Embed Size (px)
Citation preview

J. Parallel Distrib. Comput. 66 (2006) 922–930www.elsevier.com/locate/jpdc
Implications of virtualization on Grids for high energy physics applications
Laura Gilberta, Jeff Tsenga, Rhys Newmana, Saeed Iqbalb,∗, Ronald Pepperb, Onur Celebioglub,Jenwei Hsiehb, Victor Mashayekhib, Mark Cobbanc
aDepartment of Physics, University of Oxford, Oxford, OX1 3RH, UKbDell Inc. 701E Parmer Lane, Austin, TX 78753, USA
cDell Inc. Millbank House, Western Road, Bracknell, RG12 1RW Berkshire, UK
Received 23 May 2005; received in revised form 30 September 2005; accepted 1 December 2005Available online 15 May 2006
Abstract
The simulations used in the field of high energy physics are compute intensive and exhibit a high level of data parallelism. These featuresmake such simulations ideal candidates for Grid computing. We are taking as an example the GEANT4 detector simulation used for physicsstudies within the ATLAS experiment at CERN. One key issue in Grid computing is that of network and system security, which can potentiallyinhibit the widespread use of such simulations. Virtualization provides a feasible solution because it allows the creation of virtual computenodes in both local and remote compute clusters, thus providing an insulating layer which can play an important role in satisfying the securityconcerns of all parties involved. However, it has performance implications. This study provides quantitative estimates of the virtualizationand hyper-threading overhead for GEANT on commodity clusters. Results show that virtualization has less than 15% run time overhead, andthat the best run time (with the non-SMP license of ESX VMware) is achieved by using one virtual machine per CPU. We also observe thathyper-threading does not provide an advantage in this application. Finally, the effect of virtualization on run time, throughput, mean responsetime and utilization is estimated using simulations.© 2006 Elsevier Inc. All rights reserved.
Keywords: Virtualization; Hyper-threading; ATLAS; CERN; LHC; Particle physics simulations; VMware
1. Introduction
With the advent of Grid technology, the possibility of beingable to run software on millions of computers around the worldbut with wildly different software environments and hardwareconfigurations is being contemplated. One of the largest gridstoday is based around the experiments at the large hadron col-lider (LHC) in Geneva. This is known as the LHC ComputingGrid (LGC) project [11], currently surpassing 6000 CPUs in 70institutions throughout Europe. LCG is aiming to provide theequivalent of 100 000 of today’s fastest computers as data pro-cessing resources for the experiments at the LHC, which willbegin producing vast amounts of data when it is switched onin 2007.
∗ Corresponding author.E-mail addresses: [email protected] (L. Gilbert),
[email protected] (S. Iqbal).
0743-7315/$ - see front matter © 2006 Elsevier Inc. All rights reserved.doi:10.1016/j.jpdc.2005.12.013
One key issue is that on a Grid applications need to run ondifferent platforms and software environments. Given the largescale of this challenge, neither enforcing consistent hardwarenor validating all software environments is tenable. Neverthe-less, many man-years worth of effort has been put into thedata analysis software, much of which predates the use of Gridtechnology. Hence, deployment professionals face ongoingchallenges to install and run this software in the heterogeneousenvironment that the Grid presents. As can be imagined, thishas used substantial resources; development started in 2001as the European Data Grid (EDG) project [4] and with only2 years to go, more than 10 times the current number of ma-chines are still needed. (A recent technical overview of theprogress of this project is given in [20]. See [10] also.)
One solution to this problem is to use software virtualiza-tion technology [5]: the application software runs in whateverenvironment it has been validated in, and is insulated fromthe actual hardware and operating system. Consequently theresources underlying operating system can be maintained

L. Gilbert et al. / J. Parallel Distrib. Comput. 66 (2006) 922–930 923
separately, and kept current with the latest critical patches, with-out affecting the applications. Thus, virtualization allows therunning and support of legacy operating systems and code [22].In addition a clean, validated and isolated environment can beguaranteed whenever an application is to be run on the resource,and so application developers can concentrate on their preferredenvironment and spend their time developing functionality.
Nevertheless, in the past, virtualization has come at a signif-icant performance penalty. With the advent of the Grid a dif-ferent calculation is required: a 20% performance drop withina single machine is less significant if an application can runsimultaneously on 10 times the number of machines.
Add to that the possibility of automatic checkpointing ofjobs (at the virtual operating system level), and the consequentability to move jobs around the grid in response to resourceavailability, virtualization technology could provide the key tounlock the many thousands of machines needed for variouslarge computing projects, in particular the LHC in 2007.
However, few studies have sought to quantify the perfor-mance issues when virtualization is combined with the grid,especially with the data processing applications for the LHC.This paper presents the results of benchmarking the ATLASexperiment software within a series of virtualization scenar-ios to determine the extent of any potential advantages to thisapproach, and to identify any issues for further research. Anearlier version of this paper was published previously [7].
2. Background
2.1. Simulation in particle physics
Modern simulations used in applications such as high energyphysics are highly complex, and very compute intensive. Typ-ically, these types of simulations have three phases, namely,event generation, detector simulation and reconstruction.
