Embed Size (px)
Citation preview

7/18/2019 Hetero Lecture Slides 002 Lecture 1 Lecture-1-7-Kernel-multidimension
http://slidepdf.com/reader/full/hetero-lecture-slides-002-lecture-1-lecture-1-7-kernel-multidimension 1/9
Kernel-based Parallel Pr
- Multidimensional Kernel Conf
Lecture 1.7

7/18/2019 Hetero Lecture Slides 002 Lecture 1 Lecture-1-7-Kernel-multidimension
http://slidepdf.com/reader/full/hetero-lecture-slides-002-lecture-1-lecture-1-7-kernel-multidimension 2/9
O
• To understand multidimensio
• Multi-dimensional block
indices• Mapping block/thread ind
data indices
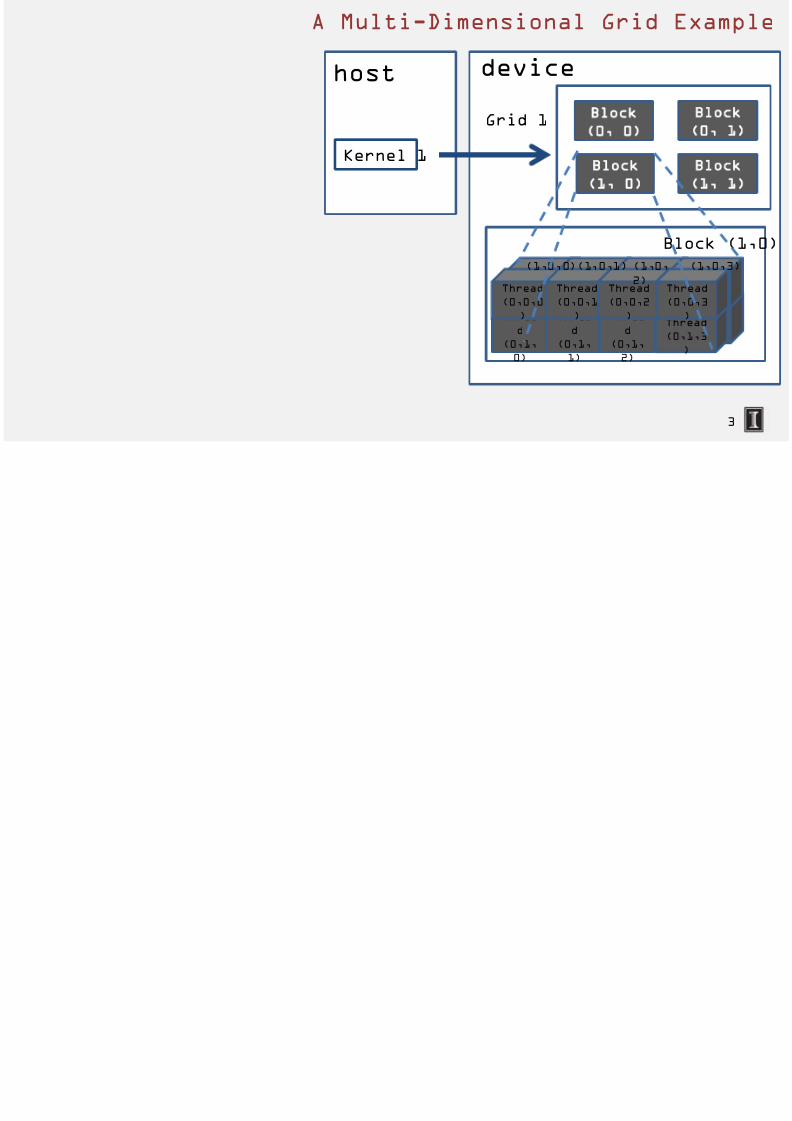
7/18/2019 Hetero Lecture Slides 002 Lecture 1 Lecture-1-7-Kernel-multidimension
http://slidepdf.com/reader/full/hetero-lecture-slides-002-lecture-1-lecture-1-7-kernel-multidimension 3/9
host device
Kernel 1
