Embed Size (px)
Citation preview

Interactive Visualization for Opportunistic Exploration of Large Document
Collections
Simon Lehmann∗, Ulrich Schwanecke, Ralf DornerDepartment of Design, Computer Science and Media, RheinMain University of Applied Sciences, Kurt-Schumacher-Ring 18,
65197 Wiesbaden, Germany
Abstract
Finding relevant information in a large and comprehensive collection of cross-referenced documents likeWikipedia usually requires a quite accurate idea where to look for the pieces of data being sought. A usermight not yet have enough domain-specific knowledge to form a precise search query to get the desired resulton the first try. Another problem arises from the usually highly cross-referenced structure of such documentcollections. When researching a subject, users usually follow some references to get additional informationnot covered by a single document. With each document, more opportunities to navigate are added and thestructure and relations of the visited documents gets harder to understand.
This paper describes the interactive visualization Wivi which enables users to intuitively navigateWikipedia by visualizing the structure of visited articles and emphasizing relevant other topics. Com-bining this visualization with a view of the current article results in a custom browser specially adaptedfor exploring large information networks. By visualizing the potential paths that could be taken, usersare invited to read up on subjects relevant to the current point of focus and thus opportunistically findingrelevant information. Results from a user study indicate that this visual navigation can be easily used andunderstood. A majority of the participants of the study stated that this method of exploration supportsthem finding information in Wikipedia.
Key words: information visualization, opportunistic exploration, browsing, searching, wikis
1. Introduction
A common approach to collect information abouta specific subject in large, cross-referenced docu-ment collections like the Wikipedia is to start withan already known term and open the associated ar-ticle. Within the article, links to other terms prob-ably relevant to the research are found. If morethan one article has to be read to get the desiredinformation, a user has to follow some of the linksto other articles. They usually have to be read oneat a time and again contain links to further articlesprobably relevant to the subject. While navigatingbetween several articles, a user has to keep trackof what they already have read and how the piece
∗Corresponding author. Tel.: +49 611 9495 1294; fax:+49 611 9495 1210
Email address: [email protected] (SimonLehmann)
of information they are currently reading relates toeverything they already have read. Additionally,a user might want to know what other links theyencountered in all the previously read articles andwhich therefore are probably worth following, espe-cially if many of them lead to a single article.
The problem arises from the complex structureof highly cross-referenced articles. They form a di-rected graph, which consists of hundreds of thou-sands of articles and usually significantly morelinks. The English language version of Wikipediacurrently comprises 3 million articles and over 70million links between them [28].
Common web-browsers used for exploring web-based information resources are not providing anymeans to help users with the specific tasks pre-sented when researching a subject in such a largenetwork of articles. They only provide a historyof visited pages which can be navigated forwards
Preprint submitted to Elsevier September 23, 2009

and backwards. Besides this simple linear historyof pages, they do not tell the users what other linksthey might consider following and how two differentpages are related to each other.
In this paper, we present a navigation concept forthe exploration of such large information resources,which visualizes the structure of articles a user hasalready seen and where a user might find furtherinformation related to the already researched sub-ject. While there have been similar approaches toon-line, interactive visualizations of hypertext doc-ument structures in general, our work focuses onthe additional visualization of all related links auser might want to follow, and how to help withchoosing potentially interesting articles. By apply-ing a weighting function to the yet unread articles,we can highlight more important articles and helpa user to opportunistically explore the vast amountof information.
This paper is organized as follows. In section 2we will review other approaches taken to interac-tively visualize large document structures. Section3 will briefly explain the concept of opportunisticexploration and how we are applying it to the taskof searching for information. The visualization andinteraction concept we developed is then describedin section 4. Section 5 is outlining the implemen-tation of our concept in the web-based applicationWivi1. In section 6, the set-up and results of theuser study we conducted are described and ana-lyzed respectively. In section 7, we finally give ourconclusion and present potential future work.
2. Related Work
There have been several approaches to interac-tively visualize large document collections in orderto make exploring and finding relevant informationeasier.
The InfoSky system developed by Andrews et al[3] is a visual explorer for news articles which con-tain no cross-references themselves, but are classi-fied into a hierarchy many levels deep. It visual-izes all articles at once in a galaxy of stars, whereeach article is visualized as a star. These stars areclustered by the hierarchical structure of the arti-cles they represent. Like earlier work in this field– such as the landscape metaphor ([7, 29]) or thehyperbolic browser ([20]) – this approach visualizes
1http://wivi.slashslash.de/
all documents at once and makes the documents ex-plorable by using a semantic zoom technique whichreveals individual documents. This works well witha fully known set of documents which can be hi-erarchically grouped (either manually or automat-ically). Even though visualizing large numbers ofdocuments in the range of ten to hundred thou-sands is possible, visualizing millions of documentsat once in an interactive environment is still a prob-lem [14].