The event generation phase generates virtual versions of theparticles we want to study. Event generators are Monte Carloprograms, built to represent the physics processes which oc-cur in the initial beam collisions. The events simulated in theseprograms cover only the initial interactions, i.e. the direct pro-duction of particles from the collisions, and if these are veryshort-lived (with lifetimes less than 10−12 s) they likely decayinto other particles. The result of this is a file containing in-formation on the number and types of simulated particle, andtheir energy and momenta. This information is then input intoa detector simulation.
Once in the detector, the particles that were originally pro-duced in the collision will alter. Some will have short lifetimesand decay into other particles, which might then decay further.Some will interact physically with the matter that makes upthe detector, both the active detecting elements and the supportstructures. The purpose of the detector simulation code is todescribe this process as closely as possible. Parameters such asthe calibration and alignment can also be varied in the simu-lation to allow the study of how these systematic effects willalter the results of an analysis. ATLAS uses the GEANT4 [6]detector simulation program, which is highly detailed, model-
CMSPoint 5
LHC-BPoint 8
CERNATLASPoint 1
ALICEPoint 2
ALICE
ATLASLHC-B
CMS LEP/LHC
TI 8 SPS TI 2
Fig. 1. Schematic view of the layout of the SPS, LHC and the ATLAS detectorat CERN. (Other experiments are also indicated.) ATLAS is situated 100 mbelow ground level. (This image was taken from the ATLAS collaborationspublic website.)
ing detector components to the microscopic scale. It modelsnot only the active detecting components, but also the supportmaterials, cooling systems, electronic readouts, and factors inthe possibility of dead cells (broken detecting elements) in thedetector and white noise in the electronics. Detector simula-tion requires many billions of calculations to be performed andseverely limits the number of complete events that can be pro-duced on a reasonable timescale. This is followed by a dig-itization phase, mimicking how real data produces electronicsignals. As a result, the simulated data will be output in exactlythe same format as real data.
The final stage of the simulation is the reconstruction, inwhich information from the detector simulation is built up intoa picture of exactly where particles passed through the detectorcomponents, and their energies and momenta at various stages.Pattern recognition software is applied to the data to producedatasets in a recognizable format of particle traces, ready for aphysicist to analyze. Niinimaki et al. [13] presents a study ofperforming high energy physics simulations in a Grid environ-ment, and Barberis et al. [2] discusses analysis within a Gridframework.
2.2. The ATLAS project
ATLAS is a particle physics experiment currently being con-structed at CERN in Geneva. It is due to start taking data in2007. It aims to refine current knowledge of particle physics,and to search for new physics beyond that which is known today[19]. Narrow beams of very high energy protons are producedat CERN in an underground circular accelerator, the super pro-ton synchrotron. These are then passed to the LHC, a larger ringaccelerator (27 km in circumference) in which they are acceler-ated to close to the speed of light. Two of these beams travelingin opposite directions will be allowed to collide at regular inter-vals at an interaction point, around which the ATLAS detectoris being built (Fig. 1). The luminosity of the collider (measuring

924 L. Gilbert et al. / J. Parallel Distrib. Comput. 66 (2006) 922–930
the number of collisions per second) is predicted to be onehundred times greater than any previously built, with collisionenergies of around 7 TeV (1 eV = 1.602×10−19 J: for compar-ison, a television set operates at around 30 KeV). The energydensities produced are similar to those present in the universeless than a billionth of a second after the Big Bang.
New particles will be formed in the resulting interaction andexpelled from the collision point with high energies. Theseparticles might include exotic, hitherto-unseen entities (such asthe famous Higgs boson), and provide a key to understandingsome of the mysteries of the universe.
ATLAS is one of the largest collaborative efforts ever at-tempted in the physical sciences. There are around 1800physicists (and many more engineers, technicians and com-puter scientists) participating from more than 150 universitiesand laboratories in 34 countries. The computer hardware bud-get is around $20 million for the CERN site alone, and much ofthe computing effort is dedicated to the development of an op-erational Grid structure to link this up with the facilities of theother participating organizations, which will supply their ownhardware (making this budget a fraction of the worldwide LHCcomputing expenditure). Jones et al. [9] details the ATLASoffline computing model and predicts the costs involved.
3. Experimental setup
3.1. Hardware
The systems used for this test case were Dell PowerEdge2650 s (PE2650) and 6650 s (PE6650). The PE2650 is a rackmountable 2U server. These systems support dual Intel XeonCPUs up to 3.2 GHz with a 533 MHz front side bus. Theyalso support up to 12 GB of 266 MHz RAM. The configura-tion used was dual 3.06 GHz CPUs with 2 GB of RAM. ThePE6650 is a rack mountable 4U server. These systems sup-port quad Intel Xeon CPUs up to 3 GHz with a 400 MHz frontside bus. They also support up to 32 GB of 266 MHz DDRRAM. The configuration used was dual 1.6 GHz CPUs with2 GB of RAM. Although these PowerEdge systems supportonboard RAID, an onboard SCSI controller was used withmultiple U160 SCSI hard drives, so that the hard drives wereindividually portable. These systems also have two embeddedBroadcom gigabit network controllers. In each case the pri-mary gigabit NIC was used for the host OS and in-band sys-tem management. The secondary gigabit NIC was dedicated toany virtual machines (VMs) running on each system. This al-lowed for the host OS and (VMs) to be on completely separatephysical networks and subnets. For monitoring system healththese machines have hardware sensors for fan speed, tempera-ture, and voltages. The data provided by these sensors can beretrieved via in-band management with simple network man-agement protocol (SNMP) agents or out-of-band means. Forout-of-band management, each system was also equipped withan embedded remote access card (ERA) that has its own fastEthernet NIC for out-of-band management. Hyper-threading isalso supported on both systems. Hyper-threading is a micro-architectural technique that enables two logical processors to
be simulated on a single physical processor [12]. Each logicalprocessor executes instruction streams from different threads,potentially improving resource utilization within the physicalprocessor. The improved utilization results in a performanceincrease. The incremental performance due to hyper-threadingis application specific.
