Embed Size (px)
Citation preview


ii
KATA SAMBUTAN
SEMINAR NASIONAL
MATEMATIKA 2017
WILAYAH
JABAR-DKI JAKARTA-BANTEN

iii
Dekan FMIPA Universitas Indonesia
Assalamu’alaikum Warahmatullahi Wabarakatuh
Salam sejahtera untuk kita semua.
Atas nama Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Indonesia,
dengan bangga saya mengucapkan selamat kepada semua peserta pada Seminar
Nasional Matematika 2017 yang diselenggarakan pada tanggal 11 Februari 2017 di
Universitas Indonesia, Depok. Ucapan terima kasih saya sampaikan kepada pihak
IndoMS Pusat dan IndoMS Wilayah JABAR, Banten, dan DKI Jakarta atas
kepercayaannya kepada Universitas Indonesia dalam hal ini Departemen
Matematika FMIPA sebagai tuan rumah kegiatan sarasehan dan sosialisasi program
kerja IndoMS Pusat dan IndoMS Wilayah JABAR, Banten, dan DKI Jakarta.
Seminar Nasional ini merupakan seminar yang telah dilaksanakan secara bergantian
oleh Universitas Indonesia dan Universitas Padjadjaran sejak 20 tahun yang lalu.
Pihak Universitas Indonesia sebagai salah satu perguruan tinggi yang menjadi
pelopor perkembangan peran ilmu pengetahuan di Indonesia tidak henti-hentinya
mendorong segenap civitas akademika, termasuk di FMIPA UI untuk menghilirkan
penelitiannya agar dapat memberikan dampak nyata pada kemajuan bangsa dan
tanah air.
Saya ucapkan terima kasih kepada para pembicara utama, peserta dan tentunya
kepada panitia pelaksana SNM 2017 ini. Semoga kegiatan ini dapat memberikan
manfaat yang besar kepada kita semua dan bangsa Indonesia.
Salam hangat,
Wassalamu’alaikum Warahmatullahi Wabarakatuh
Dekan FMIPA Universitas Indonesia
Dr. rer. nat. Abdul Haris

iv
Gubernur IndoMS JABAR, Banten, dan DKI Jakarta
Assalamu’alaikum Warahmatullahi Wabarakatuh
Salam sejahtera untuk kita semua.
Atas nama Indonesian Mathematical Society (IndoMS), sebuah kebanggaan yang
besar bagi saya untuk menyampaikan selamat kepada semua peserta Seminar
Nasional Matematika (SNM) 2017 yang diadakan pada tanggal 11 Februari 2017 di
Departemen Matematika FMIPA UI, Depok.
IndoMS pada tahun ini bekerjasama dengan pihak penyelenggara lokal, mengadakan
cukup banyak aktivitas temu ilmiah di berbagai daerah di Indonesia, termasuk salah
satunya pada tahun ini yaitu SNM 2017 yang dirangkaikan dengan Sarasehan
IndoMS Wilayah JABAR, Banten, dan DKI Jakarta serta sosialisasi program kerja
IndoMS Pusat. Penyelenggaraan SNM 2017 tidak hanya merupakan program
berkelanjutan dari pihak IndoMS, Universitas Indonesia dan Universitas
Padjadjaran, namun juga merupakan sebuah kegiatan yang akan membawa peluang
besar kepada seluruh pihak yang terlibat untuk menyeminarkan dan mendiskusikan
hasil penelitian di berbagai bidang matematika.
Kami mengucapkan terima kasih kepada para pembicara utama, peserta dari
berbagai daerah di Indonesia, dan panitia SNM 2017. Ucapan terima kasih
khususnya kami sampaikan kepada Departemen Matematika, FMIPA Universitas
Indonesia yang bersedia menjadi tuan rumah. Saya berharap agar SNM 2017 ini
dapat memberikan manfaat yang besar kepada kita semua.
Salam hangat,
Wassalamu’alaikum Warahmatullahi Wabarakatuh
Gubernur IndoMS JABAR, Banten dan DKI Jakarta.
Alhadi Bustamam, Ph.D.

v
Ketua Panitia Seminar Nasional Matematika 2017
Salam sejahtera bagi kita semua.
Matematika sebagai salah satu bidang ilmu yang penerapannya
banyak digunakan di berbagai bidang, telah diterapkan pula pada
berbagai kajian dan penelitian di masalah lingkungan. Pentingnya masalah
pelestarian dan bagaimana mengatasi perubahan-perubahan fenomena lingkungan
tersebut menjadi dasar dalam penentuan tema utama pada Seminar Nasional
Matematika (SNM) 2017 ini, yakni “Peranan Matematika dalam Memahami
Fenomena Lingkungan”.
Seminar Nasional Matematika merupakan perkembangan dari Seminar Matematika
Bersama UI-UNPAD yang telah dilaksanakan sejak lebih dari 20 tahun yang lalu.
SNM merupakan salah satu forum nasional bagi para matematikawan, peminat atau
pemerhati Matematika dan para pengguna Matematika untuk saling berbagi
pengetahuan dan pengalaman terhadap hasil penelitian dan penerapan matematika di
berbagai hal. Melalui SNM 2017 diharapkan peserta yang berasal dari berbagai
perguruan tinggi dan institusi di Indonesia dapat berpartisipasi dan berkontribusi
sesuai dengan kepakaran bidang masing-masing di dalam mengatasi dan
menyelesaikan masalah lingkungan beserta berbagai fenomenanya. Makalah yang
masuk ke pihak penyelenggara meliputi berbagai bidang, seperti Analisis dan
Geometri, Aljabar, Statistika dan aplikasinya, Matematika Keuangan dan Aktuaria,
Kombinatorika, Komputasi, Pendidikan Matematika, Optimisasi, Pemodelan
Matematika dan bidang terapan lainnya.
Penyelenggara SNM 2017 memberikan apresiasi yang setinggi-tingginya kepada
berbagai pihak, antara lain Himpunan Matematika Indonesia wilayah Jabar, DKI
Jakarta, dan Banten, Program Studi Matematika Universitas Padjadjaran, serta
FMIPA UI yang telah memberikan dukungan dan bantuan dalam penyelenggaraan
seminar nasional ini. Tidak lupa kami ucapkan terima kasih yang sebesar-besarnya
kepada para sponsor yang telah berkontribusi dan kepada panitia SNM 2017
sehingga SNM 2017 dapat terselenggara.
Hormat kami,
Ketua Panitia SNM 2017
Bevina D. Handari Ph.D

vi
UCAPAN TERIMA KASIH
Panitia Seminar Nasional Matematika 2017 menyampaikan ucapan terima kasih dan
penghargaan kepada Pimpinan Universitas, Pimpinan Fakultas, Pimpinan
Departemen, dan para sponsor, atas dukungannya dalam bentuk dana, fasilitas, dan
lain-lain, untuk terselenggaranya seminar ini.
Secara khusus Panitia Seminar Nasional Matematika 2017 menyampaikan ucapan
terima kasih kepada:
1. Rektor Universitas Indonesia
2. Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
3. Ketua Departemen Matematika FMIPA Universitas Indonesia
4. Ketua Jurusan Matematika FMIPA Universitas Padjadjaran
5. Direktur Utama PT Reasuransi Indonesia Utama
6. Rektor Universitas Gunadarma
7. Direktur Utama PT Tokio Marine Life Insurance Indonesia
8. Direktur Utama PT AIA Financial Indonesia
9. Direktur Utama PT BNI Life Insurance
10. Direktur Utama BPJS Ketenagakerjaan
11. Ketua Persatuan Aktuaris Indonesia (PAI)
12. Direktur Utama PT Asuransi Cigna
Panitia Seminar Nasional Matematika 2017 juga mengucapkan terima kasih kepada
pembicara utama Prof. Dr. Jatna Supriatna, M.Sc (Ketua RCCC Universitas
Indonesia), Dr. Sri Purwani (Dosen Departemen Matematika FMIPA Universitas
Padjadjaran), Dr. Ardhasena Sopaheluwakan (Kepala Bidang Litbang Klimatologi
dan Kualitas Udara BMKG), para pemakalah pada sesi paralel, setiap tamu
undangan, dan seluruh peserta Seminar Nasional Matematika 2017.

vii
DAFTAR PANITIA SNM 2017
PELINDUNG
1. Prof. Dr. Ir. Muhammad Anis, M.Met. (Rektor Universitas Indonesia)
2. Dr. rer. nat. Abdul Haris (Dekan FMIPA Universitas Indonesia)
KOMISI PENGARAH
1. Alhadi Bustamam, Ph.D. (Gubernur IndoMS JABAR, DKI Jakarta, dan Banten,
sekaligus sebagai Ketua Departemen Matematika, FMIPA Universitas
Indonesia)
2. Prof. Dr. A.K. Supriatna (Ketua Jurusan Matematika, FMIPA Universitas
Padjadjaran)
PANITIA PELAKSANA
1. Ketua : Bevina D. Handari, Ph.D.
2. Sekretaris : Dr. Dipo Aldila
3. Bendahara : Dra. Siti Aminah, M.Kom.
4. Pendanaan : Mila Novita, S.Si., M.Si.
Dr. Titin Siswantining, DEA.
5. Acara : Nora Hariadi, S.Si., M.Si.
Dra. Ida Fithriani, M.Si.
6. Makalah dan Prosiding : Dra. Siti Nurrohmah, M.Si.
Dr. rer. nat. Hendri Murfi
7. Perlengkapan : Maulana Malik, S.Si., M.Si.
Dr. Saskya Mary Soemartojo, M.Si.
Suci Fratama Sari, S.Si., M.Si.
Gianinna Ardaneswari, S.Si., M.Si.

viii
DAFTAR ISI
KATA SAMBUTAN .......................................................................................... ii
Dekan FMIPA Universitas Indonesia .............................................................. iii
Gubernur IndoMS JABAR, Banten, dan DKI Jakarta.................................. iv
Ketua Panitia Seminar Nasional Matematika 2017 ......................................... v
UCAPAN TERIMA KASIH ............................................................................ vi
DAFTAR PANITIA SNM 2017 ...................................................................... vii
DAFTAR ISI.................................................................................................... viii
PEMBICARA UTAMA ................................................................................... xii
PERANAN MATEMATIKA DALAM MEMAHAMI FENOMENA
LINGKUNGAN................................................................................................ xiii
Prof. Dr. Jatna Supriatna, M.Sc ..................................................................... xiii
UNDERSTANDING INDONESIAN ENVIRONMENTAL PHENOMENA,
AND IMPROVING HUMAN LIVES ............................................................. xv
Dr. Sri Purwani ............................................................................................... xv
PERSPEKTIF SINGKAT IKLIM DI INDONESIA: PEMODELAN DAN
STATUS PERUBAHAN IKLIM. ................................................................... xvi
Dr. Ardhasena Sopaheluwakan ...................................................................... xvi
SESI PARALEL ............................................................................................. 614
KOMBINATORIK ........................................................................................ 614
PENGGUNAAN MATRIKS ANTIADJACENCY DALAM MENCARI
LAST COMMON NODE UNTUK MENYELESAIKAN
MASALAHTRAFFIC ASSIGNMENT PROBLEM ................................... 615
RESKIE A. PRATAMA, KEVIN KAMAL, SYAHRIL RAMADHAN, KIKI
A. SUGENG ................................................................................................. 615
HUBUNGAN NILAI EIGEN TERBESAR MATRIKS ANTIADJACENCY
DENGAN DERAJAT GRAF SEDERHANA TAK BERARAH ................ 623
AKANE VIEBIA AYA, NURUL MAGHFIRAH, KIKI ARIYANTI
SUGENG ...................................................................................................... 623

ix
POLINOMIAL KARAKTERISTIK DAN SPEKTRUM MATRIKS
ADJACENCY DAN ANTI-ADJACENCY DARI GRAF FRIENDSHIP
TAK BERARAH DAN BERARAH ........................................................... 628
BUDI PONIAM1,2, KIKI A. SUGENG2 ....................................................... 628
PELABELAN HARMONIS PADA GRAF TANGGA SEGITIGA VARIASI
𝒙𝑵 ..................................................................................................................... 642
KURNIAWAN ATMADJA1, KIKI A. SUGENG2 ...................................... 642
KOMPUTASI ................................................................................................. 648
ALGORITMA PARTICLE SWARM OPTIMIZATION DAN
TERAPANNYA DALAM MENYELESAIKAN MASALAH
PEMOTONGAN ROL KERTAS .................................................................. 649
HELVETIKA AMPERIANA1, Y G HARTONO2 ....................................... 649
APLIKASI METODE PENGGEROMBOLAN ALGORITMA KHUSUS
DALAM PENENTUAN ZONA BIAYA HAK PENGGUNA FREKUENSI
RADIO ............................................................................................................. 660
ERFIANI ....................................................................................................... 660
ALGORITMA GENETIK STEADY STATE BERDASARKAN FUNGSI
PEMBOBOTAN BIAYA DAN RELIABILITAS DALAM MENENTUKAN
PERAWATAN OPTIMAL MESIN .............................................................. 667
BUDHI HANDOKO1, YENY KRISTA FRANTY2, SRI WINARNI3 ......... 667
PENGELOMPOKAN DAERAH RAWAN BENCANA BANJIR DI
INDONESIA TAHUN 2013 MENGGUNAKAN FUZZY C-MEAN .......... 677
AMANDA PUTRI PERTIWI1, ROBERT KURNIAWAN2 ......................... 677
APLIKASI FUZZY C-MEANS PADA PREVALENSI GLOBAL YOUTH
TOBACCO SURVEY ..................................................................................... 688
INTAN PRIMASARI, ZUHERMAN RUSTAM, DHIAN WIDYA ............ 688
APLIKASI FUZZY MADM UNTUK DETEKSI POTENSI SERANGAN
JANTUNG BERDASARKAN METODE AHP DAN TOPSIS .................. 695
ZENIA AMARTI, NURSANTI ANGGRIANI, ASEP K. SUPRIATNA .... 695
IMPLEMENTASI TEOREMA DAERAH KAJIAN DAN TEOREMA
KOMPOSISI IRISAN HIMPUNAN PADA ETNOINFORMATIKA
PENAMAAN DESA DI LIMA WILAYAH PROVINSI JAWA BARAT 706
ATJE SETIAWAN ABDULLAH1 DAN BUDI NURANI RUCHJANA2 .. 706
ALGEBRAIC ATTACK PADA SIMPLIFIED DATA ENCRYPTION
STANDARD (S-DES) ..................................................................................... 726

x
FADILA PARADISE1, SANTI INDARJANI2 ............................................. 726
BIT PATTERN BASED INTEGRAL ATTACK PADA ALGORITMA
PRESENT ........................................................................................................ 736
RYAN SETYO PAMBUDI1, SANTI INDARJANI 2 ................................... 736
PERBANDINGAN KARAKTERISTIK S-BOX ALGORITMA PRESENT
DAN I-PRESENT............................................................................................ 745
ANNISA DEWI SALDYAN1, SARI AGUSTINI HAFMAN2 .................... 745
S-NCI: DESAIN PROTOKOL KEY ESTABLISHMENT ......................... 758
MOHAMAD ALI SADIKIN1, SUSILA WINDARTA2 ............................... 758
KLASIFIKASI MULTIKELAS KANKER OTAK DENGAN METODE
SUPPORT VECTOR MACHINE ................................................................. 768
VINEZHA PANCA1, ZUHERMAN RUSTAM2 .......................................... 768
ANALISIS AKURASI DARI METODE MACHINE LEARNING UNTUK
MENYELESAIKAN MASALAH CREDIT SCORING ............................. 778
NURUL MAGHFIRAH, ZUHERMAN RUSTAM ..................................... 778
PENGEMBANGAN MEDIA AUGMENTED REALITY BERBASIS
ANDROID UNTUK PEMBELAJARAN DIMENSI TIGA ........................ 785
FARIS FATHAN1, TITA KHALIS MARYATI2, DINDIN SOBIRUDDIN3
...................................................................................................................... 785
APLIKASI ADAPTIVE NEURO-FUZZY INFERENCE SYSTEM PADA
PENGAMBILAN KEPUTUSAN DALAM INVESTASI SAHAM ............ 797
I PUTU ADITYA WARDANA, ZUHERMAN RUSTAM ......................... 797
PEMILIHAN PERSONAL COMPUTER (PC) TERBAIK BERBASIS
ANDROID MENGGUNAKAN METODE FUZZY ANALYTICAL
HIERARCHY PROCESS (FAHP) ................................................................ 805
AKIK HIDAYAT1, EBBY SYABILAL R2, RUDI ROSYADI3, ERICK
PAULUS4 ...................................................................................................... 805
PENCARIAN IMPROBABLE DIFFERENTIAL 9 DAN 10 ROUND
PRESENT ........................................................................................................ 816
AFIFAH1, SARI AGUSTINI H.2 .................................................................. 816
PENCARIAN KARAKTERISTIK DIFERENSIAL 4 ROUND PADA
ALGORITMA MACGUFFIN ....................................................................... 830
RIDWAN IMAM SYARIF1, DAN SANTI INDARJANI2 .......................... 830

xi
PEMODELAN DAN OPTIMASI ................................................................. 839
PERBANDINGAN METODE RUNGE-KUTTA-VERNER DAN
LAPLACE ADOMIAN DECOMPOSITION METHOD DALAM SOLUSI
PERSAMAAN DIFFERENSIAL NONLINEAR PADA MASALAH
BIOMATEMATIKA ...................................................................................... 840
BETTY SUBARTINI1, RIAMAN2, DAN ALIT KARTIWA3 ..................... 840
PERMODELAN DINAMIK PADA SISTEM PROSES PENGOLAHAN
AIR LIMBAH KOLAM STABILISASI FAKULTATIF ............................ 850
SUNARSIH1, DIAN HULIYUN RAHMANIA2, NIKKEN PRIMA
PUSPITA3 ..................................................................................................... 850
SOLUSI MASALAH RELAKSASI MELALUI PERSAMAAN
DIFERENSIAL FRAKSIONAL BERORDE (,) ...................................... 858
E. RUSYAMAN1 DAN K. PARMIKANTI2 ............................................... 858
KONTROL OPTIMAL PADA MODEL EPIDEMIOLOGI DENGAN
VAKSINASI .................................................................................................... 865
JONNER NAINGGOLAN ........................................................................... 865
MODEL OPTIMISASI LINEAR INTEGER UNTUK TWO-STAGE
GUILLOTINE CUTTING STOCK PROBLEM DENGAN METODE
BRANCH AND BOUND PADA INDUSTRI GARMEN ............................ 873
EMAN LESMANA1, JULITA NAHAR2, ANNISA D.P3 ............................ 873
PENERAPAN OPTIMASI MULTI RESPON DENGAN METODE
TAGUCHI FUZZY LOGIC ........................................................................... 884
SRI WINARNI1, BUDHI HANDOKO2, YENY KRISTA FRANTY3 ......... 884
TERAPAN ...................................................................................................... 893
PENCITRAAN ARAH AKUMULASI PASIR BESI BERDASARKAN
KONTRAS KEMAGNETAN DAN FORWARD MODELLING DENGAN
MENGGUNAKAN METODE GEOFISIKA PASIF PADA DAERAH
PANTAI GOA CEMARA,YOGYAKARTA ................................................ 894
RIZKY RAMADHAN DWIYANTORO ..................................................... 894
TRANSFORMASI STRUKTURAL DAN KETIMPANGAN ANTAR
DAERAH DI PROVINSI KALIMANTAN TIMUR ................................... 901
ADI SETIAWAN1 DAN FITRI KARTIASIH2 ............................................ 901
EVALUASI TIGA MODEL PENDUGAAN EVAPORASI PANCI (EPAN)
DI WILAYAH BALI ...................................................................................... 911
TRINAH WATI1 DAN FATKHUROYAN2................................................. 911

xii
PEMBICARA UTAMA
SEMINAR NASIONAL MATEMATIKA 2017

xiii
PERANAN MATEMATIKA DALAM MEMAHAMI
FENOMENA LINGKUNGAN
Prof. Dr. Jatna Supriatna, M.Sc
Ketua RCCC Universitas Indonesia
Abstrak: Pembangunan berkelanjutan (SDG-Sustainable Development Goal) yang
dicanangkan PBB untuk menggantikan Millenium Development Goal (MDG) sudah
dimulai sejak awal 2016 dan akan berakhir 2030. Dari 17 goal dari SDG, 10 goal
adalah traditional development, satu goal adalah kerjasama antar pemangku
kepentingan (SDG 17) dan 6 goal adalah emerging issues dalam permasalahamn
lingkungan yaitu Energi terbarukan (SDG 7), Pembangunan kota dan masyarakat
(SDG 11), Konsumsi bertanggung jawab (12), Perubahan iklim (SDG 13), Laut
dan kehidupan bawah air (SDG 14), dan Kehidupan Flora dan Fauna di darat (SDG
15). Ke enam permasalahan lingkungan dalam pembangunan berkelanjutan yang
baru ini tidak ada dalam target pembangunan MDG, sehingga banyak sekali
diperlukan riset untuk dapat membuat berbagai kebijakan yang berdasarkan
evidence based decision, mengadaptasikan rencana sesuai dengan kesiapan dan
ketersediaan, pembuatan berbagai computer and mathematical model
pengembangan SDG sampai 2030, mengarusutamakan SDG ke dalam rencana
pembangunan RPJM/RPJP pemerintah pusat dan daerah dan bagaimana membuat
MRV (Measuring, Reporting, Verification) dari setiap goal yang baru. Peranan
pakar matematika sangat besar dalam membantu pelaksanaan pembangunan
berkelanjutan. Sebagai contoh adalah masalah perubahan iklim. Masalah perubahan
iklim adalah masalah terbesar dunia saat ini. Hasil survey Asahi Glass Foundation
(2013) tampak bahwa masalah dunia terbesar saat ini adalah perubahan iklim (20%)
dibanding dengan masalah lingkungan lainnya yang berkisar antara 10% (polusi) ,
keanekaragaman hayati (6%) dan yang lainya. Model-model matematika dan
komputer diperlukan untuk mengetahui dampak perubahan iklim terhadap kenaikan
permukaan laut, cuaca ekstrim, kesehatan, ekonomi, pertanian, flora dan fauna,
ketersediaan pakan, air dan lainnya dalam bentuk time series. Untuk MRV,
diperlukan pedoman Pelaksanaan Pengukuran, Pelaporan, dan Verifikasi Aksi
Mitigasi dan adaptasi dari setiap program di setiap sektor pemerintah, swasta dan

xiv
juga termasuk masyarakat. Capaian Aksi Mitigasi dan adapatasi Perubahan Iklim
yang akurat, transparan, dan dapat dipertanggungjawabkan hanya dapat dilakukan
apabila dilakukan oleh berbagai pakar terintegrasi termasuk pakar matematika dan
statistik. Pemerintah harus mengatur (i) tatacara Pengukuran Aksi Mitigasi adaptasi
dan Perubahan Iklim, (ii) tatacara pelaporan aksi mitigasi dan adaptasi perubahan
iklim (iii) tatacara verifikasi capaian aksi mitigasi dan adaptasi perubahan iklim (iv)
tatacara penilaian. Semua pengaturan tersebut memerlukan perhitungan yang pasti
dan mendalam karena dampak dari perubahan iklim dapat menghancurkan
perekonomian, membahayakan keberadaan ekosistem manusia, dalam jangka
panjang dapat mempengaruhi peradaban dunia.

xv
UNDERSTANDING INDONESIAN ENVIRONMENTAL
PHENOMENA, AND IMPROVING HUMAN LIVES
Dr. Sri Purwani
Departemen Matematika, FMIPA Universitas Padjadjaran
Abstract: The universe and the environment around us were created perfectly by
Alloh. However, we find a lot of damage and disaster everywhere (Ar-Rum 30:41).
This case, afflicting the environment and people of Indonesia, of course was through
a long process. Indonesia, the country with the largest ocean border in the world, has
experienced prosperity, well-being and peace in society. Understanding what the
cause and how the process of occurrence, can provide answers for future
improvements.
Human beings as part of the environment face the same thing. Various disease
emerges, afflicts human survival. Imaging Sciences as a branch of knowledge is
widely used in medical images analysis, range from disease detection, such as
Alzheimer's, asthma, cancer and so on, up to image-guided surgery. This field
involves many disciplines, hence providing opportunities for mathematicians to
conduct research collaboration with scientists from various disciplines.
Registration and Segmentation, two important processes in the analysis of medical
images, aims to find correspondence between two or more images, and attempts to
extract structures/tissues within images, respectively. Previously, both processes are
done separately. However, information from one process can be used to assist the
other, and vice versa. Therefore, we tried to combine both processes implemented
on database of MR brain images.
One of Petrovic et al. paper shows that adding structural information in their
registration stage improved the result significantly, compared to registration using
intensity alone. However, they only used little structural information. We attempted
to include more structural information/segmentation in our new methods, and
implemented groupwise registration to sets of images, consisting of tissue fraction
images, intensity image and images with other structural information. The results of
the registration were evaluated by using ground-truth annotation. It was found that
ensemble registration using structural information can give a consistent
improvement over registration using intensity alone of 25%-35%.

xvi
PERSPEKTIF SINGKAT IKLIM DI INDONESIA:
PEMODELAN DAN STATUS PERUBAHAN IKLIM.
Dr. Ardhasena Sopaheluwakan
Kepala Bidang Litbang Klimatologi dan Kualitas Udara
Pusat Penelitian dan Pengembangan Badan Meteorologi Klimatologi dan Geofisika
(BMKG)
Abstrak: Iklim memiliki peranan penting dalam mendukung perikehidupan di bumi
ini. Memiliki pengetahuan mengenai evolusi iklim (lampau dan kini) akan
memberikan pemahaman untuk penggunaannya pada sektor yang penting, semisal
pertanian dan ketahanan pangan. Sedangkan memiliki kemampuan untuk prediksi
iklim yang akan datang, akan memberikan keunggulan untuk perencanaan strategis
pembangunan bangsa-bangsa agar perikehidupannya dapat berkelanjutan
(sustainable development).
Untuk mendapatkan deskripsi yang lengkap atas dinamika iklim di atmosfir,
melibatkan pemodelan dengan rentang skala ruang yang sangat besar, melibatkan
ukuran dari micrometer (butiran awan) hingga ribuan kilometer (planetary scale),
yang melingkupi rentang ukuran ruang hingga 10^{14} meter. Pada saat ini
pemodelan yang tersedia baru memenuhi sebagian dari skala rentang yang besar
tersebut, sehingga tantangan untuk melengkapinya masih terbuka lebar. Presentasi
ini akan memberikan beberapa highlight mengenai pemodelan iklim, karakter iklim
di

614
SESI PARALEL
KOMBINATORIK
SEMINAR NASIONAL MATEMATIKA 2017

615
Prosiding SNM 2017 Kombinatorik, Hal 615-622
PENGGUNAAN MATRIKS ANTIADJACENCY DALAM
MENCARI LAST COMMON NODE UNTUK
MENYELESAIKAN MASALAHTRAFFIC ASSIGNMENT
PROBLEM
RESKIE A. PRATAMA, KEVIN KAMAL, SYAHRIL
RAMADHAN, KIKI A. SUGENG
Departemen Matematika, FMIPA, Universitas Indonesia,
[email protected], [email protected]
[email protected], [email protected]
Abstrak. Matriks antiadjancency (B) didapatkan dari operasi antara matriks persegi
yang semua entrinya bernilai 1 (𝐉) dengan matriks adjacency (𝐀), yaitu 𝐁 = 𝐉 − 𝐀.
Makalah ini membahas mengenai penggunaan dari matriks antiadjacency dalam
mencari Last Common Node (LCN). Pencarian LCN dalam makalah ini bertujuan
untuk menyelesaikan masalah dalam pengaplikasian teori graf yaitu Traffic Assignment
Problem (TAP). Pada makalah yang telah diterbitkan, basis dari algoritma LCN adalah
matriks adjacency. Pada makalah ini dibahas pencarian LCN menggunakan matriks
antiadjacency. Dengan menggunakan polinomial karakteristik dari matriks
antiadjacency, didapatkan banyaknya jalan sederhana dari graf 𝐺. Untuk penelusuran
dalam pencarian LCN dari suatu pasangan origin-destination (OD), dilakukan
pencarian secara manual dengan menuliskan seluruh jalan yang mungkin. Setelah
diketahui seluruh jalan yang mungkin, dapat dilihat simpul mana saja yang dilalui oleh
jalan-jalan tersebut. Kemudian, dipilih simpul terakhir sesuai urutan topologi sebagai
LCN yang akan dicari..
Kata kunci: last common node, matriks antiadjacency, polinomial karakteristik, traffic
assignment problem.
1. Pendahuluan
Teori graf merupakan salah satu topik di bidang matematika yang
berkembang pesat dan dapat digunakan untuk menyederhanakan penyelesaian suatu
masalah [1]. Teori graf diperkenalkan pertama kali pada tahun 1736 oleh Leonhard
Euler. Dengan menggunakan representasi dalam bentuk graf, suatu permasalahan
akan lebih mudah untuk dipahami dan dicari solusi penyelesaiannya. Dalam
perkembangannya, teori graf masih perlu banyak diteliti lebih lanjut. Hal ini
dikarenakan masih banyak permasalahan dalam teori graf yang perlu dibahas.
Pada umumnya, graf hanya digambar dalam bentuk simpul (vertex) dan busur (edge).
Representasi lain dari graf dapat dibentuk melalui matriks dengan memperhatikan
hubungan antar simpul dan busur. Terdapat beberapa representasi matriks yang dapat
merepresentasikan graf. Pada makalah ini, yang akan diperhatikan adalah
representasi dalam bentuk matriks adjacency dan matriks antiadjacency. Adapun

616
hubungan secara umum dari kedua matriks ini yaitu matriks antiadjacency ( )
diperoleh dari 𝐁 = 𝐉 − 𝐀, dengan adalah matriks persegi dengan seluruh entrinya
bernilai 1.
Penggunaan teori graf untuk menyelesaikan suatu permasalahan sangat
banyak aplikasinya, salah satunya yaitu Traffic Assignment Problem (TAP). TAP
merupakan pembelajaran tentang jaringan lalu lintas, yang berfokus pada pemilihan
rute wisatawan dari asal (origin) ke tujuan (destination). Pada TAP, diasumsikan
bahwa semua wisatawan mencoba untuk meminimumkan biaya untuk rute yang
dipilih [2]. Banyak algoritma yang dapat digunakan untuk menyelesaikan TAP, salah
satunya yaitu algoritma yang diperkenalkan oleh Bar-Gera yang dikenal dengan
algoritma origin-based, disebut dengan konsep Last Common Node (LCN) ke dalam
algoritma dan hanya memperhatikan solusi asiklik.
Pada paper sebelumnya telah diperlihatkan penggunaan dari matriks
adjacency dalam mencari LCN. Dengan ide dari hubungan antara matriks adjacency
dan matriks antiadjacency yang sudah kami ketahui, pada makalah ini kami akan
membahas mengenai matriks antiadjacency untuk menyelesaikan pencarian LCN.
Pada makalah ini kami akan menggunakan sifat dari polinomial karakteristik dari
matriks antiadjacency dalam mencari LCN.
2. Definisi dan Notasi 2.1. Teori Graf
Definisi 2.1.1 Suatu graf 𝐺 = (𝑉, 𝐸) didefinisikan sebagai pasangan himpunan (𝑉,
𝐸), dengan 𝑉 = {𝑣1, 𝑣2, … , 𝑣𝑛} adalah himpunan simpul yang tak kosong dan 𝐸 =
{𝑒1, 𝑒2, … , 𝑒𝑛} adalah himpunan pasangan tak terurut dari simpul-simpul yang
disebut busur [1]. Banyaknya simpul pada disebut order dan dinotasikan dengan
|𝑉| atau , dan banyaknya busur disebut size dan dinotasikan dengan |𝐸| [1].
Definisi 2.1.2 Suatu graf berarah 𝐷 = (𝑉, 𝐴) adalah pasangan terurut dari dua
himpunan 𝑉 dan 𝐴 dengan 𝑉 adalah himpunan berhingga yang tak kosong dan 𝐴
merupakan koleksi pasangan terurut anggota dari 𝑉 yang berbeda Jika 𝑢 dan 𝑣
adalah simpul pada graf berarah 𝐷, maka busur berarah 𝑢𝑣 artinya
menghubungkan simpul asal 𝑢 ke simpul ujung 𝑣. [1].
Definisi 2.1.3 Graf berarah asiklik adalah graf berarah yang tidak memuat subgraf
berupa siklus berarah. Sementara, graf berarah siklik adalah graf berarah yang
memuat subgraf beruka siklus berarah [1].
Definisi 2.1.4 Misalkan 𝑢 dan 𝑣 adalah dua simpul di . Jalan 𝑢𝑣 (didefinisikan
dengan ) di graf adalah barisan simpul di yang dimulai dari dan berakhir
di , sehingga simpul-simpul yang berurutan saling bertetangga [1].
Definisi 2.1.5 Jalan dapat ditulis sebagai 𝑊 ≔ 𝑢 = 𝑣0, 𝑣1, … , 𝑣𝑘 = 𝑣, dengan 𝑘
≥ 0, 𝑣𝑖 dan 𝑣𝑖+1 bertetangga untuk 𝑖 = 0, 1, … , 𝑘 − 1. Lintasan 𝑢𝑣 adalah jalan di
mana setiap busur hanya dilalui satu kali saja. [1]

617
Definisi 2.1.6 Misalkan adalah suatu graf berarah. Barisan simpul dari
𝑊 = 𝑢 = 𝑢0, 𝑢1, … , 𝑢𝑘 = 𝑣
sedemikian sehingga 𝑢𝑖 bertetangga ke 𝑢𝑖+1 untuk semua 𝑖 = 0,1, … , 𝑘 − 1 disebut
jalan berarah 𝑢 − 𝑣 di . Jika tidak ada simpul yang berulang pada , maka
disebut lintasan berarah.
2.2. Matriks Adjacency dan Matriks Antiadjacency
Definisi 2.2.1 Matriks adjacency = (𝑎𝑖𝑗) dari suatu graf berarah adalah suatu
matriks bujur sangkar berukuran 𝑛 × 𝑛, dengan 𝑛 = |𝑉|, yang entrinya
merepresentasikan ada tidaknya busur berarah yang menghubungkan dua simpul
dengan
dengan 𝑖, 𝑗 = 1, 2, … , 𝑛 [1].
Definisi 2.2.2 Matriks antiadjacency dari graf berarah adalah matriks 𝐁 = 𝐉 − 𝐀,
dengan adalah matriks 𝑛 × 𝑛 yang semua entrinya adalah 1 [3].
2.3. Polinomial Karakteristik
Definisi 2.3.1 Misalkan adalah matriks 𝑛 × 𝑛 yang memenuhi persamaan 𝐀𝒙 =
𝜆𝒙, maka skalar disebut nilai eigen dan vektor 𝑥𝑛 × 1 ≠ 0 disebut vektor eigen
yang bersesuaian dengan nilai eigen .
Definisi 2.3.2 Polinomial karakteristik dari matriks adalah
𝑝(𝐴) = 𝑝(𝐴, 𝜆) = 𝑑𝑒𝑡(𝜆𝐼 − 𝐴) = 𝜆𝑛 + 𝑎1𝜆𝑛−1 + 𝑎2𝜆
𝑛−2 + ⋯ + 𝑎𝑛,
dengan adalah derajat tertinggi dari 𝑝(𝐀).
Persamaan karakteristik dari matriks 𝐀 adalah (𝐀) = det(𝜆𝐈 − 𝐀) = 0 [1]
Teorema 2.1.
Misalkan adalah suatu graf berarah yang asiklik dengan (𝐺) = {𝑣1, 𝑣2, … , 𝑣𝑛}.
Misalkan adalah matriks antiadjacency dari graf berarah dengan polinomial
karakteristiknya adalah
(𝐁(𝐺)) = 𝜆𝑛 + 𝑏1𝜆𝑛−1 + 𝑏2𝜆𝑛−2 + ⋯ + 𝑏𝑛.
Maka |𝑏𝑖|, 𝑖 = 1, 2, … , 𝑛, menyatakan banyaknya lintasan berarah dari graf berarah
dengan panjang 𝑖 − 1 [4].

618
2.4. Jaringan Transportasi
Jaringan transportasi dapat direpresentasikan sebagai graf berarah 𝐺 = (𝑉, 𝐸), di
mana setiap simpul akan bersesuaian dengan intersection, dan setiap busur berarah
besesuaian dengan ruas jalan dengan suatu arah tertentu [2]. Sebuah busur berarah
akan disimbolkan dengan pasangan simpul (𝑢, 𝑣) ∈ 𝐸, dengan 𝑢, 𝑣 ∈ 𝑉 yang
mengintepretasikan bahwa dimulai dari dan menuju ke .
Representasi matriks adjacency untuk jaringan transportasi adalah.
𝐀𝑢𝑣 = 1 jika (𝑢, 𝑣) ∈ 𝐸,
𝐀𝑢𝑣 = 0 jika tidak ada penghubung langsung (sebuah busur berarah) dari menuju
.
Selain itu, pada jaringan transportasi berlaku 𝐀𝑢𝑢 = 0 karena tidak terdapat self-link.
Didefinisikan sebuah lintasan sederhana atau sebuah rute sederhana dari 𝑖 ∈ 𝑉
menuju 𝑗 ∈ 𝑉 sebagai lintasan tanpa pengulangan simpul. Simpul bersama untuk
pasangan OD 𝑝𝑞 didefinisikan sebagai semua rute sederhana dari titik asal menuju
titik tujuan yang melalui , kecuali .
3. Penggunaan Matriks Antiadjacency dalam Mencari LCN
Pada bagian ini, akan dibahas matriks antiadjacency dari serta
penggunaannya dalam mencari LCN. Pertama akan dicari matriks antiadjacency ,
kemudian akan dicari persamaan polinomial karakteristik dari det(𝜆𝐈 − 𝐁). Setelah
dilihat persamaan polinomial karakteristiknya, akan diketahui banyak jalan
sederhana dari simpul 1 ke simpul 18 sebagai contoh sederhana dalam makalah ini.
Dari jalan sederhana dari simpul 1 ke simpul 18, dapat ditemukan simpul yang sering
dilalui dan dari simpul tersebut akan dicari simpul terakhir yang sering dilaluinya
(LCN).
3.1. Graf G dan Representasi Matriksnya
Untuk mengetahui sifat dari polinomial karakteristik yang diperoleh dari
det(𝜆𝐈 − 𝐁), akan digunakan graf asiklik berarah sebagai berikut.

619
Graf tersebut dapat dibuat representasi lain sebagai berikut.
Graf diatas dapat direpresentasikan dalam bentuk matriks adjacency
sebagai berikut.
Dari matriks adjacency diatas, dapat diperoleh matriks
antiadjacency 𝐁 = 𝐉 − 𝐀, dimana adalah matriks persegi dengan seluruh entrinya
bernilai 1.

620
3.2. Polinomial Karakteristik dari Matriks Antiadjacency Graf
Berdasarkan teorema, polinomial karakteristik 𝑑𝑒𝑡(𝜆𝑰 − 𝑩) dinyatakan
sebagai berikut.
𝑑𝑒𝑡(𝜆𝐼 − 𝐵) = 𝜆𝑛 + 𝑏1𝜆𝑛−1 + 𝑏2𝜆
𝑛−2 + ⋯ + 𝑏𝑛−1𝜆 + 𝑏𝑛
di mana |𝑏𝑖|, 𝑖 = 1, 2, 3, … , 𝑛 menyatakan banyaknya jalan pada graf dengan
panjang 𝑖 − 1.
Dari graf yang diberikan, dapat dibentuk polinomial karakteristik sebagai
berikut.
𝑑𝑒𝑡(𝜆𝐼 − 𝐵) = 𝜆18 − 18𝜆17 + 19𝜆16 − 19𝜆15 + 18𝜆14 − 14𝜆13 + 11𝜆12
− 8𝜆11 + 4𝜆10
Berdasarkan teorema, didapatkan bahwa dalam graf terdapat:
• 18 jalan dengan panjang 0;
• 19 jalan dengan panjang 1;
• 19 jalan dengan panjang 2;
• 18 jalan dengan panjang 3;
• 14 jalan dengan panjang 4;
• 11 jalan dengan panjang 5;
• 8 jalan dengan panjang 6; dan
• 4 jalan dengan panjang 7.
Karena graf merupakan graf asiklik berarah, maka setiap jalan dengan
panjang terbesar merupakan panjang jalan dari suatu pasangan OD. Pada graf di
atas, panjang jalan terbesar adalah 7. Ini mengartikan bahwa terdapat pasangan OD
dengan panjang 7, yang dalam kasus ini adalah pasangan OD (1,6) dan (1,18). Di
sini, akan dicari LCN dari pasangan OD (1,18).

621
3.3 Mencari Last Common Node (LCN) berdasarkan Persamaan Polinomial
Karakteristik
Dari persamaan polinomial karakteristik yang diperoleh akan dicari LCN
dari pasangan OD (1,18) dengan menyelidiki setiap rute yang mungkin.
Dari graf , dapat dilihat bahwa terdapat tiga jalan sederhana yang dapat
ditempuh dari simpul 1 ke simpul 18, antara lain:
• {1 − 2 − 3 − 4 − 10 − 11 − 12 − 18};
• {1 − 2 − 3 − 4 − 10 − 16 − 17 − 18}; dan
• {1 − 2 − 3 − 9 − 15 − 16 − 17 − 18};.
Dari tiga jalan di atas, terdapat tiga simpul yang selalu dilalui dari simpul 1
ke simpul 18, antara lain simpul 1, simpul 2, dan simpul 3. Dari tiga simpul tersebut,
sesuai dengan urutannya pada graf dapat dilihat bahwa simpul 3 adalah simpul
bersama yang terakhir dilalui dalam setiap jalan pada pasangan OD (1,18). Dengan
demikian, LCN dari pasangan OD (1,18) adalah simpul 3.
4. Kesimpulan
Dalam makalah ini, telah dikembangkan suatu cara untuk mencari Last
Common Node (LCN) dari suatu graf asiklik berarah dengan meninjau matriks
antiadjacency dari graf yang bersangkutan. Penggunaan matriks antiadjacency di
sini adalah untuk mencari persamaan polinomial karakteristik det(𝜆𝐈 − 𝐁), dengan
bentuk det(𝜆𝐈 − 𝐁) = 𝜆𝑛 + 𝑏1𝜆𝑛−1 + 𝑏2𝜆𝑛−2 + ⋯ + 𝑏𝑛−1𝜆 + 𝑏𝑛 di mana |𝑏𝑖|, 𝑖 = 1, 2, 3, … , 𝑛 adalah banyaknya jalan sederhana pada graf dengan panjang 𝑖 − 1.
Adapun langkah-langkah dalam mencari LCN dari suatu pasangan OD
dengan menggunakan matriks antiadjacency dari graf adalah sebagai berikut.
1. Tentukan matriks antiadjacency berdasarkan matriks adjacency , yaitu
𝐁 = 𝐉 − 𝐀, dimana adalah matriks persegi dengan seluruh entrinya bernilai 1.
2. Tentukan persamaan polinomial karakteristik det(𝜆𝐈 − 𝐁) untuk
mengetahui banyaknya jalan sederhana pada graf .
3. Untuk mencari LCN dari suatu pasangan OD, perlu diketahui berapa
panjang dari pasangan OD tersebut, kemudian dapat dilakukan pencarian secara
manual dengan menuliskan seluruh jalan yang mungkin.
4. Setelah diketahui seluruh jalan yang mungkin, dapat dilihat simpul mana
saja yang dilalui oleh jalan-jalan tersebut. Kemudian, dipilih simpul terakhir
seseuai urutan topologi sebagai LCN yang akan dicari.
Penggunaan matriks antiadjacency , dalam hal ini adalah untuk mencari
persamaan polinomial karakteristik saja, sedangkan untuk mencari LCN masih
menggunakan cara manual. Saran dari penulis, untuk penelitian lebih lanjut dapat
dikembangkan penggunaan matriks sehingga lebih memudahkan pencarian LCN
tanpa harus dilakukan pencarian secara manual. Selain itu, metode ini disimulasikan
dalam contoh graf yang sederhana. Untuk penelitian lebih lanjut, penulis memberi
usulan untuk menggunakan kasus riil dalam melakukan simulasi metode ini.

622
Referensi
[1] Bapat, R.B., 2010, Graphs and matrices, New York (NY): Springer.
[2] Firmansyah, F., 2014, Polinomial Karakteristik Matriks Antiadjacency dari Graf
Berarah yang Acyclic, Tesis, Departemen Matematika FMIPA UI.
[3] Gao, L., Si, B., Yang, X., Sun, H., & Gao, Z., 2012, A matrix method for finding last
common nodes in an origin-based traffic assignment problem. Physica A: Statistical
Mechanics and its Applications, 391(1), 285-290.
[4] Sugeng, K.A., Slamet, S., & Silaban, D.R., 2014, Teori Graf dan Aplikasinya.
Departemen Matematika FMIPA UI.

623
Prosiding SNM 2017 Kombinatorik, Hal 623-627
HUBUNGAN NILAI EIGEN TERBESAR MATRIKS
ANTIADJACENCY DENGAN DERAJAT GRAF
SEDERHANA TAK BERARAH
AKANE VIEBIA AYA, NURUL MAGHFIRAH, KIKI ARIYANTI
SUGENG
Departemen Matematika FMIPA, Universitas Indonesia,
[email protected], [email protected], [email protected]
Abstrak. Misal 𝐺 = (𝑉, 𝐸) adalah graf sederhana tak berarah dimana 𝑉 adalah
himpunan simpul dan 𝐸 adalah himpunan busur. Matriks adjacency dari graf 𝐺
adalah matriks 𝐴(𝐺) = [𝑎𝑖𝑗] berukuran 𝑛 𝑥 𝑛 dimana 𝑎𝑖𝑗=1 untuk 𝑖≠𝑗 jika terdapat
busur dari 𝑣𝑖 ke 𝑣𝑗 , dan 𝑎𝑖𝑗 =0 untuk lainnya Matriks antiadjacency dari graf 𝐺
didefinisikan sebagai matriks 𝐵(𝐺) = 𝐽 – 𝐴(𝐺) dengan 𝐽 adalah matriks
berukuran 𝑛 × 𝑛 yang semua entrinya 1. Pada makalah ini dibahas hubungan
antara nilai eigen terbesar dari matriks antiadjacency 𝐵(𝐺) dengan derajat
terbesar dan terkecilnya dari beberapa kelas graf, yaitu : graf bipartit lengkap,
graf lengkap, dan graf bintang.
Kata kunci: graf bipartit lengkap, graf lengkap, matriks antiadjacency, nilai eigen
terbesar.
1. Pendahuluan
Teori graf adalah salah satu cabang ilmu pengetahuan yang hingga saat ini
masih berkembang pesat. Teori graf dapat diaplikasikan untuk menyelesaikan
berbagai permasalahan, mulai dari model permasalahan sehari – hari sampai
permasalahan matematika yang rumit seperti pada bidang kimia, ilmu komputer dan
riset operasi.
Jenis graf dapat dibagi menjadi dua, yaitu graf berarah dan graf tidak
berarah. Suatu graf berarah 𝐷 memuat himpunan berhingga 𝑉 dari simpul dan
himpunan pasangan terurut dari simpul yang berbeda. Untuk 𝑢, 𝑣 ∈ 𝑉 pasangan (𝑢, 𝑣) disebut busur dan biasanya dinotasikan dengan 𝑢𝑣 [6]. Graf tidak berarah 𝐺 = (𝑉, 𝐸) dengan 𝑉 adalah himpunan simpul dan 𝐸 adalah himpunan busur atau
himpunan pasangan tek berurut dari dua simpul yang berbeda di 𝑉.
Suatu graf 𝐺 dapat direpresentasikan dalam bentuk matriks, contohnya
sebagai matriks adjacency dan matriks antiadjacency. Matriks adjacency dari graf
𝐺 digunakan untuk menyatakan hubungan antar simpul pada suatu graf, dan
dinyatakan dalam bentuk matriks 𝐴 = [𝑎𝑖𝑗] berukuran 𝑛 × 𝑛 yang didefinisikan
sebagai :
𝑎𝑖𝑗 = {1, jika 𝑣𝑖 dan 𝑣𝑗 bertetangga
0, jika 𝑣𝑖 dan 𝑣𝑗 tidak bertetangga

624
Contoh lain representasi graf adalah dengan matriks antiadjacency yaitu
dimisalkan 𝐴 adalah matriks adjacency dari graf 𝐺, matriks 𝐵 = 𝐽 – 𝐴 disebut
sebagai matriks antiadjacency dari suatu graf 𝐺 dengan 𝐽 adalah suatu matriks
berukuran 𝑛 × 𝑛 yang semua entrinya adalah 1 [2].
Jika diketahui representasi suatu graf 𝐺 dalam bentuk matriks antiadjacency,
maka dapat dicari nilai karakteristik atau nilai eigen dari matriks antiadjacency
tersebut. Untuk mencari nilai eigen dari suatu matriks dapat dilakukan dengan
berbagai cara, salah satunya adalah dengan menggunakan spektrum dari graf.
Misalkan 𝜆 adalah suatu nilai eigen dari matriks A dan 𝑚(𝜆) adalah
multiplisitas aljabar dari nilai eigen. Misalkan A(G) memiliki nilai eigen yang
berbeda, yaitu 𝜆1 > 𝜆2 > ⋯ > 𝜆𝑠 dengan multiplisitas masing – masing adalah
𝑚(𝜆1),𝑚(𝜆2),… ,𝑚(𝜆𝑠). Spektrum dari graf G, dinotasikan dengan Spec A(G), dan
dituliskan dalam bentuk sebagai berikut [3].
𝑆𝑝𝑒𝑐 𝐴(𝐺) = (𝜆1 𝜆2 … 𝜆𝑠
𝑚(𝜆1) 𝑚(𝜆2) … 𝑚(𝜆𝑠))
Terdapat berbagai jenis kelas graf, seperti : graf lintasan, graf lingkaran, graf
bintang, graf bipartit, dan sebagainya. Jenis graf berbeda juga pasti akan
menghasilkan entri matriks adjacency dan matriks antiadjacency yang berbeda pula,
sehingga nilai eigen yang dihasilkan juga akan berbeda – beda.
Dari beragam perbedaan yang mungkin akan dihasilkan, sebenarnya terdapat
suatu keterhubungan. Kaitan nilai eigen terbesar matriks adjacency dengan derajat
graf G tak berarah telh diketahui yaitu 𝛿(𝐺) ≤ 𝜆1(𝐺) ≤ ∆(𝐺), dengan 𝛿(𝐺) adalah
derajat terkecil dari graf G, ∆(𝐺) adalah derajat terbesar dari graf G, dan 𝜆1(𝐺) adalah nilai eigen terbesar dari matriks adjacency. [2]. Tetapi belum diketahui
bagaimana untuk matriks antiadjacency nya.
Hasil yang sudah diketahui adalah spektrum dari beberapa kelas graf seperti
berikut [1] :
Theorem 1. Nilai Karakteristik dari matriks antiadjacency graf lengkap 𝐾𝑛 dengan
𝑛 ≥ 4 selalu bernilai 1 dan spektrum dari graf lengkap 𝐾𝑛 adalah 𝑆𝑝𝑒𝑐 𝐾𝑛 = (1𝑛).
Theorem 2. Spektrum matriks antiadjacency graf bipartit lengkap 𝐾𝑚,𝑛 dengan 𝑚 ≥
2 dan 𝑛 ≥ 2 adalah 𝑆𝑝𝑒𝑐 𝐾𝑚,𝑛 = (0
𝑚+𝑛−2𝑚1𝑛1 ).
Theorem 3. Spektrum matriks antiadjacency graf bintang 𝑆𝑛 dengan 𝑛 ≥ 3 adalah
𝑆𝑝𝑒𝑐 𝑆𝑛 = (0
𝑛−211𝑛−11 ).
Dikarenakan masih minimnya penelitian mengenai matriks antiadjacency,
maka pada makalah ini akan dibahas keterhubungan antara nilai eigen dari matriks
antiadjacency dari suatu graf dengan derajat terkecil dan terbesar dari graf tersebut.
Makalah ini menggunakan tiga buah kelas graf, yaitu : graf bipartit lengkap, graf
lengkap, dan graf bintang.
Selanjutnya pada bagian II akan dijelaskan mengenai hasil – hasil penelitian
dan pada bagian III akan dijelaskan mengenai kesimpulan.

625
2. Hasil – Hasil Utama
Definisi 1. Graf lengkap adalah graf sederhana dimana setiap pasang simpulnya
merupakan simpul-simpul bertetangga [7].
Berdasarkan ide dari [5] maka diperoleh hasil berikut.
Theorem 4. Misal Kn adalah graf lengkap dengan n 4 diperoleh 𝜆1(𝐾𝑛) <𝛿(𝐾𝑛) = ∆(𝐾𝑛).
BUKTI Berdasarkan definisi, setiap simpul yang ada saling bertetangga maka
derajat setiap simpul dari graf lengkap 𝐾𝑛 adalah 𝑛 − 1. Sehingga dapat dikatakan
derajat terkecil dan terbesar dari graf 𝐾𝑛 adalah 𝑛 − 1. Oleh karena itu akan didapat
𝛿(𝐾𝑛) = ∆(𝐾𝑛). Sesuai Teorema 1 dari [1] didapat nilai eigen dari matriks antiadjacency graf lengkap
dengan n ≥ 4 adalah 𝜆1 = 𝜆2 = ⋯ = 𝜆𝑛 = 1
Jadi,
a. 𝜆1(𝐾𝑛) < 𝛿(𝐾𝑛) Diketahui 𝜆1(𝐾𝑛) = 1 < 𝑛 − 1 = 𝛿(𝐾𝑛) untuk n ≥ 4
Maka 𝜆1(𝐾𝑛) < 𝛿(𝐾𝑛).
b. 𝜆1(𝐾𝑛) < ∆(𝐾𝑛) Diketahui 𝜆1(𝐾𝑛) = 1 < 𝑛 − 1 = ∆(𝐾𝑛) untuk n ≥ 4
Maka 𝜆1(𝐾𝑛) < ∆(𝐾𝑛). Didapat 𝜆1(𝐾𝑛) < 𝛿(𝐾𝑛) dan 𝜆1(𝐾𝑛) < ∆(𝐾𝑛) dan (𝐾𝑛) = ∆(𝐾𝑛) , maka
𝜆1(𝐾𝑛) < 𝛿(𝐾𝑛) = ∆(𝐾𝑛) untuk graf lengkap 𝐾𝑛 dengan n ≥ 4.
Definisi 2. Suatu graf G adalah graf bipartit lengkap jika himpunan simpul V dapat
dipartisi menjadi dua sub-himpunan U dan W, disebut himpunan partisi, sedemikian
sehingga setiap busur dri G menghubungkan simpul di U dan simpul di W. Atau
dengan kata lain, setiap simpul di U bertengga dengan setiap simpul di W. Jika
|𝑈| = 𝑚 dan |𝑉| = 𝑛, maka graf bipartit lengkap dinotasikan dengan 𝐾𝑚,𝑛[4].
Theorem 5. Misal 𝐾𝑟,𝑠 adalah graf bipartit lengkap dimana 𝑟, 𝑠 ≥ 2 diperoleh
𝛿(𝐾𝑟,𝑠) ≤ ∆(𝐾𝑟,𝑠) = 𝜆1(𝐾𝑟,𝑠).
BUKTI. Graf Bipartit lengkap 𝐾𝑟,𝑠 memiliki 2 himpunan simpul 𝑋 dan 𝑌. Misalkan
himpunan simpul 𝑋 memiliki 𝑟 simpul dengan masing-masing simpulnya berderajat
𝑠 dan himpunan simpul 𝑌 memiliki 𝑠 simpul dengan masing-masing simpulnya
berderajat 𝑟 dan dapat dinyatakan sebagai berikut:
deg(𝑣𝑖) = {𝑠, 𝑖 = 1,2, . . , 𝑟,
𝑟, 𝑖 = 𝑟 + 1, 𝑟 + 2,… , 𝑟 + 𝑠.
Derajat terkecil dan terbesar dari graf bipartit lengkap 𝐾𝑟,𝑠 adalah 𝛿(𝐾𝑟,𝑠) =
min(𝑟, 𝑠) dan ∆(𝐾𝑟,𝑠) = 𝑚𝑎𝑘𝑠(𝑟, 𝑠). Karena untuk setiap graf berlaku 𝛿(𝐺) ≤
∆(𝐺) maka berlaku pula untuk graf bipartit lengkap 𝛿(𝐾𝑟,𝑠) ≤ ∆(𝐾𝑟,𝑠). Berdasarkan Teorema 2 dari [1], maka didapat nilai eigen dari matriks antiadjacency
graf bipartit lengkap 𝐾𝑟,𝑠 adalah 0, 𝑟, dan 𝑠.

626
Oleh karena itu, nilai eigen terbesar matriks antiadjacency graf bipartit lengkap 𝐾𝑟,𝑠 adalah
𝜆1(𝐾𝑟,𝑠) = {𝑟, 𝑟 ≥ 𝑠𝑠, 𝑟 < 𝑠
atau 𝜆1(𝐾𝑟,𝑠) = 𝑚𝑎𝑘𝑠 (𝑟, 𝑠).
Derajat terbesar dari graf bipartit lengkap 𝐾𝑟,𝑠 adalah ∆(𝐾𝑟,𝑠) = 𝑚𝑎𝑘𝑠(𝑟, 𝑠).
Karena 𝜆1(𝐾𝑟,𝑠) = 𝑚𝑎𝑘𝑠 (𝑟, 𝑠) = ∆(𝐾𝑟,𝑠) maka 𝜆1(𝐾𝑟,𝑠) = ∆(𝐾𝑟,𝑠).
Dari persamaan 𝛿(𝐾𝑟,𝑠) ≤ ∆(𝐾𝑟,𝑠) dan 𝜆1(𝐾𝑟,𝑠) = ∆(𝐾𝑟,𝑠) maka 𝛿(𝐾𝑟,𝑠) ≤
∆(𝐾𝑟,𝑠) = 𝜆1(𝐾𝑟,𝑠) untuk graf bipartit lengkap dimana 𝑟, 𝑠 2.
Definisi 3. Graf bintang, 𝑆𝑛, adalah graf dengan 𝑛 + 1 simpul, memiliki satu simpul
pusat 𝑣0 yang terhubung dengan 𝑛 simpul lainnya.[7].
Theorem 6. Misal 𝑆𝑛 adalah graf bintang dengan 𝑛 3 diperoleh 𝛿(𝑆𝑛) <𝜆1(𝑆𝑛) < ∆(𝑆𝑛).
BUKTI. Berdasarkan Definisi 3, derajat simpul pusat selalu lebih besar daripada
simpul daun graf bintang 𝑆𝑛 untuk 𝑛 3. Sehingga derajat terkecil 𝛿(𝑆𝑛) = 1 dan
derajat terbesar ∆(𝑆𝑛) = 𝑛.
Berdasarkan Teorema 3 dari [1] akan didapat nilai eigen dari matriks antiadjacency
graf bintang 𝑆𝑛 tersebut adalah 0, 1, dan 𝑛 − 1. Nilai eigen dari matriks antiadjacency graf bintang 𝑆𝑛 tersebut adalah 0, 1, dan 𝑛 −1. Karena 𝑛 − 1 ≥ 1 ≥ 0 untuk 𝑛 3 maka nilai eigen terbesarnya adalah
𝜆1(𝑆𝑛) = 𝑛 − 1.
Akan dibuktikan :
a. 𝛿(𝑆𝑛) < 𝜆1(𝑆𝑛). Diketahui 𝛿(𝑆𝑛) = 1.
Jadi 𝛿(𝑆𝑛) = 1 < 𝑛 − 1 = 𝜆1(𝑆𝑛) untuk 𝑛 3.
Maka 𝛿(𝑆𝑛) < 𝜆1(𝑆𝑛).
b. 𝜆1(𝑆𝑛) < ∆(𝑆𝑛). Diketahui ∆(𝑆𝑛) = 𝑛.
Jadi 𝜆1(𝑆𝑛) = 𝑛 − 1 < 𝑛 = ∆(𝑆𝑛) untuk 𝑛 3. Maka 𝜆1(𝑆𝑛) < ∆(𝑆𝑛).
Jadi 𝛿(𝑆𝑛) < 𝜆1(𝑆𝑛) < ∆(𝑆𝑛) untuk graf bintang 𝑆𝑛 dengan 𝑛 3.
3. Kesimpulan
Berdasarkan penelitian yang telah dilakukan, didapatkan kesimpulan
sebagai berikut :
1. Pada graf tak berarah G dengan representasi menggunakan matriks
antiadjacency, didapat keterhubungan antara nilai eigen terbesar dari matriks
antiadjacency tersebut dengan derajat terkecil dan terbesar dari graf G adalah
𝛿(𝐺) ≤ 𝜆1(𝐺) ≤ ∆(𝐺). 2. Untuk matriks antiadjacency dari graf tidak berarah, didapatkan keterhubungan
sebagai berikut

627
Jenis Graf
Perbandingan Nilai Eigen
Terbesar, Derajat Terkecil, dan
Derajat Terbesar
Graf lengkap 𝐾𝑛 𝜆1(𝐾𝑛) < 𝛿(𝐾𝑛) = ∆(𝐾𝑛)
Graf bipartit lengkap 𝐾𝑟,𝑠 𝛿(𝐾𝑟,𝑠) ≤ ∆(𝐾𝑟,𝑠) = 𝜆1(𝐾𝑟,𝑠)
Graf bintang 𝑆𝑛 𝛿(𝑆𝑛) < 𝜆1(𝑆𝑛) < ∆(𝑆𝑛)
Referensi
[1] Alyani, F., 2014, Spektrum Matriks Antiadjacency dari Beberapa Kelas Graf Tak
Berarah, Tesis. Departemen Matematika FMIPA UI.
[2] Bapat, R.B., 2010, Graph and Matrices, Springer.
[3] Biggs, 1993, Algebraic Graph Theory. New York, Cambridge University Press.
[4] Chartrand, G dan Zhang, 2005, Introduction to Graph Theory, New York, McGraw-
Hill.
[5] Listyaningrum, R., 2015, Kaitan Nilai Eigen Terbesar Matriks Antiadjacency dengan
Derajat Graf dan Operasi Maksimum dari Dua Graf, Tesis. Departemen Matematika
FMIPA UI.
[6] Harary, 1995, Graph Theory. New York, Addison – Wesley.
[7] Sugeng, K.A., dan Slamet, S. dan Silaban, D.R.. 2014. Teori Graf dan Aplikasinya.
Depok. Departemen Matematika FMIPA UI

628
Prosiding SNM 2017 Kombinatorik , Hal 628-641
POLINOMIAL KARAKTERISTIK DAN SPEKTRUM
MATRIKS ADJACENCY DAN ANTI-ADJACENCY
DARI GRAF FRIENDSHIP TAK BERARAH DAN
BERARAH
BUDI PONIAM1,2, KIKI A. SUGENG2
1 Departemen Pendidikan Matematika, Fakultas Pendidikan, Universitas Sampoerna,
Gedung L’Avenue (Office) Lantai 5,
Jalan Raya Pasar Minggu Kav 16, Jakarta Selatan 12780,
2 Program Magister Matematika, Departemen Matematika FMIPA,
Universitas Indonesia, Kampus UI Depok 16424, [email protected].
Abstrak. Sebuah graf friendship (C3n), baik tak berarah maupun berarah, dapat
direpresentasikan dengan sebuah matriks adjacency maupun matriks anti-
adjacency. Pada makalah ini diberikan polinomial karakteristik dan spektrum
matriks adjacency dan anti-adjacency dari graf friendship tak berarah maupun
berarah. Graf friendship berarah meliputi graf yang siklik dan asiklik. Graf
siklik dibahas hanya untuk satu jenis yaitu graf yang semua graf segitiganya
(𝐶3) siklik searah; dan graf asiklik dibahas untuk dua jenis saja. Beberapa
kesimpulan yang menarik didapatkan dari hasil perbandingan polinomial
karakteristik dan spektrum dari matriks adjacency dan matriks anti-adjacency.
Kata kunci: Polinomial karakteristik, spektrum, adjacency, anti-adjacency, graf
friendship.
1. Pendahuluan
Kajian yang umum dilakukan pada matriks representasi graf adalah
penentuan sifat-sifat polinomial karakteristik dan spektrum matriks tersebut.
Penelitian mengenai polinomial karakteristik matriks adjacency dari suatu graf tidak
berarah dilakukan oleh Bapat [3] dan Biggs [4]. Knauer [9] meneliti hubungan nilai-
nilai karakteristik matriks adjacency dari suatu graf tidak berarah sederhana.
Penelitian mengenai matriks anti-adjacency dari suatu graf masih sangat
terbatas jumlahnya. Penelitian mengenai polinomial karakeristik matriks anti-
adjacency dari graf berarah telah dilakukan oleh Bapat [3], graf pohon berarah out-
tree oleh Nugroho [12], dan graf berarah asiklik oleh Firmansah [7], serta graf
berarah oleh Wildan [13]. Adiati [2] meneliti hubungan nilai-nilai karakteristik
matriks anti-adjacency dari suatu graf berarah sederhana.
Dalam makalah ini penulis menentukan polinomial karakteristik dan spektrum
matriks adjacency dan anti-adjacency dari graf friendship tak berarah dan berarah
dan mengkaji sifat-sifatnya. Polinomial karakteristik matriks adjacency dari graf
friendship tak berarah sudah dihitung oleh Cvetkovic, Rowlinson dan Simic [6], dan
spektrum matriks adjacencynya oleh Abdollahi, Janbaz dan Oboudi [1] namun

629
pembahasan tidak terkait dengan sifat-sifatnya.
Graf friendship berarah siklik yang dibahas dalam makalah ini dibatasi
hanya graf friendship yang setiap graf segitiganya 𝐶3 berarah siklik dan mempunyai
arah yang sama. Graf friendship berarah asiklik dibatasi hanya dua jenis yaitu graf
friendship berarah asiklik (1) dan (2).
2. Hasil – Hasil Utama
Teorema 2.1. [8] Misalkan sebuah matriks 𝐴𝑛 𝑥 𝑛 = (𝑎𝑖𝑗), berukuran 𝑛 × 𝑛,
dengan 𝑛 ≥ 1. 𝑎1𝑗 adalah entri baris pertama dan kolom ke 𝑗 dari matriks 𝐴 dan
𝐴1𝑗 adalah submatriks berukuran (𝑛 − 1) × (𝑛 − 1) yang dibentuk dengan
menghapuskan baris pertama dan kolom ke 𝑗 dari matriks 𝐴 . Maka determinan
matriks 𝐴 (|𝐴|) dapat dihitung melalui persamaan |𝐴| = ∑ 𝑎1𝑗. (−1)1+𝑗 |𝐴1𝑗|
𝑛𝑗=1 .
Teorema 2.2. [8] Jika A adalah sebuah matriks bujur sangkar blok segitiga yaitu
𝐴 =
[ 𝐴1 . . ⋯ .
0 𝐴2 . ⋯ .
0 0 𝐴3 ⋯ .
⋮ ⋮ ⋮ ⋱ ⋮
0 0 0 ⋯ 𝐴𝑝]
dengan submatriks 𝐴1, 𝐴2, 𝐴3, …, 𝐴𝑝 merupakan matriks bujur sangkar maka
|𝐴| = |𝐴1|. |𝐴2|. |𝐴3| … |𝐴𝑝|.
Untuk mencari polinomial karakteristik dari graf friendship berarah siklik
dan asiklik, maka diperlukan matriks khusus yang didefinisikan berikut ini.
Definisi 2.3. Ambil sebuah matriks bujur sangkar 𝑃 = (𝑝𝑖𝑗) berukuran (2𝑛 + 1) ×(2𝑛 + 1); dengan 𝑛 ≥ 1, yang setiap entrinya didefinisikan sebagai berikut:
𝑝𝑖𝑗 =
{
𝑎, untuk 𝑖 = 𝑗
𝑏, untuk 𝑖 = {2, 4, 6, … , 2𝑛} dan 𝑗 = 𝑖 + 1
𝑐, untuk 𝑖 = {3, 5, 7, … , 2𝑛 + 1} dan 𝑗 = 𝑖 − 1
𝑒, untuk 𝑖 = 1 dan 𝑗 = {2, 4, 6, … , 2𝑛}
𝑓, untuk 𝑖 = 1 dan 𝑗 = {3, 5, 7, … , 2𝑛 + 1}
𝑔, untuk 𝑖 = {2, 4, 6,… , 2𝑛} dan 𝑗 = 1
ℎ, untuk 𝑖 = {3, 5, 7,… , 2𝑛 + 1} dan 𝑗 = 1
𝑑, untuk entri lainnya.
.
Jadi matriks P dapat ditulis sebagai berikut:
1 2 3 . 6 7 8 9 . 2𝑛 2𝑛 + 1

630
dengan 𝑛 ≥ 1; 𝑛 ∈ 𝑁 dan 𝑎, 𝑏, 𝑐, 𝑑, 𝑒, 𝑓, 𝑔, ℎ ∈ 𝑅.
Lemma 2.4. Misalkan 𝑃 adalah sebuah matriks yang didefinisikan seperti pada
Definisi 2.3. maka 𝑝1(2𝑙). (−1)1+2𝑙 |𝑃1(2𝑙)| = −𝑒. |𝑃12|, untuk 𝑙 ∈ {1, 2, 3, … , 𝑛};
dengan 𝑃1𝑗 adalah submatriks berukuran 2𝑛 × 2𝑛 yang dibentuk dengan
menghapuskan baris pertama dan kolom ke 𝑗 dari matriks 𝑃.
BUKTI. Lemma 2.4. dapat juga ditulis sebagai berikut:
𝑝12. (−1)1+2|𝑃12| = 𝑝14. (−1)
1+4 |𝑃14| = ⋯ = 𝑝1(2𝑛). (−1)1+2𝑛 |𝑃1(2𝑛)| =
−𝑒. |𝑃12|. Sesuai dengan definisi matriks 𝑃, didapatkan
𝑝12. (−1)1+2 = 𝑝14. (−1)
1+4 = ⋯ = 𝑝1(2𝑛). (−1)1+2𝑛 = −𝑒 atau
𝑝1(2𝑙). (−1)1+2𝑙 = −𝑒 , untuk 𝑙 ∈ {1, 2, 3, … , 𝑛}.
Untuk 𝑙 = 1, terbukti dengan jelas 𝑝12. (−1)1+2|𝑃12| = −𝑒. |𝑃12|.
Untuk 𝑙 = 2, perlu dibuktikan bahwa |𝑃14| = |𝑃12| . Menurut Franklin [8], jika 𝛼𝑖 adalah vektor baris ke-i dan 𝛽𝑗 adalah vektor
kolom ke-j, operasi pertukaran baris dan pertukaran kolom dapat dilakukan pada
suatu matriks yaitu vektor baris ke-r dengan vektor baris ke-s saling tukar (𝛼𝑟 ↔ 𝛼𝑠) dan vektor kolom ke-r dengan vektor kolom ke-s saling tukar (𝛽𝑟 ↔ 𝛽𝑠). Untuk
setiap pertukaran vektor baris atau kolom, determinan matriks akan berubah tanda
(negatif menjadi postif dan sebaliknya). Selain pertukaran baris dan kolom, dalam
perhitungan determinan matriks dikenal juga operasi baris 𝛼𝑟∗ = 𝛼𝑟 + 𝑡𝛼𝑠 dan
operasi kolom 𝛽𝑟∗ = 𝛽𝑟 + 𝑡𝛽𝑠 dengan 𝑡 ∈ 𝑅 dan tanda * menyatakan vektor baris
atau kolom yang baru, hasil operasi baris atau kolom. Operasi baris atau kolom ini
tidak mengubah determinan suatu matriks.
Dalam pembuktian ini, operasi pertukaran baris pada submatriks 𝑃14 akan
dilakukan yaitu (𝛼2 ↔ 𝛼4) & (𝛼1 ↔ 𝛼3), kemudian pertukaran kolom (𝛽2 ↔𝛽3) lalu (𝛽2 ↔ 𝛽4) sehingga didapatkan submatriks 𝑃12. Terbukti |𝑃14| = |𝑃12|.
Untuk 2 < 𝑙 ≤ 𝑛, akan dibuktikan|𝑃1(2(𝑙+1))| = |𝑃1(2𝑙)|. Operasi
pertukaran baris pada submatriks 𝑃1(2(𝑙+1)) akan dilakukan yaitu (𝛼2𝑙−1 ↔ 𝛼2𝑙+1)
dan (𝛼2𝑙 ↔ 𝛼2𝑙+2), kemudian pertukaran kolom (𝛽2𝑙 ↔ 𝛽2𝑙+1) lalu (𝛽2𝑙 ↔ 𝛽2𝑙+2)
sehingga didapatkan submatriks 𝑃1(2𝑙). Terbukti |𝑃1(2(𝑙+1))| = |𝑃1(2𝑙)|. Karena
𝑝14. (−1)1+4 |𝑃14| = −𝑒. |𝑃12|, maka didapatkan 𝑝1(2𝑛). (−1)
1+2𝑛|𝑃1(2𝑛)| = ⋯ =
𝑝16. (−1)1+6|𝑃16| = 𝑝14. (−1)
1+4 |𝑃14| = −𝑒. |𝑃12|.
Jadi 𝑝1(2𝑙). (−1)1+2𝑙|𝑃1(2𝑙)| = −𝑒. |𝑃12| , untuk 𝑙 ∈ {1, 2, 3, … , 𝑛}. ∎
𝑃 =
[
𝒂 𝑒 𝑓 . 𝑒 𝑓 𝑒 𝑓 . 𝑒 𝑓𝑔 𝒂 𝒃 . 𝑑 𝑑 𝑑 𝑑 . 𝑑 𝑑ℎ 𝒄 𝒂 . 𝑑 𝑑 𝑑 𝑑 . 𝑑 𝑑. . . . . . . . . . .𝑔 𝑑 𝑑 . 𝒂 𝒃 𝑑 𝑑 . 𝑑 𝑑ℎ 𝑑 𝑑 . 𝒄 𝒂 𝑑 𝑑 . 𝑑 𝑑𝑔 𝑑 𝑑 . 𝑑 𝑑 𝒂 𝒃 . 𝑑 𝑑ℎ 𝑑 𝑑 . 𝑑 𝑑 𝒄 𝒂 . 𝑑 𝑑. . . . . . . . . . .𝑔 𝑑 𝑑 . 𝑑 𝑑 𝑑 𝑑 . 𝒂 𝒃ℎ 𝑑 𝑑 . 𝑑 𝑑 𝑑 𝑑 . 𝒄 𝒂]
1
23.6789.2𝑛
2𝑛 + 1

631
Lemma 2.5. Misalkan 𝑃 adalah sebuah matriks yang didefinisikan seperti pada
Definisi 2.3. maka 𝑝1(2𝑙+1). (−1)1+2𝑙+1|𝑃1(2𝑙+1)| = 𝑓. |𝑃13|, untuk
𝑙 ∈ {1, 2, 3, … , 𝑛}; dengan 𝑃1𝑗 adalah submatriks berukuran 2𝑛 × 2𝑛 yang dibentuk
dengan menghapuskan baris pertama dan kolom ke 𝑗 dari matriks 𝑃.
BUKTI. Lemma 2.6. dapat juga ditulis sebagai berikut:
𝑝13. (−1)1+3|𝑃13| = 𝑝15. (−1)
1+5 |𝑃15| = ⋯ = 𝑝1(2𝑛+1). (−1)1+2𝑛+1 |𝑃1(2𝑛+1)| = 𝑓. |𝑃13|.
Sesuai dengan definisi matriks 𝑃, kita dapatkan
𝑝13. (−1)1+3 = 𝑝15. (−1)
1+5 = ⋯ = 𝑝1(2𝑛+1). (−1)1+2𝑛+1 = 𝑓 atau
𝑝1(2𝑙+1). (−1)1+2𝑙+1 = 𝑓 , untuk 𝑙 ∈ {1, 2, 3, … , 𝑛}.
Dengan cara pembuktian yang sama dengan cara pembuktian pada Lemma
2.5., didapatkan |𝑃1(2𝑛+1)| = ⋯ = |𝑃17| = |𝑃15| = |𝑃13| sehingga didapatkan
𝑝1(2𝑙+1). (−1)1+2𝑙+1|𝑃1(2𝑙+1)| = 𝑓. |𝑃13|, untuk 𝑙 ∈ {1, 2, 3, … , 𝑛}. ∎
Teorema 2.6. Misalkan P adalah sebuah matriks seperti yang didefinisikan seperti
pada Definisi 2.3., maka |𝑃| = 𝑎. |𝑃11| − 𝑛. 𝑒. |𝑃12| + 𝑛. 𝑓. |𝑃13|; dengan 𝑃1𝑗
adalah submatriks berukuran 2𝑛 × 2𝑛 yang dibentuk dengan menghapuskan baris
pertama dan kolom ke 𝑗 dari matriks 𝑃.
BUKTI. Berdasarkan Teorema 2.1. |𝑃| = ∑ 𝑝1𝑗. (−1)1+𝑗|𝑃1𝑗|
2𝑛+1𝑗=1 ; dengan 𝑃1𝑗
adalah submatriks berukuran 2𝑛 × 2𝑛 yang dibentuk dengan menghapuskan baris
pertama dan kolom ke 𝑗 dari matriks 𝑃, didapatkan |𝑃| = 𝑎. |𝑃11| +
∑ 𝑝1(2𝑙). (−1)1+2𝑙|𝑃1(2𝑙)| + ∑ 𝑝1(2𝑙+1). (−1)
1+2𝑙+1𝑛𝑙=1 |𝑃1(2𝑙+1)|
𝑛𝑙=1 .
Berdasarkan Lemma 2.5. dan 2.6., maka didapatkan
|𝑃| = 𝑎. 𝑃11 +∑(−𝑒.
𝑛
𝑙=1
|𝑃12|) +∑(𝑓.
𝑛
𝑙=1
|𝑃13|)
|𝑃| = 𝑎. |𝑃11| − 𝑛. 𝑒. |𝑃12| + 𝑛. 𝑓. |𝑃13| . ∎
Definisi 2.7. [8] Ambil suatu matriks A berukuran 𝑛 × 𝑛 yang memenuhi persamaan
matriks 𝐴𝑥 = 𝜆𝑥, dengan skalar 𝜆 yang disebut nilai karakteristik, dan vektor 𝑥 ≠ 0
berukuran 𝑛 × 1 disebut vektor karakteristik yang bersesuaian dengan nilai
karakteristik 𝜆. Polinomial karakteristik matriks 𝐴 berukuran 𝑛 × 𝑛 adalah
𝑃(𝐴) = 𝑑𝑒𝑡(𝜆𝐼 − 𝐴) = 𝜆𝑛 + 𝑎1𝜆𝑛−1 +⋯+ 𝑎𝑛 dengan n adalah derajat tertinggi
dari 𝑃(𝐴).
Definisi 2.8. [11] Submatriks utama dari matriks 𝐴 = [𝑎𝑖𝑗] berukuran 𝑛 × 𝑛
didefinisikan sebagai suatu submatriks berukuran (𝑛 − 𝑘) × (𝑛 − 𝑘) yang diperoleh
dengan menghapus secara bersamaan 𝑘 buah baris dan 𝑘 buah kolom yang
berindeks sama dari matriks 𝐴. Minor utama dari matriks 𝐴 didefinisikan sebagai
determinan submatriks utama dari matriks 𝐴.
Teorema 2.9. [11] Jika 𝜆𝑛 + 𝑐1𝜆𝑛−1 + 𝑐2𝜆
𝑛−2 +⋯+ 𝑐𝑛−1𝜆 + 𝑐𝑛 = 0 adalah
persamaan karakteristik untuk matriks 𝐴 berukuran 𝑛 × 𝑛 maka
𝑐𝑖 = (−1)𝑖∑|𝐴𝑖
(𝑗)|
𝑤
𝑗=1
𝑑𝑒𝑛𝑔𝑎𝑛 𝑖 = 1, 2, … , 𝑛

632
dengan |𝐴𝑖(𝑗)| adalah minor utama berukuran 𝑖 × 𝑖 dari matriks 𝐴 dan 𝑗 = 1, 2,… ,𝑤
dengan 𝑤 adalah banyaknya minor utama yang berukuran 𝑖 × 𝑖 dari matriks 𝐴.
Definisi 2.10. [3] Jika 𝑉(𝐺) = { 𝑣1, . . . , 𝑣𝑛} adalah himpunan tak kosong dari
simpul-simpul pada graf G maka matriks adjacency 𝐴(𝐺) = [𝑎𝑖𝑗] dari graf berarah
𝐺 adalah matriks 𝑛 𝑥 𝑛 yang didefinisikan sebagai berikut:
𝑎𝑖𝑗 = {1, 𝑢𝑛𝑡𝑢𝑘 𝑖 ≠ 𝑗 𝑗𝑖𝑘𝑎 𝑡𝑒𝑟𝑑𝑎𝑝𝑎𝑡 𝑏𝑢𝑠𝑢𝑟 𝑏𝑒𝑟𝑎𝑟𝑎ℎ 𝑑𝑎𝑟𝑖 𝑣𝑖 𝑘𝑒 𝑣𝑗0. 𝑢𝑛𝑡𝑢𝑘 𝑙𝑎𝑖𝑛𝑛𝑦𝑎
Definisi tersebut juga berlaku untuk graf tak berarah 𝐺 dengan 𝑎𝑖𝑗 = 1 jika untuk
𝑖 ≠ 𝑗 terdapat busur yang menghubungkan 𝒗𝒊 dan 𝒗𝒋.
Teorema 2.11. [3,4] Misalkan G adalah sebuah graf tidak berarah yang memiliki
simpul sebanyak 𝑛 dan busur sebanyak 𝑚 dengan polinomial karakteristik
𝑃(𝐴(𝐺)) = 𝜆𝑛 + 𝑎1𝜆𝑛−1 +⋯+ 𝑎𝑛, dan 𝐴(𝐺) adalah matriks adjacency dari graf
𝐺, maka koefisien 𝑎1 = 0, 𝑎2 = −𝑚 dan 𝑎3 menyatakan negatif dari dua kali
banyaknya graf segitiga (graf yang terdiri dari tiga simpul yang saling terhubung).
Definisi 2.12. [3] Matriks anti-adjacency dari suatu graf G adalah matriks 𝐵(𝐺) =𝐽 − 𝐴(𝐺) dengan 𝐽 adalah matriks berukuran sama dengan matriks 𝐴(𝐺), yang
semua entrinya adalah 1 dan matriks 𝐴(𝐺) adalah matriks adjacency dari graf G.
Teorema 2.13 [13] Misalkan 𝐺 adalah graf berarah yang memiliki 𝑛 simpul dan 𝑚
busur, dan 𝐵(𝐺) adalah matriks anti-adjacency dari 𝐺 dengan polinomial
karakteristiknya adalah 𝑃(𝐵(𝐺)) = 𝑑𝑒𝑡(𝜆𝐼 − 𝐵(𝐺)) = 𝜆𝑛 + 𝑏1𝜆𝑛−1 +⋯+
𝑏𝑛−1𝜆 + 𝑏𝑛, maka 𝑏1 = −𝑛 , 𝑏2 = 𝑚 dan 𝑏3 menunjukkan negatif dari banyaknya
subgraf terinduksi asiklik yang memiliki lintasan Hamilton dari tiga buah simpul
ditambah dua kali banyaknya lingkaran pada 𝐺. Lintasan Hamilton adalah sebuah
lintasan yang melalui semua simpul yang ada pada suatu graf tepat satu kali.
Definisi 2.14. [3,4] Spektrum matriks 𝐴𝑛×𝑛 didefinisikan sebagai
𝑆𝑝𝑒𝑐(𝐴) = (𝜆1 𝜆2 …
𝑚(𝜆1) 𝑚(𝜆2) … 𝜆𝑠
𝑚(𝜆𝑠 )) dengan nilai karakteristik matriks 𝐴,
𝜆1 > 𝜆2 > ⋯ > 𝜆𝑠 dan multiplisitas masing-masing 𝑚(𝜆1),𝑚( 𝜆2), … , 𝑚(𝜆𝑠 ). Nilai karakteristik matriks 𝐴(𝜆1, 𝜆2, … , 𝜆𝑛 ) merupakan akar-akar yang didapatkan
dari persamaan karakteristik 𝑃𝐴(𝜆) = 𝑑𝑒𝑡(𝜆𝐼 − 𝐴) = ∏ (𝜆 − 𝜆𝑖) = 0𝑛𝑖=1 .
Teorema 2.15. [9] Misalkan 𝐺 adalah suatu graf tak berarah sederhana yang
memiliki 𝑛 simpul dan 𝑚 busur, dan 𝐴 adalah matriks adjacency dari graf 𝐺 serta
𝜆1, 𝜆2, … , 𝜆𝑛 adalah nilai karakteristik dari matriks 𝐴, maka ∑ λini=1 =0 dan
∑ 𝜆𝑖2𝑛
𝑖=1 = 2𝑚.
Teorema 2.16. [2] Misalkan 𝐺 adalah suatu graf berarah asiklik maupun siklik yang
memiliki 𝑛 simpul dan 𝑚 busur, dan 𝐵 adalah matriks anti-adjacency dari graf 𝐺
serta 𝜆1, 𝜆2, … , 𝜆𝑛 adalah nilai karakteristik dari matriks 𝐵, maka ∑ 𝜆𝑖𝑛𝑖=1 = 𝑛 dan
∑ 𝜆𝑖2𝑛
𝑖=1 = 𝑛2 − 2𝑚.
Definisi 2.17. [10] Graf friendship (biasanya ditulis 𝐶3𝑛) adalah suatu graf yang
dihasilkan dengan menggabungkan sejumlah 𝑛 buah graf segitiga 𝐶3 dengan satu

633
simpul yang sama. Graf segitiga 𝐶3 merupakan graf yang memiliki tiga simpul yang
saling bertetangga.
Definisi 2.18. [5] Suatu graf berarah (directed graph/digraph) adalah graf
yang busur-busurnya berarah, sedangkan graf tak berarah adalah graf yang
busurnya tak berarah yaitu busurnya hanya menghubungkan dua simpul tanpa
ada perbedaan antara simpul asal dan simpul akhir. Graf berarah asiklik
adalah graf berarah yang tidak memuat subgraf berupa siklus berarah. Graf
berarah siklik adalah graf yang memuat subgraf berupa siklus berarah.
Dalam makalah ini, pembahasan hanya terbatas pada graf friendship yang
ditunjukkan pada Tabel 1. Pada Tabel 1 juga ditunjukkan matriks adjacency
dari graf friendship yang terkait.
Tabel 1. Gambar graf friendship (𝐶3𝑛) dan matriks adjacency yang terkait.
𝑪𝟑𝒏 Matriks Adjacency (A)
1. Tak
berarah
2. Berarah
siklik
3. Berarah
asiklik
(1)
4. Berarah
asiklik
(2)

634
Teorema 2.19. Suatu graf friendship (𝐶3𝑛) tak berarah dengan matriks
adjacency (𝐴𝐹𝑡𝑏𝑛 ) memiliki polinomial karakteristik
𝑃(𝐴𝐹𝑡𝑏𝑛 ) = (𝜆2 − 1)𝑛−1 (𝜆3 − (2𝑛 + 1)𝜆 − 2𝑛 ), dan 𝑆𝑝𝑒𝑐(𝐴𝐹𝑡𝑏
𝑛 ) =
(1
2(1 + √1 + 8𝑛) 1 −1
1 𝑛 − 1 𝑛
1
2(1 − √1 + 8𝑛)
1), dengan 𝜆 adalah nilai
karakteristik matriks 𝐴𝐹𝑡𝑏𝑛 .
BUKTI. Polinomial karakteristik matriks adjacency (𝐴𝐹𝑡𝑏𝑛 ) dari suatu graf
friendship (𝐶3𝑛) tak berarah didapatkan dengan menjabarkan det(𝜆𝐼 − 𝐴𝐹𝑡𝑏
𝑛 ); dengan 𝜆 adalah nilai karakteristik matriks adjacency (𝐴𝐹𝑡𝑏
𝑛 ) dan 𝐼 adalah
matriks identitas. Sebut 𝐶 = 𝜆𝐼 − 𝐴𝐹𝑡𝑏𝑛 . Berdasarkan Teorema 2.6., dapat
dihitung
𝑃(𝐴𝐹𝑡𝑏𝑛 ) = |𝐶| = 𝜆 |𝐶11| − 𝑛(−1) |𝐶12| + 𝑛(−1) |𝐶13|
= 𝜆 |𝐶11| + 𝑛(|𝐶12| − |𝐶13|) (1)
dengan 𝐶1𝑗 adalah submatriks yang dibentuk dengan menghapuskan baris
pertama dan kolom ke 𝑗 dari matriks 𝐶. Berdasarkan Teorema 2.2., didapatkan
|𝐶11| = (𝜆2 − 1)
2𝑛
2 = (𝜆2 − 1)𝑛, (2)
|𝐶12| = −(𝜆 + 1)(𝜆2 − 1)
2𝑛−2
2 = −(𝜆 + 1)(𝜆2 − 1)𝑛−1, (3)
|𝐶13| = (𝜆 + 1)(𝜆2 − 1)
2𝑛−2
2 = (𝜆 + 1)(𝜆2 − 1)𝑛−1. (4)
Persamaan (2), (3), dan (4) disubstitusikan ke persamaan (1), sehingga
didapatkan
𝑃(𝐴𝐹𝑡𝑏𝑛 ) = |𝐶| = 𝜆|𝐶11| + 𝑛(|𝐶12| − |𝐶13|)
= 𝜆 (𝜆2 − 1)𝑛 + 𝑛(−(𝜆 + 1)(𝜆2 − 1)𝑛−1 − (𝜆 + 1)(𝜆2 − 1)𝑛−1 ) = (𝜆2 − 1)𝑛−1 (𝜆3 − (2𝑛 + 1)𝜆 − 2𝑛 ). (5)
Dengan mencari akar-akar persamaan karakteristik pada persamaan (5)
yaitu 𝑃(𝐴𝐹𝑡𝑏𝑛 ) = (𝜆2 − 1)𝑛−1(𝜆3 − (2𝑛 + 1)𝜆 − 2𝑛 ) = 0 didapatkan 𝜆1 =
1
2(1 + √1 + 8𝑛) dengan 𝑚(𝜆1) = 1, 𝜆2 = 1 dengan 𝑚(𝜆2) = 𝑛 − 1, 𝜆3 = −1
dengan 𝑚(𝜆3) = 𝑛, dan 𝜆4 =1
2(1 − √1 + 8𝑛) dengan 𝑚(𝜆4) = 1. ∎
Teorema 2.19. sesuai dengan Teorema 2.11., 𝑃(𝐴𝐹𝑡𝑏𝑛 ) = 𝜆2𝑛+1 −
3𝑛𝜆2𝑛−1 − 2𝑛𝜆2𝑛−2 +⋯ . Koefisien 𝜆2𝑛 yaitu 𝑎1 = 0, koefisien 𝜆2𝑛−1 yaitu 𝑎2 =−3𝑛 (negatif dari banyak busur) dan koefisien 𝜆2𝑛−2 yaitu 𝑎3 = −2𝑛 (negatif dari
dua kali banyaknya graf segitiga (𝐶3𝑛). Demikian juga untuk spektrumnya sesuai
dengan Teorema 2.15. yaitu
∑ λi2n+1i=1 =
1
2(1 − √1 + 8𝑛) + 𝑛 × (−1) + (𝑛 − 1) × 1 +
1
2(1 + √1 + 8𝑛) = 0 dan
∑ 𝜆𝑖22𝑛+1
𝑖=1 = (1
2(1 − √1 + 8𝑛))
2
+ 𝑛 + (𝑛 − 1) + (1
2(1 − √1 + 8𝑛))
2
= 2 × 3𝑛 = 2𝑚,
dengan 𝑚 menyatakan banyaknya busur, yaitu sebesar 3𝑛.
Teorema 2.20. Suatu graf friendship (𝐶3𝑛) berarah siklik seperti yang ditunjukkan
di Tabel 1. dengan matriks adjacency (𝐴𝐹𝑠𝑛 ) memiliki polinomial karakteristik
𝑃(𝐴𝐹𝑠𝑛 ) = 𝜆2(𝑛−1)(𝜆3 − 𝑛), dan 𝑆𝑝𝑒𝑐(𝐴𝐹𝑠
𝑛 ) = (√𝑛3
03 2𝑛 − 2
), dengan 𝜆 adalah nilai
karakteristik matriks 𝐴𝐹𝑠𝑛 .
BUKTI. Sebut 𝐹 = (𝜆𝐼 − 𝐴𝐹𝑠𝑛 ) . Berdasarkan Teorema 2.6., dapat dihitung

635
𝑃(𝐴𝐹𝑠𝑛 ) = |𝜆𝐼 − 𝐴𝐹𝑠
𝑛 | = |𝐹| = 𝜆 |𝐹11| − 𝑛. (−1)|𝐹12| + 𝑛. (0)|𝐹13|
= 𝜆|𝐹11| + 𝑛|𝐹12|. (6)
Berdasarkan Teorema 2.2., didapatkan
|𝐹11| = 𝜆2𝑛, (7)
|𝐹12| = (−1)(𝜆2)
2𝑛−2
2 = − 𝜆2(𝑛−1). (8)
Substitusikan persamaan (7) dan (8) ke dalam persamaan (6) maka didapatkan
𝑃(𝐴𝐹𝑠𝑛 ) = |𝐹| = 𝜆2𝑛+1 + 𝑛(− 𝜆2(𝑛−1)) = 𝜆2(𝑛−1)(𝜆3 − 𝑛). (9)
Dengan mencari akar-akar persamaan karakteristik pada persamaan (9) yaitu
𝑃(𝐴𝐹𝑠𝑛 ) = 𝜆2(𝑛−1)(𝜆3 − 𝑛) = 0 didapatkan 𝜆1 = √𝑛
3 dengan 𝑚(𝜆1) = 3, 𝜆2 =
0 dengan 𝑚(𝜆2) = 2𝑛 − 2. ∎
Teorema 2.20. sesuai dengan Teorema 2.9., 𝑃(𝐴𝐹𝑠𝑛 ) = 𝜆2𝑛+1 − 𝑛 𝜆2𝑛−2.
Karena setiap entri diagonal matriksnya sama dengan nol maka koefisien 𝜆2𝑛 yaitu
𝑎1 = 0. Demikian juga semua minor utama berukuran 2 × 2 sama dengan nol maka
koefisien 𝜆2𝑛−1 yaitu 𝑎2 = 0. Karena ada sebanyak 𝑛 minor utama berukuran 3 × 3
yaitu [0 1 00 0 11 0 0
] (satu graf 𝐶3 siklik) maka koefisien 𝜆2𝑛−2 yaitu 𝑎3 = −𝑛
(banyaknya graf 𝐶3 siklik). Untuk koefisien dari suku berikutnya sama dengan nol
karena semua minor utama yang berukuran lebih besar dari 3 × 3 sama dengan nol.
Teorema 2.21. Suatu graf friendship (𝐶3𝑛) berarah asiklik (1) seperti yang
ditunjukkan di Tabel 1. dengan matriks adjacency (𝐴𝐹𝑎1𝑛 ) memiliki polinomial
karakteristik 𝑃(𝐴𝐹𝑎1𝑛 ) = 𝜆2𝑛+1 dan 𝑆𝑝𝑒𝑐(𝐴𝐹𝑎1
𝑛 ) = (0
2𝑛 + 1), dengan 𝜆 adalah nilai
karakteristik matriks 𝐴𝐹𝑎1𝑛 .
BUKTI. Berdasarkan Teorema 2.2., dapat dihitung
𝑃(𝐴𝐹𝑎1𝑛 ) = |𝜆𝐼 − 𝐴𝐹𝑎1
𝑛 | = 𝜆2𝑛+1. (10)
Dengan mencari akar-akar persamaan karakteristik pada persamaan (10) yaitu
𝑃(𝐴𝐹𝑎1𝑛 ) = 𝜆2𝑛+1 = 0 didapatkan 𝜆1 = 0 dengan 𝑚(𝜆1) = 2𝑛 + 1. ∎
Teorema 2.22. Suatu graf friendship (𝐶3𝑛) berarah asiklik (2) seperti yang
ditunjukkan di Tabel 1. dengan matriks adjacency (𝐴𝐹𝑎2𝑛 ) memiliki polinomial
karakteristik 𝑃(𝐴𝐹𝑎2𝑛 ) = 𝜆2𝑛+1 dan 𝑆𝑝𝑒𝑐(𝐴𝐹𝑎2
𝑛 ) = (0
2𝑛 + 1), dengan 𝜆 adalah nilai
karakteristik matriks 𝐴𝐹𝑎2𝑛 .
BUKTI. Sebut 𝐻 = (𝜆𝐼 − 𝐴𝐹𝑎2𝑛 ). Berdasarkan Teorema 2.6., dapat dihitung
𝑃(𝐴𝐹𝑎2𝑛 ) = |𝜆𝐼 − 𝐴𝐹𝑎2
𝑛 | = |𝐻| = 𝜆 |𝐻11| − 𝑛(−1)|𝐻12| + 𝑛(0)|𝐻13|
= 𝜆|𝐻11| + 𝑛|𝐻12|. (11)
Berdasarkan Teorema 2.1. dan Teorema 2.2., didapatkan
|𝐻11| = 𝜆2𝑛, (12)
|𝐻12| = 0. (13)
Dengan mensubstitusikan persamaan (12) dan (13) ke dalam persamaan (11) maka
didapatkan
𝑃(𝐴𝐹𝑎2𝑛 ) = |𝐻| = 𝜆2𝑛+1. (14)
Dengan mencari akar-akar persamaan karakteristik pada persamaan (14) yaitu
𝑃(𝐴𝐹𝑎2𝑛 ) = 𝜆2𝑛+1 = 0 didapatkan 𝜆1 = 0 dengan 𝑚(𝜆1) = 2𝑛 + 1. ∎

636
Teorema 2.21. dan 2.22. sesuai dengan Teorema 2.9, 𝑃(𝐴𝐹𝑎1𝑛 ) =
𝑃(𝐴𝐹𝑎2𝑛 ) = 𝜆2𝑛+1. Semua koefisien selain 𝑎0 sama dengan nol karena semua minor
utamanya sama dengan nol.
Matriks anti-adjacency dari graf friendship yang terkait dengan
pembahasan dalam makalah ini ditunjukkan pada Tabel 2.
Tabel 2. Gambar graf friendship (𝐶3𝑛) dan matriks anti-adjacency terkait.
𝑪𝟑𝒏 Matriks Antiadjacency (B)
1. Tak
berarah
2. Berarah
siklik
3. Berarah
asiklik
(1)
4. Berarah
asiklik
(2)
Teorema 2.23. Suatu graf friendship (𝐶3𝑛) tak berarah dengan matriks anti-
adjacency (𝐵𝐹𝑡𝑏𝑛 ) memiliki polinomial 𝑃(𝐵𝐹𝑡𝑏
𝑛 ) = (𝜆2 − 1)𝑛−1(𝜆3 − (2𝑛 + 1)𝜆2 +
(4𝑛 − 1)𝜆 − (2𝑛 − 1)), dan 𝑆𝑝𝑒𝑐(𝐵𝐹𝑡𝑏𝑛 ) = (
2𝑛 − 1 1 −11 𝑛 + 1 𝑛 − 1
), dengan 𝜆
adalah nilai karakteristik matriks 𝐵𝐹𝑡𝑏𝑛 .
BUKTI. Sebut 𝐷 = 𝜆𝐼 − 𝐵𝐹𝑡𝑏𝑛 . Berdasarkan Teorema 2.1., didapatkan

637
𝑃(𝐵𝐹𝑡𝑏𝑛 ) = |𝜆𝐼 − 𝐵𝐹𝑡𝑏
𝑛 | = |𝐷| = (𝜆 − 1)|𝐷11|. (15)
Secara berurutan lakukan operasi matriks pada matriks 𝐷11 yaitu: operasi baris
𝛼𝑖∗ = − 𝛼1 + 𝛼𝑖 untuk 𝑖 = 2, 3, 4, … , 2𝑛; lalu 𝛼𝑖
∗ = −1
𝜆𝛼(𝑖+1) + 𝛼𝑖 untuk 𝑖 =
3, 5, 7,… , 2𝑛 − 1; kemudian operasi kolom 𝛽𝑗∗ = −𝛽 2𝑛 + 𝛽𝑗 dilakukan dengan
𝑗 = 3, 4, … , 2𝑛 − 1 sehingga didapatkan
|𝐷11| = (𝜆 − 1)2((𝜆 − 1) (𝜆 + 1))
2𝑛−2
2 + (−1)1+2𝑛(−1) |(𝐷11)∗1(2𝑛)
|, (16)
dengan (𝐷11)∗ adalah matriks hasil akhir operasi baris dan kolom di atas. Operasi
kolom secara berurutan dilakukan pada matriks (𝐷11)∗1(2𝑛) yaitu: 𝛽2
∗ = 𝛽1 + 𝛽2,
lalu 𝛽3∗ = 𝛽2 + 𝛽3; kemudian 𝛽4
∗ = 𝛽3 + 𝛽4; dan seterusnya hingga 𝛽2𝑛−1∗ =
𝛽2𝑛−2 + 𝛽2𝑛−1. Berdasarkan Teorema 2.2., didapatkan
|(𝐷11)∗1(2𝑛)| = −(𝜆 − 1) ((𝜆 − 1) (𝜆 + 1))
(2𝑛−1)−1
2 2(𝑛 − 1).
= −2(𝑛 − 1) (𝜆 − 1)𝑛 (𝜆 + 1)𝑛−1. (17)
Dengan mensubstitusi persamaan (17) ke persamaan (16), lalu persamaan (16) ke
persamaan (15), didapatkan
𝑃(𝐵𝐹𝑡𝑏𝑛 ) = |𝜆𝐼 − 𝐵𝐹𝑡𝑏
𝑛 | = (𝜆 − 1)|𝐷11| = (𝜆2 − 1 )𝑛−1(𝜆3 − (2𝑛 + 1)𝜆2 + (4𝑛 − 1)𝜆 − (2𝑛 − 1)). (18)
Dengan mencari akar-akar persamaan karakteristik pada persamaan (18) yaitu
𝑃(𝐵𝐹𝑡𝑏𝑛 ) = (𝜆2 − 1 )𝑛−1(𝜆3 − (2𝑛 + 1)𝜆2 + (4𝑛 − 1)𝜆 − (2𝑛 − 1)) = 0 didapatkan
𝜆1 = 2𝑛 − 1 dengan 𝑚(𝜆1) = 1, 𝜆2 = 1 dengan 𝑚(𝜆2) = 𝑛 + 1, 𝜆3 = −1 dengan
𝑚(𝜆3) = 𝑛 − 1. ∎
Teorema 2.23. sesuai dengan Teorema 2.13., 𝑃(𝐵𝐹𝑡𝑏𝑛 ) = 𝜆2𝑛+1 − (2𝑛 +
1)𝜆2𝑛 + 3𝑛𝜆2𝑛−1 + (2𝑛2 − 3𝑛)𝜆2𝑛−2 +⋯. Karena setiap entri diagonal matriksnya
sama dengan 1 maka koefisien 𝜆2𝑛 yaitu 𝑎1 = −(2𝑛 + 1) (negatif dari banyaknya
simpul). Karena ada sebanyak 3𝑛 minor utama berukuran 2 × 2 yaitu [1 00 1
] (satu
busur) maka koefisien 𝜆2𝑛−1 yaitu 𝑎2 = 3𝑛 (banyaknya busur). Demikian juga untuk
spektrumnya sesuai dengan Teorema 2.16. yaitu ∑ 𝜆𝑖2𝑛+1𝑖=1 = (𝑛 − 1) × (−1) +
(𝑛 + 1) × 1 + 1 × (2𝑛 − 1) = 2𝑛 + 1 (banyaknya simpul) dan ∑ 𝜆𝑖2𝑛
𝑖=1 = (𝑛 −1) × (−1)2 + (𝑛 + 1) × 12 + (2𝑛 − 1)2 = (2𝑛 + 1)2 − 2(3𝑛).
Walaupun Teorema 2.13. dan 2.16. sebenarnya berlaku untuk graf berarah,
ternyata ada kecocokan untuk graf friendship tak berarah karena koefisien tiga suku
pertama polinomial karakteristiknya sama dengan koefisien tiga suku pertama pada
graf friendship berarah siklik maupun asiklik.
Teorema 2.24. Suatu graf friendship (𝐶3𝑛) berarah siklik seperti yang ditunjukkan
di Tabel 2. dengan matriks anti-adjacency (𝐵𝐹𝑠𝑛 ) memiliki polinomial karakteristik
𝑃(𝐵𝐹𝑠𝑛 ) = 𝜆2(𝑛−1)(𝜆3 − (2𝑛 + 1)𝜆2 + 3𝑛𝜆 − 𝑛2 − 𝑛), dan 𝑆𝑝𝑒𝑐(𝐵𝐹𝑠
𝑛 ) =
(𝜆1 𝜆21 1
𝜆31
02𝑛 − 2
), 𝜆1 𝑑𝑎𝑛 𝜆2 ∈ 𝐶, 𝜆3 ∈ 𝑅 untuk 𝑛 ≥ 2; dengan 𝜆 adalah nilai
karakteristik matriks 𝐵𝐹𝑠𝑛 .
BUKTI. Misalkan matriks (𝜆𝐼 − 𝐵𝐹𝑠𝑛 ) disebut matrik 𝐺. Berdasarkan Teorema 2.6.,
dapat dihitung
|𝐺| = (𝜆 − 1) |𝐺11| − 𝑛. (0)|𝐺12| + 𝑛. (−1)|𝐺13|. = (𝜆 − 1) |𝐺11| − 𝑛|𝐺13|. (19)
Dalam perhitungan |𝐺11|, beberapa operasi matriks dilakukan secara berurutan yaitu
operasi baris 𝛼𝑖∗ = −𝛼1 + 𝛼𝑖 untuk 𝑖 = 2, 3, 4, … , 2𝑛; lalu operasi kolom 𝛽𝑗
∗ =

638
−𝛽2𝑛 + 𝛽𝑗 untuk 𝑗 = 3, 4, … , 2𝑛 − 1; kemudian dengan menggunakan Teorema
2.1. didapatkan hasil
|𝐺11| = (𝜆 − 1)2(𝜆2)
2𝑛−2
2 + (−1)1+2𝑛. (−1) |(𝐺11)∗1(2𝑛)|
= (𝜆 − 1)2𝜆2(𝑛−1) + |(𝐺11)∗1(2𝑛)|. (20)
Dalam perhitungan |(𝐺11)∗1(2𝑛)|, beberapa operasi matriks dilakukan secara
berurutan yaitu operasi baris 𝛼𝑖∗ =
−1
𝜆𝛼𝑖+1 + 𝛼𝑖 untuk 𝑖 = 2, 4, … , 2𝑛 − 2 , lalu
operasi kolom 𝛽2∗ =
𝜆−1
𝜆𝛽1 + 𝛽2, 𝛽3
∗ =𝜆
𝜆−1 𝛽2 + 𝛽3, 𝛽4
∗ =𝜆−1
𝜆𝛽3 + 𝛽4, 𝛽5
∗ =𝜆
𝜆−1𝛽4 + 𝛽5; dan seterusnya hingga 𝛽2𝑛−1
∗ =𝜆
𝜆−1𝛽2𝑛−2 + 𝛽2𝑛−1. kemudian dengan
menggunakan Teorema 2.2. didapat hasil
|(𝐺11)∗1(2𝑛)| = −𝜆(𝜆
2)2𝑛−1−3
2 (𝑛 − 1)𝜆(2𝜆 − 1).
= −(𝑛 − 1)(2𝜆 − 1)𝜆2(𝑛−1). (21)
Persamaan (21) disubsitusikan ke persamaan (20) sehingga didapatkan
|𝐺11| = (𝜆 − 1)2𝜆2(𝑛−1) + |(𝐺11)
∗1(2𝑛)|.
= (𝜆 − 1)2𝜆2(𝑛−1) − (𝑛 − 1)(2𝜆 − 1)𝜆2(𝑛−1) = 𝜆2(𝑛−1)((𝜆 − 1)2 − (𝑛 − 1)(2𝜆 − 1)). (22)
Dalam perhitungan |𝐺13|, beberapa operasi matriks dilakukan secara berurutan yaitu
operasi baris 𝛼𝑖∗ = −𝛼1 + 𝛼𝑖 untuk 𝑖 = 2, 3, 4, … , 2𝑛; lalu operasi kolom 𝛽𝑗
∗ =
−𝛽2𝑛 + 𝛽𝑗 untuk 𝑗 = 3, 4, … , 2𝑛 − 1; kemudian operasi baris 𝛼1∗ =
𝜆−1
𝜆𝛼2 + 𝛼1;
dengan menggunakan Teorema 2.2. didapatkan hasil
|𝐺13| = (𝜆2)
2𝑛−2
2 + (−1)1+2𝑛. (−1) |(𝐺13)∗1(2𝑛)|
= 𝜆2𝑛−2 + |(𝐺13∗)1(2𝑛)|. (23)
Dalam perhitungan |(𝐺13)∗1(2𝑛)|, beberapa operasi matriks dilakukan secara
berurutan yaitu operasi baris 𝛼𝑖∗ =
−1
𝜆𝛼𝑖+1 + 𝛼𝑖 untuk 𝑖 = 2, 4, 6, … , 2𝑛 − 2; lalu
operasi kolom 𝛽2∗ = 𝜆𝛽1 + 𝛽2; dilanjutkan dengan operasi kolom 𝛽3
∗ = 𝛽2 + 𝛽3
lalu 𝛽3 ↔ 𝛽4; 𝛽5∗ = 𝛽4 + 𝛽5 dan 𝛽5 ↔ 𝛽6; 𝛽7
∗ = 𝛽6 + 𝛽7 dan 𝛽7 ↔ 𝛽8 dan
seterusnya hingga 𝛽2𝑛−1∗ = 𝛽2𝑛−2 + 𝛽2𝑛−1. Dengan menggunakan Teorema 2.2.
didapatkan hasil
|(𝐺13)∗1(2𝑛)| = 1. (−𝜆
2)2𝑛−1−3
2 ((𝑛 − 1)𝜆2)
= (𝑛 − 1)𝜆2(𝑛−1). (24)
Persamaan (24) disubstitusikan ke persamaan (23) sehingga didapatkan
|𝐺13| = 𝜆2𝑛−2 + |(𝐺13)
∗1(2𝑛)|.
= 𝜆2(𝑛−1) + (𝑛 − 1)𝜆2(𝑛−1) = 𝑛 𝜆2(𝑛−1). (25)
Dengan mensubstitusikan persamaan (22) dan (25) ke persamaan (19), didapatkan
𝑃(𝐵𝐹𝑠𝑛 ) = |𝐺| = (𝜆 − 1) |𝐺11| − 𝑛|𝐺13|
= (𝜆 − 1) (𝜆2(𝑛−1)((𝜆 − 1)2 − (𝑛 − 1)(2𝜆 − 1))) − 𝑛 (𝑛 𝜆2(𝑛−1))
= 𝜆2(𝑛−1)(𝜆3 − (2𝑛 + 1)𝜆2 + 3𝑛𝜆 − 𝑛(𝑛 + 1)). (26)
Dengan mencari akar-akar persamaan (26) yaitu 𝑃(𝐵𝐹𝑠𝑛 ) = 𝜆2(𝑛−1)(𝜆3 −
(2𝑛 + 1)𝜆2 + 3𝑛𝜆 − 𝑛(𝑛 + 1)) = 0, didapatkan masing-masing 𝜆1, 𝜆2 serta 𝜆3

639
adalah akar-akar persamaan pangkat tiga, yang secara umum 𝜆1 dan 𝜆2 merupakan
bilangan kompleks dan 𝜆3 merupakan suatu bilangan riil untuk 𝑛 ≥ 2; serta 𝜆4 = 0
dengan 𝑚(𝜆4) = 2𝑛 − 2.∎
Teorema 2.24. sesuai dengan Teorema 2.13., 𝑃(𝐵𝐹𝑠𝑛 ) = 𝜆2𝑛+1 − (2𝑛 +
1)𝜆2𝑛 + 3𝑛𝜆2𝑛−1 − (𝑛 + 𝑛2) 𝜆2𝑛−2, yakni koefisien 𝜆2𝑛 yaitu 𝑎1 = −(2𝑛 + 1) (negatif dari banyaknya simpul), koefisien 𝜆2𝑛−1 yaitu 𝑎2 = 3𝑛 (banyaknya busur)
dan koefisien 𝜆2𝑛−2 yaitu 𝑎3 = −(𝑛 + 𝑛2) (negatif dari banyaknya subgraf
terinduksi asiklik yang memiliki lintasan Hamilton dari tiga buah simpul ditambah
dua kali banyaknya 𝐶3 siklik pada graf tersebut). Setiap simpul bukan simpul pusat
(simpul luar) dalam setiap graf 𝐶3 dapat membentuk lintasan Hamilton dengan
melalui simpul pusat dan hanya satu simpul dalam graf 𝐶3 lainnya sehingga
banyaknya subgraf terinduksi asiklik yang memiliki lintasan Hamilton adalah 𝑛(𝑛−1)
2
. Karena dalam setiap graf 𝐶3 terdapat dua simpul luar maka banyaknya subgraf
terinduksi asiklik yang memiliki lintasan Hamilton dari tiga buah simpul pada graf
tersebut adalah 2 ×𝑛(𝑛−1)
2= 𝑛(𝑛 − 1). Graf friendship 𝐶3
𝑛 berarah siklik yang
dibahas dalam penelitian ini memiliki 𝑛 buah 𝐶3 sehingga 𝑎3 = −(𝑛(𝑛 − 1) +2𝑛) = −(𝑛 + 𝑛2).
Teorema 2.25. Suatu graf friendship (𝐶3𝑛) berarah asiklik (1) seperti yang
ditunjukkan di Tabel 2. dengan matriks anti-adjacency (𝐵𝐹𝑎1𝑛 ) memiliki polinomial
karakteristik 𝑃(𝐵𝐹𝑎1𝑛 ) = 𝜆2(𝑛−1)(𝜆 − 1)(𝜆2 − 2𝑛𝜆 + 𝑛) dan 𝑆𝑝𝑒𝑐(𝐵𝐹𝑎1
𝑛 ) =
(𝑛 + √𝑛(𝑛 − 1)
1 1 𝑛 − √𝑛(𝑛 − 1) 0
1 1 2𝑛 − 2); dengan 𝜆 adalah nilai
karakteristik matriks 𝐵𝐹𝑎1𝑛 .
BUKTI. Sebut matriks (𝜆𝐼 − 𝐵𝐹𝑎1𝑛 ) sebagai matriks 𝐾. Berdasarkan Teorema 2.1.,
dapat dihitung
|𝐾| = (𝜆 − 1) |𝐾11|. (27)
Karena matriks 𝐾11 sama dengan matriks 𝐺11 maka berdasarkan persamaan (22)
didapatkan
|𝐾11| = |𝐺11| = 𝜆2(𝑛−1)((𝜆 − 1)2 − (𝑛 − 1)(2𝜆 − 1)). (28)
Persamaan (28) disubstitusikan ke persamaan (27) sehingga didapatkan
𝑃(𝐵𝐹𝑎1𝑛 ) = |𝐾| = (𝜆 − 1) |𝐾11|
= (𝜆 − 1)(𝜆2(𝑛−1)((𝜆 − 1)2 − (𝑛 − 1)(2𝜆 − 1)))
= 𝜆2(𝑛−1)(𝜆 − 1)(𝜆2 − 2𝑛𝜆 + 𝑛) (29)
Dengan mencari akar-akar persamaan (29) yaitu 𝑃(𝐵𝐹𝑎1𝑛 ) = 𝜆2(𝑛−1)(𝜆 − 1)(𝜆2 −
2𝑛𝜆 + 𝑛) = 0, didapatkan 𝜆1 = 𝑛 +√𝑛(𝑛 − 1) dengan 𝑚(𝜆1) = 1, 𝜆2 =
1 dengan 𝑚(𝜆2) = 1, 𝜆3 = 𝑛 − √𝑛(𝑛 − 1) dengan 𝑚(𝜆3) = 1, dan 𝜆4 = 0 dengan
𝑚(𝜆4) = 2𝑛 − 2. ∎
Teorema 2.26. Suatu graf friendship (𝐶3𝑛) berarah asiklik (2) seperti yang
ditunjukkan di Tabel 2. dengan matriks anti-adjacency (𝐵𝐹𝑎2𝑛 ) memiliki polinomial
karakteristik 𝑃(𝐵𝐹𝑎2𝑛 ) = 𝜆2(𝑛−1)(𝜆3 − (2𝑛 + 1)𝜆2 + 3𝑛𝜆 − 𝑛2) dan
𝑆𝑝𝑒𝑐(𝐵𝐹𝑎2𝑛 ) = (
𝜆1 𝜆21 1
𝜆31 0
2𝑛 − 2), 𝜆1 𝑑𝑎𝑛 𝜆2 ∈ 𝐶, 𝜆3 ∈ 𝑅 untuk 𝑛 ≥ 2;
dengan 𝜆 adalah nilai karakteristik matriks 𝐵𝐹𝑎2𝑛 .
BUKTI. Sebut 𝑀 = (𝜆𝐼 − 𝐵𝐹𝑎2𝑛 ). Berdasarkan Teorema 2.6., dapat dihitung

640
𝑃(𝐵𝐹𝑎2𝑛 ) = |𝑀| = (𝜆 − 1) |𝑀11| − 𝑛. (0)|𝑀12| +. (−1)|𝑀13|
= (𝜆 − 1) |𝑀11| − 𝑛|𝑀13|. (30)
Submatriks 𝑀11 adalah matriks transpose dari submatriks 𝐺11 sehingga berdasarkan
sifat determinan matriks |𝐴| = |𝐴𝑇| (Franklin [8]) dan persamaan (22) didapatkan
|𝑀11| = |𝐺11| = 𝜆2(𝑛−1)((𝜆 − 1)2 − (𝑛 − 1)(2𝜆 − 1)). (31)
Dalam perhitungan |𝑀13|, beberapa operasi matriks dilakukan secara berurutan yaitu
operasi baris 𝛼𝑖∗ = −𝛼1 + 𝛼𝑖 untuk 𝑖 = 2, 3, 4, … , 2𝑛; lalu operasi kolom 𝛽𝑗
∗ =
−𝛽2𝑛 + 𝛽𝑗 untuk 𝑗 = 3, 4, … , 2𝑛 − 1; kemudian operasi baris 𝛼1∗ = 𝛼2 + 𝛼1;
sehingga dengan menggunakan Teorema 2.1. didapatkan
|𝑀13| = (−1)1+2𝑛. (−1) |(𝑀13)
∗1(2𝑛)| = |(𝑀13)
∗1(2𝑛)|. (32)
Dalam perhitungan |(𝑀13)∗1(2𝑛)|, beberapa operasi matriks dilakukan secara
berurutan yaitu operasi kolom 𝛽2∗ = (𝜆 − 1)𝛽1 + 𝛽2; lalu 𝛽3
∗ = 𝛽2 + 𝛽3 dan
𝛽3 ↔ 𝛽4; 𝛽5∗ = 𝛽4 + 𝛽5 dan 𝛽5 ↔ 𝛽6; kemudian 𝛽7
∗ = 𝛽6 + 𝛽7 dan 𝛽7 ↔ 𝛽8
dan seterusnya hingga 𝛽2𝑛−1∗ = 𝛽2𝑛−2 + 𝛽2𝑛−1. Dengan menggunakan Teorema
2.2. dan persamaan (31) didapatkan hasil
|𝑀13| = |(𝑀13)∗1(2𝑛)| = 1. (−𝜆
2)2𝑛−1−3
2 (𝑛 − 1)𝜆2 = 𝜆2(𝑛−1) (𝑛 − 1). (33)
Persamaan (31) dan (33) disubstitusikan ke persamaan (30) sehingga didapatkan
𝑃(𝐵𝐹𝑎2𝑛 ) = |𝑀| = (𝜆 − 1) |𝑀11| − 𝑛|𝑀13|
= (𝜆 − 1) 𝜆2(𝑛−1)((𝜆 − 1)2 − (𝑛 − 1)(2𝜆 − 1)) − 𝑛𝜆2𝑛−2 (𝑛 − 1) = 𝜆2(𝑛−1)(𝜆3 − (2𝑛 + 1)𝜆2 + 3𝑛𝜆 − 𝑛2). (34)
Dengan mencari akar-akar persamaan (34) yaitu 𝑃(𝐵𝐹𝑎2𝑛 ) = 𝜆2(𝑛−1)(𝜆3 −
(2𝑛 + 1)𝜆2 + 3𝑛𝜆 − 𝑛2) = 0, didapatkan masing-masing 𝜆1, 𝜆2 serta 𝜆3 adalah
akar-akar persamaan pangkat tiga, yang secara umum 𝜆1 dan 𝜆2 merupakan
bilangan kompleks dan 𝜆3 merupakan suatu bilangan riil untuk 𝑛 ≥ 2; serta 𝜆4 = 0
dengan 𝑚(𝜆4) = 2𝑛 − 2.∎
Perbedaan polinomial karakteristik matriks anti-adjacency dari graf
friendship 𝐶3𝑛 berarah asiklik (1) dan (2) maupun dari graf friendship berarah siklik
terletak pada koefisien suku keempat yang menyatakan negatif dari banyaknya
subgraf terinduksi asiklik yang memiliki lintasan Hamilton dari tiga buah simpul
ditambah dua kali banyaknya 𝐶3 siklik pada graf tersebut (Teorema 2.13). Graf
friendship berarah asiklik (1) maupun (2) tidak memiliki subgraf 𝐶3 siklik sehingga
koefisien suku keempat (𝑎3) menyatakan negatif dari banyaknya subgraf terinduksi
asiklik yang memiliki lintasan Hamilton dari tiga buah simpul. Koefisien suku
kelima dan seterusnya sama dengan nol. Hal ini bersesuaian dengan Firmansah [7],
tidak ada lintasan berarah dari graf friendship berarah asiklik (1) maupun (2) yang
memiliki panjang lebih dari dua.
Pada graf friendship berarah asiklik (1), 𝑎3 = −𝑛. Hal ini dapat dijelaskan,
hanya ada satu lintasan Hamilton pada setiap subgraf 𝐶3 dan graf 𝐶3𝑛 memiliki 𝑛
subgraf 𝐶3 sehingga ada 𝑛 subgraf terinduksi asiklik yang memiliki lintasan
Hamilton dari tiga buah simpul. Spektrumnya sesuai dengan Teorema 2.16 yaitu
∑ 𝜆𝑖2𝑛+1𝑖=1 = 1 + 𝑛 − √𝑛(𝑛 − 1) + 𝑛 + √𝑛(𝑛 − 1) = 2𝑛 + 1 (banyaknya simpul)
dan ∑ 𝜆𝑖2𝑛
𝑖=1 = 12 + (𝑛 − √𝑛(𝑛 − 1))2+ (𝑛 + √𝑛(𝑛 − 1))
2= (2𝑛 + 1)2 −
2(3𝑛). Pada graf friendship berarah asiklik (2), 𝑎3 = −𝑛
2. Hal ini dapat dijelaskan,
hanya ada satu lintasan Hamilton pada setiap subgraf 𝐶3 dan graf 𝐶3𝑛 memiliki 𝑛

641
subgraf 𝐶3 sehingga ada 𝑛 subgraf 𝐶3 terinduksi asiklik yang memiliki lintasan
Hamilton. Selain itu setiap simpul bukan simpul pusat (simpul luar) dalam setiap
graf 𝐶3 dapat membentuk lintasan Hamilton dengan melalui simpul pusat dan hanya
satu simpul dalam graf 𝐶3 lainnya sehingga banyaknya subgraf terinduksi asiklik
yang memiliki lintasan Hamilton adalah 𝑛(𝑛−1)
2 . Karena dalam setiap graf 𝐶3
terdapat dua simpul luar maka banyaknya subgraf terinduksi asiklik yang memiliki
lintasan Hamilton dari tiga buah simpul pada graf tersebut adalah 2 ×𝑛(𝑛−1)
2=
𝑛(𝑛 − 1). Jadi 𝑎3 = −(𝑛 + 𝑛(𝑛 − 1)) = −𝑛2.
Polinomial karakteristik matriks anti-adjacency dari graf friendship (𝐶3𝑛)
lebih banyak memuat informasi dibandingkan polinomial karakteristik matriks
adjacency dari graf yang sama. Hal ini tampak pada perbedaan banyaknya suku pada
polinomial karakteristik kedua matriks tersebut.
3. Kesimpulan
Berdasarkan hasil penelitian yang sudah dipaparkan pada bagian 2
didapatkan kesimpulan sebagai berikut :
1. Matriks anti-adjacency dapat membedakan polinomial karakteristik dan
spektrum graf friendship (𝐶3𝑛) berarah asiklik (1) dan (2), sedangkan matriks
adjacency memberikan hasil yang sama untuk kedua graf tersebut.
2. Polinomial karakteristik matriks anti-adjacency dari graf friendship 𝐶3𝑛 lebih
banyak memuat informasi dibandingkan polinomial karakteristik matriks
adjacency dari graf yang sama.
Referensi
[1] Abdollahi A., Janbaz S., & Oboudi M. R., 2013, Graphs Cospectral with A Friendship
Graph or Its Complement, Transactions on Combinatorics, Vol. 2 No. 4, 37-52.
[2] Adiati, N. P. R., 2015, Sifat Nilai Karakteristik Matriks Anti-adjacency dari Graph
Berarah Sederhana, Tesis, Universitas Indonesia.
[3] Bapat, R., 2010, Graphs and Matrices, India, Hindustan Book Agency.
[4] Biggs, N., 1993, Algebraic Graph Theory, 2nd ed., New York, Cambridge Mathematical
Library.
[5] Chartrand, G. & Lesniak, L., 1996, Graph & Digraphs (3rd edition), California,
Chapman & Hall/CRC.
[6] Cvetkovic D., Rowlinson P.and Simic. S., 2010, An Introduction to the Theory of Graph
Spectra, London Mathematical Society Student Texts, 75, Cambridge, Cambridge
University Press.
[7] Firmansah, F., 2014, Polinomial Karakteristik Matriks Anti-adjacency dari Graf Berarah
yang Acyclic, Tesis, Universitas Indonesia.
[8] Franklin, J. N., 2000, Matrix Theory. NY, Dover Publication, Inc.
[9] Knauer, U., 2011, Algebraic Graph Theory: Morphism, Monoids, and Matrices,
Walter de Gruyter GmbH & Co.
[10] Mertzios, G.B. & Unger, W., 2008, The Friendship Problem on Graphs, ROGICS'08.
[11] Meyer, C. D., 2000, Matrix Analysis and Applied Linier Algebra, New Jersey, SIAM.
[12] Nugroho, E., 2013, Polinomial Karakteristik Matriks Anti-adjacency dari Out-Tree,
Tesis, Universitas Indonesia.
[13] Wildan, 2015, Polinomial Karakteristik Matriks Anti-adjacency dan Adjacency dari
Graf Sederhana yang diberi Orientasi, Tesis, Universitas Indonesia.

