Embed Size (px)
DESCRIPTION
ICASSP2013 SLP-L1 Human Spoken Language Acquisition and Learning. Hsiao- Tsung Hung. Outline. SLP-L1.1: FEEDBACK UTTERANCES FOR COMPUTER-AIDED LANGUAGE LEARNING USING ACCENT REDUCTION AND VOICE CONVERSION METHOD - PowerPoint PPT Presentation
Citation preview

ICASSP2013SLP-L1
Human Spoken Language Acquisition and LearningHsiao-Tsung Hung

2
OutlineSLP-L1.1: FEEDBACK UTTERANCES FOR COMPUTER-AIDED LANGUAGE LEARNING USING ACCENT REDUCTION AND VOICE CONVERSION METHOD
Sixuan Zhao, Soo Ngee Koh, Ing Yann Soon, Kang Kwong Luke, Nanyang Technological University, Singapore
SLP-L1.2: A DIALOGUE GAME FRAMEWORK WITH PERSONALIZED TRAINING USING REINFORCEMENT LEARNING FOR COMPUTER-ASSISTED LANGUAGE LEARNING
Pei-hao Su, Yow-Bang Wang, Tien-han Yu, Lin-shan Lee, National Taiwan University, Taiwan
SLP-L1.3: AUDIOVISUAL SYNTHESIS OF EXAGGERATED SPEECH FOR CORRECTIVE FEEDBACK IN COMPUTER-ASSISTED PRONUNCIATION TRAINING
Junhong Zhao, IECAS, China; Hua Yuan, Tsinghua University, China; Wai-Kim Leung, Helen Meng, CUHK, Hong Kong SAR of China; Jia Liu, Tsinghua University, China; Shanhong Xia, IECAS, China
SLP-L1.4: A NOVEL DISCRIMINATIVE METHOD FOR PRONUNCIATION QUALITY ASSESSMENT
Junbo Zhang, Fuping Pan, Bin Dong, Yonghong Yan, Institute of Acoustics, Chinese Academy of Sciences, China
SLP-L1.5: MISPRONUNCIATION DETECTION VIA DYNAMIC TIME WARPING ON DEEP BELIEF NETWORK-BASED POSTERIORGRAMS
Ann Lee, Yaodong Zhang, James Glass, Massachusetts Institute of Technology, United States
SLP-L1.6: TOWARD UNSUPERVISED DISCOVERY OF PRONUNCIATION ERROR PATTERNS USING UNIVERSAL PHONEME POSTERIORGRAM FOR COMPUTER-ASSISTED LANGUAGE LEARNING
Yow-Bang Wang, Lin-Shan Lee, National Taiwan University, Taiwan

3
TOWARD UNSUPERVISED DISCOVERY OF PRONUNCIATION ERROR PATTERNS USINGUNIVERSAL PHONEME POSTERIORGRAM FOR COMPUTER-ASSISTED LANGUAGE LEARNINGYow-Bang Wang, Lin-Shan LeeNational Taiwan University, Taiwan

4
Introduction
• manual labeling process is very time consuming• for EP detection the need for expertise to define and label EPs may
be even more difficult and expensive• Building HMM-based ASR system for each language and acoustic
condition can be costly• lack of well annotated corpus
• In this paper, we learn the experiences of unsupervised speech pattern discovery, and propose a preliminary framework for automatic discovery of EPs from a corpus of learners’ recordings without relying on expert knowledge.

