9] introduces the group idea, and groups the usersaccording to geographic or social circumstances. Nevertheless,the geographic or social circumstances are different fromthe social network structure. Additionally, the size of eachgroup is fixed while the size of each community in socialnetwork is uncertain. Consequently, GOF is also unsuitablefor social network tasks. Whereas, the group idea is somewhateffective and even makes sense for designing fingerprints in
1556-6013 © 2014 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.

LIU et al.: KERNELIZED NPH FOR SOCIAL-NETWORK-ORIENTED DIGITAL FINGERPRINTS 2233
social network applications. Inspired by this, we design anovel two-tier Social Network Fingerprint (SNF) structure,which consists of two parts. One part corresponds to thecommunity relationship code and the other part correspondsto the user identification code. How do we apply the socialnetwork structure to design the fingerprints, and make surethat fingerprints assigned to close users are close? Recent hash-based similarity search methods [10]–[12] can map the objectsto the hash codes which preserves the neighborhood structure.Correspondingly, assuming that each user in social networkcan be viewed as an object, we introduce a hash-based simi-larity search method in order to map the users into the com-munity relationship codes (hash codes). Since the hash-basedmethod preserves the neighborhood structure of the usersin the social network, the generated community relationshipcode can reveal the relationship among community users andrepresent the structure of social networks. Similar communityrelationship codes are assigned to users in the same or closecommunities, while codes of distant community users areextremely different. To make each fingerprint identifiable,we append a unique user identification code to the communityrelationship code.
Although the proposed approach addresses the problemof preserving social network structure, there is anotherchallenging and urgent problem. The large scale of socialnetwork makes fingerprint detection/tracing very difficult eveninfeasible. As the generated community relationship code isbinary, it can be used for fast indexing and retrieval. Inspiredby recent information retrieval theories, we treat the commu-nity relationship codes as keys to construct a hash table and aninverted index table. Then, we correspondingly present an effi-cient fingerprint detection method based the constructed tables.Combining with the property of community relationship code,this method can implement efficient fingerprint detection.
The novel fingerprint coding and detection have severalaspects to be highlighted:
1) For the social network tasks, we introduce a similaritysearch method to design a novel two-tier fingerprintstructure, which consists of the community relationshipcode and the user identification code. The communityrelationship code can represent the social network struc-ture. Similar community relationship codes are assignedto users in the same or close communities, while codesof distant community users are extremely different. Thisproperty can improve the anti-collusion performanceand can be used to accelerate the fingerprint detection.
2) The proposed hashing method is a machine learningalgorithm, which can generate community relationshipcodes for new coming users, that are also neighborhood-preserving ones. In other words, the communityrelationship codes for new coming users are close tothat of their nearest neighbors.
3) The community relationship code is neighborhood-preserving and binary which can be used for efficientindex and retrieval. To accelerate fingerprint tracing,we treat the community relationship codes as a keysto construct a hash table and an inverted index table.Through these two tables, we can efficiently find the
nearest neighbors of the extracted (query) fingerprints.Then we find the real culprit fingerprint among theneighbors. Obviously, it is more efficient than traditionalfingerprint detection method which detects among thewhole fingerprint dataset. Additionally, the fingerprintdetection scheme is adaptable to tasks where its scaleis dynamically changing.
The remainder of this paper is organized as follows.In section II, we briefly review the background technologiesand related works. The proposed approach is presented indetail in section III. The experimental results and outcomesare discussed in section IV, while in the last section V wereport our conclusions.
II. RELATED WORKS
In this section, we briefly review existing digital finger-printing approaches. Since the fingerprint coding involves thehash-based similarity search, we also briefly report someclassical similarity search methods.
A. Anti-Collusion Fingerprint
Watermarking has been widely applied in fields, suchas copyright protection, content authentication and traitortracing [13]. Digital fingerprinting, as a branch of watermark-ing [14], [15], should improve the anti-collusion performancebesides addressing the problems that watermarking confronted.
In a collusion attack on a fingerprinting system, two or moreusers with different marked copies of the same host signalcome together and combine several copies to generate a newcomposite copy such that the traces of each of the “original”fingerprints are removed or attenuated. The collusion attackare divided into two categories, linear collusion and nonlinearcollusion. Linear collusion [16], [17] is one of the mostfeasible collusion attacks against multimedia fingerprinting.When users come together with a total of K differentlyfingerprinted copies of the same multimedia content, theseusers can simply linearly combine the K signals to producea colluded version. An important class of nonlinear collusionattacks is based upon such operations as taking the maximum,minimum, or median of corresponding components of theK colluders’ independent watermarked copies [18], [19].
Since collusion attack is the greatest threat to fingerprinting,researchers mainly focus on the design of anti-collusionfingerprints, and propose many effective measures. Theresearch about anti-collusion fingerprints can be broadlydivided into two directions corresponding to whether anexplicit coding procedure is involved. One direction focuseson designing non-coded fingerprints. Cox et al. first introducebinary random sequences to generate fingerprints, and provethat they are robust to usual signal processing attacks andcollusion attacks. Zhao et al. [20], [21] theoretically analyzethe collusion resistance of independent Gaussian fingerprints.Cha et al. [6] introduce the CDMA technology into digitalfingerprinting and propose a MC-CDMA-based fingerprintingsystem which has robust anti-collusion performance. Anotherclassical non-coded fingerprinting method uses the orthogonalfingerprint [1] which directly assigns to each user a non-coded

2234 IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY, VOL. 9, NO. 12, DECEMBER 2014
spread sequence as a fingerprint. The fingerprint is orthogonalto each other.
Another direction of fingerprint is coded fingerprint. Thefirst work, c-secure code, is presented by Boneh and Shaw [2].When the number of users is large, the proposed c-securecode must obviously increase the length of fingerprint, makingit unsuitable for practical tasks. To address this problem,Yacobi [22] improves the c-secure code by merging a directsequence spread spectrum embedding layer with the firstc-secure layer. Tardos [23] further improves the c-secureand proposes an optimal probabilistic fingerprint code (OPF)which is the best within a constant factor for reasonableerror probabilities. Josep et al. [24] employ the c-secure togenerate a series of binary fingerprint codes which decreasesthe length of the fingerprint while obtaining better finger-print detection efficiency. Based on Trados’s OPF fingerprint,Skoric et al. [25] propose two improved fingerprint codeschemes and analyze their anti-collusion performance.
To trace or identify colluders, researchers presentsome fingerprint design strategies based on combinatorics.Combining the combinatorics theory and traditional finger-prints, such as Traceability Code (TA) [3] and Identifi-able Parent Property (IPP) [4] code, Staddon [26] presenta series of traceable and anti-collusion fingerprint codes.Wade Trapper et al. [5] propose an anti-collusion code (ACC)based on the combinatorial design and group coding theory(such as balanced incomplete block design (BIBD)). Althoughthe anti-collusion performance of ACC is good, the combina-torial design is difficult which limits its scalability and prac-ticability. For better tracing performance, an improved ACC,logical ACC [27], is proposed by Cheng et al.. Combinatorics-based fingerprint is effective for small scale application.However, due to the complexity of combinatorial design, itis unsuitable for large scale tasks, e. g. social network.
Error correcting code (ECC) can detect and correct theerrors resulted from interference. Moreover, it can be decodedefficiently. Recently, many ECC-based fingerprints wereproposed. Silverberg et al. [28] utilize ECC to generateTA code, and apply the List Decoding algorithm to tracttraitors. Safavi-Naini [29] introduces a q-ary ECC to generatec-TA code which can resist c-user collusion, and improvesthe efficiency of the fingerprint coding and matching.To obtain better performance, some works present dynamicfingerprint [30] and Two-level fingerprint [31] based on ECC.Although ECC-based fingerprint is capable of efficient codingand matching, its anti-collusion performance is limited.
In order to improve the anti-collusion capability of thefingerprint and decrease the complexity of fingerprint detec-tion, Wang propose a group-oriented fingerprint scheme [9],which divides users into different groups according to theirgeographic or social circumstances, and assigns each groupan independent orthogonal fingerprint code. The code consistsof intragroup code and intergroup code. To improve the anti-collusion performance, He and Wu [32] combine the group-oriented code and ECC, and comprehensively take accountof fingerprint embedding, attack and detection. However, itis unadaptable to large scale tasks. Adapting the previousapproach for large scale tasks, He et al. [33] further improve
and extend the scheme so that it can contain billion of users.The advantage of group-oriented is that it can extremelyimprove the anti-collusion performance when the colludersare from the same group. Additionally, the two-tier designcan reduce the detection time, which improves the tracingefficiency. However the number of users in each group isfixed and can not be changed which makes it unsuitable forsocial networks. Moreover, the relationship between peoplehas gone beyond the restrictions of geographical and socialcircumstances with the prevalent of social networks. It is likelythat users from different groups collude to generate a newcopy, which brings great challenge to anti-collusion.
B. Similarity Search
In statistics and coding theory, a Hamming space is the setof all 2N binary strings of length N . The Hamming distancebetween two strings of equal length is the number of positionsat which the corresponding symbols are different, and it canbe computed through the XOR and bit-count operation.
