Embed Size (px)
Citation preview

1078 IEEE TRANSACTIONS ON ROBOTICS, VOL. 24, NO. 5, OCTOBER 2008
Information-Efficient 3-D Visual SLAMfor Unstructured Domains
Weizhen Zhou, Member, IEEE, Jaime Valls Miro, and Gamini Dissanayake, Member, IEEE
Abstract—This paper presents a novel vision-based sensorypackage and an information-efficient simultaneous localizationand mapping (SLAM) algorithm. Together, we offer a solutionfor building 3-D dense map in an unknown and unstructured envi-ronment with minimal computational costs. The sensory packagewe adopt consists of a conventional camera and a range imager,which provide range and bearing and elevation inputs as com-monly used by 3-D feature-based SLAM. In addition, we proposean algorithm to give the robots the ‘intelligence” to select, out ofthe steadily collected data, the maximally informative observationsto be used in the estimation process. We show that, although theactual evaluation of information gain for each frame introduces anadditional computational cost, the overall efficiency is significantlyincreased by keeping the matrix compact. The noticeable advan-tage of this strategy is that the continuously gathered data are notheuristically segmented prior to being input to the filter. Quite theopposite, the scheme lends itself to be statistically optimal and iscapable of handling large datasets collected at realistic samplingrates.
Index Terms—Delayed state formulation, information form, si-multaneous localization and mapping (SLAM), urban search andrescue (USAR), vision.
I. INTRODUCTION AND RELATED WORK
ONE of the many important applications of mobile robotsis to reach and explore terrains that are inaccessible or
considered dangerous to humans. Such environments are fre-quently encountered in search and rescue scenarios where priorknowledge of the environment is unknown but required beforeany rescue operation can be deployed. A small mobile robotequipped with an appropriate sensor package can possibly beregarded as the best aid in such scenario. The robot is expectedto navigate itself through the site and generate maps of the en-vironment that human rescuers can then use for navigating andlocating victims. Despite the wealth of research in planar robotmapping, the limitations of traditional 2-D feature maps in pro-viding useful and understandable information in these scenarios
Manuscript received December 20, 2007; revised May 20, 2007. Firstpublished September 30, 2008; current version published October 31, 2008.This paper was recommended for publication by Associate Editor J. Neira andEditor L. Parker upon evaluation of the reviewers’ comments. This work wassupported in part by the Australian Research Council (ARC) (the ARC Centreof Excellence for Autonomous Systems (CAS) is a partnership between theUniversity of Technology Sydney, the University of Sydney, and the Universityof New South Wales) through its Centre of Excellence Programme and in partby the New South Wales State Government.
The authors are with the Australian Research Council (ARC) Centre ofExcellence for Autonomous Systems, University of Technology, Sydney,N.S.W. 2007, Australia (e-mail: [email protected]; [email protected];[email protected]).
Color versions of one or more of the figures in this paper are available onlineat http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TRO.2008.2004834
have propelled increasing research efforts toward the generationof richer and more descriptive 3-D maps instead.
3-D mapping of a search and rescue scenario using alightweight and highly mobile autonomous robot is a challeng-ing predicament that can be framed within the generic simulta-neous localization and mapping (SLAM) problem [1], where arobot is expected to move with 6 DOF in a 3-D environment.This demanding picture is further complicated by the lack ofodometry information from the wheel encoders, as this tendsto be totally unreliable due to the nature of the disaster envi-ronment. The emerging approach based on the ubiquitous laserrange scanner lies in deriving odometry from 3-D scan matching,possibly fusing textured images a posteriori to recover the finalshape [2]. When the noise on the relative locations is small, asis the case of an accurate range sensor such as tilting laser rangefinders or other forms of egomotion sensors, such as large andexpensive inertial measurement units (IMUs), a good quality es-timate of the final 3-D map can be expected if the displacementbetween robot poses is limited. By doing so the SLAM problemis reduced to that of the estimation of a state vector containingall the camera/robot poses. This is the approach used by manyresearchers in the SLAM community [3], [10], [12].
Further exploitation of appearance sensors, capable of pro-viding scene texture information to the rescuer as well as salientvisual features for “place recognition” in the estimation processitself, is becoming more prominent as they provide useful andunderstandable information which humans can then use for nav-igating and locating victims in rescue scenarios. The use of astereo camera rig for 3-D mapping is advantageous as that makesthe system fully observable in that the sensor provides enoughinformation (range, bearing, and elevation) to compute the full3-D state of the observed landmarks. Some approaches rely on2-D projections of the features, such as the vertical edges corre-sponding to corners and door frames as proposed in [15], whichare subsequently tracked using an extended Kalman filter (EKF).This type of visual feature representation is not sufficiently dis-tinctive and elaborate data association solutions are required toreject spurious matches. The real-time, intelligently controlled,optical positioning system (TRICLOPS) system was used in [16]and [22] where three images are obtained at each frame. Scale-invariant feature transformation (SIFT) features are detected,matched, and used in an EKF. The approach was however notglobally consistent as the cross-correlations were not fully main-tained for computational reasons. A Rao–Blackwellised parti-cle filter was instead proposed in [20]. A motion model basedpurely on visual odometry was used, effectively generalizingthe problem to unconstrained 3-D motion. Feature managementand computational complexity, which grow exponentially with
1552-3098/$25.00 © 2008 IEEE

ZHOU et al.: INFORMATION-EFFICIENT 3-D VISUAL SLAM FOR UNSTRUCTURED DOMAINS 1079
the number of particles, is likely to make this strategy infeasiblein a large environment. Other approaches rely on iterative min-imization algorithms from vision techniques such as iterativeclosest point (ICP) to perform local 3-D alignments to solvethe SLAM problem [18], which produce good results when re-stricted to fairly structured environments and limited egomotiondynamics. Similar limitations are reported in [21], where 3-Dline segments became landmarks suitable to be used in a particlefilter implementation in which each particle also carried with itan EKF. Although these are promising approaches to solve theSLAM problem using visual cues, camera calibration and stereocorrelation are still arbitrarily fickle. But more relevant to theharsh conditions encountered in search and rescue scenarios,determining correspondences between pixels in stereo pairs is aslow process that strongly depends on accommodating surfacesfor the presence of texture, as well as the particular ambientlighting conditions [26].