5
Problem Definition
• Here we assume the task is to discover the EPs for each phoneme given a corpus of learners’ voice.
• each time we are given a set of acoustic segments corresponding to a specific phoneme, and the goal is to divide this set into several clusters, each of which corresponds to an EP.
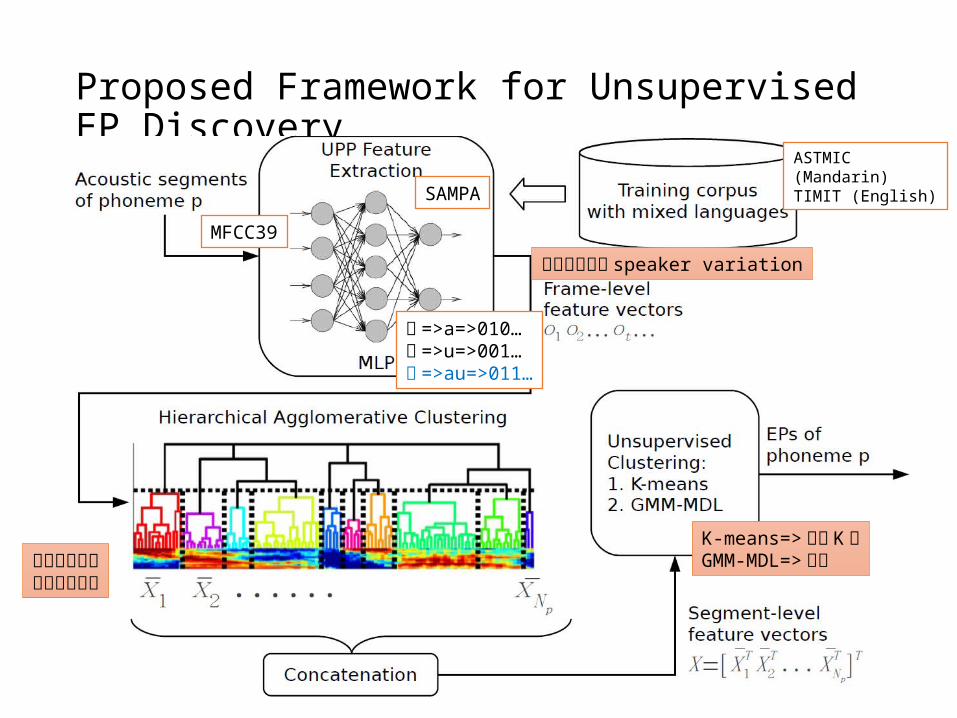
6
Proposed Framework for Unsupervised EP Discovery
SAMPA
MFCC39
ㄚ =>a=>010…ㄨ =>u=>001…ㄠ =>au=>011…
ASTMIC (Mandarin)TIMIT (English)
不同精細程度對分群的影響K-means=>已知 K群GMM-MDL=>未知
預期可以降低 speaker variation