With the explosive increment of information and data inthe Internet, it is difficult to use huge training sets to addresschallenging tasks in the fields, such as machine learning,information retrieval and computer vision. To tackle thesetasks, fast similarity search (also known as nearest neighborssearch) becomes essential. Methods for similarity searchgenerally fall into two groups. One group partitions the dataspace recursively, such as KD-tree [34], R-tree [35]. The otheris hash-based methods, such LSH [36], BRE [37], semanticHashing [38]. The most promising hash-based method isdata-aware hashing, such as Spectral Hashing (SpH) [11]and Self-Taught Hashing (STH) [10]. These methods maphigh-dimensional objects to low-dimensional binary vectors(also known as hash codes) in a manner that codes ofsimilar objects have small Hamming distances while ones ofdissimilar objects have large distances.
The hash-based similarity search has three properties asshown in [11]:
• hash codes for a novel input can be easily computed,• only a small number of bits are required to encode an
object,• it maps similar objects into close binary hash codes.
III. DIGITAL FINGERPRINT CODING AND TRACING
SUITABLE FOR SOCIAL NETWORKS
Through reviewing with discussing the different proposedfingerprinting approaches in section II-A, we note that thegroup-oriented fingerprint [9] method can deal with millionsof users which is suitable for large scale tasks. However,this method is inadequate when employed to social networks.Firstly, the independent orthogonal group code is unrelated tothe structure of the social network which leads to inefficientcode, and the coding efficiency decreases as the number ofgroups is increased. Additionally, the number of the usersin a group is fixed which makes the algorithm inappropriatefor social networks with dynamic structure. In this paper,we propose a novel two-tier fingerprint structure which issuitable for social networks. This is the first work that

LIU et al.: KERNELIZED NPH FOR SOCIAL-NETWORK-ORIENTED DIGITAL FINGERPRINTS 2235
Fig. 1. The idea of designing fingerprints oriented for social networks. (a) The sketch of the nearest neighbors search. (b) The sketch of applying the nearestneighbor search on the social networks. (c) The structure of the proposed fingerprints.
introduces hash-based similarity search methods to generatefingerprints.
A. Two-Tier Fingerprint Coding Suitable for Social Networks
In social networks, community reflects the localaggregation property of social network users. Moreover,C. L. Apicella et al. [39] have verified that people in the samecommunity are more likely to contact with each other and havemore probability to do the same thing, while the probabilityis low among people in different communities. Thus weassume that users from the same or close communities aremore likely to collude with each other. Therefore, it is criticalto employ the social network structure to generate fingerprintcodes so that close codes are assigned to neighborhood users.This not only improves the code efficiency but also increasesthe relativity of codes corresponding to neighborhood users,thereby improving the anti-collusion ability of the fingerprints.
In the field of multimedia and dataset, dealing with largescale data is a challenging problem. To address this prob-lem, some efficient hash-based methods, such as Self-TaughtHashing (STH) [10], Spectral Hashing (SpH) [11] and Neigh-borhood Preserving Hashing (NPH) [12], have been proposed.They can employ the underlying neighborhood structure toefficiently handle the tasks, such as retrieval, classification andclustering. As Fig. 1(a) shows, these methods aim to projecthigh-dimensional data to low-dimensional binary codes (alsoknown as hash code) lying on a Hamming space. The hashcodes preserve the neighborhood structure of data, while theyare binary, so they can used for efficient indexing and retrieval.
Motivated by that, we treat the user information of socialnetworks as high-dimensional data, and employ the hash-basedsimilarity search method to generate hash codes for users.The obtained hash codes preserve the relationship betweenusers and the social network structure as shown in Fig. 1(b).This is to say that neighborhood users are assigned closecodes. We treat the hash codes as community relationshipcode, and can efficiently find the nearest neighbors throughthem.
However, neighborhood-preserving property is not sufficientfor fingerprints. As hash codes (community relationship codes)may conflict, we can only find the nearest neighbors ratherthan the exact users that participate in collusion. Thus wemust additionally assign each user an long enough codenamed user identification code. Note that scale of the socialnetwork is extremely large. Therefore, user identificationcode must be unique and long enough in order to make usersidentifiable. To distinguish different users, we must ensurethat the minimum distance between user identification codesis large enough, which can be implemented by selectingan adaptable Error Correcting Code (ECC), such as RS(Reed-Solomen) code. Although the independent ECC cannot satisfy the social networks, we can append it to thecommunity relationship code constructing a novel fingerprint.
As shown in Fig. 1(c), we present a novel two-tier finger-print structure which consists of the community relationshipcode and the user identification code. This structure can notonly represent the structure of social networks, but it alsoensures each user identifiable. Moreover, the community rela-tionship code is binary which makes it convenient for indexing

2236 IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY, VOL. 9, NO. 12, DECEMBER 2014
Fig. 2. Procedure of generating community relationship code.
and retrieving fingerprints. Unlike the classical group-orientedfingerprint [9], the user number of the community is vari-able. Therefore, it is suitable for dynamically changing socialnetworks. Note that community relationship code is criticalfor this design. In this paper, we extend our previous work,neighborhood preserving hashing (NPH) [12], to generatecommunity relationship codes, which will be further depictedin the following subsections.
B. Generating Community Relationship Code
The number of the social network users is always extremelylarge. For large scale machine learning, a common method isto select parts of samples as landmarks (or anchors) and trainover the selected landmarks, then make a prediction for therest samples using the learned machines. This method has beenproved to be effective and efficient. Some algorithms randomlyselect some samples as the landmarks, such as [40], [41].Other algorithms employ the k-means [42] method to getsome cluster centers and treat them as the landmarks, suchas [43]–[45]. In this paper, we employ the random sampling.The procedure of generating community relationship codes isshown in Fig. 2.
In a social network, each user contacts with others, so thereare connections in the relationship graph. According to thegiven connection relationship, we construct an adjacent matrixA to represent it:
Aij ={
1, if Oi ∈ C(O j ) or O j ∈ C(Oi )
0, otherwise(1)
where i, j = 1, 2, . . . , n, n is the total number of users, C(Oi )represents the set of users who contact with i -th user Oi .
The value of Aij can be other positive real value, describingfor example the frequency of the contact between the i -th userand j -th user. This matrix represents the relationship amongusers, and we can analyze the structure of the social networkfrom it. After creating the adjacent matrix, we employ it togenerate community relationship code via the neighborhoodpreserving hashing (NPH) [12] method. In the following,we first introduce the motivation and background of NPH inbrief, and then depict the NPH algorithm in detail.
The Non-negative Matrix Factorization (NMF) [46], [47]has been proposed as a method for learning parts of objects.Previous studies have shown that there is psychologicaland physiological evidence for parts-based representationin the human brain. Given a non-negative matrix X =[x1, x2, . . . , xn] ∈ R
d×n , each column of X is a sample vector.NMF aims to find two non-negative matrices U = [uik ] ∈R
d×k and Y = [y1, y2, . . . , yn] ∈ Rk×n whose product can
well approximate the original matrix X . It minimizes thefollowing objective function:
ONMF = argU,Y
min ‖X − UY‖2F
s.t. U ≥ 0, Y ≥ 0 (2)
where ‖·‖F denotes the Frobenius norm. For social networkrepresentation purposes, xi can be seen as a user’s properties,such as gender, age, interest. U is the dictionary matrix, andyi is a low-dimensional representation of xi which can beregarded as the community relationship code of the i -th user.xi indicates which properties can well represent the i -th user.
Although NMF preserves the semantic information, itis incapable of preserving the neighborhood structure.This means that the community relationship codes assigned

LIU et al.: KERNELIZED NPH FOR SOCIAL-NETWORK-ORIENTED DIGITAL FINGERPRINTS 2237
to the users from the same community may be far apart.To overcome this problem, we try to combine other methods.Based on the recent studies about manifold learning the-ory [48] and dimensionality reduction [49], [50], Locally Lin-ear Embedding (LLE) [50] assumes that if a data point can bereconstructed from its neighbors in the input space, then it canbe reconstructed from its neighbors by the same reconstructioncoefficients in the low-dimensional subspace. For each datapoint xi , LLE minimizes the reconstruction error:
ε(W ) =∑
i
∥∥∥∥xi −∑
x j ∈N (xi )
wi j x j
∥∥∥∥2
2
s.t.∑
x j ∈N (xi )
wi j = 1 (3)
where Nk(xi ) denotes its k-nearest neighbors. Note thatLLE constructs a neighborhood-preserving mapping. Eachhigh-dimensional data xi is mapped to a low-dimensionalpoint yi ∈ R
k representing a global internal coordinate onthe manifold. This is done by choosing yi that minimizes thefollowing embedding cost function:
�(Y ) =∑
i
∥∥∥∥yi −∑
j
wi j y j
∥∥∥∥2
2
. (4)
This ensures that if i -th and j -th user are in the same or closecommunities, their corresponding community relationshipcodes will be close.
