Embed Size (px)
DESCRIPTION
High-Performance Reliable Distributed Storage Systems. Background – Hash-Based Distributed Storage Systems. Take as input a key and, in response, route a message to the node responsible for that key. - PowerPoint PPT Presentation
Citation preview

High-Performance Reliable Distributed Storage Systems

Background – Hash-Based Distributed Storage Systems
• Take as input a key and, in response, route a message to the node responsible for that key.
• Keys are random binary strings of fixed length (generally 128 bits). Nodes have identifiers taken from the same space as the keys.
• Each node maintains a routing table consisting of a small subset of nodes in the system.
• Nodes route queries to neighboring nodes that make the most “progress” towards resolving the query.

Background – Hash-Based Storage Systems
• Scalable, efficient, and decentralized systems:O(log(N)) routing table entries per nodeRoute in O(log(N)) number of hops

Semantic Addressing: Binary Matrix Decomposition
Motivation• Search is still an important problem in distributed storage
systems.
• Most current proposals support only keyword searches or object keys.
• Conventional hash-based systems do not support search beyond exact matches.
• Unstructured P2P systems support generic meta-information.
• How can we support more powerful search primitives?

Semantic Addressing: Binary Matrix Decomposition
• Information retrieval systems generally rely on matrix decomposition techniques, such as SVD, to solve the problem of synonymy and polysemy.
• SVD is expensive and generates dense matrices.
• We support alternate decompositions suited to binary attributed data.

Semantic Search: Binary Matrix Decomposition
• Binary-attributed datasets are ubiquitous (transactions, interactions, etc.)
• Centralized search/analyses is not viable:• Volume of data• Real-time response• Privacy

Binary Matrix Decomposition
• Given m binary vectors of size n, find a set of k binary vectors, with k << m, such that for any input vector v, there is an output vector o such that the Hamming distance between v and o is at most ε.

Binary Matrix Decomposition
• Example:
1110
1100
1100
1110
0110
1110
1110
1110
A
1111x 1110 1110y
TxyÃA

Binary Matrix Decomposition
• Proximus [Grama et al., IEE TKDE 2006, ACM TOMS 2006] provides a serial solution to the problem.
• The matrix is recursively partitioned based on successive computations of rank-one approximations.

Binary Matrix Decomposition
• Rank-one Approx: Given a matrix , find that minimize the error:
• Minimizing the error in a rank-one approximation is equivalent to maximizing:
1:2
ijT
ijF
T axyAaxyA
222,
FF
Td yxAyxyxC

Binary Matrix Decomposition
• The maximization problem can be solved in linear time in the number of non-zeros of the matrix A using an alternating iterative heuristic.
Find the optimal solution to x for a fixed y, and then use the computed value of x to find a new y. The new value of y is again used to find a new value of x. This process is repeated until there is no change to the values of x and y.

Binary Matrix Decomposition

Binary Matrix Decomposition and Distributed Storage
• The matrix is distributed.
• Find an approximation to the serial solution.
• To minimize communication overhead, we rely on subsampling.
• Hosts exchange rank-one approximations and consolidate the patterns to achieve common approximations.
• Similar approach has been successfully used in Conquest [Grama et al., Algorithmica 2006].

Binary Matrix DecompositionConsolidation Algorithm
• Proximity preserving Hash function
otherwise 1
0 if 01f
fj
1i
i
ji
yb
1
1
1
1
12
1minarg where
;0 if 0xf
fjj
Nxiii
ii
i
pssf
i
f
Break pattern into strides such that the probability of having all zeros in the stride is approximately 0.5.

Experimental Evaluation• Prototype implementation.
• Cluster of 18 workstations. Each workstation runs 15 processes, emulating a total of 270 peers.
• Dataset 1: Walmart customer’s transactions Translated into a binary matrix with 34,239 columns (items) and ~1
million rows (transactions).
• Dataset 2: Synthetic dataset generated with IBM Quest generator. Multiple datasets generated by varying the number of underlying
patterns, correlation between patterns, and confidence of a pattern. [3 million transactions]

Experimental Evaluation• Evaluation of the quality of the results in terms of
precision and recall.
• Compression• Load balancing
2
2&
F
F
Ã
ÃAprecision 2
2&
F
F
A
ÃArecall
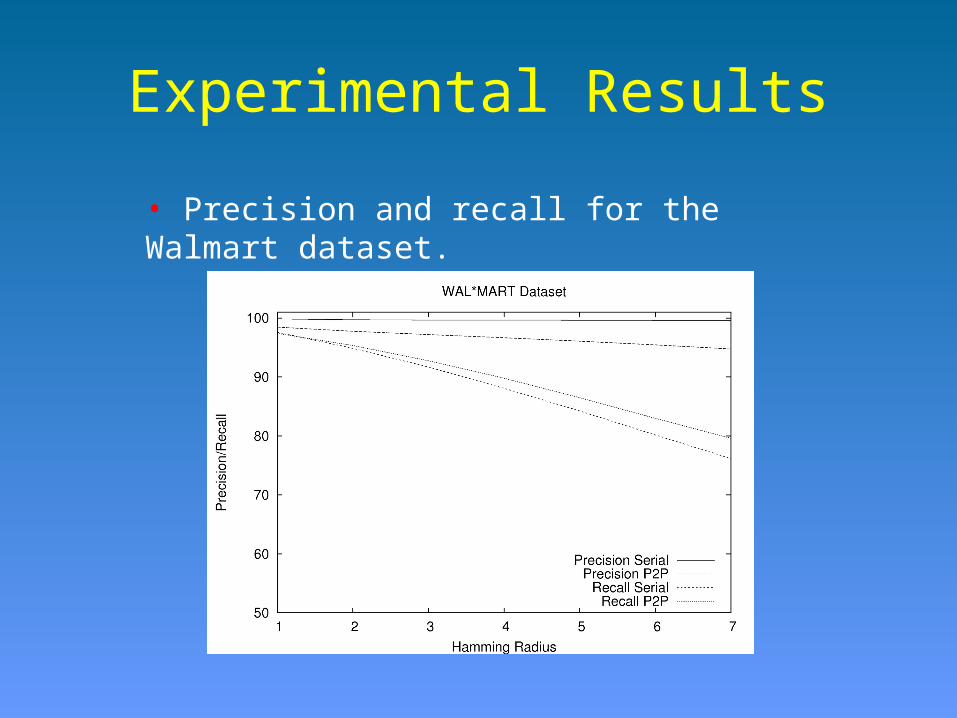
Experimental Results
• Precision and recall for the Walmart dataset.
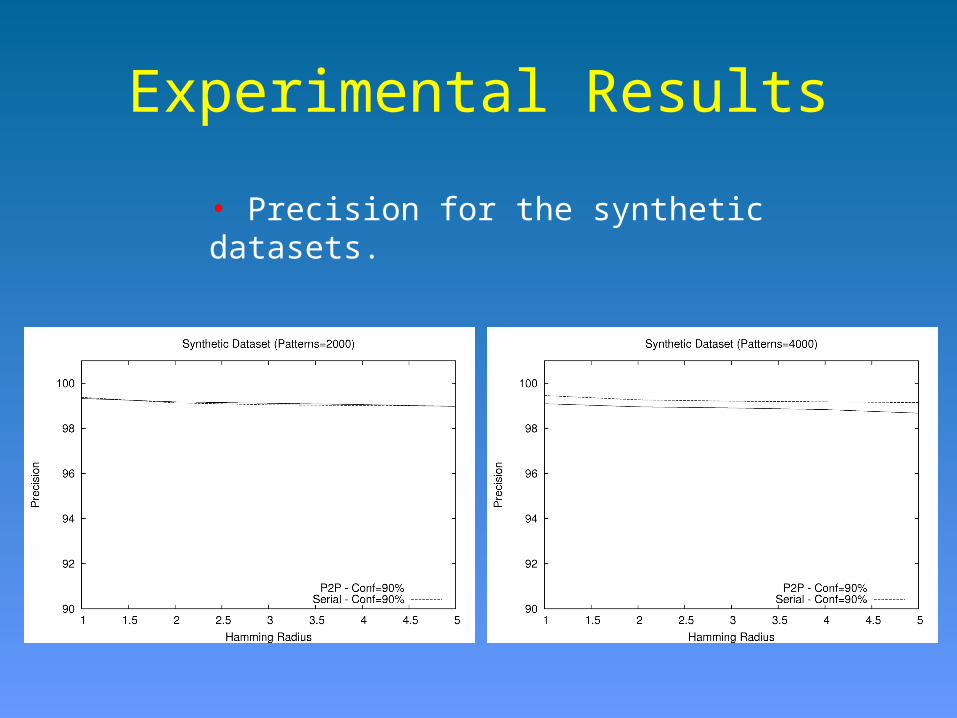
Experimental Results
• Precision for the synthetic datasets.