7
GMM-MDL
• MDL: minimum description length• Idea: 把建立模型視為資料壓縮問題,希望用較少的 bit即可表現較多資訊• objective function:

8
Experimental Results
對每個音素分別進行分群

9
Corpus, EP definition and annotation
• 278 learners• 30 sentences X 6 ~ 24 characters• There is a total of 39 canonical Mandarin phoneme units, and 152
EPs were summarized by language teachers based on their expert knowledge and pedagogical experiences
• The definition of EPs includes not only phoneme level substitution, but also insertion and deletion, and is not limited to any specific corpus including the one mentioned above
10
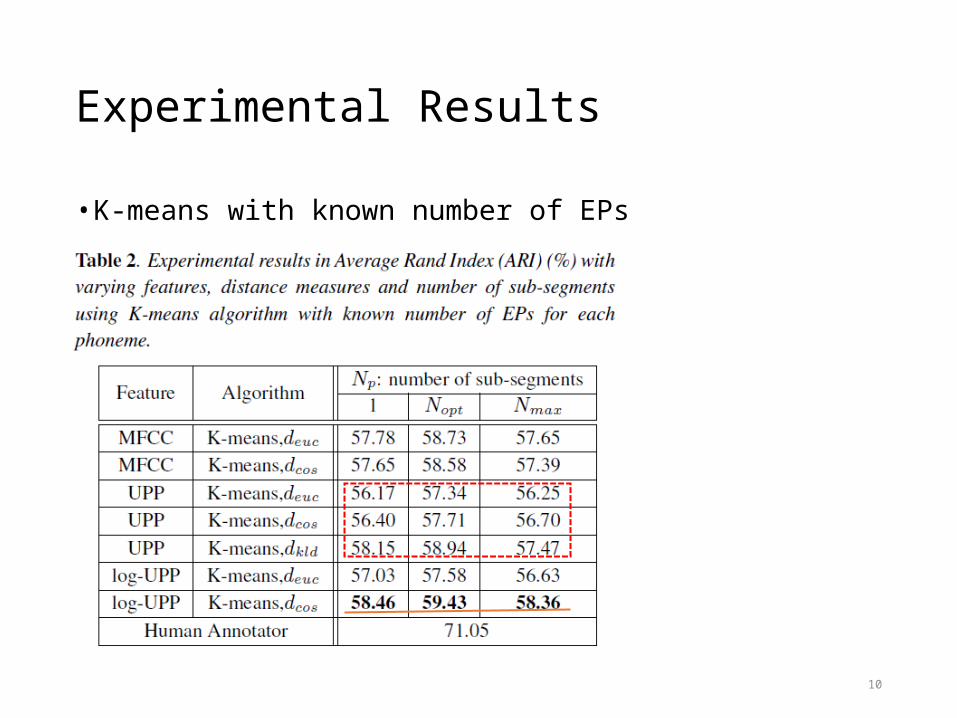
Experimental Results
• K-means with known number of EPs
11
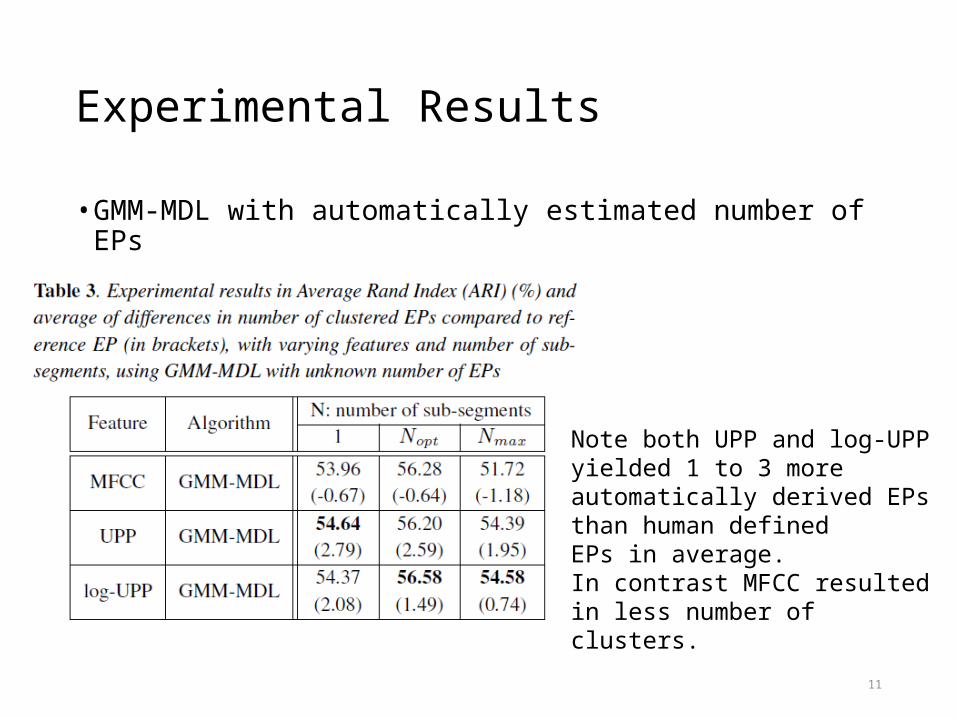
Experimental Results
• GMM-MDL with automatically estimated number of EPs
Note both UPP and log-UPP yielded 1 to 3 more automatically derived EPs than human definedEPs in average.In contrast MFCC resulted in less number of clusters.

