Embed Size (px)
Citation preview

Experiments with Automatic Indexing and a RelationalThesaurus in a Chinese Information Retrieval System
Tian-Long Wan, Martha Evens,* and Yeun-Wen WanComputer Science Department, Illinois Institute of Technology, 10 West 31st Street, Chicago, Illinois 60616.E-mail: [email protected]
Yuen-Yuan PaoAbbott Laboratory, Abbott Park, Waukegan, Illinois 60064. E-mail: [email protected]
This article describes a series of experiments with an focused interest on applying techniques developed forinteractive Chinese information retrieval system named English to collections of documents in other languages,CIRS and an interactive relational thesaurus. Two im- we hope that the problems discussed here will prove ofportant issues have been explored: whether thesauri en-
concern to wide sections of the information retrieval com-hance the retrieval effectiveness of Chinese documents,munity. The Tipster research has involved comparisonsand whether automatic indexing can compete with man-
ual indexing in a Chinese information retrieval system. between information retrieval approaches and results inRecall and precision are used to measure and evaluate English and in Japanese. Other research has applied thesethe effectiveness of the system. Statistical analysis of techniques to Arabic information retrieval problemsthe recall and precision measures suggest that the use
(Abu-Salem, 1992; Al-Kharashi & Evens, 1994; Hmeidi,of the relational thesaurus does improve the retrieval1995). Japanese and Arabic, while otherwise very differ-effectiveness both in the automatic indexing environ-
ment and in the manual indexing environment and that ent, are both agglutinating languages with very complexautomatic indexing is at least as good as manual in- morphological structure. In Arabic, subject and objectdexing.
pronouns are often combined with the main verb, whileprepositions and other particles are often combined withthe following nouns. As a result, the type to token ratioIntroductionis much smaller than for English, word frequencies are
Because of the characteristics of the Chinese written lower, and inverse document frequencies are much higher.language, researchers have been more involved in the Chinese differs from English in the opposite direction.exploration of ways to enter data into a Chinese informa- It is a more synthetic language than English, changes intion system, ways to access data, and ways to find word case and gender, and number are usually unmarked in theboundaries than in problems of bibliographic information surface structure, so that individual word frequencies areretrieval (Chen & Chang, 1992; Chang & Lee, 1993;
higher and inverse document frequencies are lower. TheseWu & Tseng, 1993, 1995). Relational thesauri have been
variables are fundamental to most techniques for auto-shown to be useful in increasing recall from information
matic indexing. It seems important, therefore, to investi-retrieval systems in other languages (Wang, Vanden-gate the application of various kinds of approaches todorpe, & Evens, 1985; Abu-Salem, 1992). We set out toautomatic indexing under these circumstances.discover whether the application of relational thesauri in
While the generalization of techniques of automatica Chinese information retrieval system can also enhanceindexing to other languages is extremely problematic,the retrieval results.there are reasons to hope that relational thesauri shouldBecause the DOD Tipster project (TREC, 1992) hasbe as effective in other languages as they are in English(Wang et al., 1985; Abu-Salem, 1992). Similar sets of
* To whom all correspondence should be addressed. lexical-semantic relations have been observed by anthro-pologists in a wide range of languages (Werner &
Received March 3, 1995; revised August 21, 1995; revised June 17, Schoepfle, 1987).1996; accepted February 20, 1997.
Chinese differs from English in yet another way thatimpacts information retrieval. Words in written text com-q 1997 John Wiley & Sons, Inc.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE. 48(12) :1086–1096, 1997 CCC 0002-8231/97/121086-11
1057/ 8N2B$$1057 10-06-97 09:11:59 jasa W: JASIS

monly consist of one, two, three, or four characters, or Sample screens of the User Interface are shown in Figures1 to 4.sometimes more, but there are no word spaces. Thus,
The Inference Engine, written in Borland C, performswords cannot be identified in the trivial manner applicablea physical search using automatic or manual indexes inin English. As a result, it is not clear what Salton’s (1989)support of query execution. The retrieval process beginstraditional definition of automatic indexing in Englishas soon as the user has formulated the query. The parserought to mean for Chinese. To avoid dealing with theputs the query into postorder form and checks that it isword segmentation problem in this project we used awell formed. If there is a problem with the syntax, thetechnical dictionary. Automatic word segmentation is anquery is returned to the user with an error message. Ifimportant problem for all kinds of Chinese natural lan-the query is correct, then it is turned into a bit string withguage processing, however, and it needs to be carrieda ‘‘1’’ in position i , if term i appears in the query, andout effectively if automatic indexing is to be maximallya ‘‘0’’ otherwise. Then the search for documents similareffective. Indeed, in a separate project (Lin & Evens,to the query is begun. Because the document vectors are1995), we have carried out an experiment in word seg-stored in the same bitmap form, the search process is verymentation ourselves.simple. The system does a logical and operation betweenIn 1995, Lin built a Chinese word-segmentation sys-the query vector and each document vector in turn. If thetem. His system, using an eight million-character corpus,result is nonzero, then the number of 1s in the resultattempted to perform word-segmentation in a statisticalvector is counted and used as a similarity measure. Theapproach. Mutual information and t-score are two statisti-document numbers are sorted in order of decreasing simi-cal tools he used in his experiment. The results of hislarity value and the array is handed over to the Userexperiment, which has a very high correct rate of aboveInterface for display to the user. Note that the information98%, has shown the feasibility of solving the Chinesein the thesaurus is used only to enhance the query; it isword segmentation problem with a statistical approach.not used in the retrieval process.Other significant results in this important area can be
