Embed Size (px)
Citation preview

ICONIP'06 1
Eukaryotic Protein SubcellularLocalization Based on Local
Pairwise Profile Alignment SVM
Jian Guo and Man Wai MAKDept. of Electronic and Information
Engineering, The Hong Kong Polytechnic University
Sun Yuan KUNGDept. of Electrical Engineering,
Princeton University

ICONIP'06 2
Outline
• Why Subcellular Localization?• Feature Extraction
• By aligning protein sequences• By aligning the profiles of protein sequences
• 1-vs-rest SVM Classifiers• Results and Conclusions
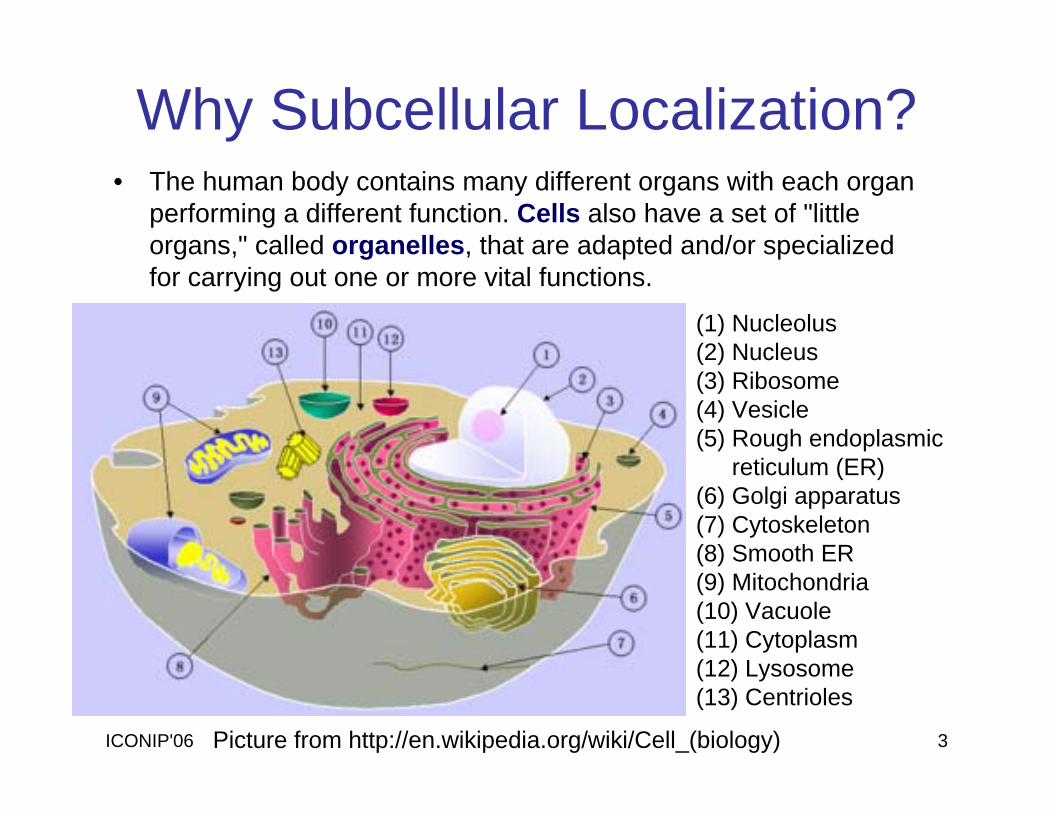
ICONIP'06 3
Why Subcellular Localization?• The human body contains many different organs with each organ
performing a different function. Cells also have a set of "little organs," called organelles, that are adapted and/or specialized for carrying out one or more vital functions.
(1) Nucleolus(2) Nucleus(3) Ribosome (4) Vesicle (5) Rough endoplasmic
reticulum (ER)(6) Golgi apparatus(7) Cytoskeleton(8) Smooth ER(9) Mitochondria (10) Vacuole(11) Cytoplasm (12) Lysosome(13) Centrioles
Picture from http://en.wikipedia.org/wiki/Cell_(biology)
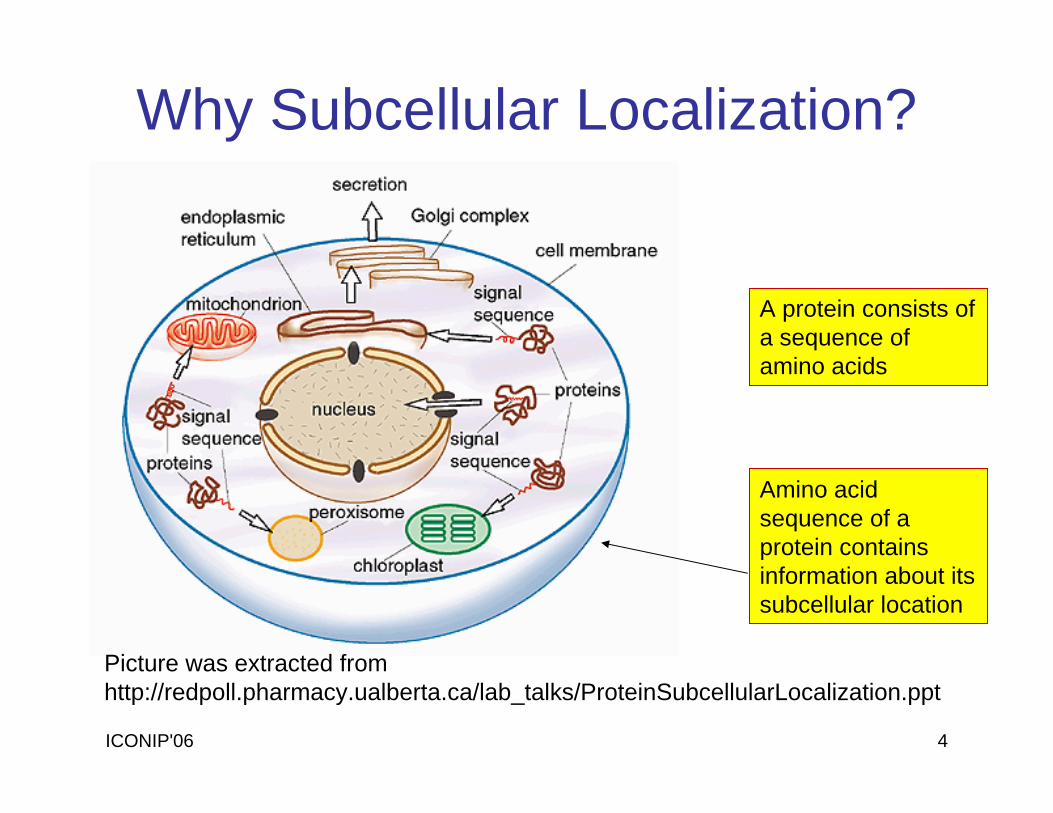
ICONIP'06 4
Amino acid sequence of a protein contains information about its subcellular location
Why Subcellular Localization?
A protein consists of a sequence of amino acids
Picture was extracted fromhttp://redpoll.pharmacy.ualberta.ca/lab_talks/ProteinSubcellularLocalization.ppt

