Embed Size (px)
Citation preview

UNIVERSITEIT GENT
FACULTEIT ECONOMIE EN BEDRIJFSKUNDE
ACADEMIEJAAR 2007 – 2008
Economische Groei en Convergentie: Een Dynamische Panel Data Analyse
Masterproef voorgedragen tot het bekomen van de graad van
Master in de Economische Wetenschappen
Tom De Groote onder leiding van
Prof. Everaert

2

3
UNIVERSITEIT GENT
FACULTEIT ECONOMIE EN BEDRIJFSKUNDE
ACADEMIEJAAR 2007 – 2008
Economische Groei en Convergentie: Een Dynamische Panel Data Analyse
Masterproef voorgedragen tot het bekomen van de graad van
Master in de Economische Wetenschappen
Tom De Groote onder leiding van
Prof. Everaert

4
Ondergetekende verklaart dat de inhoud van deze masterproef mag geraadpleegd en/of
gereproduceerd worden, mits bronvermelding.
Naam student : Tom De Groote

5
Woord vooraf
In dit voorwoord zou ik graag enkele mensen bedanken die hebben bijgedragen aan het
afronden van mijn eindverhandeling. Ten eerste is een woord van dank op zijn plaats
voor mijn promotor Prof. Everaert. Het afgelopen jaar heeft hij mij bijgestaan met
nuttige feedback over mijn masterproef. Verder wil ik graag familie en vrienden
bedanken voor de steun. Tot slot wil ik een speciaal woordje van dank richten aan mijn
ouders voor de kansen die ze me geven.

6
Inhoudsopgave
0. Inleiding ................................................................................................................... 8
1. Neoklassieke en nieuwe groei theorie ...................................................................... 9
1.1 Neoklassiek model............................................................................................. 9
1.2 Convergentie en formele vergelijking...............................................................10
1.3 Kritiek ..............................................................................................................14
1.4 Reacties op het neoklassieke model .................................................................18
1.4.1 Uitgebreid Solow model ............................................................................18
1.4.2 Endogene modellen...................................................................................20
2 Empirische literatuur ...............................................................................................22
2.1 Cross sectie benadering ...................................................................................22
2.2 Panel data ........................................................................................................25
2.3 Kritiek ..............................................................................................................28
3 Generalized Method of Moments (GMM)...................................................................33
3.1 First difference GMM schatter...........................................................................33
3.2 Prestatie van first difference GMM in kleine samples........................................35
3.3 System GMM .....................................................................................................36
3.4 Kleine steekproef eigenschappen system GMM schatter...................................38
3.5 Stacked GMM ....................................................................................................39
3.6 Extra momentvoorwaarden ..............................................................................40
4 Empirisch onderzoek: GMM versus system GMM ......................................................41
4.1 Methode ...........................................................................................................42
4.1.1 Model ........................................................................................................42
4.1.2 Schatting van de “populatieparameters” ..................................................43
4.1.3 Monte Carlo simulaties..............................................................................45
4.2 Data..................................................................................................................47
4.3 Monte Carlo simulaties .....................................................................................49
4.4 Schattingen ......................................................................................................51
5 Conclusie .................................................................................................................54
6 Bijlagen ...................................................................................................................58