642
Prosiding SNM 2017 Kombinatorik , Hal 642-647
PELABELAN HARMONIS PADA GRAF TANGGA
SEGITIGA VARIASI 𝒙𝑵
KURNIAWAN ATMADJA1, KIKI A. SUGENG2
1Prodi Matematika Institut Sains dan Teknologi Nasional, Jakarta selatan,
2Departemen Matematika, FMIPA, Universitas Indonesia , Kampus UI, Depok 16424,
Abstrak. Misalkan 𝐺 = (𝑉, 𝐸) adalah graf dengan himpunan tak kosong simpul
𝑉 = 𝑉(𝐺) dan himpunan busur 𝐸 = 𝐸(𝐺) dimana |𝑉(𝐺)| dan |𝐸(𝐺)| menyatakan
banyaknya simpul dan banyaknya busur pada 𝐺. Suatu
pemetaan 𝑓 dari 𝑉 𝑘𝑒 ℤ|𝐸(𝐺)| dimana |𝑉(𝐺)| ≤ |𝐸(𝐺)| disebut pelabelan harmonis
jika 𝒇 merupakan pemetaan injektif sedemikian hingga ketika setiap busur xy dilabel
dengan 𝑓∗(𝑥𝑦) = 𝑓(𝑥) + 𝑓(𝑦)(𝑚𝑜𝑑|𝐸(𝐺)|) menghasilkan label busur yang berbeda. Graf tangga segitiga variasi 𝑋𝑛 adalah graf yang diperoleh melalui penambahan satu
simpul 𝑤𝑖 yang diletakan di antara simpul 𝑣𝑖 dan simpul 𝑣𝑖+1 pada graf tangga 𝐿𝑛. Sehingga ada tambahan 4 jenis busur antara lain : 𝑢𝑖𝑤𝑖 | 1 ≤ 𝑖 ≤ 𝑛 ; 𝑣𝑖𝑤𝑖 | 1 ≤ 𝑖 ≤𝑛 ; 𝑢𝑖+1𝑤𝑖 | 1 ≤ 𝑖 ≤ 𝑛 − 1 ; 𝑤𝑖𝑣𝑖+1 | 1 ≤ 𝑖 ≤ 𝑛 − 1. Keempat jenis busur ini
menggantikan busur 𝑣𝑖𝑣𝑖+1 pada graf tangga semula. Sedangkan graf tangga 𝐿𝑛 adalah
graf 𝑃𝑛 × 𝑃2 dengan 𝑉(𝐿𝑛) = {𝑢𝑖𝑣𝑖|1 ≤ 𝑖 ≤ 𝑛} dan 𝐸(𝐿𝑛) = {𝑢𝑖𝑢𝑖+1, 𝑣𝑖𝑣𝑖+1} ∪{𝑢𝑖𝑣𝑖 | 1 ≤ 𝑖 ≤ 𝑛}. Pada makalah ini diberikan konstruksi pelabelan harmonis pada
graf tangga segitiga variasi.
Kata kunci : graf tangga segitiga, pelabelan graf harmonis.
1. Pendahuluan
Misalkan 𝐺 = (𝑉, 𝐸), dapat disingkat 𝐺, adalah graf yang terdiri dari himpunan
simpul tak kosong 𝑉 dan himpunan busur 𝐸. Notasi |𝑉| dan |𝐸| menyatakan
banyak simpul 𝑉 dan banyak busur 𝐸 pada graf 𝐺. Syarat |𝐸| ≥ |𝑉| merupakan
syarat agar pada graf G dapat mempunyai pelabelan harmonis. Pelabelan harmonis
pertama kali diperkenalkan oleh Graham dan Sloane [4], berawal dari masalah error-
correcting code [4]. Pelabelan harmonis didefinisikan sebagai suatu pemetaan
injektif dari 𝑉(𝐺) ke ℤ|𝐸| sedemikian sehingga ketika setiap busur 𝑥𝑦 diberi label
𝑓∗ = 𝑓(𝑥) + 𝑓(𝑦) menghasilkan label busur berbeda. Graf yang mempunyai
pelabelan harmonis disebut graf Harmonis.
Beberapa kelas graf sudah dikategorikan sebagai graf harmonis antara lain graf
firecracker, hairy cycle, korona, gabungan graf caterpillar dan gabungan graf
firecracker teratur [5], graf Tangga Segitiga [2]. Untuk hasil survey yang lengkap
dapat dilihat di Gallian survey [3].

643
2. Hasil – hasil utama
Definisi 2.1. Graf Tangga 𝐿𝑛 adalah graf tangga sederhana dengan himpunan simpul
𝑉(𝐿𝑛) = {𝑢𝑖, 𝑣𝑖 |1 ≤ 𝑖 ≤ 𝑛} dan himpunan busur 𝐸(𝐿𝑛) = {𝑢𝑖𝑢𝑖+1 |1 ≤ 𝑖 ≤ 𝑛 −1} ∪ {𝑣𝑖𝑣𝑖+1 |1 ≤ 𝑖 ≤ 𝑛 − 1} ∪ {𝑢𝑖𝑣𝑖 |1 ≤ 𝑖 ≤ 𝑛}, dan graf ini dapat dilihat
sebagai produk kartesius 𝑃2 × 𝑃𝑛.
Pada makalah ini dikaji graf tangga 𝐿𝑛 (𝑛 ≥ 2) dengan melakukan penambahan satu
simpul 𝑤𝑖 yang diletakkan di antara simpul 𝑣𝑖 dan 𝑣𝑖+1 pada lintasan 𝑣𝑖𝑣𝑖+1 untuk
1 ≤ 𝑖 ≤ 𝑛 − 1, sehingga ada tambahan 4 jenis busur yang menggantikan busur
𝑣𝑖𝑣𝑖+1, untuk setiap 𝑖, 1 ≤ 𝑖 ≤ 𝑛 − 1.
Dari kajian ini, graf tangga 𝐿𝑛 (𝑛 ≥ 2) yang mengalami penambahan busur,
berubah menjadi bentuk graf tangga baru , dan hasil modifikasinya diperoleh graf
tangga yang memuat segitiga. Grafnya disebut graf tangga segitiga variasi 𝑋𝑛.
Graf tangga segitiga variasi 𝑋𝑛 selalu mempunyai banyak busur lebih besar dari
banyak simpul, sehingga memenuhi syarat awal untuk mengkonstruksi pelabelan
harmonis.
Definisi 2.2. Graf Tangga 𝑋𝑛 adalah graf tangga segitiga variasi, dengan himpunan
simpul 𝑉(𝑋𝑛) = {𝑢𝑖, 𝑣𝑖 |1 ≤ 𝑖 ≤ 𝑛} ∪ {𝑤𝑖 |1 ≤ 𝑖 ≤ 𝑛 − 1} dan himpunan busur
𝐸(𝑋𝑛) = {𝑢𝑖𝑢𝑖+1 |1 ≤ 𝑖 ≤ 𝑛 − 1} ∪ {𝑢𝑖𝑣𝑖 |1 ≤ 𝑖 ≤ 𝑛} ∪ {𝑣𝑖𝑤𝑖 |1 ≤ 𝑖 ≤ 𝑛} ∪ {𝑤𝑖𝑣𝑖+1 |1 ≤ 𝑖 ≤ 𝑛 − 1} ∪ {𝑢𝑖𝑤𝑖 |1 ≤ 𝑖 ≤ 𝑛} ∪ {𝑢𝑖+1𝑤𝑖 |1 ≤ 𝑖 ≤ 𝑛 − 1}.
Berikut akan dibuktikan bahwa graf tangga segitiga variasi 𝑋𝑛 adalah graf
harmonis yang terangkum dalam teorema berikut.
Teorema 2.3. Graf tangga segitiga variasi 𝑋𝑛 untuk 𝑛 ≥ 2 adalah harmonis.
BUKTI. Misalkan himpunan simpul 𝑉(𝑋𝑛) = {𝑢𝑖, 𝑣𝑖 |1 ≤ 𝑖 ≤ 𝑛} ∪ {𝑤𝑖 |1 ≤ 𝑖 ≤𝑛 − 1} dan himpunan busur 𝐸(𝑋𝑛) = {𝑢𝑖𝑢𝑖+1 |1 ≤ 𝑖 ≤ 𝑛 − 1} ∪ {𝑢𝑖𝑣𝑖 |1 ≤ 𝑖 ≤𝑛} ∪ {𝑣𝑖𝑤𝑖 |1 ≤ 𝑖 ≤ 𝑛} ∪ {𝑤𝑖𝑣𝑖+1 |1 ≤ 𝑖 ≤ 𝑛 − 1} ∪ {𝑢𝑖𝑤𝑖 |1 ≤ 𝑖 ≤ 𝑛} ∪{𝑢𝑖+1𝑤𝑖 |1 ≤ 𝑖 ≤ 𝑛 − 1}. Definisikan pelabelan simpul 𝑓 ∶ 𝑉 → 𝑍𝐼𝐸𝐼 sebagai berikut :
𝑓(𝑢𝑖) = {3𝑖 − 2, untuk 𝑖 ganjil ; 1 ≤ 𝑖 ≤ 𝑛 ,3𝑖 − 3, untuk 𝑖 genap ; 2 ≤ 𝑖 ≤ 𝑛 .
.
𝑓(𝑣𝑖) = {3𝑖 − 3, untuk 𝑖 ganjil ; 1 ≤ 𝑖 ≤ 𝑛,3𝑖 − 2, untuk 𝑖 genap ; 2 ≤ 𝑖 ≤ 𝑛.
𝑓(𝑤𝑖) = 3𝑖 − 1, untuk 1 ≤ 𝑖 ≤ 𝑛 − 1.
Perhitungan label simpul di atas pada graf tangga segitiga variasi 𝑿𝒏, dapat
dikelompokan sebagai berikut :
1. Pelabelan simpul untuk 𝑖 ganjil, ; 1 ≤ 𝑖 ≤ 𝑛
𝑓(𝑢𝑖) = 3𝑖 − 2 ∈ {1,7,13,… ,3𝑛 − 2} ⊂ 1 𝑚𝑜𝑑 6 = 1… .. (1)
𝑓(𝑣𝑖) = 3𝑖 − 3 ∈ {0,6,12,… ,3𝑛 − 3} ⊂ 0 𝑚𝑜𝑑 6 = 0 ….. (2)

644
2. Pelabelan simpul untuk 𝑖 genap, ; 2 ≤ 𝑖 ≤ 𝑛
𝑓(𝑢𝑖) = 3𝑖 − 3 ∈ {3,9,15,… ,3𝑛 − 3} ⊂ 3 𝑚𝑜𝑑 6 = 3….. (3)
𝑓(𝑣𝑖) = 3𝑖 − 2 ∈ {4,10,16,… ,3𝑛 − 2} ⊂ 4 𝑚𝑜𝑑 6 = 4… (4)
3. 𝑓(𝑤𝑖) = 3𝑖 − 1 ; 1 ≤ 𝑖 ≤ 𝑛 − 1 ∈ {2,5,8,11,14,17,… ,3𝑛 − 4} ⊂ (2 𝑚𝑜𝑑 6) ∪(5 𝑚𝑜𝑑 6)
= 2 ∪ 5 .................................................................... (5)
Dari persamaan (1) sampai (5) dapat ditulis himpunan simpul sebagai
berikut :
𝑓(𝑉(𝑋𝑛)) = {0,1,2,3,4,5,6,7,8,9,10,11,12,13,… ,3𝑛 − 2}. Pelabelan simpul
yang berada di masing-masing pernyataan (1),(2), (3),(4) dan (5) akan
menghasilkan simpul yang berbeda karena masing-masing berada di
himpunan mod 6 yang berbeda. Sedangkan untuk masing masing pernyataan
juga akan menghasilkan label yang berbeda untuk
setiap 𝑖, 1 ≤ 𝑖 ≤ 𝑛 yang berbeda. Label simpul terkecil dari himpunan
simpul di atas
adalah label 𝑣1, sedangkan label simpul terbesar untuk 𝑛 bilangan ganjil
terletak pada label simpul 𝑢𝑛 , dimana 𝑓(𝑢𝑛) = 3𝑛 − 2, sedangkan untuk 𝑛 genap terletak pada label simpul 𝑣𝑛 dimana 𝑓(𝑣𝑛) = 3𝑛 − 2.
Nampak bahwa :
𝑓 (𝑉(𝑋𝑛)) ⊆ {0,1,2,3,4,5,6,7,8,… ,6𝑛 − 6} = 𝐸(𝑋𝑛) dan label setiap simpul 𝑋𝑛
berbeda .
Jadi pelabelan simpul 𝑓 yang didefinisikan pada persamaan (1) sampai
persamaan (5) merupakan pemetaan injektif (𝑉(𝑋𝑛)) →{0,1,2,3,4,5,6,7,… , (|𝐸| − 1)} .
Pelabelan f akan menginduksi pelabelan busur sebagai berikut :
(1.) 𝑓∗(𝑢𝑖𝑢𝑖+1) = 3𝑖 − 2 + 3(𝑖 + 1) − 3
= 6𝑖 − 2 ; 1 ≤ 𝑖 ≤ (𝑛 − 1).
(2. )𝑓∗(𝑢𝑖𝑣𝑖) = 3𝑖 − 2 + 3𝑖 − 3 = 6𝑖 − 5 ; 1 ≤ 𝑖 ≤ 𝑛.
(3)𝑓∗(𝑣𝑖𝑤𝑖) = {3𝑖 − 3 + 3𝑖 − 1 = 6𝑖 − 4 ; 𝑖 ganjil, ; 1 ≤ 𝑖 ≤ 𝑛 − 1,3𝑖 − 2 + 3𝑖 − 1 = 6𝑖 − 3 ; 𝑖 genap, ; 2 ≤ 𝑖 ≤ 𝑛 − 1.
(4)𝑓∗(𝑢𝑖𝑤𝑖) = {3𝑖 − 2 + 3𝑖 − 1 = 6𝑖 − 3 ; 𝑖 ganjil ; 1 ≤ 𝑖 ≤ 𝑛 − 1,3𝑖 − 3 + 3𝑖 − 1 = 6𝑖 − 4 ; 𝑖 𝜖 genap ; 2 ≤ 𝑖 ≤ 𝑛 − 1.
(5)𝑓∗(𝑢𝑖+1𝑤𝑖) = {3(𝑖 + 1) − 3 + 3𝑖 − 1 = 6𝑖 − 1 ; 𝑖 ganjil ; 1 ≤ 𝑖 ≤ 𝑛 − 1,
3(𝑖 + 1) − 2 + 3𝑖 − 1 = 6𝑖 ; 𝑖 genap ; 2 ≤ 𝑖 ≤ 𝑛 − 1.

645
(6)𝑓∗(𝑣𝑖+1𝑤𝑖)
= {3(𝑖 + 1) − 2 + 3𝑖 − 1 = 6𝑖 ; 𝑖 ganjil ; 1 ≤ 𝑖 ≤ 𝑛 − 1,
3(𝑖 + 1) − 3 + 3𝑖 − 1 = 6𝑖 − 1 ; 𝑖 genap ; 2 ≤ 𝑖 ≤ 𝑛 − 1.
Perhitungan label busur di atas pada graf tangga 𝑿𝒏 dapat dikelompokan
dalam 4(empat ) kasus, yaitu :
1. Label busur pada busur 𝑢𝑖𝑢𝑖+1 ; 1 ≤ 𝑖 ≤ 𝑛 − 1
𝑓∗(𝑢𝑖𝑢𝑖+1) = 𝑓(𝑢𝑖) + 𝑓(𝑢𝑖+1) = 3𝑖 − 2 + 3(𝑖 + 1) − 3
= 6𝑖 − 2
∈ {4,10,16,22,28,34… ,6𝑛 − 8} ⊂ (4 𝑚𝑜𝑑 12) ∪ (10 𝑚𝑜𝑑 12) = 4 ∪ 10 ..................................................... (6)
2. Label busur pada busur 𝑢𝑖𝑣𝑖 ; ≤ 1 ≤ 𝑖 ≤ 𝑛
𝑓∗(𝑢𝑖𝑣𝑖) = 𝑓(𝑢𝑖) + 𝑓(𝑣𝑖) = 3𝑖 − 2 + 3𝑖 − 3
= 6𝑖 − 5 ∈ {1,7,13,19,25,32… ,6𝑛 − 5}⊂ (1 𝑚𝑜𝑑 12) ∪ (7 𝑚𝑜𝑑 12)
= 1 ∪ 7 .......................................................... (7)
3. Label busur pada busur dengan 𝑖 ganjil terkait penambahan simpul 𝒘𝒊
𝑓∗(𝑣𝑖𝑤𝑖) = 𝑓(vi) + 𝑓(wi) = 3𝑖 − 3 + 3𝑖 − 1
= 6𝑖 − 4 ∈ {2,14,26,… ,6𝑛 − 4} ⊂ 2 𝑚𝑜𝑑 12 = 2 (8)
𝑓∗(𝑢𝑖𝑤𝑖) = 𝑓(𝑢𝑖) + 𝑓(wi) = 3𝑖 − 2 + 3𝑖 − 1
= 6𝑖 − 3 ∈ {3,15,27,…6𝑛 − 3} ⊂= 3 𝑚𝑜𝑑 12 = 3 (9)
𝑓∗(𝑢𝑖+1𝑤𝑖) = 𝑓(𝑢𝑖+1) + 𝑓(𝑤𝑖) = 3(𝑖 + 1) − 3 + 3𝑖 − 1
= 6𝑖 − 1 ∈ {5,17,29,… ,6𝑛 − 1} ⊂ 5 𝑚𝑜𝑑 12 = 5 (10)
𝑓∗(𝑣𝑖+1𝑤𝑖) = 𝑓(𝑣𝑖+1) + 𝑓(𝑤𝑖) = 3(𝑖 + 1) − 2 + 3𝑖 − 1
= 6𝑖 ∈ {6,18,30,… ,6𝑛} ⊂= 6 𝑚𝑜𝑑 12 = 6 (11)
4. Label busur pada busur dengan 𝑖 genap terkait penambahan simpul 𝒘𝒊
𝑓∗(𝑣𝑖𝑤𝑖) = 𝑓(𝑣𝑖) + 𝑓(𝑤i) = 3𝑖 − 2 + 3𝑖 − 1
= 6𝑖 − 3 ∈ {9,21,33,… ,6𝑛 − 3} ⊂ 9 𝑚𝑜𝑑 12 = 9 (12)

646
𝑓∗(𝑢𝑖𝑤𝑖) = 𝑓(𝑢𝑖) + 𝑓(𝑤𝑖) = 3𝑖 − 3 + 3𝑖 − 1
= 6𝑖 − 4 ∈ {8,20,32,… ,6𝑛 − 4} ⊂ 8 𝑚𝑜𝑑 12 = 8 (13)
𝑓∗(𝑢𝑖+1𝑤𝑖) = 𝑓(𝑢𝑖+1) + 𝑓(𝑤𝑖) = 3(𝑖 + 1) − 2 + 3𝑖 − 1
= 6𝑖 ∈ {12,24,36,… ,6𝑛} ⊂ 12 𝑚𝑜𝑑 12 = 0 (14)
𝑓∗(𝑣𝑖+1𝑤𝑖) = 𝑓(𝑣𝑖+1) + 𝑓(𝑤𝑖) = 3(𝑖 + 1) − 3 + 3𝑖 − 1
= 6𝑖 − 1 ∈ {11,23,35,… ,6𝑛 − 1} ⊂ 11 𝑚𝑜𝑑 12 = 11 (15)
Dari persamaan (6) sampai dengan (15) didapat pelabelan ini
mengakibatkan setiap busur 𝑥𝑦 diberi label(𝑓(𝑥) + 𝑓(𝑦)) 𝑚𝑜𝑑|𝐸| menghasilkan label busur yang berbeda (dengan alasan yang serupa dengan
pelabelan simpul) dan karena banyak busur adalah |E| dan label yang
digunakan adalah 1,2,…,|E|, maka pelabelan busur menghasilkan pelabelan
yang bijektif. Jadi graf 𝑋𝑛 adalah graf harmonis.
Contoh 2.4. Sebagai contoh di bawah ini diberikan pelabelan harmonis
𝑿𝟐, 𝑿𝟑, 𝑿𝟒, 𝑿𝒏 pada beberapa graf tangga segitiga variasi seperti yang terlihat
pada pada Gambar 1.
v1
u1 u2
v2w1
v1
u3
v3
u1 u2
v2w1 w2
v1
u4u3
v3
u1 u2
v2w1 w2 w3
X2
X3
X4
v1
u4u3
v4v3
u1 u2
v2w1 w2 w3
Xn
19
7
1
10
4
10
9
8
7
5 6
4
3
2
1
0
v4
1
0
2
2
3
3
3
3
97
7
2
5
5
4
4
8
1
1
0
0 6
6 8
1
10
1
1
2
2
2
2
13
3
3
3
16
1713
13
19
10
10 16
12
17
18
12
12
7
7
7
5
8
8
11
18
5
5
5
14
11
6
9
11
9
9
4
4
4
4
6
6
6
15
15
14
UnUn-1
vn-1 vnWn-1
Gambar 1
3. Kesimpulan
Graf 𝑿𝒏 adalah perluasan dari Graf Tangga 𝑳𝒏 dan merupakan graf
harmonis.

647
Pernyataan terima kasih. Akhirnya saya ucapkan terimakasih kepada
segenap panitia penyelenggara Seminar Nasional Matematika 2017
Universitas Indonesia yang telah memberi kesempatan terpublikasinya
tulisan makalah ini.
Referensi
[1] Asih, AJ, Silaban, D. R., Sugeng, K.A. Pelabelan Harmonis pada Graf
Firecracker, Graf Hairy Cycle dan Graf Korona, Prosiding Seminar Nasional
2010, Departemen Matematika FMIPA UI, 87-90.
[2] Atmadja. K, Sugeng, K.A, Yuniarko.T, Pelabelan Harmonis pada
Graf Tangga Segitiga, Prosiding Konferensi Nasional Matematika
XVII-2014, ITS Surabaya.
[3] Gallian, J. A., Dynamic Survey of Graph Labeling, The Electronic Journal of
Combinatorics, 2013, 16, #DS6.
[4] Graham ,R.L & Sloan , N.J., On Additive Bases and Harmonius Graphs.
SIAM.J.Alg. Discrete Math..1980, Vol 1, No 3, 382 – 404.
[5] Wirnadian, P, Pelabelan Harmonis pada Kombinasi Gabungan Graf
Caterpillar dan Graf Firecracker Teratur, Tesis, Fakultas Matematika dan Ilmu
Pengetahuan Alam, Program Studi Magister Matematika, Universitas
Indonesia, 2010.

648
KOMPUTASI
SEMINAR NASIONAL MATEMATIKA 2017

649
Prosiding SNM 2017 Komputasi , Hal 649-659
ALGORITMA PARTICLE SWARM OPTIMIZATION DAN
TERAPANNYA DALAM MENYELESAIKAN MASALAH
PEMOTONGAN ROL KERTAS
HELVETIKA AMPERIANA1, Y G HARTONO2
1,2Universitas Sanata Dharma Yogyakarta, [email protected], [email protected]
Abstrak. Algoritma Particle Swarm Optimization (PSO) merupakan salah satu algoritma
optimasi dengan teknik pendekatan heuristik. Pendekatan heuristik yaitu pendekatan komputasi untuk
mencari suatu penyelesaian optimal atau mendekati optimal dari suatu masalah optimasi dengan cara
mencoba secara iteratif untuk memperbaiki kandidat solusi dengan memperhatikan batasan kualitas
solusi yang diinginkan. Algoritma PSO terinspirasi dari perilaku sekawanan burung atau sekumpulan
ikan yang dapat menjelajah ruang solusi secara efektif sehingga mempunyai keefektifan yang baik
dalam menyelesaikan masalah.Algoritma PSO diharapkan juga mempunyai keefektifan untuk
menyelesaikan Cutting Stock Problem (CSP) atau masalah pemotongan persediaan.
Makalah ini mengimplementasikan algoritma PSO untuk menyelesaikan masalah pemotongan
persediaan kertas, yaitu pada rol kertas jumbo yang akan dipotong untuk mendapatkan rol kertas kecil.
Lebar rol kertas kecil ditentukan oleh permintaan pelanggan dan jumlah rol yang dipesan juga berbeda-
beda. Tujuannya adalah mencari dan menyusun pola pemotongan dari sebuah rol jumbo menjadi rol
kecil sedemikian hingga diperoleh hasil yang optimum. Berdasarkan hasil penelitian ini, diperoleh
solusi optimal yaitu jumlah rol jumbo dan sisa yang minimum untuk beberapa kasus pesanan yang
masuk. Selanjutnya dibuat suatu program tampilan dengan MATLAB berdasarkan algoritma PSO.
Dibandingkan dengan perhitungan software Quantitative Method (QM), yaitu software yang populer
digunakan untuk memproses data kuantitatif, hasilnya mendekati..
Kata kunci: Algoritma Particle Swarm Optimization (PSO), Cutting Stock Problem (CSP), optimasi,
heuristik,komputasi.
1. Pendahuluan
1. Pendahuluan
Ketika kita melibatkan masalah pemotongan persediaan dalam dunia industri
kertas seperti yang diulas oleh Parmar [5] dan Shen [7], tentu saja penyelesaian kasus
pada masalah ini adalah dengan menyertakan data sebagai input. Secara umum,
masalah-masalah ini sangat luas dan kompleks untuk diselesaikan sampai mendapat
solusi eksak. Oleh karena itu, metode heuristik menjadi salah satu algoritma yang
diharapakan dapat berjalan dengan baik untuk menemukan solusi yang optimal.
Salah satunya adalah algoritma Particle Swarm Optimization (PSO).
Dalam makalah ini, saya memberikan rumusan matematika untuk masalah
pemotongan persediaan yang berperan dalam mengambil keputusan pada saat
hendak melakukan proses pemotongan kertas dalam rangka untuk memenuhi semua
pesanan dari konsumen.

650
Berikut diagram alir dari pencarian solusi masalah pemotongan rol kertas
dengan algoritma PSO.
Gambar 1.1: Diagram alir pencarian solusi masalah pemotongan rol kertas dengan
algoritma PSO
Pada makalah ini masalah pemotongan rol kertas dibatasi hanya pada
pemotongan dari rol ke rol yang berarti hanya untuk pemotongan dari rol jumbo
menjadi rol-rol kecil dan dengan pola pemotongan satu dimensi.
1.1 Rumusan Masalah
Berdasarkan latar belakang, maka rumusan masalah utama yang akan dibahas
adalah menyelesaikan masalah pemotongan kertas satu dimensi dengan
menggunakan algoritma PSO agar didapat solusi yang optimal.
1.2 Tujuan Penelitian
Tujuan dari penelitian ini adalah mengetahui efisiensi kerja algoritma Particle
Swarm Optimization, kelebihan, serta kekurangannya pada masalah Cutting Stock
Problem yang diukur dengan beberapa parameter unjuk kerja, yaitu best function,
best variable, dan waktu perhitungan.
1.3 Sistematika Penulisan
Adapun sistematika penulisan makalah ini adalah sebagai berikut:
Bagian pertama menyatakan formulasi matematis dan menjelaskan bagaimana
mengatasi masalahnya. Bagian kedua yaitu pendekatan dengan algoritma PSO
dan fitur-fiturnya. Bagian ketiga melaporkan penyelidikan eksperimental. Bagian
keempat menyajikan penerapan algoritma PSO yang dapat digunakan secara
langsung untuk menyelesaikan masalah pemotongan kertas satu dimensi (dari rol
ke rol) menggunakan GUI yang dibuat dengan menggunakan MATLAB. Bagian
terakhir berisi kesimpulan.
2. Hasil – Hasil Utama
Definisi 2.1. Menurut Santosa [6], algoritma Particle Swarm Optimization (PSO)
adalah algoritma optimasi dengan pendekatan heuristik yang terinspirasi dari perilaku
sekelompok kawanan burung atau sekumpulan ikan yang dapat menjelajah ruang
1. Mengurutkan lebar roll kecil dari
terbesar sampai terkecil. (data)
2. Menentukan pola pemotongan kertas.
(kendala)
3. Mengoperasikan algoritma PSO sesuai
dengan data dan kendala agar nilai
optimal dari fungsi objektif tercapai.

651
solusi secara efektif sehingga mempunyai keefektifan yang baik dalam
menyelesaikan masalah.
Definisi 2.2. Menurut Suyanto [8], metode heuristik adalah suatu teknik aproksimasi
atau pendekatan yang didesain untuk memecahkan masalah optimasi dengan cara
mencoba secara iteratif sebagai upaya memperbaiki kandidat solusi dengan
memperhatikan batasan kualitas solusi yang diinginkan dengan mengutamakan
waktu komputasi dan biasanya menghasilkan solusi yang cukup baik, dalam arti
optimal atau mendekati optimal.
Definisi 2.3. Seperti yang dijelaskan oleh Mahadika [4], misalkan terdapat n
kemungkinan pola pemotongan untuk rol jumbo dengan lebar 𝑟, rol kecil memiliki
lebar 𝑤𝑖 untuk 𝑖 = 1,… ,𝑚, dan 𝑝𝑖 adalah banyaknya rol kecil dengan lebar 𝑤𝑖 (𝑝𝑖 bilangan bulat non negatif) sehingga ∑ 𝑝𝑖𝑤𝑖
𝑚𝑖=1 ≤ 𝑟. Maka masalah pemotongan ini
dapat diselesaikan dalam program linier sebagai berikut.
Minimumkan
𝑧 =∑𝑥𝑗
𝑛
𝑗=1
(2.1)
dengan kendala
∑𝑝𝑖𝑗𝑥𝑗
𝑛
𝑗=1
≥ 𝑏𝑖
𝑥𝑗 ≥ 0
(2.2)
dan 𝑝𝑖𝑗 adalah banyaknya rol kecil dengan lebar 𝑤𝑖 dalam pola pemotongan ke-j, 𝑏𝑖
adalah banyaknya permintaan rol kecil dengan lebar 𝑤𝑖, variabel 𝑥𝑗 menunjukkan
banyaknya rol jumbo yang dipotong pada jenis pemotongan ke-𝑗, variabel 𝑚
mewakili banyaknya variasi lebar kertas potongan (rol kecil), variabel 𝑛
menunjukkan banyaknya kemungkinan pemotongan yang dapat dilakukan sesuai
dengan variasi lebar kertas sesuai pesanan (pola pemotongan).
Contoh 2.1. Sebuah industri kertas menghasilkan rol jumbo dengan lebar 3 meter.
Pelanggan menginginkan rol dengan lebar yang lebih kecil. Dari rol jumbo dapat
dipotong ke dalam 2 rol dengan lebar 93 cm, 1 rol dengan lebar 108 cm, dan
menyisakan rol dengan lebar 6 cm.
Misalkan pesanan yang diterima adalah sebagai berikut.
Tabel 2.1: Tabel pesanan yang diterima
Banyak rol Lebar rol (cm)
97 135
610 108
395 93
211 42

652
Permasalahannya menjadi bagaimana menentukan pola pemotongan rol
jumbo agar pesanan dapat dipenuhi dengan banyaknya rol jumbo yang harus
dipotong sesedikit mungkin.
Ada 12 kemungkinan cara memotong rol jumbo ke dalam rol kecil sesuai
pesanan (dengan sisa pemotongan kurang dari 42 cm) yaitu:
Tabel 2.2: Tabel pola pemotongan yang dibuat sesuai pesanan
Kemungkinan
𝑗
Lebar rol
135 108 93 42
1 2 0 0 0
2 1 1 0 1
3 1 0 1 1
4 1 0 0 3
5 0 2 0 2
6 0 1 2 0
7 0 1 1 2
8 0 1 0 4
9 0 0 3 0
10 0 0 2 2
11 0 0 1 4
12 0 0 0 7
Pola 1 dari Tabel 2.2 berarti 1 rol jumbo dengan lebar 3 meter akan dipotong
menjadi 2 rol kecil dengan lebar 135 cm. Pola 2 berarti 1 rol jumbo akan dipotong
menjadi 1 rol kecil dengan lebar 135, 1 rol kecil dengan lebar 108 dan 1 rol kecil
dengan lebar 42 cm. Demikian seterusnya berlaku cara membaca data yang sama
untuk pola-pola pemotongan yang lain.
Untuk setiap kemungkinan pola 𝑃𝑗 di atas, kita memperkenalkan variabel 𝑥𝑗 ≥
0 yang menunjukkan banyaknya rol jumbo yang harus dipotong menurut pola 𝑃𝑗. Dengan demikian, fungsi tujuan adalah meminimumkan jumlah rol jumbo yang
dipotong yaitu ∑ 𝑥𝑗12𝑗=1 . Agar pesanan terpenuhi maka untuk setiap ukuran lebar yang
dipesan ditambahkan sebuah kendala. Sebagai contoh, untuk pesanan 395 rol dengan
lebar 93 cm, maka fungsi kendala dapat dituliskan

653
𝑥3 + 2𝑥6 + 𝑥7 + 3𝑥9 + 2𝑥10 + 𝑥11 ≥ 395 yang berarti jumlah rol kecil dengan lebar 93 cm yang dihasilkan dengan memotong
rol jumbo menurut berbagai pola pemotongan tidak boleh kurang dari 395 rol
(jumlah rol pesanan). Demikian seterusnya sehingga diperoleh masalah program
linier berikut.
Minimumkan ∑ 𝑥𝑗12𝑗=1
dengan kendala
𝑥3 + 2𝑥6 + 𝑥7 + 3𝑥9 + 2𝑥10 + 𝑥11 ≥ 395
2𝑥1 + 𝑥2 + 𝑥3 + 𝑥4 ≥ 97
𝑥2 + 2𝑥5 + 𝑥6 + 𝑥7 + 𝑥8 ≥ 610
𝑥2 + 𝑥3 + 3𝑥4 + 2𝑥5 + 2𝑥7 + 4𝑥8 + 2𝑥10 + 4𝑥11 + 7𝑥12 ≥ 211
𝑥𝑗 ≥ 0
Masalah tersebut dapat diselesaikan dengan perangkat lunak QM
(Quantitative Method) for Windows yang merupakan perangkat lunak digunakan
untuk membantu proses perhitungan secara teknis pengambilan keputusan secara
kuantitatif. Berikut adalah hasil yang didapat menggunakan QM.
Gambar 2.1: Gambar hasil perhitungan dengan menggunakan QM
Dari gambar di atas, didapatkan solusi optimal yaitu 𝑥1 = 48,5, 𝑥5 = 206,25,
𝑥6 = 197,5, dan selainnya bernilai 0. Itu berarti untuk memenuhi pesanan
diperlukan rol sebanyak 48,5 untuk pola pemotongan pertama, 206,25 rol untuk pola
pemotongan kelima, dan 197,5 rol untuk pola pemotongan keenam. Dengan
demikian, banyaknya rol jumbo yang digunakan sebanyak 452,25 rol.
Lagha [3] menjabarkan bahwa PSO menggunakan konsep populasi dan
kinerja serta penyesuaian individu sebagai berikut:
A. Pengkodean Partikel
Pengkodean untuk partikel ini didesain sebagai vektor berukuran m (setara
dengan jumlah potongan yang diminta). Posisi j pada partikel menandai persediaan
kertas di mana bagian j tersebut dipotong pada saat iterasi ke-i.

654
Potongan partikel
Contoh 2.2
Misal: 𝑋𝑗𝑖 = (1,2,2,3)
kita dapat mencatat bahwa solusi ini sesuai dengan ekstraksi 4 potongan dari 3 jenis
panjang kertas. Sesuai dengan contoh ini, solusi atau partikel diilustrasikan sebagai
berikut:
Gambar 2.2 : Ilustrasi partikel
B. Fungsi Fitness
Fungsi Fitness pada masalah pemotongan persediaan ini merupakan fungsi
obyektif yang bertujuan untuk mengevaluasi setiap partikel dan menemukan
banyaknya kertas yang digunakan. Nilai fitness dihitung sebagai penjumlahan semua
nilai fungsi obyektif dari masing-masing variabel (partikel).
C. Populasi Awal
Posisi sebuah partikel yang ditunjukkan oleh vektor menyajikan solusi
potensial dari masalah. PSO diinisialisasi dengan populasi partikel yang secara acak
diberikan dan mencari posisi terbaik (solusi) dengan nilai fitness terbaik.
D. Pergerakan Partikel
Setelah pembangkitan populasi awal, sebuah seleksi dilakukan untuk memilih
partikel pemimpin atau solusi terbaik global. Operasi perhitungan dilakukan pada
setiap iterasi untuk memilih antara Terbaik Global (Gbest) dan partikel acak untuk
membawanya lebih dekat ke solusi yang optimal. Pada saat itu, kawanan tumbuh dan
merangkak dengan optimal sampai tercapai kriteria penghentiannya.
Pada setiap iterasi dalam algoritma, setiap partikel xj memodifikasi kecepatan
𝑣𝑗𝑖-nya dan posisi 𝑥𝑗
𝑖 tergantung pada dua elemen penting, yaitu: Sebuah lokal utama
yaitu 𝑃𝑏𝑒𝑠𝑡𝑗𝑖 dan yang kedua yang mewakili perilaku sosial dari kawanan yaitu
𝐺𝑏𝑒𝑠𝑡𝑗𝑖. Kecepatan yang mengontrol pergerakan partikel ini dirancang sebagai
berikut:
𝑣𝑗𝑖 = 𝑣𝑗
𝑖−1 + (𝑐1𝑟1 × (𝑃𝑏𝑒𝑠𝑡𝑗𝑖 − 𝑥𝑗
𝑖−1)) + (𝑐2𝑟2 × (𝐺𝑏𝑒𝑠𝑡𝑗𝑖 − 𝑥𝑗
𝑖−1))
𝑥𝑗𝑖 = 𝑥𝑗
𝑖−1 + 𝑣𝑗𝑖
dengan 𝑐1 dan 𝑐2 masing-masing adalah learning rates untuk kemampuan individu
(cognitive) dan pengaruh sosial (group), dan 𝑟1dan 𝑟2bilangan acak (random) yang
berdistribusi seragam (uniform) dalam interval 0 dan 1. Jadi parameter 𝑐1 dan 𝑐2
menunjukkan bobot dari memori (position) sebuah partikel terhadap memori
(position) dari kelompok (swarm). Nilai dari 𝑐1 dan 𝑐2 adalah 2 sehingga partikel-
partikel akan mendekati target sekitar setengah selisihnya.
Berikut adalah hasil penyelesaian masalah pemotongan persediaan kertas
sesuai contoh yang dapat ditampilkan setelah dieksekusi dengan algoritma PSO
menggunakan bantuan MATLAB berdasarkan pengembangan dari program yang
dibuat oleh Alam [1,2]:
Final Results--------------------------------------------

655
bestfun = 452.2747
bestrun = 5
best_variables =
Columns 1 through 9
48.5080 0 0 0 206.2667 197.5001 0 0 0
Columns 10 through 12
0 0 0
>> Elapsed time is 15.217224 seconds.
Gambar 2.3: Gambar grafik konvergensi PSO pada run ke 5
Hasil perhitungan dengan algoritma PSO yang dijalankan pada program
MATLAB tidak berbeda jauh dengan hasil perhitungan yang dilakukan oleh
software QM, didapatkan solusi optimal yaitu 𝑥1 = 48.5080, 𝑥5 = 206.2667, 𝑥6 =197.5001, dan selainnya bernilai 0. Itu berarti untuk memenuhi pesanan diperlukan
rol sebanyak 48.5080 untuk pola pemotongan pertama, 206.2667 rol untuk pola
pemotongan kelima, dan 197.5001 rol untuk pola pemotongan keenam. Dengan
demikian, banyaknya rol jumbo yang digunakan sebanyak 452.2747 rol.
Dari data yang sudah didapat menghasilkan jumlah rol bukan berupa bilangan
bulat. Oleh karena itu, diperlukan suatu metode untuk memberikan solusi berupa
bilangan bulat. Metode yang digunakan adalah first-fit decreasing.
Definisi 2.4. Metode First-Fit Decreasing (FFD) seperti dikutip dari Mahadika [4]
adalah metode heuristik dimana pada iterasi ke-j dari metode ini yaitu menemukan
pola pemotongan rol jumbo ke-j. Iterasi dimulai dengan sisa permintaan setelah
jumlah rol dibulatkan ke bawah yaitu 𝑏1′ , 𝑏2
′ , … , 𝑏𝑚′ . Pola pemotongan yang
dihasilkan untuk setiap iterasi yaitu
𝑎𝑖 = 𝑚𝑖𝑛
{
𝑏𝑖
′
⌊(𝑟 −∑𝑤𝑘𝑎𝑘
𝑖−1
𝑘=1
) 𝑤𝑖⁄ ⌋
(2.3)

656
Untuk 𝑖 = 1,2, … ,𝑚, kemudian ganti setiap nilai 𝑏𝑖′ dengan 𝑏𝑖
′ − 𝑎𝑖 dan lanjutkan
proses iterasi ke-j+1.
Contoh 2.3
Mencari solusi bilangan bulat untuk Contoh 2.1 didapatkan hasil
Tabel 2.3: Tabel hasil yang diperoleh dengan menggunakan algoritma PSO
Pola
pemotongan
ke-
Lebar rol
Banyak rol
135 108 93 42
1 2 0 0 0 48,5
2 0 2 0 2 206,27
3 0 1 2 0 197,5
Karena solusi belum bernilai bilangan bulat, maka dengan menggunakan
metode first-fit decreasing solusi diubah menjadi bilangan bulat.
Pertama, semua solusi yang diperoleh dibulatkan ke bawah. Sehingga untuk
pola 1 memerlukan 48 rol, pola 2 memerlukan 206 rol, dan pola 3 memerlukan 197
rol. Karena semua solusi dibulatkan ke bawah, maka jumlah produksi rol pesanan
kurang atau sama dengan permintaan rol.
Tabel 2.4: Tabel nilai solusi yang sudah dibulatkan ke bawah dan sisa produksinya
Lebar Rol (𝑤𝑖) Permintaan (𝑏𝑖) Produksi (⌊𝑥𝐵∗ ⌋) Sisa (𝑏𝑖
′)
135 cm 97 rol 96 rol 1 rol
108 cm 610 rol 609 rol 1 rol
93 cm 395 rol 394 rol 1 rol
42 cm 211 rol 412 rol 0 rol
Iterasi 1
Diketahui 𝑏1′ = 1, 𝑏2
′ = 1, 𝑏3′ = 1, 𝑏4
′ = 0.
𝑎1 = 𝑚𝑖𝑛 {𝑏1′
⌊𝑟 𝑤1⁄ ⌋= 𝑚𝑖𝑛 {
1⌊300 135⁄ ⌋
= 𝑚𝑖𝑛 {12= 1
𝑎2 = 𝑚𝑖𝑛{
𝑏2′
⌊(𝑟 −∑𝑤𝑘𝑎𝑘
1
𝑘=1
) 𝑤2⁄ ⌋= 𝑚𝑖𝑛 {
1⌊(300 − 135.1) 108⁄ ⌋
= 𝑚𝑖𝑛 {11= 1

657
𝑎3 = 𝑚𝑖𝑛{
𝑏3′
⌊(𝑟 −∑𝑤𝑘𝑎𝑘
2
𝑘=1
) 𝑤3⁄ ⌋= 𝑚𝑖𝑛 {
1⌊(300 − (135.1 + 108.1) 93⁄ ⌋
= 𝑚𝑖𝑛 {10= 0
𝑎4 = 𝑚𝑖𝑛{
𝑏4′
⌊(𝑟 −∑𝑤𝑘𝑎𝑘
3
𝑘=1
) 𝑤4⁄ ⌋
= 𝑚𝑖𝑛 {0
⌊(300 − (135.1 + 108.1 + 93.0) 42⁄ ⌋ = 𝑚𝑖𝑛 {01= 0
Sehingga didapatkan 𝑏1′ = 0, 𝑏2
′ = 0, 𝑏3′ = 1, 𝑏4
′ = 0.
Iterasi 2
𝑎1 = 𝑚𝑖𝑛 {𝑏1′
⌊𝑟 𝑤1⁄ ⌋= 𝑚𝑖𝑛 {
0⌊300 135⁄ ⌋
= 𝑚𝑖𝑛 {02= 0
𝑎2 = 𝑚𝑖𝑛{
𝑏2′
⌊(𝑟 −∑𝑤𝑘𝑎𝑘
1
𝑘=1
) 𝑤2⁄ ⌋= 𝑚𝑖𝑛 {
0⌊(300 − 135.0) 108⁄ ⌋
= 𝑚𝑖𝑛 {02= 0
𝑎3 = 𝑚𝑖𝑛{
𝑏3′
⌊(𝑟 −∑𝑤𝑘𝑎𝑘
2
𝑘=1
) 𝑤3⁄ ⌋= 𝑚𝑖𝑛 {
1⌊(300 − (135.0 + 108.0) 93⁄ ⌋
= 𝑚𝑖𝑛 {13= 1
𝑎4 = 𝑚𝑖𝑛{
𝑏4′
⌊(𝑟 −∑𝑤𝑘𝑎𝑘
3
𝑘=1
) 𝑤4⁄ ⌋
= 𝑚𝑖𝑛 {0
⌊(300 − (135.0 + 108.0 + 93.1) 42⁄ ⌋ = 𝑚𝑖𝑛 {04= 0
Sehingga didapatkan 𝑏1′ = 0, 𝑏2
′ = 0, 𝑏3′ = 0, 𝑏4
′ = 0. Proses iterasi diberhentikan
karena semua pesanan sudah terpenuhi. Jadi, didapatkan 2 rol tambahan dengan 2
pola yang berbeda.
Tabel 2.5: Tabel jumlah rol sesuai pola dari algoritma PSO dan algoritma FFD
Pola
Lebar rol pesanan
Jumlah rol 135 108 93 42
1 2 0 0 0 48
2 0 2 0 2 206
3 0 1 2 0 197
4 1 1 0 0 1

658
5 0 0 1 0 1
TOTAL 453
Berikut ini adalah hasil penyelesaian optimal yang diproses dengan GUI MATLAB:
Gambar 2.4: Gambar hasil perhitungan dengan menggunakan GUI MATLAB
Dari gambar di atas, dapat diketahui bahwa semua pesananan sudah
terpenuhi. Hasil dari best fun adalah 452.2502 dan nilainya masih belum bulat karena
nilai tersebut hanya merupakan suatu output dari pendekatan algoritma PSO yang
akan berguna untuk mencari best variable yang akan digunakan sebagai input untuk
diproses menggunakan algoritma First-fit decreasing (FFD) agar bernilai bulat.
Tabel 2.6: Tabel jumlah rol sesuai pola dari algoritma PSO dan algoritma FFD
Pola Lebar rol pesanan
Jumlah rol 135 108 93 42
1 1 1 0 1 97
2 0 2 0 2 157
3 0 1 2 0 197
4 0 2 0 0 1
5 0 0 1 0 1
TOTAL 453

659
3. Kesimpulan
Hasil perhitungan dengan PSO sudah cukup optimal, hal ini dikonfirmasi
dengan hasil yang kurang lebih sama dengan hasil yang diperoleh dari QM
(perangkat lunak standar untuk menyelesaikan masalah program linear yang ada di
pasaran), sehingga dapat dipergunakan untuk menyelesaikan masalah pemotongan
persediaan kertas. Namun dari penyelesaian yang didapat, terlihat bahwa solusi
masih berupa bilangan desimal sehingga diperlukan metode FFD untuk mengubah
solusi ke dalam bentuk bilangan bulat.
Referensi
[1] Alam, M.N., 2016, Codes in MATLAB for Particle Swarm Optimization,
ResearchGate. (2016), 1 - 4.
[2] Alam, M.N., 2016, Particle Swarm Optimization: Algorithm and It’s Codes in
MATLAB, ResearchGate. (2016), 1 - 11.
[3] Lagha, G.B. et.al., 2014, Particle Swarm Optimization Approach for Resolving Cutting
Stock Problem, International Conference on Advanced Logistic and Transport. (2014),
1 - 11.
[4] Mahadika, R.A., 2016, Penyelesaian Masalah Pemotongan Rol Kertas dengan Metode
Penghasil Kolom, Dept. Matematika Universitas Sanata Dharma.
[5] Parmar, K. B., Cutting Stock Problem: A Survey of Evolutionary Computing Based
Solution, International Conference on Green Computing Communication and Electrical
Engineering. (2014)
[6] Santosa, B. and Willy P., 2011, Metoda Metaheuristik Konsep dan Implementasi, Guna
Widya.
[7] Shen, X. et.al., A Heuristic Particle Swarm Optimization for Cutting Stock Problem,
ICCS. (2007)
[8] Suyanto, 2010, Algoritma Optimasi Deterministik atau Probabilistik, Graha Ilmu

660
Prosiding SNM 2017 Komputasi , Hal 660-666
APLIKASI METODE PENGGEROMBOLAN
ALGORITMA KHUSUS DALAM PENENTUAN ZONA
BIAYA HAK PENGGUNA FREKUENSI RADIO
ERFIANI
Departemen Statistika FMIPA-IPB, [email protected]
Abstrak. Perkembangan teknologi telekomunikasi beriringan dengan
perkembangan spektrum fruekuensi radio. Spektrum frekuensi radio merupakan
sumber daya alam yang bersifat strategis, ekonomis, dan terbatas ( limited
natural resources), sehingga dalam penggunaan pelayanan frekuensi radio
haruslah efisien, rasional, dan optimal. Salah satu upaya pemerintah dalam
mengatur penggunaan frekuensi radio adalah melalui Peraturan Pemerintah
Republik Indonesia nomor 28 tahun 2005 tentang biaya hak pengguna (BHP)
frekuensi radio. Besaran BHP frekuensi disuatu daerah dipengaruhi beberapa
peubah indikator. Pada penelitian ini dilakukan kajian jumlah zona BHP
menggunakan data yang lebih terkini. Metode pembentukan zona dalam data
mining dikenal dengan istilah analisis gerombol (clustering analysis). Pada data
Kota/Kabupaten yang digunakan terdapat banyak Kota/Kabupaten hasil
pemekaran, sehingga terdapat data yang tidak lengkap. Oleh karena itu dalam
penentuan zona atau pembentukan gerombol diperlukan metode yang dapat
menanggulangi kondisi data tidak lengkap. Metode penggerombolan standar
yang ada kurang tepat dalam menganalisis data dengan kondisi data yang tidak
lengkap. Pada penelitian ini digunakan pendekatan metode penggerombolan
algoritma khusus untuk data tidak lengkap pada kasus penentuan zona BHP.
Hasil akhir jumlah zona BHP di Indonesia yang optimal sebanyak lima zona.
Kata kunci : biaya hak pengguna, clustering analysis, data tidak lengkap, zona
1. Pendahuluan
Frekuensi radio merupakan sumber daya alam yang terbatas yang
mempunyai nilai strategis dan ekonomis dalam penyelenggaraan telekomunikasi.
Oleh karena itu perlu dilakukan pengaturan secara efektif dan optimal guna
mewujudkan penggunaan frekuensi radio yang adil dan merata serta membuka
peluang usaha dan meningkatkan kesejahteraan masyarakat. Manfaat yang didapat
dalam penggunaan frekuensi radio ini dapat kita rasakan dalam kehidupan sehari-
hari seperti penggunaan siaran radio, televisi, seluler, dan lainnya.

661
Melalui lembaga Kementerian Komunikasi dan Informatika (Kominfo)
pemerintah mengatur segala hal dalam penggunaan frekuensi radio di Indonesia.
Hasil laporan akhir tahun 2013 mengenai Penerimaan Negara Bukan Pajak (PNBP)
Indonesia, Kominfo berhasil menjadi penyumbang terbesar kedua PNBP setelah
Kementrian Energi dan Sumber Daya Mineral (ESDM). Penghasilan PNBP
Kominfo yang terbesar berasal dari Biaya Hak Pengguna (BHP) frekuensi radio yang
merupakan sumber pendapatan yang diperoleh dari pengguna frekuensi radio.
Penetapan BHP tertuang pada Peraturan Pemerintah Republik Indonesia nomor 28
tahun 2005 tentang tarif atas jenis PNBP yang berlaku pada Departemen Kominfo
[1]. Dalam peraturan tersebut diatur rumusan perhitungan harga BHP. Pemerintah
melakukan pengelompokan BHP wilayah indonesia menjadi 5 (lima) kelompok atau
disebut dengan 5 (lima) zona. Zona ini berpengaruh terhadap penetapan harga
lainnya dalam rumusan BHP. Setiap zona mempunyai harga BHP yang berbeda.
Tingkatan zona mencerminkan keadaan ekonomi suatu wilayah. Evaluasi penentuan
zona BHP terakhir dilakukan pada tahun 2010 dengan berdasarkan 7 (tujuh) peubah
indikator.
Pada pendekatan analisis statistika, penggerombolan data umumnya
dilakukan dengan metode penggerombolan (clustering methode). Prinsip dari
penggerombolan adalah mengelompokkan objek berdasarkan kemiripan
karakteristik tertentu ke dalam gerombol-gerombol sehingga objek-objek memiliki
homogenitas yang tinggi di dalam gerombolnya dan mempunyai heteroginitas yang
tinggi antar gerombol. Metode Gerombol yang banyak digunakan berlaku pada kasus
data lengkap. Permasalahan akan muncul saat akan melakukan penggerombolan
pada kasus data tak lengkap.
Pada sekitar tahun 2012 terjadi banyak pemekaran kota/kabupaten, sehingga
akan muncul permasalahan bila akan menyusun gerombol/zona BHP. Hal ini akan
terjadi karena ada kota/kabupaten baru yang tidak memiliki data indikator yang
digunakan sebagai penyusun zona. Pada kajian ini akan dilakukan pembentukan
zona BHP kota/kabupaten penggunakan algoritma khusus.
2. Hasil – Hasil Utama
Penanganan penggerombolan data tidak lengkap dapat dilakukan dengan dua pendekatan, yaitu preprocessing dan penerapan algoritma khusus. Preprocessing adalah teknik umum untuk menangani data yang tidak lengkap dengan dua pendekatan. Pertama mengabaikan data yang tidak lengkap (marginalisasi), pendekatan ini akan mengakibatkan kehilangan banyak informasi. Kedua menduga data yang tidak lengkap sehingga diperoleh data lengkap dengan imputasi dan bersifat tetap. Kelemahan metode imputasi dikemukakan oleh Wagstaff dan Laidler [4] yang menyatakan bahwa hasil pendugaan dari metode imputasi tidak efisien karena memberikan informasi yang tidak berarti. Matyja dan Simiński [2] melakukan penelitian penggerombolan untuk data tidak lengkap menggunakan metode algortima khusus dan membandingkannya dengan metode imputasi dan

662
marginalisasi. Beberapa metode algoritma khusus yang digunakan adalah partial distance strategy (PDS), optimal completion strategy (OCS), nearest prototype strategy (NPS). Hasil perbandingan tersebut memperoleh kesimpulan bahwa metode algoritma khusus lebih unggul dalam menggerombolkan data tidak lengkap. Safitri [3] melakukan kajian perbandingan metode gerombol murni tanpa mputasi antara metode k-means soft contraints (KSC) dan metode partial distance strategy (PDS) pada data tidak lengkap. Hasil yang diperoleh menunjukkan bahwa metode PDS lebih unggul dari metode KSC.
Pada penelitian ini akan dilakukan penyusunan zona BHP frekuensi radio dengan menggunakan algoritma khusus PDS. Data yang digunakan pada penelitian ini merupakan data sekunder yang berasal dari Kementerian Komunikasi dan Informasi RI dan Badan Pusat Statistik tahun 2014. Penelitian ini dilakukan terhadap seluruh kota/kabupaten di Indonesia sebanyak 514 daerah pada tahun 2014 dengan menggunakan peubah-peubah berdasarkan Peraturan Kementerian Komunikasi dan Informasi RI. Peubah yang menjadi atribut amatan merupakan peubah numerik. Peubah yang digunakan disajikan pada Tabel 1.
Tabel 1. Daftar peubah dalam penentuan zona BHP frekuensi radio
Peubah Keterangan
X1 Produk Domestik Regional Bruto (PDRB) 2014 (Miliar Rupiah)
X2 Kepadatan Penduduk 2014 (Jiwa / Km2)
X3 Jumlah Angkatan Kerja 2014 (Ribuan Jiwa)
X4 Persentase Pertumbuhan Ekonomi 2014 (%)
X5 Pendapatan BHP 2014 (Juta Rupiah)
X6 Jumlah Base Transceiver Station (BTS) 2014 (Unit)
X7 Indeks Harga Konsumen 2014
Tahapan awal yang dilakukan dalam penelitian ini adalah melakukan pembakuan data peubah amatan. Selanjutnya dilakukan penentuan banyaknya gerombol yang akan digunakan dalam simulasi (pada penelitian ini dicobakan antara dua sampai sembilan gerombol). Pada setiap banyaknya gerombol yang ditetapkan dilakukan penggerombolan kota dan kabupaten menggunakan metode PDS.
Metode PDS merupakan suatu algoritma pengelompokan untuk data tidak lengkap dengan menghitung jarak objek ke pusat gerombol berdasarkan data yang ada (Matyja dan Simiński [2]). Tahapan awal pada proses penggerombolan data dengan menggunakan metode PDS ialah membentuk titik awal pusat gerombol. Pembentukan awal pusat gerombol umumnya dibangkitkan secara acak. Jumlah pusat gerombol yang dibangkitkan sesuai dengan jumlah gerombol yang ditentukan pada awal proses. Total jarak yang digunakan dimodifikasi oleh jumlah dimensi. Berikut algoritma metode PDS :
i. Menentukan pusat gerombol ke-c.
ii. Mencari jarak dari suatu objek ke-k ke pusat gerombol ke-c dengan metode
PDS menggunakan formula sebagai berikut:
D
d
kd
D
d
kdcdkd
ck
I
IcxD
t
1
1
2)(

663
K
k
kdck
K
k
kdkdck
cd
Iu
Ixu
c
1
2
1
2
)(
)(
Keterangan :
𝐼𝑘𝑑 = {1, Jika peubah ke − 𝑑 ada pada objek ke − 𝑘
0, selainnya
ckt = jarak objek ke-k terhadap gerombol ke-c
D = total dimensi peubah
kdx = nilai objek ke-k pada peubah ke-d
cdc = pusat gerombol ke-c berdasarkan peubah ke-d
cku = nilai keanggotan objek ke-k terhadap gerombol ke-c
iii. Mengalokasikan objek ke dalam suatu gerombol berdasarkan jarak minimal
iv. Ulangi langkah 1 hingga 3 dan berhenti sampai 4)1()(
,
10||max r
cd
r
cddc
cc ,
dengan r merupakan total dari iterasi.
Langkah selanjutnya dilakukan penggantian nilai data hilang pada setiap jumlah gerombol dengan centeroid masing-masing gerombol berdasarkan peubahnya untuk setiap jumlah gerombol. Hal ini bertujuan agar dapat menggunakan algoritma penentuan optimasi gerombol, karena keterbatasan informasi dan literatur untuk algoritma penentuan jumlah gerombol optimal dengan kondisi data tidak lengkap. Tahap akhir analisis dilakukan pemilihan jumlah gerombol optimal berdasarkan nilai IDB minimal.
Indeks Davies Bouldin (IDB) digunakan untuk menentukan jumlah gerombol yang optimal pada analisis gerombol untuk data lengkap. Pengukuran IDB memaksimalkan jarak antar gerombol Ci dan Cj dan pada waktu yang sama mencoba untuk meminimalkan jarak antar titik dalam gerombol. Jika jarak antar gerombol maksimal maka ragam antar gerombol akan tinggi, sehingga perbedaan antar gerombol terlihat jelas. Jika jarak dalam gerombol minimal maka ragam objek dalam gerombol kecil, sehingga objek dalam setiap gerombol memiliki karakteristik yang sama. Rumusan perhitungan IDB adalah sebagai berikut:
IDBnc =1
𝑛𝑐∑ max
𝑗≠𝑘{𝑆𝑐(𝑄𝑘) + 𝑆𝑐(𝑄𝑗)
𝑑𝑘𝑗(𝑄𝑘 , 𝑄𝑗)}
𝑛𝑐
𝑘=1
𝑆𝑐(𝑄𝑘) =∑ ‖𝑂𝑖 − 𝐶𝑘‖𝑖
𝑁𝑘
𝑑𝑘𝑙 = ‖𝐶𝑘 − 𝐶𝑙‖

664
nc adalah banyak gerombol, Oi adalah objek amatan dalam gerombol Qk, Nkadalah banyak observasi dalam gerombol Qk, Ck dan Cl secara berturut-turut adalah centroid gerombol ke-k dan gerombol ke-l. Skema gerombol yang optimal ialah yang memiliki nilai IDB yang minimal (Yatkiv dan Gusarova [5]).
Penelitian ini menggunakan metode PDS yang merupakan perkembangan dari
penggerombolan dengan metode k-means. Tahapan pertama dalam metode k-means
menentukan jumlah gerombol yang akan dibuat. Oleh sebab itu, pada tahapan
penggerombolan dengan metode PDS ditentukan jumlah gerombol yang akan dibuat
dari jumlah gerombol sebanyak dua hingga jumlah gerombol sebanyak sembilan.
Jumlah gerombol yang optimal adalah yang memiliki nilai IDB terkecil. Hasil dari
perhitungan nilai IDB disajikan pada Tabel 2. Ada 3 (tiga) kemungkinan jumlah
gerombol yang memiliki nilai IDB terkecil, secara berurutan dari yang terkecil, yaitu
jumlah gerombol 2, 6 dan 5.
Tabel 2. Nilai IDB pada setiap kemungkinan jumlah gerombol
Nilai IDB Jumlah gerombol
0.6803 2
0.93094 6
0.98952 5
1.01751 8
1.02205 9
1.05401 4
1.18429 3
1.22613 7
Berdasarkan Tabel 2, jumlah gerombol optimal dengan nilai IDB terkecil
adalah jumlah gerombol sebanyak dua dengan nilai IDB sebesar 0.6803.
Penggerombolan atau pembentukan zona BHP wilayah Indonesia yang sangat luas
dengan 514 kota/kabupaten hanya dalam 2 (dua) gerombol/zona, menurut peneliti
akan kurang tepat. Oleh karena itu peneliti mengusulkan jumlah gerombol/zona
BHP Indonesia sebanyak 5 atau 6 zona. Gambar-1 menyajikan sebaran wilayah zona

665
BHP untuk jumlah zona sebanyak 5 (lima). Gambar 2. menyajikan sebaran wilayah
zona BHP untuk jumlah zona sebanyak 6 (enam). Pada jumlah zona sebanyak enam
masih ditemukan zona dengan sebaran wilayah yang saling terputus. Sebagai contoh
pada gerombol 2 meliputi wilayah yang tersebar pada pulau Jawa dan Sumatera.
Sedangkan pada jumlah gerombol sebanyak lima, relatif memiliki hasil yang lebih
baik dibandingkan pada jumlah gerombol sebanyak enam.
Gambar 1. Sebaran wilayah zona BHP untuk jumlah zona sebanyak lima
Gambar 2. Sebaran wilayah zona BHP untuk jumlah zona sebanyak enam

666
3. Kesimpulan
Hasil penentuan jumlah gerombol/zona BHP menggunakan pendekatan
metode PDS, diperoleh jumlah gerombol/zona BHP sebanyak lima atau enam
gerombol/zona BHP Bila mempertimbangkan juga sebaran wilayah dalam setiap
gerombol/zona BHP jumlah gerombol/zona BHP, peneliti merekomendasikan
jumlah gerombol/zona BHP sebanyak lima.
Referensi
[1] Kementrian Komunikasi dan Informatika. 2005. Peraturan Menteri Komunikasi
dan Informatika Nomor :19/PER.KOMINFO/10/2005 tentang Petunjuk
Pelaksanaan Tarif Atas Penerimaan Negara Bukan Pajak Dari Biaya
Penggunaan Spektrum Frekuensi Radio. Jakarta (ID): Kominfo.
[2] Matyja A. and Simiński, K. 2014. Comparison of algorithms for clustering
incomplete data. Journal Foundations of Computing and Decision Sciences 39
: 107–127.
[3] Safitri, W.D. 2015. Kajian Penggerombolan Data Tidak Lengkap Dengan
Algoritma Khusus Tanpa Imputasi [Thesis].Bogor:IPB
[4] Wagstaff, K. and Laidler V. 2005. Making the most of missing values: Object
clustering with partial data in astronomy. Proceedings of Astronomical Data
Analysis Software and Systems XIV 347: 172–176. California,USA.
[5] Yatkiv, I. and Gusarova, L. 2004. The Method of Cluster Analysis Result
Validation. Proceedings of International Conference RelStat’04part 1: 75-80.
.

667
Prosiding SNM 2017 Komputasi , Hal 667-676
ALGORITMA GENETIK STEADY STATE
BERDASARKAN FUNGSI PEMBOBOTAN BIAYA DAN
RELIABILITAS DALAM MENENTUKAN PERAWATAN
OPTIMAL MESIN
BUDHI HANDOKO1, YENY KRISTA FRANTY2, SRI WINARNI3
1 Departemen Statistika Jln Bandung-Sumedang km 21Jatinangor, Email:
[email protected] 2 Departemen Statistika Jln Bandung-Sumedang km 21Jatinangor, Email :
[email protected] 3 Departemen Statistika Jln Bandung-Sumedang km 21Jatinangor, Email :
sri.winarni @unpad.ac.id
Abstrak. Kegiatan Preventive Maintainance pada suatu perusahaan manufaktur adalah suatu
hal yang sangat penting guna mempertahankan masa hidup komponen/mesin dan meningkatkan
perfomansinya. Penelitian ini membahas mengenai penentuan penjadwalan pemeliharaan
preventif yang meminimumkan biaya total sekaligus memaksimumkan reliabilitas dari
komponen/mesin. Metode yang diusulkan sebelumnya menggunakan metode eksak mengalami
kendala pada proses optimasinya yaitu kompleksitas model, lamanya proses komputasi, dan
solusi yang dihasilkan bisa tidak layak diterapkan. Oleh karena itu, untuk mengatasi kelemahan
metode eksak, penelitian ini menggunakan metode optimasi Algoritma Metaheursitik yaitu
Algoritma Genetik dan Algoritma Genetik Steady State. Penelitian ini membatasi
menggunakan fungsi fitness 1 untuk analisisnya.
Untuk menyelesaikan permasalahan optimasi penjadwalan menggunakan AGSS untuk
komponen mesin freeze drying digunakan ukuran populasi 2000 karena menghasilkan nilai
variasi solusi yang cukup kecil dan siklus genetik 500 karena menghasilkan nilai konvergensi
pada biaya maupun nilai reliabilitas. Kisaran nilai reliabilitas mesin yang dihasilkan dari hasil
optimasi ini adalah antara 88% - 90% dengan kisaran biaya antara Rp. 607.130 – Rp. 1.173.000.
Apabila perusahaan menginginkan biaya perawatan yang minimum maka menggunakan bobot
w1 = 0,1 dan w2 = 0,9 dengan nilai relibilitas yang dihasilkan 88,04%, dengan tindakan
perawatan pada bulan ke-1,2,3,5,7,dan 8 serta tindakan penggantian komponen pada bulan ke-
4,6,9,dan 11. Setelah bulan ke 11, tidak ada tindakan apapun untuk semua kombinasi bobot.
Kata Kunci : Pemeliharaan Preventif, Algoritma Genetik, Optimasi Fungsi Multiobjektif

668
1. Pendahuluan
Aktivitas produksi pada perusahaan manufaktur berjalan terus menerus setiap saat
karena tuntutan dari jumlah produksi yang menjadi target perusahaan yang sangat terkait
dengan kebutuhan pasar. Mesin yang memproduksi barang pun menjadi tumpuan utama
dalam proses produksi tersebut dan bekerja 24 jam setiap hari. Masa hidup mesin pun
semakin lama akan semakin mengalami penurunan yang apabila tidak dilakukan kegiatan
pemeliharaan preventif maka bisa menyebabkan mesin mengalami kerusakan dan
mati/berhenti berproduksi. Selama mesin mati (downtime) perusahan akan mengalami
kerugian akibat tidak memproduksi barang.
Kegiatan pemeliharaan preventif menjadi sangat penting dilakukan oleh perusahaan
dalam rangka tetap mempertahankan kinerja dan masa hidup dari mesin. Kegiatan
pemeliharaan preventif ini pun biasanya dilakukan perusahaan sesuai dengan kebutuhan dan
karakteristik kerusakan dari mesin. Namun demikian, pemeliharaan preventif ataupun
penggantian komponen menjadi suatu hal yang dipertimbangkan matang-matang oleh
perusahaan terkait dengan pembiayaan yang diperlukan. Apabila pelaksanaanya tidak
dijadwalkan dengan optimal, maka biaya total yang dikeluarkan akan membengkak dan
mempengaruhi anggaran perusahaan tersebut.
Berbagai pendekatan statistik telah diusulkan untuk meminimumkan biaya total
dalam melaksanakan penjadwalan optimum mesin. Konsep optimasi yang lazim dilakukan
adalah berdasarkan fungsi tujuan yaitu meminimumkan biaya total tanpa ada fungsi kendala
yang lain. Pendekatan optimasi multiobjektif telah diusulkan oleh [1] yang mengusulkan dua
model, yaitu model optimasi yang memiliki fungsi tujuan meminimumkan biaya total dengan
nilai reliabilitas yang telah ditetapkan. Model yang lain adalah optimasi yang memiliki fungsi
tujuan memaksimumkan reliabilitas mesin dengan biaya/anggaran yang telah ditetapkan oleh
perusahaan.
Perkembangan mengenai penelitian metode optimasi dalam reliabilitas di antaranya
metode analitik, algoritma eksak, dan algoritma metahueristik.
Beberapa penelitian mengenai metode analitik yaitu [2] meneliti tentang model optimasi
pemeliharaan preventif yang memfokuskan pada beberapa fungsi kegagalan dalam
reliabilitas sistem. Hasil penelitiannya menyatakan bahwa tindakan pemeliharaan preventif
tidak mengubah atau mempengaruhi perilaku laju kerusakan. Referensi [3] membentuk
model optimasi untuk menentukan jadwal pemeliharaan preventif untuk sistem manufaktur
multi-station. Penelitian tersebut menggunakan pendekatan simulasi untuk menyelesaikan
optimasi model. Hasilnya penelitiannya bahwa fitur operasi dari stasiun produksi saling
terkait satu sama lain. Referensi [4] memaparkan dua jenis model penjadwalan pemeliharaan
preventif yang meminimumkan biaya total. Model dibentuk berdasarkan konsep Mean Time
to Failure (MTTF) dari mesin. Model pertama berdasarkan fungsi kegagalan distribusi
Weibull, sedangkan model yang kedua mengasumsikan bahwa pemeliharaan preventif dapat
mengurangi umur efektif sistem. Referensi [5] meneliti dan melakukan review terhadap
aplikasi dari beberapa proses stokastik diantaranya homogenous poisson process (HPP) dan
non-homogenous poisson process (NHPP) dalam permasalahan penjadwalan pemeliharaan
preventif. Keduanya menyarankan agar menggunakan NHPP untuk model laju kerusakan
dari sistem perbaikan. Referensi [6] membangun model optimasi nonlinier berbasis-usia
sistem untuk menentukan jadwal pemeliharaan preventif optimum untuk sistem dengan
komponen tunggal.
Penelitan mengenai algoritma eksak dilakukan oleh beberapa peneliti berikut ini. Referensi [7] memformulasikan sebuah model matematika untuk mendapatkan jadwal
produksi optimal dengan menggunakan fungsi Gaussian Poisson dengan Proses Poisson
dependen. Dalam penelitian ini, biaya total produksi dan jadwal perawatan sebagai fungsi
objektif dan menggunakan pendekatan pemrograman dinamis. Referensi [8] mengenai model
optimasi nonlinier untuk meminimumkan biaya total dari tindakan pemeliharaan dan
penggantian dengan kendala reliabilitas mesin. Dalam studi ini, fungsi kegagalan dari mesin
yang berdistribusi Weibull dapat digunakan sebagai decision support system untuk

669
penjadwalan pekerjaan. Referensi [9] menyajikan model pemrograman linier untuk
melakukan optimasi kebijakan pemeliharaan komponen dengan laju kerusakan yang bersifat
acak. Penelitian ini memberikan hasil waktu rata-rata optimal dari tindakan pemeliharaan
preventif yang memaksimumkan ketersediaan komponen. Referensi [10] membangun tiga
buah model optimasi nonlinier, yaitu model pertama meminimumkan biaya total berdasarkan
reliabilitas yang diinginkan, model kedua memaksimumkan reliabilitas dengan anggaran
yang diberikan, dan model ketiga meminimumkan ekspektasi biaya total, biaya kerusakan,
dan biaya pemeliharaan.
Algoritma Genetik sebagai pendekatan optimasi utama telah banyak disajikan dalam
jurnal-jurnal optimasi. Referensi [11] meneliti tentang sistem multi-state dengan komponen
yang memiliki tingkat performansi yang berbeda. Model tersebut meminimumkan biaya
dengan reliabilitas yang ditetapkan. Untuk melakukan analisis tersebut, mereka menerapkan
teknik fungsi pembangkit universal dan menggunakan algoritma genetik untuk menentukan
strategi pemeliharaan terbaik. Referensi [12] membangun algoritma genetik baru dengan
memodifikasi operator dasar, operator crossover dan operator mutasi pada algoritma genetik
standar. Dengan menggunakan algoritma baru ini, konvergensi akan tercapai lebih cepat dan
mencegah solusi hasil menjadi tidak layak/sesuai dengan kondisi sebenarnya. Referensi [13]
menyajikan algoritma heuristik untuk penjadwalan pemeliharaan dari sebuah sistem yang
memiliki sekumpulan komponen. Dalam penelitian ini, semua komponen diasumsikan
memiliki laju kerusakan yang meningkat dengan nilai factor peningkatan yang konstan.
Referensi [14] mengusulkan beberapa teknik untuk merepresentasikan variable-variabel
dalam model penjadwalan pemeliharaan preventif yang menggunakan algoritma optimasi
heuristic dan metaheuristik. Pendekatan ini secara empiric lebih efektif dibandingkan
pendekatan yang lain karena dapat meningkatkan akurasi dan mengurangi waktu komputasi.
Metode optimasi yang digunakan pada pendekatan yang diusulkan oleh [1] adalah
menggunakan Algoritma Eksak atau yang dikenal dengan Mixed Integer Non-Linear
Programming (MINLP). Algoritma Eksak sendiri memiliki tingkat kompleksitas yang sangat
tinggi yang menyebabkan proses pengerjaan secara komputasi menjadi lebih lama, dan bisa
jadi tidak mendapatkan solusi yang layak dan tepat.
Penelitian ini melakukan kajian metode optimasi alternatif yang bisa mengatasi
kelemahan yang muncul pada metode eksak. Metode tersebut adalah Metaheuristik yang
memiliki fungsi yang sama yaitu melakukan optimasi fungsi multiobjektif, yaitu
meminimumkan biaya total dan memaksimumkan relibilitas.
Berdasarkan latar belakang tersebut, penelitian ini memiliki tujuan yaitu melakukan
optimasi multiobjektif yang dapat meminimumkan biaya total dan dapat memaksimumkan
fungsi reliabilitas dalam rangka melakukan pemeliharaan preventif mesin menggunakan
algoritma metaheuristik.
Penelitian ini memiliki peranan dalam pengembangan keilmuan yaitu memberikan
suatu metode yang lebih mampu memberikan jaminan solusi optimasi pada model dengan
fungsi tujuan lebih dari satu. Selain itu, secara aplikasi metode ini mampu memberikan suatu
rekomendasi yang lebih lengkap kepada perusahaan manufaktur agar dapat melakukan
kegiatan pemeliharaan preventif yang lebih optimal.

670
2. Metode Penelitian
Parameter Ekonomi Teknik
Apabila diasumsikan bahwa inflasi akan meningkatkan biaya kerusakan seiring berjalannya
waktu pada tingkat inffailure persen per periode, maka dapat didefinisikan biaya kerusakan
menurut [1] komponen ke-i pada periode ke-j adalah sebagai berikut:
,' '
. 1, , ,ji i
F F X X inffailurei j i i i j i j
(1)
dengan i = 1,2,…,N ; j = 1,2,…,T.
Selanjutnya menurut [1] dimisalkan tingkat inflasi untuk pemeliharaan (infm), tingkat inflasi
untuk penggantian (infr), dan tingkat inflasi untuk biaya tetap (infz). Sehingga diperoleh
biaya dari tindakan pemeliharaan komponen ke-i pada period ke-j, sebagai berikut:
,(1 ),j
M M infmi j
(2)
,(1 ),j
R R infri j i
(3)
,1 1 1 , ,1
NjZ Z infz m rj i j i j
i
(4)
Dengan i = 1,2,…,N ; j = 1,2,…,T; mi,j dan ri,j adalah variabel biner dari tindakan
pemeliharaan dan penggantian komponen ke-i pada periode ke-j. Untuk penambahan
komponen model adalah tingkat suku bunga pada saat ini disimbolkan sebagai int.
Model Optimasi Multiobjektif
Dengan mempertimbangkan parameter ekonomi teknik pada bagian A, dapat dibentuk fungsi
objektif biaya total yang akan diminimumkan. Model optimasi multiobjektif merupakan
optimasi yang memiliki dua fungsi tujuan yang harus dilakukan optimasi secara bersamaan
yaitu meminimumkan fungsi total biaya dan memaksimumkan fungsi reliabilitas. Bentuk dari
kedua fungsi objektif menurut [1] adalah sebagai berikut:

671
,
'. 1, ,
11 (5)(1 ) . 1 ., ,1
1 1 1 , ,1
ji iF X X inffailureN i i i j i j
T ji jMin Total Cost intM infm m R infr ri i j i i jjNj
Z infz m ri j i ji
'Re exp , (6), ,
1 1
N T i iMax liability X Xi i j i j
i j
dengan:
NiiX ,...,.1;01,
)'
1,.(1,'
1,)1,1)(1,1(, jiXijimjiXjirjimjiX ; TjNi ,...,2,...,1
J
T
jiXjiX ,',
; TjNi ,...,1,...,1
1,, jirjim ; TjNi ,...,1,...,1
10,,, ataujirjim ; TjNi ,...,1,...,1
0',,, jiXjiX ; TjNi ,...,1,...,1
Algoritma Genetik
Algoritma Genetik (AG) diusulkan oleh John Holland (1975). Algoritma ini merupakan
teknik pencarian dengan menggunakan komputasi untuk mendapatkan solusi optimasi baik
eksak maupun aproksimasi. Algoritma ini dikategorikan sebagai pencarian global
metaheuristik.
Kelebihan AG adalah dapat secara simultan menemukan wilayah pada ruang solusi yang
memungkinkan dapat menemukan solusi untuk masalah yang sulit dengan ruang solusi yang
non-konveks, diskontinu, dan multimodal.
Langkah-langkah:
1. Membentuk encoding dari solusi
2. Pemeliharaan dan Penggantan Preventif Berperan Sebagai “kromosom”.
3. Kromosom berupa array berukuran N x T, dengan N = banyak komponen, T = periode.
4. Array akan berisi nilai 0 (tanpa tindakan), 1 (tindakan perawatan), atau 2 (tindakan
perbaikan) bergantung kepada tiga macam tindakan tersebut.
5. Menentukan fungsi kecocokan (Fitness function)
𝐹𝑖𝑡𝑛𝑒𝑠𝑠1 = 𝑤1(𝑇𝑜𝑡𝑎𝑙 𝐶𝑜𝑠𝑡
𝐶𝑜𝑠𝑡max) + 𝑤2(−𝑟𝑒𝑙𝑖𝑎𝑏𝑖𝑙𝑖𝑡𝑦) (7)
Fungsi kecocokan digunakan untuk menentukan jenis optimasi yang dilakukan.
Dengan menggunakaan Fitness 1, maka optimasi dilakukan dengan
mempertimbangkan bobot antara biaya dan reliabilitas.
6. Melakukan prosedur mutasi.

672
7. Mendapatkan solusi optimasi.
Prosedur Mutasi
Prosedur mutasi diterapkan pada solusi dari “keturunan”. Dengan langkah sebagai berikut:
1. Bangkitkan bilangan acak antara 1 s.d. N x T.
2. Kemudian tandai “gen” yang berubah menjadi 1 atau 2 jika sama dengan 0, atau
berubah ke 0 jika sama dengan 1 atau 2.
3. Lakukan langkah yang sama pada periode yang sama untuk komponen yang lain.
Algoritma Genetik Steady State
Generalisasi dari AG adalah Algoritma Genetik Steady State (AGSS) yang mengganti
keseluruhan populasi pada setiap generasi. AGSS menggunakan dua populasi pada tahap
“reproduksi”. Menurut [15] dan [11] bentuk algoritma AGSS adalah sebagai berikut:
1. Hasilkan nilai awal P.
2. Tentukan nilai kecocokan keanggotaan P.
3. Lakukan iterasi dengan algoritma GA jika kondisi belum terpenuhi dan kondisi
penghentian siklus genetik belum terpenuhi:
i. Buat “keturunannya” dari “orang tua” terpilih.
ii. Mutasikan keturunan yang terbentuk dengan peluang pmutasi.
iii. Tentukan nilai kecocokan dari solusi baru yang dihasilkan.
iv. Gantikan solusi baru yang dihasilkan dengan solusi terburuk dalam P jika nilai
kecocokannya lebih baik daripada nilai kecocokan dari solusi terburuk.
v. Buang solusi yang indentik dalam P.
4. Perbarui nilai P dengan solusi baru yang dihasilkan.
3. Hasil dan Pembahasan
Algoritma Genetik Steady State diimplementasikan dalam suatu pemeliharaan
komponen mesin Freeze Drying sub Mesin A. Mesin ini digunakan untuk membuat vaksin.
Data kerusakan komponen mesin Freeze Drying dari Juni 2010 sampai Januari 2015 seperti
diperoleh oleh [16].
Setelah diuji distribusinya, waktu kerusakan berdistribusi Weibull dengan parameter
= 1,8283 dan =3202,143. Sedangkan waktu perbaikan berdistribusi eksponensial
dengan 0037,0ˆ . Nilai biaya yang diperoleh dari perusahaan pengguna mesin tersebut
yaitu biaya kerusakan Rp. 11.390.000, biaya perawatan Rp. 3.171.000, biaya penggantian
komponen Rp. 4.393.000, dan biaya tetap sebesar Rp. 4.050.000. Menurut [16], parameter
ekonomi teknik untuk inflasi dari tahun 2010 -2015 rata-rata 6,31% dan tingkat inflasi rata-
rata 6,72%.
Algoritma Genetik Steady State menggunakan nilai parameter yaitu siklus genetik
500, ukuran populasi 2000, dan peluang mutasi 0,5. Nilai gen dikodekan 0 (mencerminkan
tanpa tindakan), 1 (tindakan perawatan), dan 2 (tindakan penggantian komponen). Analisis
menggunakan fungsi fitness 1 yaitu menggunakan pembobotan antara biaya dengan
reliabilitas.
Hasil perhitungan secara komputasi menggunakan software. Diperoleh nilai
konvergensi biaya tercapai pada jumlah generasi 130 dengan nilai total biaya yang diperlukan
berkisar pada nilai Rp. 690.000 seperti tampak pada Gambar 1.

673
Gambar 1. konvergensi biaya berdasarkan jumlah iterasi
GAMBAR 2. konvergensi reliabilitas berdasarkan jumlah iterasi
Berdasarkan Gambar 2, terlihat bahwa nilai reliabilitas mulai stabil pada jumlah iterasi
ke 130 dengan nilai reliabilitas berkisar pada nilai 89%. Hal ini berarti jumlah iterasi dalam
AGSS bisa digunakan mulai pada jumlah iterasi 130 untuk menghitung nilai biaya dan
reliabilitas yang dihasilkan berdasarkan RR yang diinginkan.
Tabel 1. Solusi Optimal Penjadwalan Pemeliharaan Preventif Dengan
Menggunakan Fungsi Fitness 1
W
1
W
2
Biaya (dalam Reliabilit
as
Jadwal Preventif Maintainance (Bulan ke-)
ribuan
rupiah) 1 2 3 4 5 6 7 8 9
1
0
1
1
1
2
1
3
1
4
1
5
0,
0
1,
0 735,89 0,8841 - R M R R M R R M - R - - - -
0,
1
0,
9 607,13 0,8804 M M M R M R M M R - R - - - -

674
0,
2
0,
8 761,27 0,8886 M R - R M R R M - R R - - - -
0,
3
0,
7 955,14 0,9003 R M R R M R - R - M R - - - -
0,
4
0,
6 740,61 0,9013 R M - R R - R M R M R - - - -
0,
5
0,
5 1001,00 0,8973 M - R M R R - R R M R - - - -
0,
6
0,
4 1126,10 0,9018 M R M M M M R M R - R - - - -
0,
7
0,
3 1173,00 0,9096 M - R R - R M R M R R - - - -
0,
8
0,
2 898,20 0,8790 R - R R M M M
R - R R - - - -
0,
9
0,
1 1101,60 0,8918 M R M M M M R M R -
R - - - -
1,
0
0,
0 898,52 0,8928 R M R M R R -
M R -
R - - - -
Keterangan : M = Tindakan perawatan ; R =Tindakan penggantian ; ‘ – ‘ : Tidak ada tindakan
Tabel 1 merupakan solusi optimal penjadwalan yang bisa dilakukan untuk melakukan
pemeliharaan preventif untuk komponen freeze drying. Untuk RR = 60% belum ada tindakan
preventive maintainace yang perlu dilakukan. Pembobotan W1 = 0,7 dan W2 = 0,3
menghasilkan nilai reliabilitas paling tinggi. Sedangkan nilai cost terendah diperoleh pada
saat W1 = 0,1 dan W2 = 0,9, yaitu Rp. 607.130. Tindakan yang dilakukan pada bulan ke-11
untuk semua pembobotan adalah tindakan penggantian komponen. Sedangkan setelah itu
tidak perlu dilakukan tindakan apapun.
4. Simpulan dan Saran
Berdasarkan hasil analisis, dapat disimpulkan dan saran yang dapat disampaikan
beberapa hal sebagai berikut:
Simpulan
1. Permasalahan optimasi penjadwalan diselesaikan dengan menggunakan AGSS untuk
komponen mesin freeze drying. Digunakan ukuran populasi 500, siklus genetik 100
karena menghasilkan nilai variasi solusi yang cukup kecil dan jumlah iterasi 130
karena menghasilkan nilai konvergensi pada biaya maupun nilai reliabilitas.
2. Variasi pembobotan menghasilkan nilai total cost berkisar pada total biaya Rp.
900.000 dan nilai reliabilitas 89,5%.
3. Kecenderungan penjadwalan bervariasi dengan adanya tindakan perawatan dan
penggantian komponen mesin. Namun pada bulan ke-11 dilakukan penggantian
komponen dan setelah itu tidak ada tindakan perawatan sampai bulan ke-15.
Saran
Penelitian lanjutan yang bisa dilakukan adalah melakukan analisis sensitivitas
terhadap hasil yang telah diperoleh untuk mengetahui sejauh mana penjadwalan yang
dibentuk dapat tetap bertahan pada batasan-batasan tertentu.
Pernyataan terima kasih. Ucapan terima kasih kami sampaikan kepada Fakultas
MIPA Unpad yang telah memberikan pendanaan untuk pelaksanaan seminar ini.

