Embed Size (px)
Citation preview

HPC Challenge 2007
© 2007 IBM Corporation1
IBM
Res
earc
h
HPC Challenge 07: X10
Vijay [email protected] 13, 2007IBM Research
This material is based upon work supported by the Defense Advanced Research Projects Agency under its Agreement No. HR0011-07-9-0002.

HPC Challenge 2007
© 2007 IBM Corporation2
IBM
Res
earc
h
Teams
Application– Tong Wen (WAT)– Mark Stephenson (AUS)– Vipin Sachdeva (AUS)– Guojing Cong (WAT)
Compiler– Igor Peshansky (WAT)– Krishna Venkata (IRL)– Pradeep Varma (IRL)– Nathaniel Nystrom (WAT)
Runtime– Sreedhar Kodali (ISL)– Ganesh Bikshandi (ISL)– Sriram Krishnamurthy (WAT)– Sayantan Sur (WAT)
BG Port– Jose Castanos (WAT)
ARMCI Port– Vinod Tipparaju (PNNL)
Special thanks to Calin Cascaval, John Gunnels and Doug Lea.
HPC Challenge 2007
© 2007 IBM Corporation3
IBM
Res
earc
h
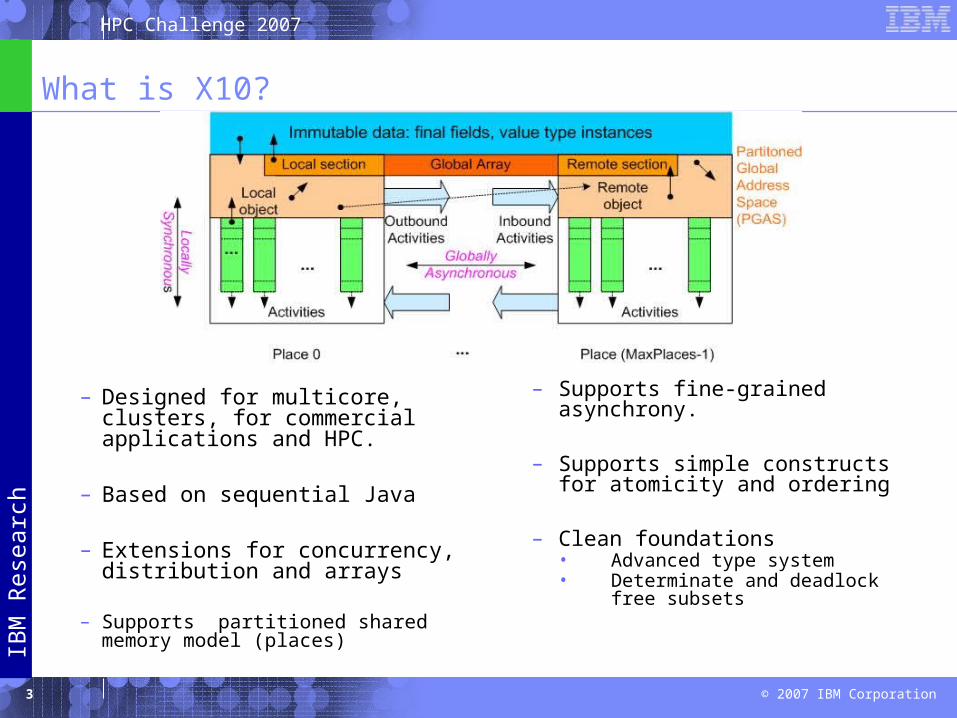
What is X10?
– Supports fine-grained asynchrony.
– Supports simple constructs for atomicity and ordering
– Clean foundations• Advanced type system• Determinate and deadlock free
subsets
– Designed for multicore, clusters, for commercial applications and HPC.
– Based on sequential Java
– Extensions for concurrency, distribution and arrays
– Supports partitioned shared memory model (places)
HPC Challenge 2007
© 2007 IBM Corporation4
IBM
Res
earc
h
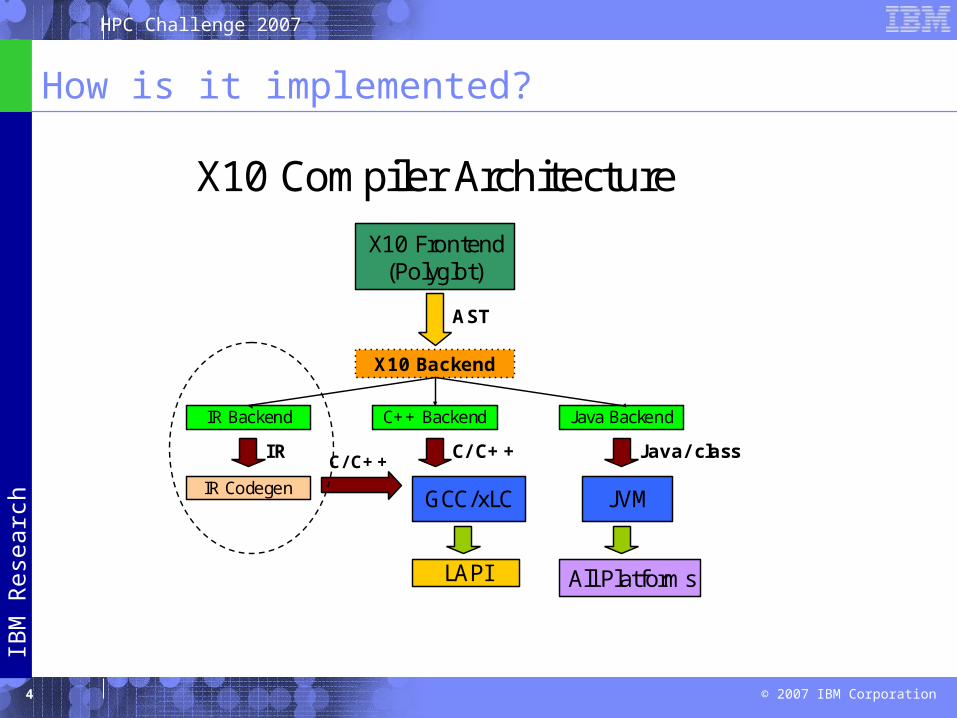
How is it implemented?
