Embed Size (px)
Citation preview

High-Level Testing and Example-Directed Development of Software Specifications
Robert L. Probert Hasan Ural ~~ive~~ity of Uttaw~
A testing-based approach for constructing and refining very high-level software fun~tionaiity repre~ntations such as intentions, natural language assertions, and for- mal specifications is presented and applied to a standard line-editing problem as an illustration. The approach in- volves the use of specification-based (black-box) test- case generation strategies, high-level specification for- malisms, redundant or parallel development and cross- validation, and a logic pr~ramming support environment. Test-case reference sets are used as software function- ality representations for the purposes of cross-validating two distinct high-level representations, and identifying ambiguities and omissions in those representations. In fact, we propose the use of successive refinements of such test reference sets as the authoritative specification throughout the software development process. Potential benefits of the approach include improvements in user/ designer communication over all life cycle phases, and an increase in the quality of specifications and designs.
INTRODUCTION TO HIGH-LEVEL TESTING
Testing activities have often been confined to the post- coding phase of the software life cycle [ 14,151. Recent investigations [ 7,121 have suggested that testing activ- ities should be carried out much earlier, in particular, at the specification [Zl] and design phases [ZO] . In this section we introduce a type of testing which is employ- able very early in the life cycle and appears to have con- siderable potential for detecting ambiguities, inconsis- tencies, and even omissions well before any target software is produced. Such testing is useful for avoiding the expenditure of considerable time and effort design- ing, coding, and testing or proving inappropriate pro-
Address correspondence to Robert L. Prober?, Software Reiia- bility Research Group, Dept. of Computer Science. University of Ottawa, Ottawa, Ontario, Canada KIN 984.
The Journal of Systems and Software 4,3 17-325 (1984) 0 Elsevier Science Publishing Co., Inc., 1984
grams. Program proving activities in particular are wasteful if the underlying specification are invalid, in- consistent, or inappropriate.
First, we propose an expanded definition of the soft- ware life-cycle, namely:
i.
ii.
. . . 111.
iv. V.
vi. vii.
Formulating intentions or implicit specifications. These intentions are typically only partially de- cided, and often cannot be directly communicated to the software designer. Constructing a natural-language representation of the specifications, referred to as explicit spec@c@ f ions. Deriving ~~rn~~ s~c~~cutio~, i.e., a much more precise representation of the specifications. The specification language might be algebraic, axio- matic, or attributed grammar based, for example. Constructing designs in increasing levels of detail Coding and preliminary debugging Testing or proving and prerelease maintenance Release and post-release maintenance
Backtracking is encouraged where validation activities indicate revisions are required.
Typically, testing activities have been confined to the final three phases above. We will focus instead on the first three phases, namely formulating implicit, explicit, and formal specifications, and refer to testing activities carried on at these phases as high-level testing. We in- corporate high-level testing into the software develop ment process from the earliest phase, The discussion which follows describes only the specification develop ment process; however, extensions to the remaining life- cycle phases appear to be quite straightforward.
A flow diagram of our proposed specification devel- opment methodology is given in Figure 1. Initially, only a set of user intentions or implicit s~ci~cations for in- tended software functionality exist. Given a test speci-
317 01661212/84/$3.00

318
/----------- INTENTIONS \ /
TCSPEC
TCGEN
1'
/-
/ /
/ /
/ /
- FORMAL SPECIFICATION
I
TCSPEC
1
TCGEN
1
TCREF
I
:
,_I___J___, DESIGN AND
REST OF DEVELOPMENT ',
\ PHASES I
I
Figure 1. Specification development.
fication language which is accessible to a user represen- tative, a test specification (TCSPEC) can be written which reflects the user’s initial understanding of the de- sired functionality over a small number of specific ex- amples. This test specification is then processed by a test case generator (TCGEN) to produce the initial version of the test case reference set (TCREF). TCREF is then validated by the user representative. This reference set provides a working definition of the desired software functionality which is accessible to both user and software vendor representatives. As the name implies, TCREF represents the authoritative or reference specification; other specifications must be modified where necessary to be consistent with it.