675
Referensi
[1] Moghaddam, Preventive maintenance and replacement scheduling : models
and algorithms. Electronic Theses and Dissertations, 2010 ,University of
Louisville
[2] Canfield, R.V., Cost optimization of periodic preventive maintenance, IEEE
Transactions on Reliability, v R-35, n 1, April 1986, p 78-81.
[3] Hsu, L.F., Optimal preventive maintenance policies in a serial production
system, International Journal of Production Research, v 29, n 12,
December1991, p 2543-2555.
[4] Jayabalan, V., Chaudhuri, D., Cost optimization of maintenance scheduling for
a system with assured reliability, IEEE Transactions on Reliability, v 41, n 1,
March 1992, p 21-25.
[5] Fard, N.S., Nukala, S., Preventive maintenance scheduling for repairable
systems, IIE Annual Conference and Exhibition 2004, 15-19 May 2004,
Houston,TX, USA, p 145-150.
[6] Shirmohammadi, A.H., Zhang, Z.G., Love, E., A computational model for
determining the optimal preventive maintenance policy with random
breakdowns and imperfect repairs, IEEE Transactions on Reliability, v 56, n 2,
June 2007, p 332-339.
[7] Westman, J.J., Hanson, F.B., Boukas, E.K., Optimal production scheduling for
manufacturing systems with preventive maintenance in an uncertain
environment, Proceedings of American Control Conference, 25-27 June 2001,
Arlington, VA, USA, p 1375-1380 vo1.2.
[8] Han, B.J., Fan, X.M., Ma, D.Z., Optimization of preventive maintenance policy
of manufacturing equipment based on simulation, Computer Integrated
Manufacturing Systems, v 10, n 7, July 2004, p 853-857.
[9] Jayakumar, A, Asagarpoor, S., Maintenance optimization of equipment by
linear programming, International Conference on Probabilistic Methods
Applied to Power Systems, 12-16 September 2004, p 145-149.
[10] Tam, AS.B., Chan, W.M., Price, J.W.H., Optimal maintenance intervals for
multi-component system, Production Planning and Control, v 17, n
8.December 2006, p 769-779.
[11] Levitin, G., Lisnianski, A., Optimal replacement scheduling in multistate series-
parallel systems, Quality and Reliability Engineering International,v 16, n 2,
March 2000, p 157-162.
[12] Wang, Y., Handschin, E., A new genetic algorithm for preventive unit
maintenance scheduling of power systems, International Journal of Electrical
Power and Energy Systems, v 22, n 5, June 2000, p 343-348.
[13] Duarte, J.A.C., Craveiro, J.C.T.A., Trigo, T.P., Optimization of the preventive
maintenance plan of a series components system, International Journal of
Pressure Vessels and Piping, v 83, n 4, April 2006, p 244-248.
[14] Limbourg, P., Kochs, H.D., Preventive maintenance scheduling by variable
dimension evolutionary algorithms, International Journal of Pressure Vessels
and Piping, v 83, n 4, April 2006, p 262-269.
[15] Goldberg, D., (1989) Genetic Algorithms in Search, Optimization, and
Machine Learning, Addison-Wesley Publishing, Reading, MA, USA
[16] Aprilia, N., (2015) Menentukan Jadwal Preventive Maintainance Mesin
Freeze Drying yang Meminimumkan Biaya Total atau Memaksimalkan
Reliabilitas Menggunakan Model Kamran, Departemen Statistika FMIPA

676
Unpad.
[17] Bank Indonesia (2015), Laporan Tahunan Pertumbuhan Ekonomi Indonesia.
Jakarta.

677
Prosiding SNM 2017 Komputasi , Hal 677-687
PENGELOMPOKAN DAERAH RAWAN BENCANA
BANJIR DI INDONESIA TAHUN 2013 MENGGUNAKAN
FUZZY C-MEAN
AMANDA PUTRI PERTIWI1, ROBERT KURNIAWAN2
1,2 Jurusan Komputasi Statistik, Sekolah Tinggi Ilmu Statistik (STIS) - Jakarta,
Abstrak. Penelitian ini menggunakan analisis fuzzy c-means clustering yang
merupakan pengembangan dari fuzzy clustering dengan c partisi untuk
menganalisis bencana banjir di 33 provinsi di Indonesia pada tahun 2013.
Jumlah kejadian banjir, jumlah korban meninggal, dan jumlah bangunan tempat
tinggal serta luas lahan yang rusak akibat banjir digunakan sebagai variabel
dalam mengelompokkan wilayah berdasarkan tingkat risikonya terhadap banjir.
Dilakukan perbandingan index validitas antar hasil pengelompokkan dengan
berbagai nilai fuzzifier (m=1,5; 2,0; 2,5; dan 3) dan jumlah kelompok (c= 2 dan
3). Hasil pengelompokkan terbaik didapatkan dengan menetapkan nilai m=1,5
dan c=3 (Rawan Bencana Tinggi, Sedang, dan Rendah). Provinsi yang masuk
ke dalam kelompok Rawan Bencana Tinggi adalah Aceh, Jawa Barat, Jawa
Tengah, Jawa Timur, Banten, dan Sulawesi Selatan. Provinsi yang masuk ke
dalam kelompok Rawan Bencana Sedang adalah Riau, Nusa Tenggara Barat,
Kalimantan Tengah, dan Sulawesi Tenggara. Dua puluh tiga provinsi lainnya
masuk ke dalam kelompok Rawan Bencana Rendah.
Kata kunci : Fuzzy C-Means; Banjir; Pengelompokan; Clustering.
1. Pendahuluan
Indonesia merupakan negara kepulauan yang terletak di sekitar garis
khatulistiwa. Secara geografis, Indonesia terletak pada pertemuan empat lempeng
tektonik. Wilayah Indonesia juga terletak di daerah iklim tropis dengan dua musim
yaitu panas dan hujan dengan ciri-ciri adanya perubahan cuaca, suhu dan arah angin
yang cukup ekstrim. Kondisi iklim tersebut digabungkan dengan kondisi topografi
permukaan dan batuan yang relatif beragam, baik secara fisik maupun kimiawi,
menghasilkan kondisi tanah yang subur. Sebaliknya, kondisi itu dapat menimbulkan
beberapa akibat buruk bagi manusia seperti terjadinya bencana hidrometeorologi
seperti banjir, tanah longsor, kebakaran hutan dan kekeringan. Seiring dengan
berkembangnya waktu dan meningkatnya aktivitas manusia, kerusakan lingkungan
hidup semakin parah dan memicu meningkatnya jumlah kejadian dan intensitas
bencana hidrometeorologi yang terjadi secara silih berganti di Indonesia [1].
Di samping potensi sumber daya alam yang kaya karena kondisi
geografisnya, Indonesia juga menjadi rentan akan bencana alam. Dalam World Risk
Report 2016 yang diterbitkan oleh United Nation University, Indonesia masuk dalam
kategori high risk dengan menduduki peringkat ke 36 dari 171 negara berdasarkan
indeks risiko terhadap bencana [2]. Jika ditelurusi beberapa tahun ke belakang,
perkembangan jumlah kejadian bencana alam yang terjadi di Indonesia sejak tahun

678
2000 hingga 2013 secara umum menunjukkan tren yang cenderung meningkat.
Meskipun terdapat penurunan yang cukup besar di tahun 2013, namun jumlah
kejadian tersebut masih tergolong tinggi jika dibandingkan dengan awal abad 21,
yakni mencapai sepuluh kali lipatnya. Seiring dengan jumlah kejadian terssebut,
perkembangan jumlah korban jiwa serta kerusakan bangunan dan lahan akibat
bencana alam cenderung fluktuatif namun menunjukkan jumlah yang cukup tinggi.
Secara keseluruhan, tidak kurang dari 300 jiwa menjadi korban bencana alam hampir
di setiap tahunnya. Tidak hanya itu, pada tahun 2008 hingga 2013, lebih dari 47.000
unit bangunan rumah, 800 unit fasilitas umum, serta 60.000 Ha lahan rusak akibat
bencana alam setiap tahunnya [3].
Di antara berbagai bencana alam yang terjadi sejak tahun 2000
hingga 2015, data BNPB menunjukkan bahwa banjir menjadi bencana alam yang
paling banyak terjadi dan mengakibatkan kerusakan cukup besar. Bahkan dalam
kurun waktu 2011 hingga 2015, data BNPB juga menunjukkan bahwa banjir
berkontribusi menghasilkan sebesar 66 persen kerusakan lahan dan 42 persen
kerusakan fasilitas umum dari total kerusakan akibat bencana alam. Dari rentang
waktu tersebut, tahun 2013 merupakan tahun dengan frekuensi kejadian banjir
tertinggi dan satu-satunya tahun dimana banjir terjadi di seluruh provinsi di
Indonesia [3].
Jika ditelurusi kejadian banjir di tahun 2013, beberapa
diantaranya memakan korban jiwa dan menyebabkan kerugian yang tidak sedikit.
Salah satunya adalah banjir yang melanda Provinsi DKI Jakarta pada Januari 2013
lalu yang menyebabkan 14 orang meninggal [4], 14.300 warga terpaksa mengungsi
[5] dan kerugian ekonomi mencapai 1 triliun rupiah [6]. Tingginya risiko bencana
alam menuntut pemerintah untuk dapat memberikan perlindungan kepada
masyarakat dari ancaman bencana. Hal ini sesuai dengan tujuan adanya
penanggulangan bencana menurut Undang-Undang Nomor 24 Tahun 2007 tentang
Penanggulangan Bencana [7]. Beberapa bentuk kegiatan perencanaan
penanggulangan bencana menurut PP Nomor 21 Tahun 2008 tentang
Penyelenggaraan Penanggulangan Bencana Pasal 6 ayat (3) di antaranya adalah
kegiatan analisis kemungkinan dampak bencana dan pilihan tindakan pengurangan
risiko bencana [8].
Kompleksitas penyelenggaran penanggulangan bencana
memerlukan suatu penataan dan perencanaan yang matang, terarah dan
terpadu.Pemaduan dan penyelarasan arah penyelenggaraan penanggulangan
bencana pada suatu kawasan membutuhkan dasar yang kuat dalam pelaksanaannya.
Hal ini dapat dilakukan melalui kajian risiko bencana [9].
Waluyo Yogo Utomo dkk [10] melakukan analisis potensi
rawan dan risiko bencana banjir dan longsor dengan memetakan kota/kabupaten di
Jawa Barat ke dalam lima tingkatan rawan dan risiko banjir dan longsor
menggunakan data BNPB tahun 2011 hingga 2012. Bambang Budi Utomo dan Rima
Dewi Supriharjo [11] melakukan pemetaan zona risiko banjir bandang di wilayah
kawasan Kali Sampean, Kabupaten Bondowoso, Jawa Timur ke dalam lima
tingkatan kelas. Sergii Skakun dkk [12] dalam penelitiannya memetakan daerah
risiko banjir menggunakan citra satelit frekuensi relatif genangan selama kurun
waktu tahun 1989 hingga 2012.
Berbeda dengan penelitian yang dilakukan oleh Junei Chen dkk [13] yang
menganalisis risiko bencana banjir di Cina tahun 2008. Metode fuzzy clustering
digunakan untuk memetakan 30 provinsi di Cina ke dalam lima tingkatan
berdasarkan risikonya terhadap banjir. Variabel yang digunakan dalam penelitiannya

679
antara lain luas area terpapar, jumlah korban meninggal, jumlah rumah yang rusak,
dan kerugian ekonomi yang diakibatkan oleh banjir.
Penelitian Utomo & Rima D. S.[11], Skakun dkk [12], serta Chen dkk [13]
tersebut menunjukkan bahwa analisis mengenai risiko bencana umumnya
berkaitanan dengan pemetaan suatu wilayah berdasarkan kerentanan atau risikonya
terhadap bencana. Soleman dkk [14] dalam penelitiannya menyebutkan bahwa peta
merupakan sarana yang paling tepat untuk menyajikan informasi-informasi yang
berkaitan dengan lokasi dan sebaran terhadap bencana alam sehingga dapat
dilakukan tindakan penanggulangan bencana alam secara komprehensif. Selain itu,
dalam RPJP 2005-2025, disebutkan bahwa identifikasi dan pemetaan daerah-daerah
rawan bencana perlu ditingkatkan agar bencana dapat diantisipasi secara dini [15].
Kajian risiko bencana menjadi perangkat untuk menilai
kemungkinan dan besaran kerugian akibat ancaman yang ada. Dengan mengetahui
hal tersebut, fokus perencanaan dan keterpaduan penyelenggaraan penanggulangan
bencana menjadi lebih efektif [9]. Pada tatanan pemerintah, hasil dari pengkajian
risiko bencana digunakan sebagai dasar untuk menyusun kebijakan penanggulangan
bencana [16]. Dengan demikian, diperlukan kajian risiko bencana di Indonesia untuk
mendukung upaya-upaya pemerintah dalam hal perencanaan penanggulangan
bencana. Oleh karena itu, dengan mengacu pada penelitian terdahulu, penelitian ini
bertujuan untuk mengelompokkan 33 provinsi di Indonesia dengan metode FCM
serta menginvestigasi pola pengelompokannya berdasarkan variabel pembentuknya.
2. Metodologi
2.1 Sumber Data dan Variabel Penelitian
Data yang digunakan merupakan data sekunder yang bersumber dari Badan
Nasional Penanggulangan Bencana (BNPB) tahun 2013. Variabel yang digunakan
dalam penelitian ini merupakan variabel yang mewakili kerugian materiel dan
nonmateriel yang diakibatkan oleh bencana banjir. Variabel-variabel tersebut adalah:
V1: Jumlah Kejadian Banjir
V2: Jumlah Korban Meninggal
V3: Luas Lahan Rusak
V4: Jumlah Rumah Rusak
2.2 Fuzzy C-Means (FCM)
Metode fuzzy clustering, telah banyak diaplikasikan untuk mengelompokkan
suatu data berdasarkan kesamaan/kemiripan yang dimiliki oleh suatu wilayah. FCM,
sebagai salah satu jenis fuzzy clustering yang paling umum digunakan, merupakan
suatu teknik pengkelompokan yang didasarkan pada logika fuzzy. Hal ini berarti
keberadaan tiap-tiap titik data dalam suatu kelompok ditentukan oleh derajat
keanggotaannya. Banyak peneliti terdahulu yang telah menerapkan FCM ke dalam
berbagai bidang permasalahan, beberapa diantaranya adalah Balafar (2014) [26]; Yu
et.al (2014) [27]; dan Ozer (2005) [28]. FCM merupakan metode pengelompokkan
yang pertama kali ditemukan oleh Dunn [17] dan dikembangkan oleh Bezdek [18].
Berikut adalah algoritma FCM:
1. Menentukan nilai dari banyak kelompok (c), fuzzifier (m), maksimum iterasi
(MaxIter), perubahan nilai fungsi objektif terkecil yang diharapkan (ε),
fungsi objektif awal (P0=0), dan iterasi awal (t=1). Maksimum iterasi
ditetapkan untuk membatasi jumlah pengulangan dalam proses
pengelompokkan sehingga terhindar dari pengulangan yang tidak terhingga.
Jumlah iterasi menentukan lama proses pengelompokkan;

680
2. Membangkitkan bilangan acak 𝑢𝑖𝑘 sebagai elemen-elemen awal matriks
keanggotaan awal U, dimana i adalah banyak data dan k adalah banyak
kelompok;
3. Menghitung pusat kelompok ke-i dengan persamaan
𝑝𝑖 =∑ (𝑢𝑖𝑘)
𝑚𝑋𝑘𝑁𝑘=1
∑ (𝑢𝑖𝑘)𝑚𝑁
𝑘=1
(1)
dimana 𝑢𝑖𝑘 adalah nilai keanggotaan objek ke-k pada kelompok ke-i, 𝑋𝑘
adalah objek data ke-k, N adalah banyak objek penelitian, dan m adalah
fuzzifier;
4. Menghitung fungsi objektif pada iterasi ke-t dengan persamaan
𝐽(𝑃, 𝑈, 𝑋, 𝑐,𝑚) = ∑ ∑ (𝑢𝑖𝑘)𝑚𝑑𝑖𝑘
2 (𝑋𝑘, 𝑝𝑖)𝑁𝑘=1
𝑐𝑖=1
(2)
dimana 𝑑𝑖𝑘2 (𝑋𝑘 , 𝑝𝑖) adalah jarak kuadrat antara vektor pengamatan ke-k
dengan pusat kelompok ke-i;
5. Menghitung perubahan matriks keanggotaan dengan persamaan
𝑢𝑖𝑘 =1
∑ (𝑑𝑖𝑘2
𝑑𝑗𝑘2 )
1𝑚−1
𝑐𝑗=1
(3)
dimana 𝑑𝑖𝑘2 adalah jarak kuadrat antara objek ke-k dengan pusat kelompok
ke-i, 𝑑𝑗𝑘2 adalah jarak kuadrat antara objek ke-k dengan pusat kelompok ke-
j;
6. Cek kondisi berhenti
Jika |𝐽𝑡 − 𝐽𝑡−1| < 휀 atau 𝑡 > 𝑀𝑎𝑥𝐼𝑡𝑒𝑟, maka berhenti;
Jika tidak t=t+1, ulangi langkah ke-3.
2.3 Indeks Validitas
Beberapa indeks validitas yang sering digunakan dalam penelitian-penelitian adalah:
1. Partition Coefficient (PC)
Indeks ini mengukur jumlah tumpang tindih antarkelompok dan dirumuskan
oleh Bezdek sebagai berikut [19]:
𝑃𝐶(𝑐) =1
𝑁∑ ∑ 𝑢𝑖𝑘
2𝑁𝑘=1
𝑐𝑖=1
(4)
dimana N adalah banyak objek penelitian, c adalah banyak kelompok, dan
𝑢𝑖𝑘 adalah nilai keanggotaan objek ke-k dengan pusat kelompok ke-i. Indeks
ini memiliki rentang 1/c sampai 1. Jumlah kelompok yang optimal
ditunjukkan oleh nilai PC yang paling besar.

681
2. Classification Entropy (CE)
CE hanya mengukur kekaburan (fuzziness) dari partisi kelompok. Indeks ini
dirumuskan sebagai berikut [20]:
𝐶𝐸(𝑐) = −1
𝑁∑ ∑ 𝑢𝑖𝑘 ln (𝑢𝑖𝑘)
𝑁𝑘=1
𝑐𝑖=1
(5)
dimana N adalah banyak objek penelitian, c adalah banyak kelompok, dan
𝑢𝑖𝑘 adalah nilai keanggotaan objek ke-k dengan pusat kelompok ke-i. Indeks
ini memiliki rentang 0 sampai ln(c). Indeks CE yang semakin kecil
menunjukkan pengelompokan yang lebih baik.
3. Partition Index (PI)/Separation and Compactness (SC)
PI merupakan rasio antara jumlah kepadatan dan pemisahan kelompok-
kelompok. Indeks ini dihitung sebagai berikut [21]:
𝑃𝐼(𝑐) = ∑∑ (𝑢𝑖𝑘)
𝑚‖𝑥𝑘−𝑣𝑖‖2𝑁
𝑘=1
𝑁𝑖∑ ‖𝑣𝑗−𝑣𝑖‖2𝑐
𝑗=1
𝑐𝑖=1
(6)
dimana N adalah banyak objek penelitian, 𝑁𝑖 adalah banyak objek penelitian
kelompok ke-i, c adalah banyak kelompok, 𝑢𝑖𝑘 adalah nilai keanggotaan
objek ke-k densgan pusat kelompok ke-i, m adalah fuzzifier, ‖𝑥𝑘 − 𝑣𝑖‖
adalah jarak euclidean titik data (𝑥𝑘) dengan pusat kelompok 𝑣𝑖, dan
‖𝑣𝑗 − 𝑣𝑖‖ jarak euclidean antar pusat kelompok. Nilai SC yang rendah
mengindikasikan partisi kelompok yang lebih baik.
4. Fukuyama Sugeno Index (FS)
Fukuyama dan Sugeno merumuskan indeks ini sebagai berikut [22]:
𝐹𝑆(𝑐) = ∑ ∑ (𝑢𝑖𝑘)𝑚‖𝑥𝑘 − 𝑣𝑖‖
2𝑁𝑘=1
𝑐𝑖=1 − ∑ ∑ (𝑢𝑖𝑘)
𝑚‖𝑣𝑖 − ��‖2𝑁
𝑘=1𝑐𝑖=1 (7)
dimana N adalah banyak objek penelitian, c adalah banyak kelompok, 𝑢𝑖𝑘
adalah nilai keanggotaan objek ke-k dengan pusat kelompok ke-i, m adalah
fuzzifier, ‖𝑥𝑘 − 𝑣𝑖‖ adalah jarak euclidean titik data (𝑥𝑘) dengan pusat
kelompok 𝑣𝑖, ‖𝑣𝑗 − 𝑣𝑖‖ adalah jarak euclidean pusat kelompok 𝑣𝑖 dengan
ratarata pusat kelompok. Nilai FS yang rendah mengindikasikan partisi
kelompok yang lebih baik.
5. Xie and Beni’s Index (XB)
XB bertujuan untuk menghitung rasio total variasi di dalam kelompok dan
pemisahan kelompok yang dirumuskan sebagai berikut [23]:
𝑋𝐵(𝑐) =∑ ∑ (𝑢𝑖𝑘)
𝑚‖𝑥𝑘−𝑣𝑖‖2𝑁
𝑘=1𝑐𝑖=1
𝑁𝑚𝑖𝑛𝑖,𝑘‖𝑣𝑘−𝑣𝑖‖2
(8)
dimana N adalah banyak objek penelitian, c banyak kelompok, 𝑢𝑖𝑘 adalah
nilai keanggotaan objek ke-k dengan pusat kelompok ke-i. m adalah
fuzzifier, ‖𝑥𝑘 − 𝑣𝑖‖ adalah jarak euclidean titik data (𝑥𝑘) dengan pusat
kelompok 𝑣𝑖, dan ‖𝑣𝑘 − 𝑣𝑖‖ adalah jarak euclidean antar pusat kelompok.
Nilai XB yang rendah mengindikasikan partisi kelompok yang lebih baik.

682
6. Modified Partition Coefficient (MPC)
Indeks ini diajukan oleh Dave (1996) untuk mengatasi kekurangan PC dan
CE. Nilai PC dan CE memiliki kecenderungan berubah secara monoton
seiring dengan berubahnya nilai c (Wang dan Zhang, 2007). Indeks ini
dirumuskan sebagai berikut [24]:
𝑀𝑃𝐶(𝑐) = 1 −𝑐
𝑐−1(1 − 𝑃𝐶)
(9)
dimana c adalah banyak kelompok dan PC adalah indeks PC. Pengolahan
data menggunakan aplikasi yang dibangun oleh peneliti dengan aplikasi R
dan berbagai modifikasi.
7. Kwon’s Index (Kwon)
Indeks ini dikembangkan oleh S. H. Kwon [25] untuk mengatasi nilai indeks
validitas yang monoton turun ketika jumlah klaster semakin besar dan
semakin mendekati jumlah elemen data. Indeks Kwon juga efektif untuk
mengatasi nilai indeks yang menurun seiring dengan meningkatnya nilai
fuzzifier. Indeks ini merupakan modifikasi dari XB dengan
mempertimbangkan nilai data. Serupa dengan XB, semakin kecil nilai
indeks Kwon maka semakin baik pula partisi klaster yang dihasilkan. Indeks
Kwon dirumuskan sebagai berikut:
𝐾𝑤𝑜𝑛(𝑐) =∑ ∑ (𝑢𝑖𝑘)
𝑚‖𝑋𝑘−𝑣𝑖‖2𝑁
𝑘=1𝑐𝑖=1 +
1
𝑐∑ ‖𝑣𝑖−��‖
2𝑐𝑖=1
𝑚𝑖𝑛𝑖≠𝑘‖𝑣𝑘−𝑣𝑖‖2
(10)
dimana N adalah banyak objek penelitian, c adalah banyak klaster, 𝑢𝑖𝑘
adalah nilai keanggotaan objek ke-k dengan pusat klaster ke-i, m adalah
fuzzifier, ‖𝑋𝑘 − 𝑣𝑖‖ adalah jarak euclidean titik data (𝑋𝑘) dengan pusat
klaster 𝑣𝑖, ‖𝑣𝑗 − ��‖ adalah jarak euclidean pusat klaster 𝑣𝑖 dengan rata-rata
pusat klaster, dan ‖𝑣𝑘 − 𝑣𝑖‖ adalah jarak euclidean antar pusat klaster.
3. Hasil dan Pembahasan
3.1 Analisis Deskriptif
Peta dibawah ini adalah gambaran dari variabel jumlah kejadian banjir yang
ada di Indonesia pada tahun 2013.
Gambar 1. Peta Indonesia Jumlah Kejadian Banjir Tahun 2013
Berdasarkan gambar 1 diatas dapat dilihat bahwa kejadian banjir yang paling

683
sering terjadi ada di pulau Jawa. Dan di tahun 2013 banjir paling banyak terjadi di
Provinsi Jawa Timur dan Jawa Barat
Gambar 2. Peta Indonesia tentang Jumlah Kematian yang terjadi akibat Banjir Tahun
2013.
Berdasarkan gambar 2 dijelaskan bahwa kejadian banjir mengakibatkan
korban yang tidak sedikit. Korban banjir yang mengalami kematian paling banyak
pada tahun 2013 terjadi pada provinsi Jawa Timur.
Gambar 3. Peta Indonesia Terkait Krusakan Lahan Akibat Banjir Tahun 2013.
Gambar 3 menggambarkan bahwa banjir tidak hanya mengakibatkan
kehilangan nyawa manusia, tetapi juga mengakibatkan kerusakan lahan. Kerusakan
lahan disini adalah kerusakan lahan pertanian dan non pertanian. Provinsi yang
paling banyak mengalami kerusakan lahan yang diakibatkan banjir yaitu Provinsi
Sulawesi Selatan. Kerusakan lahan juga terjadi di Provinsi Aceh dan beberapa
provinsi di Pulau Jawa.
Gambar 4. Peta Indonesia tentang Kerusakan Rumah yang diakibatkan Bencana Banjir
tahun 2013.
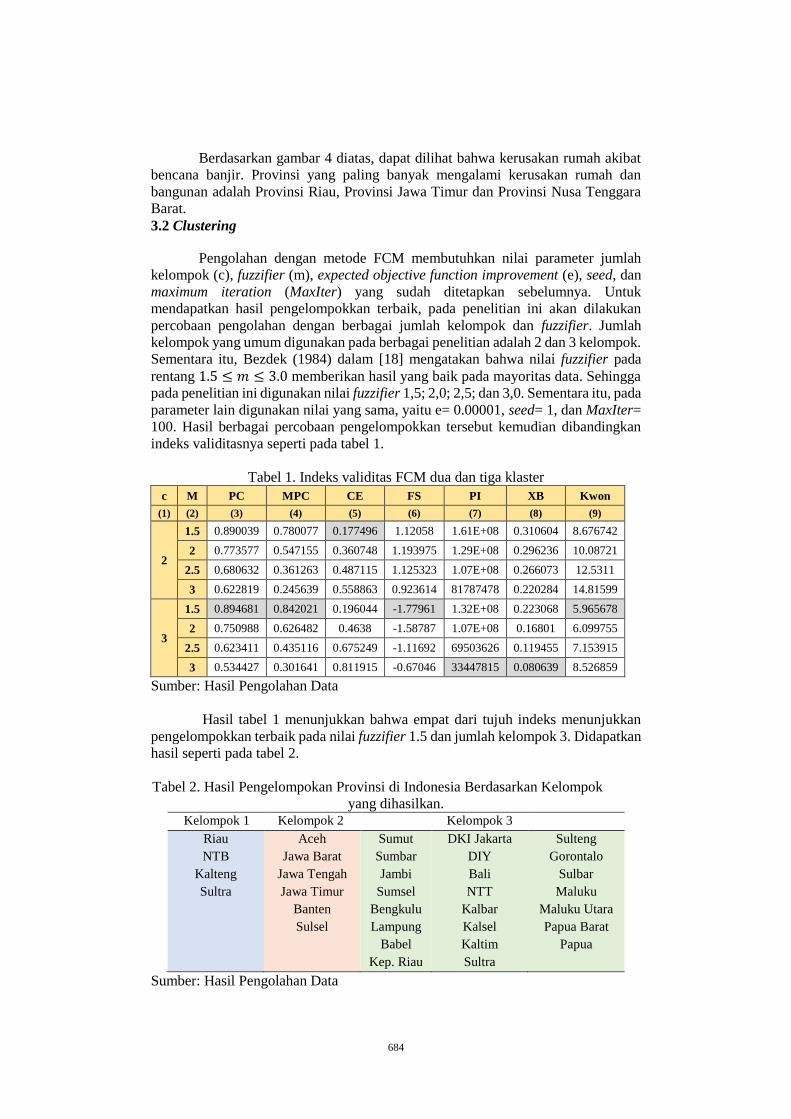
684
Berdasarkan gambar 4 diatas, dapat dilihat bahwa kerusakan rumah akibat
bencana banjir. Provinsi yang paling banyak mengalami kerusakan rumah dan
bangunan adalah Provinsi Riau, Provinsi Jawa Timur dan Provinsi Nusa Tenggara
Barat.
3.2 Clustering
Pengolahan dengan metode FCM membutuhkan nilai parameter jumlah
kelompok (c), fuzzifier (m), expected objective function improvement (e), seed, dan
maximum iteration (MaxIter) yang sudah ditetapkan sebelumnya. Untuk
mendapatkan hasil pengelompokkan terbaik, pada penelitian ini akan dilakukan
percobaan pengolahan dengan berbagai jumlah kelompok dan fuzzifier. Jumlah
kelompok yang umum digunakan pada berbagai penelitian adalah 2 dan 3 kelompok.
Sementara itu, Bezdek (1984) dalam [18] mengatakan bahwa nilai fuzzifier pada
rentang 1.5 ≤ 𝑚 ≤ 3.0 memberikan hasil yang baik pada mayoritas data. Sehingga
pada penelitian ini digunakan nilai fuzzifier 1,5; 2,0; 2,5; dan 3,0. Sementara itu, pada
parameter lain digunakan nilai yang sama, yaitu e= 0.00001, seed= 1, dan MaxIter=
100. Hasil berbagai percobaan pengelompokkan tersebut kemudian dibandingkan
indeks validitasnya seperti pada tabel 1.
Tabel 1. Indeks validitas FCM dua dan tiga klaster
c M PC MPC CE FS PI XB Kwon
(1) (2) (3) (4) (5) (6) (7) (8) (9)
2
1.5 0.890039 0.780077 0.177496 1.12058 1.61E+08 0.310604 8.676742
2 0.773577 0.547155 0.360748 1.193975 1.29E+08 0.296236 10.08721
2.5 0.680632 0.361263 0.487115 1.125323 1.07E+08 0.266073 12.5311
3 0.622819 0.245639 0.558863 0.923614 81787478 0.220284 14.81599
3
1.5 0.894681 0.842021 0.196044 -1.77961 1.32E+08 0.223068 5.965678
2 0.750988 0.626482 0.4638 -1.58787 1.07E+08 0.16801 6.099755
2.5 0.623411 0.435116 0.675249 -1.11692 69503626 0.119455 7.153915
3 0.534427 0.301641 0.811915 -0.67046 33447815 0.080639 8.526859
Sumber: Hasil Pengolahan Data
Hasil tabel 1 menunjukkan bahwa empat dari tujuh indeks menunjukkan
pengelompokkan terbaik pada nilai fuzzifier 1.5 dan jumlah kelompok 3. Didapatkan
hasil seperti pada tabel 2.
Tabel 2. Hasil Pengelompokan Provinsi di Indonesia Berdasarkan Kelompok
yang dihasilkan. Kelompok 1 Kelompok 2 Kelompok 3
Riau
NTB
Kalteng
Sultra
Aceh
Jawa Barat
Jawa Tengah
Jawa Timur
Banten
Sulsel
Sumut
Sumbar
Jambi
Sumsel
Bengkulu
Lampung
Babel
Kep. Riau
DKI Jakarta
DIY
Bali
NTT
Kalbar
Kalsel
Kaltim
Sultra
Sulteng
Gorontalo
Sulbar
Maluku
Maluku Utara
Papua Barat
Papua
Sumber: Hasil Pengolahan Data
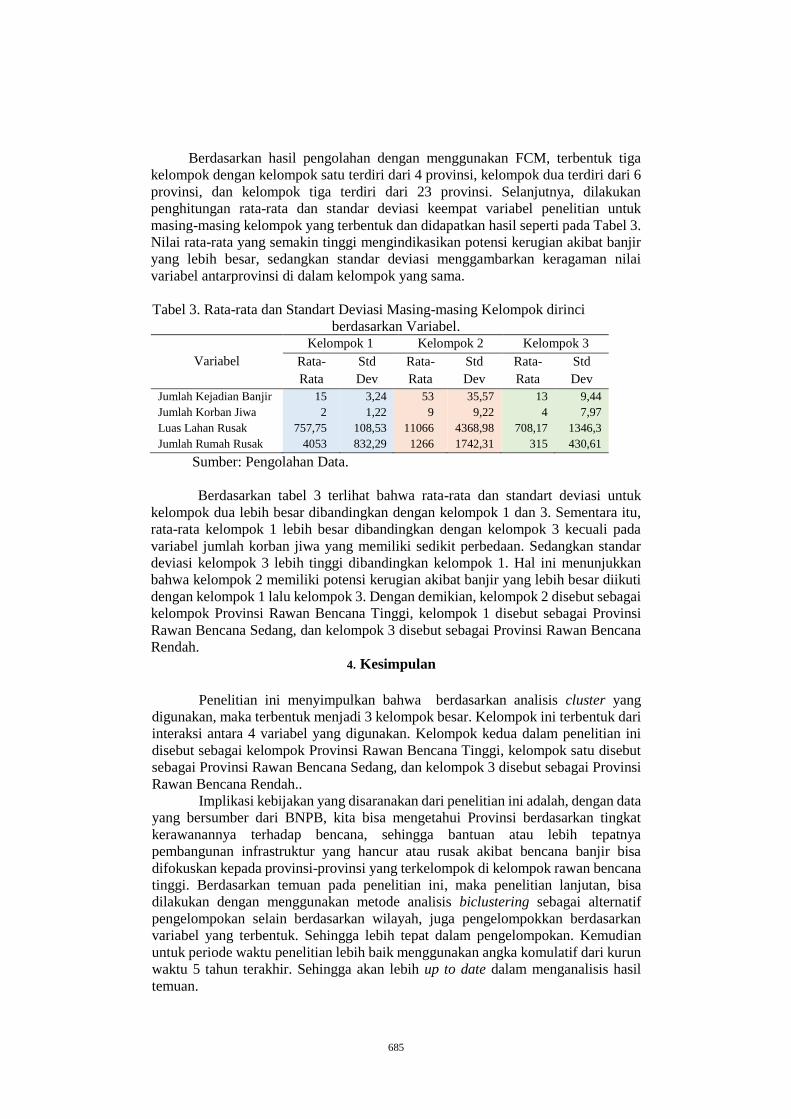
685
Berdasarkan hasil pengolahan dengan menggunakan FCM, terbentuk tiga
kelompok dengan kelompok satu terdiri dari 4 provinsi, kelompok dua terdiri dari 6
provinsi, dan kelompok tiga terdiri dari 23 provinsi. Selanjutnya, dilakukan
penghitungan rata-rata dan standar deviasi keempat variabel penelitian untuk
masing-masing kelompok yang terbentuk dan didapatkan hasil seperti pada Tabel 3.
Nilai rata-rata yang semakin tinggi mengindikasikan potensi kerugian akibat banjir
yang lebih besar, sedangkan standar deviasi menggambarkan keragaman nilai
variabel antarprovinsi di dalam kelompok yang sama.
Tabel 3. Rata-rata dan Standart Deviasi Masing-masing Kelompok dirinci
berdasarkan Variabel.
Variabel
Kelompok 1 Kelompok 2 Kelompok 3
Rata-
Rata
Std
Dev
Rata-
Rata
Std
Dev
Rata-
Rata
Std
Dev
Jumlah Kejadian Banjir
Jumlah Korban Jiwa
Luas Lahan Rusak
Jumlah Rumah Rusak
15
2
757,75
4053
3,24
1,22
108,53
832,29
53
9
11066
1266
35,57
9,22
4368,98
1742,31
13
4
708,17
315
9,44
7,97
1346,3
430,61
Sumber: Pengolahan Data.
Berdasarkan tabel 3 terlihat bahwa rata-rata dan standart deviasi untuk
kelompok dua lebih besar dibandingkan dengan kelompok 1 dan 3. Sementara itu,
rata-rata kelompok 1 lebih besar dibandingkan dengan kelompok 3 kecuali pada
variabel jumlah korban jiwa yang memiliki sedikit perbedaan. Sedangkan standar
deviasi kelompok 3 lebih tinggi dibandingkan kelompok 1. Hal ini menunjukkan
bahwa kelompok 2 memiliki potensi kerugian akibat banjir yang lebih besar diikuti
dengan kelompok 1 lalu kelompok 3. Dengan demikian, kelompok 2 disebut sebagai
kelompok Provinsi Rawan Bencana Tinggi, kelompok 1 disebut sebagai Provinsi
Rawan Bencana Sedang, dan kelompok 3 disebut sebagai Provinsi Rawan Bencana
Rendah.
4. Kesimpulan
Penelitian ini menyimpulkan bahwa berdasarkan analisis cluster yang
digunakan, maka terbentuk menjadi 3 kelompok besar. Kelompok ini terbentuk dari
interaksi antara 4 variabel yang digunakan. Kelompok kedua dalam penelitian ini
disebut sebagai kelompok Provinsi Rawan Bencana Tinggi, kelompok satu disebut
sebagai Provinsi Rawan Bencana Sedang, dan kelompok 3 disebut sebagai Provinsi
Rawan Bencana Rendah..
Implikasi kebijakan yang disaranakan dari penelitian ini adalah, dengan data
yang bersumber dari BNPB, kita bisa mengetahui Provinsi berdasarkan tingkat
kerawanannya terhadap bencana, sehingga bantuan atau lebih tepatnya
pembangunan infrastruktur yang hancur atau rusak akibat bencana banjir bisa
difokuskan kepada provinsi-provinsi yang terkelompok di kelompok rawan bencana
tinggi. Berdasarkan temuan pada penelitian ini, maka penelitian lanjutan, bisa
dilakukan dengan menggunakan metode analisis biclustering sebagai alternatif
pengelompokan selain berdasarkan wilayah, juga pengelompokkan berdasarkan
variabel yang terbentuk. Sehingga lebih tepat dalam pengelompokan. Kemudian
untuk periode waktu penelitian lebih baik menggunakan angka komulatif dari kurun
waktu 5 tahun terakhir. Sehingga akan lebih up to date dalam menganalisis hasil
temuan.

686
Referensi
[1] Badan Nasional Penanggulangan Bencana. (2016). Potensi dan Ancaman
Bencana. http://www.bnpb.go.id/home/potensi. (Diakses tanggal 13 Januari
2017).
[2] United Nation University. (2016). World Risk Report 2016. Berlin: Bündnis
Entwicklung Hilft.
[3] Badan Nasional Penanggulangan Bencana. (2017). Data Bencana.
http://dibi.bnpb.go.id/data-bencana. (Diakses tanggal 5 Januari 2017).
[4] Kistyarini, ed. (2013).
http://tekno.kompas.com/read/2013/01/19/09402451/bnpb.banjir. jakarta.
tewaskan.14.orang. (Diakses pada 17 Januari 2017 pukul 05.54 WIB).
[5] Maharani, Dian. (2013).
http://megapolitan.kompas.com/read/2013/01/23/21100024/14.300. Korban.
Banjir.Jakarta.Masih.Mengungsi. (Diakses pada 17 Januari 2017 pukul 05.53
WIB).
[6] Djumena, Erlangga, ed. (2013).
http://bisniskeuangan.kompas.com/read/2013/01 /21/0755459/ Banjir.
Jakarta.Kerugian.Ekonomi.Capai.Rp.1.Triliun. (Diakses pada 17 Januari
2017 pukul 05.53 WIB).
[7] Badan Nasional Penanggulangan Bencana. (2017). Undang-Undang Nomor
24 Tahun 2007 Tentang Penanggulangan Bencana. Disahkan oleh: Presiden
Republik Indonesia. (Diakses tanggal 5 Januari 2017).
[8] Badan Nasional Penanggulangan Bencana. (2017). Peraturan Pemerintah
Nomor 21 Tahun 2008 Tentang Penyelenggaraan Penanggulangan Bencana.
Disahkan oleh: Presiden Republik Indonesia. (Diakses tanggal 5 Januari
2017).
[9] Badan Perencanaan Pembangunan Nasional. (2014). Materi Teknis Revisi
Pedoman Penyusunan Rencana Tata Ruang Berdasarkan Perspektif Risiko
Bencana. Jakarta: Badan Perencanaan Pembangunan Nasional.
[10] Utomo, Waluyo Yogo, ,dkk. (2012). Analisis Potensi Rawan (Hazard) dan
Risiko (Risk) Bencana Banjir dan Longsor (Studi Kasus Provinsi Jawa
Barat). [Tesis]. Jakarta: Kementerian Lingkungan Hidup.
[11] Utomo, Bambang Budi & Rima Dewi S. (2012). Pemintakatan Risiko
Bencana Banjir Bandang di Kawasan Sepanjang Kali Sampean, Kabupaten
Bondowoso. Jurnal Teknik ITS 1(1) September 2012. Surabaya: Institut
Teknologi Sepuluh November.
[12] Skakun, Sergii et.al. (2014). Flood Hazard and Flood Risk Assessment Using
a Time Series of Satellite Image: A Case Study in Namibia. Risk Analysis
34(8) 2014. Ukraine: Space Research Institute NASU-SSAU.
[13] Chen, Junfei, et.al. (2011). Risk Analysis of Flood Disaster Based on Fuzzy
Clustering Method. Energy Procedia 5 2011: 1915-1919. China: Elsevier Ltd.
[14] Soleman, M. Khifni, dkk. (2012). Pemetaan Multirawan Bencana di Provinsi
Banten. Globe 14(1) Juni 2012: 46-59. Bogor: Badan Koordinasi Survei dan
Pemetaan Nasional.
[15] Badan Perencanaan Pembangunan Nasional. (2005). Rencana Pembangunan
Jangka Panjang Tahun 2005-2025. Jakarta: Badan Perencanaan
Pembangunan Nasional.
[16] Badan Nasional Penanggulangan Bencana. (2017). Peraturan Kepala Badan
Nasional Penanggulangan Bencana Nomor 2 Tahun 2012 Tentang Pedoman

687
Umum Pengkajian Risiko Bencana. Disahkan oleh: Kepala Badan Nasional
Penanggulangan Bencana. (Diakses tanggal 7 November 2016).
[17] Dunn, J.C., (1974). A Fuzzy Relative of the ISODATA Process and Its Use in
Detecting Compact, Well-Separated Clusters. Journal of. Cybernetics 3, 32–
57. UK: Taylor & Francis.
[18] Bezdek J. C., R. Ehrlich, dan W. Full. (1984). FCM: The Fuzzy c-Means
Clustering Algorithm. Computers & Geosciences 10(2-3), 1984: 191-203.
USA: Pergamon Press Ltd.
[19] Bezdek, J.C. (1974). Cluster validity with fuzzy sets. Journal of Cybernetics
3(3), 58-73.
[20] Bezdek, J.C. (1981). Pattern Recognition with Fuzzy Objective Function
Algoritms. Plenum, New York.
[21] Zahid, N., Limouri, M., Essaid, A., 1999. A new cluster-validity for fuzzy
clustering. Pattern Recognition 32, 1089–1097.
[22] Fukuyama, Y., Sugeno, M., (1989). A new method of choosing the number of
clusters for the fuzzy c-mean method. In: Proc. 5th Fuzzy Syst. Symp., pp.
247–250.
[23] Xie, X.L., Beni, G.A., (1991). A validity measure for fuzzy clustering. IEEE
Trans. Pattern Anal. Machine Intell. 13 (8), 841–847.
[24] Dave, R. N. (1996). Validating fuzzy partitions obtained through c-shells
clustering. Pattern Recognition Letters 17 (1996), 613-623.
[25] Kwon, S.H. (1998). Cluster validity index for fuzzy clustering. Electronics
Letters 34 (22), 2176-2177.
[26] Balafar, M.A. (2014). Fuzzy C-mean based brain MRI segmentation
algorithms. Artif. Intell. Rev. 41(3), 441–449.
[27] Yu, X.C., He, H., Hu, D., Zhou, W. (2014). Land cover classification of
remote sensing imagery based on interval-valued data fuzzy c-means
algorithm. Sci. China Earth Sci. 57(6), 1306–1313.
[28] Ozer, M. (2005). Fuzzy c-means clustering and Internet portals: a case study.
Eur. J. Oper. Res. 164, 696–714.

688
Prosiding SNM 2017 Komputasi, Hal 688-694
APLIKASI FUZZY C-MEANS PADA PREVALENSI
GLOBAL YOUTH TOBACCO SURVEY
INTAN PRIMASARI, ZUHERMAN RUSTAM, DHIAN WIDYA
Departemen Matematika, Fakultas Matematika dan Ilmu Pengetahuan Alam,
Universitas Indonesia, DEPOK, INDONESIA
[email protected], [email protected], [email protected]
Abstrak. Peningkatan prevalensi merokok merupakan masalah yang sangat
serius. Indonesia merupakan negara dengan tingkat penggunaan rokok yang
cukup tinggi. Rokok dikonsumsi di berbagai lapisan masyarakat, mulai dari
anak-anak, remaja, dan dewasa. Kecenderungan merokok terus meningkat dari
tahun ke tahun. Makalah ini akan membahas tentang metode Fuzzy C-Means
pada data sikap remaja terhadap rokok. Akurasi dari proses klasifikasinya akan
dibandingkan. Hasil analisis dalam makalah ini didapatkan tingkat akurasi
paling besar untuk data sikap remaja terhadap rokok adalah dengan
menggunakam 80% data training dengan akurasi sebesar 98,734% akan
didapatkan bahwa beberapa remaja memiliki kecenderungan untuk merokok.
Kata kunci: Prevalensi, kecenderungan merokok, Fuzzy C-Means, tingkat akurasi.
1. Pendahuluan
Rokok merupakan salah satu penyebab kematian terbesar di hampir setiap
negara. Peningkatan prevalensi perokok menjadi masalah yang serius. Indonesia
merupakan negara dengan tingkat penggunaan rokok yang cukup tinggi. Rokok
dikonsumsi mulai dari anak-anak, remaja, dan dewasa khususnya remaja.
Berdasarkan data Global Youth Tobbaco Survey (GYTS) 2014, terdapat data sikap
remaja terhadap produk rokok [1].
Dari data-data yang ada pada data sikap remaja terhadap produk rokok dapat
digali informasi-informasi baru yang berguna. Data tersebut digali dengan metode
data mining. Data mining merupakan suatu proses pengekstrakan informasi baru
yang diambil dari bongkahan data besar yang membantu dalam pengambilan
keputusan [2]. Oleh karena itu, penulis membuat sebuah sistem aplikasi data mining
untuk membantu proses analisa data yang diperoleh dari data.
Pada penelitian ini digunakan metode fuzzy cluster, yaitu dengan algoritma
fuzzy c-means (FCM). Algoritma ini dipilih karena data-data beserta parameternya
dapat dikelompokkan dengan kecenderungannya. Selain itu, dengan metode ini bisa
ditentukan jumlah cluster yang akan dibentuk. Dengan penentuan jumlah cluster
diawal, bisa diatur keragaman nilai akhir sesuai dengan cluster -nya. Kelebihan
algoritma ini adalah penempatan pusat cluster yang lebih tepat dibandingkan dengan

689
metode cluster lain. Selain itu, FCM juga memiliki tingkat akurasi yang tinggi dan
waktu komputasi yang cepat. Dengan algoritma FCM akan dilakukan penggalian
informasi mengenai sikap remaja terhadap produk rokok pada data GYTS 2014 [3].
Pada [4] telah dilakukan menerapkan metode Fuzzy C-Means pada data.
Tujuan dari makalah ini akan dilakukan klasifikasi menggunakan Fuzzy C-Means
pada data sikap remaja terhadap produk rokok dan diharapkan menghasilkan akurasi
terbaik dengan menggunakan metode Fuzzy C-Means pada klasifikasi data sikap
remaja terhadap produk rokok di Global Youth Tobacco Survey (GYTS) 2014.
Terdapat lima bagian pada makalah ini. Bagian 2 adalah metodologi, menjelaskan
konsep dasar dari FCM. Bagian 3 adalah analisis data. Bagian 4, hasil percobaan dan
evaluasi model. Bagian 5 adalah kesimpulan.
2. Metodologi
Pada penelitian ini, metode analisis data yang digunakan adalah fuzzy c-
means (FCM). Metode ini pertama kali diperkenalkan oleh Dunn pada tahun 1973
dan kemudian dikembangkan oleh Bezdek pada tahun 1981. FCM adalah suatu
teknik pengelompokkan atau pengclusteran data yang keberadaan tiap-tiap titik data
dalam suatu kelompok ditentukan oleh nilai/derajat keanggotaan [5].
FCM adalah salah satu teknik optimizing partitioned cluster. Kelebihan
metode ini adalah penempatan pusat cluster yang lebih tepat dibandingkan dengan
metode cluster yang lain. Caranya adalah memperbaiki pusat cluster secara
berulang, maka akan dapat dilihat bahwa pusat cluster akan bergerak menuju lokasi
yang tepat [5].
Secara umum, teknik FCM adalah meminimumkan fungsi objektif dati
FCM. Model matematis dari FCM adalah :
𝑀𝑖𝑛 𝐽𝐹𝐶𝑀(𝑉, 𝑈, 𝑋, 𝑐, 𝑚) =∑ ∑ 𝑢𝑖𝑗𝑚||𝑥𝑗 − 𝑣𝑖 ||
2𝑛
𝑘=1
𝑐
𝑖=1
(1)
dengan fungsi kendala
∑ 𝑢𝑖𝑗
𝑐
𝑖=1
(2)
dimana,
n adalah banyaknya data
c adalah banyaknya cluster
V adalah pusat cluster
𝑉 = [[
𝑣11 ⋯ 𝑣1𝑛⋮ ⋱ ⋮
𝑣𝑐1 ⋯ 𝑣𝑐𝑛]]
U adalah fungsi keanggotaan

690
𝑈 = [[
𝑢11 ⋯ 𝑢1𝑗⋮ ⋱ ⋮
𝑢𝑐1 ⋯ 𝑢𝑐𝑗]]
X adalah data yang akan di cluster
𝑋 = [[
𝑥11 ⋯ 𝑥1𝑗⋮ ⋱ ⋮
𝑥𝑛1 ⋯ 𝑥𝑛𝑗]]
m adalah derajat fuzzyness (m > 1 )
||𝑥𝑗 − 𝑣𝑖 || adalah jarak antara titik dara dengan pusat cluster
Metode FCM akan meminimumkan jarak antara setiap data dengan pusat
cluster. Setiap data dalam FCM mempunyai derajat keanggotaan untuk setiap
cluster. Derajat keanggotaan menunjukkan kecenderungan atau peluang suatu data
untuk masuk ke dalam satu cluster. Berdasarkan konsep peluang, maka jumlah dari
derajat keanggotaan suatu data untuk setiap cluster adalah 1.
Algoritma dari FCM adalah sebagai berikut [6] :
Langkah 1 : Tentukan
a. Banyaknya data training yang akan digunakan
b. Banyaknya cluster
c. Derajat fuzzyness (m >1)
d. Kriteria berhenti (ξ = nilai positif yang sangat kecil)
e. Pusat cluster awal
Langkah 2 : Bangkitkan bilangan random 𝑢𝑖𝑘, i = 1,2, ..., n; k = 1,2, ..., c sebagai
elemen matriks partisi awal U dimana
𝑢𝑖𝑘 =[∑ (𝑋𝑖𝑗 − 𝑉𝑘𝑗)
2]𝑚𝑖=1
1𝑤−1
∑ [∑ (𝑋𝑖𝑗 − 𝑉𝑘𝑗)2]𝑚
𝑖=1𝑐𝑘=1
1𝑤−1
(3)
dengan :
𝑉𝑘𝑗 = pusat cluster ke-k untuk atribut ke-j
𝜇𝑖𝑘 = derajat keanggotaan untuk data sampel ke-i pada cluster ke-k
𝑋𝑖𝑗 = data ke-i, atribut ke-j
Langkah 3 : Hitung pusat cluster ke-k, dimana
𝑉𝑘𝑗 =∑ ((𝜇
𝑖𝑘)𝑤𝑋𝑖𝑗)
𝑛𝑖=1
∑ (𝜇𝑖𝑘)𝑤𝑛
𝑖=1
(4)

691
dengan :
𝑉𝑘𝑗 = pusat cluster ke-k untuk atribut ke-j
𝜇𝑖𝑘 = derajat keanggotaan untuk data sampel ke-i pada cluster ke-k
𝑋𝑖𝑗 = data ke-i, atribut ke-j
Langkah 4 : Hitung fungsi objektif pada iterasi ke-t menggunakan persamaan
𝑃𝑡 = ∑∑([∑(
𝑚
𝑗=1
𝑐
𝑘=1
𝑛
𝑖=1
𝑋𝑖𝑗 − 𝑉𝑘𝑗)2](𝜇
𝑖𝑘)𝑤)
(5)
dengan :
𝑉𝑘𝑗 = pusat cluster ke-k untuk atribut ke-j
𝜇𝑖𝑘 = derajat keanggotaan untuk data sampel ke-i pada cluster ke-k
𝑋𝑖𝑗 = data ke-i, atribut ke-j
𝑃𝑡 = fungsi objektif pada iterasi ke-t
Langkah 5 : Hitung perubahan matriks partisi menggunakan persamaan (3).
Langkah 6 : Cek kondisi berhenti jika
(|𝑃𝑡 − 𝑃𝑡−1| < ξ) atau (t > Maxlter) maka berhenti. Jika tidak, ulangi langkah
ke-4.
3. Analisis Data
Sumber penelitian ini diambil dari data Global Youth Tobacco Survey (GYTS)
2014 di Indonesia. Data tersebut merupakan kuisoner skala dengan 62 pertanyaan
dan 5986 peserta. Mereka diantaranya berumur diantara 13 hingga 15 tahun yang
terdiri dari 51 % laki-laki dan 49 % perempuan.
Pada penelitian ini, penulis mengambil 524 sampel dan 7 variabel yang
digunakan untuk menuji keakuratan metode FCM.
Variabel yang digunakan yaitu :
1. Apakah Anda pernah mencoba merokok, satu atau dua batang?
2. Apakah Anfda berpikir merokok dari rokok orang lain berbahaya untuk
Anda?
3. Jika teman baik Anda menawarkan Anda sebuah rokok, akankah Anda
menggunakan itu?
4. Selama 12 bulan kedepan, apakah Anda akan menggunakan apapun jenis
rokok?
5. Ketika seseorang mulai merokok, apakah Anda berpikir sulit untuk mereka
berhenti merokok?
6. Apakah Anda berpikir merokok itu berbahaya?
7. Apakah Anda berpikir aman untuk merokok hanya satu tahun selama Anda
berhenti setelah itu?

692
4. Hasil Percobaan dan Evaluasi Model
Dalam hasil aplikasi ini, penulis tidak dapat menggunakan lebih dari 2 cluster.
Jika menggunakan lebih dari 2 cluster akan didapatkan tingkat akurasi yang lebih
rendah, jadi akan didapatkan nilai maksimum tingkat akurasi pada 2 cluster.
Pada tahap ini, dilakukan klasifikasi data yang terbagi atas dua kelas. Kelas
merupakan kumpulan sampel dengan kecenderungan merokok tinggi dan kelas II
merupakan kumpulan sampel dengan kecenderungan merokok rendah.
Sesuai input data, data training yang digunakan yaitu 10%-90% pada data.
Data yang bukan training atau sisamya akan menjadi data testing.
Berikut adalah hasil klasifikasi untuk data dengan menggunakan variabel:
Tabel 1. Hasil akurasi menggunakan Fuzzy C-Means
Dari tabel 1, bisa dilihat bahwa akurasi terbesar didapat berturut-turut dengan
menggunakan 80% data training dengan akurasi sebesar 98,734%.
Untuk lebih jelas, hasil pada tabel 1 akan ditampilkan pada Gambar 1.
Karena grafik pada Gambar 1 fluktuatif, maka tidak ada hubungan khusus antara
banyaknya data training yang digunakan dengan akurasi yang didapatkan. Semakin
banyak data training yang digunakan, tidak menjamin hasil akurasinya akan semakin
baik atau buruk.
Persentase Data
Training
Akurasi (%)
10 90,566
20 96,734
30 97,468
40 92,366
50 95,886
60 95,886
70 96,296
80 98,734
90 97,619

693
Gambar 1. Hasil akurasi menggunakan Fuzzy C- Means
5. Kesimpulan
Kesimpulan yang bisa diambil dari makalah ini adalah metode Fuzzy C-
Means dapat diterapkan untuk melakukan klasifikasi data sikap remaja terhadap
rokok.
Dari pengujian yang dilakukan, tanpa menggunakan seluruh variabel, kita
tetap bisa melakukan klasifikasi kecenderungan merokok. Berdasarkan cluster yang
didapatkan, pada cluster I didapatkan remaja dengan kecenderungan merokok
rendah mencapai 78%. Sedangkan cluster II didapatkan remaja dengan
kecenderungan merokok tinggi mencapai 22 %.
Dari tabel 4.1 diperoleh tingkat akurasi paling besar untuk data sikap remaja
terhadap rokok adalah dengan menggunakan 80% data training dengan akurasi
sebesar 98,734%. Tidak ada hubungan khusus antara banyaknya data training yang
digunakan dengan akurasi yang didapatkan. Semakin banyak data training yang
digunakan, tidak menjamin hasil akurasinya akan semakin baik atau buruk.
Saran dari penulis untuk pengembangan kedepannya yaitu dapat dibahas
metode klasifikasi yang lain selain metode Fuzzy C-Means. Selain itu, dapat
diterapkan juga metode pemilihan fitur-fitur informatif dari data.
Referensi [1] Ramadhana, C., Dewi Lulu, Y., dan Kartina Diah, K. W. (2013). Data Mining dengan
Algoritma Fuzzy C-Means Clustering Dalam Kasus Penjualan di PT Sepatu Bata.
Seminar Nasional Teknologi Informasi & Komunikasi Terapan 2013 (SEMANTIK
2013).
[2] Denecke, Hazel and Gülhayat, GÖLBAŞI ŞİMŞEK. (2016). An Application of Fuzzy
Clustering on Prevalence of Youth Tobacco Survey.
[3] Bezdek and James C. (1981). Pattern Recognition with Fuzzy Objective Function
Algorithms.
[4] Eko Prasetyo. (2012). Data Mining-Konsep dan Aplikasi Menggunakan Matlab.
Yogyakarta, Indonesia: C.V Andi Offset.
86
88
90
92
94
96
98
100
10 20 30 40 50 60 70 80 90
Aku
rasi
Persentase Data Training
Hasil Akurasi
Hasil Akurasi

694
[5] Eriksen, M., Hana, R., dan Judith, M. (2012). The Tobacco Atlas 4th Edition, Atlanta-
Georgia.
[6] Tan, P., N., Michael, S., and Vipin, K. (2005). Introduction to Data Mining, 1st ed.
Boston, USA: Addison-Wesley Longman Publising Co.
[7] Nugraheni, Y. (2011). Data Mining dengan Metode Fuzzy untuk Customer Relationship
Managment (CRM) pada Perusahaan Ritel. Universitas Udayana, Denpasar.

695
Prosiding SNM 2017
Komputasi , Hal 695-705
APLIKASI FUZZY MADM UNTUK DETEKSI POTENSI
SERANGAN JANTUNG BERDASARKAN METODE AHP
DAN TOPSIS
ZENIA AMARTI, NURSANTI ANGGRIANI, ASEP K.
SUPRIATNA
Departemen Matematika, FMIPA Universitas Padjadjaran
Jl. Raya Bandung-Sumedang Km 21 Jatinangor 45363 1 email: [email protected]
Abstrak. Jantung merupakan salah satu organ terpenting dalam tubuh. Jantung
berfungsi memompa dan mengalirkan darah yang mengandung oksigen ke seluruh
tubuh. Seseorang mengalami serangan jantung jika aliran darah ke jantungnya
terhambat oleh timbunan lemak ataupun kolesterol. Seringkali sekelompok orang tidak
menyadari bahwa dirinya berpotensi terkena serangan jantung. Untuk menangani
permasalahan tersebut diperlukan suatu metode yang dapat mendeteksi potensi
seseorang terkena serangan jantung lebih tinggi dari orang lainnya dalam suatu
kelompok. Masalah deteksi potensi serangan jantung ini dapat diselesaikan dengan
model fuzzy MADM (Multiple Attribute Decision Making) metode AHP (Analytic
Hierarchy Process) dan TOPSIS (Technique for Order Preference by Similarity to
Ideal Solution). Metode AHP dalam hal ini digunakan untuk menentukan bobot relatif
dari setiap kriteria, sedangkan metode TOPSIS digunakan untuk mengurutkan nilai
preferensi dari beberapa alternatif berdasarkan kedekatan dengan solusi ideal. Kriteria
yang digunakan dalam proses pengurutan adalah usia, status perokok atau bukan,
indeks massa tubuh, hipertensi dan kadar kolesterol darah. Hasil pengurutan mendeteksi
alternatif yang berpotensi paling tinggi terkena serangan jantung adalah alternatif
dengan jarak solusi ideal positif terpendek, jarak solusi ideal negatif terpanjang dan
nilai preferensi tertinggi.
Kata kunci: potensi serangan jantung, fuzzy MADM, AHP, TOPSIS.
1. Pendahuluan
Jantung adalah sebuah organ tubuh pada manusia yang memompa darah lewat
pembuluh darah oleh kontraksi berirama yang berulang. Darah menyuplai oksigen
dan nutrisi pada tubuh serta membantu menghilangkan sisa-sisa metabolisme.
Serangan jantung adalah sebuah kondisi yang menyebabkan jantung sama sekali
tidak berfungsi. Kondisi ini biasanya terjadi mendadak dan sering disebut gagal
jantung. Penyebab terjadinya serangan jantung biasanya adalah karena terhambatnya
suplai darah ke otot-otot jantung dikarenakan pembuluh-pembuluh darah yang
biasanya mengalirkan darah ke otot-otot jantung tersebut tersumbat oleh lemak dan
kolesterol ataupun oleh karena zat-zat kimia. Seringkali seseorang dalam suatu
kelompok tidak menyadari bahwa dirinya berpotensi terkena serangan jantung. Oleh
karena itu, penelitian ini bertujuan untuk melakukan pengurutan terhadap potensi

696
seseorang terkena serangan jantung dari orang yang berpotensi paling tinggi ke yang
paling rendah dalam suatu kelompok. Berdasarkan penyebab terjadinya serangan
jantung, maka kriteria yang menjadi dasar penilaian dalam mendeteksi serangan
jantung ini adalah usia, status perokok atau bukan, indeks massa tubuh, hipertensi
dan kadar kolesterol darah.
Masalah deteksi potensi serangan jantung ini merupakan masalah pengambilan
keputusan yang memiliki ketidakjelasan dan kekaburan dalam masalah data atau
bersifat fuzzy. Oleh karena itu, masalah pembobotan kriteria dan pengurutan dapat
diselesaikan dengan menerapkan fuzzy MADM (Multiple Attribute Decision
Making). Beberapa metode yang dapat digunakan untuk menyelesaikan masalah
fuzzy MADM adalah metode AHP (Analytic Hierarchy Process) dan metode
TOPSIS (Technique for Order Preference by Similarity to Ideal Solution).
Berdasarkan Koohpayehzadeh dan Sadegh [1], metode AHP merupakan salah satu
metode pengambilan keputusan yang digunakan untuk menguraikan masalah
hirarkis dan dapat diterapkan untuk memecahkan masalah pengambilan keputusan
multi-kriteria yang kompleks. Metode AHP telah diterapkan dalam berbagai bidang.
Koohpayehzadeh dan Sadegh [1] menerapkan metode AHP dalam optimisasi seleksi
situs bendungan dalam gambaran cekungan di pusat Iran. Tuysuz dan Kahraman [2]
menerapkan metode AHP dalam proyek teknologi informasi. Selain itu, AHP juga
telah diterapkan oleh Kong dan Liu [3] untuk evaluasi faktor keberhasilan e-
commerce.
Berdasarkan Opricovic dan Tzeng [4] jika dihubungkan dengan masalah
deteksi potensi serangan jantung, prinsip dasar metode TOPSIS adalah alternatif
yang berada di urutan paling tinggi harus memiliki jarak terpendek dari solusi ideal
positif dan jarak terpanjang dari solusi ideal negatif. Metode TOPSIS juga telah
banyak diterapkan dalam berbagai kasus, diantaranya untuk seleksi beasiswa yang
telah diterapkan dalam Ayu dkk [5] dan ‘Uyun dan Riadi [6]. Dalam contoh kasus
lain Nuraini dkk [7] menggabungkan metode AHP dan metode TOPSIS dalam
pemilihan campuran biodiesel terbaik. Selain itu, Soyler dan Pirim [8] menggunakan
fuzzy AHP dan fuzzy TOPSIS untuk menganalisis kriteria evaluasi pengembangan
lembaga proyek. Oleh karena itu, metode AHP dan metode TOPSIS untuk
selanjutnya digunakan dalam melakukan pengurutan terhadap potensi seseorang
terkena serangan jantung dari yang berpotensi paling tinggi ke yang berpotensi
paling rendah dalam suatu kelompok.
2. Metode Penelitian
Teori himpunan fuzzy berdasarkan Ayu dkk [5] dirancang untuk
merepresentasikan ketidakpastian, ketidakjelasan dan ketidaktepatan dari banyaknya
informasi yang ada. Pada teori himpunan fuzzy, komponen utama yang sangat
berpengaruh adalah fungsi keanggotaan. Fungsi keanggotaan merepresentasikan
derajat kedekatan suatu obyek terhadap kriteria tertentu. Penentuan keputusan dalam
kasus Multiple Attribute Decision Making (MADM) diselesaikan dengan memilih
alternatif terbaik dari beberapa alternatif. Namun, karena data yang digunakan tidak
jelas atau bersifat fuzzy, maka diterapkan fuzzy MADM. Inti dari fuzzy MADM
adalah menentukan bobot untuk setiap kriteria, diikuti dengan proses pengurutan
alternatif yang telah diberikan.

697
Metode AHP
Prosedur AHP dalam Nuraini dkk [7] terdiri dari langkah-langkah berikut.
1. Penyusunan hirarki
Struktur hirarki pada AHP ini terdiri dari tiga level atau tingkatan. Tujuan dari
keputusan ditempatkan paling atas, diikuti oleh level kedua dengan kriteria dan
level ketiga dengan alternatif.
2. Pembuatan matriks pasangan perbandingan Saaty atau Pairwise Comparasion
0,1
,1dengan ,
21
22221
11211
ij
ij
jiii
mnmm
n
n
aa
aa
aaa
aaa
aaa
A
Skala preferensi antara dua elemen berdasarkan Kong dan Liu [3] adalah seperti
pada tabel berikut.
Tabel 1. Skala Saaty untuk perbandingan berpasangan
Skala Saaty Kepentingan relatif dari dua sub-elemen
1 Kedua elemen sama pentingnya
3 Elemen yang satu sedikit lebih penting dari pada yang
lainnya
5 Elemen yang satu sangat penting dari pada elemen yang
lainnya
7 Elemen yang satu jelas lebih penting dari elemen yang
lainnya
9 Elemen yang satu mutlak lebih penting dari pada
elemen yang lainnya
2, 4, 6, 8 Nilai-nilai tengah di antara dua pertimbangan yang
berdekatan
3. Penentuan prioritas atau bobot untuk setiap kriteria
Menghitung matriks normalisasi
m
i
ij
ij
ijnorm
a
aa
1
(1)
Penentuan bobot setiap kriteria
n
a
w
n
j
ij
j
1
(2)
4. Pemeriksaan konsistensi
Menghitung perkalian matriks dengan bobot transpos t
j Aww *
(3)
Menghitung rata-rata rasio konsistensi

698
n
j j
j
w
w
nt
1
*1
(4)
Menghitung indeks konsistensi
1
n
ntCI
(5)
Memeriksa konsistensi bobot
RI
CI
(6)
dimana RI merupakan random index untuk nilai n yang berlaku dengan
syarat sebagai berikut.
a. Jika 10.0RI
CI, maka pembuat keputusan konsisten. Artinya proses analisis
dan pengolahan data dapat dilanjutkan.
b. Jika 10.0RI
CI, maka pembuat keputusan inkonsisten dan penilaian
interpretasi harus diulang. Nilai-nilai random index (RI) ditunjukkan oleh
Tabel 2.
Tabel 2. Nilai-nilai random index (RI)
N 2 3 4 5 6 7 8 9 10
RI 0 0,58 0,90 1,12 1,24 1,32 1,41 1,45 1,51
Metode TOPSIS
Prosedur TOPSIS dalam Nuraini dkk [7] mengikuti langkah-langkah
berikut.
1. Menghitung matriks keputusan ternormalisasi
Matriks keputusan ternormalisasi, R = [rij] berukuran nm dengan rij sebagai
kinerja dari setiap alternatif yang harus dinilai dengan persamaan berikut.
m
i ij
ij
x
x
1
2ijr
(7)
dengan x merupakan matriks keputusan; mi ,...,2,1 dan nj ,...,2,1 . Matriks
keputusan ternormalisasi dapat direpresentasikan sebagai berikut.
nkkk 21
mnmm
n
n
m rrr
rrr
rrr
a
a
a
R
21
22221
11211
2
1
dengan ai merupakan alternatif ke-i dan kj merupakan kriteria ke-j.
2. Menghitung matriks keputusan ternormalisasi terbobot
Matriks keputusan ternormalisasi terbobot, Y = [yij] berukuran nm dengan yij

699
merupakan penilaian bobot ternormalisasi yang dapat dinyatakan dengan
persamaan berikut.
ijjij rwy
(8)
Dimana wj merupakan bobot dari kriteria ke-j dengan batasan
n
j jj ww1
.0;1
3. Menentukan matriks solusi ideal positif (A+) dan ideal negatif (A-)
Matriks solusi ideal positif (A+) dihitung berdasarkan persamaan berikut.
miyyA ijjj ,...,2,1|max
(9)
Matriks solusi ideal negatif (A-) dihitung berdasarkan persamaan berikut.
miyyA ijjj ,...,2,1|min
(10)
4. Menghitung jarak antara nilai setiap alternatif
Jarak antara alternatif Ai dengan solusi ideal positif (Di+) dapat dirumuskan
dengan persamaan berikut.
miyyDn
j jiji ,...,2,1 ; 1
2
(11)
Jarak antara alternatif Ai dengan solusi ideal negatif (Di-) dapat dirumuskan
dengan persamaan berikut.
miyyDn
j jiji ,...,2,1 ; 1
2
(12)
5. Menghitung nilai preferensi untuk setiap alternatif
Nilai preferensi untuk setiap alternatif (Vi) diberikan sebagai berikut.
miDD
DV
ii
i
i ,...,2,1;
(13)
3. Hasil dan Pembahasan
Berdasarkan langkah-langkah MADM di atas, maka dipilih beberapa
alternatif yang akan dideteksi potensi dirinya terkena serangan jantung. Dalam
masalah ini diberikan beberapa data alternatif dengan kriteria-kriteria sebagai
berikut.
1. Kadar kolesterol darah (KKD)
Untuk kriteria kadar kolesterol darah, diasumsikan bahwa seseorang dengan
kadar kolesterol total dalam tubuh dengan ukuran > 200 mg/dl berpotensi
terkena serangan jantung.
2. Status perokok atau bukan (SPB)
Untuk kriteria status perokok atau bukan, diasumsikan bahwa semakin banyak
jumlah rokok yang dihisap per hari oleh seorang perokok, maka semakin besar

700
potensinya terkena serangan jantung. Data menunjukkan jumlah rokok (per
batang) yang dihisap per hari.
3. Hipertensi (HIP)
Untuk kriteria hipertensi, diasumsikan bahwa seseorang dengan tekanan darah
sistolik > 120 mm Hg berpotensi terkena serangan jantung (tekanan darah
diastolik diabaikan).
4. Indeks massa tubuh (IMT)
Kriteria indeks massa tubuh dalam hal ini digunakan sebagai ukuran apakah
seseorang dikatakan obesitas atau tidak. Untuk kriteria ini, diasumsikan bahwa
seseorang yang memiliki nilai IMT > 23 berpotensi terkena serangan jantung.
5. Usia (US)
Untuk kriteria usia, diasumsikan bahwa seseorang dengan usia > 45 tahun
berpotensi terkena serangan jantung.
Untuk mengurangi kompleksitas, data diambil dari 5 orang responden. Data
diperoleh dari hasil pengamatan peneliti langsung terhadap responden. Berikut
diberikan data-data dari setiap alternatif.
Tabel 3. Data alternatif
Alternatif Kriteria
KKD SPB HIP IMT US
1 155 5 140 23.5304 52
2 240 0 140 25.8065 59
3 230 12 90 32.0390 46
4 210 3 140 21.8750 62
5 230 0 145 28.8889 51
Proses pembobotan dilakukan mengikuti prosedur metode AHP.
Berdasarkan langkah pertama dalam prosedur AHP, maka disusunlah struktur hirarki
seperti pada Gambar 1.
Gambar 1. Struktur Hirarki
Selanjutnya dibuat matriks perbandingan berpasangan untuk masing-masing
kriteria seperti ditunjukkan pada Tabel 4.

701
Tabel 4. Perbandingan pasangan kriteria
Kriteria KKD SPB HIP IMT US
KKD 1 2 3 5 7
SPB 1/2 1 2 4 6
HIP 1/3 1/2 1 3 5
IMT 1/5 1/4 1/3 1 3
US 1/7 1/6 1/5 1/3 1
Elemen-elemen dalam matriks perbandingan berpasangan ditentukan secara
subyektif oleh peneliti dengan berdasarkan pada Tabel 1. Berdasarkan penilaian
peneliti dan hasil uji statistik oleh Zahrawardani dkk [9], ditentukan kriteria-kriteria
penyebab terjadinya serangan jantung dengan kepentingannya secara berturut-turut
dari yang paling tinggi ke kriteria dengan kepentingan paling rendah adalah KKD,
SPB, HIP, IMT dan US.
Untuk memperoleh matriks keputusan ternormalisasi, maka sebelumnya
elemen-elemen di dalam tabel dinormalisasi berdasarkan persamaan (1) sehingga
diperoleh matriks keputusan ternormalisasi (anorm)ij sebagai berikut.
0455.00250.00306.00426.00656.0
1364.00750.00510.00638.00919.0
2273.02250.01531.01277.01532.0
2727.03000.03061.02553.02298.0
3182.03750.04592.05106.04595.0
ijnorma
Setelah memperoleh matriks keputusan ternormalisasi, maka selanjutnya dihitung
nilai bobot setiap kriteria berdasarkan persamaan (2) sehingga diperoleh hasil
berikut. 0419.0 ; 0836.0 ; 1772.0 ; 2728.0 ; 4245.0 54321 wwwww
Matriks bobot setiap kriteria wj dinyatakan sebagai berikut.
0419.0
0836.0
1772.0
2728.0
4245.0
jw
Ada beberapa langkah dalam proses pemeriksaan konsistensi untuk setiap
kriteria. Langkah pertama adalah menghitung perkalian matriks dengan bobot
transpos mengikuti persamaan (3) sehingga diperoleh hasil berikut. 2113.0* ; 4215.0* ; 9154.0* ; 4253.1* ; 2130.2* 54321 wwwww
Matriks bobot setiap kriteria *jw dinyatakan sebagai berikut.

702
2113.0
4215.0
9154.0
4253.1
2130.2
*jw
Selanjutnya, diperoleh nilai rata-rata rasio konsistensi berdasarkan persamaan (4)
sebagai berikut.
1377.5t
Kemudian berdasarkan persamaan (5) diperoleh nilai indeks konsistensi berikut.
0344.0CI
Berdasarkan random index pada Tabel 2 dengan nilai 5n , maka diperoleh nilai
indeks konsistensi bobot berdasarkan persamaan (6) sebagai berikut.
0307.0RI
CI
Proses analisis dan pengolahan data dapat dilanjutkan karena nilai indeks konsistensi
bobot < 0.1, yaitu sebesar 0.0307. Diketahui bahwa nilai bobot untuk masing-masing
kriteria ditunjukkan pada Tabel 5.
Tabel 5. Bobot kriteria
Kriteria Bobot
KKD 0.4245
SPB 0.2728
HIP 0.1772
IMT 0.0836
US 0.0419
Proses pengurutan dilakukan berdasarkan prosedur TOPSIS. Sebelum
menghitung matriks keputusan ternormalisasi, maka dicari terlebih dahulu nilai
keanggotaan yang dicapai untuk setiap kriteria dari setiap alternatif untuk
menunjukkan seberapa besar tingkat keanggotaan elemen tersebut dalam himpunan
kriterianya seperti tampak pada Tabel 6.
Tabel 6. Nilai keanggotaan
Alternatif Kriteria
KKD SPB HIP IMT US
1 0 0.42 0.50 0.08 0.28
2 1 0 0.50 0.40 0.56
3 0.75 1 0 1 0.04
4 0.25 0.25 0.50 0 0.68
5 0.75 0 0.63 0.84 0.24
Matriks keputusan ternormalisasi disusun dari ranking kinerja tiap alternatif
terhadap suatu kriteria, maka selanjutnya dilakukan perhitungan ranking kinerja tiap
alternatif terhadap suatu kriteria berdasarkan persamaan (7) sehingga diperoleh hasil
berikut.
a. Ranking tiap alternatif KKD

703
11r 0 ; 21r
0.6761
; 31r
0.5071
; 41r
0.1690 ; 51r 0.5071
b. Ranking tiap alternatif SPB
12r
0.3773 ; 22r 0 ; 32r
0.8984
; 42r
0.2246 ; 52r 0
c. Ranking tiap alternatif HIP
13r 0.4669 ; 23r
0.4669 ; 33r 0
; 43r
0.4669 ; 53r 0.5883
d. Ranking tiap alternatif IMT
14r
0.0585
; 24r
0.2924
; 34r
0.7309
; 44r 0 ; 54r 0.6139
e. Ranking tiap alternatif US
15r 0.2929 ; 25r
0.5859
; 35r
0.0418
; 45r
0.7114 ; 55r 0.2511
Matriks keputusan ternormalisasi ijr dinyatakan sebagai berikut.
2511.06139.05883.005071.0
7114.004669.02246.01690.0
0418.07309.008984.05071.0
5859.02924.04669.006761.0
2929.00585.04669.03773.00
ijr
Selanjutnya dengan mengikuti persamaan (8), maka diperoleh matriks
keputusan ternormalisasi terbobot ijy sebagai berikut.
0105.00513.01042.002153.0
0298.000827.00613.00718.0
0018.00611.002451.02153.0
0245.00244.00827.002870.0
0123.00049.00827.01029.00
ijy
Solusi ideal positif dicari berdasarkan persamaan (9) sehingga diperoleh hasil
berikut.
0298.00611.01042.02451.02870.0A
Kemudian dicari solusi ideal negatif berdasarkan persamaan (10) sehingga diperoleh
hasil berikut.
0018.00000A
Jarak antara alternatif Ai dengan solusi ideal positif dihitung berdasarkan
persamaan (11) sehingga diperoleh hasil berikut.

704
0.2563 ; 0.2904 ; 0.1296 ; 0.2488 ; 3264.0 54321
DDDDD
Jarak antara alternatif Ai dengan solusi ideal negatif dihitung berdasarkan persamaan
(12) sehingga diperoleh hasil berikut.
0.2448 ; 0.1286 ; 0.3319 ; 0.3006 ; 0.1326 54321
DDDDD
Nilai preferensi merupakan nilai yang menjadi ukuran kedekatan setiap
alternatif terhadap solusi ideal. Setelah dilakukan perhitungan berdasarkan
persamaan (13), maka diperoleh nilai preferensi untuk masing-masing alternatif
sebagai berikut.
0.4885 ; 0.3069 ; 0.7191 ; 0.5471 ; 0.2889 54321 VVVVV
Berdasarkan perhitungan di atas, diperoleh hasil pengurutan seperti pada
Tabel 7.
Tabel 7. Nilai preferensi dan ranking tiap alternatif
No. Urut Alternatif Nilai Preferensi
1 3 0.7191
2 2 0.5471
3 5 0.4885
4 4 0.3069
5 1 0.2889
4. Kesimpulan
Dari hasil diperoleh bahwa dengan menggunakan metode AHP, diketahui
bobot untuk kriteria KKD sebesar 0.4245, kriteria SPB sebesar 0.2728, kriteria HIP
sebesar 0.1772, kriteria IMT sebesar 0.0836 dan kriteria US sebesar 0.0419.
Pengurutan dengan menggunakan metode TOPSIS memberikan hasil bahwa
alternatif yang memiliki potensi paling tinggi terkena serangan jantung adalah
alternatif 3 dengan jarak solusi ideal positif sebesar 0.1296 dan jarak solusi ideal
negatif sebesar 0.3319 dengan nilai preferensi sebesar 0.7191. Alternatif ini diikuti
oleh alternatif 2 dengan jarak solusi ideal positif sebesar 0.2488 dan jarak solusi
ideal negatif sebesar 0.3006 dengan nilai preferensi sebesar 0.5471. Kemudian
alternatif 5 dengan jarak solusi ideal positif sebesar 0.2563 dan jarak solusi ideal
negatif sebesar 0.2448 dengan nilai preferensi sebesar 0.4885. Alternatif 4 dengan
jarak solusi ideal positif sebesar 0.2904 dan jarak solusi ideal negatif sebesar 0.1286
dengan nilai preferensi sebesar 0.3069. Sedangkan alternatif 1 dengan jarak solusi
ideal positif sebesar 0.3264 dan jarak solusi ideal negatif sebesar 0.1326 dengan nilai
preferensi sebesar 0.2889 menempati urutan terakhir. Itu berarti bahwa alternatif 1
memiliki potensi paling rendah terkena serangan jantung di antara alternatif-
alternatif lainnya.

705
Referensi
[1] Koohpayehzadeh, H.E. and Sadegh, M.A.N., 2015, Using the AHP and Fuzzy-AHP
Decision Making Methods to Optimize the Dam Site Selection in illustrative basin in
the center of Iran, International Journal of Advanced Research (2015), Volume 3, Issue
9, 31 – 41.
[2] Tuysuz, F. and Kahraman, C., 2006, Project Risk Evaluation Using a Fuzzy Analytic
Hierarchy Process: An Application to Information Technology Projects, International
Journal of Intelligent Systems, Vol. 21, 559–584.
[3] Kong, F. and Liu, H., 2005, Applying Fuzzy Analytic Hierarchy Process to Evaluate
Success Factors of E-Commerce, International Journal of Information and Systems
Sciences, Vol 1, No. 3-4, 406–412.
[4] Opricovic, S. and Tzeng, G.H., 2004, Compromise solution by MCDM methods: A
comparative analysis of VIKOR and TOPSIS. European Journal of Operation
Research, 156, 445-455.
[5] Ayu, G.M.S.W., Ketut, I.G.D.P. and Wira, P.B., 2013, Multi-Attribute Decision Making
Scholarship Selection Using A Modified Fuzzy TOPSIS, International Journal of
Computer Science Issues, Vol. 10, Issue 1, No. 2, 309-317.
[6] ‘Uyun, S. dan Riadi, I., 2011, A Fuzzy Topsis Multiple-Attribute Decision Making for
Scholarship Selection. Jurnal Telkomnika, Vol. 9(1), 37-46.
[7] Nuraini, J., Yusuf, M.F. dan Harahap, E.H., 2016, Pemilihan Campuran Biodiesel
Terbaik Berdasarkan Penggabungan Analytic Hierarchy Process (AHP) dan Technique
for Order Preference by Similarity to Ideal Solution (TOPSIS), Prosiding SPeSIA 2016
Fakultas MIPA Unisba, 11 Agustus 2016.
[8] Soyler, H. and Pirim, L., 2014, Using Fuzzy AHP and Fuzzy TOPSIS Methods for the
Analysis of Development Agencies Project Evaluation Criteria, NWSA-Social Sciences,
3C0124, 9, (4), 105-117.
[9] Zahrawardani, D., Sri, K.H. dan Dewi, H.A., 2013, Analisis Faktor Risiko Kejadian
Penyakit Jantung Koroner di RSUP Dr. Kariadi Semarang, Jurnal Kedokteran
Muhammadiyah, Vol. 1, No. 2, 13-20.
.

706
Prosiding SNM 2017 Komputasi, Hal 706-725
IMPLEMENTASI TEOREMA DAERAH KAJIAN
DAN TEOREMA KOMPOSISI IRISAN HIMPUNAN
PADA ETNOINFORMATIKA PENAMAAN DESA DI
LIMA WILAYAH PROVINSI JAWA BARAT
ATJE SETIAWAN ABDULLAH1 DAN BUDI NURANI
RUCHJANA2
1Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas
Padjadjaran, Bandung, [email protected] 2Departemen Matematika, Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas
Padjadjaran, Bandung, [email protected]
Abstrak. Etnoinformatika merupakan peran ilmu informatika dalam budaya masyarakat di lokasi
tertentu, salah satu budaya yang ada di masyarakat adalah penamaan tempat yang menggambarkan ciri
dari suatu tempat yang diberikan oleh kelompok masyarakat di lokasi tersebut. Ilmu informatika yang
digunakan dalam penelitian ini adalah data mining, yaitu proses untuk mengekstrak pengetahuan secara
otomatis dari database yang besar, untuk mendapatkan pola-pola yang menarik sehingga diperoleh
suatu knowledge. Pada penelitian ini dikaji bagaimana para leluhur zaman dahulu memberikan
penamaan tempat tinggalnya, serta meneliti makna dari penamaan tempat tersebut. Pengelompokan
dilakukan berdasarkan struktur kata penamaan desa, meliputi awalan, suku kata yang terkandung, dan
kata lengkap penamaan desa, sedangkan pengelompokan makna penamaan desa berdasarkan duabelas
kategori. Database yang digunakan dalam penelitian ini memanfaatkan database desa wilayah-wilayah
di provinsi Jawa Barat, didapat dari Badan Informasi Strategis (BIG) Indonesia tahun 2014, yang
tersusun dalam hirarki provinsi, kabupaten, kecamatan dan desa. Metodologi penelitian yang digunakan
dalam penelitian ini adalah mengikuti proses knowledge discovery in database (KDD), pada data
mining. Proses tersebut terdiri dari, proses preprocessing, data mining, dan post processing. Untuk
memudahkan pencarian penamaan desa, dikembangkan aplikasi pencarian berbasis Java, yang terdiri
dari menu pemilihan lokasi, menu pencarian desa, menu rekapitulasi, dan menu irisan himpunan
penamaan desa.
Hasil penelitian menunjukkan bahwa penamaan desa di lima wilayah Jawa Barat melambangkan
karakter sendiri budaya masyarakat di masing-masing wilayahnya. Pada masyarakat di wilayah-
wilayah pegunungan, penggunaan awalan Ci, awalan Pa, dan awalan Su, dalam penamaan desa relatif
tinggi, sedangkan di wilayah-wilayah pantai penggunaan awalan tersebut relatif redah. Makna dari
penamaan desa menggambarkan karakter budaya masyarakat di wilayah masing-masing. Secara umum
makna penamaan desa menjadi karakter masyarakat di lima wilayah Jawa Barat mengutamakan
kebaikan dalam menjalankan hidupnya, selalu bekerja keras untuk mencapai kehidupan yang lebih
sejahtera, dan mencintai serta memelihara kelestarian air dan lingkungannya. Pada penelitian ini juga
dikembangkan dua teorema dan implementasinya, pertama teorema lokasi kajian, digunakan untuk
menentukan jumlah lokasi dan prioritas penelitian, dan kedua teorema komposisi irisan himpunan,
digunakan untuk menentukan kemiripan dan kekhasan di masing-masing lokasi wilayah.
Kata kunci: Data Mining, Etnoinformatika, Clustering, LokasiKajian, Komposisi Irisan
Himpunan

707
1. Pendahuluan
Nama-nama tempat tinggal sudah ada semenjak ratusan tahun yang lalu,
digunakan untuk menandai daerah tertentu. Semenjak manusia dilahirkan di dunia,
penamaan tempat sudah digunakan, hal ini tergambar pada akte kelahiran, meliputi
tempat lahir, tanggal lahir dan tahun lahir. Lalu timbul pertanyaan bagaimana para
leluhur di daerah tertentu memberikan penamaan tempat tinggalnya? Pada saat ini
sering didengar ungkapan pertanyaan dari generasi muda tentang apalah artinya
sebuah penamaan? Hal ini memberikan kesan penamaan itu tidak ada artinya.
Penelitian ini mengkaji bagaimana para leluhur bangsa memberikan penamaan pada
tempat tinggalnya, khususnya mengkaji penamaan desa, hal ini dipilih mengingat
tersedianya database yang besar penamaan desa, sumber data diambil dari Badan
Informasi Geospasial (BIG) di Indonesia tahun 2014. Selain itu pengambilan
penamaan desa didasarkan pada kenyataan sampai saat ini desa merupakan elemen
terkecil yang sudah dilengkapi dengan koordinat lokasi masing-masing, sehingga
mudah digambarkan pada peta lokasi. Database yang digunakan dibatasi dengan
hanya meneliti database penamaan desa di lokasi wilayah-wilayah yang berada di
provinsi Jawa Barat. Wilayah di provinsi Jawa Barat mengacu pada [7] terdiri dari
5 wilayah, meliputi wilayah I, terdiri dari kabupaten Bogor, kota Bogor, kota Depok,
kabupaten Sukabumi, kota Sukabumi, dan kabupaten Cianjur. Wilayah II meliputi
kabupaten Purwakarta, kabupaten Karawang, kota Bekasi, kabupaten Bekasi, dan
kabupaten Subang. Wilayah III, meliputi kabupaten Cirebon, kota Cirebon,
kabupaten Indramayu, kabupaten Kuningan, dan kabupaten Majalengka. Wilayah IV
meliputi, kabupaten Tasikmalaya, kota Tasikmalaya, kabupaten Ciamis, kota Banjar,
kabupaten Garut, kabupaten Sumedang, dan kabupaten Pangandaran. Wilayah V
terdiri dari kabupaten Bandung, kota Bandung, kota Cimahi dan kabupaten Bandung
Barat. Penelitian ini juga mengkaji tentang makna penamaan desa, baik secara
deskriptif maupun menggunakan pengelompokkan makna arti kata penamaan desa,
dengan membandingkan penamaan desa di lima wilayah yang ada di provinsi Jawa
Barat.
Penelitian ini bertujuan untuk mengkaji beberapa hal yang berkaitan dengan
etnomatematika penamaan desa di wilayah-wilayah yang ada di provinsi Jawa Barat,
sebagai berikut:
1. Mendeskripsikan nama-nama desa yang banyak digunakan di lima wilayah
provinsi Jawa Barat, serta mendeskripsikan makna penamaan desa
berdasarkan awalan penamaan desa, suku kata yang terkandung dalam
penamaan desa dan kata lengkap penamaan desa.
2. Menggambarkan deskripsi penamaan desa dalam peta lokasi, untuk melihat
kemiripan dan kekhasan di setiap lokasi yang ada di wilayah-wilayah
provinsi Jawa Barat.
3. Mengembangkan dan mengimplementasikan teorema irisan himpunan untuk
mencari daerah kajian dan komposisi irisan himpunan untuk melihat
kemiripanan dan kekhasan penamaan desa yang ada di wilayah-wilayah
provinsi Jawa Barat.

708
2. Tinjauan Pustaka
2.1 Etnomatematika dan Etnoinformatika
Etnomatematika pertama kali diperkenalkan oleh pendidik dan
matematikawan dari Brazil yaitu Ubiratan D’Ambrioso pada tahun 1997 dalam
sebuah presentasi untuk American Association for the Advancement of Science,
matematikawan tersebut menamakan program ini dengan menggunakan
etimologi akar Yunani, etno, mathema, dan tics untuk menjelaskan tentang
ethnomathematics. “Etnomatematika adalah Matematika yang dipraktekkan
diantara kelompok budaya diidentifikasi seperti masyarakat nasional, suku,
kelompok buruh, anak-anak dari kelompok usia tertentu dan kelas profesional"
[4]. “Etnomatematika sebagai mode, gaya dan teknik menjelaskan, memahami,
dan menghadapi lingkungan alam dan budaya dalam sistem budaya yang
berbeda“ [5]. Dengan menggunakan logika yang sama dengan etnomatematika,
pada penelitian ini penulis mendefinisikan etnoinformatika merupakan
penerapan ilmu informatika di dalam budaya [1, 2]. Pada penelitian ini ilmu
informatika yang digunakan adalah penambangan data atau data mining dengan
memanfaatkan database penamaan desa di lima wilayah yang terletak di
provinsi Jawa Barat.
2.2 Makna
Makna adalah arti atau maksud yang tersimpul dari suatu kata, jadi makna
dengan bendanya sangat bertautan dan saling menyatu. Jika suatu kata tidak bisa
dihubungkan dengan bendanya, peristiwa atau keadaan tertentu maka kita tidak
bisa memperoleh makna dari kata itu [11]. Terdapat beberapa istilah yang
berhubungan dengan pengertian makna kata, yakni makna donatif, makna
konotatif, makna leksikal, makna gramatikal. Makna denotatif ialah makna
dasar, umum, apa adanya, netral tidak mencampuri nilai rasa, dan tidak berupa
kiasan. Makna konotatif adalah makna yang berupa kiasan atau yang disertai
nilai rasa, tambahan-tambahan sikap sosial, sikap pribadi sikap dari suatu zaman,
dan kriteria-kriteria tambahan yang dikenakan pada sebuah makna konseptual.
Makna Leksikal ialah makna kata seperti yang terdapat dalam kamus, istilah
leksikal berasal dari leksikon yang berarti kamus. Makna kata yang sesuai
dengan kamus inilah kata yang bermakna leksikal. Contoh: Batin (hati), Belai
(usap), Cela (cacat). Makna gramatikal adalah makna kata yang diperoleh dari
hasil perstiwa tata bahasa, istilah gramatikal dari kata grammar yang artinya tata
bahasa. Makna gramatikal sebagai hasil peristiwa tata bahasa ini sering disebut
juga nosi. Contoh: Nosi-an pada kata gantungan adalah alat.
2.3 Toponimi
Pengetahuan tentang penamaan disebut onomastic, terdiri atas dua cabang.
Pertama antroponimi, yaitu pengetahuan yang mengkaji riwayat atau asal-usul
penamaan orang. Kedua adalah toponimi, yaitu pengetahuan yang mengkaji
riwayat atau asal-usul penamaan tempat [3]. Toponim atau toponym berasal dari
“topos” dan “nym”. Topos berarti “tempat” merupakan gambaran tentang
permukaan atau tempat-tempat di bumi. “Nym” berasal dari “onyma” yang
berarti “nama”. Secara harfiah, toponim diartikan penamaan tempat di muka
bumi. Kajian toponimi dengan penelusuran nama-nama unsur geografis di suatu

709
wilayah, digunakan untuk menelusuri suatu kelompok etnik yang mendiami
suatu wilayah di masa lalu, berhubungan dengan sejarah permukiman manusia
[8]. Penamaan tempat atau toponimi memiliki tiga kategori utama yang sangat
berpengaruh terhadap pemberian nama tempat. (1) Aspek perwujudan berkaitan
dengan tempat kehidupan manusia yang cenderung menyatu dengan bumi dan
lingkungan alam. Penamaan kampung, berdasarkan aspek lingkungan alam yang
dapat dilihat. (2) Aspek kemasyarakatan berkaitan dengan interaksi sosial,
termasuk kedudukan seseorang, pekerjaan dan profesinya. Keadaan masyarakat
menentukan penamaan tempat, misal tempat yang masyarakatnya mayoritas
bertani, maka diberi penamaan yang tidak jauh dari pertanian. (3) Aspek
kebudayaan berkaitan dengan penamaan tempat banyak sekali yang dikaitkan
dengan unsur kebudayaan seperti masalah mitologis, folklor, dan sistem
kepercayaan, pemberian penamaan tempat jenis ini sering pula dikaitkan dengan
cerita rakyat yang disebut legenda.
Untuk melihat kaitan antara suatu objek dengan objek lainnya, digunakan hukum
pertama dari geografi yang menyatakan sesuatu objek pasti berhubungan dengan
objek lainnya, akan tetapi sesuatu objek yang berdekatan akan memiliki tingkat
hubungan yang lebih tinggi [12]. Konsep tersebut dikombinasikan dengan
konsep irisan himpunan, yang menyatakan anggota dari hasil irisan himpunan,
sekaligus merupakan anggota bagi himpunan yang diiriskan. Konsep-konsep
tersebut diperlihatkan pada penamaan desa di wilayah-wilayah yang terletak
pada provinsi Jawa Barat.
2.4 Data Mining
Data mining, merupakan suatu proses mengekstrak pengetahuan secara
otomatis dari database yang besar, untuk memperoleh pola-pola yang menarik
yang sebelumnya tidak diketahui, sehingga terbentuk suatu knowledge [6].
Proses data mining meliputi tiga tahapan, tahapan pertama adalah data
preprocessing, meliputi pembersihan data, transformasi, penggabungan dan
seleksi data, tahapan kedua proses data mining, meliputi penggunaan model-
model matematika dan statistika untuk memproses dan mengolah data, dan
ketiga postprocessing terdiri dari visualisasi, serta interpretasi hasil pengolahan
data, untuk menghasilkan suatu knowledge. Fungsi dari data mining meliputi
deskriptif dan prediktif. Penelitian ini mendeskripsikan penamaan desa di
wilayah-wilayah yang berada di provinsi Jawa Barat, berdasarkan struktur kata
penamaan desa, meliputi awalan penamaan desa, suku kata yang terkandung
dalam penamaan desa, dan kata lengkap penamaan desa [1].
2.5 Clustering
Cluster merupakan kumpulan dari objek-objek data yang memiliki sifat
similar di dalam kluster yang sama dan dissimilar pada objek-objek kluster yang
berlainan, analisis kluster merupakan pengelompokkan beberapa objek data
menjadi cluster-cluster, sedangkan klustering merupakan proses
pengelompokkan himpunan data menjadi himpunan bagian-himpunan bagian,
atau menjadi kelas-kelas atau kluster-kluster, supaya objek-objek dalam kluster
tersebut memiliki tingkat kesamaan tinggi pada saat dibandingkan, tetapi sangat
berbeda jika dibandingkan dengan kluster yang berbeda [6]. Pada penelitian ini,
penamaan desa dikategorikan berdasarkan struktur kata, meliputi awalan kata

710
penamaan desa, suku kata yang dikandung dalam penamaan desa, dan kata
lengkap yang digunakan pada penamaan desa. Sedangkan klustering makna
penamaan desa menggunakan dua belas kategori, meliputi kategori alam,
kategori tumbuhan, kategori bunga, kategori perasaan, kategori penghormatan,
kategori buah-buahan, kategori warna, kategori arah, kategori peralatan,
kategori usaha, kategori keadaan, kategori tempat, kategori binatang, kategori
karakter dan kategori seni. Setiap kategori atau kelas-kelas divisualisasikan
dengan menggunakan distribusi penamaan desa terbanyak di masing-masing
lokasi.
3. Metodologi Penelitian
3.1 Metodologi
Metodologi penelitian yang digunakan dalam penelitian ini adalah mengikuti
tahapan process discovery in database pada data mining [6]. Tahapan-tahapan
tersebut terdiri dari: tahapan preprocessing, meliputi penyiapan database desa di
wilayah-wilayah provinsi Jawa Barat, kemudian proses pembersihan data
dengan tujuan untuk menghilangkan duplikasi data, menghilangkan eror dan
ketidak konsistennan data. Proses penggabungan data merupakan proses
penggabungan data internal yang diteliti yaitu penamaan desa dengan data
eksternal berupa koordinat masing-masing desa, hal ini untuk bisa divisualisasi
dalam bentuk peta lokasi. Data warehouse menampilkan data agregat yang dapat
diakses secara online, menentukan data yang relevan dalam hal ini yang diteliti
hanya data penamaan desa di wilayah-wilayah yang ada di provinsi Jawa Barat.
Tahapan Proses Data Mining yaitu penggunaan metode untuk mengolah data
tersebut, dalam hal ini digunakan klustering penamaan desa dengan tiga kluster,
kluster pertama penamaan desa berdasarkan awalan nama pada penamaan desa
di pulau Jawa, kluster kedua penamaan desa berdasarkan kata lengkap pada
penamaan desa di wilayah-wilayah yang ada di provinsi pulau Jawa, dan kluster
ketiga makna penamaan desa berdasarkan makna suku kata yang terkandung
pada penamaan desa di wilayah-wilayah yang ada di provinsi Jawa Barat.
Tahapan post processing, meliputi proses pencarian pola dengan memvisualisasi
hasil pengolahan data kluster menggunakan tabel, diagram dan peta lokasi.
Proses perolehan knowledge, diperoleh dengan meresume hasil interpretasi dari
table, diagram dan peta lokasi yang diperoleh pada tahap visualisasi pencarian
pola. Selain itu dikembangkan teorema yang berkaitan dengan irisan himpunan,
yaitu teorema untuk menjelaskan banyaknya lokasi kajian, dan teorema yang
berkaitan dengan komposisi hasil irisan pada penamaan desa di wilayah-wilayah
yang ada di provinsi Jawa Barat. Secara lengkap tahapan dari proses knowledge
discovery in database pada data mining dapat dilihat pada Gambar1 berikut ini.

711
Gambar 1. Tahapan Proses Knowledge Discovery in Data Mining
3.2 Database Penamaan Desa
Pada penelitian ini data yang digunakan adalah database penamaan desa di
lima wilayah provinsi Jawa Barat, terdiri dari 5760 desa, merupakan data
skunder yang didapat dari Badan Informasi Geographi (BIG), Indonesia pada
tahun 2014. Database desa tersebut kemudian disusun ke dalam hirarki wilayah
yang ada di provinsi Jawa Barat, terdiri dari 5 wilayah meliputi; wilayah 1,
terdiri dari 1269 desa, wilayah 2, terdiri dari 992 desa, wilayah 3 terdiri dari 1455
desa, wilayah 4, terdiri dari 1447 desa, serta wilayah 5, terdiri dari 597 desa.
Masing-masing penamaan desa tersebut digabungkan dengan data eksternal
berupa koordinat lokasi desa masing-masing, digunakan untuk memudahkan
menggambarkannya di peta lokasi. Secara lengkap rekapitulasi jumlah
penamaan desa di pulau Jawa dapat dilihat pada Tabel 1.
Tabel 1. Rekapitulasi Jumlah Desa Di Lima Wilayah
Provinsi Jabar
No Wilayah Jumlah Persentase
1 Wil-1 1269 22.03
2 Wil-2 992 17.22
3 Wil-3 1455 25.26
4 Wil-4 1447 25.12
5 Wil-5 597 10.36
Total
Jabar 5760 100.00
Untuk mempercepat proses pencarian pada penamaan desa di lima wilayah Jawa
Barat, dikembangkan aplikasi pencarian berbasis Java, terdiri dari tiga menu,
menu pertama terdiri dari menu pencarian penamaan desa berdasarkan awalan,

712
berdasarkan suku kata yang terkandung, dan berdasarkan kata lengkap, menu
kedua untuk rekapitulasi jumlah nama desa dan jumlah desa di wilayah tertentu,
dan menu ketiga merupakan irisan dari himpunan penamaan desa yang ada di
wilayah-wilayah provinsi Jawa Barat. Contoh penggunaan aplikasi untuk
pencarian kata lengkap dalam penamaan desa di wilayah Jawa Barat dapat
dilihat pada Gambar 2 berikut ini.
Gambar 2. Pencarian Kata Lengkap Penamaan Desa
Gambar 2 menjelaskan contoh penggunaan aplikasi pencarian nama desa
berdasarkan kata lengkap, pada menu pilih pencarian desa dan pilih kata lengkap
dan pilih provinsi tujuan, kemudian ketikkan nama desa yang akan dicari, pada
contoh di atas akan dicari nama-nama desa yang mengandung kata sidorejo,
maka akan muncul list dari desa-desa yang dimaksud, serta jumlah desanya dan
persentasenya terhadap seluruh data pada provinsi tersebut.
4. Hasil dan Pembahasan
4.1 Clustering Berdasarkan Awalan Kata pada Penamaan Desa
Berdasarkan Tabel 2 awalan pada penamaan desa di wilayah-wilayah yang
berada di provinsi Jawa Barat, menunjukan bahwa awalan CI, merupakan awalan
yang paling banyak digunakan, yaitu sebanyak 5760 (5.98%), kemudian awalan PA
sebanyak 1432 (5.76%), dan disusul awalan CI sebanyak 1047 (18,18%). Hal ini
menunjukkan bahwa masyarakat di wilayah-wilayah yang ada di provinsi Jawa Barat
mengutamakan kebaikan dalam menjalankan hidupnya, selalu bekerja keras untuk
mencapai kehidupan yang lebih sejahtera, dan mencintai serta memelihara
kelestarian air dan lingkungannya. Secara lengkap dapat dilihat pada Tabel 2.
Tabel 2. Rekapitulasi Awalan Ci, Pa dan Su di 5 Wilayah Jabar
No Awalan
Wil-
1 Persen
Wil-
2 Persen
Wil-
3 Persen
Wil-
4 Persen
Wil-
5 Persen Jabar Persen
1 CI 280 22.06 155 15.63 177 12.16 285 19.70 150 25.13 1047 18.18
2 PA 96 7.57 77 7.76 111 7.63 123 8.50 52 8.71 459 7.97
3 SU 145 11.43 92 9.27 86 5.91 175 12.09 47 7.87 545 9.46
TOTAL
WILAYAH 1269 992 1455 1447 597 5760

713
Berdasarkan Tabel 2 dapat dinyatakan beberapa hal tentang awalan kata penamaan
desa sebagi berikut: Awalan Ci, yang berarti air atau sungai, menunjukkan kecintaan
dan ketergantungan masyarakat di wilayah-wilayah provinsi Jawa Barat terhadap air
atau sungai dalam menjalankan kehidupannya. Hampir 20% penamaan desa di Jawa
Barat dimulai dengan awalan Ci, wilayah terbanyak penggunaan awalan Ci adalah
wilayah-5, wilayah-1, dan wilayah-3, masing-masing di atas 20%, sedangkan di
wilayah-2, dan wilayah-3, penggunaan awalan Ci relatif kecil yaitu di bawah 15%.
Dilihat dari peta lokasi menunjukkan di daerah dataran tinggi atau pegunungan
penggunaan awalan Ci relative tinggi, sedangkan di daerah dataran rendah, atau
pantai utara dan selatan penggunaan awalan Ci relative kecil. Awalan Pa, yang
berarti fungsinya untuk, menunjukkan budaya masyarakat di wilayah-wilayah
provinsi Jawa Barat mengutamakan bekerja keras dalam menjalankan
kehidupannya. Hampir 8% penamaan desa di Jawa Barat dimulai dengan awalan Pa,
wilayah terbanyak penggunaan awalan Pa adalah wilayah-5, dan wilayah-4, masing-
masing di atas 8%, sedangkan di wilayah-2, wilayah-3 dan wilayah-1, penggunaan
awalan Pa relatif kecil yaitu di bawah 15%. Dilihat dari peta lokasi menunjukan
bahwa di daerah dataran tinggi atau pegunungan penggunaan awalan Pa relative
tinggi, sedangkan di daerah dataran rendah, atau pantai utara dan selatan penggunaan
awalan Pa relative kecil. Awalan Su, yang berarti baik, menunjukan budaya
masyarakat di wilayah-wilayah provinsi Jawa Barat mengutamakan kebaikan dalam
menjalankan kehidupannya. Hampir 10% penamaan desa di Jawa Barat dimulai
dengan awalan Su, wilayah terbanyak penggunaan awalan Su adalah wilayah-1, dan
wilayah-4, masing-masing di atas 11,5%, sedangkan di wilayah-2, wilayah-3 dan
wilayah-5, penggunaan awalan Su relatif kecil yaitu di bawah 9%. Dilihat dari peta
lokasi menunjukan bahwa di daerah dataran tinggi atau pegunungan penggunaan
awalan Su relative tinggi, sedangkan di daerah dataran rendah, atau pantai utara dan
selatan, serta di daerah perkotaan penggunaan awalan Su relative kecil.
4.2 Clustering Makna Penamaan Desa berdasarkan Suku Kata Terkandung
Tabel 3. Persentase Kemiripan Terbanyak Suku Kata yang Terkandung
Dalam Penamaan Desa Di 5 Wilayah Jabar Terhadap Jabar
No Wilayah 5 Suku Kata Terbanyak Prosen
1 WIL-1 SUKA, BOJONG, MEKAR, PASIR, GUNUNG 60%
2 WIL-2 SUKA, JATI, KARANG, TANJUNG, KUTA 40%
3 WIL-3 SUKA, KARANG, KALI, SINDANG, JATI 40%
4 WIL-4 SUKA, MEKAR, KARANG, SINDANG, TANJUNG 80%
5 WIL-5 SUKA, MEKAR, BOJONG, MARGA, PASIR 60%
JABAR SUKA, KARANG, MEKAR, SINDANG, BOJONG
Tabel 3 menunjukkan persentase kemiripan terbanyak suku kata yang terkandung
dalam penamaan desa di setiap wilayah terhadap suku kata terkandung terbanyak di
provinsi Jawa Barat. Kemiripan tertinggi ada di wilayah-4 (80%), dikikuti wilayah-
1 dan wilayah-5 (60%), sedangkan kemiripan terkecil ada di wilayah-2 dan wilayah-
3 (40%). Hal ini menunjukkan penamaan desa di wilayah priangan yang memiliki
kontur pegunungan memiliki kemiripan tinggi, sedangkan di wilayah pantura yang
memiliki kontur pantai memiliki kemiripan yang rendah dibandingkan desa-desa di
wilayah Jawa Barat secara keseluruhan.

714
Tabel 4. Persentase Makna Penamaan Desa Terbanyak Di 5 Wilayah Provinsi Jabar
No Wilayah
Wil-1
(Bogor)
Wil-2
(Purwakarta)
Wil-3
(Cirebon)
Wil-4
(Tasikmalaya)
Wil-5
(Bandung)
1 ALAM 24.92 37.09 38.12 25.39 20.96
2 PERASAAN 25.74 15.73 9.20 26.79 14.09
3 KONDISI 14.03 9.71 16.28 15.99 21.99
4 TUMBUHAN 3.96 8.74 10.34 2.24 4.81
5 TEMPAT 11.39 4.85 10.15 4.77 13.40
6 USAHA 15.18 16.70 11.88 17.25 19.24
7 PENGHORMATAN 0.83 4.85 3.07 4.77 1.37
Dari Tabel 4 dapat disimpulkan: Masyarakat di wilayah-1, mencintai alam dan
lingkungannya, mempertimbangkan perasaan dalam menjalankan perilaku
kehidupan, giat berusaha, dan dapat menyesuaikan dengan keadaan. Masyarakat
yang ada di wilayah-2, mencintai alam dan lingkungannya, giat berusaha,
mempertimbangkan perasaan dalam menjalankan perilaku kehidupan dan dapat
menyesuaikan dengan keadaan. Masyarakat yang ada di wilayah-3, mencintai alam
dan lingkungannya, dapat menyesuaikan dengan keadaan, giat berusaha, dan
memanfaatkan tumbuhan dan tempat tinggalnya dalam kehidupan. Masyarakat yang
ada di wilayah-4, mencintai alam dan lingkungannya, mempertimbangkan perasaan
dalam menjalankan perilaku kehidupan, giat berusaha, dan dapat menyesuaikan
dengan keadaan. Masyarakat di wilayah-5, dapat menyesuaikan dengan keadaan,
mencintai alam dan lingkungannya, giat berusaha, dan mempertimbangkan perasaan
dalam menjalankan perilaku kehidupan.
4.3 Clustering Berdasarkan Kata Lengkap pada Penamaan Desa
Berdasarkan penamaan desa lengkap terbanyak di Jawa Barat, paling banyak
digunakan adalah Mekarsari, Mekarjaya, Sukamaju, Sukamulya dan Neglasari. Hal
ini menunjukkan masyarakat di Jawa Barat memiliki visi sejahtera, selalu bekerja
keras untuk kemajuan, mengerjakan pekerjaan dengan senang hati, dan menjalankan
kewajiban agamis masing-masing dalam kehidupannya.
Tabel 5. Kemiripan Berdasarkan Kata Lengkap Di 5 Wilayah Jabar
No Wilayah 5 Kata Lengkap Terbanyak Prosen
1 WIL-1 MEKARJAYA, SUKAMAJU, MEKARSARI, NEGLASARI, SUKAMULYA 100%
2 WIL-2 SINDANGSARI, SUKASARI, MEKARJAYA, MEKARSARI, SUKAMULYA 60%
3 WIL-3 KARANGANYAR, KERTAWINANGUN, MEKARJAYA, MEKARSARI, SUKAMULYA 60%
4 WIL-4 MEKARSARI, SUKAMULYA, NEGLASARI, MEKARJAYA, SUKAMAJU 100%
5 WIL-5 MEKARSARI, NEGLASARI, SUKAMULYA, SUKAMAJU, CIBODAS 80%

715
Tabel-5, menunjukkan persentase kemiripan terbanyak kata lengkap dalam
penamaan desa di setiap wilayah terhadap kata lengkap terbanyak di provinsi Jawa
Barat. Kemiripan tertinggi ada di wilayah-1 dan wilayah-4, dikikuti wilayah-5.
Kemiripan terkecil ada di wilayah-2 dan wilayah-3. Hal ini menunjukkan penamaan
desa di wilayah priangan yang memiliki kontur pegunungan memiliki kemiripan
tinggi, sedangkan di wilayah pantura yang memiliki kontur pantai memiliki
kemiripan yang rendah dibandingkan desa-desa di wilayah Jawa Barat secara
keseluruhan.
Tabel 6 menunjukkan makna penamaan desa berdasarkan kata lengkap yang
menunjukkan arti Keadaan, persentase terbanyak ada di wilayah-3 (22.90%),
persentase terkecil di wilayah-2 (12%). Makna penamaan desa berdasarkan kata
lengkap yang menunjukkan arti Alam, persentase terbanyak ada di wilayah-
2(24.36%), persentase terkecil di wilayah-4 (14.72%). Makna penamaan desa
berdasarkan kata lengkap yang menunjukkan arti Usaha, persentase terbanyak ada
di wilayah-5(24.33%), persentase terkecil di wilayah-2 (13.92%).
Makna penamaan desa berdasarkan kata lengkap yang menunjukkan arti Tempat,
persentase terbanyak ada di wilayah-5(23.67%), persentase terkecil di wilayah-
3(10.00%). Makna penamaan desa berdasarkan kata lengkap yang menunjukan arti
Penghormatan, persentase terbanyak ada di wilayah-3 (13.37%), sedangkan
persentase terkecil di wilayah-1(6.46%). Makna penamaan desa berdasarkan kata
lengkap yang menunjukkan arti Tumbuhan, persentase terbanyak ada di wilayah-
2(9.71%), persentase terkecil di wilayah-5(5.33%).
Makna penamaan desa berdasarkan kata lengkap yang menunjukan arti Perasaan,
persentase terbanyak ada di wilayah-4 (8.35%), persentase terkecil di wilayah-5
(5,00%). Makna penamaan desa berdasarkan kata lengkap yang menunjukkan arti
Binatang, persentase terbanyak ada di wilayah-1 (3.48%), persentase terkecil di
wilayah-5 (1.00%). Makna penamaan desa berdasarkan kata lengkap yang
menunjukkan arti Buah, persentase terbanyak ada di wilayah-1 (3,31%), persentase
terkecil ada di wilayah-5, yaitu sebesar 0,67%.
Tabel 6 Rekapitulasi Makna Penamaan Desa di Lima Wilayah Jawa Barat
NO KATEGORI WIL-
1 PERSEN
WIL-
2 PERSEN
WIL-
3 PERSEN
WIL-
4 PERSEN
WIL-
5 PERSEN JABAR
%
1 KEADAAN 125 20.70 65 11.90 226 22.90 130 19.73 44 14.67 590 19.06
2 ALAM 134 22.19 133 24.36 170 17.22 97 14.72 50 16.67 584 18.86
3 USAHA 95 15.73 76 13.92 179 18.14 139 21.09 73 24.33 562 18.15
4 TEMPAT 88 14.57 84 15.38 90 9.12 81 12.29 71 23.67 414 13.37
5
PENGHORMATA
N 39 6.46 71 13.00 132 13.37 88 13.35 26 8.67 356 11.50
6 TUMBUHAN 44 7.28 53 9.71 93 9.42 41 6.22 16 5.33 247 7.98
7 PERASAAN 38 6.29 35 6.41 50 5.07 55 8.35 15 5.00 193 6.23
8 BINATANG 21 3.48 14 2.56 23 2.33 14 2.12 3 1.00 75 2.42
9 BUAH 20 3.31 15 2.75 24 2.43 14 2.12 2 0.67 75 2.42
TOTAL 604 100.00 546 100.00 987 100.00 659 100.00 300 100.00 3096 100.00

716
4.4 Visualisasi peta lokasi wilayah-wilayah Jawa Barat
4.4.1 Visualisasi berdasarkan kata lengkap Karanganyar dan Kertawinangun
Gambar 3. Visualisasi Penamaaan Desa, Karanganyar dan Kertawinangun
Gambar 3, menunjukkan penamaan desa berdasarkan kata lengkap, Karanganyar dan
Kertawinangun, terbanyak berada di wilayah-3.
4.4.2 Visualisasi penamaan desa berdasarkan kata lengkap, Mekarsari dan
Neglasari
Gambar 4. Visualisasi Penamaaan Desa, Mekarsari dan Neglasari
Gambar 4, menunjukkan penamaan desa berdasarkan kata lengkap, Mekarsari
merupakan kata lengkap terbanyak berada di wilayah-4 dan wilayah-5. Sedangkan
Neglasari merupakan kata lengkap terbanyak di wilayah-1, wilayah-5, dan wilayah-
4.