Very large document collections like theWikipedia are too large to be visualized interac-tively at once and in the case of the world wideweb, the exact amount of documents and theirstructure is unknown. One approach to deal withsuch large and only partially known documentcollections is to exclusively visualize the immediatesurroundings of the document space already ex-plored by a user. The NESTOR tool implementedby Eklund et al [11] simply visualizes the historyof a user’s browsing of the world wide web. TheWebOFDAV system implemented by Huang et al.[17] (and similar, more recent systems [18, 19])provide the immediate neighbors of visited pagesas navigational elements to find new pages to visit.Most of those systems use various force-directedlayout algorithms for displaying the graph of pagesand some also use clustering methods to improvethe generated layouts. Those systems simplydisplay what a user has seen and what can beimmediately reached from there, but provide nomeans to help the user deciding which pages tovisit next.
Besides the interactive browsers for general hy-pertext documents there have been attempts tomake more specialized visual browsers for knowl-edge spaces like the Wikipedia. Hirsch et al. [16]developed two interactive visualizations of Free-base (a ”Semantic Wiki”) and Wikipedia namedThinkbase and Thinkpedia respectively. Their ap-proach uses similar techniques for visualization asthose used for general hypertext documents, bututilizes semantic web data for nodes and links. Thisleads to a different visualization concept, becausesome nodes represent actual articles while othernodes represent semantic concepts belonging to thearticles. The Thinkpedia visualization also intro-duces weighting of the semantic concepts based onthe relevance value computed by the semantic webservice used for retrieving all concepts relevant toan article. This helps a user in finding more relevantdata, but since navigating to another article results
2

in a complete regeneration of the graph which doesnot contain the previously visited articles anymore,it is only of limited use for extended exploration ofthe Wikipedia.
Another accentuation technique for expeditiouslyfinding relevant terms in text documents is thetextarc visualization [22] which displays each lineof a single text on a large circle with a very tinyfont size. Inside the circle, the words of the textare displayed with different sizes and positions ac-cording to their frequency and distribution in thetext. Words of higher frequency are made larger,and thus more visible. The position of a word isdetermined by the centroid of the points where itoccurs in the text on the circle. This allows to vi-sually spot words which are most important, andwhere the words are used predominantly in the text.Words which are used throughout the text are posi-tioned near the center of the circle, while those thatappear only in a certain section are positioned closeto that section on the circle. This visualization pro-vides a good overview of the important terms of alonger text like a book, and makes it easy to quicklynavigate to parts of the text which deal with a cer-tain term. However, it is only applicable to a singledocument which also needs to be preprocessed andthus fully known. Like other approaches which fo-cus on visualizing a single or only a few previouslyselected text documents (e.g. DocuBurst [8], Fea-tureLens [10]), this is of limited use when dealingwith a dynamically growing set of multiple articlesof an encyclopedia which are each relatively shortcompared to a book.
The usage of graph visualizations is not the onlyway to approach the problem of exploring docu-ment collections. The MedioVis system developedby Heilig et al. [15] provides multiple visualiza-tions (coordinated views) like tables, scatter plotsor node-link diagrams to search in digital libraries.It follows a top-down approach where a user is ableto look at the entire data space at once (by differ-ent selectable visualizations) and then drill downto the required information by applying differentfilters. This is similar to the galaxy of stars usedby the InfoSky system, but instead of a single vi-sualization based on a fixed hierarchical structure,MedioVis allows for a more dynamic constructionof data sets by its users.
The different systems and approaches to navigat-ing large document collections usually provide someway to navigate to new documents a user has notyet read. While some systems leave the selection of
potentially relevant material to their users, otherslike e.g. Thinkpedia provide a visual weighting ofedges to indicate how relevant two nodes are. Byweighting and highlighting new documents, userscan intuitively navigate to these documents and op-portunistically find information they are interestedin, but would not have found otherwise. This tech-nique of ’berrypicking’ [4] in online search interfacescan be supported by visualizations in different ways,as the work of [16], [23] or [6] has shown, and thusshould also be applied to exploration of large doc-ument collections.
3. Opportunistic Exploration
When researching a subject, it might happen thatusers do not have a precise understanding of whatthey are searching for. They do not know what is ofcentral importance or what exactly belongs to thesubject in question. But usually they will recognizea term they actually wanted to find or which mightbe more appropriate for the subject in question.
In order to get started, users have to pick a termthey already know. While reading the correspond-ing article, users gain more knowledge about thesubject and encounter additional cross-references toother terms potentially relevant to their research.These additional cross-references pose new navi-gational opportunities. When a term or subjectamong these is more interesting to the users thanthe current article, they will likely follow this path.This is a very natural way of searching for informa-tion [4], but unfortunately it is commonly not verywell supported by the well established informationresources available today.
To help exploring the articles of the Wikipedia,our visualization brings potentially interesting linksto new articles to the user’s attention. To determinewhich articles are presented to a user and how inter-esting articles are distinguished from other articles,we need some criteria we base our decisions on.
