Embed Size (px)
Citation preview

1
Information pragmaticsA Natural Language Processing Approach
Christopher ManningCSLI IAP meetingNovember 2000
http://nlp.stanford.edu/~manning/

2
The problem
• When people see web pages, they understand their meaning – By and large. To the extent that they don’t, there’s
a gradual degradation• When computers see web pages, they get only
character strings and HTML tags

3
The human view

4
The intelligent agent view
<HTML> <HEAD><TITLE>Ford Motor Company - Home Page</title><META NAME="Keywords" CONTENT="cars, automobiles, trucks, SUV, mazda,
volvo, lincoln, mercury, jaguar, aston martin, ford"><META NAME="description" CONTENT="Ford Motor Company corporate home
page"><SCRIPT LANGUAGE="JavaScript1.2"> … </SCRIPT><!-- Trustmark code --><DIV ID=trustmarkDiv> <TABLE BORDER="0" CELLPADDING=0 CELLSPACING=0 WIDTH=768> <TR><TD WIDTH=768 ALIGN=CENTER> <A HREF="default.asp?pageid=473"
onmouseover="logoOver('fordscript');rolloverText('ht0')" onmouseout="logoOut('fordscript');rolloverText('ht0')"><img border="0" src="images/homepage/fordscript.gif" ALT="Learn more about Ford Motor Company" WIDTH="521" HEIGHT="39"></A><br>
… </TD></TR></TABLE></DIV> </BODY></HTML>

5
The problem (cont.)
• We'd like computers to see meanings as well, so that computer agents could more intelligently process the web
• These desires have led to XML, RDF, agent markup languages, and a host of other proposals and technologies which attempt to impose more syntax and semantics on the web – in order to make life easier for agents.
• E.g., Guha (Epinions CTO/ex-Cyc, 1999): Very little of the information on the web is machine understandable. [Need to move from] a repository of data to a Web of Knowledge. … RDF and the Open Directory … might enable us to reach this goal.

6
Ontologies
The answer, it is suggested, is ontologies• Shared formal conceptualizations of particular
domains [concepts, relations, objects, and constraints]
• An ontology is a specification of a conceptualization that is designed for reuse across multiple applications
• Ontologies: controlled vocabularies, taxonomy, OO database schema, knowledge-representation system
• Ontologies, as specifications of the concepts in a given field, and of the relationships among those concepts, provide insight into the nature of information produced by that field and are an essential ingredient for any attempts to arrived at a shared understanding of concepts in a field.

7
Why is this idea appealing?
• An ontology is really a dictionary. A data dictionary.• In the world of closed company databases, one had a
clear semantics for fields and tables, and the ability to combine information across them by well-specified logical means
• In the world-wide web, you have a mess• The desire for a global or industry-wide ontology is a
desire to bring back the good old days.

8
Thesis
• The problem can’t and won’t be solved by mandating a universal semantics for the web.

9
Nuanced Thesis (1)
• Structured knowledge is important, and there will be increasing use of structure and keys … just as we started using zipcodes, and then the postoffice started barcoding.
• These processes all offer the opportunity to increase speed and precision, and agents will want to use them when available and reliable
• But successful agents will need to be able to work even when this information isn’t there.
• The postoffice still delivers your mail, even when the zipcode is missing … or wrong.

10
Nuanced Thesis/Theses? (2)
• There will never be a complete explicit and unambiguous semantics for everything needed on the web … or even a non-trivial chunk of it … both because of the scale of the problem and the speed of change
• Much of the semantic knowledge needs instead to reside in the agent
• The agent needs to be able to ‘understand’ the human web, by reasoning using contextual information and its own knowledge, and various kinds of text and image processing

11
XML?
• I’m not saying that XML won’t be used much. It certainly will be used widely– e.g., News organizations moving to adopt
NewsML for efficient production of electronic news [Reuters, 11 October 2000]
• Internally, it will be used for most content (except tabular data), so that content can be easily retargeted for browsers, WAP, iMode, and whatever comes next
• Some sites will publish XML to outside users.

12
Will XML be published?
• “Another lesson of transitions is that the old way persists for a very long time. The 4.0-level browsers will be with us for the foreseeable future.” – Dave Winer (reacting to similar conclusions of Jakob Nielsen)
• If you’re going to be serving HTML for “the foreseeable future”, why bother complicating your life by serving something else as well?
• Especially when it doesn’t look better to the user• Or people might charge for XML, while giving HTML
away for free

13
XML
• Even when it is published, XML goes only a small way to enabling knowledge transfer
• It is simply a syntax• The same meanings can be encoded by it in many
ways, and conversely, different meanings can be coded in the same way.
• This is what suggests the need for a clearly mandated semantics for web markup

14
Explicit, usable web semantics
• Will such a thing work?• That is, will web pages be consistently marked up
with a uniform explicit semantics that is easily processed by agents so that they don’t have to deal with that messy HTML that underlies what humans look at?
• I think not. For a bunch of reasons.

