Embed Size (px)
Citation preview

Information Retrieval ETH Zürich, Fall 2012 Thomas Hofmann
LECTURE 1 INTRODUCTION 19.09.2012 Information Retrieval, ETHZ 2012 1

ADMINISTRATIVA
2 Information Retrieval, ETHZ 2012

Course Description The course presents an introduction to the field of information retrieval and discusses automated techniques to effectively handle and manage unstructured and semi-structured information.
This includes methods and principles that are at the heart of various systems for information access, such as Web or enterprise search engines, categorization and recommender systems, as well as information extraction and knowledge management tools.
Main Textbook: C. Manning, P. Raghavan, H. Schütze: Introduction to Information Retrieval, 2008.
3 Information Retrieval, ETHZ 2012

Your Teaching Team Prof. Dr. Thomas Hofmann • Engineering Director at Google Zurich (main job)
• Lecturer and Titular Professor at ETHZ (fun job)
• Founder Recommind.com
• TU Darmstadt, Fraunhofer Institute, Brown University, UC Berkeley, MIT, U Bonn
4 Information Retrieval, ETHZ 2012
Anja Grünheid • PhD Candidate
• Master Sci. from TU Munich
• AT&T, IBM, U Trento, Georgia Tech, KTH, Munich
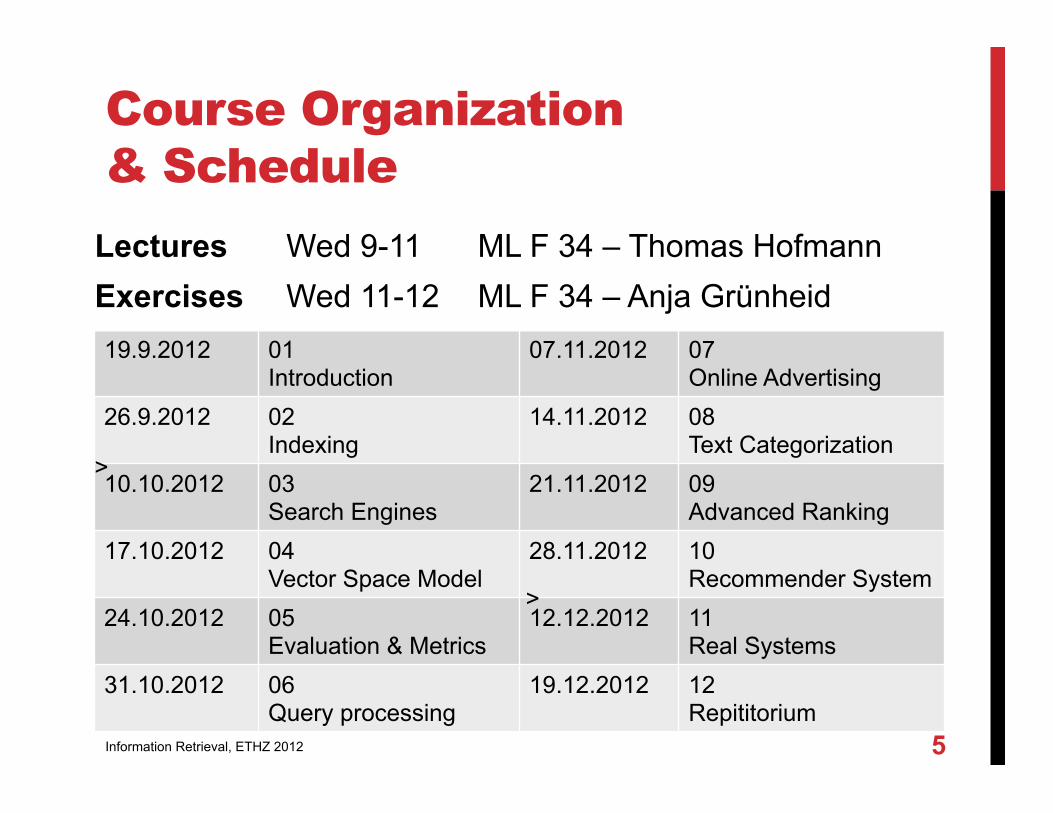
19.9.2012 01 Introduction
07.11.2012 07 Online Advertising
26.9.2012 02 Indexing
14.11.2012 08 Text Categorization
10.10.2012 03 Search Engines
21.11.2012 09 Advanced Ranking
17.10.2012 04 Vector Space Model
28.11.2012 10 Recommender System
24.10.2012 05 Evaluation & Metrics
12.12.2012 11 Real Systems
31.10.2012 06 Query processing
19.12.2012 12 Repititorium
Course Organization & Schedule
Lectures Wed 9-11 ML F 34 – Thomas Hofmann Exercises Wed 11-12 ML F 34 – Anja Grünheid
5 Information Retrieval, ETHZ 2012
>
>