Experimental Results
• Recall for the synthetic datasets.
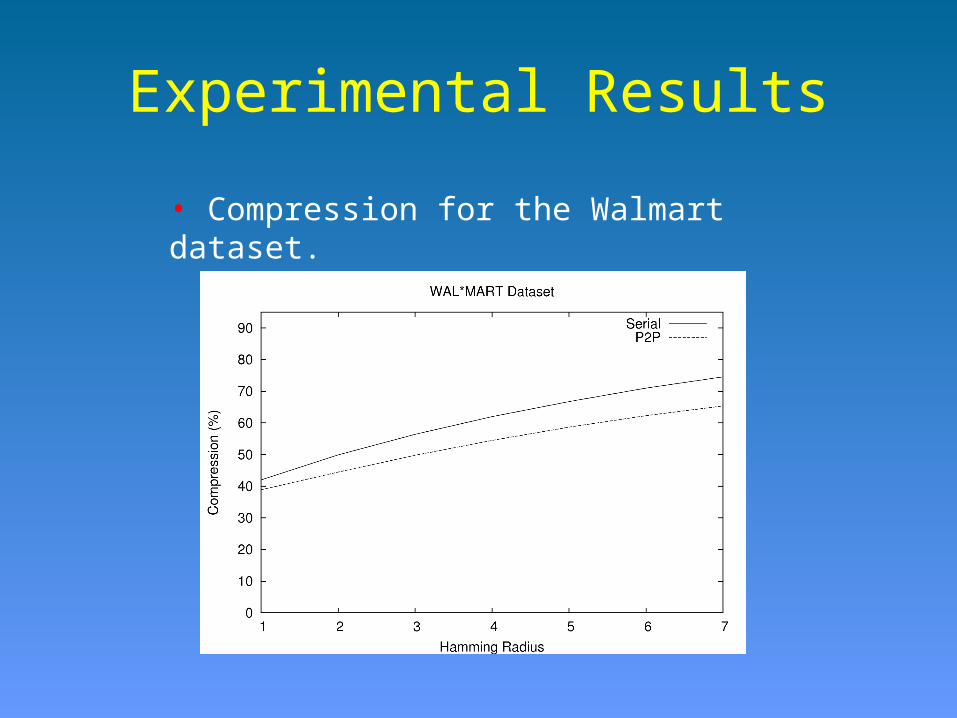
Experimental Results
• Compression for the Walmart dataset.
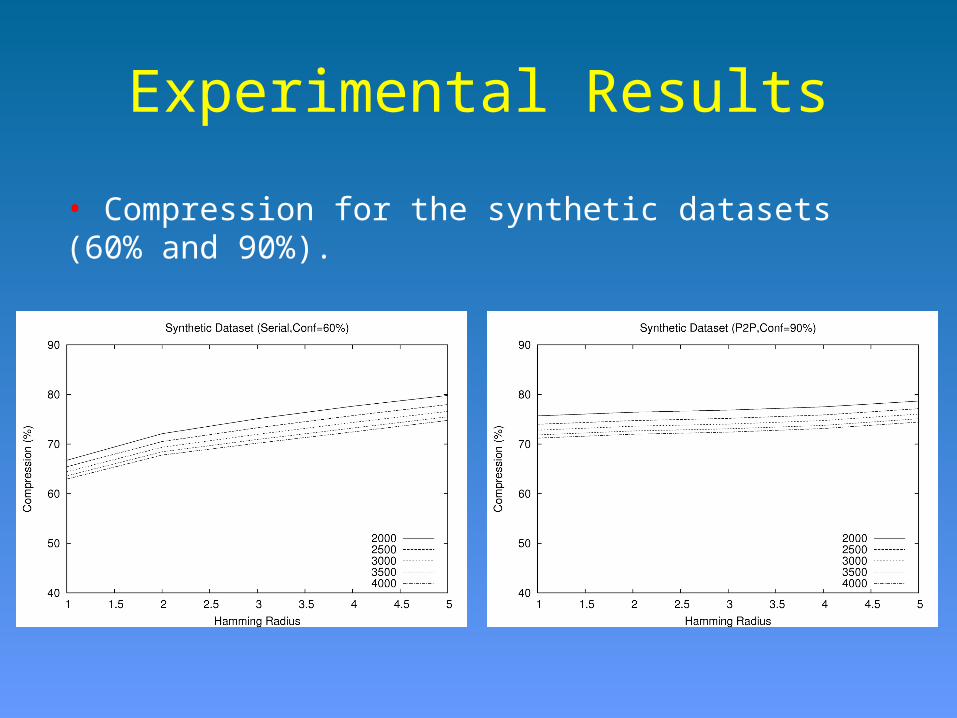
Experimental Results
• Compression for the synthetic datasets (60% and 90%).
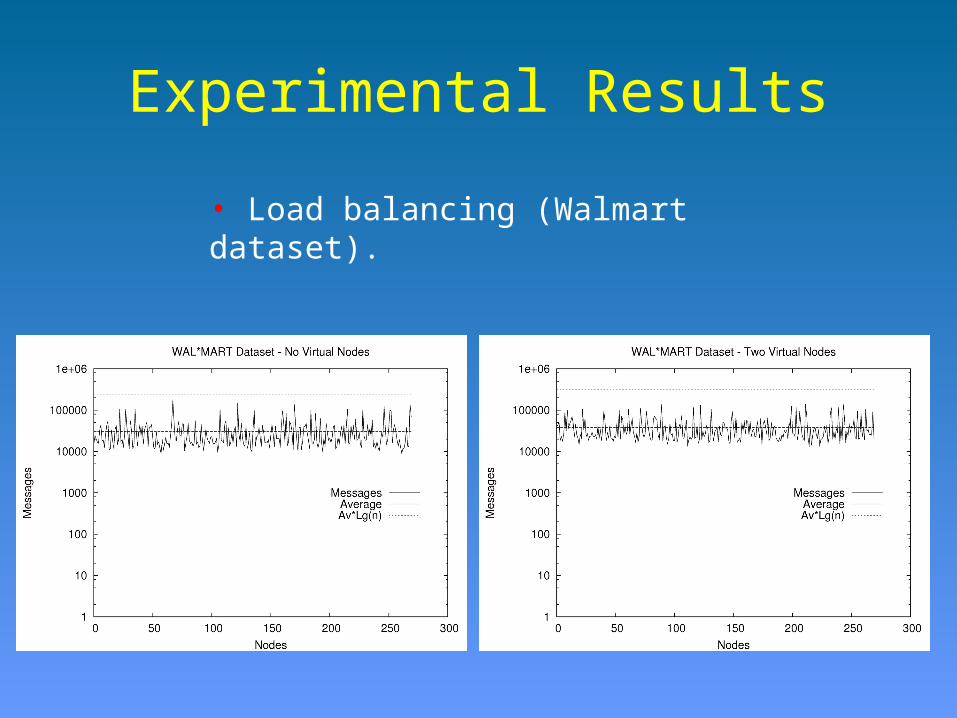
Experimental Results
• Load balancing (Walmart dataset).
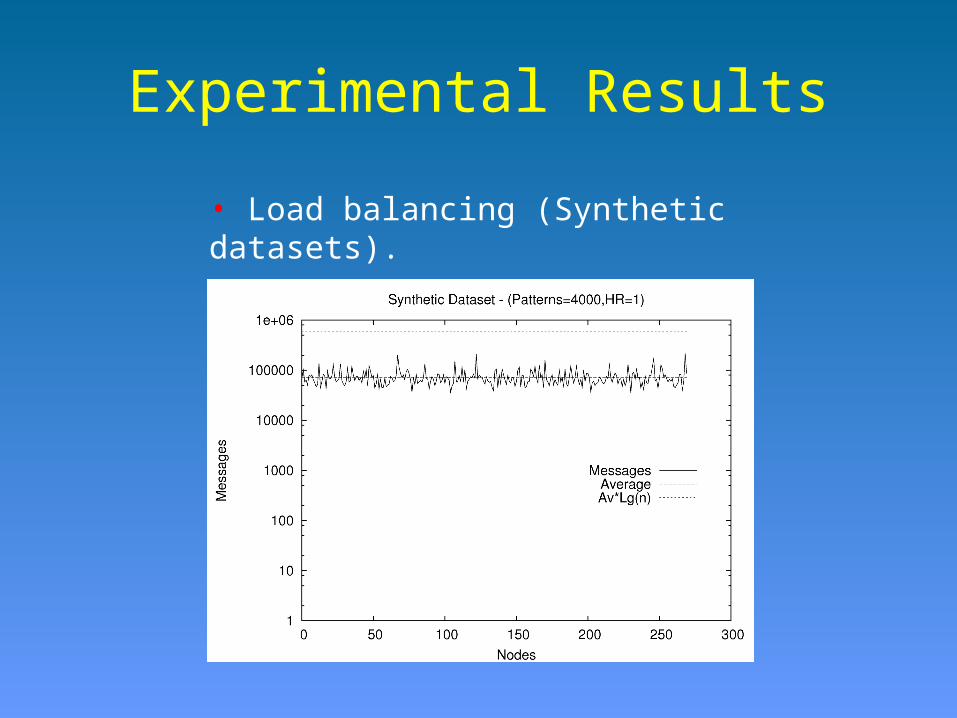
Experimental Results
• Load balancing (Synthetic datasets).