ICONIP'06 5
• Knowledge of subcellular location of proteins has important implication to drug design and discovery of drug targets.
• However, determination of subcellular localization via experimental processes is often time-consuming and laborious.
• This motivates the prediction of subcellular locations through amino acid sequences.
MITILEKISAIESEMARTQKNKATSAHLGLLKANVAKLRRELISPKGGGGGTGEAGFEVAKTGDARVGFVIEHVLNDEDVVQIVKKV…….
Subcellular LocationPredictor
SubcellularLocation
Why Subcellular Localization?

ICONIP'06 6
Feature Extraction• Because most classifiers work on numbers instead of
strings, we need to convert sequences to numbers or vectors.
• This can be solved by kernel methods
String space3,2,1, ),( )()( =ζ jiSS ji
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
0.15.02.05.00.18.02.08.00.1
K
K
K
K
LLKANKNKATSAHLA
LLKANKAKATSLHLG
LLKANKNKATSAHLG
=
=
=
)3(
)2(
)1(
SSS
Pairwisesimilarity scores
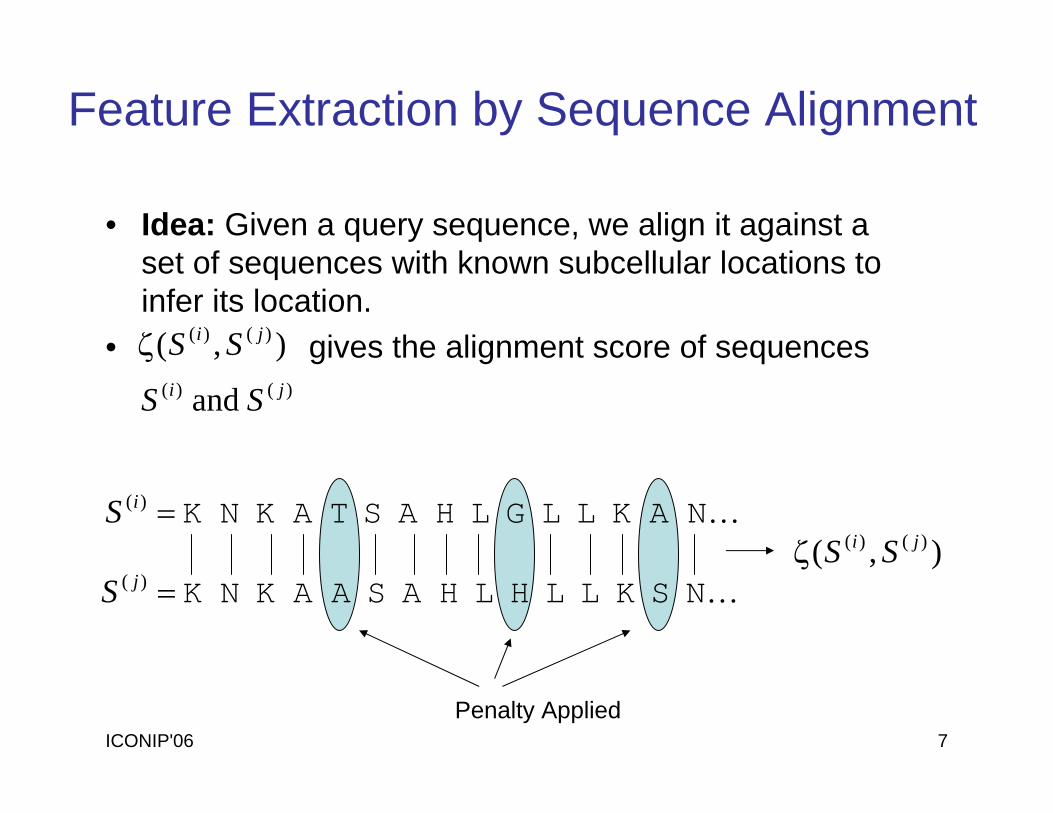
ICONIP'06 7
• Idea: Given a query sequence, we align it against a set of sequences with known subcellular locations to infer its location.
• gives the alignment score of sequences ),( )()( ji SSζ
and )()( ji SS
Feature Extraction by Sequence Alignment
KNA KLLGLHAST A K N K=)(iS
KNS KLLHLHASA A K N K=)( jS ),( )()( ji SSζ
Penalty Applied