The Grid environment used in this study consisted of aPE6650 master node and eight PE2650 compute elements. Itwas relatively easy to setup the hardware including initial in-stallation, adding and reconfiguring VMs. The initial setup forthese experiments was completed in a few days.
3.2. Software
3.2.1. Simulation within the ATLAS software frameworkThe ATLAS software [1] is based upon the GAUDI frame-
work, an open-source (C++) project that is designed to provideservices for event data processing applications in high energyphysics. The framework is accessed via the ATHENA user in-terface. To run a process ATHENA must be supplied with ajobOption file (a python script) which will specifies which otherprograms within the framework it should access, and any inputparameters needed. The ATLAS software is currently platform-specific and until recently required Red Hat Linux, version 7.3to run. It is now in the process of migration to Scientific Linuxversion 3 [16], an open-source operating system based on En-terprise Linux. For this investigation, a template jobOption filewas created to allow ATHENA to run the simulation. Thisspecifies the number of events to generate, then calls the eventgenerator Pythia [14] to create them. The types of particlesproduced in the collisions and their subsequent decay channelswere constrained to ensure continuity between experiments (inthis case W bosons were produced, and these were permitted todecay into electrons and neutrinos). The random-number seedused by Pythia was also fixed, which ensure that exactly thesame particles were generated in each comparably-sized job.The output from this was then fed into the GEANT4 detectorsimulation, to mimic the motion of the particles through thedetector and the electronic output that would be measured. Theoutput from this simulation is written into a *.root file (whichcan be read by the physics analysis tool ROOT [15]), with asize of roughly 1.5 MB per event that it contains.
The software is not multi-threaded, and it simulates eventsconsecutively so the time taken to finish can be expected to varyapproximately linearly with the number of events. However, itis worth noting that for each event successfully generated therewill be around another two that are abandoned at some pointduring the process.
3.2.2. Virtualization softwareThe Virtualization software used in this configuration was
ESX from VMware. VMware offers three Virtualization solu-tions [21]. The first is Workstation which is typically used byindividual users to run one or two virtual computers on theirday to day desktop. It runs on top of the host OS to supportthe virtual computers. The second is GSX, which is their first

L. Gilbert et al. / J. Parallel Distrib. Comput. 66 (2006) 922–930 925
server product. GSX also runs on top of a host OS (either Win-dows or Linux). GSX runs the VMs completely independentof the local display (Workstation does not) and allows users toconnect to it via remote console. The drawback of both Work-station and GSX is that they are both installed on top of a hostOS, so they cannot or do not completely virtualize any hard-ware and the system hardware is still completely accessible tothe host OS. VMware offers ESX to combat this problem.
ESX runs its own micro-kernel that completely virtualizesthe server’s hardware. A small VM service console allows lim-ited access to some of this hardware. This allows ESX to runwith a very small footprint and allow almost all of the systemresources to be used by the VMs. ESX also supports additionalfeatures such as SMP support for VMs, memory ballooning,and shared memory space. Through another VMware product,Virtual Center, an administrator can also clone machines andmove them from one ESX server to another (VMotion).
3.2.3. Sun Grid EngineSun Grid Engine 5.3 was chosen as the resource manager.
It is stable and widely used [17] as a resource manager. TheSun Grid Engine sets up a queuing system to include all thecompute nodes and a master node. Users are able to submitbatch, parallel or interactive jobs to the queues.
4. Approach and results
4.1. Experimental results
As the production of GEANT4 simulation results is verycompute intensive, it was decided to simply measure the timetaken to perform increasingly large scale jobs. For systembenchmarking, batches of one, ten, 25, 60 and 100 events weregenerated and simulated on each system, and the time to com-pletion of the job was measured. Baseline measurements of jobcompletion times were performed by averaging over three runsfor each data point. The observed variation among the threeruns was used to estimate the measurement uncertainty: 3.0%for the PE6650s and 1.9% for the PE2650s (all percentage er-rors in this section are related to execution times).
4.1.1. Effect of hyper-threadingMeasurements were taken of the performance of a PE2650
and a PE6650 with and without hyper-threading enabled, seeFigs. 2 and 3. As expected given the nature of the computations,hyper-threading slowed down the simulation, by 2.4 ± 1.1%for the PE2560s and 3.5 ± 2.6% for the PE6650s, so it wasdecided not to enable it in future tests.
4.1.2. Overhead of Sun Grid EngineA cluster was put together consisting of a PE6650 as the
master node, and eight compute nodes, which were PE2650s.The PE2650s had two processors and 2 GB of memory availableeach, so were assigned two submission queues per machine.The PE6650 had four CPUs, but only 3 GB of memory, soto allow the queues on each machine access to a comparableamount of memory three queue slots were set up on the PE6650.
