Embed Size (px)
Citation preview

Information Retrieval Modelle: Vektor-Modell
1
Karin Haenelt
25.10.2012

Inhalt
� Information Retrieval-Modelle: Systemarchitektur und Definition� Überleitung vom Booleschen Modell zum Vektormodell� Vektormodell
� Ziele� Dokument- und Anfrage-Repräsentation
� Termgewichtungen: tf und idf� Rankingfunktion
� Ähnlichkeitsmaße für Vektoren� Ähnlichkeitsmaß Cosinus
� Bedeutung des Vektormodells
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012
2
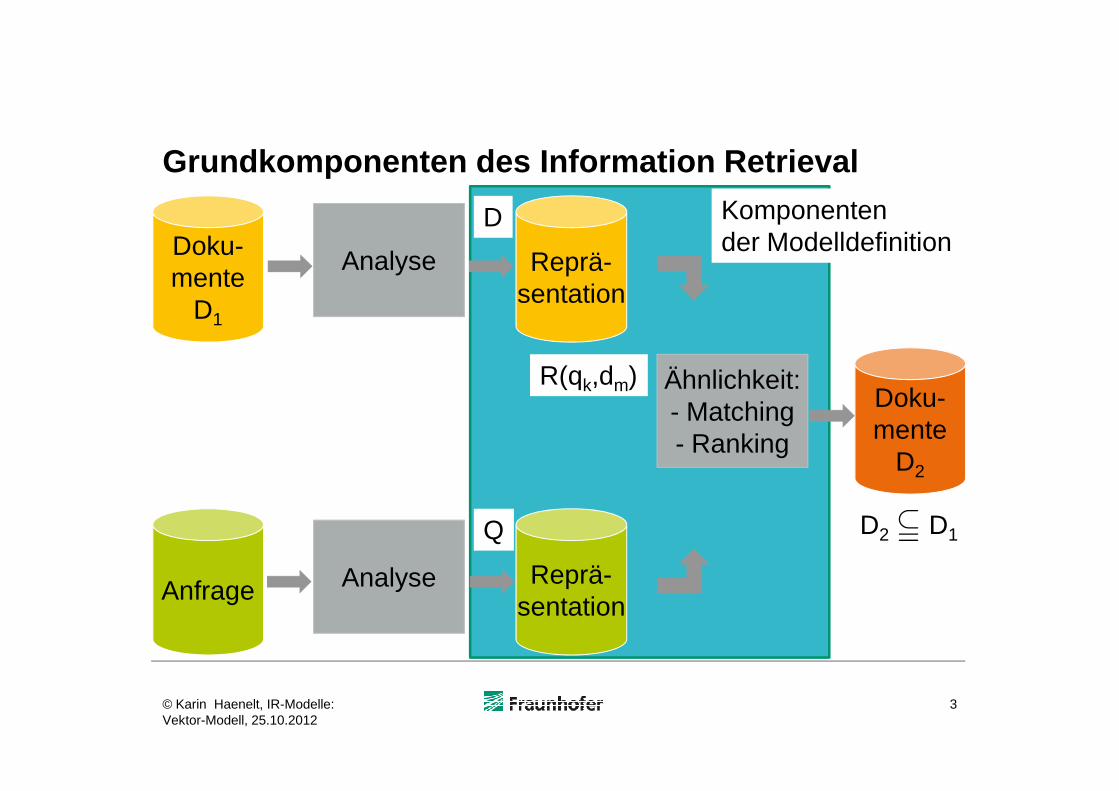
Grundkomponenten des Information Retrieval
Doku-mente
D1
Analyse Reprä-sentation
Ähnlichkeit:Doku-
D
R(qk,dm)
Komponentender Modelldefinition
3
Anfrage Analyse Reprä-sentation
- Matching- Ranking
Doku-mente
D2
D2� D1Q
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

Information-Retrieval-Modell: Definition
Ein Information-Retrieval-Modell ist ein Quadrupel (D,Q,F,R(qk,dm))
D Dokument-Repräsentation Menge logischer Sichten auf Dokumente
Q Query-Repräsentation Menge logischer Sichten auf Anfragen (Queries
F Modellierungsrahmen (Framework) für
4
F Modellierungsrahmen (Framework) für - Dokumentrepräsentationen D - Queries Q - Beziehungen zwischen D und Q
R(qk,dm) Ranking-Funktion ordnet einer Query qk aus Q und einem Dokument dm aus D einen Wert zu, der die Reihenfolge der Dokumente aus D bezüglich einer Query qk definiert
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