Locality in Hash-Based Storage Systems

Enhancing Locality in Hash-Based Storage Systems
• Computers (nodes) have unique ID Typically 128 bits long Assignment should lead to uniform distribution in the node
ID space, for example SHA-1 of node’s IP
• Scalable, efficient O(log(N)) routing table entries per node Route in O(log(N)) number of hops
• Virtualization destroys locality.
• Messages may have to travel around the world to reach a node in the same LAN.
• Query responses do not contain locality information.

Enhancing Locality in DHT• Two-level overlay
One global overlay Several local overlays
• Global overlay is the main repository of data. Any prefix-based DHT protocol can be used.
• Global overlay helps nodes organize themselves into local overlays.
• Local overlays explore the organization of the Internet in ASs.
• Local overlays use a modified version of Pastry.
• Size of the local overlay is controlled by a local overlay leader. Uses efficient distributed algorithms for merging and splitting
local overlays. The algorithms are based on equivalent operations in hypercubes.

Simulation Setup• Underlying topology is simulated using data collected
from the Internet by the Skitter project at CAIDA.
• Data contains link delays and IP addresses of the routers. IP addresses are mapped to their ASs using BGP data collected by the Route Views project at University of Oregon.
• The resulting topology contains 218,416 routers, 692,271 links, and 7,704 ASs.
• We randomly select 10,000 routers and connect a LAN with 10 hosts in each one of them.
• 10,000 overlay nodes selected randomly from the hosts.