The next step (cf. Figure 1) is to generate explicit natural language assertions (NLA) as an abstraction of
R. L. Probert and H. Ural
TCREF to reflect the user’s intentions. The assertions (NLA) are viewed as an abstraction of TCREF and a refinement of implicit specifications. At this time, the assertions NLA are validated against TCREF to check consistency of NLA. If discrepancies are found, appro- priate modifications are made, and the process contin- ues. Now, an updated TCREF is produced from a new TCSPEC based on the previous TCSPEC and the val- idated set of natural language assertions (NLA). This new TCREF is validated for consistency with the pre- vious TCREF and with NLA, and subsequently be- comes the authoritative specification of desired func- tionality. The process to this point is now repeated in the obvious way at subsequent phases of software development.
To understand the methodology, it is helpful to view the current approach to deriving formal specifications as consisting of example construction, abstraction, and successive refinement processes proceeding from a rea- sonably well-understood compact set of specific input- output relations to a significantly more complex ab- straction of desirable input-output relations. We merely make this process explicit. The methodology is therefore referred to as example-directed speci$cation development. (In general, each phase of the software development process is amenable to this approach; we refer to the use of this approach throughout the life cycle as example-directed software development.)
To facilitate the specification and cross-validation process, we use a subset of the common logic program- ming language PROLOG [ 21. The contribution of this approach lies in its emphasis on an evolving test case reference set (TCREF) to reduce inconsistencies and ambiguities in the software development process, the use of TCREF to facilitate interphase communication, and its use of logic programming to automate the spec- ification construction and testing process wherever ap- propriate. We now proceed to outline and illustrate our approach.
OVERVIEW OF THE APPROACH
The approach involves two classes of components, namely activities and supporting tools. Referring again to Figure 1, we see that a fundamental validation pro cess is the comparison of distinct functionality represen- tations ana’/or the evaluation of individual high-level representations (intentions, natural language assertions, formal specifications, test-case specifications). The re- sults of this activity provide feedback for correcting or refining current high-level representations to more ap- propriate representations. This comparison and recon- ciliation of different high-level representations is a high-level analogue of a redundant development tech-

Development of Software Specifications 319
nique proposed by Panzl [ 181. Certainly, since all high- level representations are meant to capture the same software functionality, any conflicts discovered during this comparison and reconciliation activity should be re- solved before the development process continues. Thus, this comparative validation activity is a fundamental component of our approach.
However, this kind of comparative evaluation is not effective without sets of representative test cases se- lected in such a way as to facilitate the interpretation of test results and to thoroughly exercise or stress the high-level representation. Thus, a second critical activ- ity is a test-case construction activity. Here, test cases denote inputs and expected outputs. Where it is im- practical to generate inputs and corresponding outputs, either inputs alone (test data) or outputs alone (test outputs) may be constructed and used to drive the com- parison activity above. This point will be illustrated later in the discussion of support tools. Constructing ef- fective tests is a challenging exercise requiring at least as much intellectual effort as designing or coding 131. This activity requires considerable support in the form of testing strategies and heuristics for generating dis- criminating tests, as well as suppport tools.
The final type of activity we assume is present in the approach is the specijication writing activity which should be present in any software development activity. However, we require as well that any high-level repre- sentations produced by such activities be sufficiently precise that either the representations themselves are executable, or executable equivalent representations may be derived from them. In particular, representative test case specifications can be derived from the given represen~tions. We call such represen~tions con- structable.
Underlying all these activities is a support environ- ment which is provided in our configuration by a logic programming processor called PROLOG. Other sys- tems supporting executable specifications have been proposed [ 1,4,5,17,20]. We have selected logic pro- gramming because processors such as PROLOG are widely available, and a declarative language such as PROLOG is well suited to high-level testing paradigms.
Logic programming is utilized in producing execut- able high-level representations of software functionality as well as for generating test cases from those represen- tations. The basic notion of logic programming is that a restricted subset of first-order predicate logic can be an efficient language for describing computations. In this language, a suitable set of declarative statements becomes executable when presented to an interpreter along with a goal statement to indicate the desired re- sult. The basic concepts of logic programming [ 131
have been implemented under the name PROLOG [ 21. The most highly developed PROLOG processor is the DEC-10 version [ 191 which we have used.
An important feature of PROLOG procedures is that when written appropriately they may be executed either as transducers or as generators. For example, a PROLOG program may be written to represent a dis- criminating test-case subset of the set of input-output tuples in the relation defined by a software functional- ity representation. Since it is possible to represent the complete relation between input and output in the de- sign of such a program, the PROLOG code may then be executed as a generator to generate test data and test output separately or together (i.e., as test cases). In ad- dition, that program may be modified to run as a trans- ducer to generate test input data from a given test out- put and vice versa.