ICONIP'06 8
• Five possible kernels:
( )( )∑=
≤≤
≤≤
ζζ=
+ζζ=
+ζ=
ζζ=
ζ=
T
t
tjtiji
dljli
Tl
ji
djiji
ljli
Tl
ji
jiji
SSSSSSK
SSSSSSK
SSSSK
SSSSSSK
SSSSK
1
)()()()()()(seq5
)()()()(
1
)()(seq4
)()()()(seq3
)()()()(
1
)()(seq2
)()()()(seq1
),(),(),(
1),(),(max),(
1),(),(
),(),(max),(
),(),(
T is the number of training sequences with known subcellular location
Feature Extraction by Sequence Alignment
Emphasize/deemphasize off-diagonalelements
Dot product: , )()( >ζζ< jirr
Special case of seq
5K
),( )1()( SS iζ
)(iζr
),( )()( Ti SSζ
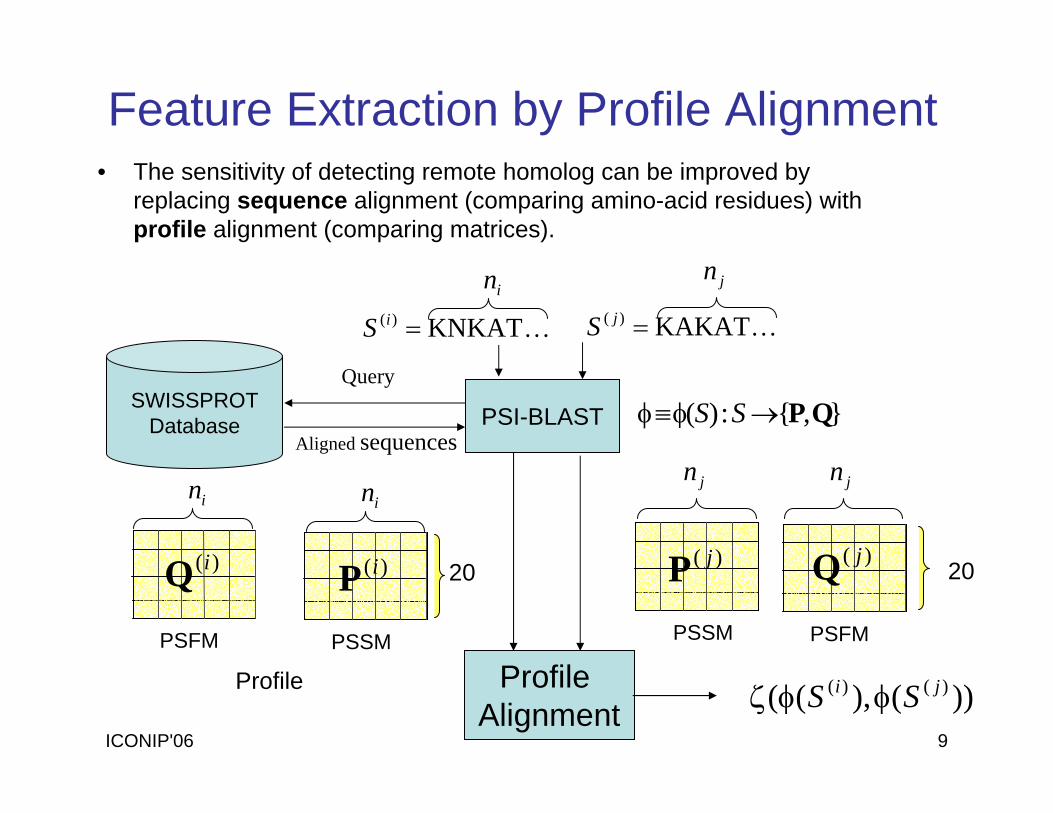
ICONIP'06 9
Feature Extraction by Profile Alignment• The sensitivity of detecting remote homolog can be improved by
replacing sequence alignment (comparing amino-acid residues) with profile alignment (comparing matrices).
Query
Aligned sequences
SWISSPROTDatabase PSI-BLAST
)(iP 20
Profile
)( jP 20
KKNKAT)( =iS KKAKAT)( =jS
Profile Alignment
},{:)( QP→φ≡φ SS
PSSM PSSM
)(iQPSFM
)( jQPSFM
in jnin jn
in jn
))(),(( )()( ji SS φφζ

ICONIP'06 10
Feature Extraction by Profile Alignment• PSSM (Position-Specific Scoring Matrix):
– The (i,j)-th entry represents the likelihood score of amino acid in the j-th position of the query sequence being mutated to amino acid typei during the evolution process.
L
Pos
ition
20 Amino Acid4)8pos|(3)1pos|(−==→−==→
HVScoreHVScore
)(iP