7
Lijst van tabellen en figuren
Tabel 1: Parameterwaarden LSDV (T=9) ................................................................................................58
Tabel 2: Parameterwaarden LSDV (T=9) ................................................................................................58
Tabel 3: Parameterwaarden LSDV correctie (T=9) ...................................................................................59
Tabel 4: Parameterwaarden LSDV correctie (T=9) ...................................................................................59
Tabel 5: Parameterwaarden LSDV (T=6) ................................................................................................60
Tabel 6: Parameterwaarden LSDV (T=6) ................................................................................................60
Tabel 7: Parameterwaarden LSDV correctie (T=6) ...................................................................................61
Tabel 8: Parameterwaarden LSDV correctie (T=6) ...................................................................................61
Tabel 9: Parameterwaarden Islam (2000) (T=6) .....................................................................................62
Tabel 10: Parameterwaarden Islam (2000) (T=6)....................................................................................62
Tabel 11: Procentuele vertekening γ (LSDV populatiewaarden) T=9 .........................................................63
Tabel 12: Procentuele vertekening κ (LSDV populatiewaarden) T=9.........................................................63
Tabel 13: Procentuele vertekening γ (LSDVcor populatiewaarden) T=9.....................................................64
Tabel 14: Procentuele vertekening κ (LSDVcor populatiewaarden) T=9.....................................................64
Tabel 15: Procentuele vertekening γ (Islam (2000) populatiewaarden) T=9 ..............................................65
Tabel 16: Procentuele vertekening κ (Islam (2000) populatiewaarden) T=9 ..............................................65
Tabel 17: Procentuele vertekening γ (LSDV populatiewaarden) T=6 .........................................................66
Tabel 18: Procentuele vertekening κ (LSDV populatiewaarden) T=6.........................................................66
Tabel 19: Procentuele vertekening γ (LSDVcor populatiewaarden) T=6.....................................................67
Tabel 20: Procentuele vertekening κ (LSDVcor populatiewaarden) T=6.....................................................67
Tabel 21: Procentuele vertekening γ (Islam (2000) populatiewaarden) T=6 ..............................................68
Tabel 22: Procentuele vertekening κ (Islam (2000) populatiewaarden) T=6 ..............................................68
Tabel 23: RMSE γ (LSDV populatiewaarden) T=9 ...................................................................................69
Tabel 24: RMSE κ (LSDV populatiewaarden) T=9...................................................................................69
Tabel 25: RMSE γ (LSDVcor populatiewaarden) T=9...............................................................................70
Tabel 26: RMSE κ (LSDVcor populatiewaarden) T=9 ..............................................................................70
Tabel 27: RMSE γ (Islam (2000) populatiewaarden) T=9 ........................................................................71
Tabel 28: RMSE vertekening κ (Islam (2000) populatiewaarden) T=9 ......................................................71
Tabel 29: RMSE γ (LSDV populatiewaarden) T=6 ...................................................................................72
Tabel 30: RMSE κ (LSDV populatiewaarden) T=6...................................................................................72
Tabel 31: RMSE γ (LSDVcor populatiewaarden) T=6...............................................................................73
Tabel 32: RMSE κ (LSDVcor populatiewaarden) T=6 ..............................................................................73
Tabel 33: RMSE γ (Islam (2000) populatiewaarden) T=6 ........................................................................74
Tabel 34: RMSE κ (Islam (2000) populatiewaarden) T=6 ........................................................................74
Tabel 35: Schattingsresultaten standaard Solow model ............................................................................75
Tabel 36: Schattingsresultaten uitgebreid Solow model ............................................................................76
Figuur 1: Scatter plot: groei inkomen per capita (1960-2000) - Per capita inkomen (1960) (NONOIL)............77
Figuur 2: Scatter plot: investeringsratio - per capita inkomen(1960) (NONOIL)...........................................77
Figuur 3: Evolutie dispersie GDP per capita.............................................................................................78
Figuur 4: Scatter plot: ln(A0) – ln(H)......................................................................................................78