The File Management Subsystem, written in Q / Efound in (Wu & Tseng, 1995).Database/VB, provides data access to dBase III databasesThe U.S. Government and the American legal estab-in order to support query construction and document dis-lishment spend enormous amounts of money on manualplay.indexing. But, Salton (Salton, 1968; Salton & McGill,
1983) argues that automatic indexing should perform bet-ter than manual indexing. He (Salton, 1989, p. 277) Previous Research in the Field of Chinese
Information Retrievalclaims, ‘‘The retrieval results that can be obtained withadvanced automatic indexing products are not inferior to In 1988, Lian introduced a technical periodical data-the output generated in controlled, manually performed base retrieval system in China (Lian, 1988). The systemindexing environments.’’ Manual indexing requires so- treated each Chinese character as a word. So, almost 7,000phisticated indexers who have been well trained. These entries were stored in the inverted file. Stop words wereindexers need to have comprehensive and up-to-date not used, so the size of the inverted file was very large.knowledge, because technology evolves quickly. There- In 1989, Shi discussed the problems of entering andfore, there may be much variability in indexing results accessing stored Chinese information in Chinese informa-produced by different indexers. tion retrieval systems. He proposed to lessen the difficulty
In addition, manual indexing is very expensive and of Chinese character entry and information retrieval bytime consuming. It may take months for newspapers and using regular expression searching (Shi, 1989).books to be indexed manually and, thus, it may take In 1992, Lee et al. described the planning and design ofmonths for research results to get to the scholars that a full text retrieval system through the Chinese Videotexneed them. By contrast, automatic indexing is fast and System (CVS) (Lee, Lo, Huang, Liang, & Chen, 1992).inexpensive. We have performed an experiment that sug- The Chinese Videotex Service provided by the Telecom-gests that automatic indexing is a feasible alternative. In munication Office in Taiwan is an interactive service,the section on Experimental Comparisons, we present our which allows clients to retrieve the desired informationevidence that automatic indexing is at least as good as through a telecommunication network. Their informationmanual indexing for Chinese documents as well. retrieval software uses a system called STATUS, devel-
These experiments were performed on CIRS, an exper- oped by Computer Power in Australia. A built-in set ofimental retrieval system that we implemented in the Mi- crossreference synonyms for the proper nouns acts as acrosoft Chinese Windows environment. It consists of medium for the client to search all the synonyms preestab-three major components: the User Interface, the Inference lished for commonly used proper nouns. They also pro-Engine, and a File Management Subsystem. The user In- vide a synonym inquiry service. The user can enter aterface, written in Visual Basic, provides users with the proper noun to query; the system will respond with allfunctions to construct queries, execute queries, and view the synonyms.
In 1992, Chang and Chen proposed a method to effi-the titles and the abstracts of the retrieved documents.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—December 1997 1087
1057/ 8N2B$$1057 10-06-97 09:11:59 jasa W: JASIS

FIG. 1. Edit menu in the query window.
ciently retrieve words in a compressed Chinese-English issues of using relational thesauri in Chinese documentsretrieval and comparing manual indexing with automaticdictionary using Huffman coding. One hundred words
were randomly selected as a sample for testing on a PC- indexing. So, we have studied and completed experimentsinvolving these two issues.AT in their experiment, which concluded with faster data
retrieval and a higher compression rate (Chang & Chen,1992).
Experiments in English Using aIn 1993, Chang and Lee did a survey of the current
Relational Thesaurussituation in the development of Information Retrieval inTaiwan. The technique of full-text searching was applied In 1980, O’Connor (1980) used some lexical relations
in a passage retrieval system. These relations includedin the areas of news, legislation, and literature. The Natu-ral Language Laboratory at the National Tsing Hua Uni- stem-identity, synonymy, generic-specific, whole-part,
and miscellaneous relations. He found that the more rela-versity (Chen & Chang, 1992) has carried out extensivestudies of Chinese text segmentation and Chinese name tions were added, the higher the recall achieved.
Fox (1981) adapted the work of Evens and Smithidentification.We have been unable to identify previous articles in (1978) by adding two relations—predicate and situa-
tional—to their existing lexical relations. The relationsthe field of Chinese information retrieval that explore the
FIG. 2. Query window with a query.
1088 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—December 1997
1057/ 8N2B$$1057 10-06-97 09:11:59 jasa W: JASIS

FIG. 3. Title window.
were regrouped into five categories. All of his experi- lexical relations in five thesauri, and implemented themin the Information Retrieval System (IRS) designed byments were run on the SMART system (Salton, 1968) in
batch mode. The results show that the combination of all Vandendorpe at the Illinois Institute of Technology. Allthese experiments were run in batch mode. The resultsfive categories gave very good results. But omitting the
antonym category improved the retrieval effectiveness show that most lexical relations enhance the retrieval ef-fectiveness. The best result again came from the combina-even more.
In 1983, Yih-Chen Wang (Wang et al., 1985) grouped tion of all the relations except antonymy.
FIG. 4. Abstract window.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—December 1997 1089
1057/ 8N2B$$1057 10-06-97 09:11:59 jasa W: JASIS

FIG. 5. Keyword selection window with the display of related keywords.
