Embed Size (px)
Citation preview

Intel Xeon Phi Programming Models���
Gilles Fourestey, Future Systems Group, CSCS Euro Trilinos User Group
June 2013

What is Xeon Phi? You might have heard it referred to as MIC (many
integrated cores) or KNC (Knights Corner).
It is a recently released accelerator based on x86 architecture (Pentium III)
Designed as a 1-Tflops co-processor “Now you can think reuse rather than recode with x86 compatibility” (Intel website) Really?...

What Xeon Phi is
Technical specifications:
• 60 x86-based cores at 1.052Ghz , 4 hardware threads per core,
• Coherent cache,
• 512-bit SIMD, FMAs (1011 Gflops Peak, ~800 measured)
• 8GB (less than 6 in reality) of GDDR5 (320 GB/s peak, ~170 measured)
• PCIe Gen 2
• TDP of 235+W
• Lightweight Linux OS, IP addressable (ssh).
This is the key feature of the MIC:
• - Node vector performance is 5 times that of SB node.
• - Core scalar performance is 1/10th of SB core.
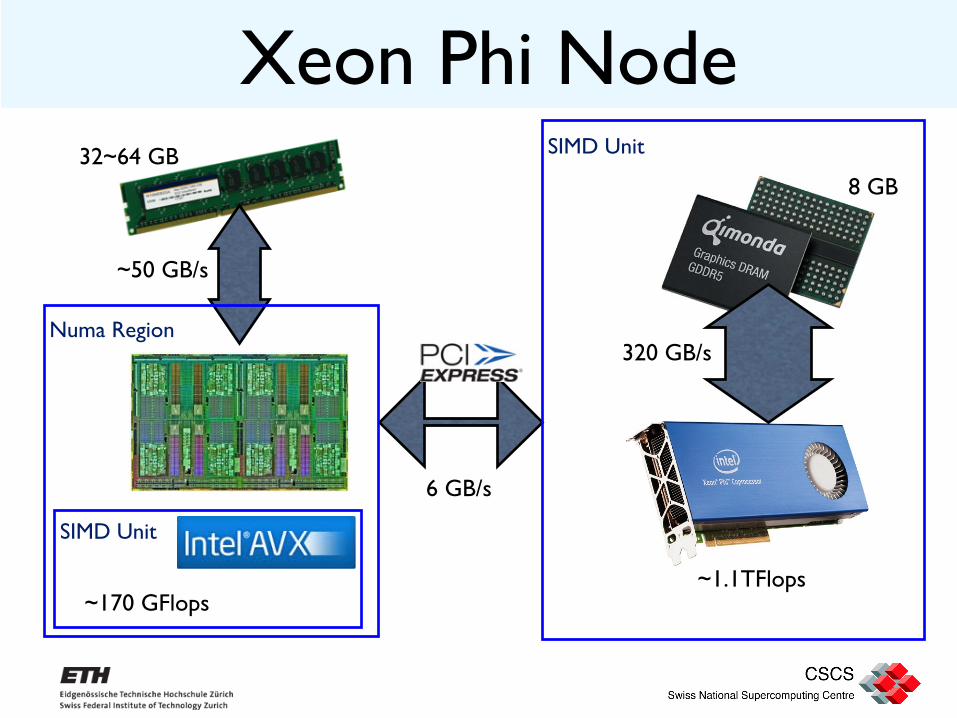
Xeon Phi Node
6 GB/s
320 GB/s
~1.1TFlops
~50 GB/s
~170 GFlops
Numa Region
SIMD Unit
SIMD Unit 32~64 GB 8 GB

