Embed Size (px)
Citation preview

TRENDS in Biotechnology Vol.19 No.8 August 2001
http://tibtech.trends.com 0167-7799/01/$ – see front matter © 2001 Elsevier Science Ltd. All rights reserved. PII: S0167-7799(01)01696-1
288 OpinionOpinion
The extraordinary pace and scale of developmentsin the field of genomics has forced a paradigm shift inthe manner with which the pharmaceutical industryapproaches the discovery and development of newdrug compounds. The completion of the first draft ofthe human genome has made it possible to foreseemajor steps forward in our understanding of themolecular basis of disease, both from attack byexternal pathogens and internally from variationswithin the human genome resulting in a plethora ofnew molecular therapeutic targets for drug designand discovery. New technologies have sprung up tocope with the avalanche of genomic data. As aconsequence of these exciting developments, theresearch process of drug discovery is becomingindustrialised with the research impetus being takenout of academic institutes and put into cutting-edgeniche research companies that have better fundingand significant commercial opportunities.
It is salutary to look at the numerical scale of theproblems that face the pharmaceutical industry.The human genome probably contains35 000–50 000 genes1. Currently, there are probably100 bacterial genomes sequenced each containing~4000 genes. Three million single nucleotidepolymorphisms (SNPs) are expected within thehuman genome and many might be linked directlywith disease conditions or affect thepharmacokinetic profiles of drug treatment. Withineach cell type in the human body, perhaps 100 genesshow significant differential expression during drugtreatment. It is estimated that the number oftherapeutic molecular targets will increase from~1000 currently used by the pharmaceutical industryto perhaps as many as 10 000.
A pharmacophore is defined as a subset of ligandatoms (such as hydrogen-bonding atoms, chargedatoms and hydrophobic residues) that areprincipally involved in binding a ligand to a target.Within a potential drug-binding site, the number ofpossible pharmacophores can be expressedcombinatorially; if there are 30 site points and aselection of any five site points form apharmacophore then the number of subsets ofpharmacophores is 140 000 per site. It has beenestimated that the number of possible moleculeswith a molecular weight of less than 500 Da is 10200
of which perhaps 1060 might possess drug-likeproperties2. Thus, the pharmaceutical industry ispresented with a universe of opportunities fromwhich to pick commercial winners. Majornumerical optimization problems have to beresolved if the industry is to efficiently explore thedrug discovery process.
This article pinpoints the major components of thisnew wave of drug discovery and looks forward to thebenefits of current progress.
Genomics and target identification
Genomics is the study of linear gene sequences andhas been used to estimate the number of differentmRNA species that could be expressed from thegenomes of living organisms. It has also prompted amore global approach to biological problems,superseding the ‘one gene at a time’approach thatcannot reveal the full diversity and complexity ofgene expression.
The field has been driven by the development ofhigh-throughput DNA sequence analysis (andincreased computing power) resulting in aproliferation of public and private databasescontaining full and partial sequences of mammals,plants and microrganisms. The ultimate objective ofany gene-sequence database is to be able to store andretrieve information on full-length genes (and byimplication, full-length proteins and regulatoryregions for transcription factor binding etc.) but thishas been a slow process. Rapid improvements insequencing technology, and subsequently reductionin costs and increased throughput, has resulted inthe expansion of public databases and the emergenceof private databases for commercial purposes. Theimpetus provided by the latter has improvedefficiencies in the overall strategic approach as wellas invigorated the public genomics enterprises. Since
Industrial-scale,
genomics-based drug
design and discovery
Philip M. Dean, Edward D. Zanders and
David S. Bailey
The demands on drug discovery organizations have increased dramatically in
recent years, partly because of the need to identify novel targets that are both
relevant to disease and chemically tractable. This is leading to an industrial
approach to traditional biology and chemistry, inspired in part by the revolution
in genomics. The purpose of this article is to highlight the flow of investigation
from gene sequence of potential therapeutic targets, through mRNA and
protein expression, to protein structure and drug design. To deal with this scale
of activity, many commercial and public organizations have been established
and some of the key players will be listed in this article.