Grid 1Block
0, 0
Block
1, 0
Grid 2
Threa
d
(0,1,
0)
Threa
d
(0,1,
1)
Thr
d
(0,
2
Thread
(0,0,0
)
Thread
(0,0,1
)
Thr
(0,
)
(1,0,0)(1,0,1)
A Multi-Dimensional Gr

7/18/2019 Hetero Lecture Slides 002 Lecture 1 Lecture-1-7-Kernel-multidimension
http://slidepdf.com/reader/full/hetero-lecture-slides-002-lecture-1-lecture-1-7-kernel-multidimension 4/9
16×16 blocks
Processing a Picture with a
62×76 picture
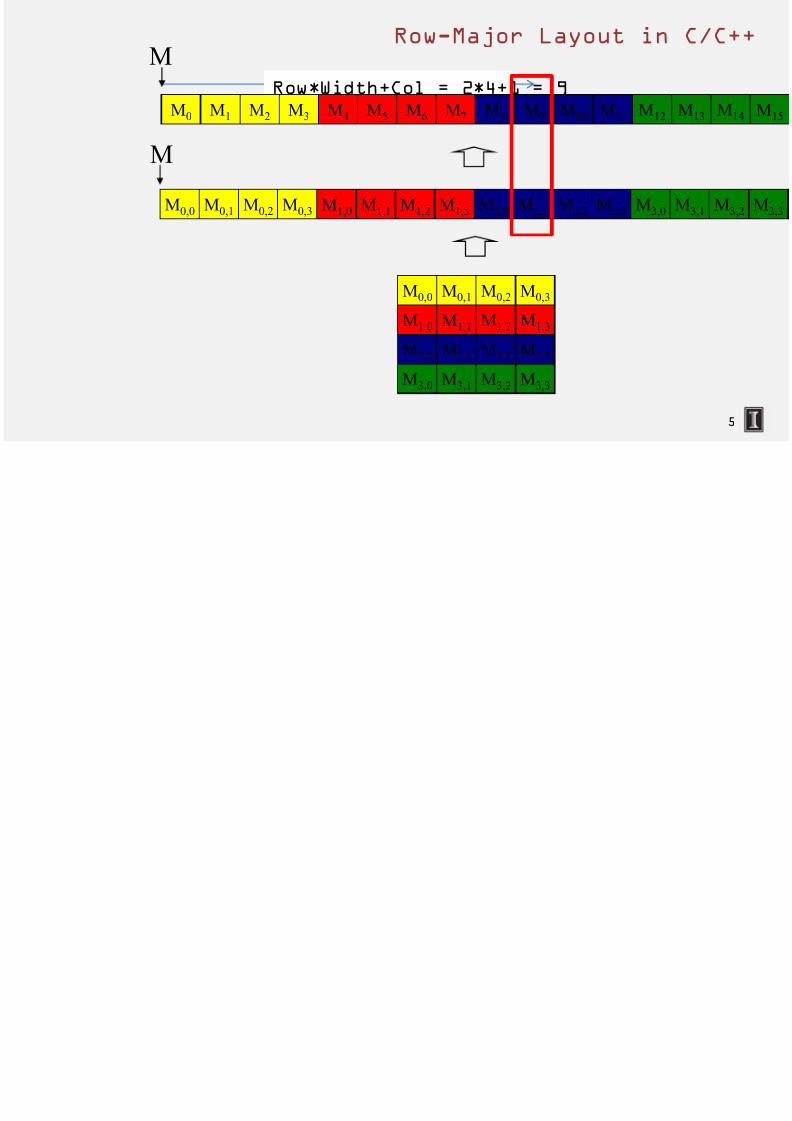
7/18/2019 Hetero Lecture Slides 002 Lecture 1 Lecture-1-7-Kernel-multidimension
http://slidepdf.com/reader/full/hetero-lecture-slides-002-lecture-1-lecture-1-7-kernel-multidimension 5/9
M0,2
M1,1
M0,1M0,0
M1,0
M0,3
M1,2 M1,3
M0,2M0,1M0,0 M0,3 M1,1M1,0 M1,2 M1,3 M2,1M2,0 M2,2 M2,3
M2,1M2,0 M2,2 M2,3
M3,1M3,0 M3,2 M3,3
M
Row*Width+Col = 2*4+1 = 9
M2M1M0 M3 M5M4 M6 M7 M9M8 M10 M11
