Embed Size (px)
Citation preview

1
In Silico Drug Design Strategies
STEFAN STEYN
Pharmacokinetics, Dynamic and MetabolismLead Generation Group
Pfizer Global Research & Development, Groton/New London Laboratories,
Groton, CT 06340

2
Ever Elusive Horizon…
Seamless integration of in silico data together with in vitro and in vivo data in drug design might have been perceived as the ever elusive horizon.
Major limitations:• High quality, large training sets. • Constant evolving chemistry space.• Confidence in models.
Solutions:• Harmonized ADME assays. • Constant retraining. • Integration with e.g. physicochemisty.

3
The Horizon is not so Elusive
• In Silico ADME enabled Hit Triage.
• In Silico enabled Mechanistic Studies to inform drug design.
• Combining In Silico and In vivo data to guide drug design.
• The Future.
The intent of this presentation is to show examples indicating that the horizon is not so elusive:
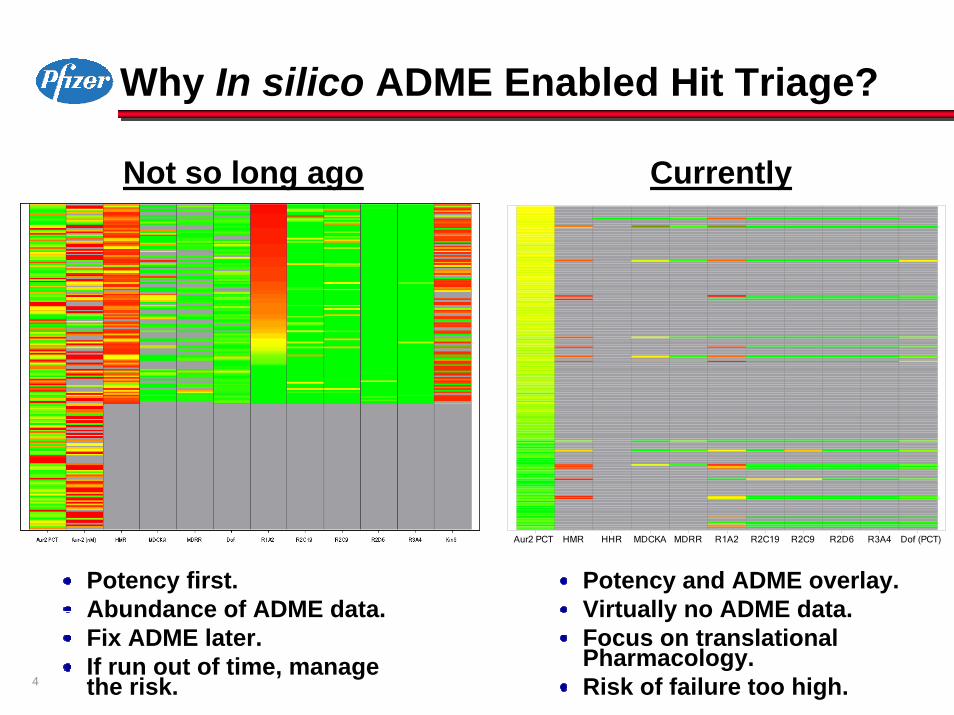
4
Why In silico ADME Enabled Hit Triage?
Currently Not so long ago
Aur2 PCT HMR HHR MDCKA MDRR R1A2 R2C19 R2C9 R2D6 R3A4 Dof (PCT)
Potency first.Abundance of ADME data.Fix ADME later.If run out of time, manage the risk.
Potency and ADME overlay.Virtually no ADME data.Focus on translational Pharmacology.Risk of failure too high.

5
In silico Enabled Hit Triage
Discovery Program – 24 Series defined from High Throughput Screening.– Need to identify series with best ADME & potency overlay.– No ADME data available – file compounds.
Approach– Multi-parametric Selection (next slide).– Use in silico for all ADME endpoints.– For best series:
Obtain small ADME dataset.Retrain in silico models with limited in vitro data.Use this retrained in silico models for final series selection.

