Embed Size (px)
Citation preview

Intel XeonNehalem Architecture
Billy BrennanChristopher Ruiz
Kay Sackey

Report Outline
• Architecture Overview• Instruction Fetch• Pipeline Organization• Out-of-Order Engine• Memory Hierarchy• On-chip Interconnect• Multithreading Organization

Nehalem Architecture Overview
• Successor to the Core microarchitecture• Focuses on performance considerations• Up to two, four, or eight cores• Modular design allows for addition or
subtraction of components (such as cores) for varying market segments

Architecture Diagram

Instruction Fetch

Instruction Fetch
• Includes SSE4.2 instruction set, SMT capabilities
• I-cache = 32KB, 4way associative, competitive sharing between two threads
• Branch predictor included in instruction fetch– Details not fully known (Intel simply claims “best
in class” and works with SMT)– Does still contain predecessors’ specialties (e.g.,
loop detector, indirect predictor)

Instruction Cache
• Fetch = 16B of instructions• Up to 6 instructions sent into 18-entry instruction queue at a
time• Decode = four decoders (1 complex, 3 simple)
– Simple = 1 uop (micro-op) (most SSE instructions)– Complex = 1-4 uops– Anything larger goes to micro-code handler
• After decode, ops go into 28-entry uop buffer (contains Loop Stream Detector any loop less than 28 uops can be cached here without using more fetch cycles or decode work)

Branching
• Nehalem uses two-level Branch Target Buffer (BTB) to predict target addresses– Guess #1: Same predictor algorithm, one used for smaller history file
BTBs in same relationship as L1,L2 caches– Guess #2: Different predictor algorithms AND different history files, 2nd
BTB’s opinion overrides first if they differ (not as likely)
• Return Stack Buffer (RSB)– Records the address prior to a function call, so the return will not end
up in the wrong place– Nehalem renames RSB to avoid overflow– Dedicated RSB for each thread to avoid cross-contamination
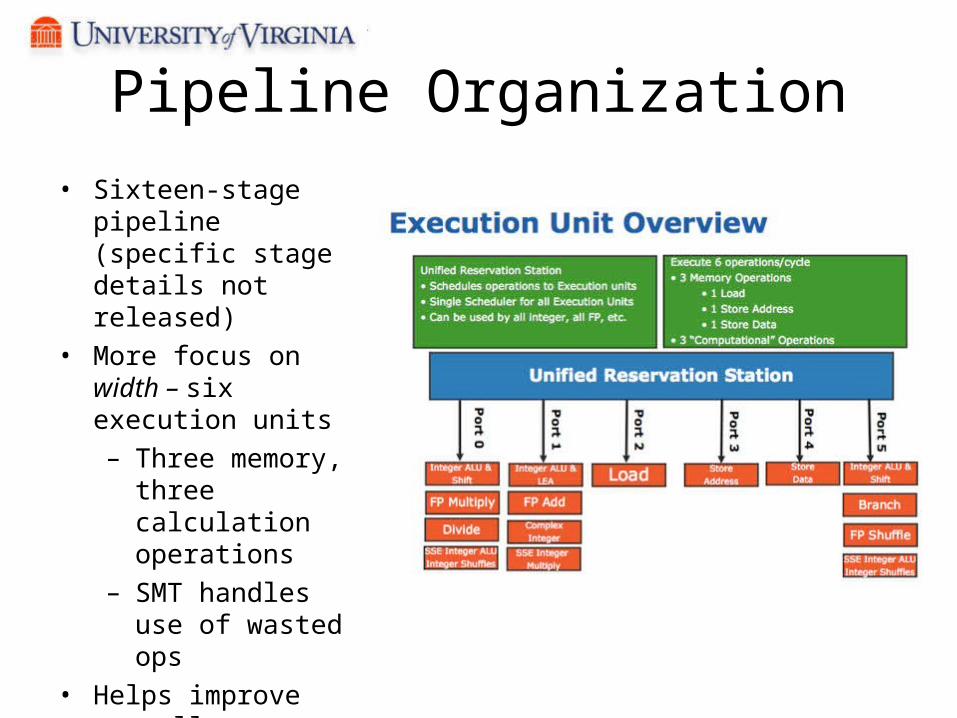
Pipeline Organization• Sixteen-stage pipeline
(specific stage details not released)
• More focus on width – six execution units– Three memory,
three calculation operations
– SMT handles use of wasted ops
• Helps improve overall parallelism through more channel options