X10 Compiler ArchitectureX10 Frontend
(Polyglot)
AST
X10 Backend
C++ Backend Java BackendIR Backend
Java/ class
JVMGCC/xLCIR Codegen
IR C/ C++C/ C++
LAPI All Platforms
HPC Challenge 2007
© 2007 IBM Corporation5
IBM
Res
earc
h
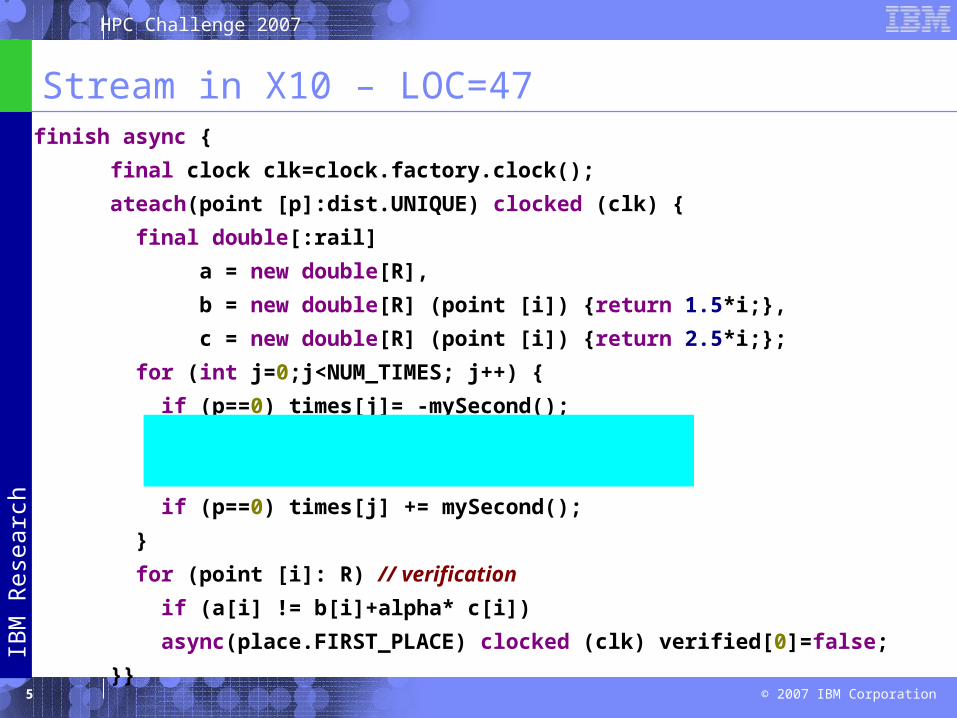
Stream in X10 – LOC=47finish async {
final clock clk=clock.factory.clock();
ateach(point [p]:dist.UNIQUE) clocked (clk) {
final double[:rail]
a = new double[R],
b = new double[R] (point [i]) {return 1.5*i;},
c = new double[R] (point [i]) {return 2.5*i;};
for (int j=0;j<NUM_TIMES; j++) {
if (p==0) times[j]= -mySecond();
for (point [i]:R ) a[i]=b[i]+alpha*c[i];
next;
if (p==0) times[j] += mySecond();
}
for (point [i]: R) // verification
if (a[i] != b[i]+alpha* c[i])
async(place.FIRST_PLACE) clocked (clk) verified[0]=false;
}}
HPC Challenge 2007
© 2007 IBM Corporation6
IBM
Res
earc
h
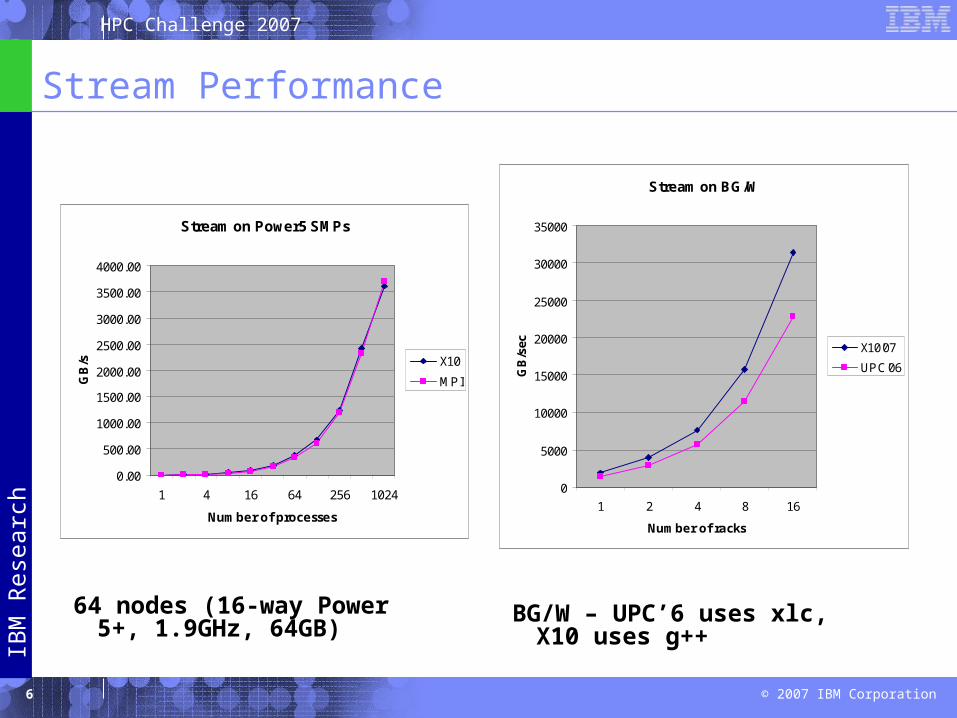
Stream Performance
Stream on Power5 SMPs
0.00
500.00
1000.00