The relational thesaurus that we built for our system formation science between June 1993 and April 1994. Tois based on the relations defined by Casagrande and Hale form a set of queries, first we asked three graduate stu-(see the list of the relations in the section on Construction dents in the Computer Science Department at Illinois In-of the Relational Thesaurus) (Casagrande & Hale, 1967; stitute of Technology, who are native speakers of ChineseEvens, Litowitz, Markowitz, Smith, & Werner, 1980). to make up queries related to their studies. A consultantBecause Fox (1981) and Wang (Wang et al., 1985) have from the Science and Technology Information Center inshown that the combination of all relations gave the best Taiwan also supplied some typical queries. The result wasresult of retrieval effectiveness, we also combined all the 76 queries. Forty-six queries were removed from the 76;relations together. The experiments done by both Fox some because they were redundant, others because there(1981) and Wang (Wang et al., 1985) were accomplished were no relevant documents to match the queries. Thirtyin batch mode, but our experiments were run in an inter- queries remained to be used in the experiments. The rele-active mode. We developed a thesaurus navigation screen vance judgements were made by Yuen-Yuan Pao, who hascontaining a keyword list on the left-hand side and related an M.S. degree in computer science and is currently em-terms on the right-hand side. Users can type in any num- ployed by Abbott Laboratories as an R&D programmingber of leading characters. Then, the keywords with the analyst. As soon as he read an abstract, he evaluated eachsame leading characters will appear on the left-hand side of the 30 queries one by one. If he decided that the abstractof the screen. Users choose the desired keyword by click- was a useful response to that query, then he recorded theing on it; its related keywords will appear on the right- relationship in the relevance table that contains the list ofhand side of the screen. Then, users can select those terms abstracts relevant to each query. He went through this entirethey desire to add to their query by clicking on them. A process for each of the 555 abstracts in turn.sample screen is shown in Figure 5. The set of queries is listed below.
Corpus and Queries
We developed a collection of 555 Chinese abstractsfrom (Ko-Chi-Chien-Shiunn, Abstracts inScience and Technology) published by the Science andTechnology Information Center, Republic of China.These included all abstracts involving computer and in-
1090 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—December 1997
1057/ 8N2B$$1057 10-06-97 09:11:59 jasa W: JASIS

distinctive or characteristic attributes Y . Example:notebook computer is portable.
(2) Function: X is defined as a means of effecting Y .Example: mouse: ‘‘with which a cursor can be con-trolled.’’
(3) Spatial: X is oriented spatially with respect to Y .Example: floppy disk drive: ‘‘it is mounted insidea computer.’’
(4) Operational: X is defined with respect to an actionof which it is a characteristic goal or recipient. Ex-ample: data: ‘‘which we enter.’’
(5) Comparison: X is defined in terms of its similarityand/or contrast with Y . Example: mainframe:‘‘they are like PCs, but they are big.’’
(6) Exemplification: X is defined by citing an appro-priate co-occurrent Y , where X is a noun, Y is acharacteristic possessor. Example: dual instructionprocessing: ‘‘Pentium CPU has dual instructionprocessing.’’
(7) Class Inclusion: X is defined with respect to itsmembership in a hierarchical class Y . Example:queue: ‘‘a kind of data structure.’’
(8) Synonymy: X is defined as being equivalent to Y .Example: identification: ‘‘a synonym for recogni-tion.’’
(9) Antonymy: X is defined as being the negation ofY , its opposite. Example: low speed: ‘‘not highspeed.’’
(10) Provenience: X is defined with respect to its sourceY . Example: output: ‘‘we get it from executing ourprogram.’’
(11) Constituent: X is defined as being a constituent orpart of Y . Example: power supply: ‘‘a part of acomputer.’’
Building a relational thesaurus is a great deal of work,so we developed a program to facilitate thesaurus con-struction. When the program is executed, a target keywordappears along with a list of all the other keywords. Here,Construction of the Relational Thesaurusa keyword may be a single character or a phrase with
