Embed Size (px)
Citation preview

HPC1
OpenMP
E. Bruce Pitman
October, 2002

HPC1
Outline
• What is OpenMP
• Multi-threading
• How to use OpenMP
• Limitations
• OpenMP + MPI
• References

HPC1
What is OpenMP?
• A portable standard for shared memory multi-processing
• A library of compiler directives
• Fine-grained (loop-level)
• To varying degrees, Sun, SGI, IBM, HP, Intel

HPC1
Multi-threading

HPC1
Multi-threading

HPC1
How to use OpenMP

HPC1
How to use OpenMP

HPC1
How to use OpenMP

HPC1
How to use OpenMP

HPC1
How to use OpenMP

HPC1
How to use OpenMP

HPC1
How to use OpenMP• schedule(static [,chunk])
– Deal-out blocks of iterations of size “chunk” to each thread.
• schedule(dynamic[,chunk])
– Each thread grabs “chunk” iterations off a queue until all iterations have been handled.
• uschedule(guided[,chunk])
– Threads dynamically grab blocks of iterations. The size of the block starts large and shrinks down to size “chunk” as the calculation proceeds.

HPC1
How to use OpenMP
• schedule(runtime) – Schedule and chunk size taken from the
OMP_SCHEDULE environment variable.

HPC1
How to use OpenMPHere’s an example of PRIVATE and FIRSTPRIVATE
variables A,B, and C = 1C$OMP PARALLEL PRIVATE(B) C$OMP& FIRSTPRIVATE(C)
Inside this parallel region “A” is shared by all threads and equals 1
“B” and “C” are local to each thread - B’s initial value is undefined - C’s initial value equals 1
Outside this parallel region the values of “B” and “C” are undefined.

HPC1
How to use OpenMP

HPC1
How to use OpenMP
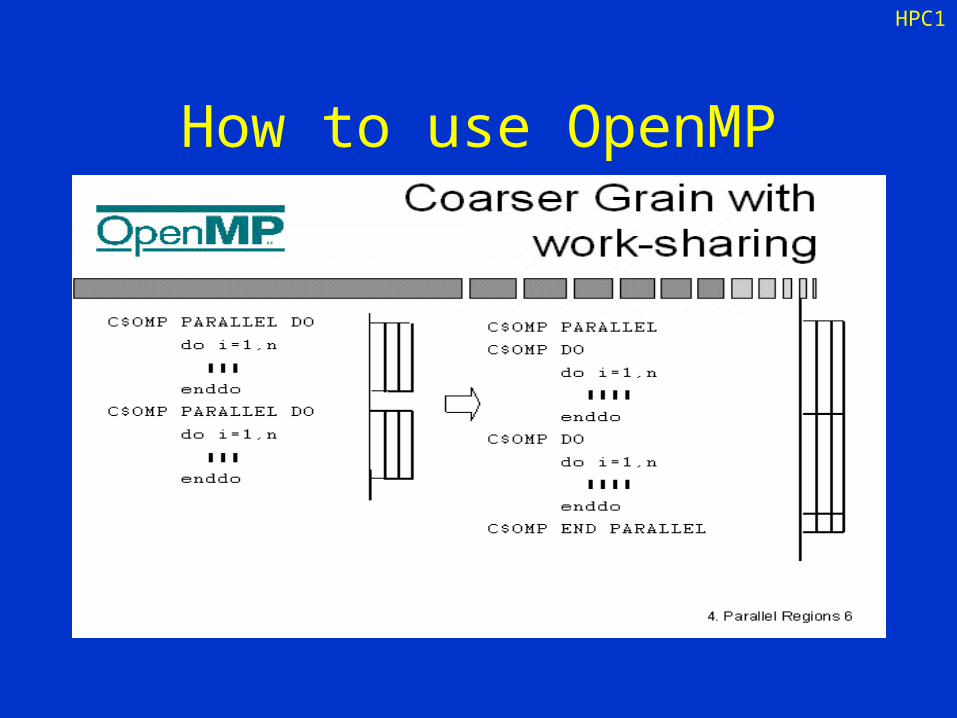
HPC1
How to use OpenMP

HPC1
How to use OpenMP

HPC1
How to use OpenMP

HPC1
How to use OpenMP

HPC1
How to use OpenMP

HPC1
How to use OpenMP
• #!/bin/csh -f
• #PBS -l ncpus=8
• #PBS -V
• #PBS -q medium_p
• #PBS -M [email protected]

HPC1
How to use OpenMP• cp /CCRSGI/home/pitman/fortran/sph/sph* $PBSTMPDIR
• cd $PBSTMPDIR
• setenv OMP_NUM_THREADS 8• f90 -O2 -LNO -IPA -n32 -mips4 -r12000 -mp -o sph sphomp.f
• time ./sph > outfile• cp outfile /CCRSGI/home/pitman/fortran/sph/
• # remove scratch directory
• cd /FCScratch
• \rm -r $PBSTMPDIR

HPC1
How to use OpenMP
k = 1
do while (k .le. maxit .and. error .gt. tol)
error = 0.0
!$omp parallel !$omp do
do j=1,m do i=1,n
uold(i,j) = u(i,j) enddo enddo

HPC1
How to use OpenMP!$omp do private(resid) reduction(+:error)
do j = 2,m-1
do i = 2,n-1
resid = (ax*(uold(i-1,j) + uold(i+1,j))
& + ay*(uold(i,j-1) + uold(i,j+1))
& + b * uold(i,j) - f(i,j))/b
u(i,j) = uold(i,j) - omega
error = error + resid*resid
end do
enddo

HPC1
How to use OpenMP
!$omp enddo nowait
!$omp end parallel
$omp end parallel
k = k + 1
error = sqrt(error)/dble(n*m)
enddo

HPC1
Limitations• Easy to port serial code to OpenMP
• OpenMP code can run in serial mode
HOWEVER
• Shared memory machines only
• Limited scalability -- after ~8 processors, not much speed-up
• Overhead of parallel do, parallel regions

HPC1
Limitations• OpenMP currently does not specify or
provide constructs for controlling the binding of threads to processors.
• Processors can migrate, causing overhead.
• This behavior is system-dependent.
• System-dependent solutions may be available.

HPC1
OpenMP and MPI

HPC1
References
• www.openmp.org
• http://www.ccr.buffalo.edu/documents/CCR_openmp_pbs.PDF
• http://www.epcc.ed.ac.uk/research/openmpbench/
• http://www.llnl.gov/computing/tutorials/workshops/workshop/openMP/MAIN.html
• http://scv.bu.edu/SCV/Tutorials/OpenMP/



















![Isaac Pitman s Short Isaac Pitman Black and White [Ebooksread.com]](https://img.dokumen.tips/doc/110x75/577cc2f71a28aba71194dba0/isaac-pitman-s-short-isaac-pitman-black-and-white-ebooksreadcom.jpg)