Administrativa You will split up in groups of 3-4 students to work on a total of 4 programming projects. Each programming project will be graded.
Obtaining a passing grade for at least 3 of 4 projects is an admission requirement for the final exam.
The final (end of term) examination is a written, open-book exam of approx. 90 minutes.
The three projects with the highest grade will contribute 10% each to the final grade. The written exam will contribute 70%.
6 Information Retrieval, ETHZ 2012

UNSTRUCTURED DATA & INFORMATION RETRIEVAL
7 Information Retrieval, ETHZ 2012
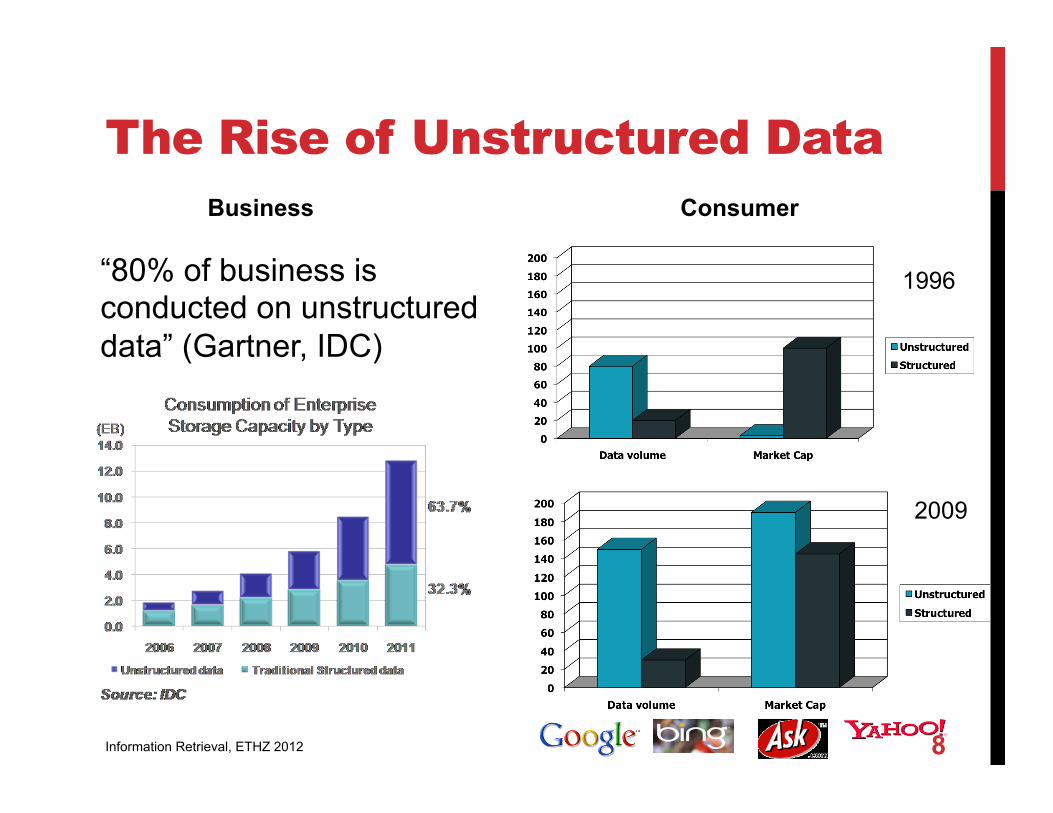
The Rise of Unstructured Data
“80% of business is conducted on unstructured data” (Gartner, IDC)
Information Retrieval, ETHZ 2012 8
1996
2009
Business Consumer

Media & Sources
What types of unstructured information exist?
• Text: Web pages, books, articles, papers, reports, letters, blogs, …
• Conversational: Emails, tweets, comments, …
• Graphics & images, presentations
• Speech & video
• Maps & satellite imagery
• Local business information, yellow pages
Mismatch: given representation in specific medium vs. semantic description of information
Information Retrieval, ETHZ 2012 9 Semantic gap needs to be bridged to establish relevance.

