Embed Size (px)
Citation preview

Genetic algorithm using iterative shrinking for solving clustering problems
P. Frwti & 0. Virrnajoki Department of Computer Science, University of Joensuu, Finland
Abstract
An iterative shrinking algorithm has been recently proposed to replace merge- based agglomerative clustering. In this work, we first extend this idea to the case where the number of clusters must also be solved. We then integrate the method within genetic algorithms that uses iterative shrinking for crossover. The proposed method outperforms all other clustering algorithms we have tested. We therefore conclude that this method is the best existing clustering algorithm in terms of minimizing the distortion function value.
1 Introduction
Clustering is an important problem that must often be solved as a part of more complicated tasks in pattern recognition, image analysis, and other fields of science and engineering [l, 2, 31. Clustering is also needed for designing a codebook in vector quantization [4]. Clustering problem is defined here as follows. Given a set of N data vectors X={xl, x2, . . ., X,}, partition the data set into M clusters such that a given distortion function f is minimized.
Agglomerative clustering generates clustering hierarchically by a sequence of merge operations. The clustering starts by initializing each data vector as its own cluster. Two clusters are merged at each step and the process is repeated until the desired number of clusters is obtained. Ward's method [5] selects the cluster pair to be merged so that it increases the given objective function value least. In the vector quantization context, this is known as the pairwise nearest neighbor (PNN) method due to [6] . Here we denote the method as the PNN.
The main restriction of the PNN is that the clusters are always merged as whole. Once the vectors have been assigned to the same cluster, it is impossible
Transactions on Information and Communications Technologies vol 29, © 2003 WIT Press, www.witpress.com, ISSN 1743-3517

194 Data Mining IV
to separate them later. In a recent work, we have proposed a more gcneral approach called iterative shrinking [7]. It generates the clustering by a sequence of clustcr removal opcrations: clusters arc removed one at a time by reassigning the vectors in the removed cluster to the remaining nearby clusters, see Fig. 1. The method uses local optimization strategy so that the cluster to be removed is always the onc that increases the cost function valuc least.
In this work, we extend the iterative shrinking to the case of unknown number of clustcrs. This can be achieved by employing suitable distortion function, which takes the number of clusters into account. The iterative shrinking is then inlcgrated with genetic algorithm as a crossover operation so that two candidate solutions of M cluslers are merged to form solution with 2M clusters. This is then reduced by thc itcrative shrinking to the final size. Experiments show that the proposed method outperforms all comparative variants in terms of minimizing the distortion function value.
Before cluster removal Afler cluster removal
Code V ( I C ~ O ~ S : Data vectors:
g Vector lo be removed X Data vectors ol the cluster to be removed
T3i R e r n a m g vectors t Olher dala veclors
Figure 1: The cluster removal process of the itcrative shrinking.
2 Iterative shrinking
Given a set of N data vectors X = ( x l , x2, . . ., x N } , clustering aims at solving the partition P = { p l , p2, . . ., p,,, ), which defines for each data vector the index of the cluster where it belongs to. Cluster S, is defined as the set of data vectors that belong to lhc same partition a:
The clustering is then represented as the set S=(sl, s2, ..., s y } . In vector quantization, the output of the clustering is a codebook C={cl, c2, . . . , cM} , which minimizes a givcn distortion function, usually the mean square error.
Transactions on Information and Communications Technologies vol 29, © 2003 WIT Press, www.witpress.com, ISSN 1743-3517

Data Mining IV 1 %
Ward's method [ 5 ] , or the pairwise nearest neighbor (PNN) as known in vector quantization [6 ] , generates the clustering hierarchically by a sequence of merge operations. In each step of the algorithm, the number of the clusters is reduced by merging two nearby clusters. The cost of merging two clusters S, and sh is the increase in the MSE-value caused by the merge. It can be calculated using the following formula [5, 61:
where n, and nb are the corresponding cluster sizes. The PNN applies local optimization strategy: all possible cluster pairs are considered and the one increasing MSE least is chosen. For details of an efficient implementation of the PNN, see [S].
The clustering result of the PNN is bounded by the fundamental restriction caused by the merge step. The Iterative Shrinking (IS) attacks this problem by replacing the merge step by cluster removal step. For every data vector, in addition to the primary partition P, the method maintains so-called secondary partition Q:
This measures the cost of merging the data vector xi to the neighbor cluster sp The move cost of a single vector ni is calculated as the increase in the distortion if the vector is moved to its secondary partition:
The removal cost of cluster S , can now be estimated as the sum of the individual move costs of the data vectors:
In practice, several data vectors can move to the same neighbor cluster and they all affect on the movement of the cluster centroid. A more accurate calculation can be obtained by considering all the vectors moving to the same neighbor cluster as a group (see [7] for details).
The primary partition P is updated for the vectors in the removed cluster by copying the information from the secondary partition. The codebook C is updated by recalculating the centroids of the affected clusters. The secondaty partition Q is updated for those vectors that belong to any of the cluster that has been changed during the process. The sketch of the IS is given in Fig. 2.
Transactions on Information and Communications Technologies vol 29, © 2003 WIT Press, www.witpress.com, ISSN 1743-3517