Considering the properties of NMF and LLE, neighborhoodpreserving hashing (NPH) combines these two classicaltechniques. Recall that NMF tries to find a dictionary whichis optimal for the linear approximation of data. We rewriteEq. (2) as follows:
ONMF = argU,Y
min∑
i
‖xi − U yi‖2, i = 1, . . . , n
s.t. U ≥ 0, Y ≥ 0. (5)
One may hope that if data points xi and x j are similar, thenyi and y j , their corresponding representations based on thedictionary U , should also be close. By introducing the idea ofLLE that yi can be reconstructed from its nearest neighbors,we construct the following objective function:
O = argU,Y
min∑
i
∥∥∥∥xi −∑
j
wi j U y j
∥∥∥∥2
, i = 1, . . . , n
s.t. U ≥ 0, Y ≥ 0 (6)
where j satisfies that x j ∈ N (xi ). After some mathematicaltransformations, the objective function can be reformulated as
O = argU,Y
min
∥∥∥∥X − UY W T
∥∥∥∥2
Fs.t. U ≥ 0, Y ≥ 0 (7)
Through solving the above optimization function, we canobtain the low-dimensional representation Y (communityrelationship code) and the dictionary U . The solving algorithmwill be depicted in next section.
C. Solving Algorithm
The objective function O of NPH in Eq. (7) is not convexon U and Y together. Therefore it is infeasible to find theglobal minima. However, it is convex alternatively on U or Y .Thus there are many techniques for numerical optimizationthat can be applied to find a local minima which is sufficientfor most realistic tasks. Among the algorithms used to solveNMF, gradient descent is perhaps the simplest technique toimplement, but its convergence can be slow. Besides, the con-vergence of gradient based methods is sensitive to the choiceof step size, which is unsuitable for large scale applications.Gonzales and Zhang [51] indicated that multiplicative updatemethod still lacks of optimization properties. Meanwhileseveral implementations of the multiplicative update have aninfinite loop, which must be interrupted by users after someiterations. Thus, such a stopping condition does not revealwhether or not a solution is close to a stationary point. In thispaper, we apply projected gradient method which refers toLin [52] to solve the objective function. This method convergesrapidly and its stop condition reveals the effect of the solution.
After some mathematic transformations, we rewrite theobjective function (7) as
O = tr[(X − UY W T )(X − UY W T )T
]= tr(X X T ) − 2tr(XWY T U T ) + tr(UY W T WY T ), (8)
where tr(·) denotes the trace of a matrix, it applies the matrixproperties tr(AB) = tr(B A) and tr(A) = tr(AT ). Then wecalculate the partial derivatives of the objective function withrespect to U and Y as follows:
∂O∂U
= 2UY W T WY T − 2XWY T (9)
∂O∂Y
= 2U T UY W T W − 2U T XW (10)
Similar to any solving algorithm for NMF, we separate theobjective function into two distinct sub-problems, and updateone variable while the other is fixed. Given U1
i j ≥ 0,
Y 1i j ≥ 0,∀i, j ,
f (Y k+1) = arg minY≥0
f (Uk, Y k) (11)
f (Uk+1) = arg minU≥0
f (Uk, Y k+1). (12)
These two problems are bounded-constrained optimization.There are some efficient methods to solve them. We takeEq. (11) as an example to describe how to solve them. Forconvenience of description, we rewrite it as
minY
f (Y ) =∥∥∥X − UY W T
∥∥∥2
F
s.t. Yi j ≥ 0,∀i, j (13)
where X , W are given matrices and U is initialized with arandom non-negative matrix. The projected gradient methodupdates the current solution yk
i to yk+1i by
yk+1i = P
[yk
i − αk∇ f (yki )
], (14)

2238 IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY, VOL. 9, NO. 12, DECEMBER 2014
where yi , i = 1, . . . , n is a column of Y and
P[yi j ] ={
0, yi j ≤ 0
yi j , otherwise(15)
maps a point back to the bounded feasible region. We applya simple and effective method that Lin [52] used. For any α,it makes yk+1
i = P[yki − αk∇ f (yk
i )] satisfying
f (yk+1i ) − f (yk
i ) ≤ σ∇ f (yki )T (yk+1
i − yki ), (16)
where σ is a given small positive constant. The second orderTaylor approximation of f at yk
i is
f (yk+1i ) ≈ f (yk
i ) + ∇ f (yki )T v + 1
2vT ∇2 f (yk
i )v, (17)
where v = yk+1i − yk
i and ∇2 f (·) is the Hessian matrix off (Y ). Substituting Eq. (17) into Eq. (16), it changes to
(1 − σ)∇ f (yki )T v + 1
2v t∇2 f (yk
i )v ≤ 0. (18)
There is no need to compute the difference of the originalfunction value on Y k and Y k+1 after this transformation, whichis less time-intensive. After obtaining the optimal α satisfyingthe condition, we then use Eq. (14) to update Y iterativelyuntil a stationary Y is achieved.
After obtained Y , we can use the similar method to obtainU by rewriting Eq. (12) as a form similar to Eq. (13):
minU
f (U) =∥∥∥X T − WY T U T
∥∥∥2
F
s.t. Uij ≥ 0, ∀i, j. (19)
The only difference between them is the first order derivationand Hessian matrix.
D. Kernel Trick
The above problem can be efficiently solved under thegiven X . However, we can only obtain the connection rela-tionship between users (represented by an adjacent matrix,e.g. A) rather than the properties of each user (e.g. X =[x1, x2, . . . , xn], where vector xi represents the property ofthe i -th user) in most social network tasks. In this paper, weintroduce a kernel trick to address this problem, and propose akernelized neighborhood preserving hashing (KNPH) method.For convenience, we assume that there is a high-dimensionalmatrix X which is unnecessary in practice.
Suppose that the Euclidean space Rn is mapped to a Hilbert
space H through a non-linear mapping function φ : Rn → H.
Let φ(X) denote the data matrix in the Hilbert space,φ(X) = [φ(x1), φ(x2), . . . , φ(xn)]. Now, the objectivefunction Eq. (7) in the Hilbert space can be rewritten as:
O = argU,Y
min∥∥∥φ(X) − UY W T
∥∥∥2
F
s.t. U ≥ 0, Y ≥ 0. (20)
After some mathematic transformations, it can bereformulated as:
O = tr[(φ(X) − UY W T )T (φ(X) − UY W T )
]= tr(K ) − 2tr(φ(X)T UY W T ) + tr(WY T U T UY W T ),
(21)
where K = φ(X)T φ(X) is the kernel matrix which representsthe relationship among users.
To generalize NPH, we formulate it in a way that uses dotproduct exclusively. Therefore, we consider an expression ofdot product on the Hilbert space H given by the followingkernel function:
K (xi , x j ) = (φ(xi ) · φ(x j )) = φ(xi )T φ(x j )
Assuming that U is linear combinations ofφ(x1), φ(x2), . . . , φ(xn), there is a coefficient matrix Csuch that U = φ(X)CT. Replacing U with φ(X)CT inEq. (21), we can finally obtain the following objectivefunction:
O = arg minC,Y
(tr(K ) − 2tr(K CT Y W )
+ tr(WY T C K CT Y W T ))
s.t. C ≥ 0, Y ≥ 0. (22)
Because K is always positive semi-defined, the constraintC ≥ 0 can make W ≥ 0. These reformations transformthe kernelized objective function into the projected gradientproblem as NPH, thereby, it can be efficiently solved by theaforementioned solving method.
As shown in Eq. (22), the objective function does not referto X . Generally, the kernel matrix is constructed though Xwhich represents the similarity between each data. The kernelfunction can be seen as a black-box function of X to generatethe similarity matrix. As the adjacent matrix A in Eq. (1) is arepresentation of the similarity between data, we can directlyregards the adjacent matrix A as the kernel matrix. In socialnetwork tasks, although it may be hard to get the X , we caneasily obtain the adjacent matrix A using the methods listedin [53]. The kernel trick finally transforms the problem into anobjective function over K . Thus we said that X is unnecessarybefore.
E. Generating Community Relationship Code forUsers not in Training Set
As shown in ki j = K (xi , x j ) = (φ(xi ) · φ(x j )) =φ(xi )
T φ(x j ), the kernel matrix in Eq. (22) is a n × n matrix.Because of the limitation of computer source, it is difficultto store it in memory and do computation over it especiallywhen the sample size is extremely large. In the field of largescale machine learning, a common method is to select partsof samples as landmarks (or anchors) and trains over theselected landmarks, which have been proved to be effectiveand efficient. The desired results for the rest samples canbe generated by the learned machines. The landmarks canbe either randomly sampled from the whole dataset, suchas [40] and [41], or cluster centers generated by k-means [42],such as [43]–[45]. In the study, because of the limitation ofcomputer resource, it is difficult to load all the data set in mem-ory and generate community relationship codes Y . Therefore,we employ the random sampling method to construct a trainingset. Through training, we get the community relationship codesY for the training set. Then we utilize the following method

LIU et al.: KERNELIZED NPH FOR SOCIAL-NETWORK-ORIENTED DIGITAL FINGERPRINTS 2239
Fig. 3. Inverted index structure and procedure of fingerprint detection.
to generate community relationship codes Y for the rest users,which can be viewed as the out-of-sample extension.
After calculating the dictionary U, we also require toproduce representations for the rest samples. Given out-of-sample data Z = [z1, z2, . . . , zl ] ∈ R
d×l , and denoting theircorresponding representations Y = [y1, y2, . . . , yl ] ∈ R
k×l ,we first reconstruct Z from the original training set X via LLE,and obtain Z . For the purpose of generating representationsfor out-of-sample data, the following minimization problem isconstructed:
minY
∥∥Z − UY∥∥2
F + β∥∥Y
∥∥2F
s.t. Y ≥ 0. (23)
This problem can also be solved through projected gradientmethod, and the regularization term is added to avoid over-fitting. The U is a constant matrix, the dictionary learnedfrom in-sample data, and β can be fixed by experience.In our experiment, we fix it at 0.1. This optimization can besolved during several iterations, we should not worry about itsefficiency.
