Embed Size (px)
Citation preview

HBase Operations:Best Practices
Yaniv YancovichData Group Leader @ Gigya

Agenda
● HBase internals● Replication● Backup and Recovery● Monitoring & Diagnostic ● Deploy● Useful tools● Hardware recommendations● The future
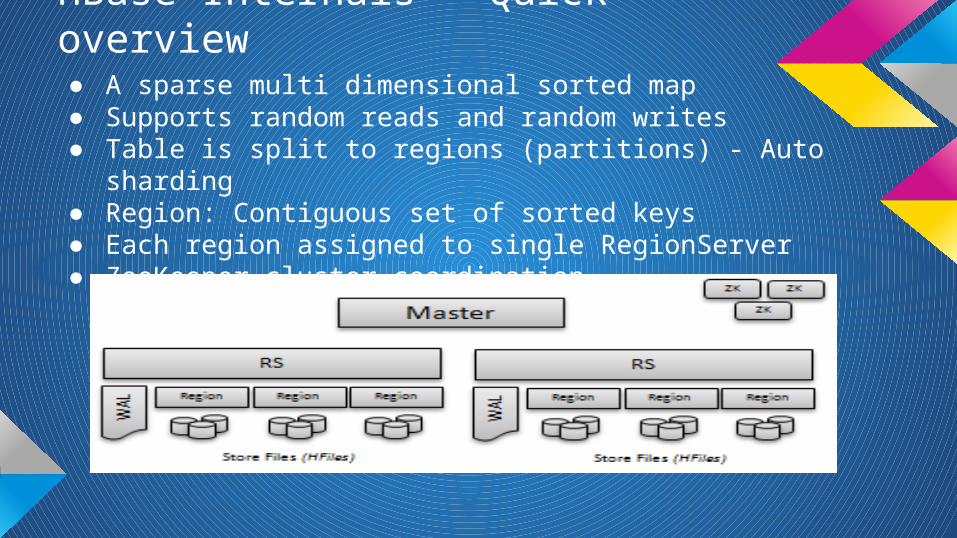
HBase Internals - Quick overview● A sparse multi dimensional sorted map● Supports random reads and random writes● Table is split to regions (partitions) - Auto sharding ● Region: Contiguous set of sorted keys● Each region assigned to single RegionServer● ZooKeeper cluster coordination

HBase Internals - Quick Overview● Table contains rows● Each row contains cells:
o row key, column family, column qualifier, timestamp● Rows are sorted lexicographically based on row key
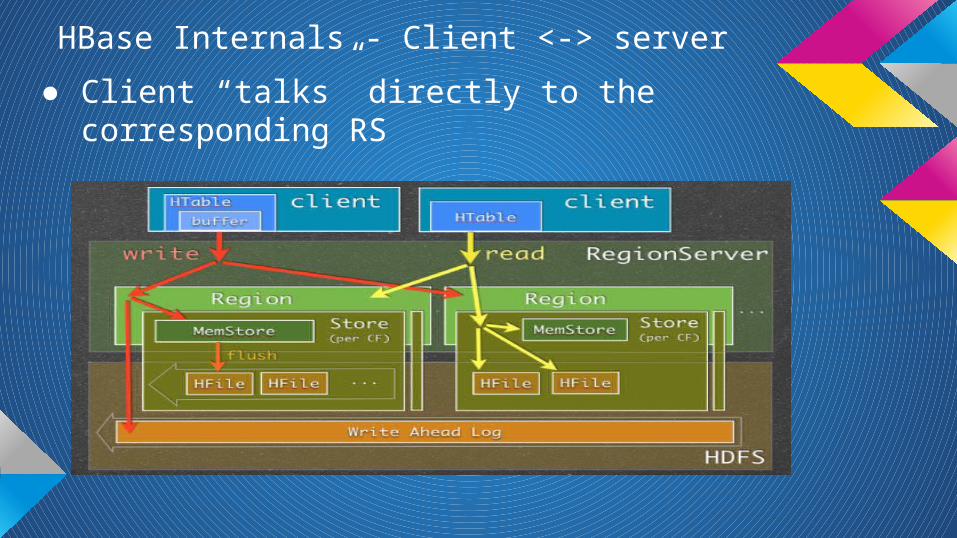
HBase Internals - Client <-> server
● Client “talks” directly to the corresponding RS

● Meet Mr. E, our Operation Director● A very calm person until...

