Embed Size (px)
Citation preview

UNCLASSIFIED
Hierarchical High Level Information FusionUsing Graph Structures, Subgraph Matching and State Space
Search
Moises SuditRakesh Nagi
Kedar Sambhoos
February 7, 2007
This research is partially supportedby the Office of Naval Research

UNCLASSIFIED
In Nearly Every Application: 2

UNCLASSIFIED
Technology Approach and Justification 3
Sensor Location and Settings
Initial Knowledge ofDomain and Objectives
Cleansing, Filtering and Homogenizing Data
Physical/Virtual Domain of Interest
SensorsType 1
SensorsType 2
SensorsType n
sensed data
Target Graph Generation
Automatic SME
TargetGraphs
Database
Data GraphGenerator
INFERD
Graph Matching(TruST)
Decision Maker
Level 0/1 Level 2/3
Level 4 AdaptiveLearning
Minimize Apriori Knowledge
Real-Time
CompletenessMultiple Formats
Efficient Deployment
SA/IA Visualization

UNCLASSIFIED
Data Graph and Template Graph
• Decision-maker often encounter complex uncertain situations and they needto develop relationship between situational elements.
• Attributed Relational Graphs (ARGs) represent situational elements and relationships
Slide 4 of 23Data Graph Template Graph
Location 8
Location 7 Material 6
Material 5Event 10
Event 9
LocationMerchandise
Buyer
BrokerPerson 4 4
Person 2 Person 0
Person 1
Person 3
Bought
LinkedLinked
OrganizerRecruiter
Location
Stolen
Thief
Recruiter Associate
Friend
Location 8
Location 7 Material 6
Material 5Event 10
Event 9
Location
Merchandise
BuyerBroker
Person 4 4
Person 2 Person 0
Person 1
Person 3
Bought
LinkedLinked
OrganizerRecruiter
Location
Stolen
Thief
Recruiter Associate Friend
Location 8
Location 7 Material 6
Material 5Event 10
Event 9
Location
Merchandise
BuyerBroker
Person 4 4
Person 2 Person 0
Person 1
Person 3
Bought
Linked
Linked
OrganizerRecruiter
Location
Stolen
Thief
RecruiterAssociate
Friend
Location 8
Location 7 Material 6
Material 5Event 10
Event 9
LocationMerchandise
BuyerBroker
Person 4 4
Person 2 Person 0
Person 1
Person 3
Bought
LinkedLinked
OrganizerRecruiter
Location
Stolen
Thief
RecruiterAssociate
Friend
Location 8
Location 7 Material 6
Material 5Event 10
Event 9
Location
Merchandise
BuyerBroker
Person 4 4
Person 2 Person 0
Person 1
Person 3
Bought
LinkedLinked
OrganizerRecruiter
Location
Stolen
Thief
RecruiterAssociate Friend
MerchandiseMerchandise
Recruiter
Recruiter
Recruiter
Organizer
Organizer
Location
Location
Location
Location
Location

UNCLASSIFIED
Graph Matching Structures
Exact Inexact
Syntactic (labelled-graphs) Graph Isomorphism Graph Homeomorphism
Semantic(attributed-graphs)
Structured- attributed-vertex graph
- Greedy Search- attributed-vertex graph
- Greedy Search
Semistructured- attributed-vertex graph- Graph Isomorphism
- Graph Bundling
- attributed-vertex graph- Graph Homeomorphism
- Graph Bundling
Unstructured Heuristics Heuristics
• Structured data is rigidly organized & well defined: Predictable• Semistructured data is organized enough to be predictable
• Data is organized in semantic entities• Similar entities are grouped together but,
• Entities in the same group may not have the same attributes• The order of the attributes is not necessarily important• The presence of some attributes may not always be required• The size of same attributes of entities in a same group may not be the same• The type of the same attributes of entities in a same group may not be of the same type
• Unstructured data is disordered and unruly: Unpredictable
• Difference between Graph Matching and Subgraph Matching