15
(1) The semantics
• Are there adequate and adequately understood methods for marking up pages with such a consistent semantics, in such a way that it would support simple reasoning by agents?
• No.

16
What are some AI people saying?
“Anyone familiar with AI must realize that the study of knowledge representation—at least as it applies to the “commensense” knowledge required for reading typical texts such as newspapers—is not going anywhere fast. This subfield of AI has become notorious for the production of countless non-monotonic logics and almost as many logics of knowledge and belief, and none of the work shows any obvious application to actual knowledge-representation problems. Indeed, the only person who has had the courage to actually try to create large knowledge bases full of commonsense knowledge, Doug Lenat …, is believed by everyone save himself to be failing in his attempt.” (Charniak 1993:xvii–xviii)

17
(2) Many of the problems are pragmatics not semantics
pragmatic relating to matters of fact or practical affairs often to the exclusion of intellectual or artistic matters
pragmatics linguistics concerned with the relationship of the meaning of sentences to their meaning in the environment in which they occur
• A lot of the meaning in web pages (as in any communication) derives from the context – what is referred to in the philosophy of language tradition as pragmatics
• Communication is situated

18
The crêperie
• After making use of 3 different picture search engines, and spending at least ½ an hour on the site of a very dedicated French photographer, I had found the setting for my story … a crêperie.
• Well, almost. The visuals didn’t really convey what I needed, so let me settle for a worse quality picture of a gyro shop.

19
Not actually a crêperie

20
Important points
• “Multimedia” information sources are vital• The meaning of a ‘text’ is strongly determined by its
context of use• Indeed, you can think of language as conveying the
minimal amount of information necessary given the context and assumed shared knowledge
• Humans are used to communicating even when they don’t completely hear or understand the signal [even if this example is a bit extreme]

21
Pragmatics on the web
• Information supplied is incomplete – humans will interpret it– Numbers are often missing units– A “rubber band” for sale at a stationery site is a
very different item to a rubber band on a metal lathe
– A “sidelight” means something different to a glazier than to a regular person
• Humans will evaluate content using information about the site, and the style of writing– value filtering

22
(3) The world changes
• The way in which business is being done is changing at an astounding rate– or at least that’s what the ads from ebusiness
companies scream at us• Semantic needs and usages evolve (like languages)
more rapidly than standards (cf. the Académie française)
People use words that aren’t in the dictionary.Their listeners understand them.

23
Rapid change
• Last year Rambus wasn’t a concept in computer memory classification, now it is
• Cell phones have long had attributes like size and battery life– Now whether they support WAP is an attribute– In a couple of years time that attribute will
probably have disappeared again
People will introduce new products when they’re ready, not when some committee has added the terms to an ontology

24
(4) Interoperation
Ontology: a shared formal conceptualization of a particular domain
• Meaning transfer frequently has to occur across the subcommunities that are currently designing *ML languages, and then all the problems reappear, and the current proposals don't do much to help

25
Many products cross industries
http://www.interfilm-usa.com/Polyester.htm
• Interfilm offers a complete range of SKC's Skyrol® brand polyester films for use in a wide variety of packaging and industrial processes.
• Gauges: 48 - 1400• Typical End Uses: Packaging, Electrical, Labels,
Graphic Arts, Coating and Laminating– labels: milk jugs, beer/wine, combination forms,
laminated coupons, …

26
Mismatches
• When interoperation involves distinct domains or just distinct subcommunities within an industry, semantic mismatch ensues
• Local representational power conflicts with global consistency [you want to advertise your new feature]– Your own needs will take priority
• Systems will need to deal with this heterogeneity• Integration of information across XML markup
languages is scarcely easier than integration of the same information represented in HTML.

27
Semantic mismatches
Different Usages• Cell phone = mobile phone• Data projector = beamerDifferent levels of specialized vocabulary• “water table” = the strip of wood that points outward
at the bottom of the door– [hydrologists mean something very different by “water table”]
Ambiguity of reference• Is “C.D. Manning” the same person as “Christopher
Manning”?