8
0. Inleiding De vraag of arme landen de kloof in per capita inkomen dichten met rijke landen
vormt niet alleen vanuit welvaartsoogpunt een interessante vraag. Groeitheorieën
verschaffen een duidelijke conclusie in verband met deze convergentievraag. In dit
oogpunt is empirisch onderzoek dan ook interessant. Het laat immers toe de
theorieën te toetsen aan de werkelijkheid.
Binnen het convergentiedebat kunnen we twee stromingen onderscheiden:
neoklassieke groeimodellen en endogene groeimodellen. De empirie kan aanwijzen
welke stroming het bij het rechte einde heeft. Veelal vertrekt men hierbij van de
formeel afgeleide vergelijking door Mankiw, Weil en Romer (1992). Deze vertrekt van
het neoklassieke Solow model en een schatting ervan levert dan ook direct informatie
over de sterkte van dit model. Schattingen van deze vergelijking zijn echter
onderhevig aan een aantal empirische problemen. We zullen deze empirische
problemen dan ook uiteenzetten. Schattingen die gebruik maken van panel data zijn
een staat een aantal empirische problemen te omzeilen (meetfouten, omitted variable
probleem, endogeniteit, …). De kleine steekproefeigenschappen van panel data
schatters zijn echter niet altijd bekend. De juiste keuze van een schatter is dan ook
cruciaal. Islam (2000) en Harris en Matyas (2004) voeren een aantal Monte Carlo
experimenten uit. Deze maken duidelijk dat de prestaties van verschillende schatters
sterk uiteenlopen. Dit heeft dan ook gevolgen voor de geschatte parameters en
conclusies over de geldigheid van het Solow model. Vooraleer we overgaan tot de
schatting van deze groeivergelijking, voeren we dan ook eerst een Monte Carlo
experiment uit, gelijkaardig aan dat van Islam. We concentreren ons op de first
difference GMM en system GMM schatter. Blundell en Bond (1998) vinden een
neerwaartse vertekening terug voor de first difference GMM schatter. Een system
GMM schatter levert mogelijks een sterke verbetering van de schattingen.
In deel 1 bespreken we het neoklassieke Solow model. We vermelden de zwakke
punten van dit model en presenteren vervolgens een aantal endogene groeimodellen.
Deel 2 bevat een overzicht van de voornaamste empirische studies. Hierbij
concentreren we ons op cross sectie en panel data onderzoek. Daarnaast presenteren
we de sterke en zwakke punten van het empirisch onderzoek. Deel 3 gaat dieper in
op de first difference GMM en system GMM schatter. We overlopen de methode,
kleine steekproefeigenschappen en een aantal aanvullingen. In deel 4 voeren we het
Monte Carlo experiment en de schattingen uit. We starten met een uiteenzetting van
de werkwijze en lichten de data toe. Tot slot concluderen we in deel 5.

9
1. Neoklassieke en nieuwe groei theorie
Het convergentiedebat kan teruggebracht worden tot twee stromingen: de neoklassieke
en de nieuwe, endogene, groeitheorie (NGT). Het Solow model dateert reeds van 1956,
maar domineerde tot de jaren tachtig de literatuur. Tot op de dag van vandaag vormt het
Solow model een vertrekpunt voor een groot deel van de empirische literatuur naar
convergentie. In de jaren tachtig luidde de idee van endogene groei een nieuw tijdperk
in, in de groeitheorie. Het concept van endogene groei was echter niet nieuw. Arrow
(1962) introduceert bijvoorbeeld het concept learning-by-doing. Endogene groei kwam
vooral onder de aandacht dankzij Romer( 1986 en 1990). De en NGT leiden beide tot
sterk uiteenlopende conclusies in inzake convergentie. Daar waar het vinden van
convergentie de neoklassieke modellen ondersteunt, levert afwezigheid van
convergentie, doorgaans, bewijs ten gunste van de endogene groei modellen. Er bestaat
dan ook een zekere rivaliteit tussen beide modellen.
In wat volgt zetten we eerst het neoklassieke Solow model uiteen. Vervolgens leiden we,
een vergelijking af die toelaat het Solow model empirisch te toetsen en verduidelijken we
een aantal begrippen inzake convergentie. De derde paragraaf gaat dieper in op de
tekortkomingen van het Solow model. Nieuwe modellen doken op het voorplan als reactie
op deze zwakke punten in het Solow model. In een vierde deel komen het uitgebreide
Solow model en de NGT aan bod. Tot slot geven we een overzicht van een aantal
empirische studies. De aandacht gaat hierbij voornamelijk uit naar cross sectie en panel
data onderzoek en de specifieke problemen waarmee beide benaderingswijzen te
kampen hebben.
1.1 Neoklassiek model
Neoklassieke groeimodellen zoals deze van Solow (1956), Cass (1965) en Koopmans
(1965) veronderstellen afnemende meeropbrengsten in kapitaal. Dit impliceert dat het
marginale product van kapitaal in arme landen met relatief weinig kapitaal hoger ligt dan
dat van relatief rijkere landen. Als gevolg zullen relatief armere landen sneller groeien
dan rijkere landen. Dit leidt tot een inverse relatie tussen economische groei en een
initieel inkomensniveau. Er zal met andere woorden convergentie optreden.
Solow (1956) vertrekt in zijn uitwerking van het Harrod-Domar model. Dit model vertrekt
van de sterke assumptie dat kapitaal en investeringen in een vaste proportie tot output
staan. Dit heeft tot gevolg dat er geen substitutiemogelijkheden bestaan tussen arbeid
en kapitaal. Het Harrod-Domar model leidt, bij kleine afwijkingen van evenwicht, tot
periodes van stijgende werkloosheid, afgewisseld met periodes van krapte op de