In the process of constructing a relational thesaurus, multiple Chinese characters. We evaluate any possiblewe used the relations defined by Casagrande and Hale link between the target keyword and the list of candidate(1967) to label relationships between words. Casagrande keywords. When we find a link, we click on the candidate.and Hale studied definitions of everyday objects in Pima The software then stores the target word and the candidateand Papago and extracted a number of relations. We have keyword as a pair (keyword, related word) in a text file.replaced their examples by computer-related terms to This process was repeated for every keyword in the file.make them easier for users to understand. Then, the text file was imported into an intermediate data-
base table shown in Table 1. This table has two fields: onefor keywords, and one for related keywords. Keywords in(1) Attributive: X is defined with respect to one more
TABLE 1. Relevant thesaurus entries.
Target keyword Related keyword
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—December 1997 1091
1057/ 8N2B$$1057 10-06-97 09:11:59 jasa W: JASIS
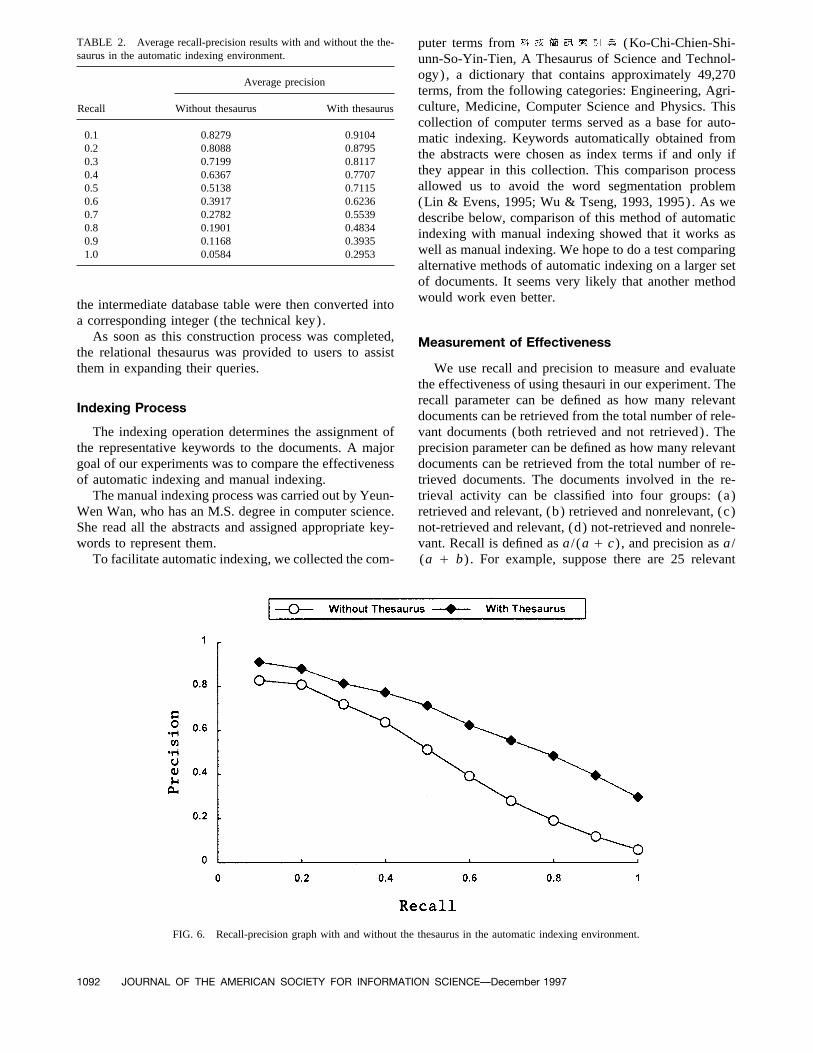
TABLE 2. Average recall-precision results with and without the the- puter terms from (Ko-Chi-Chien-Shi-saurus in the automatic indexing environment. unn-So-Yin-Tien, A Thesaurus of Science and Technol-
ogy), a dictionary that contains approximately 49,270Average precision
terms, from the following categories: Engineering, Agri-culture, Medicine, Computer Science and Physics. ThisRecall Without thesaurus With thesauruscollection of computer terms served as a base for auto-
0.1 0.8279 0.9104 matic indexing. Keywords automatically obtained from0.2 0.8088 0.8795 the abstracts were chosen as index terms if and only if0.3 0.7199 0.8117
they appear in this collection. This comparison process0.4 0.6367 0.7707allowed us to avoid the word segmentation problem0.5 0.5138 0.7115
0.6 0.3917 0.6236 (Lin & Evens, 1995; Wu & Tseng, 1993, 1995). As we0.7 0.2782 0.5539 describe below, comparison of this method of automatic0.8 0.1901 0.4834 indexing with manual indexing showed that it works as0.9 0.1168 0.3935
well as manual indexing. We hope to do a test comparing1.0 0.0584 0.2953alternative methods of automatic indexing on a larger setof documents. It seems very likely that another methodwould work even better.the intermediate database table were then converted into
a corresponding integer ( the technical key).As soon as this construction process was completed, Measurement of Effectiveness
the relational thesaurus was provided to users to assistthem in expanding their queries. We use recall and precision to measure and evaluate
the effectiveness of using thesauri in our experiment. Therecall parameter can be defined as how many relevant
Indexing Processdocuments can be retrieved from the total number of rele-vant documents (both retrieved and not retrieved). TheThe indexing operation determines the assignment of
the representative keywords to the documents. A major precision parameter can be defined as how many relevantdocuments can be retrieved from the total number of re-goal of our experiments was to compare the effectiveness
of automatic indexing and manual indexing. trieved documents. The documents involved in the re-trieval activity can be classified into four groups: (a)The manual indexing process was carried out by Yeun-
Wen Wan, who has an M.S. degree in computer science. retrieved and relevant, (b) retrieved and nonrelevant, (c)not-retrieved and relevant, (d) not-retrieved and nonrele-She read all the abstracts and assigned appropriate key-
words to represent them. vant. Recall is defined as a / (a / c) , and precision as a /(a / b) . For example, suppose there are 25 relevantTo facilitate automatic indexing, we collected the com-
FIG. 6. Recall-precision graph with and without the thesaurus in the automatic indexing environment.
1092 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—December 1997
1057/ 8N2B$$1057 10-06-97 09:11:59 jasa W: JASIS
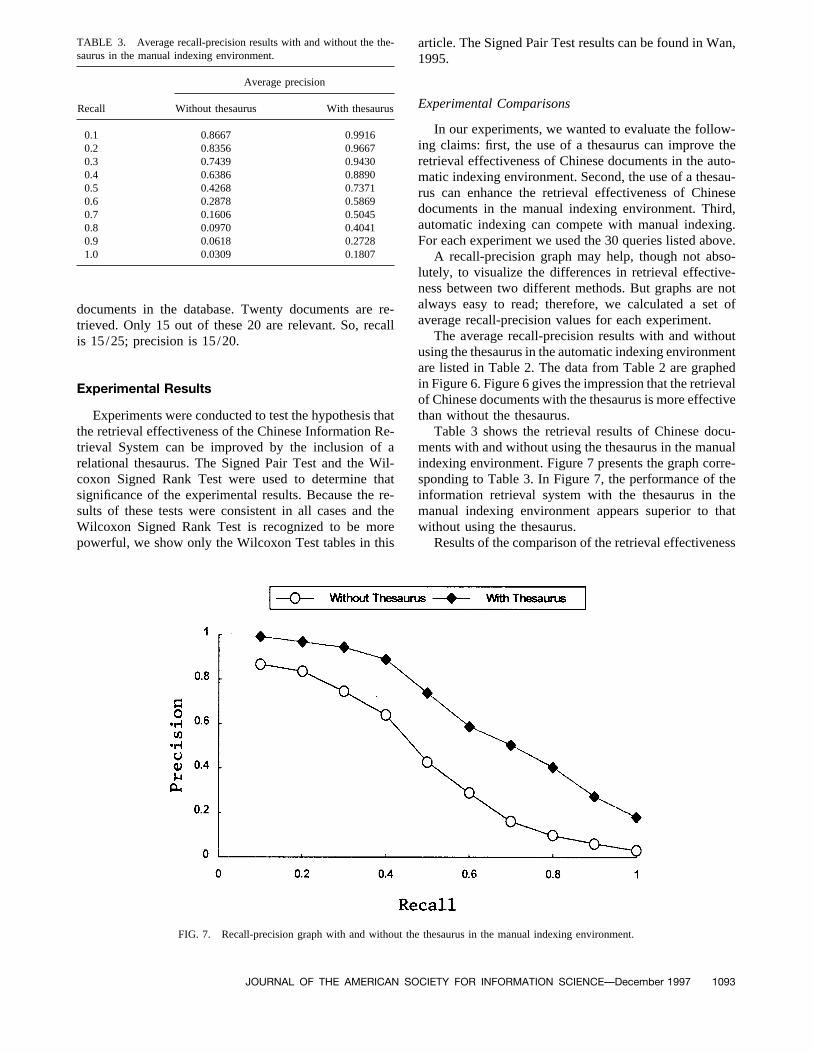
TABLE 3. Average recall-precision results with and without the the- article. The Signed Pair Test results can be found in Wan,saurus in the manual indexing environment. 1995.