717
4.4.3 Visualisasi berdasarkan kata lengkap Mekarjaya dan Sukamaju
Gambar 5. Visualisasi Penamaaan Desa Berdasarkan Kata Mekarjaya dan
Sukamaju
Gambar 5, menunjukan penamaan desa berdasarkan kata lengkap, penamaan desa
Mekarjaya terbanyak berada di wilayah-1, wilayah-2, dan wilayah-3. Sedangkan
penamaan desa Sukamaju terbanyak di wilayah-1.
4.4.4 Visualisasi berdasarkan kata lengkap Mekarsari dan Sukamulya
Gambar 6. Visualisasi Penamaaan Desa Berdasarkan Kata Lengkap, Mekarsari
dan Sukamulya
Gambar 6, menunjukkan penamaan desa berdasarkan kata lengkap, penamaan desa
Sukamulya, terbanyak berada di wilayah-5. Sedangkan Mekarsari terbanyak berada
di wilayah-4 dan wilayah-5.

718
4.4.5 Visualisasi berdasarkan kata lengkap Sindangsari dan Sukasari
Gambar 7. Visualisasi Penamaaan Desa, Sindangsari dan Sukasari
Gambar 7, menunjukkan penamaan desa berdasarkan kata lengkap, penamaan desa
Sindangsari terbanyak berada di wilayah-4, wilayah-1, dan wilayah-2. Sedangkan
penamaan desa Sukasari terbanyak berada di wilayah-2.
4.4 Teorema Jumlah Lokasi Kajian dan Komposisi Irisan Himpunan
4.4.1 Teorema Jumlah Lokasi Kajian
Jika banyak himpunan adalah 1 maka jumlah daerah hasil irisannya ada 1 daerah,
jika banyak himpunan 2 maka jumlah daerah hasil irisannya ada 3 daerah, jika
banyak himpunan 3 maka jumlah daerah hasil irisannya ada 7 daerah, …, jika banyak
himpunan 6 maka daerah hasil irisannya ada 31. Banyaknya daerah kajian hasil irisan
himpunan tersebut dapat dituliskan dengan rumus deret berikut ini: 1, 3, 7, 13, 21,
31, … , secara umum jika banyaknya himpunan sama dengan n maka jumlah daerah
kajiannya ada n(n-1)+1, formula tersebut dapat dibuktikan dengan menggunakan
induksi matematika.
Teorema-1. Jika n adalah banyaknya himpunan dan n>= 1, dengan n bilangan
bulat, maka jumlah daerah yang dibentuk oleh hasil irisan himpunan tersebut
adalah (n(n-1)+1) [2].
4.4.2 Teorema Komposisi Irisan Himpunan
Jika jumlah himpunan 1, maka jumlah komposisi irisan himpunan ada 1 = 1.1, Jika
jumlah himpunan 2, maka jumlah komposisi irisan himpunan ada 2 = 2.1, Jika
jumlah himpunan 3, maka jumlah komposisi irisan himpunan ada 6 = 3.2.1, Jika
jumlah himpunan 4, maka jumlah komposisi irisan himpunan ada 24 = 4.3.2.1, Jika
jumlah himpunan 5, maka jumlah komposisi irisan himpunan ada 120 = 5.4.3.2.1,
Jika jumlah himpunan n, maka jumlah komposisi irisan himpunan ada n! = n(n-1)(n-
2)…2.1. Secara umum dapat ditulis jika banyaknya himpunan n maka jumlah daerah
kajiannya ada n! , formula tersebut dapat dibuktikan dengan menggunakan induksi
matematika.

719
Teorema-2. Jika n adalah banyaknya himpunan dengan n bilangan asli, dan n
saling beririsan, maka jumlah dari komposisi atau susunan urutan (Variasi)
irisan himpunan adalah ada sama dengan n! , setiap susunan urutan (komposisi)
irisan himpunan yang berbeda memiliki jumlah anggota himpunan yang berbeda
[2].
4.5 Implementasi Teorema berdasarkan suku kata Terkandung
Teorema-1 digunakan untuk mencari jumlah lokasi yang dikaji pada saat penelitian,
sedangkan teorema-2 digunakan untuk mencari komposisi himpunan yang mana
yang diteliti. Pada kasus yang diteliti himpunan wilayah-wilayah di provinsi Jawa
Barat, karena terdapat 5 wilayah, maka jumlah lokasi yang harus dikaji menerapkan
teorema-1 yaitu daerah kajian= 5(5-1)+1= 21 lokasi. Sedangkan jumlah komposisi
irisan wilayah yang dipilih dapat menerapkan teorema-2, karena ada 5 wilayah maka
banyaknya komposisi yang diteliti = 5! = 5.4.3.2.1 =120 komposisi. Dalam
menentukan komposisi himpunan yang diteliti biasanya disesuaikan dengan kondisi
nyata lokasi yang ada. Dalam hal ini wilayah-wilayah yang berdekatan, sesuai
dengan prinsip Tobler, bahwa lokasi yang berdekatan memiliki kemiripan yang
tinggi. Contoh implementasi dapat dilihat pada Diagram berikut.
Gambar 8. Jumlah Nama Desa Komposisi Irisan Himpunan (wil-1, wil-2, wil-3,
wil-4, wil-5)
4.5.1 Ciri Khas 5 Wilayah
n(5 wilayah) = Wil-1 ⋂ wil-2 ⋂ wil-3 ⋂ wil-4 ⋂ wil-5 = 10 ={suka, karang, mekar,
sindang, bojong, kerta, pasir, tanjung, marga, gunung}.
Jumlah nama desa yang mengandung suku kata yang sama yang digunakan di 5
wilayah di provinsi Jawa Barat ada 10, Hal ini menunjukkan bahwa ke sepuluh suku
kata tersebut merupakan suku kata yang paling disukai oleh para leluhur untuk
digunakan dalam penamaan desa di ke 5 wilayah di Jawa Barat. Selain itu kesepuluh
suku kata tersebut menjadi ciri khas di 5 wilayah-wilayah Jawa Barat, yang memiliki
arti bahwa masyarakat di ke lima wilayah di Jawa Barat memiliki karakter-karakter
berikut: Memiliki motivasi untuk maju dan sejahtera, pekerja keras, teguh dan tegar,
bermasyarakat, serta mencintai tempat kelahirannya dan mencintai lingkungan alam
sekitarnya.

720
4.5.2 Ciri Khas 4 Wilayah
n(tanpa wilayah-5) = wil-1 ⋂ wil-2 ⋂ wil-3 ⋂ wil-4 = 3={kali, jati, kuta}, n(tanpa
wilayah-4) = wil-1 ⋂ wil-2 ⋂ wil-3 ⋂ wil-5 = 0={ }, n(tanpa wilayah-3) = wil-1
⋂ wil-2 ⋂ wil-4 ⋂ wil-5 = 3={batu, karya, sirna}, n(tanpa wilayah-2) = wil-1 ⋂
wil-3 ⋂ wil-4 ⋂ wil-5 = 3={banjar, giri, pada}, n(tanpa wilayah-1) = wil-2 ⋂ wil-
3 ⋂ wil-4 ⋂ wil-5 = 1={ranca},
Ciri khas 4 wilayah tanpa wil-5(Bandung) adalah penamaan desa yang mengandung
suku kata; kali, jati, dan kuta. Tidak ada penamaan desa yang menjadi ciri khas 4
wilayah tanpa wil-4 (Tasik). Ciri khas 4 wilayah tanpa wil-3(Cirebon) adalah
penamaan desa yang mengandung suku kata; batu, karya, dan sirna. Ciri khas 4
wilayah tanpa wil-2(Purwakarta) adalah penamaan desa yang mengandung suku
kata; banjar, giri, dan pada. Ciri khas 4 wilayah tanpa wil-1(Bogor) adalah penamaan
desa yang mengandung suku kata; ranca.
4.5.3 Ciri Khas 3 Wilayah
n(tanpa wil-1 dan wil-2) = wil-3 ⋂ wil-4 ⋂ wil-5 = 0 = { }, n(tanpa wil-2 dan wil-
3) = wil-1 ⋂ wil-4 ⋂ wil-5 = 1 = {beureum}, n(tanpa wil-3 dan wil-4) = wil-1 ⋂
wil-2 ⋂ wil-5 = 0 = { }, n(tanpa wil-4 dan wil-5) = wil-1 ⋂ wil-2 ⋂ wil-3 = 3 =
{curug, kedung, tegal}, n(tanpa wil-5 dan wil-1) = wil-2 ⋂ wil-3 ⋂ wil-4 = 2 =
{bantar, lingga}. Tidak ada ciri khas 3 wilayah tanpa wil-1(Bogor) dan wil-
2(Purwakarta). Ciri khas 3 wilayah tanpa wil-2(Purwakarta) dan wil-3(Cirebon)
adalah nama desa yang mengandung suku kata; beureum.Tidak ada ciri khas 3
wilayah tanpa wil-3(Cirebon) dan wil-4(Tasikmalaya).Ciri khas 3 wilayah tanpa wil-
4(Tasikmalaya) dan wil-5 (Bandung) adalah nama desa yang mengandung suku kata;
curug, kedung, dan tegal. Ciri khas 4 wilayah tanpa wil-5(Bandung) dan wil-
1(Bogor) adalah penamaan desa yang mengandung suku kata; bantar, dan lingga.
4.5.4 Ciri Khas 2 Wilayah
n(wil-1 dan wil-2) = wil-1 ⋂ wil-2 = 1 = {parakan}. n(wil-2 dan wil-3) = wil-2 ⋂
wil-3 =2 = {lemah, sumber}. n(wil-3 dan wil-4) = wil-3 ⋂ wil-4 = 2 = {kadu,
sida}. n(wil-4 dan wil-5) = wil-4 ⋂ wil-5 = 1 = {mandala}. n(wil-5 dan wil-1) =
wil-5 ⋂ wil-1 = 4 = {bodas, kebon, negla, wangun}. Ciri khas wil-1(Bogor) dan
wil-2(Purwakarta) adalah penamaan desa yang mengandung suku kata parakan. Ciri
khas wil-2(Purwakarta) dan wil-3(Cirebon) adalah penamaan desa yang
mengandung suku kata; lemah, sumber. Ciri khas wil-3(Cirebon) dan wil-
4(Tasikmalaya) adalah penamaan desa yang mengandung suku kata; kadu dan sida.
Ciri khas wil-4(Tasikmalaya) dan wil-5 (Bandung) adalah penamaan desa yang
mengandung suku kata; mandala. Ciri wil-5(Bandung) dan wil-1(Bogor) adalah
penamaan desa yang mengandung suku kata; bodas, kebon, negla, wangun.

721
4.5.5 Ciri Khas 1 Wilayah
n(wil-1) = 12. n(wil-2) =18. n(wil-3) = 18. n(wil-4) = 12 . n(wil-5) = 22
Ciri khas wil-1(Bogor) adalah penamaan desa yang mengandung suku kata; badak,
pondok, caringin, nagrak, sarua, pabuaran, bitung, manggu, tugu, warga, herang dan
hurip. Ciri khas wil-2 (Purwakarta) adalah nama desa yang mengandung suku kata;
rawa, sumur, pantai, kampek, pusaka, sri, tambak, teluk, dawuan, ganda, gempol,
asem, bogo, Kiara, muara, naga, parung, dan pulo. Ciri khas wil-3(Cirebon) adalah
penamaan desa yang mengandung suku kata; dukuh, wana, raja, jaga, windu, gara,
sura, ujung, awi, gebang, haur, arga, astana, gegesik, gintung, junti, sugeng, dan
ledug. Ciri khas wil-4(Tasikmalaya) adalah penamaan desa yang mengandung suku
kata; negla, naga, kersa, puspa, darma, kota, singa, bangun, bunar, lengkong, pager,
dan pamalayan. Ciri wil-5(Bandung) adalah nama desa yang mengandung suku kata;
padung, cangkuang, gondewah, saranten, tenjo, leunyi, antapani, baduyut, calengka,
pangauban, ancol, baros, cadas, campaka, hanjuang, hapit, jagra, jaura, kalong,
kawao, koneng, dan lame.
4.6 Implementasi Teorema berdasarkan Suku Kata Lengkap
4.6.1 Komposisi (WIL-1, WIL-5, WIL-3, WIL-4 DAN WIL-2)
a. Kemiripan jumlah penamaan desa di 5 wilayah pada komposisi 1-5-3-4-2 ada
28 penamaan Desa, dengan jumlah desa 457 desa.
b. Kemiripan 4 wilayah tanpa wil-1 ada 11 nama desa, dengan jumlah desa 74,
kemiripan tanpa wil-2 ada 12 nama desa dengan jumlah desa 75, kemiripan
tanpa wil-3 ada 24 nama desa dengan jumlah desa 227, kemiripan tanpa wil-
4 ada 7 nama desa dengan jumlah desa 40, dan kemiripan tanpa wil-5 ada
23 nama desa dengan jumlah desa 169.
c. Kemiripan 3 wilayah tanpa wil-1 dan wil-2 ada 8 nama desa, dengan jumlah
desa 8, kemiripan tanpa wil-1 dan wil-5 ada 17 nama desa dengan jumlah
desa 74, kemiripan tanpa wil-5 dan wil-3 ada 34 nama desa, desa 172,
kemiripan tanpa wil-3 dan wil-4 ada 4 nama desa dengan jumlah desa 14,
dan kemiripan tanpa wil-4 dan wil-2 ada 3 nama desa dengan jumlah desa
10.
d. Kemiripan 2 wilayah wil-1 dan wil-5 ada 21 nama desa, dengan jumlah desa
44, kemiripan wil-5 dan wil-3 ada 8 nama desa dengan jumlah desa 19,
kemiripan wil-3 dan wil-4 ada 53 nama desa dengan jumlah desa 128,
kemiripan wil-4 dan wil-2 ada 43 nama desa dengan jumlah desa 116, dan
kemiripan wil-2 dan wil-1 ada 37 nama desa dengan jumlah desa 97.
e. Kekhasan 1 wilayah adalah sebagai berikut, wil-1 ada 604 nama desa dan 656
jumlah desa, kekhasan wil-2 ada 546 nama desa dan 575 jumlah desa,
kekhasan wil-3 ada 987 nama desa dengan 1082 jumlah desa, kekhasan wil-
4 ada 659 nama desa dengan 719 jumlah desa, dan kekhasan wilayah-5 ada
300 nama desa dengan jumlah desa 314.

722
Komposisi wilayah 1-5-3-4-2, secara lebih lengkap dapat dilihat pada Gambar 9.
Gambar 9. Jumlah penamaan desa untuk Komposisi (WIL-1,WIL-5,WIL-3,WIL-4
DAN WIL-2)
Gambar-9, menunjukan komposisi irisan penamaan desa di 5 wilayah Jawa Barat,
dapat disimpulkan beberapa hal berikut;
a. Banyaknya penamaan desa lengkap yang menunjukan kekhasan di lima
wilayah dengan komposisi tersebut sebanyak 28 nama desa, sedangkan
jumlah desanya ada 457 desa.
b. Makna dari 28 desa tersebut terbanyak 42,45% menunjukkan arti Perasaan,
25,60% menunjukkan arti Usaha, 11,82% menunjukkan arti Alam.
Sedangkan makna lainnya di bawah 10%. Hal ini menunjukkan bahwa
masyarakat di 5 wilayah Jawa Barat selalu menggunakan perasaan dalam
menjalani kehidupan, pekerja keras untuk mencapai sejahtera, dan mencintai
dan memelihara lingkungannya.
c. Kekhasan di masing-wilayah adalah; WIL-1 (604 Nama Desa, 656 Dessa),
WIL-2 (546 Nama Desa, 575 Desa ), WIL-3 (987 Nama Desa, 1082 Desa),
WIL-4 (659 Nama Desa, 719 Desa), Wil-5 (300 Nama Desa, 314 Desa).
Dengan desa terbanyak adalah di Wil-3, Wil-4, Wil-1, Wil-2, dan Wil-5.
d. Jumlah penamaan desa dengan komposisi (WIL-1, WIL-5, WIL-3, WIL-4
DAN WIL-5) adalah 3420 dengan jumlah desa 5024. Sedangkan perbedaan
jumlah terjadi pada 4 wilayah, 3 wilayah, dan 2 wilayah.
4.6.2 Komposisi (WIL-1, WIL-2, WIL-3, WIL-4 DAN WIL-5)
a. Kemiripan jumlah penamaan desa di 5 wilayah pada komposisi 1-2-3-4-5 ada
28 nama Desa, dengan jumlah desa 457 desa.
b. Kemiripan 4 wilayah tanpa wil-1 ada 11 nama desa, dengan jumlah desa 74,
kemiripan tanpa wil-2 ada 12 nama desa dengan jumlah desa 75, kemiripan
tanpa wil-3 ada 24 nama desa dengan jumlah desa 227, kemiripan tanpa wil-
4 ada 7 nama desa dengan jumlah desa 40, dan kemiripan tanpa wil-5 ada
23 nama desa dengan jumlah desa 169.
c. Kemiripan 3 wilayah tanpa wil-1 dan wil-2 ada 8 nama desa, dengan jumlah
desa 8, kemiripan tanpa wil-2 dan wil-3 ada 23 nama desa dengan jumlah
desa 128, kemiripan tanpa wil-3 dan wil-4 ada 4 nama desa dengan jumlah

723
desa 14, kemiripan tanpa wil-4 dan wil-5 ada 5 nama desa dengan jumlah
desa 24, dan kemiripan tanpa wil-5 dan wil-1 ada 17 nama desa dengan
jumlah desa 17.
d. Kemiripan 2 wilayah wil-1 dan wil-2 ada 37 nama desa, dengan jumlah desa
97, kemiripan wil-2 dan wil-3 ada 37 nama desa dengan jumlah desa 89,
kemiripan wil-3 dan wil-4 ada 53 nama desa dengan jumlah desa 128,
kemiripan wil-4 dan wil-5 ada 38 nama desa dengan jumlah desa 87, dan
kemiripan wil-5 dan wil-1 ada 21 nama desa dengan jumlah desa 44.
e. Kekhasan 1 wilayah adalah sebagai berikut, wil-1 ada 604 nama desa dan 656
jumlah desa, kekhasan wil-2 ada 546 nama desa dan 575 jumlah desa,
kekhasan wil-3 ada 987 nama desa dengan 1082 jumlah desa, kekhasan wil-
4 ada 659 nama desa dengan 719 jumlah desa, dan kekhasan wilayah-5 ada
300 nama desa dengan jumlah desa 314.
Komposisi wilayah 1-2-3-4-5, secara lebih jelas dapat dilihat pada Gambar 10.
Gambar 10. Jumlah Penamaan Desa Komposisi (WIL-1,WIL-2,WIL-3,WIL-4
DAN WIL-5)
Gambar-10, menunjukkan komposisi irisan penamaan desa di 5 wilayah Jawa Barat,
dapat disimpulkan beberapa hal berikut;
a. Banyaknya penamaan desa lengkap yang menunjukkan kekhasan di lima
wilayah dengan komposisi tersebut sebanyak 28 nama desa, sedangkan
jumlah desanya ada 457 desa.
b. Dari Tabel 6 maka, Makna dari 28 desa tersebut terbanyak 42,45%
menunjukkan arti Perasaan, 25,60% menunjukkan arti Usaha, 11,82%
menunjukkan arti Alam. Sedangkan makna lainnya di bawah 10%. Hal ini
menunjukkan bahwa masyarakat di 5 wilayah Jawa Barat, menggunakan
perasaan dalam menjalani kehidupan, pekerja keras untuk mencapai
sejahtera, dan mencintai dan memelihara lingkungannya.
c. Kekhasan di masing-wilayah adalah; WIL-1 (604 Nama Desa, 656 DESA),
WIL-2 (546 Nama Desa, 575 Desa), WIL-3 (987 Nama Desa, 1082 Desa),
WIL-4 (659 Nama Desa, 719 Desa), Wil-5 (300 NAMA DESA, 314 DESA).
Dengan desa terbanyak adalah di Wil-3, Wil-4, Wil-1, Wil-2, dan Wil-5.

724
d. Jumlah penamaan desa dengan komposisi (WIL-1, WIL-2, WIL-3, WIL-4
DAN WIL-5) adalah 3524 dengan jumlah desa 5070. Sedangkan perbedaan
jumlah terjadi pada 4 wilayah, 3 wilayah, dan 2 wilayah.
5. Kesimpulan
1. Berdasarkan pengelompokan menggunakan struktur kata, awalan Ci
merupakan awalan yang yang paling banyak di gunakan, suku kata Suka
merupakan suku kata paling banyak terkandung dalam penamaan desa,
sedangkan kata lengkap yang paling banyak digunakan adalah Mekarsari.
Hal ini menunjukkan bahwa masyarakat di wilayah-wilayah Jawa Barat
mengutamakan kebaikan dalam menjalankan hidupnya, selalu bekerja keras
untuk mencapai kehidupan lebih sejahtera, mencintai serta memelihara
kelestarian air dan lingkungannya, dan memiliki visi sejahtera, mengerjakan
pekerjaan dengan senang hati, dan religious.
2. Persentase kemiripan terbanyak suku kata yang terkandung dalam penamaan
desa di setiap wilayah terhadap terbanyak di Jawa Barat, kemiripan tertinggi
ada di wilayah-4 (80%), dikikuti wilayah-1 dan wilayah-5 (60%), sedangkan
kemiripan terkecil ada di wilayah-2 dan wilayah-3 (40%). Prosentase
kemiripan terbanyak kata lengkap, kemiripan tertinggi ada di wilayah-1 dan
wilayah-4 (100%), dikikuti wilayah-5 (80%), dan kemiripan terkecil ada di
wilayah-2 dan wilayah-3 (60%). Hal ini menunjukkan penamaan desa di
wilayah priangan yang memiliki kontur pegunungan memiliki kemiripan
tinggi, sedangkan di wilayah pantura yang memiliki kontur pantai memiliki
kemiripan rendah.
3. Wilayah-wilayah di provinsi Jawa Barat yang memiliki tingkat kemiripan
tinggi, adalah Wilayah-1, wilayah-4, dan wilayah-5, umumnya nama-nama
desa pada wilayah tersebut berkaitan dengan lingkungan pegunungan dan
alam sekitarnya, hal ini sesuai dengan kontur ketiga wilayah tersebut yang
umumnya merupakan pegunungan dan dataran tinggi. Sesuai dengan prinsip
Tobler, bahwa lokasi yang berdekatan memiliki tingkat kemiripan tinggi.
4. Wilayah-wilayah lain yang memiliki tingkat kemiripan relative tinggi adalah
wilayah-2 dan wilayah-3, umumnya nama-nama desa pada wilayah tersebut
berkaitan dengan lingkungan pantai, hal ini sesuai dengan kontur kedua
wilayah tersebut yang umumnya merupakan dataran rendah dan pesisir
pantai. Hal ini sesuai dengan prinsip Tobler, bahwa lokasi yang berdekatan
memiliki tingkat kemiripan yang tinggi.
5. Secara umum masyarakat yang ada di lima wilayah provinsi Jawa Barat
memiliki karakter yang sama yaitu, mencintai alam dan lingkungannya,
mempertimbangkan perasaan dalam menjalankan perilaku kehidupan, giat
berusaha, dan dapat menyesuaikan dengan keadaan, sedangkan
perbedaannya adalah dalam komposisi dan jumlah desa di masing-masing
wilayah.
6. Pada penelitian ini dikembangkan dan diimplementasikan teorema jumlah
lokasi kajian, untuk memilih prioritas kajian penelitian, dan teorema
komposisi irisan himpunan, untuk menentukan kekhasan dan kemiripan di
masing-masing lokasi kajian. Kemudian diterapkan dalam penamaan desa
di wilayah-wilayah provinsi Jawa Barat. Hasil implementasi menunjukkan
bahwa teorema-teorema tersebut layak untuk digunakan.

725
Pernyataan Terima Kasih. Paper ini didanai oleh Hibah Internal Universitas
Padjadjaran Tahun 2017 dan Academic Leadership Grant Universitas Padjadjaran
Tahun 2017 dengan Nomor Kontrak: 872/UN6.3.1/LT/2017.
Referensi
[1] Abdullah, A.S. Ethnomathematics in Perspective Sundanese Culture, Journal of
Mathematics Education , Vol 8 (1), ISSN 2087-8885, (2017), 1-15.
[2] Abdullah, A.S., Ruchjana, B.N., Jaya, I.G.N.M, and Hermawan, E. Clustering Ethno-
informatics of Naming Village in Java Island using Data Mining, World Academy of
Science, Engineering, and Technology Conference Proceedings, International
Conference on Computer and Information Technologies, Innovationas and Applications
(18th ICCITIA), ISSN 2010-3778. Part II, p. 337-342, Amsterdam, (2016).
[3] Ayatrohaédi, Kata, Nama, Dan Makna. Pidato Pengukuhan Diucapkan pada Upacara
Penerimaan Jabatan Gurubesar Madya Tetap. Depok: Fakultas Sastra Universitas
Indonesia, (1993).
[4] D’Ambrosio, U., Ethnomathematics and its place in the history and pedagogy of
mathematics, For the Learning of Mathematics, (1985).
[5] D'Ambrosio, U., Literacy, Matheracy, and Technoracy: A Trivium for Today
Mathematical Thinking and Learning, (1999).
[6] Han, J, Kamber, M., and Jian, P., Data Mining Concepts and Techniques, Morgan
Kaufman Publishers, USA, (2012).
[7] Ingold, T., The Perception of The Environment: Essays on livelihood, dwelling and skill.
London, UK: Routledge, (2000).
[8] Rais, J., et al. Toponimi: Sejarah Budaya yang Panjang dari Pemukiman Manusia dan
Tertib Administrasi, Jakarta: Pradnya Paramita, (2008).
[9] Rosidi, A. dkk., Ensiklopedi Sunda, Pustaka Jaya, Jakarta, (2000).
[10] Teeuwen, D., Goverment of the Netherlands East-Indies, Political division of territories
in N.E.Indies, (2007).
[11] Tjiptadi, B., Tata Bahasa Indonesia. Cetakan II. Jakarta: Yudistira, (1984).
[12] Tobler W., A Computer Movie Simulating urban Growth in the Detroit Region,
Economyc Geography, 46(2), (1970), 234-240.

726
Prosiding SNM 2017 Komputasi , Hal 726-735
ALGEBRAIC ATTACK PADA SIMPLIFIED DATA
ENCRYPTION STANDARD (S-DES)
FADILA PARADISE1, SANTI INDARJANI2
Abstrak. Data Encryption Standard (DES) merupakan algoritma yang
ditetapkan sebagai standar dalam Federal Information Processing Standards
(FIPS) pada tahun 1999, yang digunakan untuk melindungi data rahasia hingga
tahun 2001. Beberapa serangan terhadap DES sudah dilakukan, seperti linear
attack, differential attack, dan algebraic attack. Dalam makalah ini, penulis
menerapkan algebraic attack pada Simplified DES (S-DES) yang merupakan
penyederhanaan dari DES untuk mengetahui apakah algoritma S-DES rentan
terhadap algebraic attack. Sesuai struktur S-DES, maka dalam penerapan
algebraic attack pada S-DES akan dicari delapan persamaan linier yang
merepresentasikan ciphertext. Dalam penelitian ini, penulis telah berhasil
menemukan lima persamaan dari delapan persamaan yang ditargetkan.
Penelitian akan dilanjutkan untuk menentukan ketiga persamaan lainnya.
Dengan diperolehnya bentuk persamaan aljabar linier tersebut, maka pada
tahap selanjutnya dapat dilakukan pencarian solusi persamaan linier yang
berpotensi ditemukannnya kunci input yang benar pada algoritma S-DES.
Kata kunci: algebraic attack, S-DES.
1. Pendahuluan
Data Encryption Standard (DES) merupakan algoritma yang ditetapkan
sebagai standar dalam Federal Information Processing Standards (FIPS) pada tahun
1999, yang digunakan untuk melindungi data rahasia hingga tahun 2001 [2].
Beberapa serangan terhadap DES sudah dilakukan, seperti linear attack, differential
attack, dan lainnya. Serangan-serangan tersebut merupakan serangan yang
menggunakan pendekatan statistik untuk mencari nilai kunci yang tepat. Namun
dalam praktiknya, ada beberapa faktor yang menyebabkan kunci yang didapat dari
pendekatan statistik tersebut tidak sesuai dengan kunci yang sesungguhnya. Seiring
berkembangnya ilmu dalam melakukan kriptanalisis, ditemukan metode untuk
menyerang suatu algoritma melalui pendekatan linier dengan mengubah algoritma
tersebut ke dalam bentuk persamaan linier, yaitu algebraic attack. Penelitian ini
membahas penerapan algebraic attack pada Simplified DES (S-DES) yang
merupakan penyederhanaan dari algoritma DES untuk mengetahui penerapan
algebraic attack pada algoritma S-DES dan ketahanan algoritma S-DES terhadap
serangan algebraic attack.

727
2. Hasil – Hasil Utama
2.1 Algebraic Attack
Dalam tesis yang ditulis oleh Martin Voros (2007) tertulis bahwa algebraic
attack pertama kali diperkenalkan oleh Kipnis dan Shamir dalam paper yang
berjudul ”Cryptanalysis of The HFE Public Key Cryptosystem by Relinearization”.
Prinsip utama dari algebraic attack yaitu mengubah permasalahan dalam menyerang
sistem kriptografi menjadi penyelesaian sistem persamaan polinomial. Secara
mendasar, terdapat dua tahapan dalam algebraic attack, yaitu mencari sebuah
persamaan dan mencari solusi dari persamaan [6].
2.2 S-DES
Algoritma enkripsi S-DES terdiri dari lima fungsi, yaitu Initial Permutation
(IP), fungsi permutasi dan substitusi yang berada dalam 𝑓𝐾, sebuah fungsi permutasi
sederhana yang menukar dua buah data yang telah dibagi menjadi dua bagian (SW),
dan fungsi permutasi yang merupakan invers dari Intial Permutation (IP-1) [4].
Fungsi-fungsi tersebut dapat dituliskan menjadi persamaan berikut:
𝑐𝑖𝑝ℎ𝑒𝑟𝑡𝑒𝑥𝑡 = 𝐼𝑃−1(𝑓𝐾2(𝑆𝑊(𝑓𝐾1(𝐼𝑃(𝑝𝑙𝑎𝑖𝑛𝑡𝑒𝑥𝑡)))))) (1)
𝑝𝑙𝑎𝑖𝑛𝑡𝑒𝑥𝑡 = 𝐼𝑃−1(𝑓𝐾1(𝑆𝑊(𝑓𝐾2(𝐼𝑃(𝑐𝑖𝑝ℎ𝑒𝑟𝑡𝑒𝑥𝑡))))) (2)
dengan kunci:
𝐾1 = 𝑃8(𝑆ℎ𝑖𝑓𝑡(𝑃10(𝑘𝑒𝑦))) (3)
𝐾2 = 𝑃8(𝑆ℎ𝑖𝑓𝑡(𝑆ℎ𝑖𝑓𝑡(𝑃10(𝑘𝑒𝑦))))). (4)
Skema S-DES dapat dilihat pada Gambar 1.
Gambar 1. Skema S-DES
Pada algoritma S-DES terdapat dua buah s-box berukuran 4x2. Input dari s-
box berupa plaintext yang telah di XOR dengan kunci. Berikut adalah s-box 0 dan s-
box 1 pada S-DES:
P10
Shift
10 bit kunci
P8
IP
𝑓𝐾
8 bit plaintext
SW
𝑓𝐾
IP-1
8 bit ciphertext
IP
𝑓𝐾
8 bit plaintext
SW
𝑓𝐾
IP-1
8 bit ciphertext
Shift
P8
𝐾1 𝐾1
𝐾2 𝐾2
ENKRIPSI DEKRIPSI

728
Tabel 1. S-Box 0 Tabel 2. S-Box 1
0 1 2 3
0 0 1 2 3
1 2 0 1 3
2 3 0 1 0
3 2 1 0 3
2.3 Algebraic Attack pada S-DES
Berikut adalah penerapan algebraic attack pada S-DES, dengan input
plaintext 01101101 dan output ciphertext 01000110. Nilai pasangan plaintext dan
ciphertext ini diambil dari simulasi yang dibuat oleh David Morgan dan di-publish
pada http://homepage.smc.edu/ [1].
2.3.1 Subkey Generation
Pertama-tama dilakukan proses key generation. Dalam proses key
generation, kunci diinisialisasi menjadi 𝑘1, 𝑘2, 𝑘3, 𝑘4, 𝑘5, 𝑘6, 𝑘7, 𝑘8, 𝑘9, 𝑘10. Berikut
perubahan posisi bit kunci dalam proses key generation.
Tabel 3. Permutation 10 (P10)
Sebelum 𝑘1 𝑘2 𝑘3 𝑘4 𝑘5 𝑘6 𝑘7 𝑘8 𝑘9 𝑘10
Sesudah 𝑘3 𝑘5 𝑘2 𝑘7 𝑘4 𝑘10 𝑘1 𝑘9 𝑘8 𝑘6
Tabel 4. Split
Sebelum 𝑘3 𝑘5 𝑘2 𝑘7 𝑘4 𝑘10 𝑘1 𝑘9 𝑘8 𝑘6
Sesudah 𝑘3 𝑘5 𝑘2 𝑘7 𝑘4 Split 𝑘10 𝑘1 𝑘9 𝑘8 𝑘6
Tabel 5. LS-1
Sebelum 𝑘5 𝑘2 𝑘7 𝑘4 𝑘10 split 𝑘1 𝑘9 𝑘8 𝑘6 𝑘3
Sesudah 𝑘2 𝑘7 𝑘4 𝑘10 𝑘5 split 𝑘9 𝑘8 𝑘6 𝑘3 𝑘1
Tabel 6. Permutation 8 (P8) Untuk 𝐾1
Sebelum 𝑘2 𝑘7 𝑘4 𝑘10 𝑘5 split 𝑘9 𝑘8 𝑘6 𝑘3 𝑘1
Sesudah 𝑘9 𝑘4 𝑘8 𝑘10 split 𝑘6 𝑘5 𝑘1 𝑘3
Tabel 7. LS-2
Sebelum 𝑘2 𝑘7 𝑘4 𝑘10 𝑘5 split 𝑘9 𝑘8 𝑘6 𝑘3 𝑘1
0 1 2 3
0 1 0 3 2
1 3 2 1 0
2 0 2 1 3
3 3 1 3 2

729
Sesudah 𝑘10 𝑘5 𝑘2 𝑘7 split 𝑘6 𝑘3 𝑘1 𝑘9 𝑘8
Tabel 8. Permutation 8 (P8) Untuk 𝐾2
Sebelum 𝑘4 𝑘10 𝑘5 𝑘2 𝑘7 split 𝑘6 𝑘3 𝑘1 𝑘9 𝑘8
Sesudah 𝑘6 𝑘5 𝑘3 𝑘2 split 𝑘1 𝑘7 𝑘8 𝑘9
Output dari P8 yang pertama diambil sebagai nilai 𝐾1. Output dari P8 yang kedua diambil sebagai nilai 𝐾2. Dengan demikian didapat kunci 𝐾1 ={𝑘9, 𝑘4, 𝑘8, 𝑘10, 𝑘6, 𝑘5, 𝑘1, 𝑘3} dan 𝐾2 = {𝑘6, 𝑘5, 𝑘3, 𝑘2, 𝑘1, 𝑘7, 𝑘8, 𝑘9}.
2.3.2 Proses Enkripsi Round 1
Sebelum memasuki proses enkripsi pada round ke-1, dicari persamaan dari
s-box S-DES. Untuk dapat menemukan persamaan dari keseluruhan algoritma S-
DES, s-box harus diubah terlebih dahulu menjadi persamaan linier dengan mencari
kombinasi dari tabel kebenaran yang dapat menghasilkan output sesuai dengan bit
output pada s-box 0 dan s-box 1. Didapat persamaan linier bit pertama pada s-box 0:
𝑆10 = 𝑥2 + 𝑥3 + 𝑥1𝑥3 + 𝑥1𝑥4 + 𝑥1𝑥2𝑥3𝑥4, (5)
persamaan linier bit kedua pada s-box 0:
𝑆20 = 𝑥1 + 𝑥4 + 𝑥1𝑥2 + 𝑥1𝑥3 + 𝑥1𝑥4 + 𝑥1𝑥2𝑥3 + 𝑥1𝑥2𝑥3𝑥4, (6)
persamaan linier bit pertama pada s-box 1:
𝑆11 = 𝑥1 + 𝑥2 + 𝑥3 + 𝑥1𝑥2 + 𝑥1𝑥4 + 𝑥2𝑥4 + 𝑥1𝑥2𝑥4 + 𝑥1𝑥3𝑥4
+𝑥1𝑥2𝑥3𝑥4, (7)
dan persamaan`linier bit kedua pada s-box 1:
𝑆21 = 𝑥1 + 𝑥4 + 𝑥1𝑥2 + 𝑥2𝑥3 + 𝑥2𝑥4 + 𝑥3𝑥4 + 𝑥1𝑥2𝑥3 + 𝑥1𝑥2𝑥4
+𝑥1𝑥3𝑥4 + 𝑥2𝑥3𝑥4 + 𝑥1𝑥2𝑥3𝑥4. (8)
Selanjutnya dilakukan proses enkripsi. Tahap pertama dalam algoritma S-
DES yaitu Initial Permutation (IP). Input pada IP berupa 8 bit plaintext. Pada
Gambar 2. Skema Enkripsi Round 1 Algoritma S-DES
8
4 4
4
4
2 2
IP
E/P
S0 S1
P4
𝐾1
𝐶1

730
percobaan ini digunakan plaintext 01101101.
0 1 1 0 1 1 0 1
1 1 1 0 0 1 1 0
Gambar 3. Initial Permutation (IP)
Setelah dipermutasi, plaintext dibagi menjadi dua bagian, yaitu 𝑃𝐻 dan 𝑃𝐿.
Didapatkan 𝑃𝐻 = 1110 dan 𝑃𝐿 = 0110. Selanjutnya masuk ke fungsi
Expansion/Permutation (E/P), key addition (𝑓𝐾1), dan s-box dengan input 𝑃𝐿.
0 1 1 0
0 0 1 1 1 1 0 0
Gambar 4. Expansion/Permutation (E/P) 1
Tabel 9. Key Addition Dengan 𝐾1
𝐾1 Plain Plain ⨁ 𝐾1
𝑘9 0 𝑘9
𝑘4 0 𝑘4
𝑘8 1 𝑘8⨁1
𝑘10 1 𝑘10⨁1
𝑘6 1 𝑘6⨁1
𝑘5 1 𝑘5⨁1
𝑘1 0 𝑘1
𝑘3 0 𝑘3
Pada bagian ini, persamaan linier dari s-box disubstitusi dengan
𝑃𝐿. Bit pertama dan bit kedua dari output s-box 0 dan 1 pada round 1 diberi simbol
𝑆10, 𝑆2
0, 𝑆11, 𝑆2
1. Didapat empat persamaan berikut.
Persamaan bit pertama dari output s-box 0 pada round 1:
𝑆10 = 𝑘4⨁𝑘8⨁𝑘4𝑘9⨁𝑘8𝑘9⨁𝑘9𝑘10⨁𝑘4𝑘8𝑘9𝑘10⨁𝑘4𝑘9𝑘10⨁𝑘4𝑘8𝑘9⨁1. (9)
Persamaan bit kedua dari output s-box 0 pada round 1:
𝑆20 = 𝑘9⨁𝑘10⨁𝑘4𝑘9⨁𝑘8𝑘9⨁𝑘9𝑘10⨁𝑘4𝑘9𝑘10 ⨁𝑘4𝑘8𝑘9𝑘10⨁1. (10)

731
Persamaan bit pertama dari output s-box 1 pada round 1:
𝑆11 = 𝑘3⨁𝑘5⨁𝑘1𝑘6⨁𝑘3𝑘5⨁𝑘1𝑘3𝑘5⨁𝑘1𝑘3𝑘6⨁𝑘3𝑘5𝑘6
⨁𝑘1𝑘3𝑘5𝑘6⨁1. (11)
Persamaan bit kedua dari output s-box 1 pada round 1:
𝑆21 = 𝑘3⨁𝑘5⨁𝑘1𝑘6⨁𝑘3𝑘6⨁𝑘5𝑘6⨁𝑘1𝑘5𝑘6⨁𝑘3𝑘5𝑘6⨁𝑘1𝑘3𝑘5𝑘6. (12)
Setelah masuk ke fungsi s-box, 𝑃𝐿 memasuki fungsi P4. Pada fungsi P4, 4
bit output s-box pada round 1 dipermutasi.
𝑆10 𝑆2
0 𝑆11 𝑆2
1
𝑆20 𝑆2
1 𝑆11 𝑆1
0
Gambar 5. Permutation 4 (P4) - 1
Berdasarkan gambar di atas, didapat 𝐶1 = 𝑆20 𝑆2
1 𝑆11 𝑆1
0, dengan 𝐶1 merupakan output
dari algoritma S-DES pada round 1.
Selanjutnya dihitung 𝑃𝐻 = 𝐶1⨁𝑃𝐻 . Setelah itu, 𝐶1 dan 𝑃𝐻 di-swap,
kemudian 𝑃𝐻 memasuki fungsi E/P, key addition (𝑓𝐾2), dan s-box dengan input 𝑃𝐻.
𝐶1 : 𝑆20 𝑆2
1 𝑆11 𝑆1
0
𝑃𝐻 : 1 1 1 0 ⨁
𝑃𝐻 : 𝑆20⨁1 𝑆2
1⨁1 𝑆11⨁1 𝑆1
0
Gambar 6. 𝐶1⨁𝑃𝐻 2.3.3 Proses Enkripsi Round 2
Gambar 7. Skema Enkripsi Round 2 Algoritma S-DES
Pada round 2, pertama-tama 𝑃𝐻 memasuki fungsi Expansion Permutation
(E/P).
𝑆20⨁1 𝑆2
1⨁1 𝑆11⨁1 𝑆1
0
𝑆10 𝑆2
0⨁1 𝑆21⨁1 𝑆1
1⨁1 𝑆21⨁1 𝑆1
1⨁1 𝑆10 𝑆2
0⨁1
Gambar 8. Expansion Permutation (E/P) 2
𝑃𝐿 𝑃𝐻
𝑃𝐻 𝐶2 F

732
Setelah memasuki fungsi E/P, 𝑃𝐻 di-XOR dengan 𝐾2.
Tabel 10. Key Addition Dengan 𝐾2
𝐾2 Plain Plain ⨁ 𝐾2
𝑘6 𝑆10 𝑆1
0. 𝑘6
𝑘5 𝑆20⨁1 𝑆2
0. 𝑘5⨁𝑘5
𝑘3 𝑆21⨁1 𝑆2
1. 𝑘3⨁𝑘3
𝑘2 𝑆11⨁1 𝑆1
1. 𝑘2⨁𝑘2
𝑘1 𝑆21⨁1 𝑆2
1. 𝑘1⨁𝑘1
𝑘7 𝑆11⨁1 𝑆1
1. 𝑘7⨁𝑘7
𝑘8 𝑆10 𝑆1
0.𝑘8
𝑘9 𝑆20⨁1 𝑆2
0. 𝑘9⨁𝑘9
Selanjutnya persamaan linier dari s-box disubstitusi dengan 𝑃𝐻. Bit
pertama output s-box 0, bit kedua output s-box 0, bit pertama output s-box 1, dan bit
kedua output s-box 1 pada round 2 secara berturut-urut diberi simbol 𝑃10, 𝑃2
0, 𝑃11,
𝑃21. Didapat empat persamaan berikut.
Persamaan bit pertama dari output s-box 0 pada round 2:
𝑃10 = (𝑆2
0. 𝑘5)⨁𝑘5⨁(𝑆21. 𝑘3)⨁𝑘3⨁(𝑆1
0. 𝑆21. 𝑘3. 𝑘6)⨁(𝑆1
0. 𝑘3. 𝑘6)⨁
(𝑆10. 𝑆1
1. 𝑘2. 𝑘6)⨁(𝑆10. 𝑘2. 𝑘6)⨁(𝑆1
0. 𝑆20. 𝑆1
1. 𝑆21. 𝑘2. 𝑘3. 𝑘5. 𝑘6)⨁
(𝑆10. 𝑆1
1. 𝑆21. 𝑘2. 𝑘3. 𝑘5. 𝑘6) ⨁(𝑆1
0. 𝑆11. 𝑘2. 𝑘3. 𝑘5. 𝑘6)⨁
(𝑆10. 𝑆2
0. 𝑆11. 𝑘2. 𝑘3. 𝑘5. 𝑘6)⨁(𝑆1
0. 𝑆20. 𝑆2
1. 𝑘2. 𝑘3. 𝑘5. 𝑘6)⨁
(𝑆10. 𝑆2
1. 𝑘2. 𝑘3. 𝑘5. 𝑘6)⨁(𝑆10. 𝑘2. 𝑘3. 𝑘5. 𝑘6)⨁
(𝑆10. 𝑆2
0. 𝑘2. 𝑘3. 𝑘5. 𝑘6). (13) Persamaan bit kedua dari output s-box 0 pada round 2:
𝑃20 = (𝑆1
0. 𝑘6)⨁(𝑆11. 𝑘2)⨁𝑘2⨁(𝑆1
0. 𝑆20. 𝑘5. 𝑘6)⨁(𝑆1
0. 𝑘5. 𝑘6)⨁
(𝑆10. 𝑆2
1. 𝑘3. 𝑘6)⨁(𝑆10. 𝑘3. 𝑘6)⨁(𝑆1
0. 𝑆11. 𝑘2. 𝑘6)⨁(𝑆1
0. 𝑘2. 𝑘6)⨁
(𝑆10. 𝑆2
0. 𝑆21. 𝑘3. 𝑘5. 𝑘6)⨁(𝑆1
0. 𝑆21. 𝑘3𝑘5. 𝑘6)⨁(𝑆1
0. 𝑆20. 𝑘3. 𝑘5. 𝑘6)⨁
(𝑆10. 𝑘3. 𝑘5. 𝑘6)⨁(𝑆1
0. 𝑆20. 𝑆1
1. 𝑆21. 𝑘2. 𝑘3. 𝑘5. 𝑘6)⨁
(𝑆10. 𝑆1
1. 𝑆21. 𝑘2. 𝑘3. 𝑘5. 𝑘6)⨁(𝑆1
0. 𝑆11. 𝑘2. 𝑘3. 𝑘5. 𝑘6)⨁
(𝑆10. 𝑆2
0. 𝑆11. 𝑘2. 𝑘3. 𝑘5. 𝑘6)⨁(𝑆1
0. 𝑆20. 𝑆2
1. 𝑘2. 𝑘3. 𝑘5. 𝑘6)⨁
(𝑆10. 𝑆2
1. 𝑘2. 𝑘3. 𝑘5. 𝑘6)⨁ (𝑆10. 𝑘2. 𝑘3. 𝑘5. 𝑘6)⨁
(𝑆10. 𝑆2
0. 𝑘2. 𝑘3. 𝑘5. 𝑘6). (14)
Persamaan bit pertama dari output s-box 1 pada round 2:
𝑃11 = (𝑆2
1. 𝑘1⨁𝑘1)⨁(𝑆11. 𝑘7⨁𝑘7)⨁(𝑆1
0.𝑘8)⨁(𝑆11. 𝑆2
1. 𝑘1. 𝑘7⨁𝑆11. 𝑘1. 𝑘7⨁
𝑆21. 𝑘1. 𝑘7⨁𝑘1. 𝑘7)(𝑆2
0. 𝑆21. 𝑘1. 𝑘9⨁𝑆2
0. 𝑘1. 𝑘9⨁𝑆21. 𝑘1. 𝑘9⨁𝑘1. 𝑘9) ⨁
(𝑆20. 𝑆1
1. 𝑘7. 𝑘9⨁𝑆20. 𝑘7. 𝑘9⨁𝑆1
1. 𝑘7. 𝑘9⨁𝑘7. 𝑘9) ⨁
(𝑆20. 𝑆1
1. 𝑆21. 𝑘1. 𝑘7. 𝑘9⨁𝑆2
0. 𝑆11. 𝑘1. 𝑘7. 𝑘9⨁𝑆2
0. 𝑆21. 𝑘1. 𝑘7. 𝑘9⨁
𝑆20. 𝑘1. 𝑘7. 𝑘9⨁𝑆1
1. 𝑆21. 𝑘1. 𝑘7. 𝑘9⨁𝑆1
1. 𝑘1. 𝑘7. 𝑘9⨁𝑆21. 𝑘1. 𝑘7. 𝑘9⨁

733
𝑘1. 𝑘7. 𝑘9)⨁(𝑆20. 𝑆2
1. 𝑘1. 𝑘8. 𝑘9⨁𝑆20. 𝑘1. 𝑘8. 𝑘9)⨁
(𝑆10. 𝑆2
0. 𝑆11. 𝑆2
1. 𝑘1. 𝑘7. 𝑘8. 𝑘9⨁𝑆10. 𝑆2
0. 𝑆11. 𝑘1. 𝑘7. 𝑘8. 𝑘9⨁
𝑆10. 𝑆2
0. 𝑆21. 𝑘1. 𝑘7. 𝑘8. 𝑘9⨁𝑆1
0. 𝑆20. 𝑘1. 𝑘7. 𝑘8. 𝑘9⨁𝑆1
0. 𝑆11. 𝑆2
1. 𝑘1. 𝑘7. 𝑘8. 𝑘9⨁𝑆1
0. 𝑆11. 𝑘1. 𝑘7. 𝑘8. 𝑘9⨁𝑆1
0. 𝑆21. 𝑘1. 𝑘7. 𝑘8. 𝑘9⨁𝑆1
0. 𝑘1. 𝑘7. 𝑘8. 𝑘9). (15)
Persamaan bit kedua dari output s-box 1 pada round 2:
𝑃21 = (𝑆2
1. 𝑘1⨁𝑘1)⨁(𝑆20. 𝑘9⨁𝑘9)⨁(𝑆1
1. 𝑆21. 𝑘1. 𝑘7⨁𝑆1
1. 𝑘1. 𝑘7⨁𝑆21. 𝑘1⨁
𝑘1. 𝑘7)⨁(𝑆11. 𝑘7. 𝑘8⨁𝑘7. 𝑘8)⨁(𝑆2
0. 𝑆11. 𝑘7. 𝑘9⨁𝑆2
0. 𝑘7. 𝑘9⨁
𝑆11. 𝑘7. 𝑘9⨁𝑘7. 𝑘9)⨁(𝑆1
0. 𝑆20. 𝑘8. 𝑘9⨁𝑆1
0. 𝑘8. 𝑘9)⨁(𝑆10. 𝑆1
1. 𝑆21. 𝑘1.
𝑘7. 𝑘8⨁𝑆11. 𝑘1. 𝑘7. 𝑘8⨁𝑆1
0. 𝑆21. 𝑘1. 𝑘7. 𝑘8⨁𝑘1. 𝑘7. 𝑘8)⨁(𝑆2
0. 𝑆11.
𝑆21. 𝑘1. 𝑘7. 𝑘9⨁𝑆2
0. 𝑆11. 𝑘1. 𝑘7. 𝑘9⨁𝑆2
0. 𝑆21. 𝑘1. 𝑘7. 𝑘9⨁𝑆2
0. 𝑘1. 𝑘7. 𝑘9⨁
𝑆11. 𝑆2
1. 𝑘1. 𝑘7. 𝑘9⨁𝑆11. 𝑘1. 𝑘7. 𝑘9⨁𝑆2
1. 𝑘1. 𝑘7. 𝑘9⨁𝑘1. 𝑘7. 𝑘9)⨁
(𝑆20. 𝑆2
1. 𝑘1. 𝑘8. 𝑘9⨁𝑆20. 𝑘1. 𝑘8. 𝑘9)⨁(𝑆1
0. 𝑆20. 𝑆1
1. 𝑘7. 𝑘8. 𝑘9⨁𝑆10. 𝑆2
0. 𝑘7. 𝑘8. 𝑘9⨁𝑆1
0. 𝑆11. 𝑘7. 𝑘8. 𝑘9⨁𝑆1
0. 𝑘7. 𝑘8. 𝑘9)⨁(𝑆10. 𝑆2
0. 𝑆11. 𝑆2
1. 𝑘1. 𝑘7. 𝑘8. 𝑘9⨁𝑆1
0. 𝑆20. 𝑆1
1. 𝑘1. 𝑘7. 𝑘8. 𝑘9⨁𝑆10. 𝑆2
0. 𝑆21. 𝑘1. 𝑘7. 𝑘8. 𝑘9⨁𝑆1
0. 𝑆20. 𝑘1. 𝑘7. 𝑘8. 𝑘9⨁𝑆1
0. 𝑆11. 𝑆2
1. 𝑘1. 𝑘7. 𝑘8. 𝑘9⨁𝑆10. 𝑆1
1. 𝑘1. 𝑘7. 𝑘8. 𝑘9⨁
𝑆10. 𝑆2
1. 𝑘1. 𝑘7. 𝑘8. 𝑘9⨁𝑆10. 𝑘1. 𝑘7. 𝑘8. 𝑘9). (16)
Selanjutnya, jika 𝑆10, 𝑆2
0, 𝑆11, dan 𝑆2
1 diuraikan kembali menjadi variabel 𝑘, maka
didapat persamaan bit pertama dari output s-box 0 pada round 2:
𝑃10 = 𝑘3𝑘5⨁𝑘1𝑘3𝑘5⨁𝑘1𝑘5𝑘6𝑘1𝑘3𝑘4𝑘6⨁𝑘1𝑘3𝑘5𝑘6⨁𝑘1𝑘3𝑘6𝑘8⨁
𝑘1𝑘3𝑘4𝑘6𝑘9⨁𝑘1𝑘3𝑘6𝑘8𝑘9⨁𝑘1𝑘3𝑘6𝑘9𝑘10⨁𝑘1𝑘3𝑘4𝑘6𝑘8𝑘9⨁
𝑘1𝑘3𝑘4𝑘6𝑘9𝑘10⨁𝑘1𝑘3𝑘4𝑘6𝑘8𝑘9𝑘10⨁𝑘3𝑘4𝑘5𝑘6𝑘8𝑘9𝑘10⨁
𝑘3𝑘4𝑘6⨁𝑘3𝑘4𝑘6𝑘9⨁𝑘3𝑘4𝑘5𝑘6𝑘8𝑘9𝑘10⨁𝑘3𝑘5𝑘6⨁𝑘3𝑘6𝑘8⨁
𝑘3𝑘6𝑘8𝑘9⨁𝑘3𝑘6𝑘9𝑘10⨁𝑘3𝑘4𝑘6𝑘8𝑘9𝑘10⨁𝑘3𝑘4𝑘6𝑘9𝑘10⨁
𝑘3𝑘4𝑘6𝑘8𝑘9⨁𝑘2𝑘3𝑘4𝑘6⨁𝑘2𝑘4𝑘5𝑘6⨁𝑘1𝑘2𝑘4𝑘6⨁𝑘1𝑘2𝑘3𝑘4𝑘6⨁ 𝑘2𝑘3𝑘6𝑘8⨁𝑘2𝑘5𝑘6𝑘8⨁𝑘1𝑘2𝑘6𝑘8⨁𝑘1𝑘2𝑘3𝑘6𝑘8⨁ 𝑘2𝑘3𝑘4𝑘6𝑘9⨁𝑘2𝑘4𝑘5𝑘6𝑘9⨁𝑘1𝑘2𝑘4𝑘6𝑘9⨁𝑘1𝑘2𝑘3𝑘4𝑘6𝑘9⨁ 𝑘2𝑘3𝑘6𝑘8𝑘9⨁𝑘2𝑘5𝑘6𝑘8𝑘9⨁𝑘1𝑘2𝑘6𝑘8𝑘9⨁𝑘1𝑘2𝑘3𝑘6𝑘8𝑘9⨁ 𝑘2𝑘3𝑘6𝑘9𝑘10⨁𝑘2𝑘5𝑘6𝑘9𝑘10⨁𝑘1𝑘2𝑘6𝑘9𝑘10⨁𝑘1𝑘2𝑘3𝑘6𝑘9𝑘10⨁ 𝑘2𝑘3𝑘4𝑘6𝑘8𝑘9⨁𝑘2𝑘4𝑘5𝑘6𝑘8𝑘9⨁𝑘1𝑘2𝑘4𝑘6𝑘8𝑘9⨁𝑘1𝑘2𝑘3 𝑘4𝑘6⨁𝑘2𝑘3𝑘4𝑘6𝑘9𝑘10⨁𝑘2𝑘4𝑘5𝑘6𝑘9𝑘10⨁𝑘1𝑘2𝑘4𝑘6𝑘9𝑘10⨁ 𝑘1𝑘2𝑘3𝑘4𝑘6𝑘9𝑘10⨁𝑘2𝑘3𝑘4𝑘6𝑘8𝑘9𝑘10⨁𝑘2𝑘4𝑘5𝑘6𝑘8𝑘9𝑘10⨁ 𝑘1𝑘2𝑘4𝑘6𝑘8𝑘9𝑘10⨁𝑘1𝑘2𝑘3𝑘4𝑘6𝑘8𝑘9𝑘10𝑘2𝑘3𝑘6⨁𝑘2𝑘5𝑘6 𝑘1𝑘2𝑘6⨁𝑘1𝑘2𝑘3𝑘6⨁𝑘2𝑘3𝑘4𝑘5𝑘6𝑘9⨁𝑘1𝑘3𝑘4𝑘5𝑘6⨁𝑘1𝑘3𝑘5𝑘6
𝑘8⨁𝑘1𝑘3𝑘4𝑘5𝑘6𝑘9⨁𝑘1𝑘3𝑘5𝑘6𝑘8𝑘9⨁𝑘1𝑘3𝑘5𝑘6𝑘9𝑘10⨁
𝑘1𝑘3𝑘4𝑘5𝑘6𝑘8𝑘9𝑘10⨁𝑘1𝑘3𝑘4𝑘5𝑘6𝑘9𝑘10⨁𝑘1𝑘3𝑘4𝑘5𝑘6𝑘8𝑘9⨁ 𝑘2𝑘3𝑘4𝑘5𝑘6𝑘8𝑘9⨁𝑘1𝑘2𝑘3𝑘5𝑘6⨁𝑘1𝑘2𝑘3𝑘4𝑘5𝑘6⨁𝑘1𝑘2𝑘3𝑘5 𝑘6𝑘8⨁𝑘1𝑘2𝑘3𝑘5𝑘6𝑘9⨁𝑘1𝑘2𝑘3𝑘4𝑘5𝑘6𝑘8⨁𝑘1𝑘2𝑘3𝑘4𝑘5𝑘6𝑘9⨁ 𝑘1𝑘2𝑘3𝑘4𝑘5𝑘6𝑘9𝑘10⨁𝑘1𝑘2𝑘3𝑘5𝑘6𝑘8𝑘9⨁𝑘1𝑘2𝑘3𝑘5𝑘6𝑘9𝑘10⨁ 𝑘1𝑘2𝑘3𝑘5𝑘6𝑘10⨁𝑘1𝑘2𝑘3𝑘4𝑘5𝑘6𝑘10⨁𝑘1𝑘2𝑘3𝑘5𝑘6𝑘8𝑘10⨁
𝑘1𝑘2𝑘3𝑘4𝑘5𝑘6𝑘8𝑘9⨁𝑘1𝑘2𝑘3𝑘4𝑘5𝑘6𝑘8𝑘9𝑘10. (17)
Proses yang sama dilakukan terhadap tiga persamaan lainnya, yaitu persamaan (14),
(15), dan (16).
Setelah masuk ke fungsi s-box, 𝑃𝐻 memasuki fungsi P4. Pada fungsi P4, 4
bit output s-box pada round 2 dipermutasi.Selanjutnya masuk ke fungsi P4.

734
𝑃10 𝑃2
0 𝑃11 𝑃2
1
𝑃20 𝑃2
1 𝑃11 𝑃1
0
Gambar 9. Permutation 4 (P4) - 2
Berdasarkan gambar 7, didapat ciphertext pada round 2, yaitu
𝐶2 = 𝑃20 𝑃2
1 𝑃11 𝑃1
0. Tahap terakhir dalam proses enkripsi yaitu masuk ke fungsi IP-
1. Sebelum memasuki IP-1, 𝑃10, 𝑃2
0, 𝑃11, 𝑃2
1 di-XOR terlebih dahulu dengan nilai 𝑃𝐿
awal.
𝑃10 𝑃2
0 𝑃11 𝑃2
1
0 1 1 0 ⨁
𝑃10 𝑃2
0⨁1 𝑃11⨁1 𝑃2
1
Gambar 10 𝐶2⨁𝑃𝐿
Output dari IP-1 merupakan output dari enkripsi algoritma S-DES yang
diambil sebagai nilai ciphertext.
𝑃10 𝑃2
0⨁1 𝑃11⨁1 𝑃2
1 𝑆20⨁1 𝑆2
1⨁1 𝑆11⨁1 𝑆1
0
𝑃20⨁1 𝑆2
1⨁1 𝑃11⨁1 𝑃1
0 𝑃21 𝑆1
0 𝑆20⨁1 𝑆1
1⨁1
Gambar 11 Initial Permutation (IP-1)
Setiap persamaan merepresentasikan bit output S-DES. Kemudian nilai
ciphertext dijadikan hasil dari persamaan yang berkorespondensi. Contohnya, bit
output yang ke 6 direpresentasikan sebagai 𝑆10, ciphertext yang digunakan yaitu
01000110, kemudian dibuat persamaan 𝑆10 = 𝑐6, sehingga didapat
𝑘3⨁𝑘5⨁𝑘1𝑘6⨁𝑘3𝑘5⨁𝑘1𝑘3𝑘5⨁𝑘1𝑘3𝑘6⨁𝑘3𝑘5𝑘6⨁𝑘1𝑘3𝑘5𝑘6⨁1 = 1 (18)
Dalam penelitian ini, telah ditemukan lima persamaan yang merepresentasikan lima
bit ciphertext, yaitu 𝑆10, 𝑆2
0⨁1, 𝑆11⨁1, 𝑆2
1⨁1, dan 𝑃10.
3. Kesimpulan
Berdasarkan pembahasan di atas, persamaan linier dari 8 bit output S-DES
dapat ditemukan. Dengan demikian dapat disimpulkan bahwa algoritma S-DES
rentan terhadap algebraic attack, karena dengan didapatnya persamaan-persamaan
tersebut, penyerang dapat mencari solusi dari persamaan yang ditemukan
berdasarkan metode-metode yang sudah ada, seperti Grobner Basis, Linearization,
Extended Linearization (XL) Algorithm, dan Extended Sparse Linearization (XSL)
Algorithm [5].

735
Pernyataan terima kasih. Pernyataan terima kasih disampaikan saudari
Sundari Tianingrum, dan Sekolah Tinggi Sandi Negara yang telah memberikan
sumbangsih dan dukungan dalam segala hal kepada penulis.
Referensi
[1] David, M. S-DES Encryption Sample, (online). (http://homepage.smc.edu/morgan_
david/vpn/assignments/assgt-sdes-encrypt-sample.htm. diakses pada 17 Januari 2017).
[2] FIPS 46-3. (Oktober 1999). FIPS 46-3, Data Encryption Standard (DES) (withdrawn
May 19, 2005), (online). (http://csrc.nist.gov/publications/fips/fips46-3/fips46-3.pdf.
diakses 18 Januari 2017).
[3] Menezes, A.J., Oorschot, P.C. Van, Vanstone, S.A., 1997. Handbook of Applied
Cryptography. Electr. Eng. doi:10.1.1.99.2838.
[4] Stallings, W. 2014. Cryptography and Network Security, Sixth Edition. Pearson
Education, Inc. USA.
[5] Tianingrum, S. 2015. Algebraic Attack pada Algoritma Mini AES. Sekolah Tinggi Sandi
Negara. Bogor.
[6] Voros M. 2007. Algebraic Attack on Stream Cipher. Comenius University, Department
of Computer Science. Bratislava.

736
Prosiding SNM 2017 Komputasi , Hal 736-744
BIT PATTERN BASED INTEGRAL ATTACK PADA
ALGORITMA PRESENT
RYAN SETYO PAMBUDI1, SANTI INDARJANI 2
1Sekolah Tinggi Sandi Negara, [email protected]
2 Sekolah Tinggi Sandi Negara, santi.indarjani@ stsn-nci.ac.id
Abstrak. PRESENT merupakan salah satu algoritma penyandian lightweght
block cipher dengan struktur SPN (Substitution Permutation Network) dengan
ukuran blok sebesar 64-bit dan menerima input kunci dengan variasi 80 bit dan
128 bit. Bit pattern based integral attack merupakan salah satu serangan pada
suatu algoritma block cipher. Output bit pada suatu s-box diperlakukan secara
independen, yaitu tidak digabungkan/dicampurkan dengan bit-bit lain dan
sesuai dengan batas-batas s-box. Pencarian karakteristik integral attack
tersebut berdasarkan pengamatan pada perubahan bit-bit yang terjadi pada
suatu algoritma. Pada penelitian ini dilakukan penerapan bit pattern based
integral attack pada algoritma PRESENT. Serangan dilakukan dengan
membangkitkan 24 chosen-plaintext yang bersifat balance dimasukkan dalam
algoritma PRESENT. Hasil yang didapatkan ialah plainteks secara umum
menjadi tidak balance setelah melewati empat round PRESENT, sehingga
proses recovery kunci dapat dilakukan pada round kelima PRESENT.
Algoritma PRESENT dengan iterasi sebanyak 5 round tidak tahan terhadap bit
pattern based integral attack.
Kata kunci: bit pattern based integral attack , PRESENT
1. Pendahuluan
Kriptanalisis adalah studi tentang cara atau metode untuk
mendapatkan/mengetahui pesan dalam informasi yang terenkripsi (ciphertext) tanpa
mempunyai akses terhadap ciphertext tersebut. Metode ini biasanya hanya berkaitan
dengan cara menemukan kunci rahasia yang digunakan, namun dalam
perkembangannya diartikan juga sebagai usaha untuk mengeksploitasi kelemahan
dari suatu algoritma [4].
PRESENT merupakan salah satu algoritma lightweight block cipher dengan
struktur SPN (Substitution Permutation Network) dengan ukuran blok sebesar 64-bit
dan menerima input kunci dengan variasi 64 bit dan 128 bit. PRESENT memiliki
iterasi sebanyak 32 round. PRESENT-80 adalah algoritma PRESENT dengan input
kunci sepanjang 80-bit. Sedangkan PRESENT-128 adalah algoritma PRESENT
dengan input kunci sepanjang 128 bit [2]. PRESENT merupakan algoritma
lightweight standard yang ditetapkan oleh International Standard Organization
(ISO) berdasarkan ISO/IEC 29192 pada tahun 2012.
Munculnya algoritma PRESENT menarik perhatian dan penelitian oleh

737
berbagai ilmuwan kriptografi. Sejak munculnya PRESENT kriptanalis telah
melakukan berbagai serangan terhadap PRESENT untuk menguji kekuatan dan
ketahanan algoritma PRESENT terhadap berbagai serangan.
Bit pattern based integral attack merupakan salah satu teknik serangan baru
yang diperkenalkan oleh Z’aba, dkk [3] pada tahun 2008. Konsep serangan integral
attack merupakan ide dasar dari munculnya serangan ini. Integral attack bertujuan
mencari karakteristik pada suatu algoritma dengan menggunakan n buah teks terang
𝑃𝑖 yang bersifat balance (hasil XOR nya sama dengan nol). n buah teks terang
tersebut kemudian dienkripsi dan diproses sesuai fungsi pada suatu algoritma. Hasil
enkripsi menghasilkan teks sandi 𝐶𝑖 kemudian dianalisis keseimbangannya dan
dibandingkan dengan kondisi sebelum proses enkripsi. Apabila diketahui 𝐶𝑖 bersifat
tidak balance, maka penyerang dapat melakukan recovery kunci, yaitu proses
menebak kemungkinan kunci yang digunakan.
Serangan berbasis bit pattern based integral attack yaitu output bit pada
suatu s-box diperlakukan secara independen, yaitu tidak digabungkan/dicampurkan
dengan bit-bit lain dan sesuai dengan batas-batas s-box [3] . Pencarian karakteristik
integral attack tersebut berdasarkan pengamatan pada perubahan bit-bit yang terjadi
pada suatu algoritma. Serangan ini merupakan salah satu jenis serangan choosen
plaintext attack.
Pada penelitian ini akan dilakukan penerapan bit pattern based integral
attack pada algoritma PRESENT. Penelitian bertujuan untuk mengetahui ketahanan
algoritma PRESENT dari serangan bit pattern based integral attack. Algoritma
PRESENT yang dipilih ialah PRESENT-80 dengan ukuran kunci 80 bit. Serangan
dilakukan pada reduced round PRESENT-80, yaitu sebanyak lima round.
2. Hasil – Hasil Utama
2.1. Algoritma PRESENT
Algoritma PRESENT merupakan ultra-lightweight block cipher yang
diajukan oleh Bogdanov dkk [2] yang digunakan pada tag RFID dan sensor
networks. Algoritma PRESENT merupakan algoritma lightweight block cipher yang
memiliki struktur Subtitution Permutation Network (SPN) dan terdiri dari 31 round.
Panjang bloknya adalah 64-bit dengan variasi input kunci 80-bit dan 128-bit. Untuk
aplikasi direkomendasikan menggunakan input kunci 80-bit, karena dengan panjang
input kunci 80-bit sudah memenuhi keamanan yang dibutuhkan untuk aplikasi
berbasis RFID [2]. Berikut merupakan struktur algoritma PRESENT.
2.1.1 Key Addition Layer Pada algoritma PRESENT, tahap pertama adalah proses Key Addition Layer
atau Add Round Key Layer yakni setiap bit pada plaintext atau pun bit-bit hasil
akhir dari P-Layer dari tiap round akan di-xor dengan bit-bit sub kunci (round
key) yang merupakan hasil key schedule.
𝐾𝑖 merupakan sub kunci, dimana 𝐾𝑖 = 𝑘63𝑖 … 𝑘0
𝑖 untuk 0 ≤ 𝑖 ≤ 31 dan
posisi bit dinotasikan 𝑏63… 𝑏0. Add round key merupakan operasi yang
dilakukan untuk 0 ≤ 𝑗 ≤ 63,
𝑏𝑗 = 𝑏𝑗⨁ 𝑘𝑗𝑖 (1)
2.1.2 Substitution Layer

738
Plainteks yang telah melewati key addition layer selanjutnya diproses
memasuki s-box (substitution box). S-box yang digunakan pada algoritma
PRESENT adalah s-box 𝑆 berukuran 4×4, 𝑆 = 𝔽24 → 𝔽24. Tabel 2.1
merupakan tabel Sbox pada algoritma PRESENT.
Tabel 1 Substitution box algoritma PRESENT
Dari Tabel 1 pada Sbox layer state pesan 𝑏63, … , 𝑏0 dikelompokkan menjadi
16 bagian dengan 4-bit words 𝑤63, … , 𝑤0 dimana 𝑤𝑖 = 𝑏4∗𝑖+3 ∥ 𝑏4∗𝑖+2 ∥𝑏4∗𝑖+1 ∥ 𝑏4∗𝑖 untuk 1 ≤ 𝑖 ≤ 15. Nilai dari 𝑆[𝑤𝑖] merupakan output dari sbox
layer dan state untuk proses selanjutnya.
2.1.3 Permutation Layer
Selanjutnya bit-bit yang telah diproses pada substitution layer diproses pada
permutation layer, yaitu proses perpindahan posisi bit pada algoritma
PRESENT. Tabel 2 menunjukkan permutasi pada algoritma PRESENT.
Tabel 2 Permutasi Algoritma PRESENT
2.1.4 Key Schedule
Input kunci sepanjang 80-bit akan melalui proses key schedule sehingga
menghasilkan kunci sepanjang 64-bit yang selalu diperbarui setiap roundnya.
Kunci disimpan dalam register kunci 𝐾 dan direpresentasikan sebagai
𝑘79𝑘78𝑘77…𝑘0. Pada round ke 𝑖, kunci round sepanjang 64-bit yaitu 𝐾𝑖 =𝑘63𝑘62𝑘61…𝑘0 adalah 64-bit paling kiri dari kunci yang ada pada register
kunci 𝐾. Dengan demikian kunci round ke 𝑖 adalah 𝐾𝑖 = 𝑘63𝑘62𝑘61…𝑘0 =𝑘78𝑘77𝑘76…𝑘16. Pada round selanjutnya register kunci 𝐾𝑖 =𝑘79𝑘78𝑘77…𝑘16harus diperbarui dengan cara berikut:
[𝑘78𝑘77…𝑘1𝑘0] = [𝑘18𝑘17…𝑘20𝑘19] (2)
[𝑘79𝑘78𝑘77𝑘76] = 𝑆[𝑘79𝑘78𝑘77𝑘76] (3)
[𝑘19𝑘18𝑘17𝑘16𝑘15] = [𝑘19𝑘18𝑘17𝑘16𝑘15] ⊕ 𝑟𝑜𝑢𝑛𝑑_𝑐𝑜𝑢𝑛𝑡𝑒𝑟 (4)
2.2. Integral Attack
Integral attack merupakan basis dari serangan terbaik pada AES, dan telah
menjadi standar ketika mengembangkan kriptanalisis. Ide dasar attack ini adalah
untuk menganalisis bagaimana menetapkan sifat yang spesifik pada sejumlah
plainteks yang melewati proes enkripsi pada algoritma dan menggunakan
keberadaan sifat tersebut untuk memverifikasi kunci yang ditebak [3]. Pada skema

739
serangan ini, bit-bit dipilih konstan dengan tujuan agar tidak terpengaruh oleh
subtitution bytes pada s-box bijektif. Dengan menggunakan pendekatan pada bit
oriented cipher, output bit dari suatu s-box tidak dipandang sebagai suatu blok. Hal
ini pada umumnya menyatakan bahwa semua nilai pada output s-box setelah itu akan
dikaburkan oleh linear layer.
Algoritma yang berbasis bit, dapat diterapkan integral attack. Output bit
pada suatu s-box diperlakukan secara independen, yaitu tidak
digabungkan/dicampurkan dengan bit-bit lain dan sesuai dengan batas-batas s-box
[3]. Pencarian karakteristik integral attack tersebut berdasarkan pengamatan pada
perubahan bit-bit yang terjadi pada suatu algoritma. Input pada s-box di round
selanjutnya akan memiliki beberapa bit yang konstan dan beberapa lainnya tidak
konstan. Struktur tersebut akan hilang pada round kedua. Oleh karena itu, penamaan
pada serangan ini ialah bit pattern based integral attack.
2.3. Bit Pattern Attack pada Algoritma PRESENT
Dalam proses serangan pada algoritma ini digunakan suatu himpunan
pasangan 𝑃𝑖 dan 𝐶𝑖 yang berkorespondensi. 𝑃𝑖 merupakan himpunan teks
terang/plainteks dan 𝐶𝑖 merupakan himpunan teks sandi/cipherteks. Plainteks terdiri
dari 16 teks terang dengan 0 ≤ 𝑖 ≤ 15. Setiap teks berukuran 64 bit yang terdiri dari
16 sbox, yang dikelompokkan menjadi empat blok. Empat buah sbox diaktifkan pada
blok terakhir 𝑥3. Sbox yang memiliki nilai tetap disebut sbox pasif, sedagkan sbox
yang memiliki bit-bit aktif disebut sbox aktif.
Langkah awal yaitu dengan membangkitkan suatu himpunan teks terang 𝑃𝑖. Gambar 1 menunjukkan teks terang yang digunakan sebanyak 16 buah.
𝑃0 = 8𝑎8𝑎 1212 𝑐3𝑐3 888816 𝑃1 = 8𝑎8𝑎 1212 𝑐3𝑐3 888916
𝑃2 = 8𝑎8𝑎 1212 𝑐3𝑐3 889816
𝑃3 = 8𝑎8𝑎 1212 𝑐3𝑐3 889916
𝑃4 = 8𝑎8𝑎 1212 𝑐3𝑐3 898816
𝑃5 = 8𝑎8𝑎 1212 𝑐3𝑐3 898916
𝑃6 = 8𝑎8𝑎 1212 𝑐3𝑐3 899816
𝑃7 = 8𝑎8𝑎 1212 𝑐3𝑐3 899916
𝑃8 = 8𝑎8𝑎 1212 𝑐3𝑐3 988816
𝑃9 = 8𝑎8𝑎 1212 𝑐3𝑐3 988916
𝑃10 = 8𝑎8𝑎 1212 𝑐3𝑐3 989816
𝑃11 = 8𝑎8𝑎 1212 𝑐3𝑐3 989916
𝑃12 = 8𝑎8𝑎 1212 𝑐3𝑐3 998816
𝑃13 = 8𝑎8𝑎 1212 𝑐3𝑐3 998916
𝑃14 = 8𝑎8𝑎 1212 𝑐3𝑐3 999816
𝑃15 = 8𝑎8𝑎 1212 𝑐3𝑐3 999916
Gambar 1 Teks Terang yang Digunakan
Blok 𝑥0,𝑥1,𝑥2 memiliki sbox pasif, sedangkan pada blok 𝑥3 memiliki empat
sbox aktif. Keempat sbox aktif tersebut masing-masing memiliki tiga buah bit
konstan pada inputannya, yaitu 100_ , dimana blank tersebut yang nantinya akan
diisi oleh bit-bit teks terang yang dipilih. Apabila seluruh 16 teks terang di-XOR-
kan, maka XOR dari masing-masing sbox baik sbox aktif maupun pasif adalah

740
bernilai 000016. Dalam proses enkripsi, dipilih kunci yang digunakan untuk proses
enkripsi. Kunci berukuran 80 bit dengan subkunci yang dihasilkan masing-masing
berukuran 64 bit. Berikut kunci yang digunakan :
𝐾 = 7𝑑7𝑑7𝑑7𝑑7𝑑7𝑑7𝑑7𝑑7𝑑7𝑑16
2.3.1 Bit Pattern Based Integral Attack pada 1 round PRESENT
Langkah pertama yang dilakukan untuk melakukan serangan pada satu
round PRESENT ialah membangkitkan 16 buah plainteks 𝑃𝑖 pada Gambar 1
kemudian lakukan enkripsi 1 round. Enkripsi 1 round menghasilkan teks sandi
𝐶𝑖1 sejumlah 16 buah. Berikut merupakan 𝐶𝑖
1.
𝐶01 = 5𝑎𝑎05000𝑎𝑓0𝑎5050 16
𝐶11 = 5𝑎𝑎15000𝑎𝑓0𝑎5051 16
𝐶21 = 5𝑎𝑎05000𝑎𝑓085052 16
𝐶31 = 5𝑎𝑎15000𝑎𝑓085053 16
𝐶41 = 5𝑎𝑎45000𝑎𝑓0𝑎5054 16 𝐶51 = 5𝑎𝑎55000𝑎𝑓0𝑎5055 16 𝐶61 = 5𝑎𝑎45000𝑎𝑓085056 16 𝐶71 = 5𝑎𝑎55000𝑎𝑓085057 16 𝐶81 = 5𝑎𝑎05000𝑎𝑓025058 16 𝐶91 = 5𝑎𝑎15000𝑎𝑓025059 16 𝐶101 = 5𝑎𝑎05000𝑎𝑓00505𝑎 16 𝐶111 = 5𝑎𝑎15000𝑎𝑓00505𝑏 16 𝐶121 = 5𝑎𝑎45000𝑎𝑓02505𝑐 16 𝐶131 = 5𝑎𝑎55000𝑎𝑓02505𝑑 16 𝐶141 = 5𝑎𝑎45000𝑎𝑓00505𝑒 16
𝐶151 = 5𝑎𝑎55000𝑎𝑓00505𝑓 16
Gambar 2 Hasil Enkripsi 1 Round
Dari hasil enkripsi didapat bahwa terdapat satu sbox aktif dengan pola
𝑑3, 𝑑2, 𝑑1, 𝑎0 pada blok 𝑥3. Hal ini ditunjukkan oleh perubahan nilai bit hasil
enkripsi yang menghasilkan semua kemungkinan nilai pada 𝑠0. Kondisi ini
disebabkan karena variabel bit yang diubah pada himpunan plainteks 𝑃𝑖 pada
round pertama masing-masing dipetakan pada 𝑠0.
Sbox aktif juga terdapat pada blok 𝑥0, 𝑥1, 𝑥2 yang terletak pada posisi
sbox 4, 8, dan 12. Hasil enkripsi menunjukkan bahwa teks sandi hasil enkripsi
pesan masih bersifat balance. Karena hasil XOR antara seluruh blok pada 16
buah teks sandi sama dengan nol.

741
2.3.2 Bit Pattern Based Integral Attack pada 2 round PRESENT
Enkripsi pada round kedua menggunakan output dari round pertama,
kemudian diproses sesuai fungsi iterasi pada PRESENT. Hasil enkripsi 2 round
menghasilkan teks sandi 𝐶𝑖2.
𝐶02 = 𝑎2𝑒0𝑎2𝑒09𝑓2𝑓8220 16
𝐶12 = 𝑎2𝑒0𝑎2𝑒08𝑓2𝑒9221 16
𝐶22 = 𝑎2𝑓0𝑎2𝑓19𝑓2𝑓8231 16
𝐶32 = 𝑎2𝑓0𝑎2𝑓18𝑓2𝑒9230 16
𝐶42 = 𝑏2𝑒1𝑎2𝑒08𝑓2𝑒8220 16 𝐶52 = 𝑏2𝑒1𝑏2𝑒19𝑓2𝑓9221 16
𝐶62 = 𝑏2𝑓1𝑎2𝑓18𝑓2𝑓8230 16 𝐶72 = 𝑏2𝑓0𝑏2𝑓09𝑓2𝑓9231 16 𝐶82 = 𝑎2𝑒1𝑎2𝑓19𝑓3𝑒8231 16
𝐶92 = 𝑎2𝑒1𝑎2𝑓08𝑓3𝑓9230 16 𝐶102 = 𝑎2𝑒0𝑎2𝑒09𝑓3𝑒8220 16 𝐶112 = 𝑎2𝑒1𝑎2𝑒08𝑓3𝑒9221 16
𝐶122 = 𝑏2𝑒1𝑎2𝑓08𝑓3𝑓8231 16 𝐶132 = 𝑏2𝑒0𝑏2𝑓19𝑓3𝑓9230 16
𝐶142 = 𝑏2𝑒0𝑎2𝑒18𝑓3𝑒8221 16 𝐶152 = 𝑏2𝑒1𝑏2𝑒19𝑓3𝑒9220 16
Gambar 3 Hasil Enkripsi 2 Round
Pada teks sandi 𝐶𝑖2 telah terdapat pengaruh permutasi bit yang
mengakibatkan sebagian besar sbox pada tiap blok teraktifkan, kecuali pada
sbox kedua dari masing-masing blok, yaitu 𝑠2, 𝑠6, 𝑠10, dan 𝑠14, karena masih
menunjukkan pola yang tetap yaitu 𝑎3, 𝑎2, 𝑑1, 𝑎0 untuk semua plainteks. Hasil
enkripsi menunjukkan bahwa teks sandi hasil enkripsi pesan masih bersifat
balance. Karena hasil XOR antara seluruh blok pada 16 buah teks sandi sama
dengan nol.
2.3.3 Bit Pattern Based Integral Attack pada 3 round PRESENT
Hasil enkripsi round ketiga menghasilkan 𝐶𝑖3 sebanyak 16 buah.
𝐶03 = 𝑐0𝑑𝑑667𝑒04𝑓2667𝑓 16
𝐶13 = 𝑐0𝑑𝑐66𝑒6046𝑎66𝑒6 16
𝐶23 = 𝑒3𝑑𝑐667𝑒04𝑓0457𝑐 16
𝐶33 = 𝑒3𝑑𝑑66𝑒6046845𝑒5 16
𝐶43 = 𝑑0𝑑𝑑𝑒6𝑒𝑒8462𝑓6𝑒𝑓 16 𝐶53 = 𝑑9𝑑𝑐𝑒67684𝑓𝑎𝑓𝑓76 16 𝐶63 = 𝑓3𝑑𝑑𝑒6𝑓𝑒8470𝑑5𝑓𝑑 16 𝐶73 = 𝑒𝑎𝑑𝑐𝑒67684𝑓8𝑐𝑐74 16
𝐶83 = 𝑑3𝑑𝑐666𝑒04𝑐0754𝑐 16
𝐶93 = 𝑑2𝑑𝑑66𝑓6045874𝑑5 16 𝐶103 = 𝑐0𝑑𝑑666𝑒04𝑐2664𝑓 16 𝐶113 = 𝑑0𝑑𝑐66𝑒6044𝑎76𝑐6 16

742
𝐶123 = 𝑑2𝑑𝑐𝑒6𝑓𝑒8450𝑓4𝑑𝑐 16 𝐶133 = 𝑐𝑏𝑑𝑑𝑒67684𝑑8𝑒𝑑5516 𝐶143 = 𝑐1𝑑𝑐𝑒6𝑒𝑒8442𝑒7𝑐𝑒 16
𝐶153 = 𝑑9𝑑𝑑𝑒66684𝑐𝑎𝑓𝑓47 16
Gambar 4 Hasil Enkripsi 4 Round
Hasil enkripsi menunjukkan bahwa sbox aktif tersebar dan hampir
mengaktifkan semua sbox pada tiap blok, kecuali sbox 𝑠13 pada blok 𝑥0, sbox
𝑠10 pada blok 𝑥1, dan sbox 𝑠6 pada blok 𝑥2. Hal ini berarti bahwa active bit
telah tersebar pada masing-masing sbox, kecuali ketiga sbox pasif tersebut.
Meskipun active bit telah tersebar pada hampir semua sbox, namun teks sandi
masih mempertahankan keseimbangannya. Dari hasil percobaan didapat bahwa
hasil XOR dari 16 buah 𝐶𝑖3 yang dihasilkan adalah bernilai nol.
2.3.4 Bit Pattern Based Integral Attack pada 4 round PRESENT
Enkripsi pada round keempat menghasilkan teks sandi 𝐶𝑖4. Setelah
melewati round keempat, teks sandi telah kehilangan keseimbangannya.
Berikut merupakan hasil enkripsi 4 round PRESENT.
𝐶04 = 35𝑒18𝑏3𝑏𝑏00𝑐540𝑐 16
𝐶14 = 24𝑓19829𝑏12𝑑451𝑐 16
𝐶24 = 𝑎5𝑒5𝑑𝑏2270094411 16
𝐶34 = 𝑏4𝑓5𝑐82171395501 16
𝐶44 = 𝑏𝑑𝑒90131𝑏0𝑎4𝑑𝑐8𝑐 16 𝐶54 = 𝑒𝑐𝑓95227𝑏181𝑐𝑑9𝑐 16
𝐶64 = 3𝑓𝑐𝑒𝑐10170𝑎9𝑑𝑒𝑏2 16 𝐶74 = 𝑒𝑐𝑓9922𝑒31944𝑑88 16
𝐶84 = 𝑎5𝑒55𝑏08𝑓223𝑐631 16
𝐶94 = 𝑏6𝑓7482𝑑𝑏1379725 16 𝐶103 = 35𝑒18𝑏19𝑏22𝑒562𝑐 16 𝐶114 = 𝑎4𝑓3180𝑏𝑏105𝑐516 16 𝐶124 = 𝑎𝑓𝑒𝑓5124𝑏0𝑎78𝑒𝑏𝑑 16 𝐶134 = 3𝑐𝑑58221𝑏1𝑏51𝑑87 16 𝐶144 = 2𝑑𝑒69117𝑓0840𝑐83 16
𝐶154 = 𝑓𝑐𝑓84204𝑏3𝑎3𝑑𝑓𝑏𝑑 16
Gambar 5 Hasil Enkripsi 5 Round
Dari gambar 5 dapat dilihat bahwa pada round keempat, semua bit pada
tiap-tiap blok telah terpengaruh. Semua sbox menjadi aktif. Tidak ada lagi
nibble yang konstan. Teks sandi telah kehilangan keseimbangannya, hal ini
ditunjukkan dengan hasil XOR nilai pada tiap-tiap blok 𝐶𝑖4 sudah tidak
menghasilkan nilai nol.
Ketika teks sandi yang dihasilkan bersifat unbalance, sesuai konsep
integral attack maka dapat dilakukan recovery kunci untuk menebak subkunci
yang digunakan. Berdasarkan struktur algoritma PRESENT diketahui bahwa
proses XOR kunci pada round keempat terletak di awal fungsi round dan masih
bersifat balance. Teks sandi mulai bersifat tidak balance setelah melewati
proses substitution layer dan permutation layer pada round keempat. Oleh

743
karena itu dibutuhkan satu round tambahan, yaitu pada round kelima untuk
dapat menebak kunci yang digunakan. Fungsi round yang digunakan pada
round kelima hanya proses XOR kunci 2.4. Recovery Kunci
Proses recovery kunci dilakukan sebagai berikut:
1) Lakukan enkripsi 16 buah plainteks 𝑃𝑖 menggunakan kunci yang dipilih sebanyak
empat round.
2) Hasil enkripsi 5-round tersebut kemudian dilakukan dekripsi parsial satu round
menggunakan kandidat kunci yang dipilih. Kandidat kunci dapat dipilih pada
posisi nibble ke-k pada blok pesan ke-i, yaitu mulai blok pertama hingga blok
keempat.
3) Lakukan XOR semua nilai pada hasil dekripsi tersebut terhadap hasil enkripsi
pada round sebelumnya.
4) Apabila hasil 𝑋𝑂𝑅 = 0, maka kandidat kunci yang ditebak pada nibble ke-k
adalah benar. Jika hasil 𝑋𝑂𝑅 ≠ 0, maka coret kandidat kunci dari daftar daftar
nibble-k.
Proses di atas dilakukan untuk semua kemungkinan kunci, sehingga didapat
kunci pada round kelima.
2.5. Analisis Keamanan Algoritma PRESENT
Algoritma PRESENT 5 round tidak tahan terhadap bit pattern based integral
attack. Hal ini disebabkan penyerang dapat melakukan eksploitasi pada kunci
dengan memanfaatkan ketidakseimbangan plainteks setelah melewati round
keempat.
Penyerang dapat melakukan recovery kunci yang dapat dilakukan pada
round kelima untuk menebak subkunci pada round kelima PRESENT. Hal ini
dikarenakan setelah melewati round keempat plainteks masih balance, namun
setelah melewati substitution dan permutaton layer pada round keempat menjadi
tidak balance. Namun pada round keempat belum dapat dilakukan recovery kunci,
karena proses XOR kunci berada di awal fungsi iterasi dan teks sandi masih bersifat
balance. Oleh karenanya proses tambahan pada round kelima harus dilakukan untuk
dapat menebak kunci pada round kelima. Sbox yang dapat dipilih ialah pada sbox
yang tidak seimbang setelah pada round keempat. Apabila penyerang mampu
menebak kunci pada round kelima, maka penyerang dapat mengkesploitasi subkunci
pada round-round sebelumnya dengan metode yang sama.
3. Kesimpulan Berdasarkan penelitian yang telah dilakukan dapat disimpulkan bahwa Bit
Pattern Based Integral Attack dapat diterapkan pada reduced round PRESENT-80,
yaitu sebanyak 5 round. Algoritma PRESENT 5 round tidak tahan terhadap Bit
Pattern Based Integral Attack, karena terdapat ketidakseimbangan teks sandi mulai
round keempat yang memungkinkan penyerang dapat melakukan recovery kunci
Pernyataan terima kasih. Pernyataan terimakasih disampaikan kepada kedua
orang tua penulis, Dr. Santi Indarjani, S.Si.,M.MSI. dan institusi pendidikan Sekolah
Tinggi Sandi Negara yang telah memberikan sumbangsih dan dukungannya dalam
segala hal kepada penulis.

744
Referensi
[1] A. J. Menezes, P. C. v. Oorschot and S. A. Vanstone, "Handbook of Applied
Cryptography," Massachusetts Institute of Technology, 1997.
[2] Bogdanov, L.R.Knudsen, G.Lender, C.Paar, A.Pochmann, M. Robshaw, Y. Seurin and
C. Vikkelsoe, "PRESENT : An Ultra-Lightweight Block Cipher," CHES 2007, pp. 450-
466, 2007.
[3] M. R. Z'aba, H. Raddum, M. Henricksen and E. Dawson, "Bit-Pattern Based Integral
Attack. In: Neyberg K.(eds) Fast Software Encryption 15th," Berlin, Heidelberg, 2008.
[4] Sumarkidjo, P. Prasetyaningtyas, Y. Susilo, S. Indarjani, A. Setiawan and Y.
Adikusuma, Jelajah Kriptologi, Jakarta, 2007.

745
Prosiding SNM 2017 Komputasi, Hal 745-757
PERBANDINGAN KARAKTERISTIK S-BOX
ALGORITMA PRESENT DAN I-PRESENT
ANNISA DEWI SALDYAN1, SARI AGUSTINI HAFMAN2
1 Lembaga Sandi Negara, [email protected]
2 Lembaga Sandi Negara, [email protected]
Abstrak. Algoritma I-PRESENT merupakan algoritma modifikasi dari
algoritma PRESENT dan dinyatakan lebih aman dibandingkan algoritma
PRESENT. Perbedaan kedua algoritma tersebut terletak pada S-box yang
digunakannya. Meskipun demikian, karakteristik S-box algoritma I-PRESENT
sama dengan karakteristik S-box algoritma PRESENT dari segi ketahanan
terhadap differential cryptanalysis dan linear cryptanalysis. Akibatnya ketika
Tezcan menemukan bahwa S-box algoritma PRESENT mempunyai 6
undisturbed bit serta 6 struktur linear, maka kemungkinan S-box algoritma I-
PRESENT akan memiliki undisturbed bit dan struktur linear seperti S-box
algoritma PRESENT. Undisturbed bit pada suatu S-box dapat diamati dengan
menggunakan 3 tools, yaitu DDT, LAT dan ACT. Hasil penelitian menunjukkan
bahwa meskipun ke-16 S-box I-PRESENT memiliki karakteristik yang sama
dengan S-box PRESENT tetapi hanya 4 buah S-box yang mempunyai jumlah
undisturbed bit dan struktur linear sama dengan S-box algoritma PRESENT.
Empat buah S-box I-PRESENT lain, mempunyai jumlah undisturbed bit dan
struktur linear yang lebih sedikit dari S-box algoritma PRESENT yaitu 3
undisturbed bit dan 2 struktur linear, sedangkan 8 buah S-box tidak memiliki
undisturbed bit tetapi memiliki 2 struktur linear.
Kata kunci: Algoritma PRESENT, algoritma I-PRESENT, S-box, undisturbed bit,
truncated differential.
1. Pendahuluan
Fungsi nonlinear dalam block cipher biasanya menggunakan operasi
substitusi dan implementasinya menggunakan lookup table yang disebut substitution
box atau S-box [12]. Menurut Dawson & Tavares [5] kualitas S-box yang digunakan
menentukan kekuatan sistem kriptografi algoritma berstruktur substitution
permutation network (SPN). Salah satu algoritma block cipher berstruktur SPN yang
mengandalkan S-box sebagai komponen non-linear untuk meningkatkan kekuatan
sistem kriptografinya adalah algoritma PRESENT. Algoritma PRESENT [3]
merupakan salah satu algoritma standar lightweight block cipher berdasarkan
ISO/IEC 29192-2:2012 [7] yang dipublikasikan Bogdanov pada tahun 2007.
Terdapat beberapa penelitian terkait kriptanalisis terhadap algoritma
PRESENT diantaranya adalah Differential Cryptanalysis [14], Linear Cryptanalysis
[4] dan Improbable Differential Attack using Undisturbed Bits [13]. Tezcan [13]
melakukan improbable differential attack menggunakan Differential Distribution

746
Table (DDT) S-box algoritma PRESENT dengan memanfaatkan adanya undisturbed
bit. Undisturbed bit dapat dijadikan parameter dalam menentukan resistensi suatu
algoritma block cipher karena undisturbed bit merupakan struktur linear dalam
fungsi koordinat [14]. Menurut Tezcan [13] undisturbed bit bermanfaat untuk
mengkonstruksi truncated, impossible dan improbable differential yang lebih
panjang dan lebih baik. Makarim dan Tezcan juga menyatakan bahwa keberadaan
undisturbed bit berguna untuk mengkonstruksi karakteristik truncated suatu block
cipher [12].
Pencarian undisturbed bit dilakukan dengan mengamati input dan output
difference yang memiliki pola dari Least Significant Bit (LSB) pada persebaran
probabilitasnya. Pada tahun 2014, Makarim dan Tezcan [12] melanjutkan penelitian
Tezcan [13] dengan mengamati hubungan antara undisturbed bit dan sifat S-box
melalui pembuktian matematis terhadap sifat S-box yang memiliki undisturbed bit.
Undisturbed bit tersebut dihasilkan dari tiga tools yaitu DDT, Linear Approximation
Table (LAT) dan Autocorrelation Table (ACT).
Untuk meningkatkan keamanan PRESENT, Aldabbagh dan Fakhri [1]
memodifikasi algoritma PRESENT menjadi Improved PRESENT (I-PRESENT)
dengan mengubah komponen S-box tetap menjadi S-box yang pemilihannya
bergantung pada kunci. Menurut Aldabbagh dan Fakhri, keamanan PRESENT
meningkat karena S-box yang digunakan tiap round berbeda dan bersifat rahasia
serta memiliki karakteristik S-box yang sama dengan S-box algoritma PRESENT
berkaitan dengan ketahanan terhadap linear cryptanalysis dan differential
cryptanalysis.
Mengingat S-box algoritma I-PRESENT memiliki karakteristik yang sama
dengan S-box PRESENT yaitu dari segi ketahanan terhadap linear cryptanalysis dan
differential cryptanalysis, serta belum dilakukan penelitian mengenai ada atau
tidaknya undisturbed bit pada ke-16 S-box algoritma I-PRESENT maka pada
penelitian ini dilakukan pencarian undisturbed bit berdasarkan DDT, LAT, ACT
pada S-box algoritma PRESENT dan I- PRESENT dengan menggunakan metode
yang diajukan Makarim dan Tezcan[12].
2. Landasan Teori
Berikut adalah konsep dan teori yang berkaitan dengan penelitian yang dilakukan yaitu S-box yang digunakan pada algoritma PRESENT dan algoritma I-PRESENT, DDT, LAT, ACT dan undisturbed bit.
2.1 S-box Algoritma PRESENT
Algoritma PRESENT merupakan salah satu algoritma lightweight block cipher berstruktur SPN yang memiliki ukuran blok input sebesar 64-bit dan memiliki dua jenis ukuran kunci, yaitu 80 dan 128-bit. Algoritma PRESENT terdiri dari 31-round dengan komponen yang terdapat dalam algoritma PRESENT adalah AddRoundKey, sBoxLayer dan pLayer. S-box pada algoritma PRESENT (dinotasikan dengan 𝑆: 𝔽2
4 → 𝔽24) digunakan pada sBoxLayer . Representasi S-box
PRESENT dalam bilangan heksadesimal dapat dilihat pada Tabel 1.

747
Tabel 1. S-box PRESENT [3]
2.2 S-box algoritma I-PRESENT
Algoritma I-PRESENT merupakan algoritma PRESENT yang dimodifikasi oleh Aldabbagh dengan mengubah penggunaan S-box menjadi S-box yang pemilihannya bergantung pada kunci. Algoritma I-PRESENT mempunyai 16 S-box yang memiliki karakteristik sama dengan S-box PRESENT, dengan rincian 8 S-box merupakan S-box algoritma Serpent [2], 4 S-box [11], dan 4 S-box merupakan S-box algoritma Hummingbird [6]. S-box yang digunakan pada algoritma I-PRESENT, yaitu:
𝑆0 = [3, 8, 15, 1, 10, 6, 5, 11, 14, 13, 4 ,2, 7, 0, 9, 12] 𝑆1 = [15, 12, 2, 7, 9, 0, 5, 10, 1, 11, 14, 8, 6, 13, 3, 4] 𝑆2 = [8, 6, 7, 9, 3, 12, 10, 15, 13, 1, 14, 4, 0, 11, 5, 2] 𝑆3 = [0, 15, 11, 8, 12, 9, 6, 3, 13, 1, 2, 4, 10, 7, 5, 14] 𝑆4 = [1, 15, 8, 3, 12, 0, 11, 6, 2, 5, 4, 10, 9, 14, 7, 13] 𝑆5 = [15, 5, 2, 11, 4, 10, 9, 12, 0, 3, 14, 8, 13, 6, 7, 1]; 𝑆6 = [7, 2, 12, 5, 8, 4, 6, 11, 14, 9, 1, 15, 13, 3, 10, 0] 𝑆7 = [1, 13, 15, 0, 14, 8, 2, 11, 7, 4, 12, 10, 9, 3, 5, 6] 𝑆8 = [0, 3, 5, 8, 6, 9, 12, 7, 13, 10, 14, 4, 1, 15, 11, 2]; 𝑆9 = [0, 3, 5, 8, 6, 12, 11, 7, 9, 14, 10, 13, 15, 2, 1, 4] 𝑆10 = [0, 3, 5, 8, 6, 10, 15, 4, 14, 13, 9, 2, 1, 7, 12, 11] 𝑆11 = [0, 3, 5, 8, 6, 12, 11, 7, 10, 4, 9, 14, 15, 1, 2, 13] 𝑆12 = [7, 12, 14, 9, 2, 1, 5, 15, 11, 6, 13, 0, 4, 8, 10, 3] 𝑆13 = [4, 10, 1, 6, 8, 15, 7, 12, 3, 0, 14, 13, 5, 9, 11, 2] 𝑆14 = [2, 15, 12, 1, 5, 6, 10, 13, 14, 8, 3, 4, 0, 11, 9, 7] 𝑆15 = [15, 4, 5, 8, 9, 7, 2, 1, 10, 3, 0, 14, 6, 12, 13, 11]
Pemilihan S-box pada algoritma I-PRESENT ditentukan oleh algoritma pemilihan
S-box berikut ini.
Algoritma Pemilihan S-box pada I-PRESENT.
INPUT: Mkey 80-bit dan plaintext 64-bit.
OUTPUT: ciphertext 80-bit
Key = Left most 64-bit from Mkey
S-boxes_Array = 𝑆0, 𝑆1, 𝑆2, … , 𝑆15
State = plaintext
For 𝑖= 1 to 31
In_key = Key[0. .3] ⊕… ⊕ Key[60. .63]. New_Sbox= S-boxes_Array[In_key].
State = State XOR Key.
New_Sbox(State).
P-box(State).
Key update.
End
Cipher = State XOR Key.
Key update
Proses key update yang digunakan pada algoritma I-PRESENT sama dengan proses

748
key update yang terdapat pada algoritma PRESENT, yaitu:
[𝑘79𝑘78… 𝑘1𝑘0] = [𝑘18𝑘17… 𝑘20𝑘19][𝑘79𝑘78 𝑘77𝑘76] = 𝑆[𝑘79𝑘78𝑘77𝑘76] [𝑘19𝑘18𝑘17𝑘16𝑘15] = [𝑘19𝑘18𝑘17𝑘16𝑘15] ⊕ 𝑟𝑐𝑜𝑛,
dengan 𝑟𝑐𝑜𝑛 adalah round counter.
2.3 DDT
DDT merupakan suatu tabel yang dibentuk dari S-box untuk mengecek berapa banyak output difference tertentu dari S-box yang terjadi untuk suatu input difference. Misal 𝑥, 𝑥′ ∈ 𝐹2
𝑛 adalah dua input S-box dan 𝑦 = 𝑆(𝑥), 𝑦′= 𝑆(𝑥′)
adalah output yang berkorespondensi. Input difference adalah 𝑥 ⊕ 𝑥′= 𝛼. 𝑦 ⊕
𝑦′= 𝛽 adalah sebagai difference dari output 𝑆 yang berkorespondensi terhadap input
difference 𝛼.
Definisi 2.1. [12] (DDT) Untuk suatu S-box 𝑆 berukuran 𝑛 ×𝑚, isi dari baris 𝛼 ∈
𝐹2𝑛 dan kolom 𝛽 ∈ 𝐹2
𝑚 (direpresentasikan dalam nilai integer) dari DDT S-box 𝑆
didefinisikan dengan
𝐷𝐷𝑇 (𝛼, 𝛽) = |{𝑥 ∈ 𝐹2𝑛 |𝑆(𝑥)⊕ 𝑆(𝑥 ⊕ 𝛼) = 𝛽}| (1)
Contoh 2.2. Tabel DDT S-box 𝑆0 I-PRESENT dapat dilihat pada Tabel 2.
Tabel 2. DDT S-box 𝑺𝟎 I-PRESENT
2.4 LAT
LAT merupakan suatu tabel yang digunakan untuk menemukan persamaan linear terbaik dari suatu S-box dengan melibatkan bit-bit yang sama dari input dan output.
Definisi 2.3. [12] (LAT) LAT dari S-box 𝑆 berukuran 𝑛 ×𝑚 pada baris 𝛼 ∈ 𝐹2𝑛 dan
kolom 𝛽 ∈ 𝐹2𝑛 (representasi nilai integer) didefinisikan dengan
𝐿𝐴𝑇 (𝛼, 𝛽) = |{𝑥 ∈ 𝐹2𝑛 | 𝛼 ∙ 𝑥 = 𝑆(𝑥) ∙ 𝛽}| − 2𝑛−1 (2)
Contoh 2.4. LAT S-box 𝑆0 I-PRESENT dapat dilihat pada Tabel 3.
Tabel 3. LAT S-box 𝑆0 I-PRESENT

749
2.5 ACT
Autocorrelation table adalah suatu tabel yang terbentuk dengan mengamati DDT dari suatu S-box.
Definisi 2.5. [12] (ACT) Autocorrelation table S-box 𝑆 berukuran 𝑛 ×𝑚
(dinotasikan dengan 𝐴𝐶𝑇) adalah tabel dengan entri dari baris 𝑎 dan kolom 𝑏 serta
𝑎, 𝑏 ∈ 𝐹2𝑛 didefinisikan sebagai
𝐴𝐶𝑇(𝑎, 𝑏) = 𝑟𝑏.𝑆(𝑎) = ∑ 𝐷𝐷𝑇(𝑎, 𝑣) (−1)𝑏∙𝑣𝑣𝜖𝐹2𝑚 (3)
Contoh 2.6. ACT S-box 𝑆0 I-PRESENT dapat dilihat pada Tabel 4.
Tabel 4. ACT S-box 𝑆0 I-PRESENT
2.6 Undisturbed bit
Keberadaan dari undisturbed bit yang merupakan suatu bit tetap ternyata menjadi sesuatu yang dapat dimanfaatkan dalam melakukan serangan terhadap improbable differential attack.
Definisi 2.7. [12] (Undisturbed Bit) 𝑥 ∈ 𝐹2𝑛 adalah input difference tidak nol pada
S-box S (untuk S-box berukuran 𝑛 ×𝑚 yang dinotasikan dengan 𝑆: 𝐹2𝑛 → 𝐹2
𝑚) dan
𝛺𝛼 = {𝛽 = (𝛽𝑚−1, … , 𝛽0)𝜖𝐹2𝑚|𝑷𝒓𝑆[𝛼 → 𝛽] > 0} adalah himpunan dari semua
kemungkinan output difference dari S yang berkorespondensi dengan 𝛼. Jika 𝛽𝑖 = 𝑐
untuk 𝑐 ∈ 𝐹2 tetap dan untuk semua 𝛽 ∈ 𝛺𝛼, dengan 𝑖 ∈ {0,… ,𝑚 − 1}, maka S-box
𝑆 memiliki undisturbed bit, sehingga dapat dinyatakan untuk input difference 𝛼, bit
ke-𝑖 pada output difference 𝑆 adalah undisturbed yang bernilai 𝑐.
Hasil penelitian Tezcan [13] menunjukkan bahwa S-box pada algoritma PRESENT
memiliki 6 undisturbed bit, yaitu:
1. Jika input difference dari S-box bernilai 9, maka LSB dari output difference
adalah undisturbed yang bernilai 0.
2. Jika input difference dari S-box bernilai 1 atau 8, maka LSB dari output
difference adalah undisturbed yang bernilai 1.
3. Jika output difference dari S-box bernilai 1 atau 4, maka LSB dari input
difference adalah undisturbed yang bernilai 1.
4. Jika output difference dari S-box bernilai 5, maka LSB dari input difference
adalah undisturbed yang bernilai 0.
Menurut Makarim dan Tezcan [12], pencarian undisturbed bit dapat dilakukan
dengan mengamati DDT, LAT dan ACT. Berikut adalah lemma, teorema, corollary,

750
proposisi dan remark yang berkaitan dengan pencarian undisturbed bit.
Corollary 2.8. [12] (DDT dan undisturbed bit) Untuk suatu nonzero input difference
�� ∈ 𝐹2𝑛, bit ke-𝑖 dari output difference 𝑆 itu undisturbed jika dan hanya jika
∑ 𝐷𝐷𝑇(𝛼, 𝑣) (−1)𝑒𝑖∙𝑣𝑣𝜖𝐹2𝑚 = ±2𝑛 (4)
untuk 𝑖 ∈ {0,… ,𝑚 − 1} dan 𝑒�� adalah basis standar ke- 𝑖 dari 𝐹2𝑚.
Teorema 2.9. [12] (LAT dan Undisturbed bit) Untuk suatu nonzero input difference
�� ∈ 𝐹2𝑛, bit ke-𝑖 dari output difference 𝑆 itu undisturbed jika dan hanya jika
22−𝑛∑ 𝐿𝐴𝑇(𝑎, 2𝑖)2(−1) ��∙ �� = ±2𝑛 ��∈𝐹2
𝑛 (5)
untuk 𝑖 ∈ {0,… ,𝑚 − 1} dan 𝑎 ∈ 𝐹2𝑛.
Corollary 2.10. [12] (ACT dan Undisturbed bit) Untuk suatu input difference tidak
nol ��, bit ke-𝑖 dari output difference 𝑆 itu undisturbed jika dan hanya jika
𝐴𝐶𝑇(𝛼, 2𝑖) = ±2𝑛 (6)
untuk 𝑖 ∈ {0,… ,𝑚 − 1}.
3. Hasil – Hasil Utama
3.1 Pencarian Undisturbed Bit Menggunakan DDT
Pencarian undisturbed bit menggunakan DDT meliputi dua tahap. Tahap pertama menghitung DDT dan tahap kedua mencari undisturbed bit dari DDT yang telah diperoleh. a. Proses perhitungan DDT
Pada proses pehitungan DDT, terdapat dua langkah yang dilakukan, yaitu
menentukan nilai 𝛼 yang akan digunakan dan menghitung seluruh kemungkinan
nilai 𝛽 yang dihasilkan. Perhitungan DDT S-box PRESENT dilakukan
menggunakan persamaan 1.
b. Pencarian Undisturbed Bit berdasarkan DDT
Pencarian undisturbed bit berdasarkan DDT pada S-box dilakukan melalui dua
cara, yaitu menggunakan S-box 𝑆 untuk melihat undisturbed bit dari sisi input
difference dan menggunakan S-box invers 𝑆−1 untuk melihat undisturbed bit
dari sisi output difference. Berdasarkan persamaan 4, variabel yang ditentukan
terlebih dahulu adalah 𝛼 dan 𝑒𝑖 dengan �� ∈ 𝐹24 merupakan nonzero input
difference yang nilainya berkisar antara 0001 s.d.1111 dan 𝑒𝑖 merupakan basis
standar (basis yang memiliki hamming weight 1, karena menggunakan basis
yang memiliki hamming weight 1 bertujuan untuk mengecek undisturbed bit di
setiap posisi bit dari mulai bit ke-0 s.d ke-3) dari 𝐹24 sehingga nilai 𝑒𝑖 adalah
0001, 0010, 0100 dan 1000.Undisturbed bit dapat diperoleh apabila
∑ 𝐷𝐷𝑇(𝛼, 𝑣) (−1)𝑒𝑖∙𝑣𝑣𝜖𝐹2𝑚 menghasilkan nilai ±2𝑛.
Contoh 3.1. Pencarian undisturbed bit berdasarkan input dan output difference pada S-box 𝑆0 I-PRESENT dengan menggunakan seluruh variasi nilai 𝛼 dan 𝑒𝑖, ditunjukkan pada Tabel 5 dan Tabel 6.