We have observed that it is often straightforward to incorporate well known test case generation strategies [ 11,151 in the design of the PROLOG programs imple- menting a high-level representation to generate test cases. In the case of boundary value analysis [ 15], e.g., corresponding generation strategies would include rep- resentative on-by-one and off-by-one testing [6]. Each test-case generation strategy defines a set of test-case specifications each of which, in turn, specifies a set of intellectually manageable size of representative test cases. It is also useful to write higher level PROLOG procedures to explicitly represent test case generation strategies which selectively invoke a PROLOG imple- mentation of a high-level functionality representation to generate test cases [22]. We will illustrate some of these logic programming concepts in the discussion of our approach to evaluating formal s~ci~cations of the Naur line editor problem in the next section.
AN EXAMPLE: EVOLUTION OF SPECIFICATIONS FOR THE NAUR LINE EDITOR PROBLEM
Briefly, the input to the line editing program is a se- quence of characters classified as break and nonbreak characters. A break character is a blank (“BL”), a new-line ((‘NL”), or an end-of-text (“ET”) character. In other words, the input can be viewed as a sequence of words (i.e., nonempty sequences of nonbreak char- acters) separated by breaks (i.e., sequences of one or more break characters) with possible leading and trail- ing breaks, and ending with an ET character. The pro- gram outputs the text as an array of lines each of which contains as many words as possible in the same se- quence as the input, and compresses the breaks into a single break character. Some authors have given the specifications for this problem in terms of input and output assertions [ 41. An example of such an input as-
320
sertion is “The final character in the text is ET and the program will stop reading as soon as it sees an ET”. An example of an output assertion is “As many words as possible should be placed in each line”.
Specifications for a line editing problem appear or are analyzed in a number of articles [ 4,6,9,10,16]. Few,
if any, of these specifications are the same, and yet they all appear to capture the same kind of line editing op- eration. This problem is somewhat notorious in the test- ing literature; in [8] the difficulty of formulating an English-like specification for this problem without some ambiguity or excessive length was noted. Duncan and Hutchison [4] observe that test cases for this probIem are more naturally derived by considering outputs first, implying that the computation from output to input is more easily understood than in the normal direction. At the same time, it seems that a good, standard sense of the function of a line editor should exist among com- puter scientists. Thus, the intentions in each instance should be relatively similar.
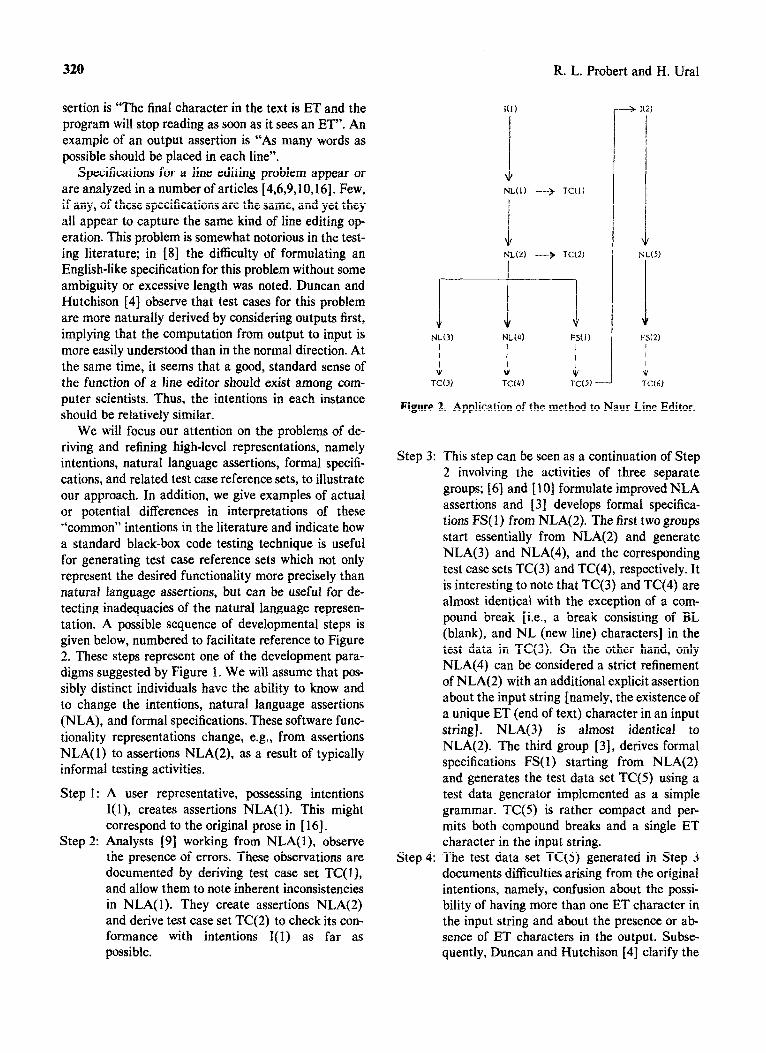
We wilf focus our attention on the problems of de- riving and refining high-level representations, namely intentions, natural language assertions, formal specifi- cations, and related test case reference sets, to illustrate our approach. In addition, we give examples of actual or potential differences in interpretations of these “‘common” intentions in the literature and indicate how a standard black-box code testing technique is useful for generating test case reference sets which not only represent the desired functionality more precisely than natural language assertions, but can be useful for de- tecting