Embed Size (px)
Citation preview

Marcus Gründler | aixigo AG
Financial Portfolio
Management on Steroids

About me
Marcus Gründler
@marcusgruendler
Head of Portfolio Management Systems
Architect at aixigo AG, Germany
www.aixigo.de
JAX Finance 2016 - London

Agenda
• Financial portfolio management
• Hardware
• Java memory
• Programming patterns
• Scaling

What exactly is
Financial Portfolio
Management?

Portfolio Management
• Transactions, prices, securities
• Financial algorithms
• Historical analysis
• Time series

Portfolio Management
• No extreme low latency
• High data throughput (1 mio rec/sec)
• Low response times (100ms/10,000 rec)
• Very large datasets

Is
high performance
computing
possible with
Java?

Yes ...
... read the fine print!
Matrix Sum
23 101 2 34 88 120 4
44 12 234 211 112 189 11
33 1 86 201 3 11 22
65 32 62 22 34 15 67
43 178 105 138 192 38 41
11 58 35 25 27 16 21
Row major access
Matrix Sum
23 101 2 34 88 120 4
44 12 234 211 112 189 11
33 1 86 201 3 11 22
65 32 62 22 34 15 67
43 178 105 138 192 38 41
11 58 35 25 27 16 21
Column major access
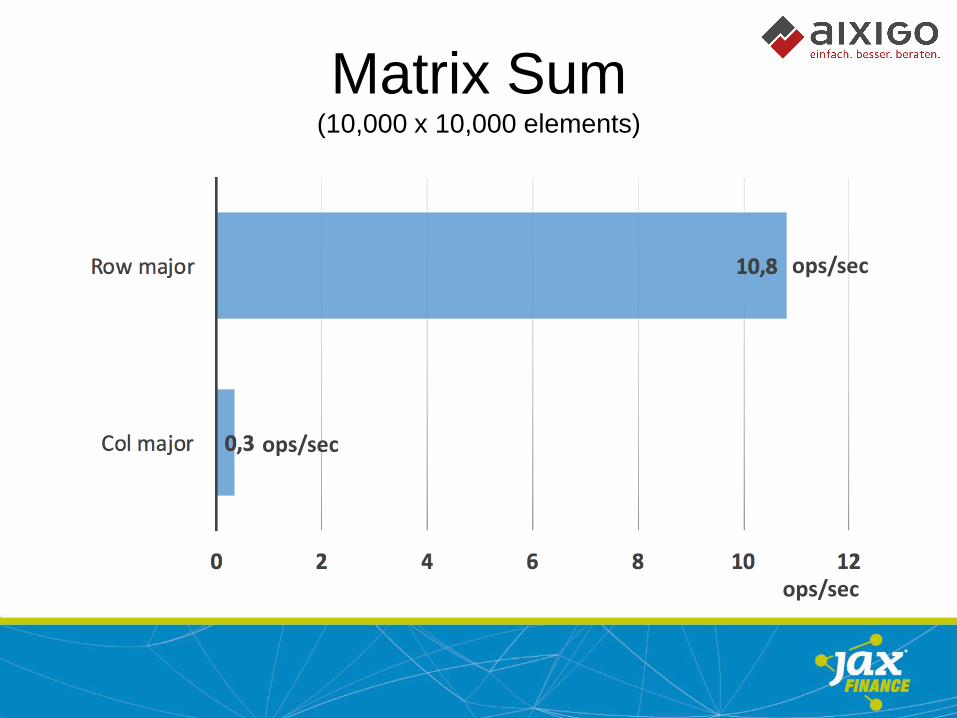
Matrix Sum (10,000 x 10,000 elements)
ops/sec
ops/sec
ops/sec
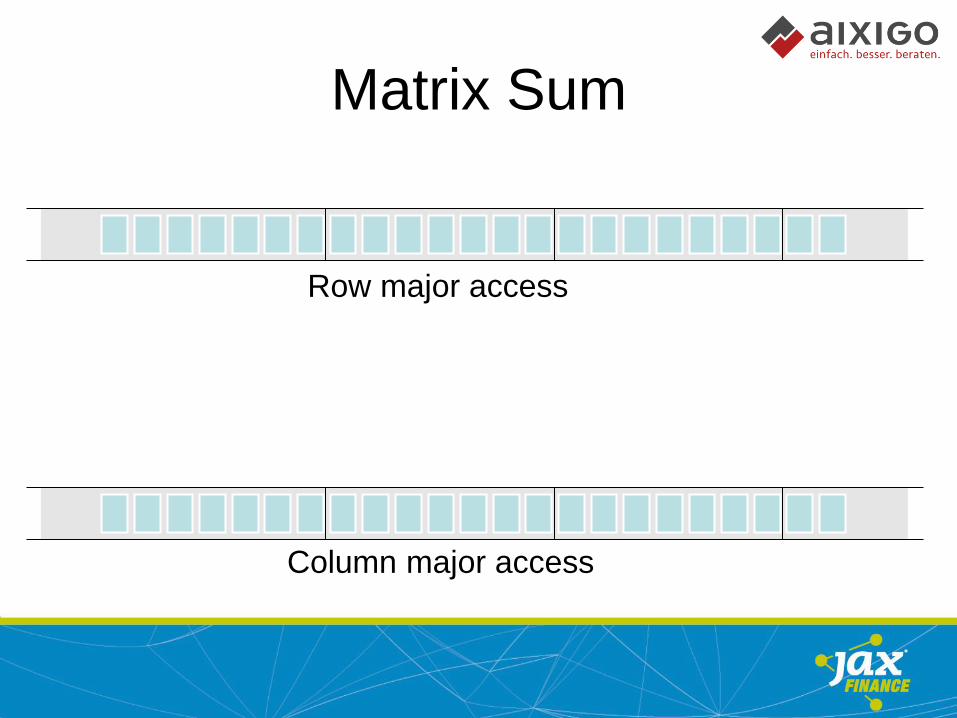
Matrix Sum
Row major access
Column major access