Xeon Phi Node
6 GB/s
320 GB/s
~1.1TFlops
~50 GB/s
~170 GFlops
32~64 GB
8 GB

Xeon Phi vs. GPUs There are some similarities between Xeon Phi and GPUs
• Both require a host CPU (for now…)
• Communicate with the host CPU via PCI
• Very fast at data-parallel computational tasks (like many of those we tackle in HPC), very slow at everything else
• High memory bandwidth
• Allow the host CPU to “offload” work to the device
• Both use “long” vectors (8 DP on Xeon Phi, 32 DP on GPUs), FMA
But with some interesting differences
• Based on x86 architecture
• Fully coherent cache (MESI protocol)
• OpenMP code for x86 can be compiled to run on KNC with little or no modification.
• Offer some useful alternatives to offload operation (ssh, native, MPI)

What Xeon Phi is NOT Technical specifications:
• ~60 x86-based cores but is not x86 compatible (cross-compilation needed)
• Coherent cache but evidences show cache behavior similar to GPU
• FPU is powerful (32 8-fold DP registers, FMA), nice masked instructions but some serious limitations (permutations, broadcast in the 256-bit lanes only…)
• You can run in native mode, but performance will be limited:
• Memory size
• Single core performance is REALLY slow, Amdahl’s Law will hit hard
• Xeon standard tools (MPI, OpenMP, pthreads, intrinsics…) are available in offload mode but require specific code to match the architecture (SMT, FPU…).

Is Xeon Phi good for me?
You will benefit from using Xeon Phi if you can:
- take advantage of high memory bandwidth
- take advantage of wide vectors
- take advantage of the high thread count
If you cannot, you’re probably better off with Xeons.
Bottom line: if you want performance, you will need to refactor your code by extracting parallelism (OpenMP, SIMD vectorization, cilk, OpenCL…). This is a least the same amount of work you would put into porting to CUDA. However, optimizing for Xeon Phi will also benefinit Xeon.
http://software.intel.com/en-us/articles/is-the-intel-xeon-phi-coprocessor-right-for-me

Programming Models There are three different routes that we can take to
- Native: Recompiling source code to run directly on coprocessor as a separate many-core SMP compute node
- Symmetric: Using each coprocessor as a node in an MPI cluster or, alternatively, as a device containing a cluster of MPI nodes
It is possible to use the Xeon Phi as a standard Xeon … but you will not get good performance because Xeon is focusing on single core performance while Xeon Phi is focusing on node performance.
- Offload: Using pragmas to augment existing codes so they offload work from the host processor to the Intel Xeon Phi coprocessors(s) or accessing the coprocessor as an accelerator through optimized libraries such as the Intel MKL (Math Kernel Library)
$> mpirun -n 2 -host <hostname> ./whatever.on.host : -n 3 -host mic0 ./whatever.on.mic : -n 5 -host mic1 ./whatever.on.mic

Language Extensions for Offload
… or LEO, Intel’s programming model for offload
- Based on pragmas (like OpenMP),
- Works alongside OpenMP,
- Similar to OpenAcc in spirit, very different in implementation.

Offload dgemm with LEO In offload mode, functions that will be executed on the Xeon Phi have to
be incapsulated using a special function in order to tell the compiler to create a compatible symbol for this function:
__declspec(target(mic)) void gemm( char transa, char transb, int M, int N, int K, double alpha, double* A, int lda, double* B, int ldb, double beta, double* C, int ldc) { DGEMM( &transa, &transb,&M, &N, &K, &alpha, A, &lda, B, &ldb, &beta, C, &ldc); }

Offload dgemm on Xeon Phi Then we create an offload region with variables that need to be sent to
the device:
#pragma offload target(mic) in(A[0:M*K]:align(Align)) in(B[0:K*N]:align(Align)) inout(Cg[0:M*N]:align(Align)) inout(otime) { otime -‐= mysecond(); gemm( transa, transb, M, N, K, alpha, A, lda, B, ldb, beta, Cg, ldc); otime += mysecond(); }

DGEMM on Xeon Phi Our Xeon Phis have 60 cores, 4 HW threads/core:
$ export OMP_NUM_THREADS=240
Let’s run the code:!
$./dgemm_offload!
M N K = 10000 ! 10000 ! 10000 ! Gflops Max: 285.3
Theoretical peak performance is:
peak = (# cores)*(vector size)*(ops/cycle)*(frequency)
peak = 60*8*2*1.052 = 1011 Gflops!
So, where are the flops?
$ export OMP_NUM_THREADS=240
$ ./dgemm_offload
M N K = 10000 10000 10000 Gflops Max: 285.3