1500.00
2000.00
2500.00
3000.00
3500.00
4000.00
1 4 16 64 256 1024
Number of processes
GB
/s X10
MPI
64 nodes (16-way Power 5+, 1.9GHz, 64GB)
Stream on BG/W
0
5000
10000
15000
20000
25000
30000
35000
1 2 4 8 16
Number of racksG
B/s
ec X10'07
UPC'06
BG/W – UPC’6 uses xlc, X10 uses g++
HPC Challenge 2007
© 2007 IBM Corporation7
IBM
Res
earc
h
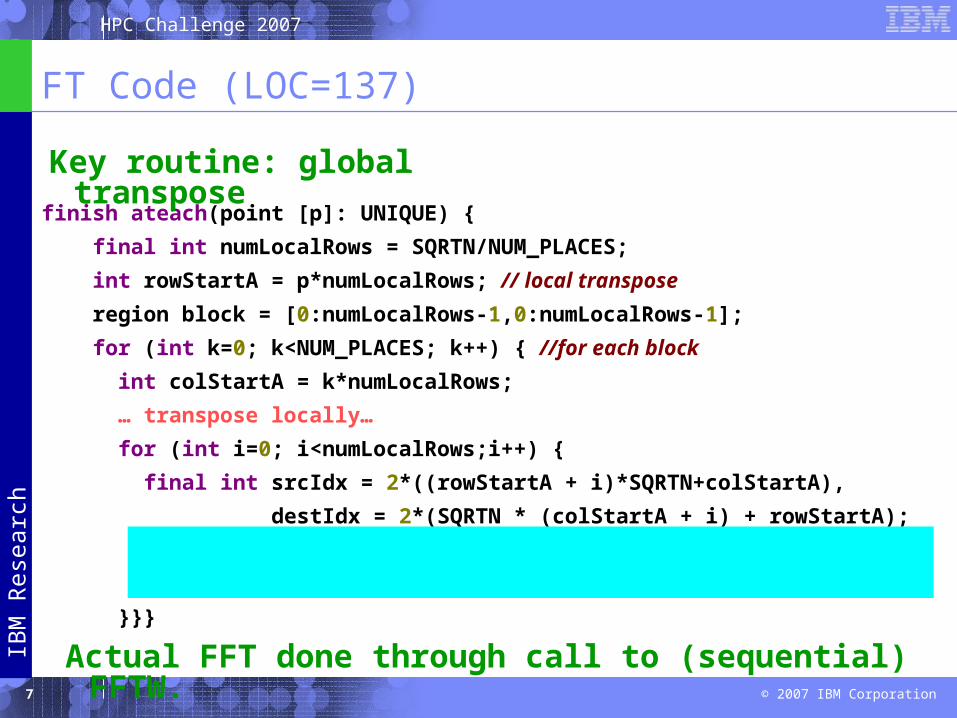
FT Code (LOC=137)
finish ateach(point [p]: UNIQUE) {
final int numLocalRows = SQRTN/NUM_PLACES;
int rowStartA = p*numLocalRows; // local transpose
region block = [0:numLocalRows-1,0:numLocalRows-1];
for (int k=0; k<NUM_PLACES; k++) { //for each block
int colStartA = k*numLocalRows;
… transpose locally…
for (int i=0; i<numLocalRows;i++) {
final int srcIdx = 2*((rowStartA + i)*SQRTN+colStartA),
destIdx = 2*(SQRTN * (colStartA + i) + rowStartA);
async (UNIQUE[k])
Runtime.arrayCopy(Y, srcIdx, Z, destIdx, 2*numLocalRows);
}}}
Actual FFT done through call to (sequential) FFTW.