UNCLASSIFIED
Isomorphism, Homeomorphism and Bundle Matching
Country 1
Transaction Sell-Artifact
Missiles
Buyer
Artifact
Country 1
Transaction Sell-Oil
Seller
Buyer
Transaction Sell-Artifact
Missiles
Buyer
Artifact
Country 2
Country 1
Transaction Sell-Oil
Seller
Buyer
Transaction Sell-Artifact
Tubes
Seller
Artifact
Country 2
Buyer
Transaction Sell-Artifact
War Heads
Seller
Artifact
Country 4
Transaction Sell-Artifact
Trigger
Seller
Artifact
Country 3
Buyer
Isomorphism Homeomorphism Bundle matching

UNCLASSIFIED
Motivation for our Approach
• Enhancements in Level 2 and 3 fusion capabilities through a new class of models and algorithms in graph matching.
• Create a Framework to Span Temporal Decision-Making (from “real-time” to forensics”)
• Most of literature is in subgraph isomorphism (Cordella et al., 2004)• Most of the matching techniques are restricted to Simple Graphs• Truncated branch and bound performs several times better than the local
search (Zhang, 2000) motivates for Unstructured Graphs• Attributed Relational Graphs are Visually Appealing, but don’t give us much
value-added compared with Classical Graph Structures in Solving GraphMatching Problems.Theorem: Any graph matching problem over an attributed-graph (attributed-vertices and attributed-edges) can be polynomiallytransformed in to an equivalent attributed-vertex graph (no attributes on the edges)
1. L. P. Cordella, P. Foggia, C. Sansone, and M. Vento. A (sub)graph isomorphism algorithm for matching large graphs. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 26(10):1367, 2004.
2. W. Zhang. Depth-first branch-and-bound versus local search: A case study. In Proc. 17th National Conf. on Artificial Intelligence, pages 930–935, 2000.

UNCLASSIFIED
Definitions and Notation
• Attributed Graph StructureG = (V, E, Av, AE)
where V - the set of nodes; E - the set of arcs;Av - the set of node attributes; Av - the set of arc attributes.
Slide 8 of 23
GD = (VD, ED, AVD, AE
D) GT = (VT, ET, AVT, AE
T)
D8
D4
D9
D6
D10
D1
D2
D7D3 D5
D11
T4
T3
T2
T1
Data Graph Template
ED4 ED
11
ED1
ED
2
ED3
ED7
ED
8
ED6
ED12
ED10
ED5
ED9
ED13
ET1
ET2
ET3

UNCLASSIFIED
Most Graph Matching Techniques based on Triplets
• Triplets:
Template Data Graph• One-to-one Scores of Nodes and Arcs:
S(vi, vj) = 0.9 S(vh, vk) = 0.7 S(eih, ejk) = 0.8
• Similarity Functions for Triplets:
fihjk = f(S(vi, vj), S(vh, vk), S(eih, ejk))= 0.8
Slide 9 of 23
vi vheih vj vk
ejk