As said earlier, the articles and the links betweenthem form a directed graph G = (V,E), where eacharticle is represented as a vertice v ∈ V and eachlink is represented as an edge e ∈ E going from thearticle vertex where it is found to the article vertexit points to. In Wivi, this article graph contains ev-erything the user has read and everything the usercould have reached from the introductory sectionsof the articles. Initially, the graph contains justthe first article the user has started with and thearticles linked from the first section of this article.
3

Figure 1: A partial graph of a large document collection,containing all visited (filled circles) and referenced, unvisited(empty circles) articles.
Further articles and edges are added to the graphwith every new article the user visits (an exampleis seen in figure 1). Because the amount of linksfound in a single article can easily get very large,only links found in the first section of the article areused to add new navigational opportunities to thegraph. This decision is based on the assumption,that the most important cross-references are foundin the introductory section, where a rough overviewof the article is given.
Among the articles not yet read are some ofhigher importance than others. While it is impossi-ble to know what a user actually is searching for, wecan make some assumptions about their potentialinterests based on the history of articles they read.We define a relative degree of interest (DOI) a userhas in an article based on the structure and historyof the article graph. Every article in the graph hassome importance to a user which is independent ofwhich article they are currently reading. This is thea-priori-importance (API) of an article. Addition-ally, articles gain or loose importance depending onthe current focus of interest of the user. How muchan article gains or looses is defined by the distance
(D) between this article and the current focus ofthe user. These measures can be combined into afunction yielding the current DOI of an article v:
DOI(v) = API(v)−D(v)
This function is essentially the same as the DOIfunction defined by Furnas [13], except we define D
not as a distance between two points.By assuming that users are interested in all arti-
cles they read and that the links the authors of thearticles have placed are sensible, we inferred thatan unvisited article with more inbound links fromalready visited articles can be seen as more impor-tant to a user. This is used asAPI of an unvisitedarticle in the article graph. With dG(v) being theinbound degree of an article v and ∆(G) the largestdegree over all vertices, API of the unvisited arti-cles can be formally defined as:
API(v) =dG(v)∆(G)
(1)
Because users are potentially more interested inarticles they recently read, and are less interestedin articles they visited in the beginning, we use theage of the visited articles to weight their outboundlinks. The age of a visited article is determined bythe number of articles a user has visited since thelast visit to that article. In other words, the age ofeach visited article increases by one with each newarticle a user visits. This can be seen as the tem-poral distance between the current focus of interestand the focus at the time the user was reading aprevious article. The temporal distance D of anunvisited article v can then be defined as:
D(v) =1
dG(v)A(G)
�
vi∈NG(v)
a(vi) (2)
A(G) is the highest age of all visited vertices, a(x)the age of a single vertex and NG(x) the neighbor-hood of a vertex.
Those two functions define how the DOI of eachunvisited article is determined. For every unvisitedvertex v of the graph G, the DOI function assignsa degree of interest to that vertex depending onthe already visited vertices. It yields a value in theinterval [−1, 1], where −1 represents the lowest and1 represents the highest degree of interest.
In essence, this function provides a guess on whata user might read next based on the history of vis-ited articles, weighted by the order they were vis-ited. Based on this DOI function, our visualizationis able to put emphasis on potentially interestingarticles a user might be looking for. When present-ing the user these potential next articles, they are
4

enabled to opportunistically choose the article theywere actually looking for.
4. Interactive Visualization
The goal of Wivi is on the one hand to preventthe user getting lost in the vast amount of articlesto explore and on the other hand to highlight op-portunities for their next navigation step. Whilethis might be done solely in the article text itself,there are several reasons why a separate graphicalrepresentation is more suitable for this purpose.
The amount of text present in most articles usu-ally is large enough to span multiple screen pageseven on large displays. A highlighting techniqueapplied to links within a text can only bring at-tention to links currently visible within the currentwindow. While the problem of highlighting poten-tially interesting links in the current text might beovercome in some way, it is considerable more diffi-cult to maintain a representation of the previouslyvisited articles and their connections to the currentarticle just within the text itself, because not everyarticle previously visited is necessarily present as ahyperlink in the text.
In order to present this information to the user,a separate representation of the articles needs to beprovided. By choosing a graphical representationover a simple textual listing of the browsing his-tory, the connections between the history of visitedarticles and potentially interesting, yet unvisited ar-ticles can be visualized.
Our visualization is based on the article graphG = (V,E), as defined earlier. Every node ofthis graph is visualized as a text label on a greybackground shape. The visualization strictly distin-guishes between visited and unvisited articles, bothin shape and layout of the nodes, as they fulfill twodifferent functions – visualizing the past and thepossible future. A schematic view of the generallayout can be seen in figure 2.