Simulation Setup• NLANR web proxy trace with 500,254 objects.
• Zipf distribution parameters: {0.70, 0.75, 0.80, 0.85, 0.90}
• Maximum overlay sizes: {200; 300; 400; 500; 1,000; 2,000}
• Local cache size: 5MB (LRU replacement policy).
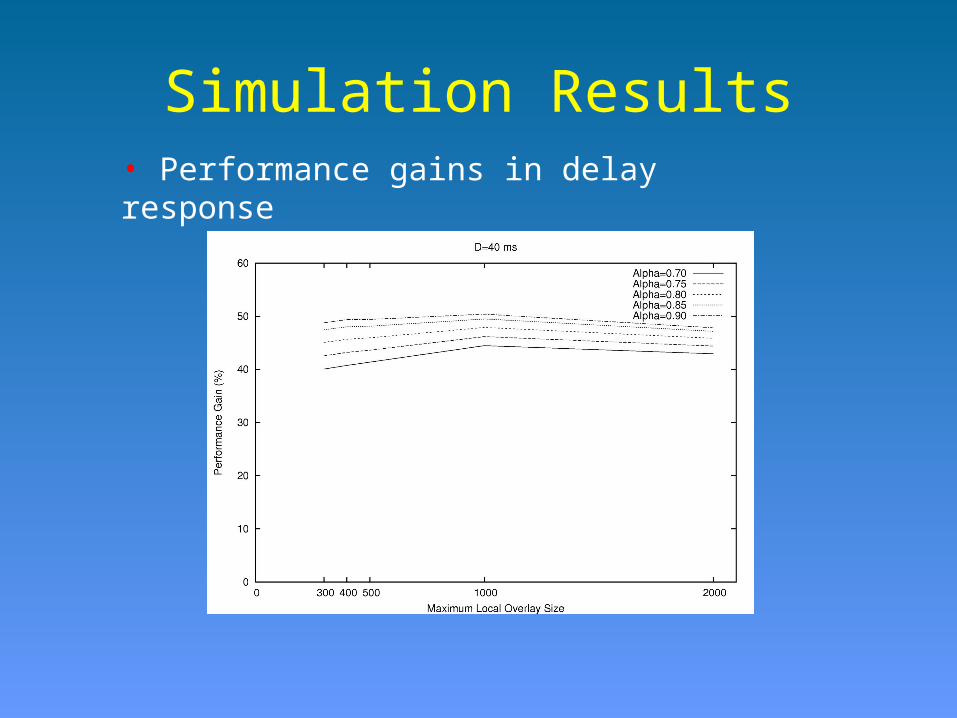
Simulation Results• Performance gains in delay response
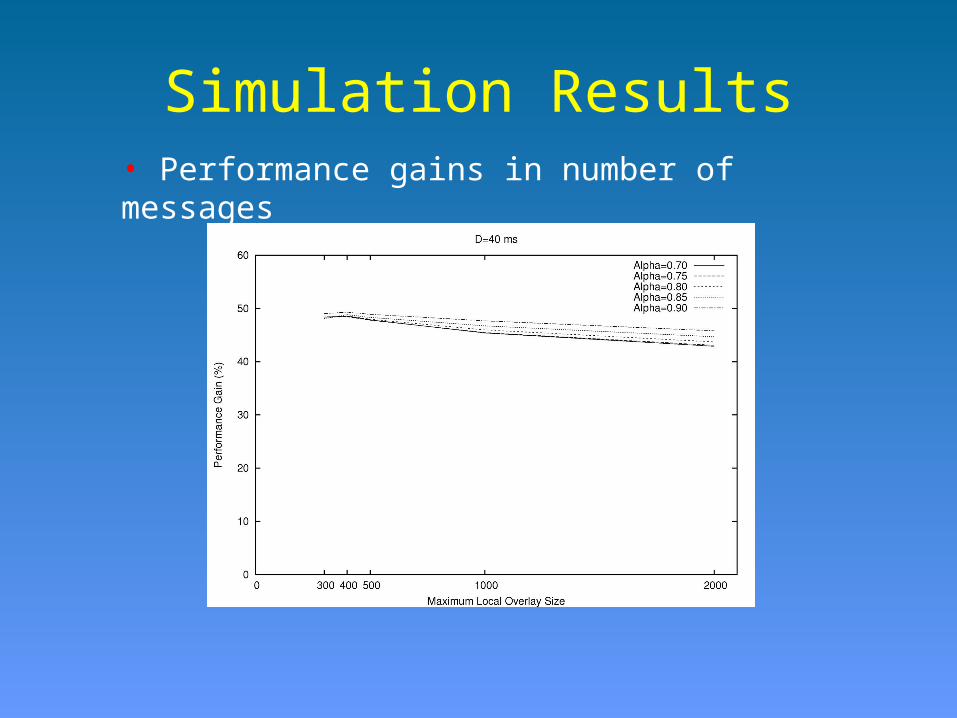
Simulation Results• Performance gains in number of messages

Search with Probabilistic Guarantees

Unstructured Distributed Systems Randomized Algorithms
• Randomization and Distributed SystemsBreak symmetry (e.g. Ethernet backoff)Load balancing.Fault handling.Solutions to problems that are unsolvable
deterministically. (e.g., Consensus under failure)
• Uniform sampling is a key component in the development of randomized algorithms.

Uniform Sampling
• Substrate for the development of randomized algorithmsSearch with probabilistic guarantees.Duplicate elimination. Job distribution with load balancing.
• Definition: An algorithm samples uniformly at random from
a set of nodes in a connected network if and only if it selects a node i belonging to the network with probability 1/n, where n is the number of nodes in the network.

Uniform Sampling• In a complete network, the problem is trivial.
• Random walks of a prescribed minimum length gives random sampling – independent of origin of walk.
• A long walk reaches stationary distribution π,
πi = di / 2|E|. Not a uniform sample if network nodes have different
degrees.
• In [Awan et al 04], we study different algorithms that change the transition probabilities among neighbors in order to achieve uniform sampling using random walks. We show, using simulation, that the length of the random walk is O(log n).

Search with Probabilistic Guarantees
Algorithm• To share its content with other peers in the network, a
peer p installs references to each of its objects at a set Qp of peers. Any metainformation can be published.
• To provide guarantees that content published by a peer p can be found by any other peer in the network, three fundamental questions need to be answered:
1. Where should the nodes in Qp be located in the network?
2. What is the size of the set Qp?3. When a peer q attempts to locate an object, how many
peers must q contact?