MRow-Major Layout

7/18/2019 Hetero Lecture Slides 002 Lecture 1 Lecture-1-7-Kernel-multidimension
http://slidepdf.com/reader/full/hetero-lecture-slides-002-lecture-1-lecture-1-7-kernel-multidimension 6/9
Source Code of a Pictu
__global__ void PictureKernel(float* d_Pin,
int n, in
{
// Calculate the row # of the d_Pin and d_
int Row = blockIdx.y*blockDim.y + threadId
// Calculate the column # of the d_Pin and
int Col = blockIdx.x*blockDim.x + threadId
// each thread computes one element of d_Pif ((Row < m) && (Col < n)) {
d_Pout[Row*n+Col] = 2.0*d_Pin[Row*n+Col]
}
}
Scale every pixel va
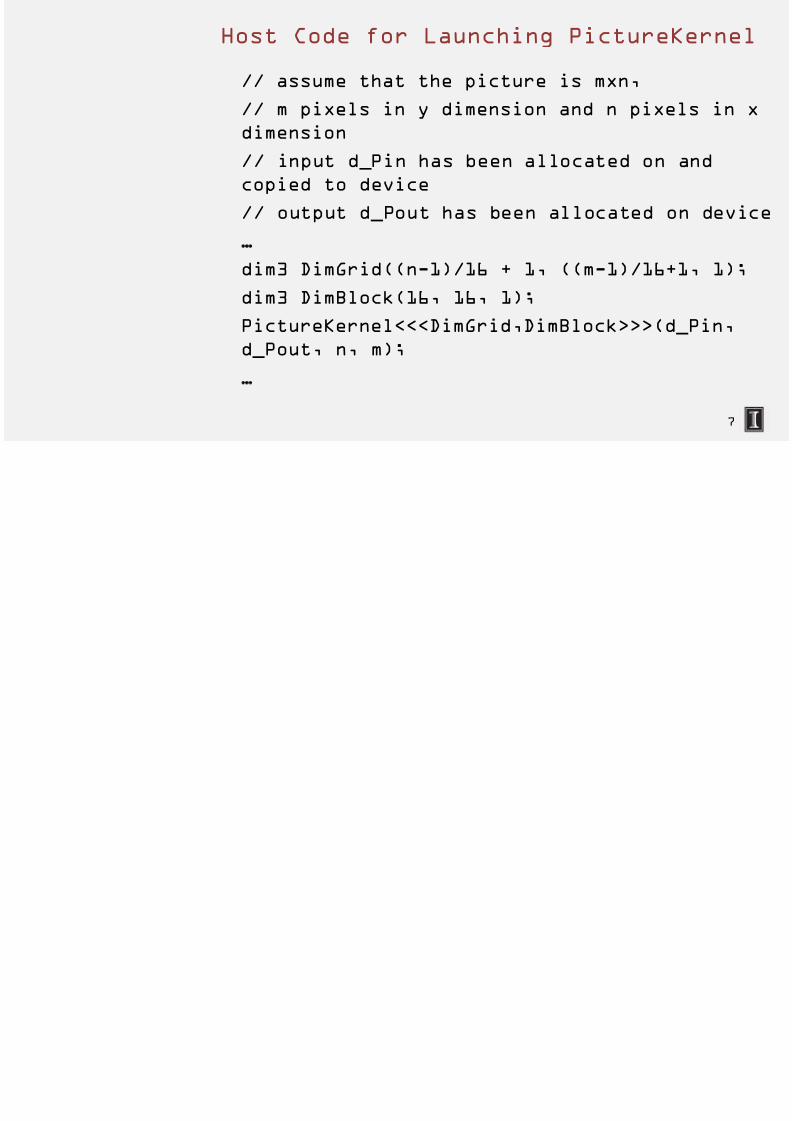
7/18/2019 Hetero Lecture Slides 002 Lecture 1 Lecture-1-7-Kernel-multidimension
http://slidepdf.com/reader/full/hetero-lecture-slides-002-lecture-1-lecture-1-7-kernel-multidimension 7/9