Philip M. Dean*,
Edward D. Zanders and
David S. Bailey
De Novo PharmaceuticalsLtd, St Andrew’s House,59 St Andrew’s Street,Cambridge, UK CB2 3DD.*e-mail: [email protected]
‘It is estimated that the number of
therapeutic molecular targets will
increase from ~1000 currently used
by the pharmaceutical industry to
perhaps as many as 10 000.’

1992, the ability to sequence only cDNA copies ofmRNA (expressed sequence tags, ESTs) as opposedto waiting for the entire genomic sequence of anorganism, has led to the creation of thousands of genefragments for use with microarray and relatedtechnologies. In addition, many new genes have beendiscovered on the basis of the biological activity oftheir encoded proteins. For some organisms,including humans, the peak of EST sequencing hasbeen reached and the way ahead is clear forrevisiting the original objective of creating acatalogue of full-length genes. This is also the timefor the companies that sell databases of genomicinformation to adapt to the necessity for addingsignificant extra value to sequence information, forexample through detailed annotation, expressionanalysis and proteomics.
The recent landmark publications on the humangenome sequence suggest that the total number ofhuman genes is likely to be in the region of 35 000(Ref. 3). The expected diversity of gene expression istherefore likely to derive from alternative splicing ofthe mRNA; this phenomenon is well known to createfunctionally different proteins from a single gene,one such example being the dopamine receptor4.
Several companies have recognised theimportance of this alternative splicing issue inbiological and pharmaceutical research and offer theability to search for known and putative splicevariants within their databases of human genes.
Genetics and pharmacogenetics
With the recognition that many diseases involve aninterplay between multiple genes andenvironmental factors, genetic association studies athigh throughput have been required to tease outthese complex traits. Luckily, the discovery SNPs,which are distributed throughout the humangenome, offers a way forward. Furthermore, SNPsallow the application of genetics to efficacy of drugaction at the level of the individual patient, thusrevitalising the field of pharmacogenetics. Thus,there is a considerable effort being undertaken inbig pharmaceutical and biotechnology companies tolocate a sufficiently high density of SNPs along thehuman genome to map disease-related genes in amatter of months rather than years. It would benaïve to expect that every disease locus will providea drug target in its own right, but these studies willprovide some insight into complex pathologicalprocesses that are still poorly understood for majordiseases such as asthma.
There is considerable interest in pharmacogenetics,that is the concept of ‘the right drug for the rightpatient’using genetics to identify responders ornon-responders to a particular medicine5. SNPs arebeing used to classify patients whose target proteinfor their prescribed medicine shows sequencevariation or differences in expression level. Theresults of these trials will have obvious implications
for clinical practice, as well as future scientific andcommercial aspects of drug discovery.
Although some private companies have been SNPmapping on an individual basis, substantial resourcesare required to do so. This consideration hasencouraged a group of large pharmaceuticalcompanies to acquire and share data as a consortiumto contain overall costs. Thus, the most significantgenetic data on major Western diseases will probablyemerge from the SNP consortium working in closeassociation with academic laboratories over the nextfew years.
Gene expression and array technology
Early attempts to systematically catalogue the fullcomplement of mRNA molecules expressed by a cellor tissue, relied on large-scale sequencing of cDNAlibraries. The relative abundance of a particularmRNA is related to the proportion of sequencesobtained6. This approach has been used successfullyby Incyte (Palo Alto, CA, USA) to produce electronicnorthern blots of cells and tissues, and by publicresources such as the IMAGE consortium.Improvements in differential gene expressiontechnology based on PCR [differential display, serialanalysis of gene expression (SAGE)] or arrayhybridization (such as nylon, glass microarrays andoligonucleotide chips) have changed the landscapecompletely7. Few aspects of biology have beenuntouched by the application of array technologies inone form or another. Several themes have emergedfrom published reports over the past few years thatinvolve the expression analysis of mRNAs from yeastand humans in particular. In broad terms, thesethemes consist of evaluations of gene expressionchanges in systems undergoing biological responses,for example during the cell cycle8. In addition,statistical analyses of gene expression in tissuesamples have been employed in the search forpathological markers of disease9. All these studiesfind a place in drug discovery, both as an aid to targetidentification and also for evaluating the detailedefficacy and side-effect profiles of experimentalcompounds, as well as the identification of surrogatemarkers of drug action.