ICONIP'06 11
Feature Extraction by Profile Alignment• PSFM (Position-Specific Frequency Matrix):
– The (i,j)-th entry represents the chance of having amino acid type i in position j of the query sequence.
20 Amino Acid
L
Pos
ition
36.0)1pos|H'' AA( ===P
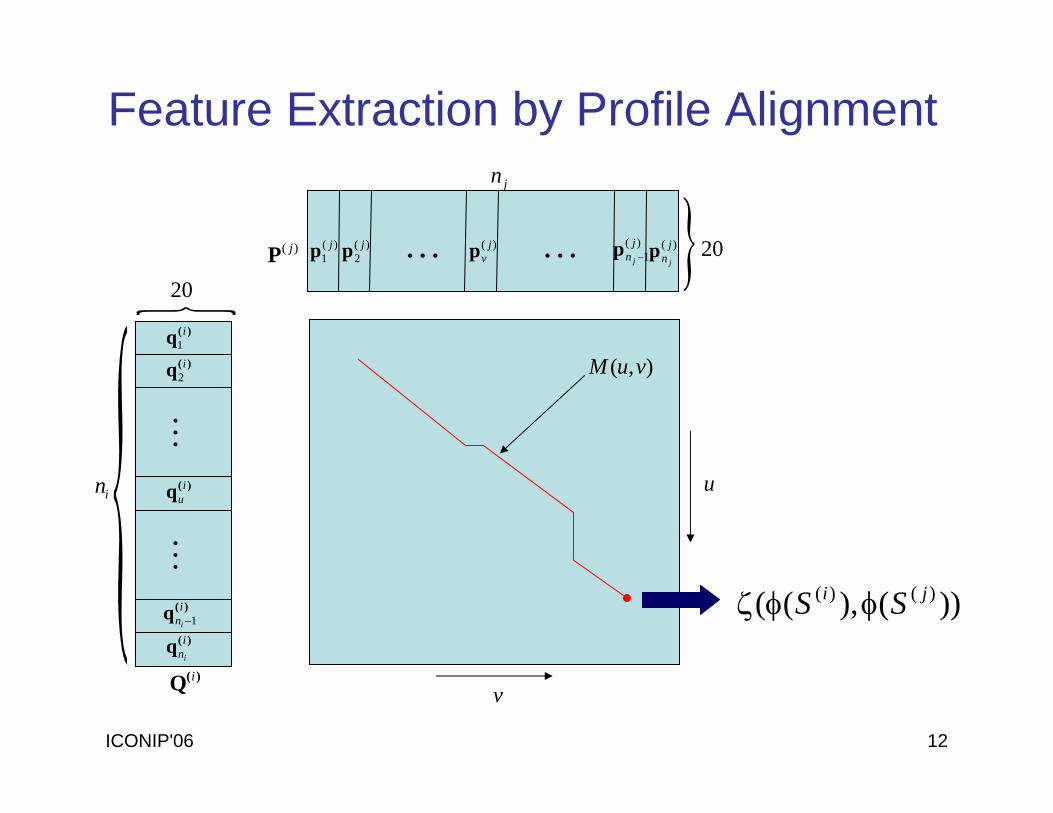
ICONIP'06 12
)(q i1
)(q i2
)(q iu
)(q ini 1−
)(q ini
)(Q i
}20
in
M
M
)( jvp)(
1jp )(
2jp )(
1j
n j −p )( j
n jp
jn
}20L L)( jP
),( vuM
u
v
))(),(( )()( ji SS φφζ
Feature Extraction by Profile Alignment

ICONIP'06 13
Score for best path
Sequence 1
Seq
uenc
e 2
100 200 300 400 500
50
100
150
200
250
0
2
4
6
8
10
12
14
16
18
Feature Extraction by Profile Alignment

ICONIP'06 14
Profile Alignment KernelsDenote the operation of PSI-BLAST search as
},{)( )()()()( iiii S QP→φ≡φ
The 5 profile alignment kernels are defined as
( )( )∑=
≤≤
≤≤
φφζφφζ=φφ
+φφζφφζ=φφ
+φφζ=φφ
φφζφφζ=φφ
φφζ=φφ
T
t
tjtiji
dljli
Tl
ji
djiji
ljli
Tl
ji
jiji
SSK
SSK
SSK
SSK
SSK
1
)()()()()()(pro5
)()()()(
1
)()(pro4
)()()()(pro3
)()()()(
1
)()(pro2
)()()()(pro1
),(),())(),((
1),(),(max))(),((
1),())(),((
),(),(max))(),((
),())(),((
PSSM PSFM