UNCLASSIFIED
Triplet Deficiency
Problem:• Two totally different topological
templates could receive exactly the same similarity values.
Goal:• Develop an algorithm that uses
the current system's rule based scoring engine while increasing its topological accuracy during matching.
T1
T2 T3
T4
T1
T2
T3
T4
T2
T4
T1
T3
T’1 T’4T’3T’2 T’5
T’1
T’2
T’4
T’5
T’3
T’4
T’2
T’3
UNCLASSIFIED
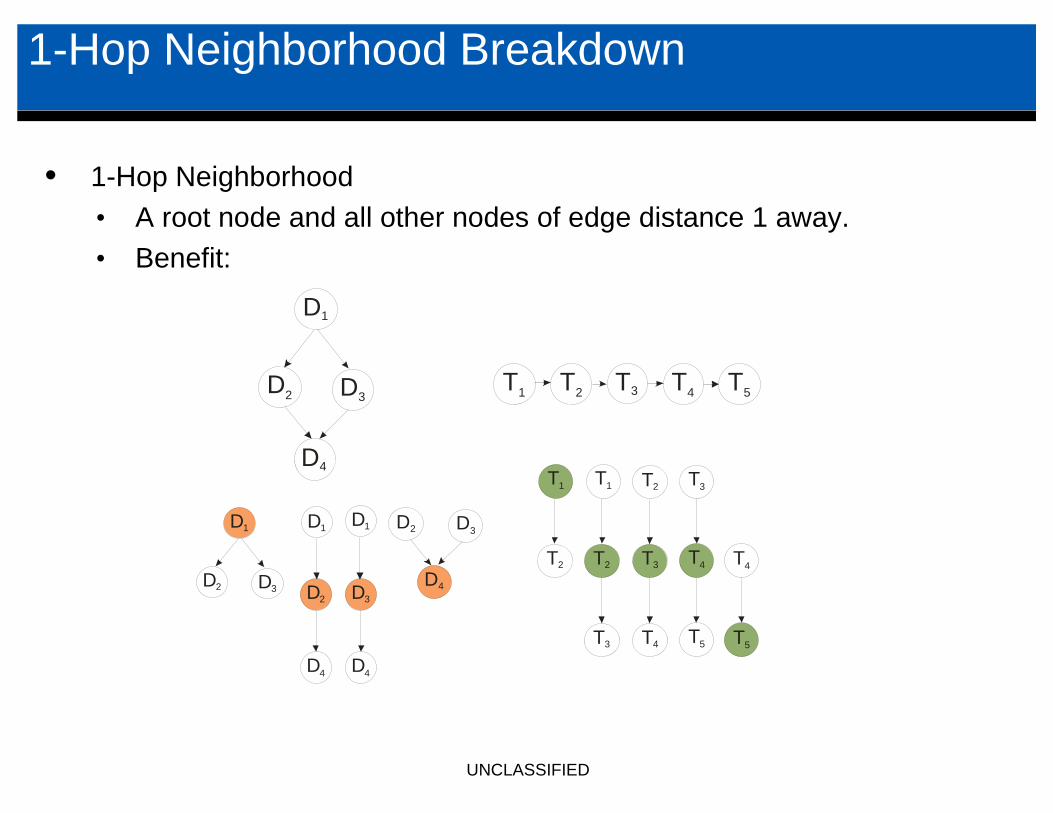
1-Hop Neighborhood Breakdown
• 1-Hop Neighborhood• A root node and all other nodes of edge distance 1 away.• Benefit:
D1
D2 D3
D4
D1
D3
D4
D2
D4
D1
T1 T4T3T2 T5
T1
T2 T4
T5
T3
T4
T2
T3
D1
D2 D3
D2 D3
D4
T1 T2
T4
T5
T3

UNCLASSIFIED
Slide 121-Hop Neighbor Matching
B2,e4
B1,e3
B2,e4
B3,e1
Y2,f7
Y1,f1
Y4,f3
Y3,f2
Y6,f5
Y5,f4
Y8,f8
Y7,f6
B1
A
B2
B3 B4
e1 e2
e4e3
Y7
X
Y6
Y2 Y3
f1
f2
f5f6
Y1
Y8
Y4
Y5
f3
f4
f7
f8
• Algorithm
Step 1: Compute a node score, denoted asCij , for each node in the template graph to each node in the data graph.
Step 2: Compute the scores, denoted asWij , for the 1-Hop neighbors of each root node pair.
The score is given by α Cij + (1-α) Wij
“α” is the Score vs. Topology Parameter