6
Multi-Parametric Series Selection
Multi-parametric in-house tool
Reward or penalize distribution of properties e.g.:– HBD = 0 – maximum points e.g. 1.– HBD from 0 to 2 – gradually being penalized down to 0.1.– HBD > 2 – maximum penalty e.g. 0.1.
Use Weighting to prioritize properties e.g.:– HBD = 3– cLogP = 2– Potency = 1– Toxicity = 4
In Silico ADME:– Use ADME models trained on huge training sets.– Correlation between predictions used to sense validity.

7
MULTI-PARAMETRIC ANALYSIS (MPA)
• Distribution of properties are “rewarded” or “penalized”.
• Certain weightings are given to properties.

8
Multi-Parametric Combination
Series5 10 15 20
50
100
150
200
250
300
Series5 10 15 20
0
2
4
6
8
10
12
14
Series5 10 15 20
200
300
400
500
600
700
800
900
1000
Series5 10 15 20
0
5
10
15
20
25
30
35
40
Series5 10 15 20
-1.4
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
Series5 10 15 20
0
10
20
30
40
50
60
70
80
90
• All properties combined in a single readout

9
Multi-Parametric Selection Readout
Series5 10 15 20
50
100
150
200
250
300
Series5 10 15 20
0
2
4
6
8
10
12
14
Series5 10 15 20
200
300
400
500
600
700
800
900
1000
Series5 10 15 20
0
5
10
15
20
25
30
35
40
Series5 10 15 20
-1.4
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
Series5 10 15 20
0
10
20
30
40
50
60
70
80
90
Series5 10 15 20
3
4
5
6
7
8
9
10
Series
Wei
ghte
d D
esira
bilit
y S
core
Score is relative.

10
Multi-Parametric Selection Final Result
0
2
4
6
8
10
12
7 16 5 23 12 1 17 20 8 13 9 14 19 22 15 6 2 10 4 11 3 24 18 21
Series #
Des
irab
ility
Wei
ght
Results expressed as mean ± SD (n=200)
• Combining Chemical do-ability with average MPS scores lead to final series selection.• Focus on Series 1 and Series 4 for illustrating point.

11
ADME Follow Up – Series 1
• In silico data used to select compounds for obtaining select ADME data.• Extrapolate back to in silico data to validate cADME conclusions.• Retrain, where possible, in silico models with new data.
CLOGP0 1 2 3 4
810
20
40
60
80100
200
400
600
cMDCK0 5 10 15 20 25 30 35 40 45
0
2
4
6
8
10
12
14
cMDCK
cMD
R1
cHLM
_CLI
A,fr
ee
clogP
- ADME Selections (same compounds for HLM, MDCK & MDR1)

12
Impact of MDCK Data on In Silico Model
Before Data Generation
G5743A MDCK_AB Papp AB, corr10 20 30 40 50 60
10
15
20
25
30
35
40
45
50
55
cMD
CK
MDCK_cAB
cMDCK_NN0 0.1 0.2 0.3 0.4 0.5
0
0.1
0.2
0.3
0.4
0.5
After Data Generation
cMDCK_NN0 0.5 1 1.5 2 2.5 3
0
0.2
0.4
0.6
0.8
1
• cMDCK model benefited from selected in vitro data.
• Use in silico model.

13
Impact of MDR1 Data on In Silico Model
Before Data Generation
After Data Generation
MDR1G_01 MDCK/MDR1 Perm BA/ABcorr0 2 4 6 8 10
0
2
4
6
8
10
cMD
R1
MDR1_cBA/AB
cMDR_NN-0.2 0 0.2 0.4 0.6 0.8 1 1.2
0
0.2
0.4
0.6
0.8
cMDR_NN0 1 2 3 4 5 6
0
0.2
0.4
0.6
0.8
1
• cMDR1 model benefited from selected in vitro data.
• Use in silico model.