0
5
10
15
20
25
1 10 25 60 100
Tot
al R
untim
e (H
ours
)
PE6650 without HTPE6650 with HT
Fig. 2. Effect of hyper-threading on different problem sizes on PE6650.
0
2
4
6
8
10
12
1 10 25 60 100
Tot
al R
untim
e (H
ours
)
PE2650 without HTPE2650 with HT
Fig. 3. Effect of hyper-threading on different problem sizes on PE2650.
The overhead of submitting jobs to the machines via SGE wasmeasured in comparison to the system running the softwaredirectly in each case and was found to be minimal, 0.01±0.03%for the PE2650s and 0.1 ± 4.2% for the PE6650. As both thesenumbers fall well below the measured errors in the basic jobtiming on both the PE2650 and PE6650, the overhead of SGEon each of the system is negligible. The master node was theremoved from the batch system so that jobs submitted in futuretests would run only on the compute elements (the PE2650s).
4.1.3. Overhead of virtualizationThe ESX version of VMware was installed on each of the
PE2650s. Two VMs were installed with RH7.3 and the ATLASsoftware. Each VM was assigned half of the physical memoryavailable (1 GB each) and could access one of the two CPUs.The error in measuring the times of individual jobs on thevirtualized nodes was found to be 3.0%, and the overhead dueto the addition of VMware and was 11.1 ± 3.8% (see Fig. 4).
4.1.4. Overhead of virtualization for batch jobsTo test the performance of the machines in a Grid environ-
ment, SGE was installed on each of the VMs and each VM was
926 L. Gilbert et al. / J. Parallel Distrib. Comput. 66 (2006) 922–930
0
2
4
6
8
10
12
1 10 25 60 100
Tot
al R
untim
e (H
ours
)
PE2650PE2650 with VMWare
Fig. 4. Overhead due to the addition of VMware (one virtual machine perCPU) on different problem sizes on PE2650.
assigned one queue slot. The cluster then had the same num-ber of slots in total as it did when each machine was physical,but twice the number of compute elements, each with a sepa-rate instance of the software running. In both cases one queuecorresponds to one processor.
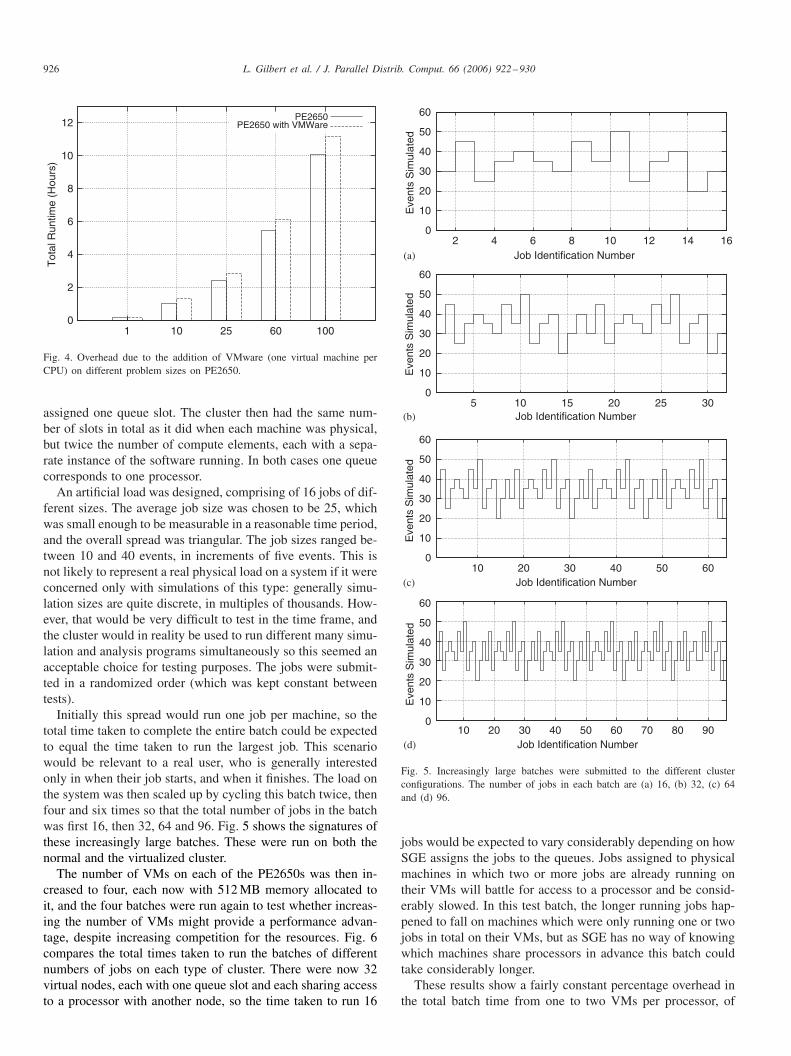
An artificial load was designed, comprising of 16 jobs of dif-ferent sizes. The average job size was chosen to be 25, whichwas small enough to be measurable in a reasonable time period,and the overall spread was triangular. The job sizes ranged be-tween 10 and 40 events, in increments of five events. This isnot likely to represent a real physical load on a system if it wereconcerned only with simulations of this type: generally simu-lation sizes are quite discrete, in multiples of thousands. How-ever, that would be very difficult to test in the time frame, andthe cluster would in reality be used to run different many simu-lation and analysis programs simultaneously so this seemed anacceptable choice for testing purposes. The jobs were submit-ted in a randomized order (which was kept constant betweentests).