Search with Probabilistic Guarantees
Algorithm
• We select nodes in Qp uniformly at random from the network. It provides fault tolerance. In the event of a node failure, the
node can be easily replaced. It facilitates search, since there is no consistent global routing
infrastructure.
• Questions 2 and 3 can be answered using the “birthday paradox” (or a “balls and bins” abstraction). “How many people must there be in a room before there is a
50% chance that two of them were born on the same day of the year?” (at least 23)
If we set Qp to and we search in an independent set of the same size, we have high probability of intersection.
nn ln

Search with Probabilistic Guarantees
Controlled Installation of References• If every replica inserts reference pointers, popular
objects may have their reference pointers on all peers.• We use a probabilistic algorithm to decide if a node
should install pointers to its objects.• When a peer p joins the network, it sends a query for
an object using a random walk of length γ√n: If the query is unsuccessful, then p installs the pointers with
probability one. If the query is successful and the responding peer q is at a
distance l from p, then p installs pointers with probability l/γ√n.
Search with Probabilistic Guarantees
Simulation Setup• Overlay topology composed of 30,607 nodes Partial view of the Gnutella network. Power-law graph. Random graph.
• Node dynamics: Static Dynamic: simulates changes of connections Failures without updates Failures with updates
• Measurements: Distribution of replication ratios. Average number of hops (unbounded TTL). Percentage of query failures (bounded TTL). Percentage of object owners that install pointers. Number of messages per peer.
Search with Probabilistic Guarantees
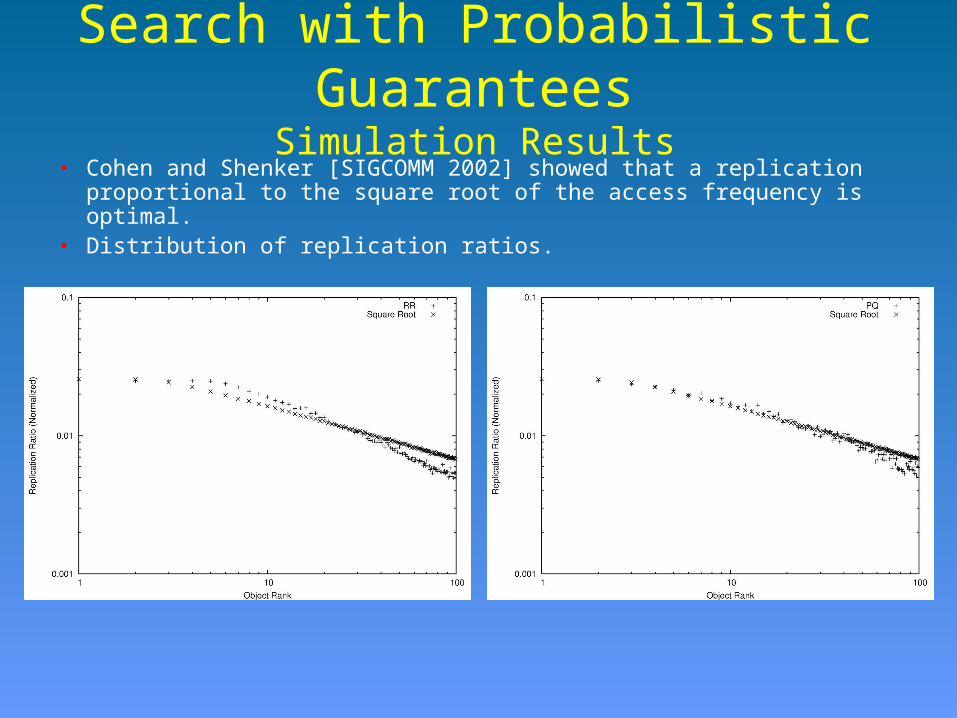
Simulation Results• Cohen and Shenker [SIGCOMM 2002] showed that a replication
proportional to the square root of the access frequency is optimal.• Distribution of replication ratios.

Search with Probabilistic Guarantees
Simulation Results• Percentage of failures of a query as a function of object
popularity (left γ=1, right γ=2).
Search with Probabilistic Guarantees
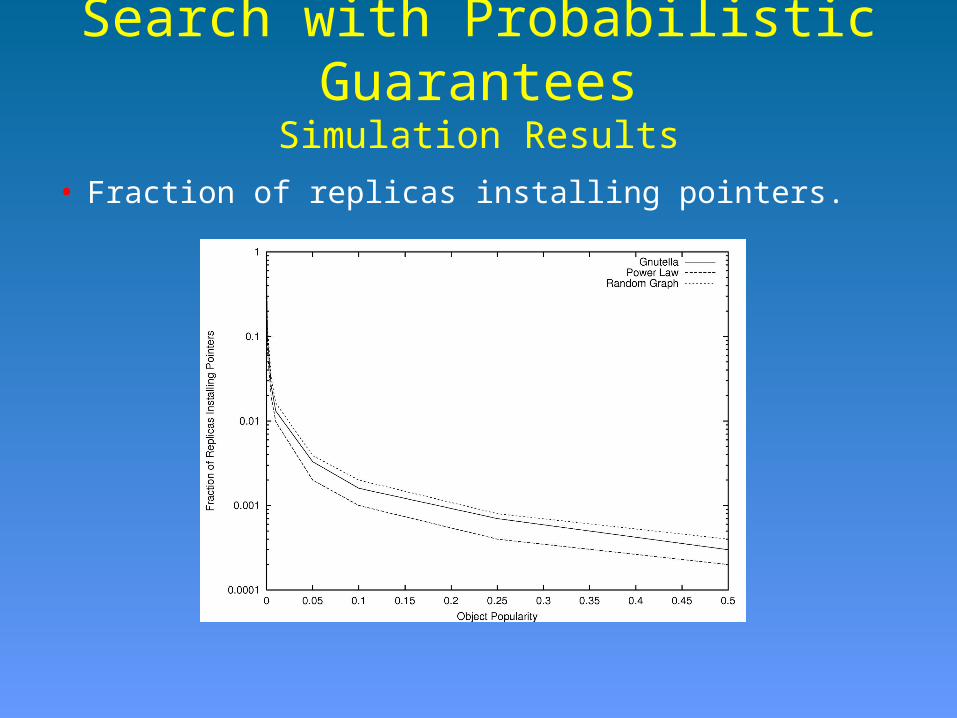
Simulation Results
• Fraction of replicas installing pointers.

Duplicate Elimination in Distributed Storage Systems

Duplicate Elimination• Consider a distributed storage system, designed
without any assumptions on the structure of the overlay network, and which contains multiple peers, each peer holding numerous files.
• How can a peer determine which files need to be
kept using minimum communication overhead?
• How can the storage system as a whole make sure that each file is present in at least k peers, where k is a system parameter chosen to satisfy a client or application’s availability requirements?

Duplicate Elimination• Problem can be abstracted to a relaxed and probabilistic
version of the leader election problem.
• Divide the process of electing a leader into two phases
• First Phase: Reduce the number of potential leaders by half in every round. Number of messages exchanged in the system is O(n) At the end of the first phase, have at least C contenders.
(0 < C < sqrt(n/lnn))
• Second Phase: Use birthday paradox (Probabilistic Quorum) solution.

Duplicate Elimination
• Contender – Node that wants to be a leader
• Mediator – Node that arbitrates between any two contenders for a given round
• Winner – Node that proceeds as contender to the next round

Duplicate Elimination
• Each contender sends sqrt(n ln2/(E[Xi]-1)) in round i of the first phase. Where E[Xi] is the expected number of contenders in round i.
• The total number of messages in the first phase is O(n).
• Each contender sends sqrt(nln n) messages in the second phase.
• The total number of messages in second phase is O(n).