The visited articles represented by circularshapes and are laid out by using the radial-tree al-gorithm [9]. In order to use this algorithm, a treehas to be generated from the general article graph.This is done by using a breadth-first traversal start-ing from the first visited article on the graph, obey-ing the direction of edges and stopping at unvisitedarticles. The layout algorithm then starts at theroot of the tree (the first visited article) and laysout each node by using preorder traversal. Thefirst article is put into the center of the viewport
Figure 2: Placement of unvisited arcticles on concentric cir-cles based on their DOI-value around the already visited ar-ticles which are laid out using a radial tree algorithm.
and each level of depth of the tree is displayed us-ing a circular layout where the radius increases witheach level. Both the edges present in the generatedtree as well as those present in the article graph aredrawn as straight, gray lines between the nodes.The tree edges are drawn slightly wider and darkerthan the other edges to make the hierarchy of thenavigation history stand out.
The still unvisited articles are represented byrectangular shapes, and are laid out on three ringsaround the visited articles. Which ring an articleis assigned to is determined by the DOI functionas defined earlier. Each ring represents a third ofthe the functions’ range ([−1; 1]). An article foundto be more relevant is placed on a ring closer tothe center articles. This proximity to the alreadyvisited articles indicates to the user that this arti-cle is considered as potentially important to whatthey are searching for and might be worth reading.Most edges connected to unvisited articles are hid-den to reduce the visual clutter they would produceotherwise. Only the edges connected to the articlecurrently read by the user are shown.
Due to the space consuming nature of articletexts and the visualization of structural informa-tion, they have to be separated from each other.However, the user should be able to keep the con-nection between the structure and the currently
5

Figure 3: The user interface of Wivi. On the left, the currentarticle text is displayed, on the right the visualization of thearticle graph.
viewed article. As the work of Lai et al. [19] indi-cates, users do not want to use graphical represen-tations alone for navigation. Thus, Wivi providesthe user with an integrated browser, which containsboth the visualization and the display of the currentarticle itself.
Because the article text and the visualized articlegraph are displayed together, both can be used fornavigation. The user can read through the articleand click on any link to another article, just like in astandard web-browser. Alternatively, the user canalso click on any article node in the visualization.In either way, the application then loads the new ar-ticle and inserts it and any newly found referencedarticles into the article graph. To make the connec-tion between the article text and the visualizationmore apparent, the corresponding article node ofthe currently loaded article and its connected edgesare highlighted in green. Also, when the user hov-ers over a link in the article text, which has a cor-responding node in the article graph, this node andits edges are temporarily highlighted in blue (seefigure 3). This highlighting is also done, when theuser hovers over a node in the article graph itself.In this case, all hidden edges are made visible dur-ing highlighting, which allows the user to find outwhich unvisited articles are referenced by a certainvisited article or which visited articles reference acertain unvisited article (see figure 4).
When changes of the graph or layout of the vi-sualization are made, the user must be able to un-derstand how it has changed. Not only does this
Figure 4: Highlighting of visited (left) and unvisited (right)article nodes when hovered over with the mouse. All out-and inbound edges are made visible.
help maintaining the mental map, but it is alsoimportant if the user wants to go back to earliervisited articles and thus has to locate them. Tran-sitions between two states of the graph can be ani-mated, which allows the user to efficiently perceivethe changes and maintain their mental map [21, 12].The animation of position changes, which happenswhen the DOI of one ore more unvisited articleschanges or new articles are inserted, are done byinterpolating between polar coordinates. Unlike aninterpolation between Cartesian coordinates, thiscreates circular movements and results in reducedcrossing of animation paths, which helps the user tofollow the transition between two states [30]. Fig-ure 5 shows how the visualization changes when newarticles are visited.
Besides the interaction necessary to navigate be-tween articles, the application also provides a zoomlens in the visualization which follows the mousepointer. It enlarges nodes close to the mousepointer and makes them fan out, to make readingand selecting overlapping nodes easier. The dis-tortion of the node positions is also based on polarcoordinates which integrates well with the other an-imations.
5. Implementation
We realized Wivi as a web-based application.While our approach to navigate Wikipedia and sim-ilar document structures could have been imple-mented in a native desktop application, we decidedagainst it. Today, web-based applications can berun in a common web-browser present on virtuallyevery desktop computer with internet connectivity.Wikipedia itself is a web-based application whichmakes its information easily and simply accessibleby anyone with a web-browser. Because we want
6

Figure 5: An example of how Wivi visualizes the history and navigational opportunities over the course of time. The currentlyread article is marked green and all its out- and inbound edges are shown. The different computed DOI values, changing withevery navigation step, can be clearly seen.
7

to improve the exploration of Wikipedia, our visu-alization has to be at least equally simple to accessand use.
The visualization and user interface part of theapplication was developed with the Adobe FlexFramework [2] and the prefuse flare visualization li-brary [27]. By using the Adobe Flash [1] platform,which is available on most web-browsers, we wereable to provide an interactive visualization whichcan be used inside a normal web-browser and stilluse high quality drawing and animation techniqueswith reasonable performance. This also had pos-itive effects on the complexity of the implementa-tion, because we did not have to deal with the state-less nature of HTTP.