Correspondingly, for KNPH, the coefficient matrix C isobtained during training. To generate community relationshipcode for the rest user, we construct the objection function asNPH:
minY
f (Y ) = ∥∥φ(Z) − φ(X)CT Y∥∥2
F
s.t. Y ≥ 0, (24)
By left multiplying φ(X)T , the objective function can berewritten as
minY
f (Y ) = ∥∥φ(X)T φ(Z) − φ(X)T φ(X)CT Y∥∥2
F + β∥∥Y
∥∥2F
= ∥∥K (X, Z) − K CT Y∥∥2
F + β∥∥Y
∥∥2F
s.t. Y ≥ 0, (25)
This problem is also a projected gradient problem over Y .
For the new-coming users of a social network, we can treatthem as the rest user outside the training set, using the samemethod to generate community relationship codes for them.Based on this procedure, we can say that the proposed methodis scalable.
F. Fingerprint Detection
For social networks applications containing billions of users,it is especially critical to speed up the fingerprint detection andtracing. Since the scale of social network is extremely large,to make the user identifiable, the dimensionality of fingerprintmust be high enough. The high dimension and large scale willincur “the curse of dimensionality”. At present, there are threecommon detection statistics available to test the presence of theoriginal fingerprint in the extracted fingerprint [18], [54], [55].They all are extension of linear scan which orderly comparethe extracted fingerprint with each original fingerprint. Whenthe sample size of the fingerprint is extremely large, thelinear scan methods are infeasible to deal with the “curseof dimensionality”. Wang et al. [9] proposed an efficientdetection method for group-oriented fingerprint. However, itis only suitable for group-oriented fingerprint which limits itsapplication.
Motivated by theory of information retrieval, we employ ahash table and an inverted index table to implement fingerprintdetection and tracing as shown in Fig. 3. Firstly, we extractthe fingerprint from the suspicious copy, and pick up thesegment of the community relationship code. By comparingwith the hash table of community relationship codes, closecommunities can be identified. Collusion always occurs amongclose communities and the community relationship codes ofusers in close communities are similar. Therefore, the corre-sponding community relationship code after collusion changesvery little. It is said that even if collusion happened, thecommunity relationship code is close to ones of the collusionfingerprints. Considered that other attacks may affect thecommunity relationship code, we aptly extend the detection

2240 IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY, VOL. 9, NO. 12, DECEMBER 2014
range, which treats all the users in close communities ascandidates.
To efficiently trace the suspicious traitors, we construct aninverted index table (List of Users Table, LUT) over commu-nity relationship code. For each item, it links to a list of idnumber of users with the same community relationship code.Thus through computing the correlation between the extractedcommunity relationship code and the hash table, we canefficiently obtain the ID numbers of the suspicious candidates,and then measure the correlation of the corresponding useridentification code. If the correlation is larger than a giventhreshold, its corresponding user can be regarded as a traitorwho illegally leaks the copy or participates the collusion.
Compared with the traditional fingerprint detectionalgorithm, it has serval advantages to be highlighted:
• Due to the hash table and inverted index table, the timecost of fingerprint detection is low.
• It is scalable which is adaptable to tasks where the scalemay change. Moreover, the query time is sub-linear tothe sample size of the users.
• In practical social network tasks, collusion always occursin the same or close communities. The communityrelationship code changes very little after collusionwhich can ensure the detection performance.
IV. EXPERIMENTS AND ANALYSIS
A. Dataset
To evaluate the performance of the proposed method, weconducted extensive experiments over three public socialnetwork dataset, facebook, twitter and Google+, which aredownloaded from the homepage of Stanford Network AnalysisPlatform (SNAP) 1. Each dataset is an adjacent graph whichrepresents the connection between users. Each node in thegraph represents a user, and an edge between nodes meansthat two users have a connection. The detailed information ofthe datasets [56] is as follow:
• Facebook is an online social networking service ofimage/video sharing, about 8.5 million images areuploaded to this service website every day. UntilMarch 31, 2013, the number of its users has been up to1, 110 millions. The facebook dataset downloaded fromSNAP is an undirected graph, contains 4039 nodes and88, 234 edges. The 4039 users belong to 10 differentcommunities.
• Twitter is an online social networking service andmicroblogging service that enables its users to sendand read text-based messages of up to 140 characters,known as “tweets”. The service has gained worldwidepopularity, with over 500 million registered usersuntil 2012, generating over 340 million tweets dailyand handling over 1.6 billion search queries per day.The downloaded Twitter dataset is a directed graphwhich consists of 81, 306 nodes and 1, 768, 149 edges.The users are divided into 1, 000 communities.
• Google+ is a multilingual social networking andidentity service owned and operated by Google Inc.
1http://snap.stanford.edu/data/index.html
It is the second largest social networking site in theworld, having surpassed Twitter in January 2013. UntilDecember 2012, it has a total of 500 million registeredusers, of whom 235 million are active in a given month.The dataset from SNAP contains part of google+ userswhich is represented by a directed graph. It contains107, 614 nodes and 13, 673, 453 edges. The 107, 614users are divided into 133 communities.
B. Performance of Neighborhood Preserving
In this paper, we introduce kernelized neighborhoodpreserving hashing (KNPH) [12] into the field of digitalfingerprinting, and address the problem of lacking of high-dimensional representations of users via kernel trick. Readersmay concern whether neighborhood preserving hashing iseffective to represent the structure of social networks or not.Thus we first conduct a set of experiments to verify its fea-sibility. In this experiments we vary the length of communityrelationship codes from 16 bits to 64 bits, and record theperformance. All experiments are implemented by MATLABand all the reported results are obtained on a Linux server witha 2.40 GHz quad-core Intel Xeon CPU and 12 GB of memory.
To fairly evaluate the proposed algorithm, we have executedthe experiment many times and recorded the average values.k-fold cross validation is an effective model selection and eval-uation approach. It first divides the dataset into k equal parts,trains on any k −1 subset, and evaluate on the rest one subset.Employing the k-fold cross validation strategy (on the Twitterand Google+ dataset), it leads to “out-of-memory” becauseof the limitation of computer memory. In these experiments,we employ the hold-out (simple) cross validation strategyinstead of the k-fold cross validation. During the experiments,we randomly selected 30% dataset as training samples, andthe rest dataset as test samples. In fact, the selected numberof training samples is much less than the number of the testsamples. If it has good performance under this condition,it illustrates that the model has better generalization ability.The following experiments are based on this strategy.
Firstly, we generate hash codes for all users, then constructa matrix D to record the Hamming distance between users.The nonnegative integer di j is the Hamming distance betweenthe community relationship codes of the i -th and j -th user.Finally, we set di j =1 when di j is less than a given Hammingdistance (0-3), otherwise set di j = 0. di j = 1 means that thehamming distance between the two users is small, so we canview them as close neighbors. Through comparing D with theadjacent matrix A, we obtain the accuracy of preserving theneighborhood structure of the social networks. The accuracyrecords the ratio of whether the obtained neighbors are theexact ones. The accuracy under different given hammingdistance (0-3) is plotted in Fig. 4. As shown in the figure,the accuracy increases with the length of the communityrelationship codes.
In real-world tasks, fingerprint embedding and extractingmay change the fingerprints. To validate the neighborhood-preserving performance after embedding and extracting thefingerprints, we firstly embed them into the test images and
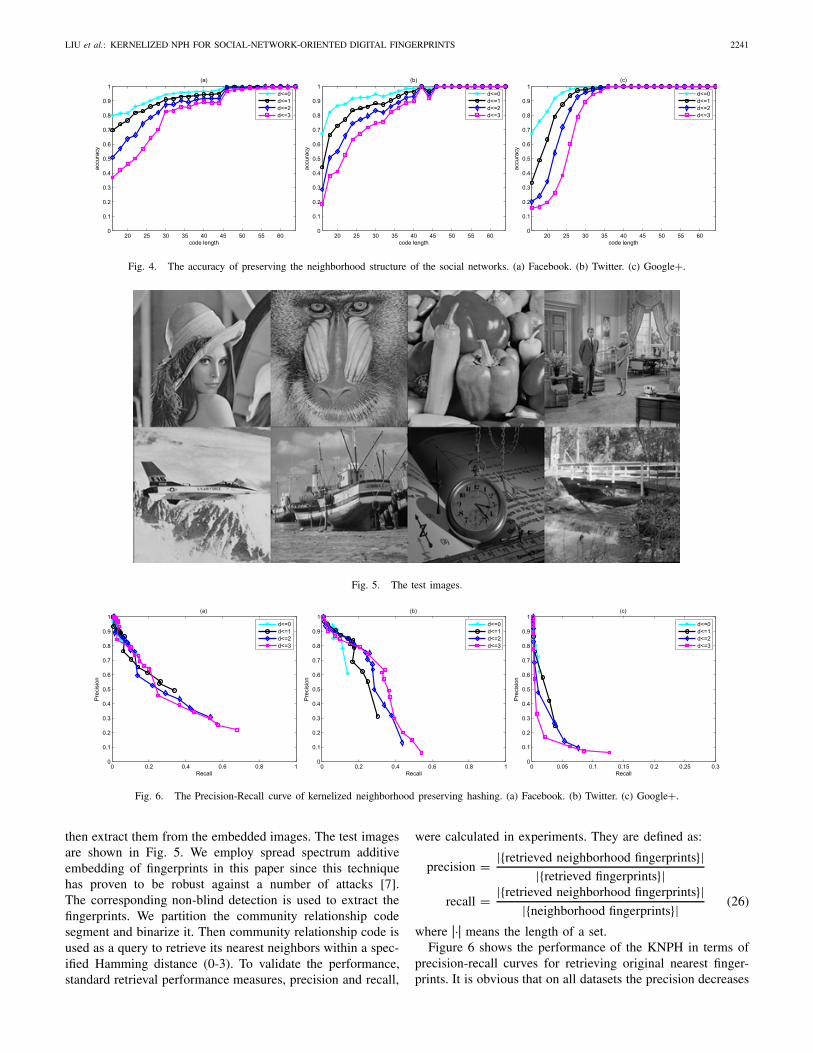
LIU et al.: KERNELIZED NPH FOR SOCIAL-NETWORK-ORIENTED DIGITAL FINGERPRINTS 2241
Fig. 4. The accuracy of preserving the neighborhood structure of the social networks. (a) Facebook. (b) Twitter. (c) Google+.