Key routine: global transpose
HPC Challenge 2007
© 2007 IBM Corporation8
IBM
Res
earc
h
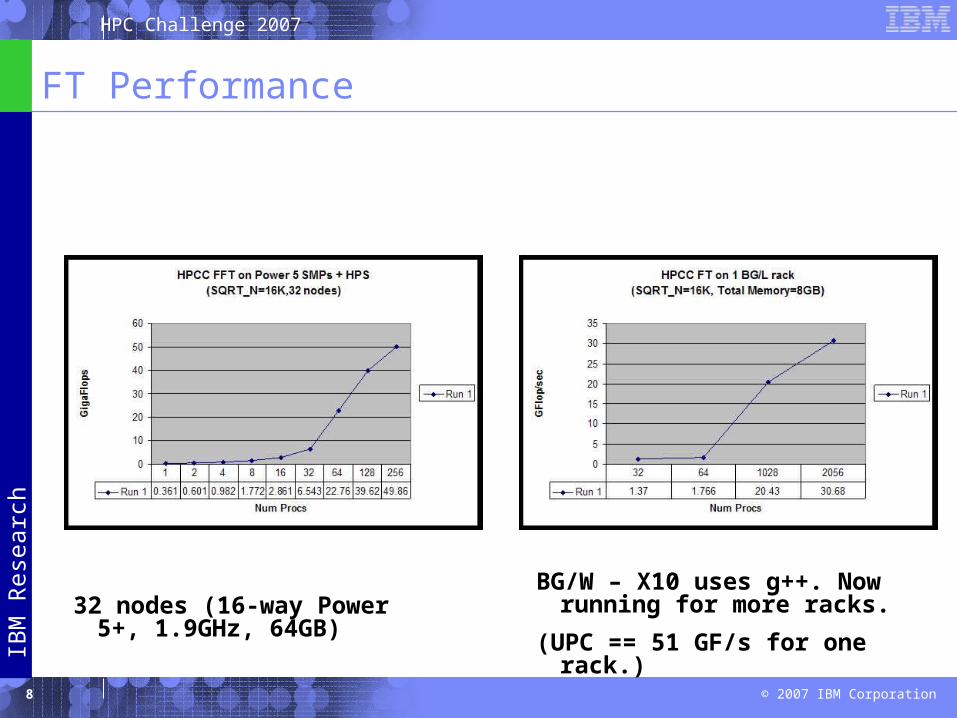
FT Performance
32 nodes (16-way Power 5+, 1.9GHz, 64GB)
BG/W – X10 uses g++. Now running for more racks.
(UPC == 51 GF/s for one rack.)
HPC Challenge 2007
© 2007 IBM Corporation9
IBM
Res
earc
h
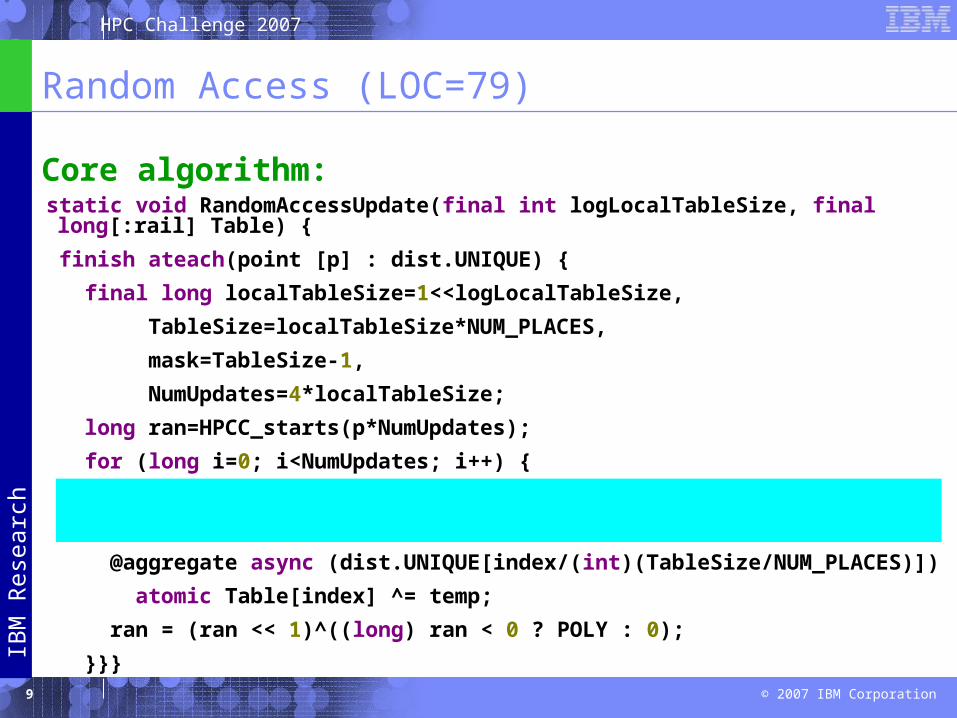
Random Access (LOC=79)
static void RandomAccessUpdate(final int logLocalTableSize, final long[:rail] Table) {
finish ateach(point [p] : dist.UNIQUE) {
final long localTableSize=1<<logLocalTableSize,
TableSize=localTableSize*NUM_PLACES,
mask=TableSize-1,
NumUpdates=4*localTableSize;
long ran=HPCC_starts(p*NumUpdates);
for (long i=0; i<NumUpdates; i++) {
final long temp=ran;
final int index = (int)(temp & mask);
@aggregate async (dist.UNIQUE[index/(int)(TableSize/NUM_PLACES)])
atomic Table[index] ^= temp;
ran = (ran << 1)^((long) ran < 0 ? POLY : 0);
}}}
Core algorithm:
HPC Challenge 2007