Because of the security restrictions of today’sweb-browsers and especially the Adobe FlashPlayer in which the client part is run, we couldnot directly access the data of the Wikipedia fromwithin the client application itself. Instead weneeded to implement a server-side proxy, which pro-vides the necessary data needed for the visualiza-tion – mainly article texts and links to other arti-cles. The server-part was implemented in Java as aWebservice. It was deployed on an Apache Tomcat[25] installation with an Apache Axis2 [24] webser-vice engine.
To retrieve the article texts and the links to otherarticles found within one article, we use the HTTP-based API provided by the MediaWiki software onwhich the Wikipedia runs. This API allows access-ing most of the information the wiki contains. Touse the API from our webservice, we developed aclient library in Java, which hides the details ofsending and retrieving the raw data over the HTTPprotocol from the application.
The separation into a client part, which is respon-sible for the graphical user interface and the stateof the application, and a server part, which imple-ments the operations to retrieve article texts andlinks to other articles, makes it possible to changethe way how the visualized data is retrieved. Espe-cially, it allows to change how links to other articlesare retrieved and thus makes implementing othermethods for extracting links from articles simple.As mentioned earlier, we currently use the linksfrom the content of the introductory section of thearticle.
Figure 6: The architecture of Wivi.
6. Evaluation
After implementing Wivi we conducted ananonymous remote usability test to gain data onhow people benefit from our visualization whensearching for information in the Wikipedia. Weonly asked the participants to perform one singletask: To search for some subject they were inter-ested at the time. We also offered a random selec-tion of articles to choose from as a starting point, incase a participant could not think of a subject theywere interested in. In order to allow the partici-pants to familiarize with Wivi and the task, everyparticipant was allowed to perform the task up tofive times.
Additionally, all participants had to fill in a ques-tionnaire, where they had to answer the followingquestions:
1. How often do you use the Wikipedia?2. Do you use the search feature of the
Wikipedia?3. How many links do you follow on average, when
doing research on a subject?4. How do you rate your computer usage and
skills?5. How well did you know ...? (This question
was asked for every subject a participant hadsearched for)
6. How much did the graphical representation ofthe visited articles help you with your search?
8

7. How much did the weighting of unvisited arti-cles help you with your search?
8. How do you rate the usefulness of the graphicalrepresentation in general?
9. Would you use the application for future re-search in the Wikipedia?
6.1. Set-Up
Due to the web-based nature of Wivi, we wereable to conduct a remote usability test instead ofdoing a test in a local usability lab. By choosinga remote usability test, we could reach significantlymore participants. It also resembles more closelythe typical scenario a user encounters when doingsome research on a subject they are interested in[26].
As the test was to be conducted by the userthemselves, without a moderator guiding them, wehad to make the test completely self-explanatoryand keep the tasks they should perform very sim-ple and easy to understand. The test consisted ofthree parts, each separately presented on a sim-ple web page. The first page, which was the entrypoint to the test, contained a short introduction toWivi, the goals of the test and the following steps.When visitors agreed to participate in the test, theywere taken to a separate page on which the taskthey should perform was explained. This page alsocontained a link to open the application in a newbrowser-window. When the users finished the task,they were presented the final questionnaire whichthey had to complete.
Each participant was assigned a random andunique session identifier at the beginning of thetest, which was then used to associate the activ-ity and questionnaire data to the participants. Theactivity of a participant within the application wasrecorded on the server via a separate web-service,which stored the type of activity together with thesession identifier and the current timestamp. Thisdata was used to reconstruct and understand whatthe participants were doing and how long they wereusing the application.
6.2. Results
During the period of 14 days in which the test wasconducted, a total of 157 people were willing to par-ticipate in the test. Out of those, 72 participants(45.9%) finished the test by filling in the question-naire. From the recorded activity of each partic-ipant, we computed the time a participant spent
using the application by computing the differencein time between the first and last action a user hasperformed. This duration was then used to filterout the data of those participants, who had spentless than 100 seconds using the application. Thiswas done because we assume that at lower periodsof use, a reasonable evaluation of the applicationis not possible. After this final filtering, the dataof 56 participants remained and were used for ourfurther statistical evaluation.
For statistical tests, we used the Mann-WhitneyU Test for unpaired and the Wilcoxon signed ranktest for paired values [5]. The significance thresholdwas chosen at p = 0.05 and p values lower than0.003 are regarded as highly significant.
The majority of participants (69.6 percent) foundthe user interface of Wivi easy to understand anduse. This indicates that further usage was not pre-vented by a cumbersome or unclear interface andthus the main part of the session duration was spentwith actually using the application. It might alsobe inferred that the other ratings are based on theactual usefulness of the visualization.