inadequacies of the natural language represen- tation. A possible sequence of developmental steps is given below, numbered to facilitate reference to Figure 2. These steps represent one of the development para- digms suggested by Figure 1. We will assume that pos- sibly distinct indi~duals have the ability to know and to change the intentions, natural language assertions (NLA), and formal specifications. These software func- tionality representations change, e.g., from assertions NLA(I) to assertions NLA(2), as a result of typically informal testing activities.
Step 1: A user representative, possessing intentions I(l), creates assertions NLA(l). This might correspond to the original prose in [ 161.
Step 2: Analysts [9] working from NLA(I), observe the presence of errors. These observations are documented by deriving test case set TC( I), and allow them to note inherent inconsistencies in NLA(1). They create assertions NLA(2) and derive test case set TC(2) to check its con- formance with intentions I(1) as far as possible.
R. L. Probert and H. Ural
NL(l) ----) TC(I)
NL(2) ----, TC’J)
NL(3) NL14) FSU 1 FS(2) I I I I I
T&)
\: :1 :
I; \1
TC(4) TCU) TC(6)
Figure 2, Application of the method to Naur Line Editor.
Step 3:
Step 4:
This step can be seen as a continuation of Step 2 involving the activities of three separate groups; [6] and [lo] formulate improved NLA assertions and [3] develops formal specifica- tions FS( 1) from NLA(2). The first two groups start essentially from NLA(2) and generate NLA(3) and NLA(4), and the corresponding test case sets TC(3) and TC(4), respectively. It is interesting to note that TC(3) and TC(4) are almost identical with the exception of a com- pound break [i.e., a break consisting of BL (blank), and NL (new line) characters] in the test data in TC(3). On the other hand, only NLA(4) can be considered a strict refinement of NLA(2) with an additional explicit assertion about the input string [namely, the existence of a unique ET (end of text) character in an input string]. NLA(3) is almost identical to NLA(2). The third group [3], derives formal specifications FS( 1) starting from NLA(2) and generates the test data set TC(5) using a test data generator implemented as a simple grammar. TC(5) is rather compact and per- mits both compound breaks and a single ET character in the input string. The test data set TC(5) generated in Step 3 documents di~cu~ties arising from the original intentions, namely, confusion about the possi- bility of having more than one ET character in the input string and about the presence or ab sence of ET characters in the output. Subse- quently, Duncan and Hutchison [4] clarify the

Development of Software Specifications 321
intentions by constructing test cases with more than one ET in the input string and also with ET appearing in the output, thus ~plicitly cre- ating intentions I(2). Further, they develop natural language assertions NLA(5) and from these generate the formal specifications FS(2). Note that I(2) must be a new intention set since from it, Duncan and Hutchison have pro- duced NLA(5) which allows multiple ETs in the input and an ET appearing in the output and therefore directly contradicts the previous NLA(4) assertions. Using the same approach as in Step 3, they generate the test case set TC(6) from FS(2) but this time using a gen- erator implemented as an attributed grammar.
We will describe a brief example of using our ap- proach to compare high-level representations and to use the results of such a comparison to refine those repra sentations in the following section.