Scale (also: Big Data)
How much data is out there? • Hundreds billions of documents?
Approx. 10 KB/doc → several PB
• Everything else: Email, personal files, proprietary databases, broadcast media, print
• Estimated 5 Exabytes p.a. (growing at 30%)
• 800 MB p.a. and person
Information Retrieval, ETHZ 2012 10
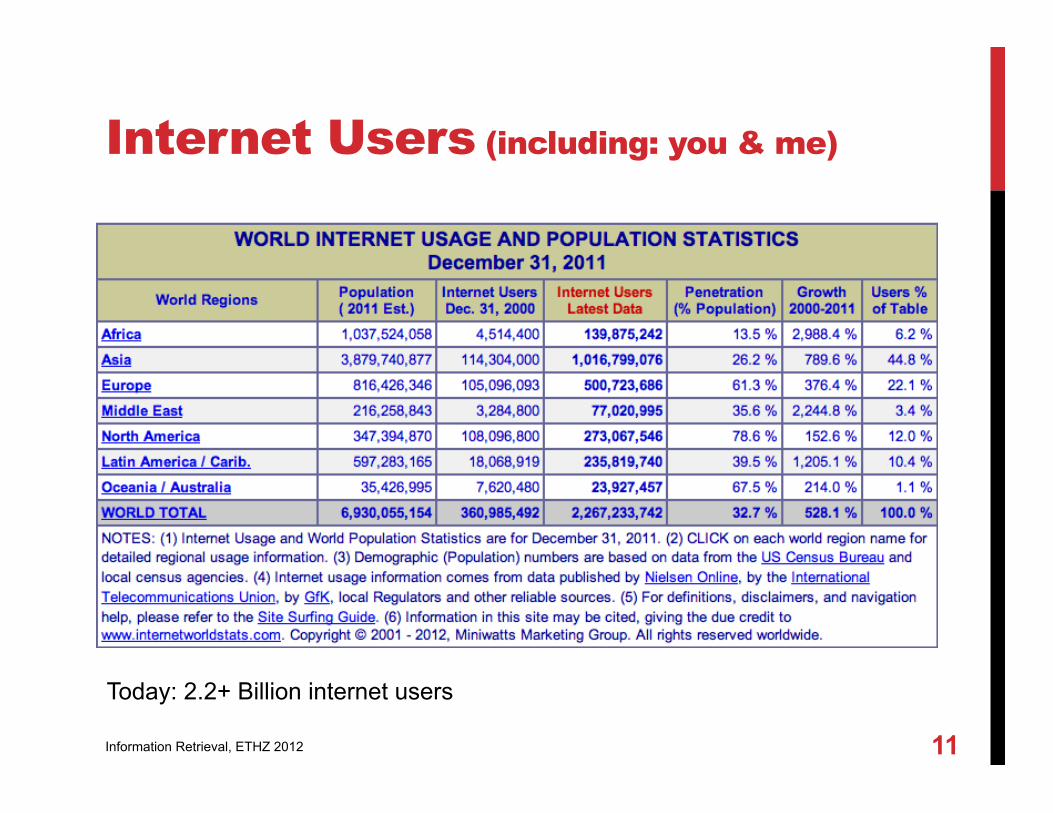
Internet Users (including: you & me)
Information Retrieval, ETHZ 2012 11
Today: 2.2+ Billion internet users

The Use of Search Engines
Information Retrieval, ETHZ 2012 12
70-80% of users use search engines to find Web sites
More than 60% of online shoppers use search engines (and many more other search technologies)
[ compete.com, US 2011 ]
How frequently do you use the following tools, when shopping online?

A BRIEF HISTORIC PERSPECTIVE
13 Information Retrieval, ETHZ 2012

The Library Libraries have been the main knowledge repositories of our civilization § Library of Alexandria (280 BC): 700,000 scrolls
§ Vatican Library (1500): 3,600 codices
§ Herzog-August-Bibl.(1661): 116,000 books
§ British Museum (1845): 240,000 books
§ Library of Congress (1990): 100,000,000 docs
§ Organizing principle: categorization (e.g.Dewey decimal system v11 in 2011, 200k libraries in 136 countries) to map books to shelves
Information Retrieval, ETHZ 2012 14