Inhalt
� Information Retrieval-Modelle: Systemarchitektur und Definition� Überleitung vom Booleschen Modell zum Vektormodell� Vektormodell
� Ziele� Dokument- und Anfrage-Repräsentation
� Termgewichtungen: tf und idf� Rankingfunktion
� Ähnlichkeitsmaße für Vektoren� Ähnlichkeitsmaß Cosinus
� Bedeutung des Vektormodells
5© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012
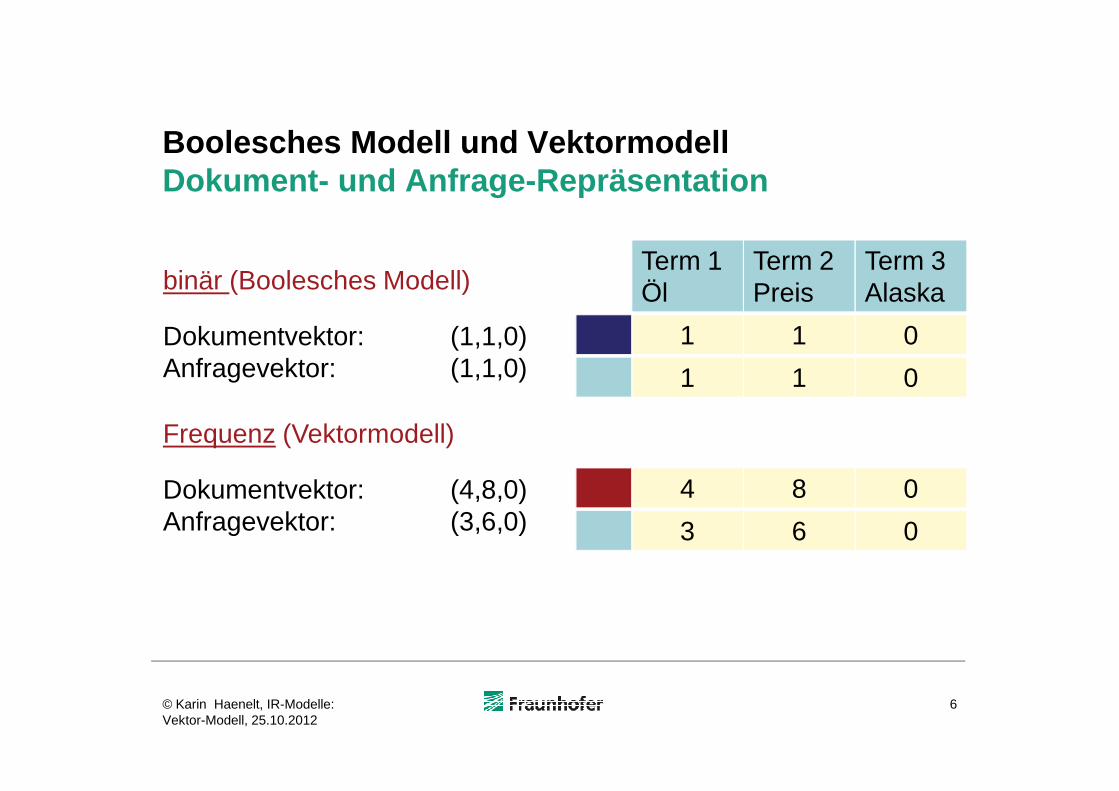
Boolesches Modell und VektormodellDokument- und Anfrage-Repräsentation
Dokumentvektor: (1,1,0)Anfragevektor: (1,1,0)
Term 1Öl
Term 2Preis
Term 3Alaska
1
1
1
1
0
0
binär (Boolesches Modell)
6
Dokumentvektor: (4,8,0)Anfragevektor: (3,6,0)
4
3
8
6
0
0
Frequenz (Vektormodell)
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012
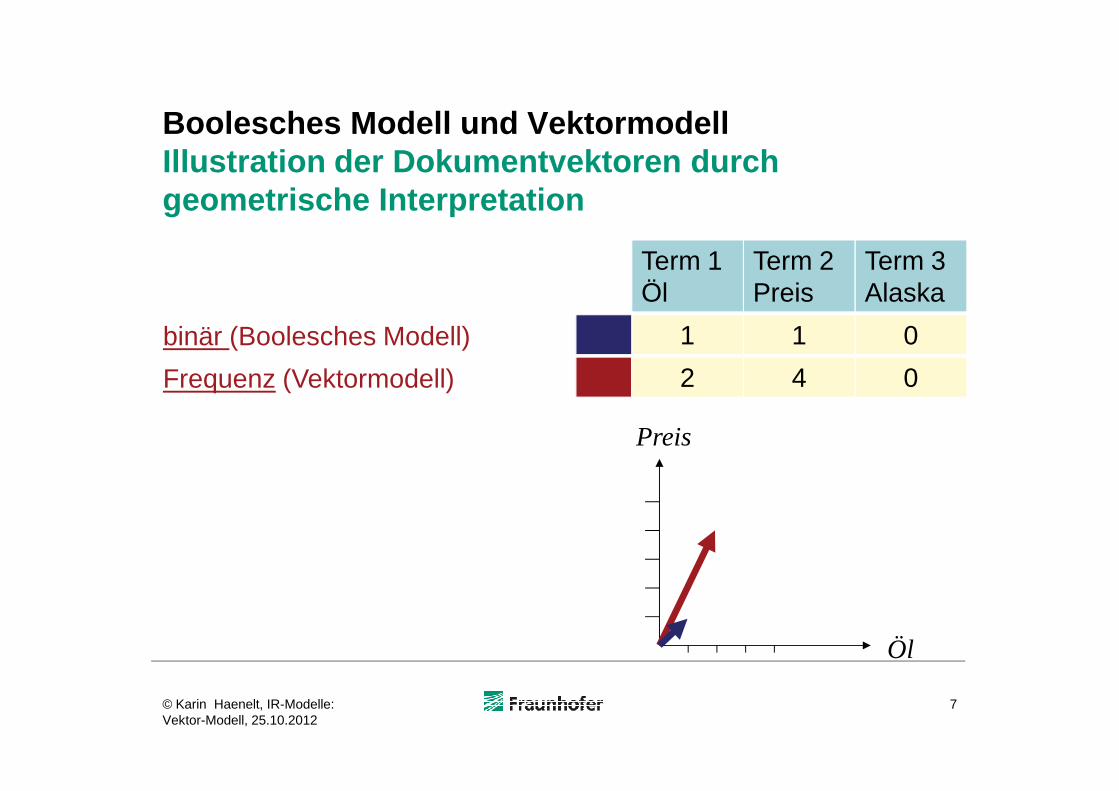
Boolesches Modell und VektormodellIllustration der Dokumentvektoren durch geometrische Interpretation
Term 1Öl
Term 2Preis
Term 3Alaska
1
2
1
4
0
0
binär (Boolesches Modell)
Frequenz (Vektormodell)
7
Öl
Preis
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012
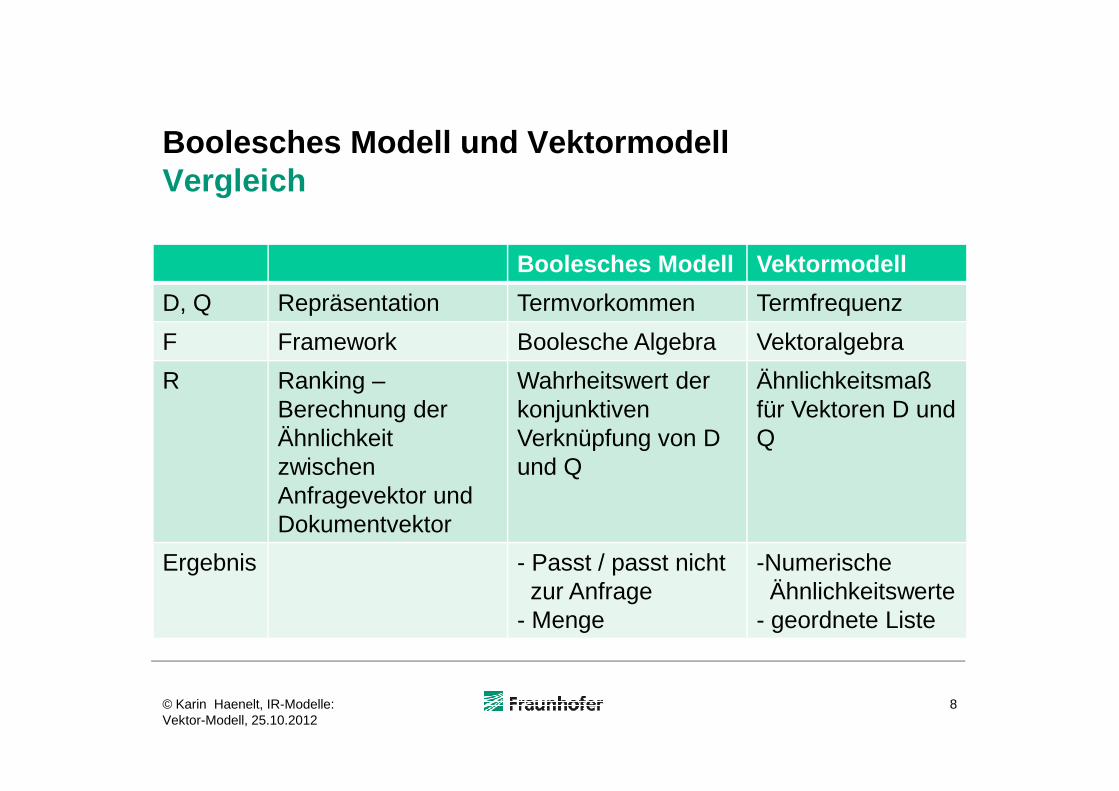
Boolesches Modell und VektormodellVergleich
Boolesches Modell Vektormodell
D, Q Repräsentation Termvorkommen Termfrequenz
F Framework Boolesche Algebra Vektoralgebra
R Ranking – Wahrheitswert der Ähnlichkeitsmaß Berechnung der Ähnlichkeit zwischenAnfragevektor und Dokumentvektor
konjunktiven Verknüpfung von D und Q
für Vektoren D und Q
Ergebnis - Passt / passt nichtzur Anfrage
- Menge
-NumerischeÄhnlichkeitswerte
- geordnete Liste
8© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