Recently, more research effort has been directed toward theidea of fusing visual and range sensorial data to obtain dense3-D maps. For example, a rotating laser scanner was employedin [2] to generate an initial rough 3-D map using ICP registra-tions, improved with dense texture images to recover the final3-D shape. A tilting 2-D laser scanner and a camera for SLAM inan outdoor environment was also used in [24] and [25], wherethe camera was mainly used in the detection of loop closure.Our work in [6] was also focused on sequential 3-D dense mapreconstruction within a visual SLAM framework. The noveltywas in the shape of a combined visual sensor package proposedto enhance the salient features and scene textures captured froma conventional passive camera, with the 3-D data of the corre-sponding scene as provided by a low-resolution range imager—successfully proved in [17] to have the ability to be used for somesimple local navigation. The combined observations made bythese two cameras were then used as the sole input to a conven-tional extended information filter (EIF) based SLAM algorithmthereafter. The key idea is to use the traditional pinhole cameraimage for textural 3-D reconstruction and to help in the dataassociation, and use a selection of the combined 3-D featuresfrom the aggregated camera and range scans to update the filter.Once the accurate camera pose sequence (in the global frame) atwhich the scans were taken was available, the textured rangingimages could be combined to produce the final 3-D point cloudmap.
In the proposed technique, the robot and feature poses neededto be recovered at the end of each “acquire, update” cycle. How-ever, the inversion of the information matrix evoked during eachestimation cycle came at a significant computational cost. Al-though the sensor package was capable of delivering data at aframe rate of 5–10 Hz, which theoretically guaranteed in itselfappropriate frame registration, the increasing sampling delaybetween consecutive frames caused by extensive computationcould yield inadequate data association and therefore unsuccess-ful frame registration. Such problem is particularly magnifiedin an unstructured environment where the robot’s sights changerapidly and unpredictably along its undulating path.
Many efforts have been made in recent years to reduce thecomputational encumbrance generally faced by most SLAM
algorithms, particularly in its most efficient information form.In related work [11], Eustice et al. implemented an exactlysparse delayed-state filter (ESDSF) that maintained a sequenceof delayed robot poses at places where low overlap images werecaptured manually. A delayed-state EKF was also used in [12]to fuse the data acquired with a 3-D laser range finder. A seg-mentation algorithm was employed to separate the data streaminto distinct point clouds based on orientation constraints, eachreferenced to a vehicle position. Both implementations signif-icantly reduced the computational cost by eliminating featuresfrom the state vector to achieve practical performance. How-ever, one noticeable common problem of these strategies is thatloop closure cannot be automatically detected. Separate loopclosure methods were required in conjunction with their pro-posed techniques, unlike the visual (and outlier removal) dataassociation contemplated in [6]. Furthermore, both methods re-quire either human supervision over the data acquisition processor raw odometry measurements to minimize the number of crit-ical robot poses that should be maintained, none of which areavailable in the settings of a search and rescue scenario. Analternative strategy has recently been contemplated in [19] witha global batch rectification strategy that minimizes mutual in-formation between images in order to achieve a manageablenumber of variables for the fusion process. The scheme essen-tially provides an efficient optimization solution at a claimedhigh-action compression rate. However, the robot and featureuncertainty beliefs are not accounted for and actions cannot bedecompressed when needed.
II. PROPOSED METHODOLOGY
While it has been demonstrated [6] that dense 3-D maps canbe constructed with carefully prepared datasets collected in astatic fashion, in the sense that each camera pose needs to bemanually situated to ensure extensive overlapping between con-secutive frames as well as the full coverage of the arena, in realapplications such as search and rescue, it is unrealistic to expectsuch “ideal” datasets. The sensor package is more likely to beoperated at its maximum rate to overcome problems such asmotion blurriness and drastic changes in the scene due to theinherent nature of unstructured environments. Thus, an alterna-tive approach to address the computational issues encounteredin more realistic settings is proposed here: instead of focusingon minimizing the information gathered and trying to computethem in mathematically efficient ways, we seek a solution wherewe can collect information at maximum sensor rates and givethe robot the “intelligence” to choose the critical observationsthat should be incorporated in the estimation process. To ac-complish that, in this paper, we extend our current methodologywith an improved filtering technique whereby for some givenestimation error bounds, a buffer of continuous visual scans canbe sampled but only those providing maximal information gainneed actually be introduced in the filter.
With this technique, the filter incorporates only a minimalnumber of robot poses, but critically distributed along the tra-jectory in an automatic manner based on the robot uncertaintybelief. As discussed in [14], by incorporating all of the robot

1080 IEEE TRANSACTIONS ON ROBOTICS, VOL. 24, NO. 5, OCTOBER 2008
poses in the state vector, the potential for divergence comparedto an EKF or an EIF SLAM that maintains only the last poseof the robot in the state vector is reduced. Moreover, we canalso afford to maintain both robot and feature poses in the statevector, in contrast with the state vector proposed by other re-searchers [3], [10], [12]. By adding features in the state vector,the estimation accuracy of the camera poses is expected to im-prove compared to strategies where only robot poses are kept,since there are uncertainties associated with the feature loca-tions. Hence, including feature locations in the state vector isexpected to aid the filter in adjusting both camera poses andfeature locations to better fit the observation data. Moreover,adding features to the state vector also means that observationnoise can also be dealt with directly in the filter. If only the cam-era poses are included in the state vector, the raw observationsneed to be converted back into the relative camera pose trans-formations and the uncertainty of the transformation needs to becomputed. Usually, some approximation is needed to computethe covariance of the transformation. For example, it is assumedin [3] that range noise for each point has the same Gaussiandistribution, whereas the covariance matrix is derived in [12] bysampling the error surface around the converged minima, andthen, fitting a Gaussian to that local surface. For 3-D laser scans,it is probably acceptable to assume that the range noise is thesame for each point. But in the case of the SwissRanger, rangenoise associated with different pixels is quite different.
The rest of this paper is structured as follows. Section III de-scribes the visual sensor package. The 3-D feature extraction andregistration process is explained in Section IV. Section V coversthe mathematical formulation of the EIF SLAM algorithm andthe proposed information-efficient strategy. Section VI presentsboth simulation and experimental results. Discussion and con-cluding remarks are drawn in Sections VII and VIII where im-provements and future work directions are also proposed.
III. VISUAL 3-D SENSOR PACKAGE
In this paper, we have employed an improved version ofthe sensor package used in [6] that consists of a time-of-flightrange camera (SwissRanger SR-3000, low resolution, 176 ×144 pixels) and a higher resolution conventional camera (PointGrey Dragonfly2, 1024 × 768 pixels). The two cameras are fixedrelative to each other, as illustrated in Fig. 1.