10
arbeidsmarkt en inflatie. Solow laat de assumpties over vaste proporties varen en
bekomt een minder scherp model.
We vertrekken van een standaard Cobb-Douglas functie:
1( ) , 0< <1,Y K ALα α α−= (1)
Hierin staat Y voor output, K voor kapitaal, L voor arbeid en A het technologieniveau. L
en A groeien aan een exogene snelheid:
( ) (0) ,ntL t L e= (2)
( ) (0) ,ntA t A e= (3)
Gedurende elke periode investeert men een exogene fractie s van het inkomen in
kapitaal. De totale voorraad kapitaal groeit dan ook met:
ˆ ˆ ˆ( ) ( ) ,k sf k n g kδ= − + +�
(4)
Waarbij ˆ / en /ˆk K AL y Y AL= = respectievelijk staan voor output en kapitaal per
effectieve arbeidseenheid en δ de depreciatievoet voorstelt. In steady state moet ˆ 0k =�
.
Dit levert:
1/(1 )
* ,s
kn g
α
δ
−
= + +
(5)
Het steady state niveau is dus een positieve functie van de spaarquote en negatief
gerelateerd aan de bevolkingsgroei, de depreciatievoet en de groei van technologie. Na
substitutie van (5) in (1) en het nemen van logaritmen krijgen we:
t
t
YA gt s n g
L
α αδ
α α
= + + − + +
− − 0ln ln( ) ln( ) ln( ),
1 1 (6)
1.2 Convergentie en formele vergelijking
Het Solow model vormt de basis voor een groot deel van het empirisch onderzoek in de
literatuur. Het laat ons toe een formele vergelijking af te leiden die rekening houdt met
situaties out-of-steady-state en biedt meteen een instrument om de validiteit van de
neoklassieke groeitheorieën te verifiëren. We baseren ons op Mankiw et al. en Islam

11
(2000). We starten door een Taylor expansie rond de steady state toe te passen op
vergelijking (4).
k sf k n g k sf k n g k kδ δ′= − + + + − + + −� * * * *ˆ ˆ ˆ ˆ ˆ ˆ( ) ( ) ( ( ) ( ))( ) (7)
In steady state geldt bovendien:
sf k n g kδ= + +* *ˆ ˆ( ) ( ) (8)
We schrappen de eerste twee termen in (7), herschrijven (8) naar s, substitueren (8) in
(7) en maken gebruik van:
ˆ ˆ ˆ( ( )) / ( )kf k f kα ′= (9)
Dit levert de volgende vergelijking:
k k kλ= −� *ˆ ˆ ˆ( ), (10)
waarbij (1 )( )n gλ α δ= − + + . We kunnen λ interpreteren als de snelheid waarmee de
kloof tussen de steady state en de huidige kapitaalvoorraad wordt gedicht. Het geeft dus
informatie over de snelheid waaraan een land zijn lange termijn evenwichtspad bereikt.
De convergentiesnelheid van kapitaal zal dezelfde zijn als deze voor inkomen per
effectieve arbeidseenheid. Dit kan eenvoudig aangetoond worden. We passen opnieuw
een taylor-expansie toe, ditmaal op de productiefunctie:
y f k f k k k′= + −* * *ˆ ˆ ˆ ˆ( ) ( )( )ˆ (11)
Na differentiatie aan linker- en rechterlid krijgen we:
y f k k′=�� * ˆ( )( )ˆ (12)
Hieruit volgt:
y y f k k k′− = −* * *ˆ ˆ ˆ( )( )ˆ ˆ (13)
Substitutie van (10) en (13) in (12) levert dan:
y y yλ= −� *( )ˆ ˆ ˆ (14)