28
Name matching/Object identity knowledge
• Database theory is built around ideas of unique identifiers, determinate relational operations, …
• (Human) natural language processing is built around context-embedded reasoning about issues of identity and meaning– Around Stanford, the president is John Hennessy– Elsewhere it’s … well, either Gore or Bush
• Integrating information sources requires probabilistic reasoning about object identity

29
(5) Pain but no gain
• A lot of the time people won’t put in information according to standards for semantic/agent markup, even if they exist.
• Three reasons…

30
(5.1) Pain no gain
Laziness: • Only 0.3% of sites currently use the (simple) Dublin
Core metadata standard. (Lawrence and Giles 1999).• Even less are likely to use something that is more
work
• Why? They don’t appear to perceive much value, I guess. What would change this?

31
Inconsistency: digital cameras
• Image Capture Device: 1.68 million pixel 1/2-inch CCD sensor• Image Capture Device Total Pixels Approx. 3.34 million Effective
Pixels Approx. 3.24 million• Image sensor Total Pixels: Approx. 2.11 million-pixel• Imaging sensor Total Pixels: Approx. 2.11 million 1,688 (H) x 1,248
(V)• CCD Total Pixels: Approx. 3,340,000 (2,140[H] x 1,560 [V] )
– Effective Pixels: Approx. 3,240,000 (2,088 [H] x 1,550 [V] )– Recording Pixels: Approx. 3,145,000 (2,048 [H] x 1,536 [V] )
• These all came off the same manufacturer’s website!!• And this is a very technical domain. Try sofa beds.

32
(5.2) Pain no gain
• “Sell the sizzle, not the steak”• The way businesses make money is by selling
something at a profit (for more than necessary)
• The way you do this is by getting people to want it from you:– advertising– site stickiness (“while I’m here…”)– trust
Newspaper advertisements rarely contain spec sheets

33
(5.2) Pain no gain
• Having an easily robot-crawlable site is a recipe for turning what you sell into a commodity
• This may open new markets• But most would prefer not to be in this business • Having all your goods turned into a commodity by a
shopping bot isn’t in your best interest.– the profits are very low

34
(5.3) Gain, no pain
• The web is a nasty free-wheeling place• There are people out there that will abuse the
intended use and semantics of any standard, providing they see opportunities to profit from doing so
• An agent cannot simply believe the semantics• It will have to reason skeptically based on all
contextual and world knowledge available to it.

35
(6) Less structure to come
• “the convergence of voice and data is creating the next key interface between people and their technology. By 2003, an estimated $450 billion worth of e-commerce transactions will be voice-commanded.*”
• Question: will these customers speak XML tags?
Intel ad, NYT, 28 Sep 2000*Data Source: Forrester Research.

36
Summary so far
• With large-scale distributed information sources like the web, everyone suddenly needs to deal with highly heterogeneous data sources of uncertain correctness and value, where there are frequent semantic mismatches in which terms are used or what they mean. Contextual information is often needed to determine the meaning or reference of terms. In other words, the problems look a lot like Natural Language Processing, regardless of whether the data is text as narrowly defined.

37
The connection to language
Decker et al. IEEE Internet Computing (2000):
• “The Web is the first widely exploited many-to-many data-interchange medium, and it poses new requirements for any exchange format:– Universal expressive power– Syntactic interoperability– Semantic interoperability”
But human languages have all these properties, and maintain superior expressivity and interoperability through their flexibility and context dependence

38
The direction to go
• Successful agents will need prior knowledge, and use ontologies, etc. to help interpret web pages – they become a locus of semantics
• But they will also depend on contextual knowledge and reasoning in the face of uncertain information.
• They will use well-marked up information, if available and trusted, but they will be able to extract their own metadata from information intended for humans, regardless of the form in which the information appears.

39
The scale of the problem
• The web is too big a thing for it to be likely for humans to hand-enter metadata for most pages
• Hand-building ontologies and reasoning systems hasn’t been very successful
• Agents must be able to extract propositions or relations from information intended for humans
• A useful observation in seeking this goal is that text statistics can often be used as a surrogate for world knowledge