The SwissRanger works on the principle of emitting modu-lated infrared light on the scene with a 20 MHz frequency, andthen, measuring the phase shift of the reflection to provide 3-Drange data without an additional tilting/panning mechanism, al-beit within a limited range (the known nonambiguity range ofthe sensor [4] is 7.5 m). In addition to distance information,the SwissRanger is also able to return information about thereflected signal’s amplitude, hence capturing an intensity imageof the scene. However, this is currently too noisy and subject tosubstantial changes in illumination as the camera pose changes.Hence, the proposal for a conventional camera, insensitive tothe infrared light emitted by the SwissRanger, is to capturescene texture and extract salient visual features to aid the SLAMalgorithm.
Fig. 1. Sensor package: a conventional pinhole camera aligned with the Swis-sRanger SR-3000 ranger.
IV. FEATURE EXTRACTION AND FRAME REGISTRATION
With no prior knowledge of the robot motion nor the scene,an efficient mechanism to estimate the relative pose betweentwo images is required as an input to the filter. A popular choicedrawn from computer vision as a fundamental component ofmany image registration and object recognition algorithmsis the SIFT [9]. The main strength of SIFT is to produce afeature descriptor that allows quick comparisons with otherfeatures and is rich enough to allow these comparisons to behighly discriminatory. Robust data association between SIFTfeatures is particularly effective as the descriptor representationis designed to avoid problems due to boundary effects, i.e.,smooth changes in location, orientation, and scale do notcause radical changes in the feature vector. Furthermore, therepresentation is surprisingly resilient to deformations such asthose caused by perspective effects [5]. The process for theframe registrations is as follows: first, the two cameras arestereo calibrated (the MATLAB camera calibration toolboxatwww.vision.caltech.edu/bouguetj/calib docwas used for that purpose). SIFT features are then detected inthe 2-D camera image and matched across those in the previousimages. Due to the offset between the two cameras, there is nota one-to-one corresponding pixel that can be obtained directlyfrom the SwissRanger’s intensity image. However, given thecalibration information, we can compute the 3-D position at thepoint where the feature visual cue (bearing) should intersectthe 3-D point cloud. If a point can indeed be located aroundthe intersection point and its distance is within the knownSwissRanger’s measurement precision at that depth, we registerthis 3-D point as a potential feature. This process is illustratedin Fig. 2 for a single SIFT point. Applying a least square 3-Dpoint set registration algorithm [8] and an outlier removal [13],we obtain a subset of features that can then be used for

ZHOU et al.: INFORMATION-EFFICIENT 3-D VISUAL SLAM FOR UNSTRUCTURED DOMAINS 1081
Fig. 2. Example of feature 2-D to 3-D registration. (a) 2-D SIFT feature is first extracted from the traditional camera image before their 3-D location is registered.(b) Bearing to feature intersecting with point cloud. Darker points indicate area of search in the point cloud around the bearing line depending on effective rangerresolution around that range. (c) Potential 3-D feature projected back onto the intensity image. Feature location is the closest match within given measurementuncertainty boundaries, yet it does not match exactly that of the pinhole camera due to resolution differences and calibration accuracies.
estimating the initial value of the new camera pose, with theprevious camera pose as prior. All features are introducedas individual observations. While under normal illuminationcondition hundreds of SIFT features can be extracted fromeach image, the number of features used at the actual filteringstage is significantly reduced by the aforementioned pairwisematching and registration with depth information.
V. EFFICIENT EIF SLAM
A. Information-Efficient Filtering Strategy
As described in Section I, in the search and rescue scenario,the desire is for a system that can deliver not only maximalinformation but also a human comprehensible presentation ofthe environment in minimal time. To do so, a “look-ahead andsearch backwards” algorithm is proposed. The idea is maximiz-ing data collection by buffering up all the information availablebut only choosing the most crucial data to be processed for map-ping and localization. Pseudocode for the proposed algorithmis described in Algorithm 1. Assuming the robot begins at theorigin [0, 0, 0] of the global coordinate frame at time t = 0, thefeature global poses can be established and used as the first“base” frame Fbase . For the following individual frames Fi ,matching features are found between Fbase and each Fi , unlessthe number of common features reaches a predefined minimumor the number of frames being examined exceeds the look-ahead buffer size. The minimal number of common features isrestricted by the 3-D registration algorithm [8] while buffer sizeis an empirical number determined by the traveling speed of thedevice in order to guarantee a set of images with sufficient over-lapping across the sequence, as well as the desired coarsenessof the map. 3-D registration is performed on each frame withrespect to their matching Fbase (all global coordinates). Givennew observations made at each new robot pose, informationgain can be obtained without recovering the state vector, whichis the major computational expense in EIF SLAM. Since eachnew frame introduces a different number of new features, the in-formation matrix is expanded with the minimal number of new
features found across all frames in the buffer. This procedureis to guarantee that the expanded information matrices containthe same number of elements so that their determinants can becompared. The camera pose at which the observations providemaximal information gain is added to the filter, and the corre-sponding frame is included as a new entry in the Fbase database.Frames in the look-ahead buffer previous to the new Fbase aredropped, and a new buffer is started from the consecutive frameafter the last entry in Fbase . The same procedure is repeateduntil the end of the trajectory.
For the occasional circumstance when there are no matchesbetween frames in the look-ahead buffer and frames in the Fbasedatabase, matching is attempted with the previously droppedframes. If one of these frames provides sufficient matching fea-tures, it will be treated as a new frame and both will be updatedin the filter. This mechanism ensures that crucial informationcan be added back to the filter at any time to mitigate such unde-sirable situation in search and rescue as when rescuers becomerescuees themselves. Although the robot is not processing everyframe it acquired during the traversed course, its comprehen-sive collection of information about the environment becomeshandy when the “kidnap” situation manifests itself. The robot’sknowledge is not limited to a set of known positions as it isalso in possession of additional nonfiltered information fromthe scenes in between base positions which it can retrieve topotentially recover to a known position. While the sudden riskof not knowing its whereabouts is certainly always looming insuch risky and unpredictable environment, the proposed mech-anism nevertheless increases the chances for a robot to regainits estimated location based on past knowledge in an efficientmanner.