© 2007 IBM Corporation10
IBM
Res
earc
h
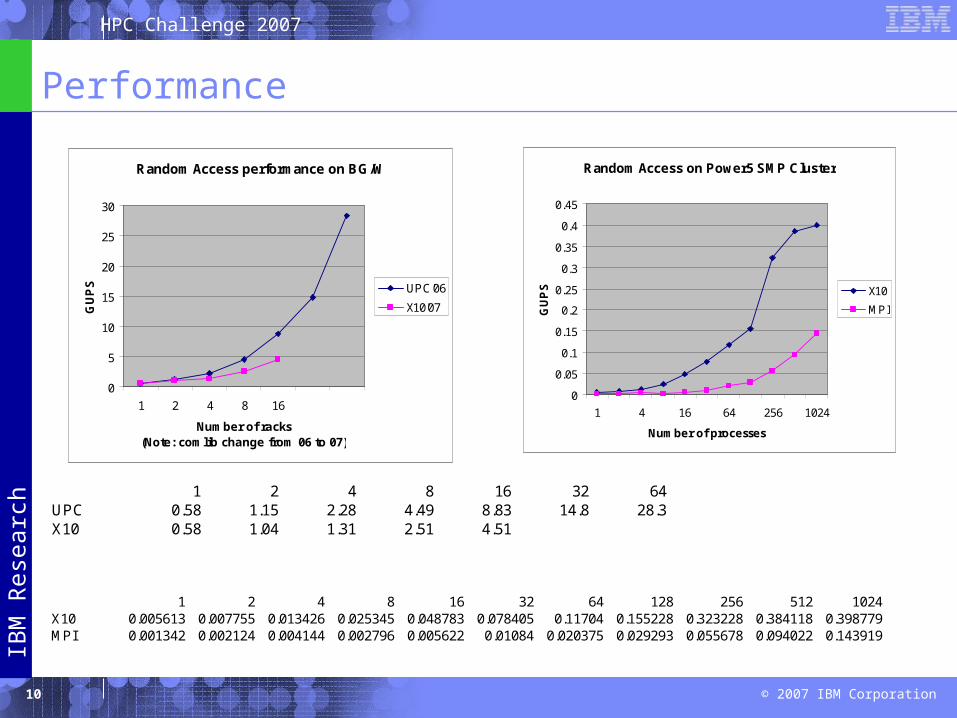
Performance
Random Access performance on BG/W
0
5
10
15
20
25
30
1 2 4 8 16
Number of racks (Note: comlib change from 06 to 07)
GU
PS UPC'06
X10'07
Random Access on Power5 SMP Cluster
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
1 4 16 64 256 1024
Number of processes
GU
PS X10
MPI
1 2 4 8 16 32 64UPC 0.58 1.15 2.28 4.49 8.83 14.8 28.3X10 0.58 1.04 1.31 2.51 4.51
1 2 4 8 16 32 64 128 256 512 1024X10 0.005613 0.007755 0.013426 0.025345 0.048783 0.078405 0.11704 0.155228 0.323228 0.384118 0.398779MPI 0.001342 0.002124 0.004144 0.002796 0.005622 0.01084 0.020375 0.029293 0.055678 0.094022 0.143919
HPC Challenge 2007
© 2007 IBM Corporation11
IBM
Res
earc
h
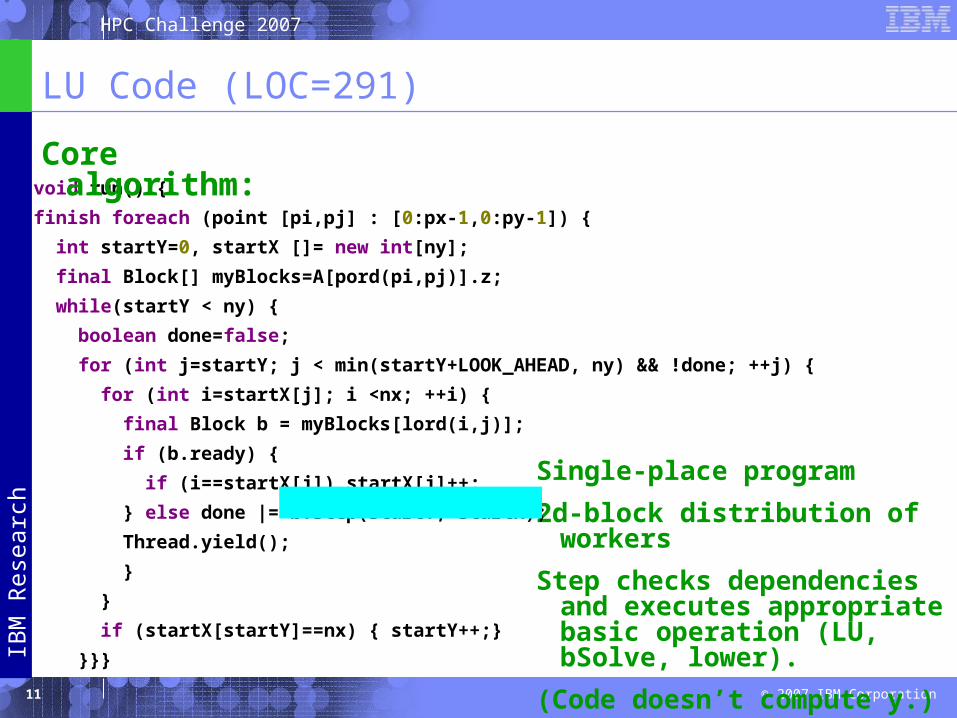
LU Code (LOC=291)
Single-place program
2d-block distribution of workers
Step checks dependencies and executes appropriate basic operation (LU, bSolve, lower).