UNCLASSIFIED
TruST (Truncated Search Tree) Algorithm
• Advantages: • Easier to implement, faster to execute and requires less computing
resources.• User can decide tradeoff between time and quality.• Converges to optimality.
• Disadvantages: • Not guaranteed to yield an optimal solution.• Parametric approach• Greedy in nature.
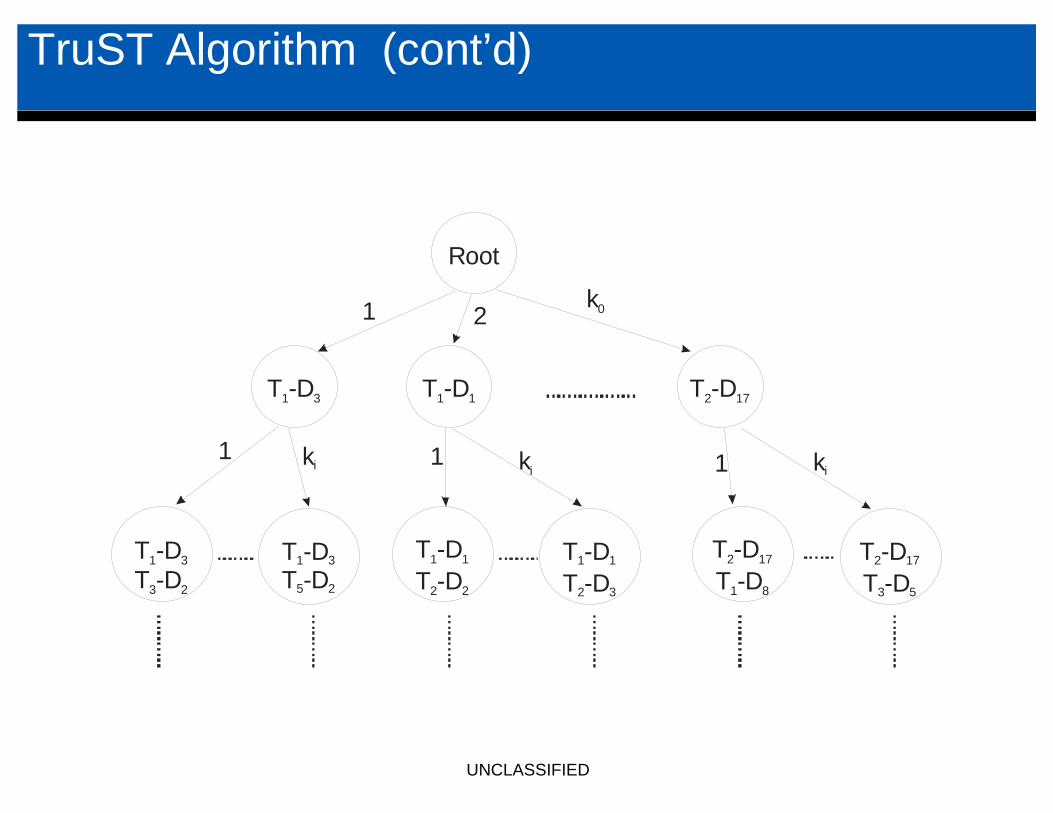
• Parameters of controlling state space• k0 : The number of child problems of the root.
• ki : The number of child problems of the problem at level i-1.
• β : The total number of problems.• δ : The total number of levels.
Slide 13 of 23
UNCLASSIFIED
TruST Algorithm (cont’d)
Slide 14 of 23
Root
T -D1 3 T -D1 1 T -D2 17
T -D1 3
T -D3 2
T -D1 3
T -D5 2
T -D1 1
T -D2 2
T -D1 1
T -D2 3
T -D2 17
T -D1 8
T -D2 17
T -D3 5
1 2k0
1 1 1ki ki ki