751
Tabel 5. Undisturbed bit S-box 𝑆0 I-PRESENT berdasarkan input difference
DDT
Input Difference
1 2 3 4 5 6 7 8 9 A B C D E F
Bit
ke-
i
0 0 0 -8 0 8 -8 0 -8 0 0 0 0 -8 8 0
1 -8 0 0 0 0 -8 8 0 0 -8 0 8 -8 0 0
2 -8 -8 8 0 0 0 0 -8 0 8 -8 0 0 0 0
3 0 -
16 0
-
16 0 16 0 0 0 0 0 0 0 0 0
Tabel 6. Undisturbed bit S-box S-box 𝑆0 I-PRESENT berdasarkan output
difference DDT
Output Difference
1 2 3 4 5 6 7 8 9 A B C D E F
Bit
ke-
i
0 0 -8 0 0 -8 0 0 -8 0 8 0 0 8 0 -8
1 -8 -8 0 0 0 0 0 0 0 -8 0 -8 8 8 -8
2 0 0 0 -
16 0 0 0
-
16 0 0 0 16 0 0 0
3 -8 0 0 0 0 -8 0 -8 8 0 0 0 0 8 -8
Berdasarkan Tabel 5 dan Tabel 6 terlihat bahwa S-box 𝑆0 I-PRESENT memiliki 3
buah undisturbed bit jika dilihat dari sisi input difference, yaitu terletak pada bit ke-
3 dengan nilai input difference sebesar 2,4 dan 6 serta memiliki 3 buah undisturbed
bit jika dilihat dari output difference, yaitu pada output difference 4, 8 dan C pada
posisi bit ke-2. Ke-6 undisturbed bit pada S-box 𝑆0 I-PRESENT dapat dinyatakan
sebagai berikut :
a. Jika input difference dari S-box adalah 6 maka most significant bit dari output
difference adalah undisturbed dan bernilai 0.
b. Jika input difference dari S-box adalah 2 atau 4 maka most significant bit dari
output difference adalah undisturbed dan bernilai 1.
c. Jika output difference dari S-box adalah 4 atau 8 maka bit ke-2 dari input
difference adalah undisturbed dan bernilai 1.
d. Jika output difference dari S-box adalah 12 maka bit ke-2 dari input difference
adalah undisturbed dan bernilai 0.
3.2 Pencarian Undisturbed Bit Berdasarkan LAT
Terdapat dua langkah untuk mencari undisturbed bit menggunakan LAT, yaitu menghitung LAT lalu mencari undisturbed bit dari LAT yang telah diperoleh. a. Proses Perhitungan LAT

752
Pada proses perhitungan LAT, terdapat dua langkah yang dilakukan, yaitu
menentukan nilai 𝛼 dan 𝛽 yang akan digunakan kemudian menghitung
𝐿𝐴𝑇 (𝛼, 𝛽) menggunakan persamaan 2.
b. Pencarian Undisturbed bit berdasarkan LAT.
Pencarian undisturbed bit berdasarkan LAT pada S-box dilakukan melalui dua
cara, yaitu menggunakan S-box 𝑆 untuk melihat undisturbed bit dari sisi input
difference dan menggunakan S-box invers 𝑆−1 untuk melihat undisturbed bit
dari sisi output difference. Berdasarkan persamaan 5, variabel yang ditentukan
terlebih dahulu adalah 𝛼 dan 𝑖 dengan 𝛼 ∈ 𝐹24 adalah nonzero 𝛼 yang nilainya
berkisar antara 0001 s.d 1111 dan 𝑖 ∈ {0,… , 3} merupakan bit ke-i dari 𝛽 𝑆. Berdasarkan persamaan 2.5, undisturbed bit dapat diperoleh apabila
22−𝑛∑ 𝐿𝐴𝑇(𝑎, 2𝑖)2(−1) ��∙ �� ��∈𝐹2
𝑛 menghasilkan nilai ±2𝑛.
Contoh 3.2. Pencarian undisturbed bit pada salah satu S-box I-PRESENT yaitu 𝑆0 dengan menggunakan seluruh variasi nilai 𝛼 dan 𝑖 ditunjukkan pada Tabel 7 sedangkan dengan menggunakan seluruh variasi 𝛽 dan 𝑖 ditunjukkan pada Tabel 8.
Tabel 7 Undisturbed bit S-box 𝑆0 I-PRESENT berdasarkan seluruh variasi nilai 𝛼 dan 𝑖
Tabel 8 Undisturbed bit S-box 𝑆0 I-PRESENT berdasarkan seluruh variasi nilai 𝛽 dan 𝑖
Berdasarkan Tabel 7 dan Tabel 8 diketahui bahwa S-box 𝑆0 I-PRESENT memiliki 6 buah undisturbed bit dengan rincian 3 buah undisturbed bit pada 𝛼=2,4,6 saat bit ke-3 dan 3 buah undisturbed bit pada 𝛽=4,8 dan 12 saat bit ke-2. Ke-6 undisturbed bit pada S-box 𝑆0 I-PRESENT dapat dinyatakan sebagai berikut: a. Jika 𝛼 dari S-box adalah 6 maka most significant bit dari 𝛽 adalah undisturbed
dan bernilai 0. b. Jika 𝛼 dari S-box adalah 2 atau 4 maka most significant bit dari 𝛽 adalah
undisturbed dan bernilai 1. c. Jika 𝛽 dari S-box adalah 4 atau 8 maka bit ke-2 dari 𝛼 adalah undisturbed dan
bernilai 1. d. Jika 𝛽 dari S-box adalah 12 maka bit ke-2 dari 𝛼 adalah undisturbed dan bernilai 0.
3.3 Pencarian Undisturbed Bit Berdasarkan ACT
Terdapat dua langkah untuk mencari undisturbed bit dengan menggunakan ACT. Langkah pertama menghitung ACT kemudian langkah kedua mencari undisturbed bit dari ACT yang telah diperoleh pada langkah pertama. a. Proses Perhitungan ACT

753
Terdapat dua langkah yang dilakukan untuk menghitung ACT, yaitu
menentukan nilai 𝑎 dan 𝑏 yang nilainya berkisar dari 0000 -1111 dimana
masing-masing merepresentasikan baris dan kolom dari ACT. Kemudian
menghitung nilai 𝐴𝐶𝑇(𝑎, 𝑏) berdasarkan nilai 𝑎 dan 𝑏 yang sudah ditentukan.
Proses perhitungan ACT S-box 𝑆2 I-PRESENT menggunakan persamaan 3.
b. Pencarian Undisturbed bit berdasarkan ACT
Pencarian undisturbed bit berdasarkan ACT pada S-box dilakukan melalui dua
cara, yaitu menggunakan S-box 𝑆 untuk melihat undisturbed bit dari sisi input
difference dan menggunakan S-box invers 𝑆−1 untuk melihat undisturbed bit
dari sisi output difference. Berdasarkan persamaan 6, undisturbed bit dapat
diperoleh apabila 𝐴𝐶𝑇(𝛼, 2𝑖) = ±16. Artinya berapapun nilai nonzero input
difference 𝛼 yang digunakan, nilai undisturbed bit hanya bergantung pada kolom
2𝑖 dengan nilai 𝑖 mulai dari 0 s.d 3 yang merupakan representasi dari posisi bit
atau yang disebut dengan fungsi koordinat (fungsi boolean) ke- 𝑖. Contoh 3.3. Pencarian undisturbed bit pada S-box 𝑆0 I-PRESENT berdasarkan input dan output difference ditunjukkan pada Tabel 9 dan Tabel 10. Indeks baris pada Tabel 9 merepresentasikan input difference sedangkan pada Tabel 10 merepresentasikan output difference. Indeks kolom pada kedua tabel merepresentasikan fungsi komponen dari S-box yang dinyatakan �� ∙ 𝑆(𝑥) untuk semua nonzero �� ∈ 𝐹2
𝑚. Fungsi komponen merupakan generalisasi dari suatu fungsi koordinat suatu S-box dengan melihat kombinasi linearnya. Input difference yang memiliki undisturbed bit memiliki korespondensi dengan output difference. Hal ini dapat diamati pada kolom 1 yang merupakan autocorrelation spectrum dari fungsi koordinat ke-1 (rightmost). Autocorrelation spectrum adalah fungsi koordinat dari S-box yang merepresentasikan posisi bit, sehingga fungsi koordinat yang termasuk ke dalam autocorrelation spectrum adalah fungsi koordinat bit ke-0 s.d ke-3 yang terdapat pada kolom 2𝑖, dengan nilai 𝑖 adalah posisi bit atau fungsi koordinat ke- 𝑖.
Tabel 9. Perhitungan Pencarian Undisturbed Bit S-box 𝑆0 I-PRESENT
Berdasarkan Input Difference ACT
Keterangan:
= Undisturbed bit, = Struktur linear
= Struktur linear yang memenuhi undisturbed bit

754
Pada Tabel 9 terlihat bahwa di baris 4,9,D pada kolom 3, di baris 2,4,6 pada kolom 8 dan di baris 4,B,F pada kolom B memiliki nilai ±16. Berdasarkan persamaan 6, maka kolom 8 menunjukkan terdapat undisturbed bit pada 𝑆0 I-PRESENT dengan rincian, undsturbed bit bernilai 1 ketika input difference-nya 2 dan 4, dan bernilai 0 ketika input difference-nya 6. Kolom 3 dan 𝐵 menunjukkan bahwa pada 𝑆0 I-PRESENT terdapat fungsi komponen yang memiliki struktur linear nontrivial. Fungsi tersebut direpresentasikan dengan 3 ∙ 𝑆(𝑥) dan 𝐵 ∙ 𝑆(𝑥).
Tabel 10. Perhitungan Pencarian Undisturbed Bit S-box 𝑆2 I-PRESENT
Berdasarkan Output Difference ACT
Pada Tabel 10 di baris 4,8,C pada kolom 4, baris 4,B,F pada kolom 9 dan di baris 3,4,7 pada kolom D memiliki nilai ±16. Berdasarkan persamaan 6, maka kolom 4 menunjukkan terdapat undisturbed bit pada 𝑆2
-1 I-PRESENT bernilai 1 ketika input difference-nya 4 dan 8, sedangkan bernilai 0 ketika input difference C. Kolom 9 dan D menunjukkan bahwa pada 𝑆2
-1 I-PRESENT terdapat fungsi komponen yang memiliki struktur linear nontrivial. Fungsi tersebut direpresentasikan dengan 9 ∙𝑆(𝑥) dan 𝐷 ∙ 𝑆(𝑥). Ke-6 undisturbed bit pada S-box 𝑆0 I-PRESENT berdasarkan ACTdapat dinyatakan sebagai berikut : a. Jika input difference dari S-box adalah 6 maka most significant bit dari output
difference itu undisturbed dan bernilai 0.
b. Jika input difference dari S-box adalah 2 atau 4 maka most significant bit dari
output difference itu undisturbed dan bernilai 1.
c. Jika output difference dari S-box adalah 4 atau 8 maka bit ke-2 dari input
difference itu undisturbed dan bernilai 1.
d. Jika output difference dari S-box adalah 12 maka bit ke-2 dari input difference
itu undisturbed dan bernilai 0.
Berdasarkan hasil perhitungan undisturbed bit baik dengan menggunakan DDT, LAT maupun ACT diperoleh 8 dari 16 S-box I-PRESENT memiliki undisturbed bit dengan S-box yang memiliki undisturbed bit terbanyak adalah 𝑆0,𝑆1,𝑆2 dan 𝑆6 yaitu sebanyak 6 buah. Selain itu, pencarian undisturbed bit yang diperoleh dari DDT, LAT dan ACT mendapatkan hasil yang sama untuk jumlah, posisi dan nilai undisturbed bit bagi keseluruhan S-box I-PRESENT.

755
Berikut adalah undisturbed bit pada S-box I-PRESENT :
a. S-box 𝑆0 I-PRESENT memiliki 6 undisturbed bit, yaitu :
1) Jika input difference dari S-box adalah 6 maka most significant bit dari output
difference itu undisturbed dan bernilai 0.
2) Jika input difference dari S-box adalah 2 atau 4 maka most significant bit dari
output difference itu undisturbed dan bernilai 1.
3) Jika output difference dari S-box adalah 4 atau 8 maka bit ke-2 dari input
difference itu undisturbed dan bernilai 1.
4) Jika output difference dari S-box adalah 12 maka bit ke-2 dari input difference
itu undisturbed dan bernilai 0.
b. S-box 𝑆1 I-PRESENT memiliki 6 undisturbed bit, yaitu :
1) Jika input difference dari S-box adalah 12 maka bit ke-2 dari output difference
adalah undisturbed dan bernilai 0.
2) Jika input difference dari S-box adalah 4 atau 8 maka bit ke-2 dari output
difference adalah undisturbed dan bernilai 1.
3) Jika output difference dari S-box adalah 1 atau 4 maka most significant bit dari
input difference adalah undisturbed dan bernilai 1.
4) Jika output difference dari S-box adalah 5 maka most significant bit dari input
difference adalah undisturbed dan bernilai 0.
c. S-box 𝑆2 I-PRESENT memiliki 6 undisturbed bit, yaitu :
1) Jika input difference dari S-box adalah 10 maka least significant bit dari
output difference adalah undisturbed dan bernilai 0.
2) Jika input difference dari S-box adalah 2 atau 8 maka least significant bit dari
output difference adalah undisturbed dan bernilai 1.
3) Jika output difference dari S-box adalah 1 atau 12 maka least significant bit
dari input difference adalah undisturbed dan bernilai 1.
4) Jika output difference dari S-box adalah 13 maka least significant bit dari input
difference adalah undisturbed dan bernilai 0.
d. S-box 𝑆4 I-PRESENT memiliki 3 undisturbed bit, yaitu :
1) Jika input difference dari S-box adalah 15 maka least significant bit dari output
difference adalah undisturbed dan bernilai 0.
2) Jika input difference dari S-box adalah 4 atau 11 maka least significant bit dari
output difference adalah undisturbed dan bernilai 1.
e. S-box 𝑆5 I-PRESENT memiliki 3 undisturbed bit, yaitu :
1) Jika input difference dari S-box adalah 15 maka least significant bit dari output
difference itu adalah undisturbed dan bernilai 0.
2) Jika input difference dari S-box adalah 4 atau 11 maka least significant bit dari
output difference adalah undisturbed dan bernilai 1.
f. S-box 𝑆6 I-PRESENT memiliki 6 undisturbed bit, yaitu :
1) Jika input difference dari S-box adalah 6 maka bit ke-1 dari output difference
itu adalah undisturbed dan bernilai 0.
2) Jika input difference dari S-box adalah 2 atau 4 maka bit ke-1 dari output
difference adalah undisturbed dan bernilai 1.
3) Jika output difference dari S-box adalah 2 atau 8 bit ke-1 dari input difference
adalah undisturbed dan bernilai 1.
4) Jika output difference dari S-box adalah 10 maka bit ke-1 dari input difference
adalah undisturbed dan bernilai 0.
g. S-box 𝑆14 I-PRESENT memiliki 3 undisturbed bit, yaitu :
1) Jika input difference dari S-box adalah 15 maka most significant bit dari output
difference adalah undisturbed dan bernilai 0.

756
2) Jika input difference dari S-box adalah 2 atau 13 maka most significant bit dari
output difference adalah undisturbed dan bernilai 1.
h. S-box 𝑆15 I-PRESENT memiliki 3 undisturbed bit, yaitu :
1) Jika output difference dari S-box adalah 15 maka least significant bit dari input
difference adalah undisturbed dan bernilai 0.
2) Jika output difference dari S-box adalah 1 atau 14 maka least significant bit
dari input difference adalah undisturbed dan bernilai 1
Delapan S-box I-PRESENT lain yaitu 𝑆3, 𝑆7, 𝑆8, 𝑆9, 𝑆10, 𝑆11, 𝑆12, 𝑆13 tidak memiliki
undisturbed bit.
Selain undisturbed bit, diperoleh juga jumlah struktur linear yang dimiliki oleh
masing-masing S-box I-PRESENT. Jumlah struktur linear tersebut ditunjukkan pada
Tabel 11.
Tabel 11 Jumlah struktur linear pada setiap S-box I-PRESENT
Dari Tabel 11 terlihat bahwa 4 buah S-box I-PRESENT yaitu 𝑆0,𝑆1,𝑆2 dan 𝑆6
memiliki jumlah struktur linear yang sama dengan S-box PRESENT, sedangkan
dua belas S-box lainnya memiliki struktur linear yang lebih sedikit dari S-box
PRESENT yaitu 2 struktur linear.
4. Kesimpulan
Berdasarkan hasil pencarian undisturbed bit pada algoritma I-PRESENT
diperoleh hasil bahwa meskipun ke-16 S-box I-PRESENT memiliki karakteristik
yang sama dengan S-box PRESENT tetapi :
a. Hanya empat buah S-box algoritma I-PRESENT (𝑆0,𝑆1,𝑆2 dan 𝑆6) yang
mempunyai jumlah undisturbed bit dan struktur linear yang sama dengan S-
box algoritma PRESENT yaitu 6 undisturbed bit serta 6 struktur linear.
b. Empat buah S-box algoritma I-PRESENT (𝑆4,𝑆5,𝑆14 dan 𝑆15) mempunyai
jumlah undisturbed bit dan struktur linear yang lebih sedikit dari S-box
algoritma PRESENT yaitu 3 undisturbed bit dan 2 struktur linear.
c. Delapan buah S-box algoritma I-PRESENT tidak memiliki undisturbed bit
tetapi memiliki 2 struktur linear.

757
Referensi
[1] Aldabbagh, S. & Fakhri, I. 2013. Improving PRESENT Lightweight Algorithm. IEEE
[2] Biham, E., Anderson, R. & Knudsen, L. 1998. Serpent: A Proposal for the Advanced
Encryption Standard. NIST AES Proposal.
[3] Bogdanov, A. et al. 2007. PRESENT: An Ultra-Lightweight Block Cipher. Springer
Berlin Heidelberg.
[4] Cho, J. C. 2010. Linear Cryptanalysis of Reduced-Round PRESENT. Berlin: Springer
Berlin Heidelberg.
[5] Dawson, M.H. & Tavares, S.E. 1998. An Expanded Set of S-box Design Criteria Based
on Information Theory and its Relation to Differential-Like Attacks. Springer.
[6] Engels, D., Markku-Juhani, O., Schweitzer, P. & Smith, E. 2012. The Hummingbird-2
Lightweight Authenticated Encryption Algorithm. Springer Berlin Heidelberg.
[7] International Organization of Standardization/ International Electrotechnical
Commission 29192-2. 2012. Information Technology-Security techniques- Lightweight
Cryptography Part 2: Block Ciphers. Switzerland: ISO
[8] Kaminsky, P. A. 2014. CSCI 462- Introduction to Cryptography, (online),
http://www.cs.rit.edu/~ark/462/attacks/notes.shtml. (diakses 1 Desember 2015).
[9] Knudsen, L. R. 1994. Truncated and Higher Order Differentials. Springer.
[10] Knudsen, L. R. 2011. COSIC, (online),
https://www.cosic.esat.kuleuven.be/ecrypt/courses/albena11/slides/LRK-
truncated_differentials.pdf. (diakses 11 Agustus 2016).
[11] Leander, G. & Poschmann, A. 2007. On the Classification of 4 Bit S-boxes Arithmetics
of Finite Fields. Springer Berlin Heidelberg.
[12] Makarim, R. & Tezcan, C. 2014. Relating Undisturbed Bits to Other Properties of
Substitution Boxes. Springer Berlin Heidelberg.
[13] Tezcan, C. 2014. Improbable Differential Attack on PRESENT using Undisturbed Bits.
ELSEVIER.
[14] Tezcan, C. 2015. Differential Factors Revisited: Corrected Attacks on PRESENT and
SERPENT. Springer.
[15] Wang, M. 2008. Differential Cryptanalysis of PRESENT. IAC

758
Prosiding SNM 2017 Komputasi , Hal 758 -767
S-NCI: DESAIN PROTOKOL KEY ESTABLISHMENT
MOHAMAD ALI SADIKIN1, SUSILA WINDARTA2
1Sekolah Tinggi Sandi Negara, [email protected]
2Sekolah Tinggi Sandi Negara, [email protected]
Abstrak. Dalam penelitian ini, didesain sebuah protokol key establishment baru
dengan nama S-NCI. Prinsip kerja dari protokol ini yaitu menggunakan pihak
ketiga terpercaya sebagai pusat translasi kunci (Key Translation Center). Kami
menggunakan algoritma block cipher, fungsi hash MAC, nonce, dan timestamp
untuk menjamin aspek kerahasiaan, integritas data, dan otentikasi serta
mencegah beberapa serangan yaitu man in the middle, replay attack,
modification attack, dan typing attack. Desain dari protokol ini
diimplementasikan dengan simulasi menggunakan bahasa pemograman Java.
Berdasarkan hasil simulasi dan analisis protokol S-NCI memenuhi keamanan,
integritas dari data, otentikasi dan tidak rentan terhadap man in the middle
attack, replay attack, modification attack, dan typing attack serta memiliki rata-
rata waktu eksekusi yaitu 0.6726 detik.
Kata kunci: S-NCI, Replay Attack, Man In The Middle, Modification Attack, Typing
Attack.
1. Pendahuluan
Kunci kriptografi merupakan sebuah parameter yang dioperasikan bersama
algoritma kriptografi sehingga pihak yang memiliki kunci dapat menjalankan operasi
tersebut [2]. Berdasarkan prinsip Kerckhoffs bahwa “security of a cryptosystem must
lie in the choice of its keys only, everything else (including the algorithm itself)
should be considered public knowledge” [15]. Dalam hal ini kekuatan dari suatu
algoritma kriptografi terletak pada kunci yang digunakan. Pernyataan Kerckoffs
diperkuat oleh Shannon yang menyatakan bahwa sebuah sistem kriptografi harus
dirancang sehingga sistem tersebut akan tetap aman walaupun publik mengetahui
seluruh detail dari sistem, kecuali kunci kriptografi yang digunakan di dalamnya
[13][19].
Key establishment (penyediaan kunci) adalah suatu proses atau protokol
yang menyediakan shared secret untuk dua atau lebih pihak, untuk penggunaan
secara kriptografis selanjutnya [10][11]. Dilihat dari aspek keamanan, sebuah
protokol key establishment harus memperhatikan faktor kerahasiaan, integritas data,
otentikasi dan nir-penyangkalan serta ketahanan terhadap berbagai ancaman
serangan. Beberapa serangan yang mungkin terjadi pada protokol key establishment
yaitu: man in the middle attack, replay attack, typing attack, modification attack
[3][4][9].
Banyak protokol key establishment yang telah dikembangkan yaitu salah
satunya berbasis server sebagai trusted third party. Beberapa protokol berbasis
server yang telah diajukan masih rentan terhadap replay attack [3][5][7][12], man in

759
the middle attack [3][13], typing attack[3][5], modification attack [3][14][20].
Dalam paper ini kami mencoba mendesain sebuah protokol key
establishment dengan nama S-NCI yang merupakan protokol berbasis server dengan
pihak ketiga sebagai key translation center (KTC). Dalam mendesain protokol ini
kami menggunakan prinsip yang dikemukakan oleh Abadi dan Needham [1]. Selain
itu, kami juga menggunakan timestamp dan nounce untuk mencegah man in the
middle attack dan replay attack serta fungsi hash dan enkripsi untuk mencegah
terjadinya typing attack dan modification attack. Protokol ini akan disimulasikan
menggunakan bahasa pemograman berbasis Java.
2. Kajian Terkait
A. Protokol Key Establishment
Protokol adalah serangkaian tahapan yang melibatkan dua atau lebih pihak untuk menyelesaikan permasalahan secara berurutan agar tercapainya suatu tujuan [16]. Key establishment (penyediaan kunci) adalah suatu proses atau protokol yang menyediakan shared secret untuk dua atau lebih pihak, untuk penggunaan secara kriptografis selanjutnya [10]. Key establishment Pembagian klasifikasi teknik key establishment dapat dilihat pada Gambar 1. Key establishment merupakan hal yang paling mendasar dalam membangun kriptografi yang didefinisikan sebagai proses yang digunakan untuk menyediakan shared secret bagi setiap entitas untuk penggunan secara kriptografis [6].
Gambar 1 Penyederhanaan klasifikasi teknik key establishment [21]
Salah satu jenis protokol key establishment yaitu berbasis server. Pada Tabel 1
disajikan perbandingan beberapa protokol key establishment yang sudah ada.
§12.2 Classification and framework 491
contrast, dynamic key establishment schemes are those whereby the key established by a
fixed pair (or group) of users varies on subsequent executions.
Dynamic key establishment is also referred to as session key establishment. In this case
the session keys are dynamic, and it is usually intended that the protocols are immune to
known-key attacks.
key establishment
key transport key agreement
asymmetrictechniques
techniquessymmetric
keypre-distribution
dynamic
key establishment
Figure 12.1: Simplified classification of key establishment techniques.
Use of trusted servers
Many key establishment protocols involve a centralized or trusted party, for either or both
initial system setup and on-line actions (i.e., involving real-time participation). This party
is referred to by a variety of names depending on the role played, including: trusted third
party, trusted server, authentication server, key distribution center (KDC), key translation
center (KTC), and certification authority (CA). The various roles and functions of such
trusted parties are discussed in greater detail in Chapter 13. In the present chapter, discus-
sion is limited to the actions required of such parties in specific key establishment protocols.
Entity authentication, key authentication, and key confirmation
It is generally desired that each party in a key establishment protocol be able to determine
the true identity of the other(s) which could possibly gain access to the resulting key, imply-
ing preclusion of any unauthorized additional parties from deducing the same key. In this
case, the technique is said (informally) to provide secure key establishment. This requires
both secrecy of the key, and identification of those parties with access to it. Furthermore,
the identification requirement differs subtly, but in a very important manner, from that of
entity authentication – here the requirement is knowledge of the identity of parties which
may gain access to the key, rather than corroboration that actual communication has been
established with such parties. Table 12.1 distinguishes various such related concepts, which
are highlighted by the definitions which follow.
While authentication may be informally defined as the process of verifying that an
identity is as claimed, there are many aspects to consider, including who, what, and when.
Entity authentication is defined in Chapter 10 (Definition 10.1), which presents protocols
providing entity authentication alone. Data origin authentication is defined in Chapter 9
(Definition 9.76), and is quite distinct.

760
Tabel 1 Perbandingan Protokol Key Establishment berbasis Server
Keterangan: T: pihak ketiga terpercaya (server), A: entitas A, B: entitas B
Key control: entitas yang membangkitkan kunci
Fresh key: entitas yang menjamin fresh key
Key authentication: entitas yang menjalankan proses otentikasi kunci
Key confirmation: entitas yang melakukan proses konfirmasi kunci
B. Serangan pada Protokol (Protocol Attacks)
Berikut adalah beberapa serangan umum pada sebuah protokol:
1. Man in the middle attack (MITM): sebuah bentuk penyadapan dimana
penyerang membuat sebuah koneksi yang independen antara korban dan
mengirimkan pesan diantara para korban yang mengira mereka sedang
berkomunikasi pada sebuah koneksi privat yang sebenarnya semua
percakapan tersebut diatur oleh penyerang [16]. Gambar 2 merupakan
gambaran man in the middle attack.
2. Gambar 2 Man In The Middle Attack
Karakteristik Jumlah
langkah
Key
Control
Fresh
Key
Key
Authentication
Key
Confirmation Serangan
Protokol
Needham- Schroeder
[3][12][18] 5 T A(*) A+B A
Denning- Sacco [3]
[7][18] 3 T A+B A+B No
Otway-Rees [3][14] 4 T A+B A+B No
ISO/IEC 11770-2
mekanisme 10
[3][5][8]
3 T A+B A+B No
ISO/IEC 11770-2
mekanisme 11
[3][5][8]
3 A A+B A+B No
ISO/IEC 11770-2
mekanisme 12
[3][5][8]
4 B A+B A+B No

761
3. Replay attack: Serangan ini dilakukan dengan menggunakan kembali
pesan pada komunikasi sebelumnya oleh pihak ketiga untuk melakukan
kecurangan. Biasanya penyerang tidak dapat membaca isi pesan karena
terenkripsi sehingga penyerang harus menentukan saat yang tepat untuk
menggunakan kembali pesan tersebut [17]. Untuk lebih jelasnya,
Gambar 3 merupakan gambaran replay attack.
Gambar 3 Replay Attack
4. Typing attack: Serangan ini dilakukan dengan memanfaatkan kesamaan dari bagian pesan terenkripsi yang pertama dan pesan terenkripsi lain menggunakan kunci yang sama [3]. Typing attack mengeksploitasi pesan dengan membuat penerima salah menafsirkan pesan, yaitu menerima sebuah elemen protokol sebagai elemen yang lain (pesan dari tipe yang berbeda) [14].
5. Modification attack: penyerang memanfaatkan kelemahan dalam protokol disebabkan tidak adanya koreksi terhadap pesan, sehingga jika terjadi perubahan terhadap pesan maka penerima tidak dapat mengetahuinya. Serangan ini dapat dicegah menggunakan layanan kriptografi yaitu message integrity (integritas pesan) [20].
3. Protokol Key Establishment S-NCI
Pada Tabel 2 didefinisikan notasi yang digunakan pada protokol S-NCI.
Tabel 2 Notasi dan Definisi
Notasi Definisi
𝑇 Trusted Third Party (KTC)
𝐴 Alice
𝐵 Bob
𝐾𝐴𝑇 Kunci antara A dan T
𝐾𝐵𝑇 Kunci antara B dan T
𝐾𝑠 Session key (kunci sesi)
𝐼𝐷𝐴 Identitas A

762
Notasi Definisi
𝐼𝐷𝑩 Identitas B
𝐸 Fungsi Enkripsi
𝐻𝑘 Fungsi hash MAC (𝐾𝑠 sebagai kunci)
𝐻 Fungsi hash MDC
𝑡 Timestamp
𝑁 Nonce
|| Concate
A. Protokol S-NCI
Protokol key establishment S-NCI dirancang untuk menjamin
kerahasiaan, integritas, dan otentikasi dari proses key establishment. Protokol ini
menggunakan pihak ketiga dalam proses pembentukan kunci. algoritma block
cipher, fungsi hash, timestamp, dan nonce. Pada Tabel 3 dijabarkan tahapan
protokol S-NCI. Tabel 3 Protokol Key establishment S-NCI
Ringkasan : A berinteraksi dengan trusted server T dan entitas B.
Hasil : otentikasi entitas (A dan B) serta 𝐾𝑠 hasil proses key establishment
dengan konfirmasi kunci.
1. Persiapan
a. A dan T sudah menyepakati sebuah kunci 𝐾𝐴𝑇 untuk enkripsi pesan.
b. B dan T juga sudah menyepakati kunci 𝐾𝐵𝑇.
c. T merupakan pihak ketiga terpercaya.
2. Pertukaran pesan pada protokol S-NCI
𝐴 → 𝑇 ∶ 𝐸𝐾𝐴𝑇(𝐾𝑠 || 𝐼𝐷𝐴 || 𝐼𝐷𝐵|| 𝑡1)||𝐻(𝐾𝑠 || 𝐼𝐷𝐴 || 𝐼𝐷𝐵|| 𝑡1) (1)
𝑇 → 𝐵 ∶ 𝐸𝐾𝐵𝑇(𝐾𝑠|| 𝐼𝐷𝐴 || 𝑡2)||𝐻(𝐾𝑠|| 𝐼𝐷𝐴 || 𝑡2) (2)
𝐴 ← 𝐵 ∶ 𝐸𝐾𝑆( 𝑁𝐵||𝑡3) (3)
𝐴 → 𝐵 ∶ 𝐻𝑘(𝑁𝐵) (4)
3. Langkah-langkah pertukaran pesan dalam protokol a. A membangkitkan kunci sesi dan kemudian mengirimkan kunci sesi tersebut
kepada T bersama dengan 𝐼𝐷𝐴 , 𝐼𝐷𝐵, dan 𝑡1 yang dienkripsi menggunakan 𝐾𝐴𝑇. Selain itu A juga mengirimkan nilai hash dari 𝐾𝑠 || 𝐼𝐷𝐴 || 𝐼𝐷𝐵|| 𝑡1. T menerima pesan dari A yang kemudian didekripsi menggunakan 𝐾𝐴𝑇 dan melakukan hashing pesan yang di terima untuk mengecek keutuhan pesan yang di terima.
b. T mengenkripsi pesan yang berisi 𝐾𝑠|| 𝐼𝐷𝐴 || 𝑡2 dengan menggunakan 𝐾𝐵𝑇, dan melakukan hashing terhadap 𝐾𝑠|| 𝐼𝐷𝐴 || 𝑡2, kemudian pesan dan nilai hash dikirimkan kepada B.
c. B mendekripsi pesan yang di terima dari T untuk mendaptkan nilai dari kunci sesi dan menghitung nilai hash untuk mengecek keutuhan pesan. Kemudian B membangkitkan bilangan acak 𝑁𝐵 dan nilai timestamp 𝑡3. Nilai acak dan timestamp kemudian di enkripsi dan dikirimkan kepada A.

763
d. A mendekripsi 𝐸𝐾𝑆( 𝑁𝐵||𝑡3) dengan menggunakan 𝐾𝑆. Selanjutnya A akan menghitung nilai MAC dengan kunci 𝐾𝑠 dari 𝑁𝐵 dan mengirimkanya kepada B. Ketika B menerima nilai MAC yang dikirimkan oleh A, sebelumnya B sudah menghitung nilai MAC dari 𝑁𝐵. B akan membandingkan nilai MAC yang lama dan baru sehingga jika keduanya sama maka protokol tersebut sukses dijalankan dan A dan B memiliki kunci sesi yang baru yaitu 𝐾𝑆.
Gambaran skema dari protokol S-NCI dapat dilihat pada Gambar 4.
Gambar 4 Skema Protokol S-NCI
B. Analisis terhadap Replay Attack
Analisis replay attack pada protokol S-NCI dapat dijelaskan sebagai berikut: 1. Langkah 1
𝐴 → 𝑇 ∶ 𝐸𝐾𝐴𝑇(𝐾𝑠 ||𝐼𝐷𝐴|| 𝐼𝐷𝐵|| 𝑡1)||𝐻(𝐾𝑠 || 𝐼𝐷𝐴 || 𝐼𝐷𝐵|| 𝑡1).
Penyerang mencoba mendapatkan pesan terenkripsi 𝐸𝐾𝐴𝑇 dan nilai hash dari pesan. Meskipun memiliki pesan terenkripsi pada protokol sebelumnya, penyerang tidak dapat melakukan replay attack karena terdapat 𝑡1, ketika pesan merupakan pesan lama akan menghasilkan nilai 𝑡1 yang tidak valid (tidak sama).
2. Langkah 2
𝑇 → 𝐵 ∶ 𝐸𝐾𝐵𝑇(𝐾𝑠|| 𝐼𝐷𝐴 || 𝑡2)||𝐻(𝐾𝑠|| 𝐼𝐷𝐴 || 𝑡2).
Seperti pada langkah 1, ketika penyerang melakukan replay attack maka serangan dapat terdeteksi dari nilai 𝑡2 yang berbeda.
3. Langkah 3
𝐴 ← 𝐵 ∶ 𝐸𝐾𝑆( 𝑁𝐵||𝑡3).
Pada langkah 3, serangan replay attack dapat dicegah dengan menggunakan 𝑡3 dan 𝑁𝐵. Ketika terjadi replay attack maka nilai 𝑡3 akan berbeda karena perbedaan waktu pengiriman dan nilai 𝑁𝐵 juga akan berbeda karena setiap sesi 𝑁𝐵 selalu identik.
4. Langkah 4 𝐴 → 𝐵 ∶ 𝐻𝑘(𝑁𝐵).
A
T
B
(2)(1)
(3)
(4)

764
Seperti langkah 3, karena 𝑁𝐵 merupakan nilai yang identik pada setiap sesi protokol maka nilai MAC setiap sesi juga akan berbeda. Ketika terjadi replay attack maka akan terdeteksi dari nilai MAC.
C. Analisis terhadap Man In The Middle Attack
Tujuan dari serangan man in the middle adalah penyerang ingin mendapatkan pesan atau data yang dikirimkan tanpa sepengetahuan pengirim dengan maksud untuk memodifikasi, memperoleh atau bahkan menghapus data.
Berikut analisis man in the middle attack pada protokol S-NCI. 1. Langkah 1
𝐴 → 𝑇 ∶ 𝐸𝐾𝐴𝑇(𝐾𝑠 ||𝐼𝐷𝐴|| 𝐼𝐷𝐵|| 𝑡1)||𝐻(𝐾𝑠 || 𝐼𝐷𝐴 || 𝐼𝐷𝐵|| 𝑡1).
Penyerang harus mengetahui kunci 𝐸𝐾𝐴𝑇 yang digunakan oleh user untuk
mengirimkan kunci sesi kepada 𝐾𝑇𝐶 agar mengetahui pesan yang
dikirimkan. Jika penyerang mencoba untuk memanfaatkan kelemahan
dalam S-NCI maka itu sulit untuk dilakukan, Karena ada parameter lain
yang harus diketahui dan saling berkaitan ketika proses pengiriman kunci.
2. Langkah 2
𝑇 → 𝐵 ∶ 𝐸𝐾𝐵𝑇(𝐾𝑠|| 𝐼𝐷𝐴 || 𝑡2)||𝐻(𝐾𝑠|| 𝐼𝐷𝐴 || 𝑡2).
Penggunaan 𝐸𝐾𝐵𝑇 akan menyebabkan penyerang tidak bisa mendapatkan
pesan asli dari ciphertext yang didapatkan. Selain itu, ketika penyerang
melakukan man in the middle attack maka nilai dari 𝑡2 akan berubah ketika
sampai pada tujuan.
3. Langkah 3
𝐴 ← 𝐵 ∶ 𝐸𝐾𝑆( 𝑁𝐵||𝑡3).
Ketika penyerang melakukan man in the middle attack maka akan terdeteksi
dari nilai 𝑡3 yang dikirimkan oleh B kepada A. Selain itu penyerang harus
mengetahui 𝐾𝑠 untuk bisa mengetahui pesan yang dikirimkan.
4. Langkah 4
𝐴 → 𝐵 ∶ 𝐻𝑘(𝑁𝐵). Serangan man in the middle attack akan dideteksi dengan nilai 𝑁𝐵 yang
identik. Jika penyerang ingin mendapatkan nilai 𝑁𝐵 maka penyerang harus
mengetahui 𝐾𝑠 agar bisa menghitung nilai MAC yang sama.
D. Analisis terhadap Modification Attack
Tujuan dari modification attack yaitu penyerang ingin memodifikasi atau
merubah pesan yang dikirimkan tanpa sepengetahuan pengirim dengan maksud agar
penerima menerima pesan palsu.
Ketika fungsi hash yang digunakan merupakan fungsi hash yang memiliki
sifat preimage resistant, second preimage resistant, dan collision resistant maka
penyerang tidak akan bisa melakukan modifikasi terhadap pesan, karena setiap
perubahan yang terjadi pada pesan akan menyebabkan nilai hash nya berubah dan
ketika di bandingkan dengan nilai hash yang awal maka nilainya akan berbeda,
sehingga pesan tidak valid (terjadi modifikasi).
Sebagai contoh pada langkah 1.
𝐴 → 𝑇 ∶ 𝐸𝐾𝐴𝑇(𝐾𝑠 ||𝐼𝐷𝐴|| 𝐼𝐷𝐵|| 𝑡1)||𝐻(𝐾𝑠 || 𝐼𝐷𝐴 || 𝐼𝐷𝐵|| 𝑡1).

765
Jika penyerang mencoba untuk melakukan modifikasi terhadap pesan yang
terenkripsi 𝐸𝐾𝐴𝑇 maka penyerang pertama harus mendapatkan 𝐾𝐴𝑇 terlebih dahulu.
Sedangkan 𝐾𝐴𝑇 merupakan kunci yang hanya di ketahui oleh 𝐴 dan 𝑇. Selain itu,
penggunaan fungsi hash 𝐻(𝐾𝑠 || 𝐼𝐷𝐴 || 𝐼𝐷𝐵|| 𝑡1) akan menyebabkan jika penyerang
dapat melakukan modifikasi terhadap pesan, maka perubahan akan terdeteksi dari
nilai hash yang dihitung.
E. Analisis terhadap Typing Attack
Ketika penyerang mencoba untuk membuat pesan baru, misalkan penyerang
mencoba untuk melakukan intercept maka penyerang harus mengetahui kunci antar
entitas dengan T. Pada langkah 1 penyerang harus mengetahui 𝐾𝐴𝑇, sedangkah pada
langkah 2 harus mengetahui 𝐾𝐵𝑇, dan ketika ingin menyerang pada langkah 3 dan 4
harus mengetahui 𝐾𝑠 terlebih dahulu.
Selain itu, pada protokol S-NCI setiap langkah terdapat identifier yang sudah
didefinisikan dengan jelas sehingga penerima akan mudah melakukan identifikasi
terhadap pesan yang diterima apakah asli atau palsu. Penggunaan fungsi hash MDC
dan MAC serta enkripsi akan menjamin kerahasiaan, integritas data, dan otentikasi
dari entitas yang benar.
F. Implementasi S-NCI Protokol Key Establishment
Dalam penelitian ini, protokol key establishment S-NCI telah diimplementasikan dalam simulasi sederhana menggunakan bahasa Java. Hasil dari implementasi dari protokol S-NCI dapat dilihat pada Gambar 5 sampai Gambar 8.
1. A mengirimkan EK_AT(K_S,ID_A, ID_B,T_A) kepada T
Hasil concate 1 = O2zr9Q==#A#B#1486620809673
Hasil Enkripsi oleh A = 9xDWuwve+GaD55oWDknbM+iYWTvp6iO3MhaFnEnTb/I=
Gambar 5 Simulasi Protokol S-NCI pada Langkah Pertama
2. T mengirimkan EK_BT(K_S,ID_A,T_T) kepada B
Hasil concate 2 = O2zr9Q==#A#1486620811284
Hasil Enkripsi oleh T = hdHKZCibv8ZSv8r4gk+d7e4Ea38w21wV7jsavdwLZP8=
Gambar 6 Simulasi Protokol S-NCI pada Langkah Kedua
3. B mengirimkan EK_S(N_B,T_B) kepada A
Hasil concate 3 = VG+urw==#A#1486620809943
Hasil Enkripsi oleh B = ijGICGyx1Qr0f1nC4H8Nd9IOD6Y9jE1LkRnn3X0PM6Q=
Gambar 7 Simulasi Protokol S-NCI pada Langkah Ketiga

766
4. A mengirimkan H(N_B) kepada B
Hasil hashing yang dilakukan A terhadap N_B =
JW1FzdPKUXYNbWx1KABot1RTN8/s6U1TKUp++2jNevc=
Gambar 8 Simulasi Protokol S-NCI pada Langkah Keempat
Pada Tabel 4 disajikan data hasil simulasi protokol S-NCI berdasarkan waktu eksekusi protokol.
Tabel 4 Data Hasil Eksekusi Protokol
Simulasi Waktu Eksekusi Protokol (detik)
1 0.648
2 0.772
3 0.681
4 0.629
5 0.633
Berdasarkan data hasil simulasi pada Tabel 4 didapatkan rata-rata waktu eksekusi protokol yaitu 0.6726 detik.
4. Kesimpulan
Protokol key establishment S-NCI merupakan protokol yang di desain
berbasis server dengan memanfaatkan pihak ketiga terpecaya sebagai Key
Translation Center (KTC). Berdasarkan hasil simulasi dan analisis, protokol S-NCI
memenuhi kebutuhan keamanan terhadap serangan man in the middle attack, replay
attack, modification attack, dan typing attack. Man in the middle attack dan replay
attack dapat dicegah menggunakan timestamp dan nonce, sedangkan modification
attack, dan typing attack dapat dicegah menggunakan fungsi hash dan enkripsi.
Selain itu, berdasarkan data hasil simulasi didapatkan rata-rata waktu eksekusi
protokol yaitu 0.6726 detik.
Pernyataan terima kasih. Kami mengucapkan terimakasih kepada Sekolah
Tinggi Sandi Negara atas dukungan secara finansial dan non-finansial.

767
Referensi
[1] Abadi, M and Needham, R. Prudent engineering practice for cryptographic protocols. In
IEEE Symposium on Research in Security and Privacy, pages 122-136. IEEE Computer
Society Press, 1995.
[2] Barker, E, Barker, W, Burr, W, Polk, W, & Smid, M. 2005. Recommendation for Key
Management – Part 2: Best Practices for Key Management Organization. NIST Special
Publication 800-57. US Departement of Commerce.
[3] Boyd, C., & Mathuria, A. (2003). Authentication and Key Establishment. Springer. New
York. Retrieved from http://link.springer.com/content/pdf/10.1007/978-3-642-14313-
7.pdf.
[4] Carlsen, U. Cryptographic protocol flaws - know your enemy. In 7th IEEE Computer
Security Foundations Workshop, pages 192-200. IEEE Computer Society Press, June
1994.
[5] Cheng, Z, and Comley, R. Attacks on An ISO/IEC 11770-2 Key Establishment Protocol.
International Journal of Network Security, Vol.3, No.3, PP.290–295, Nov. 2006.
[6] Choo, KKR. 2009. Secure Key Establishment. Austalian Institute of Criminology :
Springer.
[7] Denning, D.E and Sacco, G.M. Timestamps in key distribution protocols.
Communications of the ACM, 24(8):533-536, August 1981.
[8] ISO/IEC 11770. 1996. Information Technology Security Techniques-Key Management
Part 2: Mechanism Using Symmetric Techniques.
[9] Kaufman, C., Perlman R., Speciner M., 2002. Network security: private communication
in a public world. 2nd ed. Upper Saddle River, New Jersey: Prentice Hall.
[10] Menezes, A.J., van Oorschot, P.C, Vanstone, S.A. 1997. Handbook of Applied
Cryptography. Boca Raton: CRC Press LLC.
[11] Mao, W and Boyd, C. On the use of encryption in cryptographic protocols. In P. G.
Farrell, editor, Codes and Cyphers - Cryptography and Coding IV, pages 251-262, 1995.
[12] Needham, R and Schroeder, M.D. Using encryption for authentication in large networks
of computers. Communications of the ACM, 21(12):993-999, December 1978.
[13] Oppliger, R. 2005. Contemporary Cryptography. USA: Artech House, Inc.
[14] Otway, D and Rees, O. Efficient and timely mutual authentication. ACM Operating
Systems Review, 21(1):8-10, January 1987.
[15] Petitcolas, F.A.P, 2011. Kerchoff’s Principle in Encyclopedia of Cryptography and
Security. USA: Springer US.
[16] Ramadhan, K., 2010. Pengujian Man-in-the-middle Attack Skala Kecil dengan Metode
ARP Poisoning. Program Studi Teknik Informatika: Institut Teknologi Bandung.
[17] Schmeh, K. 2003. Cryptoghraphy and Public Key Infrastructure on the Internet.
England: John Wiley and Sons. Ltd.
[18] Schneier, B. 1996. Applied Cryptography. 2nd ed. USA: John Wiley and Sons.
[19] Stallings, W. 2014. Cryptography and Network Security Principles and Practices, sixth
Edition. Prentice Hall.
[20] Stubblebine, S.G. and Gligor, V.D. On message integrity in cryptographic protocols. In
IEEE Symposium on Research in Security and Privacy, pages 85-104. IEEE Computer
Society Press, 1992.
[21] Sumarkidjo, dkk., 2007. Jelajah Kriptologi. Jakarta: Lembaga Sandi Negara.

768
Prosiding SNM 2017 Komputasi , Hal 768 -777
KLASIFIKASI MULTIKELAS KANKER OTAK DENGAN
METODE SUPPORT VECTOR MACHINE
VINEZHA PANCA1, ZUHERMAN RUSTAM2
1Universitas Indonesia, Depok, [email protected]
2 Universitas Indonesia, Depok, [email protected]
Abstrak. Masalah klasifikasi kanker otak merupakan masalah klasifikasi
multikelas. Support Vector Machine merupakan metode klasifikasi yang umum
digunakan untuk menyelesaikan masalah dua kelas. Salah satu cara untuk
menerapkan metode klasifikasi Support Vector Machine pada kasus multikelas
adalah dengan mengubahnya terlebih dahulu ke dalam beberapa masalah dua
kelas. Dua pendekatan yang umum digunakan adalah one versus rest dan one
versus one. Pada masalah klasifikasi dengan melibatkan k kelas, apabila
digunakan pendekatan one versus rest akan dibentuk sebanyak k masalah dua
kelas. Setelah semua masalah dua kelas diselesaikan, akan ditentukan satu
prediksi kelas final untuk masalahmultikelas tersebut. Metode yang digunakan
untuk melakukan hal tersebut apabila digunakan pendekatan one versus rest
adalah winner takes all, yakni memilih kelas dimana nilai fungsi objektifnya
paling besar. Sedangkan pada pendekatan one versus one metode yang
digunakan untuk menggabungkan hasil-hasil prediksi masalah dua kelas adalah
max wins, yaitu memilih kelas yang paling sering menjadi solusi masalah dua
kelas. Pada makalah ini dilakukan pembandingan akurasi yang dihasilkan oleh
pendekatan one versus rest dan one versus one dalam menyelesaikan masalah
klasifikasi multikelas kanker otak dengan metode Support Vector Machine.
Kata kunci : kanker otak, masalah klasifikasi multikelas, Support Vector Machine, one
versus rest, one versus one
1. Pendahuluan
Kanker merupakan pertumbuhan sel tubuh yang tidak normal. Kanker yang
terjadi pada sistem saraf pusat disebut kanker otak. Kanker otak merupakan jenis
kanker yang paling sering dialami oleh orang berusia di bawah 40 tahun dan
merupakan jenis kanker penyebab kematian terbesar pada golongan usia tersebut [1].
Pun demikian, penyakit ini kurang mendapatkan sorotan, dibandingkan penyakit-
penyakit kanker lainnya. Kontribusi yang dapat dilakukan oleh matematikawan
dalam dunia kanker otak adalah membantu pendeteksian kanker otak dengan
mengaplikasikan metode - metode machine learning.
Aplikasi metode machine learning telah umum dilakukan dalam
pendeteksian penyakit, termasuk kanker. Permasalahan pendeteksian penyakit
merupakan permasalahan klasifikasi, dimana sampel digolongkan ke dalam suatu

769
kelas berdasarkan atribut atau karakteristik yang dimilikinya. Masalah ini tergolong
supervised learning, dimana akan dipelajari pola karakteristik dari data pelatihan
berisi sampel-sampel yang telah diketahui kelasnya, kemudian digeneralisasi
sehingga model yang terbentuk dapat digunakan untuk memprediksi kelas dari suatu
sampel baru yang tidak dilibatkan dalam proses pembelajaran.
Support Vector Machine (SVM) merupakan suatu metode untuk
menyelesaikan masalah klasifikasi. Konsep SVM adalah mencari suatu hyperplane
yang memaksimumkan margin, yakni jarak hyperplane tersebut ke titik data terdekat
dari masing-masing kelas [2]. Metode SVM biasa digunakan untuk masalah
klasifikasi dua kelas. Namun, SVM dapat dikembangkan untuk menyelesaikan
masalah multikelas, yakni dengan membagi masalah multikelas tersebut ke dalam
beberapa masalah dua kelas, kemudian dilakukan pelatihan SVM pada masing-
masing masalah dua kelas tersebut. Terdapat beberapa pendekatan yang dapat
digunakan, dua diantaranya yakni one versus rest dan one versus one [3].
Pada penelitian ini, akan dihitung akurasi dari metode SVM ketika
diterapkan pada data multikelas kanker otak, baik dengan pendekatan one versus rest
maupun one versus one. Harapannya, hasil penelitian ini dapat menjadi salah satu
masukan untuk dijadikan bahan pertimbangan dokter atau ahli medis dalam bidang
kanker otak untuk memprediksi jenis kanker otak secara cepat dan objektif.
Sistematika penelitian ini adalah dengan studi literatur mengenai SVM
untuk multikelas dan simulasi program dengan menggunakan bahasa pemrograman
R.
2. Klasifikasi Multikelas Kanker Otak dengan Metode
Support Vector Machine
2.1 Support Vector Machine
Support Vector Machine (SVM) adalah sebuah metode yang mencari
suatu hyperplane yang memaksimumkan margin, yaitu jaraknya dengan data-
data masing-masing kelas yang paling dekat dengan hyperplane tersebut.
Semakin besar margin, semakin kecil nilai error pada generalisasi.
Hyperplane yang dicari adalah : [5]
dimana w merupakan parameter bobot dan b
merupakan parameter bias.
Secara umum, model matematis dari masalah optimisasi primal Support
Vector Machine adalah:[5]
(1)

770
Dengan adanya faktor toleransi kesalahan, formulasi Support Vector Machine
dapat dituliskan sebagai berikut.
(2)
Parameter C (C>0) adalah parameter regulasi yang mengatur keseimbangan dalam
meminimumkan kesalahan klasifikasi dan memaksimumkan margin hyperplane,
sedangkan i adalah variable slack. Berikut adalah kriteria nilai
i [5]:
Jika 0i , data ke-i terletak tepat pada margin atau pada sisi kelas yang
benar.
Jika 10 i , data ke-i terletak di dalam wilayah margin namun masih
pada sisi kelas yang benar.
Jika 1i , data ke-i terletak pada sisi kelas yang salah dan terjadi kesalahan
klasifikasi.
Untuk menyelesaikan SVM, masalah optimisasi primal pertama-tama ditransformasi
ke dalam masalah optimisasi dual dengan menggunakan pengali Lagrange. Model
permasalahan yang terbentuk dituliskan sebagai berikut [5].
(3)
dimana 𝛼𝑖 adalah pengali Lagrange. Setelah 𝛼𝑖 diperoleh dengan pendekatan
numerik[2] , vektor bobot dan nilai parameter bias dapat dinyatakan sebagai berikut
: [2].
(4) (5)
Dengan demikian, terbentuklah persamaan hyperplane yang optimum.
2.2 One-Versus-Rest
Dengan pendekatan one-versus-rest, dibentuk sebanyak k masalah
dua kelas, di mana setiap masalah dua kelas terdiri atas sebuah kelas yang
berisi seluruh data dari kelas tertentu (dinamakan kelas 1) dan sebuah kelas
yang berisi gabungan data dari kelas-kelas lainnya (dinamakan kelas -1).

771
Dengan melakukan pelatihan, akan diperoleh fungsi target dari setiap masalah
dua kelas. Misalkan *x adalah suatu sampel uji yang belum diketahui
kelasnya. Jika nilai fungsi target dari *x positif, maka label kelas prediksinya
adalah 1, sedangkan jika nilai fungsi targetnya negatif, label kelas prediksinya
adalah -1. Prediksi kelas final untuk *x adalah kelas yang dirujuk oleh
masalah dua kelas dengan nilai fungsi target terbesar . Metode penentuan
kelas ini disebut winner-takes-all [6].
2.3 One-Versus-One
Pada pendekatan one versus one, dilakukan sebanyak 2
)1( kk masalah
dua kelas, di mana setiap masalah dua kelas terdiri atas pasangan kelas-kelas
yang mungkin. Misalkan terdapat suatu sampel x yang belum diketahui
kelasnya. Masukkan x ke fungsi target masing-masing masalah dua kelas.
Kelas yang paling sering muncul sebagai hasil prediksi masalah-masalah dua
kelas akan menjadi prediksi akhirnya. Metode penentuan kelas ini disebut
max-wins [6].
2.4 K fold cross validation
K fold cross validation merupakan salah satu metode untuk melakukan
validasi. Pada metode ini, data dibagi ke dalam k bagian. Bagian yang pertama
menjadi data pengujian sedangkan k-1 bagian sisanya menjadi data pelatihan.
Setelah dilakukan pelatihan dan pengujian, akan ditemukan akurasi pada data
pengujian tersebut. Selanjutnya, jadikan bagian yang kedua dari k bagian data
tersebut sebagai data pengujian dan k-1 bagian lainnya sebagai data pelatihan,
serta temukan akurasi data pengujian. Lakukan prosedur yang sama
sedemikan sehingga setiap bagian data mendapatkan kesempatan untuk
menjadi data pengujian. Kemudian, hitung rata-rata dari nilai-nilai akurasi
yang dihasilkan.[4]
2.5 Kernel
Untuk sebuah pemetaan 𝜙(𝑥) pada ruang fitur, kernel didefinisikan sebagai [2]
)()()',( xxxxk T (6)
Beberapa kernel pada SVM antara lain [2]:
Linier : ')',( xxxxk T (7)
Polinomial : 2)'()',( cxxxxk T (8)
Sigmoid : )'tanh()',( bxaxxxk T (9)

772
Radial Basis Function : (10)
3. Hasil
Data yang digunakan dalam penelitian ini bersumber dari http://www.broadinstitute.org/cgi-bin/cancer/datasets.cgi. Data ini berisi 42 sampel dengan 4 kelas jenis kanker otak dan 1 kelas normal, yang masing-masing adalah Medulloblastoma(10 sampel), Malignant Glioblastoma (10 sampel), Primitive Neuroectodermal Tumors (8 sampel), Atypical Teratoid Rhabdoid Tumor (10 sampel), dan Normal (4 sampel). Terdapat 7129 macam gen atau fitur yang digunakan oleh data tersebut.
SVM diimplementasikan dengan mengadaptasi library e1071 pada R.
Terdapat empat simulasi yang dilakukan, masing-masing dengan pendekatan one
versus rest dan one versus one. Validasi dilakukan dengan k-fold cross validation
dengan k=3. Terdapat dua aspek yang dijadikan acuan, yakni akurasi dan running
time. Akurasi menunjukkan banyaknya sampel pada data uji yang jenis penyakitnya
dapat diprediksi dengan benar dibandingkan dengan keseluruhan sampel data uji.
Running time menunjukkan durasi komputasi yang dibutuhkan untuk melakukan
pembelajaran dan prediksi. Berikut adalah hasil-hasil dari simulasi yang dilakukan.
1. Simulasi pertama menggunakan kernel linier. Dengan melakukan simulasi dengan berbagai nilai parameter C, akurasi optimum diperoleh dengan nilai C=1.
Tabel 1 Simulasi dengan Kernel Linier Menggunakan Pendekatan One Versus Rest
Bagian data yang menjadi data uji Rata-Rata
1 2
3
Akurasi (%) 76,471 83,33 92,31 84,3903
Running Time (detik)
7,44603 7,92604 7,52503 7,632363
Tabel 1 menunjukkan simulasi dengan kernel linier menggunakan pendekatan one versus rest, menghasilkan rata-rata akurasi sebesar 84,3903% dengan rata-rata running time 7,632363 detik.
Tabel 2 Simulasi dengan Kernel Linier Menggunakan Pendekatan One Versus One
Bagian data yang menjadi data uji Rata-Rata
1 2
3
Akurasi (%) 76,471 83,33 76,923 76,6968

773
Running Time (detik)
9,62123 9,35023 9,83743 9,602966
Tabel 2 menunjukkan simulasi dengan kernel linier menggunakan pendekatan one versus one, menghasilkan rata-rata akurasi sebesar 76,6968% dengan rata-rata running time 9,602966 detik.
2. Simulasi kedua dengan menggunakan kernel polinomial, dengan C=1000 dan coef0=10 Catatan : c pada persamaan (8) merupakan coef0.
Tabel 3 Simulasi dengan Kernel Polinomial Menggunakan Pendekatan One Versus Rest
Bagian data yang menjadi data uji Rata-Rata
1 2 3
Akurasi (%) 76,47 83,33 84,62 81,4733
Running Time (detik)
9,34254 10,8696 9,84256 10,01824
Tabel 3 menunjukkan simulasi dengan kernel polinomial menggunakan pendekatan one versus rest, menghasilkan rata-rata akurasi sebesar 81,4733% dengan rata-rata running time 10,01824 detik.
Tabel 4 Simulasi dengan Kernel Polinomial Menggunakan Pendekatan One Versus One
Bagian data yang menjadi data uji Rata-Rata
1 2
3
Akurasi (%) 76,47 75 84,62 78,6967
Running Time (detik)
13,8958 13,8608 13,44777 13,73478
Tabel 4 menunjukkan simulasi dengan kernel polinomial menggunakan pendekatan one versus one, menghasilkan rata-rata akurasi sebesar 78,6967% dengan rata-rata running time 13,73478 detik.
3. Simulasi ketiga dengan menggunakan kernel sigmoid, dengan C=1000, gamma=1/7129 (gamma=1/data dimension) , dan coef0=0,1
Catatan : a pada persamaan (9) merupakan gamma, b merupakan coef0.

774
Tabel 5 Simulasi dengan Kernel Sigmoid Menggunakan Pendekatan One Versus Rest
Bagian data yang menjadi data uji Rata-Rata
1 2 3
Akurasi % 70,59 66,67 92,31 76,5233
Running Time (detik)
10,1176 10,1196 10,8606 10,36593
Tabel 5 menunjukkan simulasi dengan kernel sigmoid menggunakan pendekatan one versus rest, menghasilkan rata-rata akurasi sebesar 76,5233% dengan rata-rata running time 10,36593 detik.
Tabel 6 Simulasi dengan Kernel Sigmoid Menggunakan Pendekatan One Versus One
Bagian data yang menjadi data uji Rata-Rata
1 2
3
Akurasi (%) 76,47 75 84,62 78,6967
Running Time (detik)
14,4368 13,8278 14,5358 14,26682
Tabel 6 menunjukkan simulasi dengan kernel sigmoid menggunakan pendekatan one versus one, menghasilkan rata-rata akurasi sebesar 78,6967% dengan rata-rata running time 14,26682 detik.
4. Simulasi keempat menggunakan kernel radial, dengan C=1000 dan gamma=0,0000001. Nilai 22/1 pada persamaan (10) merupakan gamma.
Tabel 7 Simulasi dengan Kernel Radial Menggunakan Pendekatan One Versus Rest
Bagian data yang menjadi data uji Rata-Rata
1 2
3
Akurasi (%) 76,471 83,33 84,62 81,4737
Running Time (detik)
9,49843 9,66683 9,91215 9,692472
Tabel 7 menunjukkan simulasi dengan kernel radial menggunakan pendekatan one versus rest, menghasilkan rata-rata akurasi sebesar 81,4737% dengan rata-rata running time 14,26682 detik.

775
Tabel 8 Simulasi dengan Kernel Radial Menggunakan Pendekatan One Versus One
Bagian data yang menjadi data uji Rata-Rata
1 2 3
Akurasi (%) 76,47 75 84,62 78,6967
Running Time (detik)
16,7715 13,1828 14,6628 14,87239
Tabel 8 menunjukkan simulasi dengan kernel radial menggunakan pendekatan one versus one, menghasilkan rata-rata akurasi sebesar 78,6967% dengan rata-rata running time 14,87239 detik.
Hasil-hasil tersebut dapat dirangkum dalam bentuk grafik sebagai berikut.
Berdasarkan grafik di atas, diketahui bahwa pada pendekatan one versus rest, akurasi tertinggi diperoleh saat menggunakan kernel linier, sedangkan akurasi terendah diperoleh saat menggunakan kernel sigmoid.
0,7
0,75
0,8
0,85
Linier Polinomial Sigmoid Radial
Perbandingan Akurasi dengan Pendekatan One
Versus Rest
Akurasi
Gambar 1 Perbandingan Akurasi dengan Pendekatan One Versus Rest menggunakan kernel
Linier , Polinomial , Sigmoid dan Radial
0
5
10
15
Linier Polinomial Sigmoid Radial
Perbandingan Running Time dengan Pendekatan
One Versus Rest (dalam detik)
Running TimeGambar 2 Perbandingan Running Time dengan Pendekatan One Versus Rest (dalam detik)
menggunakan kernel Linier , Polinomial , Sigmoid dan Radial

776
Berdasarkan grafik di atas, diketahui bahwa pada pendekatan one versus rest running time tercepat diperoleh saat menggunakan kernel linier dan running time terlama diperoleh saat menggunakan kernel sigmoid.
Berdasarkan grafik di atas, diketahui bahwa pada pendekatan one versus one nilai akurasi yang diperoleh saat menggunakan kernel polinomial, sigmoid, dan radial sama besarnya.
0,755
0,76
0,765
0,77
0,775
0,78
0,785
0,79
Linier Polinomial Sigmoid Radial
Perbandingan Akurasi dengan Pendekatan One
Versus One
Akurasi
0
2
4
6
8
10
12
14
16
Linier Polinomial Sigmoid Radial
Perbandingan Running Time dengan Pendekatan
One Versus One (dalam detik)
Running Time
Gambar 3 Perbandingan Akurasi dengan Pendekatan One Versus One menggunakan kernel Linier ,
Polinomial , Sigmoid dan Radial
Gambar 4 Perbandingan Running Time dengan Pendekatan One Versus One (dalam detik)
menggunakan kernel Linier , Polinomial , Sigmoid dan Radial

777
Berdasarkan grafik tersebut, diketahui bahwa pada pendekatan one versus one
running time tercepat diperoleh saat menggunakan kernel linier dan running time
terlama diperoleh saat menggunakan kernel radial.
3. Kesimpulan
Pada makalah ini, dibahas mengenai dua pendekatan dalam menyelesaikan
masalah multikelas kanker otak dengan metode Support Vector Machine, yakni one
versus rest dan one versus one. Adapun kernel yang digunakan adalah kernel linier,
polinomial, sigmoid, dan radial. Berdasarkan hasil simulasi, rata-rata akurasi tertinggi
dengan pendekatan one versus rest diperoleh pada simulasi menggunakan kernel linear,
yaitu 84,3%. Adapun dengan pendekatan one versus one, simulasi menggunakan ketiga
kernel nonlinear (polinomial, sigmoid, dan radial) menghasilkan rata-rata akurasi yang
sama, yakni 78,7%. Untuk selanjutnya, dapat dicari nilai parameter yang optimum pada
masing-masing kernel yang digunakan, dan dapat dilakukan aplikasi Support Vector
Machine pada permasalahan klasifikasi lainnya, baik dua kelas maupun multikelas.
Referensi
[1] https://www.curebraincancer.org.au/page/8/facts-stats diakses 12 Januari
2017 pukul 22.51
[2] Bishop, C.M., 2006, Pattern Recognition and Machine Learning, New York: Springer
[3] Hsu, C.W. & Lin, C.J., 2002, A Comparison of Methods for Multiclass Support
Vector Machines, IEEE Transactions on Neural Networks,13(2), 415-425
[4] Refaeilzadeh, P., Tang,L., dan Liu, H. (2009). Cross Validation, dalam Ozsu,M.T.,
dan Liu,L (Ed). Encyclopedia of Database Systems, Berlin : Springer
[5] Panca, V., 2016, Application of Machine Learning on Brain Cancer Multiclass
Classification, submit pada The 2nd International Symposium on Current
Progress in Mathematics and Sciences 2016 (ISCPMS)
[6] Duan, K.B. & Keerthi, S.S,2005, Which Is the Best Multiclass SVM Method? An
Empirical Study, dalam N.C. Oza et al., MCS 2005, LNCS 3541, pp. 278–285,

778
Prosiding SNM 2017 Komputasi , Hal 778 -784
ANALISIS AKURASI DARI METODE MACHINE
LEARNING UNTUK MENYELESAIKAN MASALAH
CREDIT SCORING
NURUL MAGHFIRAH, ZUHERMAN RUSTAM
Departemen Matematika FMIPA, Universitas Indonesia,
[email protected], [email protected]
Abstrak. Credit scoring adalah ekspresi numerik berdasarkan analisis file
kredit seseorang, untuk mewakili kelayakan kredit dari orang tersebut. Pemberi
pinjaman, seperti bank menggunakan credit scoring untuk mengevaluasi potensi
risiko yang ditimbulkan dari meminjamkan uang kepada konsumen dan untuk
mengurangi kerugian akibat kredit macet. Sehingga akan digunakan machine
learning untuk mengevaluasi risiko – risiko yang ada. Oleh karena itu, pada
makalah ini akan dibandingkan tingkat akurasi perhitungan credit scoring dari
german credit dataset menggunakan tiga buah metode machine learning, yaitu
: Fuzzy C-Means, Support Vector Machine, dan Logistic Regression. Sebagai
hasil didapatkan akurasi metode Fuzzy C-Means adalah sebesar 64%, metode
Support Vector Machine adalah sebesar 78,7%, dan metode Logistic Regression
adalah sebesar 87,6%.
Kata kunci: credit scoring, fuzzy c – means, support vector machine, logistic
regression.
1. Pendahuluan
Kredit atau cicilan saat ini telah menjadi konsumsi sehari – hari masyarakat.
Banyaknya institusi finansial dan pihak pemberi pinjaman yang menawarkan
beragam bentuk kredit mempermudah masyarakat dalam memenuhi kebutuhan
primer, sekunder, bahkan tersier mereka.
Meski begitu, tidak menutup kemungkinan adanya beberapa peminjam yang
mungkin akan bermasalah pada saar proses pembayaran cicilan atau kredit macet.
Oleh karena itu institusi finansial membutuhkan metode atau alat untuk
meminimalkan risiko tersebut.
Credit scoring adalah himpunan dari model pembuat keputusan untuk
membantu pihak pemberi pinjaman memberikan pinjaman kepada pihak
peminjam[1]. Metode ini mampu menentukan baik atau buruknya nilai kredit
peminjam, sehingga dapat diketahui seberapa berisiko jika pihak pemberi pinjaman
meminjamkan sejumlah uang untuk peminjam tersebut.
Data – data credit scoring didapatkan dari data historis peminjam. Data ini
berukuran sangat besar, sehingga akan mempengaruhi tingkat akurasi dari penentuan

779
baik atau buruknya nilai kredit peminjam tersebut. Sehingga digunakan metode
machine learning untuk menentukan metode mana yang baik dan menghasilkan
tingkat akurasi yang sangat tinggi.
Metode machine learning atau metode – metode data mining lainnya dapat
diaplikasikan untuk menyelesaikan permasalahan yang berhubungan dengan
forecasting atau fitting data. Algoritma machine learning dibuat untuk mempelajari
sifat – sifat data historis berukuran besar dan kemudian membuat perkiraannya. Pada
kasus credit scoring contohnya, data – data historis peminjam diketahui berukuran
sangat besar. Sehingga akan cocok jika menggunakan algoritma machine learning
yang akan mempelajari sifat – sifat data historis dan kemudian membuat perkiraan
apakan peminjam memiliki nilai kredit yang baik atau buruk. Pada makalah ini akan
dibandingkan hasil pengukuran tingkat akurasi dari tiga buah algoritma machine
learning dalam menentukan credit scoring. Algoritma yang digunakan yaitu : Fuzzy
C – Means, Support Vector Machine, dan Regresi Logistik.
Metode Fuzzy C – Means (FCM) adalah teknik pengelompokkan data yang
posisi datanya ditentukan oleh derajat keanggotaan[2]. Support Vector Machine
(SVM) adalah suatu metode untuk melakukan prediksi, dengan cara membangun
sebuah hyperplane terbaik sebagai pemisah dua kelas data. Metode Regresi Logistik
suatu metode prediksi dengan cara menghitung probabilitas antara variabel dependen
dan variabel independennya
Ketiga metode tersebut digunakan untuk mengukur tingkat akurasi yang
kemudian akan dibandingkan hasilnya. Data credit scoring yang digunakan adalah
german credit dataset, kemudian dilakukan simulasi program untuk metode SVM
dan Regresi Logistik menggunakan python, sementara untuk metode FCM
menggunakan matlab.
Selanjutnya pada bagian II akan dijelaskan mengenai hasil – hasil penelitian
dan pada bagian III akan dijelaskan mengenai kesimpulan.
2. Hasil – Hasil Utama
Metode Fuzzy C – Means (FCM) adalah teknik pengelompokkan data yang
posisi datanya ditentukan oleh derajat keanggotaan. Konsep dasar dari metode ini
adalah menentukan pusat klaster awal atau lokasi rata – rata dari masing – masing
klaster. Kemudian di tiap – tiap iterasi, pusat klaster ini akan diperbaiki hingga
mengarah ke lokasi yang sesuai. Hal ini berdasar pada peminimuman fungsi objektif
yang menggambarkan jarak antara titik data dengan pusat klaster[2].
Dari konsep dasar tersebut, dapat dibangun sebuah fungsi objektif fari FCM
tersebut. Model matematis dari FCM adalah[2]:
𝑀𝑖𝑛 𝐽𝐹𝐶𝑀(𝑉, 𝑈, 𝑋, 𝑐,𝑚) = 𝑀𝑖𝑛 ∑ ∑ 𝑢𝑖𝑘𝑚‖𝑥𝑘 − 𝑣𝑖‖
2𝑁𝑘=1
𝑐𝑖=1
dengan fungsi kendala
∑ 𝑢𝑖𝑘 =𝑐𝑖=1 1
dimana,
N adalah banyaknya data
c adalah banyaknya cluster

780
V adalah pusat cluster, dengan V = (
𝑣11 ⋯ 𝑣1𝑁⋮ ⋱ ⋮𝑣𝑐1 ⋯ 𝑣𝑐𝑁
)
U adalah fungsi keanggotaan, dengan U = (
𝑢11 ⋯ 𝑢1𝑘⋮ ⋱ ⋮𝑢𝑐1 ⋯ 𝑢𝑐𝑘
)
X adalah data yang akan di – cluster, dengan X = (
𝑥11 ⋯ 𝑥1𝑘⋮ ⋱ ⋮𝑥𝑛1 ⋯ 𝑥𝑛𝑘
)
m adalah derajat fuzzyness (m > 1)
‖𝑥𝑘 − 𝑣𝑖‖2 adalah jarak antara titik data dengan pusat cluster
Model matematis tersebut kemudian akan digunakan untuk membangun
sebuah algoritma dalam menentukan tingkat akurasi dari credit scoring. Secara
umum, algoritma dari FCM pada kasus ini bekerja dengan cara memperbaharui nilai
pada tiap klaster (U) dan pusat klaster (V), dan akan melakukan pengulangan atau
looping sampai memenuhi kriteria berhenti atau stopping criteria.
Berikut ini adalah algoritma FCM menggunakan matlab[2]:
Algoritma FCM
start
step 1 Inisialisasi banyaknya data training yang
akan digunakan, banyaknya klaster, besar
derajat fuzzyness (𝑚 > 1), kriteria berhenti
(휀 = 𝑛𝑖𝑙𝑎𝑖 𝑝𝑜𝑠𝑖𝑡𝑖𝑓 𝑦𝑎𝑛𝑔 𝑠𝑎𝑛𝑔𝑎𝑡 𝑘𝑒𝑐𝑖𝑙), dan pusat
klaster awal
step 2 Hitung fungsi keanggotaan awal setiap data,
lalu perbaharui nilai pada tiap klaster
(U), dimana
𝑢𝑖𝑘 =1
∑ (‖𝑥𝑘 − 𝑣𝑖‖
‖𝑥𝑘 − 𝑣𝑗‖)𝑐
𝑖=1
2𝑚−1
𝑢𝑖𝑘 ∈ 𝑈, 𝑘 = 1,2, … , 𝑛
step 3 Perbaharui pusat klaster untuk setiap kalster
ke – I dengan

781
𝑣𝑖 =∑ 𝑢𝑖𝑘
𝑚𝑥𝑘𝑁𝑘=1
∑ 𝑢𝑖𝑘𝑚𝑁
𝑘=1
𝑖 = 1,… , 𝐶
step 4 Tentukan kriteria penghentian iterasi, yaitu
apabila selisih fungsi objektif sekarang dan
fungsi objektif sebelumnya < 휀 atau selisih
dari pusat klaster sekarang dan pusat
klaster sebelumnya < 휀, jika belum mencapai
kriteria ulangi step 2
end
Support Vector Machine (SVM) adalah suatu metode untuk memprediksi
data, dengan konsep dasar berupa membagi data menjadi dua kelas berbeda.
Pembagian data dilakukan dengan cara membuat hyperplane atau bidang pemisah
terbaik. Hyperplane ini dicari dengan cara mengukur margin hyperplane dan
mencari titik maksimalnya. Margin adalah jarak antara hyperplane dengan pattern
terdekat dari masing – masing kelas. Pattern ini dikenal sebagai support vector.
Dari konsep dasar tersebut, didapatkan model matematis sebagai berikut[3]:
𝑦(𝒙) = 𝒘𝑇𝒙 + 𝑏
dimana w merupakan vektor yang berisi nilai parameter bobot, 𝒘 = {𝑤1, 𝑤2, … , 𝑤𝑘}; k adalah jumlah atribut dan b adalah skalar yang disebut dengan bias.
Saat dataset yang dimiliki sudah terbagi menjadi dua kelas, maka sebuah
garis lurus dapat digambarkan untuk memisah semua data yang telah dikelompokkan
ke dalam kelas negatif ataupun kelas positif.
Model matematis tersebut kemudian akan digunakan untuk membangun
sebuah algoritma dalam menentukan tingkat akurasi dari credit scoring. Secara
umum, algoritma dari SVM pada kasus ini bekerja dengan cara memperbaharui nilai
bobot (𝒘) dan nilai bias (𝑏) dan akan melakukan pengulangan atau looping hingga
semua datanya sudah terpisah ke dalam dua kelas yang ada. Metode regresi logistik adalah suatu metode machine learning yang berbasis
statistika. Konsep dasar dari metode regresi logistik adalah dengan mengukur
keterhubungan antara variabel dependen dan variabel independennya dengan cara
menghitung probabilitas yang ada.
Gambar 2.1 Ilustrasi hyperplane
● +1
○ -1

782
Dari konsep dasar tersebut, didapat model matematis sebagai berikut:
𝜋 =𝑒��
1 + 𝑒��=
1
1 + 𝑒−��
dengan
𝛽 = (𝑥𝑇𝑥)−1𝑥𝑇𝑦
�� = 𝛽0 + 𝛽1𝑥1 + 𝛽2𝑥2 +⋯+ 𝛽𝑛𝑥𝑛
dimana
x dan y adalah data
𝛽 adalah koefisien regresi
�� fungsi linear dari variabel 𝑥
𝜋 adalah probabilitas dari variabel dependen
Model matematis tersebut kemudian akan digunakan untuk mengklasifikasikan data
menjadi dua buah hasil, yaitu hasil dianggap benar, dan hasil dianggap salah. Proses
klasifikasi data dilakukan dengan cara menghitung probabilitas dan
mengelompokkan berdasarkan hasil yang didapatkan.
Berikut ini adalah gambaran secara umum bagaimana regresi logistik
bekerja:

783
Tabel 2.1 Hasil klasifikasi metode FCM
Pada makalah ini, data yang digunakan adalah german credit dataset yang diperoleh
dari UCI Machine Learning Repository[4]. Data ini digunakan karena setiap sampel
sudah diberi label dan fitur – fitur yang ada cukup banyak.
Kemudian akan dibandingkan tingkat akurasi dari ketiga metode yang
digunakan. Untuk menghitung tingkat akurasi, digunakan empat kemungkinan hasil
klasifikasi, yaitu :
1. Positif Benar (TP)
Adalah kasus dimana sampel dengan nilai kredit baik dideteksi sebagai nilai
kredit baik
2. Positif Salah (FP)
Adalah kasus dimana sampel dengan nilai kredit buruk dideteksi sebagai nilai
kredit baik
3. Negatif Benar (TN)
Adalah kasus dimana sampel dengan nilai kredit buruk dideteksi sebagai nilai
kredit buruk
4. Negatif Salah (FN)
Adalah kasus dimana sampel dengan nilai kredit baik dideteksi sebagai nilai
kredit buruk
Tingkat akurasi didapatkan dari persamaan akurasi berikut :
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝑇𝑃 + 𝑇𝑁
𝑇𝑃 + 𝐹𝑃 + 𝑇𝑁 + 𝐹𝑁 × 100%
Pada proses klasifikasi menggunakan metode FCM, dilakukan klasifikasi
data yang terbagi atas dua kelas. Kelas I merupakan kumpulan sampel dengan nilai
kredit baik dan kelas II merupakan kumpulan sampel dengan nilai kredit buruk. Data
training yang digunakan yaitu 10% - 70% pada data. Data yang bukan training
kemudian akan menjadi data testing.
Berikut ini adalah hasil klasifikasi dataset credit scoring menggunakan
metode FCM :
Persentase Training Data Akurasi (%)
10 27,222
20 50,000
30 16,571
40 27,500
50 10,000
60 64,000
70 27,333

784
Dari tabel 2.1, dapat dilihat bahwa akurasi terbesar didapat menggunakan
60% data training dengan akurasi sebesar 64%.
Sementara untuk metode SVM dan regresi logistik, simulasi program
dilakukan menggunakan python. Proses klasifikasi dilakukan dengan membangun
model yang tepat untuk kedua metode ini, data yang ada dibagi menjadi data training
dan data testing. Sehingga didapatkan hasil pengukuran tingkat akurasi
menggunakan metode SVM sebesar 78,7% dan tingkat akurasi menggunakan
metode regresi logistik sebesar 87,6%.
Berikut ini adalah grafik perbandingan hasil pengukuran tingkat akurasi
menggunakan ketiga metode tersebut.
3. Kesimpulan
Dari pengujian yang dilakukan menggunakan ketiga metode tanpa adanya
proses pemilihan fitur, diperoleh tingkat akurasi sebesar 64% untuk metode FCM,
sebesar 78,7% untuk metode SVM, dan sebesar 87,6% untuk metode regresi logistik.
Sehingga dari ketiga metode tersebut, dapat disimpulkan bahwa metode regresi
logistik adalah metode yang paling baik untuk prediksi credit scoring menggunakan
german credit dataset dikarenakan memberikan hasil tingkat akurasi paling besar
dengan nilai 87,6%.
Referensi
[1] Thomas, Lyn C. (2002). Credit Scoring and Its Application. Society for Industrial and
Applied Mathematics. Philadelphia
[2] Rachman, Arvan Aulia. (2016). Klasifikasi Data Kanker Menggunakan Fuzzy C –
Means dengan Pemilihan Fitur Menggunakan Fisher’s Ratio. Skripsi. Departemen
Matematika FMIPA UI
[3] Janati, Melati Vidi. (2016). Klasifikasi Kanker Paru – paru Menggunakan Support
Vector Machine dengan Pemilihan Fitur Berbasis Fungsi Kernel. Skripsi. Departemen
Matematika FMIPA UI
[4] Hoffman, Hans. (2000). Statlog(German Credit Data) Data Set. January 27, 2017.
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
64,7578,7
87,6
Hasil Pengukuran Tingkat Akurasi
FCM SVM Regresi Logistik
Gambar 2.3 Hasil Pengukuran Tingkat Akurasi

785
Prosiding SNM 2017 Komputasi , Hal 785 -796
PENGEMBANGAN MEDIA AUGMENTED REALITY
BERBASIS ANDROID UNTUK PEMBELAJARAN
DIMENSI TIGA
FARIS FATHAN1, TITA KHALIS MARYATI2, DINDIN
SOBIRUDDIN3
1 UIN Syarif Hidayatullah Jakarta, [email protected]
2 UIN Syarif Hidayatullah Jakarta, [email protected]
3 UIN Syarif Hidayatullah Jakarta, [email protected]
Abstrak. Augmented reality merupakan suatu teknologi yang memungkinkan
konten virtual digabung dengan dunia nyata yang dapat diterapkan pada android
smartphone. Pada penelitian ini kami mengembangkan media augmented reality
basis android untuk pembelajaran berdimensi tiga. Media dikembangkan
dengan menggunakan software Unity dengan model pengembangan ADDIE
(Analysis, Design, Development, Implementation, and Evaluation). Melalui
tahapan peninjauan ahli materi, ahli media, pengguna guru dan siswa, media
augmented reality berbasis android yang dikembangkan ini memperoleh umpan
balik berupapenilaian dengan tingkat kelayakan kategori baik.
Kata kunci: Media Pembelajaran, Augmented Reality, Smartphone Android, Materi
Dimensi Tiga, Model Pengembangan ADDIE.
1. Pendahuluan
Di era globalisasi ini, banyak sekali perkembangan teknologi dalam proses
pendidikan. Dengan adanya perkembangan teknologi dalam proses pendidikan maka
akan melahirkan beragam jenis kegiatan yang baru bagi dunia pendidikan. Sebelum
adanya teknologi dalam pendidikan, proses pembelajaran selalu menitik beratkan
peranan guru dan buku sebagai penyampaian informasi yang utama. Teknologi yang
telah berkembang sampai saat ini khususnya dalam dunia pendidikan dapat
membantu peranan guru dalam memperkuat penyampaian informasi. Siswa juga
dapat belajar lebih banyak secara individual atau kelompok dengan memanfaatkan
perkembangan teknologi pendidikan.
Perkembangan media pembelajaran merupakan salah satu alternatif dalam
mencari informasi pendidikan sehingga akan membawa berbagai kemajuan bagi
siswa. Dalam hal ini guru juga dituntut untuk selalu dapat memanfaatkan atau
bahkan mengembangkan produk teknologi pendidikan salah satunya adalah
kemampuan merancang dan memanfaatkan berbagai media dan sumber belajar[7].

786
Bidang pendidikan, khususnya matematika memiliki banyak peranan
penting dalam kehidupan. Matematika disebut juga sebagai Queen of Sciences,
karena matematika merupakan akar dari ilmu pengetahuan lainnya dan juga
berkaitan dengan kehidupan sehari-hari. Namun matematika juga merupakan salah
satu mata pelajaran yang abstrak. Untuk memahami konsep abstrak anak
memerlukan benda-benda riil sebagai perantara atau visualisasinya. Bahkan orang
dewasapun yang pada umumnya sudah dapat memahami konsep abstrak, dalam
keadaan tertentu masih memerlukan visualisasi[9].
Geometri merupakan salah satu materi yang memuat konsep tentang titik,
garis, bidang dan ruang beserta sifat-sifatnya, ukuran-ukurannya, dan hubungan
antara satu dengan lainnya. Salah satu topik yang dibahas dalam geometri adalah
dimensi tiga. Di jenjang Sekolah Menengah Atas (SMA), materi yang diajarkan
meliputi kedudukan titik, garis, dan bidang dalam ruang dimensi tiga, serta jarak dan
sudut antara titik, garis, dan bidang.
Menurut Wahyuni[10] dalam penelitian terkait konsep jarak dalam ruang
dimensi tiga dapat diidentifikasi beberapa hambatan belajar siswa, salah satunya
adalah siswa kesulitan dalam membangun concept image mengenai visualisasi jarak
dalam ruang dimensi tiga. Pada pembelajaran sebelumnya, biasanya siswa lebih
terbiasa dengan konsep jarak pada dimensi dua. Hal ini berpengaruh ketika
dihadapkan dengan persoalan jarak dimensi tiga, siswa akan mengalami
kebingungan. Selain itu, terbiasanya siswa dalam memahami konsep-konsep dalam
dimensi tiga yang hanya terbatas pada sumber buku akan membuat pembelajaran
kurang bermakna sehingga konsep yang dibangun oleh siswa akan lebih sulit dan
cenderung membosankan, sehingga perlu adanya pengembangan media
pembelajaran alternatif guna mencapai pembelajaran yang lebih bermakna.
Sudah selayaknya lembaga-lembaga pendidikan yang ada mulai
memanfaatkan teknologi sebagai media pembelajaran yang lebih mutakhir. Menurut
Darmawan pengembangan pendidikan berbasis TIK memberikan dua keuntungan,
yaitu sebagai pendorong dari setiap bagian dalam pendidikan termasuk guru untuk
lebih apresiatif dan proaktif dalam memaksimalkan potensi pendidikan, serta
memberikan kesempatan luas kepada peserta didik dalam memanfaatkan setiap
potensi yang ada, yang dapat diperoleh dari sumber-sumber tak terbatas[5].
Pesatnya pertumbuhan teknologi membuat jumlah penggunaan perangkat
android smartphone semakin meningkat. Riset Google bersama TNS Australia
menunjukkan bahwa Indonesia bersama dengan Australia dan India termasuk dalam
kelompok driven social. Dari tiga indikator utama pemakaian smartphone, ketiga
negara mendominasi aktivitas media sosial di pringkat pertama dan chat di peringkat
kedua. Sementara peringkat ketiga indikator di Indonesia didominasi dengan
aktivitas googling[3]. Hal ini menunjukkan bahwa masih kurangnya pemanfaatan
teknologi di bidang smartphone bagi pendidikan.
Augmented reality merupakan salah satu perkembangan teknologi.
Teknologi ini dikenal dengan pembuatan objek yang mirip dengan kondisi nyata.
Augmented reality merupakan sebuah teknologi yang memungkinkan konten virtual
digabung dengan dunia nyata[4]. Hal ini menunjukkan bahwa augmented reality
sangat mendukung dalam penyampaian informasi pada dimensi tiga jika diterapkan
sebagai media pembelajaran alternatif matematika.

787
Dengan adanya perkembangan teknologi ini maka peneliti bertujuan untuk:
a. Menghasilkan produk pembelajaran berbentuk aplikasi augmented reality yang
berjalan pada platform android dalam membantu visualisasi siswa pada materi
dimensi tiga.
b. Mengetahui tanggapan responden terhadap media pembelajaran yang dihasilkan.
2. Hasil – Hasil Utama
Menurut Azhar[2], istilah ‘media’ sering dikaitkan atau dipergantikan
dengan kata ‘teknologi’ yang berasal dari kata latin tekne (bahasa inggris art) dan
logos (bahasa indonesia ‘ilmu’). Media pembelajaran menurut Aqib[1] merupakan
segala sesuatu yang dapat digunakan untuk menyalurkan pesan dan merangsang
pembelajaran pada siswa. Seperti halnya menurut Sanjaya[7] bahwa media
pengajaran meliputi perangkat keras (hardware) dan perangkat lunak (software).
Hardware berupa alat yang dapat mengantarkan pesan seperti televisi, komputer,
radio, dan sebagainya. Sedangkan software merupakan suatu program yang
mengandung pesan atau informasi seperti aplikasi yang terdapat pada komputer, film
yang ditampilkan pada televisi, dan lain sebagainya.
Salah satu faktor penting dalam proses pembelajaran adalah media
pembelajaran. Dalam memahami peranan media pembelajaran, Edgar Dale[7] pada
Gambar 1 melukiskan sebuah kerucut pengalaman (cone of experience) yang pada
saat ini dianut secara luas dalam menentukan media apa yang sesuai agar siswa
memperoleh pengalaman belajar secara mudah.
Dari kerucut pengalaman yang telah dikemukakan oleh Edgar Dale tersebut
telah memberikan pandangan mengenai pengalaman belajar siswa. Semakin konkret
siswa mempelajari bahan ajar, contohnya pengalaman langsung, maka akan semakin
banyak pengalaman yang didapat oleh siswa. Sebaliknya, semakin abstrak siswa
mempelajari bahan ajar, contohnya menggunakan bahasa verbal saja, maka semakin
sedikit pengalamannya.
Adapun beberapa persyaratan dari alat peraga antara lain[8]:
a. Tahan lama.
b. Bentuk dan warnanya menarik.
c. Sederhana dan mudah dikelola.
d. Ukurannya sesuai.
e. Dapat menyajikan konsep matematika baik dalam bentuk real, gambar, atau
diagram.
f. Sesuai dengan konsep matematika.
g. Dapat memperjelas konsep matematika dan bukan sebaliknya.
h. Peragaan itu supaya menjadi dasar bagi tumbuhnya konsep berpikir abstrak bagi
siswa.
i. Menjadikan siswa belajar aktif dan mandiri dengan memanipulasi alat peraga.
j. Bila mungkin alat peraga tersebut bisa berfaedah lipat (banyak).

788
Gambar 1 Kerucut Pengalaman Edgar
Model ADDIE (Analysis, Design, Development, Implementation, and
Evaluation) merupakan salah satu model yang dapat digunakan untuk berbagai
macam bentuk pengembangan produk seperti model, strategi pembelajaran, metode
pembelajaran, media dan bahan ajar. Pada prosedur penelitian dan pengembangan
memiliki beberapa tahapan yang harus dikerjakan dalam penelitian. Berikut ini
tahapan model ADDIE yang dilakukan dalam penelitian ini, yaitu[6]:
a. Analisis
Tahapan kali ini bertujuan untuk menganalisis perlunya pengembangan media
pembelajaran alternatif. Pengembangan media pembelajaran didasari oleh
beberapa latar belakang masalah yang ada yaitu, perlunya media sebagai alat
bantu visual pada materi dimensi tiga dan kurangnya pemanfaatan teknologi
dalam media pembelajaran matematika.
b. Desain Tahapan yang dilakukan meliputi perancangan materi yang akan disampaikan,
pembuatan bagan alur media, pembuatan storyboard media, penyusunan modul
yang diintegrasikan dengan perangkat android, dan pengumpulan bahan lainnya
yang diperlukan dalam pengembangan media. Rancangan inilah yang akan
mendasari pada proses pengembangan berikutnya.
c. Pengembangan Sebagaimana pada tahap desain kerangka prosedural yang telah disusun akan
direalisasikan agar menjadi produk yang siap diimplementasikan. Dalam
merealisasikan produk tersebut terdapat beberapa langkah yang akan ditempuh
antara lain yaitu, pembuatan user interface menggunakan Unity 3D, pembuatan
Abstrak
Konkret

789
objek tiga dimensi menggunakan blender, pembuatan gambar seperti; tombol,
background, dan marker, pengkodingan (coding), serta penjalanan aplikasi (test
aplication/run) pada emulator android, baik dengan PC maupun android
smartphone. Setelah melalui langkah tersebut maka prototip akan dihasilkan.
Prototip yang telah dihasilkan akan di uji oleh para ahli. Setiap ahli akan
memberikan penilaian baik dari segi kualitas media maupun kesesuaian materi
dan komentar serta saran perbaikan agar prototip yang ada dapat diperbaiki.
Setelah para ahli memvalidasi prototip, maka prototip dapat diimplementasikan
ke lapangan.
d. Implementasi Pada tahap ini, prototip akan diujicobakan kepada pengguna dalam skala yang
kecil terlebih dahulu. Setelah media diujicobakan, evaluasi awal akan dilakukan
untuk melihat bagaimana tanggapan atau penilaian responden terhadap media
yang telah dihasilkan yang kemudian akan dilakukan perbaikan guna
mendapatkan hasil yang maksimal. Kemudian media yang telah diperbaiki akan
diterapkan kembali ke lapangan dengan jumlah siswa yang lebih banyak.
e. Penilaian
Evaluasi bertujuan agar kualitas media yang dikembangkan dapat sesuai dengan
tujuan awal. Dalam pengembangan media ini, evaluasi akan dilakukan terus
menerus agar setiap kesalahan kecil dapat terlihat dan dapat diperbaiki langsung
tanpa menunggu produk akhir selesai. Namun evaluasi pada kali ini merupakan
tahapan terakhir dalam proses pengembangan media pembelajaran. Hal ini
dapat dilihat berdasarkan data yang diperoleh saat implementasi guna
melakukan revisi tahap akhir.
Produk akhir dari penelitian ini merupakan media pembelajaran matematika
yang berbentuk aplikasi android dan modul pembelajaran augmented reality pada
materi dimensi tiga. Media pembelajaran augmented reality berbasis android ini
diberi nama “Dimensi 3 AR”, dengan nama file Dimensi3AR.apk. Adapun tujuan
pembelajaran yang terdapat pada modul antara lain, agar siswa dapat menentukan:
a. Jarak dari titik ke titik.
b. Jarak dari titik ke garis.
c. Jarak dari titik ke bidang.
d. Jarak dari garis ke garis.
e. Jarak dari garis ke bidang.
f. Jarak dari bidang ke bidang.
g. Besar sudut antara garis dengan garis.
h. Besar sudut antara garis dengan bidang.
i. Besar sudut antara bidang dengan bidang.

790
Gambar 2 Tampilan Sampul Modul
Gambar 3 Tampilan Splash Screen
Ketika aplikasi ini dijalankan, tampilan awal yang pertama kali muncul adalah
splash screen seperti Gambar 2 dengan durasi sekitar 7 detik. Setelah aplikasi
terbuka, maka akan langsung masuk ke tampilan utama. Tampilan utama ini
merupakan tampilan dari kamera pada perangkat smartphone android dengan
beberapa tombol yang sudah tersedia yang dapat dilihat pada Gambar 3. Berikut ini
adalah fungsi dari setiap tombol yang ada pada tampilan utama:
a. Tombol dan adalah tombol on-off, berfungsi untuk memunculkan atau
menyembunyikan dari tombol rotasi terhadap sumbu x, y, dan z, tombol zoom
in dan zoom out, tombol garis bantu, serta tombol reset objek ilustrasi.
b. Tombol dan adalah tombol rotasi terhadap sumbu x, berfungsi
untuk merotasi objek ilustrasi terhadap sumbu x.
c. Tombol dan adalah tombol rotasi terhadap sumbu y, berfungsi
untuk merotasi objek ilustrasi terhadap sumbu y.
d. Tombol dan adalah tombol rotasi terhadap sumbu z, berfungsi
untuk merotasi objek ilustrasi terhadap sumbu z.

791
e. Tombol dan adalah tombol zoom in dan zoom out, berfungsi untuk
memperbesar atau memperkecil objek ilustrasi.
f. Tombol adalah tombol garis bantu, berfungsi untuk memunculkan garis
bantu pada objek ilustrasi yang terdapat di contoh soal.
g. Tombol adalah tombol reset, berfungsi untuk mengembalikan objek
ilustrasi ke ukuran dan posisi awal.
h. Tombol adalah tombol petunjuk, berfungsi untuk memunculkan tampilan
petunjuk penggunaan dari media pembelajaran ini.
i. Tombol adalah tombol profil, berfungsi untuk memunculkan tampilan
profil dari peneliti pada media pembelajaran ini.
j. Tombol adalah tombol petunjuk, berfungsi untuk keluar dari media
pembelajaran ini.
Gambar 4 Tampilan utama
Pada tampilan utama, kamera sudah siap untuk membaca marker yang tersedia
pada modul pembelajaran yang sudah didesain. Aplikasi ini hanya bisa membaca
marker yang sudah terdaftar ketika proses pembuatan.
Gambar 4 Contoh Marker pada Modul

792
Pada materi jarak dalam dimensi tiga, materi disajikan dalam bentuk teks serta
objek ilustrasi. Objek ilustrasi yang digunakan merupakan animasi tiga dimensi yang
dapat membantu penggambaran dari setiap materi yang dijelaskan. Misal pada
Gambar 5a, objek ilustrasi dapat dilihat pada titik A yang berwarna merah dan titik
B yang berwarna biru dan disambungkan dengan sebuah garis. Garis penghubung
tersebut merupakan jarak antara titik A dengan titik B. Dalam aplikasi yang dibuat,
garis penghubung dari setiap materi jarak diberikan penekanan dengan
menambahkan efek bergerak agar siswa dapat memahami materi dengan baik.
Selain itu, objek ilustrasi juga dapat dirotasi terhadap sumbu x, sumbu y,
maupun sumbu z sehingga siswa lebih mudah dalam mengamati objek ilustrasi.
Misal pada Gambar 5b, objek ilustrasi dapat dirotasi sehingga siswa dapat
mengamati jarak yang merupakan panjang ruang garis AP yang tegak lurus terhadap
bidang V.
Gambar 6 Tampilan Contoh Soal 1
Gambar 5 Tampilan Materi Jarak
(a) (b)

793
Gambar 7 Tampilan Contoh Soal 2
Gambar 8 Tampilan Contoh Soal 3
Pada contoh soal, garis bantu dapat dimunculkan pada objek ilustrasi. Contoh
garis bantu dan sudut dapat dilihat pada gambar di atas. Garis bantu dan sudut yang
dibuat disesuaikan dengan contoh soalnya dan juga disesuaikan dengan langkah-
langkah pengerjaannya. Hal ini bertujuan agar siswa mengetahui jarak yang
dimaksud.
Pada materi sudut dalam dimensi tiga, materi disajikan tidak jauh berbeda
seperti materi jarak dalam dimensi tiga. Materi yang disajikan masih sama yaitu
dalam bentuk teks serta objek ilustrasi. Dari Gambar 6. dapat dilihat bahwa sudut
pada objek ilustrasi diberikan penekanan warna merah. Begitu pula pada materi
sudut yang lainnya.
Selain tampilan utama, aplikasi ini juga dilengkapi dengan menu petunjuk dan
menu profil. Menu petunjuk dan menu profil dapat diakses dengan menyentuh salah
satu dari tombol-tombol tersebut. Menu petunjuk berisikan tentang informasi
bagaimana cara menggunakan media pembelajaran ini. Sedangkan menu profil
berisikan tentang profil dari peneliti. Berikut ini adalah tambilan dari menu petunjuk
dan menu profil.

794
Gambar 9 Tampilan Materi Sudut
Gambar 10 Tampilan Menu Petunjuk 1 pada Aplikasi
Gambar 11 Tampilan Menu Petunjuk 2 pada Aplikasi

795
Gambar 12 Tampilan Menu Profil pada Aplikasi
Produk akhir dari penelitian ini memiliki beberapa kelebihan dan kekurangan.
Kelebihan dari media pembelajaran yang telah dikembangkan antara lain:
a. Media ini dapat digunakan pada android smartphone dengan minimum android
v4.2.2 “Jelly Bean” (API level 17) dan perangkat komputer/laptop basis
windows dengan menggunakan aplikasi bluestack.
b. Media ini menyajikan materi berupa teks dan objek ilustrasi yang bergrafis tiga
dimensi.
c. Media ini berupa modul dan aplikasi android sehingga mudah untuk digunakan
kapanpun dan dimanapun.
Adapun kekurangan dari media pembelajaran ini adalah:
a. Materi yang disajikan pada media pembelajaran ini terbatas pada materi
dimensi tiga yang ada di tingkat SMA.
b. Objek ilustrasi pada media ini jumlahnya terbatas, karena aplikasi ini hanya
dapat membaca marker pada modul pembelajaran yang telah disediakan.
c. Contoh soal pada media ini sangat terbatas dan tidak dapat dirandom.
3. Kesimpulan
Perkembangan teknologi pada dunia pendidikan sangat membantu
khususnya pada pembelajaran matematika. Salah satu perkembangan teknologi
adalah augmented reality dimana teknologi ini memungkinkan penggabungan
konten virtual dengan dunia nyata sehingga sangat baik untuk diterapkan dalam
media pembelajaran matematika terutama pada materi dimensi tiga. Hasil dari
penelitian ini merupakan media pembelajaran matematika yang berbentuk aplikasi
android dan modul pembelajaran augmented reality pada materi dimensi tiga.
Berdasarkan uji coba media pembelajaran tersebut yang dilakukan kepada ahli
materi, ahli media, guru dan siswa, mendapatkan umpan balik yaitu tingkat
kelayakan media pembelajaran augmented reality basis android pada materi dimensi
tiga secara keseluruhan termasuk dalam kategori baik. Diharapkan media
pembelajaran ini dapat membantu dalam pembelajaran matematika khususnya
materi dimensi tiga.

796
Referensi
[6] Aqib, Zainal. Model-model, Media, dan Strategi Pembelajaran Kontekstual (Inovatif).
Bandung: Yrama Widya, 2013.
[7] Arsyad, Azhar. Media Pembelajaran. Jakarta: PT RajaGrafindo Persada, 2011.
[8] Auliani, Palupi Annisa. “Mau Tahu Hasil Riset Google soal Penggunaan “Smartphone”
di Indonesia?”.
(http://tekno.kompas.com/read/2015/11/19/23084827/Mau.Tahu.Hasil.Riset.Google.so
al.Penggunaan.Smartphone.di.Indonesia), 13 November 2016.
[9] Azuma, Ronald, Mark Billinghurst, dan Gudrun Klinker. Special Section on Mobile
Augmented Reality. Computers and Graphics Journal. 35, 2011.
[10] Darmawan, Deni. Teknologi Pembelajaran. Bandung: PT Remaja Rosdakarya, 2011.
[11] Mulyatiningsih, Endang. Metode Penelitian Terapan Bidang Pendidikan. Bandung:
Alfabeta, 2012.
[12] Sanjaya, Wina. Strategi Pembelajaran: Berorientasi Standar Proses Pendidikan.
Jakarta: Kencana, 2014.
[13] Sundayana, Rostina. Media Pembelajaran Matematika. Bandung: Alfabeta, 2013.
[14] Tim MKPMB Jurusan Pendidikan Matematika. Strategi Pembelajaran Matematika
Kontemporer. Bandung: JICA-UPI, 2011.
[15] Wahyuni, Dwi. “Desain Didaktis Konsep Jarak Dalam Ruang Dimensi Tiga Dengan
Pendekatan Kontekstual Pada Pembelajaran Matematika SMA Kelas X”, Skirpsi pada
Sarjana UPI. Bandung: 2013.