196 Data Mining IV
m t N ;
FOR b' i~ [l, m]: Ci t X(
p i t i; n i t l ;
FOR 'v' k [ l , m]: q; t FindSecondNearestCluster(C, xi);
REPEAT CalculateRemovalCosts(C, P, Q, d); a t SelectClusterToBeRernoved(d); RemoveCluster(P, Q, a); UpdateCentroids(C, P, a); UpdateSecondaryPartitions(C, P, Q, a); m+- m - l ;
UNTIL m M .
Figure 2: Pseudo code of the IS method.
3 Generalizations of the iterative shrinking
We next generalize the iterative shrinking approach to the case when the number of clusters must also be solved. The method is then augmented with the genetic algorithm in the same way as the PNN has been applied [g]. The proposed combination is denoted as GAZS (genetic algorithm with iterative shrinking). We consider both thc fixed and variable number of clusters.
3.1 Unknown number of clusters
In many cases, the number of clusters is not known beforehand but solving the correct number of clusters is part of the problem. The simplest approach is to generate solutions for all possible number of clusters M in a given range [M,;,, M,,], and then select the best clustering according to a suitable evaluation functionf. This multiplies the computation time by (M,,,,-Mmin).
The iterative shrinking, on the other hand, produces all possible number of clusters M during the same run. It is therefore enough to replace the distortion function by a suitable clustering validity index. Among the many different indexes [10, 11, 121, it was found out in [l31 that variance-ratio F-test based on a statistical ANOVA test procedure [l41 works pretty well in the case of Gaussian clusters. Moreover, we have shown in [l51 that the same distance function can be applied with the F-test than with the MSE. Therefore, no additional changes is required in the algorithm because of F-ratio.
Transactions on Information and Communications Technologies vol 29, © 2003 WIT Press, www.witpress.com, ISSN 1743-3517

Data Mining IV 197
3.2 Genetic algorithm
The idea of genetic algorithm (CA) is to maintain a set of solutions called population, which is iteratively improved by genetic operations such as crossover and by the selection principle of evolution. The G A is applied in the problem domain by operating on the codebook and partition (C, P).
The sketch of the algorithm is outlined in Fig. 3, and it works as follows. A set of random solutions are first generated by selecting M random data vectors as the codebook, and by solving optimal partition with respect to this codebook. The best solution survives to the next generation as such, and the rest of the population is filled by new solutions created by crossover. The process is iterated and the best solution in the final generation is the result of the algorithm.
The crossover starts by merging the parent solutions by taking the union of their centroids (Combinecentroids). The artition P""" is then constructed on the P basis of the existing partitions P' and P (CombinePartitions). The partition of data vector xi is either pi' or pi2. The one with smaller distance to xi is chosen. The codebook C"" is then updated (UpdateCentroids) with respect to the new partition Pnew. This procedure gives a solution in which the codebook has twice the size as it is allowed to. Empty clusters are next removed (RemoveEmptyClusters), and iterative shrinking is then applied to reduce the number of clusters from 2.M to M. Finally, the solution is fine-tuned by a few iterations of the standard K-means algorithm [16, 171.
The number of iterations (T), the population size (Q, and the number of K- means iterations (G) are the main parameters of the algorithm. Here we consider the following two strategies:
1. GAIS short: Iterate only as long as the best solution keeps improving (T=*). Use small population size ( Z l O ) , and apply two iterations of K- means (G=2).
2. GAIS long: Iterate long (T=100) with a large population size (2=100) and iterate K-means relatively long (G=10).
It is expected that the short variant is good enough to compete with the other clustering algorithms in terms of quality. The purpose of the long variant is to squeeze out the best possible result at the cost of a very long computation time. It is also possible to apply the C A with unknown number of clusters. In this case, we take any initial number of clusters MO, and generate the initial population accordingly. The new solutions in the crossover are reduced from 2M to 1 and the intermediate clustering that minimizes F-ratio is taken as the new candidate solution. The number of clusters will be automatically determined during the optimisation process of the GA.
Transactions on Information and Communications Technologies vol 29, © 2003 WIT Press, www.witpress.com, ISSN 1743-3517