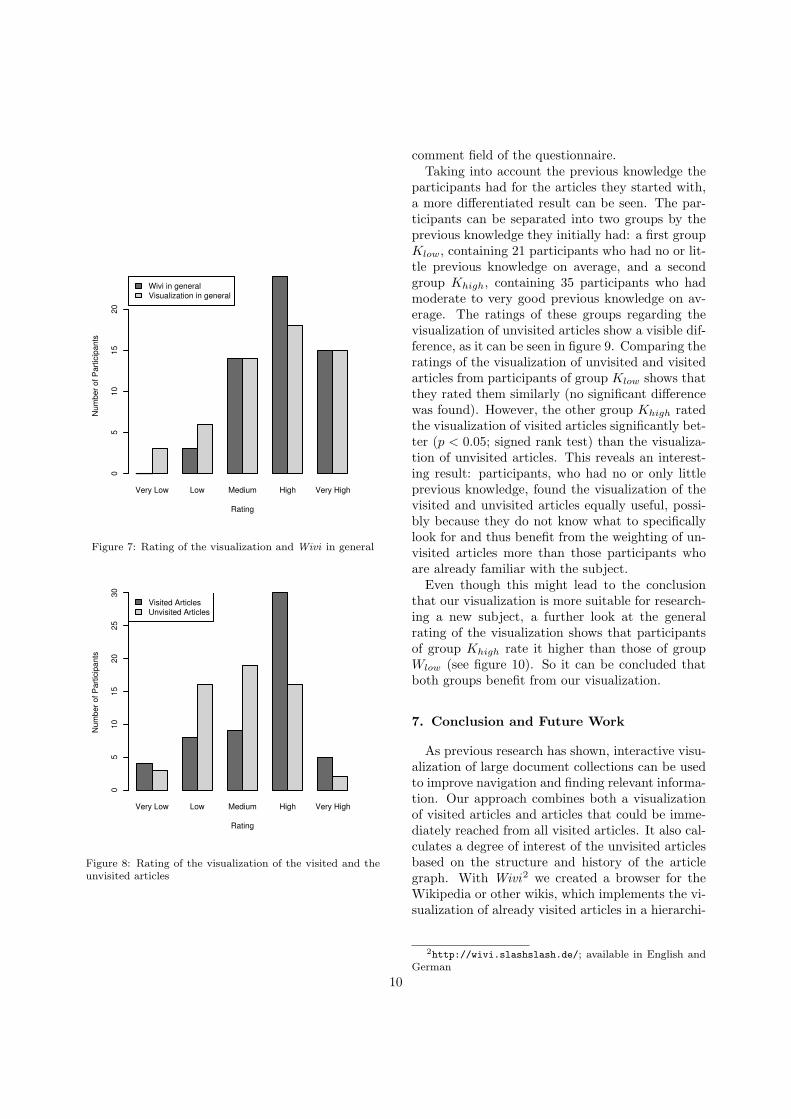
As figure 7 shows, the usefulness of the visu-alization and the application was positively ratedby the majority of participants. The question, ifthey would use Wivi for future research in theWikipedia, was confirmed by 74.5 percent of all par-ticipants. This already indicates that our visualiza-tion presents a viable alternative for searching andbrowsing the Wikipedia and can be used withoutfurther instructions.
Comparing the subjective usefulness of the visu-alization of visited articles to the visualization ofunvisited articles shows a highly significant (p <
0.003; signed rank test) difference. While the lay-out of the unvisited articles was seen as moderatelyuseful, a majority of participants declared that thevisualization of visited articles was useful for search-ing the Wikipedia (see figure 8). These differentratings are probably caused by the fact that the vi-sualization of visited articles has a clear structurewhich is based on the navigational history and thelinks between the articles. This structure is easierto comprehend, because it is directly controlled bythe user and is always made visible by the edgesdrawn between the nodes. On the other hand, theway how unvisited articles are placed on the outerrings might not be immediately understood, due tothe invisibility of the edges leading to the nodes andthe implied age of the visited articles. This was alsoexplicitly mentioned by several participants in the
9
Very Low Low Medium High Very High
Rating
Num
ber
of P
art
icip
an
ts
05
10
15
20
Wivi in generalVisualization in general
Figure 7: Rating of the visualization and Wivi in general
Very Low Low Medium High Very High
Rating
Num
ber
of P
art
icip
ants
05
10
15
20
25
30
Visited ArticlesUnvisited Articles
Figure 8: Rating of the visualization of the visited and theunvisited articles
comment field of the questionnaire.Taking into account the previous knowledge the
participants had for the articles they started with,a more differentiated result can be seen. The par-ticipants can be separated into two groups by theprevious knowledge they initially had: a first groupKlow, containing 21 participants who had no or lit-tle previous knowledge on average, and a secondgroup Khigh, containing 35 participants who hadmoderate to very good previous knowledge on av-erage. The ratings of these groups regarding thevisualization of unvisited articles show a visible dif-ference, as it can be seen in figure 9. Comparing theratings of the visualization of unvisited and visitedarticles from participants of group Klow shows thatthey rated them similarly (no significant differencewas found). However, the other group Khigh ratedthe visualization of visited articles significantly bet-ter (p < 0.05; signed rank test) than the visualiza-tion of unvisited articles. This reveals an interest-ing result: participants, who had no or only littleprevious knowledge, found the visualization of thevisited and unvisited articles equally useful, possi-bly because they do not know what to specificallylook for and thus benefit from the weighting of un-visited articles more than those participants whoare already familiar with the subject.