(Code doesn’t compute y.)
void run() {
finish foreach (point [pi,pj] : [0:px-1,0:py-1]) {
int startY=0, startX []= new int[ny];
final Block[] myBlocks=A[pord(pi,pj)].z;
while(startY < ny) {
boolean done=false;
for (int j=startY; j < min(startY+LOOK_AHEAD, ny) && !done; ++j) {
for (int i=startX[j]; i <nx; ++i) {
final Block b = myBlocks[lord(i,j)];
if (b.ready) {
if (i==startX[j]) startX[j]++;
} else done |= b.step(startY, startX);
Thread.yield();
}
}
if (startX[startY]==nx) { startY++;}
}}}
Core algorithm:
HPC Challenge 2007
© 2007 IBM Corporation12
IBM
Res
earc
h
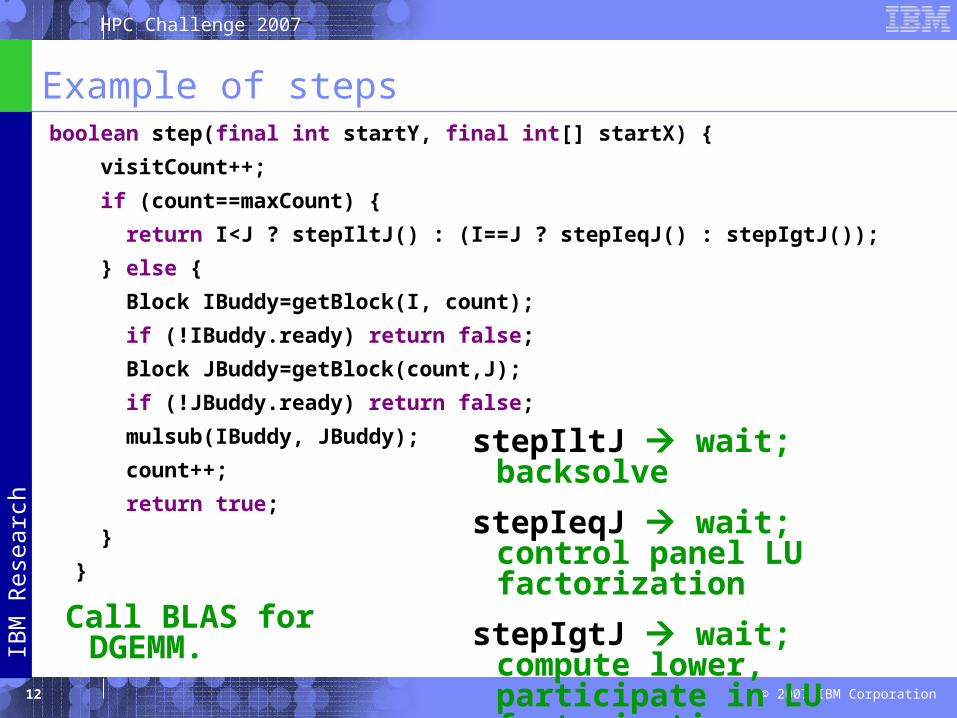
Example of steps boolean step(final int startY, final int[] startX) {
visitCount++;
if (count==maxCount) {
return I<J ? stepIltJ() : (I==J ? stepIeqJ() : stepIgtJ());
} else {
Block IBuddy=getBlock(I, count);
if (!IBuddy.ready) return false;
Block JBuddy=getBlock(count,J);
if (!JBuddy.ready) return false;
mulsub(IBuddy, JBuddy);
count++;
return true;
}
}
stepIltJ wait; backsolve
stepIeqJ wait; control panel LU factorization
stepIgtJ wait; compute lower, participate in LU factorizationCall BLAS for DGEMM.