Digital Information Repositories
The digital revolution: large digital information repositories have been created § World Wide Web (100s billion documents) § Digital Libraries (e.g. CDL) § Proprietary content providers (e.g. Lexis Nexis) § Company intranets, digital assets, the ’cloud’ § Scientific literature libraries (e.g. citeseer) § Information portals (e.g. MedlinePlus) § Patent databases (e.g. US Patent Office) § Photo and video sharing sites (e.g. Flickr, YouTube) § Social networking sites (e.g. Facebook, MySpace) Information Retrieval, ETHZ 2012 15

Pioneers: Memex The idea of an easily accessible, individually configurable storehouse of knowledge, the beginning of the literature on mechanized information retrieval (Vannevar Bush)
Information Retrieval, ETHZ 2012 16
Consider a future device for individual use, which is a sort of mechanized private file and library. It needs a name, and to coin one at random, memex will do. A memex is a device in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory. – Vannevar Bush, 1945.

A Civilizational Challenge
The difficulty seems to be, not so much that we publish unduly in view of the extent and variety of present day interests, but rather that publication has been extended far beyond our present ability to make real use of the record. The summation of human experience is being expanded at a prodigious rate, and the means we use for threading through the consequent maze to the momentarily important item is the same as was used in the days of square-rigged ships.
Information Retrieval, ETHZ 2012 17
¤ Vannevar Bush: As We May Think, article at The Atlantic Monthly, July 1945.

Semantic Gap Hans Peter Luhn, 1957 & 1961 § Words of similar or related meaning are grouped into
notional families § Encoding of documents in terms of notional elements
Matching by measuring the degree of notional similarity
§ A common language for annotating documents
§ ’... the faculty of interpretation is beyond the talent of machines.’
§ Statistical cues extracted by machines to assist human indexer
Information Retrieval, ETHZ 2012 18
¤ H. P. Luhn: A statistical approach to mechanical literature searching, New York, IBM Research Center, 1957.

Probabilistic Relevance Model M. E. Maron and J. L. Kuhns, 1960 S. E. Robertson and K. Spärck Jones, 1976
§ Various models of relevance, e.g., binary independence model
§ Problem: how to estimate these conditional
probabilities?
Information Retrieval, ETHZ 2012 19
Probability of a word occurring vs. not-occurring in a relevant vs. non-relevant document
¤ Robertson, S. E., & Sparck Jones, K.: Relevance weighting of search terms, Journal of the American Society for Information Science, 27:129-146, 1972.

Vector Space Model
Gerard Salton, 1960-70ies Instead of indexing documents by selected index terms, preserve (almost) all terms in automatic indexing = full text indexing
Information Retrieval, ETHZ 2012 20
¤ G. Salton, Automatic text processing: The transformation, analysis and retrieval of information by computer. Reading, MA: Addison-Wesley, 1989.
§ Represent documents by a high-dimensional vector
§ Each term can be associated with a weight
§ Geometrical interpretation

BEYOND RETRIEVAL
21 Information Retrieval, ETHZ 2012

Text Categorization
Information Retrieval, ETHZ 2012 22
¤ F. Sebastiani: Machine learning in automated text categorization. ACM Computing Surveys, 34(1):1-47, 2002

Authorities from Links
Pioneered by Larry Page and Sergey Brin in the late 1990ies (PageRank, Google) and Jon Kleinberg (Hubs–And–Authorities)
Information Retrieval, ETHZ 2012 23
§ Query-independent measure of web page importance
§ Designed to model the behavior of web surfers
§ Importance = aggregate importance of pages linking to it
§ Matrix computation involving 10+B nodes and 40+B edges
¤ Jon M. Kleinberg: Authoritative Sources in a Hyperlinked Environment. SODA pp.668-677, 1998.
¤ Brin, S & Page, L.: The anatomy of a large-scale hypertextual Web search engine". Computer Networks and ISDN Systems 30:107–117, 1998.