Even though this might lead to the conclusionthat our visualization is more suitable for research-ing a new subject, a further look at the generalrating of the visualization shows that participantsof group Khigh rate it higher than those of groupWlow (see figure 10). So it can be concluded thatboth groups benefit from our visualization.
7. Conclusion and Future Work
As previous research has shown, interactive visu-alization of large document collections can be usedto improve navigation and finding relevant informa-tion. Our approach combines both a visualizationof visited articles and articles that could be imme-diately reached from all visited articles. It also cal-culates a degree of interest of the unvisited articlesbased on the structure and history of the articlegraph. With Wivi2 we created a browser for theWikipedia or other wikis, which implements the vi-sualization of already visited articles in a hierarchi-
2http://wivi.slashslash.de/; available in English andGerman
10

Previous Knowledge
Ratin
g
Unvisited ArticlesVisited Articles
None Little Moderate Good Very good
Very
Low
Low
Modera
teH
igh
Very
hig
h
Figure 9: Rating of the visualization of the visited and un-visited articles, grouped by the average previous knowledgethe participants had for the chosen subjects
Previous Knowledge
Ratin
g
None Little Moderate Good Very good
Very
Low
Low
Modera
teH
igh
Very
hig
h
Figure 10: Rating of the visualization in general, groupedby the average previous knowledge the participants had forthe chosen subjects
cal tree layout and shows the related unvisited ar-ticles weighted by their degree of interest on circlesaround the visited articles. As the result of a usertest shows, this approach is generally accepted andpositively perceived as a viable interface to browseand search the Wikipedia. Especially the visualiza-tion of the visited part was well received, but alsoour concept of weighting and displaying the unvis-ited articles to enable opportunistic exploration ap-pears to be promising.
As future work it would be interesting to exploreother ways to visualize the unvisited articles andhow the underlying weighting might be improved.One way to improve the weighting might be to takethe categories of the articles into account, whichprovide some sort of clustering of articles. Also,it would be interesting to know how different ap-proaches to extract the links between articles affecthow well the concept of opportunistic explorationworks. While Wivi uses a simple way to retrieveother articles, the implementation of more sophis-ticated methods could be easily integrated.
References
[1] Adobe Systems Incorporated, 2009. Adobe FlashPlayer. http://www.adobe.com/de/products/flashplayer/.
[2] Adobe Systems Incorporated, 2009. Adobe Flex 3.http://www.adobe.com/de/products/flex/.
[3] Andrews, K., Kienreich, W., Sabol, V., Becker, J.,Droschl, G., Kappe, F., Granitzer, M., Auer, P.,Tochtermann, K., 2002. The infosky visual explorer:exploiting hierarchical structure and document similar-ities. Information Visualization 1 (3/4), 166–181.
[4] Bates, M. J., 1989. The design of browsing and berryp-icking techniques for the online search interface. OnlineReview 13 (5), 407–424.
[5] Bradley, J. V., 1968. Distribution Free Statistical Tests.Prentice Hall, Englewood Cliffs, NJ, USA.
[6] Bryan, D., Gershman, A., 1999. Opportunistic explo-ration of large consumer product spaces. In: EC ’99:Proceedings of the 1st ACM conference on Electroniccommerce. ACM, New York, NY, USA, pp. 41–47.
[7] Chalmers, M., 1993. Using a landscape metaphor torepresent a corpus of documents. In: Proceedingsof the European Conference COSIT ’93. Springer,Berlin/Heidelberg, Germany, pp. 377–390.
[8] Collins, C., Carpendale, S., Penn, G., 2009. Docuburst:Visualizing document content using language structure.In: Proceedings of Eurographics/IEEE-VGTC Sympo-sium on Visualization (EuroVis ’09). Eurographics As-sociation, pp. 1039–1046.
[9] Di Battista, G., Eades, P., Tamassia, R., Tollis, I. G.,1998. Graph Drawing: Algorithms for the Visualizationof Graphs. Prentice Hall, Upper Saddle River, NJ, USA.
[10] Don, A., Zheleva, E., Gregory, M., Tarkan, S., Auvil,L., Clement, T., Shneiderman, B., Plaisant, C., 2007.
11

Discovering interesting usage patterns in text collec-tions: integrating text mining with visualization. In:CIKM ’07: Proceedings of the sixteenth ACM confer-ence on Conference on information and knowledge man-agement. ACM, New York, NY, USA, pp. 213–222.