12
A DIALOGUE GAME FRAMEWORK WITH PERSONALIZED TRAINING USING REINFORCEMENT LEARNING FOR COMPUTER-ASSISTED LANGUAGE LEARNING
Pei-hao Su, Yow-Bang Wang, Tien-han Yu, Lin-shan LeeNational Taiwan University, Taiwan
13
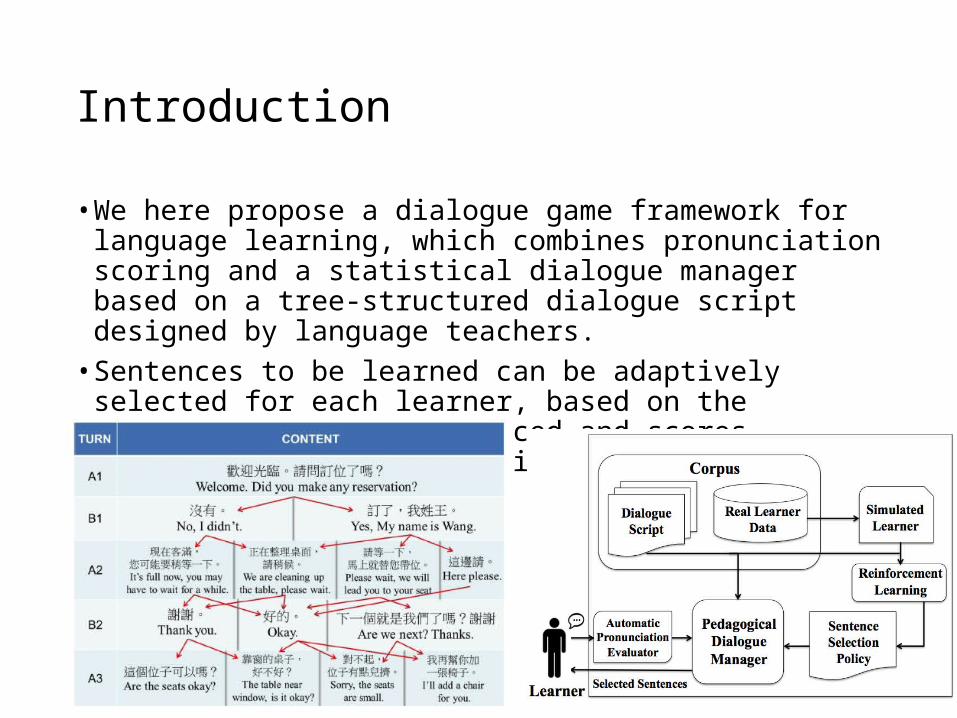
Introduction
• We here propose a dialogue game framework for language learning, which combines pronunciation scoring and a statistical dialogue manager based on a tree-structured dialogue script designed by language teachers.• Sentences to be learned can be adaptively selected for each learner,
based on the pronunciation unit practiced and scores obtained along with the dialogue progress
14
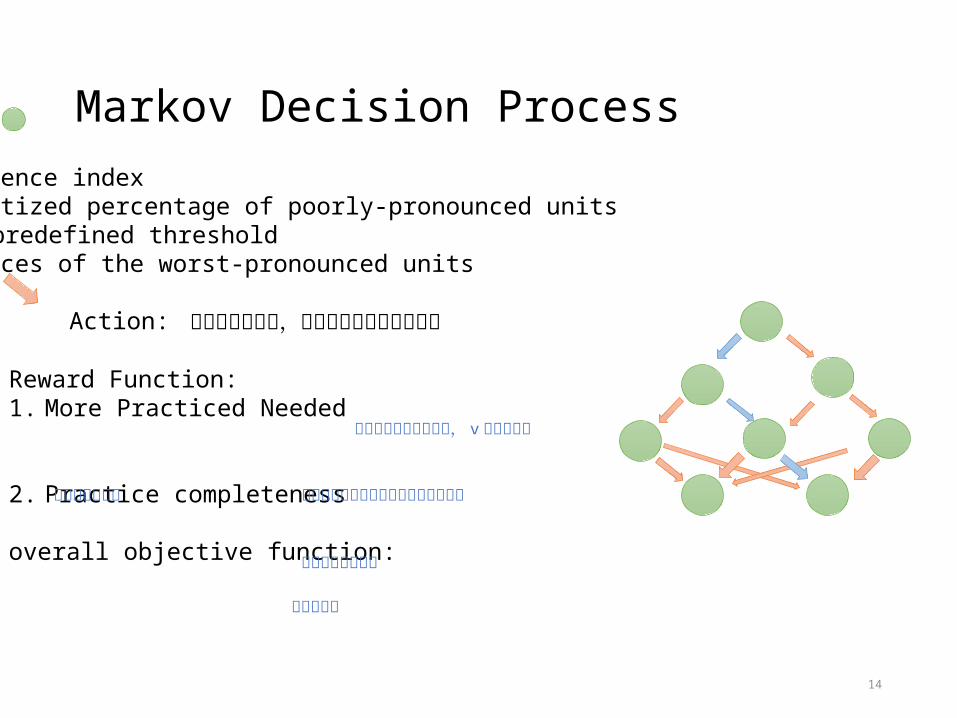
Markov Decision ProcessState:• Sentence index• quantized percentage of poorly-pronounced units
• predefined threshold• Indices of the worst-pronounced units
Action: 根據現在的狀態,選取接下來要練習的句子Reward Function:1. More Practiced Needed
2. Practice completeness
overall objective function:
發音不好的音素
分數越低的重要性越高, v為挑整參數
選定的對話出現和平均對話會出現次數
可以練習到的音素所有的音素