HPC Challenge 2007
© 2007 IBM Corporation13
IBM
Res
earc
h
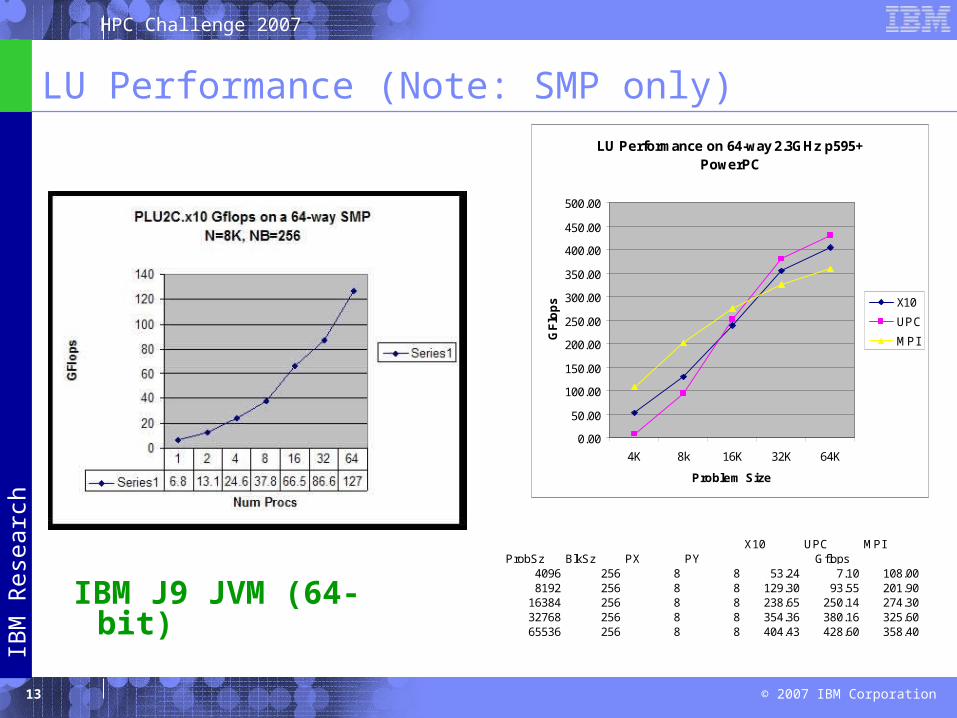
LU Performance (Note: SMP only)LU Performance on 64-way 2.3GHz p595+
PowerPC
0.00
50.00
100.00
150.00
200.00
250.00
300.00
350.00
400.00
450.00
500.00
4K 8k 16K 32K 64K
Problem Size
GF
lop
s X10
UPC
MPI
X10 UPC MPIProbSz BlkSz PX PY
4096 256 8 8 53.24 7.10 108.008192 256 8 8 129.30 93.55 201.90
16384 256 8 8 238.65 250.14 274.3032768 256 8 8 354.36 380.16 325.6065536 256 8 8 404.43 428.60 358.40
Gflops
IBM J9 JVM (64-bit)

IBM Research: Software Technology
© 2005 IBM Corporation14
Pro
gram
min
g T
echn
olog
ies
Backup slides
HPC Challenge 2007
© 2007 IBM Corporation15
IBM
Res
earc
h
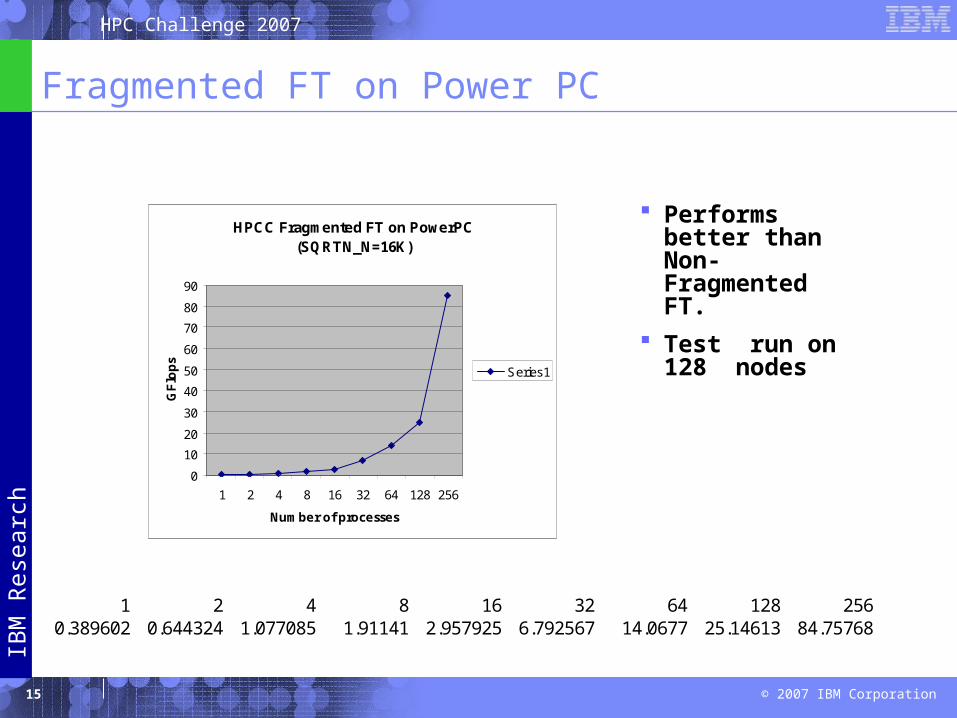
Fragmented FT on Power PC
1 2 4 8 16 32 64 128 2560.389602 0.644324 1.077085 1.91141 2.957925 6.792567 14.0677 25.14613 84.75768
HPCC Fragmented FT on PowerPC(SQRTN_N=16K)
0
10
20
30
40
50
60
70
80
90
1 2 4 8 16 32 64 128 256
Number of processes
GF
lop
s
Series1
Performs better than Non-Fragmented FT.