Affinity Affinity is VERY important on manycore systems. By setting KMP_AFFINITY, let‘s see how the code
behaves.
Scatter affinity:
$ export MIC_ENV_PREFIX=MIC; export MIC_KMP_AFFINITY=scatter; ./dgemm_offload!
PEs = 1, M N K = 10000 ! 10000 ! 10000 ! Gflops Max: 374.741736!
Compact affinity:
$ export MIC_KMP_AFFINITY=compact; ./dgemm_offload!
PEs = 1, M N K = 10000 ! 10000 ! 10000 ! Gflops Max: 641.1 !
Balanced affinity:!
$ export MIC_KMP_AFFINITY=balanced; ./dgemm_offload!
M N K = 10000 10000 10000 Gflops Max: 641.63!
Balanced was introduced to the MIC and seems to be a good trade-off. Compact is also working in this case. However, we are far from the peak performance.
$ export MIC_ENV_PREFIX=MIC; export MIC_KMP_AFFINITY=scatter; ./dgemm_offload M N K = 10000 10000 10000 Gflops Max: 374.741736
$ export MIC_KMP_AFFINITY=compact; ./dgemm_offload M N K = 10000 10000 10000 Gflops Max: 641.1
$ export MIC_KMP_AFFINITY=balanced; ./dgemm_offload
M N K = 10000 10000 10000 Gflops Max: 641.63

Alignment As a general rule, we need to align arrays to the vector size. For example, 16-byte alignement for SSE
processors, 32-byte alignement for AVX processors, 64-byte for Xeon Phi. Unfortunately, in offload mode the compiler will consider that arrays alignment is the same on both the host and the device. We need to change the alignement on the host to match that on the device:
double *A = (double*) _mm_malloc(sizeof(double)*size_A, Alignment);!
Alignment = 16:!
$./t3_offload!
M N K = 10000 10000 10000 Gflops Max: 641.63!
Alignement = 64:
$ ./t3_offload!
M N K = 10000 10000 10000 Gflops Max: 724.22!
A little (a lot) better...

Huge pages
As you saw before, huge pages might help. Let’s try this here:
$ export MIC_USE_2MB_BUFFERS=100M!
This means that for any array allocation bigger than 100MB, use use pages.
$ ./t3_offload !
PEs = 1, M N K = 10000 10000 10000 Gflops Max: 806.9!
That’s about 80% of peak performance. This is the best we can get… for now.
When working on the MIC use those techniques as much as you can!
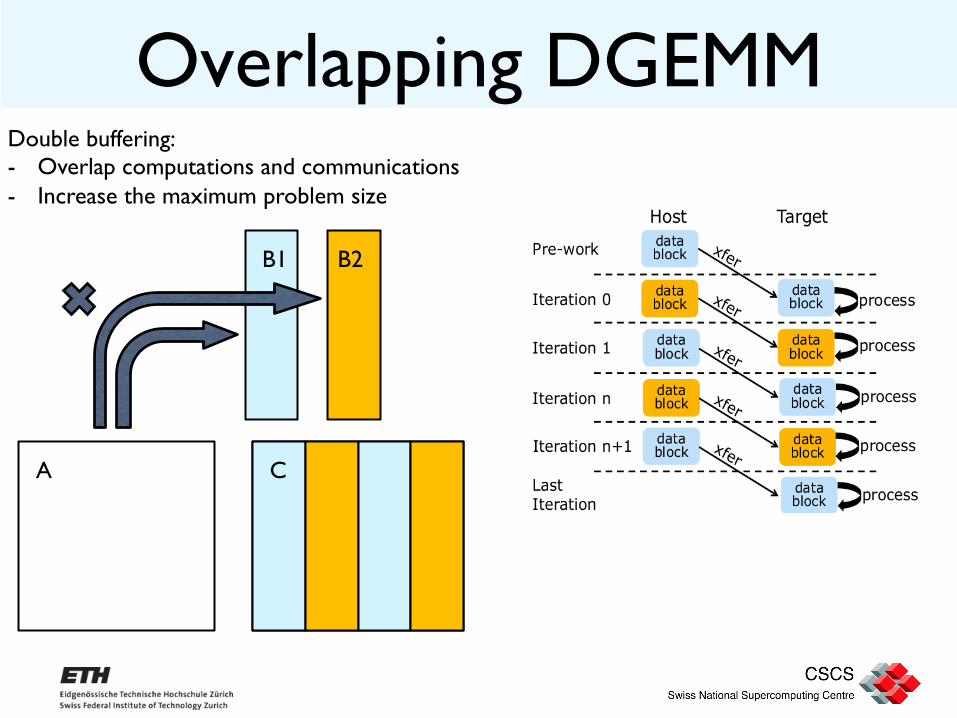
Overlapping DGEMM Double buffering: - Overlap computations and communications - Increase the maximum problem size
A C
B1 B2