Illustration of First Phase
Round 1:
F
G
E
D
H
A B
C
DD
AAHH
G,FG,F
B,EB,E
CC
Numbers are for illustrative purposes
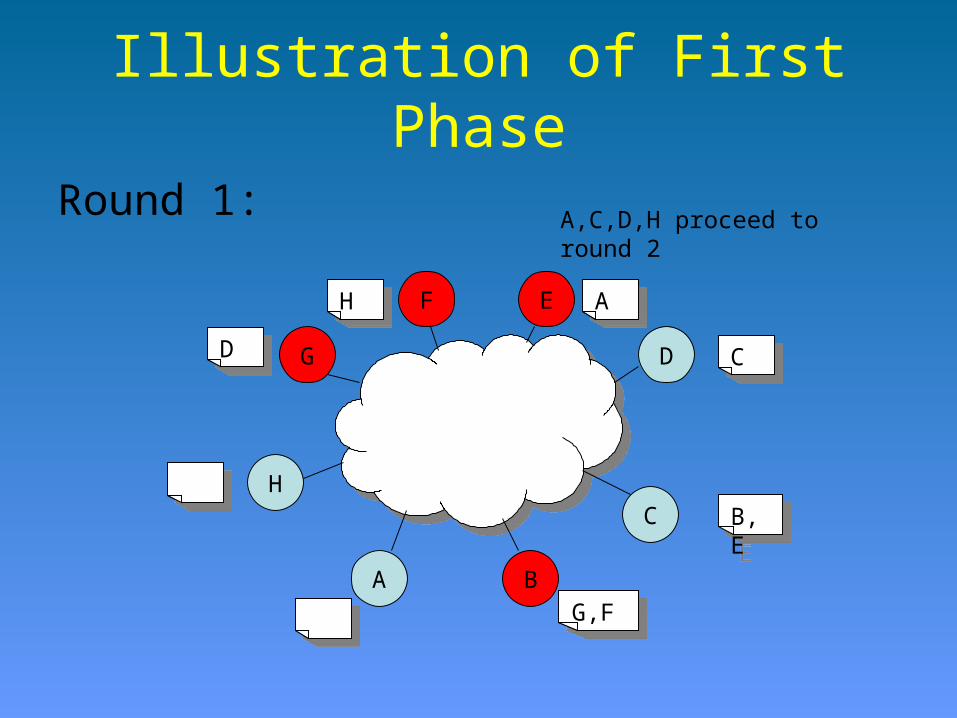
Illustration of First Phase
Round 1:
F
G
E
D
H
A B
C
DD
AAHH
G,FG,F
B,EB,E
CC
A,C,D,H proceed to round 2
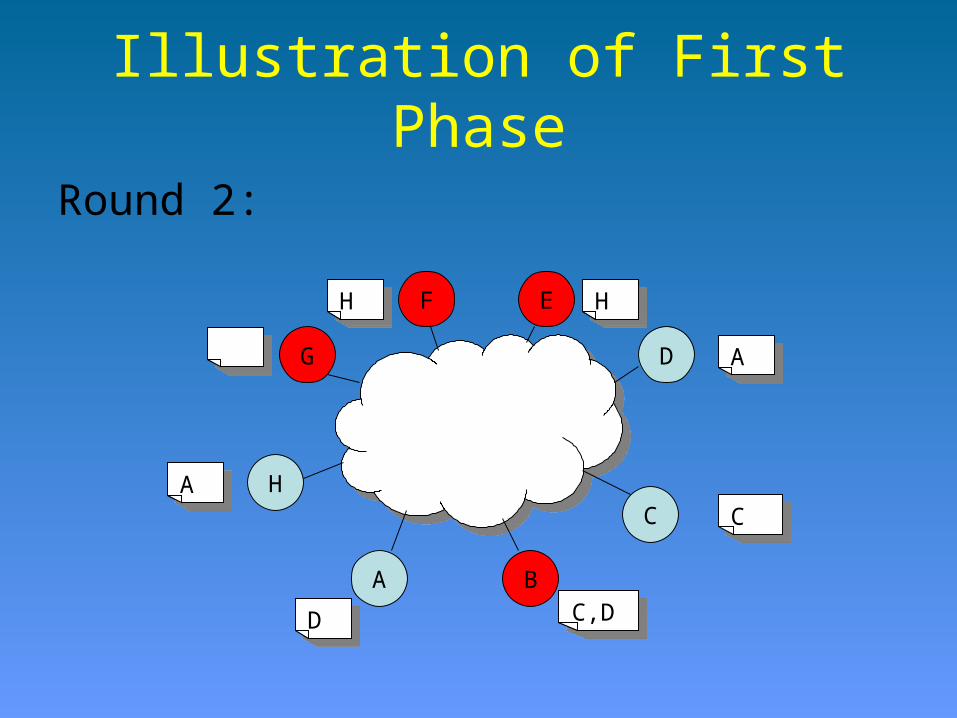
Illustration of First Phase
Round 2:
F
G
E
D
H
A B
CAA
HHHH
DD C,DC,D
CC
AA
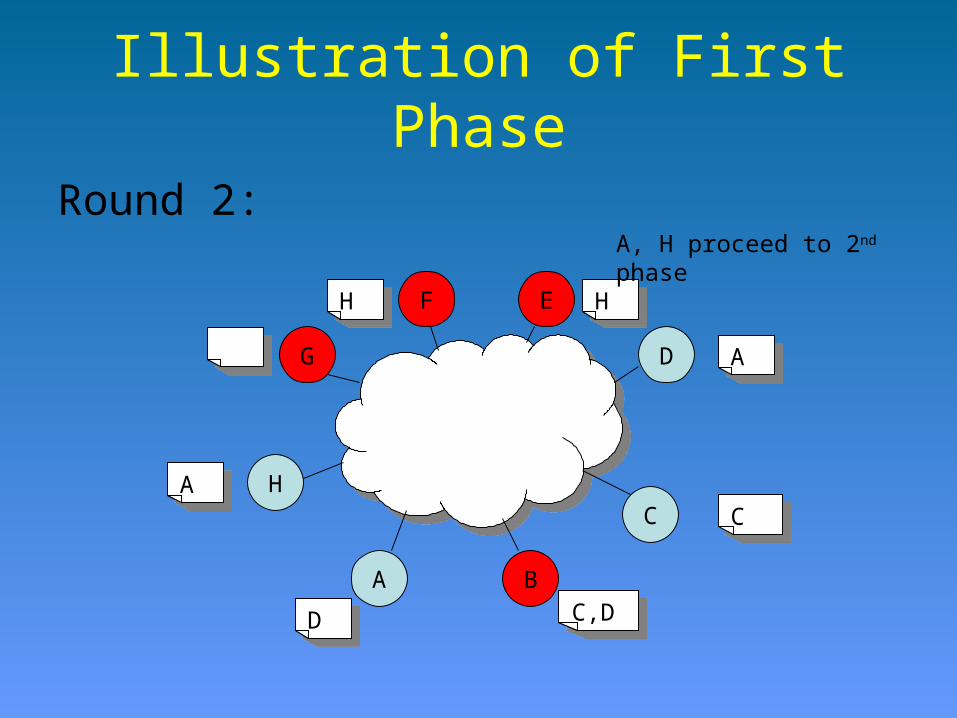
Illustration of First Phase
Round 2:
F
G
E
D
H
A B
CAA
HHHH
DD C,DC,D
CC
AA
A, H proceed to 2nd phase
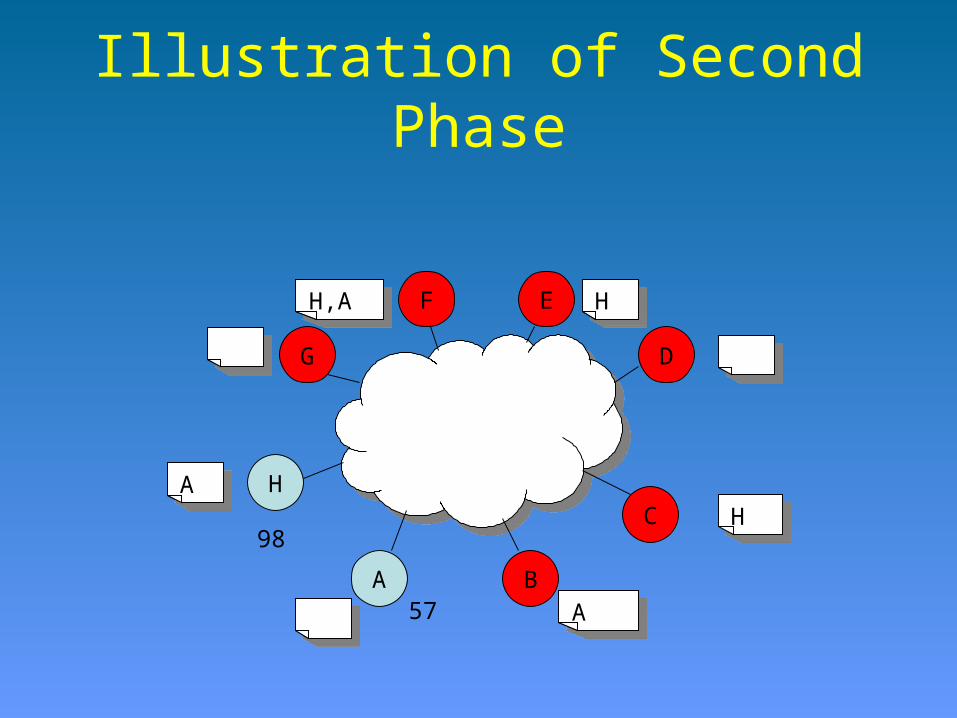
Illustration of Second Phase
F
G
E
D
H
A B
CAA
HHH,AH,A
AA
HH
57
98
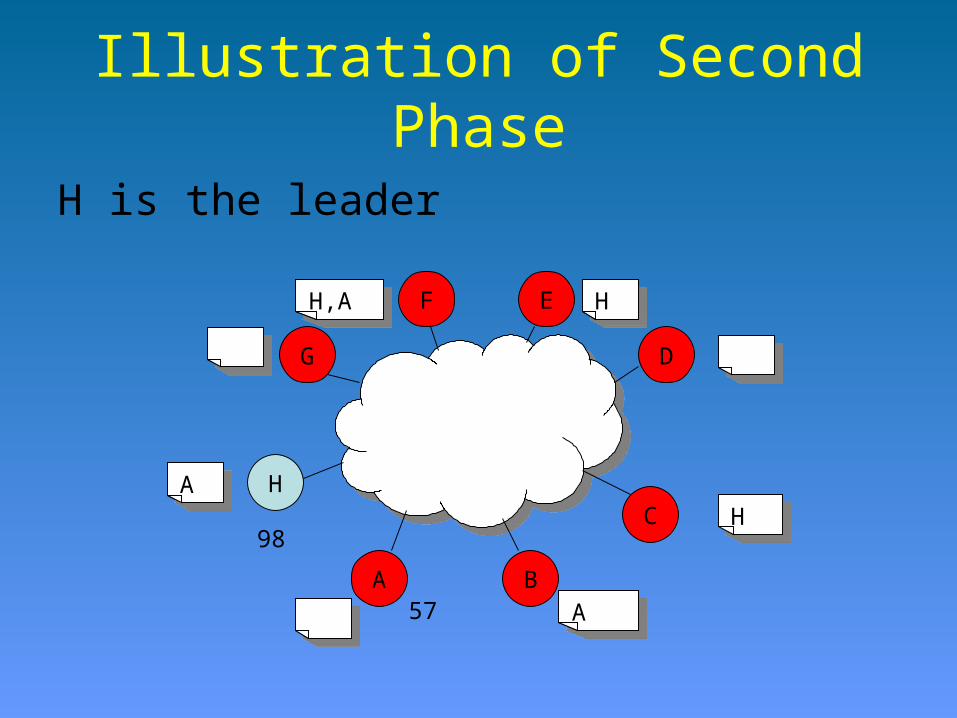
Illustration of Second Phase
H is the leader
F
G
E
D
H
A B
CAA
HHH,AH,A
AA
HH
57
98