ICONIP'06 15
Sequence Kernels Vs. Profile Kernels
SequenceKernels
ProfileKernels ( )
( )∑=
≤≤
≤≤
φφζφφζ=φφ
+φφζφφζ=φφ
+φφζ=φφ
φφζφφζ=φφ
φφζ=φφ
T
t
tjtiji
dljli
Tl
ji
djiji
ljli
Tl
ji
jiji
SSK
SSK
SSK
SSK
SSK
1
)()()()()()(pro5
)()()()(
1
)()(pro4
)()()()(pro3
)()()()(
1
)()(pro2
)()()()(pro1
),(),())(),((
1),(),(max))(),((
1),())(),((
),(),(max))(),((
),())(),((
( )( )∑=
≤≤
≤≤
ζζ=
+ζζ=
+ζ=
ζζ=
ζ=
T
t
tjtiji
dljli
Tl
ji
djiji
ljli
Tl
ji
jiji
SSSSSSK
SSSSSSK
SSSSK
SSSSSSK
SSSSK
1
)()()()()()(seq5
)()()()(
1
)()(seq4
)()()()(seq3
)()()()(
1
)()(seq2
)()()()(seq1
),(),(),(
1),(),(max),(
1),(),(
),(),(max),(
),(),(
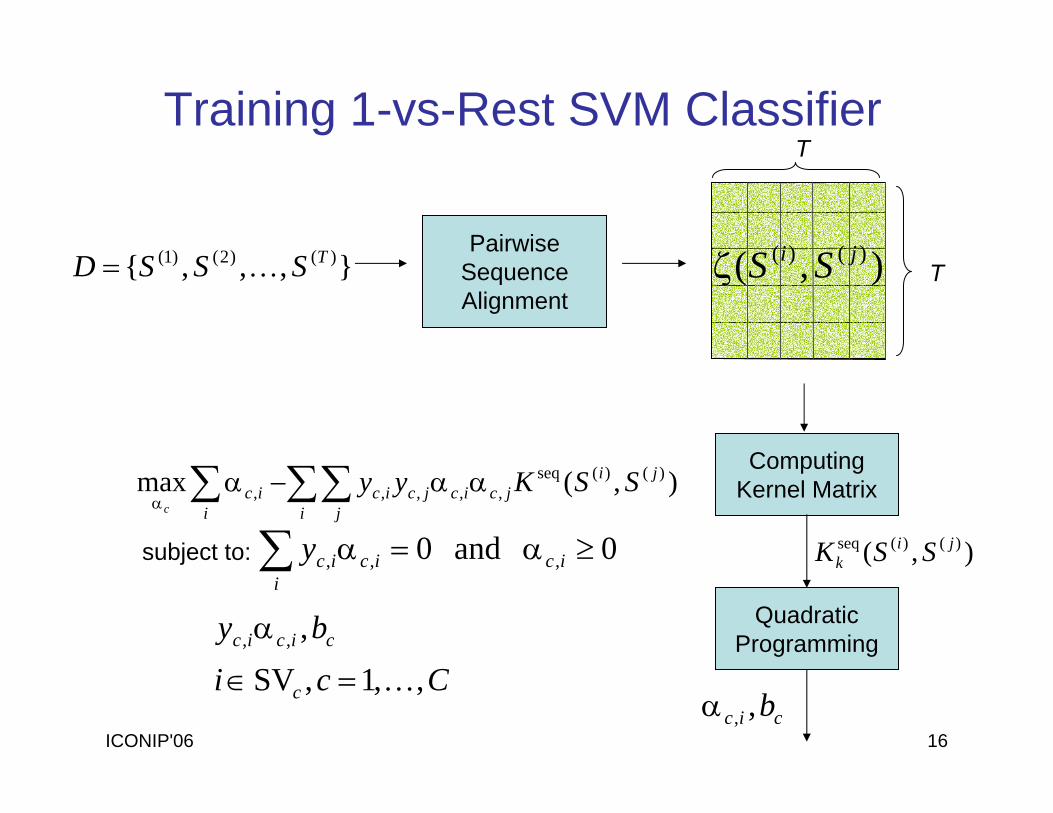
ICONIP'06 16
Training 1-vs-Rest SVM Classifier
T
T
),( )()( ji SSζ
0 and 0 ,,, ≥α=α∑ ici
icicy
QuadraticProgramming
Cciby
c
cicic
,,1,SV,,,
K=∈
α
∑∑∑ αα−αα i j
jijcicjcic
iic SSKyy
c
),(max )()(seq,,,,,
subject to:
},,,{ )()2()1( TSSSD K=Pairwise
SequenceAlignment
ComputingKernel Matrix
),( )()(seq jik SSK
cic b,,α
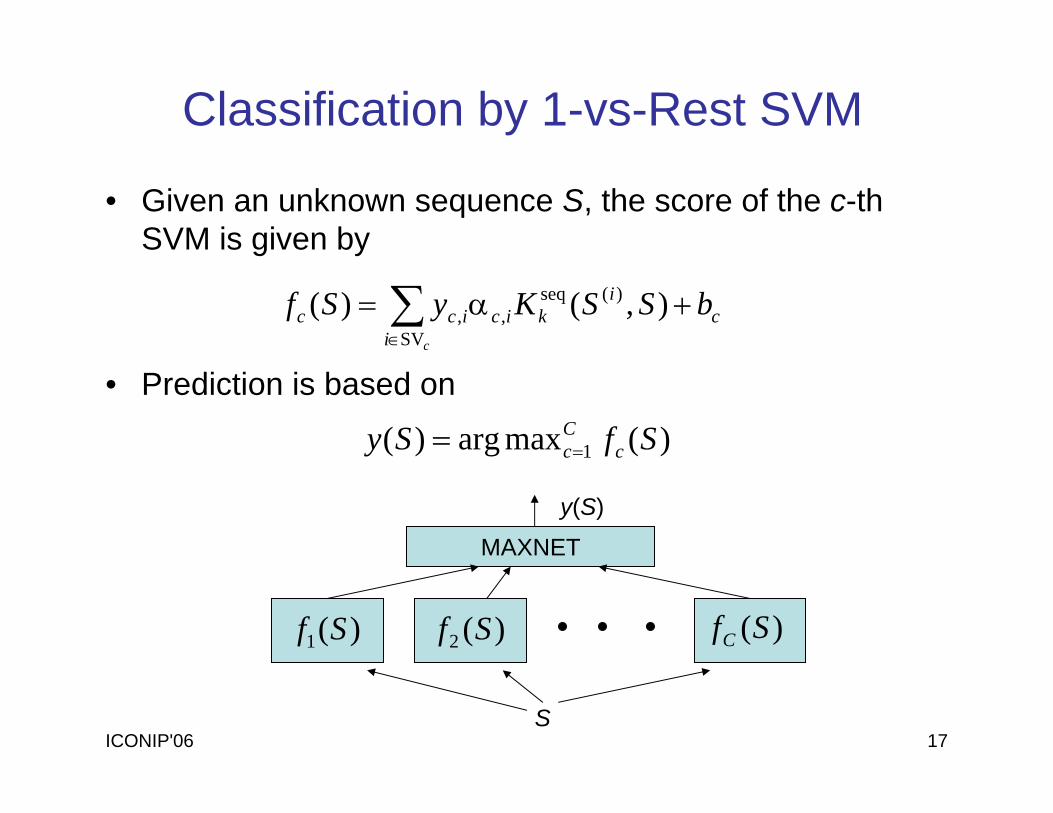
ICONIP'06 17
• Given an unknown sequence S, the score of the c-thSVM is given by