Collaborative Filtering
Attributes of users or similarities between persons are used to make recommendation or predict user preferences
è Recommender Systems
Information Retrieval, ETHZ 2012 24
¤ P. Resnick, N. Iacovou, M. Suchak, P. Bergstrom, and J. Riedl: GroupLens: An open architecture for collaborative filtering of netnews, Proceedings of the Conference on Computer Supported Cooperative Work, pp. 175-186, 1994

INDEXING END-TO-END
25 Information Retrieval, ETHZ 2012

Indexing: End-to-End View
Motivational example: What does it take to build a basic search engine for Boolean retrieval? § Queries are Boolean expressions, e.g., ‘Caesar and
Brutus’ (predicates for term occurrence) § Search engine returns all documents that satisfy the
Boolean expression Conceptually simple and easy to understand
§ Basic operation: identify set of documents containing a certain term
Information Retrieval, ETHZ 2012 26

Unstructured data in 1650: Shakespeare Which plays of Shakespeare contain the words BRUTUS and CAESAR, but NOT CALPURNIA?
One could grep all of Shakespeare’s plays for BRUTUS and CAESAR, then strip out lines containing CALPURNIA. Why is grep not the solution?
§ Slow (for large collections)
§ “NOT CALPURNIA” is non-trivial
§ Other operations (e.g., find the word Romans near countryman) not feasible
§ Ranked retrieval (best documents to return)
Information Retrieval, ETHZ 2012 27

Term - Document Incidence Matrix
Information Retrieval, ETHZ 2012 28

Incidence Vectors
§ We have a 0/1 vector for each term (characteristic functions for term occurrence predicates)
§ To answer the query BRUTUS AND CAESAR AND NOT CALPURNIA:
• Take the vectors for BRUTUS, CAESAR, and CALPURNIA • Complement the vector of CALPURNIA • Do a (bitwise) and on the three vectors
110100 and 110111 and 101111 = 100100
Information Retrieval, ETHZ 2012 29

Bigger Collections
§ Consider N = 106 documents, each with about 1000 tokens
§ On average 6 bytes per token, including spaces and punctuation ⇒ size of document collection is about 6 GB
§ Assume there are M = 500,000 distinct terms in the collection
§ (Notice that we are making a term/token distinction.)
Information Retrieval, ETHZ 2012 30

Sparseness
§ M = 500,000 × 106 = half a trillion 0s and 1s. But the matrix has no more than one billion 1s.
§ Matrix is extremely sparse.
§ What is a better representations? We only explicitly record the 1s.
Information Retrieval, ETHZ 2012 31

Inverted File Index
For each term t, we store a list of all documents that contain t.
Information Retrieval, ETHZ 2012 32

Inverted Index Construction
Information Retrieval, ETHZ 2012 33

Tokenization and Preprocessing
Information Retrieval, ETHZ 2012 34

Posting Generation
Information Retrieval, ETHZ 2012 35
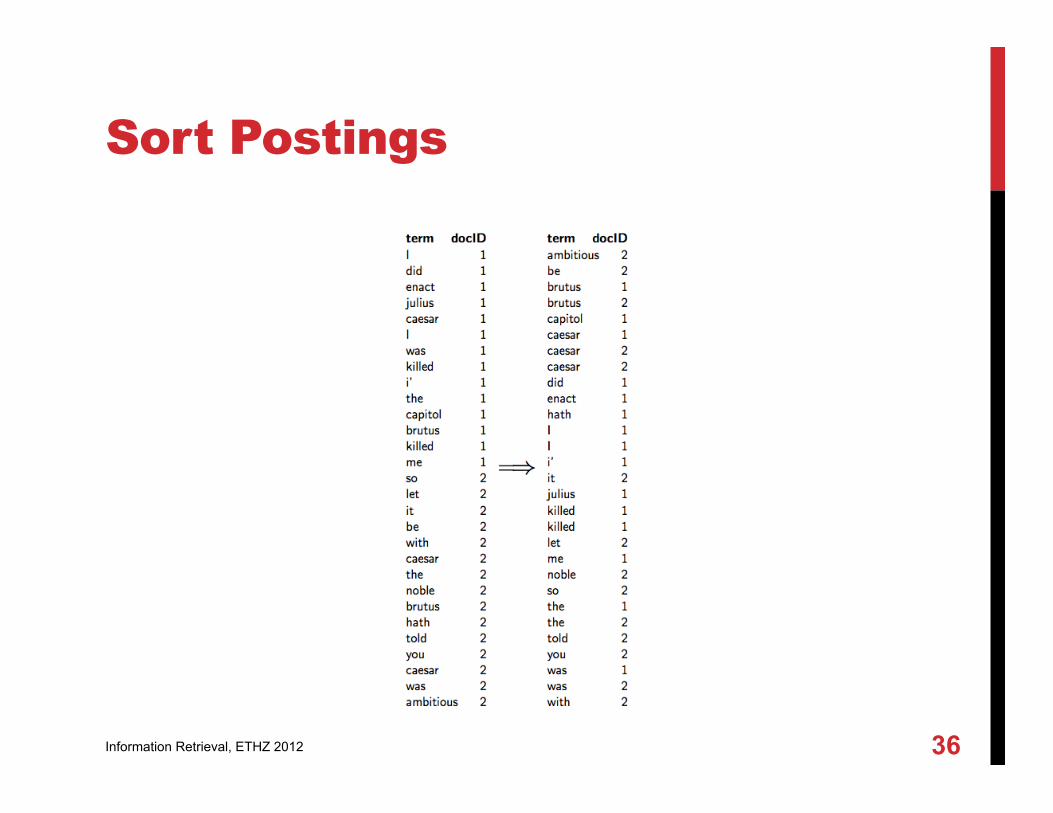
Sort Postings
Information Retrieval, ETHZ 2012 36