40
Processing textual data
Use language technology to add value to data by:• interpretation• transformation• value filtering• augmentation (providing metadata)
Two motivations:• The large amount of information in textual form• Information integration needs NLP-style methods
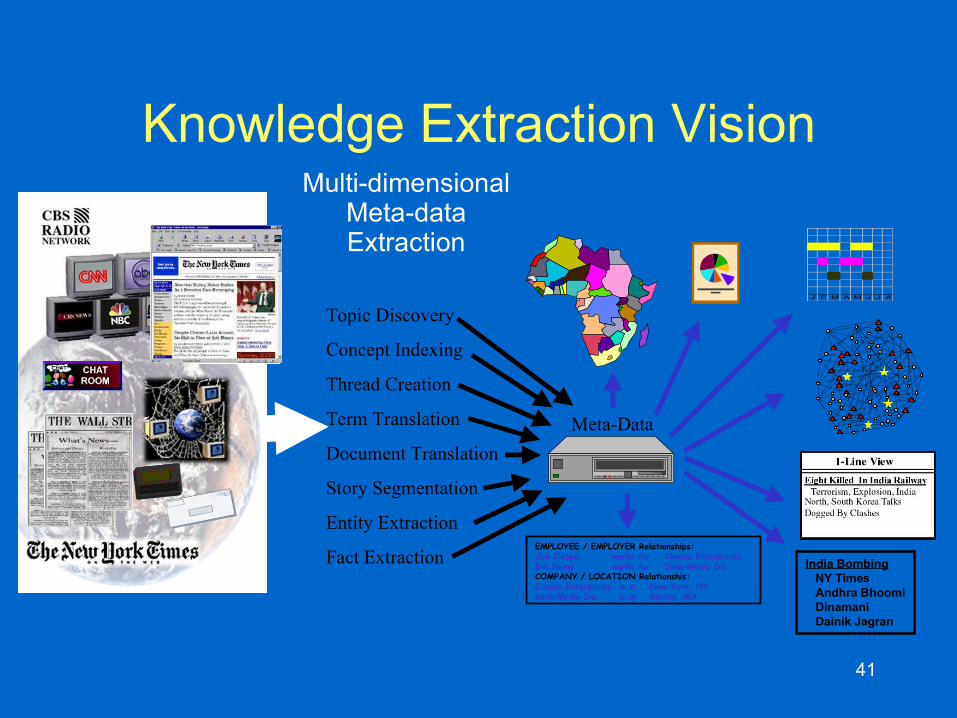
41
Knowledge Extraction VisionMulti-dimensional
Meta-data Extraction
J F M A M J J A
EMPLOYEE / EMPLOYER Relationships:Jan Clesius works for Clesius EnterprisesBill Young works for InterMedia Inc.COMPANY / LOCATION Relationshis:Clesius Enterprises is in New York, NYInterMedia Inc. is in Boston, MA
Meta-Data
India Bombing NY Times Andhra Bhoomi Dinamani Dainik Jagran
Topic Discovery
Concept Indexing
Thread Creation
Term Translation
Document Translation
Story Segmentation
Entity Extraction
Fact Extraction

42
Task: Text Categorization
• Take a document and assign it a label representing its content.• Classic example: decide if a newspaper article is about politics,
business, or sports?• But there are many relevant web uses for the same technology:
– Is this page a laser printer product page?– Does this company accept overseas orders?– What kind of job does this job posting describe?– What kind of position does this list of responsibilities
describe?– What position does this this list of skills best fit?

43
Task: Information Extraction / Wrapper Induction
• A lot of information that could be represented in a structured semantically clear format isn’t
• It may be costly, not desired, or not in one’s control (screen scraping) to change this.
• Information extraction systems– Find and understand relevant parts of texts.– Produce a structured representation of the
relevant information: relations (in DB sense)• Goal: being able to answer semantic queries using
“unstructured” natural language sources