∑∈
+α=ci
ci
kicicc bSSKySfSV
)(seq,, ),()(
)(maxarg)( 1 SfSy cCc==
Classification by 1-vs-Rest SVM
• Prediction is based on
)(1 Sf )(2 Sf )(SfC
S
MAXNET
y(S)
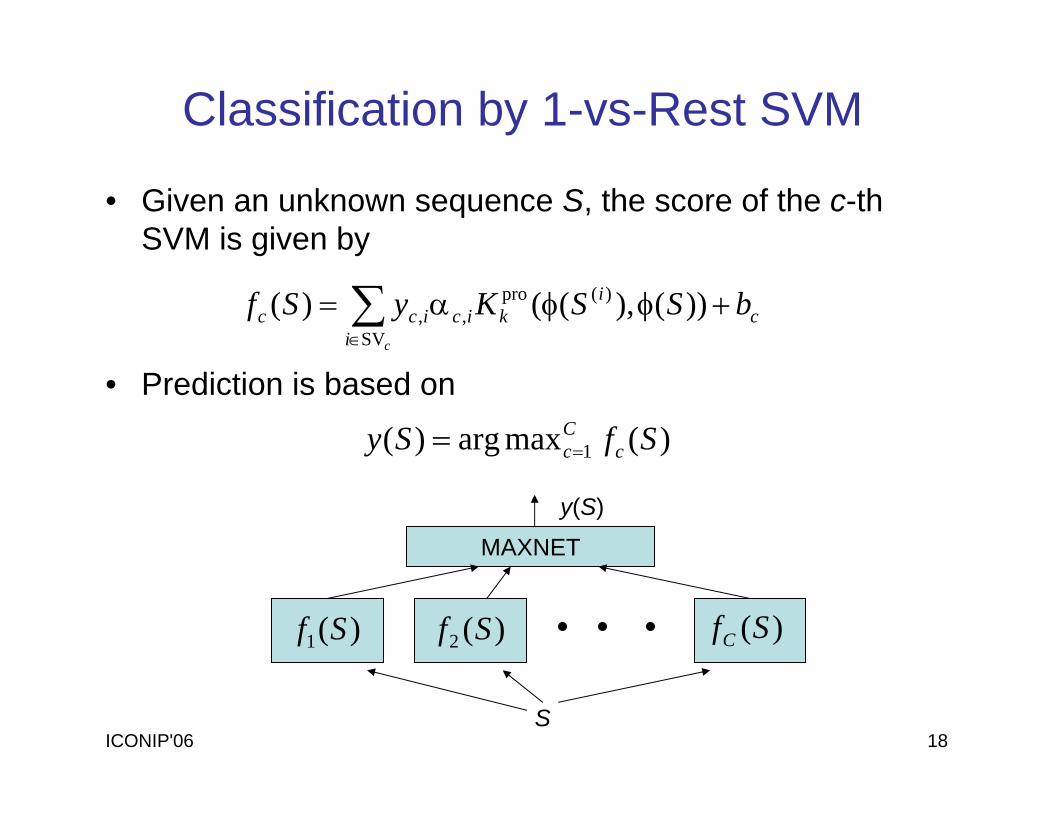
ICONIP'06 18
• Given an unknown sequence S, the score of the c-thSVM is given by
∑∈
+φφα=ci
ci
kicicc bSSKySfSV
)(pro,, ))(),(()(
)(maxarg)( 1 SfSy cCc==
Classification by 1-vs-Rest SVM
• Prediction is based on
)(1 Sf )(2 Sf )(SfC
S
MAXNET
y(S)
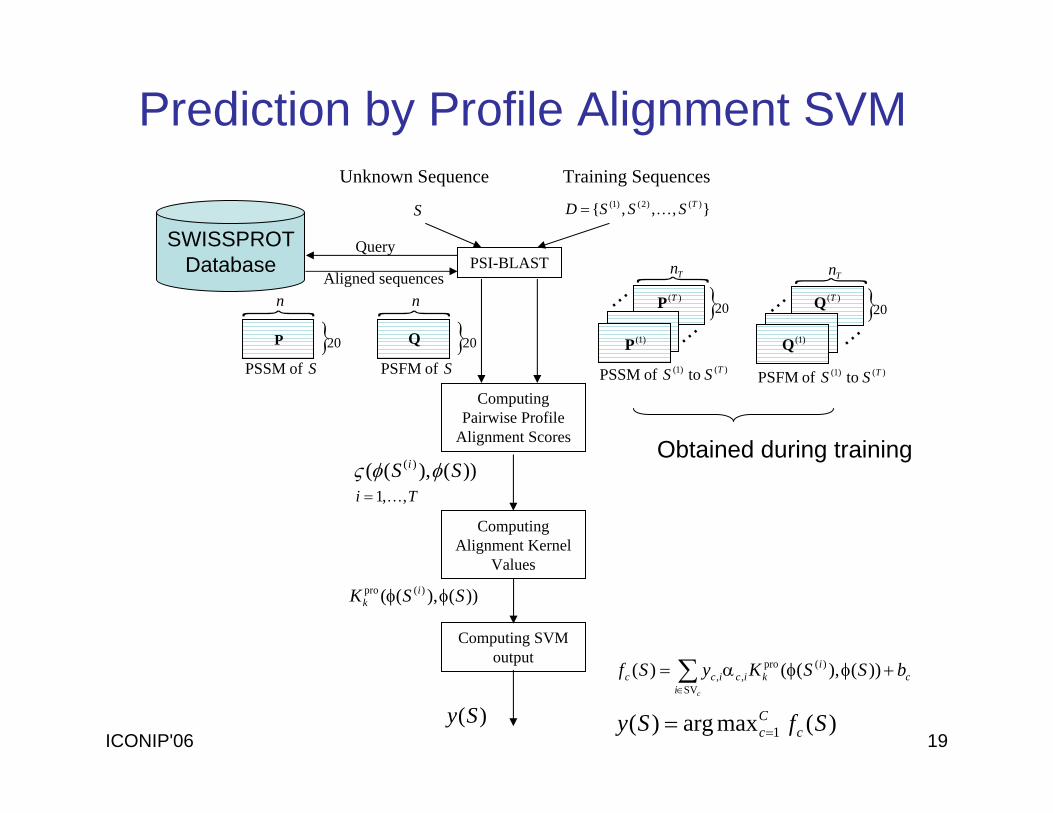
ICONIP'06 19
PSI-BLAST
Computing Pairwise Profile
Alignment Scores
Computing SVM output
}
}20
)1(P
Tn
}
}20
n
Q
S },,,{ )()2()1( TSSSD K=
Unknown Sequence
Query
Aligned sequences
}20
n
P
}
S of PSSM S of PSFM )()1( to of PSSM TSS
Training Sequences
Computing Alignment Kernel
Values
))(),(( )(pro SSK ik φφ
))(),(( )( SS i φφς
)(Sy
Ti ,,1K=
Prediction by Profile Alignment SVM
… )(TP
}
}20
)1(Q
Tn
… )(TQ
)()1( to of PSFM TSS
……
SWISSPROTDatabase
Obtained during training
∑∈
+φφα=ci
ci
kicicc bSSKySfSV
)(pro,, ))(),(()(
)(maxarg)( 1 SfSy cCc==