12
We schakelen over op logaritmen en lossen deze niet-homogene, eerste orde
differentiaalvergelijking op. Na linker en rechterlid te verminderen met t
y1ˆ en enige
herschikking bekomen we:
t
t t t ty y y y e
λ−− = − −2 1 1 1
*ln ln (ln ln )(1 )ˆ ˆ ˆ ˆ (15)
In deze laatste vergelijking kunnen we tot slot lnt
y1
*ˆ invullen:
t t t
t ty e y e s e n gλ λ λα α
δα α
− − −= + − − − + +− −2 2
ln ln (1 ) ln (1 )ln( )ˆ ˆ1 1
(16)
Vergelijking (16) staat geschreven in inkomen per effectieve arbeidseenheid. Rekening
houdend met (3), herschrijven deze naar inkomen per capita.
Y Y
A gtAL L
= − −0ln( ) ln( ) ln( ) , (17)
Na substitutie van (17) in (16) bekomen we de vergelijking die het vertrekpunt vormt
voor empirisch onderzoek. In meer algemene vorm kunnen we deze vergelijking als volgt
schrijven:
j
it i t j it i t it
j
y y xγ κ µ η ν−
=
= + + + +∑2
, 1 ,1
(18)
t t t
it it it i t i t i t
t t
it it i t
met y Y L y Y L e en e
e A g t e t
λ λ λ
λ λ
α αγ κ κ
α α
δ µ η
− − −
− − −
− −
= = = − = − −− −
= − = − −
, 1 , 1 , 1 1 2
1 2
0
ln( / ), ln( / ), =e , (1 ) (1 ) , 1 1
x =ln(s), x =ln(n+g+ ), (1 ) en ( ( 1)).
Vergelijking (18) verschilt met (6) in die zin dat deze laatste veronderstelt dat de landen
zich ofwel in steady state bevinden ofwel dat afwijkingen van steady state willekeurig
zijn. Vergelijking (17) houdt rekening met de out of steady state dynamiek.
Uit (10) volgt dat (1 )( )n gλ α δ= − + + . Dit laat ons toe de theoretische voorspelling voor
de convergentiesnelheid te berekenen. Onder perfecte concurrentie, geeft α het aandeel
van het totale inkomen als vergoeding voor kapitaal. Mankiw et al. stelt deze gelijk aan
1/3. Wanneer we veronderstellen dat de populatie groeit met 1 procent en g+δ =0.05,
voorspelt het neoklassieke model een convergentiesnelheid van 4 procent. Dit impliceert
dat de economie er ongeveer 17 jaar over doet om de helft van de kloof tot steady state
te dichten. Endogene groeimodellen introduceren de aanwezigheid van externaliteiten.
Dit impliceert de afwezigheid van dalende meeropbrengsten van kapitaal. Endogene