Now that gene expression technology and dataanalysis methodology has matured, there has been a call for data sharing and standardisation.These are clearly difficult issues, with the need toaccommodate different experimental platforms andanalytical systems, but the first step forward hasbeen taken with the establishment of the GeneExpression Omnibus (http://www.ncbi.nlm.nih.gov/geo/) and ArrayExpress (http://www.ebi.ac.uk/arrayexpress). As the input of quality data into these resources becomes significant, it will beeasier to compare gene expression under widelydiffering conditions in vitro and in vivo, thusestablishing the rules under which living systemsoperate at the transcriptional level.
TRENDS in Biotechnology Vol.19 No.8 August 2001
http://tibtech.trends.com
289OpinionOpinion

Proteomics – analysing the protein complement of the
genome
High-throughput analysis of protein sequences andstructures has lagged behind that of gene sequencesbecause of the greater technical challenges involved.This information, however, is fundamentallyimportant for drug discovery because proteins are thephysical targets of most drugs (small molecules orproteins). Not surprisingly, there is substantial effortand progress in this area, particularly after theintroduction of specialised mass spectrometrytechniques to analyse small amounts of protein withhigh precision using information from sequencedatabases to aid in their identification. Initialapplications were concerned with the identificationof proteins that had been resolved using one or two-dimensional gel electrophoresis. This has provenhighly successful in the characterisation of membersof protein complexes (for example from signallingcomplexes or organelles) as a complementaryapproach to the yeast two-hybrid system. (In thelatter case, it is possible to identify interactionsbetween individual pairs of proteins using geneticmethods.) Matthias Mann, one of the pioneers of theapplication of mass spectrometry to proteomics, hasnow commercialized his research to form Protana(now acquired by MDS Proteomics, Calgary, Canada)to scale up this technology.
An exciting further application of massspectrometry is the detection of low molecular weightcompounds that are bound to proteins by affinityadsorption. This could dramatically reduce the timerequired to identify and characterize lead compoundsfor drug discovery. This is also possible with a logical
extension of cDNA microarrays, in which proteins areimmobilized at high density on solid supports. In thiscase, these targets might be interrogated using otherproteins or small molecules in a screening format.The standard fluors used for nucleic acid arrays havebeen employed to measure protein–protein andprotein–drug interactions on glass slides thusavoiding the use of expensive mass spectrometers10.
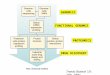
These novel assay systems will begin to take overfrom high-throughput screening (HTS) as a primarymethod for identifying lead compounds. A moreefficient process than either method would be todirectly identify potential leads in silico by exploitingthe 3D structures of proteins and advances incomputer-aided drug design. This requirement is, inpart, currently driving the intense activity instructural genomics and bioinformatics; madepossible both through the increased number of 3Dprotein structures being solved using X-raycrystallography and NMR, or being inferred throughhomology modelling. Recently, several new companieshave been formed to generate revenues frompartnerships with drug discovery organisations. Astructural genomics consortium (SGC) is planned forlate 2001 by major pharmaceutical companies for thesame reasons that the SNP consortium was founded –that is to benefit from sharing information withoutbearing a disproportionate amount of cost. Likewise,major national efforts are underway to achieve thesame result in recognition of the fundamentalimportance of protein structure in exploiting thegenome for drug discovery. Figure 1 summarizes theflow of activity from sequence identification toexploiting the proteome to provide targets for drugdiscovery. The main companies involved in theseprocesses are listed in Box 1.
Small molecule discovery
The modern pharmaceutical industry was foundedon the manufacture of low molecular weightcompounds (<500 Da) for clinical use. Despite thesuccessful introduction of protein therapeutics andthe promise of gene therapy, the discovery of smallmolecule drugs remains the dominant activity of theindustry. As the following sections will make clear,this activity is no longer confined to traditional largepharmaceutical companies, it is also beingundertaken by biotechnology companies that areusing a new generation of discovery tools based oncomputer-aided design and combinatorial chemistry. Many reviews of genomics andproteomics stop short of discussing how targetinformation can be efficiently converted to smallmolecule drug candidates.