UNCLASSIFIED
Example of Best-Bound with Topology
Slide 15 of 23
Root
T -D1 3 T -D1 1 T -D2 1
T -D1 3
T -DT -DT -D
2 5
3 1
4 2
T -D1 3
T -DT -DT -D
2 5
3 2
4 7
T -D1 3
T -DT -D
2 5
3 1
T -D1 3
T -DT -D
2 5
3 2
T -D1 3
T -DT -D
3 1
4 2
T -D1 3
T -D3 2
T -D4 7
T -D1 3
T -D2 5
T -D1 3
T -D3 1
T -D1 3
T -D3 2
T -DT -DT -D
1 1
2 3
3 4
T -D4 6
T -DT -DT -D
1 1
3 4
4 6
T -D2 2
T -DT -D
1 1
2 3
T -D3 4
T -DT -D
1 1
3 4
T -D4 6
T -D1 1
T -D2 3
T -D1 1
T -D3 4
T -D1 1
T -D2 2
T -DT -D
2 1
1 4
T -D3 8
T -D2 1
T -D1 4
0.900 0.8000.800
0.825 0.825 0.765
0.800 0.760 0.683 0.660
0.700 0.6825
0.755 0.660 0.505
0.677 0.557
0.595 0.470
0.725
0.630T1 T2 T3 T4
D3 0.9 D1 0.8 D6 0.77 D10 0.6
D1 0.8 D5 0.75 D1 0.75 D7 0.45
D9 0.75 D3 0.71 D2 0.63 D2 0.4
D6 0.73 D7 0.68 D4 0.52 D6 0.35
D5 0.7 D9 0.55 D8 0.44 D4 0.28
D4 0.65 D6 0.53 D9 0.27 D8 0.18
D2 0.4 D4 0.23 D3 0.23 D1 0.15
D7 0.17 D2 0.21 D7 0.17 D3 0.14
D10 0.15 D10 0.13 D11 0.11 D5 0.12
D11 0.11 D8 0.09 D5 0.09 D9 0.1
D8 0.09 D11 0.05 D10 0.05 D11 0.07
1-Hop Neighbor Optimal Assignments

UNCLASSIFIED
Design of experiment
• But we still don’t know what are the optimal parameters to be set.• Responses: Runtime and Maximum Heuristic Score.• 2-level factorial design: 9 {512 (29) runs}• Screening experiment: 1/4th factorial design with 128 runs.
• depth δ = 6
Slide 16 of 23
Factors Levels RangeNumber of nodes in data graph 25 50 - -
Number of nodes in template graph 6 10 - -Data graph density 10% 15% 0% 100%
Template graph density 24% 50% 0% 100%t 0.1 1 0 1
0.1 1 0 1k0 50 100 0 mnki 50 100 0 mn
50 300 0 ∏i
ik
m =The number of data graph nodes.n =The number of data graph nodes.

UNCLASSIFIED
Design of experiment
INTUITIVE CONCLUSIONS• Template graph density has less
effect on runtime as compared to data graph density.
• dominates all other parameters for runtime.
• The constant are much more significant in obtaining quality of the heuristic.
Slide 17 of 23
UNCLASSIFIED
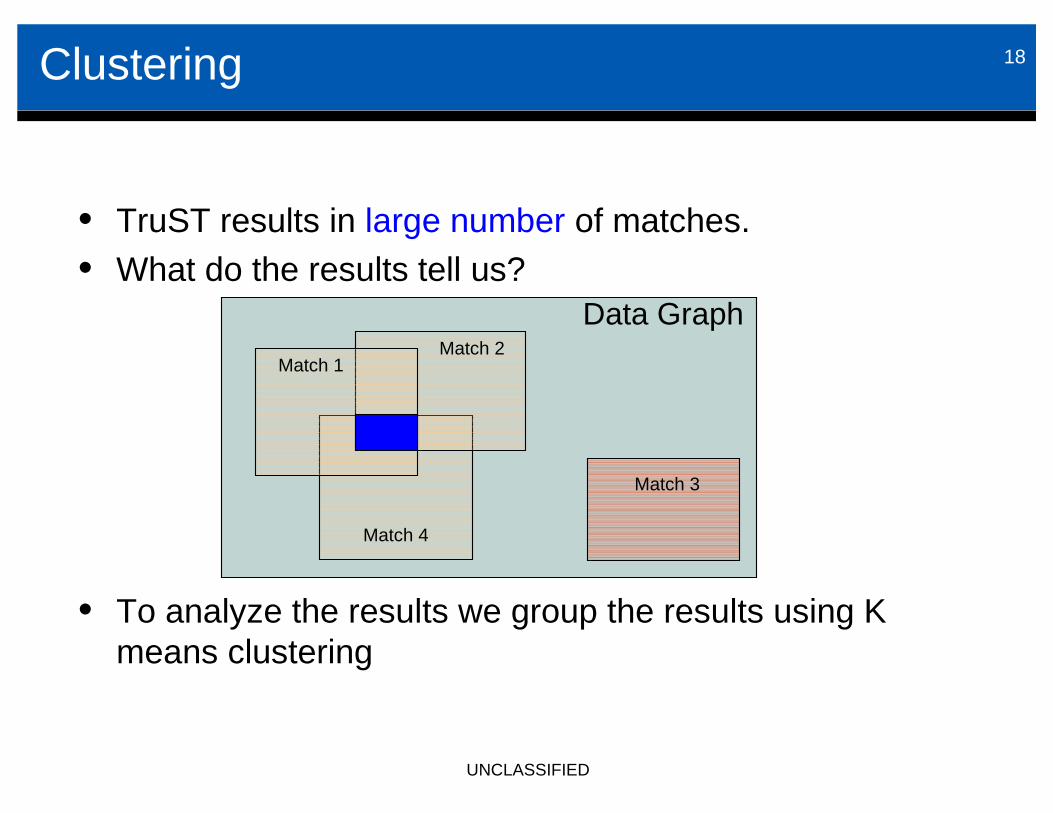
Clustering 18
• TruST results in large number of matches.• What do the results tell us?
• To analyze the results we group the results using K means clustering
Data Graph
Match 3
Match 2
Match 4
Match 1