Tool Support - JMH
• OpenJDK JMH (Java Microbenchmark Harness)
• Eliminates measurement (in)accuracy
• Statistically robust measurements
• Maven and Jenkins support
http://openjdk.java.net/projects/code-tools/jmh/
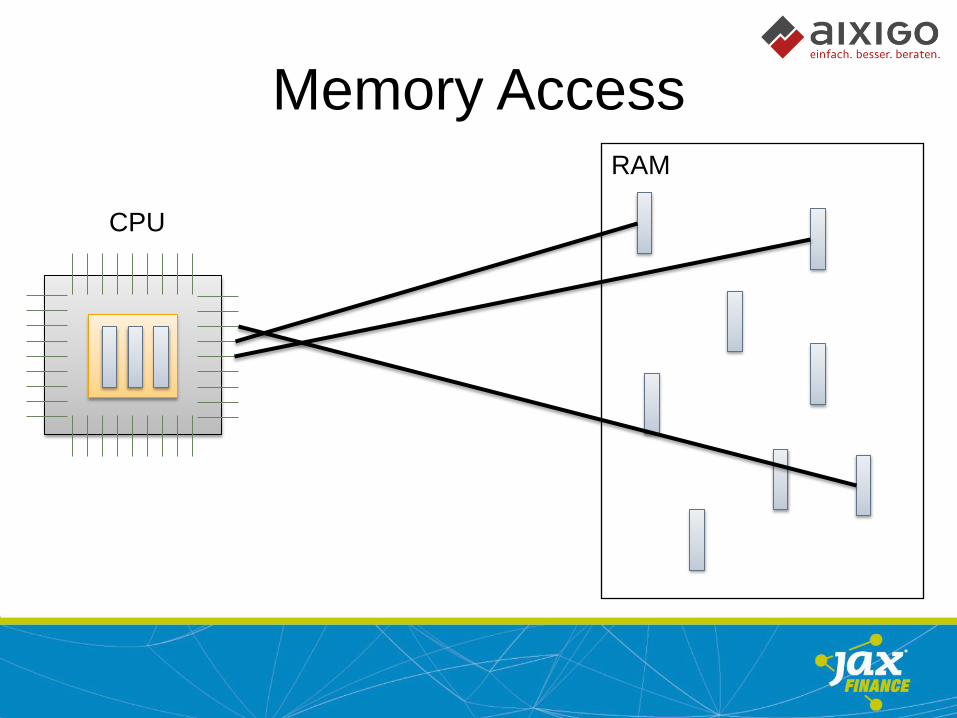
Memory Access
CPU
RAM
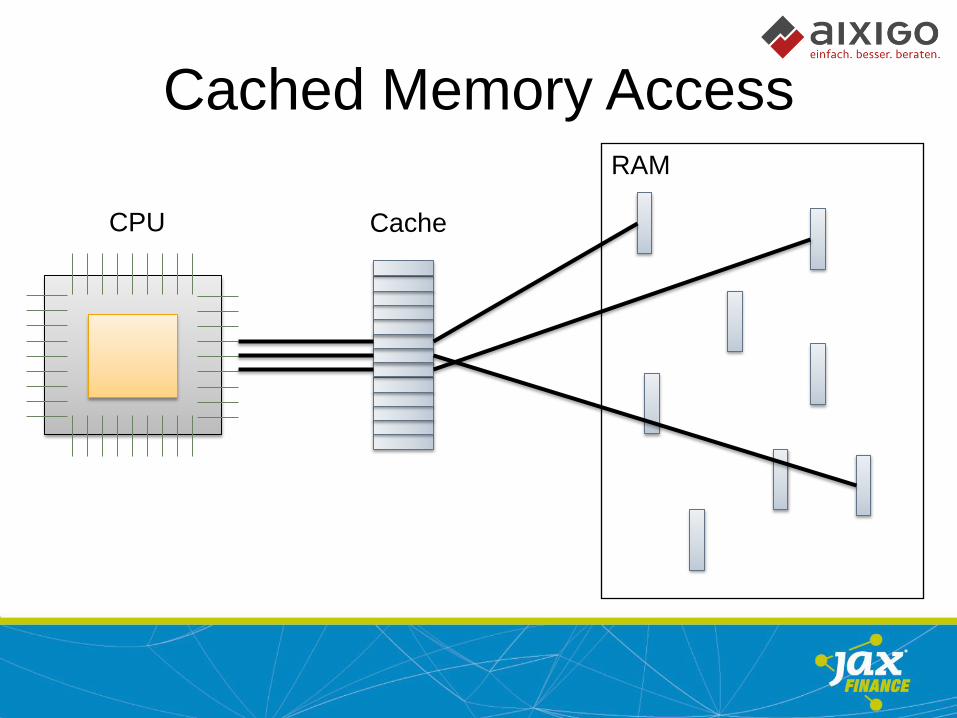
Cached Memory Access
CPU
RAM
Cache
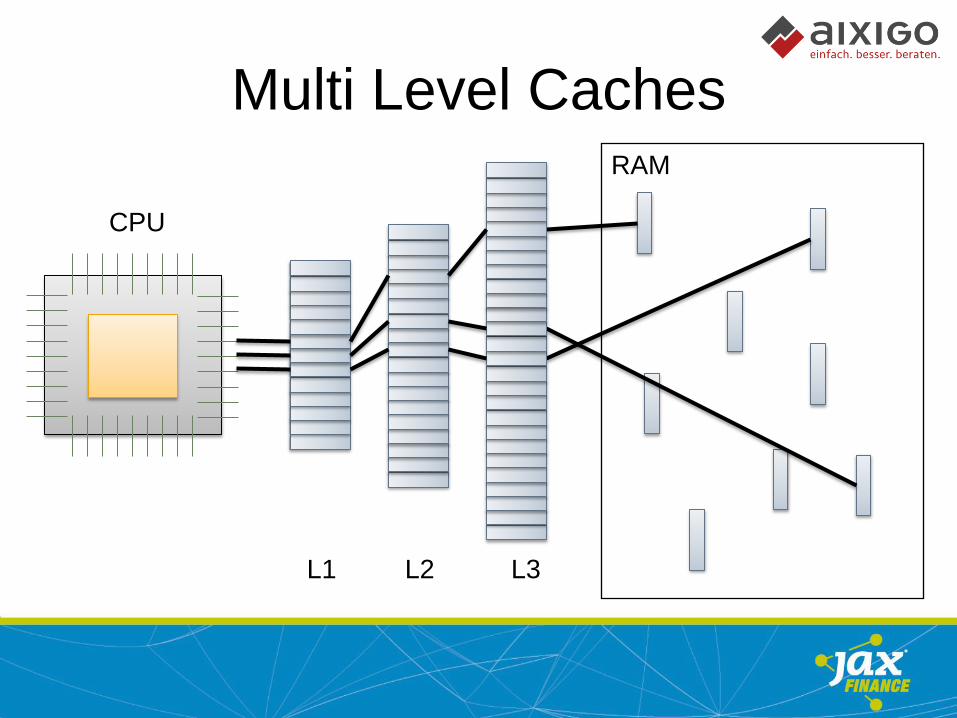
Multi Level Caches
CPU
RAM
L1 L2 L3
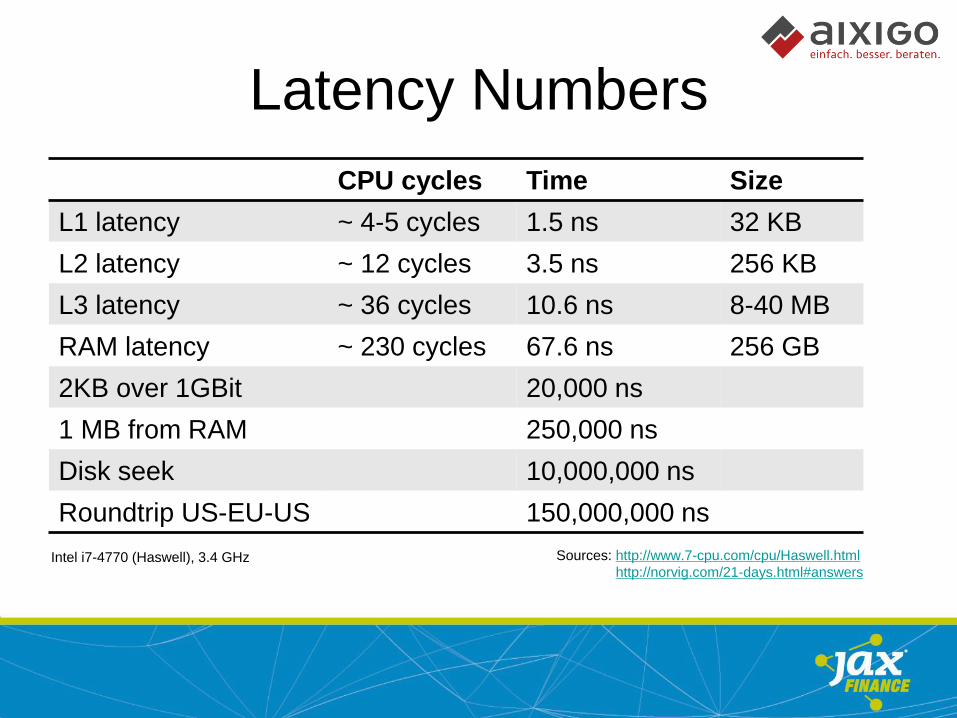
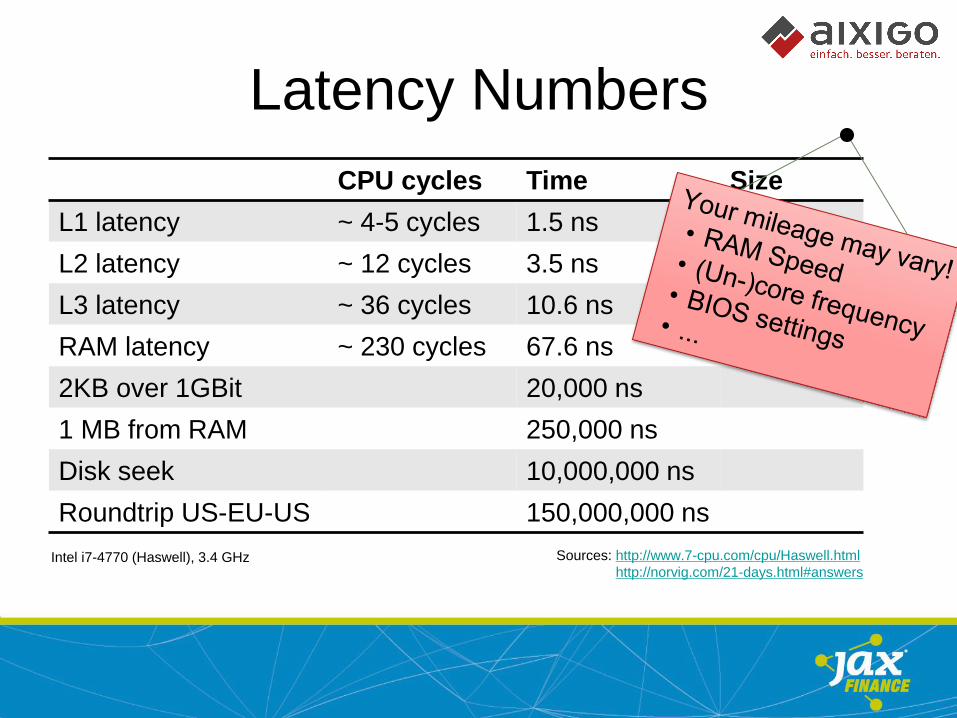
Latency Numbers
CPU cycles Time Size
L1 latency ~ 4-5 cycles 1.5 ns 32 KB
L2 latency ~ 12 cycles 3.5 ns 256 KB
L3 latency ~ 36 cycles 10.6 ns 8-40 MB
RAM latency ~ 230 cycles 67.6 ns 256 GB
2KB over 1GBit 20,000 ns
1 MB from RAM 250,000 ns
Disk seek 10,000,000 ns
Roundtrip US-EU-US 150,000,000 ns
Intel i7-4770 (Haswell), 3.4 GHz Sources: http://www.7-cpu.com/cpu/Haswell.html
http://norvig.com/21-days.html#answers
Latency Numbers
CPU cycles Time Size
L1 latency ~ 4-5 cycles 1.5 ns 32 KB
L2 latency ~ 12 cycles 3.5 ns 256 KB
L3 latency ~ 36 cycles 10.6 ns 8-40 MB
RAM latency ~ 230 cycles 67.6 ns 256 GB
2KB over 1GBit 20,000 ns
1 MB from RAM 250,000 ns
Disk seek 10,000,000 ns
Roundtrip US-EU-US 150,000,000 ns
Intel i7-4770 (Haswell), 3.4 GHz Sources: http://www.7-cpu.com/cpu/Haswell.html
http://norvig.com/21-days.html#answers