Fig. 5. The test images.
Fig. 6. The Precision-Recall curve of kernelized neighborhood preserving hashing. (a) Facebook. (b) Twitter. (c) Google+.
then extract them from the embedded images. The test imagesare shown in Fig. 5. We employ spread spectrum additiveembedding of fingerprints in this paper since this techniquehas proven to be robust against a number of attacks [7].The corresponding non-blind detection is used to extract thefingerprints. We partition the community relationship codesegment and binarize it. Then community relationship code isused as a query to retrieve its nearest neighbors within a spec-ified Hamming distance (0-3). To validate the performance,standard retrieval performance measures, precision and recall,
were calculated in experiments. They are defined as:
precision = |{retrieved neighborhood fingerprints}||{retrieved fingerprints}|
recall = |{retrieved neighborhood fingerprints}||{neighborhood fingerprints}| (26)
where |·| means the length of a set.Figure 6 shows the performance of the KNPH in terms of
precision-recall curves for retrieving original nearest finger-prints. It is obvious that on all datasets the precision decreases
2242 IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY, VOL. 9, NO. 12, DECEMBER 2014
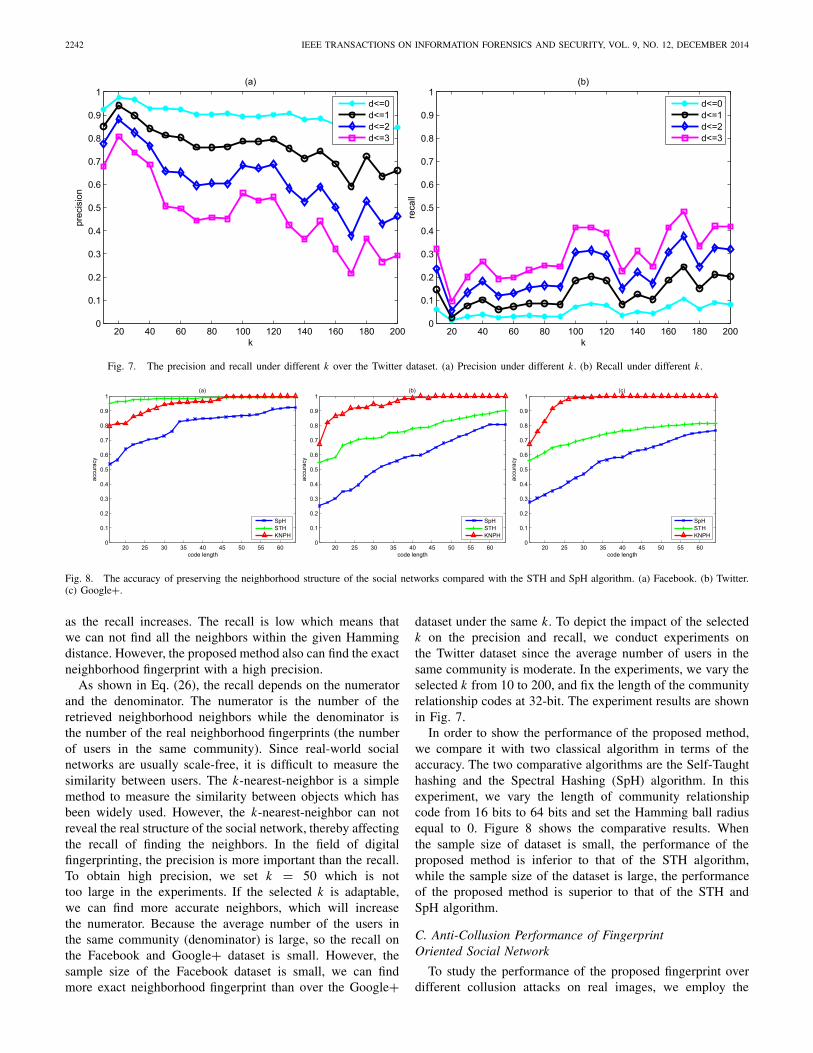
Fig. 7. The precision and recall under different k over the Twitter dataset. (a) Precision under different k. (b) Recall under different k.
Fig. 8. The accuracy of preserving the neighborhood structure of the social networks compared with the STH and SpH algorithm. (a) Facebook. (b) Twitter.(c) Google+.
as the recall increases. The recall is low which means thatwe can not find all the neighbors within the given Hammingdistance. However, the proposed method also can find the exactneighborhood fingerprint with a high precision.
As shown in Eq. (26), the recall depends on the numeratorand the denominator. The numerator is the number of theretrieved neighborhood neighbors while the denominator isthe number of the real neighborhood fingerprints (the numberof users in the same community). Since real-world socialnetworks are usually scale-free, it is difficult to measure thesimilarity between users. The k-nearest-neighbor is a simplemethod to measure the similarity between objects which hasbeen widely used. However, the k-nearest-neighbor can notreveal the real structure of the social network, thereby affectingthe recall of finding the neighbors. In the field of digitalfingerprinting, the precision is more important than the recall.To obtain high precision, we set k = 50 which is nottoo large in the experiments. If the selected k is adaptable,we can find more accurate neighbors, which will increasethe numerator. Because the average number of the users inthe same community (denominator) is large, so the recall onthe Facebook and Google+ dataset is small. However, thesample size of the Facebook dataset is small, we can findmore exact neighborhood fingerprint than over the Google+
dataset under the same k. To depict the impact of the selectedk on the precision and recall, we conduct experiments onthe Twitter dataset since the average number of users in thesame community is moderate. In the experiments, we vary theselected k from 10 to 200, and fix the length of the communityrelationship codes at 32-bit. The experiment results are shownin Fig. 7.
In order to show the performance of the proposed method,we compare it with two classical algorithm in terms of theaccuracy. The two comparative algorithms are the Self-Taughthashing and the Spectral Hashing (SpH) algorithm. In thisexperiment, we vary the length of community relationshipcode from 16 bits to 64 bits and set the Hamming ball radiusequal to 0. Figure 8 shows the comparative results. Whenthe sample size of dataset is small, the performance of theproposed method is inferior to that of the STH algorithm,while the sample size of the dataset is large, the performanceof the proposed method is superior to that of the STH andSpH algorithm.
C. Anti-Collusion Performance of FingerprintOriented Social Network
To study the performance of the proposed fingerprint overdifferent collusion attacks on real images, we employ the

LIU et al.: KERNELIZED NPH FOR SOCIAL-NETWORK-ORIENTED DIGITAL FINGERPRINTS 2243
images shown in Fig. 5 as test samples, which have a varietyof representative visual features such as the texture, sharpedges, and smooth areas. Identically, we use the human visualmodel based spread spectrum embedding, and embed thefingerprints in the DCT domain as the above experiments.Since anti-collusion performance is independent to the socialnetwork dataset, we conduct experiments on the Google+dataset with the largest user scale (compared with the othertwo datasets). In these experiments, each fingerprint con-sists of a 64-dimension community relationship code and a4544-dimension user identification code (RS code).
We embed the fingerprints into the test images viaspread spectrum embedding, then collude the embeddedimages through different collusion attacks, and finally extractfingerprints from the colluded images via non-blind detection.Afterwards, each extracted collusion fingerprint is dividedinto the community relationship code and user identificationcode according to the structure of fingerprints shown inFig. 1(c). We treat the obtained community relationshipcode as a query to find its nearest neighbors within a givenHamming distance, and we finally apply different detectors toidentify the colluders over three evaluations: probability (Pd )of catching one, many and all real colluders. To facilitatefurther illustration, here we write down the expression of thecorrelation detector in Eq. (27). For each user, we examine acorrelation-based statistic as
T (i)N = cT fi√
‖ fi‖2, (27)
where c is the colluder fingerprint extracted from the colludedimages via non-blind detector, fi represents the fingerprintof the i -th user. For different evaluations, we apply differentdetectors over different neighbor sets as follow:
1) Catch one. We apply the Maximum Correlation Detectorto identify one colluder among the nearest neighborswithin a small Hamming distance d . Set d ≤ 3 andi ∈ N (c), where N (c) represents the set of userswhose community relationship code is a neighbor of thecommunity relationship code segment of c.