Initially this spread would run one job per machine, so thetotal time taken to complete the entire batch could be expectedto equal the time taken to run the largest job. This scenariowould be relevant to a real user, who is generally interestedonly in when their job starts, and when it finishes. The load onthe system was then scaled up by cycling this batch twice, thenfour and six times so that the total number of jobs in the batchwas first 16, then 32, 64 and 96. Fig. 5 shows the signatures ofthese increasingly large batches. These were run on both thenormal and the virtualized cluster.
The number of VMs on each of the PE2650s was then in-creased to four, each now with 512 MB memory allocated toit, and the four batches were run again to test whether increas-ing the number of VMs might provide a performance advan-tage, despite increasing competition for the resources. Fig. 6compares the total times taken to run the batches of differentnumbers of jobs on each type of cluster. There were now 32virtual nodes, each with one queue slot and each sharing accessto a processor with another node, so the time taken to run 16
0
10
20
30
40
50
60
2 4 6 8 10 12 14 16
Eve
nts
Sim
ulat
ed
Job Identification Number
0
10
20
30
40
50
60
5 10 15 20 25 30E
vent
s S
imul
ated
Job Identification Number
0
10
20
30
40
50
60
10 20 30 40 50 60
Eve
nts
Sim
ulat
ed
Job Identification Number
0
10
20
30
40
50
60
10 20 30 40 50 60 70 80 90
Eve
nts
Sim
ulat
ed
Job Identification Number
(a)
(b)
(c)
(d)
Fig. 5. Increasingly large batches were submitted to the different clusterconfigurations. The number of jobs in each batch are (a) 16, (b) 32, (c) 64and (d) 96.
jobs would be expected to vary considerably depending on howSGE assigns the jobs to the queues. Jobs assigned to physicalmachines in which two or more jobs are already running ontheir VMs will battle for access to a processor and be consid-erably slowed. In this test batch, the longer running jobs hap-pened to fall on machines which were only running one or twojobs in total on their VMs, but as SGE has no way of knowingwhich machines share processors in advance this batch couldtake considerably longer.
These results show a fairly constant percentage overhead inthe total batch time from one to two VMs per processor, of

L. Gilbert et al. / J. Parallel Distrib. Comput. 66 (2006) 922–930 927
0
5
10
15
20
25
16 32 64 96
Tot
al B
atch
Run
time
(Hou
rs)
Real Cluster (onequeueper CPUVirtual Cluster (onequeueper CPU
Virtual Cluster (twoqueuesper CPU)
Fig. 6. The total runtime when batches of different number of jobs are submit-ted to a cluster of eight PE2650s using Sun Grid Engine. The Virtualizationresults shown are for cases where there is one VM/CPU and two VMs/CPU.
5.0 ± 2.2%. The overhead of running a single VM on one pro-cessor, rather than running the operating system directly on theplatform was previously measured to be 11.1 ± 3.8%, and sowe would expect this to remain approximately the case whenwe run a batch on both the real system with one grid queueper CPU and a virtualized system of 16 nodes. This was ob-served when running small batches. For 16 jobs the virtual-ized cluster ran around 8% slower than the physical, whichdecreased to 6% for 32 jobs. However, as the batch size in-creased the virtualized systems could be seen to outperform thephysical.
4.2. Load-balancing simulation results
The effect of varying the number of VMs per CPU on variousscheduler performance metrics was studied. The parametersof interest are total batch run time, job throughput rate, meanresponse time and resource utilization (CPU). The total runtimeof the batch is the time interval between the submission of thefirst job and the completion of the last job. The throughputmeasures the rate of jobs completed per unit time. The responsetime of a job is the time between its submission to the queueand the start of its execution, and mean response time (MRT) isthe average of the response times of all jobs. The utilization ofa compute node is the ratio of the time when its processors areactive (executing jobs) to the total runtime. The mean servicetime of jobs is the average runtime of jobs (also see [18]).
A batch of 160 jobs was selected at random from a populationwhich is normally distributed as shown in Fig. 7. Each job inthe population has a number of events from one to 80, the meannumber of events is 35 (and the number of events submittedfor generation in the detector simulator should determine theruntime of the job). Runtime was modelled from the results forthe PE2650s in the previous section. The inter-arrival rate ofjobs in this study is not varied, and it can be assumed that it ismuch higher than the mean service time of the jobs. In essence,the measurement starts with a queue of the selected 160 jobssubmitted for execution.
0
100
200
300
400
500
600
10 20 30 40 50 60 70
Num
ber
of J
obs
Number of Events
Fig. 7. The population of jobs is taken to be normally distributed as shown.The mean is 35 events.
As before, we assume a cluster with eight dual processorcompute nodes running SGE as a resource manager, and thensimulate the scenarios in which the virtual clusters have 16 andthen 32 nodes (corresponding to one and then two VMs perCPU). In each case, the jobs were scheduled in a first-come-first-serve (FCFS) manner to the next available processor. If noVMs are available the job was held in the queue.