Cache-oblivious Algorithms
• Optimized for minimal memory transfer
• All computation with L1 cache
• Cache-“oblivious“: no knowledge about
cache hierarchy
• Keeps CPU permanently „under pressure“
• Empowers cache prefetching
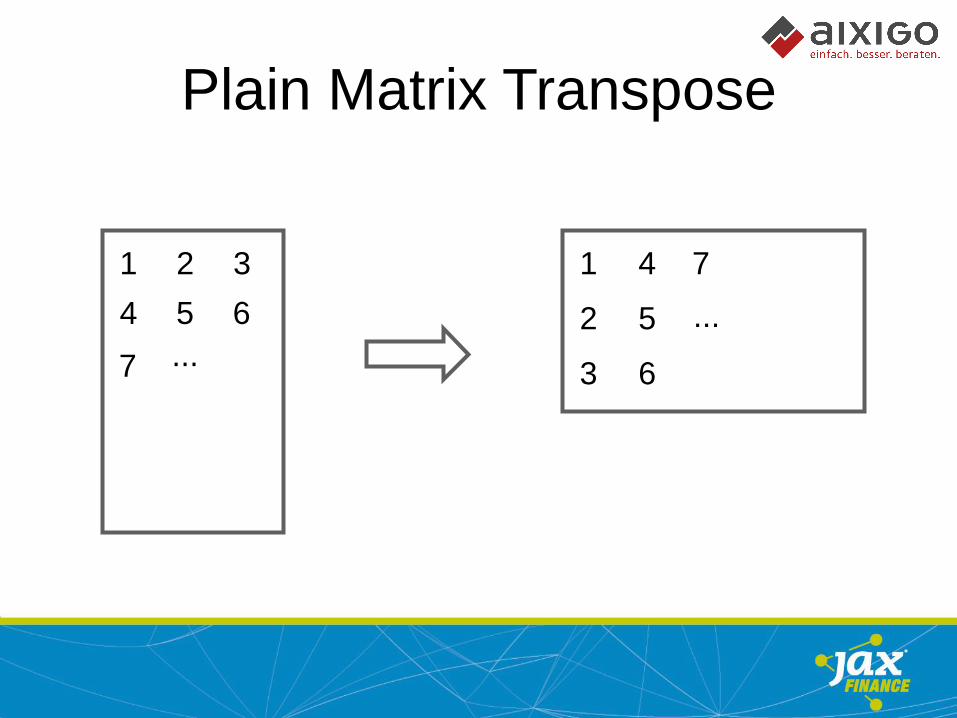
Plain Matrix Transpose
1 2 3
4 5 6
...
1 4
... 2 5
6 3 7
7
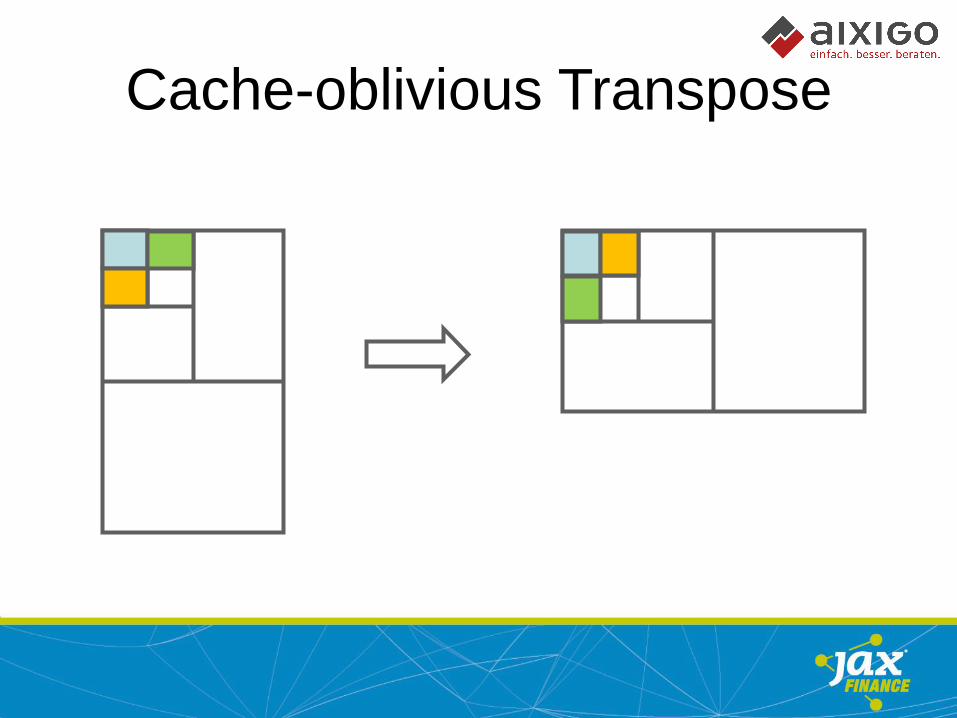
Cache-oblivious Transpose
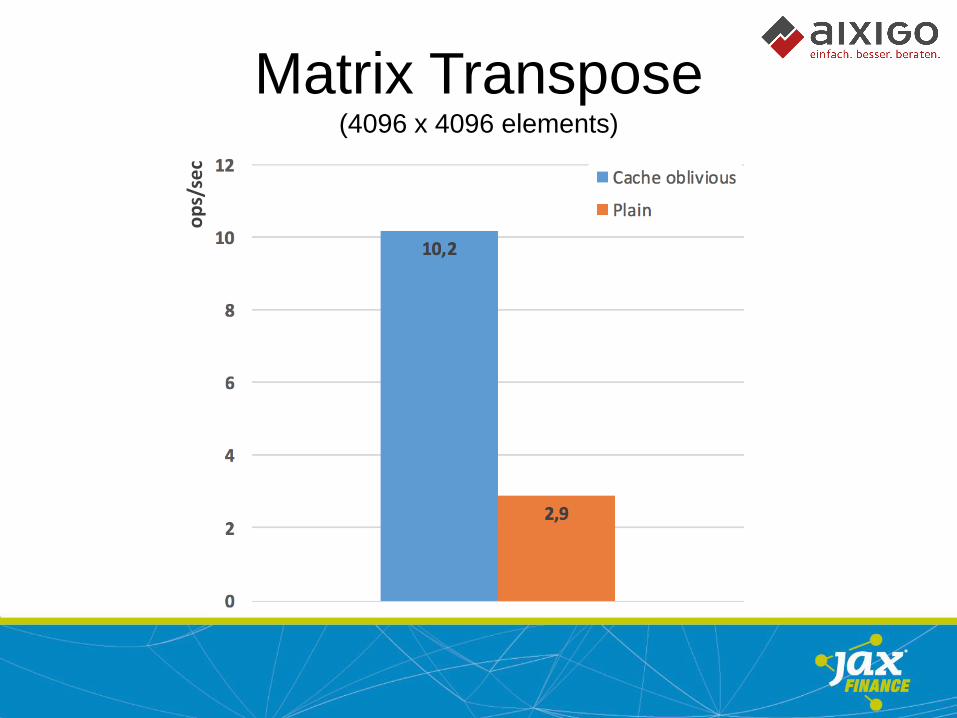
Matrix Transpose (4096 x 4096 elements)
op
s/se
c
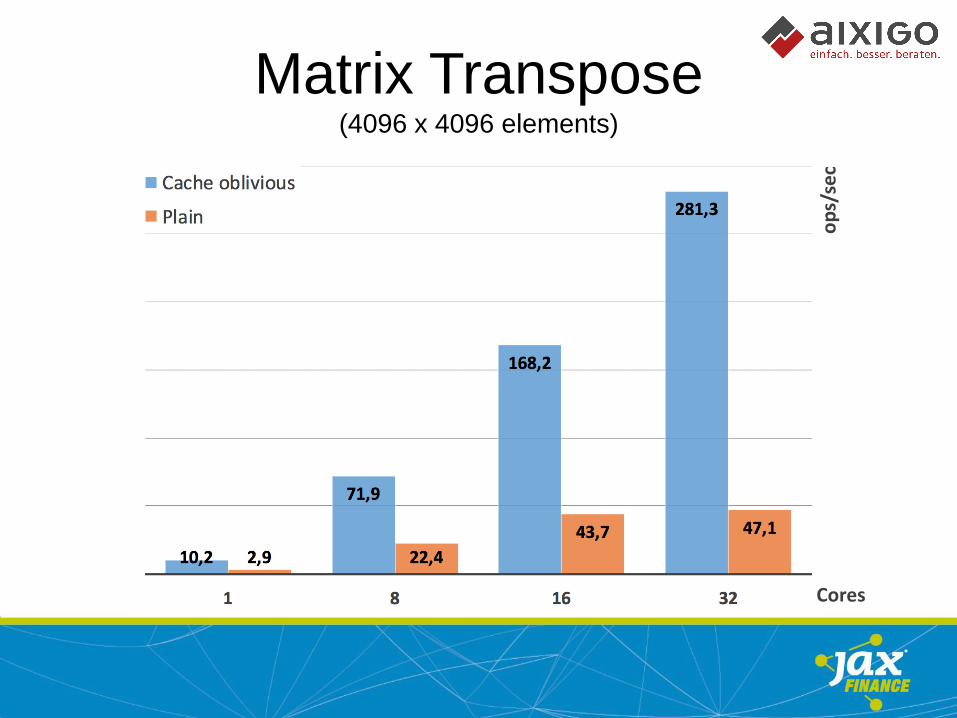
Matrix Transpose (4096 x 4096 elements)
Cores
op
s/se
c