2) Catch many. We apply the Threshold CorrelationDetector to identify one colluder among all users.Assume Pf p = 10−4 and compute the maximum num-ber (Nc) of users could be caught. The minimum valueof the maximum Nc correlation value TN ( fi ) is viewedas the threshold, where, i = 1, 2, . . . , n.
3) Catch all. We apply the Threshold Correlation Detectorto identify all colluders among the neighbors. Theminimum correlation value TN ( fi ) of the real colludersin the neighbor set is viewed as the threshold.
In this experiment, we record the above evaluationsover three collusion attacks (Average attack [57], MinMaxattack [16] and Interleaving attack [32]) varying the numberof colluders from 5 to 50. Since we made an assumption thatan adversary is more likely to collude with others in the sameor close communities than others in distant communities, thecolluders are randomly selected from the same communitywhich are randomly chosen from all the communities. Whenusers come together with a total of M differently fingerprinted
copies of the same multimedia content, these users cancombine the M signals to produce a colluded version.
• Average Attack: Since normally no colluder is willingto take more of a risk than any other colluder, thefingerprinted signals are typically averaged with an equalweight for each user.
• MinMax Attack: Each component of the attacked signalis the average of the maximum and minimum of thecorresponding components of the M watermarked signals.
• Interleaving Attack: Colluders contribute their copiessegment by segment (or equivalently, symbol by symbolat the code level) with approximately equal share.
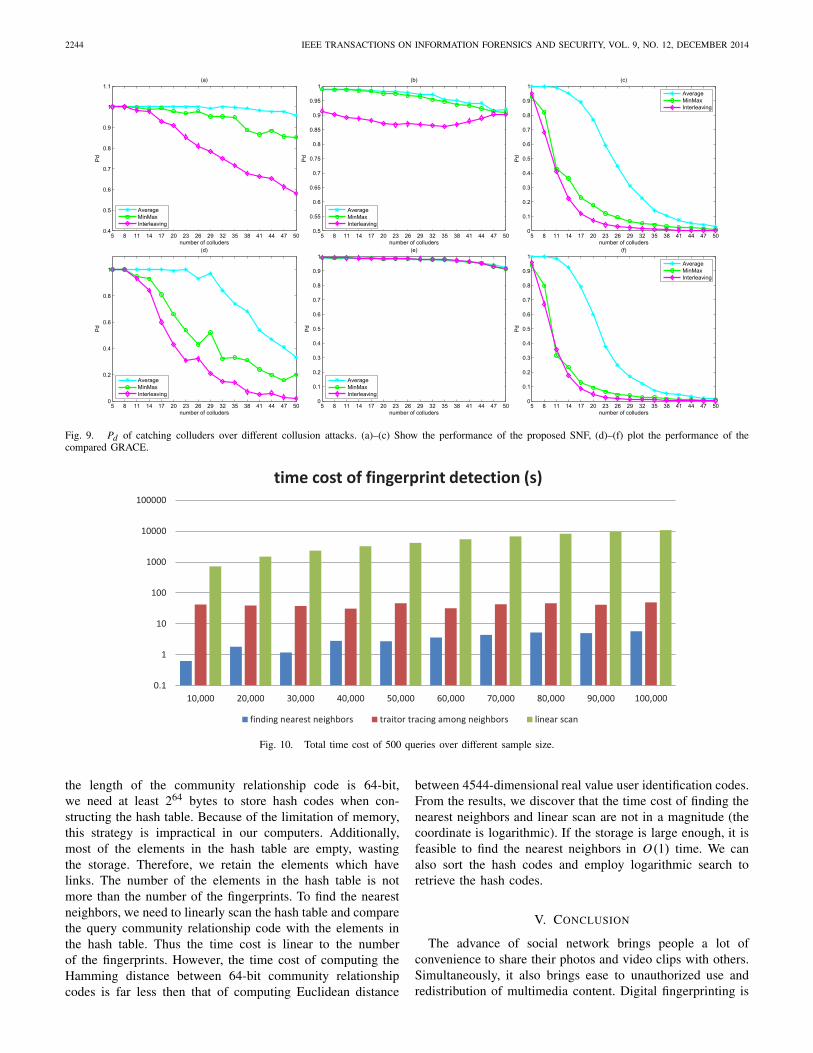
To validate its performance, we compare the proposedmethod with the popular GRACE [32] algorithm. For GRACE,we apply the correlation detection method to compute the Pd .As shown in Fig. 9, the anti-collusion performance againstaverage attack is the best among the three collusion attacks,and the performance decreases as the number of colludersis increased. Compared with the threshold of catching allcolluders, the threshold of catching many colluders is smaller.This means that we can find more suspicious traitors in theexperiment of catching many. From the experiments, we notethat we can find many colluders with a high probability.As shown in Fig. 9, the proposed fingerprint is superior toGRACE in terms of Pd of catching one and all colluders.
D. Detection Efficiency
In the field of digital fingerprinting, in order to find theexact traitors, many linear scan methods [18], [54], [55]were proposed. To improve the efficiency, Trapper et al [58]proposed tree-based method. However, the precision of tracingthe exact traitors is not high and it’s performance will degradewith the increment of the dimensionality of the fingerprints.Wang et al. [9] proposed an efficient detection methodscorresponding to the group-oriented fingerprinting. Whereas,it is only suitable for group-oriented fingerprint. Therefore, thelinear methods are still widely applied. When the sample sizeof the fingerprint is extremely large, it is time-consuming eveninfeasible because of the “curse of dimensionality”. Thus, wepresent a novel fingerprint detection method for the proposedfingerprint. To evaluate the efficiency, we only compare itwith the simplest and effective method shown in Eq. (27).As shown in Fig. 3, the time cost of the proposed detector isdivided into two parts. One part is the cost of computing thehamming distance and obtaining nearest neighbors which islinear to the user number of the social network. The other is thecost of identifying the colluder among the retrieved neighbors.For convenient illustration, we selected the top 500 neighborswith the smallest Hamming distance, which makes the timecost of identifying the colluder among the retrieved neighborsapproximates to a constant. In this experiment, we randomlyselect 100, 000 fingerprints from the above experiments,and choose 500 fingerprint as query to trace the colluders.Figure 10 shows the total time cost of executing 500 querieswith different fingerprints.
As shown in the Fig. 3, the time cost of finding the nearestneighbors should be a constant O(1). In this experiment,
2244 IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY, VOL. 9, NO. 12, DECEMBER 2014
Fig. 9. Pd of catching colluders over different collusion attacks. (a)–(c) Show the performance of the proposed SNF, (d)–(f) plot the performance of thecompared GRACE.
Fig. 10. Total time cost of 500 queries over different sample size.
the length of the community relationship code is 64-bit,we need at least 264 bytes to store hash codes when con-structing the hash table. Because of the limitation of memory,this strategy is impractical in our computers. Additionally,most of the elements in the hash table are empty, wastingthe storage. Therefore, we retain the elements which havelinks. The number of the elements in the hash table is notmore than the number of the fingerprints. To find the nearestneighbors, we need to linearly scan the hash table and comparethe query community relationship code with the elements inthe hash table. Thus the time cost is linear to the numberof the fingerprints. However, the time cost of computing theHamming distance between 64-bit community relationshipcodes is far less then that of computing Euclidean distance
between 4544-dimensional real value user identification codes.From the results, we discover that the time cost of finding thenearest neighbors and linear scan are not in a magnitude (thecoordinate is logarithmic). If the storage is large enough, it isfeasible to find the nearest neighbors in O(1) time. We canalso sort the hash codes and employ logarithmic search toretrieve the hash codes.
V. CONCLUSION
The advance of social network brings people a lot ofconvenience to share their photos and video clips with others.Simultaneously, it also brings ease to unauthorized use andredistribution of multimedia content. Digital fingerprinting is

LIU et al.: KERNELIZED NPH FOR SOCIAL-NETWORK-ORIENTED DIGITAL FINGERPRINTS 2245
a promising technique to address this problem. However, mostexisting fingerprints are not adaptable to social network tasks.Inspired by the success of recent hash-based similarity searchmethods, we introduced the hash-based similarity methodinto digital fingerprinting and proposed a novel and effectivefingerprint structure suitable for social network tasks.
The novel fingerprint consists of a community relationshipcode and a user identification code. The user identificationcode can be one of the existing fingerprints, such as TA codeand RS code. The innovation of this paper is about thecreation of the community relationship code. In this paper, weextended our pervious work, called neighborhood preservinghashing (NPH), to generate community relationship code,which preserves the social network structure. Whereas, insome cases, social network datasets only have the relationshipbetween users, while do not contain the properties of theusers, which brings great challenge to NPH. We employ akernel trick to address the problem, and propose a kernelizedneighborhood preserving hashing (KNPH) method. KNPHensures that similar community relationship codes are assignedto neighborhood users in the same or close communities.In real-world tasks, users in the same or close communitiesare more likely to collude with each other. Thus, even ifserious collusion occurs, the community relationship codechanges a little, due to the neighborhood-preserving property,thereby improving the anti-collusion performance. Throughexperiments, we verify that the community relationship codecan well preserve the social network structure and we caneffectively find the real nearest neighbors of the collusionfingerprint.