COMPARISON OF HIGH-LEVEL REPRESENTATIONS
One of the initial assertions in each set of NL assertions except NLA(5) is that the end of the input is indicated by the appearance of an ET character as the final input character. One, namely NLA(4) asserts that there is exactly one ET character. It is natural in on-byone and
off-by-one testing, as in ESTCA testing, to construct test cases which contain more than one ET character. A single test case with two consecutive ET characters in the input would not necessarily distinguish between sets of NL assertions, e.g., the test case A_BL_A-ET- ET. An additional test case with two nonconsecutive ET characters would identify differences between some of the sets of assertions for both the definition of breaks and for the input termination. An example could be A-BL-NL_ET-A_BL_NL_ET, where A represents an alpha character, BL represents a blank, NL reprs sents a new line, and ET represents an end-of-text character.
Using the relatively st~ightfo~ard technique of boundary value analysis [ 151 for both input and output condition boundaries, we arrive at some interesting ET- directed comparisons. A small subset of these are sum- marized in the Table 1. In this table we assume that MAXPOS = 3 and the test input in each case is ET~L-NL~NL~L~T.
Thus, the processing of ET characters alone suffices to distinguish between different representations of the “same” intentions. This implies that the original inten- tions I(I) are unclear and need to be refined with re- spect to this point. The intentions of each author can more clearly be estimated by examining TC values than by examining sets of NL assertions. For example, ex- amining these test case sets, we see that Goodenough and Gerhart, and Foster exclude ETs from the output, whereas Duncan and Hutchison include ETs in the out-
Table 1. ET-Directed Specification Comparisons
NL assertions which affect ET in input or output or both
NL( 1): [ 161. ET character is not described here
NL(2): 191. ET is considered as a break character. Final character in the text is ET. A break is a sequence of one or more break characters. A break in the input is reduced to a single break character in the output.
NL(4): [IO]. ET is considered as a special character (i.e., neither a break nor a nonbreak character). There is exactly one ET character in each input stream. Rest is the same as in NL(2).
Expected output
n/a
From assertions: BLABL or NLANL or ETAET or ET. From program: null output.
Null output.
Components of published TC(i)
n/a
Every test input contained only one ET character. No consecutive pairs BL,NL or BL,ET. One case contained NL,ET. No ET in output.
Same as TC(2).
NL(3): [6f. The same as NL(2) except: program output shall be words with characters in the same sequence as the input, and new line indicators. (No blanks?..)
From assertions: null output or NLANL.
No ET in output. Strings of multiple NLs and one BL were compressed to one BL appearing in the output.
NL(5): [4]. ET is considered as in NL(4). The final character in the text is ET and the program will stop reading as soon as it sees an ET. The output should terminate with an ET, regardless of how many characters are put out.
From assertions: ET. Formal specifications allow more than one ET in input but only edits text up to and including the leftmost ET.

322 R. L. Probert and H. Ural
put. This type of comparison could be done with the processing of NL and BL characters as well.
ularly straightforward because FS(2) was expressed in extended BNF.
This example very briefly illustrates the main activ- ities involved in our high-level testing based approach for developing high-level representations. These activi- ties would be extremely tedious and time consuming without the support provided by the logic programming environment which we outline in the next section.
LOGIC PROGRAMMING SUPPORT ENVIRONMENT
At this point the logic programming environment con- tains only a PROLOG processor. By perspicacious use of the processor, however, we are able to support our exampledirected development approach.
As an example, we discuss the PROLOG program in Figure 3 to represent interesting test cases derived from formal specifications FS(2). This program con- sists of two procedures: namely, textin which is essen- tially a grammar for describing representative input text; and textout which is used to construct correspond- ing expected outputs. This separation of functions im- proves clarity and simplifies the derivation process. The derivation of these procedures from FS(2) was partic-
Referring to Figure 3, the first line of the PROLOG program is the procedure definition testcase with an 8- tuple of selectors, Gl to G7 and Maxpos. These selec- tors determine attributes of the input text string and are described below. The right-hand side of “: -” in the def- inition of testcuse contains the PROLOG primitive setofwhich, through PROLOG’s automatic backtrack- ing and reversing capability, returns a list Z of all input texts which satisfy the production labeled textin. That is, textin is invoked automatically and repeatedly, as long as there are alternatives in the textin grammar sat- isfying the constraints imposed by selectors. For ex- ample, if G6 = 3, then for each string of breaks (i.e., leading breaks, breaks between words, and trailing breaks) there exists three alternatives: namely, all BLs, all NLs, and mixed breaks (i.e., containing both BL and NL).