• Memory access patterns matter
• Avoid main memory jumps
• Algorithms should support prefetching

How much
memory
do we
consume?

How large is an object?
double = 8 byte
Double = ? byte
BigDecimal = ? byte
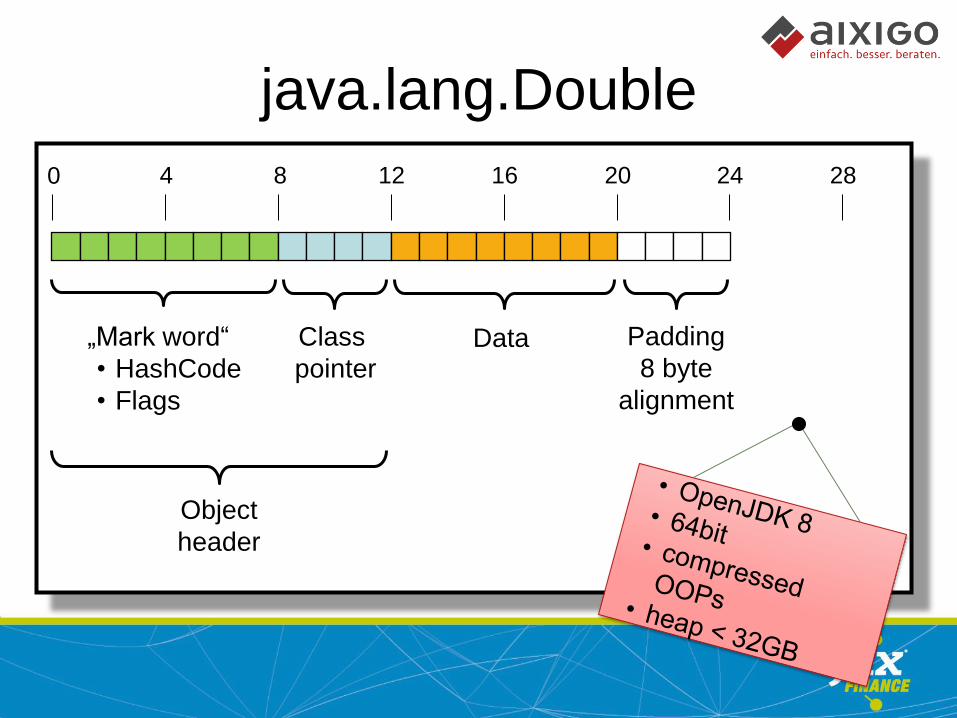
java.lang.Double
double = 8 byte
Double = ? byte
BigDecimal = ? byte
0 4 8 12 16 20 24 28
Padding
8 byte
alignment
Object
header
„Mark word“
• HashCode
• Flags
Class
pointer Data
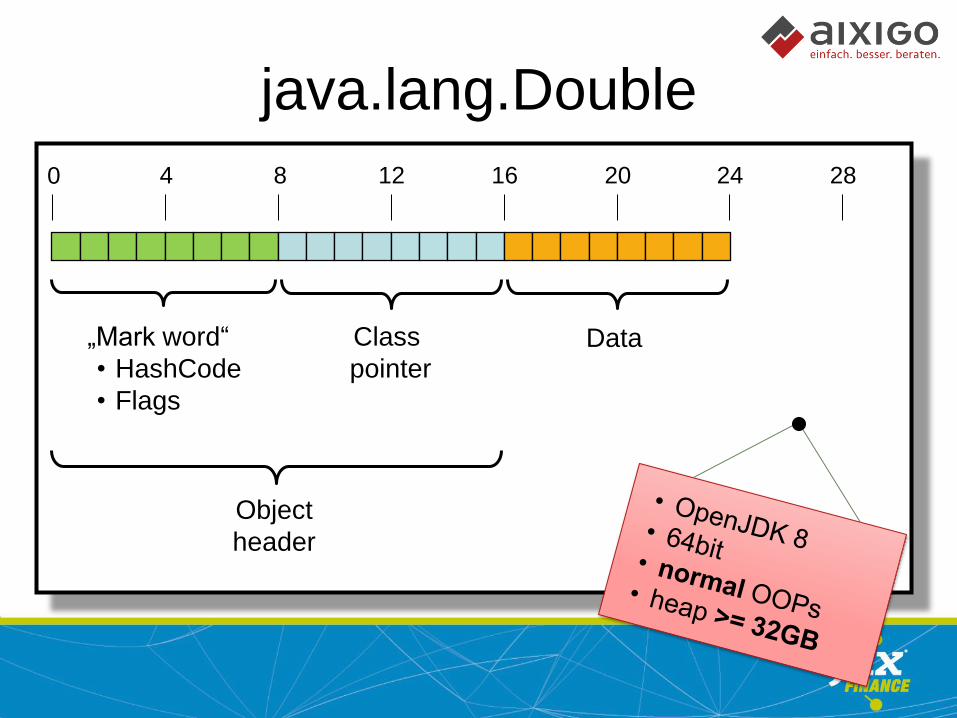
java.lang.Double
double = 8 byte
Double = ? byte
BigDecimal = ? byte
0 4 8 12 16 20 24 28
Object
header
„Mark word“
• HashCode
• Flags
Class
pointer Data
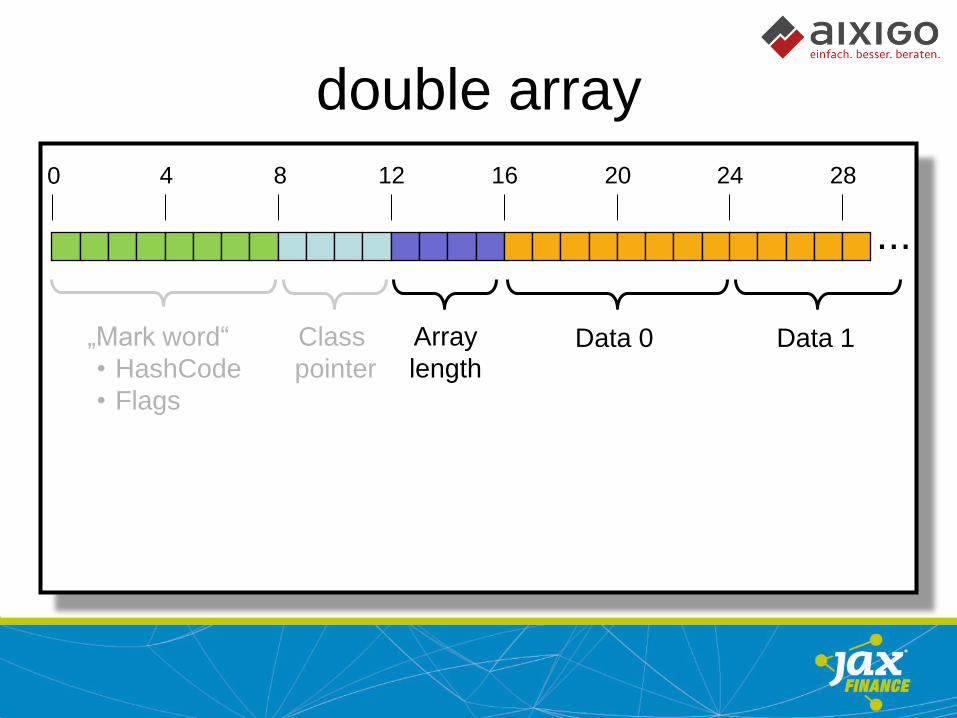
double = 8 byte
Double = 24 byte
BigDecimal = ? byte
double array
0 4 8 12 16 20 24 28
„Mark word“
• HashCode
• Flags
Class
pointer Data 0 Data 1 Array
length
...
double = 8 byte
Double = 24 byte
BigDecimal = ? byte
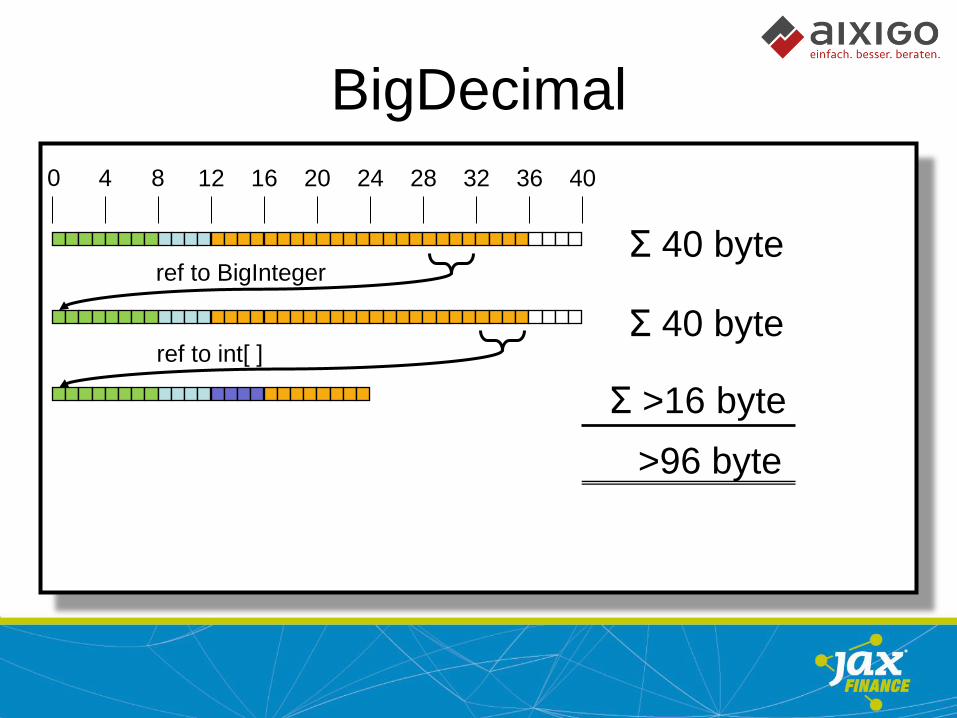
BigDecimal
0 4 8 12 16 20 24 28 32 36 40
ref to BigInteger
ref to int[ ]
Σ 40 byte
Σ 40 byte
Σ >16 byte
>96 byte
double = 8 byte