Inhalt
� Information Retrieval-Modelle: Systemarchitektur und Definition� Überleitung vom Booleschen Modell zum Vektormodell� Vektormodell
� Ziele� Dokument- und Anfrage-Repräsentation
� Termgewichtungen: tf und idf� Rankingfunktion
� Ähnlichkeitsmaße für Vektoren� Ähnlichkeitsmaß Cosinus
� Bedeutung des Vektormodells
9© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

VektormodellZiele
� Berücksichtigung partieller Übereinstimmung zwischen � Anfragetermen und � Dokumenttermendurch nicht-binäre Werte für Termgewichtung
� Berechnung der Ähnlichkeit zwischen Anfragetermen und Dokumenttermen
� Sortierung von Dokumenten nach Grad der Ähnlichkeit� Präzisere Beantwortung der Anfrage als Boolesches Modell
10
(Baeza-Yates/Ribeiro-Neto, 1999,27)
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

Inhalt
� Information Retrieval-Modelle: Systemarchitektur und Definition� Überleitung vom Booleschen Modell zum Vektormodell� Vektormodell
� Ziele� Dokument- und Anfrage-Repräsentation
� Termgewichtungen: tf und idf� Rankingfunktion
� Ähnlichkeitsmaße für Vektoren� Ähnlichkeitsmaß Cosinus
� Bedeutung des Vektormodells
11© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

VektormodellDokument- und Query-Vektoren: Definition
wi,m Gewicht für des Terms i in Dokument m;positiv, nicht binär
wi,k Gewicht des Terms i in Query k
x Anzahl der Index-Terme im System
Dokument-Vektor
Query-Vektor
12
),...,,( ,,2,1 kxkkk wwwq =),...,,( ,,2,1 mxmmm wwwd =
(Baeza-Yates/Ribeiro-Neto, 1999,27)
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

VektormodellTermgewichtungen
� einfache Häufigkeit� berücksichtigt Dokumentlänge nicht� ergibt keine normalisierten Termvektoren� nur mit normalisierenden Ähnlichkeitsmaßen (z.B. Cosinus) sinnvoll
verwendbar
� tf: normalisierte Termfrequenz (Term-Frequenz)� tf: normalisierte Termfrequenz (Term-Frequenz)� berücksichtigt Dokumentlänge� ergibt normalisierte Termvektoren
� tf-idf-Gewichtung (Term-Frequenz–inverse Dokument-Frequenz)� berücksichtigt die Häufigkeitsverteilung von Termen im Corpus� Terme, die in vielen Dokumenten vorkommen
� haben möglicherweise wenig Unterscheidungswert� werden abgewertet
13© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