Problem #1: “The entire cluster went down!!!”
● The service is down!● “Well, we have another cluster but it isn’t
up to date”● “Maybe move to DR?”
o “DR? Who needs it?”
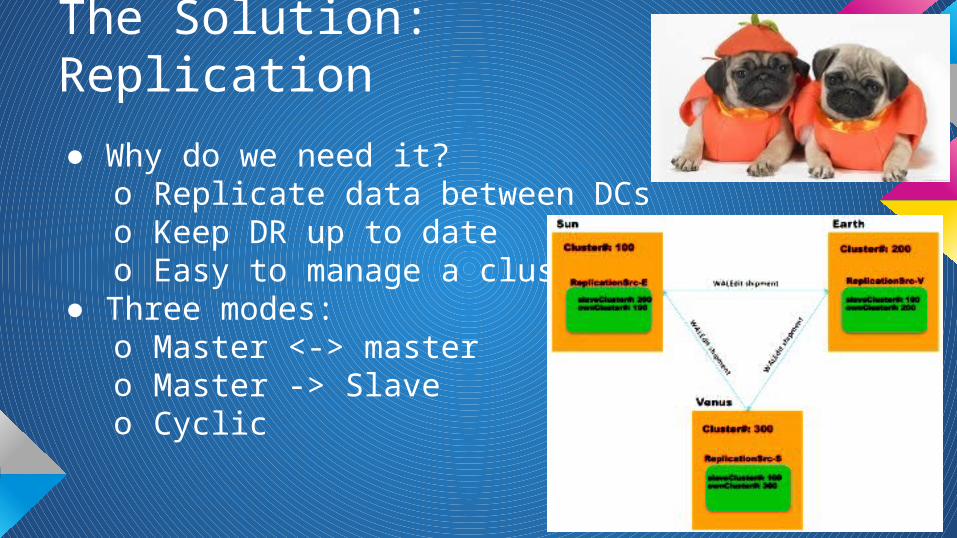
The Solution: Replication
● Why do we need it?o Replicate data between DCso Keep DR up to dateo Easy to manage a cluster
● Three modes:o Master <-> mastero Master -> Slave o Cyclic

Replication: Design
● Push in favor of Pull (MySQL)● Async● Cluster can be distinct (# clusters, security, etc)● .Meta isn’t replicated● ZooKeeper as a key player● Replaying WALEdits from the WALs (Write Ahead
Log) ● TS of replicated HLog are being kept intact● Per column family
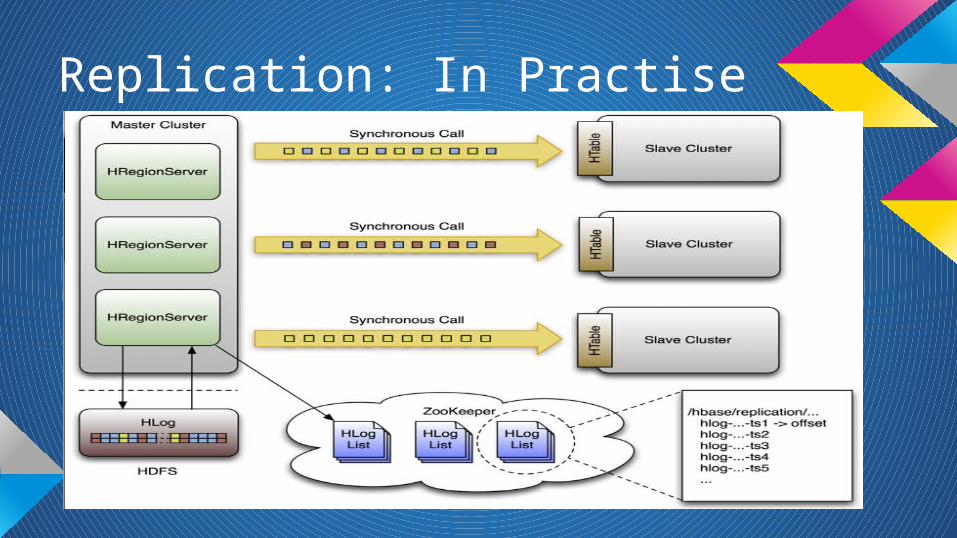
Replication: In Practise

Replication: Issues, Best Practices
● Not so good over bad network● Monitor, Monitor, Monitor● Problems with recovery● Master and slave should be sync by NTP● Avoid loops in cyclic replication

● So now when we have replication we can sleep like...
Well...

The Problem: “I see half of my DATA!!!”
● “The “smart” guys from R&D wrote a very sophisticated tool to clean unnecessary records.”
● “Well... They did a “great” job and deleted 50% of the records! “
● “They said they are sorry...”● “We thought replication is enough...”

The Solution: Backup
● Why do we need it?o Prevent Data losso Recover to point in timeo Use for offline processing

Backup (Method #1) - CopyTable
● MapReduce (MR) job● Copy part or all table● Incremental copies (StartTime -> EndTime)● Limitations:
o Can only copy to an HBase tableo Newly rows won’t be includedo High latency

● Not production friendly...● Affects production latency

The Solution (Method #2): Backup by Export
● MR job● Dump the data to HDFS● Copy data without going through Hbase● Pros: Simple, point in time, heavily tested● Cons: Slow, have impact on running
server

● "There is not enough memory or disk space to complete the operation"
● You are killing our HDFS!