13
groeimodellen voorspellen dan ook doorgaans dat er geen convergentie optreed1. Deze
duidelijke theoretische tegenstellingen inzake convergentie, maakt empirisch onderzoek
ernaar interessant. Het laat ons toe de geldigheid van verschillende theorieën te
controleren.
Islam (2003) maakt duidelijk dat men het begrip convergentie op verschillende manieren
kan interpreteren. Zo kan men onder convergentie, convergentie in termen van groei of
in termen van inkomensniveau, verstaan. NGCT gaat ervan uit dat de evolutie van
technologie exogeen is en gelijk voor alle landen. Dit resulteert in convergentie van
groei. Wanneer men ook een identieke productiefunctie veronderstelt, hebben we te
maken met gelijkheid in termen van inkomensniveau.
Een ander belangrijk onderscheid kunnen we maken tussen onconditionele en
conditionele convergentie. Onconditionele convergentie, ook wel bekend als absolute β -
convergentie gaat na of er een negatief verband bestaat tussen een initieel
inkomensniveau en de groei in de daaropvolgende periode. Conditionele convergentie
vormt een striktere definitie van convergentie. Uit het eerder beschreven Solow model
blijkt dat steady state niveaus kunnen verschillen tussen landen. Wanneer men
conditionele convergentie nagaat, controleert men voor deze verschillen in steady state
door variabelen op te nemen die een proxy vormen voor steady state. Men stelt dus
impliciet de steady state’s gelijk voor de verschillende landen. Uit het Solow model volgt
dat bevolkingsgroei, spaarquote, depreciatievoet en de groei van technologie de steady
state bepalen. Na een schatting van γ in (18) kan men de overeenkomstige empirische
conditionele convergentiesnelheid eenvoudig berekenen. De convergentiesnelheid
bedraagt log( ) / tλ γ− . In de empirische literatuur vindt men over het algemeen een
convergentiesnelheid van 2 procent terug. We merken op dat conditionele convergentie
niet noodzakelijk absolute convergentie impliceert. Een stijging van de verschillen in de
investeringsratio zal leiden tot grotere inkomensongelijkheid. In deze context kunnen we
ook club convergentie vermelden. Dit begrip kan eigenlijk beschouwd worden als een als
een alternatieve manier om conditionele convergentie te schatten. Landen met
gelijkaardige kenmerken zullen vaak een gelijkaardig steady state niveau delen. Het is
dan ook niet nodig te controleren voor de verschillen in steady state. De landen van de
OECD vormen bijvoorbeeld zo een groep. Sala-i-Martin (1996) vindt voor de staten van
de Verenigde Staten, 47 prefecturen van Japan en een aantal regio’s binnen Duitsland,
Verenigd Koninkrijk, Frankrijk, Italië en Spanje sterk bewijs voor absolute convergentie.
1 Sommige endogene groeimodellen voorspellen, net als het neoklassieke model, convergentie. Howitt (2000)
vormt hier een voorbeeld van (zie infra)

14
De conditionele convergentiesnelheden wijken nauwelijks af. Clubconvergentie geldt dus
voor deze voorbeelden.
Naast β -convergentie, kan men ook de variantie van de inkomensniveaus van een groep
landen beschouwen. Deze methode staat ook bekend als σ -convergentie. Er is sprake
van σ -convergentie wanneer de dispersie van de inkomensdistributies daalt over de tijd.
Sala-i-Martin maakt duidelijk dat de aanwezigheid van β -convergentie een noodzakelijk,
maar niet voldoende voorwaarde is voor het vinden van σ -convergentie. Beide
convergentiebegrippen mogen niet verward worden. Daar waar β -convergentie de intra-
distributie mobiliteit meet, zegt σ -convergentie iets over de evolutie van de distributie in
zijn geheel. Figuur 3 geeft de evolutie van de dispersie voor OECD, INTER en NONOIL
(zie 4.2 voor meer informatie omtrent de dataset) weer gedurende 1960-2000. Voor
OECD bemerken we een lichte daling met een tendens tot stagnering in de laatste 10
jaar. Sala-i-Martin (1997) vinden een gelijkaardige dalende tendens die zich reeds inzet
vanaf 1950. Baumol en Wolff (1988) bemerken dat de distributie in 1950 vermoedelijk
atypisch divers was als gevolg van de schade die een aantal industriële landen leden in
WO II. De initiële daling in de variantie valt dan te verklaren door het herstel van deze
landen. In INTER en NONOIL stijgt de inkomensongelijkheid vanaf 1970. De ongelijkheid
lijkt wel te stagneren in de NONOIL groep tussen de periode 1995-2000.
1.3 Kritiek
Mankiw et al. onderzoeken of empirisch onderzoek de theoretische bevindingen
ondersteunen. Ze passen een OLS cross sectie schatting toe op drie verschillende
datasets: NONOIL, INTER en OECD. In een eerste deel schatten ze vergelijking (6). Deze
veronderstelt, in tegenstelling tot (18) dat de landen zich in steady state bevinden.
Onder de assumptie dat s en n onafhankelijk zijn van de landspecifieke factor A0, zal OLS
geen vertekening vertonen. De resultaten onderschrijven deels de theoretische
verwachtingen. De verschillende variabelen beschikken over het juiste teken en zijn voor
twee van de drie datasets sterk significant. Bovendien verklaren de verschillen tussen de
spaarquote en de bevolkingsgroei voor een groot stuk de variantie in de
inkomensverschillen. Kwalitatief ondersteunt het empirisch onderzoek dus het
neoklassieke model. Wanneer we echter de kwantitatieve kant van de zaak bekijken,
loopt een en ander fout. De waarden van de geschatte parameters, wijken af van de
theoretische verwachtingen. Uit (6) volgt dat, voor 1 / 3α = de theoretische waarde voor
de parameters gelijk zijn aan 0,5. Mankiw et al. vinden echter waarden die sterk afwijken
van de theoretische voorspelingen. De α waardes geïmpliceerd door de schattingen
bedragen 0.6 voor NONOIL en INTER en 0,36 voor OECD. Hieruit blijkt dat het Solow