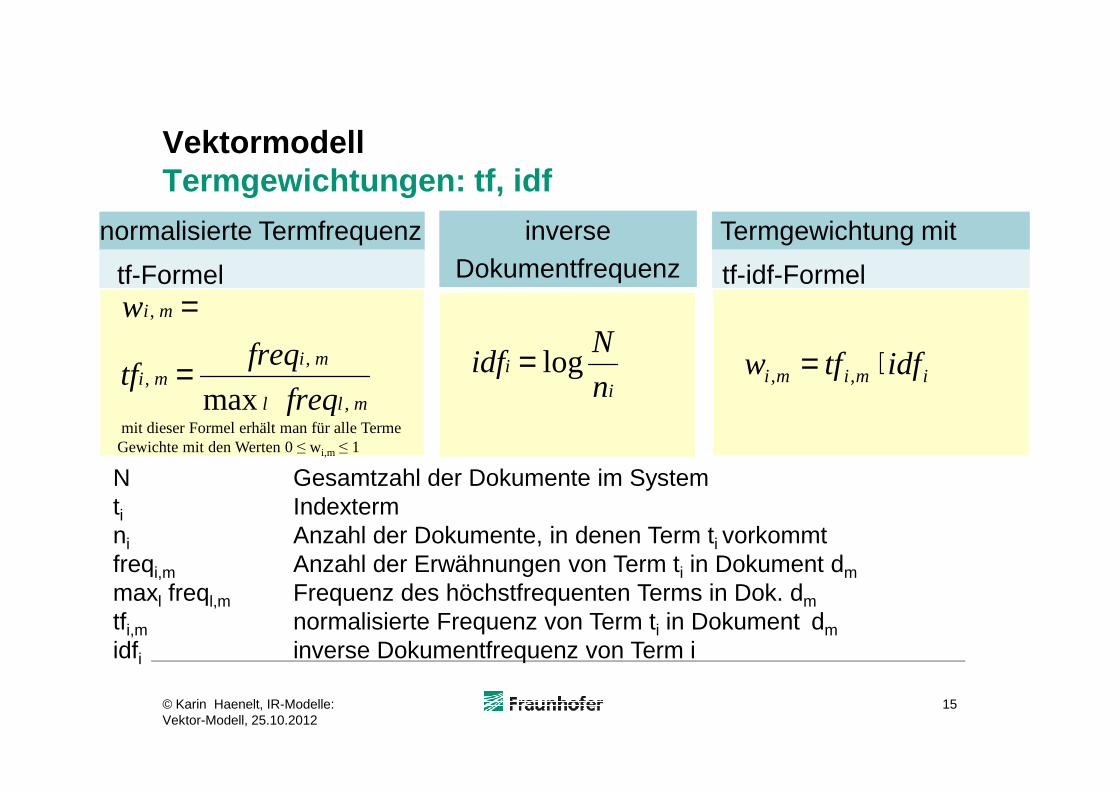
VektormodellTermgewichtungen: tf, idf
� tf Termfrequenz-Faktor� Bedeutung: relative Anzahl der Vorkommen von
Term ti in Dokument dm
� Zweck: soll besagen, wie gut ein Term denInhalt eines Dokuments beschreibt
� idf inverse Dokument-Frequenz � Sinn: Terme, die in vielen Dokumenten vorkommen,
sind möglicherweise nicht nützlich zurDifferenzierung relevanter und irrelevanter Dokumente
� Beispiel:
14
(Baeza-Yates/Ribeiro-Neto, 1999,29)
d2
ein Brot200150
5050
d1
und Bier100150
5050
bei ungewichteter Anfrage„ein, Brot. und, ein, Bier“würden hier die Vorkommenvon „ein“ und „und“ über dieÄhnlichkeit entscheiden
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012
inverseDokumentfrequenz
VektormodellTermgewichtungen: tf, idf
mll
mimi
mi
freq
freqtf
w
,
,,
,
max=
=
imimi idftfw ⋅= ,,i
in
Nidf log=
Termgewichtung mitnormalisierte Termfrequenz
tf-Formel tf-idf-Formel
15
N Gesamtzahl der Dokumente im Systemti Indextermni Anzahl der Dokumente, in denen Term ti vorkommtfreqi,m Anzahl der Erwähnungen von Term ti in Dokument dmmaxl freql,m Frequenz des höchstfrequenten Terms in Dok. dmtfi,m normalisierte Frequenz von Term ti in Dokument dmidfi inverse Dokumentfrequenz von Term i