15
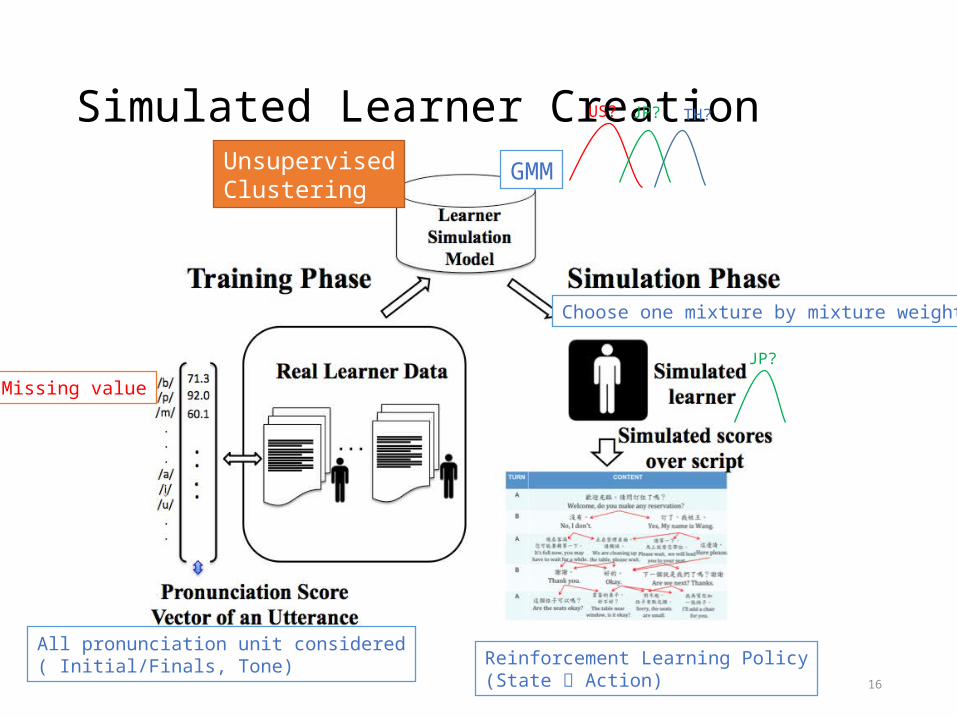
Learner Simulation From Real Data
• it is practically infeasible to collect “enough” real dialogue episodes for policy training, studies have focused on generating simulated users to interact with the dialogue manager
• Real Learner Data• 278 learners• 36 different countries• 30 sentences (6~24 characters)
16
Simulated Learner Creation
All pronunciation unit considered( Initial/Finals, Tone)
GMM
US?
JP?
TH?JP?
UnsupervisedClustering
Choose one mixture by mixture weight
Reinforcement Learning Policy(State Action)
Missing value

18
Training Phase:Reinforcement Learning•使用 Q-Learning學習預期報酬
• Optimal policy
• Choose the action with the highest Q value with probability and the remaining actions with probability .
Q=10Q=9
Q=18 Q’ = 18 +[ 7 + 10]