The resulting simulated schedule on the 16 VM cluster isshown in Fig. 8(a): the x-axis represents time in hours and they-axis gives the VM IDs (corresponding to the queue slots).Similarly, Fig. 8 shows the same batch of jobs scheduled on 32VMs.
A summary of the relative performance of these schedules isshown in Fig. 9. The total batch run time of using two VMs/CPUwas 15.6% longer than using one, due to the overhead associ-ated with two VMs sharing a physical CPU, and the throughputin the case of two VMs/CPU was lower by 13.6%. It is inter-esting to note that the MRT was improved by about 7.1%, dueto the increased availability from the additional slots (equal tothe number of VMs). The 16 VM schedule is more efficientlyload-balanced and had a resource utilization (CPU) of 91.9%compared to 83.3%, so the relative resource utilization is betterfor one VM/CPU. (All results in this section were estimated tobe accurate to better than 3%.) Note that this relative compar-ison can vary with large change in batch size.
5. Discussion
The overhead on running these compute-intensive simula-tions from installing RH7.3 on VMware was found to be around11%, which seems reasonable when measured against the ad-vantages of security (for a discussion see [8]) and conveniencewhich it provides.
The results displayed in Fig. 6 show that in this case the over-head of increasing the number of VMs per processor from oneto two is positive and significant, as would be expected, so thisis probably not the best use of resources in this case, despitethe increase in overall MRT as shown by the scheduling simu-lations. Also, as the batch size increases on the latter system,

928 L. Gilbert et al. / J. Parallel Distrib. Comput. 66 (2006) 922–930
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0 10 20 30 40Simulated Time (hours)
Virt
ual M
achi
ne
31
29
27
25
23
21
19
17
15
13
11
9
7
5
3
1
0 10 20 30 40Simulated Time (hours)
Virt
ual M
achi
ne
(a)
(b)
Fig. 8. Simulated job schedules for (a) 16 VMs and (b) 32 VMs: the x-axisshows run time in hours and the y-axis shows the VM queue ID.
the individual time for a specific job becomes less consistent,and tests showed that some jobs would even hang indefinitely.This suggests that 512 MB RAM is insufficient to run this ap-plication reliably.
For batches of large numbers of jobs we also saw that it waspossible for the virtual cluster to outperform (in improved runtime) the physical one. More work needs to be done to ascertainthe reason for this.
One possible explanation was that the jobs could have beensubmitted in a different way to the clusters. As SGE works on
0
0.2
0.4
0.6
0.8
1
1.2
1.4
Runtime Throughput MRT Utilization
Rel
ativ
e P
erfo
rman
ce
1VM/CPU2VM/CPU
Fig. 9. The relative performance of the scheduler for one VM/CPU comparedto two VMs/CPU. The one VM/CPU results are used as baseline numbers.The total batch run time, job throughput and CPU utilization are decreased inthe two VMs/CPU case; however, there is an improvement in mean responsetime.
a FCFS basis the jobs will always run in the same order, andthe overall arrangement of jobs should be the same (thoughon different machines each time) if they are labeled in termsof job size rather than ID. If, however, the differences in themaximum and minimum times that a job might take on thesame system were large enough it could cause one machine torun more events in total in a faster time than another, and thustake the next job in the queue before the machine processingfewer events had finished. The measured errors were quicklyseen to be far too small to allow this effect on these timescales,though. Bearing in mind that the minimum difference in jobsize was five events (taking approximately 40 min to run), andthat the physical installation of RH7.3 on a PE2650 gave timingerrors of around 2%, and the VMware installations a slightlylarger 3%: even assuming that one VM randomly ran all itsjobs 3% slower than the mean, and different machine ran 3%faster, they would still have to run for of the order of 700 h tomanifest this effect.
It seems far more likely to be an issue of resources. Weknow already that the physical machines share 2 GB of memorybetween two jobs running simultaneously, whereas VMwareallocates 1 GB explicitly to each machine (so each simulationcan access these independently). This should mean that nearthe end of the run, jobs on the physical machines that continuerunning after the other job on the same machine should then beable to access the full memory and accelerate, whereas thoseon the VMs are still limited to 1 GB.
However, the isolation of the memory into two discrete partsmay reduce contention in longer running batches, and it isalso possible that VMware simply manages its memory moreeffectively than the direct installation does. To test for memoryissues, 2 GB more of memory was installed on each PE2650(making a total of 4 GB) and the 64-job batch was run again onthe physical installation. The results showed an 8% decreasein the time taken to run this batch, suggesting that there issignificant memory contention. This brings the run time down

L. Gilbert et al. / J. Parallel Distrib. Comput. 66 (2006) 922–930 929
to nearly the original level of the 32 node cluster, which wasrunning with only 512 MB RAM per VM. The run time remainsabout 4% greater than that of the original 16 node virtual clusterso this does not completely answer the question.
Another possible explanation might be that, for this case,there is an excessive context switching overhead when two pro-cesses are executing on dual CPU physical machines. Contextswitching is much simpler under VMs, as ESX only has toschedule each machine to run entirely on one processor at anygiven time. Possibly when large numbers of jobs are run theoverhead from this process could exceed the basic VMwareoverhead. Testing of this theory should be possible using kernelinstrumentation.