The most commonly used method of identifying alead molecule for a protein target is HTS ofcompound databases. This promised much fordelivering hits from a company’s own resources, withnumerous contract screening organizations beingestablished to provide this service. Two types of
TRENDS in Biotechnology Vol.19 No.8 August 2001
http://tibtech.trends.com
290 OpinionOpinion
TRENDS in Biotechnology
Genome-wide
sequencing
Genome-wideSNPs
GlobalmRNA
expressionprofiling
Proteome-wide proteinexpression
profiling
Proteinstructure
New chemical entities
Industrialscale drugdesign and
testing
Globalprotein–protein
interactions
Fig. 1. Thebiotechnology-baseddrug discovery assemblyline. The figure shows thecomponents of thegenomics-based drugdiscovery process andassociated organisations.Initial nucleotidesequence analysisprovides the basis of geneidentification and geneticanalysis using singlenucleotidepolymorphisms (SNPs).This is followed by mRNAand protein expressionanalyses to determine thecell and tissue distributionof the gene of interest inhealth and disease. Thestructure of the proteinof interest is determined,to provide a frameworkfor small moleculediscovery through insilico design. In addition,the association of thetarget with other proteinsin functional complexesmight add value to theanalysis.

compound database have been used, large companycompound collections, and optimally diverse subsetsof the compounds. However, in general, the resultsobtained using HTS have not been as attractive ashoped11 for two reasons: (1) the numbers ofcompounds that can be economically screened issmall compared with the chemical space available,and (2) the theoretical coverage of moleculardiversity within the screening set is limited. Thus,there might be no compound in the collection thathas an appropriate pharmacophore for the targetbinding-site. Furthermore, the hits obtained mightnot be amenable for further elaboration into leadcompounds through medicinal chemistry.
There will, however, be several cases in which HTSwill provide a number of hits that can then beanalysed by molecular similarity studies. Theseidentify the different pharmacophore subsets presentin the screening data and provide clues for differentpossible lead series. For these molecular similarityapproaches to be useful, they must be able to identifypartial molecular similarity within a set of diversehits, something that is not always obvious on visual
inspection of the structures. The SLATE algorithm forexample12, is capable of extracting this informationfrom structurally distinct molecules that bind to thehistamine H3 receptor allowing the design of a novelchemical series with potent activity at H3.
Virtual screening
As implied previously, in silico screening is animportant complementary technology to HTS usingvirtual compounds rather than in-house collections.The technique requires a 3D molecular structure ofthe target molecule, either determined using X-raycrystallography and/or NMR, or by homologymodelling. The molecular structures to be screenedmight be an existing compound collection or a virtualcollection of molecular structures obtained from apreferred set of combinatorial chemistries. Theadvantage of the virtual set is that it is not necessaryfor the structures to have been synthesised before thein silico docking experiments. In silico screeningrelies on the generation of a representation of theligand binding site on a protein that can be used fordocking, the aim is to identify molecules that have
TRENDS in Biotechnology Vol.19 No.8 August 2001
http://tibtech.trends.com
291OpinionOpinion
Genome wide sequencing
Celera Genomics (Rockville, MD, USA); http://www.celera.com
European Bioinformatics Institute (EBI, Hinxton, UK); http://www.ebi.ac.uk
Human Genome Sciences (Rockville, MD, USA); http://www.hgsi.com
Incyte Genomics (Palo Alto, CA, USA); http://www.incyte.comNational Center for Biotechnology information (NCBI, Bethesda,
MD, USA); http://www.ncbi.nlm.nih.gov