Existing fingerprint detection methods are extensions oftime-consuming linear scan, which makes it infeasible forsocial network tasks. Therefore, we present an efficient finger-print detector method corresponding to the proposed finger-print. Inspired by recent information retrieval, we introducehash table and inverted index table to accelerate fingerprinttracing. We treat the community relationship code as indexkey to construct the hash table and inverted index table.As the collusion fingerprint are colluded by users in the sameor close communities, the community relationship code isclose to that of the original fingerprints of colluders. Thus,we can efficiently find the nearest neighbors through thecommunity relationship code. This means that we can findthe real colluders among a few neighbors whose communityrelationship code to the query is within a small Hammingdistance. We can also view a given number (such as 500)of users with the smallest hamming distance as nearestneighbors.
Although the proposed scheme is adaptable to socialnetwork tasks, we have a lot to do in order to achievebetter anti-collusion performance. In future works, we willintroduce more novel hashing methods to improve the designof community relationship code.
ACKNOWLEDGMENT
The authors appreciate the valuable suggestions from theanonymous reviewers and the Editors.
REFERENCES
[1] Z. J. Wang, M. Wu, H. V. Zhao, W. Trappe, and K. J. R. Liu,“Anti-collusion forensics of multimedia fingerprinting using orthogonalmodulation,” IEEE Trans. Image Process., vol. 14, no. 6, pp. 804–821,Jun. 2005.
[2] D. Boneh and J. Shaw, “Collusion-secure fingerprinting for digital data,”IEEE Trans. Inf. Theory, vol. 44, no. 5, pp. 1897–1905, Sep. 1998.
[3] D. Boneh and M. K. Franklin, “An efficient public key traitor tracingscheme,” in Proc. 19th Annu. Int. Cryptol. Conf., 1999, pp. 338–353.
[4] H. D. L. Hollmann, J. H. van Lint, J.-P. Linnartz, andL. M. G. M. Tolhuizen, “On codes with the identifiable parentproperty,” J. Combinat. Theory, Ser. A, vol. 82, no. 2, pp. 121–133,May 1998.
[5] S. He and M. Wu, “Joint coding and embedding techniques for multi-media fingerprinting,” IEEE Trans. Inf. Forensics Security, vol. 1, no. 2,pp. 231–247, Jun. 2006.
[6] B.-H. Cha and C.-C. J. Kuo, “Robust MC-CDMA-based fingerprintingagainst time-varying collusion attacks,” IEEE Trans. Inf. ForensicsSecurity, vol. 4, no. 3, pp. 302–317, Sep. 2009.
[7] I. J. Cox, J. Kilian, F. T. Leighton, and T. Shamoon, “Secure spreadspectrum watermarking for multimedia,” IEEE Trans. Image Process.,vol. 6, no. 12, pp. 1673–1687, Dec. 1997.
[8] C. Ye, H. Ling, F. Zou, and Z. Lu, “Social networks based fingerprintcode: SNBFC and its pirates tracing algorithm to majority attack,” inProc. IEEE Int. Conf. Multimedia Inf. Netw. Secur. (MINS), Nov. 2010,pp. 345–350.
[9] Z. J. Wang, M. Wu, W. Trappe, and K. J. R. Liu, “Group-orientedfingerprinting for multimedia forensics,” EUPASIP J. Appl. SignalProcess., vol. 2004, pp. 2153–2173, Jan. 2004.
[10] D. Zhang, J. Wang, D. Cai, and J. Lu, “Self-taught hashing for fastsimilarity search,” in Proc. 33rd Annu. Int. ACM SIGIR Conf. Res.Develop. Inf. Retr., 2010, pp. 18–25.
[11] Y. Weiss, A. Torralba, and R. Fergus, “Spectral hashing,” in Advances inNeural Information Processing Systems, vol. 21. Cambridge, MA, USA:MIT Press, 2008, pp. 1753–1760.
[12] C. Liu, H. Ling, F. Zou, and L. Yan, “Neighborhood preserving hashingfor fast similarity search,” in Proc. 20th ACM Int. Conf. Multime-dia (ACM MM), 2012, pp. 945–948.
[13] Y. Yang, X. Sun, H. Yang, C.-T. Li, and R. Xiao, “A contrast-sensitivereversible visible image watermarking technique,” IEEE Trans. CircuitsSyst. Video Technol., vol. 19, no. 5, pp. 656–667, May 2009.
[14] I. J. Cox, M. L. Miller, and J. A. Bloom, “Watermarking applicationsand their properties,” in Proc. Int. Conf. Inf. Technol., Coding Comput.,2000, pp. 6–10.
[15] J. Dittmann, P. Schmitt, E. Saar, J. Ueberberg, and J. Schwenk, “Com-bining digital watermarks and collusion secure fingerprints for digitalimages,” J. Electron. Imag., vol. 9, no. 4, pp. 456–467, 2000.
[16] M. Wu, W. Trappe, Z. J. Wang, and K. J. R. Liu, “Collusion-resistantfingerprinting for multimedia,” IEEE Trans. Image Process., vol. 21,no. 2, pp. 15–27, Mar. 2004.
[17] J. K. Su, J. J. Eggers, and B. Girod, “Capacity of digital watermarkssubjected to an optimal collusion attack,” in Proc. Eur. Signal Process.Conf. (EUSIPCO), 2000, pp. 17–20.
[18] H. S. Stone, “Analysis of attacks on image watermarks with randomizedcoefficients,” NEC Res. Inst., Tokyo, Japan, Tech. Rep. 96-045, 1996.
[19] H. Zhao, M. Wu, Z. J. Wang, and K. J. R. Liu, “Nonlinear collusionattacks on independent fingerprints for multimedia,” in Proc. IEEE Int.Conf. Acoust., Speech, Signal Process. (ICASSP), vol. 5. Jul. 2003,pp. V-664–667.
[20] H. V. Zhao, M. Wu, J. Wang, and K. J. R. Liu, “Forensic analysis ofnonlinear collusion attacks for multimedia fingerprinting,” IEEE Trans.Image Process., vol. 14, no. 5, pp. 646–661, May 2005.
[21] H. V. Zhao, M. Wu, J. Wang, and K. J. R. Liu, “Forensic analysis ofnonlinear collusion attacks for multimedia fingerprinting,” IEEE Trans.Image Process., vol. 14, no. 5, pp. 646–661, May 2005.
[22] Y. Yacobi, “Improved Boneh-shaw content fingerprinting,” in Topics inCryptology (Lecture Notes in Computer Science), vol. 2020. Berlin,Germany: Springer-Verlag, 2001, pp. 378–391.
[23] G. Tardos, “Optimal probabilistic fingerprint codes,” in Proc. 25th Annu.ACM Symp. Theory Comput., New York, NY, USA, 2003, pp. 116–125.
[24] J. Cotrina-Navau and M. Fernández, “A family of asymptotically goodbinary fingerprinting codes,” IEEE Trans. Inf. Theory, vol. 56, no. 10,pp. 5335–5343, Oct. 2010.
[25] B. Skoric, S. Katzenbeisser, H. G. Schaathun, and M. U. Celik, “Tardosfingerprinting codes in the combined digit model,” IEEE Trans. Inf.Forensics Security, vol. 6, no. 3, pp. 906–919, Sep. 2011.

2246 IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY, VOL. 9, NO. 12, DECEMBER 2014
[26] J. N. Staddon, D. R. Stinson, and R. Wei, “Combinatorial properties offrameproof and traceability codes,” IEEE Trans. Inf. Theory, vol. 47,no. 3, pp. 1042–1049, Mar. 2001.
[27] M. Cheng and Y. Miao, “On anti-collusion codes and detection algo-rithms for multimedia fingerprinting,” IEEE Trans. Inf. Theory, vol. 57,no. 7, pp. 4843–4851, Jul. 2011.
[28] A. Silverberg, J. Staddon, and J. Walker, “Efficient traitor trac-ing algorithms using list decoding,” in Advances in Cryptology(Lecture Notes in Computer Science), vol. 2248. Berlin, Germany:Springer-Verlag, 2001, pp. 175–192.
[29] R. Safavi-Naini and Y. Wang, “Collusion secure q-ary fingerprintingfor perceptual content,” in Security and Privacy in Digital RightsManagement (Lecture Notes in Computer Science), vol. 2320. Berlin,Germany: Springer-Verlag, 2002, pp. 57–75.
[30] S. He and M. Wu, “Collusion-resistant dynamic fingerprinting formultimedia,” in Proc. IEEE Int. Conf. Acoust., Speech SignalProcess. (ICASSP), Apr. 2007, pp. II-289–II-292.
[31] N. P. Anthapadmanabhan and A. Barg, “Two-level fingerprinting:Stronger definitions and code constructions,” in Proc. IEEE Int. Symp.Inf. Theory (ISIT), Jun. 2010, pp. 2528–2532.