Double = 24 byte
BigDecimal = >96 byte
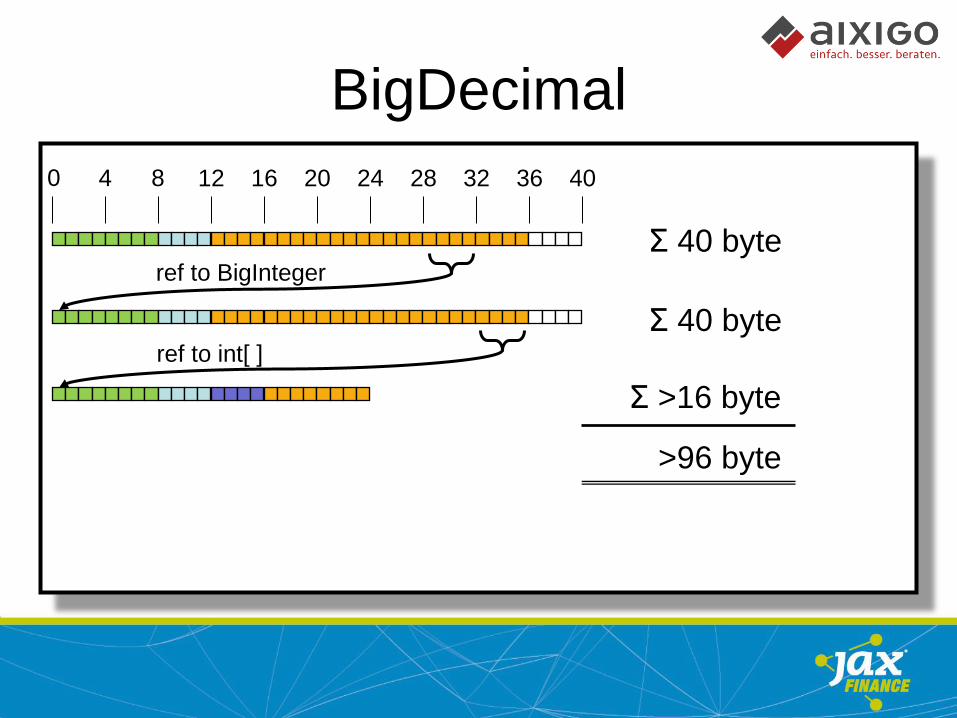
BigDecimal
0 4 8 12 16 20 24 28 32 36 40
ref to BigInteger
ref to int[ ]
Σ 40 byte
Σ 40 byte
Σ >16 byte
>96 byte

Tool Support - JOL
• OpenJDK tool – JOL (Java Object Layout)
• Insight into memory layout
• Heap dump analysis
• Exact memory usage
• Graphical layout visualization
• Maven module
http://openjdk.java.net/projects/code-tools/jol/

Tool Support - JOL
java -jar jol-cli.jar \
internals java.math.BigDecimal
or
java –cp jol-cli.jar:my-own.jar \
org.openjdk.jol.Main \
internals foo.MyClass

Tool Support - JOL
java.math.BigDecimal object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 4 int BigDecimal.scale N/A
16 8 long BigDecimal.intCompact N/A
24 4 int BigDecimal.precision N/A
28 4 BigInteger BigDecimal.intVal N/A
32 4 String BigDecimal.stringCache N/A
36 4 (loss due to the next object alignment)
Instance size: 40 bytes (estimated, the sample instance is not available)
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total