The Solution: Backup by Snapshots
● Recover to point-in-time● Inexpensive way to freeze a table state● Recover from user error● Compliance (monthly snapshot)● Pros:
o Point in timeo Fasto Quick recovery: table from SnapShot

Backup - Snapshots
● Not a copy of a table, but set of operations on Table’s metadata and the data
● A snapshot manifest contains references to files in the original table
● On HDFS level (without cache hits)● What happens in compactions? splits?
o Archiving - HFile archiver● Offline and online snapshots

Snapshots - Offline Vs Online● Offline:
o Disabled table -> all data is flushed on disko Fully consistento Atomicy, Fasto Master takes the snapshot
● Online:o Master asks each RS to take for its regionso Two phase commit using ZooKeepero Pluggable snapshots: Currently “Flush snapshot”o Few seconds

Another Scenario:● So our data analyst just wanted to run a
“SMALL” HIVE query to check something
● Unfortunately it was on production cluster

The Solution: Export\Clone Snapshots
● Clone Snapshot - New table from Snapshot. No data copy!
● Export snapshot - copy snapshot to remote cluster - faster than CopyTable
● Restore Snapshot - rollback● Full support in shell● No incremental snapshots● Little impact on production
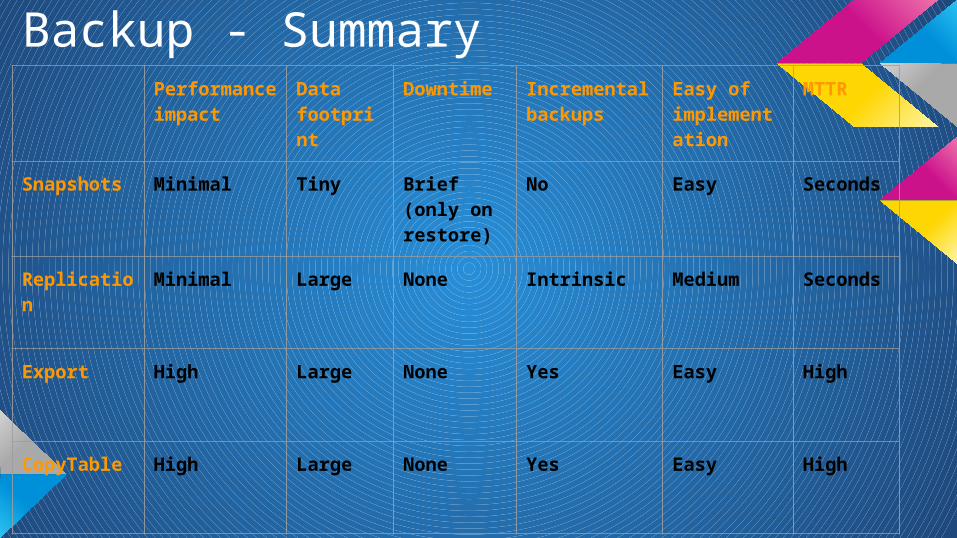
Backup - SummaryPerformance impact
Data footprint
Downtime Incremental backups
Easy of implementation
MTTR
Snapshots Minimal Tiny Brief (only on restore)
No Easy Seconds
Replication Minimal Large None Intrinsic Medium Seconds
Export High Large None Yes Easy High
CopyTable High Large None Yes Easy High

● Something seems to bother these people
● But what???
● If just we had a decent monitoring system...
● “When nothing is sure, everything is possible” (Margaret Atwood)

Monitoring● JMX based on few levels:
o Mastero Regionso Replicationo OSo GC
● Web UI renewed at 0.98o Block cache
● Zabbix, Ganglia, Nagios, Graphite● SemaText
● It seems they also have a problem
● Look on the man in the middle - He was told that he need to change a single setting on all of them...
● After doing it, they figured out they need to upgrade each one...
● They just were asked to install 100 HBase nodes one after another
● But what???

The Solution: Automation● Puppet
o Can build a cluster very fasto Hadoop, ZooKeeper, HBaseo Userso Carefull!!!

Meet Mr. Slow our production manager
● “We have all backups and replication in place but...● Production is so SLOW!”● High latency

We might call him for help!
Or...
Solution: Hardware and OS Recommendations
● SSD - Not cost effective yet● Virtual storage isn’t recommended● Recommended RAM between 24-72● Min dual 1G network● Raid\JBOD on masters● No swap● NTP

Useful Tools
● HBase web interface (master, regions)
● rowCount\CellCount● VerifyReplication● hbck for inconsistency● HFile - examine HFile file content● HLog - examine content of HLog file

General Operational Best Practices
● Upgrades● Built in web tools for quick checks● Monitoring (JMX, JSON)● Alerting system● Configuration: Block size, Block cache,
comparison● Optimize to read\write

The Future
● Upcoming: HDFS snapshots● Major compaction timing ● New pluggable snapshots

Open discussion
● Tell us about your experience in production:o Replicationo Hardwareo Backupso DRo Anything else?

Open discussion 2
● Any suggestions for next meetups?






