Overlapping DGEMM Data allocation and deallocation: #define ALLOC alloc_if(1) #define REUSE alloc_if(0) #define FREE free_if(1) #define RETAIN free_if(0) - Offload pragma with target - nocopy clause - [start: length] - Alignments - Allocate and keep in memory - Deallocate previously allocated
#pragma offload target(mic:0) \
nocopy(A [0:M*K ]:align(Align) ALLOC RETAIN)\
nocopy(C1[0:M*N2]:align(Align) ALLOC RETAIN) \
nocopy(C2[0:M*N2]:align(Align) ALLOC RETAIN) \
nocopy(B1[0:M*N2]:align(Align) ALLOC RETAIN) \
nocopy(B2[0:M*N2]:align(Align) ALLOC RETAIN)
{}
<Kernel>
#pragma offload target(mic:0) \
nocopy( A[0:M*K] :align(Align) REUSE FREE) \
nocopy(C1[0:M*N2]:align(Align) REUSE FREE) \
nocopy(C2[0:M*N2]:align(Align) REUSE FREE) \
nocopy(B1[0:M*N2]:align(Align) REUSE FREE) \
nocopy(B2[0:M*N2]:align(Align) REUSE FREE)
{}

Overlapping DGEMM Data transfer and computation: - If statement to transfer conditionally - Signal and wait: set asynchronous
operations - Into(array[start:length]): select
memory destination on the host/device
- out clause to copy back the result
All operations are asynchronous, the key point here is to use signal to keep control over the operations flow.
#pragma offload_transfer target(mic:0) if (ii != BLOCKS - 1)\
in( B[(ii + 1)*K*N2:K*N2]:align(Align) REUSE RETAIN into(B2[0:K*N2])) \
in(Cg[(ii + 1)*M*N2:M*N2]:align(Align) REUSE RETAIN into(C2[0:M*N2])) \
signal(C2)
#pragma offload target(mic:0) \
nocopy(transa, transb, M, N, K, alpha, beta, lda, ldb, ldc) \
nocopy( A[0:M*K]:align(Align) REUSE RETAIN) \
nocopy(B2[0:K*N2]:align(Align) REUSE RETAIN) \
out(C2[0:M*N2]:align(Align) REUSE RETAIN into(Cg[ii*M*N2:K*N2])) \
wait(C2) { gemm(A, B2, C2); }