Test run on 128 nodes

HPC Challenge 2007
© 2007 IBM Corporation16
IBM
Res
earc
h
Environment variable settings on V20
## MPI
# Eager/Rendezvous protocol
#export MP_BUFFER_MEM=64M
#export MP_EAGER_LIMIT=32768
# Time source
#export MP_CLOCK_SOURCE=SWITCH
export MP_CSS_INTERRUPT=no
export MP_SHARED_MEMORY=yes
export MP_WAIT_MODE=poll
export MP_SINGLE_THREAD=yes
# Uncomment the following for RDMA
#export MP_USE_BULK_XFER=yes
#export MP_BULK_MIN_MSG_SIZE=16384
## LAPI
export LAPI_USE_SHM=yes
export MP_ADAPTER_USE=dedicated
export MP_CPU_USE=unique
# user space protocol
export MP_EUIDEVICE=sn_all
export MP_EUILIB=us
## Set this in run script.
#export MP_MSG_API=mpi
## POE - job specification
export MP_PGMMODEL=spmd
export MP_TASK_AFFINITY=MCM
export MEMORY_AFFINITY=MCM
## POE - job specification
export MP_PGMMODEL=spmd
export MP_TASK_AFFINITY=MCM
export MEMORY_AFFINITY=MCM
## POE - i/o control
#export MP_LABELIO=yes
export MP_EUIDEVELOP=MIN
HPC Challenge 2007
© 2007 IBM Corporation17
IBM
Res
earc
h
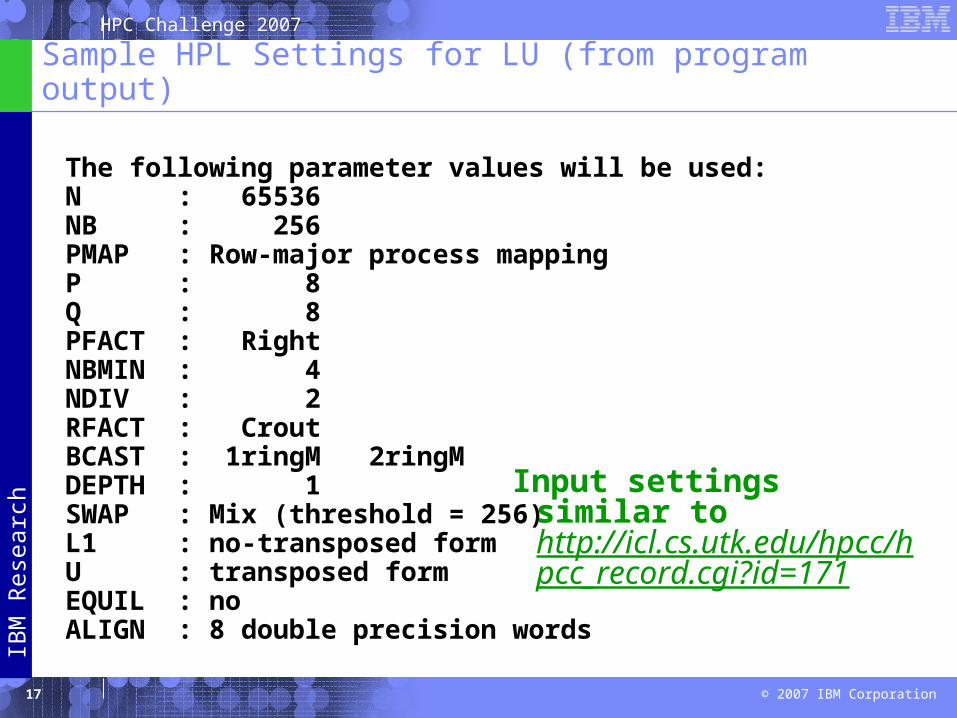
Sample HPL Settings for LU (from program output)
The following parameter values will be used:N : 65536 NB : 256 PMAP : Row-major process mappingP : 8 Q : 8 PFACT : Right NBMIN : 4 NDIV : 2 RFACT : Crout BCAST : 1ringM 2ringM DEPTH : 1 SWAP : Mix (threshold = 256)L1 : no-transposed formU : transposed formEQUIL : noALIGN : 8 double precision words
Input settings similar to http://icl.cs.utk.edu/hpcc/hpcc_record.cgi?id=171


























![[IBM Korea 김상훈] HPC on IBM Public Cloud (금융분야)](https://img.dokumen.tips/doc/110x75/587004761a28ab427f8b5ba7/ibm-korea-hpc-on-ibm-public-cloud-.jpg)