B. EIF SLAM
Computational advantages of using an EIF rather than an EKFare now well known, particularly in situations where excessiveinformation is to be processed. This work employs an EIF thatmaintains all the features as well as the entire sequence of cam-era poses in the state vector. New camera poses are initialized

1082 IEEE TRANSACTIONS ON ROBOTICS, VOL. 24, NO. 5, OCTOBER 2008
with respect to the best matching frame at a known pose, andmeasurement updates are additive in the information form. Thesensor package is assumed to operate in full 6 DOF without aprocess model; therefore, the formulation of the filter becomessimpler and results in a naturally sparse information matrix:there is no motion prediction step to correlate the current statewith previous states. For full 6 DOF SLAM, the state vector Xcontains a set of 3-D features and a set of camera poses. Thecamera poses are represented as
(xC , yC , zC , αC , βC , γC ) (1)
in which the notation αC , βC , and γC represents the ZY X Eulerangle rotation and the corresponding rotation matrix is referredto as RPY (αC , βC , γC ). A 3-D point feature in the state vectoris represented by
(xF , yF , zF ) (2)
expressed in the global coordinate frame. Let i represent theinformation vector and I be the associated information matrix.The relationship between the estimated state vector X , the cor-responding covariance matrix P , the information vector i, andthe information matrix I is
X = I−1i, P = I−1 . (3)
The first camera pose is chosen as the origin of the global coor-dinate system. At time t = 0, the state vector X contains onlythe initial camera pose [0, 0, 0, 0, 0, 0]T , and the corresponding6 × 6 diagonal information matrix I is filled with large diagonalvalues representing the camera starting at a known position. A3-D feature is detected by the sensor package as a pixel locationu, v and a depth d. These observed parameters can be writtenas a function of the local coordinates (xL , yL , zL ) of the 3-Dfeature with respect to the current camera pose
uvd
=
−fxL
zL
−fyL
zL√x2
L + y2L + z2
L
(4)
where f is the focal length. For convenience, this relationshipis referred to as
uvd
= H1
xL
yL
zL
. (5)
The relation between the feature local coordinates and the statevector X , represented in global coordinates, is
xL
yL
zL
= RPY (αC , βC , γC )T
xF
yF
zF
−
xC
yC
zC
(6)
referred to as
xL
yL
zL
= H2(X). (7)
Thus, the observation model becomes
uvd
= H(X) = H1(H2(X)) + w (8)
where w is the observation noise. It is assumed that w is (approx-imately) a zero-mean Gaussian noise (3-D vector). In the updatestep, the information vector and information matrix update canbe described by
I(k + 1) = I(k) + ∇HTk+1Q
−1k+1∇Hk+1
i(k + 1) = i(k) + ∇HTk+1Q
−1k+1
× [z(k + 1)−Hk+1(X(k))+∇Hk+1X(k)] (9)
where Qk+1 is the covariance matrix of the observation noisewk+1 and z(k + 1) is the observation vector. The corresponding
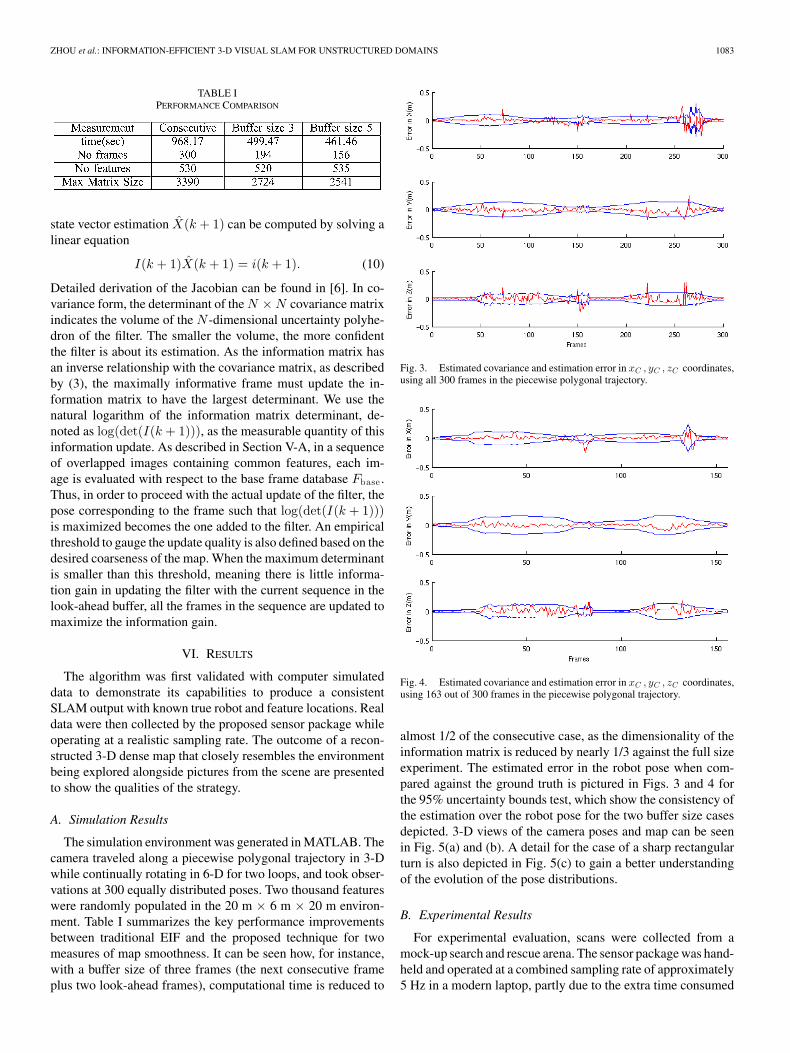
ZHOU et al.: INFORMATION-EFFICIENT 3-D VISUAL SLAM FOR UNSTRUCTURED DOMAINS 1083
TABLE IPERFORMANCE COMPARISON
state vector estimation X(k + 1) can be computed by solving alinear equation
I(k + 1)X(k + 1) = i(k + 1). (10)
Detailed derivation of the Jacobian can be found in [6]. In co-variance form, the determinant of the N × N covariance matrixindicates the volume of the N -dimensional uncertainty polyhe-dron of the filter. The smaller the volume, the more confidentthe filter is about its estimation. As the information matrix hasan inverse relationship with the covariance matrix, as describedby (3), the maximally informative frame must update the in-formation matrix to have the largest determinant. We use thenatural logarithm of the information matrix determinant, de-noted as log(det(I(k + 1))), as the measurable quantity of thisinformation update. As described in Section V-A, in a sequenceof overlapped images containing common features, each im-age is evaluated with respect to the base frame database Fbase .Thus, in order to proceed with the actual update of the filter, thepose corresponding to the frame such that log(det(I(k + 1)))is maximized becomes the one added to the filter. An empiricalthreshold to gauge the update quality is also defined based on thedesired coarseness of the map. When the maximum determinantis smaller than this threshold, meaning there is little informa-tion gain in updating the filter with the current sequence in thelook-ahead buffer, all the frames in the sequence are updated tomaximize the information gain.