Average precision
Experimental ComparisonsRecall Without thesaurus With thesaurus
In our experiments, we wanted to evaluate the follow-0.1 0.8667 0.9916ing claims: first, the use of a thesaurus can improve the0.2 0.8356 0.9667
0.3 0.7439 0.9430 retrieval effectiveness of Chinese documents in the auto-0.4 0.6386 0.8890 matic indexing environment. Second, the use of a thesau-0.5 0.4268 0.7371 rus can enhance the retrieval effectiveness of Chinese0.6 0.2878 0.5869
documents in the manual indexing environment. Third,0.7 0.1606 0.5045automatic indexing can compete with manual indexing.0.8 0.0970 0.4041
0.9 0.0618 0.2728 For each experiment we used the 30 queries listed above.1.0 0.0309 0.1807 A recall-precision graph may help, though not abso-
lutely, to visualize the differences in retrieval effective-ness between two different methods. But graphs are notalways easy to read; therefore, we calculated a set ofdocuments in the database. Twenty documents are re-average recall-precision values for each experiment.trieved. Only 15 out of these 20 are relevant. So, recall
The average recall-precision results with and withoutis 15/25; precision is 15/20.using the thesaurus in the automatic indexing environmentare listed in Table 2. The data from Table 2 are graphedin Figure 6. Figure 6 gives the impression that the retrievalExperimental Resultsof Chinese documents with the thesaurus is more effectivethan without the thesaurus.Experiments were conducted to test the hypothesis that
the retrieval effectiveness of the Chinese Information Re- Table 3 shows the retrieval results of Chinese docu-ments with and without using the thesaurus in the manualtrieval System can be improved by the inclusion of a
relational thesaurus. The Signed Pair Test and the Wil- indexing environment. Figure 7 presents the graph corre-sponding to Table 3. In Figure 7, the performance of thecoxon Signed Rank Test were used to determine that
significance of the experimental results. Because the re- information retrieval system with the thesaurus in themanual indexing environment appears superior to thatsults of these tests were consistent in all cases and the
Wilcoxon Signed Rank Test is recognized to be more without using the thesaurus.Results of the comparison of the retrieval effectivenesspowerful, we show only the Wilcoxon Test tables in this
FIG. 7. Recall-precision graph with and without the thesaurus in the manual indexing environment.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—December 1997 1093
1057/ 8N2B$$1057 10-06-97 09:11:59 jasa W: JASIS
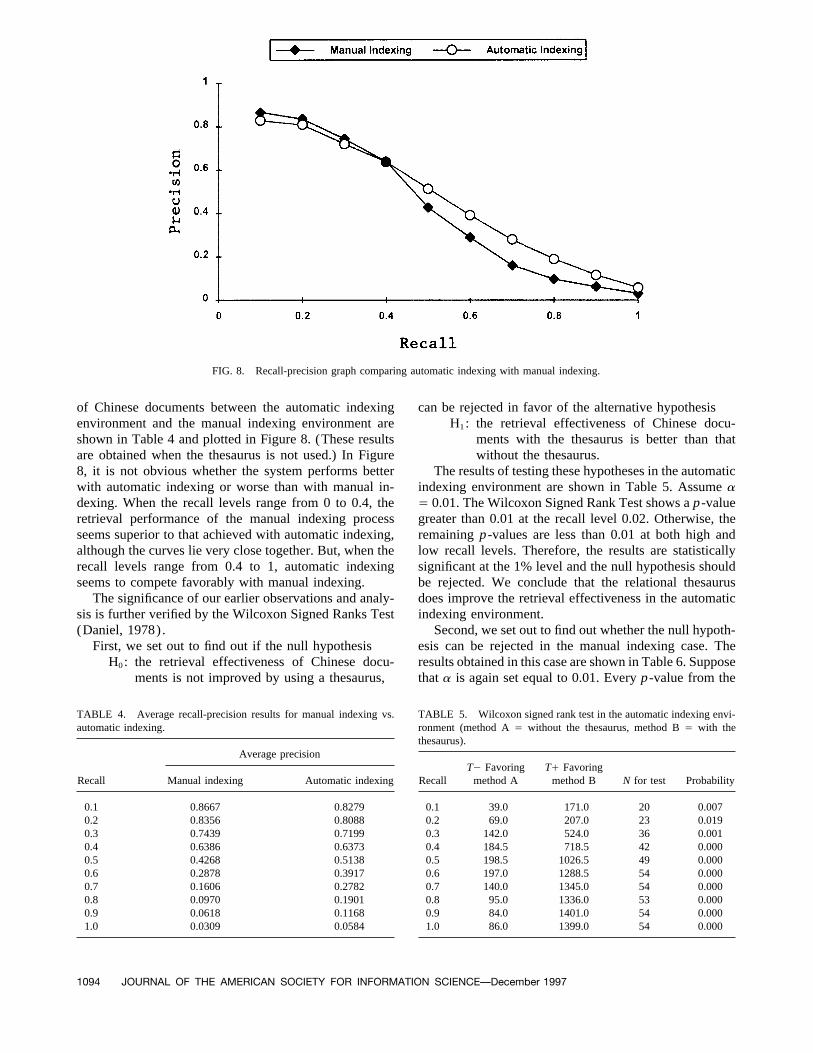
FIG. 8. Recall-precision graph comparing automatic indexing with manual indexing.