Create Posting Lists
Information Retrieval, ETHZ 2012 37
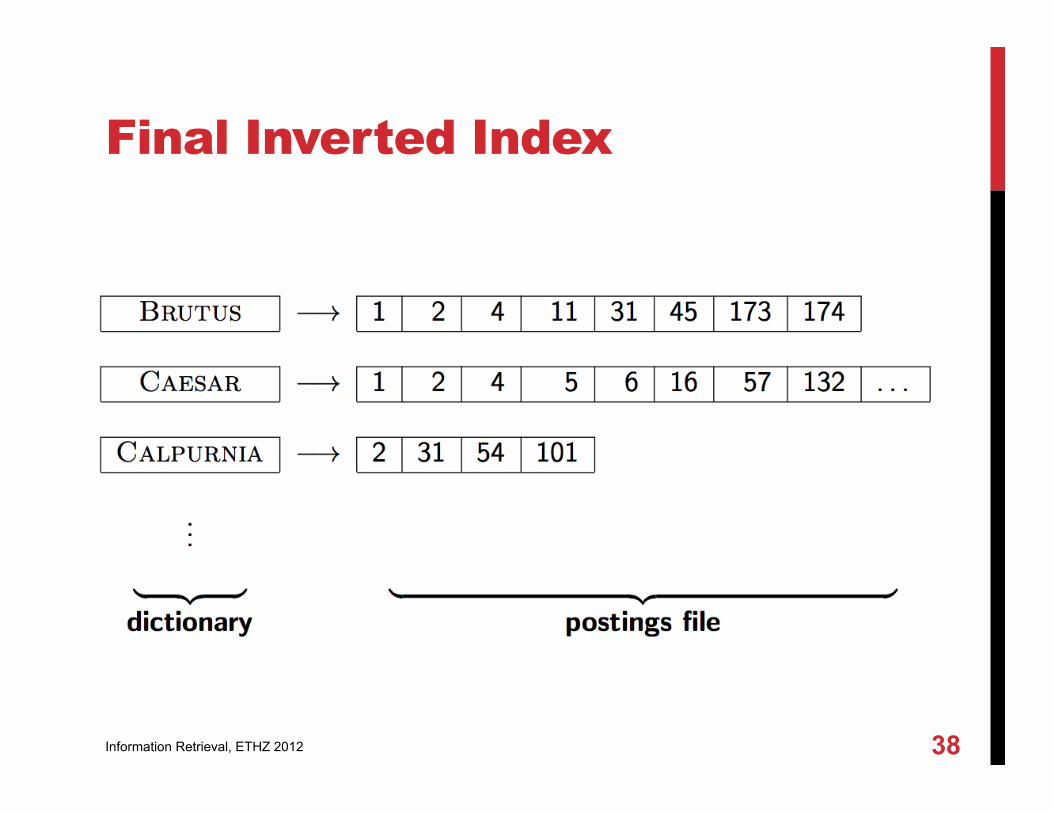
Final Inverted Index
Information Retrieval, ETHZ 2012 38

Later in this course …
Information Retrieval, ETHZ 2012 39
§ Index construction: how can we create inverted indexes for large collections?
§ How much space do we need for dictionary and index?
§ Index compression: how can we efficiently store and process indexes for large collections?
§ Ranked retrieval: what does the inverted index look like when we want the “best” answer?

Simple Conjunctive Query (two terms)
§ Consider the query: Brutus AND Calpurnia § To find all matching documents using inverted index:
Information Retrieval, ETHZ 2012 40

Example: Intersecting two postings lists
Information Retrieval, ETHZ 2012 41

THE END
42 Information Retrieval, ETHZ 2012

