6. Future work
VMware was chosen for this study because it is commonlyused and has advanced memory management. We worked withthe ESX version, which installs directly onto the platform. How-ever, the GSX version can be installed on top of another operat-ing system, and this may turn out to be more useful for this classof application. The administrator of a large, multi-disciplinecluster may wish to install a different operating system on thecompute elements to allow other kinds of application to runsimultaneously with the VMs used by particle physicists.
VMware is not the only option for Virtualization. We wish tocompare the performance hit of VMware with that of BOCHS[3] and Xen [23], for example, which are open-source and free.Like GSX, BOCHS is installed on top of another operatingsystem. It is a completely virtual PC, it simulates a completeprocessor and peripherals in software. Unlike VMware it en-ables non-native code to run on any hardware, though at theexpense of a greater performance hit. Xen is currently beingdeveloped at the University of Cambridge computer laboratoryand is a lightweight virtualization tool. It currently does notsupport Windows, and it requires small changes to the kernelin order to run on Linux.
The VMware license used allowed each VM to access oneprocessor. It is possible to obtain a symmetric multi-processing(SMP) license that allows a VM to access more than one CPU.This could potentially allow a single VM installed on a physical2650 to access both processors, and so reduce the overhead frommultiple VMs competing for resources, though still permittingfull CPU utilization.
Another avenue of investigation could involve varying thehardware configuration of the compute nodes. The reliabilityof the virtual clusters could be economically improved with theaddition of more physical memory dedicated to each machine(at least 1 GB per machine seemed to be required).
In future we should also like to broaden this research to in-clude different kinds of applications, such as analysis programsrunning on very large data files, but this is some time away.
7. Conclusions
It has been shown that hyper-threading causes an unneces-sary overhead in this class of computation (compute intensive)
and should not be used. The overhead of Sun Grid Engine, how-ever, is negligible in this case. The overhead from installingRH7.3 on ESX VMware and running simulations directly wasfound to be around 11.1 ± 3.8%. We have also studied thequantitative estimates of the virtualization and hyper-threadingoverhead for GEANT on commodity clusters. Results show thatvirtualization offers a very feasible solution. The potential ben-efits of massive deployment at a large number of sites come atan acceptable cost of 15% performance hit.
The number of VMs should be equal to the number of phys-ical processors for maximum performance. Running two VMsper CPU caused a performance hit of 5.0 ± 2.2% when com-pared with a single VM/CPU for this type of simulation. How-ever, in a Grid environment, when handling large loads foran extended period, the virtualized cluster can give better runtimes than the physical in this case. The interaction of VMswith physical processors is clearly complex and needs moreexploration.
Acknowledgments
The authors wish to thank the HPCC team at Dell in Austin,especially Monica Kashyap, Baris Guler, Garima Kochhar,Rinku Gupta and Balasubramanian Chandrasekaran. We alsowish to thank Pamela Dickie at Dell, Dr. Joseph Boudreauat the University of Pittsburgh and Prof. Susan Cooper at theUniversity of Oxford.
References
[1] Atlas Software Homepage 〈http://atlas.web.cern.ch/Atlas/GROUPS/SOFTWARE/OO/〉.
[2] D. Barberis, et al., Common use cases for a HEP commonapplication layer for analysis, 2003 〈http://lcg.web.cern.ch/LCG/sc2/GAG/HEPCAL-II.doc〉.
[3] Bochs 〈 http://bochs.sourceforge.net/〉.[4] EDG Homepage 〈http://eu-datagrid.web.cern.ch/eu-
datagrid/〉.[5] R. Figueiredo, P. Dinda, J. Fortes, A case for grid computing on
virtual machines, in: Proceedings of the 23rd International Conferenceon Distributed Computing Systems, 2003.
[6] GEANT4/ATLAS Homepage 〈http://atlas.web.cern.ch/Atlas/GROUPS/SOFTWARE/OO/simulation/geant4/〉.
[7] L. Gilbert, S. Iqbal, O. Celebioglu, J. Hsieh, R. Pepper, J. Tseng,R. Newman, M. Cobban, Performance implications of hyper-threadingand virtualization for grid-enabled high energy physics applications, in:Proceedings of 19th IPDPS, April, 2005.
[8] M. Humphrey, M Thompson, Security implications of typical gridcomputing useage scenarios, Cluster Comput. 5 (3) (2002).
[9] R. Jones, et al., Principles of cost sharing for the ATLAS offlinecomputing resources 〈http://atlas.web.cern.ch/Atlas/GROUPS/SOFTWARE/OO/computing-model/StartupResources.html〉.
[10] P. Kunszt, European datadrid project: status and plans, Nucl. Instrum.Methods Phys. Res. A 502 (2003) 376–381.
[11] LCG Homepage 〈http://lcg.web.cern.ch/LCG/〉.[12] D.T. Marr, et al., Hyper-threading technology architecture and micro-
architecture, Intel Technol. J. 6 (1) (2002).[13] M. Niinimaki, J. White, J. Herrala, Executing and visualising high
energy physics simulations with Grid technologies, in: Proceedings of theSecond International Symposium on Parallel and Distributed Computing,2003.