Genetics and SNP analysis
DeCode Genetics (Reykjavic, Iceland); http://www.decode.com/Genset (Paris, France); http://www.genxy.comSNP consortium; http://snp.well.ox.ac.ukGenaissance Pharmaceuticals (New Haven, CT, USA);
http://www.genaissance.com
mRNA expression profiling and altenative splicing
Compugen (Jamesburg, NJ, USA); http://www.cgen.com/science/splicing.htm
I.M.A.G.E. consortium (Livermore, CA, USA); http://image.llnl.govIncyte Genomics (Palo Alto, CA, USA); http://www.incyte.comRosetta Inpharmatics (Kirkland, WA, USA); http://www.rii.comAffymetrix (Santa Clara, CA, USA); http://www.affymetrix.comGeneLogic (Rockville, MD, USA); http://www.genelogic.com
Proteome-wide expression profiling
OGS (Oxford, UK); http://www.ogs.com/AboutOGS/auoverviewSwiss 2D-PAGE; http://www.expasy.ch/ch2dCiphergen Biosystems (Freemont, CA, USA);
http://www.ciphergen.comLSB (Vacaville, USA); http://www.lsbc.com
Protein structure
Astex (Cambridge, UK); http://www.astex-technology.comInpharmatica (London, UK); http://www.inpharmatica.comIntegrative Proteomics (Toronto, Canada);
http://www.integrativeproteomics.comNIGMS Structural genomics initiative (Bethesda, MD, USA);
http://www.nih.gov/nigms/fundingpsi.htmlProtein Data Bank (PDB); http://www.rcsb.org/pdbProtein Structure Factory (Berlin, Germany);
http://userpage.chemie.fu-berlin.de/~psfProspect Genomics Inc. (San Francisco, CA, USA);
http://www.prospectgenomics.comRIKEN (Saitama, Japan); http://www.riken.go.jpStructural Bioinformatics (San Diego, CA, USA);
http://www.strubix.comStructural Genomix (San Diego, CA, USA); http://www.stromix.comSyrrx (San Diego, CA, USA); http://www.syrrx.com
Global protein–protein interactions
Caprion Proteomics (Montreal, Canada); http://www.caprion.comCuragen (New Haven, CT, USA); http://www.curagen.comHybrigenics (Paris, France); http://www.hybrigenics.comMDS Proteomics (Calgary, Canada); http://www.mdsintl.com
Industrial scale drug design and testing
De Novo Pharmaceuticals (Cambridge, UK); http:/www.denovopharma.com
Prospect Genomics Inc. (San Francisco, CA, USA); http://www.prospectgenomics.com
CEREP (Rueil-Malmaison, France); http://www.cerep.fr/CerepEvotec (Hamburg, Germay); http://www.evotec.deNeogenesis (Cambridge, MA, USA); http://www.neogenesis.comProtherics (Macclesfield, UK); http://www.protherics.com
Box 1. Companies involved in genomics-based drug design and discovery

the correct geometric and electronic features to fitthe designated sites. As might be expected, thedevelopment of computer algorithms that have thesecapabilities is a large field of study in itself and hasbeen ongoing for many years.
Although in silico virtual screening has beensuccessful, there is always room for improvement inidentifying structures that have a high chance ofbeing pharmacologically active and these issues arediscussed below. First, the rapid versions of in silicoscreening that employ flexible docking only deal withflexible compounds and ignore the computationallydemanding problem of including flexibility withinthe sites. Recently, Carlson and McCammon13
reviewed these problems of flexible docking andspeculated that loop fluctuation and domainmovement models need to be developed to tackleflexibility within sites. Second, the generic weaknessof current docking algorithms is that they require anaccurate scoring function to prioritise the virtualhits. Scoring function technology is not particularlyadvanced and does not usually take into accountexplicit water molecules in the site. However, thereare some interesting successes; a notable one beingthe discovery that some steroids bind to FK506binding protein (FKBP; Ref.14).
Further evidence of activity in the field of virtualdocking is provided by the large-scale dockingcollaboration (Dockcrunch, Macclesfield, UK) thathas been established to combine novel software withspecial hardware systems (http://www.protherics.com/crunch) to overcome some of the problemshighlighted above.