ICONIP'06 20
Complexity Analysis
4,,1 ,),()(SV
)(seq,, K=+α= ∑
∈
kbSSKySfci
ci
kicicc
),( )2(seq SSKk
),( )4(seq SSKk
}4 ,2{SV =c
For , S only needs to be aligned with the training sequences that correspond to the support vectors
to seq4
seq1 KK
( )( )dljli
Tl
ji
djiji
ljli
Tl
ji
jiji
SSSSSSK
SSSSK
SSSSSSK
SSSSK
1),(),(max),(
1),(),(
),(),(max),(
),(),(
)()()()(
1
)()(seq4
)()()()(seq3
)()()()(
1
)()(seq2
)()()()(seq1
+ζζ=
+ζ=
ζζ=
ζ=
≤≤
≤≤

ICONIP'06 21
∑
∑ ∑∑
∈
∈ =∈
+>ζζ<α=
+ζζα=+α=
c
cc
SVic
iicic
SVic
T
t
ttiicic
SVic
iicicc
by
bSSSSybSSKySf
rr,
),(),(),()(
)(,,
1
)()()(,,
)(seq5,,
),( )1(SSζ
}4 ,2{SV =cT
T
}4 ,2{ ,)( ∈>ζζ< iirr
),( )()(seq1
ji SSK
ζr
)(iζr
For , S needs to be aligned with all training sequencesseq5K
),( )(TSSζ
Complexity Analysis

ICONIP'06 22
Complexity Analysis
• One possible solution to reduce the complexity of K5 is select the relevant features (rows) from the kernel matrix.
M.W. Mak and S.Y. Kung. "A solution to the Curse of Dimensionality Problem in PairwiseScoring Techniques", ICONIP'06
Session: TB408Thur. 13:30 – 15:10Theoretical Modeling and Analysis II

ICONIP'06 23
Experiments
• We applied the sequence alignment SVM and profile alignment SVM to a eukaryotic protein dataset (Reinhardt and Hubbard, 1998).
• The dataset comprises 2427 annotated sequences extracted from SWISSPORT 33.0, which amounts to 684 cytoplasm, 325 extracellular, 321 mitochondrial, and 1097 nuclear proteins.
• To mitigate homology bias, we constructed two redundancy-removed datasets by eliminating the most similar sequences.
• 5-Fold cross validation was used to obtain the accuracy.