UNCLASSIFIED
19K-Means Clustering: Hypercube vs. Fuzzy Hamming Distance
• Hypercube Distance• Result becomes a point M in the N dimensional hypercube• The metric to minimize distance will determine the shape of the optimum
clusters. Hypercube distance measure is used
( )( )BA,( ) ( )
( )
( )
( ) ( )
B andA of maxima wise-Element
B andA of minima wise-Element
;
;1,0
where,
1,
1
=∪=∩
=
≤∆≤
∪∩−=∆
∑=
BA
BA
ymA
BA
BA
BABA
n
iiAµ
µµ
M =
m11
m
m
21
N1
31
.
.
.
m N-dimensional Hypercube(N x N)
• Fuzzy Hamming Distance• Fuzzy Cardinality CardA of a fuzzy set A =
where µCardA(i) = min(µi, (1 - µi+1)). µi denotes the ith largest value of µ. 1
ni
i i
x
µ=∑
0 ( )
n
i CardA
iCardA
iµ=
=∑
Compared using Silhouette validation technique and Mann-Whitney test andHypercube Distance performed better.

UNCLASSIFIED
20Aggregating cluster elements
• Aggregate the matches to find the correlated nodes & edges in the formed clusters.
• The matches are combined using union and intersection operationDP3 DP4
D1 D1
ED2 ED
1
D3 D2
ED3 ED
3
D4 D4
ED6 ED
6
D6 D6
NodesEdges
D1 ED1
D2 ED2
D3 ED3
D4 ED6
D5
D6
D4
D6
D1
D2
D3ED1
ED2
ED3
ED6
Diversification (Union)
NodesEdges
D1 ED3
D4 ED6
D6
D4
D6
D1
ED3
ED6
Intensification (Intersection)

UNCLASSIFIED
21Neighborhood Information
• Pi is the periphery node score• NT is the number of nodes in the match• dij is the shortest path distance (Floyd-Marshall) between periphery node
i and core node j
T
jij
i N
d
P∑
=
Core
PeripheryT4
T3
T2
T1ET
1
ET
2
ET
3
D8
D4
D9
D6
D10
D1
D2
D7D3 D5
D11
ED4 ED
11
ED
1
ED
2
ED3
ED7
ED8
ED6
ED12
ED10
ED5
ED9
ED13

UNCLASSIFIED
TruST Capabilities and Functionality 22
Data Graph
Match 3
Match 2
Match 4
Match 1Data Graph
Match 3
Match 2
Match 4
Match 1
Match 2
Match 4
Match 1
Data Graph
Match 2
Match 4
Match 1
Data Graph
Intensification Diversification
Ranking of Patterns of Interest Clustering Patterns of Interest
Match 2
Match 4
Match 1
Data Graph
Pattern Discovery