mll freq ,max inmit dieser Formel erhält man für alle TermeGewichte mit den Werten 0 ≤ wi,m ≤ 1
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012
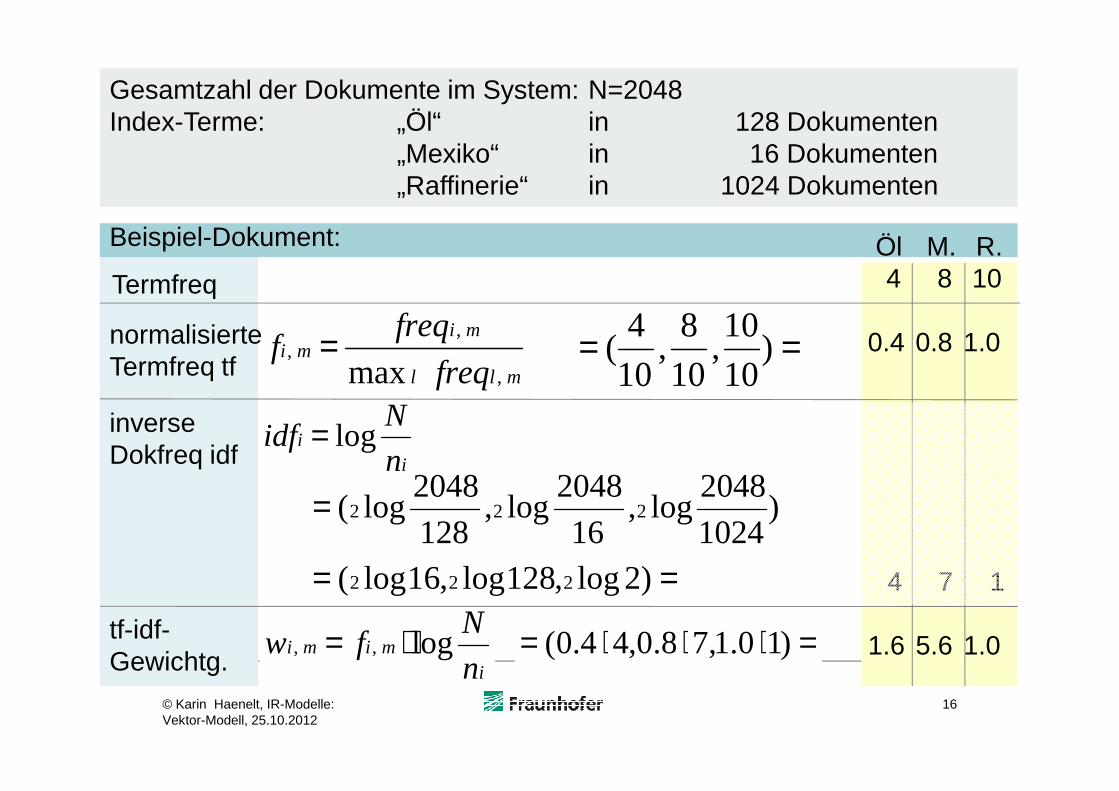
== )10
10,
10
8,
10
4(
mll
mimi
freq
freqf
,
,,
max=normalisierte
Termfreq tf
Termfreq
Gesamtzahl der Dokumente im System: N=2048Index-Terme: „Öl“ in 128 Dokumenten
„Mexiko“ in 16 Dokumenten„Raffinerie“ in 1024 Dokumenten
Beispiel-Dokument:
4 8 10
0.4 0.8 1.0
Öl M. R.
16
)1024
2048log,
16
2048log,
128
2048log( 222=
=⋅⋅⋅= )10.1,78.0,44.0(
ii
n
Nidf log=inverse
Dokfreq idf
imimi
n
Nfw log,, ⋅=tf-idf-
Gewichtg.
== )2log,128log,16log( 222 4 7 1
1.6 5.6 1.0
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012
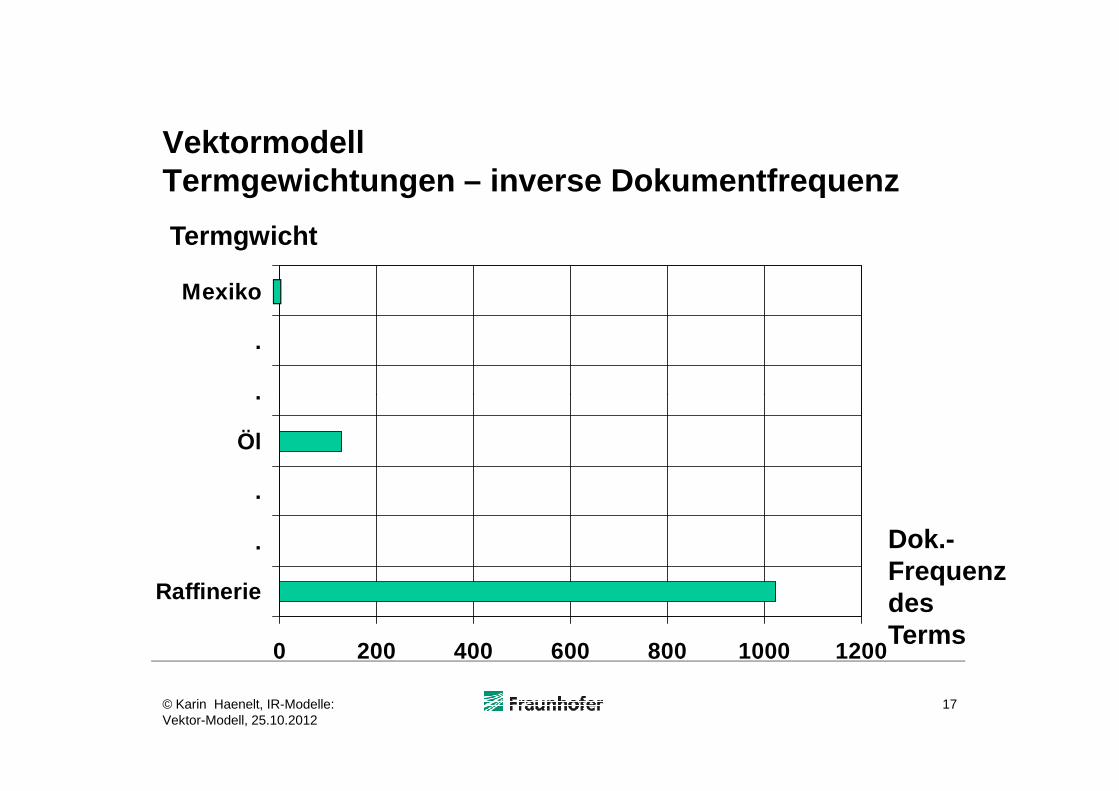
VektormodellTermgewichtungen – inverse Dokumentfrequenz
.
.
Mexiko
Termgwicht
17
0 200 400 600 800 1000 1200
Raffinerie
.
.
Öl
.
Dok.-FrequenzdesTerms
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