of Chinese documents between the automatic indexing can be rejected in favor of the alternative hypothesisH1: the retrieval effectiveness of Chinese docu-environment and the manual indexing environment are
shown in Table 4 and plotted in Figure 8. (These results ments with the thesaurus is better than thatwithout the thesaurus.are obtained when the thesaurus is not used.) In Figure
8, it is not obvious whether the system performs better The results of testing these hypotheses in the automaticindexing environment are shown in Table 5. Assume awith automatic indexing or worse than with manual in-
dexing. When the recall levels range from 0 to 0.4, the Å 0.01. The Wilcoxon Signed Rank Test shows a p-valuegreater than 0.01 at the recall level 0.02. Otherwise, theretrieval performance of the manual indexing process
seems superior to that achieved with automatic indexing, remaining p-values are less than 0.01 at both high andlow recall levels. Therefore, the results are statisticallyalthough the curves lie very close together. But, when the
recall levels range from 0.4 to 1, automatic indexing significant at the 1% level and the null hypothesis shouldbe rejected. We conclude that the relational thesaurusseems to compete favorably with manual indexing.
The significance of our earlier observations and analy- does improve the retrieval effectiveness in the automaticindexing environment.sis is further verified by the Wilcoxon Signed Ranks Test
(Daniel, 1978). Second, we set out to find out whether the null hypoth-esis can be rejected in the manual indexing case. TheFirst, we set out to find out if the null hypothesis
H0: the retrieval effectiveness of Chinese docu- results obtained in this case are shown in Table 6. Supposethat a is again set equal to 0.01. Every p-value from thements is not improved by using a thesaurus,
TABLE 4. Average recall-precision results for manual indexing vs. TABLE 5. Wilcoxon signed rank test in the automatic indexing envi-ronment (method A Å without the thesaurus, method B Å with theautomatic indexing.thesaurus).
Average precisionT0 Favoring T/ Favoring
Recall method A method B N for test ProbabilityRecall Manual indexing Automatic indexing
0.1 0.8667 0.8279 0.1 39.0 171.0 20 0.0070.2 69.0 207.0 23 0.0190.2 0.8356 0.8088
0.3 0.7439 0.7199 0.3 142.0 524.0 36 0.0010.4 184.5 718.5 42 0.0000.4 0.6386 0.6373
0.5 0.4268 0.5138 0.5 198.5 1026.5 49 0.0000.6 197.0 1288.5 54 0.0000.6 0.2878 0.3917
0.7 0.1606 0.2782 0.7 140.0 1345.0 54 0.0000.8 95.0 1336.0 53 0.0000.8 0.0970 0.1901
0.9 0.0618 0.1168 0.9 84.0 1401.0 54 0.0001.0 86.0 1399.0 54 0.0001.0 0.0309 0.0584
1094 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—December 1997
1057/ 8N2B$$1057 10-06-97 09:11:59 jasa W: JASIS
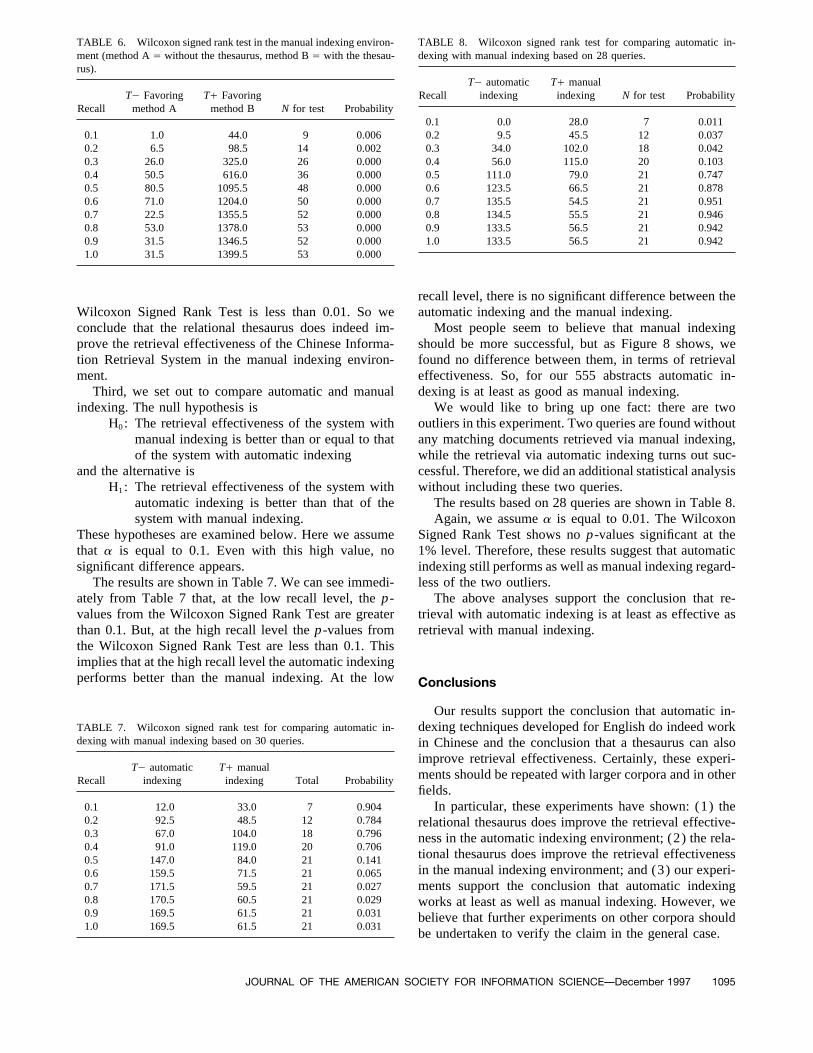
TABLE 6. Wilcoxon signed rank test in the manual indexing environ- TABLE 8. Wilcoxon signed rank test for comparing automatic in-dexing with manual indexing based on 28 queries.ment (method A Å without the thesaurus, method B Å with the thesau-
rus).T0 automatic T/ manual
Recall indexing indexing N for test ProbabilityT0 Favoring T/ FavoringRecall method A method B N for test Probability
0.1 0.0 28.0 7 0.0110.2 9.5 45.5 12 0.0370.1 1.0 44.0 9 0.006
0.2 6.5 98.5 14 0.002 0.3 34.0 102.0 18 0.0420.4 56.0 115.0 20 0.1030.3 26.0 325.0 26 0.000
0.4 50.5 616.0 36 0.000 0.5 111.0 79.0 21 0.7470.6 123.5 66.5 21 0.8780.5 80.5 1095.5 48 0.000
0.6 71.0 1204.0 50 0.000 0.7 135.5 54.5 21 0.9510.8 134.5 55.5 21 0.9460.7 22.5 1355.5 52 0.000
0.8 53.0 1378.0 53 0.000 0.9 133.5 56.5 21 0.9421.0 133.5 56.5 21 0.9420.9 31.5 1346.5 52 0.000
1.0 31.5 1399.5 53 0.000