14
Impact of HLM Data on In silico ModelBefore Data Generation After Data Generation
• Sim. & NN-scores did not change – algorithm problem.cHLMG_01_NN
0 0.2 0.4 0.6 0.8 1
0
0.2
0.4
0.6
0.8
cHLMG_01_NN0 0.2 0.4 0.6 0.8 1
0
0.2
0.4
0.6
0.8
HLM_CLint_free0 20 40 60 80 100 120 140 160
0
50
100
150
200
250
300
350
400
• cHLM predictions changed but,• No good correlation between in vitro and in silico data observed.• In vitro HLM data to be used during series evaluation.
cLogP-0.5 0 0.5 1 1.5 2 2.5 3 3.5 4
6
810
20
40
60
80100
200
400

15
Effect of Constant Re-training on cHLMModel
Before Data Generation After Data Generation
cHLMG_01_NN0 0.2 0.4 0.6 0.8 1
0
0.2
0.4
0.6
0.8
cHLMG_01_NN0 0.2 0.4 0.6 0.8 1
0
0.2
0.4
0.6
0.8
Current Model
cHLMG_01_NN
0
0.2
0.4
0.6
0.8
1
0 10 20 30 40 50
• cHLM model constantly evolving to include new chemistry space.

16
ADME & Potency Space: Series 1
Binned cMDCKx ≤ 5 5 < x ≤ 10 10 < x ≤ 15 15 < x ≤ 20 20 < x ≤ 25 25 < x
x ≤ 5
5 < x ≤10
10 < x ≤15
15 < x ≤20
20 < x
Binned cMDCKx ≤ 5 5 < x ≤ 10 10 < x ≤ 15 15 < x ≤ 20 20 < x ≤ 25 25 < x
x ≤ 5
5 < x ≤10
10 < x ≤15
15 < x ≤20
20 < x
N = 46
ADME/Phys Chem. Potency (n = 50)
Binned CLOGPx ≤ 2 2 < x ≤ 3 3 < x ≤ 4 4 < x ≤ 5 5 < x
x ≤ 40
40 < x ≤60
60 < x ≤80
80 < x
Binned CLOGPx ≤ 2 2 < x ≤ 3 3 < x ≤ 4 4 < x ≤ 5 5 < x
x ≤ 40
40 < x ≤ 60
60 < x ≤ 80
80 < x
ADME & Potency space appears to over lap.

17
ADME & Potency Space: Series 4
ADME/Phys Chem. Potency (n = 69)
Binned cMDCKx ≤ 5 5 < x ≤ 10 10 < x ≤ 15 15 < x ≤ 20 20 < x ≤ 25 25 < x
x ≤ 5
5 < x ≤10
10 < x ≤15
15 < x ≤20
20 < x
N = 7
N = 8
Binned cMDCKx ≤ 5 5 < x ≤ 10 10 < x ≤ 15 15 < x ≤ 20 20 < x ≤ 25 25 < x
x ≤ 5
5 < x ≤10
10 < x ≤15
15 < x ≤20
20 < x
N = 30
Binned CLOGPx ≤ 2 2 < x ≤ 3 3 < x ≤ 4 4 < x ≤ 5 5 < x
x ≤ 40
40 < x ≤60
60 < x ≤80
80 < x
Binned CLOGPx ≤ 2 2 < x ≤ 3 3 < x ≤ 4 4 < x ≤ 5 5 < x
x ≤ 40
40 < x ≤ 60
60 < x ≤ 80
80 < x
N = 12
Potency appears to be dependent on lipophilicity while some low clearance space overlaps with efflux and poor permeability.

18
Conclusion
• In silico ADME based Multi-Parametric Selection:– correctly identified enabled series.– In silico data seamlessly integrated into decision making.
• Selected series are now represented by in silico ADMEmodels through re-training:
– In silico ADME part of drug design strategy.
• Generation of ADME data for re-training of in silicomodels resulted in:
– More chemistry space covered than by wet data alone.