#pragma offload target(mic:0) \
nocopy( A[0:M*K ]:align(Align) REUSE RETAIN) \
nocopy(B1[0:K*N2]:align(Align) REUSE RETAIN) \
out (C1[0:M*N2]:align(Align) REUSE RETAIN into(Cg[ii*M*N2:M*N2])) \
wait(C1 { gemm(A, B1, C1); }
#pragma offload_transfer target(mic:0) if (ii != BLOCKS -1 )\
in( B[(ii + 1)*K*N2:K*N2]:align(Align) REUSE RETAIN into(B1[0:K*N2])) \
in(Cg[(ii + 1)*M*N2:M*N2]:align(Align) REUSE RETAIN into(C1[0:M*N2])) \
signal(C1){}
Even iterations
Odd iterations
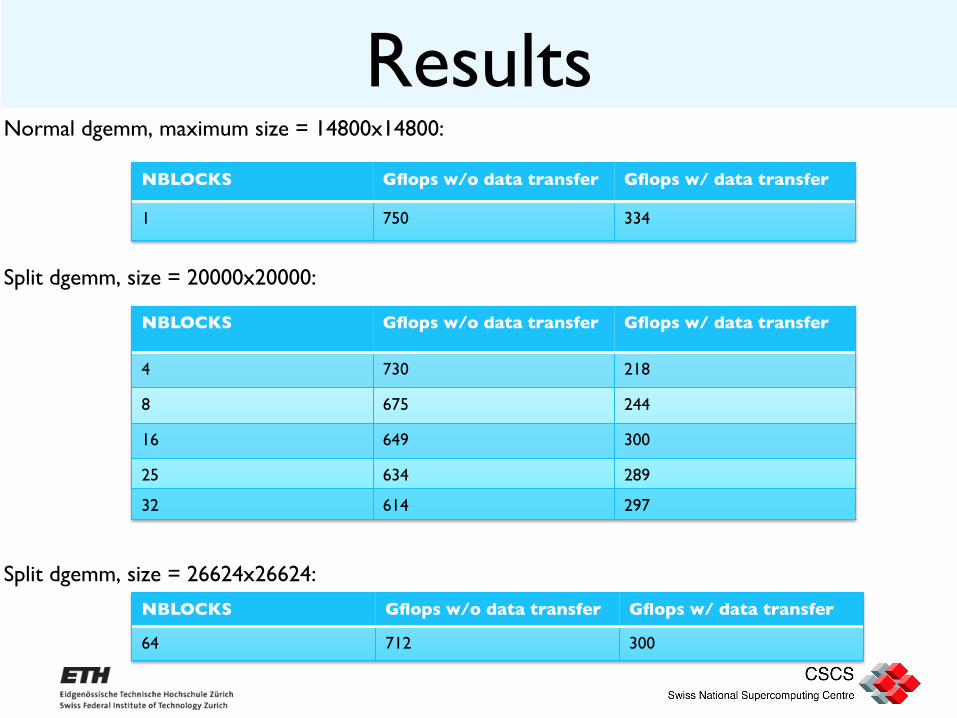
Results
Normal dgemm, maximum size = 14800x14800:
Split dgemm, size = 20000x20000:
Split dgemm, size = 26624x26624:
NBLOCKS Gflops w/o data transfer Gflops w/ data transfer
4 730 218
8 675 244
16 649 300
25 634 289
32 614 297
NBLOCKS Gflops w/o data transfer Gflops w/ data transfer
1 750 334
NBLOCKS Gflops w/o data transfer Gflops w/ data transfer
64 712 300

Xeon Phi Online
Intel have only recently publically unveiled Xeon Phi, and the first commercially available cards are being delivered. You can find more information about developing for Xeon Phi as it comes available on the Intel developer site:
The Intel Software development website has a guide for developing software on Xeon Phi (KNC). The guide has a very good summary of vectorization techniques with the Intel compiler that is equally valid for Sandy Bridge:
Online Documentation: http://software.intel.com/en-‐us/articles/programming-‐and-‐compiling-‐for-‐intel-‐many-‐integrated-‐core-‐architecture
http://software.intel.com/mic-‐developer

Xeon Phi dommic access:
http://www.cscs.ch/nss/becoming_a_user/new_user_of_existing_project/index.html
Sadaf Alam as PI.
Any question?





