VI. RESULTS
The algorithm was first validated with computer simulateddata to demonstrate its capabilities to produce a consistentSLAM output with known true robot and feature locations. Realdata were then collected by the proposed sensor package whileoperating at a realistic sampling rate. The outcome of a recon-structed 3-D dense map that closely resembles the environmentbeing explored alongside pictures from the scene are presentedto show the qualities of the strategy.
A. Simulation Results
The simulation environment was generated in MATLAB. Thecamera traveled along a piecewise polygonal trajectory in 3-Dwhile continually rotating in 6-D for two loops, and took obser-vations at 300 equally distributed poses. Two thousand featureswere randomly populated in the 20 m × 6 m × 20 m environ-ment. Table I summarizes the key performance improvementsbetween traditional EIF and the proposed technique for twomeasures of map smoothness. It can be seen how, for instance,with a buffer size of three frames (the next consecutive frameplus two look-ahead frames), computational time is reduced to
Fig. 3. Estimated covariance and estimation error in xC , yC , zC coordinates,using all 300 frames in the piecewise polygonal trajectory.
Fig. 4. Estimated covariance and estimation error in xC , yC , zC coordinates,using 163 out of 300 frames in the piecewise polygonal trajectory.
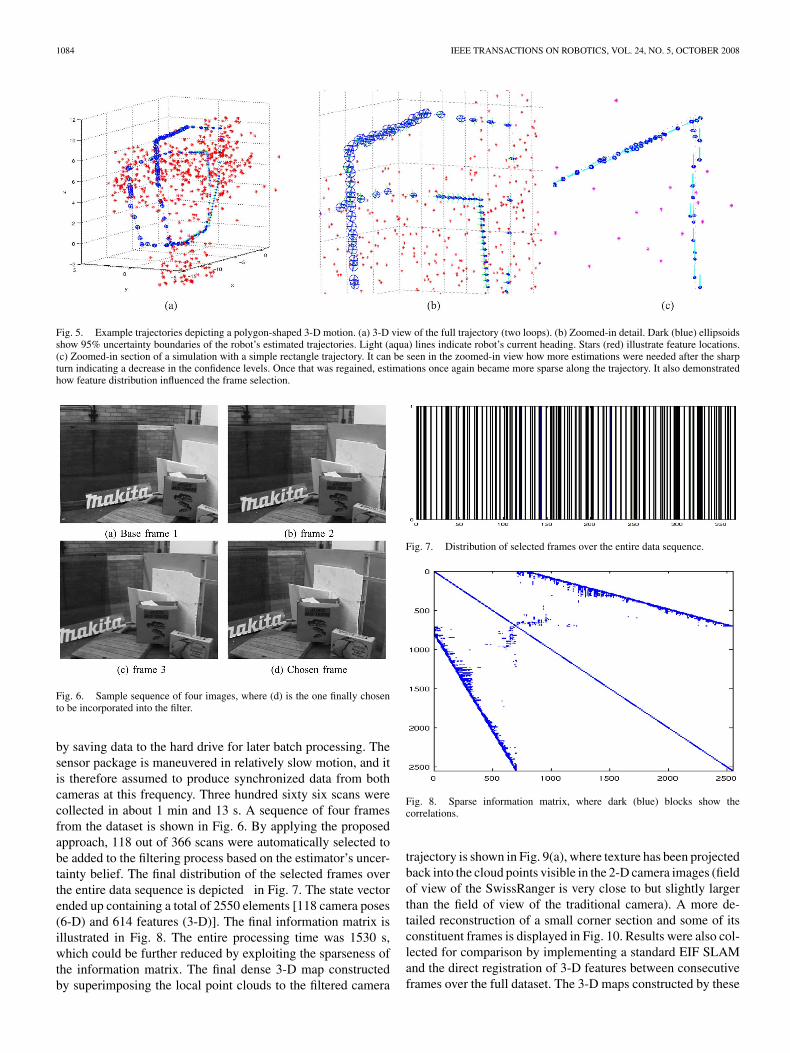
almost 1/2 of the consecutive case, as the dimensionality of theinformation matrix is reduced by nearly 1/3 against the full sizeexperiment. The estimated error in the robot pose when com-pared against the ground truth is pictured in Figs. 3 and 4 forthe 95% uncertainty bounds test, which show the consistency ofthe estimation over the robot pose for the two buffer size casesdepicted. 3-D views of the camera poses and map can be seenin Fig. 5(a) and (b). A detail for the case of a sharp rectangularturn is also depicted in Fig. 5(c) to gain a better understandingof the evolution of the pose distributions.
B. Experimental Results
For experimental evaluation, scans were collected from amock-up search and rescue arena. The sensor package was hand-held and operated at a combined sampling rate of approximately5 Hz in a modern laptop, partly due to the extra time consumed
1084 IEEE TRANSACTIONS ON ROBOTICS, VOL. 24, NO. 5, OCTOBER 2008
Fig. 5. Example trajectories depicting a polygon-shaped 3-D motion. (a) 3-D view of the full trajectory (two loops). (b) Zoomed-in detail. Dark (blue) ellipsoidsshow 95% uncertainty boundaries of the robot’s estimated trajectories. Light (aqua) lines indicate robot’s current heading. Stars (red) illustrate feature locations.(c) Zoomed-in section of a simulation with a simple rectangle trajectory. It can be seen in the zoomed-in view how more estimations were needed after the sharpturn indicating a decrease in the confidence levels. Once that was regained, estimations once again became more sparse along the trajectory. It also demonstratedhow feature distribution influenced the frame selection.