UNCLASSIFIED
TruST Implementation 23
UNCLASSIFIED
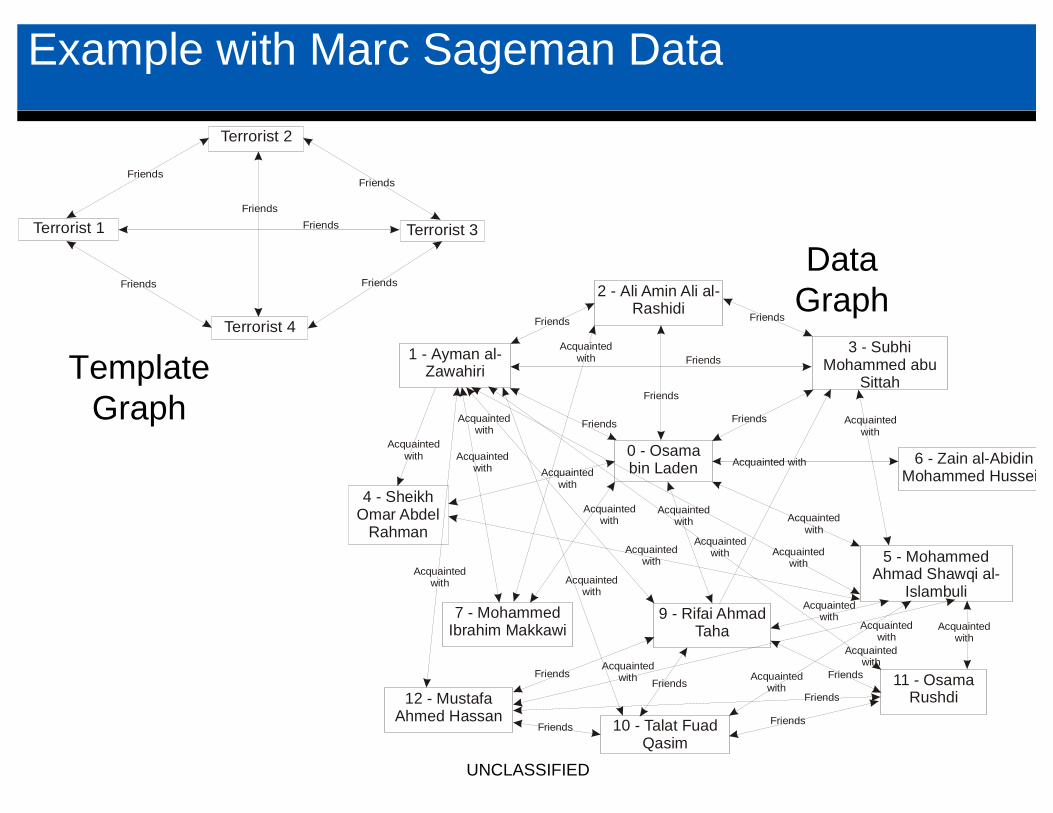
Example with Marc Sageman Data
0 - Osama bin Laden
2 - Ali Amin Ali al-Rashidi
1 - Ayman al-Zawahiri
3 - Subhi Mohammed abu
Sittah
4 - Sheikh Omar Abdel
Rahman
7 - Mohammed Ibrahim Makkawi
9 - Rifai Ahmad Taha
6 - Zain al-Abidin Mohammed Hussein
5 - Mohammed Ahmad Shawqi al-
Islambuli
10 - Talat Fuad Qasim
11 - Osama Rushdi12 - Mustafa
Ahmed Hassan
FriendsFriends
Friends
Acquainted with
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith Acquainted
with
Acquaintedwith
Acquaintedwith
Friends
Friends
FriendsFriends
FriendsFriends
Friends Friends
Friends
Terrorist 2
Terrorist 4
Terrorist 3Terrorist 1
Friends
FriendsFriends
Friends
Friends
Friends
Data Graph
Template Graph