The selectors Gl through G7 are interpreted as follows:
1. If Gl = 0, an empty input string is generated. This empty input string and corresponding expected out-
tc~tc~re(C1,C2,C3,C4,CS,C6,G7,~rxpos) :- T =.. [tcxtin,Cl.C2,C3,G4,G5,C6,C7,~~xpor,H,i j]
; setof(R,T,Z) ; outprint(Z,Maxpor).
/* This code invoker the procedure definition textin using PROLOG primitive setof. 2 will be a list of input texts defined by the procedure definition textin. Bach input text is then passed to the procedure definition textout to generate the corresponding expected output. */
textin(C1,C2,C3,C4.C5,C6,C7,Maxpos~ --> = 0 : nil
I:: = I :
: textbody(CZ,C3,G4,G5,G6,~8xpos) ; eot ; tail(C7).
textbody(GZ,G3,G4,CS,C6,Maxpos~ --> lesdingbreaks(C2.G6) ; vords(C3,CS,G6)
tr~ilingbreaks(G4,Cb). vords([WordlengthlReet~,GS,G6) --; word(Wordlength)
; ((Rest = empty : nil) (kest # empty : breaks(CS,Gb)
; words(Rest,CS,Gb))). vord(Wordlength) --> Wordlength = 0 : nil
1 Wordlength > 0 : letter ; x <- Wordlength - 1 ; word(X).
breaks(GS,Gb) --? G5 = 0 : nil 1 65 > 0 : i* code here to generate a string
of, break characters whose type and length is specified by the values of C6, GS respectively. */
leedingbreaks(C2.G6) --> /* similar to breaks(GS,C6) */ trailingbrc~ks(G4.G6) --> /* similar to breakstGS,Cb) ‘f letter __) ,‘A”
break(O) --> “BL”. break(l) --> “NL”. Figure 3. Part of the PROLOG program for cot --> “ET” .
tail(C7) --> G7 = 0 : nil the Test-Case Generation. - indicates pro-
1 c7 > 0 : /* code here to generate a string of break duction rule symbol; : - indicates PROLOG and ET characters whose length is
*! procedure defintion; - indicates assignment
determined by 67. textout(Textin.H~xpor)
indicates concatenate or se- :- I* code here to generate the output
7 lines corresponding to the input
operator; ; quence; : indicates guard separator; 1 indi-
text along vith the value of alarm *I cates alternative.

Development of Software Specifications 323
2.
3.
4.
6.
7.
put (i.e., no output line) represent a test case to test the defensive behavior of an implementation of the software functionality. If Gl = 1, at least one input string containing at least an ET character is gener- ated. The values of selectors G2, G3, G4; and G7 control the presence or absence of textbody and tail, respectively. A textbody is composed of zero or more leading break characters, zero or more words, and zero or more trailing break characters. The possible combinations of breaks and words are determined by selectors G2,G3,G4,G5. If G2 = 0, no leading break is generated. If G2 > 0, a string of leading break characters whose length is G2 is generated. The composition of the break characters used in this string depends on the value of selector G6. G4 and G5 are used in a context similar to that of G2. If list G3 is empty, no word is generated. That is, the textbody being generated may contain only lead- ing and/or trailing breaks. If list G3 is not empty, a nonempty sequence of words is generated. The num- ber of words and their lengths are determined by the nonempty list of word lengths, G3. Two consecutive words are separated by a string of break characters whose length and type of break characters are de- termined by G5 and G6. IfG6 = OorG6 = 1, each break character in the input text being generated is represented by a BL and NL, respectively. If G6 = 2, each string of break characters is composed of both BL and NL. If G6 = 3, three strings of break characters are gen- erated, one with all BLs, one with all NLs, and one with compound break characters. IfG7 = 0, no tail is generated. If G7 > 0, a string of break and ET characters is generated.
Thus all such possible alternatives will appear in the input text’s list Z. Each element (i.e., input text) of Z is then passed to the procedure textout which generates the expected output corresponding to that input text. The expected output is an array of lines followed by the value of variable alarm which is set to one when a word containing more than Maxpos characters is encoun- tered or set to zero otherwise.
An important feature of the procedure testcase is that it allows selective generation of test cases rather than random generation. Each invocation of the pro cedure carries values for selectors Gl to G7, and Max- pos which control the generation of representative and discriminating test cases according to test case genera- tion strategies included in a suitable test plan. For ex- ample, in boundary value analysis it is natural to gen- erate off-by-one (invalid input) input text strings.