VektormodellTermgewichtungen – Erläuterungen des Beispiels
� Der signifikanteste Term für das Beispieldokument ist „Mexiko“, da „Mexiko“ außer im Beispieldokument nur in 15 weiteren Dokumenten vorkommt
� Der am häufigsten im Beispieldokument vorkommende Term „Raffinerie“ ist weniger signifikant, da er in 50% der Dokumente „Raffinerie“ ist weniger signifikant, da er in 50% der Dokumente vorkommt
18
(Kowalski, 1997, 105)
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

Inhalt
� Information Retrieval-Modelle: Systemarchitektur und Definition� Überleitung vom Booleschen Modell zum Vektormodell� Vektormodell
� Ziele, Definitionen� Dokument- und Anfrage-Repräsentation
� Termgewichtungen: tf und idf� Rankingfunktion
� Ähnlichkeitsmaße für Vektoren� Ähnlichkeitsmaß Cosinus
� Bedeutung des Vektormodells
19© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

VektormodellRankingfunktion
� Berechnung der Ähnlichkeit zwischen Anfrage und Dokument nach einem Ähnlichkeitsmaß zwischen Vektoren
� Am häufigsten verwendetes Ähnlichkeitsmaß:Cosinus des Winkels zwischen zwei Vektoren
� Andere Ähnlichkeitsmaße� Andere Ähnlichkeitsmaße� Dice-Koeffizient, Jaccard-Koeffizient,
Overlap-Koeffizient� Euklidische Distanz� …
20© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

VektormodellRanking-Funktion: Cosinus-Formel
� Berechnung der Ähnlichkeit zweier Vektorennach dem Cosinus des Winkels zwischen den beiden Vektoren
Winkel: Aussage über den Grad derGemeinsamkeit der Richtungder Vektoren
b
21
der Vektoren(Richtung: ~ Thema im IR)
Cosinus: Aussage über einen Winkelmit Wertebereich von-1 bis +1(bei Vektoren mit positiven Zahlenvon 0 bis +1)
Cosinus besser geeignet für Ranking-Angabeals Winkel
a
α
Wertebereich-1 <= cos <= 1
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