Fig. 6. Sample sequence of four images, where (d) is the one finally chosento be incorporated into the filter.
by saving data to the hard drive for later batch processing. Thesensor package is maneuvered in relatively slow motion, and itis therefore assumed to produce synchronized data from bothcameras at this frequency. Three hundred sixty six scans werecollected in about 1 min and 13 s. A sequence of four framesfrom the dataset is shown in Fig. 6. By applying the proposedapproach, 118 out of 366 scans were automatically selected tobe added to the filtering process based on the estimator’s uncer-tainty belief. The final distribution of the selected frames overthe entire data sequence is depicted in Fig. 7. The state vectorended up containing a total of 2550 elements [118 camera poses(6-D) and 614 features (3-D)]. The final information matrix isillustrated in Fig. 8. The entire processing time was 1530 s,which could be further reduced by exploiting the sparseness ofthe information matrix. The final dense 3-D map constructedby superimposing the local point clouds to the filtered camera
Fig. 7. Distribution of selected frames over the entire data sequence.
Fig. 8. Sparse information matrix, where dark (blue) blocks show thecorrelations.
trajectory is shown in Fig. 9(a), where texture has been projectedback into the cloud points visible in the 2-D camera images (fieldof view of the SwissRanger is very close to but slightly largerthan the field of view of the traditional camera). A more de-tailed reconstruction of a small corner section and some of itsconstituent frames is displayed in Fig. 10. Results were also col-lected for comparison by implementing a standard EIF SLAMand the direct registration of 3-D features between consecutiveframes over the full dataset. The 3-D maps constructed by these

ZHOU et al.: INFORMATION-EFFICIENT 3-D VISUAL SLAM FOR UNSTRUCTURED DOMAINS 1085
Fig. 9. 3-D map obtained from filtering of 118 (out of 366) frames of the 6 m × 3 m search and rescue arena. (a) Resulting 3-D point cloud map of the entirearea superimposed on the selected estimated camera poses, as viewed from one of the corners. (b) EIF SLAM result obtained by incorporating all frames. (c) Final3-D point cloud reconstructed by direct 3-D registration between consecutive frames. (d) Overall view of the search and rescue arena.
methods are presented in Fig. 9(b) and (c), respectively, andfurther discussed in the following section.
VII. DISCUSSION
Unlike most conventional fixed time step or fixed displace-ment approaches, our proposed technique exhibits the ability tofuse the minimal information required based on the robot un-certainty belief, which is, in turn, dynamically influenced by thecomplexity of the robot trajectory, the observation quality, andthe estimation of the last known robot position. Results depictedin zoomed-in Fig. 5(b) and (c) are particularly relevant, as theyclearly show how at areas with a reduced number of featuresand sharper motions, such as corners in the depicted trajec-tory, information losses due to sudden changes in the scenes arecompensated for by the nature of the proposed filtering mecha-nism. As robot pose uncertainty increases and information getsscarcer, a larger number of pose estimations are necessary tocompensate for the reduced quality of the observations withinthe robot’s field of view. Thus, the consistency of the filter ismaintained despite this information loss, as shown earlier inFig. 4 during simulation.
Fig. 10. Partial 3-D map reconstructed for the corner area covered by frames94–140 (46 frames). Only 14 frames were actually processed in the filter thatwas sufficient to produce the highly detailed map seen in (a) (we choose topresent this corner with an advertising tool for easy scene recognition for thereaders). (b) Frame 94. (c) Frame 118. (d) Frame 140.
1086 IEEE TRANSACTIONS ON ROBOTICS, VOL. 24, NO. 5, OCTOBER 2008
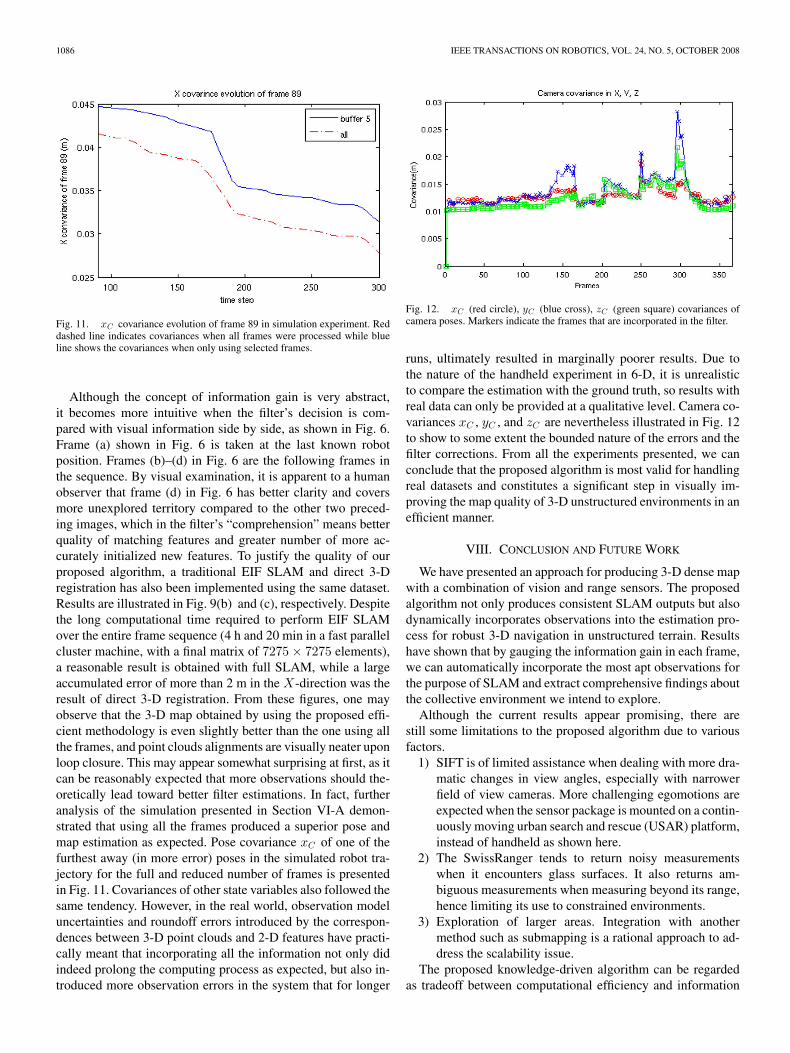
Fig. 11. xC covariance evolution of frame 89 in simulation experiment. Reddashed line indicates covariances when all frames were processed while blueline shows the covariances when only using selected frames.