Generally, off-by-one testing strategy is accompanied by single-error-at-a-time testing to simplify the test case intepretation and reconciliation efforts. In our ex- ample, a natural off-byone test case specification is to generate an invalid input text containing an oversized word (i.e., the length of the word being one greater than Maxpos). To do this, procedure testcase is invoked as follows: testcase( 1,3, [ 3,2,2,7] ,1,2,1,6). This invocation causes the generation of the following testcase:
input text: NL_NL_NL-A-AA_NL_NL-A_A-NL-NL_ A_A_NL_NL_AA-AAAA-A_NL-ET
output lines: A-A_A_BL_A_A
alarm: 1
On the other hand, according to an on-byone testing strategy, one may want to generate compound breaks. A possible invocation of procedure testcase to accom- plish this is testcase(1,2,[3,2],5,3,2,7). The test case generated by this invocation is as follows:
input text: BL-NL-A-A-A-BL_NL_BL_A_A_BL_NL_ BL-NL_BL_ET
output lines: A-A-A-BL_A_A_ET alarm: 0
EXTENSIONS AND CONCLUSIONS
Research is proceeding in two directions. The first di- rection is towards a natural and effective test specifi- cation language, appropriate to the specification of high-level test reference sets, and therefore easily deriv- able from natural language assertions and formal spec- ifications expressed in any of a wide variety of formal- isms. The specification language must facilitate the representation of testing strategies and the language processor must support standard testing activities. Also, the processor should fit easily into the paradigms of high-level representation, evaluation, and refinement represented in Figure 1. In preliminary studies [22], the authors suggest that a universally acceptable spec- ification language may not be feasible, and propose that a family of specification languages be developed in- stead. Some related work appears in [5].
The second direction of extension is in the develop- ment of the logic programming support environment in our approach. For example, in Figure 1 and in the dis- cussion of the line editing problem, we indicated that it is desirable on occasion to generate discriminating test outputs, and to compare high-level representations on the basis of their specifications with respect to such out- puts. The PROLOG processor allows us to specify dis- criminating test outputs first, e.g. a test output of par- ticular interest to our example might be “-ET”

324 R. L. Probert and H. Ural
where maxpos is set to 3. This output tests whether a special character such as ET should appear if the out- put line is already as full as possible. Several specifica- tions suggest either that ET does not appear in the out- put, or that it should appear on a subsequent line by itself. This case is handled relatively awkwardly in NLA(5) [4]. For example, in the input assertion (l), ET is first set aside from break and nonbreak charac- ters, and subsequently included as a nonbreak charac- ter by the final sentence in (1). The assertion is tech- nically correct, yet could be easily misunderstood. Panzl [ 181 has observed that such potential sources of error can be caught by using an independent develop- ment approach at the code level; our approach attempts to utilize a similar principle even before any code is de- veloped. Another interesting output which tends to point out an omission in all of the sets of NL assertions found in the literature is the test output involving an oversize word. Exactly what output appears in such a case is not precisely specified. This may or may not be important from a quality assurance point of view, but such an omission should be at least documented.
In summary, we have presented an example-directed specification development methodology which can be used to evaluate and refine high-level functionality rep- resentations such as intentions, natural language asser- tions, and formal specifications. The method is based on the observation that each of the above entities, as well as test case reference sets derived from any entity, are distinct but highly related representations of the under- lying desired software functionality. Moreover, test case reference sets appear to be a highly effective for- mulation for specifications. A set of such related rep- resentations describing a line editing module were pre- sented as they had been proposed in the software engineering literature, and used to illustrate aspects of a specification development environment. The logic programming based environment appears to allow some existing code testing strategies to be used for design of test case reference sets. We feel that this is an effective approach to produce more reliable specifications and thus, more reliable software.
In addition to extending testing heuristics to test out- put generation, it is straightforward in PROLOG to set up a testing system consisting of several modules, thus allowing for more flexibility in testing activities [23]. For example, module A could generate test output based on certain parameters or selectors involving max- pos, number of words per line, number of lines, and so on. Module B could generate output selector values based on a specific testing strategy such as boundary value analysis. Module C could parse test output selec- tors and depending on input generation selectors could generate input descriptors either for all allowed inputs from those outputs, or for only a discriminating subset. Module C is the PROLOG program which represents the input-output relation defined by the high-level rep- resentation being evaluated. Module D generates spe- cific input text strings according to the input descriptors specified (G 1 -G7 in the PROLOG program described earlier). An invocation sequence of B-A-C-D generates output-directed test cases for the line editing problem. Any of B,A,C,D may be run forward or backward. For example,
ACKNOWLEDGMENTS
The authors are grateful to D. Skuce for discussions and advice on PROLOG programming, especially in the initial stages of this research, and to the National Science and Ef'IQineerinQ Research Council of Canada for its support.