Drug design
Whereas virtual screening is a powerful adjunct toreal HTS, true de novo design of drug candidates is in aclass of its own with promises and challenges to
match. A new generation of de novo design algorithmscan produce large numbers of molecular structuraltypes for a particular protein site. Furthermore, thestructures can be provided in combinatorial chemistryformats and tailored to the preferences of clientcompanies by enabling synthesis to be performed in-house using proprietary chemistries. The algorithmswork by exhaustively building virtual structures inthe site and can be geared to create novel diversescaffolds that can be subsequently ‘decorated’withsubstituents as a combinatorial library. The use ofsophisticated optimisation algorithms ensures thatlarge chemical spaces can be explored, thus increasingby many orders of magnitude the numbers ofstructures that can be considered for design.
Coupling these algorithms to large-scale structuralgenomics and high-throughput chemistry will providenovel and patentable compounds within a fasttimeframe. This industrialisation of the gene-to-drugdiscovery process is essential if the plethora of newtargets spawned from genomics is to be capitalisedupon. Because of the sheer number of targets, it will benecessary to identify families of functional proteinclasses (e.g. hydrolases and kinases) as targets for drugdesign. This has the advantage of creating the chemicalstrategies that are appropriate for a particular familyand also helps in the all-important issue of selectivity.Large pharmaceutical companies have nottraditionally invested as much in this area as in HTSand therefore it is likely that niche companies capableof synergizing with complementary companies will bethe main beneficiaries of this approach to drugdiscovery. Exploitation of data from the public andprivate domains has been a significant catalyst in thiscommercialisation process, despite the patentingissues on privately generated gene and proteinsequences. This new biotechnology-driven aspect of thedrug discovery process will benefit from organisationalstrategies that are commonplace in other hightechnology industries such as semiconductors. Thus,the implementation of an assembly line process via theseamless integration of target discovery, validation anddrug design modules and the use of automatedprocedures, will result in dramatic increases inefficiency to the benefit of all concerned.
TRENDS in Biotechnology Vol.19 No.8 August 2001
http://tibtech.trends.com
292 OpinionOpinion
References
1 Lawrence, R. (2001) Craig Venter discusses lifeafter the Human Genome Project. Drug Discov.Today 6, 10–12
2 Bohacek, R.S. et al. (1996) The art and practice ofstructure-based drug design: a molecularmodeling perspective. Med. Res. Rev. 16, 3–50
3 International Human Genome SequencingConsortium (2001) Initial sequencing and analysisof the human genome. Nature 409, 862–921
4 Usiello, A. et al. (2000) Distinct functions of thetwo isoforms of dopamine D2 receptors. Nature408, 199–203
5 Drazen, J.M. et al. (1999) Pharmacogeneticassociation between ALOX5 promoter genotypeand the response to anti-asthma treatment.Nat. Genet. 22, 168–170
6 Audic, S. and Claverie, J.M. (1997) Thesignificance of digital gene expression profiles.Genome Res. 7, 986–995
7 Lockhart, D.J. and Winzeler, E.A. (2000)Genomics, gene expression and DNA arrays.Nature 40, 827–836
8 Spellman, P.T. et al. (1998) A comprehensiveidentification of cell cycle-regulated genes of the yeast Saccharomyces cerevisiae bymicroarray hybridisation. Mol. Biol. Cell9, 3273–3297
9 Golub, T.R. et al. (1999) Molecular classificationof cancer; class discovery and class prediction bygene expression monitoring. Science 286,531–537
10 MacBeath, G. and Schreiber, S.L. (2000) Printing proteins as microarrays for
high-throughput function determination. Science289, 1760–1763
11 Bailey, D.S. and Brown, D. (2001)High-throughput chemistry and structure-baseddesign: survival of the smartest. Drug Discov.Today 6, 57–59
12 Mills, J.E.J. et al. (2001) SLATE: a method for thesuperposition of flexible ligands. J. Comput. Mol.Design 15, 81–96
13 Carlson, H.A. and McCammon, J.A. (2000)Accommodating protein flexibility incomputational drug design. Mol. Pharmacol.57, 213–218
14 Burkhard, P. et al. (1999) The discovery of steroidsand other novel FKBP inhibitors using amolecular docking program. J. Mol. Biol.16, 853–858
‘…industrialisation of the gene-to-
drug discovery process is
essential…’