Out-of-Order Engine

OOE Analysis
• The OOE for Nehalem was significantly augmented for general performance and to accommodate SMT
• The register alias table (RAT) points each register either into the ROB or the RRF and holds the most recent speculative state (while the RRF holds the most recent non-speculative and committed state). The RAT can rename up to 4 µops each cycle, giving each a destination register in the ROB

OOE Analysis (cont’d)Increased the size of many data structures and the size of the out of order scheduling window, giving a 33% improvement over Penryn

Improved TLB
• Nehalem increases the sizes of its TLBs and also adds a 2nd level unified TLB for both code and data

Memory Hierarchy

Cache Hierarchy
• 64KB L1: (32 KB I + 32KB D), 4 way associative
• 256KB L2: per core, unshared, 8 way associative
• 8MB L3: shared among all cores, 16 way associative

Cache Analysis
• L1: same size as its predecessor, Penryn, but slower (4 cycles vs. 3 cycles)
• L2: considerably smaller compared to Penryn (246KB vs 6MB), but quicker; intended to act as a buffer to the L3
• L3: inclusive (contains all data stored in L1 and L2), reducing core snoop traffic on misses, which improves performance and reduces power consumption
• Further, the inclusive cache helps with future scalability by preventing snooping from getting out of hand as the number of cores increases for future designs based on Nehalem

Memory & Multi-ThreadingIntroduction
Nehalem has major changes from the Peyrn micro-architecture.
The most notable two are: The FSB is replaced by a QuickPath Interface (QPI), and the processor has an on-board memory controller.
This combined with other changes give the Nahalem superior multi-threading.
- Faster locking primitives- QPI replacing FSB + On-board memory controller- HyperThreading- More Memory Bandwidth- Wider pipeline- Better loop detection

Fast Locking Primitives
Scalability of multi-thread applications limited by speed of synchronization primitives: LOCK prefix, XCHG.
Compared to the Pentium 4, Nehalem's primitives are 60% faster.

HyperThreadingHyperThreading is what the rest of the industry calls Simultaneous MultiThreading.
It allows instructions from two threads to run on the same core. When one thread stalls, the other is allowed to proceed.
1) Nehalem has much more memory bandwidth and larger caches than Pentium 4, giving it the ability to get data to the core faster and more predictably
2) Nehalem is a much wider architecture than Pentium 4, taking advantage of it demands the use of multiple threads per core.

HyperThreading Resource Allocation
Only the register state, renamed return stack buffer and large page instruction TLBs are duplicated.- During HyperThreading, the rest of the resources are either partitioned in half or dynamically allocated in a process called competitive sharing.
The chart below shows the policy for each of the processor elements.

Turbo Mode
- 1st introduced in the mobile Penyrn
- Boosts the clock speed when the thermal design power hasn't been exceeded
In the mobile Penyrn, this only worked if: - You had dual core running a single threaded application and one core is completely idle.
However Windows Vista would always schedule more threads so the the cores would never be idle. The concept was good, but the application left something to be desired.

Turbo ModeNehalem processors however can go up at least a single clock step (133Mhz), and at most 2 clcock steps (266Mhz) in Turbo mode so long as the PCU detects the TDP is low enough.
All cores can be active when this occurs.

Integrated Memory Controller
- Triple-channel DDR3 memory controller on-die- Allows for more memory bandwidth to keep the wider cores at peak throughput- Pre-fetchers can work more aggressively
- Aggressiveness of the pre-fetcher can be throttled. In the server side, applications with high bandwidth utilization can be harmed the pre-fetcher if all available memory bandwidth is directed to it instead.
Intel found this out in the Core 2 when customers reported that the pre-fetchers were disabled.

On-chip Interconnect
QPI
It's 20-bits but using a standard 8/10 encoding mechanism, so of the 20 bits only 16 are used to transmit data and the other four bits are (I believe) for clock signaling and/or error correction. It's the same thing we see with SATA and HyperTransport.
QPI uses 20-bits in a standard 8/10 encoding mechanism:- 16 bits transmit data- 4 bits are used for clock signaling and error correction
This scheme is reminiscent of AMD's HyperTransport and provides 12.8 GB/s per link in each direction (25.6 GB/s total).
Nehalem processors can have one or two QPU links each with its own local memory.

On-chip InterconnectDrawbacks
Since each QPI has its own memory interface with separate local and remote memory, the new processor is a NUMA platform.
Developers now have to ensure that the processor has data in memory attached to it rather than having to go over bus to get it.





