Data Locality
56 + 520 = 576 bytes 64 Bytes
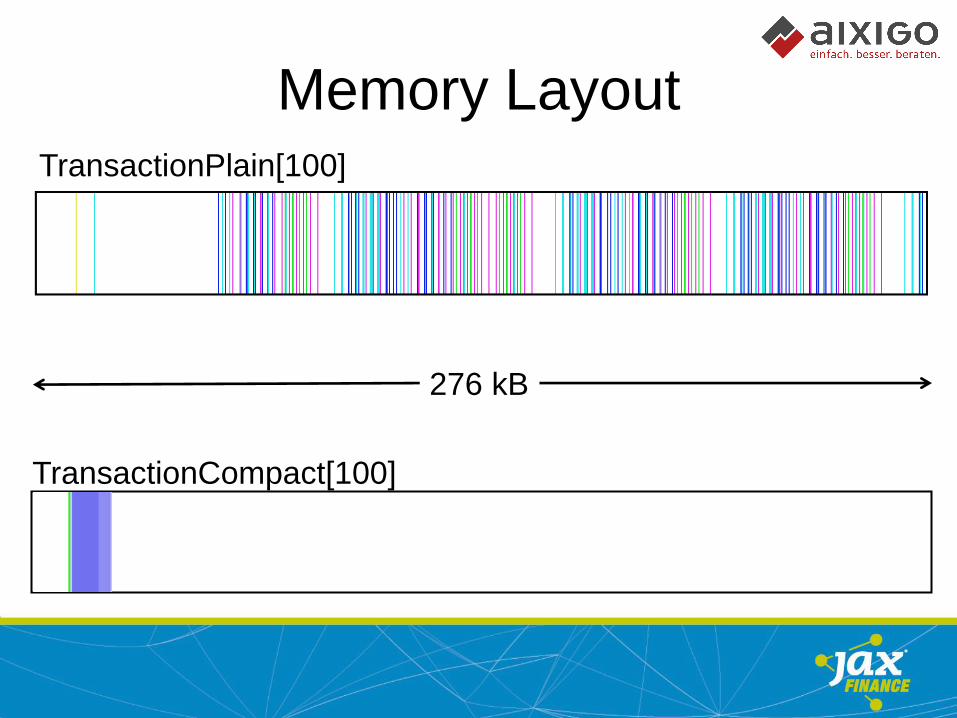
Memory Layout TransactionPlain[100]
TransactionCompact[100]
276 kB

• Keep data compact
• Think about data types
• Keep memory allocations low
• Keep garbage collection rate low

And...
Which patterns
should I
use?
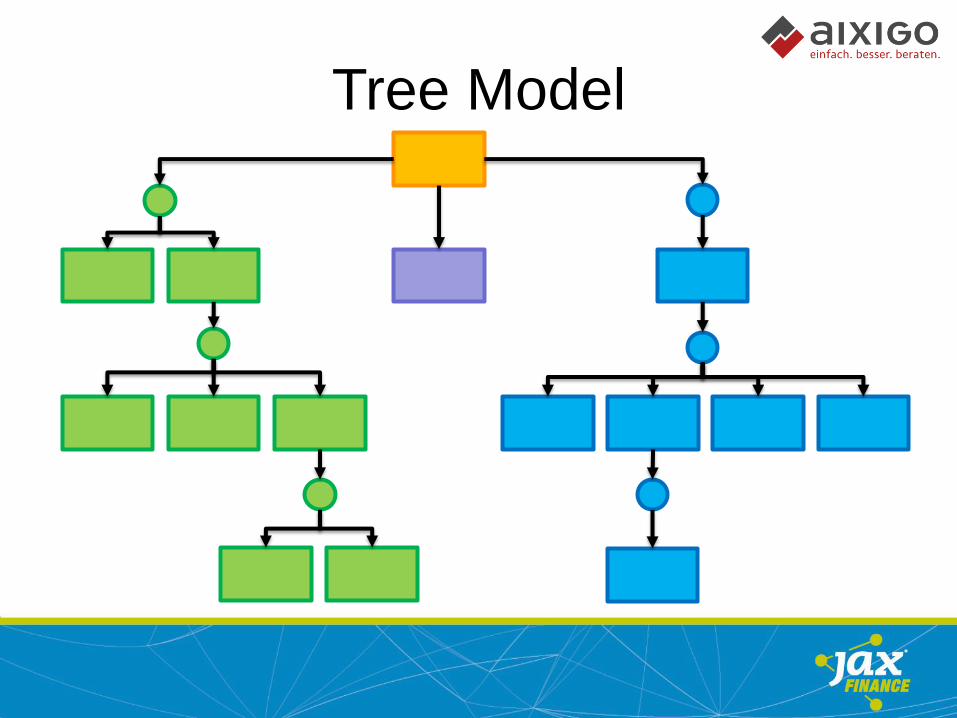
Tree Model
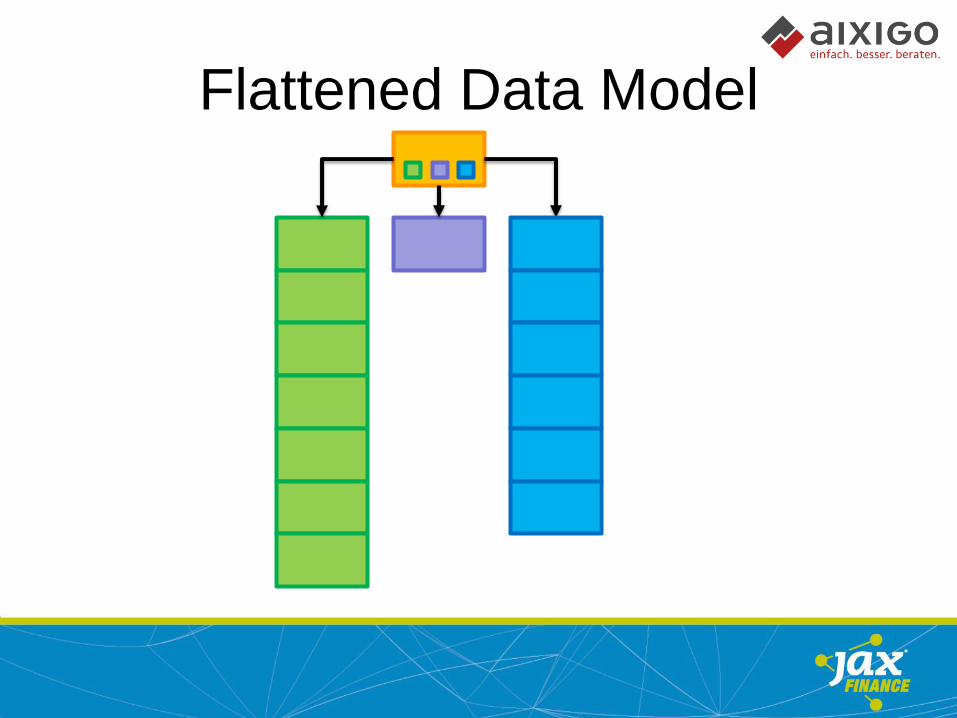
Flattened Data Model
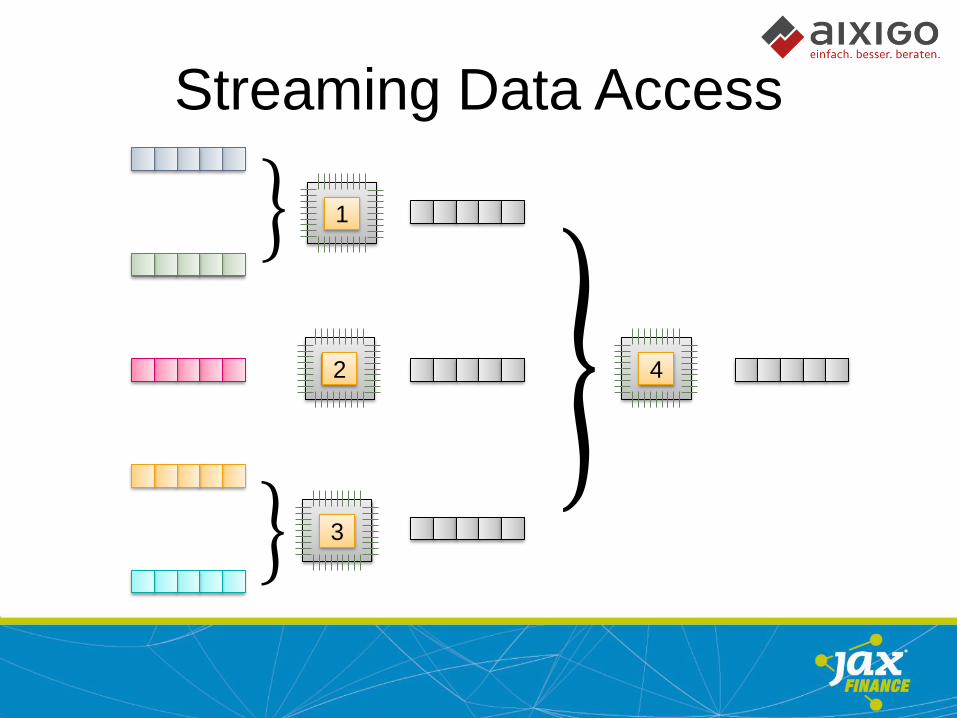
Streaming Data Access
𝑧𝑦𝑥
4
𝑦𝑥
1 𝑥𝑥
3
2
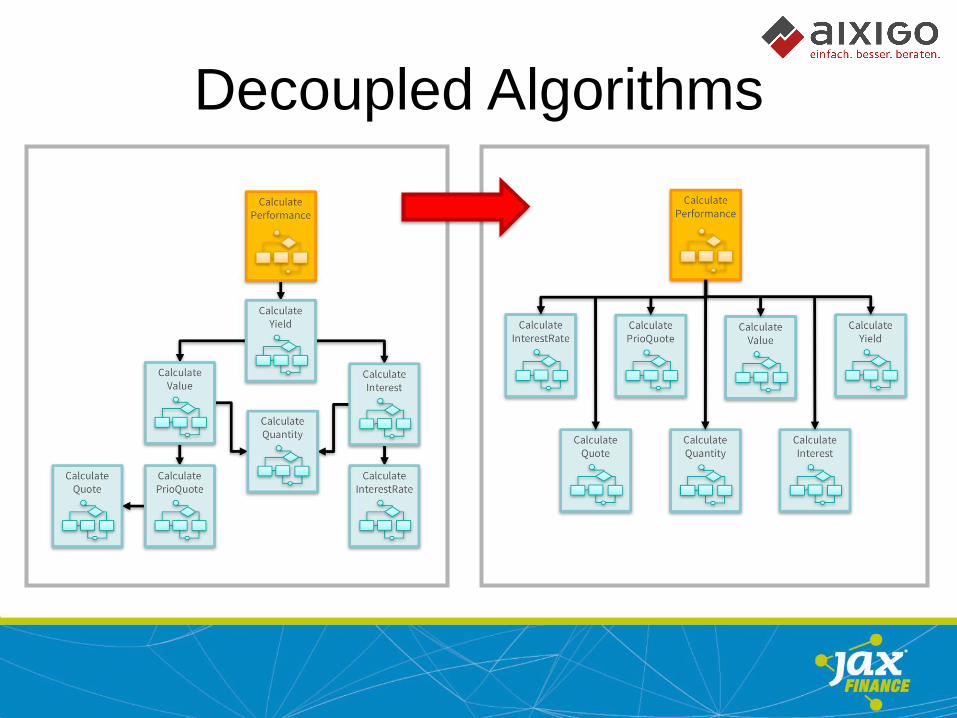
Decoupled Algorithms