ICONIP'06 24
Results: Sequence Vs ProfileSequence Alignment Kernel
seq1K seq
2K seq3K seq
4K seq5K
Accuracy 87.0% 87.1% 87.0% 87.1% 87.1%% of negative eigenvalues in seqK 0 0 0 0 0
Meeting Mercer’s condition Yes Yes Yes Yes Yes
Profile Alignment Kernel pro
1K pro2K pro
3K pro4K pro
5K Accuracy 45.9% 73.6% 77.1% 82.9% 99.1%% of negative eigenvalues in proK 8.5 6.2 0.3 0.2 0.0
Meeting Mercer’s condition No No No No Yes
Key Observations:
1. The performance of profile alignment SVM is sensitive (and somewhat proportional) to the degree of its kernel matrix meeting the Mercer’s condition.
2. When Mercer’s condition is met, profile alignment SVM achieve higher prediction accuracy.
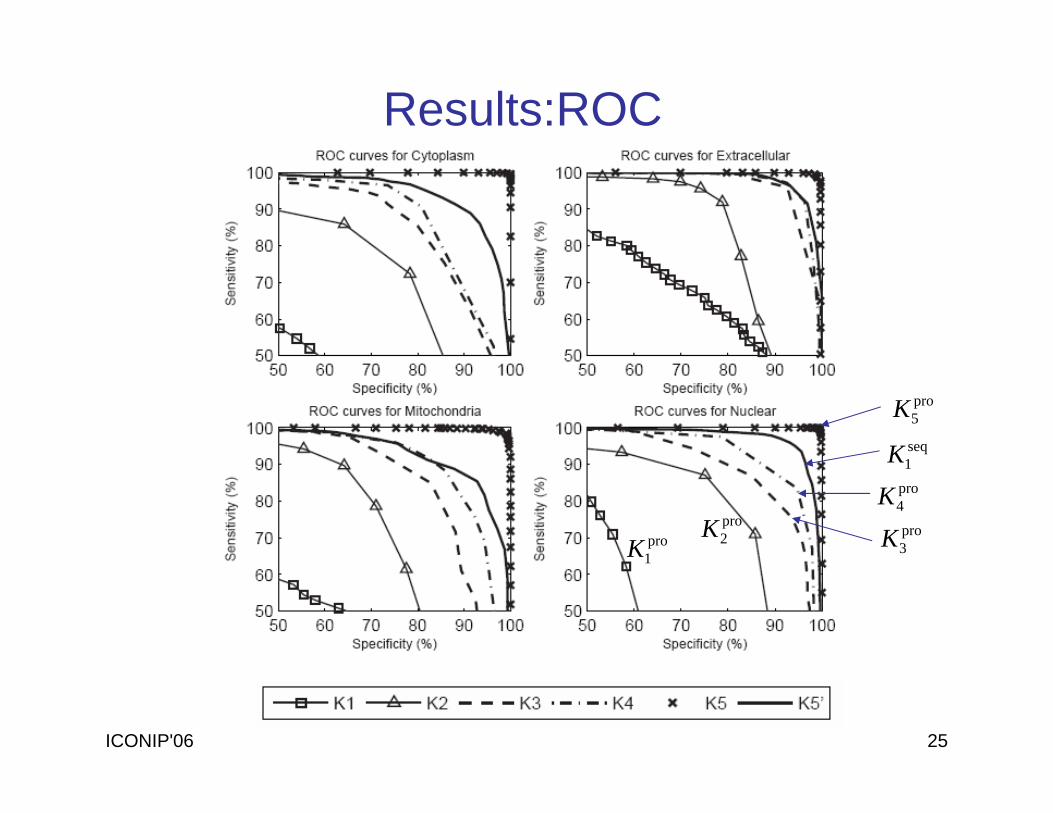
ICONIP'06 25
Results:ROC
pro5K
pro4Kpro3K
pro2Kpro
1K
seq1K

ICONIP'06 26
Results: Comparison with Existing Methods
)( pro5K)( seq
5K

ICONIP'06 27
ConclusionsSequence-Based Method (Direct)
Pros: Simpler and Meet Mercer’s condition
Cons: Could not capture remote homology information for subcellular localization
Profile-Based Method (Indirect)Pros: PSI-BLAST makes use of un-annotated
sequences in database to capture richer subcellular localization information
Cons: Most kernels do not meet Mercer’s condition. Only K5 does, but it is computationally expensive.

ICONIP'06 28
Further Informationhttp://www.eie.polyu.edu.hk/~mwmak/BSIG/PairProSVM.htm
J. Guo, M.W. Mak and S.Y. Kung. "Eukaryotic Protein Subcellular Localization Based on Local Pairwise Profile Alignment SVM", 2006 IEEE International Workshop on Machine Learning for Signal Processing (MLSP'06), 2006, pp. 391-396





