UNCLASSIFIED
TruST matches
0 - Osama bin Laden
2 - Ali Amin Ali al-Rashidi
1 - Ayman al-Zawahiri
3 - Subhi Mohammed abu
Sittah
4 - Sheikh Omar Abdel
Rahman
7 - Mohammed Ibrahim Makkawi
9 - Rifai Ahmad Taha
6 - Zain al-Abidin Mohammed Hussein
5 - Mohammed Ahmad Shawqi al-
Islambuli
10 - Talat Fuad Qasima
11 - Osama Rushdi12 - Mustafa
Ahmed Hassan
FriendsFriends
Friends
Acquainted with
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith Acquainted
with
Acquaintedwith
Acquaintedwith
Friends
Friends
FriendsFriends
FriendsFriends
Friends Friends
Friends
Match 1
0 - Osama bin Laden
2 - Ali Amin Ali al-Rashidi
1 - Ayman al-Zawahiri
3 - Subhi Mohammed abu
Sittah
4 - Sheikh Omar Abdel
Rahman
7 - Mohammed Ibrahim Makkawi
9 - Rifai Ahmad Taha
6 - Zain al-Abidin Mohammed Hussein
5 - Mohammed Ahmad Shawqi al-
Islambuli
10 - Talat Fuad Qasim
11 - Osama Rushdi12 - Mustafa
Ahmed Hassan
FriendsFriends
Friends
Acquainted with
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith Acquainted
with
Acquaintedwith
Acquaintedwith
Friends
Friends
FriendsFriends
FriendsFriends
Friends Friends
Friends
Match 2

UNCLASSIFIED
Clustering and Neighborhood Information
0 - Osama bin Laden
2 - Ali Amin Ali al-Rashidi
1 - Ayman al-Zawahiri
3 - Subhi Mohammed abu
Sittah
4 - Sheikh Omar Abdel
Rahman
7 - Mohammed Ibrahim Makkawi
9 - Rifai Ahmad Taha
6 - Zain al-Abidin Mohammed Hussein
5 - Mohammed Ahmad Shawqi al-
Islambuli
10 - Talat Fuad Qasim
11 - Osama Rushdi12 - Mustafa
Ahmed Hassan
FriendsFriends
Friends
Acquainted with
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith Acquainted
with
Acquaintedwith
Acquaintedwith
Friends
Friends
FriendsFriends
FriendsFriends
Friends Friends
Friends
CLUSTER 1
CLUSTER 2
0 - Osama bin Laden
2 - Ali Amin Ali al-Rashidi
1 - Ayman al-Zawahiri
3 - Subhi Mohammed abu
Sittah
4 - Sheikh Omar Abdel
Rahman
7 - Mohammed Ibrahim Makkawi
9 - Rifai Ahmad Taha
6 - Zain al-Abidin Mohammed Hussein
5 - Mohammed Ahmad Shawqi al-
Islambuli
10 - Talat Fuad Qasim
11 - Osama Rushdi12 - Mustafa
Ahmed Hassan
FriendsFriends
Friends
Acquainted with
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith
Acquaintedwith Acquainted
with
Acquaintedwith
Acquaintedwith
Friends
Friends
FriendsFriends
FriendsFriends
Friends Friends
Friends
Hypercube Distance Clustering Discovery of Neighborhood Information

UNCLASSIFIED
Conclusion and Issues to Overcome
• Millions of possible Templates (Hypothesis) of interest• INformation Fusion Engine for Real Time Decision-making (INFERD)
• Ad-hoc choice of TruST parameters• We have done design of experiments to bound the best choice• We are working on trying to Characterize problem structure
• Graph Matching requires initial similarity values• We are working on automated process using the semantic features
of the nodes and edges (Conceptual Spaces)
• Graph Matching could take to long for some domains• We span temporal decision-making process with INFERD and TruST
• Performance on multiple domains• Implemented in Asymmetric Warfare, Chem/Bio Warfare, Maritime
Domain, Cyber Security, Sensor Management COA, etc.
27











![VISAGE: Interactive Visual Graph Querying · process is formally called graph querying (or subgraph matching) [29, 28]. Many graph databases now support pattern matching and over-come](https://img.dokumen.tips/doc/110x75/5f8b4d897b929c29e26a8e16/visage-interactive-visual-graph-querying-process-is-formally-called-graph-querying.jpg)

