• Prefer primitives over classes
• Prefer arrays over object trees
• Process one array at a time

What about
cluster
replication?
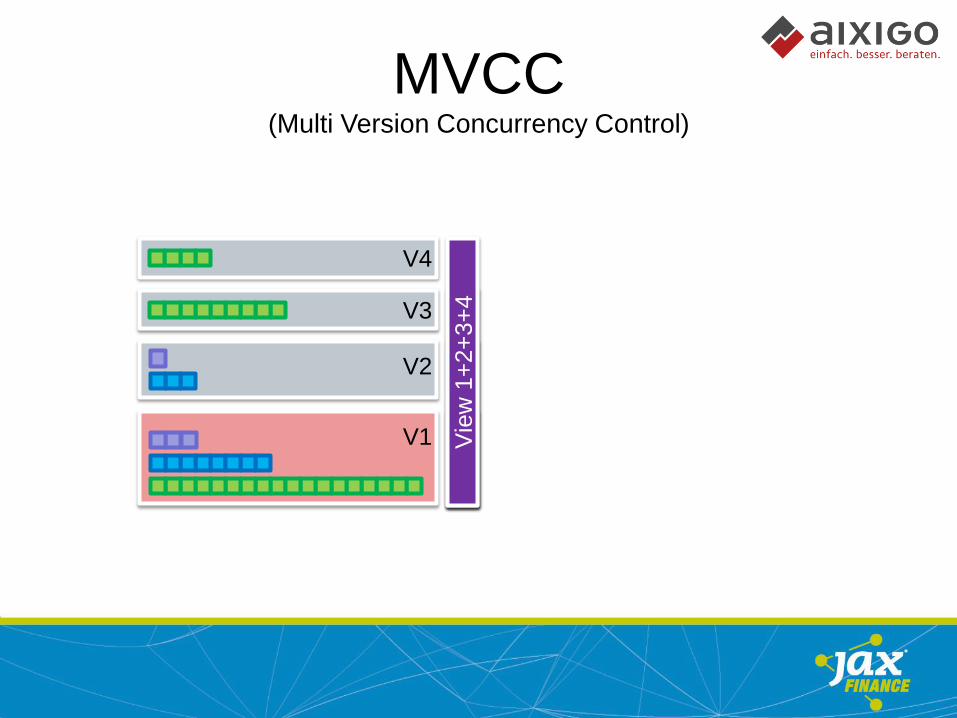
MVCC (Multi Version Concurrency Control)
V1
V2
V3
V4
Vie
w 1
V
iew
1+
2
Vie
w 1
+2+
3
Vie
w 1
+2+
3+
4
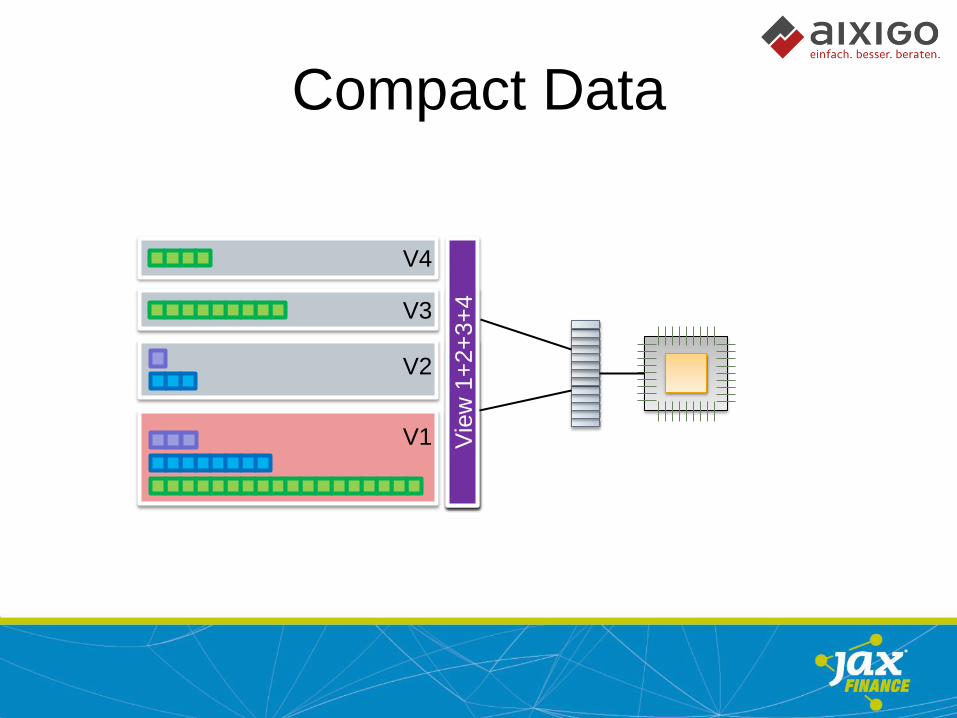
Compact Data
V1
V2
V3
V4
Vie
w 1
V
iew
1+
2
Vie
w 1
+2+
3
Vie
w 1
+2+
3+
4
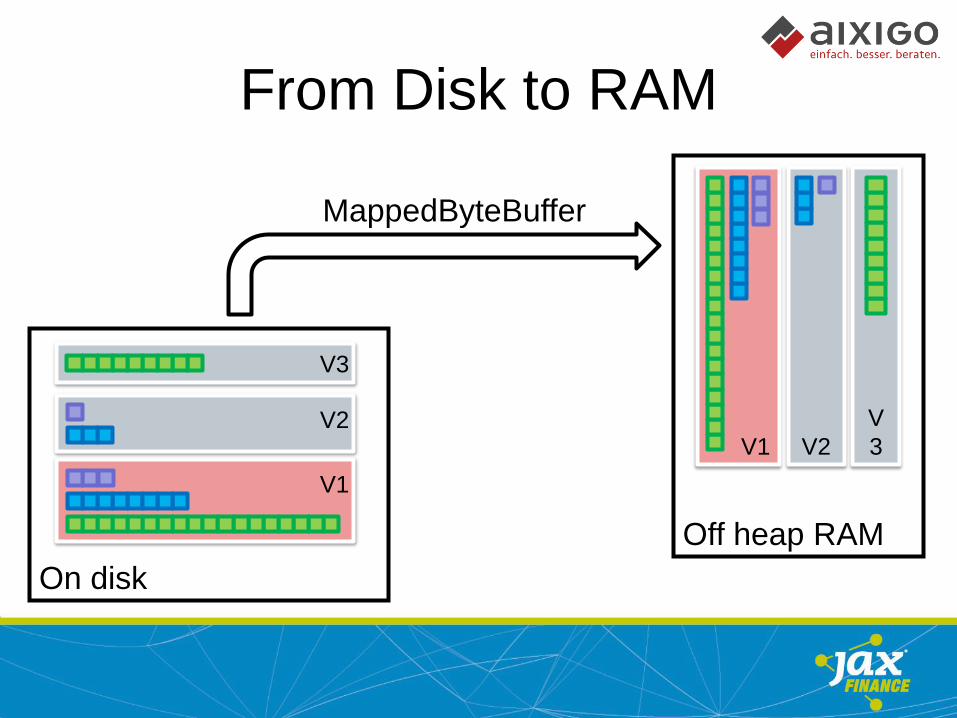