Duplicate EliminationSimulation Setup
• Power-law random graph with 50,000 nodes.• One object is replicated at the nodes (1% to 50%)• Measurements
Message overheadLoad distributionAccuracy of the protocols
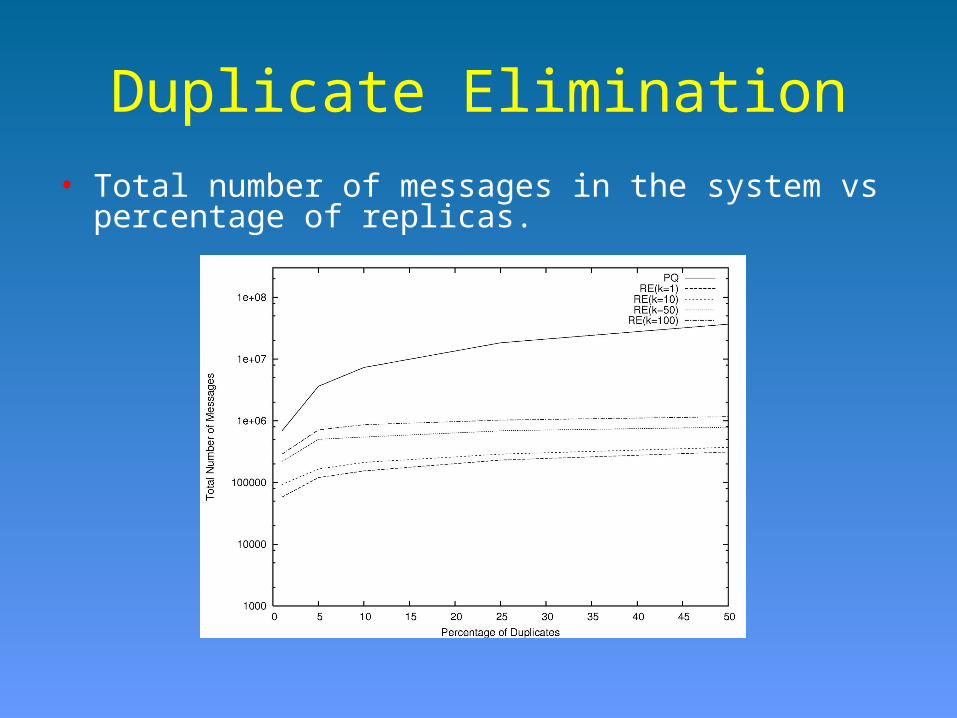
Duplicate Elimination• Total number of messages in the system vs percentage of
replicas.
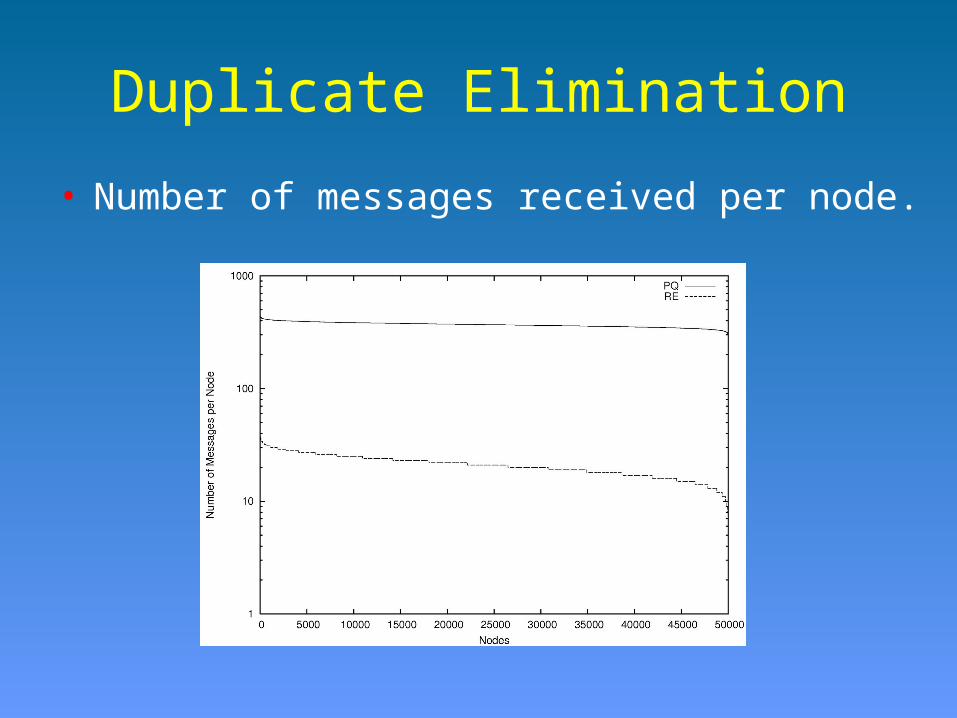
Duplicate Elimination
• Number of messages received per node.

