Embed Size (px)
Citation preview

ERRORI IN EPIDEMIOLOGIA

Errori in Epidemiologia
• Accuratezza (o validità)
– Errori sistematici
• Confondimento
• Misclassificazione
• Selezione
• Precisione
– Errori random
Numerosità del campione
Errore
Errore sistematico
Errore random

Accuratezza e precisione

Precisione
• È di solito espressa utilizzando gli intervalli di confidenza
• Dipende dalla grandezza del campione e dall’efficienza dello studio

Accuratezza (o validità)
• Bias di selezione
• Bias di informazione (misclassificazione)
• Confondimento

Bias di selezione
• Selezione del campione nello studio
• I partecipanti allo studio potrebbero essere differenti in qualche aspetto rispetto ai non partecipanti
• Esempi

Bias di selezione
• Esempio n. 1
• Studio della prevalenza dell’obesità
• Se per qualche motivo i soggetti obesi partecipano meno frequentemente dei soggetti non obesi, allora la stima della prevalenza dell’obesità sarà distorta

Bias di selezione
• Esempio n. 2
• Studio sull’effetto degli zaini pesanti sul mal di schiena nei ragazzi
• Durante l’ora di educazione fisica, si misura sia il peso dello zaino che la presenza di mal di schiena

Calcolo del Rischio Relativo
Mal di schiena Non mal di schiena Totale
Zaino pesante 10 10 20
Zaino leggero 30 150 180
𝑅𝑅 =10/20
30/180= 3

Bias di selezione
• Gli studenti più atletici potrebbero essere assenti perché impegnati in competizioni al di fuori della scuola
– Se gli studenti più atletici portano più spesso zaini pesanti
– E se soffrono di meno di mal di schiena
• Si può avere una stima distorta dell’effetto del portare uno zaino pesante

Calcolo del Rischio Relativo
Mal di schiena Non mal di schiena Totale
Zaino pesante 10 10 20
Zaino leggero 30 150 180
𝑅𝑅 =10/20
30/180= 3
Questa cella è sotto-rappresentata per l’assenza di soggetti atletici

Calcolo del Rischio Relativo
Mal di schiena Non mal di schiena Totale
Zaino pesante 10 20 30
Zaino leggero 30 150 180
𝑅𝑅 =10/30
30/180= 2
Con 10 soggetti atletici esposti non malati in più

Calcolo del Rischio Relativo
Mal di schiena Non mal di schiena Totale
Zaino pesante 10 30 40
Zaino leggero 30 150 180
𝑅𝑅 =10/40
30/180= 1.5
Con 20 soggetti atletici esposti non malati in più

Misclassificazione
• Assegnazione dei soggetti in studio alla categoria sbagliata di una variabile categorica
• La misclassificazione può riguardare:
– La variabile di esposizione
– La variabile d’effetto
– La variabile confondente
– Più variabili

Misclassificazione
• Non differenziale
– L’errore è uguale per tutti i soggetti
• Differenziale
– L’errore dipende dalle caratteristiche del soggetto
• Ad esempio, la misclassificazione dell’esito può essere più grande per i non esposti e più piccola per gli esposti
• Oppure, la misclassificazione dell’esposizione può essere più grande nei controlli e più piccola nei casi (recall bias)

Conseguenze della misclassificazione
• Non differenziale
– Sottostima dell’effetto
• Differenziale
– Sottostima o sovrastima dell’effetto

Effetto senza misclassificazione dell’esposizione
ESPOSTI
Effetto senza misclassificazione
NON ESPOSTI

Effetto con misclassificazione non differenziale dell’esposizione
ESPOSTI NON ESPOSTI
Effetto con misclassificazione
Effetto senza misclassificazione

Esempio di misclassificazione
Se il 10% degli esposti viene classificato
come “non esposto”
Esposti Non esposti
Casi 18 12
N° a rischio 90 110
RR=1.8
Dati corretti
Esposti Non esposti
Casi 20 10
N° a rischio 100 100
RR=2
Se il 20% degli esposti viene classificato
come “non esposto”
Esposti Non esposti
Casi 16 14
N° a rischio 80 120
RR=1.7

Esempio di misclassificazione
Se il 20% degli esposti viene classificato
come “non esposto” ed il 20% dei non
esposti viene classificato come “esposto”
Esposti Non esposti
Casi 17 13
N° a rischio 100 100
RR=1.3
Se il 10% degli esposti viene classificato
come “non esposto” ed il 10% dei non
esposti viene classificato come “esposto”
Esposti Non esposti
Casi 19 11
N° a rischio 100 100
RR=1.7

Confondimento
• Un errore nella stima di una misura epidemiologica o nella stima di un effetto che deriva da uno squilibrio tra i gruppi posti a confronto di altri fattori causali della malattia
• Un confondente – È associato con la malattia tra i non esposti
– È associato con l’esposizione nella popolazione che dà origine ai casi
– Non è una causa intermedia