797
Prosiding SNM 2017 Komputasi , Hal 797 -804
APLIKASI ADAPTIVE NEURO-FUZZY INFERENCE
SYSTEM PADA PENGAMBILAN KEPUTUSAN DALAM
INVESTASI SAHAM
I PUTU ADITYA WARDANA, ZUHERMAN RUSTAM
Departemen Matematika FMIPA, Universitas Indonesia,
[email protected], [email protected]
Abstrak. Selama bertahun-tahun, memprediksi pergerakan harga saham-saham dan
mengambil keputusan di tengah-tengah ketidakpastian pasar sudah menjadi perhatian
bagi para investor untuk memilih saham-saham yang tepat. Penelitian ini bertujuan
untuk menentukan keputusan.yang dapat mengurangi risiko-risiko dalam investasi
saham, agar investor memperoleh keuntungan. Technical analysis merupakan salah satu
metode yang digunakan oleh technicalist untuk memprediksi harga saham. Penelitian
ini menggunakan pendekatan Adaptive Neuro-Fuzzy Inference System (ANFIS) untuk
menentukan keputusan berdasarkan indikator-indikator pada technical analysis. Ada
beberapa indikator technical analysis yang digunakan di dalam penelitian ini, antara
lain RSI, MACD, SO dan OBV.
Kata kunci: pasar saham, analisis teknikal, indikator teknikal, pengambilan keputusan,
adaptive neuro-fuzzy inference system.
1. Pendahuluan
Pasar saham merupakan sarana investasi alternatif untuk mengelola aset. Saham
dinilai mempunyai sejumlah karakteristik yang unik. Harga saham yang cenderung
lebih fluktuatif dibandingkan dengan jenis investasi lain menjadikan pergerakan
harga saham lebih sulit untuk diprediksi. Prediksi mengenai pergerakan harga saham
menjadi perhatian khusus di bidang keuangan. Hal tersebut dapat dicapai dengan
menentukan keputusan yang tepat di masa sekarang agar dapat memperoleh
keuntungan dengan meminimalisasi resiko pasar.
Investor yang baik harus mampu menentukan keputusan yang tepat. Idealnya,
saham dibeli saat harga lebih murah daripada harga biasanya dan dijual saat harga
saham lebih mahal daripada harga beli. Namun, kerapkali investor ragu dalam
menentukan waktu yang tepat untuk membeli, menjual, atau menahan saham lebih
lama karena ketidakpastian pergerakan harga saham.
Artificial neural networks (ANN) sudah digunakan selama beberapa dekade
terakhir untuk memprediksi pergerakan harga saham. Neural networks mempunyai
karakteristik yang relevan untuk memprediksi pergerakan harga saham, seperti
interpolasi tidak linier, kemampuan mempelajari pemetaan tidak linier yang
kompleks, dan kemampuan self-adaptation untuk beragam distribusi statistik.
Namun, neural networks mempunyai kekurangan karena ia tidak dapat mencari
hubungan antara variabel input dan output. Pendekatan fuzzy logic juga relevan

798
digunakan dalam berbagai kasus prediksi. Fuzzy logic mempunyai tingkat akurasi
yang tinggi. Namun, perancangan sistemnya tergantung dari proses heuristik,
sehingga tidak selalu memberi hasil terbaik. Pemilihan membership functions pada
sistem fuzzy logic pun masih berdasarkan proses trial and error. Berdasarkan
kelebihan dan kelemahan artificial neural networks dan fuzzy logic, sistem yang
digunakan pada penelitian ini memanfaatkan pendekatan Adaptive Neuro-Fuzzy
Inference System (ANFIS). [1]
Seorang investor tidak dianjurkan untuk berspekulasi saat berinvestasi. Investor
harus melakukan analisis terlebih dahulu sebelum menentukan keputusan. Secara
umum, saham dievaluasi dengan dua metode, yaitu analisis teknikal dan analisis
fundamental. Penelitian ini menggunakan pendekatan ANFIS berdasarkan indikator-
indikator teknikal, antara lain RSI, MACD, SO, dan OBV. Kemudian, informasi dari
indikator-indikator tersebut dikombinasikan untuk membangun sebuah sistem yang
mampu menentukan keputusan dalam investasi saham.
Bagian lain dari paper ini terdiri dari: Bagian 2 mengenai hasil-hasil utama dan
Bagian 3 mengenai kesimpulan.
2. Hasil – Hasil Utama
Secara umum, saham dievaluasi dengan dua metode, yaitu analisis teknikal dan
analisis fundamental. Analisis teknikal adalah suatu metode pengevaluasian dengan
cara menganalisis indikator-indikator teknikal di masa lampau untuk memprediksi
pergerakan harga saham. Sedangkan, analisis fundamental menggunakan data-data
internal dan eksternal emiten untuk menilai saham. [4]
Penelitian ini menggunakan analisis teknikal dengan beberapa indikator
teknikal. Ada tiga dasar pemikiran analisis teknikal, yaitu:
- Pergerakan harga yang terjadi di pasar telah mewakili semua faktor lain.
- Terdapat suatu tren dalam pergerakan harga.
- Sejarah akan terulang.
2.1. Pemilihan Indikator dan Parameter
Terdapat banyak indikator teknikal, tapi tidak semua indikator dipakai di dalam
penelitian ini. Hal ini bertujuan untuk menyederhanakan sistem dengan prinsip tidak
mengurangi kemampuan sistem dalam memprediksi pergerakan harga saham.
Berdasarkan publikasi sebelumnya, peneliti memusatkan perhatian pada RSI,
MACD, OBV dan SO. Indikator-indikator tersebut dapat membantu untuk
mempredisi pergerakan harga saham. [2]
MACD adalah indikator teknikal yang sering digunakan karena mempunyai
karakteristik yang sederhana dan akurat. MACD terdiri dari dua exponential moving
average (EMA) yang berfungsi untuk mendeteksi tren pergerakan harga saham.
Penelitian ini menggunakan EMA-12 dan EMA-26 (periode baku).
𝐸𝑀𝐴(𝑡) = 𝑝(𝑡)
2
𝑃𝑒𝑟𝑖𝑜𝑑 + 1+ 𝐸𝑀𝐴(𝑡 − 1) (1 −
2
𝑃𝑒𝑟𝑖𝑜𝑑 + 1).
(1)
Nilai MACD adalah hasil pengurangan EMA periode yang lebih pendek dengan
EMA periode yang lebih panjang.
Apabila garis EMA periode lebih pendek memotong garis EMA periode lebih

799
panjang dari arah bawah, maka itu merupakan indikasi bahwa pergerakan harga
saham akan cenderung naik. Sebaliknya, apabila garis EMA periode lebih pendek
memotong garis EMA periode lebih panjang dari arah atas, maka itu merupakan
indikasi bahwa pergerakan harga saham akan cenderung turun. Gambar 2.1
menunjukkan grafik indikator EMA-12 dan EMA-26 dari PT Agung Podomoro
Land, Tbk.
Gambar 2.1: EMA-12 dan EMA-26 APLN.JK (Yahoo! Finance)
Selain nilai MACD, terdapat juga nilai signals. Pada penelitian ini, nilai signals
merupakan EMA-9 dari MACD. Lebih lanjut, perbandingan nilai signals dengan
nilai MACD dapat memberi sinyal jual atau beli. [2]
(i) Jika nilai MACD berada di atas nilai signals, maka BUY.
(ii) Jika nilai MACD berada di bawah nilai signals, maka SELL.
RSI (Relative Strength Index) merupakan indikator teknikal lain yang sering
dipakai. Nilai indikator RSI berkisar antara 0 sampai 100. Apabila RSI bernilai lebih
dari 70, maka sekuritas dikatakan overbought. Apabila RSI bernilai kurang dari 30,
maka sekuritas dikatakan oversold. RSI dapat digunakan untuk menyelidiki apakah
arah pergerakan harga saham mengikuti suatu tren atau tidak. Gambar 2.2
menunjukkan grafik indikator RSI-14 dari PT Agung Podomoro Land, Tbk.
𝑅𝑆𝐼 = 100 −
100
1 + 𝑅𝑆.
(2)
Catatan: RS adalah rasio antara rata-rata kenaikan pergerakan harga saham
selama 14 hari dan rata-rata penurunan pergerakan harga saham selama 14 hari.
Gambar 2.2: RSI APLN.JK (Yahoo! Finance)
SO (Stochastic Oscillator) merupakan indikator yang dapat mengukur tingkat
kejenuhan pasar (oversold atau overbought). Nilai SO berkisar antara 0 sampai 100.
Apabila SO bernilai lebih dari 80, maka sekuritas dikatakan overbought. Sebaliknya,

800
apabila SO bernilai kurang dari 20, maka sekuritas dikatakan oversold. Sekilas, SO
mirip dengan RSI. Namun, SO dapat memberi sinyal jual atau beli. Indikator SO
terdiri dari 2 parameter, yaitu %K dan %D. Kedua parameter ini mempunyai nilai
dan diplot bersamaan. Gambar 2.3 menunjukkan grafik indikator stochastic
oscillator dari PT Agung Podomoro Land, Tbk.
Gambar 2.3: SO APLN.JK (Yahoo! Finance)
%𝐾 = 100 ×
𝑃𝑟𝑖𝑐𝑒(𝑡) − 𝐿𝑜𝑤𝑒𝑠𝑡 𝑃𝑟𝑖𝑐𝑒(𝑃𝑒𝑟𝑖𝑜𝑑)
𝐻𝑖𝑔ℎ𝑒𝑠𝑡 𝑃𝑟𝑖𝑐𝑒(𝑃𝑒𝑟𝑖𝑜𝑑) − 𝐿𝑜𝑤𝑒𝑠𝑡 𝑃𝑟𝑖𝑐𝑒(𝑃𝑒𝑟𝑖𝑜𝑑) (3)
%𝐷 = 𝐴𝑣𝑒𝑟𝑎𝑔𝑒 %𝐾(𝑃𝑒𝑟𝑖𝑜𝑑) (4)
Sinyal jual atau beli dapat dilihat dari grafik %K dan %D. [2]
(i) Jika garis %K memotong garis %D dari atas, maka sinyal jual.
(ii) Jika garis %K memotong garis %D dari bawah, maka sinyal beli.
Indikator terakhir yang digunakan dalam penelitian ini adalah OBV (On Balance
Volume). OBV merupakan indikator yang menggunakan informasi volume
perdagangan untuk memperkuat keyakinan investor dalam menentukan keputusan.
𝑂𝐵𝑉(𝑡) = {
𝑉𝑜𝑙𝑢𝑚𝑒(𝑡 − 1) + 𝑉𝑜𝑙𝑢𝑚𝑒(𝑡),𝑉𝑜𝑙𝑢𝑚𝑒(𝑡), 𝑉𝑜𝑙𝑢𝑚𝑒 (𝑡 − 1) − 𝑉𝑜𝑙𝑢𝑚𝑒(𝑡),
Jika 𝑝(𝑡) > 𝑝(𝑡 − 1)
Jika 𝑝(𝑡) = 𝑝(𝑡 − 1)
Jika 𝑝(𝑡) < 𝑝(𝑡 − 1) (5)
Namun, nilai OBV tidak menggambarkan hal yang berarti karena OBV lebih
berfokus pada tren yang terbentuk. Jika upward, maka buy. Sebaliknya, jika
downward, maka sell. [2]
Tabel 2.1 menunjukkan indikator teknikal dan periodenya yang dipakai pada
penelitian ini. Metode perhitungan moving average yang dipakai adalah exponential
(EMA).
Indikator Teknikal Parameter
MACD Long = 26
Short = 12
Signals = 9
RSI
SO
OBV
N = 14
K = 10
D = 3
Moving Average
Method = Exponential
Tabel 2.1: Indikator Teknikal (Periode Baku)

801
2.2. Membangun rules dan membership functions
Pada dasarnya, sistem fuzzy logic terdiri dari aturan-aturan (if-then) yang
dirancang berdasarkan kasus yang diteliti. Sehingga, sistem diharapkan mampu
mendefinisikan keadaan nyata secara akurat. Aturan-aturan diperoleh dari informasi
indikator teknikal yang sudah dibahas pada Bagian 2.A. Berikut ini merupakan
beberapa aturan yang diimplementasikan:
Tabel 2.2: Aturan-aturan pada Fuzzy Logic
No.
IF
MACD RSI SO OBV
THEN
REKOMENDASI
1 LOW LOW LOW LOW SELL
2 LOW MED MED LOW SELL
3 LOW MED HIGH LOW SELL
4 LOW HIGH MED LOW SELL
5 LOW HIGH HIGH LOW SELL
6 HIGH LOW LOW HIGH BUY
7 HIGH LOW MED HIGH BUY
8 HIGH MED MED HIGH BUY
9 HIGH MED LOW LOW HOLD
10 HIGH MED LOW HIGH BUY
11 HIGH MED MED LOW HOLD
12 HIGH HIGH HIGH HIGH BUY
13 LOW MED MED HOLD
14 LOW HIGH HIGH SELL
15 HIGH LOW LOW BUY
16 HIGH MED MED HOLD
17 LOW LOW HIGH BUY
18 MED MED HIGH HOLD
19 HIGH HIGH LOW SELL
20 MED MED LOW HOLD

802
Membership functions adalah suatu kurva yang menunjukkan pemetaan setiap
titik di dalam ruang anggota ke dalam derajat keanggotaannya yang nilainya berkisar
antara 0 sampai 1. Membership functions dirancang sedemikian sehingga ia dapat
mengurangi efek minor yang mempengaruhi akurasi.
Gambar 2.4: MATLAB Fuzzy Logic Toolbox
2.3. Adaptive Neuro-Fuzzy Inference System (ANFIS)
Metode Adaptive Neuro-Fuzzy Inference System (ANFIS) merupakan metode
yang menggunakan jaringan syaraf tiruan untuk mengimplementasikan fuzzy
inference system.[1] ANFIS dapat mencari hubungan antara variabel input-output,
yang tidak dapat dilakukan oleh neural networks. Sedangkan, fuzzy logic dapat
memodelkan aspek kualitatif pengetahuan dan penalaran manusia. Penggabungan
neural networks dan fuzzy logic dapat mengatasi keterbatasan dalam pemetaan input-
output yang banyak dan tidak linier.
Fuzzy inference system terdiri dari empat blok. Blok pertama, knowledge base,
terdiri dari database dan rule base (Takagi-Sugeno). Database berisi membership
functions, sedangkan rule base berisi aturan if-then. Blok kedua, fuzzification
interface, mengubah crisp input ke fuzzy input. Blok ketiga, inference interface,
mengubah fuzzy input menjadi fuzzy output. Blok keempat, defuzzification interface,
mengubah fuzzy output ke crisp output. Hal ini divisualisasikan ke dalam Gambar
2.5.
Gambar 2.5: Fuzzy Inference System
Arsitektur ANFIS ditunjukkan pada Gambar 2.6. Node lingkaran adalah fixed
parameter, sedangkan node persegi adalah parameter yang akan dipelajari. Pada
Gambar 2.6, arsitektur ANFIS terdiri dari dua input, 𝑥 dan 𝑦, dengan masing-masing
Knowledge
Base
Fuzzification Input
Inference
Defuzzification Output

803
variabel input mempunyai dua membership functions, dan satu output 𝑓, dan dua
aturan if-then.
Gambar 2.6: Arsitektur ANFIS
(https://www.computer.org/csdl/trans/lt/2012/03/tlt2012030226.html)
Rule 1: 𝑖𝑓(𝑥 𝑖𝑠 𝐴1)𝑎𝑛𝑑 (𝑦 𝑖𝑠 𝐵1) 𝑡ℎ𝑒𝑛 (𝑓1 = 𝑝1𝑥 + 𝑞1𝑦 + 𝑟1) Rule 2: 𝑖𝑓(𝑥 𝑖𝑠 𝐴2)𝑎𝑛𝑑 (𝑦 𝑖𝑠 𝐵2) 𝑡ℎ𝑒𝑛 (𝑓2 = 𝑝2𝑥 + 𝑞2𝑦 + 𝑟2)
Dengan, 𝑥 dan 𝑦 sebagai variabel input, 𝐴 dan 𝐵 sebagai fuzzy sets, dan, 𝑝, 𝑞 dan 𝑟
sebagai parameter output.
Layer 1 dan Layer 2 merupakan adaptive layer. Layer 1 berkaitan dengan
membership functions (Gaussmf). Sedangkan, pada Layer 2 terjadi proses perkalian
antar derajat keanggotaan. Parameter input (𝐴 dan 𝐵) pada Layer 1 disebut parameter
premis dan parameter output (𝑝, 𝑞 dan 𝑟) pada Layer 4 disebut parameter konsekuen.
Node berlabel N menunjukkan adanya normalisasi. Output yang dihasilkan oleh
Layer 4 adalah perkalian hasil normalisasi dengan polinomial. Pada Layer 5 terdapat
node berlabel ∑ yang menghitung keseluruhan output.
Proses pelatihan pada arsitektur ANFIS bertujuan untuk menyesuaikan semua
parameter. Algoritma pembelajaran pada ANFIS menggunakan metode least-square
dan back propagation.
2.4. Hasil Eksperimen
Eksperimen menggunakan data dari emiten di Indonesia yang diperoleh dari
situs Yahoo! Finance. Situs tersebut menyediakan grafik untuk beberapa indikator
teknikal dan data riwayat saham setiap hari mengenai harga pembukaan, harga
penutupan, harga tertinggi, harga terendah, dan volume. Proses pelatihan sistem
menggunakan data harian dari 11 November 2010 sampai dengan 31 Desember
2015. Sedangkan, proses pengujian sistem menggunakan data harian dari 1 Januari
2016 sampai dengan 31 Desember 2016.
Untuk menguji sistem ANFIS, peneliti cukup memasukkan nilai setiap variabel
input dari data testing pada fuzzy inference system yang sudah dihasilkan oleh
ANFIS, kemudian sistem akan menghasilkan nilai output dan rekomendasi
keputusan. Lalu, peneliti akan menguji tingkat akurasinya dengan cara
membandingkan harga penutupan hari ke-𝑡 dengan harga penutupan hari ke−(𝑡 +𝑝). Periode pembandingan disesuaikan dengan trading period masing-masing
investor. Pada penelitian ini, peneliti membandingkan harga penutupan hari ke−𝑡 dengan harga penutupan hari ke−(𝑡 + 7). Apabila harga penutupan hari ke-𝑡 jauh
lebih tinggi dibandingkan harga penutupan hari ke-(𝑡 + 7), maka sell. Apabila harga
penutupan hari ke-𝑡 jauh lebih rendah dibandingkan harga penutupan hari ke-(𝑡 +7), maka buy. Sedangkan, apabila harga penutupan hari ke-𝑡 tidak jauh berbeda atau

804
sama dibandingkan harga penutupan hari ke-(𝑡 + 7), maka sistem hold. Selanjutnya,
bandingkan rekomendasi keputusan oleh sistem dengan rekomendasi keputusan
yang seharusnya.
Emiten Periode Jumlah Data Akurasi Sistem
BUMI 1-1-2016 s/d 30-12-2016 244 70.90%
3. Kesimpulan
Penelitian ini mengimplementasikan pendekatan ANFIS berdasarkan indikator
teknikal pada pengambilan keputusan dalam investasi saham. Dari hasil eksperimen,
ANFIS telah terbukti sesuai untuk digunakan dalam kasus prediksi yang melibatkan
pemetaan tidak linier dan kompleks. Tentunya, tingkat akurasi sistem sangat
bergantung dari karakteristik data training. Semakin volatil pergerakan harga saham
dari suatu emiten, semakin sulit pula pergerakan sahamnya untuk diprediksi. Hal ini
tercermin dari tingkat akurasi sistem untuk emiten PT Bumi Resources Tbk. (periode
11 November 2010 – 31 Desember 2016) belum mendekati 100%.
Ada beberapa hal yang dapat ditambahkan atau dimodifikasi untuk
mengembangkan sistem. Penelitian bisa dilakukan dengan jenis membership
functions lain dan indikator teknikal lain dengan parameter lain. Pengembangan
sistem yang terintegrasi langsung dengan sumber data di internet secara real-time
online dan kemampuan penentuan bobot atau persentase uang yang digunakan pada
transaksi merupakan fitur-fitur yang dapat ditambahkan ke dalam pengaturan sistem
dalam penelitian berikutnya.
Referensi
[1] S. Agrawal, M. Jindal, and G. N Pillai, “Momentum Analysis based Stock Market
Prediction using Adaptive Neuro-Fuzzy Inference System (ANFIS),” Int.
multiconference Eng. Comput. Sci., vol I, pp. 526-531, 2010.
[2] Bala, V. Devsaer, “Analysing and Handling Anomalies in Stock Market using Fuzzy
System,” Int. journal Comput. Sci. Eng., vol 6, issue 4, pp 538-542, 2016.
[3] J. -S. R. Jang, C. –T. Sun, E. Mizutani. Neuro-Fuzzy and Soft-Computing: A
Computational Approach to Learning and Machine Intelligence. Eanglewood
Cliffs, NJ: Prentice-Hall, 1997.
[4] Ong, Edianto. Technical Analysis for Mega Profit. Jakarta: PT Gramedia Pustaka
Utama, 2016.

805
Prosiding SNM 2017 Komputasi, Hal 805-815
PEMILIHAN PERSONAL COMPUTER (PC) TERBAIK
BERBASIS ANDROID MENGGUNAKAN METODE
FUZZY ANALYTICAL HIERARCHY PROCESS (FAHP)
AKIK HIDAYAT1, EBBY SYABILAL R2, RUDI ROSYADI3,
ERICK PAULUS4
1)Prodi Teknik Informatika, Fakultas MIPA, Universitas Pdjadjaran Jl. Raya Bandung Sumedang KM 21
Jatinangor Sumedang 45363, [email protected] 2)Prodi Matematika, Fakultas MIPA, Universitas Pdjadjaran Jl. Raya Bandung Sumedang KM 21
Jatinangor Sumedang 45363, [email protected] 3) Prodi Teknik Informatika, Fakultas MIPA, Universitas Pdjadjaran Jl. Raya Bandung Sumedang KM
21 Jatinangor Sumedang 45363, [email protected] 4)Prodi Teknik Informatika, Fakultas MIPA, Universitas Pdjadjaran, Jl. Raya Bandung Sumedang KM 21
Jatinangor Sumedang 45363, [email protected]
Abstrak: Dewasa ini banyak merk Personal Computer (PC) dengan beragam spesifikasi dan harga
yang dijual dipasaran membuat konsumen menjadi kesulitan dalam menentukan pilihan yang sesuai
dengan keinginan dan anggaran yang mereka miliki. Sejalan dengan itu, perkembangan penggunaan
komputer juga meningkat, salah satunya adalah penggunaan komputer dalam memberikan keputusan
terbaik pada suatu masalah, dalam hal ini adalah masalah pemilihan Personal Computer (PC). Oleh
karena itu, maka dalam hal ini telah dikembangkan perancangan sebuah system pendukung keputusan
pemilihan Personal Computer (PC) dengan menggunakan metode Fuzzy Analytical Hierarchy Process
(FAHP), dengan tujuan konsumen dapat menentukan pilihan Personal Computer (PC dengan tepat
sesuai dengan keinginan dan anggaran yang dimilikinya sedangkan hasil akhir akan direkomendasikan
10 daftar merek Personal Computer (PC) terbaik yang sesuai dengan kriteria yang diinputkan.
Kata kunci: Fuzzy Analytical Hierarchy Process, pemilihan Personal Computer (PC),
sistem pendukung keputusan,
1. Pendahuluan
Seiring pesatnya perkembangan teknologi, handphone yang dulu digunakan
hanya untuk SMS (Short Message Service) dan telepon, kini handphone hadir
dengan fitur-fitur tambahan yang membuatnya kini dikenal dengan sebutan
smartphone. Fitur tambahan tersebut sangat mendukung segala aktifitas
penggunanya seperti camera, games, internet browser, email, GPS (Global
Positioning System), dan masih banyak lagi fitur lainnya. Android yang kini sangat
dikenal dalam lingkup smartphone merupakan suatu Operating System (OS) yang
berbasis Linux yang menjadi platform-nya. Android dengan sifatnya yang open
source membuat pengembang leluasa untuk menciptakan aplikasi mereka yang
berbasis Android, salah satunya aplikasi pemilihan Personal Computer (PC).
Untuk mempertimbangkan beberapa faktor yang berkaitan dengan
pemilihan Personal Computer (PC) tersebut, dibutuhkan suatu sistem pendukung
keputusan yang dapat mempercepat dan mempermudah pengguna. Fuzzy Analytical

806
Hierarchy Process (FAHP) adalah suatu sistem pendukung keputusan yang
merupakan gabungan antara metode AHP dengan pendekatan konsep fuzzy.
Sedangkan Tujuan adalah untuk menerapkan metode FAHP dalam pemilihan
Personal Computer (PC), Membangun aplikasi pemilihan Personal Computer (PC)
menggunakan metode FAHP sehingga Mempermudah pembeli untuk memilih
Personal Computer (PC) sesuai kriteria yang diinginkan.
2. Metode Penelitian
Metode yang digunakan dalam penelitian yaitu melakukan studi literatur
dan Merancang program menggunakan Java Android.
3. Hasil dan Pembahasan
3.1 Fuzzy Analytical Hierarchy Process (FAHP)
Metode FAHP memecahkan masalah pemilihan yang menggunakan konsep
teori himpunan fuzzy dan analisis struktur hirarkis. Pada dasarnya, metode FAHP
merupakan perluasan dari metode AHP biasa yang menggunakan perhitungan
bilangan real, menjadi metode FAHP yang melakukan perhitungan menggunakan
bilangan fuzzy.
Karena pada dasarnya AHP tidak mengikutsertakan ketidakjelasan
pertimbangan personal, maka AHP telah diperbaiki dengan memanfaatkan
pendekatan logika fuzzy. Pada FAHP, alternatif kriteria dari perbandingan
berpasangan ditunjukan dengan variabel linguistik.
Fuzzy Analytical Hierarchy Process (FAHP) memasukkan nilai fuzzy pada
Analytic Hierarchy Process (AHP) yang telah dikembangkan oleh Thomas L. Saaty.
Dalam pendekatan FAHP digunakan Triangular Fuzzy Number (TFN)
untuk proses fuzzyfikasi dari matriks perbandingan yang bersifat crisp. Data yang
kabur akan dipresentasikan dalam TFN. Setiap fungsi keanggotaan didefinisikan
dalam 3 parameter yakni, l, m, dan u, dimana l adalah nilai kemungkinan terendah,
m adalah nilai kemungkinan tengah dan u adalah nilai kemungkinan teratas pada
interval putusan pengambil keputusan. Nilai l, m, dan u dapat juga ditentukan oleh
pengambil keputusan itu sendiri. Tulisan ini mengajukan tiga parameter bilangan
fuzzy untuk merepresentasikan skala Saaty (1-9) sesuai dengan tingkat
kepentingannya, yakni (Alias, Hashim, & Samsudin, 2009):
(3.1)
Triangular Fuzzy Number (TFN) dapat menunjukkan kesubjektifan
perbandingan berpasangan atau dapat menunjukkan derajat yang pasti dari
kekaburan (ketidakpastian). Dalam hal ini variabel linguistik dapat digunakan oleh
pengambil keputusan untuk merepresentasikan kekaburan data seandainya ada
ketidaknyamanan dengan TFN. TFN dan variabel linguistiknya sesuai dengan skala
Saaty ditunjukkan pada tabel berikut (Alias, Hashim, & Samsudin, 2009):

807
Tabel 3.1 Tabel Fungsi Keanggotaan Fuzzy Definisi Skala Saaty TFN
Equally Important (sama penting) 1 (1,1,1)
Moderately more important (sedikit lebih
penitng) 3 (2,3,4)
Strongly More Important (lebih penting) 5 (4,5,6)
Very strongly more important (sangat
penting)
7 (6,7,8)
Extremely more important (mutlak lebih
penting) 9 (9,9,9)
Intermediate Values (nilai yang
berdekatan) 2,4,6,8 (1,2,3),(3,4,5),(5,6,7), dan (7,8,9)
Untuk melakukan prioritas lokal dari matriks fuzzy pairwise comparison
sudah banyak metode yang dikembangkan oleh para ahli sebelumnya. Dengan
mengkombinasikan prosedur AHP dengan operasi aritmetik untuk bilangan fuzzy,
prioritas lokal dapat diperoleh dengan menggunakan persamaan berikut
(Febryansyah, 2006):
𝑆𝑖 = ∑ 𝑀𝑔𝑖𝑗⊗𝑚
𝑗=𝑖 [∑ ∑ 𝑀𝑔𝑖𝑗𝑚
𝑗=1𝑛𝑖=1 ]
−1
(3.2)
dimana 𝑆𝑖 = fuzzy synthetic extent
gi = goal set (i = 1, 2, 3, …, n)
𝑀𝑔𝑖𝑗 = Triangular Fuzzy Number (j = 1, 2, 3, ... , m)
∑ 𝑀𝑔𝑖𝑗= (∑ 𝑙𝑗
𝑚𝑗=1 ; ∑ 𝑚𝑗
𝑚𝑗=1 ; ∑ 𝑢𝑗
𝑚𝑗=1 )𝑚
𝑗=𝑖
(3.3)
Dan
[∑ ∑ 𝑀𝑔𝑖𝑗𝑚
𝑗=1𝑛𝑖=1 ]
−1= (∑ 𝑙𝑗
𝑚𝑗=1 ; ∑ 𝑚𝑗
𝑚𝑗=1 ; ∑ 𝑢𝑗
𝑚𝑗=1 )
−1
(3.4)
karena l < m < u, sehingga persamaan (3.4) menjadi:
[∑ ∑ 𝑀𝑔𝑖𝑗𝑚
𝑗=1𝑛𝑖=1 ]
−1=
(1
∑ 𝑢𝑖𝑛𝑖=1
;1
∑ 𝑚𝑖𝑛𝑖=1
;1
∑ 𝑙𝑖𝑛𝑖=1
) (3.5)
sehingga persamaan (3.2) menjadi:
𝑆𝑖 = (∑ 𝑙𝑗𝑚𝑗=1 ; ∑ 𝑚𝑗
𝑚𝑗=1 ; ∑ 𝑢𝑗
𝑚𝑗=1 )⊗ (
1
∑ 𝑢𝑖𝑛𝑖=1
;1
∑ 𝑚𝑖𝑛𝑖=1
;1
∑ 𝑙𝑖𝑛𝑖=1
)
(3.6)
dengan: l = nilai batas bawah (kemungkinan terendah)
m = nilai yang paling menjanjikan (kemungkinan tengah)
u = nilai batas atas (kemungkinan teratas)
Untuk menentukan nilai perbandingan berpasangan dari 𝑆𝑖 digunakan rumus:
𝑉(𝑆𝑖 ≥ 𝑆𝑘) =
{
1; 𝑚𝑆𝑖 ≥ 𝑚𝑆𝑘
0; 𝑙𝑆𝑘 ≥ 𝑢𝑆𝑖(𝑙𝑆𝑘−𝑢𝑆𝑖)
((𝑚𝑆𝑖−𝑢𝑆𝑖)−(𝑚𝑆𝑘
−𝑙𝑆𝑘)); 𝑙𝑎𝑖𝑛𝑛𝑦𝑎
(3.7)
dimana: 𝑉(𝑆𝑖 ≥ 𝑆𝑘) = nilai perbandingan antara fuzzy synthetic extent
𝑆𝑖 = nilai fuzzy synthetic extent kriteria i
𝑆𝑘 = nilai fuzzy synthetic extent kriteria k

808
𝑑′𝑖 = 𝑚𝑖𝑛(𝑉(𝑆𝑖 ≥ 𝑆𝑘)) ; untuk 𝑘 = 1,2,3,… , 𝑛; 𝑘 ≠ 𝑖
(3.8)
𝑊′ = (𝑑′𝑖, 𝑑′𝑖+1, 𝑑′𝑖+2, … , 𝑑′𝑖+𝑛−1)𝑇;
(3.9)
𝑑𝑖 =𝑑′𝑖
∑ 𝑑′𝑖𝑛𝑖=1
(3.10)
𝑊 =(𝑑𝑖 , 𝑑𝑖+1, 𝑑𝑖+2, … , 𝑑𝑖+𝑛−1)
𝑇 (3.11)
dimana : 𝑑′𝑖 = bobot kriteria i
𝑊′ = vektor bobot kriteria
𝑑𝑖 = normalisasi bobot
𝑊 = normalisasi vektor bobot kriteria
𝑛 = jumlah kriteria
Operasi aritmetik untuk bilangan fuzzy dapat dilihat dari persamaan berikut:
1. ��1⊕ ��2 = (��1𝑙 + ��2𝑙; ��1𝑚 + ��2𝑚; ��1𝑢 + ��2𝑢) 2. ��1⊗��2 = (��1𝑙 × ��2𝑙; ��1𝑚 × ��2𝑚; ��1𝑢 × ��2𝑢)
3. 1 ��1⁄ =
(1 ��1𝑢⁄ ; 1 ��1𝑚
⁄ ; 1 ��1𝑙⁄ )
(3.12)
Sedangkan prioritas global diperoleh dengan mengalikan normalisasi skala
setiap kriteria wj dengan normalisasi bobot 𝑑(𝐴𝑖) dan menjumlahkan semua hasil
perkalian dari setiap kriteria. Persamaan dapat dituliskan sebagai berikut:
��𝑖 = (��1⊗𝑑(𝐴1)) ⊕ (��2⊗𝑑(𝐴2)) ⊕⋯⊕ (��𝑗⊗𝑑(𝐴𝑖)) (3.13)
3.2 Contoh Kasus dan Perhitungan
Pada contoh kasus ini akan diinputkan skala prioritas pada setiap kriteria
yang ada sebagai berikut: jumlah inti 2, kecepatan processor 6, RAM 3, lebar layar
7, kapasitas SSD 1, kapasitas HDD 4, harga 9.
Tabel 3.2 Input Kriteria oleh User
INPUT
Jumlah Inti C1 2
Kecepatan Processor C2 6
RAM C3 3
Lebar Layar C4 7
Kapasitas SSD C5 1
Kapasitas HDD C6 4
Harga C7 9

809
Setelah ditentukan skala prioritas, kemudian akan dilakukan perhitungan
sebagai berikut:
1. Menghitung matriks perbandingan berpasangan
Tabel 3.3 Rumus Umum Matriks Perbandingan Berpasangan Matriks Perbandingan Berpasangan
C1 C2 C3 C4 C5 C6 C7
C1 C1/C1 C1/C2 C1/C3 C1/C4 C1/C5 C1/C6 C1/C7
C2 C2/C1 C2/C2 C2/C3 C2/C4 C2/C5 C2/C6 C2/C7
C3 C3/C1 C3/C2 C3/C3 C3/C4 C3/C5 C3/C6 C3/C7
C4 C4/C1 C4/C2 C4/C3 C4/C4 C4/C5 C4/C6 C4/C7
C5 C5/C1 C5/C2 C5/C3 C5/C4 C5/C5 C5/C6 C5/C7
C6 C6/C1 C6/C2 C6/C3 C6/C4 C6/C5 C6/C6 C6/C7
C7 C7/C1 C7/C2 C7/C3 C7/C4 C7/C5 C7/C6 C7/C7
Tabel 3.4 Hasil Perhitungan Matriks Perbandingan Berpasangan Matriks Perbandingan Berpasangan
C1 C2 C3 C4 C5 C6 C7
C1 1.0000 0.3333 0.6667 0.2857 2.0000 0.5000 0.2222
C2 3.0000 1.0000 2.0000 0.8571 6.0000 1.5000 0.6667
C3 1.5000 0.5000 1.0000 0.4286 3.0000 0.7500 0.3333
C4 3.5000 1.1667 2.3333 1.0000 7.0000 1.7500 0.7778
C5 0.5000 0.1667 0.3333 0.1429 1.0000 0.2500 0.1111
C6 2.0000 0.6667 1.3333 0.5714 4.0000 1.0000 0.4444
C7 4.5000 1.5000 3.0000 1.2857 9.0000 2.2500 1.0000

810
2. Menghitung TFN dari matriks perbandingan berpasangan
Tabel 3.5 Rumus Umum TFN Matriks Perbandingan Berpasanga
C1 C2 C3 C4
l m u l m u l M u l m u
C1 mC1-
1 C1/C1 mC1+1 mC2-1 C1/C2 mC2+1 mC3-1 C1/C3 mC3+1 mC4-1 C1/C4 mC4+1
C2 mC1-
1 C2/C1 mC1+1 mC2-1 C2/C2 mC2+1 mC3-1 C2/C3 mC3+1 mC4-1 C2/C4 mC4+1
C3 mC1-
1 C3/C1 mC1+1 mC2-1 C3/C2 mC2+1 mC3-1 C3/C3 mC3+1 mC4-1 C3/C4 mC4+1
C4 mC1-
1 C4/C1 mC1+1 mC2-1 C4/C2 mC2+1 mC3-1 C4/C3 mC3+1 mC4-1 C4/C4 mC4+1
C5 mC1-
1 C5/C1 mC1+1 mC2-1 C5/C2 mC2+1 mC3-1 C5/C3 mC3+1 mC4-1 C5/C4 mC4+1
C6 mC1-
1 C6/C1 mC1+1 mC2-1 C6/C2 mC2+1 mC3-1 C6/C3 mC3+1 mC4-1 C6/C4 mC4+1
C7 mC1-
1 C7/C1 mC1+1 mC2-1 C7/C2 mC2+1 mC3-1 C7/C3 mC3+1 mC4-1 C7/C4 mC4+1
C5 C6 C7
l M u l m u l m u
C1 mC5-
1 C1/C5 mC5+1 mC6-1 C1/C6 mC6+1 mC7-1 C1/C7 mC7+1
C2 mC5-
1 C2/C5 mC5+1 mC6-1 C2/C6 mC6+1 mC7-1 C2/C7 mC7+1
C3 mC5-
1 C3/C5 mC5+1 mC6-1 C3/C6 mC6+1 mC7-1 C3/C7 mC7+1
C4 mC5-
1 C4/C5 mC5+1 mC6-1 C4/C6 mC6+1 mC7-1 C4/C7 mC7+1
C5 mC5-
1 C5/C5 mC5+1 mC6-1 C5/C6 mC6+1 mC7-1 C5/C7 mC7+1
C6 mC5-
1 C6/C5 mC5+1 mC6-1 C6/C6 mC6+1 mC7-1 C6/C7 mC7+1
C7 mC5-
1 C7/C5 mC5+1 mC6-1 C7/C6 mC6+1 mC7-1 C7/C7 mC7+1
Jika m = 1, maka l = 1 dan u = 1; jika m = 9, maka l = 9 dan u = 9; jika l ≤ 0,
maka l = m; jika u ≥ 0, maka u = m.
Tabel 3.6 Hasil Perhitungan TFN Matriks Perbandingan Berpasangan
C1 C2 C3 C4
l m u l m u l M u l M u
C1 1.0000 1.0000 1.0000 0.3333 0.3333 1.3333 0.6667 0.6667 1.6667 0.2857 0.2857 1.2857
C2 2.0000 3.0000 4.0000 1.0000 1.0000 1.0000 1.0000 2.0000 3.0000 0.8571 0.8571 1.8571
C3 0.5000 1.5000 2.5000 0.5000 0.5000 1.5000 1.0000 1.0000 1.0000 0.4286 0.4286 1.4286
C4 2.5000 3.5000 4.5000 0.1667 1.1667 2.1667 1.3333 2.3333 3.3333 1.0000 1.0000 1.0000
C5 0.5000 0.5000 1.5000 0.1667 0.1667 1.1667 0.3333 0.3333 1.3333 0.1429 0.1429 1.1429
C6 1.0000 2.0000 3.0000 0.6667 0.6667 1.6667 0.3333 1.3333 2.3333 0.5714 0.5714 1.5714
C7 3.5000 4.5000 5.5000 0.5000 1.5000 2.5000 2.0000 3.0000 4.0000 0.2857 1.2857 2.2857
C5 C6 C7
l M u l m u l m u

811
C1 1.0000 2.0000 3.0000 0.5000 0.5000 1.5000 0.2222 0.2222 1.2222
C2 5.0000 6.0000 7.0000 0.5000 1.5000 2.5000 0.6667 0.6667 1.6667
C3 2.0000 3.0000 4.0000 0.7500 0.7500 1.7500 0.3333 0.3333 1.3333
C4 6.0000 7.0000 8.0000 0.7500 1.7500 2.7500 0.7778 0.7778 1.7778
C5 1.0000 1.0000 1.0000 0.2500 0.2500 1.2500 0.1111 0.1111 1.1111
C6 3.0000 4.0000 5.0000 1.0000 1.0000 1.0000 0.4444 0.4444 1.4444
C7 9.0000 9.0000 9.0000 1.2500 2.2500 3.2500 1.0000 1.0000 1.0000
3. Menghitung jumlah baris ∑ 𝑀𝑔𝑖𝑗= (∑ 𝑙𝑗
𝑚𝑗=1 ; ∑ 𝑚𝑗
𝑚𝑗=1 ; ∑ 𝑢𝑗
𝑚𝑗=1 )𝑚
𝑗=𝑖
Tabel 3.7 Rumus Umum Perhitungan Jumlah Baris Jumlah Baris
l m U
C1T lC1+..+lC7 mC1+..+mC7 uC1+..+uC7
C2T lC1+..+lC7 mC1+..+mC7 uC1+..+uC7
C3T lC1+..+lC7 mC1+..+mC7 uC1+..+uC7
C4T lC1+..+lC7 mC1+..+mC7 uC1+..+uC7
C5T lC1+..+lC7 mC1+..+mC7 uC1+..+uC7
C6T lC1+..+lC7 mC1+..+mC7 uC1+..+uC7
C7T lC1+..+lC7 mC1+..+mC7 uC1+..+uC7
Tabel 3.8 Hasil Perhitungan Jumlah Baris Jumlah Baris (Sigma TFN)
l m U
C1T 4.0079 5.0079 11.0079
C2T 11.0238 15.0238 21.0238
C3T 5.5119 7.5119 13.5119
C4T 12.5278 17.5278 23.5278
C5T 2.5040 2.5040 8.5040
C6T 7.0159 10.0159 16.0159
C7T 17.5357 22.5357 27.5357
4. Menghitung jumlah kolom
[∑ ∑ 𝑀𝑔𝑖𝑗𝑚
𝑗=1𝑛𝑖=1 ] = (∑ 𝑙𝑗
𝑚𝑗=1 ; ∑ 𝑚𝑗
𝑚𝑗=1 ; ∑ 𝑢𝑗
𝑚𝑗=1 )

812
Tabel 3.12 Rumus Umum Perhitungan Jumlah Kolom
Tabel 3.9 Hasil Perhitungan Jumlah Kolom
Jumlah Kolom
l m U
JK 60.1270 80.1270 121.1270
5. Menghitung invers jumlah kolom
[∑ ∑ 𝑀𝑔𝑖𝑗𝑚
𝑗=1𝑛𝑖=1 ]
−1= (
1
∑ 𝑢𝑖𝑛𝑖=1
;1
∑ 𝑚𝑖𝑛𝑖=1
;1
∑ 𝑙𝑖𝑛𝑖=1
)
Tabel 3.10 Rumus Umum Perhitungan Invers Jumlah Kolom
Invers Jumlah Kolom
l m u
iJK 1/uJK 1/mJK 1/lJK
Tabel 3.11 Hasil Perhitungan Invers Jumlah Kolom
Invers Jumlah Kolom
l m u
iJK 0.0083 0.0125 0.0166
6. Menghitung nilai Fuzzy Synthetic Extent
𝑆𝑖 = ∑ 𝑀𝑔𝑖𝑗⊗𝑚
𝑗=𝑖 [∑ ∑ 𝑀𝑔𝑖𝑗𝑚
𝑗=1𝑛𝑖=1 ]
−1
Tabel 3.12 Rumus Umum Perhitungan Fuzzy Synthetic Extent Fuzzy Synthetic Extent
l m u
S1 lC1T x liJK mC1T x miJK uC1T x uiJK
S2 lC2T x liJK mC2T x miJK uC2T x uiJK
S3 lC3T x liJK mC3T x miJK uC3T x uiJK
S4 lC4T x liJK mC4T x miJK uC4T x uiJK
S5 lC5T x liJK mC5T x miJK uC5T x uiJK
S6 lC6T x liJK mC6T x miJK uC6T x uiJK

813
S7 lC7T x liJK mC7T x miJK uC7T x uiJK
Tabel 3.17 Hasil Perhitungan Fuzzy Synthetic Extent
Fuzzy Synthetic Extent
l m u
S1 0.0331 0.0625 0.1831
S2 0.0910 0.1875 0.3497
S3 0.0455 0.0938 0.2247
S4 0.1034 0.2188 0.3913
S5 0.0207 0.0313 0.1414
S6 0.0579 0.1250 0.2664
S7 0.1448 0.2813 0.4580
7. Menghitung perbandingan Fuzzy Synthetic Extent
𝑉(𝑆𝑖 ≥ 𝑆𝑘) =
{
1; 𝑚𝑆𝑖 ≥ 𝑚𝑆𝑘
0; 𝑙𝑆𝑘 ≥ 𝑢𝑆𝑖(𝑙𝑆𝑘 − 𝑢𝑆𝑖)
((𝑚𝑆𝑖 − 𝑢𝑆𝑖) − (𝑚𝑆𝑘 − 𝑙𝑆𝑘)); 𝑙𝑎𝑖𝑛𝑛𝑦𝑎
Tabel 3.13 Hasil Perhitungan Fuzzy Synthetic Extent Perbandingan Fuzzy Synthetic Extent
S1>= S2>= S3>= S4>= S5>= S6>= S7>=
S1 1.0000 1.0000 1.0000 1.0000 0.7761 1.0000 1.0000
S2 0.4241 1.0000 0.5878 1.0000 0.2440 0.7372 1.0000
S3 0.8149 1.0000 1.0000 1.0000 0.6055 1.0000 1.0000
S4 0.3376 0.8874 0.4925 1.0000 0.1685 0.6348 1.0000
S5 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000
S6 0.6669 1.0000 0.8422 1.0000 0.4711 1.0000 1.0000
S7 0.1490 0.6861 0.2989 0.7978 0.0000 0.4376 1.0000
8. Menghitung nilai bobot 𝑑′𝑖 = 𝑚𝑖𝑛(𝑉(𝑆𝑖 ≥ 𝑆𝑘))
Tabel 3.14 Rumus Umum Perhitungan Nilai Bobot
Nilai Bobot
Bobot S1 S2 S3 S4 S5 S6 S7 Total
(Td'(An))
d'(An)

814
min
(S1>=
(S1,..,S7))
min
(S2>=
(S1,..,S7))
min
(S3>=
(S1,..,S7))
min
(S4>=
(S1,..,S7))
min
(S5>=
(S1,..,S7))
min
(S6>=
(S1,..,S7))
min
(S7>=
(S1,..,S7))
d'(A1)
+..+
d'(A7)
Tabel 3.15 Hasil Perhitungan Nilai Bobot Nilai Bobot
Bobot S1 S2 S3 S4 S5 S6 S7 Total
d'(An) 0.1490 0.6861 0.2989 0.7978 0.0000 0.4376 1.0000 3.3694
9. Normalisasi nilai bobot (𝑑𝑖 =𝑑′𝑖
∑ 𝑑′𝑖𝑛𝑖=1
)
Tabel 3.16 Rumus Umum Normalisasi Bobot
Normalisasi Nilai Bobot
Bobot S1 S2 S3 S4 S5 S6 S7
d(An) d'(A1)
/Td'(An)
d'(A2)
/Td'(An)
d'(A3
)/Td'(An)
d'(A4)
/Td'(An)
d'(A5)
/Td'(An)
d'(A6)
/Td'(an)
d'(A7)
/Td'(an)
Tabel 3.17 Hasil Normalisasi Bobot Normalisasi Nilai Bobot
Bobot S1 S2 S3 S4 S5 S6 S7
d(An) 0.0442 0.2036 0.0887 0.2368 0.0000 0.1299 0.2968
10. Menghitung bobot global
��𝑖 = (��1⊗𝑑(𝐴1) ⊕ (��2⊗𝑑(𝐴2)) ⊕⋯⊕ (��𝑗⊗𝑑(𝐴𝑖))
dimana ��𝑖 adalah bobot global dari Personal Computer (PC) ke i
��1 adalah normalisasi skala dari kriteria 1
��2 adalah normalisasi skala dari kriteria 2
��𝑗 adalah normalisasi skala dari kriteria j
Maka rumus umum untuk menghitung bobot global dari kasus diatas
adalah:
��1 = (��1⊗𝑑(𝐴1)⊕ (��2⊗𝑑(𝐴2)) ⊕⋯⊕ (��7⊗𝑑(𝐴7)) ��1 = (��1⊗0.0442)⊕ (��2⊗0.2036)⊕ (��3⊗0.0887)
⊕ (��4⊗0.2368)⊕ (��5⊗0)⊕ (��6⊗0.1299)⊕ (��7⊗0.296))
dan dihitung hingga semua Personal Computer (PC) mendapatkan nilai
prioritas globa
3. Kesimpulan dan Saran
Dari hasil analisi terhadap masalah dan aplikasi yang telah dikembangkan,
maka dapat disimpulkan yaitu Proses penggunaan aplikasi dilakukan oleh user. User
melakukan input memilih skala prioritas dari setiap kriteria. Aplikasi akan
melakukan perhitungan, kemudian output yang dihasilkan adalah 10 rekomendasi

815
Personal Computer (PC) dengan nilai bobot tertinggi. Adapun sarannya adalah
Menambah kriteria lain seperti VGA, tipe RAM, berat Personal Computer (PC),
ketebalan Personal Computer (PC), dan fitur-fitur tambahan lainnya agar kriteria
yang diperhitungkan lebih lengkap sebagai pertimbangan bagi user.
Referensi
[1]. Alias, M. A., Hashim, S. Z., & Samsudin, S. (2009). Using fuzzy analytic Hierarchy
process for southern johor river ranking. Int. J. Advance. Soft Comput. Appl. Vol. 1. No.
1, 62-76.
[2]. Anton, H. (2000). Elementary Linear Algebra. NJ: John Wiley and Sons.
[3]. Febryansyah, A. (2006). Mengukur kesuksesan produk pada tahap desain: sebuah
pendekatan fuzzy-mcdm. Jurnal Teknik Industri Volume 8 Nomor 2, 122-130.
[4]. Kusumadewi, S., & Hartati, S. (2010). NEURO-FUZZY Integrasi Sistem FUzzy &
Jaringan Syaraf (2nd ed.). Yogyakarta: Graha Ilmu.
[5]. Safaat, N. (2011). Pemrograman Aplikasi Mobile Smartphone dan Tablet PC
Berbasis Android. Bandung: Penerbit Informatika.

816
Prosiding SNM 2017 Komputasi , Hal 816 -829
PENCARIAN IMPROBABLE DIFFERENTIAL 9 DAN 10
ROUND PRESENT
AFIFAH1, SARI AGUSTINI H.2
1 Lembaga Sandi Negara, [email protected]
2 Lembaga Sandi Negara, [email protected]
Abstrak. Pencarian improbable differential adalah langkah awal dalam
melakukan improbable differential attack. Pada tahun 2014, Tezcan, telah
melakukan pencarian improbable differential dengan memanfaatkan
undisturbed bit pada PRESENT sebanyak 9 round [2] dan 10 round [5] dengan
probabilitas yang diperoleh adalah 𝑝′ ≈ 2−9.29 untuk 9 round dan 𝑝′ ≈ 2−19.29
untuk 10 round. Untuk mengetahui ada atau tidak improbable differential 9 dan
10 round lain maka dilakukan penelitian untuk mencari improbable differential
9 dan 10 round lainnya dengan menggunakan undisturbed bit seperti yang
dilakukan Tezcan. Berdasarkan pencarian improbable differential 9 round
PRESENT dengan menggunakan input difference 1, 8, dan 9 yang diawali satu
dan dua S-box aktif pada round pertama diperoleh improbable differential 9 round
dengan probabilitas lebih besar dari 2−9.24511242 sebanyak 3 karakteristik
sedangkan yang memiliki probabilitas lebih kecil dari 2−9.24511242 sebanyak 124
karakteristik. Pada pencarian improbable differential 10 round diperoleh satu
karakteristik yang memiliki probabilitas sama dengan 2−19.24511337, sebanyak 56
karakteristik memiliki probabilitas lebih besar dari 2−19.24511337, dan sebanyak
971 karakteristik mempunyai probabilitas lebih kecil dari 2−19.24511337.
Kata kunci: Improbable differential, PRESENT, differential characteristic, impossible
differential, undisturbed bit.
1. Pendahuluan
PRESENT merupakan salah satu algoritma block cipher ultra lightweight
yang didesain untuk memenuhi efisiensi implementasi dan keamanan [1]. Algoritma
PRESENT mempunyai struktur SPN (Substitution Permutation Network) sehingga
salah satu kekuatan PRESENT terletak pada komponen substitution box (S-box). S-
box mempunyai nilai difference yang didapatkan dari DDT (Differential
Distribution Table). Nilai difference tersebut dapat dimanfaatkan pada penerapan
improbable differential attack untuk mengetahui kekuatan algoritma PRESENT.
Improbable differential attack merupakan serangan yang menghubungkan celah
antara differential dan impossible differential attack [2].
Suatu S-box yang memiliki nilai difference dengan persebaran yang merata
mempunyai ketahanan yang lebih baik terhadap differential cryptanalysis [3].
Persebaran nilai difference dari S-box PRESENT cukup seragam sehingga
mempersulit usaha dalam melakukan attack karena titik awal untuk menemukan
differential characteristic mempunyai banyak kemungkinan serta probabilitas yang
didapatkan relatif kecil. Meskipun demikian, S-box PRESENT masih mempunyai

817
kelemahan, salah satunya adalah terdapat undisturbed bit pada S-box PRESENT
yang dapat dimanfaatkan untuk mempermudah konstruksi improbable differential.
Suatu S-box dikatakan mempunyai undisturbed bit jika diberikan suatu nilai
input difference tertentu, maka peluang dihasilkan nilai Least Significant Bit (LSB)
pada output difference dari S-box adalah satu dan sebaliknya [2]. Berdasarkan
kelemahan tersebut, maka dapat dilakukan pencarian differential characteristic
maupun impossible differential dengan memanfaatkan undisturbed bit pada
algoritma PRESENT yang dapat dikombinasikan secara tepat untuk memperoleh
improbable differential.
Tezcan telah melakukan pencarian improbable differential dengan
memanfaatkan undisturbed bit pada PRESENT sebanyak 9 round [2] dan 10 round
[5] dengan probabilitas yang diperoleh adalah 𝑝′ ≈ 2−9.29 untuk 9 round dan 𝑝′ ≈2−19.29 untuk 10 round. Untuk mengetahui ada atau tidak improbable differential 9
dan 10 round lain maka dilakukan penelitian untuk mencari improbable differential
9 dan 10 round lainnya dengan menggunakan undisturbed bit.
Pencarian improbable differential 9 round lain dilakukan dengan
memanfaatkan semua kemungkinan differential characteristic 3 round selain yang
digunakan oleh Tezcan [2] namun impossible differential 6 round yang digunakan
sama untuk semua improbable differential 9 round. Semua kemungkinan differential
characteristic 3 round yang digunakan untuk membentuk satu improbable
differential memiliki differential characteristic 1 round yang sama. Jadi banyaknya
kemungkinan improbable differential 9 round lain yang dapat dibentuk sama dengan
banyaknya kemungkinan differential characteristic 1 round, sedangkan banyaknya
differential characteristic 3 round untuk setiap improbable differential tergantung
dari banyaknya differential characteristic 3 round dengan differential characteristic
1 round yang sama dan mempunyai output difference pada round ketiga dengan S-
box aktif bernilai 9𝐻.
Untuk pencarian improbable differential 10 round dilakukan dengan
memanfaatkan impossible differential 5 round yang sama dengan yang digunakan
Tezcan [5] namun menggunakan semua kemungkinan differential characteristic 5
round dengan input difference satu dan dua S-box aktif pada round pertama.
Pencarian improbable differential 10 round pada prinsipnya sama dengan pencarian
improbable differential 9 round yaitu mencari semua kemungkinan differential
characteristic yang memiliki output difference di round terakhir dengan S-box aktif
bernilai 9𝐻. Setiap pembentukan satu improbable differential 10 round
membutuhkan semua kemungkinan differential characteristic 5 round dengan
differential characteristic 3 round yang sama dan memiliki output difference pada
round kelima dengan S-box aktif bernilai 9𝐻 . Oleh karena itu, pada pencarian semua
kemungkinan improbable differential 10 round lain digunakan semua variasi
differential characteristic 3 round.

818
2. Landasan Teori
Berikut adalah konsep dan teori yang berkaitan dengan penelitian yaitu algoritma PRESENT, improbable differential attack, dan undisturbed bit.
2.1 Algoritma PRESENT
PRESENT adalah salah satu algoritma lightweight block cipher yang mempunyai panjang blok sebesar 64-bit, variasi input key 80 dan 128-bit, serta jumlah round sebanyak 31. PRESENT mempunyai dua komponen utama yaitu key schedule dan algoritma enkripsi/dekripsi.
2.1.1 Key Schedule
Proses key schedule untuk setiap round PRESENT dengan input kunci 80 bit (𝑘79𝑘78…𝑘1𝑘0) yaitu:
(1) Subkey pada round ke-𝑖 dengan (30 ≥ 𝑖 ≥ 0): 𝐾𝑖 = 𝑘63𝑘62…𝑘1𝑘0 =𝑘79𝑘78…𝑘15𝑘16
(2) [𝑘79𝑘78…𝑘1𝑘0] = [𝑘18𝑘17…𝑘20𝑘19] (3) [𝑘79𝑘78𝑘77𝑘76] = 𝑆[𝑘79𝑘78𝑘77𝑘76] (4) [𝑘19𝑘18𝑘17𝑘16𝑘15] = [𝑘19𝑘18𝑘17𝑘16𝑘15] ⨁ 𝑟𝑜𝑢𝑛𝑑_𝑐𝑜𝑢𝑛𝑡𝑒𝑟
2.1.2 Enkripsi
Skema enkripsi pada PRESENT dapat dilihat pada Gambar 2.1.
Gambar 2.1 Skema Enkripsi PRESENT
Komponen algoritma enkripsi PRESENT sebagai berikut:
(1) AddRoundKey
Proses AddRoundKey dilakukan setiap round, sebanyak 64-bit plaintext di-XOR
dengan 64-bit subkey.
(2) sBoxLayer (ditunjukkan pada Tabel 2.1)
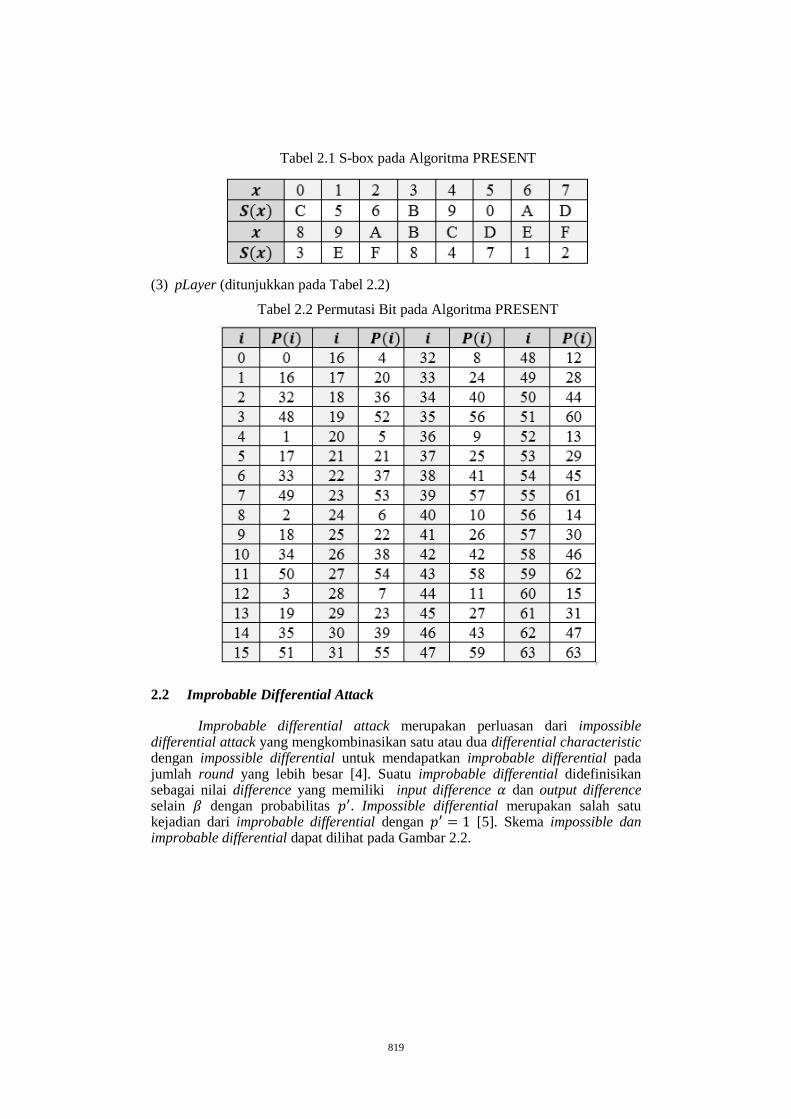
819
Tabel 2.1 S-box pada Algoritma PRESENT
(3) pLayer (ditunjukkan pada Tabel 2.2)
Tabel 2.2 Permutasi Bit pada Algoritma PRESENT
2.2 Improbable Differential Attack
Improbable differential attack merupakan perluasan dari impossible differential attack yang mengkombinasikan satu atau dua differential characteristic dengan impossible differential untuk mendapatkan improbable differential pada jumlah round yang lebih besar [4]. Suatu improbable differential didefinisikan sebagai nilai difference yang memiliki input difference 𝛼 dan output difference selain 𝛽 dengan probabilitas 𝑝′. Impossible differential merupakan salah satu kejadian dari improbable differential dengan 𝑝′ = 1 [5]. Skema impossible dan improbable differential dapat dilihat pada Gambar 2.2.

820
Gambar 2.2 Skema Impossible Differential dan Improbable Differential [4]
2.3 Undisturbed Bit
Undisturbed bit pada S-box PRESENT sebanyak 6 yaitu berdasarkan input dan output difference masing-masing berjumlah tiga [2]. Berikut definisi dan corollary terkait undisturbed bit:
Definisi 2.1. [6] Misal �� ∈ 𝔽2𝑛 adalah input difference bukan nol pada S-box 𝑆 dan
𝛺�� = {�� = (𝛽𝑚−1, . . . , 𝛽0) ∈ 𝔽2
𝑚|Ρr𝑠[�� → ��] > 0} adalah himpunan semua
output difference dari 𝑆 yang berkorespondensi dengan ��. Jika 𝛽𝑖 = 𝑐 untuk 𝑐 ∈ 𝔽2
tetap dan untuk semua �� ∈ 𝛺�� dengan 𝑖 ∈ {0, . . . , 𝑚 − 1} maka S-box 𝑆
mempunyai undisturbed bit, sehingga dapat dinyatakan bahwa untuk input
difference ��, bit ke-𝑖 pada output difference S-box 𝑆 adalah undisturbed yang
bernilai c.
Corollary 2.2. [6] Untuk input difference bukan nol �� ∈ 𝔽2𝑛, bit ke-𝑖 dari output
difference S-box 𝑆 adalah undisturbed bit jika dan hanya jika:
∑ 𝐷𝐷𝑇(𝛼, 𝜐)(−1)𝑒��.�� =
��∈𝔽2𝑚
±2𝑛
dengan 𝑖 ∈ {0, . . . , 𝑚 − 1} dan 𝑒�� adalah standar basis ke-𝑖 dari 𝔽2𝑛.
3. Hasil – Hasil Utama
Sebelum melakukan pencarian improbable differential 9 dan 10 round, terlebih dahulu dilakukan perhitungan kembali differential characteristic 3 round. Hasil perhitungan menunjukkan bahwa differential characteristic 3 round yang diperoleh penulis berbeda dengan yang dituliskan Tezcan [2], ditunjukkan pada Tabel 3.1. Tezcan menuliskan nilai 𝑥12 pada 𝑋(2, 𝑃) sebesar 1𝐻 sedangkan berdasarkan hasil perhitungan, nibble yang bernilai 1𝐻 berada pada 𝑥11. Selain itu, hasil dari 𝑋(3, 𝑆) diperoleh nilai 3𝐻 pada nibble 𝑥11 sedangkan menurut Tezcan nibble yang bernilai 3𝐻 berada pada nibble 𝑥12. Namun, output difference pada round ketiga 𝑋(3, 𝑃) yang dituliskan Tezcan sama dengan hasil perhitungan kembali, yaitu 𝑥2 = 𝑥6 = 9, sehingga tidak mempengaruhi proses selanjutnya untuk melakukan pencarian impossible differential 6 round yang memanfaatkan nilai ouput difference pada round ketiga dari difference characteristic 3 round sebagai input difference pada impossible differential 6 round.

821
Tabel 3.1 Perbedaan Differential Characteristic 3 Round antara Hasil
Perhitungan Kembali dengan Hasil yang diperoleh Tezcan
Rounds Differential Characteristic [2]
Differential Characteristic
Hasil Perhitungan
Kembali
𝛼 𝑥3 = 1, 𝑥0 = 1 𝑥3 = 1, 𝑥0 = 1
𝑋(1, 𝑆) 𝑥3 = 9, 𝑥0 = 9 𝑥3 = 9, 𝑥0 = 9
𝑋(1, 𝑃) 𝑥12 = 9, 𝑥0 = 9 𝑥12 = 9, 𝑥0 = 9
𝑋(2, 𝑆) 𝑥12 = 4, 𝑥0 = 4 𝑥12 = 4, 𝑥0 = 4
𝑋(2, 𝑃) 𝑥12 = 1, 𝑥8 = 1 𝑥11 = 1, 𝑥8 = 1
𝑋(3, 𝑆) 𝑥12 = 3, 𝑥8 = 3 𝑥11 = 3, 𝑥8 = 3
𝑋(3, 𝑃) 𝑥6 = 9, 𝑥2 = 9 𝑥6 = 9, 𝑥2 = 9
3.1. Pencarian Improbable Differential 9 Round Lain
Berdasarkan differential characteristic 3 round pada diperoleh pada Tabel 3.1 diperoleh kemungkinan differential characteristic 1 round sebanyak 128 buah yang tercantum pada Tabel 3.2, sehingga dapat dibentuk 128 improbable differential 9 round dengan memanfaatkan semua kemungkinan differential characteristic 1 round yang terdiri dari variasi 1-24 sebanyak 32 differential characteristic dan variasi 2-22 sebanyak 96 differential characterictic. Yang dimaksud dengan variasi 1-24 adalah jumlah S-box aktif hasil differential characteristic pada round pertama hingga ketiga berturut-turut 1, 2, dan 4, sedangkan variasi 2-22 adalah jumlah S-box aktif hasil differential characteristic pada round pertama hingga ketiga berturut-turut 2, 2, dan 2.
Berdasarkan Tabel 3.2, pada variasi 1-24 terdapat dua variasi probabilitas yaitu 2−2 dan 2−3, masing-masing probabilitas mempunyai differential characteristic 1 round berjumlah 16. Pada variasi 2-22 terdapat tiga variasi probabilitas yaitu 2−4, 2−5, dan 2−6 dengan jumlah differential characteristic 1 round pada masing-masing variasi probabilitas berturut-turut 24, 48, dan 24. Tezcan menggunakan satu dari 24 differential characterictic pada variasi 2-22 yaitu dengan probabilitas differential characteristic 1 round sebesar 2−4 sehingga terdapat 127 kemungkinan improbable differential 9 round lain yang dapat dibentuk.
Tabel 3.2 Rekapitulasi Jumlah Differential Characteristic 1 Round dari
Differential Characteristic 3 Round Berdasarkan Probabilitas pada Setiap Variasi S-Box Aktif
No. Probabilitas Jumlah Differential Characteristic
Variasi 1-24 Variasi 2-22
1. 2−2 16 -
2. 2−3 16 -
3. 2−4 - 24
4. 2−5 - 48
5. 2−6 - 24
Total 32 96

822
Setiap kemungkinan differential characteristic 1 round dilanjutkan dengan pencarian characteristic hingga tiga round yang menghasilkan semua kemungkinan nilai output differential pada round ketiga dengan S-box aktif bernilai 9𝐻. Setelah dilakukan pencarian differential characteristic 3 round dari 128 differential characteristic 1 round yang diperoleh sebelumnya, dihasilkan 128 improbable differential dengan probabilitas yang berbeda-beda. Hasil pencarian 128 improbable differential 9 round dengan perhitungan probabilitas dari setiap improbable differential sebagian tercantum pada Tabel 3.3 dan Tabel 3.4. Tabel 3.3 merupakan hasil perhitungan untuk S-box aktif dengan variasi 1-24 sedangkan Tabel 3.4 untuk variasi 2-22.
Tabel 3.3 Improbable Differential 9 Round untuk Variasi 1-24
Tabel 3.4 Improbable Differential 9 Round untuk Variasi 2-22
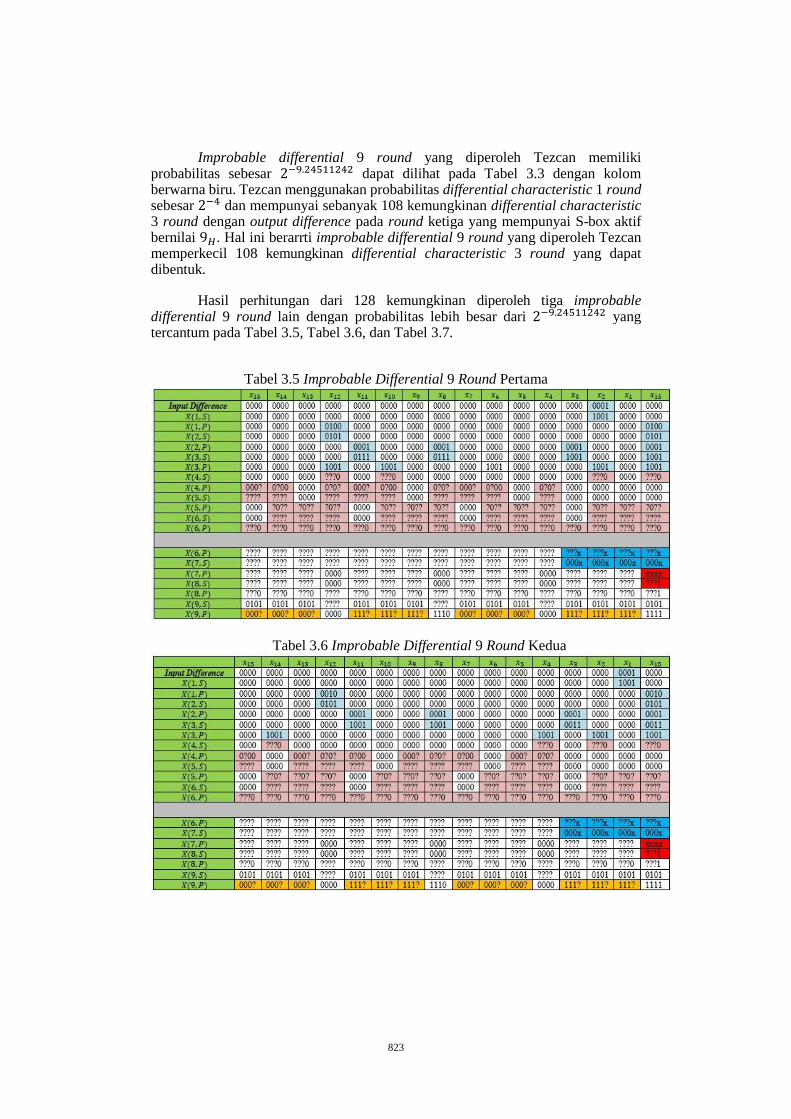
823
Improbable differential 9 round yang diperoleh Tezcan memiliki probabilitas sebesar 2−9.24511242 dapat dilihat pada Tabel 3.3 dengan kolom berwarna biru. Tezcan menggunakan probabilitas differential characteristic 1 round sebesar 2−4 dan mempunyai sebanyak 108 kemungkinan differential characteristic 3 round dengan output difference pada round ketiga yang mempunyai S-box aktif bernilai 9𝐻. Hal ini berarrti improbable differential 9 round yang diperoleh Tezcan memperkecil 108 kemungkinan differential characteristic 3 round yang dapat dibentuk.
Hasil perhitungan dari 128 kemungkinan diperoleh tiga improbable differential 9 round lain dengan probabilitas lebih besar dari 2−9.24511242 yang tercantum pada Tabel 3.5, Tabel 3.6, dan Tabel 3.7.
Tabel 3.5 Improbable Differential 9 Round Pertama
Tabel 3.6 Improbable Differential 9 Round Kedua

824
Tabel 3.7 Improbable Differential 9 Round Ketiga
Ketiga improbable differential 9 round tersebut memiliki S-box aktif dengan
variasi 1-24 dan nilai probabilitas differential characteristic 1 round sebesar 2−2. Berdasarkan Tabel 3.3 hasil perhitungan probabilitas dari ketiga improbable differential 9 round tersebut, dua diantaranya bernilai 2−8.91253757 dan sisanya bernilai 2−8.67807198. Dua improbable differential 9 round dengan probabilitas 2−8.91253757, masing-masing memiliki jumlah semua kemungkinan differential characteristic 3 round yang mempunyai output difference pada round ketiga dengan S-box aktif bernilai 9𝐻 sebanyak 208. Improbable differential 9 round yang ketiga memiliki probabilitas sebesar 2−8.67807198 dan mempunyai jumlah semua kemungkinan differential characteristic 3 round dengan output difference S-box aktif pada round ketiga bernilai 9𝐻 sebanyak 160.
Pencarian improbable differential 9 round menggunakan S-box aktif dengan variasi 2-22 atau berpola sama pada setiap round tidak menjamin diperoleh improbable differential 9 round dengan probabilitas terbesar. Pencarian improbable differential dengan diawali satu atau dua S-box aktif memiliki dampak yang berbeda-beda dalam mengaktifkan S-box aktif pada round-round selanjutnya. Hal ini bergantung pada nilai input difference dan permutasi yang digunakan. Berdasarkan hasil perhitungan diperoleh tiga improbable differential 9 round yang memanfaatkan satu S-box aktif pada round pertama dengan probabilitas lebih besar dari

825
2−9.24511242 dan kemungkinan differential characteristic 3 round yang diperkecil pada setiap improbable differential berjumlah lebih besar yaitu sebanyak 160 dan 208. Pada variasi 1-24 mempunyai potensi ditemukan improbable differential dengan probabilitas lebih besar daripada variasi 2-22 karena S-box aktif yang dihasilkan di round pertama pada variasi 1-24 hanya berjumlah satu dengan probabilitas terbesar bernilai 2−2 sedangkan pada variasi 2-22 mempunyai S-box aktif pada round pertama berjumlah dua dengan probabilitas terbesar bernilai 2−4.
Berdasarkan hasil perhitungan pada Tabel 3.3 dan Tabel 3.4, improbable differential 9 round lain yang diperoleh tidak hanya memiliki probabilitas lebih besar dari 2−9.24511242, namun juga diperoleh improbable differential 9 round lain sebanyak 124 dengan probabilitas yang lebih kecil dari 2−9.24511242 yaitu mempunyai nilai probabilitas berkisar dari 2−13.39984035 hingga 2−9.5821476 yang meliputi variasi 1-24 maupun 2-22.
3.2. Pencarian Improbable Differential 10 Round Lain
Pada Tabel 3.8 tercantum semua variasi differential characteristic 3 round, diperoleh dari semua variasi differential characteristic 5 round. Berdasarkan Tabel 3.8 diperoleh probabilitas yang berbeda-beda untuk setiap variasi S-box aktif. Variasi 1-2442 adalah variasi yang mempunyai probabilitas paling kecil diantara variasi yang lainnya karena memiliki jumlah S-box aktif hingga round ketiga paling banyak yaitu berjumlah 7. Variasi 1-1244 dan variasi 2-1124 mempunyai probabilitas paling besar diantara variasi yang lainnya karena kedua variasi tersebut mempunyai jumlah S-box aktif paling sedikit yaitu berjumlah 4.
Tabel 3.8 Rekapitulasi Jumlah Differential Characteristic 3 Round dari Differential Characteristic 5 Round Berdasarkan Probabilitas pada
Setiap Variasi S-Box Aktif
No Probabilitas
Jumlah Differential Characteristic
Total Variasi
1-1244
Variasi
1-2442
Variasi
2-1124
Variasi
2-1244
Variasi
2-2222
1. 2−8 4 - 1 - - 5
2. 2−9 18 - 14 - - 32
3. 2−10 28 - 26 4 - 58
4. 2−11 36 - 28 12 - 76
5. 2−12 40 - 48 16 2 106
6. 2−13 - - - 48 4 52
7. 2−14 - 8 - 16 32 56
8. 2−15 - 16 - 48 56 120
9. 2−16 - 20 - - 104 124
10. 2−17 - 40 - - 96 136
11. 2−18 - 16 - - 96 112
12. 2−19 - 32 - - - 32
13. 2−20 - 40 - - - 40
14. 2−21 - 80 - - - 80
Total 126 252 117 144 390 1029

826
Berdasarkan Tabel 3.8, semua kemungkinan differential characteristic yang dimanfaatkan untuk membentuk improbable differential 10 round sebanyak 1029. Improbable differential 10 round yang diperoleh Tezcan mempunyai probabilitas sebesar 2−19.245 dan menggunakan satu dari 56 differential characteristic yang mempunyai probabilitas round pertama hingga round ketiga sebesar 2−14 dari variasi 2-222, sehingga terdapat 55 differential characteristic lain yang dapat digunakan untuk membentuk improbable differential 10 round lain dengan kemungkinan probabilitas sama dengan 2−19.245 dari variasi 2-222. Selain itu, terdapat 329 differential characteristic 3 round yang dapat digunakan untuk membentuk improbable differential 10 round lain dengan kemungkinaan probabilitas yang lebih besar dari 2−19.245 sedangkan untuk membentuk improbable differential 10 round lain dengan kemungkinan probabilitas yang lebih kecil dari 2−19.245 terdapat sebanyak 644 differential characteristic 3 round.
Pada setiap variasi differential characteristic 3 round, dilanjutkan pencarian pada round keempat dan kelima hingga diperoleh output difference dengan nilai S-box aktif sebesar 9𝐻 agar dapat dikombinasikan dengan impossible differential 5 round sehingga menghasilkan improbable differerential 10 round. Salah satu hasil rekapitulasi perhitungan probabilitas improbable differential 10 round menggunakan 1029 differential characteristic 3 round tercantum pada Tabel 3.9. Tabel 3.9 Rekapitulasi Hasil Perhitungan Probabilitas Improbable Differential 10
Round dari Variasi 1-1244
Differential
Characteristic 3 Round
Total Differential Characteristic Round
Keempat dan Kelima yang dapat
dibentuk dengan Output Difference
Bernilai 9𝐻 untuk Setiap Differential
Characteristic 3 Round
Probabilitas
Improbable
Differential 10
Round Probabilitas Jumlah
2−8
1 32236 2−19.51542854
3 64972 2−19.7832737
2−9
3 32236 2−20.51542854
2 145300 2−20.59871864
5 64972 2−20.7832737
4 126532 2−20.86836243
3 160545 2−21.38402557
1 51600 2−21.44205856
2−10
4 32236 2−21.51542854
2 145300 2−21.59871864
8 64972 2−21.7832737
4 126532 2−21.86836243
2 191880 2−22.23085976
2 160545 2−22.38402557
4 261807 2−22.40595245
2 51600 2−22.44205856
2−11
6 32236 2−22.51542854
4 145300 2−22.59871864
10 64972 2−22.7832737

827
Differential
Characteristic 3 Round
Total Differential Characteristic Round
Keempat dan Kelima yang dapat
dibentuk dengan Output Difference
Bernilai 9𝐻 untuk Setiap Differential
Characteristic 3 Round
Probabilitas
Improbable
Differential 10
Round Probabilitas Jumlah
8 126532 2−22.86836243
6 160545 2−23.38402557
2 51600 2−23.44205856
2−12
4 32236 2−23.51542854
4 145300 2−23.59871864
4 64972 2−23.7832737
8 126532 2−23.86836243
4 191880 2−24.23085976
4 160545 2−24.38402557
8 261807 2−24.40595245
4 51600 2−24.44205856
Improbable differential 10 round yang diperoleh Tezcan memiliki probabilitas sebesar 2−19.24511337 dengan variasi 2-222. Berdasarkan hasil pencarian improbable differential 10 round dan perhitungan probabilitas dari semua variasi S-box aktif, diperoleh 1029 improbable differential 10 round. Sebanyak 1029 improbable differential 10 round terdiri dari 56 improbable differential yang memiliki probabilitas yang lebih besar dari 2−19.24511337, satu improbable differential yang memiliki probabilitas sama dengan 2−19.24511337, dan 971 improbable differential yang memiliki probabilitas lebih kecil dari 2−19.24511337. Differential characteristic dengan variasi 1-1244, variasi 1-2442, dan variasi 2-1244 tidak menghasilkan improbable differential 10 round dengan probabilitas lebih besar dari 2−19.24511337. Hal ini dikarenakan jumlah S-box aktif dari ketiga variasi tersebut cukup banyak yaitu berjumlah 12 dan 13, sedangkan untuk variasi 2-1124 dan variasi 2-222 dengan S-box aktif berjumlah 10 menghasilkan improbable differential 10 round dengan probabilitas lebih besar dari 2−19.24511337.
Improbable differential 10 round lain dengan probabilitas sama dengan 2−19.24511337 menggunakan differential characteristic 5 round yang memiliki difference input 𝑥0 = 𝑥1 = 1𝐻 dan jumlah S-box aktif pada setiap round berjumlah dua. Differential characteristic round pertama hingga ketiga yang digunakan sebagai berikut:
Difference Input 0000000000000011
Round ke-1
sBoxLayer 0000000000000099
pLayer 0003000000000003
Round ke-2
sBoxLayer 0001000000000001
pLayer 0000000000001001
Round ke-3
sBoxLayer 0000000000009009
pLayer 0009000000000009

828
Hasil differential characteristic 3 round dilanjutkan pada round keempat dan kelima hingga diperoleh semua kemungkinan differential characteristic 5 round dengan output difference pada round kelima mempunyai S-box aktif bernilai 9𝐻. Setelah dilanjutkan pencarian differential characteristic pada round keempat dan kelima diperoleh 108 differential characteristic 5 round, yang tercantum pada Tabel 3.10.
Tabel 3.10 Jumlah Differential Characteristic Berdasarkan Variasi Probabilitas dari Round ke-4 dan ke-5 untuk Pencarian Improbable Differential 10 Round lain
No Probabilitas Banyaknya Differential Characteristic
1. 2−8 4
2. 2−10 8
3. 2−14 32
4. 2−16 64
Jumlah 108
Berdasarkan Tabel 3.10 hasil perhitungan probabilitas dari improbable differential 10 round sebagai berikut:
p′ = 2−14(4. 2−8 + 8. 2−10 + 32. 2−14 + 64. 2−16). 1
= 2−14(22. 2−8 + 23. 2−10 + 25. 2−14 + 26. 2−16) = 2−14(2−6 + 2−7 + 2−9 + 2−10) = 2−14 . 0.0263671875
≈ 2−19.245.
Improbable differential 10 round lain dengan probabilitas lebih besar dari 2−19.24511337 sebanyak 56 karakteristik yang terdiri dari variasi 2-1124 sebanyak 52 karakteristik dan variasi 2-222 sebanyak 4 karakteristik.
Berdasarkan 56 improbable differential yang diperoleh, banyaknya differential characteristic 5 round yang membentuk satu improbable differential 10 round mempunyai jumlah paling sedikit sebesar 208 dan paling banyak berjumlah 931 sedangkan hasil pencarian Tezcan hanya berjumlah 108. Sehingga, improbable differential tersebut dapat menjadi alternatif untuk diterapkan pada improbable differential attack karena selain memiliki probabilitas besar juga jumlah differential characteristic 5 round dari setiap satu improbable differential yang dibentuk cukup banyak
3. Kesimpulan
Dari hasil penelitian yang telah dilakukan, disimpulkan sebagai berikut:
a. Berdasarkan pencarian improbable differential 9 round PRESENT
menggunakan input difference 1, 8, dan 9 yang diawali satu dan dua S-box aktif
pada round pertama diperoleh improbable differential 9 round dengan
probabilitas lebih besar dari 2−9.24511242 sebanyak 3 karakteristik dan yang

829
memiliki probabilitas lebih kecil dari 2−9.24511242 sebanyak 124 karakteristik.
b. Berdasarkan pencarian improbable differential 10 round diperoleh satu
karakteristik yang memiliki probabilitas sama dengan 2−19.24511337, sebanyak
56 karakteristik memiliki probabilitas lebih besar dari 2−19.24511337, dan
sebanyak 971 karakteristik mempunyai probabilitas lebih kecil dari
2−19.24511337 c.
Referensi
[1] A. Bogdanov, R. L. Knudsen, G. Leander, C. Paar dan A. Poschmann,
“PRESENT: An Ultra-Lightweight Block Cipher,” Springer Berlin
Heidelberg Volume 4727, pp. pp. 450-466, 2007.
[2] C. Tezcan, “Improbable Differential Attack on PRESENT using Undisturbed
Bits,” 2014a. [Online]. Available:
http://cihangir.forgottenlance.com/papers/ICACM_Extended_Abstract.pdf.
[3] C. Tezcan dan F. Özbudak, “Differential factors: Improved attacks on
SERPENT,” Springer International Publishing, pp. In International Workshop
on Lightweight Cryptography for Security and Privacy (pp. 69-84), 2014.
[4] C. Tezcan, “The Improbable Differential Attack: Cryptanalysis of Reducedd
Round CLEFIA,” Springer Berlin Heidelberg, pp. In International Conference
on Cryptology in India (pp. 197-209), 2010.
[5] C. Tezcan, “Improbable Differential Attacks On Present Using Undisturbed
Bits,” Journal of Computational and applied mathematics, pp. Volume 259,
Part B, pp. 503-511, 2014b.
[6] R. Makarim dan C. Tezcan, “Relating undisturbed bits to other properties of
substitution boxes,” Springer International Publishing, pp. Volume 8898, pp.
109-125, 2014.
.

830
Prosiding SNM 2017 Komputasi , Hal 830 -838
PENCARIAN KARAKTERISTIK DIFERENSIAL 4
ROUND PADA ALGORITMA MACGUFFIN
RIDWAN IMAM SYARIF1, DAN SANTI INDARJANI2
SEKOLAH TINGGI SANDI NEGARA 1,2
1. Ridwan Imam Syarif, [email protected]
2. Santi Indarjani, [email protected]
Abstrak. Algoritma MacGuffin merupakan algoritma block cipher
berstruktur unbalanced feistel network dengan operasi XOR, permutasi,
dan S-box. Algoritma ini menggunakan input 64 bit dan kunci 128 bit.
Rijmen dan Preneel menerapkan differential crytanalysis pada algoritma
MacGuffin 4 round dan didapat probabilitas terbaik 1
149. Dalam paper
yang dituliskan tidak dijabarkan bagaimana cara memperoleh
karakteristik terbaik tersebut. Dalam makalah ini penulis menjelaskan
secara detail proses penentuan karakteristik diferensial setiap round pada
algoritma MacGuffin 4 round.
Kata kunci: karakteristik diferensial, MacGuffin, probabilitas.
1. Pendahuluan
Kriptografi merupakan sistem yang mempelajari secara ilmiah metode
perahasiaan berita/informasi agar terjamin kerahasiaannya.[4] Dengan adanya hal
tersebut banyak pengembangan tentang kriptografi baik algroritmanya maupun
protokol yang digunakan.
Kriptanalisis memiliki dua aspek yaitu proses/prosedur kriptografi dan perilaku
huruf huruf dalam menjadi kata-kata dan selanjutnya menjadi kalimat kalimat[4].
Tujuannya untuk mengetahui kelemahan dari suatu kriptografi sehingga dapat
diperbaiki untuk lebih menjamin keamanan.
Salah satu teknik kriptanalisis adalah dengan kriptanalisis diferensial.
Kriptanalisis diferensial merupakan metode kriptanalisis chosen plaintext attack,
yaitu asumsi penyerang mampu memilih sebagian input, memeriksa output dan
menganalisis untuk mendapatkan kunci[1]. Dengan adanya kunci maka ciphertext
(pesan sandi) dapat diubah menjadi plaintext (pesan terang) dengan asumsi bahwa
algoritma diketahui secara umum.
Algoritma MacGuffin merupakan algoritma block cipher berstruktur
unbalanced feistel network dengan operasi XOR, permutasi, dan s-box.
Algoritma MacGuffin merupakan algoritma yang hampir sama dengan
algoritma Data Encryption Standard (DES). Dengan round sebanyak 32 round

831
atau 2 x round DES, dimana setiap round algoritma MacGuffin akan berimbas
pada setengah jumlah bit pada setiap round DES[2].
Beberapa serangan pada algoritma DES telah dilakukan salah satunya adalah
Differential Cryptanalysis sehingga algoritma DES menjadi tidak aman lagi. Vincent
Rijmen pada tahun 1995 mencoba menerapkan serangan differential cryptanalysis
kepada MacGuffin dan didapatkan MacGuffin lebih lemah daripada DES[5]. Pada
tulisan ini akan dijelaskan mengenai tahapan tahapan pencarian karakteristik
diferensial pada MacGuffin yang berguna untuk serangan differential cryptanalysis.
2. Hasil – Hasil Utama
2.1. Algoritma MacGuffin
Algoritma MacGuffin merupakan algoritma block cipher yang berdasarkan
pada Generalized Unbalanced Feistel Network (GUFN). Algoritma MacGuffin
memiliki 32 round (2 ×round DES) dimana setiap round dari algoritma
MacGuffin akan berimbas pada setengah dari jumlah bit pada setiap round DES
dan kunci yang berjumlah 128 bit[2].
Algoritma ini memiliki input 64 bit yang dibagi menjadi 16 bit merupakan
blok target dan 48 bit blok kontrol. Blok target merupakan blok yang mengalami
proses pembagian bit dan blok kontrol merupakan blok yang telah mengalami
proses pembagian bit. Dimana fungsi 𝐹 pada MacGuffin menggunakan input
48 bit yang paling kanan atau blok kontrol, operasi XOR dengan subkey pada
setiap round dan dibagi menjadi 8 bagian dimana setiap bagian akan masuk ke
dalam s-box. S-box terdiri dari 8 buah s-box (𝑆1, 𝑆2, 𝑆3, 𝑆4, 𝑆5, 𝑆6, 𝑆7, 𝑆8) dengan
input masing masing s-box adalah 6 bit yang dipetakan ke 2 bit. Output dari
setiap s-box akan digabungkan sehingga mendapatkan jumlah bit sebanyak 16
bit. Output yang telah digabungkan akan di XOR kan dengan 16 bit blok target
sehingga akan menghasilkan output dari fungsi 𝐹 algoritma MacGuffin[2].
Gambar. 2.2 Skema Algoritma MacGuffin
F

832
Table 2.1. Tabel permutasi S-box[2].
S-box Input Bit
0 1 2 3 4 5
𝑆1 𝑎2 𝑎5 𝑏6 𝑏9 𝑐11 𝑐13
𝑆2 𝑎1 𝑎4 𝑏7 𝑏10 𝑐2 𝑐14
𝑆3 𝑎3 𝑎6 𝑏8 𝑏13 𝑐0 𝑐15
𝑆4 𝑎12 𝑎14 𝑏1 𝑏2 𝑐4 𝑐10
𝑆5 𝑎0 𝑎10 𝑏3 𝑏14 𝑐6 𝑐12
𝑆6 𝑎7 𝑎8 𝑏12 𝑏15 𝑐1 𝑐5
𝑆7 𝑎9 𝑎15 𝑏5 𝑏11 𝑐2 𝑐7
𝑆8 𝑎11 𝑎13 𝑏0 𝑏4 𝑐3 𝑐9
Tabel 2.2. Tabel Permutasi Output S-box[2].
S-box Output Bit
0 1
𝑆1 𝑡0 𝑡1
𝑆2 𝑡2 𝑡3
𝑆3 𝑡4 𝑡5
𝑆4 𝑡6 𝑡7
𝑆5 𝑡8 𝑡9
𝑆6 𝑡10 𝑡11
𝑆7 𝑡12 𝑡13
𝑆8 𝑡14 𝑡15
Tabel 2.3. S-box Algoritma MacGuffin[2].
𝑆1
2 0 0 3 3 1 1 0 0 2 3 0 3 3 2 1 1 2 2 0 0 2 2 3 1 3 3 1 3 1 1 2
0 3 1 2 2 2 2 0 3 0 0 3 0 1 3 1 3 1 2 3 3 1 1 2 1 2 2 0 1 0 0 3
𝑆2
3 1 1 3 2 0 2 1 0 3 3 0 1 2 0 2 3 2 1 0 0 1 3 2 2 0 0 3 1 3 2 1
0 3 2 2 1 2 3 1 2 1 0 3 3 0 1 0 1 3 2 0 2 1 0 2 3 0 1 1 0 2 3 3
𝑆3
2 3 0 1 3 0 2 3 0 1 1 0 3 0 1 2 1 0 3 2 2 1 1 2 3 2 0 3 0 3 2 1
3 1 0 2 0 3 3 0 2 0 3 3 1 2 0 1 3 0 1 3 0 2 2 1 1 3 2 1 2 0 1 2
𝑆4
1 3 3 2 2 3 1 1 0 0 0 3 3 0 2 1 1 0 0 1 2 0 1 2 3 1 2 2 0 2 3 3
2 1 0 3 3 0 0 0 2 2 3 1 1 3 3 2 3 3 1 0 1 1 2 3 1 2 0 1 2 0 0 2
𝑆5
0 2 2 3 0 0 1 2 1 0 2 1 3 3 0 1 2 1 1 0 1 3 3 2 3 1 0 3 2 2 3 0
0 3 0 2 1 2 3 1 2 1 3 2 1 0 2 3 3 0 3 3 2 0 1 3 0 2 1 0 0 1 2 1
𝑆6

833
2 2 1 3 2 0 3 0 3 1 0 2 0 3 2 1 0 0 3 1 1 3 0 2 2 0 1 3 1 1 3 2
3 0 2 1 3 0 1 2 0 3 2 1 2 3 1 2 1 3 0 2 0 1 2 1 1 0 3 0 3 2 0 3
𝑆7
0 3 3 0 0 3 2 1 3 0 0 3 2 1 3 2 1 2 2 1 3 1 1 2 1 0 2 3 0 2 1 0
1 0 0 3 3 3 3 2 2 1 1 0 1 2 2 1 2 3 3 1 0 0 2 3 0 2 1 0 3 1 0 2
𝑆8
3 1 0 3 2 3 0 2 0 2 3 1 3 1 1 0 2 2 3 1 1 0 2 3 1 0 0 2 2 3 1 0
1 0 3 1 0 2 1 1 3 0 2 2 2 2 0 3 0 3 0 2 2 3 3 0 3 1 1 1 1 0 2 3
2.2. Differential Cryptanalysis
Differential Cryptanalysis adalah metode kriptanalisis chosen
plaintext attack, yaitu asumsi penyerang mampu memilih sebagian input,
memeriksa output dan menganalisis untuk mendapatkan kunci. Misal sistem
dengan input 𝑋 = [ 𝑋1, 𝑋2, … . . , 𝑋𝑛] dan output 𝑌 = [ 𝑌1, 𝑌2, … . . , 𝑌𝑛] memiliki input 𝑋′ dan 𝑋" dengan output 𝑌′ dan 𝑌" yang saling
berkorespodensi. Input difference adalah ∆𝑋 = 𝑋′⨁𝑋" dan output difference-
nya adalah ∆𝑌 = 𝑌′⨁𝑌"[1].
Kontruksi diferensial (∆𝑋, ∆𝑌) meliputi memeriksa karakter diferensial
dengan peluang tinggi. Karakteristik diferensial merupakan barisan dari
sejumlah pasangan input diferensial dan output diferensial untuk setiap round-
nya, dimana output diferensial yang dihasilkan dari suatu round akan
terhubung dengan input diferensial pada round selanjutnya. Dengan
karakteristik diferensial yang memiliki peluan yang tinggi akan
mempermudah dalam perolehan bit bit subkunci pada round terakhir.[1]
Karakteristik diferensial diperoleh dengan cara memeriksa sifat
nonlinearity-nya yaitu menentukan input diferensial dan output diferensial
dengan pasangan yang dipilih memiliki peluang diferensial yang tinggi[1].
2.3. Pencarian Karakteristik Diferensial 4 Round pada Algoritma MacGuffin
Dalam paper Rijmen dan Prenel telah ditemukan bahwa Algoritma
MacGuffin memiliki karakteristik iteratif diferensial 4 round dengan
probabilitas 1
149 dengan pola sebagai berikut.

834
Probabilitas tersebut merupakan probabilitas setelah dilakukan pencarian
karakteristik diferensial. Dalam mencari karakteristik diferensial pada round
MacGuffin dapat dicari dengan:
1. Menentukan input difference ∆𝑃(∆𝐿, ∆𝑅). 2. Memilih pasangan difference dari s-box yang memiliki kemunculan
tertinggi dengan memanfaatkan fungsi nonlinear-nya
3. Dalam kasus ini kunci tidak diperhatikan karena nilai pasangan berurut
(𝑥, 𝑥∗) ketika masing masing di XOR-kan dengan kunci maka didapat (𝑥⨁𝑘)⨁(𝑥∗⨁𝑘) = (𝑥⨁𝑥∗) (1)
dalam hal ini kunci tidak berpengaruh, sehingga hanya fungsi s-box saja
yang diperhatikan.
4. Menentukan karakteristik pada masing masing round
a) Karakteristik round ke-1
Gambar 2.2. Fungsi 𝐹 pada algoritma MacGuffin
Langkah untuk menghitung probabilitas round 1 :
1. Ubah input fungsi 𝐹 ke biner
Input fungsi 𝐹 = 2000 0001 0000
Input 1 = 2000 : Register A
0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0
𝑎15 𝑎14 𝑎13 𝑎12 𝑎11 𝑎10 𝑎9 𝑎8 𝑎7 𝑎6 𝑎5 𝑎4 𝑎3 𝑎2 𝑎1 𝑎0
𝑆1, 𝑆2, … . , 𝑆8
Gambar 2.3 Karakteristik diferensial pada 4 round MacGuffin [5]
Gambar 2.4 Karakteritik differential round ke-1
f
2000
0001
0040 0001
0040 0000
0000
2000
K

835
Input 2 = 0001 : Register B
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
𝑏15 𝑏14 𝑏13 𝑏12 𝑏11 𝑏10 𝑏9 𝑏8 𝑏7 𝑏6 𝑏5 𝑏4 𝑏3 𝑏2 𝑏1 𝑏0
Input 3 = 0000 : Register C
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
𝑐15 𝑐14 𝑐13 𝑐12 𝑐11 𝑐10 𝑐9 𝑐8 𝑐7 𝑐6 𝑐5 𝑐4 𝑐3 𝑐2 𝑐1 𝑐0
2. Masukkan input ke tabel permutasi input S-box
S-box Permutasi Input S-box
𝑆1 𝑐13𝑐11𝑏9𝑏6𝑎5𝑎2 000000
𝑆2 𝑐14𝑐2𝑏10𝑏7𝑎4𝑎1 000000
𝑆3 𝑐15𝑐0𝑏13𝑏8𝑎6𝑎3 000000
𝑆4 𝑐10𝑐4𝑏2𝑏1𝑎14𝑎12 000000
𝑆5 𝑐12𝑐6𝑏14𝑏3𝑎10𝑎0 000000
𝑆6 𝑐5𝑐1𝑏15𝑏12𝑎8𝑎7 000000
𝑆7 𝑐7𝑐2𝑏11𝑏5𝑎15𝑎9 000000
𝑆8 𝑐9𝑐3𝑏4𝑏0𝑎13𝑎11 000110
3. Masukkan input S-box
4. Pilih output 0 dengan input yang telah diberikan
5. Lihat tabel Differential Distribution Table (DDT) pada S-box yang aktif
S-box 8
6. Didapatkan nilai probabilitas yaitu 20
64
7. Masukkan output yang dipilih ke dalam tabel permutasi output S-box
𝑥/𝑦 0 1 2 3
0 64 0 0 0
1 10 22 22 10
... .....
5 16 12 16 20
6 20 16 12 16
7 28 20 4 12
... ......
62 10 18 14 22
63 16 20 16 12

836
8. Output yang dihasilkan adalah
0000 0000 0000 0000 0000 : biner
0000 : heksadesimal
9. Untuk round ke dua, tiga, dan empat cara pencarian nilai probabilitasnya
sama.
Langkah mencari karakteristik diferensial
Jika ∆𝑃 = 0040 2000 0001 0000 maka 𝑎′ = ∆𝑅 = 2000 0001 0000 𝐴′ = 0000 ∆𝐶 = (2000 0001 0000 0040)
S-box yang aktif adalah S-box ke delapan. Dengan input pada S-box
adalah 000110 atau jika dalam bentuk desimal adalah 6. Probabilitas dari S-
box yang aktif pada round 1 adalah 20
64, sedangkan S-box yang lainnya (yang
tidak aktif) dianggap bernilai 0, sehingga probabilitas untuk s-box yang tidak
aktif adalah 1.
Input Difference = ∆𝑃(0040, 2000 0001 0000) Output difference = ∆𝐶(2000, 0001 0000 0040)
Probabilitas yang didapat round ke-1 = 1 × 1 × 1 × 1 × 1 × 1 × 1 ×20
64=
20
64
b) Karakteristik round ke-2
Langkah mencari karakteristik diferensial
Jika ∆𝑃 = 2000 0001 0000 0040 maka
𝑏′ = ∆𝑅 = 0001 0000 0040
𝐵′ = 0000
∆𝐶 = (0001 0000 0040 2000)
S-box yang aktif adalah S-box ke lima. Dengan input pada S-
box adalah 010001 atau jika dalam bentuk desimal adalah 17. S-box
yang aktif probabilitasnya 22
64, sedangkan S-box yang lainnya (yang
tidak aktif) dianggap bernilai 0, sehingga probabilitas untuk S-box
yang tidak aktif adalah 1.
S-box Permutasi Output S-box
𝑆1 𝑡0𝑡1 00
𝑆2 𝑡2𝑡3 00
𝑆3 𝑡4𝑡5 00
𝑆4 𝑡6𝑡7 00
𝑆5 𝑡8𝑡9 00
𝑆6 𝑡10𝑡11 00
𝑆7 𝑡12𝑡13 00
𝑆8 𝑡14𝑡15 00

837
Input Difference = ∆𝑃 (2000, 0001 0000 0040) Output Difference = ∆𝐶 (0001, 0000 0040 2000)
Probabilitas yang didapat round ke-2 = 1 × 1 × 1 × 1 ×22
64× 1 ×
1 × 1 =22
64
c) Karakteristik round ke-3
Jika ∆𝑃 = 0001 0000 0040 2000 maka
𝑏′ = ∆𝑅 = 0000 0040 2000
𝐵′ = 0000
∆𝐶 = (0000 0040 2000 0001)
S-box yang aktif adalah S-box ke satu. Dengan input pada S-box
adalah 100100 atau jika dalam bentuk desimal adalah 36. S-box yang
aktif probabilitasnya 16
64, sedangkan S-box yang lainnya (yang tidak
aktif) dianggap bernilai 0, sehingga probabilitas untuk S-box yang
tidak aktif adalah 1.
Input Difference = ∆𝑃 (0000, 0040 2000 0001) Output Difference = ∆𝐶 (0040, 2000 0001 0000)
Probabilitas yang didapat round ke-3 = 16
64× 1 × 1 × 1 × 1 × 1 ×
1 × 1 =16
64
d) Karakteristik round ke-4 Jika ∆𝑃 = 0000 0040 2000 0001 maka
𝑏′ = ∆𝑅 = 0040 2000 0001
𝐵′ = 0000
∆𝐶 = (0040 2000 0001 0000)
S-box yang aktif adalah S-box ke tiga. Dengan input pada S-box
adalah 011010 atau jika dalam bentuk desimal adalah 22. S-box yang
aktif probabilitasnya 16
64, sedangkan S-box yang lainnya (yang tidak
aktif) dianggap bernilai 0, sehingga probabilitas untuk S-box yang
tidak aktif adalah 1.
Input Difference = ∆𝑃 (0000, 0040 2000 0001) Output Difference = ∆𝐶 (0040, 2000 0001 0000)
Probabilitas yang didapat round ke-4 = 1 × 1 ×16
64,× 1 × 1 × 1 ×
1 × 1 =16
64
5. Menghitung Probabilitas Total/ Rasio Propagasi Total
𝑅𝑝 𝑡𝑜𝑡𝑎𝑙 =20
64×22
64×16
64×16
64=
112640
16777216= 0.006714 =
1
149
Dari hasil penghitungan probabilitas total didapat hasil 1
149. Hasil ini sama
dengan hasil yang telah ditemukan oleh Rijmen dan Preneel. Sehingga karakteristik
diferensial yang di dapat diatas yaitu 0040 2000 0001 0000 dimana input dan
output diferensial yang sama sehingga karakteristik diferensial tersebut merupakan
karakteristik iteratif yang dipakai oleh Rijmen dan Preneel dalam menyusun paper
yang mereka publikasikan.

838
3. Kesimpulan MacGuffin merupakan salah satu algoritma block cipher yang berstruktur
unbalanced feistel network. Input algoritma adalah 64 bit plaintext dan 128 bit kunci
dengan 32 round dimana setiap roundnya memiliki fungsi permutasi, s-box dan
XOR. MacGuffin termasuk dalam algoritma yang mudah untuk diserang
menggunakan differential cryptanalysis. Pada karakteristik 4 round probabilitas
yang didapat adalah 20
64,22
64,16
64 dan
16
64 untuk round pertama, kedua, ketiga dan
keempat dengan probabilitas total adalah 0.012274.
Pernyataan terima kasih. Terima kasih kepada saudara Jimmy, Ryan Setyo
dan Fadila yang memberikan bantuan dalam menyelesaikan makalah ini. Terima
kasih pula kepada pihak penyelenggara Sekolah Tinggi Sandi Negara yang selalu
memberikan dukungan.
.
Referensi
[1] Heys, H.M. 2002. A Tutorial Linear and Differential Cryptanalysis. Canada.
[2] Blaze, M. Schneier, B. 1994. The MacGuffin Block Cipher Algorithm. USA :
International Workshop on Fast Software Encryption
[3] Hafman, S.A. Santi Indarjani. 2007. Diktat Mata Kuliah Statistika Kriptografi.
Sekolah Tinggi Sandi Negara
[4] Soemarkidjo, et al. 2008. Jelajah Kriptologi. Jakarta : Lembaga Sandi Negara
[5] Rijmen, V. Preneel, B. 1994.Cryptanalysis of McGuffin. Belgium : National Fund for
Scientific Research

839
PEMODELAN DAN OPTIMASI
SEMINAR NASIONAL MATEMATIKA 2017

840
Prosiding SNM 2017 Pemodelan dan Opt imisas i , Hal 840 -849
PERBANDINGAN METODE RUNGE-KUTTA-VERNER
DAN LAPLACE ADOMIAN DECOMPOSITION METHOD
DALAM SOLUSI PERSAMAAN DIFFERENSIAL
NONLINEAR PADA MASALAH BIOMATEMATIKA
BETTY SUBARTINI1, RIAMAN2, DAN ALIT KARTIWA3
1 Universitas Padjadjaran, [email protected]
2. Universitas Padjadjaran, [email protected]
3. Universitas Padjadjaran, [email protected]
Abstrak. A Paper ini berisi perbandingan dua solusi numerik yang digunakan
untuk menyelesaikan masalah-masalah Biologi, seperti model populasi
serangga dan model Lotka-Volterra satu-spesies. Salah satu metodenya adalah
metode Runge-Kutta-Verner yaitu suatu metode yang menjanjikan hasil nilai
pendekatan pada solusi sistem persamaan diferensial non-linear. Tehnik
penggambarannya diilustrasikan melalui simulasi numerik, kemudian
mengubah model populasi dengan mengambil (Fungsional respon Holing tipe
III) dan membandingkan dengan metode lain yaitu Laplace Adomian
Decomposition Method, sehingga hasil yang diperoleh dari kedua metode yang
dilakukan adalah metode Runge-Kutta-Verner yang paling baik.
Kata kunci: : Solusi persamaan diferensial nonlinear, Runge-Kutta-Verner, Laplace
Adomian Decomposition Method.
1. Pendahuluan
Model matematika dari pertumbuhan populasi telah dibentuk dan dibuktikan
secara signifikan dalam situasi ekologi yang nyata. Arti dan pentingnya dari setiap
parameter dalam model telah didefinisikan secara biologis oleh R.A. Parker dan
C.Qiwu [3,4]. Contohnya dalam kasus populasi serangga, tingkat kelahiran dan
kematian spesies biasanya tidak konstan; sebagaimana, mereka bervariasi secara
periodik tergantung musim, sedangkan persamaan Lotka-Volterra dipengaruhi oleh
jumlah pesaing ekologi (atau predator-mangsa) suatu model yang dinamis di alam.
Contoh lain model pertumbuhan penduduk sangat penting dalam matematika biologi
yang digunakan sebagai dasar untuk menunjukkan sistem kontrol nonlinear
sederhana dalam pertumbuhan populasi. Untuk mendapatkan populasi yang
sebenarnya Fungsional respon Holing tipe III mempunyai peran penting dalam
dinamika populasi, sebagaimana dasar penelitiannya[2]. Fungsional respon Holing
tipe III model ekologinya memasukan spesies predator sebagai fungsi kepadatan
mangsa.