[11] Eklund, J., Sawers, J. Zeiliger, R., 1999. Nestor nav-igator: A tool for the collaborative construction ofknowledge through constructive navigation. In: Proc.AusWeb ’99: Fifth Australian World Wide Web Con-ference.
[12] Friedrich, C., Houle, M. E., 2002. Graph drawing inmotion ii. In: GD ’01: Revised Papers from the 9thInternational Symposium on Graph Drawing. Springer,London, UK, pp. 220–231.
[13] Furnas, G. W., 1986. Generalized fisheye views. SIGCHIBull. 17 (4), 16–23.
[14] Harrison, C., 2006. Wikiviz: Visualizing wikipedia.http://www.chrisharrison.net/projects/wikiviz/index.html.
[15] Heilig, M., Demarmels, M., Konig, W. A., Gerken, J.,Rexhausen, S., Jetter, H.-C., Reiterer, H., 2008. Medio-vis: visual information seeking in digital libraries. In:AVI ’08: Proceedings of the Working Conference on Ad-vanced Visual Interfaces. ACM, New York, NY, USA,pp. 490–491.
[16] Hirsch, C., Hosking, J., Grundy, J., Feb. 2009. In-teractive visualization tools for exploring the seman-tic graph of large knowledge spaces. In: Workshop onVisual Interfaces to the Social and the Semantic Web(VISSW2009).
[17] Huang, M. L., Eades, P., Cohen, R. F., 1998. Webof-dav — navigating and visualizing the web on-line withanimated context swapping. In: WWW7: Proceedingsof the seventh international conference on World WideWeb 7. Elsevier B. V., Amsterdam, The Netherlands,pp. 638–642.
[18] Huang, M. L., Eades, P., Lai, W., 2003. On-line visual-ization and navigation of the global web structure. In-ternational Journal of Software Engineering and Knowl-edge Engineering 13 (1), 27–52.
[19] Lai, W., Huang, X., Nguyen, Q. V., Huang, M. L., 2007.Applying graph layout techniques to web informationvisualization and navigation. In: CGIV ’07: Proceed-ings of the Computer Graphics, Imaging and Visualisa-tion. IEEE Computer Society, Washington, DC, USA,pp. 447–453.
[20] Lamping, J., Rao, R., 1994. Laying out and visualizinglarge trees using a hyperbolic space. In: UIST ’94: Pro-ceedings of the 7th annual ACM symposium on User in-terface software and technology. ACM, New York, NY,USA, pp. 13–14.
[21] Misue, K., Eades, P., Lai, W., Sugiyama, K., 1995. Lay-out adjustment and the mental map. Journal of VisualLanguages & Computing 6 (2), 183–210.
[22] Paley, W. B., 2002. Textarc: Showing word frequencyand distribution in text. Interactive Poster at the IEEESymposium on Information Visualization 2002 (InfoVis2002).
[23] Pu, P., Janecek, P., Jun. 2003. Visual interfaces for op-portunistic information seeking. In: Proceedings of the10th International Conference on Human - ComputerInteraction (HCII ’03). Human Computer InteractionGroup, Swiss Federal Institute of Technology, Lausanne(EPFL), Lawrence Erlbaum Associates, Philadelphia,PA, USA, pp. 1131–1135.
[24] The Apache Software Foundation, 2009. Apache Axis2.http://ws.apache.org/axis2/.
[25] The Apache Software Foundation, 2009. Apache Tom-cat. http://tomcat.apache.org/.
[26] Tullis, T., Fleischman, S., McNulty, M., Cianchette, C.,Bergel, M., Jul. 2002. An empirical comparison of laband remote usability testing of web sites. In: Proceed-ings of the Usability Professionals Association Confer-ence. UPA, Bloomingdale, IL, USA.
[27] UC Berkeley Visualization Lab, 2009. prefuse flare vi-sualization toolkit. http://flare.prefuse.org/.
[28] Wikimedia Foundation, 2009. Data dump of the englishlanguage wikipedia. http://download.wikimedia.org/enwiki/20090816/.
[29] Wise, J. A., Thomas, J. J., Pennock, K., Lantrip, D.,Pottier, M., Schur, A., Crow, V., 1995. Visualizingthe non-visual: spatial analysis and interaction withinformation from text documents. In: INFOVIS ’95:Proceedings of the 1995 IEEE Symposium on Informa-tion Visualization. IEEE Computer Society, Washing-ton, DC, USA, pp. 51–58.
[30] Yee, K.-P., Fisher, D., Dhamija, R., Hearst, M., 2001.Animated exploration of dynamic graphs with radiallayout. INFOVIS ’01: Proceedings of the IEEE Sympo-sium on Information Visualization 2001, 43–50.
12





