19
The Horizon is not so Elusive
• In Silico ADME enabled Hit Triage.
• In Silico enabled Mechanistic Studies to inform drug design.
• Combining In Silico and In vivo data to guide drug design.
• The Future.
The intent of this presentation is to show examples indicating that the horizon is not so elusive:

20
Mechanistic Studies
• Following Hit confirmation:– Compounds divided into structural classes and “Core” or “template”
are identified – chemically enabled.– Limited ADME data available to influence series selection or initial
library design rounds.
• Critical to define metabolic stable template.
• Template identified, but is current template the most stable metabolic unit?
• Which R-groups and/or arrangements would likely protect template from metabolism?
ON
F
N
N
N
O
(Risperidone used to illustrate concept)
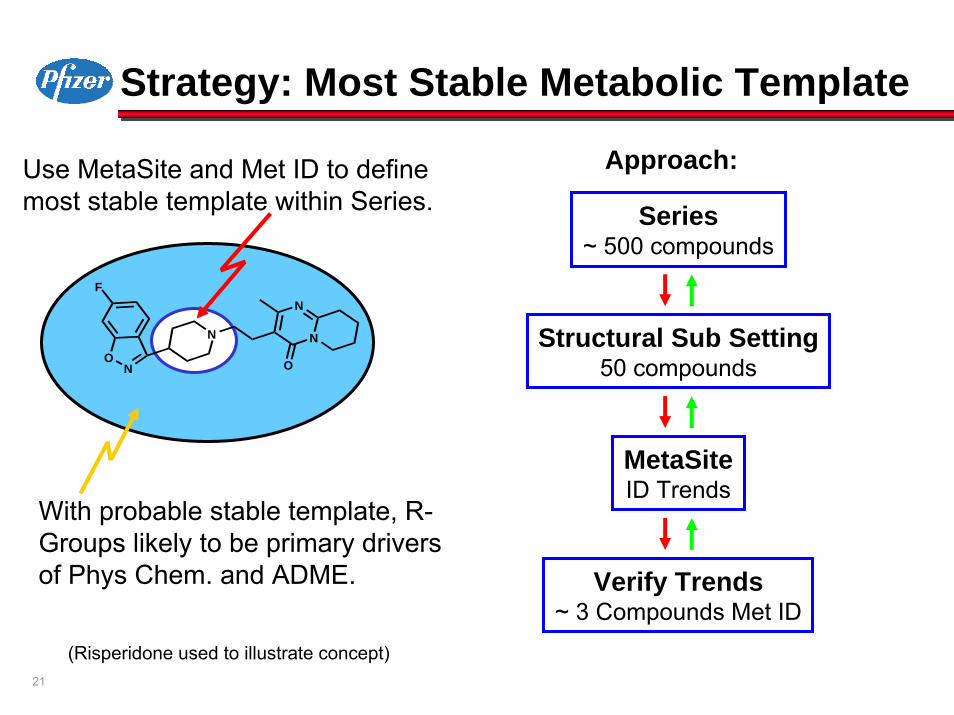
21
Strategy: Most Stable Metabolic Template
Series~ 500 compounds
Structural Sub Setting50 compounds
MetaSiteID Trends
Verify Trends~ 3 Compounds Met ID
Approach:Use MetaSite and Met ID to define most stable template within Series.
With probable stable template, R-Groups likely to be primary drivers of Phys Chem. and ADME.
ON
F
N
N
N
O
(Risperidone used to illustrate concept)

22
Series A - Analysis
Series A withtemplate illustrated
MetaSiteTrends
Test Trends
- Primary - Secondary- Tertiary- Actual Site
Site of Metab. Predictions:
R R
Likely Stable Template Synthetic Directions
R3
R2
R1
Heterocycle N or O

23
Conclusion
• Outcome:– “Bad” templates not pursued.– SAR identified which could lead to more stable templates.– First library designs attempt to address liability in the core.
• From the first library, ADME weak spots are being addressed.
• A validated in silico understanding of series allow for better design and testing of design hypothesis.