44
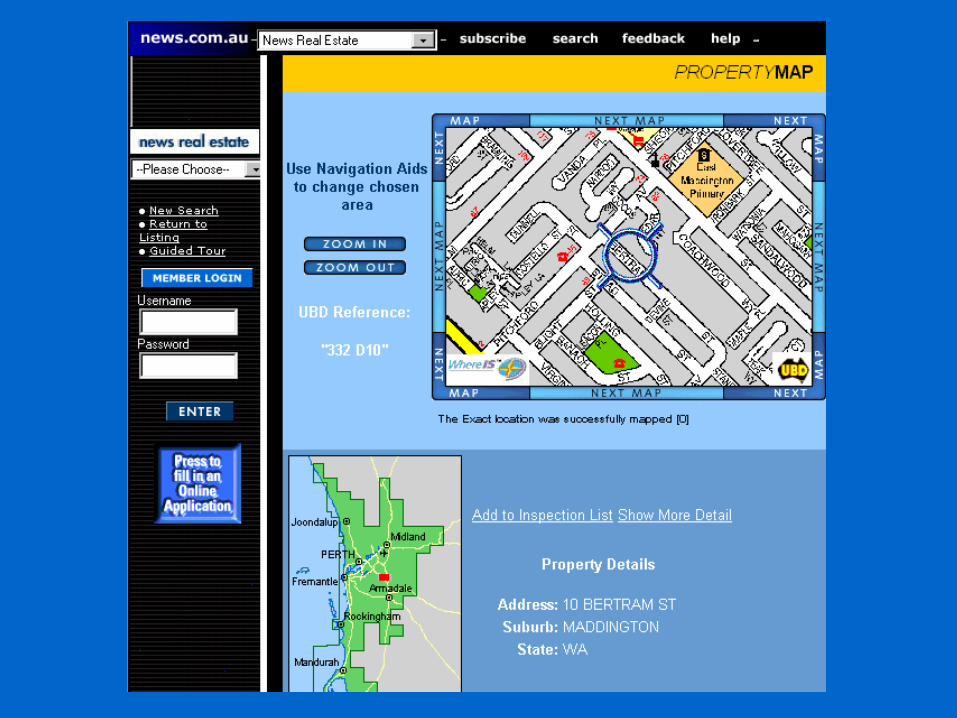
Example: Classified Ads
<ADNUM>2067206v1</ADNUM><DATE>March 02, 1998</DATE><ADTITLE>MADDINGTON $89,000</ADTITLE><ADTEXT>OPEN 1.00 - 1.45<BR>
U 11 / 10 BERTRAM ST<BR> NEW TO MARKET Beautiful<BR> 3 brm freestanding<BR> villa, close to shops & bus<BR> Owner moved to Melbourne<BR> ideally suit 1st home buyer,<BR> investor & 55 and over.<BR> Brian Hazelden 0418 958 996<BR> R WHITE LEEMING 9332 3477
</ADTEXT>

45
Real Estate Ads: Output
• Output is database tables• But the general idea in slot-filler format:
SUBURB: MADDINGTON
ADDRESS: (11,10,BERTRAM,ST)
INSPECTION: (1.00,1.45,11/Nov/98)
BEDROOMS: 3
TYPE: HOUSE
AGENT: BRIAN HAZELDEN
BUS PHONE: 9332 3477
MOB PHONE: 0418 958 996

47
Why doesn’t text search (IR) work?
What you search for in real estate advertisements:• Suburbs. You might think easy, but:
– Real estate agents: Coldwell Banker, Mosman– Phrases: Only 45 minutes from Parramatta– Multiple property ads have different suburbs
• Money: want a range not a textual match– Multiple amounts: was $155K, now $145K– Variations: offers in the high 700s [but not rents
for $270]• Bedrooms: similar issues (br, bdr, beds, B/R …)

48
Task: ParsingModern statistical parsers
• A greatly increased ability to do accurate, robust, broad coverage parsing
• Achieved by converting parsing into a classification task and using ML methods
• Statistical methods (fairly) accurately resolve structural and real world ambiguities
• Quickly: rather than cubic complete parse algorithms, find ‘best’ parse in linear time
• Provide probabilistic language models that can be integrated with speech recognition systems.

49
From structure to meaning
• Syntactic structures aren't meanings, but heads and dependents essentially gives one relations:– orders(president, review(spectrum(wireless)))
• We don't do issues of noun phrase scope, but that's probably too hard for robust NLP
• Remaining problems: synonymy and polysemy:– Words have multiple meanings– Several words can mean the same thing
• But there are statistical methods for these tasks• So the goal of transforming a text into relations of
“facts” is close

50
Precision & Semantic markup
The story so far:• We can get a fair way with text learning!• In some places, moderate accuracy is okay
• But often business needs precision – as Gio Wiederhold points out in his talks
• These methods may not offer sufficient accuracy

51
Precision & Semantic markup
• This is where semantic markup comes back in• If a page has reliable semantic markup, such a
program can use it to provide much higher accuracy levels
• Agents will need to check the provided markup• But deciding that provided semantic markup is
trustworthy is a lot easier (and hence more reliable) decision than working out the meaning from unstructured text

52
Data verification
• Humans are very good at checking if data is reasonable:– 5525 Beverly Place,
Pittsburgh– 361-5525
• They know if content is reasonable by content analysis

53
Data verification
• Most programs are dumb– especially if they expect to just rely on semantic
markup• Again one needs unstructured text classification and
learning– one needs to check that field contents are
reasonable• Richly semantically marked up data has a real use
here, since it allows agents to continue to learn (especially as usage changes over time)

54
Conclusion
• Rich semantic markup has an important place: improving the precision of agent understanding
• But there will be no substitute for agents that can work with “unstructured” data– part of that data is text [what I know about!]– but visual and other information is also incredibly
important• one really needs to use how a page looks
• All of it involves reasoning from uncertain situated information more in the style of NLP

55
Thank you!





