198 Data Mining IV
GeneticAlgorithm(X) + (C, P)
FOR it-l TO Z DO d t RandomCodebook(X); P t OptirnalPaltition(X. C'):
SortSolutions(C,P);
REPEAT {C,P) c CreateNewSolutions( {C,P) ); SortSolutions(C,P);
UNTIL no improvement;
CreateNewSolutlons({C, 0) + {CsW, paw } t""1 , p e w 4 t c ' , ~ ' ; FOR i t 2 TO Z DO
(a.b),t SelectNextPair: C""', PP"' c Cross(C8, P, Cb, P); 1terate~-~eans(C"'"', PwW');
Cross(Ci, P', e, p) + (P'", P"''") C"" c ~ombine~entroids(~' , e); Pew c ~ombine~artit ions(~', P); pw t UpdateCentroid~(C"~~, Pew); RernoveEmptyClusters(C"BW, Pew); IS(CnBW, P e y ;
CombinePartitlon~(C'~, P', p) I, PM FOR i t 1 TO N DO
p""" c ELSE
t pi2
END-FOR
~ p d a t e ~ e n t r o i d s ( ~ l , e) -+ C?OW
FOR j t l TO IC"eWI DO
CY t CalculateCentroid(PBW. 1 ) ;
Figure 3: Pseudo code of the Genetic algorithm with iterative shrinlung (GAIS).
4 Experiments
We consider three image data sets [7] and four synthetically generated data sets (Fig. 4). The vectors in the first set (Bridge) are 4x4 blocks taken from gray- scale image, and in the second set (Miss America) 4x4 difference blocks of two subsequent frames in video sequence. The third data set (House) consists of color values of the RGB image. The number of clusters is fixed to M=256. The data sets S1 to S4 are two-dimensional sets with varying complexity in terms of spatial data distributions with M=15 clusters.
Data set S, Data set S2 Data set S3 Data set S4
Figure 4: Two-dimensional data sets with N=5000 vectors from M=15 clusters.
Transactions on Information and Communications Technologies vol 29, © 2003 WIT Press, www.witpress.com, ISSN 1743-3517
Data Mining IV 199
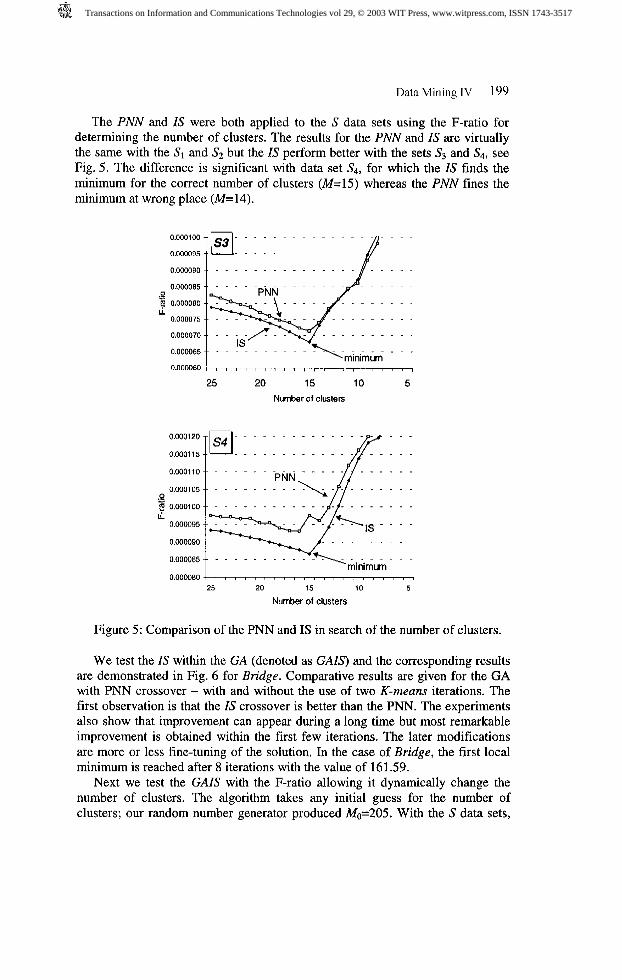
The PNN and IS were both applied to the S data sets using the F-ratio for determining the number of clusters. The results for the PNN and IS are virtually the same with the S1 and S2 but the IS perform better with the sets S3 and S,+ see Fig. 5. The difference is significant with data set S4, for which the IS finds the minimum for the correct number of clusters (M=15) whereas the PNN fines the minimum at wrong place (M= 14).
0 . 0 0 0 0 8 0 4 , , , , , , , , , , . , . , . . , . , , , 25 20 l 5 10 5
Nurrber of clusters
. . . . . . .
. . . . . . . . .
. . . . . . . . . . 0.000070 -. - - - - 0.000065.- . - - - - - - - - . \. : . . . . . . .
Figure 5: Comparison of the PNN and IS in search of the number of clusters.
0.000060-
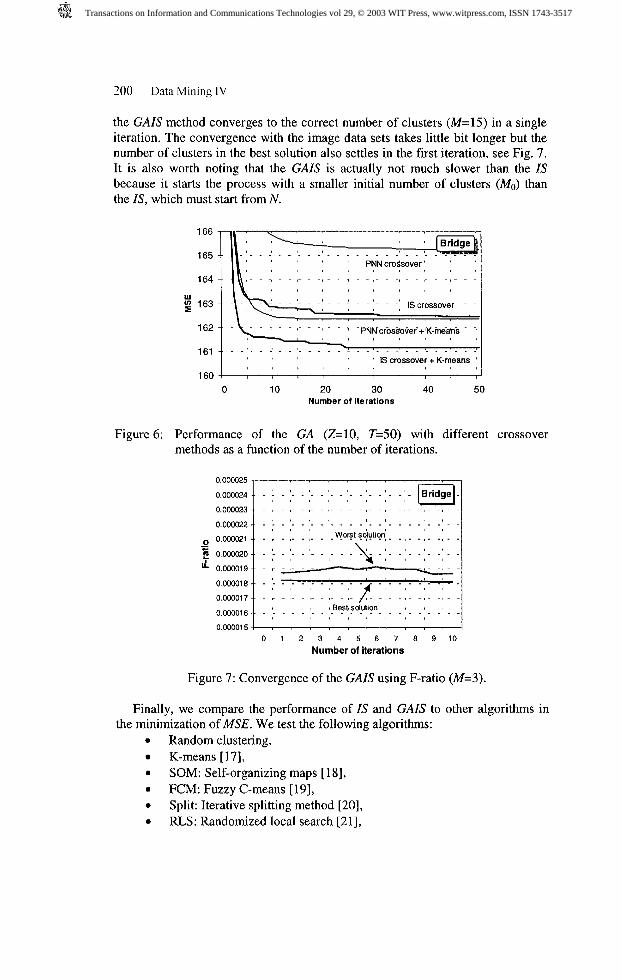
We test the IS within the G A (denoted as GAIS) and the corresponding results are demonstrated in Fig. 6 for Bridge. Comparative results are given for the GA with PNN crossover - with and without the use of two K-means iterations. The first observation is that the IS crossover is better than the PNN. The experiments also show that improvement can appear during a long time but most remarkable improvement is obtained within the first few iterations. The later modifications are more or less fine-tuning of the solution. In the case of Bridge, the first local minimum is reached after 8 iterations with the value of 161.59.
Next we test the GAIS with the F-ratio allowing it dynamically change the number of clusters. The algorithm takes any initial guess for the number of clusters; our random number generator produced Mo=205. With the S data sets,
mlnlmm I , , , I , , , r , , , , , , , , , , , 8
25 20 15 10 5
Number of clusters
Transactions on Information and Communications Technologies vol 29, © 2003 WIT Press, www.witpress.com, ISSN 1743-3517
200 Data Mining IV
the GAIS method converges to the correct number of clusters (M=15) in a single iteration. The convergence with the image data sets takes little bit longer but the number of clusters in the best solution also settles in the first iteration, see Fig. 7. It is also worth noting that thc GAIS is actually not much slower than the IS because it starts the process with a smaller initial number of clusters (MO) than the IS, which must start from N.
, I I , , , , , , I
160 1 0 10 20 30 40 50
Number of Iterations
Figure 6; Performancc of thc GA (Z=10, T=50) with different crossover methods as a function of the number of iterations.
0 1 2 3 4 5 6 7 8 9 1 0
Number of iterations
Figurc 7: Convergcnce of thc GAIS using F-ratio (M=3).
Finally, we compare the performance of IS and GAIS to other algorithms in the minimization of MSE. We test the following algorithms:
Random clustering, K-means [l7], SOM: Self-organizing maps [l X], FCM: Fuzzy C-means [19], Split: Iterative splitting method [20], RLS: Randomizcd local search [21],
Transactions on Information and Communications Technologies vol 29, © 2003 WIT Press, www.witpress.com, ISSN 1743-3517