24
The Horizon is not so Elusive
• In Silico ADME enabled Hit Triage.
• In Silico enabled Mechanistic Studies to inform drug design.
• Combining In Silico and In vivo data to guide drug design.
• The Future.
The intent of this presentation is to show examples indicating that the horizon is not so elusive:

25
In Vivo Studies: Brain Penetration
• To define brain penetration space per series:– In silico predictions.– Physicochemical space.– Understand impairment.– Define “equity” of brain penetration space.
• In silico model:– About 750 compounds and drugs used for training and
validation.– Continuous-valued Random Forest model.– Reports computational Log Brain to plasma ratio – cLog B/P.

26
cLogB/P In Silico Model
In Vivo Log B/P-1.5 -1 -0.5 0 0.5 1
-1.5
-1
-0.5
0
0.5
1
• Relevance/confidence towards current chemical series unknown.•Attempt to understand Physicochemical basis of in silico model.•Use “understanding” to formulate hypothesis to enable directive library
design.• “Understanding” could lead to extrapolation vs. intrapolation.
cLog
B/P
In vivo LogB/P

27
Deconvoluting Physicochemical SpacecLogB/P vs. PSAcLogB/P vs. cLogP
MW250 300 350 400 450 500 550
-1.5
-1
-0.5
0
0.5
1
HBD0 1 2 3 4
-1.5
-1
-0.5
0
0.5
1
PSA0 20 40 60 80 100 120
-1.5
-1
-0.5
0
0.5
1
ClogP1 2 3 4 5 6 7 8
-1.5
-1
-0.5
0
0.5
1
cLogB/P vs. MWcLogB/P vs. HBD
Series 1
Selected for In vivoSeries 2
Comparator compound
cLog
B/P
cLog
B/P
cLog
B/P
cLog
B/P
cLogP PSA
HBD MW

28
Example: PSA and Brain PenetrationSeries 1
TPSA:Topological Polar Surface Area0 20 40 60 80 100 120
-0.5
0
0.5
1
In Silico Log B/P model apparently under estimates impact of PSA for Series 1 at HDB = 2.Steep slope.
cLog
B/P
Series 2
TPSA:Topological Polar Surface Area0 20 40 60 80 100 120
-0.5
0
0.5
1
PSA
cLog
B/P
PSA apparently not the most critical factor for either in silico or in vivo B/P-ratio’s in Series 2. Series in good brain penetration space.
PSA

29
Hydrogen Bond Donors & Series 1
cLogB/P vs. HBD
HBD0 1 2 3
-0.5
0
0.5
1Series 1
Selected for in vivoSeries 2
In vivo B/P
cLog
B/P
HBD0 1 2 3
• Potency suggest HBD = 1 or 2.• HBD of 0 would push Series 2 closer to Series1 – limited diversity.• As analyzed in vivo only HDB = 2.• In silico LogB/P –model is suggesting for design:
– Decreasing HBD count from 2 to 1 would improve B/P, but– No added value reducing HBD count to 0.

30
Conclusion
• In silico analysis allowed for informed in vivo study design.
• Combining in vivo and in silico data positioned in silicomodel for use in design.
• In silico analysis impacted chemistry design:– Did not predict the endpoint but,– Suggested design strategy.

31
The Horizon is not so Elusive
• In Silico ADME enabled Hit Triage.
• In Silico enabled Mechanistic Studies to inform drug design.
• Combining In Silico and In vivo data to guide drug design.
• The Future.
The intent of this presentation is to show examples indicating that the horizon is not so elusive:

32
The Future…
• In the future: – Current horizon will be breached.– New horizon:
Automatic compound selection for ADME data generation.Selection based on supplementing chemistry space for retraining of in silico model.In silico model always current.For some endpoints, only in silico ADME data available for decision making.
near
^

33
Summary
• In Silico ADME enabled Hit Triage.• In Silico enabled Mechanistic Studies to inform
drug design.• Combining In Silico and In vivo data to guide drug
design.• The Future.
In silico drug design strategies illustrated:
The next horizon awaits:- In silico data for some ADME endpoints.- Generation of wet data solely for better training of relevant
in silico models.

34
Acknowledgements
• Mary Piotrowski• Lead Generation group• ADME Technology Group• Computational Chemistry





