19
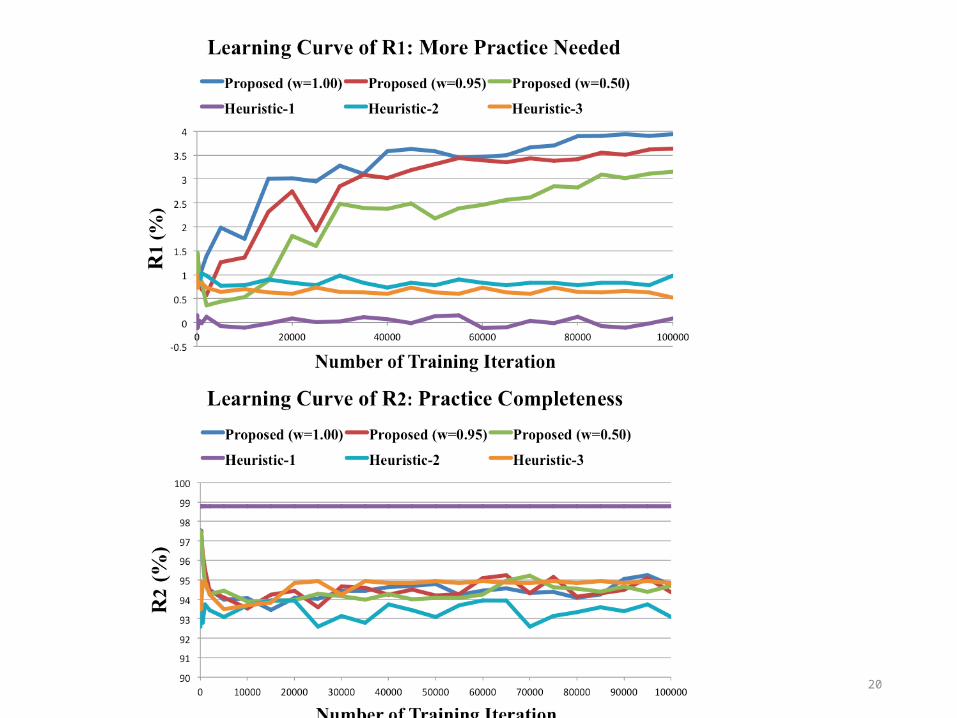
EXPERIMENT
• We compared the proposed approach with the following polices:1. Always select the sentence with the most diverse pronunciation units from
learner’s practiced units2. Always select the sentence with the most count of worst-pronounced units3. Cast the above two heuristic policies as two actions in an MDP.
20
21
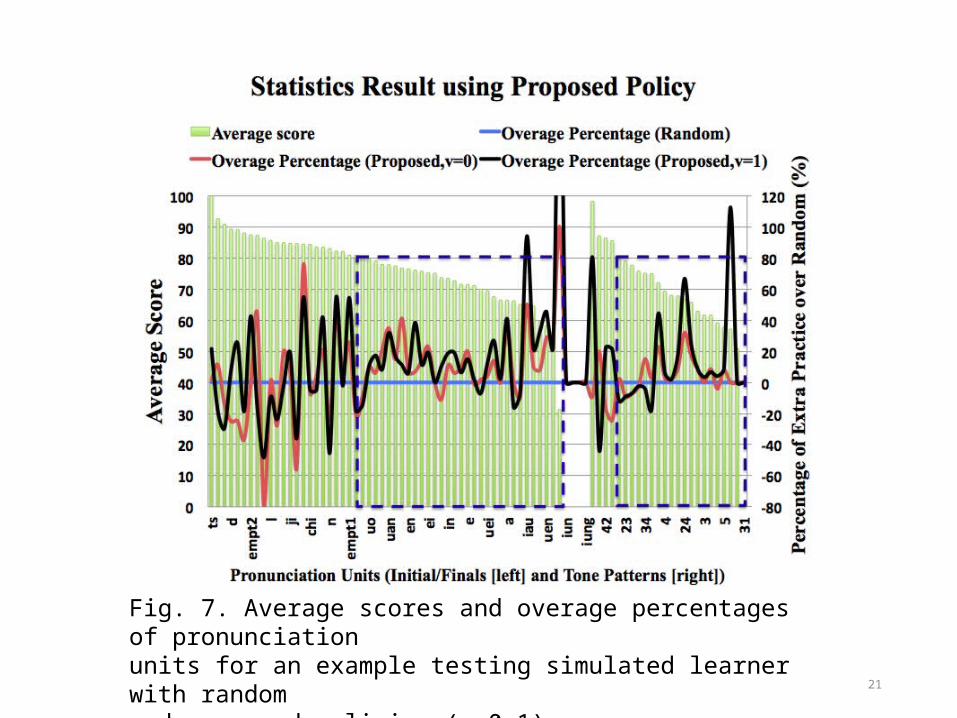
Fig. 7. Average scores and overage percentages of pronunciationunits for an example testing simulated learner with randomand proposed policies (v=0,1).





