Duplicate EliminationPlanetLab Experiment
• 132 PlanetLab nodes.• File traces from Microsoft
10,568 file systems4,801 Windows machines10.5TB of data
• Measurements:Message overheadSpace reclaimedMemory overhead per node
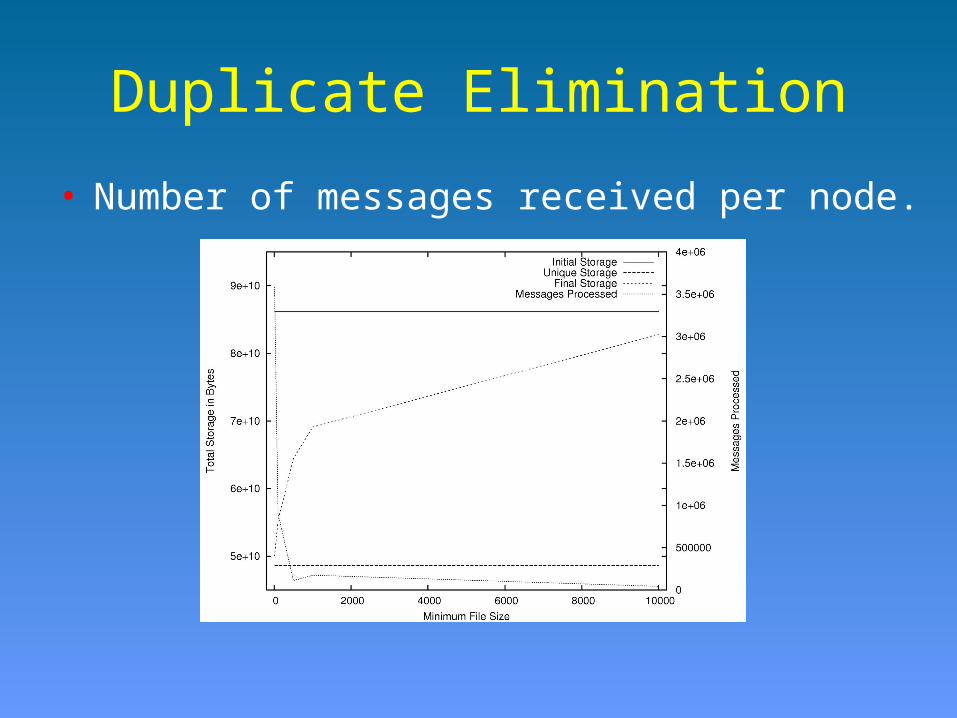
Duplicate Elimination
• Number of messages received per node.

Conclusion
• Problems relating to search, semantic queries and resource management have been addressed for structured and unstructured distributed storage systems.









![Cloud Storage Theo Benson. Outline Distributed storage – Commodity server, limited resources, – Geodistribution, scalable, reliable Cassandra [FB] – High](https://img.dokumen.tips/doc/110x75/56649ce15503460f949ab317/cloud-storage-theo-benson-outline-distributed-storage-commodity-server.jpg)



