recall level, there is no significant difference between theautomatic indexing and the manual indexing.Wilcoxon Signed Rank Test is less than 0.01. So we
conclude that the relational thesaurus does indeed im- Most people seem to believe that manual indexingshould be more successful, but as Figure 8 shows, weprove the retrieval effectiveness of the Chinese Informa-
tion Retrieval System in the manual indexing environ- found no difference between them, in terms of retrievaleffectiveness. So, for our 555 abstracts automatic in-ment.
Third, we set out to compare automatic and manual dexing is at least as good as manual indexing.We would like to bring up one fact: there are twoindexing. The null hypothesis is
H0: The retrieval effectiveness of the system with outliers in this experiment. Two queries are found withoutany matching documents retrieved via manual indexing,manual indexing is better than or equal to that
of the system with automatic indexing while the retrieval via automatic indexing turns out suc-cessful. Therefore, we did an additional statistical analysisand the alternative is
H1: The retrieval effectiveness of the system with without including these two queries.The results based on 28 queries are shown in Table 8.automatic indexing is better than that of the
system with manual indexing. Again, we assume a is equal to 0.01. The WilcoxonSigned Rank Test shows no p-values significant at theThese hypotheses are examined below. Here we assume
that a is equal to 0.1. Even with this high value, no 1% level. Therefore, these results suggest that automaticindexing still performs as well as manual indexing regard-significant difference appears.
The results are shown in Table 7. We can see immedi- less of the two outliers.The above analyses support the conclusion that re-ately from Table 7 that, at the low recall level, the p-
values from the Wilcoxon Signed Rank Test are greater trieval with automatic indexing is at least as effective asretrieval with manual indexing.than 0.1. But, at the high recall level the p-values from
the Wilcoxon Signed Rank Test are less than 0.1. Thisimplies that at the high recall level the automatic indexingperforms better than the manual indexing. At the low Conclusions
Our results support the conclusion that automatic in-TABLE 7. Wilcoxon signed rank test for comparing automatic in- dexing techniques developed for English do indeed workdexing with manual indexing based on 30 queries. in Chinese and the conclusion that a thesaurus can also
improve retrieval effectiveness. Certainly, these experi-T0 automatic T/ manual
ments should be repeated with larger corpora and in otherRecall indexing indexing Total Probabilityfields.
0.1 12.0 33.0 7 0.904 In particular, these experiments have shown: (1) the0.2 92.5 48.5 12 0.784 relational thesaurus does improve the retrieval effective-0.3 67.0 104.0 18 0.796 ness in the automatic indexing environment; (2) the rela-0.4 91.0 119.0 20 0.706
tional thesaurus does improve the retrieval effectiveness0.5 147.0 84.0 21 0.141in the manual indexing environment; and (3) our experi-0.6 159.5 71.5 21 0.065
0.7 171.5 59.5 21 0.027 ments support the conclusion that automatic indexing0.8 170.5 60.5 21 0.029 works at least as well as manual indexing. However, we0.9 169.5 61.5 21 0.031 believe that further experiments on other corpora should1.0 169.5 61.5 21 0.031
be undertaken to verify the claim in the general case.
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—December 1997 1095
1057/ 8N2B$$1057 10-06-97 09:11:59 jasa W: JASIS

Daniel, W. (1978). Applied nonparametric statistics. Boston MA:Future ResearchHoughton Mifflin Company.