841
Di bidang ilmu pengetahuan dan teknologi, banyak fenomena fisik yang
signifikan sering dimodelkan dengan persamaan diferensial nonlinear. Persamaan
tersebut seringkali sangat sulit untuk diselesaikan secara analitis, seperti model
pertumbuhan populasi serangga tersebut sulit diselesaikan secara Analitik. Oleh
Karena itu ada beberapa metode secara Numerik, diantaranya metode Homotopy
Perturbation (HPM), Homotopy Analysis Method (HAM), Differential Transform
Methode (DTM), Variational Iteration Method (VIM), Laplace Adomian
Decomposition Method (LADM), dan Runge-Kutta-Felberg (RKF).
Para ilmuwan banyak menggunakan metode numerik dalam masalah yang
berbeda-beda, seperti pada paper ini kami mencoba memberikan beberapa referensi
yang menunjukkan pentingnya teknik atau metode kuasi-numerik pada saat ini.
Kumar dan Baskar[10]membahas kuasi-interpolasi metode numerik berdasarkan B-
spline untuk beberapa jenis persamaan Sobolev, Liu dkk[5] membahas kompleksitas
kuasi-optimal metode elemen hingga adaptif untuk masalah elastisitas linier dalam
dua dimensi.
Tujuan dari makalah ini adalah untuk membawa solusi numerik dari
berbagai model populasi dengan menggunakan pendekatan LADM dan RKVe, serta
membandingkan keakuratannya. Makalah ini disusun sebagai berikut :
• Studi literatur tentang dasar dari model pertumbuhan populasi
• Mempelajari tehnik-teknik numerik
• Memberikan contoh solusi numerik dalam model matematika biologi, serta
model perluasannya
• Membandingkan diantara model- model yang kita gunakan dengan ilustrasi.
2. Hasil – Hasil Utama
2.1. Laplace Adomian Decomposition Method(LADM)
2.1.1 LADM untuk Persamaan Differensial Nonlinear.
Metode LADM [6,7] telah diperkenalkan oleh Khuri dan telah berhasil
digunakan untuk menentukan solusi persamaan differensial linear dan nonlinear.
Transformasi Laplace adalah sebagai teknik dasar dari solusi persamaan differensial
biasa yang banyak digunakan oleh para ilmuwan dan insinyur dalam menanggulangi
model linear. Masalah utama dari metode ini adalah metode solusi yang disajikan
dalam deret takhingga yang konvergen ke nilai sebenarnya dan tidak akan memakan
waktu dalam perhitungannya.
Bentuk Umum Persamaan differensial nonlinear sebagai berikut :
𝐿𝑢(𝑡) + 𝑅𝑢(𝑡) + 𝑁𝑢(𝑡) = 𝑔(𝑡), (1) dengan 𝐿 adalah operator linear dari turunan tingkat tinggi. yang diasumsikan
dibalik dengan mudah, 𝑅 adalah sisa operator linear order kurang dari 𝐿 dan 𝑁 adalah
operator nonlinear, dan 𝑔(𝑡) adalah sebagai sumber
Buat Transformasi Laplace kedua ruas dari persamaan(1), didapat :
ℒ[𝐿𝑢(𝑡)] + ℒ[𝑅𝑢(𝑡)] + ℒ[𝑁𝑢(𝑡)] = ℒ[𝑔(𝑡)], (2) gunakan sifat turunan dari transformasi Laplace dan gunakan syarat awal, didapat :
𝑠𝑛ℒ[𝑢(𝑡)] − 𝑠𝑛−1𝑢(0) − 𝑠𝑛−2𝑢′(0) − ⋯− 𝑢𝑛−1(0) + ℒ[𝑅𝑢(𝑡)] + ℒ[𝑁𝑢(𝑡)] = ℒ[𝑔(𝑡)], (3)

842
Atau
ℒ[𝑢(𝑡)] = 𝑢(0)
𝑠+ 𝑢′(0)
𝑠2+⋯+
𝑢𝑛−1(0)
𝑠𝑛−ℒ[𝑅𝑢(𝑡)]
𝑠𝑛−ℒ[𝑁𝑢(𝑡)]
𝑠𝑛+ℒ[𝑔(𝑡)]
𝑠𝑛 . (4)
Sekarang kita definisikan fungsi 𝑢(𝑡) dalam bentuk deret takhingga :
𝑢(𝑡) = ∑𝑢𝑛(𝑡),
∞
𝑛=0
(5)
Komponen 𝑢𝑛(𝑡) biasanya ditentukan berulang dan 𝑁(𝑢) dapat diuraikan dalam deret takhingga berikut
𝑁(𝑢) = ∑𝐴𝑛
∞
𝑛=0
, (6)
dengan 𝐴𝑛 adalah polinom Adomian dari 𝑢0, 𝑢1, … , 𝑢𝑛 yang didefinisikan sebagai
berikut
𝐴𝑛 = 1
𝑛!
𝑑𝑛
𝑑𝜆𝑛[𝑁(∑ 𝜆𝑖𝑢𝑖
∞
𝑖=0
)]
𝜆=0
, 𝑛 = 0,1,2, …. (7)
Olah karena itu, persamaan (4) menjadi
ℒ [∑𝑢𝑛(𝑡)
∞
𝑛=0
] = 𝑢(0)
𝑠+ 𝑢′(0)
𝑠2+⋯+
𝑢𝑛−1(0)
𝑠𝑛−ℒ[𝑅{∑ 𝑢𝑛(𝑡)
∞𝑛=0 }]
𝑠𝑛−ℒ[∑ 𝐴𝑛
∞𝑛=0 ]
𝑠𝑛
+ℒ[𝑔(𝑡)]
𝑠𝑛. (8)
Secara rekursif pada umumnya ditulis sebagai berikut:
ℒ[𝑢0(𝑡)] = 𝑢(0)
𝑠+ 𝑢′(0)
𝑠2+⋯+
𝑢𝑛−1(0)
𝑠𝑛+ℒ[𝑔(𝑡)]
𝑠𝑛 ,
ℒ[𝑢𝑛+1(𝑡)] = −ℒ[𝑅(𝑢𝑛(𝑡))]
𝑠𝑛−ℒ[𝐴𝑛]
𝑠𝑛 . (9)
Gunakan invers transformasi Laplace untuk kedua ruas persamaan (9), kita peroleh
𝑢𝑛,(𝑛 ≥ 0, kemudian substitusi ke persamaan (5).
Untuk Perhitungan numerik, kita sajikan sebagai
𝜙𝑛(𝑡) =∑𝑢𝑘(𝑡) ,
𝑛
𝑘=0
(10)
Yang merupakan pendekatan ke-n dari 𝑢(𝑡) dan solusi berbentuk deret yang akan
konvergen ke nilai sebenarnya.
2.1.2 Algoritma Solusi Numerik LADM
Langkah 1. Bagi persaman (1) dalam 2 bagian.
Ruas pertama adalah −[𝑅𝑢(𝑡) + 𝑁𝑢(𝑡)], (11)
dan ruas kedua 𝐿𝑢(𝑡) − 𝑔(𝑡). (12)
Langkah 2. Gunakan transformasi Laplace untuk ruas kedua, tentukan
koefisien dari ℒ[𝑢(𝑡)], dan diperoleh ℒ[𝑢0] Langkah 3. Hitung Polinomial Adomian untuk fungsi 𝑁𝑢(𝑡), kemudian
gunakan transformasi Laplace.
Langkah 4. Bagi Ruas pertama oleh koefisien ℒ[𝑢(𝑡)], Lakukan looping
untuk menghitung ℒ[𝑢𝑛+1(𝑡)], dengan mensubstitusikan ℒ[𝐴𝑛 ], dan ℒ[𝑢𝑛(𝑡)], pada ruas pertama.
Langkah 5. Konstruksi solusi dengan menggunakan Invers Transformasi

843
Laplace pada ℒ[𝑢𝑛(𝑡)]. Langkah 6. Selesai
2.2. Metode Runge -Kutta Verner (RKVe)
RKVe adalah salah satu metode untuk menyelesaikan masalah persamaan
diferensial nonlinear[1]. Salah satu metode yang paling dikenal adalah metode
Runge-Kutta orde 4 (RK4). Metode Runge-Kutta layak digunakan, karena tingkat
keakuratanya dan tidak memerlukan perhitungan turunan tingkat tinggi seperti
metode Taylor. Bagaimanapun juga, dalam hal estimasi kesalahan metode satu-
langkah dengan ukuran langkah adaptif metode RKVe[8,9], memberikan estimasi
error yang paling baik dibandingkan dengan satu metode Runge-Kutta yang tetap.
Pada setiap langkah Metode RKVe dijelaskan perhitungan dua metode Runge-Kutta
yang berbeda Ordenya (RK5 dan RK7). Jika kedua jawaban cukup kontinu dapat
diterapkan pada kasus model persamaan non-linear masalah stokastik, fisika, kimia
dan biologi.
Bentuk Umum masalah nilai awal persamaan Diferensial biasa:
𝑦′(𝑡) = 𝑓(𝑡, 𝑦(𝑡)), 𝑦(𝑡0) = 𝑦0. (13)
RKVe adalah salah satu cara untuk menyelesaikan masalah nilai awal persamaan
(13) dengan cara pertama sebagai prediktor dengan rumus:
𝑦𝑖+1
= 𝑦𝑖+
13
160 𝑘1 +
2375
5984 𝑘3 +
5
16𝑘4 +
12
85𝑘5 +
3
44𝑘6, (14)
kemudian korektor dengan rumus :
𝑧𝑖+1 = 𝑦𝑖 + 3
40 𝑘1 +
875
2244 𝑘3 +
23
72𝑘4 +
264
1955𝑘5 +
125
11592𝑘7 +
43
616 𝑘8, (15)
dengan rumus untuk 𝑘1, 𝑘2, … , 𝑘8 didefinisikan pada [1],
𝑘1 = ℎ𝑓(𝑡𝑖, 𝑦𝑖),
𝑘2 = ℎ𝑓 (𝑡𝑖 +1
6ℎ, 𝑦
𝑖+1
6 𝑘1)
𝑘3 = ℎ𝑓 (𝑡𝑖 +4
15ℎ, 𝑦
𝑖+4
75 𝑘1 +
16
75𝑘2)
𝑘4 = ℎ𝑓 (𝑡𝑖 +2
3ℎ, 𝑦
𝑖+5
6 𝑘1 −
8
3𝑘2 +
5
2𝑘3)
𝑘5 = ℎ𝑓 (𝑡𝑖 +5
6ℎ, 𝑦
𝑖−165
64 𝑘1 +
55
6𝑘2 −
425
64𝑘3 +
85
96𝑘4)
𝑘6 = ℎ𝑓 (𝑡𝑖 + ℎ, 𝑦𝑖 +12
5 𝑘1 − 8𝑘2 +
4015
612𝑘3 −
11
36𝑘4 +
88
255𝑘5)
𝑘7 = ℎ𝑓 (𝑡𝑖 +1
15ℎ, 𝑦
𝑖−8263
15000 𝑘1 +
124
75𝑘2 −
643
680𝑘3 −
81
250𝑘4 +
2484
10625𝑘5)
𝑘8 = ℎ𝑓 (𝑡𝑖 + ℎ, 𝑦𝑖 +3501
1720 𝑘1 −
300
43𝑘2 +
297275
52632𝑘3 −
319
2322𝑘4 +
24068
84065𝑘5
+3850
26703𝑘6)
(16)
Pendekatan Numerik dari kesalahan diskritisasi global(lokal) pada titik 𝑡𝑖+1 adalah
𝜖 = |𝑦𝑖+1 − 𝑧𝑖+1|. (17) Jika 𝜖𝑚𝑖𝑛 ≤ 𝜖 ≤ 𝜖𝑚𝑎𝑥, (dimana toleransi maksimum dan minimum untuk kesalahan
pemotongan lokal, masing-masing, yang didefinisikan dari awal) maka 𝑦𝑖+1 adalah
pendekatan yang dapat diterima dari 𝑦(𝑡𝑖+1) dan ukuran langkah(interval) cukup
besar untuk langkah berikutnya. Jika tidak, ukuran langkah baru 𝑠ℎ yang dapat
ditentukan dari perkalian scalar 𝑠 dengan ukuran langkah ℎ. Skalar 𝑠 diberikan oleh

844
𝑠 = (𝜖ℎ
2|𝑦𝑖+1 − 𝑧𝑖+1|)
14= 0,8408964153(
𝜖ℎ
|𝑦𝑖+1 − 𝑧𝑖+1|)
14. (18)
dengan 𝜖 adalah toleransi error kontrol.
2.2.2 Algoritma untuk menentukan solusi numerik RKVe
Langkah 1. Diberikan fungsi 𝑓(𝑡, 𝑦1) Langkah 2. baca 𝑡(0), 𝑦1(0), ℎ, limit, 𝜖𝑚𝑖𝑛 , 𝜖𝑚𝑎𝑥
Langkah 3. For 𝑖 = 0(1) limit, do call 𝑘1, 𝑘2, . . . , 𝑘8 in equation (16)
Langkah 4. Calculate
𝑦𝑖+1 = 𝑦𝑖 + 13
160 𝑘1 +
2375
5984 𝑘3 +
5
16𝑘4 +
12
85𝑘5 +
3
44𝑘6, (19)
Langkah 5. Calculate
𝑧𝑖+1 = 𝑦𝑖 + 3
40 𝑘1 +
875
2244 𝑘3 +
23
72𝑘4 +
264
1955𝑘5 +
125
11592𝑘7 +
43
616 𝑘8. (20)
Langkah 6.
𝜖 = |𝑦𝑖+1 − 𝑧𝑖+1| (21) Langkah 7. Anggap 𝜖𝑚𝑖𝑛 ≤ 𝜖 ≤ 𝜖𝑚𝑎𝑥, Langkah 8. 𝑡𝑖+1 = 𝑡𝑖 + ℎ. Tulis 𝑧𝑖(𝑡𝑖+1), 𝑡𝑖 Langkah 9. ulangi sampai mendapatkan pendekatan yang paling baik
Langkah 10. end program
Langkah 11. jika tidak, ℎ = 𝑠ℎ dengan
𝑠 = (𝜖ℎ
2|𝑦𝑖+1 − 𝑧𝑖+1|)
14= 0,8408964153(
𝜖ℎ
|𝑦𝑖+1 − 𝑧𝑖+1|)
14
Langkah 12. ulangi langkah 8-10 untuk mendapatkan nilai akurasi yang baik
atau berhenti sampai disini
2.3. Solusi dari beberapa model populasi dengan teknik Numerik
2.3.1 Model Populasi Serangga
Misalkan 𝑃 suatu populasi serangga yang menunjukkan model pertumbuhan
musiman yang dibahas Erbe dkk, [11]. Persamaan diferensial model pertumbuhan
serangga diberikan oleh : 𝑑𝑃
𝑑𝑡= 𝐾𝑃 cos𝜆𝑡 (22)
Dengan 𝐾 𝑑𝑎𝑛 𝜆 adalah konstanta positif
Selesaikan masalah nilai awal persamaan (22) dengan metode LADM dengan nilai
awal 𝑃(0), sehingga
∑𝑃𝑛(𝑡) =
∞
𝑛=0
𝑃(0) + 𝐾ℒ−1 [1
𝑠ℒ (∑𝑃𝑛(𝑡) cos 𝜆𝑡
∞
𝑛=0
)]. (23)
Sekarang gunakan algorithma rekursif dengan menerapkan LADM
𝑃0 = 𝑃(0)
𝑃𝑛+1(𝑡) = 𝐾ℒ−1 [
1
𝑠ℒ(𝑃𝑛(𝑡)𝑐𝑜𝑠 𝜆𝑡)] , 𝑛 ≥ 0 (24)
Sekarang kita gunakan metode RKVe, bentuk masalah nilai awal persaman (13)
menjadi
𝑃′(𝑡) = 𝑓(𝑡, 𝑃(𝑡)) = 𝐾𝑃 𝑐𝑜𝑠 𝜆𝑡, 𝑃(𝑡0) = 𝑃0
Pertama kita definisikan berdasarkan (16). Maka solusi pendekatan masalah nilai
awal persamaan (22) sebagai prediktor menggunakan rumus :

845
𝑃𝑛+1 = 𝑃𝑛 + 13
160 𝑘1 +
2375
5984 𝑘3 +
5
16𝑘4 +
12
85𝑘5 +
3
44𝑘6 (26)
Dan solusi terbaik sebagai korektor menggunakan rumus:
𝑧𝑛+1 = 𝑃𝑛 + 3
40 𝑘1 +
875
2244 𝑘3 +
23
72𝑘4 +
264
1955𝑘5 +
125
11592𝑘7 +
43
616 (27)
Pengembangan dari model populasi serangga (model II) yang dikembangkan oleh
Fungsional respon Holling tipe III sebagai berikut :
𝑑𝑃
𝑑𝑡= 𝐾𝑃 cos 𝜆𝑡 −
𝛼𝑃2
𝛽 + 𝑃2 , (28)
dengan 𝛼 dan 𝛽 konstanta positif dan 𝛼 menunjukkan tingkat penangkapan
maksimum serangga dengan spesies predator.
Persamaan (28) diselesaikan terlebih dahulu oleh LADM, dengan nilai awal 𝑁(0), secara recursif diperoleh:
𝑃𝑜 = 𝑃(0) − 𝛼𝑡,
𝑃𝑛+1 = 𝐾ℒ−1 [
1
𝑠ℒ(𝑃𝑛(𝑡)𝑐𝑜𝑠 𝜆𝑡)] + 𝛼𝛽ℒ
−1 [1
𝑠ℒ (𝐴𝑛)] , 𝑛 ≥ 0 (29)
Oleh Karena itu 𝑃 dapat disajikan dalam deret takhingga 𝑃 = ∑ 𝑃𝑛∞𝑛=0 dan
polynomial Adomian dihitung dengan rumus di bawah ini:
𝐴𝑛 = 1
𝑛!
𝑑𝑛
𝑑𝜆𝑛[𝑁 (∑𝜆𝑘𝑃𝑘
∞
𝑘=0
)]
𝜆=0
. (30)
Sekarang kita selesaikan persamaan (29) dengan metode RKVe. Anggap masalah
nilai awal berbentuk:
𝑃′(𝑡) = 𝑓(𝑡, 𝑃(𝑡)) = 𝐾𝑃 cos 𝜆𝑡 −𝛼𝑃2
𝛽 + 𝑃2 , 𝑃(𝑡0) = 𝑃0 . (31)
Pertama kita definisikan:
𝑘1 = ℎ𝐾 𝑃0 cos 𝜆𝑡0 −𝛼𝑃0
2
𝛽 + 𝑃02
𝑘2 = ℎ𝐾 (𝑃0 +1
6 𝑘1) cos 𝜆 (𝑡0 +
1
6ℎ ) −
𝛼 (𝑃0 +16 𝑘1)
2
𝛽 + (𝑃0 +16 𝑘1)
2
𝑘3 = ℎ𝐾 ( 𝑃0 +4
75 𝑘1 +
16
75𝑘2) cos 𝜆 (𝑡0 +
4
15ℎ) −
𝛼 (𝑃0 +475 𝑘1 +
1675𝑘2)
2
𝛽 + (𝑃0 +475 𝑘1 +
1675𝑘2)
2
𝑘4 = ℎ𝐾 ( 𝑃0 +5
6 𝑘1 −
8
3𝑘2 +
5
2𝑘3) cos 𝜆 ( 𝑡0 +
2
3ℎ)
−𝛼 (𝑃0 +
56 𝑘1 −
83𝑘2 +
52𝑘3)
2
𝛽 + (𝑃0 +56 𝑘1 −
83𝑘2 +
52𝑘3)
2
𝑘5 = ℎ𝐾 ( 𝑃0 −165
64 𝑘1 +
55
6𝑘2 −
425
64𝑘3 +
85
96𝑘4) cos 𝜆 (𝑡0 +
5
6ℎ, )
−𝛼 (𝑃0 −
16564
𝑘1 +556𝑘2 −
42564
𝑘3 +8596𝑘4)
2
𝛽 + (𝑃0 −16564
𝑘1 +556𝑘2 −
42564
𝑘3 +8596𝑘4)
2

846
𝑘6 = ℎ𝐾 ( 𝑃0 +12
5 𝑘1 − 8𝑘2 +
4015
612𝑘3 −
11
36𝑘4 +
88
255𝑘5) cos 𝜆(𝑡0 + ℎ, )
−𝛼 (𝑃0 +
125 𝑘1 − 8𝑘2 +
4015612
𝑘3 −1136𝑘4 +
88255
𝑘5)2
𝛽 + (𝑃0 +125 𝑘1 − 8𝑘2 +
4015612
𝑘3 −1136𝑘4 +
88255
𝑘5)2
𝑘7 = ℎ𝐾 ( 𝑃0 −8263
15000 𝑘1 +
124
75𝑘2 −
643
680𝑘3 −
81
250𝑘4 +
2484
10625𝑘5) cos 𝜆 (𝑡0 +
1
15ℎ)
−𝛼 (𝑃0 +
125 𝑘1 − 8𝑘2 +
4015612
𝑘3 −1136𝑘4 +
88255
𝑘5)2
𝛽 + (𝑃0 +125 𝑘1 − 8𝑘2 +
4015612
𝑘3 −1136𝑘4 +
88255
𝑘5)2
𝑘8
= ℎ𝑓 ( 𝑃0 +3501
1720 𝑘1 −
300
43𝑘2 +
297275
52632𝑘3 −
319
2322𝑘4 +
24068
84065𝑘5
+3850
26703𝑘6) cos 𝜆(𝑡0 + ℎ)
−𝛼 (𝑃0 +
35011720
𝑘1 −30043
𝑘2 +29727552632
𝑘3 −3192322
𝑘4 +2406884065
𝑘5 +385026703
𝑘6)2
𝛽 + (𝑃0 +35011720
𝑘1 −30043
𝑘2 +29727552632
𝑘3 −3192322
𝑘4 +2406884065
𝑘5 +385026703
𝑘6)2
(32)
Kemudian solusi pendekatannya dengan menggunakan metode Runge-Kutta orde 5
𝑃𝑛+1 = 𝑃𝑛 + 13
160 𝑘1 +
2375
5984 𝑘3 +
5
16𝑘4 +
12
85𝑘5 +
3
44𝑘6 . (33)
Dan solusi terbaiknya gunakan metode Runge-Kutta orde 7
𝑧𝑛+1 = 𝑃𝑛 + 3
40 𝑘1 +
875
2244 𝑘3 +
23
72𝑘4 +
264
1955𝑘5 +
125
11592𝑘7 +
43
616 𝑘8. (34)
2.4. Hasil Perhitungan
Tabel 1 Solusi Model I degan nilai awal 𝑃(0) = 1000 𝑑𝑎𝑛 𝐾 = 2 , 𝜆 = 𝜋, ℎ = 0,1
t Solusi eksak solusi RKVe
Solusi
LADM 3
iterasi
ERRVe ERRLADM
0 1000,0000 1000,0000 1000,0000 0,E+00 0,E+00
0,1 1217,4076 1217,2047 1216,0738 2,E-01 1,E+00
0,2 1453,7921 1453,2372 1444,1789 6,E-01 1,E+01
0,3 1673,5898 1673,4973 1647,5683 9,E-02 3,E+01
0,4 1831,8332 1831,7952 1788,5216 4,E-02 4,E+01
0,5 1889,5970 1889,5634 1838,8428 3,E-02 5,E+01
0,6 1831,3776 1831,2582 1788,1223 1,E-01 4,E+01
0,7 1672,7982 1672,5945 1646,8516 2,E-01 3,E+01
0,8 1452,8457 1452,7963 1443,2843 5,E-02 1,E+01
0,9 1216,4762 1216,4072 1215,1581 7,E-02 1,E+00
1 999,1956 999,1804 999,1956 2,E-02 0,E+00

847
Gambar 1 Perbandingan solusi eksak, LADM, RKVe untuk Model I
Tabel 2 : Solusi Model 2 dengan Nilai Awal 𝑃(0) = 100, 𝑑𝑎𝑛 𝛼 = 0,5, 𝛽 = 0,03, 𝐾 = 2, 𝜆 = 𝜋, ℎ = 0,05
T Solusi
eksak
Solusi
RKVe
Solusi
LADM 3
iterasi
ERRVe ERRLADM
0 100,0000 100,0000 100,0000 0,E+00 0,E+00
0,05 110,4454 110,2788 110,4297 2,E-01 2,E-02
0,1 121,6856 121,2084 121,5572 5,E-01 1,E-01
0,15 133,4239 132,8734 133,0020 6,E-01 4,E-01
0,2 145,2587 144,1945 144,3173 1,E+00 9,E-01
0,25 156,6939 156,3465 155,0163 3,E-01 2,E+00
0,3 167,1668 166,4323 164,6054 7,E-01 3,E+00
0,35 176,0921 174,7453 172,6181 1,E+00 3,E+00
0,4 182,9208 182,0651 178,6494 9,E-01 4,E+00
0,45 187,2017 185,6547 182,3860 2,E+00 5,E+00
0,5 188,6384 186,7861 183,6299 2,E+00 5,E+00
0,55 187,1284 184,6437 182,3137 2,E+00 5,E+00
0,6 182,7774 182,0000 178,5057 8,E-01 4,E+00
0,65 175,8845 174,6345 172,4051 1,E+00 3,E+00
0,7 166,9031 165,0572 164,3261 2,E+00 3,E+00
0,75 156,3834 154,8673 154,6740 2,E+00 2,E+00
0,8 144,9109 143,7689 143,9164 1,E+00 1,E+00
0,85 133,0478 133,3725 132,5464 -3,E-01 5,E-01
0,9 121,2890 120,8674 121,0507 4,E-01 2,E-01
0,95 110,0347 109,9000 109,8757 1,E-01 2,E-01
1 99,5797 99,7869 99,4013 -2,E-01 2,E-01
0,0000
200,0000
400,0000
600,0000
800,0000
1000,0000
1200,0000
1400,0000
1600,0000
1800,0000
2000,0000
0 0,2 0,4 0,6 0,8 1 1,2
y(So
lusi
)
tSolusi eksak solusi RKVe Solusi LADM 3 iterasi

848
Gambar 2. Perbandingan solusi eksak, solusi LADM dan Solusi RKVe (Model II)
3. Kesimpulan
Hasil dari solusi numerik dengan menggunakan metode LADM dan RKVe,
dan dibandingkan dengan solusi eksak dari model populasi yang berbeda, dapat
disimpulkan sebagai berikut :
1. Dari tabel 1 dan gambar 1 untuk model 1, dengan nilai awal 𝑃(0) =1000, 𝑑𝑎𝑛 𝐾 = 2, 𝜆 = 𝜋, ℎ = 0,1 dapat dilihat bahwa metode RKVe yang
paling baik tingkat akurasinya.
2. Dari tabel 2 dan gambar 2 untuk model II, dengan mengambil 𝛼 = 0,5, 𝛽 =0,03,𝐾 = 2, 𝜆 = 𝜋, ℎ = 0,05, dan 𝑃(0) = 100. Sekali lagi, hasil metode
numerik RKVe. menunjukan tingkat akurasi yang baik.
Sebagai saran bagi peneliti selanjutnya, dapat dikembangkan untuk model
persamaan differensial non linear yang lebih kompleks lagi seperti solusi taksiran
penyebaran penyakit demam berdarah.
Pernyataan terima kasih. Terima Kasih pada semua pihak yang telah
membantu materil dan spiritual sehingga terselesaikannya makalah ini
Referensi
[16] Burden L Richard , Faires J Douglas, 2005, Numerical Analysis 8th , Thomson
Brooks/Cole, printed in the United State of America
[17] C. S. Holling, 1965, The functional response of predators to prey density and its role in
mimicry and population regulation. Memoirs of the Entomological Society of Canada,
vol. 97, no. 45, pp. 5-60.
[18] R. A. Parker, 1993, Feedback control of birth and death rates for oftimal population
density, Ecologycal modelling, vol. 65, no. 1-2, pp. 137-146.
[19] C. Qiwu and G.J. Lawson, 1982, Study on Models of single population : expansion of
the logistic and exponensial equations, Journal of Theoretical Biology, vol. 98, no. 4
pp. 645-659.
0,0000
50,0000
100,0000
150,0000
200,0000
0 0,2 0,4 0,6 0,8 1 1,2
y(s
olu
si)
t
Solusi eksak Solusi RKVe Solusi LADM 3 iterasi

849
[20] C. Liu, L. Zhong, S.Shu, and Y Xiao, 2016, Quasi-optimal complexity of adaptive finite
element method for linear elasticity problems in two dimensions, Applied Mathematics
and mechanic, English edition, vol. 37, no. 2, pp. 151-168
[21] S. A. Khuri, 2001, A Laplace Decomposition algorithm applied to a class of of
Nonlinear Equations, Journal of Applied Mathematics, vol. 1, no.4, pp. 141-155.
[22] O. Kiymaz, 2009, A Algorithm for solving initial value problems using Laplace
Adomian decomposition method, Applied Mathematical Sciences, vol.3 no. 29-32, pp.
1453-1459.
[23] P. Albrecht, 1996, the Runge-Kutta theory in a nutshell, SIAM Journal of Numerical
Analysis, vol. 33, no. 5, pp. 1712-1735
[24] P. J. Prince and J. R. Dormand, 1981, High order embedded Runge-Kutta formulae,
Journal of computational and Applied Mathematics, vol. 7, no. 1, pp. 67-75
[25] R. Kumar and S Baskar, 2016, B-Spline Quasi-interpolation based numerical methods
for some Sobolev type equation, Journal of computational and applied Mathematics,
vol. 18, no. 6, article ID 10206, pp. 41-66
[26] L. H. Erbe, H. I. Freedman, and V. Sree Hari Rao, 1986, Three-species food-chain
models with mutual interference and time delays, Mathematical Biosciences, vol. 80,
no. 1, pp. 57-8

850
Prosiding SNM 2017 Pemode lan dan Opt imisas i , Hal 850 -857
PERMODELAN DINAMIK PADA SISTEM PROSES
PENGOLAHAN AIR LIMBAH KOLAM STABILISASI
FAKULTATIF
SUNARSIH1, DIAN HULIYUN RAHMANIA2, NIKKEN PRIMA
PUSPITA3
1Departemen Matematika Fakultas Sains dan Matematika Universitas Diponegoro
e-mail : [email protected] 2Departemen Matematika, Fakultas Sains dan Matematika Universitas Diponegoro
email : [email protected] 3Departemen Matematika Fakultas Sains dan Matematika Universitas Diponegoro
e-mail : [email protected]
Abstrak. Karakteristik air buangan perkotaan yang menonjol adalah kandungan bahan
organik yang tinggi yaitu dengan ditandainya kandungan Biological Oxygen Demand
(BOD), termasuk air buangan kota Yogyakarta Indonesia yang diolah melalui Instalasi
Pengolahan Air Limbah (IPAL) Sewon Bantul. Air buangan perkotaan tidak termasuk
air buangan industri walaupun tidak mengandung bahan kimia yang berbahaya,
sehingga dalam pengolahan pada umumnya tidak menggunakan bahan kimia khusus,
tetapi dengan pengolahan secara biologi atau secara alamiah. Pengolahan biologi
ditujukan untuk mendegradasi bahan organik dengan memanfaatkan mikrobiologi.
Banyak metode evaluasi pemantauan kualitas limbah cair yang menggunakan prediksi.
Permasalahan yang ada adalah trend yang ada ditentukan melalui ekstrapolasi dari data
sampel dengan cara regresi. Metode regresi ini memiliki keakuratan dan presisi yang
cukup baik, tetapi memiliki keterbatasan dalam proses pengembangan permodelan
kualitas air. Tujuan dari tulisan ini adalah melakukan permodelan dinamik terhadap
kualitas air limbah dengan 4 (empat) sistem diferensial non linier yang diselesaikan
secara simultan sebagai metode evaluasi kinerja sistem pengolahan air limbah kolam
stabilisasi. Hasil penelitian adalah model sebagai metode evaluasi kinerja sistem proses
pengolahan air limbah yang diselesaikan secara numerik dengan menggunakan metode
Euler. Model divalidasi dan disimulasi pada sistem pengolahan air limbah kolam
stabilisasi fakultatif. Hasil simulasi model menunjukkan bahwa terdapat tingkat
kesalahan relatif kurang dari 10% yaitu dengan membandingkan data model dan data
observasi terhadap konsentrasi alga, bakteri, oksigen terlarut, dan BOD.
Kata kunci: Biological Oxygen Demand, Kolam Stabilisasi, Metode Evaluasi, Model
Dinamik, Metode Euler
1. Pendahuluan
1.1. Latar Belakang
Karakteristik air buangan perkotaan yang menonjol adalah kandungan bahan
organik yang tinggi yaitu dengan ditandainya kandungan Biological Oxygen
Demand (BOD). Air buangan perkotaan ini biasanya disebut dengan limbah cair
domestik. Limbah cair domestik merupakan limbah yang dihasilkan dari limbah
rumah tangga sebagai cirinya adalah kandungan bahan organik yang tinggi. Limbah

851
ini terdiri dari pembuangan air kotor dari kamar mandi, kakus, dan dapur. Air
buangan ini tidak termasuk air buangan industri, walaupun tidak mengandung bahan
kimia yang berbahaya dalam pengolahannya pada umumnya tidak menggunakan
penambahan bahan kimia khusus. Pada umumnya pengolahan air limbah ini
menggunakan kolam stabilisasi. Sistem pengolahan limbah pada kolam stabilisasi
dipergunakan untuk memperbaiki kualitas air limbah dengan mengandalkan proses-
proses alamiah untuk mengolah air limbah dengan memanfaatkan keberadaan
bakteri, alga, dan zooplankton untuk mereduksi bahan pencemar organik yang
terkandung dalam air limbah [1].
Oleh karena air buangan perkotaan ini yang menonjol adalah bahan organik,
maka sistem pengolahannya diutamakan secara biologi menggunakan kolam
stabilisasi. Pengolahan biologi ditujukan untuk mendegradasi kandungan bahan
organik dengan memanfaatkan mikrobiologi, yang akan mendegradasi bahan
organik tersebut. Untuk mendukung berlangsungnya proses degradasi bahan organik
diperlukan kondisi air yang mendukung antara lain suhu, pH dan kandungan oksigen
dalam air. Sistem pengolahan limbah pada kolam stabilisasi dipergunakan untuk
memperbaiki kualitas air limbah dengan mengandalkan proses-proses alamiah yang
memanfaatkan keberadaan bakteri dan alga yang terkandung dalam air limbah [2,3].
Salah satu jenis sistem proses pengolahan limbah domestik adalah menggunakan
unit Instalasi Pengolahan Air Limbah (IPAL) terpusat Sewon Bantul Yogyakarta.
Karakteristik hidrolis merupakan salah satu faktor yang mendukung kinerja
unit pengolahan secara optimal, apabila kondisi hidrolis didalamnya tidak
mendukung terjadinya pengolahan maka kinerja unit tersebut dapat menjadi buruk.
Kolam stabilisasi limbah ini sangat cocok diterapkan pada negara berkembang
(terutama daerah tropis yang iklimnya hangat), karena pengoperasian kolam ini tidak
membutuhkan biaya investasi dan biaya pengoperasian yang tinggi [2-7, 11].
Dalam upaya melakukan mengendalikan kualitas air pada sistem pengolahan
air limbah diperlukan metode evaluasi yang menggunakan permodelan matematika
yaitu model dinamik. Model ini berdasarkan [8] yang kemudian dikontruksikan
kembali menjadi 4 (empat) variabel yaitu alga, bakteri, Dissolved Oxygen dan
substrat (Biochemecal Oxygen Demand) berupa sistem persamaan diferensial
dengan dasar model monod sebagai model pertumbuhan mikroba.
1.2.Bahan dan Metode
Asumsi Pengembangan Model
Pengembangan model berdasarkan pada proses pengolahan air limbah IPAL
dengan persamaan matematis yaitu persamaan diferensial non linier simultan. Model
direpresentasikan sebagai model dinamik dengan asumsi bahwa dasar kolam adalah
tidak aktif dan sistem pengolahan air limbah diilustrasikan seperti Gambar 1.

852
Alga
CO2 Substrat
(BOD)
I
N
L
E
T
F Sinar
Matahari Fotosintesiss µ1
ℎ3𝜇2
ℎ4𝜇1
𝐷1
𝑚1
Bakteri
ℎ1𝜇1
O
U
T
L
E
T
ℎ2𝜇2
Reaerasi
𝑘𝐿𝑎
𝑟1
F
𝜇2 oksidasi
Oksigen
Terlarut
𝑚2
Gambar 1. Diagram Sistem Pengolahan Air Limbah Kolam Stabilisasi
Gambar 1, menunjukkan sistem pengolahan air limbah secara biologi yang
digunakan untuk mengembangkan model yang berupa laju perubahan/ pertumbuhan
dari variabel pembentuk persamaan mass balance ke dalam sistem persamaan
diferensial non linier simultan.
1.3. Model Dinamik
Bentuk persamaan mass balance untuk setiap komponen pada sistem persamaan
yang dibangun dalam 4 (empat) persamaan diferensial nonlinear. Dengan 4 (empat)
persamaan yang dikembangkan diaplikasikan dari persamaan monod terhadap
koreksi waktu sebagai pertumbuhan maksimum [1, 8-10].
Berdasarkan Gambar 1. diperoleh model matematika berbentuk sistem
persamaan diferensial nonlinear orde satu yang menggambarkan laju perubahan
konsentrasi : alga (𝐴), bakteri (𝐵), Dissolved Oxygen (𝐷𝑂) dan substrat (𝑆) pada
kolam stabilisasi sebagai berikut : 𝑑𝐴
𝑑𝑡 = 𝜇1
𝑆
𝑘1 + 𝑆𝐴 −𝑚1𝐴 − 𝐷1𝐴
𝑑𝐵
𝑑𝑡= 𝜇2
𝑆
𝑘2 + 𝑆
𝐷𝑂
𝑘3 + 𝐷𝑂𝐵 −𝑚2𝐵 − 𝐷1𝐵
𝑑𝐷𝑂
𝑑𝑡= ℎ1𝜇1
𝑆
𝑘1 + 𝑆𝐴 − 𝐷1𝐷𝑂 + 𝑘𝐿𝑎(𝐷0 − 𝐷𝑂)
−ℎ2𝜇2𝑆
𝑘2 + 𝑆
𝐷𝑂
𝑘3 + 𝐷𝑂𝐵 − 𝑟1𝐴
𝐷𝑂
𝑘0 + 𝐷𝑂𝑑𝑆
𝑑𝑡 = −ℎ3𝜇2
𝑆
𝑘2 + 𝑆
𝐷𝑂
𝑘3 + 𝐷𝑂𝐵 − 𝐷1𝑆 − ℎ4𝜇1
𝑆
𝑘1 + 𝑆𝐴,
(1)
dengan 𝜇1 > 0, 𝜇2 > 0,𝑚1 > 0, 𝑚2 > 0, ℎ1 > 0, ℎ2 > 0, ℎ3 > 0, ℎ4 > 0, 𝑘0 >0, 𝑘1 > 0, 𝑘2 > 0, 𝑘3 > 0, 𝑘𝐿𝑎 > 0, 𝑟1 > 0,𝐷0 > 0, dan 𝐷1 > 0.
Metode Euler dan Model Program Persamaan (1) yang terdiri atas 4 (empat) persamaan differensial non linier
diselesaikan dengan Metode Euler sebagai teknik integrasi untuk mendapatkan
konsentrasi setiap komponen terhadap waktu simulasi dilakukan menggunakan

853
program Matlab(R2008a) dan sebagai input data awal adalah kondisi awal alga
𝐴(0) = 33 jumlah individu, bakteri 𝐵(0) = 490 mg/l, Dissolved Oxygen DO (0) =0.9 mg/l dan subtrat (Biochemical Oxygen Demand 𝑆(0) = 250 mg/l. Nilai awal
konsentrasi ini merupakan hasil pengukuran pada inlet kolam stabilisasi.
Model Validasi
Uji validasi model dilakukan dengan menggunakan data pengukuran pada
IPAL Sewon Bantul Yogyakarta meliputi konsentrasi: alga, bakteri, DO dan BOD.
Uji dilakukan dengan menbandingkan antara data observasi dan data hitung dengan
toleransi kesalahan 10%. Menurut [12] untuk mengukur kualitas yang merupakan
suatu istilah realtif yang sangat bergantung pada situasi, maka dengan
membandingkan standar dan pengukuran kinerja suatu hal adalah perbedaan/
Perbedaan ini menurut [13] bisa sampai dengan toleransi kesalahan 20%.
2. Hasil – Hasil Utama
Sistem persamaan (1) digunakan untuk menggambarkan bagaimana daya
dukung lingkungan pada sistem proses unit pengolahan air limbah yang dapat
mendegradasi bahan organik. Sebuah sistem yang dapat mengilustrasikan proses
degradasi adalah sistem IPAL yang terjadinya interaksi antar unsur-unsur variabel
konsentrasi. Kondisi ini merupakan keadaan dinamik dimana keadaan sistem
berubah terhadap waktu, yang ditandai dari keadaan tak tunak (unsteady state)
sampai keadaan tunak (steady state). Untuk mengetahui kesetimbangan dari sistem
berikut ini ditentukan titik ketimbangan dari model yaitu :
A. Penentuan Titik Kesetimbangan
Untuk menentukan titik kesetimbangan terlebih dahulu disimbolkan sebagai
titik (𝐴∗, 𝐵∗, 𝐷𝑂∗, 𝑆∗) yang merupakan titik dari persamaan (1) jika memenuhi 𝑑𝐴
𝑑𝑡=
0,𝑑𝐵
𝑑𝑡= 0,
𝑑𝐷𝑂
𝑑𝑡= 0,
𝑑𝑆
𝑑𝑡= 0, maka sistem persamaan pada persamaan (1) disekitar
titik kesetimbangan (𝐴∗, 𝐵∗, 𝑂2∗, 𝑆∗) menjadi :
𝜇1
𝑆∗
𝑘1 + 𝑆∗ 𝐴
∗ − 𝑚1𝐴∗ − 𝐷1𝐴
∗ = 0 (2)
𝜇2
𝑆∗
𝑘2 + 𝑆∗
𝐷𝑂∗
𝑘3 + 𝐷𝑂∗ 𝐵
∗ − 𝑚2𝐵∗ − 𝐷1𝐵
∗ = 0 (3)
ℎ1𝜇1𝑆∗
𝑘1 + 𝑆∗ 𝐴
∗ − 𝐷1𝐷𝑂∗ + 𝑘𝐿𝑎(𝐷0 − 𝐷𝑂
∗) − ℎ2𝜇2𝑆∗
𝑘2 + 𝑆∗
𝐷𝑂∗
𝑘3 + 𝐷𝑂∗ 𝐵
∗ (4)
−𝑟1𝐴∗
𝐷𝑂
𝑘0 + 𝐷𝑂= 0
−ℎ3𝜇2𝑆∗
𝑘2 + 𝑆∗
𝐷𝑂∗
𝑘3 + 𝐷𝑂∗ 𝐵
∗ − 𝐷1𝑆∗ − ℎ4𝜇1
𝑆∗
𝑘1 + 𝑆∗ 𝐴
∗ = 0. (5)
Dari persamaan (2), (3), (4) dan (5) dapat diperoleh empat titik
kesetimbangan, yaitu titik kesetimbangan pada kondisi kolam tercemar yang berarti
bahwa kolam mengandung alga, bakteri, dan substrat: 𝐸1(𝐴∗, 𝐵∗, 𝐷𝑂∗, 𝑆∗) =
(𝐴∗, 𝐵∗,(𝑚2+𝐷1)(𝑘2(−𝜇1+𝑚1+𝐷1)+𝑘1(−𝑚1−𝐷1))𝑘3
𝜇2𝑘1(−𝑚1−𝐷1)−(𝑚2+𝐷1)(𝑘2(−𝜇1+𝑚1+𝐷1)+𝑘1(−𝑚1−𝐷1)),𝑘1(−𝑚1−𝐷1)
−𝜇1+𝑚1+𝐷1), titik kese-
timbangan pada kondisi kolam tidak mengandung bakteri 𝐸2(𝐴∗, 𝐵∗, 𝐷𝑂∗, 𝑆∗) =
(𝐷1𝑘1
ℎ4(−𝜇1+𝑚1+𝐷1), 0, 𝐷𝑂∗,
𝑘1(−𝑚1−𝐷1)
−𝜇1,𝑚𝑎𝑥+𝑚1+𝐷1), titik kesetimbangan pada kondisi kolam

854
tidak mengandung alga 𝐸3(𝐴∗, 𝐵∗, 𝐷𝑂∗, 𝑆∗) = (0, 𝐵∗,
ℎ2𝐷1𝑆∗+ℎ3𝑘𝐿𝑎𝐷0
ℎ3(𝐷1+𝑘𝐿𝑎), 𝑆∗) dan titik
kesetimbangan pada kondisi kolam tidak mengandung alga, bakteri dan substrat
𝐸4(𝐴∗, 𝐵∗, 𝐷𝑂∗, 𝑆∗) = (0,0,
𝑘𝐿𝑎𝐷0(𝐷1+𝑘𝐿𝑎)
, 0).
B. Kestabilan dari Titik Kesetimbangan
Penentuan kestabilan dari titik kesetimbangan dilakukan untuk 4 (empat) titik
kondisi setimbangan, yaitu kesetimbangan pada kondisi kolam mengandung alga,
bakteri dan substrat, kesetimbangan pada kondisi kolam tidak mengandung alga,
kesetimbangan pada kondisi kolam tidak mengandung bakteri dan kesetimbangan
pada kondisi kolam tidak mengandung alga, bakteri dan substrat. Kestabilan dari
sistem persamaan non linier (1) di sekitar titik kesetimbangan dapat diketahui dengan
melakukan pelinieran sistem non linier menggunakan ekspansi Taylor, sehingga
diperoleh matriks Jacobian sebagai berikut [10]:
𝐽(𝐴∗, 𝐵∗, 𝐷𝑂∗, 𝑆∗) =
[ 𝜕𝑓1
𝜕𝐴
𝜕𝑓1
𝜕𝐵
𝜕𝑓1
𝜕𝐷𝑂
𝜕𝑓1
𝜕𝑆
𝜕𝑓2
𝜕𝐴
𝜕𝑓2
𝜕𝐵
𝜕𝑓2
𝜕𝐷𝑂
𝜕𝑓2
𝜕𝑆
𝜕𝑓3
𝜕𝐴
𝜕𝑓3
𝜕𝐵
𝜕𝑓3
𝜕𝐷𝑂
𝜕𝑓3
𝜕𝑆
𝜕𝑓4
𝜕𝐴
𝜕𝑓4
𝜕𝐵
𝜕𝑓4
𝜕𝐷𝑂
𝜕𝑓4
𝜕𝑆 ]
=
[ 𝜇1𝑆
∗
𝑘1+𝑆∗ −𝑚1 − 𝐷1 0 0
𝜇1𝐴∗
𝑘1+𝑆∗ −
𝜇1𝑆∗𝐴∗
(𝑘1+𝑆∗)2
0𝜇2𝑆
∗
𝑘2+𝑆∗
𝐷𝑂
𝑘3+𝐷𝑂
𝜇2𝑆∗
(𝑘2+𝑆∗)(𝑘3+𝐷𝑂
∗)𝐵∗
𝜇2𝐷𝑂∗𝐵∗
(𝑘2+𝑆∗)(𝑘3+𝐷𝑂
∗)−
0 −𝑚2 −𝐷1 −𝜇2𝑆
∗𝐷𝑂∗
(𝑘2+𝑆∗)(𝑘3+𝐷𝑂
∗)2𝐵∗
𝜇2𝑆∗𝐷𝑂 ∗𝐵∗
(𝑘2+𝑆∗)2(𝑘3+𝐷𝑂
∗)
ℎ1𝜇1𝑆∗
𝑘1+𝑆∗
−ℎ2𝜇2𝑆∗
𝑘2+𝑆∗
𝐷𝑂 ∗
𝑘3+𝐷𝑂∗ −𝐷1 − 𝑘𝐿𝑎 −
ℎ2𝜇2𝑆∗𝐵∗
(𝑘2+𝑆∗)(𝑘3+𝐷𝑂
∗)
ℎ1𝜇1𝐴∗
𝑘1+𝑆∗−ℎ1𝜇1𝑆
∗𝐴∗
(𝑘1+𝑆∗)2
−𝑟1𝐷𝑂
∗
𝑘0+𝐷𝑂∗ 0 +
ℎ2𝜇2𝑆∗𝐷𝑂 ∗𝐵∗
(𝑘2+𝑆∗)(𝑘3+𝐷𝑂
∗)2−
ℎ2𝜇2𝐷𝑂∗𝐵∗
(𝑘2+𝑆∗)(𝑘3+𝐷𝑂
∗)
0 0 −𝑟1𝐴
∗
𝑘0+𝑂2∗ +
𝑟1𝐴∗𝐷𝑂 ∗
(𝑘0+𝐷𝑂∗)2
+ℎ2𝜇2𝑆
∗𝐷𝑂 ∗𝐵∗
(𝑘2+𝑆∗)2(𝑘3+𝐷𝑂
∗)
−ℎ4𝜇1𝑆∗
𝑘1+𝑆∗
−ℎ3𝜇2𝑆∗
𝑘2+𝑆∗
𝐷𝑂 ∗
𝑘3+𝐷𝑂∗ −
ℎ3𝜇2𝑆∗𝐵∗
(𝑘2+𝑆∗)(𝑘3+𝐷𝑂
∗)+ −
ℎ3𝜇2𝐷𝑂∗𝐵∗
(𝑘2+𝑆∗)(𝑘3+𝐷𝑂
∗)+
0 0ℎ3𝜇2𝑆
∗𝐷𝑂 ∗𝐵∗
(𝑘2+𝑆∗)(𝑘3+𝐷𝑂
∗)2ℎ3𝜇2𝑆
∗𝐷𝑂 ∗𝐵∗
(𝑘2+𝑆∗)2(𝑘3+𝐷𝑂
∗)− 𝐷1
0 0 0 −ℎ4𝜇1𝐴
∗
𝑘1+𝑆∗ +
ℎ4𝜇1𝑆∗𝐴∗
𝑘+𝑆∗ ]
.
Dengan mensubstitusikan titik kesetimbangan yang telah diperoleh kedalam
matriks Jacobian. Nilai eigen dapat diperoleh dengan det (𝐽(𝐴∗, 𝐵∗, 𝐷𝑂∗, 𝑆∗) −𝜆𝐼) = 0. Nilai eigen untuk titik kesetimbangan pada kondisi kolam tidak
mengandung alga, bakteri dan substrat adalah 𝜆1 = −𝑚1 − 𝐷1, 𝜆2 = −𝑚2 − 𝐷1,
𝜆3 = −𝐷1 − 𝑘𝐿𝑎 dan 𝜆4 = −𝐷1. Untuk menganalisis kestabilan sistem pada sisitem
(1) didasarkan pada sifat kestabilan di sekitar titik kesetimbangan. Dengan
menggunakan nilai eigen, maka titik kesetimbangan diketahui jenisnya. Pada titik
kesetimbangan bebas pencemar 𝐸4 merupakan stabil asimtotik jika semua nilai eigen
bernilai negatif atau 𝜆𝑖 < 0 untuk 𝑖 = 1,2,3,4. Nilai eigen 𝜆1, 𝜆2, 𝜆3 dan 𝜆4 bernilai
negatif, sehingga titik kesetimbangan bebas pencemar 𝐸4 stabil asimtotik. Pada titik
kesetimbangan 𝐸1(𝐴∗, 𝐵∗, 𝐷𝑂∗, 𝑆∗), 𝐸2(𝐴
∗, 𝐵∗, 𝐷𝑂∗, 𝑆∗), 𝐸3(𝐴∗, 𝐵∗, 𝐷𝑂∗, 𝑆∗)
diselesaikan secara metode numerik karena sulit untuk dapat diselesaikan secara
eksak oleh karenanya simulasi numerik diuraikan pada sub bab berikut.

855
D. Simulasi Numerik
Simulasi numerik untuk penerapan model digunakan data penelitian dari IPAL
Sewon, Bantul Yogyakarta. Model diselesaikan secara numerik dengan bantuan
program Matlab. Parameter yang digunakan untuk simulasi ditentukan berdasarkan
hasil estimasi parameter dengan menggunakan metode kuadrat terkecil dan hasilnya
disajikan pada Tabel 1.
Table 1. Nilai Parameter Model
Simbol Nama Dimensi Nilai
𝜇1 Laju pertumbuhan alga maksimum hari-1 0,118
𝜇2 Laju pertumbuhan bakteri maksimum hari-1 0,12
𝑚1 Koefisien kematian alga hari-1 0,001
𝑚2 Koefisien kematian bakteri hari-1 0,06
𝑘0 Konstanta kenitika saturasi respirasi mg/L 0,003
𝑘1 Konstanta saturasi alga pada subtrat mg/L 0,001
𝑘2 Konstanta saturasi alga pada bakteri mg/L 250
𝑘3 Konstanta saturasi bakteri pada oksigen
terlarut. mg/L 0,0001
ℎ1 Koefisien produksi oksigen pada alga mg/mg 0,0496
ℎ2 Koefisien konsumsi oksigen pada bakteri mg/mg 1,289
ℎ3 Koefien subtrat pada bakteri mg/mg 3
ℎ4 Koefisien substrat pada alga mg/mg 0.2
𝑘𝐿𝑎 Koefisien intertransfer oksigen terlarut m/hari 12,4
𝐷0 Saturasi oksigen terlarut mg/L 4,3
𝑟1 Laju respirasi alga hari-1 0,0001
𝐷1 Laju dilusi hari-1 0,148
Dengan diperolehnya nilai parameter-parameter tersebut selanjutnya diguna-
kan untuk menghitung nilai konsentrasi pada sistem persamaan (1) yang terdiri dari
4 (empat) variabel yaitu konsentrasi alga, bakteri, DO dan substrat (BOD). Hasil
simulasi model dan validasi model disajikan pada Gambar 2.
Gambar 2. Nilai Konsentrasi Hasil Simulasi Numerik
Gambar 2. menunjukkan hasil simulasi model dengan nilai konsentrasi awal

856
pada alga 𝐴(0) = 33 jumlah individu, bakteri 𝐵(0) = 490 mg/l, DO 𝑂2(0) = 0.9
mg/l dan BOD 𝑆(0) = 250 mg/l yang diukur pada inlet kolam stabilisasi fakultatif.
Selanjutnya dilakukan validasi model yaitu dengan membandingkan data observasi
dan data perhitungan model. Data observasi yang diukur di IPAL Sewon untuk ke 4
(empat) variabel diawali pada waktu ke nol. Untuk mengetahui kecocokan dari suatu
model, maka dilihat dari nilai 휀 (error)-nya yaitu dengan membandingkan nilai
hitung model dan observasi.
Dari variabel alga menunjukkan bahwa alga hitung dan data observasi
mempunyai kesalahan relatif 3,81%, variabel bakteri menunjukkan bahwa hasil
simulasi model dengan bakteri hitung dan data observasi mempunyai kesalahan
relatif 7,96%, variabel DO menunjukkan bahwa hasil simulasi model dengan
kandungan DO hitung dan data observasi mempunyai kesalahan relatif sebesar
6,97% dan variabel BOD yang mewakili substrat menunjukkan bahwa hasil simulasi
model dengan substrat hitung dan data mempunyai kesalahan relatif sebesar 7,91%.
Hasil validasi menunjukkan bahwa tingkat kesalahan pada keempat konsentrasi
mempunyai kesalahan < 10% hal sesuai dengan [12,13].
3. Kesimpulan Model dinamik dengan sistem persamaan diferensial non linier berdimensi
4 (empat) dengan 4 (empat) variabel konsentrasi alga, bakteri, DO dan substrat dapat
dijadikan sebagai metode evaluasi pada sistem pengolahan air limbah kolam
stabilisasi. Hal ini ditunjukkan dari hasil simulasi numerik dengan model yang telah
tervalidasi dengan tingkat kesalahan relatif <10%, sehingga model sesuai dengan
kondisi lapangan.
Hasil penelitian ini masih dapat dikembangkan dengan melakukan
modifikasi model dengan menambah variabel dan parameter yang dapat mendukung
sistem proses pengolahan air limbah di IPAL sejenis.
Pernyataan terima kasih. Balai Pengelolaan Infrastruktur Sanitasi dan Air
Minum Perkotaan DIY dan Dinas PU, Perumahan dan ESDM DIY.
Referensi
[1] Sunarsih, Purwanto, Wahyu Setia Budi, “Mathematical Modeling Regime
Steady State for Domestic Wastewater Treatment Facultative Stabilization
Ponds” Journal of Urban and Environmental Engineering (JUEE),V.7, n.2, pp.
293 -301, 2013.
[2] Kayombo, S., T.S.A. Mbwette, A.W. Mayo, J.H.Y Katima, S.E. Jorgensen,
“Diurnal cycles of variation physical-chemical parameters in waste stabilization
ponds”. Ecological Engineering 18 pp 287-291, 2002
[3] B. Beran B. and K. Kargi, “A dynamic mathematical model for waste water
stabilization ponds”. Ecological Modelling 181 pp 39-57, 2005.
[4] D.A. Mashauri, S. Kayombo, “Application of the two coupled models for water
quality management : facultative pond cum constructed wetland models”.
Physics and Chemistry of the Earth 27 pp 773-781, 2002.
[5] D. Mara, “Domestic Wastewater Treatment ini Developing Countries” First
Published by Earthscan in the UK and USA, 2004.
[6] Naddafi, 1K, 1M.S. Hassanvand, 1E. Dehghanifard, 2D. Faezi Razi, 2S.

857
Mostofi, 2N. Kasaee, 1R.Nabizadeh, 1M. Heidari, “Perfornance Evaluation of
Wastewater Stabilization Ponds in Arak Iran”. Iran. J. Environ. Health. Sci.
Eng.Vol. 6, No. 1, pp. 41-46, 2009.
[7] Amoo O.T. and Aremu A.S., “Tretability of Institutional Wastewater Using
Waste Stabilization Pond System”. Open Access http://www.trisanita.org/jates.
Volume 2, Number 4: 217-222, November, 2012. Department of Environmental
Engineering Sepuluh Nopember Institute of Technology, Surabaya &
Indonesian Society of Sanitary and Environmental Engineers, Jakarta.
[8] Dochain, D., Gregoire, S., Pauss, A., Schaegger, M. “Dynamical Modelling of
a Waste Stabilization Pond”. Bioprocess Biosyst Eng 26: pp. 19-26, 2003
[9] Moreno-Grau S., Garcia-Sanchez A., Moreno-Clavel J., Serrano-Aniorte J.,
Moreno-Grau, M.D.. “A mathematical model for waste water stabilization
ponds with macrophytes and microphytes”. Journal Ecological Modelling 91
pp 77-103, 1996.
[10] L.M. Situma, L. Etiegni, S.M. Shitote and B.O. Oron, “Biochemical Modeling
of Pan African Paper mills aerated Lagoons, Webuye, Western Kenya”. African
Pulp and Paper Week. ‘Adding Value in a Global Industry’ International
Convention Centre, Durban, 8 – 11 October, 2002.
[11] Tu, Pierre, N. V. “Dynamical System: An Introduction with Applications in
Economics and Biology”. New York: Springer-Verlag, 1994.
[12] Juran, J.M, 1992. Juran on Quality by Desain. The Free Press, New York.
[13] Feigenbaum, A.V, 1992. Kendali Mutu Terpadu, Penerbit Erlangga.

858
Prosiding SNM 2017 Pemodelan dan Opt imisas i , Hal 858 -864
SOLUSI MASALAH RELAKSASI MELALUI
PERSAMAAN DIFERENSIAL FRAKSIONAL BERORDE
(,)
E. RUSYAMAN1 DAN K. PARMIKANTI2
1Departemen Matematika FMIPA Unpad, [email protected]
2Departemen Matematika FMIPA Unpad, [email protected]
Abstrak. Akhir-akhir ini bidang ilmu kalkulus fraksional, khususnya
Persamaan Diferensial berorde bilangan fraksional berkembang dengan sangat
pesat. Aplikasinyapun telah menyebar pada berbagai ilmu seperti Fisika,
Ekonomi, dan lain-lain. Makalah ini akan membahas bentuk Persamaan
Diferensial Fraksional berorde (,) disertai solusi dan aplikasinya dalam
menentukan nilai regangan suatu benda apabila diketahui koefisien relaksasi
dan tegangan yang diberikan. Metode pencarian solusi akan menggunakan
Transformasi Laplace, sedangkan hasilnya berupa fungsi solusi dalam bentuk
Mittag-Lefler.
Kata kunci : fraksional, Laplace, relaksasi, Mittag-Lefler..
1. Pendahuluan
Kalkulus fraksional adalah adalah hasil pengembangan kalkulus yang
biasanya menggunakan bilangan asli menjadi bilangan rasional. Khususnya masalah
turunan dan integral suatu fungsi, yang biasanya berorde bilangan asli n menjadi
turunan dan integral berorde bilangan rasional α. Kalkulus fraksional ini sebenarnya
sudah muncul lebih dari 300 tahun yang lalu, yaitu saat Leibniz bertanya tentang
turunan ke-1,5 kepada L'Hospital di tahun 1695 [4]. Pertanyaan tersebut telah
menginspirasi banyak ilmuwan matematika seperti Liouville, Riemann, dan Weyl
untuk mengembangkan turunan berorde fraksional. Selanjutnya pengembangan
kalkulus fraksional dilanjutkan oleh Fourier, Abel, Leibniz, Grünwald, dan
Letnikov, yang selama bertahun-tahun telah berkontribusi besar dalam ilmu ini.
Saat ini, banyak ilmuwan dan ahli teknik yang tertarik untuk memperdalam
dan mengaplikasikan ilmu ini dalam berbagai bidang seperti Adam Loverro, 2004,
dalam [1] memanfaatkan turunan fraksional dalam bidang teknik fisika khususnya
masalah mekanika dan aerodinamik, serta Podlubny, 2004, dalam [3] yang
mengkaji masalah persamaan diferensial parsial berorde fraksional dan aplikasinya.
Selanjutnya E. Rusyaman, dkk, 2009, dalam [5] mengaplikasikan turunan
fraksional dalam masalah interpolasi yang meminimumkan nilai energi potensial.
Demikian pula F.C. Meral, T.J. Royston , R. Magin, 2010 dalam [2] telah membahas
tentang masalah viskoelastisitas sebagai presentasi dari orde fraksional.

859
Dalam makalah ini disajikan masalah eksistensi dan solusi dari persamaan
diferensial fraksiolanal berbentuk:
𝑎𝑛 𝑦(𝛼𝑛) + 𝑎𝑛−1 𝑦
(𝛼𝑛−1) + ⋯ + 𝑎1 𝑦(𝛼1) + 𝑎0 𝑦 = 𝑢(𝑡) (1)
di mana 𝑦(𝛼) menyatakan turunan fraksional dari y terhadap x dengan orde α , 𝑎𝑛
adalah konstanta real, dan 𝑢(𝑥) fungsi dalam x. Selain itu grafik fungsi solusi
disajikan untuk membantu pemahaman tentang kaitan kekonvergenan barisan
bilangan orde turunan dengan kekonvergenan barisan fungsi solusi. Terakhir
diperlihatkan aplikasi dari persamaan diferensial fraksional.
2. Hasil – Hasil Utama
Seperti yang telah disebutkan di atas, turunan fraksional adalah hasil
generalisasi dari turunan biasa di mana orde yang tadinya berupa bilangan asli
diperluas menjadi bilangan rasional α. Penurunan rumus turunan fraksional dari
suatu fungsi disajikan secara berbeda oleh beberapa ahli matematika. Riemann-
Liouville mendefinisikan turunan fraksional sebagai berikut.
Definisi 2.1. Turunan fraksional dari fungsi 𝑓(𝑥) dengan orde- di sekitar x = a
adalah
𝐷𝑥𝛼 𝑓(𝑥)𝑎 =
1
(𝑛 − 𝛼) (𝑑
𝑑𝑥)𝑛
∫ 𝑓(𝑡) (𝑥 − 𝑡)−(𝛼−𝑛+1)𝑥
𝑎
𝑑𝑡
di mana n – 1 ≤ α < n atau n – 1 = ⌊𝛼⌋.
Berbeda dengan Riemann-Liouville, Grunwald-Letnikov mendefinisikan turunan
fraksional dari f(x) berorde-α pada interval [a , b] dengan definisi berikut.
Definisi 2.2. Turunan fraksional dari f(x) berorde-α pada interval [a , b] adalah
𝐷𝑥𝛼 𝑓(𝑥) = lim
ℎ→0
1
ℎ𝑛 ∑(−1)𝑖𝑛
𝑖=0
(𝛼 + 1)
(𝑖 + 1) (𝛼 − 𝑖 + 1) 𝑓(𝑥 − 𝑖ℎ)
dengan n = ⌊𝑏−𝑎
𝑛⌋ .
Secara sederhana, dari rumus di atas diperoleh bahwa turunan ke-α dari fungsi
𝑓(𝑥) = 𝑥𝑝 terhadap x adalah
𝐷𝑥𝛼 𝑥𝑛 =
(𝑝 + 1)
(𝑝 − 𝛼 + 1) 𝑥𝑝−𝛼 . (2)
Karena makalah ini akan membahas tentang masalah solusi persamaan
diferensial fraksional menggunakan transformasi Laplace dan fungsi Mittag-Lefler,
berikut diberikan definisi tentang keduanya.
Definisi 2.3: Transformasi Laplace dari fungsi f(t) didefinisikan sebagai
𝐿{𝑓(𝑡)} = 𝐹(𝑠) = ∫ 𝑒−𝑠𝑡 𝑓(𝑡)𝑑𝑡∞
0
.

860
Teorema 2.4: Jika f(t) fungsi yang terdiferensial n kali, maka berlaku
L{f(n)(t)} = sn L {f(t)} – sn-1 f(0) – sn-2 f’(0) – . . . – f (n-1) (0) .
Dalam hal 𝐷𝑡𝛼𝑓(𝑡) merupakan turunan dari f(t) terhadap t dengan orde fraksional
, maka tranformasi Laplace dengan syarat awal
f (k)(0) = 0 untuk k = 0, 2, ..., (n-1),
akan mengakibatkan
L {𝐷𝑡𝛼𝑓(𝑡); 𝑠} = s L {f(t)} = s F(s) . (3)
Salah satu fungsi khusus lain yang sangat penting dalam kalkulus fraksional
adalah fungsi Mittag-Leffler yang diperkenalkan th.1953. Fungsi tersebut tersaji
sebagai berikut [3],[5].
Definisi 2.5: Fungsi Mittag-Leffler dengan dua parameter dan didefinisikan
sebagai
𝐸𝛼,𝛽(𝑧) = ∑𝑧𝑘
(𝛼𝑘 + 𝛽)
∞
𝑘=0
; 𝛼 > 0 , 𝛽 > 0.
Fungsi ini benar-benar sangat fleksibel, karena dengan mengganti
kedua parameter dengan konstanta akan menghasilkan fungsi lain yang
sangat berbeda.
Contoh 2.6. Untuk pasangan parameter = 1 = 1 dan = 2 = 1 berturut-turut
menghasilkan fungsi:
1. 𝐸1,1(𝑧) = ∑𝑧𝑘
(𝑘 + 1)=
∞
𝑘=0
∑𝑧𝑘
𝑘!=
∞
𝑘=0
𝑒𝑧 .
2. 𝐸2,1(−𝑧2) = ∑
(−𝑧2)𝑘
(2𝑘 + 1)
∞
𝑘=0
= ∑(−1)𝑘 𝑧2𝑘
(2𝑘)!
∞
𝑘=0
= cos 𝑧 .
Tipe lain dari fungsi Mittag-Leffler yang juga diperkenalkan oleh Podlubny dalam
[3] adalah
𝑘(𝑡, ; 𝛼, 𝛽) = 𝑡𝛼𝑘+𝛽−1 𝐸𝛼,𝛽
(𝑘)( 𝑡𝛼) , (4)
di mana 𝐸𝛼,𝛽(𝑘)(𝑧) adalah turunan ke-k dari fungsi Mittag-Leffler dua parameter
yaitu
𝐸𝛼,𝛽(𝑘)(𝑧) = ∑
(𝑖 + 𝑘)! 𝑧𝑖
𝑖! (𝛼𝑖 + 𝛼𝑘 + 𝛽)
∞
𝑖=0
; 𝑘 = 0, 1, 2,⋯ .
Dengan demikian transformasi Laplace dari fungsi pada (4) diperoleh
L {𝑘(𝑡, ± ; 𝛼, 𝛽)} = 𝑘! 𝑠𝛼−𝛽
(𝑠𝛼 ∓ )𝑘+1 (5)
Bentuk umum Persamaan Diferensial Fraksional yang disajikan dalam (1)
akan memiliki banyak bentuk yang lebih spesifik. Hal ini tergantung pada pemilihan
𝑢(𝑡) sebagai fungsi dalam t, sehingga bisa berbentuk fungsi polinom ataupun fungsi

861
transenden. Demikian pula pemilihan (𝛼𝑛) sebagai orde berupa bilangan fraksional,
akan menyebabkan perbedaan cara dalam menentukan penyelesaian. Yang akan
dibahas dalam makalah ini adalah Persamaan Diferensial Fraksional berorde (𝛼, 𝛽) , yaitu
𝑎𝑦(𝛼) + 𝑏𝑦(𝛽) = 𝑢(𝑡), (6)
di mana α > β , a dan b konstanta real, serta 𝑢(𝑡) fungsi sembarang dalam t .
Theorem 2.7. Solusi dari Persamaan Diferensial Fraksional berorde (𝛼, 𝛽) dengan 𝑢(𝑡) = 𝑡𝑖 adalah
𝑦(𝑡) = 𝑖!
𝑎 𝑡𝛼+𝑖∑
(−𝑏𝑎𝑡(𝛼−𝛽))
𝑘
Γ((𝛼 − 𝛽)𝑘 + 𝛼 + 𝑖 + 1)
∞
𝑘=0
. (7)
Bukti:
Transformasi Laplace dari peramaan (6) menghasilkan
L{ 𝑎𝑦(𝛼) + 𝑏𝑦(𝛽)} = L{ 𝑡𝑖}. Dengan sifat kelinearan transformasi Laplace , syrat awal nol, dan menggunakan
persamaa (3) maka didapat
𝑎𝑠𝛼𝐹(𝑠) + 𝑏𝑠𝛽𝐹(𝑠) = 𝑖!
𝑠𝑖+1
sehingga diperoleh
𝐹(𝑠) =
𝑖!𝑠𝑖+1
(𝑎𝑠𝛼 + 𝑏𝑠𝛽)=
𝑖! 𝑠−𝑖−1
𝑎𝑠𝛽 (𝑠𝛼−𝛽 +𝑏𝑎) .
Dengan mengadakan penyesuaian untuk mendapatkan fungsi solusi, diperoleh
𝑦(𝑡) = L−1{𝐹(𝑠)} = 𝑖!
𝑎 L−1 {
𝑠−𝑖−1−𝛽
(𝑠𝛼−𝛽 +𝑏𝑎)} =
𝑖!
𝑎 L−1 {
0! 𝑠𝛼−𝛽−(𝛼+𝑖+1)
(𝑠𝛼−𝛽 +𝑏𝑎)
0+1}.
. Selanjutnya dengan menggunakan bentuk (5) tentang invers transformasi Laplace
maka diperoleh
𝑦(𝑡) =𝑖!
𝑎 휀0 (𝑡,−
𝑏
𝑎; 𝛼 − 𝛽, (𝛼 + 𝑖 + 1)).
Berdasarkan bentuk (4), solusi umum 𝑦(𝑡) dapat dituliskan menjadi
𝑦𝑖(𝑡) =𝑖!
𝑎 𝑡(𝛼−𝛽)∙0+𝛼+𝑖+1−1𝐸𝛼−𝛽,(𝛼+𝑖+1) (−
𝑏
𝑎𝑡(𝛼−𝛽))
=𝑖!
𝑎 𝑡𝛼+𝑖𝐸𝛼−𝛽,(𝛼+𝑖+1) (−
𝑏
𝑎𝑡(𝛼−𝛽)).
Dengan mengembalikan bentuk ini menjadi fungsi Mittag-Leffler type pertama,
maka bentuk fungsi solusi menjadi
𝑦(𝑡) =𝑖!
𝑎 𝑡𝛼+𝑖∑
(−𝑏𝑎𝑡(𝛼−𝛽))
𝑘
Γ((𝛼 − 𝛽)𝑘 + 𝛼 + 𝑖 + 1)
∞
𝑘=0
∎

862
Contoh 2.8.
Berdasarkan rumus pada Teorema 2.7 di atas, dengan mengambil nilai-nilai a = 2,
b=1, i = 0, dan syarat awal y(0) = 0, y’(0) = 0, maka solusi dari Persamaan
Diferensial Fraksional berorde (𝛼, 𝛽) = (1,9 , 0) dan (1 , 0) berturut turut adalah
𝑦(𝑡) = 1
2 𝑡1,9∑
(−12𝑡1,9)
𝑘
(1,9𝑘 + 2,9)!
∞
𝑘=0
dan
𝑦(𝑡) = 1
2 𝑡∑
(−12 𝑡)
𝑘
(𝑘 + 1)!
∞
𝑘=0
= 1 − ∑(−
12 𝑡)
𝑘
𝑘!
∞
𝑘=0
= 1− 𝑒−12𝑡 .
Adapun grafik fungsi solusi dari Persamaan Diferensial Fraksional berorde (𝛼, 𝛽) =(1,9 , 0) dan (1 , 0) berturut-turut tampak pada Gambar.1 berikut.
Gambar.1 Grafik Fungsi Solusi PD Fraksional
Teorema di atas dapat dijadikan landasan untuk mengembangkan 𝑢(𝑡) baik
menjadi fungsi polinom secara umum maupun menjadi fungsi transenden. Sebagai
contoh, jika 𝑢(𝑡) = ∑ 𝑐𝑖𝑡𝑖𝑛
𝑖=0 (polinom), maka solusi dari (6) akan berbentuk
penjumlahan solusi pada (7) dengan i = 0, 1, 2, 3, ... , n. Demikian juga apabila 𝑢(𝑡) dikembangkan menjadi fungsi transenden, dengan mengubahnya menjadi polinom
melalui deret Mac Lauren atau Deret Taylor, solusi dapat dicari seperti sebelumnya.
Contoh 2.9. Solusi persamaan diferensial fraksional
𝑦(𝛼) + 2𝑦(𝛽) = 1 + 2𝑡 + 𝑡2.
dengan orde (𝛼, 𝛽) = (5
3 ,
1
2) dan syarat awal 𝑓(0) = 0 dan 𝑓′(0) = 0 maka
solusinya adalah
𝑦(𝑡) = 𝑡53∑
(−2𝑡23)𝑘
(23 𝑘 +
83) !
∞
𝑘=0
+ 2𝑡83∑
(−2𝑡23)𝑘
(23𝑘 +
113 ) !
∞
𝑘=0
+ 2𝑡113 ∑
(−2𝑡23)𝑘
(23𝑘 +
143 ) !
.
∞
𝑘= 0
Dalam uraian berikut ini, akan disampaikan aplikasi Persamaan Diferensial
Fraksional dalam bidang fisika, khususnya masalah relaksasi, yaitu masalah
peregangan suatu benda yang diakibatkan adanya tegangan yang diberikan pada

863
benda tersebut. Jika R menyatakan regangan dan T menyatakan tegangan, menurut
hukum Hooke-material, elastisitas material adalah rasio dari tegangan dengan
regangan. Di sisi lain, dalam fluida ada istilah viskositas yang menurut hukum
Netonian-fluida viskositas adalah laju perubahan regangan terhadap waktu dibagi
dengan tegangan. Secara matematika dapat ditulis sebagai berikut [2].
model Hooke-material : 𝑇(𝑡) = 𝐸 𝑅(𝑡) ,
model Newtonian-fluida: 𝑇(𝑡) = 𝜇 𝑑𝑅(𝑡)
𝑑𝑡 .
Dengan memasukkan unsur sebagai rasio 𝜇 terhadap 𝐸, kedua model tersebut
dapat dikombinasikan dan diperluas dalam bentuk model persamaan diferensial
fraksional
𝑇(𝑡) = 𝐸 𝛼 𝑑𝛼𝑅(𝑡)
𝑑𝑡𝛼 (8)
yakni untuk = 0 model (10) akan kembali ke model Hooke-material, sedangkan
untuk = 1 model (10) akan kembali ke model Newtonian-fluida. Dengan demikian
untuk orde fraksional nilai di mana 0 < < 1 diperkenalkan istilah
viskoelastisitas.
Secara umum, bentuk Persamaan Diferensial Fraksional untuk masalah
relaksasi adalah
𝑅 (α) (t) + A 𝑅(t) = 𝑇(t)
di mana 0 1 , syarat awal 𝑅 (0) = 𝑅′(0) = 0 , A adalah koefisien relaksasi,
𝑇(t) menyatakan tegangan sebagai fungsi dalam waktu, dan 𝑅(t) menyatakan
regangan.
Contoh 2.10
Misalkan suatu benda yang memiliki koefisien relaksasi A = 2 diberi tegangan
sebesar 𝑇(t) = 𝑡 sin 𝑡 , maka persamaan diferensial fraksional orde = 0,5 adalah
𝑅 (0.5)(t) + 2 𝑅(t) = t sin t.
Dengan menggunakan deret Maclaurin, persamaan menjadi
𝑅(0.5)(𝑡) + 2 𝑅(𝑡) = ∑(−1)𝑖+1
(2𝑖 − 1)! 𝑡2𝑖
∞
𝑖=1
.
Dengan (7), fungsi solusi dari persamaan diferensial fraksional tersebut adalah
𝑅(𝑡) = ∑((−1)𝑖+1 .2𝑖 𝑡0.5+2𝑖∑(−2𝑡0.5)𝑘
(0.5𝑘 + 0.5 + 2𝑖)!
∞
𝑘=0
)
∞
𝑖=1
.
Grafik fungsi tersebut terlihat di bawah ini.
Gambar.2 Hubungan Regangan dan Tegangan

864
Dari Gambar.2 terlihat bahwa apabila koefisien relaksasi dan tegangan
diketahui, maka besarnya regangan akan diketahui pula. Sangat mungkin terjadi,
regangan akan terus membesar manakala tegangan sudah mengecil melewati nilai
maksimum.
3. Kesimpulan
Dari uraian yang telah disampaikan dapat disimpulkan bahwa perubahan
orde fraksional maupun perubahan fungsi u(t) yang dapat berperan sebagai fungsi
regangan dapat menghasilkan metode dan solusi yang berbeda. Dalam masalah
relaksasi khususnya masalah viskoelastisitas, orde fraksional merepresentasikan
suatu zat/benda yang merupakan peralihan antara cairan dan material, antara
Newtonian-fluida dan Hooke-material.
Penelitian ini masih perlu dikembangkan, terutama mencari hubungan
antara viskoelastisitas dengan tegangan permukaan yang juga masih merupakan
bagian dari masalah relaksasi. Pengembangan lain bisa dilakukan dengan
memperluas bentuk persamaan diferensial fraksional menjadi persamaan diferensial
parsial fraksional.
Pernyataan Terima Kasih
Materi pada makalah ini merupakan bagian dari rangkaian Penelitian Unggulan
Perguruan Tinggi No. 718/UN6.3.1/PL/2017, Universitas Padjadjaran.
Referensi
[1] Adam Loverro, 2004 , Fractional Calculus: History , Definitions and
Applications for the Engineer, Department of Aerospace and Mechanical
Engineering,University of Notre Dame, IN 46556, U.S.A.
[2] F.C. Meral, T.J. Royston , R. Magin, 2010, Fractional calculus in viscoelasticity:
An experimental study, Commun Nonlinear Sci Numer Simulat 15 pg 939–945
[3] Podlubny, I .; Chechkin. A.; Skovranek, T.; Chen , Y. Q. and Vinagre, B. M. J,
2009 , Matrix approach to discrete fractional calculus II: Partial fractional
Differential equations, Journal of Computational Physics, Vol. 228, 3137–3153.
[4] Petraš, I. Fractional Derivatives, Fractional Integrals, and Fractional
Differential Equations in Matlab Technical University of Košice Slovak
Republic, 2011.
[5] Rusyaman , 2009 , A 2-D interpolation method that minimizes an energy
integral, IndoMS International Conference on Mathematics and Its Applications
(IICMA). Yogyakarta.
.

865
Prosiding SNM 2017 Pemodelan dan Optimisasi, Hal 865-872
KONTROL OPTIMAL PADA MODEL EPIDEMIOLOGI
DENGAN VAKSINASI
JONNER NAINGGOLAN
Jurusan Matematika FMIPA Universitas Cenderawasih Jayapura, [email protected]
Abstrak. Paper ini mengkaji kontrol optimal pada model epidemiologi dengan vaksinasi. Kontrol
pengobatan optimal dilakukan untuk mengoptimalkan pengobatan pada pengendalian penyebaran suatu
penyakit menular. Kemudian ditentukan the reproduction ratio vaksinasi. Selanjutnya diberikan
perhitungan numerik dengan menggunakan software Matlab untuk mengetahui pengaruh kontrol
pengobatan terhadap penurunan jumlah individu kompartemen infected.
Kata kunci: Kontrol pengobatan optimal, epidemiologi, the reproduction ratio vaksinasi.
1. Pendahuluan
Model penyebaran penyakit tipe SIR (Susceptible-Infected-Recovered)
klasik telah dikaji oleh Kermak & McKendrick [6]. Selanjutnya Hethcote [5]
mengembangkan model dari tipe SIR klasik dengan memperhatikan kompartemen
exposed, Brauer and Castillo-Chavez [2] mengembangkan model tipe SIR dengan
memperhatikan struktur umur. Pengendalian suatu penyakit yang mewabah dapat
dilakukan tindakan melalui vaksinasi. Model dinamika vaksinasi telah dikaji oleh
beberapa peneliti antara lain: Model vaksinasi tipe SVI yang telah ditulis oleh
Kribs-Zaleta [7], Liu dkk. [8], dimana V adalah kompartemen vaksinasi.
Ambang batas untuk mengetahui terjadinya endemik suatu penyakit dapat
dilihat dari nilai the reproduction ratio. Pada model penyebaran suatu penyakit
keadaan bebas penyakit stabil secara lokal jika the reproduction ratio lebih kecil dari
satu, dan jika the reproduction ratio lebih besar dari satu maka penyakit akan
menyebar (Castillo-Chavez et al. [3]; Driessche and Watmough, [4]).
Model matematika merupakan alat yang penting untuk mengoptimalkan
pencegahan, pengobatan dan pengontrolan infeksi suatu penyakit (Hethcote [5]).
Untuk mengoptimalkan pengendalian suatu penyakit dapat dengan memberikan
tindakan kontrol optimal (Neilan and Leinhart [9]). Penyelesaian model kontrol
optimal dapat digunakan dengan metode Prinsip Maksimum Pontryagin. Agusto [1]
mengkaji kontrol optimal, dengan tindakan chemoprophylaxis dan pengobatan pada
penyebaran penyakit tuberkulosis tanpa memperhatikan kompartemen vaksinasi.
Paper ini mengkaji model kontrol pengobatan suatu penyakit tipe SVIR
(Susceptible-Vaccination-Infected-Recovered) yang dikaji oleh Liu et al. [8].
Sebelum mengkaji kontrol pengobatan optimal ditentukan dahulu titik ekuilibrium
endemik, nonendemik, dan the reproduction ratio. Selanjutnya dibahas karakterisasi
model kontrol untuk menentukan variabel co-state (adjoint), kontrol optimal, dan
simulasi numerik untuk mengetahui pengaruh kontrol pengobatan terhadap
penurunan jumlah individu kompartemen terinfeksi dengan menggunakan software
Matlab.

866
Organisasi dalam tulisan ini adalah bagian pertama pendahuluan, bagian dua
membahas model epidemiologi tipe SVIR, kontrol pengobatan optimal, simulasi
numerik, dan terakhir kesimpulan.
2. Model Epidemiologi tipe SVIR
Model tipe SVIR yang dikaji oleh Liu et al. [8], seseorang individu yang
kebal permanen terhadap suatu infeksi jika individu yang terinfeksi telah sembuh,
atau telah divaksinasi. Model tipe SVIR dapat diaplikasikan pada penyakit menular
yang realistis digunakan pada penyakit cacar, polio, campak, serta meningitis (Liu
et al. [8]). Vaksinasi diberikan sebelum individu tersebut terinfeksi, dan vaksinasi
kemungkinan dapat berhasil atau tidak berhasil. Keberhasilan vaksin bergantung dari
kualitas vaksin dan keadaan individu yang divaksin.
Laju infeksi yang terjadi melalui kontak antara individu kompartemen
susceptible dengan terinfeksi misalkan dinotasikan dengan /N. Laju kelahiran dan
kematian alami dari masing-masing kompartemen adalah . Kemudian proporsi S
yang divaksinasi masuk ke kompartemen vaksinasi V dengan laju . Selanjutnya laju
kekebalan individu yang vaksinasi memperoleh kekebalan permanen sebesar 1,
sedangkan laju individu yang sembuh dari infeksi sebesar . Perbandingan antara
individu yang sukses divaksinasi dengan individu yang divaksinasi tetapi masih
terinfeksi, proporsional dengan perkalian antara interaksi kompartemen V dan I. Satu
individu yang tidak berhasil divaksinasi kemudian kontak dengan populasi yang
terinfeksi sebesar 1/N persatuan waktu. Adapun diagram alur model tipe SVIR yang
dikaji oleh Liu et al. [8] dapat dilihat seperti Gambar 1.
Berdasarkan Gambar 1 dapat dinyatakan dalam persamaan berikut:
𝑑𝑆
𝑑𝑡= – 𝑆𝐼 – ( + 𝜃)𝑆
𝑑𝑉
𝑑𝑡= 𝜃𝑆 – (1 − )𝑉𝐼 – ( + 𝛾1)𝑉
𝑑𝐼
𝑑𝑡 = 𝑆𝐼 + (1 − )𝑉𝐼 – ( + )𝐼
𝑑𝑅
𝑑𝑡= 𝛾1𝑉 + 𝐼 – 𝑅 }
.
(1)
dimana parameter-parameter , 𝛽, 𝜇, 𝜃, 𝜎, 𝛾, 𝛾1 0 dan jumlah awal kompartemen-
kompartemen S(0) = S0 0, V(0) = V0 0, I(0) = I0 0, R(0) = R0 0. Pada
VI
S (1-)VI I
S V I R
1V
Gambar 1. Dinamika transmisi epidemik SVIR
S V I R

867
kompartemen I diberikan pengobatan dengan laju sebesar r yang masuk ke
kompartemen R, sehingga persamaan (1) menjadi seperti persamaan (2).
𝑑𝑆
𝑑𝑡= – 𝑆𝐼 – ( + 𝜃)𝑆
𝑑𝑉
𝑑𝑡= 𝜃𝑆 – (1 − )𝑉𝐼 – ( + 𝛾1)𝑉
𝑑𝐼
𝑑𝑡 = 𝑆𝐼 + (1 − )𝑉𝐼 – ( + 𝑟 + )𝐼
𝑑𝑅
𝑑𝑡= 𝛾1𝑉 + (+ 𝑟)𝐼 – 𝑅 }
.
(2)
2.1 Analisis Model Epidemiologi Tipe SVIR
Pada analisis epidemiologi tipe SVIR ditentukan titik ekuilibrium dan the
reproduction ratio dengan vaksinasi. Titik ekuilibrium non-endemik dari persamaan
(2) diperoleh pada waktu laju masing-masing kompartemen sama dengan nol dan
jumlah individu kompartemen terinfeksi sama dengan nol. Titik ekuilibrium non-
endemik dari persamaan (2) adalah (Perko [10])
𝐸0 = (𝑆0, 𝑉0, 𝐼0, 𝑅0) = (
𝜇+,
𝜃
(𝜇+𝜃)(𝜇+𝛾1), 0,
𝛾1𝜃
𝜇(𝜇+𝜃)(𝜇+𝛾1)).
The reproduction ratio vaksinasi persamaan (2) adalah (Liu et al. [8])
ℜ0𝑣 =𝛽
(𝜇+𝜃)(𝜇+𝑟+𝛾)+
(1−𝜎)𝛽𝜃
(𝜇+𝜃)(𝜇+𝛾1)(𝜇+𝑟+𝛾),
dan the reproduction ratio tanpa vaksinasi ( = 0) adalah
ℜ0 =𝛽
𝜇(𝜇+𝑟+𝛾) .
Akibatnya ℜ0𝑣 =𝜇ℜ0
𝜇+𝜃(1 +
(1−𝜎)𝜃
𝜇+𝛾1) ≤ ℜ0, karena 𝜇(𝜇 + 𝛾1 + (1 − 𝜎)) < (𝜇 +
𝜃)(𝜇 + 𝛾1).
Teorema 2.1
Titik ekuilibrium endemik E0 bersifat stabil secara lokal jika ℜ(𝜃) < 1 dan tidak
stabil jika ℜ(𝜃) > 1. BUKTI:
Pelinearan matriks Jacobian model (2) di titik ekuilibrium E0. Matriks Jacobi 𝐽𝐸0
ekuilibrium non-endemik adalah
01
1
0
1
0 0
(1 )0
( )( )
0 0 1 0
0
EJ
r
.
Titik ekuilibrium non-endemik E0 stabil secara lokal jika semua nilai eigen dari
Det(𝐽𝐸0- ) = 0 bernilai real negatif (Perko [10]; Brauer and Castillo-Chavez [2]).
Nilai eigen dari Det(𝐽𝐸0- ) = 0 adalah: 1 < 0 dengan syarat 𝛼 < 𝜇, 2 < 0,
dengan syarat 𝛾1 < 𝜇, 3 = −𝜇 < 0, 4 = ℜ0 − 1, jadi agar semua nilai eigen dari
Det(𝐽𝐸0- ) = 0 adalah negatif ekivalen dengan ℜ0 < 1. Sebaliknya nilai eigen dari

868
Det(𝐽𝐸0- ) = 0, jika yang bernilai real positif jika ℜ0 > 1 dengan kata lain E0 tidak
stabil.
2.2 Kontrol Pengobatan Optimal
Pada persamaan (2) diberikan variabel kontrol U = { u(t) | terbatas
dan terukur
0 ≤ 𝑢(𝑡) ≤ 𝑏 ≤ 1, 𝑡𝜖[0, 𝑡𝑓]}, dimana u(t) adalah kontrol pengobatan per unit
waktu, interpretasi r(1 + u(t)) adalah kontrol terhadap pengobatan dalam upaya
menurunkan jumlah individu kompartemen terinfeksi persatuan waktu, atau
meningkatkan jumlah individu yang sembuh persatuan waktu karena pengobatan.
Persamaan epidemiologi tipe SVIR setelah diberikan kontrol pengobatan (u) pada
individu kompartemen terinfeksi, persamaan (2) menjadi
𝑑𝑆
𝑑𝑡= – 𝑆𝐼 – ( + 𝜃)𝑆
𝑑𝑉
𝑑𝑡= 𝜃𝑆 – (1 − )𝑉𝐼 – ( + 𝛾1)𝑉
𝑑𝐼
𝑑𝑡 = 𝑆𝐼 + (1 − )𝑉𝐼 – ( + 𝑟(1 + 𝑢) + )𝐼
𝑑𝑅
𝑑𝑡= 𝛾1𝑉 + (+ 𝑟(1 + 𝑢))𝐼 – 𝑅 }
.
(3)
Berdasarkan persamaan (3) dengan menggunakan operator Next Generation Matrix
(Driessche and Watmough [4] the reproduction ratio dengan vaksinasi dan kontrol
(ℜ0𝑣𝑢) adalah
ℜ0𝑣𝑢 =𝛽
(𝜇+𝜃)(𝜇+𝑟(1+𝑢)+𝛾)+
(1−𝜎)𝛽𝜃
(𝜇+𝜃)(𝜇+𝛾1)(𝜇+𝑟(1+𝑢)+𝛾) .
Akibatnya ℜ0𝑣𝑢 ≤ ℜ0𝑣 ≤ ℜ0.
Fungsional objektif pada model kontrol pengobatan optimal pada model tipe SVIR
dengan reinfeksi adalah
min 𝐽(𝑢) = ∫ 𝐴𝐼(𝑡) + 𝐶𝑢2(𝑡)𝑑𝑡𝑡𝑓0
,
dimana A adalah bilangan positif sebagai bobot jumlah individu kompartemen
infected, C adalah suatu bobot parameter yang bersesuaian dengan kontrol u(t) dan
tf adalah waktu akhir periode.
Langkah pertama untuk mengkaji model kontrol optimal yaitu mencari
persamaan Lagrangian dan Hamilton dari masalah kontrol optimal. Persamaan
Lagrangian masalah kontrol optimal yaitu:
𝐿(𝐼, 𝑢) = 𝐴𝐼(𝑡) + 𝐶𝑢2(𝑡). (4)
dibentuk fungsional objektif atau integral indeks performance untuk
meminimumkan persamaan Hamilton H dari persamaan (3) dan (4) yaitu:
H(S,V,I,R,u ,1,2,3,4,t)= 𝐴𝐼(𝑡) + 𝐶𝑢2(𝑡) + 1𝑑𝑆(𝑡)
𝑑𝑡+2
𝑑𝑉(𝑡)
𝑑𝑡+
3𝑑𝐼(𝑡)
𝑑𝑡+ 4
𝑑𝑅(𝑡)
𝑑𝑡. (5)
Sebelum menentukan solusi model kontrol optimal, lebih dahulu dikarakterisasi
model kontrol seperti yang dinyatakan dalam Teorema 2.2 berikut.

869
Teorema 2.2
Misalkan S*(t), V*(t), I*(t), R*(t) adalah penyelesaian yang bersesuaian dengan
sistem persamaan (3) dan kontrol optimum 𝑢∗(𝑡) maka terdapat variabel-variabel
adjoint 1, 2, 3, 4 yang memenuhi: 𝑑1
𝑑𝑡= (1 − 2)+ (1 − 3)𝛽𝐼 + 1𝜇
(6) 𝑑2
𝑑𝑡= (2 − 3)(1 − 𝜎)𝛽𝐼 + (2 − 4)𝛾1 + 2𝜇
(7) 𝑑3
𝑑𝑡= −𝐴 + (1 − 3)𝛽𝑆 +
(2 − 3) (1 − 𝜎)𝛽𝑉 + (3 − 4)(𝛾 + 𝑟(1 + 𝑢) + 3𝜇 (8) 𝑑4
𝑑𝑡= 4𝜇,
(9)
dengan syarat batas (transversality)
1(tf) = 2(tf) = 3(tf) = 4(tf) = 0,
(10)
dan kontrol optimum 𝑢∗(𝑡), yaitu
𝑢∗(𝑡) = 𝑚𝑖𝑛 {1,𝑚𝑎𝑘𝑠 {0,(3−4)𝑟𝐼
∗(𝑡)
2𝐶}}
(11)
BUKTI:
Untuk menentukan persamaan adjoint dan syarat batas, digunakan persamaan
Hamiltonian persamaan (5), dengan menggunakan Prinsip Maksimum Pontryagin,
diperoleh persamaan adjoint berikut: 𝑑1
𝑑𝑡= −
𝜕𝐻
𝜕𝑆, 𝑑2
𝑑𝑡= −
𝜕𝐻
𝜕𝑉,𝑑3
𝑑𝑡= −
𝜕𝐻
𝜕𝐼, 𝑑4
𝑑𝑡= −
𝜕𝐻
𝜕𝑅, sehingga diperoleh persamaan
(6)-(9), dengan 1(𝑡𝑓) = 2(𝑡𝑓) = 3(𝑡𝑓) = 4(𝑡𝑓) = 0. Kondisi optimalisasi
bentuk Hamiltonian terhadap kontrol optimal 𝜕𝐻
𝜕𝑢= 2𝐶𝑢∗(𝑡) − 3𝑟𝐼
∗(𝑡) +
4𝑟𝐼∗(𝑡) = 0, sehingga diperoleh 𝑢∗(𝑡) =
(3−4)𝑟𝐼∗(𝑡)
2𝐶, dengan menggunakan sifat
ruang kontrol diperoleh
𝑢∗(𝑡) =
{
0,
(3−4)𝑟𝐼∗(𝑡)
2𝐶 ≤ 1
(3−4)𝑟𝐼∗(𝑡)
2𝐶, 0 <
(3−4)𝑟𝐼∗(𝑡)
2𝐶 < 1
1, (3−4)𝑟𝐼
∗(𝑡)
2𝐶 ≥ 1
,
atau dapat dituliskan dalam bentuk
𝑢∗(𝑡) = 𝑚𝑖𝑛 {1,𝑚𝑎𝑘𝑠 {0,(3−4)𝑟𝐼
∗(𝑡)
2𝐶}}.
Solusi dari fungsi adjoint persamaan (6)-(9) yaitu 1∗(𝑡),2
∗(𝑡), 3∗(𝑡), dan 4
∗(𝑡) dapat diperoleh secara numerik.
2.3 Simulasi Numerik
Langkah pertama penyelesaian kontrol optimal dari persamaan (3) dengan
memasukkan tebakan awal pada kontrol pengobatan u*(t). Kemudian
mensubstitusikan tebakan awal nilai kontrol pada variabel state. Selanjutnya nilai
kontrol dan nilai variabel state disubstitusi ke variabel adjoint dengan kondisi
transversality. Nilai variabel state dan adjoint disubstitusi kembali ke variabel
kontrol, sehingga diperoleh nilai variabel kontrol kedua. Proses ini dilanjutkan
sehingga diperoleh nilai variabel state, adjoint, dan kontrol sampai pada waktu akhir

870
yang ditentukan. Simulasi persamaan state dan adjoint diselesaikan dengan metode
Runge-Kutta orde empat skema maju-mundur dengan menggunakan software
Matlab. Adapun simbol, deskripsi, dan estimasi parameter dan nilai awal yang
digunakan simulasi numerik seperti pada Tabel 1 berikut. Sebagian besar nilai
parameter diambil dari jurnal Agusto [1] dan Liu [8], sebagian lagi diasumsikan.
Jumlah awal masing-masing kompartemen yaitu: S(0) = 150000 , V(0) =
45000, I(0) = 5000, R(0) = 0. Kontrol pengobatan 1 + u(t) yaitu upaya mengurangi
jumlah individu kompartemen terinfeksi dan meningkatkan jumlah individu
kompartemen recovered.
Tabel 1. Simbol, Deskripsi, dan Parameter Model
Simbol Deskripsi Estimasi Referensi
Laju rekruitmen 3500 per
tahun
Asumsi
Laju transmisi infeksi 14 per tahun [1]
Laju kematian alamiah masing-
masing kompartemen
0,01 per tahun [1]
Proporsi vaksinasi 0,3 per tahun [8]
Tingkat efektifitas vaksinasi 0,8 per tahun [8]
Laju recovered alamiah dari
kompartemen I
0,08 per tahun [1]
1 Laju recovered karena efektifitas
vaksinasi
0,4 per tahun [8]
r Laju recovered karena pengobatan 0,6 per tahun [1]
Grafik dinamika dengan pengobatan, kontrol dan tanpa kontrol dapat dilihat
sebagai berikut.
Pada Gambar 2 dapat dilihat bahwa dengan pengobatan dan vaksinasi lebih efektif
menurunkan jumlah individu kompartemen terinfeksi dibandingkan dengan tanpa
vaksinasi, vaksinasi dan tanpa pengobatan lebih efektif menurunkan jumlah
individu kompartemen terinfeksi dibandingkan dengan tanpa vaksinasi dan tanpa
pengobatan.
Gambar 2. Dinamika kompartemen terinfeksi dengan pengobatan dan vaksinasi
0 5 10 15 20 25 300
0.5
1
1.5
2x 10
5
Waktu (Tahun)
Kom
aprt
em
en T
erinfe
ksi
Dengan pengobatan dan vaksinasi
Dengan vaksinasi dan tanpa pengobatan
Tanpa pengobatan dan vaksinasi

871
Pada Gambar 3 dapat dilihat bahwa dengan kontrol pengobatan lebih efektif
menurunkan jumlah individu kompartemen terinfeksi dibandingkan dengan tanpa
kontrol. Gambar 4 dapat dilihat bahwa dengan kontrol pengobatan lebih efektif
meningkatkan jumlah individu kompartemen recovered dibandingkan dengan tanpa
kontrol.
Pada Gambar 5, biaya kontrol pengobatan dengan bobot biaya C = 50 kontrol
pengobatan optimal pada tahun ke 27, untuk bobot biaya C = 100 kontrol pengobatan
Gambar 4. Dinamika kompartemen recovered dengan kontrol dan tanpa kontrol
0 5 10 15 20 25 30-0.5
0
0.5
1
1.5
2
2.5x 10
5
Waktu (Tahun)
Kom
part
em
en R
ecovere
d
Dengan kontrol pengobatan
Tanpa kontrol pengobatan
Gambar 5. Kontrol pengobatan
0 5 10 15 20 25 300
0.2
0.4
0.6
0.8
1
Waktu(Tahun)
Ko
ntr
ol p
en
go
ba
tan
Kontrol u dengan C = 50
Kuntrol u dengan C = 100
Kontrol u dengan C = 150
Gambar 3. Dinamika kompartemen terinfeksi dengan kontrol dan tanpa kontrol
0 5 10 15 20 25 300
2
4
6
8
10
12
14
16x 10
4
Waktu (Tahun)
Kom
part
em
en T
erinfe
ksi
Tanpa kontrol pengobatan
Dengan kontrol pengobatan

872
optimal pada tahun ke 28, dan bobot biaya C = 150 kontrol pengobatan optimal pada
tahun ke 29. Sehingga dari grafik dapat dilihat bahwa, makin besar biaya kontrol
maka makin cepat optimalisasi pengobatannya.
3. Kesimpulan
Berdasarkan dari hasil kajian model transmisi penyebaran suatu penyakit
tipe SVIR diperoleh bahwa:
1. Tindakan pengobatan dan vaksinasi lebih efektif menurunkan jumlah individu
kompartemen terinfeksi dibandingkan dengan tanpa vaksinasi.
2. Tindakan pengobatan lebih efektif menurunkan jumlah individu kompartemen
terinfeksi dibandingkan dengan tanpa pengobatan.
3. Berdasarkan kajian model kontrol pengobatan optimal model transmisi
penyebaran suatu penyakit tipe SVIR diperoleh kontrol pengobatan optimal lebih
efektif menurunkan jumlah individu kompartemen terinfeksi dibandingkan
dengan tanpa kontrol.
Pada pembaca yang tertarik mengembangkan pelitian ini, secara teoritis
masalah penelitian ini dapat dikembangkan pada kontrol optimal pengendalian
penyebaran suatu epidemik dengan dua strain atau tiga strain, dan dapat
diimplementasikan pada pengendalian penyebaran suatu penyakit epidemik,
misalnya tuberkulosis, malaria, HIV/AIDS dan penyakit tropis lainnya.
Referensi
[1] Agusto, F.B., 2009, Optimal Chemoprophylaxis and Treatment Control
Strategies of A Tuberculosis Transmission Model, World Journal of Modelling
and Simulation, 3(5), 163-173.
[2] Brauer F. and Castilllo-Chavez, C., 2000, Mathematical Model in Population
Biology and Epidemiology, Springer.
[3] Castillo-Chavez, C., Feng, Z., dan Huang, W., 2002, On The Computation of
R0 and its Role on Global Stability. Mathematical Approaches for Emerging
and Reemerging Infectious Disease: An Introduction, IMA, Springer-Verlag,
125, 229 - 250.
[4] Driessche, P.v.d., and Watmough, J., 2002, Reproduction Numbers and Sub-
Threshold Endemic Equilibria for Compartmental Models of Disease
Transmission, Mathematical Biosciences 180, 29–48. [5] Hethcote, H.W., 2000, The Mathematics of Infectious Disease. SIAM REVIEW,
42, 599-653.
[6] Kermack, W. O., and McKendrick, A. G., 1927, A Contribution to the
Mathematical Theory of Epidemics, Royal Society, 115, 700-721
[7] Kribs-Zaleta, C. M., Velasco-Hernandez, J. X., 2000, A Simple Vaccination
Model with Multiple Endemic States, Mathematical Biosciences 164,183-201.
[8] Liu, X., Takeuchi, Y. and Iwamin S., 2008, SVIR Epidemic Models with
Vaccination Strategies, Theoretical Biology: 253, 1 – 11.
[9] Neilan, R.M. and Lenhart, S., 2010, An Introduction to Optimal Control with an
Application in Disease Modeling, DIMACS Series in Discrete Mathematics
75,67-81.
[10] Perko, L., 1991, Differential Equation and Dynamical Systems, Springer
Verlag, New York.

873
Prosiding SNM 2017
Pemodelan dan Optimisasi, Hal 873-883
MODEL OPTIMISASI LINEAR INTEGER UNTUK TWO-
STAGE GUILLOTINE CUTTING STOCK PROBLEM
DENGAN METODE BRANCH AND BOUND PADA
INDUSTRI GARMEN
EMAN LESMANA1, JULITA NAHAR2, ANNISA D.P3
1. Departemen Matematika FMIPA Unpad, [email protected]
2. Departemen Matematika FMIPA Unpad , [email protected]
3. Departemen Matematika FMIPA Unpad , [email protected]
Abstrak: Makalah ini membahas tentang Two-Stage Guillotine Cutting Stock Problem
(2GCSP) pada industri garmen, yaitu bagaimana menentukan pola two-stage guillotine yang
digunakan untuk memotong stok kain menjadi beberapa bahan kaos ukuran tertentu yang
diproduksi berdasarkan permintaan setiap ukuran kaos. 2GCSP ini dimodelkan dalam bentuk
Optimisasi Linear Integer dan pencarian solusi menggunakan metode Branch and Bound.
Dalam makalah ini juga disajikan Graphical User Interface dengan software Maple sebagai
alat interaktif untuk menemukan pola pemotongan stok kain terbaik. Hasilnya menunjukkan
bahwa solusi optimal dapat ditentukan dengan penyelesaian secara numerik menggunakan
metode Branch and Bound dan paket optimization pada Maple. Solusi tersebut ditampilkan
dengan ilustrasi pola dan jumlah kain yang dipotong berdasarkan pola tersebut.
Kata kunci : Masalah Cutting Stock Dua Dimensi, Pola Guillotine dua tahap,
Pemrograman Linear Integer, Metode Branch and Bound, Graphical
User Interface
1. Pendahuluan
Industri garmen adalah industri yang memproduksi pakaian jadi dan
perlengkapan pakaian. Salah satu bahan baku yang digunakan pada industri garmen
yaitu kain. Kain tersebut memiliki standar ukuran yang lebih besar daripada ukuran
bahan yang digunakan untuk membuat items pesanan. Oleh karena itu, muncul
masalah pemotongan yang disebut sebagai Two Dimensional Cutting Stock Problem.
Masalah tersebut dapat diklasifikasikan berdasarkan aturan pola pemotongannya,
salah satunya yaitu two-stage guillotine. Terdapat dua tahap untuk menentukan pola
potong two-stage guillotine. Tahap pertama yaitu tentukan pola potong stok kain
hingga membentuk beberapa strip. Tahap kedua yaitu tentukan pola strip tersebut
sehingga membentuk bahan kaos yang dibutuhkan. Masalah 2GCSP ini ditemukan
dalam industri garmen Merch Cons Bandung dalam memproduksi kaos. Industri
tersebut harus memproduksi sejumlah ukuran kaos sesuai permintaan, tetapi dengan
penggunaan stok kain yang minimum. Untuk menyelesaikan masalah tersebut,
2GCSP dapat dimodelkan dalam formulasi Optimisasi Linear Integer dengan fungsi

874
tujuan minimisasi jumlah stok kain yang dipotong. Untuk mempermudah industri
tersebut dalam mencari pola optimal, dibutuhkan aplikasi yang mampu memberikan
solusi tersebut.
Berdasarkan uraian tersebut, maka persoalan yang dibahas dalam penelitian
ini adalah bagaimana 2GCSP pada industri garmen dapat dinyatakan sebagai
masalah Optimisasi Linear Integer. Kemudian bagaimana solusi optimal 2GCSP
dengan menggunakan metode Branch and Bound pada studi kasus di industri garmen
Merch Cons Bandung. Terakhir yaitu bagaimana Graphical User Interface (GUI)
pencari pola memberikan pendahuluan (latar belakang, tujuan, sistematika) dari
makalah anda.
2. Tinjauan Pustaka
2.1 Metode Branch and Bound
1. Tahap inisialisasi
Untuk fungsi objektif maksimisasi, tetapkan 𝑍∗ = −∞. Sedangkan untuk
fungsi objektif minimisasi, tetapkan 𝑍∗ = ∞.
2. Tahap iterasi
a. Branching (percabangan)
Misal 𝑥𝑗 adalah variabel keputusan yang bernilai noninteger, 𝑥𝑗 = 𝑟𝑗, 𝑟𝑗 ∈ ℝ.
Bentuk dua subproblem dengan penambahan kendala 𝑥𝑗 ≤ ⌊𝑟𝑗⌋ untuk
subproblem pertama dan 𝑥𝑗 ≥ ⌊𝑟𝑗⌋ + 1 untuk subproblem kedua pada model
pemrograman integer linear awal. Menurut John W. Chinneck (2010),
terdapat beberapa aturan pemilihan subproblem yang akan dicabangkan,
diantaranya yaitu:
Best-first atau global-best: pilih subproblem yang memiliki batas
terbaik dari subproblem manapun. Untuk masalah minimisasi, pilih
subproblem dengan batas terkecil. Untuk masalah maksimisasi, pilih
subproblem dengan batas terbesar.
Depth-first: pilih subproblem yang memiliki batas terbaik dari
subproblem yang baru dicabangkan. Jika tidak ada subproblem yang
bisa dicabangkan pada level tersebut, kembali satu level dan lakukan
percabangan pada subproblem yang belum dicabangkan.
Breadth-first: cabangkan subproblem sesuai urutan dalam satu level.
b. Bounding (pembatasan)
Lakukan pembulatakan kebawah pada nilai fungsi tujuan (𝑍) untuk masalah
maksimisasi. Sebaliknya, lakukan pembulatan keatas pada nilai fungsi
tujuan untuk masalah minimisasi.
c. Fathoming (penghilangan)
Untuk setiap subproblem baru, terapkan uji fathoming sebagai berikut.
Uji 1 : Pada masalah maksimisasi, fathom jika batasnya ≤ 𝑍∗. Sedangkan pada masalah minimisasi, fathom jika batasnya ≥ 𝑍∗. 𝑍∗ adalah nilai 𝑍 incumbent saat ini.
Uji 2 : Fathom jika PL relaksasi tidak memiliki solusi yang layak.
Uji 3 : Fathom jika solusi optimal untuk PL relaksasinya adalah bilangan
bulat. Apabila solusi ini lebih baik dari pada incumbent, maka
solusi ini menjadi incumbent baru dan uji 1 diterapkan kembali

875
pada subproblem yang tidak dihilangkan dengan 𝑍∗ baru.
3. Uji Optimalitas
Berhenti jika tidak ada lagi subproblem yang tersisa. Incumbent (calon solusi
optimal) yang berlaku adalah optimal. Jika tidak, kembali lakukan iterasi
selanjutnya.
2.2 Two-Stage Guillotine Cutting Stock Problem (2GCSP)
Two-Stage Gullotine Cutting Stock Problem (2GCSP) adalah permasalahan
yang muncul dalam industri ketika barang-barang berbentuk persegi atau persegi
panjang harus dipotong dari bahan baku dengan aturan pola potong guillotine dua
tahap (M Mrad, et al., [7]). Klasifikasi pemotongan bentuk items pada 2GCSP adalah
bentuk regular. Pola guillotine merupakan pola pemotongan yang dimulai dari satu
sisi bahan baku yang kemudian dilanjutkan pada sisi lainnya. Pada masalah ini,
terdapat dua tahap dalam menentukan pola pemotongan. Tahap pertama, tentukan
pola potong dimana pemotongan tersebut dilakukan berdasarkan lebar items atau
panjang items pada bahan baku, sehingga menghasilkan beberapa strip. Tahap kedua
adalah pemotongan satu persatu bagian strip sesuai ukuran items yang diminta.
Gambar 2.1 Pola Two-Stage Guillotine Berdasarkan Lebar Items
Gambar 2.2 Pola Two-Stage Guillotine Berdasarkan Panjang Items
3. Hasil – Hasil Utama
3.1 Model Optimisasi Linear Integer 2GCSP pada Industri Garmen
Asumsi-asumsi pada model ini adalah :
1. Stok kain dan bahan kaos berbentuk persegi panjang.
2. Pola pemotongan sesuai dengan pola two-stage guillotine dengan ketentuan
pola berdasarkan lebar bahan kaos, panjang bahan kaos, dan tanpa rotasi.
3. Pola pemotongan optimal hanya dipengaruhi oleh banyaknya permintaan setiap
ukuran kaos, faktor lain tidak diperhitungkan, misal harga stok kain atau harga
jual kaos.
4. Pembentukan pola potong stok kain berdasarkan lebar bahan kaos pada
tahap pertama dimulai dari strip dengan lebar bahan kaos terbesar yang ada
dalam pola stok kain tersebut. Sedangkan pembentukan pola potong stok
kain berdasarkan panjang bahan kaos pada tahap pertama dimulai dari strip

876
dengan panjang bahan kaos terbesar yang ada dalam pola stok kain tersebut.
5. Pembentukan pola potong strip berdasarkan lebar bahan kaos pada tahap
kedua dimulai dari bahan kaos dengan lebar terbesar yang ada dalam pola
strip tersebut dan lebar bahan kaos tersebut kurang dari atau sama dengan
lebar strip. Sedangkan pembentukan pola potong strip berdasarkan panjang
bahan kaos pada tahap kedua dimulai dari bahan kaos dengan panjang
terbesar yang ada dalam pola strip tersebut dan panjang bahan kaos tersebut
kurang dari atau sama dengan panjang strip.
6. Pada pola potong strip tahap kedua minimal terdapat satu bahan kaos yang
memiliki lebar yang sama dengan lebar strip untuk pola potong berdasarkan
lebar bahan kaos dan minimal terdapat satu bahan kaos yang memiliki
panjang yang sama dengan panjang strip untuk pola potong berdasarkan
panjang bahan kaos.
7. Hasil potong (bahan kaos) boleh lebih dari permintaan.
Tabel 3.1 Parameter untuk Model 2GCSP pada Industri Garmen
No Notasi Keterangan
1 𝑚𝑙 banyaknya lebar bahan kaos yang berbeda
2 𝑚𝑝 banyaknya panjang bahan kaos yang berbeda
3 𝑙(𝑖) lebar bahan kaos terkecil ke-𝑖 (𝑖 = 1, … ,𝑚𝑙)
4 𝑝(𝑖)
panjang bahan kaos terkecil ke-𝑖 (𝑖 = 1, … ,𝑚𝑝)
5 𝜋𝑙 banyaknya pola potong stok kain berdasarkan lebar bahan kaos
6 𝜋𝑝 banyaknya pola potong stok kain berdasarkan panjang bahan kaos
7 𝜌𝑖𝑙
banyaknya pola strip dengan lebar 𝑙(𝑖) (𝑖 = 1, … , 𝑚𝑙) dan panjang 𝑃 yang
dipotong menjadi persegi panjang sesuai ukuran bahan kaos yang diminta
8 𝜌𝑖𝑝
banyaknya pola strip dengan panjang 𝑝(𝑖) (𝑖 = 1, … ,𝑚𝑝) dan lebar 𝐿 yang
dipotong menjadi persegi panjang sesuai ukuran bahan kaos yang diminta
9 𝑎𝑖𝑗𝑙
banyaknya strip dengan lebar 𝑙(𝑖) pada pola potong stok kain ke-𝑗, 𝑖 =
1,… ,𝑚𝑙, 𝑗 = 1,… , 𝜋𝑙
10 𝑎𝑖𝑗𝑝
banyaknya strip dengan panjang 𝑝(𝑖) pada pola potong stok kain ke-𝑗, 𝑖 =
1,… ,𝑚𝑝, 𝑗 = 1,… , 𝜋𝑝
11 𝑏𝑠𝑖𝑘𝑙
banyaknya bahan kaos tipe s yang termasuk dalam pola strip ke-𝑘 dengan
lebar 𝑙(𝑖), 𝑠 ∈ ℕ: 𝑙𝑠 ≤ 𝑙(𝑖), 𝑘 = 1, … , 𝜌𝑖𝑙, 𝑖 = 1, … ,𝑚𝑙
12 𝑏𝑠𝑖𝑘𝑝
banyaknya bahan kaos tipe s yang termasuk dalam pola strip ke-𝑘 dengan
panjang 𝑝(𝑖), 𝑠 ∈ ℕ: 𝑝𝑠 ≤ 𝑝(𝑖), 𝑘 = 1, … , 𝜌𝑖𝑝, 𝑖 = 1, … , 𝑚𝑝
Tabel 3.2 Variabel untuk Model 2GCSP pada Industri Garmen
No Notasi Keterangan
1 𝑥𝑗𝑙
banyaknya pola stok kain berdasarkan lebar bahan kaos ke-𝑗 yang
dipotong pada tahap pertama, 𝑗 = 1,… , 𝜋𝑙
2 𝑥𝑗𝑝
banyaknya pola stok kain berdasarkan panjang bahan kaos ke-𝑗 yang
dipotong pada tahap pertama, 𝑗 = 1,… , 𝜋𝑝
3 𝑦𝑖𝑘𝑙
banyaknya pola strip ke-𝑘 dengan lebar 𝑙(𝑖) dan panjang 𝑃 yang
dipotong pada tahap kedua, 𝑘 = 1,… , 𝜌𝑖𝑙 , 𝑖 = 1, … ,𝑚𝑙
4 𝑦𝑖𝑘
𝑝
banyaknya pola strip ke-𝑘 dengan panjang 𝑃(𝑖) dan lebar 𝐿 yang
dipotong pada tahap kedua, 𝑘 = 1,… , 𝜌𝑖𝑝, 𝑖 = 1, … ,𝑚𝑝

877
Menurut Mrad, Meftahi, dan Haouari [7], jumlah total strip dengan lebar 𝑙(𝑖) pada
pola stok kain yang dipotong pada tahap pertama lebih besar atau sama dengan jumlah total
pola strip dengan lebar 𝑙(𝑖) dan panjang 𝑃 yang dipotong pada tahap kedua, sehingga:
1 1
, 1,...,
lli
l l l l
ij j ik
j k
a x y i m
(3.1)
Kemudian jumlah total strip dengan panjang 𝑝(𝑖) pada pola stok kain yang dipotong
pada tahap pertama lebih besar atau sama dengan jumlah total pola strip dengan panjang 𝑝(𝑖)
dan lebar 𝐿 yang dipotong pada tahap kedua, sehingga:
1 1
, 1,...,
ppi
p p p p
ij j ik
j k
a x y i m
(3.2)
Karena strip yang dipotong pada tahap kedua harus dapat memproduksi bahan kaos
sesuai dengan permintaan dan diizinkan lebih dari permintaan, maka jumlah total produksi
bahan kaos tipe 𝑠 lebih besar atau sama dengan permintaan sehingga:
, 1 1
, 1,...,
ttim
t t
sik ik s
t l p i k
b y d s m
(3.3)
Kemudian, setiap variabel keputusan merupakan variabel nonnegatif dan merupakan
bilangan bulat, maka dapat dituliskan:
0, 1,..., , ,
0, 1,..., , 1,..., , ,, integer
t t
jt t t
ik i
x j t l p
y k i m t l px y
(3.4)
Karena tujuan utama dari model ini adalah untuk meminimumkan jumlah stok kain
yang digunakan, maka fungsi tujuannya yaitu meminimumkan jumlah pola potong stok kain
pada tahap pertama berdasarkan lebar kaos dan panjang kaos. Sehingga dapat dirumuskan
sebagai berikut :
, 1
t
t
j
t l p j
Minimize x
(3.5)
3.2 Studi Kasus
3.2.1 Pengolahan Data
Data permintaan produksi kaos pada industri garmen Merch Cons Bandung dapat
dilihat pada Tabel 3.3.
Tabel 3.3 Permintaan Kaos ukuran S, M, L, dan XL
Ukuran Kaos Permintaan (buah)
S 24
M 24
L 36
XL 24
Bahan baku yang digunakan untuk memproduksi kaos tersebut yaitu kain katun
combed 20s dengan panjang 200 cm dan lebar 100 cm. Standar ukuran bahan kaos yang
digunakan di Merch Cons yaitu standar ukuran internasional USA dengan rincian ukuran
setiap kaosnya yaitu dalam Tabel 3.4.