REFERENCES
1.
2.
3.
4.
5.
6. (D run backwards)-(C run backwards)-A
would compute the line editing functions. Additional modules could be added and run in a variety of test- ing paradigms, especially to compare high-level representations.
7.
8.
Finally, enhancements to make the whole system more user-friendly, and user-accountable are under- way. Additional support tools such as a configuration manager and coverage monitors are being developed.
9.
J. A. Bauer and A. B. Finger, Test Plan Generation Using Formal Grammars, Proc. of 4th ConJ on Soft- ware Engineering, 425-432 (1979). A. Colmerauer, Natural language communication with computers, in Lecture Notes in Computer Science (L. Bolt, ed.), Springer-Verlag, New York, 1978. A. G. Duncan, Test Grammars: A Method for Gener- ating Program Test Data, Digest for Workshop on Soft- ware Testing and Test Documentation, Fort Lauderdale 270-28 1 (1978). A. G. Duncan and J. S. Hutchison, Using Attributed Grammars to Test Designs and Implementations, Proc. of 5th Conf. onsoff. Eng. 170-177 (1981). A. G. Duncan, J. S. Hutchison, and R. L. Probert, For- mal specification of requirements, designs, and tests (in preparation). K. A. Foster, Error Sensitive Test Case Analysis (ESTCA), IEEE Trans. on Soft. Eng. SE-6, 258-264 (1980). M. S. Fujii, Independent Verification of Highly Reliable Programs, Proc. of COMPSAC 77 38-44 (1977). S. L. Gerhart and L. Yelowitz, Observations of Fallibil- ity in Applications of Modern Programming Methodol- ogies, IEEE Trans. on Soft. Eng. SE-2, 195-207 (1976). J. B. Goodenough and S. L. Gerhart, Toward a Theory of Test Data Selection, IEEE Trans. on Soft. Eng. SE- 1, 156-173 (1975).

Development of Software Specifications
10. J. B. Goodenough and S. L. Gerhart, Toward a theory of testing: data selection criteria, in Current Trends in Programming ~eth~o~o~, Vol. 2 (R. T. Yeh, ed.), Prentice-Hall, Englewood Cliffs, NJ, 1977.
11. W. E. Howden, Functional Program Testing, IEf?E Trans. on Soft. Eng. SE-6, 162-169 (1980).
12. W. E. Howden, Life-cycle Software Validation, Com- puter 7 l-78 (Feb 1982).
13. R. Kowalski, Logic For Problem Solving, North-Sol- land, New York, 1979.
14. E. Miller and W. E. Howden, Tutorial: Software Test- ing and Validation Techniques, IEEE Computer Soci- ety, 1978.
15. G. J. Myers, The Art of Software Testing, Wiley, New York, 1979.
16. P. Naur, Programming by Action Clusters, BIT 9,250- 258 (1969).
17. R. E. Noonan, Structured Programming and Formal Specificatins, IEEE Trans. on Soft. Eng. SE-l, 421-425 (1975).
325
18. D. Panzl, A Method for Evaluating Software Develop ment Techniques, ACM SIGSOFT STME ( 198 1).
19. L. M. Pereira et al. User’s Guide to DEC system-10 PROLOG, Dept. of AI, University of Edinburg, Sept. 1978.
20. R. L. Probert, Grey-box (Design Based) Testing Tech- niques, Proc. of 15th Hawaii Int. Conf. on System Sci- ences 94-102 (1982).
21. R. L. Probert and H. Ural, Incremental Improvement of Specifications by Testing, Proc. of Workshop on Ef- fectiveness of Testing and Proving Methods, Avolon, CA 37-49 (May 1982).
22. R. L. Probert, D. R. Skuce, and H. Ural, Specification of Representative Test Cases Using Logic Program- ming, Proc. of 16th Hawaii Int. Co@ on System Sci- ences 190-196 (1983).
23. H. Ural and R. L. Probert, User Guided Test Sequence Generation, in Protocol Specification. Testing, and Ver- ification (H. Rudin and C. H. West, eds.), North Hol- land, 1983, pp. 421-436.





