Confondimento
ESPOSIZIONE MALATTIA
CONFONDENTE

Esempio di confondimento
Dati grezzi
Esposti Non esposti
Casi 40 101
Tempo-persona 1100 1100
RR=0.4
Giovani Anziani
Esposti Non esposti Esposti Non esposti
Casi 20 1 Casi 20 100
Tempo-
persona
1000 100 Tempo-
persona
100 1000
RR=2.0 RR=2.0

Confondimento
• Misura – Cambiamento nella stima dell’effetto
• Controllo – Prevenzione
• Restrizione • Randomizzazione • Appaiamento
– Terapia • Analisi stratificata • Standardizzazione • Modelli multivariabili

La standardizzazione • Immaginiamo di voler confrontare i tassi di
mortalità di una serie di popolazioni indice (A, B, C, …)
• La diversità nella distribuzione dell’età tra le popolazioni può introdurre un bias
• Il bias può essere eliminato con la standardizzazione dei tassi di mortalità, utilizzando una comune popolazione di riferimento (Z)

Popolazione A
Età Anni-persona Morti Tasso di mortalità (per 1,000 anni-persona)
0-14 4,000 8 2
15-44 3,000 15 5
45-64 2,000 20 10
65+ 1,000 25 25
totale 10,000 68 6.8

Popolazione B
Età Anni-persona Morti Tasso di mortalità (per 1,000 anni-persona)
0-14 1,000 8 8
15-44 2,000 40 20
45-64 3,000 120 40
65+ 4,000 400 100
totale 10,000 568 56.8

Confronto tra tassi grezzi
• Il tasso grezzo di mortalità in A (6.8) è circa 1/9 di quello di B (56.8)
• Il confronto tra tassi specifici suggerisce invece che il rapporto è circa 1/4
• BIAS!
– Diversa distribuzione dell’età tra A e B

Utilizzo di una popolazione di riferimento Z
Età Anni-persona Morti Tasso di mortalità (per 1,000 anni-persona)
0-14 25,000 100 4
15-44 25,000 250 10
45-64 25,000 500 20
65+ 25,000 1250 50
totale 100,000 2100 21.0

Standardizzazione diretta
• Quale sarebbe la mortalità in Z se Z avesse gli stessi tassi di mortalità specifici per età di A, B, …?
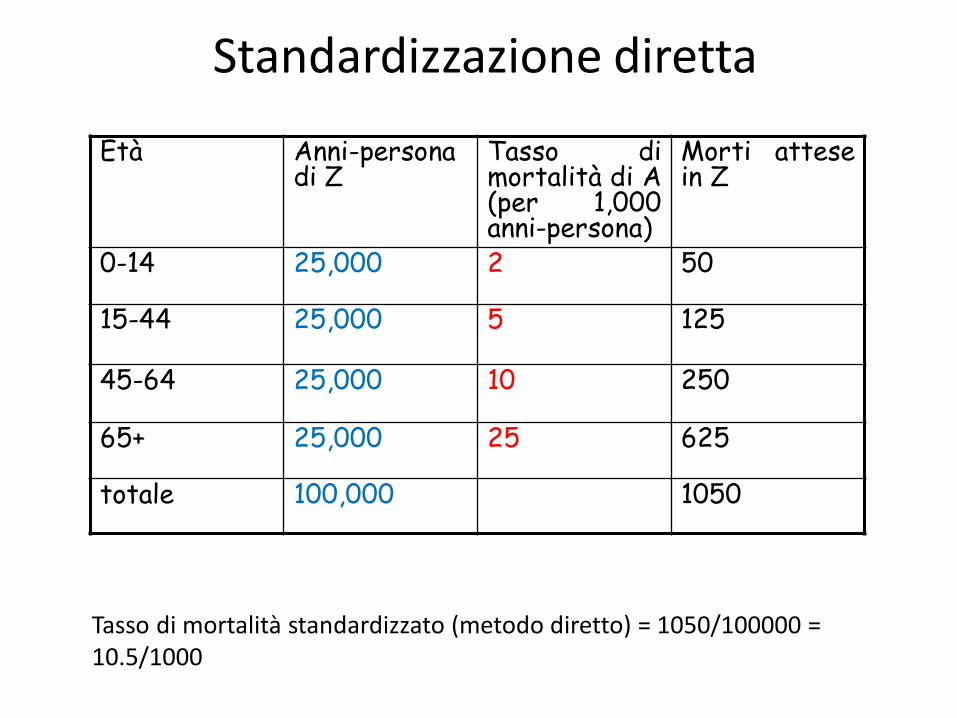
Standardizzazione diretta
Età Anni-persona di Z
Tasso di mortalità di A (per 1,000 anni-persona)
Morti attese in Z
0-14 25,000 2 50
15-44 25,000 5 125
45-64 25,000 10 250
65+ 25,000 25 625
totale 100,000 1050
Tasso di mortalità standardizzato (metodo diretto) = 1050/100000 = 10.5/1000