Host Code for Launching Pictu
// assume that the picture is mxn
// m pixels in y dimension and n
dimension// input d_Pin has been allocated
copied to device
// output d_Pout has been allocat
dim3 DimGrid((n-1)/16 + 1, ((m-1)dim3 DimBlock(16, 16, 1);
PictureKernel<<<DimGrid,DimBlock>
d_Pout, n, m);
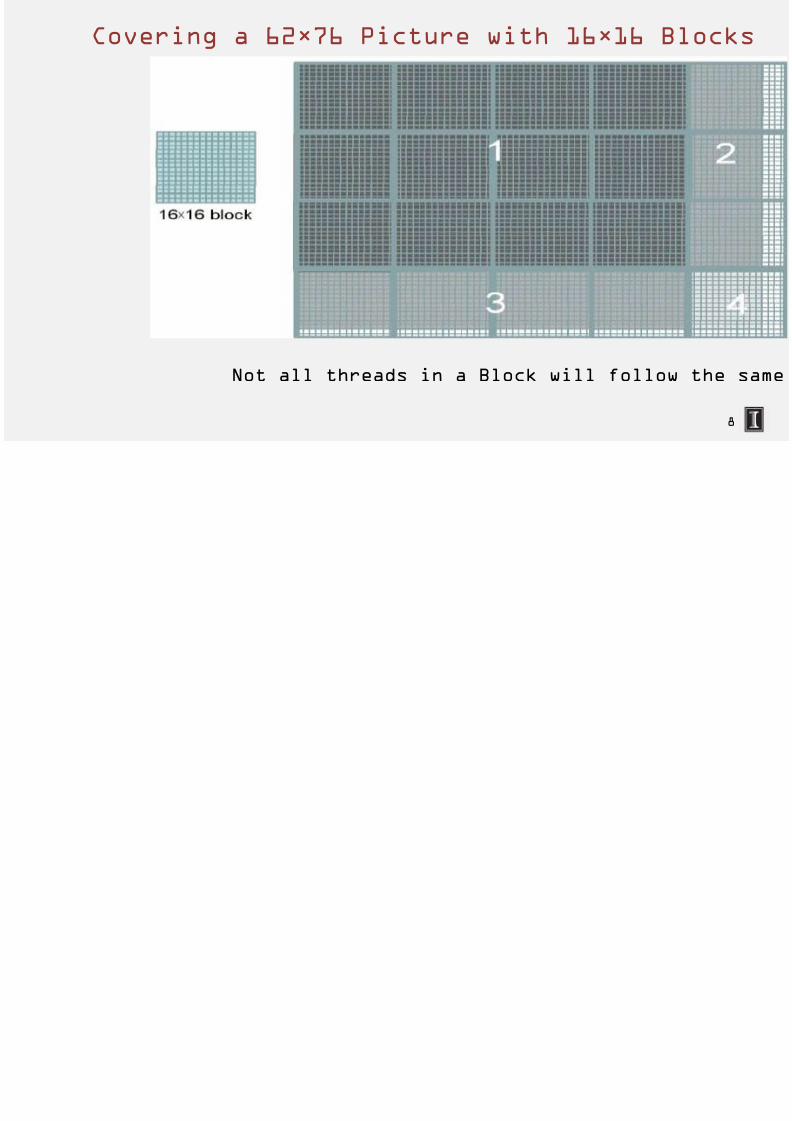
7/18/2019 Hetero Lecture Slides 002 Lecture 1 Lecture-1-7-Kernel-multidimension
http://slidepdf.com/reader/full/hetero-lecture-slides-002-lecture-1-lecture-1-7-kernel-multidimension 8/9
Covering a 62×76 Picture with 16×1
Not all threads in a Block will fo

7/18/2019 Hetero Lecture Slides 002 Lecture 1 Lecture-1-7-Kernel-multidimension
http://slidepdf.com/reader/full/hetero-lecture-slides-002-lecture-1-lecture-1-7-kernel-multidimension 9/9
To learn m
Sections





