Data Mining IV 20 1
Split-and-merge [22], SR: Stochastic relaxation [23], PNN: Pairwise nearest neighbor [6, 81, IS: Iterative shrinking [7], GA: Genetic algorithm with PNN crossover [9], GAIS: Genetic algorithm with IS crossover (proposed).
We have included in the comparison only methods that have consistently provided good quality clustering results in our experiments, and methods that are popular for other reasons. The hierarchical approaches are also combined with the K-means to get further improvement whereas the other algorithms implicitly include K-means iterations in one form or another. The average results of the algorithms are summarized in Table 1. The Random, K-means, FCM, and SR have been repeated 10 times.
Table 1: Performance comparison of the algorithms. The numbers are average MSE-values and the results of the S sets have been multiplied by log.
The K-means, SOM and FCM are well known and popular due to their simple implementation. Despite of this, the K-means is sensitive to the initialization and the SOM is very sensitive to a proper parameter setup. Even a slightest change in the parameter setup can provide noticeable improvement with one data set but turn out to give significant weaker result with another set. With the chosen parameter setup 1241 the method finds the best solution with S2 and S4 but gives significantly weaker results for the S, and S3. The FCM finds the best solutions for S,-S4 but is inferior to SOM with the image data sets. The K-means is implemented here as proposed in [25].
Transactions on Information and Communications Technologies vol 29, © 2003 WIT Press, www.witpress.com, ISSN 1743-3517