930 L. Gilbert et al. / J. Parallel Distrib. Comput. 66 (2006) 922–930
[14] T. Sjstrand, et al., Pythia, Computer Phys. Commun. 135 (2001) 238(LU TP 00-30, hep-ph/0010017).
[15] ROOT Homepage 〈http://root.cern.ch/〉.[16] Scientific Linux Homepage 〈https://www.scientificlinux.
org/〉.[17] Sun Grid Engine 〈 http://gridengine.sunsource.net/〉.[18] A. Takefusa, A. Matsuoka, O. Tatebe, Y. Morita, Performance analysis
of scheduling and replication algorithms on grid datafarm architecturefor high energy physics applications, in: Proceedings of the 12th IEEEInternational Symposium on High Performance Distributed Computing,2003.
[19] The ATLAS Homepage 〈 http://atlas.web.ch/Atlas/Welcome.html〉.
[20] The GridPP Collaboration, A Grid for particle physics—from testbed toproduction, in: Proceedings of the UK e-Science All Hands Meeting,2004.
[21] VMware products 〈 http://www.VMware.com/products/〉.[22] WMWare White Paper, OS Migration and Legacy Application
Support Using VMware Virtual Machine Software 〈http://bdn.borland.com/article/borcon/files/sefiles/VMware/WKS_os_migration_whitepaper.pdf〉.
[23] Xen 〈 http://www.cl.cam.ac.uk/Research/SRG/netos/xen/〉.
Laura Gilbert is in the third year of her DPhil atUniversity of Oxford, studying particle physics.Her areas of research are strange quark asymme-tries in the parton sea of the proton, and virtu-alization of the Grid for ATLAS, for which sheis partially sponsored by Dell UK. She receivedher BA and MS degrees in Natural Sciencesfrom the University of Cambridge in 2002.
Jeff Tseng is a University Lecturer in theDepartment of Physics at Oxford University,and Tutorial Fellow of St Edmund Hall. Heearned his BS from the California Institute ofTechnology in 1989 and PhD from The JohnsHopkins University in 1996, following whichhe joined the Massachusetts Institute of Tech-nology as a postdoctoral research associate andlater research scientist. He has been at Oxfordsince 2003, where he leads the particle physicssubdepartment’s Grid computing research groupas well as its physics analysis group for theinternational ATLAS experiment, which is
currently under construction at CERN. His current main research interest isin electroweak probes of proton structure and extra spatial dimensions, buthe has also been active in harnessing and improving large-scale, globallydistributed computing systems for physics analysis as well as a number ofinterdisciplinary efforts.
Rhys Newman has recently joined Oxford Uni-versity as Manager of Interdisciplinary Grid de-velopment to do innovative research into gridmiddleware and support the growing interest ingrid computing in the wider academic commu-nity. He has come from a varied background, in-cluding geophysical modeling, computer vision,internet start-up companies and most recently aspell in the London banking industry. The re-cipient of many academic and industry awardshe is also interested in fostering collaborationbetween academia and industry to broaden theuser base of Grid technology.
Saeed Iqbal received his PhD in Computer En-gineering in May 2003, from the University ofTexas at Austin. He has an MS in ComputerEngineering and a BS in Electrical Engineering.His current work is on Job Schedulers and Re-source Managers used in commodity high per-formance computing clusters and metacomput-ing environments. His interests include paralleland distributed computing, micro-architecture,neural computing and system architecture. Heis a member of IEEE, ACM and Computer So-ciety.
Ronald Pepper is a systems engineer and advi-sor in the Scalable Systems Group at Dell. Heworks on the Dell HPC Cluster team developingGrid environments. Ron attended the Universityof Madison at Wisconsin, where he worked ona degree in Computer Science; he is continuinghis degree at Saint Edwards University.
Onur Celebioglu has an MS in Electrical andComputer Engineering from Carnegie MellonUniversity. Currently he is an engineering man-ager in the Scalable Systems Group at Dell andis responsible for developing HPC clusteringproducts. His areas of focus are networking andHPC interconnects.
Jenwei Hsieh has a PhD. Computer Sciencefrom the University of Minnesota and a B.E.from Tamkang University in Taiwan. Currentlyhe is an engineering manager in the ScalableSystems Group at Dell, where he is responsiblefor developing high-performance clusters. Hiswork in the areas of multimedia computing andcommunications, high-speed networking, serialstorage interfaces and distributed network com-puting has been published extensively.
Victor Mashayekhi obtained BA, MS, andPhD degrees in Computer Science from theUniversity of Minnesota. His current researchinterests are in the areas of distributed systems,database systems, multimedia systems, soft-ware engineering, clustered systems, storagetechnologies, Virtualization, High AvailabilityClustering, High Performance Cluster Comput-ing, and high-speed, low latency interconnects.Victor has over 30 publications in conferencesand journals.
Mark Coban is the manager of the AdvancedSystems Group for Dell Corporation Ltd basedin the UK. Mark is responsible for the relation-ships between Dell Corporation and the Educa-tion area for Dell Servers. Areas of particularinterest are clustered systems, storage technolo-gies, Virtualization, High Availability Cluster-ing, High Performance Cluster Computing, andhigh-speed, low latency interconnects.





