Off heap RAM
On disk
From Disk to RAM
V1
V2
V3
V1 V2
V
3
MappedByteBuffer
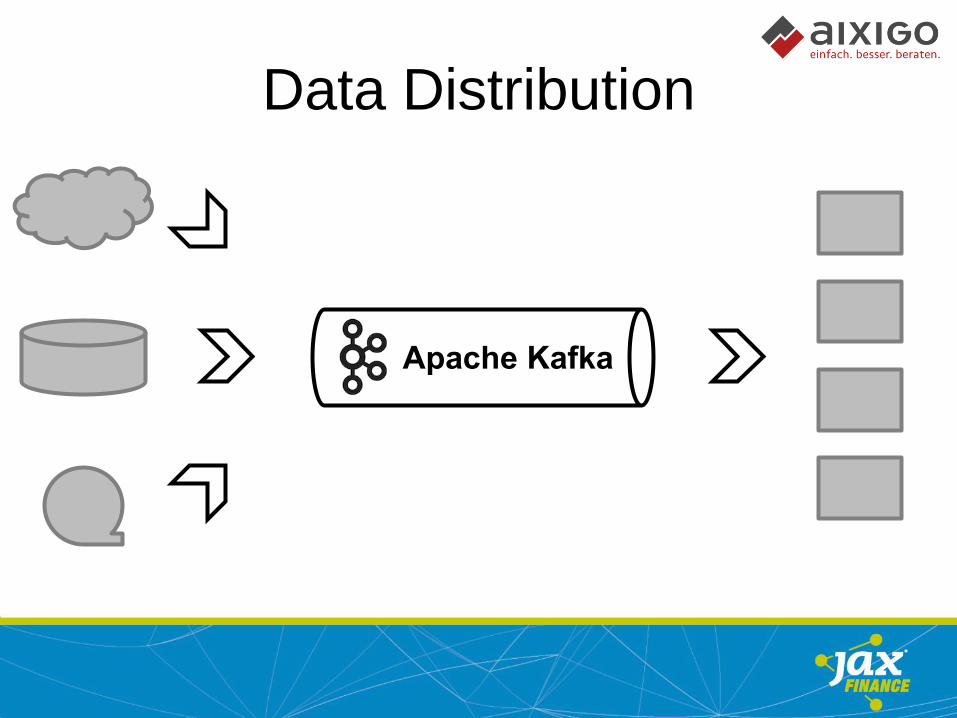
Data Distribution
Apache Kafka
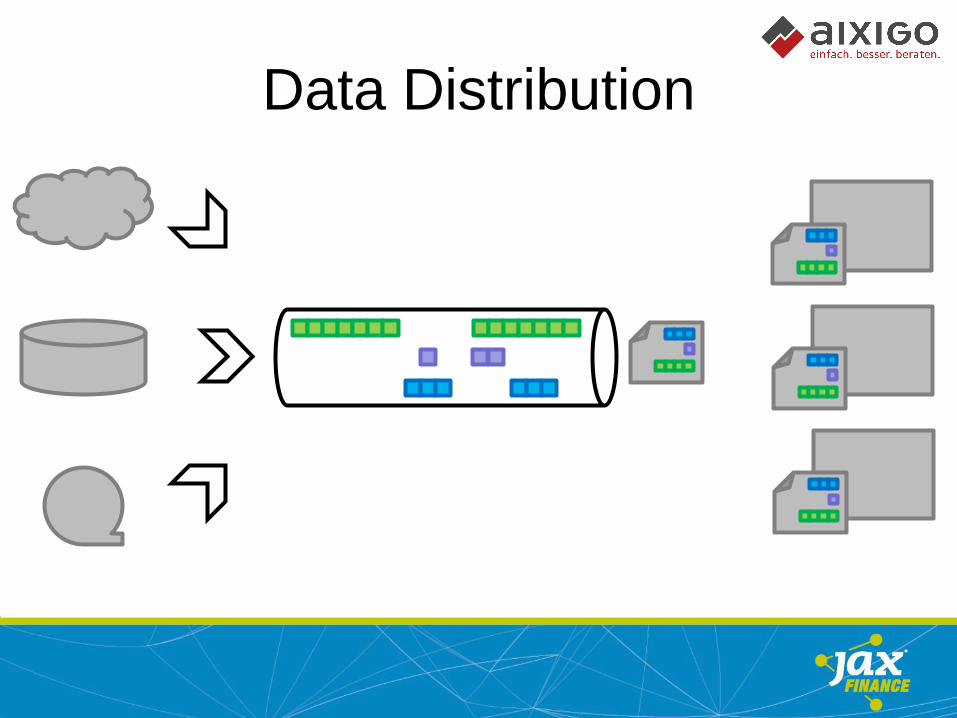
Data Distribution
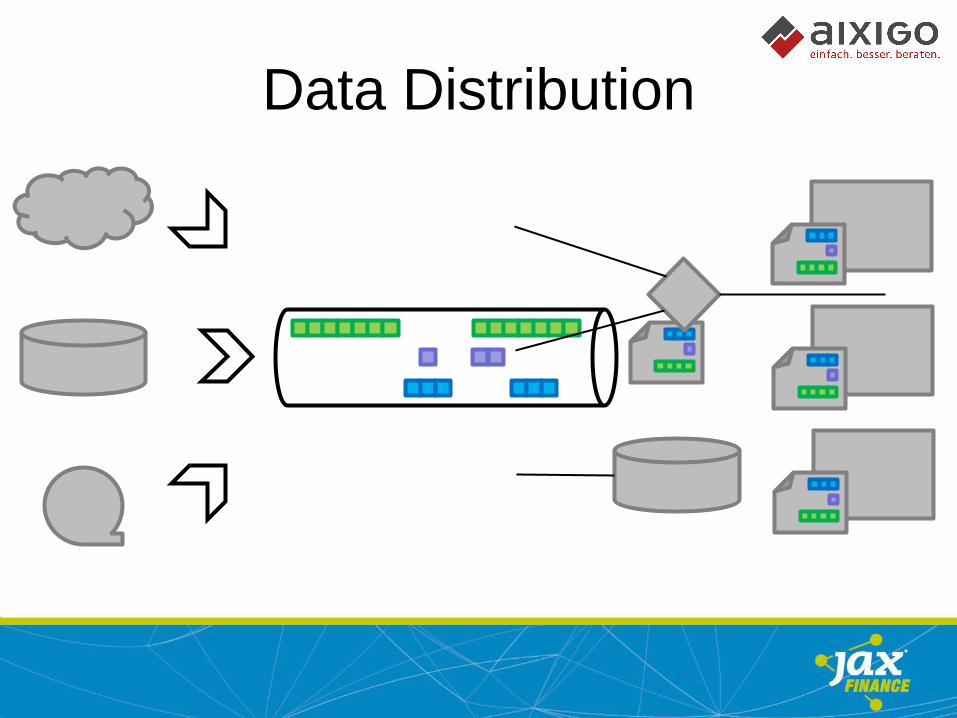
Data Distribution

Summary

• Large speedups through cache
optimized algorithms
• Memory layout it crucial
• Scale by cache replication
@marcusgruendler

Thank
you!





