202 Data Mining IV
The Split method [20] always selects optimal hyperplane dividing the particular cluster along its principal axis, augmented with a local repartitioning phase at each division step. This chosen Split variant is optimized for quality rather than speed. There also exist other faster Split variants but their results vary somewhere between that of the K-means and Random clustering.
The RLS, Split-and-Merge, and SR are all competitive in terms of clustering quality. The RLS is probably the most attractive of them even though the Split- and-Merge sometimes gives slightly better results but with a significantly more complex implementation. The RLS and SR are relatively simple to implement but the SR is somewhat sensitive to the initialization: it works well for the image data sets but fails to find good clustering in about 10-20% of times with the easier S data sets, which shows here as weaker MSE-values.
Among the PNN and IS variants, the PNN works rather well in most cases but sometimes (with S3 and S4) the results are clearly inferior to that of the IS. The combination with the K-means makes sense because the PNN and IS do not make local fine-tuning of the clusters during the process except the clustering update operations in the IS. In particular, the IS + K-means outperforms the other variants except the genetic algorithms.
The genetic algorithms are the best. They give the lowest MSE-values in the case of image data sets. In the case of S data sets, there are also other methods (FCM, RLS, IS+K-means) that reach the same result (presumably optimum). We would like to note that the MSE-difference obtained with the image data sets by the GAIS in comparison to IS+K-means is probably unnoticeable in practice. Nevertheless, we conclude that, as far as we know, the GAIS is the best clustering algorithm in terms of minimizing the distortion function value.
5 Conclusions
We have proposed iterative shrinking (IS) as a crossover method in genetic algorithm (GAIS). This combination outperforms all tested clustering algorithms in terms of minimizing the cost function. The method was also extended to the case where the number of clusters must be solved, which can be solved during a single run of the algorithm without increasing the time complexity.
References
[ l ] B.S. Everitt, Cluster Analysis (3rd edition), Edward Arnold 1 Halsted Press, London, 1992.
121 L. Kaufman and P.J. Rousseeuw, Finding Groups in Data: An Introduction to Cluster Analysis, John Wiley Sons, New York, 1990.
[3] R. Dubes and A. Jain, Algorithms that Cluster Data, Prentice-Hall, Englewood Cliffs, NJ, 1987.
[4] A. Gersho and R.M. Gray, Vector Quantization and Signal Compression. Kluwer Academic Publishers, Dordrecht 1992.
[5] J.H. Ward, "Hierarchical grouping to optimize an objective function", J. Amer. Statist.Assoc., 58,236-244, 1963.
Transactions on Information and Communications Technologies vol 29, © 2003 WIT Press, www.witpress.com, ISSN 1743-3517