Evens, M., Litowitz, B., Markowitz, J., Smith, R., & Werner, O. (1980).Wu and Tseng (1995) implemented an automatic Chi-Lexical-semantic relations: A comparative survey, Edmonton, Al-nese text segmentation system. Here at Illinois Instituteberta: Linguistic Research Inc.
of Technology Lin and Evens (1995) have also performed Evens, M., & Smith, R. (1978). A lexicon for a computer question-automatic segmentation experiments. It is worth compar- answering system. American Journal of Computational Linguistics,
Microfiche 83, 1–98.ing the retrieval effectiveness between a precoordinated,Fox, E. (1981). Lexical relations: Enhancing effectiveness of informa-controlled indexing language environment and a postco-
tion retrieval systems. ACM SIGIR Forum, 15, 5–36.ordinated indexing language environment. Hmeidi, I. (1995). Design and implementation of automatic word and
In our experiment, all the query keywords had equal phrase indexing for information retrieval with Arabic documents.Unpublished Ph.D. dissertation, Chicago, IL: Department of Com-weight. Fox (1981) gave less weight to the related key-puter Science, Illinois Institute of Technology.words, so the related keywords do not outweigh the origi-
Jones, J., Gatford, M., Robertson, S., Hancock-Beaulieu, M., Secker,nal query keywords. It would be interesting to see whatJ., & Walker, S. (1995). Interactive thesaurus navigation: Intelligence
results can be obtained with Fox’ methods. Additionally, rules OK? Journal of the American Society for Information Science,we can also allow users to adjust the weight of all key- 46, 52–59.
Lee, Y. S., Lo, B. R., Huang, S. F., Liang, S. W., & Chen, Y. C. (1992).words based on how they rate the importance of eachThe planning and designing of full text retrieval system through Chi-keyword. That may lead to more satisfactory query en-nese videotex system. The Bimonthly Journal of Telecommunication
hancement. Research, Taiwan, 22, 461–469 (in Chinese) .Of course, we plan to use our system in a larger experi- Lian, Y. (1988). Technical periodicals data base retrieval system. Pro-
ceedings of 1988 International Conference on Computer Processingment involving 5 to 10 times as many abstracts. Now thatof Chinese and Oriental Languages, Toronto, Canada, 367–370.the first author has returned to teach in Taiwan, it may
Lin, W. H., & Evens, M. (1995). Statistical approaches to Chinese wordbe possible also to obtain enough expertise in other fields segmentation. Proceedings of the Sixth Midwest Artificial Intelligenceto collect queries and relevance judgements. and Cognitive Science Society Conference, Carbondale, IL, 83–87.
To facilitate thesaurus navigation, we can develop our O’Connor, J. (1980). Answer-passage retrieval by text searching. Jour-nal of the American Society for Information Science, 31, 227–239.thesaurus in a hypertext format. This implementation
Salton, G. (1968). Automatic information organization and retrieval.might allow users to access and manipulate the thesaurusNew York: McGraw-Hill, Inc.
more easily (Jones et al., 1995). Salton, G. (1989). Automatic text processing: The transformation, anal-ysis, and retrieval of information by computer. Reading, MA: Addi-son-Wesley Publishing Company, Inc.
Salton, G., & McGill, M. J. (1983). Introduction to Modern InformationReferencesRetrieval. New York: McGraw-Hill Book Company.
Shi, Y. (1989). Regular expression searching in Chinese informationAbu-Salem, H. (1992). A microcomputer based Arabic bibliographic retrieval. Ph.D Dissertation. Berkeley, CA: Library and Information
information retrieval system with relational thesauri, Unpublished Studies, University of California at Berkeley, CA.Ph.D. Dissertation. Chicago, IL: Department of Computer Science, TREC. (1992). Proceedings of the text retrieval conference, NationalIllinois Institute of Technology, Chicago, IL. Institute of Standards and Technology, Special Publication 500-207,
Al-Kharashi, I., & Evens, M. (1994). Words, stems, and roots in an Washington, November, 1992.Arabic information retrieval system. Journal of the American Society Wan, T.-L. (1995). Experiments with automatic indexing and a Rela-for Information Science, 45, 548–560. tional Thesaurus in a Chinese Information Retrieval System. Unpub-
Casagrande, J., & Hale, K. (1967). Semantic relations in Papago folk lished Ph.D. Dissertation, Chicago, IL: Department of Computer Sci-definitions. In D. Hymes, & W. E. Bittle, Eds., Studies in Southwest- ence, Illinois Institute of Technology.ern Ethnolinguistics (pp. 165–193). The Hague, The Netherlands: Wang, Y.-C., Vandendorpe, J. R., & Evens, M. (1985). Relational the-Mouton & Co., Publishers. sauri in information retrieval. Journal of the American Society for
Chang, C. C., & Chen, Y. W. (1992). Looking up words in a com- Information Science, 36, 15–27.pressed Chinese-English dictionary. Journal of Electrical Engi- Werner, O., & Schoepfle, G. M. 1987. Systematic fieldwork. Newburyneering, 35, 145–154 (in Chinese) . Park, CA: Sage Publications.
Chang, C. S., & Lee, P. C. (1993). The situation and development of Wu, Z., & Tseng, G. (1993). Chinese text segmentation for text re-information retrieval. Computers and Communication, Taiwan, 17, trieval: Achievements and problems. Journal of the American Society3–6 (in Chinese) . for Information Science, 44, 532–542.
Chen, J. N., & Chang, C. C. (1992). A Chinese character retrieval Wu, Z., & Tseng, G. (1995). ACTS: An automatic Chinese text segmen-scheme using Shuang Pinyin. Journal of Information Science and tation system for full text retrieval. Journal of the American Society
for Information Science, 46, 83–96.Engineering, 83, 487–507.
1096 JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE—December 1997
1057/ 8N2B$$1057 10-06-97 09:11:59 jasa W: JASIS











![Derwent World Patents Index · Introduction The Polymer Indexing Thesaurus provides an ... UF Acetyl cyclohexyl sulfonyl peroxide R00327 Acetylene [polymer formers] BT Acetylenic](https://img.dokumen.tips/doc/110x75/5f07a3397e708231d41dfb4d/derwent-world-patents-index-introduction-the-polymer-indexing-thesaurus-provides.jpg)

