[32] S. He and M. Wu, “Joint coding and embedding techniques for multi-mediafingerprinting,” IEEE Trans. Inf. Forensics Security, vol. 1, no. 2,pp. 231–247, Jun. 2006.
[33] S. He and M. Wu, “Collusion-resistant video fingerprinting for large usergroup,” IEEE Trans. Inf. Forensics Security, vol. 2, no. 4, pp. 697–709,Dec. 2007.
[34] J. H. Friedman, J. L. Bentley, and R. A. Finkel, “An algorithm for findingbest matches in logarithmic expected time,” ACM Trans. Math. Softw.,vol. 3, no. 3, pp. 209–226, Sep. 1977.
[35] A. Guttman, “R-trees: A dynamic index structure for spatial searching,”in Proc. Annu. Meeting SIGMOD, vol. 14. 1984, pp. 47–57.
[36] M. Datar, N. Immorlica, P. Indyk, and V. S. Mirrokni, “Locality-sensitivehashing scheme based on p-stable distributions,” in Proc. 20th Annu.Symp. Comput. Geometry (SCG), 2004, pp. 253–262.
[37] B. Kulis and T. Darrell, “Learning to hash with binary reconstructiveembeddings,” Dept. Elect. Eng. Comput. Sci., Univ. California, Berkeley,CA, USA, Tech. Rep. UCB/EECS-2009-101, Jul. 2009.
[38] R. Salakhutdinov and G. Hinton, “Semantic hashing,” Int. J. Approx.Reasoning, vol. 50, no. 7, pp. 969–978, Jul. 2009.
[39] C. L. Apicella, F. W. Marlowe, J. H. Fowler, and N. A. Christakis,“Social networks and cooperation in hunter-gatherers,” Nature, vol. 481,no. 7382, pp. 497–501, 2012.
[40] T. Sakai and A. Imiya, “Fast spectral clustering with random pro-jection and sampling,” in Proc. 3rd Int. Conf. Mach. Learn. DataMining (MLDM), Jul. 2009, pp. 372–384.
[41] X. Chen and D. Cai, “Large scale spectral clustering with landmark-based representation,” in Proc. 25th AAAI Conf. Artif. Intell. (AAAI),2011. pp. 313–318.
[42] J. A. Hartigan and M. A. Wong, “A K-means clustering algorithm,”J. Roy. Statist. Soc., vol. 28, pp. 100–108, Jan. 1979.
[43] D. Yan, L. Huang, and M. I. Jordan, “Fast approximate spectralclustering,” in Proc. 15th ACM SIGKDD Int. Conf. Knowl. DiscoveryData Mining (KDD), 2009, pp. 907–916.
[44] W. Liu, J. Wang, and S.-F. Chang, “Hashing with graphs,” in Proc. 28thInt. Conf. Mach. Learn., Bellevue, WA, USA, 2011.
[45] Y. Lin, R. Jin, D. Cai, and X. He, “Random projection with filtering fornearly duplicate search,” in Proc. 26th AAAI Conf. Artif. Intell. (AAAI),2012, pp. 641–647.
[46] D. D. Lee and H. S. Seung, “Learning the parts of objects by non-negative matrix factorization,” Nature, vol. 401, no. 6755, pp. 788–791,1999.
[47] D. D. Lee and H. S. Seung, “Algorithms for non-negative matrixfactorization,” in Advances in Neural Information Processing Systems,vol. 13. Cambridge, MA, USA: MIT Press, 2001, pp. 556–562.
[48] M. Belkin and P. Niyogi, “Laplacian eigenmaps and spectral techniquesfor embedding and clustering,” in Advances in Neural InformationProcessing Systems, vol. 14. Cambridge, MA, USA: MIT Press, 2002,pp. 585–591.
[49] M. Belkin and P. Niyogi, “Laplacian eigenmaps for dimensionalityreduction and data representation,” Neural Comput., vol. 15, no. 6,pp. 1373–1396, Jun. 2003.
[50] S. T. Roweis and L. K. Saul, “Nonlinear dimensionality reduction bylocally linear embedding,” Science, vol. 290, no. 5500, pp. 2323–2326,2000.
[51] E. F. Gonzalez and Y. Zhang, “Accelerating the Lee-Seung algorithmfor non-negative matrix factorization,” Dept. Comput. Appl. Math.,Rice Univ., Houston, TX, USA, Tech. Rep. TR-05-02, 2005.
[52] C.-J. Lin, “Projected gradient methods for nonnegative matrix factoriza-tion,” Neural Comput., vol. 19, no. 10, pp. 2756–2779, 2007.
[53] J. Yang and J. Leskovec, “Defining and evaluating network communitiesbased on ground-truth,” in Proc. IEEE Int. Conf. Data Mining (ICDM),May 2012, pp. 745–754.
[54] W. Zeng and B. Liu, “A statistical watermark detection techniquewithout using original images for resolving rightful ownerships of digitalimages,” IEEE Trans. Image Process., vol. 8, no. 11, pp. 1534–1548,Nov. 1999.
[55] H. V. Poor, An Introduction to Signal Detection and Estimation, 2nd ed.New York, NY, USA: Springer-Verlag, 1999.
[56] J. J. McAuley and J. Leskovec, “Learning to discover social circlesin ego networks,” in Proc. Neural Inf. Process. Syst. (NIPS), 2012,pp. 539–547.
[57] Y. Wu, “Linear combination collusion attack and its application on ananti-collusion fingerprinting,” in Proc. IEEE Int. Conf. Acoust., Speech,Signal Process., vol. 2. Mar. 2005, pp. 13–16.
[58] W. Trappe, M. Wu, Z. J. Wang, and K. J. R. Liu, “Anti-collusionfingerprinting for multimedia,” IEEE Trans. Signal Process., vol. 51,no. 4, pp. 1069–1087, Apr. 2003.
Cong Liu received the B.E. degree from the Collegeof Computer Science and Technology, Wuhan Uni-versity of Science and Technology, Wuhan, China, in2009. He is currently pursuing the Ph.D. degree withthe College of Computer Science and Technology,Huazhong University of Science and Technology,Wuhan. His current research interests in hash-basedsimilarity search, machine learning, sparse represen-tation, and digital fingerprinting.
Hefei Ling received the B.E. and M.S. degrees inenergy and power engineering and the Ph.D. degreein computer science from the Huazhong Universityof Science and Technology (HUST), Wuhan, China,in 1999, 2002, and 2005, respectively. Since 2011,he has been a Professor with the College of Com-puter Science and Technology, HUST. From 2008 to2009, he joined the Department of Computer Sciencewith University College London, London, U.K., as aVisiting Scholar. His research interests include digi-tal watermarking and fingerprinting, copy detection,
content security, and protection. He has coauthored over 50 publications,including journal and conference papers. He was a recipient of the ExcellentPh.D. Dissertation of HUST in 2006, the Foundation Research ContributionAward of HUST in 2005, and the Best Graduate Student Award from HUSTin 1999.
Fuhao Zou received the B.E. degree in com-puter science from Huazhong Normal University,Wuhan, China, in 1998, and the M.S. and Ph.D.degrees in computer science and technology fromthe Huazhong University of Science and Technology(HUST), Wuhan, in 2003 and 2006, respectively.From 2010 to 2011, he joined the Departmentof Computer Science with the University ofQueensland, Brisbane, QLD, Australia, as a VisitingScholar. His research interests include digital water-marking and fingerprinting, copy detection, content
security, protection, digital right management, and machine learning. He iscurrently an Associate Professor with the College of Computer Science andTechnology, HUST.

LIU et al.: KERNELIZED NPH FOR SOCIAL-NETWORK-ORIENTED DIGITAL FINGERPRINTS 2247
Lingyu Yan received the B.S. degree in mechanicalengineering and the M.S. degree in software engi-neering from the Huazhong University of Scienceand Technology, Wuhan, China, in 2008 and 2010respectively, where she is currently pursuing thePh.D. degree in computer science. Her researchinterests include copy detection and video represen-tation.
Yunfei Wang received the B.E. degree from the Col-lege of Computer Science and Technology, WuhanUniversity of Science and Technology, Wuhan,China, in 2012. He is currently pursuing the master’sdegree with the College of Computer Science andTechnology, Huazhong University of Science andTechnology, Wuhan. His current research interestsinclude machine learning and pattern recognition.
Hui Feng received the B.E. degree in computerscience, and energy and power engineering fromthe Wuhan University of Technology (WHUT),Wuhan, China, in 2004, and the Ph.D. degree fromthe College of Computer Science and Technol-ogy, Huazhong University of Science and Technol-ogy, Wuhan. He was a Software Engineering withFaw Car Company, Changchun, China, from 2004to 2007. He is currently a Lecturer with the Schoolof Transportation, WHUT. His research interestsinclude signal processing, state estimation, and dig-
ital fingerprinting.
Xinyu Ou received the B.E. degree in electronicinformation science and technology and the M.S.degree in software engineering from Yunnan Uni-versity, Kunming, China, in 2004 and 2009, respec-tively. He is currently pursuing the Ph.D. degreein computer science with the Huazhong Universityof Science and Technology, Wuhan, China. Hisresearch interests include computer vision, machinelearning, and deep learning.

