Data Mining IV 203
W.H. Equitz, "A new vector quantization clustering algorithm", IEEE Transactions on Acoustics, Speech, and Signal Processing 37 (10), 1568- 1575, October 1989. 0. Virmajoki, P. Franti and T. Kaukoranta, "Iterative shrinking method for generating clustering", IEEE Int. Con$ on Image Processing (ICIP'02), Rochester, New York, USA, vol. 2,685-688, September 2002. P. Franti, T. Kaukoranta, D.-F. Shen and K.-S. Chang, "Fast and memory efficient implementation of the exact PNN", IEEE Transactions on Image Processing, 9 (9,773-777, May 2000. P. Franti, J. KivijPvi, T. Kaukoranta and 0. Nevalainen, "Genetic algorithms for large scale clustering problem", The Computer Journal, 40 (9), 547-554, 1997. J.C. Bezdek and N.R. Pal, "Some new indexes of cluster validity", IEEE Transactions on Systems, Man and Cybernetics 28 (3), 302-315, 1998. D.L. Davies and D.W. Bouldin, 1979. "A cluster separation measure", IEEE Transactions on Pattern Analysis and Machine Intelligence 1 (2), 224-227, 1979. M. Sarkar, B. Yegnanarayana, D. Khemani, "A clustering algorithm using an evolutionary programming-based approach", Pattern Recognition Letters, 18 (10), 975-986, 1997. I. KPkkainen and P. Franti, "Stepwise algorithm for finding unknown number of clusters", Advanced Concepts for Intelligent Vision Systems (ACIVS'2002), Gent, Belgium, 136-143, September 2002. P.K. Ito, Robustness of ANOVA and MANOVA Test Procedures. In: Handbook of Statistics I : Analysis of Variance. North-Holland Publishing Company, pp 199-236,1980. M. Xu and P. Franti, "Delta-MSE dissimilarity in partitional clustering", 2003. (submitted) Y. Linde, A. Buzo and R.M. Gray, "An algorithm for vector quantizer design". IEEE Transactions on Communications, 28 (l), 84-95, January 1980. J.B.McQueen, "Some methods of classification and analysis of multivariate observations", Proc. 5th Berkeley Symp. Mathemat. Statist. Probability 1, 281-296. Univ. of California, Berkeley, USA, 1967. T. Kohonen, Self-Organization and Associative Memory. Springer-Verlag, New York, 1988. J.C. Dunn, "A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters". Journal of Cybernetics 3 (3), 32-57, 1974. P. Franti, T. Kaukoranta and 0 . Nevalainen, "On the splitting method for vector quantization codebook generation", Optical Engineering, 36 (1 l), 3043-305 1, November 1997. P. Franti and J. KivijPvi, "Randornized local search algorithm for the clustering problem", Pattern Analysis and Applications, 3 (4), 358-369, 2000.
Transactions on Information and Communications Technologies vol 29, © 2003 WIT Press, www.witpress.com, ISSN 1743-3517

204 Data Mining IV
[22] T. Kaukoranta, P. Franti and 0. Nevalainen, "Iterative split-and-merge algorithm for VQ codebook generation", Optical Engineering. 37 (10), 2726-2732, October 1998.
[23] K. Zeger and A. Gersho, 1989. Stochastic relaxation algorithm for improved vector quantiser design. Electronics Letters 25 (14), 896-898, 1989.
[24] P. Franti, "On the usefulness of self-organizing maps for the clustering problem in vector quantization", 11th Scandinavian Con$ on Image Analysis (SCIA199), Kangerlussuaq, Greenland, vol. 1,415-422, 1999.
[25] T. Kaukoranta, P. Franti and 0 . Nevalainen, "A fast exact GLA based on code vector activity detection", IEEE Trans. on Image Processing, 9 (g), 1337-1 342, August 2000.
Transactions on Information and Communications Technologies vol 29, © 2003 WIT Press, www.witpress.com, ISSN 1743-3517














![Scaling iterative closest point algorithm using dual ... iterative closest point algorithm... · 1100 W. Xia et al. / Optik 140 (2017) 1099–1109 [15] improved the ICP algorithm](https://img.dokumen.tips/doc/110x75/5cf401de88c993d5048c2231/scaling-iterative-closest-point-algorithm-using-dual-iterative-closest-point.jpg)