VektormodellRanking-Funktion: Cosinus-Formel
� Ähnlichkeit von Dokument dm und Anfrage q
∑∑
∑ =
×
×=
ו=
xx
x
iqimi
m
mm
ww
ww
qd
qdqdsim
22
1,,
||||),(
22
∑∑ ==××
i qii mim wwqd
1 ,1 ,||||
Anmerkung:der Operator steht grundsätzlich für dieeindeutige positive Lösung x2 = a
2
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012
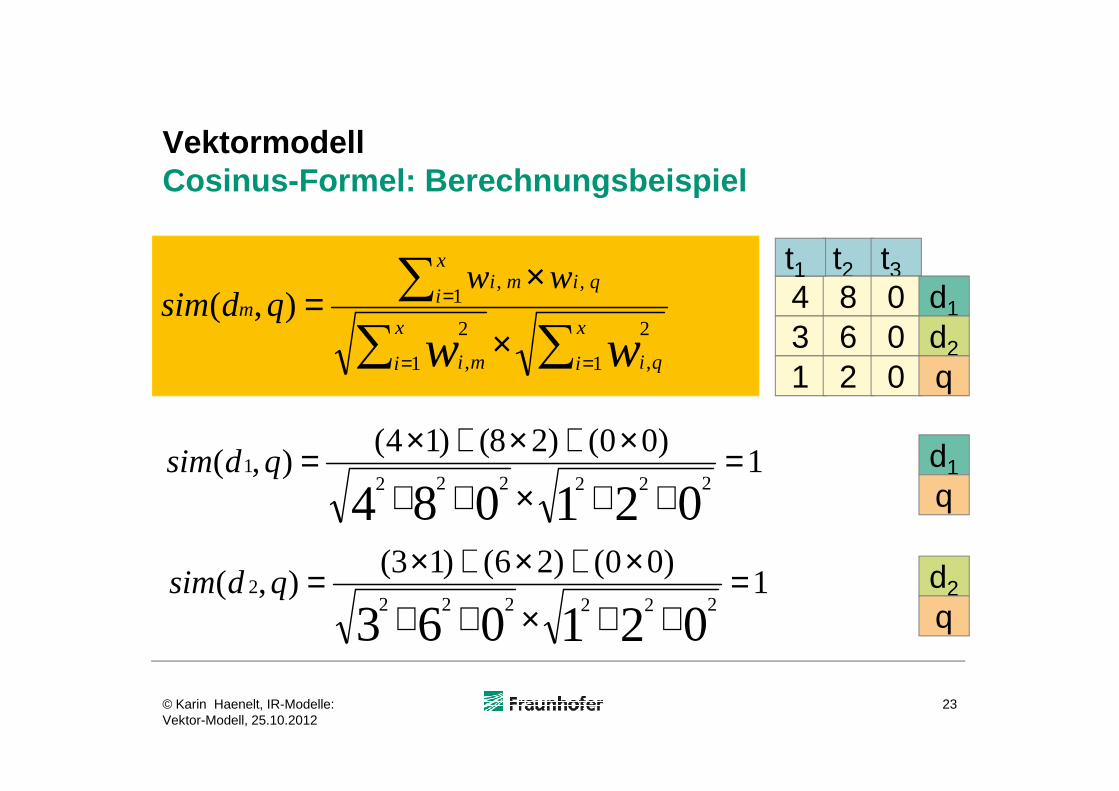
VektormodellCosinus-Formel: Berechnungsbeispiel
∑∑
∑
==
=
×
×=
x
i qi
x
i mi
x
iqimi
m
ww
wwqdsim
1
2
,1
2
,
1,,
),(t2 t3
431
862
000
d1
d2
q
t1
23
1)00()28()14(
),(
021084222222
1 =++×++
×+×+×=qdsim
1)00()26()13(
),(
021063222222
2 =++×++
×+×+×=qdsim
d1
q
d2
q
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012
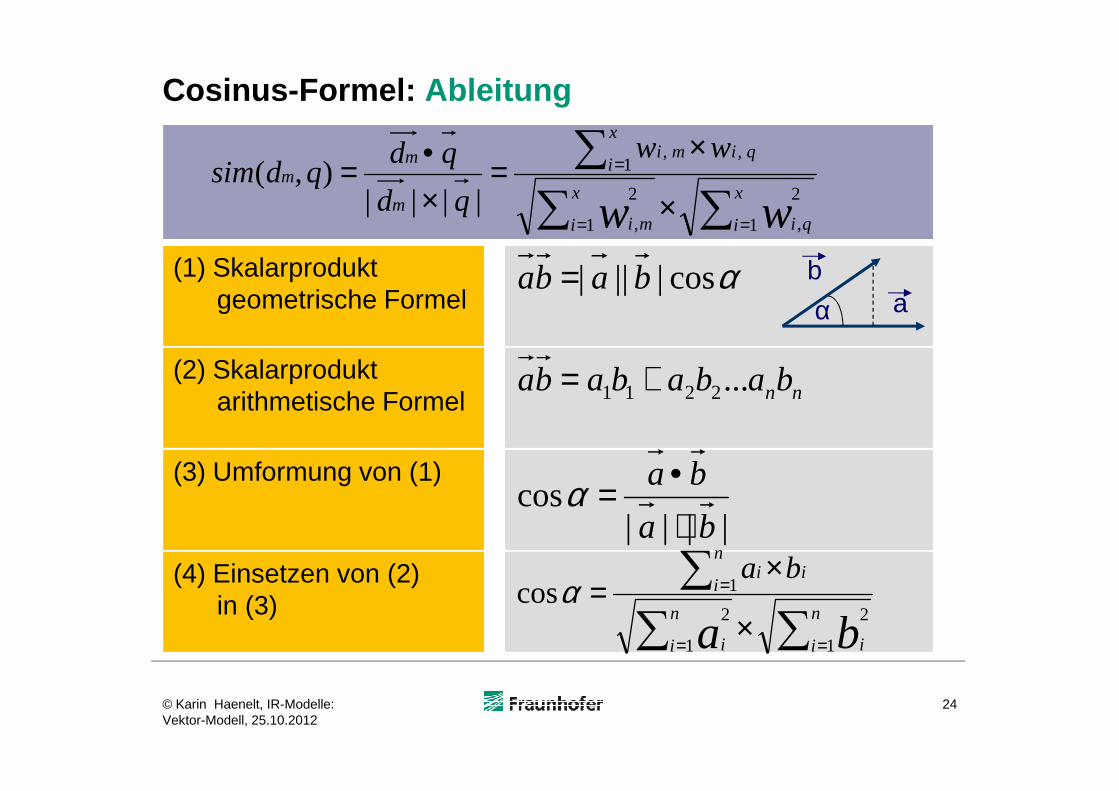
Cosinus-Formel: Ableitung
αcos|||| baba =(1) Skalarproduktgeometrische Formel
(2) Skalarproduktarithmetische Formel nnbabababa ...2211 +=
∑∑
∑
==
=
×
×=
ו=
x
i qi
x
i mi
x
iqimi
m
mm
ww
ww
qd
qdqdsim
1
2
,1
2
,
1,,
||||),(
ab
α
24
||||cos
ba
ba
⋅•=α
arithmetische Formel nnbabababa ...2211 +=
(3) Umformung von (1)
(4) Einsetzen von (2)in (3)
∑∑
∑
==
=
×
×=
n
i i
n
i i
n
iii
ba
ba
1
2
1
2
1cosα
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012
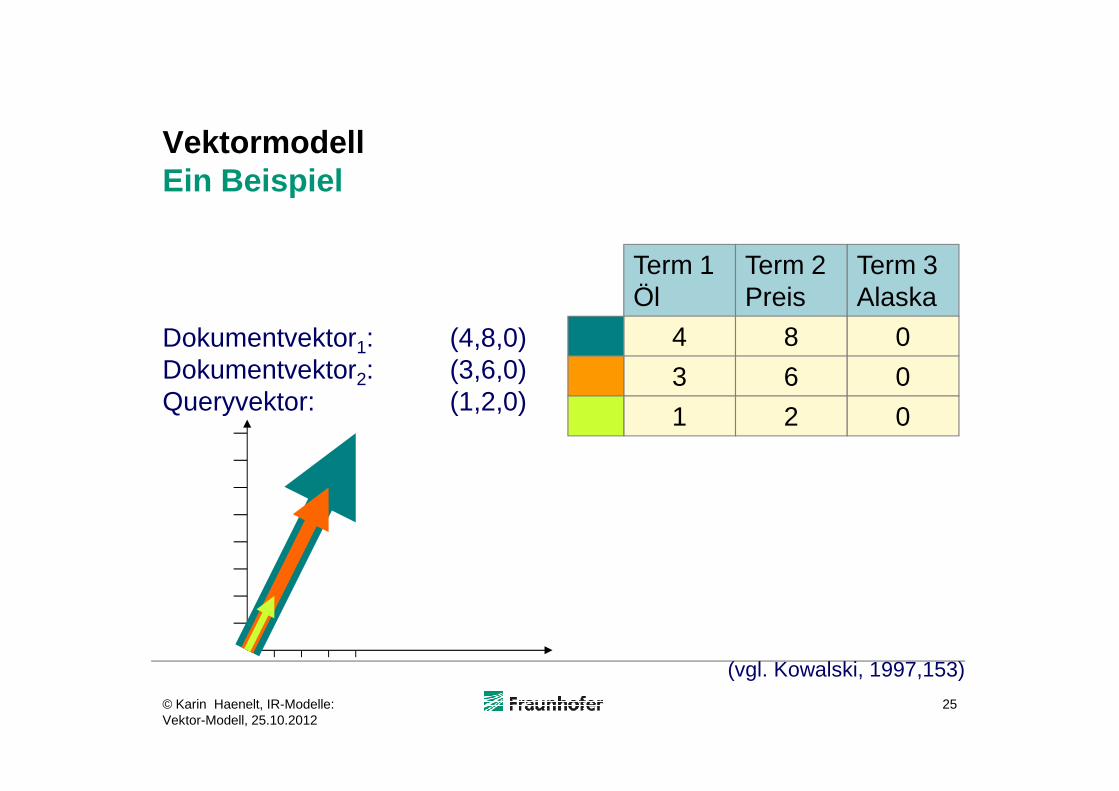
VektormodellEin Beispiel
Dokumentvektor1: (4,8,0)Dokumentvektor2: (3,6,0)Queryvektor: (1,2,0)
Term 1Öl
Term 2Preis
Term 3Alaska
4
3
8
6
0
0
25
Queryvektor: (1,2,0) 1 2 0
(vgl. Kowalski, 1997,153)
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