Although the concept of information gain is very abstract,it becomes more intuitive when the filter’s decision is com-pared with visual information side by side, as shown in Fig. 6.Frame (a) shown in Fig. 6 is taken at the last known robotposition. Frames (b)–(d) in Fig. 6 are the following frames inthe sequence. By visual examination, it is apparent to a humanobserver that frame (d) in Fig. 6 has better clarity and coversmore unexplored territory compared to the other two preced-ing images, which in the filter’s “comprehension” means betterquality of matching features and greater number of more ac-curately initialized new features. To justify the quality of ourproposed algorithm, a traditional EIF SLAM and direct 3-Dregistration has also been implemented using the same dataset.Results are illustrated in Fig. 9(b) and (c), respectively. Despitethe long computational time required to perform EIF SLAMover the entire frame sequence (4 h and 20 min in a fast parallelcluster machine, with a final matrix of 7275 × 7275 elements),a reasonable result is obtained with full SLAM, while a largeaccumulated error of more than 2 m in the X-direction was theresult of direct 3-D registration. From these figures, one mayobserve that the 3-D map obtained by using the proposed effi-cient methodology is even slightly better than the one using allthe frames, and point clouds alignments are visually neater uponloop closure. This may appear somewhat surprising at first, as itcan be reasonably expected that more observations should the-oretically lead toward better filter estimations. In fact, furtheranalysis of the simulation presented in Section VI-A demon-strated that using all the frames produced a superior pose andmap estimation as expected. Pose covariance xC of one of thefurthest away (in more error) poses in the simulated robot tra-jectory for the full and reduced number of frames is presentedin Fig. 11. Covariances of other state variables also followed thesame tendency. However, in the real world, observation modeluncertainties and roundoff errors introduced by the correspon-dences between 3-D point clouds and 2-D features have practi-cally meant that incorporating all the information not only didindeed prolong the computing process as expected, but also in-troduced more observation errors in the system that for longer
Fig. 12. xC (red circle), yC (blue cross), zC (green square) covariances ofcamera poses. Markers indicate the frames that are incorporated in the filter.
runs, ultimately resulted in marginally poorer results. Due tothe nature of the handheld experiment in 6-D, it is unrealisticto compare the estimation with the ground truth, so results withreal data can only be provided at a qualitative level. Camera co-variances xC , yC , and zC are nevertheless illustrated in Fig. 12to show to some extent the bounded nature of the errors and thefilter corrections. From all the experiments presented, we canconclude that the proposed algorithm is most valid for handlingreal datasets and constitutes a significant step in visually im-proving the map quality of 3-D unstructured environments in anefficient manner.
VIII. CONCLUSION AND FUTURE WORK
We have presented an approach for producing 3-D dense mapwith a combination of vision and range sensors. The proposedalgorithm not only produces consistent SLAM outputs but alsodynamically incorporates observations into the estimation pro-cess for robust 3-D navigation in unstructured terrain. Resultshave shown that by gauging the information gain in each frame,we can automatically incorporate the most apt observations forthe purpose of SLAM and extract comprehensive findings aboutthe collective environment we intend to explore.
Although the current results appear promising, there arestill some limitations to the proposed algorithm due to variousfactors.
1) SIFT is of limited assistance when dealing with more dra-matic changes in view angles, especially with narrowerfield of view cameras. More challenging egomotions areexpected when the sensor package is mounted on a contin-uously moving urban search and rescue (USAR) platform,instead of handheld as shown here.
2) The SwissRanger tends to return noisy measurementswhen it encounters glass surfaces. It also returns am-biguous measurements when measuring beyond its range,hence limiting its use to constrained environments.
3) Exploration of larger areas. Integration with anothermethod such as submapping is a rational approach to ad-dress the scalability issue.
The proposed knowledge-driven algorithm can be regardedas tradeoff between computational efficiency and information

ZHOU et al.: INFORMATION-EFFICIENT 3-D VISUAL SLAM FOR UNSTRUCTURED DOMAINS 1087
loss. We believe it is critical for intelligent systems in the fieldto be able to attribute a measure of relevance to the informationattained given the objective at hand. It is not hard to imaginehow when exploring inside a collapsed building, it seems ofhigher priority to place exits, stairways, large cavities, etc., withrelative accuracy, rather than yielding undue emphasis on gen-erating perfectly straight walls. Active trajectory planning andexploration seem like natural companions to our proposed strat-egy in order to best comprehend the environment surroundingthe robot, in minimum time and within bounded estimation er-rors. This is decidedly the case in the domain of autonomousrobotics for search and rescue contemplated under the umbrellaof this research paper.
REFERENCES
[1] G. Dissanayake, P. Newman, S. Clark, H. Durrant-Whyte, and M. Csorba,“A solution to the simultaneous localization and map building (SLAM)problem,” IEEE Trans. Robot. Autom., vol. 17, no. 3, pp. 229–241, Jun.2001.
[2] K. Ohno and S. Tadokoro, “Dense 3D map building based on LRF dataand color image fusion,” in Proc. IEEE Int. Conf. Intell. Robot Syst., 2005,pp. 1774–1779.
[3] F. Lu and E. Milios, “Globally consistent range scan alignment for envi-ronment mapping,” Auton. Robots, vol. 4, no. 4, pp. 333–349, 1997.
[4] T. Oggier, M. Lehmann, R. Kaufmann, M. Schweizer, M. Richter,P. Metzler, G. Lang, F. Lustenberger, and N. Blanc, “An all-solid-stateoptical range camera for 3D real-time imaging with sub-centimeter depthresolution (SwissRanger),” Proc. SPIE, vol. 5249, pp. 534–545, 2004.
[5] K. Mikolajczyk and C. Schmid, “A performance evaluation of local de-scriptors,” in Proc. IEEE Comp. Soc. Conf. Comput. Vision Pattern Recog-nit., 2003, pp. 257–263.
[6] L. P. Ellekilde, S. Huang, J. Valls Miro, and G. Dissanayake, “Dense 3Dmap construction for indoor search and rescue,” J. Field Robot., vol. 24,no. 1/2, pp. 71–89, 2007.
[7] W. Zhou, J. Valls Miro, and G. Dissanayake, “Information efficient 3Dvisual SLAM in unstructured domains,” in Proc. IEEE Int. Conf. Intel.Sensors, Sensor Netw. Inf. Process., Melbourne, Qld., Australia, 2007,pp. 323–328.