878
Tabel 3.4 Standar Ukuran Internasional USA untuk Bahan Kaos
Ukuran
Kaos
Panjang Bahan
Bagian Badan
(cm)
Lebar Bahan
Bagian Badan
(cm)
Panjang Bahan
Bagian Lengan
(cm)
Lebar Bahan
Bagian Lengan
(cm)
S 70 46 43 22 M 72 51 48 24.5 L 75 56 52.5 25
XL 77 61 57.5 28 Untuk membuat satu buah kaos dibutuhkan dua lembar bahan bagian badan, yaitu
bagian depan dan belakang kaos sehingga kebutuhan bahan untuk membuat setiap ukuran
kaos dapat dilihat pada Tabel 3.5.
Tabel 3.5 Permintaan Setiap Bahan
Bahan Permintaan (Lembar)
Bahan bagian lengan ukuran S (𝑆𝑙) 48
Bahan bagian lengan ukuran M (𝑀𝑙) 48
Bahan bagian lengan ukuran L (𝐿𝑙) 72
Bahan bagian lengan ukuran XL (𝑋𝐿𝑙) 48
Bahan bagian badan ukuran S (𝑆𝑏) 48
Bahan bagian badan ukuran M (𝑀𝑏) 48
Bahan bagian badan ukuran L (𝐿𝑏) 72
Bahan bagian badan ukuran XL (𝑋𝐿𝑏) 48
3.2.2 Penyelesaian Masalah
Pertama, tentukan semua pola pemotongan tahap pertama dan tahap kedua yang
mungkin. Berikut ilustrasi pola pemotongan tahap pertama dan tahap kedua berdasarkan
lebar bahan kaos dan panjang bahan kaos.
Gambar 3.1 Ilustrasi Pola Tahap Pertama Berdasarkan Lebar Kaos dan Panjang Kaos
Gambar 3.2 Ilustrasi Pola Tahap Kedua Berdasarkan Lebar Kaos dan Panjang Kaos
Dengan menentukan pola tersebut, dapat ditentukan nilai-nilai dari
parameter sehingga masalah 2GCSP pada industri garmen Merch Cons Bandung
dapat dinyatakan dalam model Optimisasi Linear Integer.
Kemudian, berikut langkah-langkah untuk mencari solusi model Optimisasi
Linear Integer dengan software Maple berdasarkan metode Branch and Bound:
1. Ketik restart untuk menghapus data yang telah di-input sebelumnya seperti
berikut >
2. Gunakan paket optimization dan linalg pada worksheet dengan cara ketik: >
>

879
3. Bentuk matriks pola pemotongan tahap pertama berdasarkan lebar bahan
kaos ([𝑎𝑖𝑗𝑙 ]) dimana setiap elemennya merupakan koefisien kendala 1-8
dengan syntax berikut.
matrix([[𝑎11𝑙 , … , 𝑎1𝑗
𝑙 ],… , [𝑎81𝑙 , … , 𝑎8𝑗
𝑙 ]])
4. Bentuk matriks pola pemotongan tahap pertama berdasarkan panjang bahan
kaos ([𝑎𝑖𝑗𝑝]) dimana setiap elemennya merupakan koefisien kendala 9-16
dengan syntax berikut.
matrix([[𝑎11𝑝, … , 𝑎1𝑗
𝑝],… , [𝑎81
𝑝, … , 𝑎8𝑗
𝑝]])
5. Bentuk matriks koefisien kendala 17-24 berdasarkan pola pemotongan tahap
kedua dengan syntax berikut.
matrix
([[𝑏1,1,1𝑙 , … , 𝑏1,8,18
𝑙 , 𝑏1,1,1𝑝
, … , 𝑏1,8,4𝑝
],… , [𝑏8,1,1𝑙 , … , 𝑏8,8,18
𝑙 , 𝑏8,1,1𝑝
, … , 𝑏8,8,4𝑝
]])
6. Bentuk matriks 𝐘 sebagai variabel kendala 17-24 seperti berikut.
7. Buat fungsi ruas kiri kendala dengan menggunakan for seperti berikut.
>
>
>
8. Buat fungsi ruas kanan kendala seperti berikut.

880
9. Untuk tahap inisialisasi, set 𝑍1 = ∞ dan tentukan solusi dari LP relaksasi dengan
syntax berikut.
10. Untuk tahap iterasi lakukan sesuai algoritma Branch and Bound, selesaikan LP
relaksasi di setiap subproblem dengan menambahkan kendala yang baru pada syntax
solusi di poin 9.
Berikut solusi yang dapat diberikan untuk industri garmen Merch Cons Bandung
menggunakan metode Branch and Bound dengan aturan pemilihan variabel yaitu urutan
natural yang memiliki nilai noninteger dan aturan pemilihan subproblem yaitu Depth First
Selection (DFS).
Ilustrasi Pola Pemotonga Stok
Kain
Jumlah
(Lembar)
Ilustrasi Pola Pemotonga Stok
Kain
Jumlah
(Lembar)
24
2
30
1
3
14

881
8
2
Jadi, banyaknya bahan kaos yang dihasilkan dengan pola potong tersebut
diberikan dalam Tabel 3.6.
Tabel 3.6 Banyaknya Bahan Kaos yang Dihasilkan
Bahan Persediaan (Lembar)
Bahan bagian lengan ukuran S (𝑆𝑙) 48
Bahan bagian lengan ukuran M (𝑀𝑙) 48
Bahan bagian lengan ukuran L (𝐿𝑙) 72
Bahan bagian lengan ukuran XL (𝑋𝐿𝑙) 48
Bahan bagian badan ukuran S (𝑆𝑏) 48
Bahan bagian badan ukuran M (𝑀𝑏) 48
Bahan bagian badan ukuran L (𝐿𝑏) 72
Bahan bagian badan ukuran XL (𝑋𝐿𝑏) 48
3.3 GUI Pencari Pola Pemotongan Optimum pada Stok Kain
Pada GUI yang dibuat terdapat 2 pilihan input. Pertama yaitu input data
permintaan ukuran kaos dan yang kedua yaitu input data permintaan bahan kaos
seperti pada Gambar 3.3.
Gambar 3.3 Jendela Input
Misal masukkan data permintaan ukuran kaos pada industri Garmen Merch Cons
Bandung. Kemudian setelah klik solusi, hasil jumlah banyaknya stok kain yang
digunakan akan muncul dalam textbox. Rincian pola tahap pertama dan tahap kedua
dapat dilihat pada file Microsoft Excel seperti berikut.

882
Gambar 3.4 Rincian Pola Tahap Pertama dan Tahap Kedua pada Microsoft Excel
4. KESIMPULAN
Two-Stage Guillotine Cutting Stock Problem (2GCSP) pada industri garmen
dapat dinyatakan dalam model Optimisasi Linear Integer dengan fungsi
tujuannya yaitu meminimumkan jumlah stok kain yang dipotong dan
kendala yaitu aturan pola pemotongan berdasarkan lebar kaos, aturan pola
pemotongan berdasarkan panjang kaos, dan aturan pola tahap kedua
berdasarkan permintaan kaos.
Solusi optimal 2GCSP pada studi kasus di industri garmen Merch Cons

883
Bandung dapat ditentukan dengan menggunakan metode Branch and Bound.
Metode tersebut memberikan solusi yang bernilai integer pada setiap
variabel keputusan. Solusi tersebut merupakan pola pemotongan stok kain
pada tahap pertama dan tahap kedua yang optimal dimana pola pemotongan
stok kain tersebut dapat memenuhi permintaan setiap ukuran kaos.
Graphical User Interface (GUI) untuk mencari pola pemotongan optimal
dapat dibuat menggunakan software Maple. GUI tersebut digunakan sebagai
alat interaktif untuk pengguna dalam menginput data permintaan produksi
kaos pada industri garmen. Hasilnya berupa pola pemotongan tahap satu dan
tahap dua yang optimal dalam file Microsoft Excel. Hasil tersebut
merupakan solusi dari model Optimisasi Linear Integer 2GCSP yang sudah
dibuat berdasarkan paket Optimization pada software Maple.
Referensi
[1] Chinneck, John W. 2010. Practical Optimization: a Gentle Introduction.
(lms.ipb.ac.id/file.php/307/Integer_Programming_Via_Branch_and_Bound
.pdf, diakses 27 Desember 2016).
[2] Clausen, Jens. 1999. Branch and Bound Algorithms – Principles and Examples.
Denmark: University of Copenhagen.
[3] Gilmore, P.C., & Gomory, R.E. 1961. A Linear Programming Approach to The
Cutting Stock Problem. Journal of Operations Research 9:849-859.
[4] Gilmore, P.C., & Gomory, R.E. 1965. Multistage Cutting Stock Problems of Two
and More Dimensions. Journal of Operations Research 13:94-120.
[5] Hillier, F.S., & Lieberman, G.J. 2001. Introduction to Operation Research,
Seventh Edition. New York: The McGraw-Hill.
[6] Lodi, Andrea, & Monaci, Michele. 2003. Integer Linear Programming Models
for The 2-Staged Two-Dimensional Knapsack Problems. Math. Program., Ser
B 94:257-278.
[7] Mrad, M., Meftahi, I., & Haouari, M. 2012. A Branch-and-Price Algorithm for
The Two-Stage Guillotine Cutting Stock Problem. Journal of the Operational
Research Society 1-9.
[8] Parlar, Mahmut. 2000. Interactive Operations Research with Maple: Methods
and Models. Boston: Birkhauser.
[9] Rao, S.S. 2009. Engineering Optimization: Theory and Practice, Forth Edition.
New Jersey: John Wiley & Sons, Inc.
[10] Taha, Hamdy A. 2007. Operations Research: an Introdaction. New Jersey:
Pearson Education, Inc.

884
Prosiding SNM 2017
Pemodelan dan Optimisasi, Hal 884-892
PENERAPAN OPTIMASI MULTI RESPON DENGAN
METODE TAGUCHI FUZZY LOGIC
SRI WINARNI1, BUDHI HANDOKO2, YENY KRISTA FRANTY3
1, 2, 3. Departemen Statistika FMIPA UNPAD,
[email protected], [email protected]
Abstrak. Optimasi multi respon merupakan proses optimasi dengan
mempertimbangkan beberapa respon secara simultan. Tujuan dari penelitian ini
adalah mendapatkan titik optimum pada proses optimasi multi respon
menggunakan metode taguchi fuzzy logic. Titik optimum ditentukan dari
variabel Multi Performance Characteristics Index (MPCI) yang merupakan
konversi dari nilai Signal to Noise Ratio respon-respon yang terlibat. Contoh
kasus yang digunakan dalam penelitian ini adalah kasus optimasi karakteristik
kualitas lead-slag perisai radiasi beton dengan mempertimbangkan beberapa
karakteristik kualiatas yang diukur. Hasil optimasi didapatkan faktor rasio
air/semen 0,42, kuantitas semen 390kg, fraksi valume 60% dan rasio semen
0,15.
Kata kunci: Optimasi Multi Respon, Taguchi Fuzzy Logic.
1. Pendahuluan
Optimasi respon merupakan upaya mendapatkan kombinasi perlakuan yang
menghasilkan respon optimum. Pada bidang industri, optimasi respon seringkali
digunakan untuk mendapatkan desain produk yang optimum. Desain taguchi
merupakan desain yang umum digunakan untuk mendapatkan desain produk yang
robust (kokoh). Optimasi respon dapat dilakukan dengan pendekatan single respon
dan pendekatan multi respon, Monthgomery [4].
Pendekatan optimasi single respon dilakukan ketika optimasi hanya satu
respon saja yang dipertimbangkan dalam proses optimasi. Titik optimum yang
didapatkan berupa kombinasi perlakuan yang mengoptimumkan respon tersebut,
Mohan and Paul [7]. Pendekatan optimasi single respon digunakan jika kualitas
produk yang dihasilkan hanya dipertimbangkan dari satu karateriktik produk saja.
Ketika kualiatas produk tidak hanya mempertimbangkan satu karakteristik produk
maka pendekatan optimasi yang digunakan adalah optimasi multi respon. Jika yang
digunakan adalah pendekatan optimasi single respon maka titik optimum yang
didapat belum tentu merupakan titik optimum secara simultan Monthgomery [4].
Skema analisis optimasi respon diberikan pada Gambar 1.

885
Gambar 1. Skema Analisis Optimasi Respon pada Desain Taguchi
Pada skema Gambar 1. Metode analisis yang dapat digunakan pada
pendekatan single respon adalah metode Signal to Noise Ratio (SNR) dan metode
response surface. Analisis pada metode SNR relatif mudah, sehingga metode ini
merupakan metode yang paling umum digunakan untuk optimasi single respon.
Sedangkan metode response surface digunaan ketika faktor yang digunakan adalah
faktor kuantitatif. Pada pendekatan optimasi multi respon terdapat beberapa metode
analisis yang digunakan. Multiple SNR merupakan pengembangan dari metode
SNR. Metode overlaid surface plot dan desirability function merupakan
pengembangan dari metode response surface. Metode lain yang dapat digunakan
pada optimasi multi respon adalah metode grey relational analysis, principal
component analysis, TOPSIS dan fuzzy logic, Bahloul [8].
Penelitian ini akan dilakukan pengembangan analisis optimasi multi respon
menggunakan metode taguchi fuzzy logic. Tujuan dari penelitian ini adalah
mendapatkan titik optimum pada kasus optimasi multi respon desain taguchi
menggunakan metode taguchi fuzzy logic.
2. Bahan dan Metode
Contoh kasus yang digunakan dalam penelitian ini adalah kasus optimasi pada
Electrical Discharge Machining (EDM), Mohan & Paul [7]. Ilustrasi kasus beserta
faktor dan respon percobaan diberikan pada Gambar 2.
Gambar 2. Kasus Optimasi EDM

886
Faktor percobaan yang digunakan pada kasus ini adalah faktor gap voltage,
peak current dan duty factor. Masing-masing faktor dilakukan pada tiga taraf seperti
yang diberikan pada Gambar 2. Performance mesin diukur dari respon percobaan
Material Removal Rate (MRR) dan Surface Roughness (SR). Kedua respon ini akan
dipertimbangkan secara simultan sehingga didapatkan komposisi perlakuan yang
menghasilkan MRR dan SR yang optimum. Desain eksperimen yang digunakan
pada kasus ini adalah desain taguchi L9. Data percobaan diberikan pada Tabel 1.
Tabel 1. Data Percobaan Kasus Optimasi EDM dengan Desain Taguchi L9
Desain taguchi L9 merupakan desain ortoghonal array dengan 9 kombinasi
perlakuan. Kombinasi perlakuan A1B1C1 artinya perlakuan dengan gap voltage
40V, peak current 9 A, dan duty factor 0.4. Respon MRR dan SR merupakan
parameter dari EDM.
Metode analisis yang digunakan dalam penelitian ini adalah metode taguchi
fuzzy logic. Tahapan analisis diberikan pada Gambar 3.
Gambar 3. Tahapan Analisis Metode Taguchi Fuzzy Logic
Metode taguchi fuzzy logic merupakan kombinasi dari metode SNR dan
fuzzy logic. Tahapan analisis dimulai dari desain orthogonal array yang merupakan
input dari fuzzy logic. Tahapan analisis fuzzy logic terdiri dari tiga tahapan yaitu
fuzzifier, fuzzy inference engine, dan defuzzifier, Liu, et.all [3]. Output dari analisis
fuzzy logic berupa Multi Performance Characteristics Index (MPCI). Titik
optimum ditentukan dari pengaruh faktor dengan nilai MPCI tertinggi.
Tahapan analisis selengkapnya dapat dijelaskan sebagai berikut :

887
1. Menghitung nilai SNR dan normalisasinya
Pada metode fuzzy logic, respon percobaan akan masuk sebagai variabel input
pada proses fuzzy, dalam kasus penelitian ini MRR dan SR. Perhitungan nilai
SNR terbagi menjadi tiga kriteria: Husain, et.all [9] .
a. Larger the better
SNR larger the better digunakan ketika tujuan optimasi respon adalah
yang terbesar yang terbaik (memaksimumkan respon). Formula SNR
untuk larger the better diberikan pada Persamaan 1. dengan 𝑖𝑗 adalah
nilai SNR respon ke-i perlakuan ke-j, dan yij adalah nilai respon ke-i
perlakuan ke-j.
................................. (1)
b. Smaller the better
SNR smaller the better digunakan ketika tujuan optimasi respon adalah
yang terkecil yang terbaik (meminimumkan respon). Formula SNR
smaller the better diberikan pada Persamaan 2.
................................. (2)
c. Nominal is the best
SNR nominal is the best digunakan ketika tujuan optimasi respon adalah
pada nilai target tertentu.
Nilai SNR selanjutnya dinormalisasi, formula untuk menormalisasi SNR dengan
kriteria larger the better diberikan pada Persamaan 3. Anand & Vijay [5]
𝑖𝑗∗ =
𝑖𝑗 −min𝑖𝑗
max𝑖𝑗 −min𝑖𝑗
................................. (3)
dengan 𝑖𝑗∗ adalah nilai normalisasi SNR respon ke-i perlakuan ke-j. min𝑖𝑗 adalah
nilai dari 𝑖𝑗 dan maks 𝑖𝑗 adalah nilai maksimum dari 𝑖𝑗. Normalisasi SNR
dengan kriteria smaller the better diberikan pada persamaan 4.
𝑖𝑗∗ =
maks 𝑖𝑗 − 𝑖𝑗
max𝑖𝑗 −min𝑖𝑗
................................. (4)
Nilai normalisasi SNR dijadikan sebagai input pada proses fuzzy
2. Fuzzy logic
Analisis fuzzy logic terbagi menjadi tahap fuzzifier, inference fuzzy engine, defuzzifier. Pada
tahap fuzzifier, dilakukan konversi variabel linguistik menjadi variabel fuzzy. Masuk pada
tahap inference fuzzy engine, dibentuk aturan-aturan fuzzy (fuzzy rules) yang berbasis pada
aturan “IF and THEN”. Untuk dua variabel input dan satu variabel output, fuzzy rule dapat
dibentuk sebagai berikut : Pandey & Dubay [1]
Rule 1 : if x1 is A1 and x2 is B2 then y is C1 else,

888
Rule 2 : if x1 is A2 and x2 is B2 then y is C2 else,
Rule 3 : if x1 is A3 and x2 is B3 then y is C3 else,
.
.
.
Rule n : if x1 is An and x2 is Bn then y is Cn else.
Variabel Ai , Bi , dan Ci merupakan fuzzy subset yang menghubungkan variabel
input normalisasi MRR, normalisasi SR dan variabel output MPCI. Pada penelitian ini
variabel input dibentuk dalam tiga subset, yaitu low (L), medium (M), dan Hight (H).
Sedangkan variabel output dibentuk dalam lima subset, yaitu very small (VS), small (S),
medium (M), large (L) dan very large (VL). dengan fuzzy set variabel input dan output
dapat terbentuk fuzzy rule yang diberikan pada Tabel 2. Bahloul [8]
Tabel 2. Fuzzy Rule
Normalisasi SR Normalisasi MRR
Low Medium Hight
Low Very Small Small Medium
Medium Small Medium Large
Hight Medium Large Very Large
Tabel 2. Menunjukkan jika normalisasi MRR low dan normalisasi SR low maka
MPCI very small, jika normalisasi MRR medium dan normalisasi SR low maka MPCI
small, begitu seterusnya. Aturan ini dapat disimulasikan dengan operator mamdani sebagai
berikut : Anand & Vijay, [5]
𝜇𝐶0(𝑦) = (𝜇𝐴1(𝑥1) 𝜇𝐵1(𝑥2))(𝜇𝐴2(𝑥1) 𝜇𝐵2(𝑥2))…(𝜇𝐴𝑛(𝑥1) 𝜇𝐵𝑛(𝑥2))
Dengan adalah operator minimum dan adalah operator maksimum. Selanjutnya adalah
tahap defuzzifier, yaitu mentransformasi variabel fuzzy output menjadi variabel non fuzzy
MPCI, Ramaiah [9]. Transformasi tersebut menggunakan persamaan berikut :
𝑦0 =∑𝑦𝜇𝐶0(𝑦)
∑𝜇𝐶0(𝑦)
Variabel non fuzzy MPCI digunakan untuk menentukan titik optimum.
3. Penentuan titik optimum
Titik optimum ditentukan dari pengaruh faktor utama MPCI yang terbesar. Penentuan
pengaruh faktor utama menggunakan plot pengaruh utama, Bahloul [8].
3. Hasil dan Pembahasan
1. Hasil normalisasi SNR MRR dan SR
Pada kasus EDM dalam penelitian ini optimasi mempertimbangkan respon MRR
dengan kriteria larger the better dan respon SR dengan kriteria smaller the better. Hasil
SNR dan normalisasinya diberikan pada Tabel 3.

889
Tabel 3. SNR dan normalisasi SNR untuk respon MRR dan SR
Perlakuan Respon SNR SNR*
MRR SR MRR SR MRR* SR*
1 4.74 3.26
13.516 -10.264
0.000 1.000
2 8.60 6.98
18.690 -16.877
0.502 0.408
3 9.51 11.78
19.564 -21.423
0.587 0.000
4 7.46 4.58
17.455 -13.217
0.383 0.736
5 12.80 9.62
22.144 -19.663
0.838 0.159
6 8.38 6.99
18.469 -16.889
0.481 0.407
7 15.51 6.53
23.812 -16.298
1.000 0.460
8 10.90 4.82
20.748 -13.661
0.702 0.696
9 13.36 8.98 22.516 -19.065 0.874 0.213
Nilai SNR respon MRR dan S diperoleh dari Persamaan 1 dan Persamaan 2.
Normalisasi SNR dilakukan dengan Persamaan 3 dan 4. Nilai normalisasi berada pada
selang nilai 0 sampai 1. Nilai normalisasi SNR yang mendekati 1 menunjukkan bahwa nilai
respon tersebut mendekati target. Pada MRR dengan kriteria larger the better nilai respon
yang besar akan menhasilkan normalisasi SNR yang mendekati 1. Sedangkan untuk respon
SR dengan kriteria smaller the better nilai normalisasi SNR yang mendekati 1 adalah nilai
respon yang kecil. Sebaliknya untuk hasil normalisasi yang mendekati 0 adalah MRR yang
bernilai kecil dan SR yang bernilai besar.
2. Hasil analisis fuzzy logic
Pada penelitian ini analisisis fuzzy logic dilakukan denga bantuan software matlab. Tahap
awal adalah pendefinisian variabel input dan output yang diberikan pada Gambar 4.

890
Gambar 4. Input dan Output fuzzy logic
Variabel input yang digunakan adalah normalisasi SNR untuk MRR dan SR,
sedangkan outputnya adalah MPCI. Pembentuakan variabel fuzzy diberikan pada Gambar
5.
Gambar 5. Variabel fuzzy untuk input dan output
Variabel fuzzy untuk normalisasi MRR dan normalisasi SR terbagi dalam tiga
subset; low (L), medium (M) dan hight (H). Sedangkan untuk variabel fuzzy output MPCI
terbagi dalam lima subset; very small (VS), small (S), medium (M), large (L) dan very large
(VL). Fuzzy rule pada tahap inference fuzzy engine dan tahap defuzzifier diberikan pada
Gambar 6.

891
Gambar 6. Fuzzy rule dan tahap defuzzifier
Pada tahap inference fuzzy engine terdapat sembilan fuzzy rule yang terbentuk.
Rule tersebut mentransformasi variabel fuzzy input menjadi fuzzy output. Selanjutnya
adalah tahap defuzzifier, mentransformasi output fuzzy menjadi output MPCI non
fuzzy. Pada Gambar 6 jika normalisasi MRR bernilai 0 dan normalisasi SR bernilai
1 maka MPCI akan bernilai 0.5. Hasil MPCI diberikan pada Tabel 4.
Tabel 4. Hasil Output MPCI
Faktor MPCI
A B C
1 1 1 0.500
1 2 2 0.703
1 3 3 0.250
2 1 2 0.594
2 2 3 0.498
2 3 1 0.500
3 1 3 0.750
3 2 1 0.600
3 3 2 0.568
Nilai MPCI yang mendekati 1 menunjukkan bahwa nilai respon yang dekat
dengan nilai target, sebaliknya nilai MPCI yang mendekati 0 menunjukkan bahwa nilai
respon jauh dari nilai targetnya. MPCI merupakan variabel konversi dari beberapa respon
yang dipertimbangkan pada proses optimasi. Selanjutnya MPCI digunakan untuk
menentukan titik optimum.
3. Hasil penentuan titik optimum
Titik optimum ditentukan dari pengaruh faktor utama terbesar dari masing-masing faktor
percobaan. Penentuan titik optimum secara visual dilakukan dengan main effect plot yang
diberikan pada Gambar 7.

892
Gambar 7. Main effect plot untuk MPCI
Pada Gambar 7 didapatkan bahwa untuk faktor A pengaruh utama MPCI terbesar
dihasilkan pada taraf 3. Pada faktor B, pengaruh MPCI terbesar dihasilkan pada taraf 1.
Sedangan pada faktor C pengaruh MPCI terbesar dihasilkan oleh taraf 2. Dengan demikian
titik optimum yang didapatkan adalah perlakuan A3B1C2. Artinya bahwa MRR dan SR
optimum dapat dihasilkan dengan oleh perlakuan A3B1C2.
4. Kesimpulan
Kesimpulan yang didapat pada penelitian ini adalah bahwa metode analisis
taguchi fuzzy logic dapat dijadikan sebagai alternatif metode pada optimasi multi
respon. Pada kasus optimasi EDM yang digunakan pada penelitian ini didapatkan
bahwa kombinasi perlakuan yang menghasilkan MRR dan SR optimum adalah
faktor gap voltage 70 V, peak current 9 A dan duty factor 0,6
Referensi [1] A. K. Pandey and A. K. Dubey, 2012, “Taguchi based fuzzy logic optimization of
multiple quality characteristics in laser cutting of Duralumin sheet,” Opt. Lasers
Eng., vol. 50, no. 3, pp. 328–335.
[2] B. Das, S. Roy, R. N. Rai, and S. C. Saha, 2014, “Surface roughness of Al-5Cu alloy
using a taguchi-fuzzy based approach,” J. Eng. Sci. Technol. Rev., vol. 7, no. 2, pp.
217–222.
[3] C. L. Liu, Y. S. Chiu, Y. H. Liu, Y. H. Ho, and S. S. Huang, 2013, “Optimization of
a fuzzy-logic-control-based five-stage battery charger using a fuzzy-based taguchi
method,” Energies, vol. 6, no. 7, pp. 3528–3547.
[4] D. C. Montgomery, 2013, Design and Analysis of Experiments, Internatio. John
Wiley & Sons.
[5] K. Anand Babu and G. Vijaya Kumar, 2015, “Determination of optimum parameters
for multi responses in drilling of Al 7075 - 10%SiCp Metal Matrix Composite under
MQL condition using Taguchi-Fuzzy Approach,” Int. J. Eng. Technol., vol. 7, no. 4,
pp. 1200–1211.
[6] P. V. Ramaiah, N. Rajesh, and K. D. Reddy, 2013, “Determination of Optimum
Influential Parameters in Turning of Al6061 Using Fuzzy Logic,” vol. 2, no. 10, pp.
5555–5560.
[7] R. Mohan, J. P. C, and B. Paul, 2014, “Multi Output Optimization of CNC High
Speed Hard Turning of AISI 52100 Bearing Steel using Taguchi Method and Fuzzy
Logic Unit,” vol. 15, no. 3, pp. 118–123.
[8] S. A. El-bahloul, 2015, “Optimization of Thermal Friction Drilling Process Based on
Taguchi Method and Fuzzy Logic Technique,” vol. 4, no. 2, pp. 55–59.
[9] S. A. Hussain, V. Pandurangadu, and K. Palanikumar, 2014, “Multiple Performance
Characteristic Optimization in Turning of GFRP Composites Using Fuzzy Logic,”
Int. J. Eng. Res., vol. 3, no. 1, pp. 106–111.

893
TERAPAN
SEMINAR NASIONAL MATEMATIKA 2017

894
Prosiding SNM 2017 Terapan, Hal 894-900
PENCITRAAN ARAH AKUMULASI PASIR BESI
BERDASARKAN KONTRAS KEMAGNETAN DAN
FORWARD MODELLING DENGAN MENGGUNAKAN
METODE GEOFISIKA PASIF PADA DAERAH PANTAI
GOA CEMARA,YOGYAKARTA
RIZKY RAMADHAN DWIYANTORO
Jurusan Teknik Geofisika, Universitas Pembangunan Nasional “Veteran” Yogyakarta Jalan SWK 104 Condongcatur Yogyakarta
Abstrak. Magnet merupakan fenomena yang dimiliki oleh bumi, dalam pemanfaatannya magnet dapat diterapkankan sebagai alat yang berfungsi untuk mencitrakan suatu keadaan bawah permukaan dengan
menggunakan kontras perbedaan nilai intensitas kemagnetan batuan dengan menggunakan salah satu metode tertua dalam geofisika yaitu geomagnet. Geomagnet adalah metode geofisika pasif yang memanfaatkan nilai kemagnetan batuan untuk mengetahui kondisi bawah permukaan, menentukan arah litologi maupun perlapisan. Pasir besi yang terdapat pada pantai goa cemara merupakan hasil dari endapan merapi muda yang tertransportasi lalu terakumulasi pada permukaan pantai tersebut, lalu pasir silika yang berada pada daerah penelitian bersumber dari tinggian wonosari yang tertransport lalu terakumulasi. survei geomagnet yang bersifat regional berfungsi untuk memodelkan, memetakan dan
menentukan arah akumulasi hasil transportasi pasir besi secara regional. Interpretasi dari survei magnetik, berupa arah akumulasi pasir besi secara regional berdasarkan peta kuat medan magnetik yang telah melalui reduksi dan pemodelan 2,5 dimensi. Penelitian ini dilakukan dengan jumlah 12 lintasan (grid) pengukuran dengan interval setiap titik 10 meter dan hasil pengukuran secara umum dari daerah penelitian memiliki 2 litologi yang dominan yaitu pasir besi dan pasir silika didapatkan nilai intensitas magnetik setelah direduksi (reduce to the pole) sebesar 120,9 nT sampai 387,5 nT dapat di
interpretasikan sebagai pasir besi sementara itu, batu pasir silika memiliki nilai lebih rendah antara -242,0 nT sampai -22,1 nT. Dari data pengolahan tersebut diproyeksikan lebih lanjut kedalam model forward 2,5 dimensi dengan menggunakan perangkat lunak merupakan pemodelan kedepan menggunakan persamaan matematika yang diturunkan dari konsep fisika, dalam pemodelan geofisika dicari suatu model yang cocok dengan data lapangannya (fit). dengan nilai persentase kesalahan model sebesar 22.276 % terlihat bahwa model bawah permukaan sesuai dengan peta kontinuasi keatasnya,
akumulasi pasir besi mengarah dari tenggara ke barat laut sesuai dengan arah media transportasinya
Kata Kunci: Geomagnetik, pemodelan kedepan, reduksi ke kutub
1. Pendahuluan
Matematika merupakan ilmu yang mendasari banyak ilmu salah satunya
adalah geofisika, Terapan dari matematika banyak digunakan untuk
menghubungkan antara data observasi dengan model fisis. Dengan memanfaatkan
fenomena yang ada di bumi, yaitu gaya magnet, menjadi dasar dari salah satu
metode pasif dalam geofisika yaitu geomagnetik. sebagai salah satu metode tertua

895
dalam geofisika, geomagnetik memanfaatkan sifat kemagnetan bumi dalam
mencitrakan kondisi bawah permukaan.
Penelitian bermaksud untuk memetakan kawasan pantai goa cemara dengan
parameter fisis kemagnetan dan mendapatkan arah endapan pasir besi
(akumulasi) dengan tujuan mengetahui kondisi bawah permukaannya berdasarkan
pemodelan kedepan (forward modelling) dan kontras nilai kemagnetan dalam
geofisika, model dan parameter model digunakan untuk mengkarakterisasi suatu
kondisi geologi bawah-permukaan. Pemodelan merupakan proses estimasi model
dan parameter model berdasarkan data yang diamati di permukaan bumi, Pemodelan
ke depan menyatakan proses perhitungan "data" yang secara teoritis akan teramati
di permukaan bumi, persamaan matematis untuk model yang memiliki kesalahan
minimum dinyatakan dengan:
E = ∑ (𝑒𝑖𝑁𝑖=1 ) 2
dimana:
𝑒𝑖 adalah (𝑇𝑖𝑐𝑎𝑙 − 𝑇𝑖
𝑜𝑏𝑠) 2
E adalah merupakan fungsi dari parameter model (a, b)
T cal adalah prediksi data
T obs adalah data lapangan
Hubungan linier antara data (d) dengan parameter model (m) atau intensitas
magnetisasi dinyatakan oleh:
d = G m
dimana G adalah matriks kernel (N × M) yang memetakan sumber anomali
menjadi data observasi, dengan N adalah jumlah data dan M adalah jumlah
parameter model. [1] persamaan diatas merupakan persamaan pemodelan kedepan
yang digunakan untuk memodelkan bawah permukaan bumi dengan parameter fisis
dari geomagnetik adalah intensitas kemagnetan (I) yaitu tingkat kemampuan
menyearahnya momen-momen magnetik dalam medan magnet luar, atau
didefinisikan sebagai momen (M) magnet persatuan volume (V) :
I = M/V Medan magnet, dalam ilmu Fisika adalah suatu medan yang dibentuk dengan
menggerakan muatan listrik (arus listrik) yang menyebabkan munculnya gaya di
muatan listrik yang bergerak lainnya. (Putaran mekanika kuantum dari satu partikel
membentuk medan magnet dan putaran itu dipengaruhi oleh dirinya sendiri seperti
arus listrik; inilah yang menyebabkan medan magnet dari ferromagnet. medan
magnet adalah medan vektor Bumi merupakan medan magnetik raksasa, yang
pembuktiannya dapat dilakukan dengan kompas. Penunjukkan arah kompas
menyatakan arah kutub-kutub magnet bumi, Intensitas medan magnetik yang
terukur di atas permukaan bumi senantiasa mengalami perubahan terhadap waktu.
Berdasarkan faktor-faktor penyebabnya perubahan medan magnetik bumi dapat
terjadi antara lain:
Variasi sekuler Variasi sekuler adalah variasi medan bumi yang berasal dari variasi medan magnetik
utama bumi, sebagai akibat dari perubahan posisi kutub magnetik bumi.

896
Variasi harian Variasi harian adalah variasi medan magnetik bumi yang sebagian besar bersumber
dari medan magnet luar. Medan magnet luar berasal dari perputaran arus listrik di
dalam lapisan ionosfer yang bersumber dari partikel-partikel terionisasi oleh radiasi
matahari sehingga menghasilkan fluktasi arus yang dapat menjadi sumber medan
magnet. [3]. geomagnetik, merupakan metode yang didasarkan pada pengukuran
variasi intensitas magnetik di permukaan bumi yang disebabkan adanya variasi
distribusi (anomali) benda termagnetisasi di bawah permukaan bumi. Hal ini terjadi
sebagai akibat adanya perbedaan sifat kemagnetan suatu material. Kemampuan
untuk termagnetisasi tergantung dari suseptibilitas magnetik masing-masing
batuan.[4] Dalam geomagnet terdapat beberapa cara survei salah satunya yaitu
dengan teknik satu alat. Akuisisi menggunakan satu alat adalah survei geomagnetik
dengan cara titik pengukuran geomagnetik akan kembali lagi menuju titik semula.
Pengukuran menggunakan satu alat merupakan suatu konsep pengukuran dengan
memanfaatkan titik awal yang digunakan sebagai titik acuan dan pengukuran awal
hingga terakhir akan kembali pada titik tersebut
Gambar 1.1 desain survei penelitian
Pengukuran dilakukan pada Pantai Goa Cemara, Kabupaten Bantul, Daerah Istimewa Yogyakarta pada 5 April 2015 dengan kondisi cuaca cerah, penelitian ini terdiri dari 12 lintasan secara (grid ), Lintasan pada desain survei tersebut dipilih dengan arah memotong arah hembusan angin agar mendapat respon anomali dari target dalam penelitian ini informasi geologi sangat penting dikarenakan desain survei dari geofisika sangat bergantung pada infomasi geologi
2. Hasil-hasil utama
Genesa Target Pembentukan endapan pasir besi memiliki perbedaan genesa dibandingkan dengan mineralisasi logam lainnya yang umum terdapat. Pembentukan pasir besi adalah merupakan produk dari proses kimia dan fisika dari batuan berkomposisi intermediet hingga basa atau dari batuan bersifat andesitik hingga basaltik [2]. di pulau Flores secara umum terletak pada busur batuan vulkano-plutonik yang masih aktif mirip dengan pulau jawa dimana endapan pasir besi ditemukan sepanjang

897
pantai selatan. Pasir besi termasuk ke dalam endapan sedimenter, karena mengalami proses: 1. Perombakan 2. Transportasi 3. Pemilahan
4. Pengkayaan pasir besi yang berasal dari gunung berapi, mengalir melewati sungai, berkumpul di sepanjang sungai (terutama pada lekukan sungai), dan mengendap di sungai, muara, hingga menuju laut. Ombak yang menyapu di sepanjang pantai membuat pasir besi terpilahkan dan menjadi butiran bebas, yang terkayakan. Proses ini terjadi berulang-ulang, sehingga bisa terbentuk menjadi endapan pasir besi yang ditemukan di sungai maupun di pantai.
Total intensitas magnetik peta total intensitas magnetik adalah peta rata-rata dari respon intensitas magnetik atau sering disebut kuat medan total, perbedaan warna yang signifikan melambangkan kontras kuat medan magnetik pada daerah penelitian. Pada peta total intensitas magnetik batuan yang memiliki intensitas sedang ditunjukkan pada warna hijau hingga kuning dan memiliki nilai -174,7 nT hingga –12,4 nT merupakan
pasir silika yang berasal dari tinggian wonosari.
Gambar 2.1 penggabungan peta intensitas magnetik dengan topografi
Gambar 2.2 Peta intensitas magnetik

898
Peningkatan kualitas data Upaya peningkatan kualitas data untuk mendekatkan data observasi dengan
anomali target dengan proses Reduksi ke kutub yaitu filterasi yang mereduksi ke
kutub sehingga pada anomali pengukuran hanya dipengaruhi oleh satu kutub. hal ini
dilakukan agar anomali dari total intesitas magnetik berada tepat dibawah titik
pengukuran. Peta total intensitas magnetik merupakan hasil medan magnetik dari
daerah pengukuran dengan anomali yang masih dipengaruhi 2 kutub maka
dibutuhkan filterasi agar menemui target dengan menyearahkan momen magnetik
pada satu kutub magnet bumi.
Gambar 2.3 penggabungan peta reduksi ke kutub dengan topografi
Gambar 2.4 Peta reduksi kutub

899
Pemodelan kedepan dan kontinuasi keatas Peta kontinuasi keatas adalah salah satu upaya melihat anomali dari target
pengukuran dengan asumsi bahwa pada ketinggian ini anomali regional sudah dapat dihilangkan dan sudah mencakup area pengukuran. Tingkat proses kontinuasi dilakukan menurut target yang diinginkan yaitu bergantung pada kedalaman target itu sendiri. Proses kontinuasi dengan uji trial and error dilakukan dengan melihat kecenderungan pola kontur hasil kontinuasi pada ketinggian tertentu, sangat jelas terlihat bahwa penyebaran searah dengan media transportasi pasir besi dengan udara maka didapatkanlah arah tenggara barat laut dengan dasar 3 peta diatas, kontinuasi keatas, Total intesitas magnet dan reduksi ke kutub dengan nilai intensitas
magnetik sebesar 120,9 nT sampai 387,5 nT dapat diinterpretasikan sebagai pasir besi sementara itu, batu pasir silika memiliki nilai lebih rendah antara -242,0 nT sampai -22,1 n. pasir besi pada daerah pengukuran termasuk produk lepasan andesit yang tertransport dari merapi menuju selatan Yogyakarta dan terkumpul sepanjang pantai dengan pola penyebaran mengikuti arah angin. Garis hitam pada peta upward continuation adalah sayatan yang digunakan untuk membuat model bawah permukaan dari target. Pemodelan kedepan (forward modeling) yang menggunakan persamaan matematika yang diturunkan dari konsep fisika, dalam pemodelan geofisika dicari suatu model yang cocok dengan data observasi [1] dengan nilai persentase kesalahan model sebesar 22.276 % Pemodelan ini merupakan gambaran bawah permukaan hasil intepretasi berdasarkan data observasi dan kondisi geologi, dapat terlihat bahwa dimana lapisan pasir besi yang lebih dominan dibandingkan dengan pengendapan pasir silika model ini dicocokan dari kondisi geologinya yang menyatakan bahwa terdapat material lepas berupa pasir besi dan berdasarkan arah sayatan maka dapat diinterpretasikan akumulasi dari pasir besi mengarah tenggara-barat laut berada pada permukaan maupun bawah permukaan pada pantai.
Gambar 2.5 penggabungan peta kontinuasi keatas dengan topografi

900
Gambar 2.6 pemodelan kedepan
3. Kesimpulan
dari penelitian ini dapat ditarik kesimpulan : Berdasarkan peta reduksi ke kutub,kontinuasi ke atas dan pemodelan
kedepan penyebaran arah akumulasi pasir besi mengarah barat laut menuju tenggara dengan media transportasi pasir besi adalah udara dan air berdasarkan dari ketiga peta magnetik maka dapat diketahui bahwa hanya terdapat 2 litologi pada daerah penelitian yaitu, pasir silika dan pasir besi, Pasir silika merupakan hasil dari tinggian wonosari yang tersisipkan bersilang bersama pasir besi lalu tertransportasi dengan media udara dan terendapkan. pasir besi pada pantai goa cemara merupakan merupakan batuan yang bersumber dari aktivitas merapi, merupakan hancuran andesite tertransportasi hingga daerah pantai goa cemara hal ini diduga berdasarkan dari nilai magnetiknya yang tinggi, pantai goa cemara memiliki fenomena geologi ini yang disebut barchan dune dimana bentukan dari timbunan
pasir yang terjadi karena pengendapan material-material yang terbawa oleh angin yang terbentuk pada daerah dataran yang terbuka.
Referensi
[1] Hendra Grandis,2009, Pengantar Pemodelan Inversi Geofisika,Himpunan Ahli
Geofisika,Jakarta [2] Subandoro dan Pudjowaluyo, 1978, Iron Sand Occurrences In The Coastal Areas of
Flores, Mineral Resources In Asian Offshore Areas, CCOP , Singapore [3] Telford, W., Geldart, L., Sheriff, R., and Keys, D., (1976). Applied Geophysics,
Cambridge University Press, New York. [4] Tri, Audi. 2016. Identification of Paleo-extraction zone of ironsand deposit by magnetic
responses combined with fourier transform analysis: new development in geomagnetic exploration. MGEI 8th Conference proceeding 2016. Bandung

901
Prosiding SNM 2017 Terapan, Hal 901-910
TRANSFORMASI STRUKTURAL DAN KETIMPANGAN
ANTAR DAERAH DI PROVINSI KALIMANTAN TIMUR
ADI SETIAWAN1 DAN FITRI KARTIASIH2
1Badan Pusat Statistik Kota Jakarta Pusat, [email protected]
2 Sekolah Tinggi Ilmu Statistik, [email protected]
Abstrak
Tingginya ketimpangan pendapatan mengindikasikan tidak meratanya pembangunan terutama
dalam bidang ekonomi di Indonesia. Kalimantan Timur adalah contoh provinsi yang mengalami
“growth without development”: pertumbuhan ekonomi daerah memang terjadi namun pembangunan
tidak dinikmati oleh sebagian besar rakyat Kalimantan Timur (Mubyarto, 2005). Hal ini dapat dilihat
dari indeks eksploitasi dan angka kemiskinan di Kalimantan Timur. Penelitian ini bertujuan untuk
menganalisis transformasi struktural di Provinsi Kalimantan Timur, mengklasifikasikan
kabupaten/kota menurut tingkat pertumbuhan dan pendapatan per kapitanya, menganalisis tingkat
ketimpangan pendapatan antar kabupaten/kota dan mengetahui hubungan antara pendapatan perkapita
dengan ketimpangan pendapatan. Penelitian ini menggunakan analisis deskriptif, Tipologi Klassen,
Indeks Williamson, Indeks Theil T dan Indeks Theil L. Hasil penelitian menunjukkan bahwa struktur
ekonomi Provinsi Kalimantan Timur masih bertumpu pada sektor primer dan belum terjadi
transformasi struktur ekonomi. Berdasarkan Indeks Williamson, tingkat ketimpangan antar daerah di
Provinsi Kalimantan Timur relatif tinggi. Berdasarkan Indeks Theil T dan Theil L, ketimpangan antar
daerah lebih banyak disebabkan oleh ketimpangan dalam kelompok kabupaten (within) dibanding
ketimpangan antar kelompok kabupaten penghasil migas-non penghasil migas (between). Hipotesis
Kuznets berlaku atau terjadi di Provinsi Kalimantan Timur selama periode penelitian.
Kata Kunci : ketimpangan, Indeks Williamson, Indeks Theil, Kuznets, Kalimantan Timur
1. Pendahuluan
Pembangunan yang dilaksanakan sejauh ini cukup mampu mendorong
peningkatan laju pertumbuhan ekonomi, tetapi dalam banyak kasus relatif tidak bisa
mengurangi ketimpangan (disparity). Tingginya ketimpangan pendapatan
mengindikasikan tidak meratanya pembangunan terutama dalam bidang ekonomi di
Indonesia. Selain itu, tingginya ketimpangan pendapatan juga memperlihatkan
adanya heterogenitas antar wilayah. Faktor-faktor penyebab terjadinya ketimpangan
meliputi faktor biofisik/karakteristik wilayah (sumberdaya alam), sumberdaya
buatan (ketersediaan sarana dan prasarana sosial ekonomi), sumberdaya manusia,
karakteristik struktur ekonomi wilayah dan kebijakan pemerintah daerah (Daryanto
dan Hafizrianda [4] ; Rustiadi dkk [6], Sjafrizal [7];).
Ketimpangan antardaerah dapat menimbulkan krisis yang lebih kompleks
seperti masalah kependudukan, ekonomi, sosial, politik dan lingkungan serta dalam

902
konteks makro sangat merugikan proses dan hasil pembangunan yang ingin dicapai
suatu wilayah. Beberapa daerah dapat mencapai pertumbuhan yang signifikan,
sementara beberapa daerah lainnya mengalami pertumbuhan yang lambat.
Provinsi Kalimantan Timur merupakan provinsi terkaya di Indonesia dengan
Produk Domestik Regional Bruto (PDRB) per kapita Rp 129,26 juta (BPS [2]).
Provinsi ini terkenal kaya dengan sumber daya alam (SDA) terutama minyak, gas
bumi, batubara, emas, perikanan dan kelautan serta hasil-hasil hutan yang melimpah.
Kalimantan Timur adalah contoh provinsi yang mengalami “growth without
development”: pertumbuhan ekonomi daerah memang terjadi namun pembangunan
tidak dinikmati oleh sebagian besar rakyat Kalimantan Timur (Mubyarto [5]). Hal
ini dapat dilihat dari indeks eksploitasi dan angka kemiskinan di Kalimantan Timur.
Jumlah penduduk miskin di Provinsi Kalimantan Timur pada tahun 2008 tercatat
sebesar 9,51 persen. Sedangkan indeks eksploitasi ekonomi Kalimantan Timur
sebesar 93,10 persen dan merupakan angka yang paling tinggi dibanding dengan
provinsi-provinsi lain di Indonesia.
Berdasarkan uraian diatas maka tujuan dari penelitian ini antara lain: 1)
Menganalisis transformasi struktural di Provinsi Kalimantan Timur pada periode
tahun 2010-2015; 2) Mengklasifikasikan kabupaten/kota di Provinsi Kalimantan
Timur menurut tingkat pertumbuhan ekonomi dan pendapatan per kapitanya; 3)
Menganalisis tingkat ketimpangan pendapatan antar kabupaten/kota di Provinsi
Kalimantan Timur, dan 4) Mengetahui hubungan antara pendapatan per kapita
dengan ketimpangan pendapatan.
Pembangunan harus dipandang sebagai suatu proses multidimensional yang
mencakup berbagai perubahan mendasar atas struktur sosial, sikap-sikap masyarakat
dan institusi-institusi nasional disamping tetap mengejar akselerasi pertumbuhan
ekonomi, penanganan ketimpangan pendapatan serta pengentasan kemiskinan.
Menurut Kuznets, pertumbuhan ekonomi adalah kenaikan kapasitas dalam jangka
panjang dari suatu negara yang bersangkutan untuk menyediakan berbagai barang
ekonomi kepada penduduknya. Kenaikan kapasitas itu sendiri ditentukan oleh
adanya kemajuan atau penyesuaian-penyesuaian teknologi, instistusional, dan
ideologis tehadap berbagai keadaan yang ada (Todaro dan Smith [9]).
Teori pola pembangunan Chenery memfokuskan terhadap perubahan
struktur dalam tahapan proses perubahan ekonomi, industri dan struktur institusi dari
perkonomian negara sedang berkembang, yang mengalami transformasi dari
pertanian tradisional beralih ke sektor industri sebagai roda penggerak ekonomi.
Penelitian yang dilakukan Hollis Chenery tentang transformasi struktur produksi
menunjukkan bahwa sejalan dengan peningkatan pendapatan perkapita,
perekonomian suatu negara akan bergeser dari yang semula mengandalkan sektor
pertanian menuju ke sektor industri (Todaro dan Smith [9]).
Ketimpangan pendapatan itu tidak dapat dihindari, tetapi bukan berarti hal
tersebut boleh dibiarkan terus-menerus tinggi. Ketimpangan yang tinggi dapat
membawa dampak buruk terhadap kestabilan ekonomi dan kestabilan politik. Oleh
sebab itu perlu diupayakan ketimpangan yang terjadi tidak terlalu menyolok, atau
perkembangan ketimpangan sedapat mungkin jangan sampai membesar. Akan
tetapi, usaha untuk menciptakan pemerataan atau pengurangan ketimpangan
pendapatan dalam suatu proses pembangunan ekonomi sangatlah sulit. Terutama
disebabkan karena adaya trade off antara pendapatan dengan laju pertumbuhan
ekonomi (Daryanto dan Hafizrianda [4]).
Penelitian ini menggunakan data sekunder yang diperoleh dari Badan Pusat
Statistik (BPS). Data yang digunakan adalah data Produk Domestik Regional Bruto

903
(PDRB) atas dasar harga berlaku; PDRB atas dasar harga konstan (PDRB riil) tahun
dasar 2010 serta data jumlah penduduk kabupaten/kota di Provinsi Kalimantan
Timur tahun 2010-2015. Metode analisis yang digunakan dalam penelitian ini adalah
analisis deskriptif, Tipologi Klassen, Indeks Williamson, Indeks Theil T dan Indeks
Theil L.
Tipologi Klassen membagi daerah berdasarkan dua indikator utama, yaitu
pertumbuhan ekonomi dan PDRB per kapitanya (Sjafrizal [7]). Daerah-daerah
pengamatan dibagi dalam empat kuadran, yaitu:
(1) daerah cepat maju dan cepat tumbuh (high growth and high income);
(2) daerah berkembang cepat (high growth but low income);
(3) daerah maju tapi tertekan (high income but low growth); dan
(4) daerah relatif tertinggal (low growth and low income)
Ketimpangan pendapatan antar daerah dalam penelitian ini digunakan 3
metode pengukuran yaitu Indeks Williamson, Indeks Theil T dan Indeks Theil L.
Formula Indeks Williamson ini pada dasarnya sama dengan coefficient of variation
(CV) biasa dimana standar deviasi dibagi dengan rataan.
𝐶𝑉𝑤 =√∑(𝑌𝑖−𝑌)
2𝑛𝑖 𝑛⁄
𝑌 (1)
Keterangan:
Yi = PDRB per kapita kabupaten/kota i
Y = PDRB per kapita Provinsi Kalimantan Timur
ni = jumlah penduduk kabupaten/kota i
n = jumlah penduduk Provinsi Kalimantan Timur
Sjafrizal [7] menetapkan sebuah kriteria yang digunakan untuk menentukan
apakah ketimpangan antardaerah berada pada ketimpangan taraf rendah, sedang,
atau tinggi. Untuk itu ditentukan kriteria sebagai berikut: ketimpangan taraf rendah
bila indeks Williamson < 0,3 ; ketimpangan taraf sedang bila indeks Williamson
antara 0,3 – 0,50 dan ketimpangan taraf tinggi bila indeks Williamson > 0,50.
Indeks Theil memiliki karakteristik utama yaitu kemampuannya untuk
membedakan ketimpangan antar daerah (between-region inequality) dan
ketimpangan dalam suatu daerah (within-region inequality). Ketidakmerataan antar
kelompok (between) yang dimaksud dalam penelitian ini adalah ketidakmerataan
antar wilayah atau kelompok kabupaten/kota, sedangkan ketidakmerataan dalam
kelompok (within) adalah ketidakmerataan yang terjadi di dalam satu wilayah atau
kelompok kabupaten/kota tertentu. Dalam penelitian ini akan dilihat ketimpangan
pendapatan yang dibagi menjadi dua kelompok wilayah analisis, antara lain:
1. Kelompok kabupaten/kota penghasil migas yang terdiri dari: Kabupaten
Kutai Kartanegara, Kutai Timur, Penajam Paser Utara, Kota Balikpapan,
Samarinda dan Bontang.
2. Kelompok kabupaten/kota bukan penghasil migas yang terdiri dari:
Kabupaten Paser, Kutai Barat dan Berau.
Koefisien Theil diukur dengan menggunakan rumus sebagai berikut (Tadjoedin [8])
:
𝑇 = ∑ ∑ [𝑌𝑖𝑗
𝑌] ln [
��𝑖𝑗
��]𝑗𝑖 (2)
𝐿 = ∑ ∑ [𝑛𝑖𝑗
𝑛] ln [
��
��𝑖𝑗]𝑗𝑖 (3)
Keterangan:
T = indeks Theil T
L = indeks Theil L

904
Yij = PDRB kabupaten i, kelompok j
Y = PDRB Provinsi Kalimantan Timur (Σ Σ Yij)
��𝑖𝑗 = PDRB per kapita kabupaten i, kelompok j
�� = PDRB per kapita Provinsi Kalimantan Timur
Selanjutnya dihitung ketimpangan dalam kelompok dan antar kelompok, dengan
rumus sebagai berikut :
Total Ketimpangan = Ketimpangan dalam kelompok+ketimpangan antar kelompok
𝑇 = 𝑇𝑤+𝑇𝐵
𝑇 = ∑ (𝑌𝑖
𝑌)𝑇𝑖𝑖 + ∑ (
𝑌𝑖
𝑌) ln (
𝑌��
��) =𝑖 𝑇𝑤+𝑇𝐵 (4)
𝑇𝑖 = ∑ (𝑌𝑖𝑗
𝑌𝑖) ln (
��𝑖𝑗
��𝑖)𝑗 (5)
𝐿 = 𝐿𝑤+𝐿𝐵
𝐿 = ∑ (𝑛𝑖
𝑛)𝐿𝑖𝑖 + ∑ (
𝑛𝑖
𝑛) ln (
��
𝑌��) =𝑖 𝐿𝑤+𝐿𝐵 (6)
𝐿𝑖 = ∑ (𝑛𝑖𝑗
𝑛𝑖) ln (
��𝑖
��𝑖𝑗)𝑗 (7)
TW dan LW adalah ketimpangan dalam kelompok (within-region inequality)
TB dan LB adalah ketimpangan antar kelompok (between-region inequality)
Konsep pemikiran Kuznets (Todaro dan Smith [9]) yang dituangkan dalam
bentuk kurva U terbalik, yaitu sewaktu pendapatan per kapita naik, ketidakmerataan
mulai muncul dan mencapai maksimum pada saat pendapatan berada pada tingkat
menengah dan kemudian menurun sewaktu telah dicapai tingkat pendapatan yang
sama dengan karakteristik negara industri. Ketidakmerataan pendapatan akan
memburuk pada tahap awal disebabkan upah buruh masih relatif rendah. Dengan
demikian pertumbuhan tidak banyak memberikan manfaat bagi golongan miskin
atau golongan buruh. Namun dengan semakin meningkatnya pendapatan per kapita,
maka permintaan terhadap sarana publik (transportasi, komunikasi, pendidikan, dsb)
juga meningkat. Kondisi ini akan memunculkan trickle-down effect bagi golongan
miskin dengan meningkatnya upah buruh melalui sektor lain. Hipotesis Kuznets
(Kurva U-Terbalik) dapat dibuktikan dengan membuat grafik antara Produk
Domestik Regional Bruto (PDRB) per kapita dan indeks ketimpangan (indeks
Williamson, indeks Theil T dan indeks Theil L).
2. Hasil – Hasil Utama
Kalimantan Timur merupakan provinsi terluas kedua di Indonesia setelah
Papua, dengan luas wilayah kurang lebih sekitar 204,5 ribu km2 atau sekitar satu
setengah kali Pulau Jawa dan Madura. Daerah ini dapat dikatakan berpenduduk
jarang apabila dilihat dari tingkat kepadatannya yang hanya 15,94 jiwa/km2.Selain
itu tingkat penyebaran penduduknya timpang atau tidak merata.
Kontribusi Kalimantan Timur terhadap perekonomian nasional relatif
tinggi. Produk Domestik Regional Bruto (PDRB) Kalimantan Timur pada tahun
2015 sebesar 442,39 triliun rupiah atau 4,89 persen dari Produk Domestik (PDB)
Indonesia. Angka ini merupakan angka kontribusi yang terbesar untuk daerah di luar
Jawa. Sedangkan secara nasional, Kalimantan Timur masuk sebagai empat besar
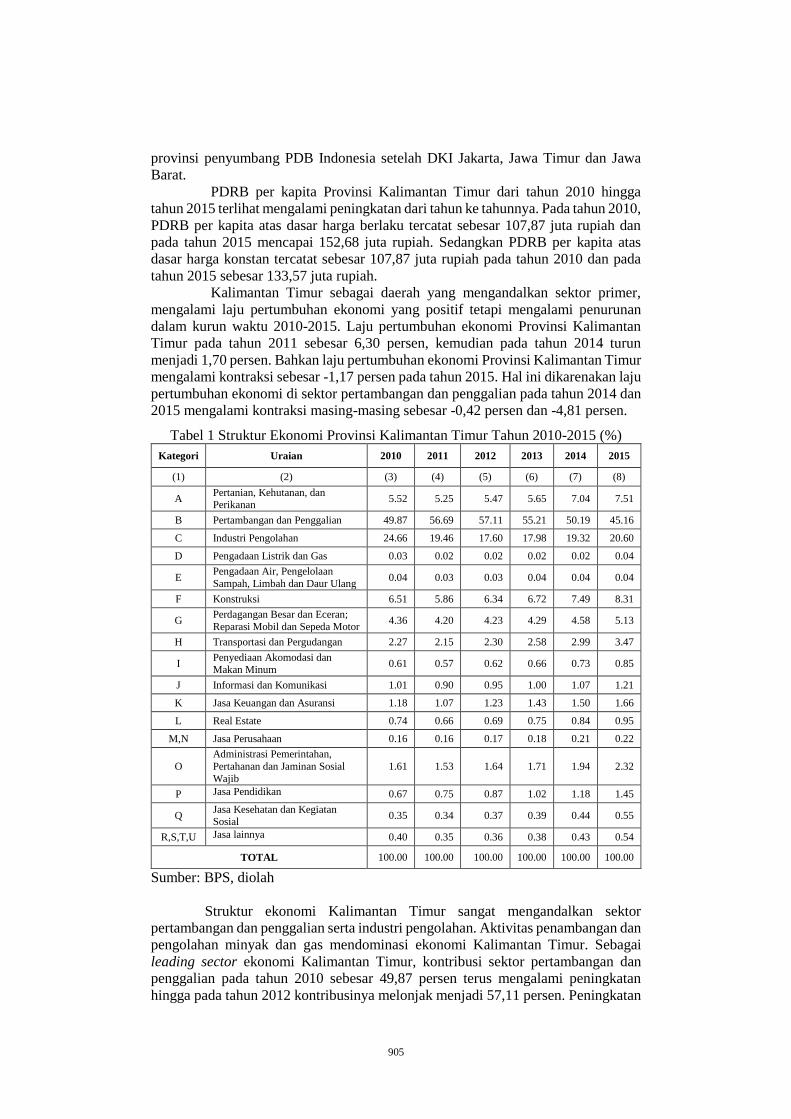
905
provinsi penyumbang PDB Indonesia setelah DKI Jakarta, Jawa Timur dan Jawa
Barat.
PDRB per kapita Provinsi Kalimantan Timur dari tahun 2010 hingga
tahun 2015 terlihat mengalami peningkatan dari tahun ke tahunnya. Pada tahun 2010,
PDRB per kapita atas dasar harga berlaku tercatat sebesar 107,87 juta rupiah dan
pada tahun 2015 mencapai 152,68 juta rupiah. Sedangkan PDRB per kapita atas
dasar harga konstan tercatat sebesar 107,87 juta rupiah pada tahun 2010 dan pada
tahun 2015 sebesar 133,57 juta rupiah.
Kalimantan Timur sebagai daerah yang mengandalkan sektor primer,
mengalami laju pertumbuhan ekonomi yang positif tetapi mengalami penurunan
dalam kurun waktu 2010-2015. Laju pertumbuhan ekonomi Provinsi Kalimantan
Timur pada tahun 2011 sebesar 6,30 persen, kemudian pada tahun 2014 turun
menjadi 1,70 persen. Bahkan laju pertumbuhan ekonomi Provinsi Kalimantan Timur
mengalami kontraksi sebesar -1,17 persen pada tahun 2015. Hal ini dikarenakan laju
pertumbuhan ekonomi di sektor pertambangan dan penggalian pada tahun 2014 dan
2015 mengalami kontraksi masing-masing sebesar -0,42 persen dan -4,81 persen.
Tabel 1 Struktur Ekonomi Provinsi Kalimantan Timur Tahun 2010-2015 (%)
Kategori Uraian 2010 2011 2012 2013 2014 2015
(1) (2) (3) (4) (5) (6) (7) (8)
A Pertanian, Kehutanan, dan Perikanan
5.52 5.25 5.47 5.65 7.04 7.51
B Pertambangan dan Penggalian 49.87 56.69 57.11 55.21 50.19 45.16
C Industri Pengolahan 24.66 19.46 17.60 17.98 19.32 20.60
D Pengadaan Listrik dan Gas 0.03 0.02 0.02 0.02 0.02 0.04
E Pengadaan Air, Pengelolaan
Sampah, Limbah dan Daur Ulang 0.04 0.03 0.03 0.04 0.04 0.04
F Konstruksi 6.51 5.86 6.34 6.72 7.49 8.31
G Perdagangan Besar dan Eceran;
Reparasi Mobil dan Sepeda Motor 4.36 4.20 4.23 4.29 4.58 5.13
H Transportasi dan Pergudangan 2.27 2.15 2.30 2.58 2.99 3.47
I Penyediaan Akomodasi dan Makan Minum
0.61 0.57 0.62 0.66 0.73 0.85
J Informasi dan Komunikasi 1.01 0.90 0.95 1.00 1.07 1.21
K Jasa Keuangan dan Asuransi 1.18 1.07 1.23 1.43 1.50 1.66
L Real Estate 0.74 0.66 0.69 0.75 0.84 0.95
M,N Jasa Perusahaan 0.16 0.16 0.17 0.18 0.21 0.22
O
Administrasi Pemerintahan,
Pertahanan dan Jaminan Sosial
Wajib
1.61 1.53 1.64 1.71 1.94 2.32
P Jasa Pendidikan 0.67 0.75 0.87 1.02 1.18 1.45
Q Jasa Kesehatan dan Kegiatan Sosial
0.35 0.34 0.37 0.39 0.44 0.55
R,S,T,U Jasa lainnya 0.40 0.35 0.36 0.38 0.43 0.54
TOTAL 100.00 100.00 100.00 100.00 100.00 100.00
Sumber: BPS, diolah
Struktur ekonomi Kalimantan Timur sangat mengandalkan sektor
pertambangan dan penggalian serta industri pengolahan. Aktivitas penambangan dan
pengolahan minyak dan gas mendominasi ekonomi Kalimantan Timur. Sebagai
leading sector ekonomi Kalimantan Timur, kontribusi sektor pertambangan dan
penggalian pada tahun 2010 sebesar 49,87 persen terus mengalami peningkatan
hingga pada tahun 2012 kontribusinya melonjak menjadi 57,11 persen. Peningkatan

906
ini ditopang oleh peningkatan pada subsektor pertambangan migas maupun tanpa
migas (batubara). Akan tetapi kontribusi sektor ini mengalami penurunan pada tahun
2013 hingga 2015, dimana kontribusi pada tahun 2015 sebesar 45,16 persen.
Kontribusi sektor industri pengolahan juga mengalami penurunan selama periode
pengamatan yaitu dari 24,66 persen pada tahun 2010 turun menjadi 20,60 persen
pada tahun 2015.
Sektor pertanian, kehutanan dan perikanan merupakan sektor keempat
terbesar dalam menyumbang PDRB Kalimantan Timur setelah sektor petambangan
dan penggalian; industri pengolahan dan konstruksi. Kontribusi sektor ini
mengalami peningkatan selama periode tahun 2010-2015 yaitu dari 5,52 persen pada
tahun 2010 naik menjadi 7,51 persen pada tahun 2015. Akan tetapi sektor pertanian
merupakan sektor yang paling banyak menyerap tenaga kerja. Pada tahun 2014
sebanyak 25,53 persen angkatan kerja bekerja pada sektor pertanian, sedangkan
penyerapan tenaga kerja di sektor industri pengolahan hanya sebesar 6,15 persen
(BPS [1]).
Perekonomian suatu daerah dalam jangka panjang akan terjadi perubahan
struktur perekonomian dimana semula mengandalkan sektor pertanian menuju
sektor industri. Dari sisi tenaga kerja akan menyebabkan terjadinya perpindahan
tenaga kerja dari sektor pertanian desa ke sektor industri kota, sehingga
menyebabkan kontribusi pertanian menurun. Menurut Chennery [3], sejalan dengan
peningkatan pendapatan perkapita, perekonomian suatu daerah akan bergeser dari
yang semula mengandalkan sektor pertanian menuju ke sektor industri. Hal-hal
tersebut di atas belum ditemukan di Provinsi Kalimantan Timur. Dengan demikian
dapat disimpulkan bahwa belum terjadi transformasi struktur ekonomi di Provinsi
Kalimantan Timur selama periode tahun 2010-2015.
Klasifikasi Kabupaten/Kota di Provinsi Kalimantan Timur
Tipologi Klassen membagi daerah yang diamati dalam empat klasifikasi,
yaitu: (1) daerah cepat maju dan cepat tumbuh (high growth and high income); (2)
daerah berkembang cepat (high growth but low income); (3) daerah maju tapi
tertekan (high income but low growth); dan (4) daerah relatif tertinggal (low growth
and low income). Analisis dalam penelitian ini menggunakan data PDRB per kapita
daerah tahun 2010-2015 untuk mengklasifikasikan kabupaten/kota.
Gambar 1 Plot Laju Pertumbuhan Ekonomi dan PDRB perkapita Kabupaten
/Kota di Provinsi Kalimantan Timur Tahun 2011
Paser
Kubar
KukarKutim
Berau
PPU
Balikpapan
Samarinda
Bontang
(10,00)
(5,00)
-
5,00
10,00
15,00
20,00
0,00 50,00 100,00 150,00 200,00 250,00 300,00 350,00 400,00
Per
tum
bu
han
Eko
no
mi (
%)
PDRB perkapita (Juta Rp)
I. Daerah cepat maju dan cepat tumbuh
II. Daerah berkembang cepat
III. Daerah maju tapi tertekan IV. Daerah relatif tertinggal

907
Dari Gambar 1 terlihat bahwa kabupaten/kota mengelompok pada tiga
kuadran. Kabupaten Penajam Paser Utara (PPU) dan Paser serta Kota Samarinda
berada di posisi kuadran dua sebagai daerah berkembang cepat. Kabupaten Kutai
Kartanegara (Kukar) dan Kutai Timur (Kutim) serta Kota Bontang berada di
kuadaran tiga yaitu menempati klasifikasi sebagai daerah maju tapi tertekan.
Kabupaten Kutai Barat (Kubar), Berau dan Kota Balikpapan menempati kuadran
empat dimana baik pertumbuhan ekonomi maupun pendapatan perkapitanya di
bawah angka provinsi. Tidak ada kabupaten/kota yang menempati kuadran pertama.
Gambar 2 Plot Laju Pertumbuhan Ekonomi dan PDRB perkapita Kabupaten
/Kota di Provinsi Kalimantan Timur Tahun 2015
Pada tahun 2015 terjadi pergeseran posisi dari beberapa kabupaten/kota.
Kabupaten Paser, Kutai Timur dan Kota Bontang menempati kuadran pertama
sebagai daerah maju. Kabupaten Kukar tetap berada di kuadran dua. Kuadran tiga
ditempati oleh lima kabupaten/kota lainnya. Tidak ada kabupaten/kota yang berada
di kuadran empat. Secara umum dapat dilihat bahwa terjadi peningkatan laju
pertumbuhan ekonomi maupun pendapatan perkapita dari masing-masing
kabupaten/kota sehingga terjadi pergeseran kuadran pada tahun 2015.
Tabel 2 Indeks Williamson Provinsi Kalimantan Timur Tahun 2010-2015 Tahun Indeks Williamson
(1) (2)
2010 0,6977
2011 0,6399
2012 0,6169
2013 0,5730
2014 0,5437
2015 0,5591
Paser
Kubar
Kukar
Kutim
Berau
PPU
Balikpapan
Samarinda
Bontang
(10,00)
(8,00)
(6,00)
(4,00)
(2,00)
-
2,00
4,00
6,00
8,00
0,00 50,00 100,00 150,00 200,00 250,00 300,00
Per
tum
bu
han
Eko
no
mi (
%)
PDRB perkapita (Juta Rp)
I. Daerah cepat maju dan cepat tumbuh
III. Daerah maju tapi tertekan
II. Daerah berkembang cepat
IV. Daerah relatif tertinggal

908
Hasil penghitungan tingkat ketimpangan antardaerah di Provinsi
Kalimantan Timur menggunakan Indeks Williamson dapat dilihat pada Tabel 2.
Tingkat ketimpangan antardaerah di Provinsi Kalimantan Timur selama tahun 2010-
2015 termasuk dalam kriteria ketimpangan yang tinggi yaitu di atas 0,5. Akan tetapi
selama kurun waktu penelitian menunjukkan tren menurun dari 0,6977 pada tahun
2010 turun menjadi 0,5591 pada tahun 2015. Adanya sejumlah kabupaten/kota yang
memiliki PDRB per kapita yang sangat tinggi, yang antara lain disebabkan oleh
keberadaan migas di daerah tersebut menyebabkan terjadinya ketimpangan
antardaerah di Provinsi Kalimantan Timur.
Ketimpangan ini terjadi karena masing-masing kabupaten/kota memiliki
kelimpahan sumber daya alam yang berbeda-beda dimana kekayaan alam tersebut
menghasilkan pendapatan yang begitu besar bagi daerah yang memilikinya.
Kabupaten/kota di Provinsi Kalimantan Timur memiliki kelimpahan sumberdaya
alam non migas seperti batubara, emas, perak, kehutanan maupun sektor pertanian
yang menghasilkan nilai tambah bruto (PDRB) dalam perekonomian daerah.
Kabupaten Kutai Timur, Paser dan Berau serta Kota Bontang merupakan
kabupaten/kota yang memiliki pendapatan per kapita tertinggi walaupun tanpa
memasukkan sektor migas. Dengan adanya perusahaan-perusahaan besar batubara
seperti PT Kalimantan Timur Prima Coal (PT. KPC) di Kabupaten Kutim, PT. Berau
Coal di Kabupaten Berau maupun PT Pupuk Kalimantan Timur (Pupuk Kalimantan
Timur) di Kota Bontang yang merupakan perusahaan produsen pupuk urea dan
amoniak terbesar di Indonesia, memberikan kontribusi yang besar terhadap
perekonomian Kalimantan Timur. Migas diduga memicu ketimpangan antardaerah
menjadi lebih tinggi.
Tabel 3 Dekomposisi Indeks Theil T Provinsi Kalimantan Timur Tahun 2010-2015
Tahun
Indeks
Theil T
Ketimpangan
antar kelompok
Ketimpangan
dalam kelompok
Indeks Kontribusi
(%)
Indeks Kontribusi
(%) (1) (2) (3) (4) (5) (6)
2010 0,2152 0,0060 2,85 0,2028 97,15
2011 0,1874 0,0043 2,34 0,1804 97,66
2012 0,1809 0,0021 1,20 0,1750 98,80
2013 0,1657 0,0010 0,59 0,1643 99,41
2014 0,1499 0,0006 0,39 0,1489 99,61
2015 0,1547 0,0001 0,05 0,1427 99,95
Tingkat ketimpangan antar daerah di Provinsi Kalimantan Timur jika
dilihat menggunakan indeks Theil T dan Theil L menunjukkan ketimpangan yang
rendah. Selama periode tahun 2010-2015 indeks Theil T mengalami penurunan dari
0,2152 pada tahun 2010 menjadi 0,1547 pada tahun 2015. Indeks Theil T dan Theil
L dapat didekomposisi untuk melihat ketimpangan antar kelompok wilayah
(between) dan ketimpangan dalam kelompok wilayah (within) yang diamati.
Wilayah Kalimantan Timur dibagi menjadi 2 kelompok yaitu kelompok
kabupaten/kota penghasil migas dan kelompok kabupaten/kota bukan penghasil
migas.

909
Tabel 4 Dekomposisi Indeks Theil L Provinsi Kalimantan Timur Tahun 2010-2015
Tahun
Indeks
Theil L
Between Within
Indeks Kontribusi
(%)
Indeks Kontribusi
(%) (1) (2) (3) (4) (5) (6)
2010 0,2250 0,0064 2,83 0,2186 97,17
2011 0,1996 0,0046 2,29 0,1950 97,71
2012 0,1982 0,0022 1,11 0,1960 98,89
2013 0,1865 0,0010 0,53 0,1855 99,47
2014 0,1683 0,0006 0,35 0,1677 99,65
2015 0,1594 0,0001 0,04 0,1593 99,96
Berdasarkan Tabel 3 dan Tabel 4 dapat dilihat bahwa ketimpangan dalam
kelompok lebih besar kontribusinya dibandingkan ketimpangan antar kelompok.
Kontribusi ketimpangan dalam kelompok sebesar 99,95 persen terhadap
ketimpangan total di Provinsi Kalimantan Timur. Hal ini terutama disebabkan
ketimpangan dalam kelompok kabupaten/kota penghasil migas. Sedangkan sisanya
0,05 persen disebabkan oleh ketimpangan antar kelompok.
Untuk melihat apakah hubungan antara pendapatan per kapita dengan
tingkat ketimpangan antardaerah di Provinsi Kalimantan Timur baik dengan
menggunakan Indeks Williamson maupun Indeks Theil sesuai dengan Hipotesis
Kurva U-Terbalik Kuznets, maka dilakukan plot terhadap data-data tersebut.
Sumbu vertikalnya (sumbu Y) adalah indeks ketimpangan (Indeks Williamson,
Indeks Theil T dan Indeks Theil L) dan rata-rata PDRB per kapita sebagai sumbu
horizontalnya (sumbu X).
(a) Indeks Williamson (b) Indeks Theil T (c) Indeks Theil L
Gambar 3 Kurva Hubungan Antara Indeks Williamson, Indeks Theil T dan Indeks
Theil L dengan PDRB per kapita di Provinsi Kalimantan Timur Tahun 2010-2015
Pada Gambar 3 dapat dilihat bahwa kurva hubungan antara Indeks
Williamson dan Indeks Theil dengan PDRB per kapita di Provinsi Kalimantan Timur
pada tahun 2010-2015 seperti huruf U yang terbalik, artinya hipotesis Kuznets terjadi
di provinsi ini selama periode penelian. Hal ini menunjukkan bahwa semakin
meningkatnya PDRB per kapita akan menurunkan tingkat ketimpangan pendapatan
antar daerah di Provinsi Kalimantan Timur.
0,40
0,45
0,50
0,55
0,60
0,65
0,70
128 130 132 134
Ind
eks
Will
iam
son
PDRB perkapita (Juta Rp)
0,05
0,10
0,15
0,20
0,25
128 130 132 134
Ind
eks
Thei
l T
PDRB perkapita (Juta Rp)
0,05
0,10
0,15
0,20
0,25
125 130 135
Ind
eks
Thei
l L
PDRB perkapita (Juta Rp)

910
3. Kesimpulan Berdasarkan hasil dan pembahasan di atas, maka dapat diambil beberapa
kesimpulan sebagai berikut:
1. Belum terjadi transformasi (pergeseran) struktur ekonomi di Provinsi
Kalimantan Timur selama tahun 2010-2015. Struktur ekonomi provinsi ini
masih bertumpu pada sektor primer terutama pertambangan dan penggalian.
2. Berdasarkan analisis Tipologi Klassen, kabupaten/kota mengelompok di
kuadran dua (klasifikasi daerah berkembang cepat).
3. Ketimpangan antardaerah yang terjadi di Provinsi Kalimantan Timur relatif
tinggi jika diukur menggunakan indeks Williamson, akan tetapi termasuk
ketimpangan rendah jika diukur menguunakan indeks Theil T dan Theil L.
Ketimpangan antar kelompok daerah (between) penghasil migas dan bukan
penghasil migas lebih rendah bila dibandingkan dengan ketimpangan dalam
kelompok (within).
4. Hipotesis Kuznets berlaku atau terjadi di Provinsi Kalimantan Timur selama
tahun 2010-2015.
Referensi
[1] BPS Provinsi Kalimantan Timur. 2015. Kalimantan Timur Dalam Angka 2015. BPS
Provinsi Kalimantan Timur, Samarinda.
[2] BPS Provinsi Kalimantan Timur. 2016. Kalimantan Timur Dalam Angka 2016. BPS
Provinsi Kalimantan Timur, Samarinda.
[3] Chenery, H., Ahluwalia, Bell, Duloy, dan Jolly. 1974. Redistribution with Growth.
Oxford University Press, Oxford.
[4] Daryanto, Arief & Yundy Hafizrianda. 2010. Model-Model Kuantitatif Untuk
Perencanaan Pembangunan Ekonomi Daerah: Konsep dan Aplikasi. PT Penerbit IPB
Press, Bogor
[5] Mubyarto. 2005. Menggugat Ketimpangan dan Ketidakadilan Ekonomi Nasional.
PUSTEP-UGM & Aditya Media, Yogyakarta.
[6] Rustiadi, E., S. Saefulhakim, dan DR. Panuju. 2009. Perencanaan dan Pengembangan
Wilayah. Yayasan Obor Indoneisa, Jakarta.
[7] Sjafrizal. 2008. Ekonomi Regional, Teori dan Aplikasi. Baduose Media, Padang.
[8] Tadjoeddin, M.Z., W.I. Suharyo dan S. Mishra. 2003. Regional Disparity and Centre-
Regional Conflicts in Indonesia. Working Paper (01/01-E). UNSFIR, Jakarta.
[9] Todaro, M. P. dan Stephen C. Smith. 2006. Pembangunan Ekonomi Jilid 1. Haris dan
Puji [penerjemah]. Erlangga, Jakarta.

911
Prosiding SNM 2017 Terapan , Hal 911 -922
EVALUASI TIGA MODEL PENDUGAAN EVAPORASI
PANCI (EPAN) DI WILAYAH BALI
TRINAH WATI1 DAN FATKHUROYAN2
1Pusat Informasi Perubahan Iklim BMKG, [email protected]
2 Pusat Penelitian dan Pengembangan BMKG, [email protected]
Abstrak. Dalam penelitian ini dilakukan evaluasi model pendugaan
evaporasi/penguapan panci Klas A (Epan) metode Penman [1], KNF (Kohler -
Nordenson-Fox) [2] dan Linacre [3] dengan Epan hasil pengukuran di 5 stasiun
cuaca di wilayah Bali. Analisis menggunakan Metode RMSE (Root Mean
Square Error) digunakan untuk mengetahui keakuratan dan keandalan ketiga
model pendugaan tersebut. Hasil menunjukkan metode Penman terbaik di empat
stasiun yaitu di stasiun Sanglah, Kahang, Negara dan BBMKG wilayah 3
sedangkan di stasiun Ngurah Rai metode KNF yang terbaik. Nilai RMSE yang
semakin kecil menunjukkan hasil pendugaan semakin mendekati data observasi.
Nilai RMSE hasil pendugaan metode Penman, KNF dan Linacre juga
dibandingkan dengan model pendugaan yang dilakukan secara lokal yaitu Wati
[4] menghasilkan nilai yang lebih besar. Hal ini menunjukkan bahwa keandalan
model pendugaan Epan dipengaruhi oleh tipe iklim. Pendugaan yang dilakukan
di iklim yang sama dengan lokasi penelitian lebih akurat dibandingkan iklim
sub tropis pada ketiga model tersebut.
Kata kunci : evaporasi panci, Penman, KNF, Linacre, Bali
1. Pendahuluan
Pemahaman besaran nilai dan variasi kehilangan air akibat
penguapan/evaporasi dibutuhkan pada sektor pertanian dan hidrologi. Pada sektor
tersebut dibutuhkan dalam perencanaan dan managemen sumber daya air, desain
waduk, penilaian efisiensi sistem irigasi, evaluasi persyaratan drainase di masa
mendatang, kuantifikasi kehilangan air akibat perkolasi di bawah tanah, kebutuhan
ketersediaan air yang diusulkan dalam suatu projek irigasi dan dalam sistem
prakiraan debit sungai [5]. Bentuk dari proses evaporasi ada dua yaitu evaporasi dari
permukaan air terbuka dan transpirasi dari vegetasi. Evaporasi adalah jumlah air
yang mengalami penguapan dari permukaan air terbuka atau dari permukaan tanah,
sedangkan transpirasi didefinisikan sebagai proses perpindahan air dari vegetasi ke
atmosfer dalam bentuk uap air. Kedua proses evaporasi dan transpirasi disebut
dengan istilah evapotranspirasi dimana merupakan jumlah uap air yang
berevaporasi/menguap dari tanah dan tanaman ketika permukaan tanah pada
kandungan kelengasan yang alami [6].
Pengukuran evaporasi di Indonesia dilakukan di stasiun-stasiun pengamatan
cuaca menggunakan panci terbuka standar yaitu Clas A pan (panci klas A). Data
pengamatan evaporasi panci klas A mengunakan satuan tinggi air dalam milimeter
yang secara langsung dapat dibandingkan dengan curah hujan. Besarnya laju

912
evaporasi panci (Epan) berbeda dengan laju evapotranspirasi di permukaan
bervegetasi, keduanya dihubungkan dengan koefisien panci [5]. Besaran koefisien
panci klas A berbeda-beda tergantung pada penempatan dan lingkungan pada
beberapa tingkatan kelembaban relatif dan kecepatan angin [7].
Terdapat beberapa kendala dalam pengukuran Epan antara lain : biaya yang
cukup tinggi karena sistem pengukuran otomatis, ketidakcocokan dengan beberapa
lingkungan seperti di wilayah yang mengalami pembekuan pada suhu tertentu dan
curah hujan juga mempengaruhi keakuratan pengukuran Epan [8]. Namun seiring
dengan kemajuan teknologi, sistem pengukuran Epan secara otomatis semakin
berkembang, sehingga data dapat tercatat secara otomatis dan dapat dimonitor dari
jarak jauh (remote system) [9]. Di Indonesia sendiri ketersedian data Epan cukup
terbatas, sehingga pendugaan menggunakan metode yang sudah ada lebih diminati
dengan menggunakan data pengamatan cuaca.
Dalam penelitian ini dilakukan evaluasi model pendugaan Epan yang telah
berkembang antara lain : metode Penman [1], KNF (Kohler-Nordenson-Fox) [2] dan
Linacre [3] dengan Epan hasil pengukuran di 5 stasiun cuaca di wilayah Bali.
Analisis menggunakan Metode RMSE (Root Mean Square Error) digunakan untuk
mengetahui keakuratan dan keandalan ketiga model pendugaan tersebut.
Perbandingan hasil RMSE dilakukan juga antara hasil dugaan ketiga model tersebut
dengan hasil model pendugaan lokal Wati [4] yang pernah dilakukan di stasiun
penelitian.
2. Model Pendugaan Evaporasi Panci
Formula Penman (1948) untuk menghitung evaporasi air terbuka berdasarkan prinsip fisika mengkombinasi pendekatan perpindahan massa (aerodinamik) dan keseimbangan energi. Formula Penman dalam mengestimasi evaporasi yaitu :
𝐸𝑝𝑎𝑛 = ∆H+ γEa
∆+γ (1)
H = E (1+β)
= (1-r)Ra (0.18 + 0.55 n/N) – σT4 (0.56 – 0.092√ed)(0.10 +0.90n/N) (2)
𝐸𝑎 = 0.35 (0.5 +𝑈2
100)(ea − ed) (3)
Keterangan :
γ : konstanta psychrometri
H : Radiasi Netto dalam unit evaporasi merupakan komponen keseimbangan
energi dengan rumus pada persamaan (2)
r : koefisien pemantulan permukaan (untuk nilai rata-rata tahunan, Penman
menggunakan 0.05 untuk air terbuka, 0.10 untuk tanah gundul dan 0.20
untuk vegetasi hijau)
Ra : Radiasi Angot
n/N : nisbah antara lama penyinaran dan panjang hari
σ : konstanta Stefan Boltzman
∆ : kemiringan (slope) kurva tekanan uap jenuh dengan suhu (𝑑𝑒
𝑑𝑇 ≅
𝑒𝑎−𝑒𝑑
𝑇𝑎−𝑇𝑑 )

913
pada suhu udara tertentu T dalam mb/°C
ea : tekanan uap air jenuh pada suhu T dalam mm Hg
ed : tekanan uap air jenuh pada suhu titik embun dalam mm Hg
Ea : komponen aerodinamik (perpindahan massa uap air) dengan rumus pada
persamaan (3):
Metode Penman 1948 banyak diaplikasikan di Amerika dan Eropa untuk
evaporasi air terbuka sedangkan di India diaplikasikan untuk lahan terbuka dan di
Kepulauan Inggris untuk lahan gambut [1]. Pendugaan Epan metode KNF (Kohler-
Nordenson-Fox) [2] telah banyak digunakan untuk menduga besaran evaporasi [10]
contohnya pada percobaan di Danau Hefner, Okla dan komputasi di 21 stasiun di
Amerika Serikat dan satu di Alaska dengan mengadopsi metode Penman, formula
metode KNF [2] yaitu:
𝐸𝑝𝑎𝑛 = ∆𝑅𝑛+𝛾+𝐸𝑎
∆+ 𝛾 (4)
𝐸𝑎 = 25.2[0.96(𝑒𝑎 − 𝑒𝑑)0.88(0.37 + 0.00255 𝑈𝑝)] (5)
∆𝑅𝑛 = 154.4 exp[(1.8𝑇 − 180)(0.1024 − 0.01066 ln (0.239𝑅𝑠)) −0.01544] (6)
Metode Linacre [3] menyederhanakan metode Penman dengan hanya
menggunakan suhu udara untuk meduga Epan, berikut adalah formula metode
Linacre :
𝐸𝑝𝑎𝑛 = (700 𝑇𝑚100−𝐴
)+15(𝑇−𝑇𝑑)
80−𝑇 (7)
𝑇𝑑 = 243.5 log(
𝑒𝑑6.112
)
17.67− log(𝑒𝑑6.112
) (8)
Keterangan :
Rn : Radiasi netto
Rs : Radiasi matahari
T : Suhu udara
Tm : T – 0.006 h dengan h adalah ketinggian
A : derajat lintang posisi stasiun cuaca
Td : suhu titik embun dengan rumus pada persamaan (8)
Wati [4] melakukan pendugaan Epan di wilayah Pulau Jawa dan Bali
Indonesia dengan parameter cuaca yang memiliki korelasi tertinggi dengan Epan.
Analisis regresi dan korelasi dilakukan antara Epan dengan unsur – unsur cuaca yaitu
suhu udara, kelembapan relatif, lama penyinaran, defisit tekanan uap air dan
kecepatan angin. Hasil model pendugaan Epan untuk 5 stasiun cuaca di Pulau Bali
antara lain :

914
1. Negara
Epan = 2.29 + 0.36VPD (9)
2. Ngurah Rai
Epan = 14.62 – 0.11RH (10)
3. Balai Besar BMKG wilayah 3
Epan = 7.14 – 0.10T (11)
4. Sanglah
Epan = 2.38 + 0.30VPD (12)
5. Kahang
Epan = 1.844 + 0.37LP (13)
Keterangan :
VPD : defisit tekanan uap air
RH : kelempaban relatif
T : suhu udara rata-rata
LP : lama penyinaran
Evaluasi keandalan model pendugaan dalam penelitian ini dilakukan
menggunakan analisis Root Mean Square Error (RMSE) dengan formula sebagai
berikut:
𝑅𝑀𝑆𝐸 = √∑ (𝑋𝑖−𝑌𝑖)
2𝑛𝑖=1
𝑛 (14)
dengan Xi dan Yi merupakan data observasi dan hasil dugaan.
Uji hasil model dilakukan dengan uji beda nilai tengah dua populasi dengan
asumsi keragaman sama. Tujuan uji t ini adalah untuk menentukan apakah dua
populasi yaitu Epan observasi dan Epan hasil pendugaan memiliki nilai tengah yang
sama atau tidak. Uji beda nyata ini pada taraf α 5 %.
Hipotesis : H0 : µ1 = µ2
H1 : µ1 ≠ µ2
|𝑡𝐻𝑖𝑡𝑢𝑛𝑔| = (��1−��2)−𝛿0
𝑆(��1−��2) (15)
𝑆(��1−��2) = 𝑠𝑔√(1
𝑛1+
1
𝑛2) (16)
𝑠𝑔 = √(𝑛1−1)𝑠1
2+(𝑛2−1)𝑠22
𝑛1+𝑛2−2 (17)
Keterangan:
µ = nilai tengah
n = jumlah data
s = ragam

915
Dengan derajat bebas (db) sebesar n1 + n2 – 2, Sg merupakan ragam gabungan dari
kedua populasi. Keputusan jika |thitung| > ttabel(α,db) maka menolak hipotesis H0, jika
sebaliknya maka terima H0..
3. Hasil – Hasil Utama
Data yang digunakan dalam penelitian ini adalah data harian pengamatan
Epan, suhu udara rata-rata, kelembapan relatif, lama penyinaran dan kecepatan
angin. Periode data cuaca yang digunakan dan posisi stasiun cuaca disajikan pada
Tabel 1 dan Gambar 1. Data penelitian observasi sebelum digunakan dalam analisis
sudah dilakukan quality control terlebih dahulu [4]. Deskripsi statistik data evaporasi
harian di Bali menunjukkan kisaran data evaporasi harian antara 0 mm – 3,9 mm,
standar deviasi berkisar antara 1,5 – 2,0 mm dengan median antara 4,3 – 5,6 mm.
Quartil ke-1 data evaporasi harian berkisar antara 3,1 – 4,4 mm dan quartil ke-3
berkisar antara 3,0 - 6,5 mm [4].
Tabel 1. Lokasi stasiun penelitan dan periode data yang digunakan
No Stasiun
Penelitian
Lintang Bujur Ketinggian
(m)
Periode
data
1 Negara -8.3400 114.6164 23.7 1999-2012
2 Ngurah Rai -8.7450 115.1710 6.0 1979-2012
3 BBMKG
wilayah 3
-8.7392 115.1786 3.5 2002-2010
4 Sanglah -8.6769 115.2100 15.0 1995-2012
5 Kahang -8.3560 115.6110 140.0 1994-2012
Gambar 1. Posisi Stasiun Penelitian
Gambar 2 hingga 6 merupakan grafik ploting data Epan observasi dengan
hasil dugaan model rata-rata harian di masing-masing stasiun. Berdasarkan gambar,
hasil dugaan Epan model Linacre di semua stasiun overestimate dibandingkan
dengan data observasi, sedangkan model Penman dan KNF underestimate
dibandingkan data observasi. Epan hasil dugaan Wati lebih mendekati observasi
dibandingkan ketiga model lainnya, meskipun pola tidak sama kecuali di stasiun

916
Kahang yang paling mendekati pola Epan observasi. Berdasarkan pola data harian,
pendugaan metode Penman paling mendekati pola observasi meskipun
underestimate.
Gambar 2. Epan rata-rata harian hasil dugaan dengan observasi di stasiun Negara
Gambar 3. Epan rata-rata harian hasil dugaan dengan observasi di stasiun Ngurah
Rai
Gambar 4. Epan rata-rata harian hasil dugaan dengan observasi di BBMKG
Wilayah 3

917
Gambar 5. Epan rata-rata harian hasil dugaan dengan observasi di stasiun Sanglah
Gambar 6. Epan rata-rata harian hasil dugaan dengan observasi di stasiun Kahang
Epan observasi bulanan di Pulau Bali rata-rata sepanjang tahun sebesar 141
mm dengan kisaran antara 127 – 167 mm. Sedangkan Epan tahunan rata-rata sebesar
1656 mm dengan kisaran antara 1485 – 1959 mm. Pola Epan bulanan di pulau Bali
menurut Wati [4] terendah rata-rata terjadi di bulan Februari dan tertinggi di bulan
Oktober. Di pulau Bali pola Epan memiliki dua puncak yaitu pada bulan Oktober
dan bulan Maret.
Gambar 7 merupakan grafik ploting Epan rata-rata bulanan observasi dan
hasil dugaan di 5 stasiun penelitian. Gambar menunjukkan hal yang sama dengan
data rata-rata harian, yaitu model Linacre overestimate sedangkan model Penman
dan KNF underestimate dibandingkan dengan observasi di semua stasiun di Bali.
Sedangkan model pendugaan Wati yang paling mendekati nilai observasi
dibandingkan ketiga model tersebut. Besaran rata-rata bulanan Epan observasi dan
hasil dugaan disajikan pada Tabel 3 hingga Tabel 7.
RMSE digunakan untuk mengukur tingkat keakuratan hasil pendugaan suatu
model dan merupakan nilai rata-rata dari jumlah kuadrat kesalahan [10]. RMSE
dapat dinyatakan sebagai ukuran besarnya kesalahan yang dihasilkan oleh suatu

918
model pendugaan. Nilai RMSE yang rendah menunjukkan bahwa variasi nilai yang
dihasilkan oleh suatu model dugaan mendekati variasi nilai obeservasinya.
(a) (b)
(c)
(d) (e)
Gambar 7. Epan rata-rata bulanan hasil dugaan dengan observasi di stasiun cuaca
wilayah Bali
Tabel 2. Nilai RMSE dari pendugaan evaporasi data harian
No Stasiun Penelitian Penman KNF Linacre Wati
1 Negara 2.2 3.2 3.7 1.5
2 Ngurai Rai 3.0 2.4 3.3 1.8
3 BBMKG wil 3 2.5 3.6 4.1 1.8
4 Sanglah 1.9 3.1 3.9 1.4

919
5 Kahang 2.3 3.3 3.0 1.9
Hasil analisis RMSE data harian ketiga model pendugaan Epan
menunjukkan model Penman memiliki nilai terkecil dibandingkan model KNF dan
Linacre di empat stasiun cuaca di Bali yaitu di Negara, BBMKG wilayah 3, Sanglah
dan Kahang seperti yang disajikan dalam Tabel 2. Sedangkan di stasiun Ngurah Rai
nilai RMSE terendah adalah model KNF. Nilai RMSE Epan hasil dugaan Penman
bervariasi antara 1,9 hingga 3,0, model KNF 2,4 hingga 3,3, sedangkan model
Linacre 3,0 hingga 4,1. Jika dibandingkan dengan ketiga model Epan maka nilai
RMSE model Wati memiliki nilai paling rendah yaitu 1,5 hingga 1,9.
Hasil uji t uji beda nilai tengah antara populasi Epan observasi dengan hasil
pendugaan disajikan pada tabel 3. Keputusan hasil uji t menolak hipotesis H0 pada
taraf α 5%, nilai tengah pendugaan Epan metode Penman, KNF dan Linacre berbeda
nyata dengan Epan observasi di 5 stasiun penelitian, sedangkan hasil pendugaan
Wati memiliki nilai tengah yang sama dengan Epan observasi di stasiun Negara dan
Kahang, di stasiun lainnya berbeda nyata.
Pada penelitian sebelumnya, evaluasi 5 metode estimasi Epan di Florida,
Amerika Serikat [5] dilakukan untuk penggunaan jadwal irigasi dan pengisian data
Epan yang hilang. Hasil menunjukkan metode KNF memiliki RMSE paling kecil
dibandingkan dengan metode Penman, Cristiansen, Priestley-Taylor dan Linacre
sehingga metode KNF yang terbaik digunakan untuk pendugaan Epan di wilayah
tersebut.
Tabel 3. Nilai |t hitung| dengan t tabel = 1.96
No Stasiun Penelitian Penman KNF Linacre Wati
1 Negara 53.55 130.96 148.11 0.66
2 Ngurai Rai 101.21 44.39 172.44 25.42
3 BBMKG wil 3 45.78 100.59 112.85 2.84
4 Sanglah 46.17 156.07 190.60 2.11
5 Kahang 52.37 113.24 94.92 1.62

920
Tabel 4. Persentase kesalahan dari pendugaan evaporasi data bulanan di stasiun
Negara
Tabel 5. Persentase kesalahan dari pendugaan evaporasi data bulanan di stasiun
Ngurah Rai
Tabel 6. Persentase kesalahan dari pendugaan evaporasi data bulanan di BBMKG
Wilayah 3
Epan (mm) Observasi Penman % Ey KNF % Ey Linacre % Ey Wati % Ey
Januari 126 85 32 45 64 248 -97 135 -7
Februari 112 73 35 39 65 222 -99 119 -7
Maret 125 83 34 44 65 246 -97 133 -7
April 116 84 28 42 64 236 -104 126 -9
Mei 115 86 25 43 62 238 -107 131 -14
Juni 110 75 32 40 64 218 -98 123 -12
Juli 118 80 32 41 65 216 -83 126 -7
Agustus 134 93 31 45 67 218 -62 133 1
September 140 100 29 45 68 223 -59 133 5
Oktober 144 110 23 50 65 247 -72 144 0
November 130 96 27 47 64 245 -88 136 -4
Desember 115 82 29 47 59 252 -118 139 -21
rata-rata 29.8 64.3 -90.4 -6.8
tahunan 1484.8 1044.6 29.6 528.9 64.4 2808.6 -89.2 1578.8 -6.3
MetodeStasiun Negara
Epan (mm) Observasi Penman % Ey KNF % Ey Linacre % Ey Wati % Ey
Januari 158 100 36 121 24 263 -67 177 -12
Februari 147 92 38 113 23 238 -62 163 -11
Maret 167 89 47 105 37 261 -56 177 -6
April 156 99 37 114 27 252 -62 170 -9
Mei 152 103 33 135 11 255 -67 179 -17
Juni 150 96 36 145 3 240 -60 176 -18
Juli 161 95 41 164 -2 241 -50 186 -16
Agustus 177 93 48 165 7 240 -36 187 -6
September 180 85 53 136 24 238 -32 177 1
Oktober 186 97 48 129 31 259 -39 183 1
November 169 101 40 118 30 259 -53 176 -4
Desember 157 114 27 137 13 266 -69 180 -14
rata-rata 40.1 19.0 -54.5 -9.2
tahunan 1959.0 1164.5 40.6 1581.5 19.3 3010.8 -53.7 2132.0 -8.8
MetodeStasiun Ngurah Rai
Epan (mm) Observasi Penman % Ey KNF % Ey Linacre % Ey Wati % Ey
Januari 138 87 37 42 70 265 -92 134 3
Februari 121 49 59 33 73 228 -88 124 -2
Maret 134 78 42 41 69 265 -98 134 0
April 125 88 30 38 70 253 -102 130 -4
Mei 135 81 40 40 71 257 -90 136 0
Juni 135 92 32 39 71 239 -78 134 1
Juli 137 100 27 43 69 243 -77 139 -2
Agustus 150 99 34 39 74 238 -58 140 7
September 128 99 23 41 68 237 -84 134 -5
Oktober 148 103 30 42 71 247 -67 139 6
November 133 91 32 42 68 263 -97 129 3
Desember 137 78 43 41 70 267 -95 134 2
rata-rata 35.7 70.4 -85.5 0.8
tahunan 1622.4 1045.2 35.6 480.2 70.4 3001.1 -85.0 1606.5 1.0
MetodeBBMKG Wilayah 3

921
Tabel 7. Persentase kesalahan dari pendugaan evaporasi data bulanan di stasiun
Sanglah
Tabel 8. Persentase kesalahan dari pendugaan evaporasi data bulanan di stasiun
Kahang
Persentase kesalahan/error (% Ey) hasil pendugaan Epan rata-rata bulanan
terhadap data observasi di masing-masing stasiun disajikan pada tabel 4 hingga tabel
8. Berdasarkan tabel tersebut diperoleh bahwa metode Penman memiliki persentase
kesalahan paling rendah di 4 stasiun di wilayah Bali yaitu Negara, BBMKG wilayah
3, Sanglah dan Kahang dengan kisaran antara 23,8% hingga 40,1%. Sedangkan di
stasiun Ngurah Rai metode KNF memiliki persentase kesalahan paling rendah
sebesar 19%, persentase kesalahan metode KNF di stasiun lainnya antara 59,6
hingga 70,4%. Persentase kesalahan model Linacre di 5 stasiun penelitian antara -
54,5% hingga -90,4%. Sedangkan persentase kesalahan model Wati lebih kecil
dibandingkan dengan metode Penman, KNF dan Linacre yaitu sebesar -9,8% hingga
0,8%.
Epan (mm) Observasi Penman % Ey KNF % Ey Linacre % Ey Wati % Ey
Januari 143 100 30 54 63 261 -82 141 2
Februari 132 86 34 50 62 238 -81 130 1
Maret 142 107 25 56 61 263 -86 145 -2
April 140 109 22 55 61 256 -82 142 -1
Mei 135 111 18 58 57 260 -93 148 -10
Juni 122 101 17 55 54 242 -99 142 -16
Juli 129 105 19 56 56 242 -89 144 -12
Agustus 145 116 20 58 60 242 -67 147 -2
September 146 119 19 56 61 241 -65 143 2
Oktober 166 133 20 60 64 263 -59 152 9
November 148 110 25 58 61 261 -77 147 0
Desember 139 89 36 56 60 264 -90 145 -4
rata-rata 23.8 60.0 -80.7 -2.8
tahunan 1685.7 1284.7 23.8 672.4 60.1 3034.2 -80.0 1725.5 -2.4
MetodeStasiun Sanglah
Epan (mm) Observasi Penman % Ey KNF % Ey Linacre % Ey Wati % Ey
Januari 91 56 39 39 57 206 -127 109 -20
Februari 77 45 41 34 56 185 -141 94 -23
Maret 103 65 37 43 58 212 -106 117 -14
April 121 74 39 49 59 213 -77 122 -1
Mei 132 93 30 56 58 221 -68 148 -12
Juni 130 79 39 53 59 207 -59 136 -5
Juli 139 95 31 54 61 206 -48 161 -16
Agustus 153 118 23 57 63 203 -32 179 -17
September 168 123 27 57 66 205 -22 173 -3
Oktober 168 128 24 61 63 228 -36 168 0
November 142 104 27 57 60 224 -57 143 0
Desember 107 65 39 47 56 217 -103 112 -5
rata-rata 32.9 59.6 -73.0 -9.5
tahunan 1530.2 1044.8 31.7 608.1 60.3 2526.7 -65.1 1660.4 -8.5
MetodeStasiun Kahang

922
4. Kesimpulan
Hasil Evaluasi tiga model menunjukkan baik data harian maupun bulanan
metode Penman terbaik di empat stasiun yaitu di stasiun Sanglah, Kahang, Negara
dan BBMKG wilayah 3, sedangkan di stasiun Ngurah Rai metode KNF yang terbaik.
Nilai RMSE hasil pendugaan metode Penman, KNF dan Linacre lebih besar
dibandingkan dengan model pendugaan Wati menunjukkan keandalan model
pendugaan Epan dipengaruhi oleh tipe iklim. Pendugaan yang dilakukan di iklim
yang sama (meskipun hanya dengan parameter yang lebih sedikit) lebih akurat
dibandingkan dengan ketiga model tersebut yang dilakukan pada tipe iklim yang
berbeda (iklim sub tropis).
Pernyataan terima kasih. Terima kasih diucapkan kepada stasiun Badan
Meteorologi Klimatologi dan Geofisika dan Balai Besar MKG wilayah 3 di wilayah
Bali atas ketersediaan datanya dalam penelitian ini.
Referensi
[1] Penman, H.L., 1948, Natural evaporation from open water, bare soil and grass. In Proc.
of the Royal Soc. of London A: Math., Physic. and Eng. Sci. (Vol. 193, No. 1032, pp.
120-145). The Royal Society.
[2] Kohler, M.A., Nordenson, T.J. and Fox, W.E., 1955, Evaporation from pans and lakes.
[3] Linacre, E.T., 1977, A simple formula for estimating evaporation rates in various
climates, using temperature data alone. Agri. Met., 18(6), pp.409-424.
[4] Wati, T., 2015, Kajian Evaporasi Pulau Jawa dan Bali Berdasarkan Data Pengamatan
1975-2013, Tesis, Sekolah Pascasarjana Institut Pertanian Bogor.
[5] Irmak, S. dan Haman, D.Z., 2003, Evaluation of five methods for estimating class A pan
evaporation in a humid climate. Hort. Tech., 13(3), pp.500-508.
[6] World Meteorological Organization. 1992, International Meteorological Vocabulary.
Second edition, WMO-No.182, Geneva.
[7] Allen R.G., Pereira L.S., D. Raes dan M. Smith, 1998, Crop Evapotranspiration
Guidelines for Computing Crop Water Requirements, FAO Irrigation and Drainage
Paper, No 56.
[8] Lindsey, S. D., dan R. K. Farnsworth, 1997, Sources of solar radiation estimates and
their effect on daily potential evaporation for use in streamflow modeling. J. Hydrol.
201(1-4): 348-366.
[9] Hoogenboom, G., 1996, The Georgia Automated Environmental Monitoring Network.
In Preprints of the 22nd Conf. on Agri. and Forest Met., 343-346. Boston, Mass.:
American Meteorological Society.
[10] Makridakis, S., Andersen, A., Carbone, R., Fildes, R., Hibon, M., Lewandowski, R.,
Newton, J., Parzen, E. and Winkler, R., 1982. The accuracy of extrapolation (time
series) methods: Results of a forecasting competition. J. of forecast., 1(2), pp.111-153






