VektormodellKommentar zum Beispiel
Ähnlichkeitsmaß: Cosinus-Formel� Wenn Dokument- und Query-Vektor völlig ohne Beziehung sind,
sind die Vektoren orthogonal und der Cosinus-Wert ist 0� Die Länge der Vektoren bleibt unberücksichtigtDaher ist die Formel verschiedentlich weiterentwickelt worden
26
(Kowalski, 1997,153)
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

Inhalt
� Information Retrieval-Modelle: Systemarchitektur und Definition� Überleitung vom Booleschen Modell zum Vektormodell� Vektormodell
� Ziele, Definitionen� Dokument- und Anfrage-Repräsentation
� Termgewichtungen: tf und idf� Rankingfunktion
� Ähnlichkeitsmaße für Vektoren� Ähnlichkeitsmaß Cosinus
� Bedeutung des Vektormodells
27© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

VektormodellVorteile
� Termgewichtungsschema verbessert Retrievalergebnisse� Strategie der partiellen Übereinstimmung ermöglicht Retrieval
von Dokumenten, die der Retrievalanfrage nahe kommen� Cosinus-Ranking-Funktion ermöglicht Sortierung nach Grad der
ÄhnlichkeitÄhnlichkeit
28
(Baeza-Yates/Ribeiro-Neto, 1999,30)
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

VektormodellNachteile
Annahme der Unabhängigkeit der Index-Terme� Fall 1: Ist in der Praxis ein Vorteil
� Viele Abhängigkeiten sind lokal� Lokale Eigenschaften würden Gesamtauswertung negativ
beeinflussen
� Fall 2: Ist problematisch� Beispiel: Dokument mit zwei Schwerpunkten:
„Öl in Mexiko“ und „Kohle in Pennsylvania“hohe Werte für Anfrage: „Kohle in Mexiko“
29
(Baeza-Yates/Ribeiro-Neto, 1999,30)
(Kowalski, 1997, 105)
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

VektormodellBedeutung
� Mindestens genauso gut wie andere Modelle� Möglicherweise besser� Einfach� Schnell
30
(Baeza-Yates/Ribeiro-Neto, 1999,30)
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

Vielen Dank
Für das Aufspüren von Fehlern in früheren Versionen und für Verbesserungsvorschläge danke ich
� Christian Roth� Anand Mishra
31
Versionen: 25.10.2012, 25.10.2009, 13.10.2008, 20.12.2006, 24.10.2006,20.10.2006,26.10.2001
© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

Literatur
� Baeza-Yates, Ricardo; Ribeiro-Neto, Berthier (Eds.) (1999): Modern Information Retrieval.Essex: Addison Wesley Longman Limited
� Ferber, Reginald (2003) � Information Retrieval. Suchmodelle und Data-Mining-Verfahren für
Textsammlungen und das Web. Heidelberg: dpunkt-Verlag. Textsammlungen und das Web. Heidelberg: dpunkt-Verlag. http://information-retrieval.de/irb/ir.html
� frühere Fassung (1998): Data Mining und Information Retrieval. Skript zur Vorlesung an der TH Darmstadt WS 1998/99
� Kowalski, Gerald (1997): Information Retrieval Systems: Theoryand Implementation. Kluwer Academic Publishers: Boston/Dordrecht/London.
� Robertson, S.E.; Sparck Jones, Karen (1976): RelevanceWeighting of Search Terms. In: Journal of the American Society for Information Science. May-June, 129-146
32© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012

Copyright
� © Karin Haenelt, 2006All rights reserved. The German Urheberrecht (esp. § 2, § 13, § 63 , etc.). shallbe applied to these slides. In accordance with these laws these slides are a publication which may be quoted and used for non-commercial purposes, if thebibliographic data is included as described below.� Please quote correctly.
� If you use the presentation or parts of it for educational and scientific purposes, please includethe bibliographic data (author, title, date, page, URL) in your publication (book, paper, coursethe bibliographic data (author, title, date, page, URL) in your publication (book, paper, courseslides, etc.).
� please add a bibliographic reference to copies and quotations� Deletion or omission of the footer (with name, data and copyright sign) is not permitted
if slides are copied� Bibliographic data. Karin Haenelt. Information Retrieval Modelle. Vektormodell.
Kursfolien. 25.10.2009 (1 26.10.2001) http://kontext.fraunhofer.de/haenelt/kurs/folien/Haenelt_IR_Modelle_Vektor.pdf
� graphics, texts or other objects which have not been created by me are markedas quotations
� For commercial use: In case you are interested in commercial use pleasecontact the author.
� Court of Jurisdiction is Darmstadt, Germany
33© Karin Haenelt, IR-Modelle: Vektor-Modell, 25.10.2012





