Standardizzazione diretta
Età Anni-persona di Z
Tasso di mortalità di B (per 1,000 anni-persona)
Morti attese in Z
0-14 25,000 8 200
15-44 25,000 20 500
45-64 25,000 40 1,000
65+ 25,000 100 2,500
totale 100,000 4,200
Tasso di mortalità standardizzato (metodo diretto) = 4,200/100,000 = 42.0/1000

Standardizzazione diretta
• Il confronto tra i due tassi standardizzati di mortalità evidenzia un rapporto 1/4
– Pop. A: 10.5/1000 py
– Pop. B: 42/1000 py
• L’utilizzo di una stessa popolazione di riferimento (Z) ha rimosso il confondimento legato alla differente distribuzione dell’età in A e B

Standardizzazione indiretta
• Quale sarebbe la mortalità in A, B, … se A, B, … avessero gli stessi tassi di mortalità specifici per età di Z?
• La standardizzazione indiretta permette di calcolare per ogni popolazione il rapporto standardizzato di mortalità (SMR), che è il rapporto tra eventi osservati ed eventi attesi

Standardizzazione indiretta
Età Anni-persona di A
Tasso di mortalità di Z (per 1,000 anni-persona)
Morti attese in A
0-14 4,000 4 16
15-44 3,000 10 30
45-64 2,000 20 40
65+ 1,000 50 50
totale 10,000 136
SMR = casi osservati/casi attesi = 68/136 = 0.50
Tasso di mortalità standardizzato (metodo indiretto) = 0.50*21/1000 = 10.5/1000
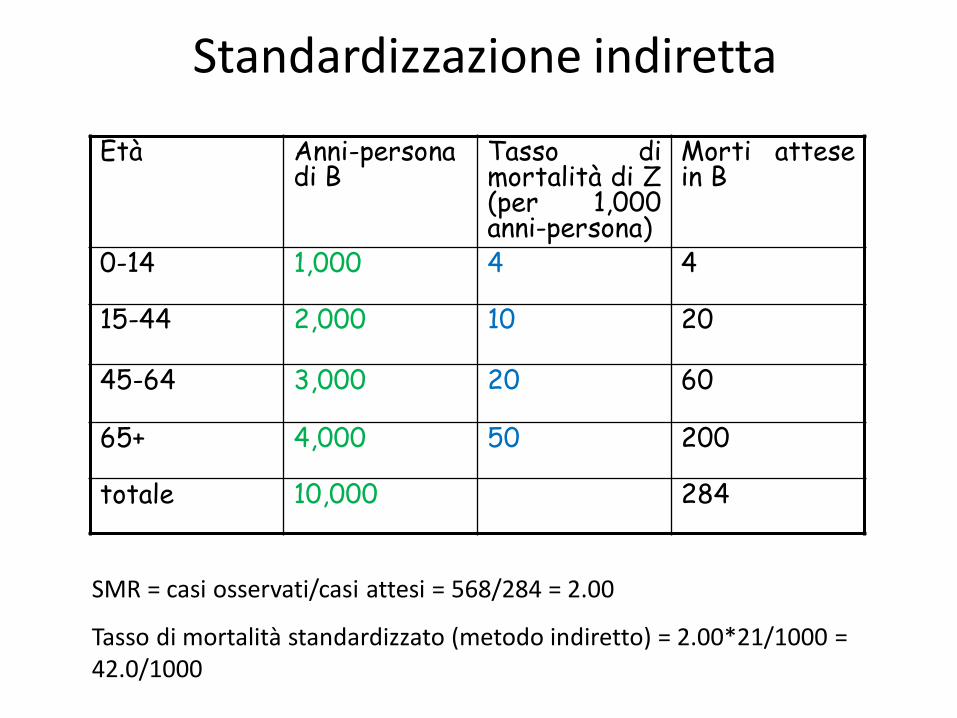
Standardizzazione indiretta
Età Anni-persona di B
Tasso di mortalità di Z (per 1,000 anni-persona)
Morti attese in B
0-14 1,000 4 4
15-44 2,000 10 20
45-64 3,000 20 60
65+ 4,000 50 200
totale 10,000 284
SMR = casi osservati/casi attesi = 568/284 = 2.00
Tasso di mortalità standardizzato (metodo indiretto) = 2.00*21/1000 = 42.0/1000

Standardizzazione diretta ed indiretta
• I tassi di mortalità standardizzati di A e B possono quindi essere confrontati: la mortalità di A è ¼ quella di B
• In questo caso, i due metodi, diretto ed indiretto, forniscono lo stesso risultato
• A volte i due metodi danno risultati diversi

Standardizzazione diretta ed indiretta
• Il metodo diretto fornisce risultati più validi
• Il metodo indiretto consente di ottenere una maggiore precisione (errori standard più piccoli) poiché i tassi specifici della popolazione indice non vengono utilizzati nel calcolo





