[8] K. S. Arun, T. S. Huang, and S. D. Blostein, “Least square fitting of two3-D point sets,” IEEE Pattern Anal. Mach. Intell., vol. 9, no. 5, pp. 698–700, Sep. 1987.
[9] D. G. Lowe, “Distinctive image features from scale-invariant keypoints,”Int. J. Comput. Vision, vol. 60, no. 2, pp. 91–110, 2004.
[10] R. M. Eustice, O. Pizarro, and H. Singh, “Visually augmented navigationin an unstructured environment using a delayed state history,” in Proc.IEEE Int. Conf. Robot. Autom., 2004, pp. 25–32.
[11] R. M. Eustice, H. Singh, and J. J. Leonard, “Exactly sparse delayed-statefilters,” in Proc. IEEE Int. Conf. Robot. Autom., 2005, pp. 2417–2424.
[12] D. M. Cole and P. M. Newman, “Using laser range data for 3D SLAMin outdoor environments,” in Proc. IEEE Int. Conf. Robot. Autom., 2006,pp. 1556–1563.
[13] M. Fischler and R. Bolles, “Random sampling consensus: A paradigm formodel fitting with application to image analysis and automated cartogra-phy,” Commun. Assoc. Comput. Mach., vol. 24, pp. 381–395, 1981.
[14] F. Dellaert, “Square root SAM,” in Proc. Robot.: Sci. Syst., Cambridge,MA, 2005.
[15] A. J. Castellanos, J. M. M. Montiel, J. Neira, and J. D. Tardos, “Sensorinfluence in the performance of simultaneous mobile robot localizationand map building,” in Proc. 6th Int. Symp. Exp. Robot., 1999, pp. 203–212.
[16] S. Se, D. G. Lowe, and J. Little, “Mobile robot localization and mappingwith uncertainty using scale-invariant visual landmarks,” Int. J. Robot.Res., vol. 21, no. 8, pp. 735–758, 2002.
[17] J. W. Weingarten, G. Gruener, and R. Siegwart, “A state-of-art 3D sensorfor robot navigation,” in Proc. IEEE Int. Conf. Intell. Robot Syst., Sendai,Japan, 2004, pp. 2155–2160.
[18] J. M. Saez and F. Escolano, “Entropy minimization SLAM using stereovision,” in Proc. IEEE Int. Conf. Robot. Autom., Barcelona, Spain, 2005,pp. 36–43.
[19] J. M. Saez and F. Escolano, “6DOF entropy minimization SLAM,” inProc. IEEE Int. Conf. Robot. Autom., 2006, pp. 1548–1555.
[20] R. Sim, P. Elinas, M. Griffin, and J. J. Little, “Vision-based SLAM usingRao–Blackwellised particle filter,” presented at the Int. Joint Conf. Artif.Intell. Workshop Reasoning Uncertainty Robot., Edinburgh, U.K., 2005.
[21] M. N. Dailey and M. Parnichkun, “Landmark-based simultaneous local-ization and mapping with stereo vision,” in Proc. IEEE Asian Conf. Ind.Autom. Robot., 2005, pp. 108–113.
[22] S. Se, D. G. Lowe, and J. J. Little, “Vision-based global localization andmapping for mobile robots,” IEEE Trans. Robot., vol. 21, no. 3, pp. 364–375, Jun. 2005.
[23] S. Huang, Z. Wang, and G. Dissanayake, “Mapping large scale environ-ments using relative position information among landmarks,” in Proc.IEEE Int. Conf. Robot. Autom., 2006, pp. 2297–2302.
[24] P. Newman, D. Cole, and K. Ho, “Outdoor SLAM using visual appear-ance and laser ranging,” in Proc. IEEE Int. Conf. Robot. Autom., 2006,pp. 1180–1187.
[25] D. M. Cole and P. Newman, “Using laser range data for 3D SLAM inoutdoor environments,” in Proc. IEEE Int. Conf. Robot. Autom., 2006,pp. 1556–1563.
[26] S. Se and P. Jasiobedzki, “Photo-realistic 3D model reconstruction,” inProc. IEEE Int. Conf. Robot. Autom. Workshop SLAM, 2006, pp. 3076–3082.
Weizhen Zhou (S’06–M’08) received the B.Eng.degree in computer system engineering in 2004from the University of Technology Sydney (UTS),Sydney, N.S.W., Australia, where she is currentlyworking toward the Ph.D. degree with the AustralianResearch Council (ARC) Centre of Excellence forAutonomous Systems.
Her current research interests include visual si-multaneous localization and mapping, with particularinterest in 3-D environments.
Jaime Valls Miro received the B.Eng. and M.Eng.degrees in computer science systems from ValenciaPolytechnic University, Valencia, Spain, in 1990 and1993, respectively, and the Ph.D. degree in roboticsfrom Middlesex University, London, U.K., in 1998.
He was with the underwater robot industry for 5years. He is currently a Senior Research Fellow withthe Australian Research Council (ARC) Centre ofExcellence for Autonomous Systems, University ofTechnology Sydney, Sydney, N.S.W., Australia. Hiscurrent research interests include autonomous nav-
igation and mapping of unstructured scenarios—urban search and rescue, inparticular, visual simultaneous localization and mapping (SLAM), underwaterand health care robotics, kino-dynamic manipulator control, and human–robotinteraction.
Gamini Dissanayake (M’05) received the B.Sc.(Eng.) Hons. degree in mechanical/production en-gineering from the University of Peradeniya,Peradeniya, Sri Lanka, in 1977 and the M.Sc. degreein machine tool technology and the Ph.D. degree inmechanical engineering (robotics) from the Univer-sity of Birmingham, Birmingham, U.K., in 1981 and1985, respectively.
He is currently the James N. Kirby Professor ofMechanical and Mechatronic Engineering with theUniversity of Technology Sydney (UTS), Sydney,
N.S.W., Australia, where he leads the UTS node of the Australian ResearchCouncil (ARC) Centre of Excellence for Autonomous Systems. He has exper-tise in a broad range of topics in robotics, including robot localization, mappingand simultaneous localization and mapping (SLAM) using sensors such as laser,radar, vision and inertial measurement units, terrain mapping, multirobot coor-dination for SLAM, target tracking and probabilistic search, motion planningfor single and multiple robot manipulators, legged robots and cranes, and theapplication of robotic systems in urban search and rescue.





