15
model toch met een aantal problemen kampt. Het kapitaal aandeel ligt veel te hoog. De
geschatte convergentiesnelheden liggen ook lager dan de 4 procent die de theorie
voorspelt. Dit wijst opnieuw wijst opnieuw op een hogere kapitaalelasticiteit. Hamilton en
Monteagudo (1998) geven een paar mogelijke verklaringen hiervoor. De aanwezigheid
van bepaalde vaste kosten bij het aanwerven van arbeid, zoals verzekeringskosten,
pensoenen en legale kosten zorgen ervoor dat het arbeidsaandeel de werkelijke
arbeidselasticiteit overschat. Verder is het mogelijk dat fysiek kapitaal voor een stuk het
effect van een aantal omitted variables meet zoals eigendomsrechten. Deze zullen een
positieve impact hebben op groei. Ze faciliteren immers investeringen. Tot slot kan een
vintage effect aan de basis liggen. Technologische vooruitgang kan vervat zitten in fysiek
kapitaal. De productiviteit zal dan niet stijgen indien men geen nieuwe
kapitaalinvesteringen uitvoert. Men kan dan aantonen dat het factoraandeel de
elasticiteit overschrijdt.
Ook Romer (1994) uit gelijkaardige kritiek op het Solow model vanuit een eerder
theoretisch oogpunt. Figuur 1 zet de gemiddelde jaarlijkse groei over de periode 1960-
2000 uit tegenover inkomen per capita relatief ten opzichte van Zwitserland voor de
dataset NONOIL (zie infra. voor meer informatie omtrent de dataset). Voor deze ruime
dataset levert deze figuur geen bewijs dat arme landen sneller groeien dan rijke. Om het
specifieke probleem van het Solow model duidelijker naar voor te brengen, herschrijven
we bovenstaand neoklassiek model. Vertrekkend van de productiefunctie geldt:
ˆy k
y kα=
��
(19)
Substitueren we vergelijking (1):
1ˆ ˆ( ( ))y
sk n gy
αα δ−= − + +�
(20)
Tot slot kunnen we 1k
α − nog herschrijven naar y :
(1 )/ˆ( ( ))ˆ
ysy n g
y
α αα δ− −= − + +�
(21)
We vergelijken Zwitserland met Kameroen. Het inkomen per capita van Kameroen in
1960 was ongeveer tien keer kleiner dan dat van de Zwitserland. Toch groeiden beide
landen gemiddeld over de periode 1960-2000 aan dezelfde snelheid. Vergelijking (21)
impliceert dat, voor α =1/3, de spaarquote van de Verenigde Staten 100 keer hoger
moet liggen dan deze van de Filippijnen opdat deze landen een gelijke groei zouden

16
kennen. Voor 0.4α = zou de spaarquote ongeveer 30 keer groter moeten zijn. Deze
ratio’s blijken niet te stroken met de realiteit. Figuur 2 indiceert dat rijkere landen wel
degelijk een hogere spaarquote hebben dan arme. Op basis van de neoklassieke theorie
verwacht men echter een veel grotere variantie. Wanneer we veronderstellen dat het
technologieniveau gelijk is in beide landen, kan het verschil in productiviteit enkel
verklaard worden door het verschil in de kapitaalstock. Vanuit de productiefunctie volgt
dan dat de kapitaalstock 0.1α bedraagt. Dit betekent dat de kapitaalstock in Kameroen
tussen 0.1 en 0.36 procent ligt van de kapitaalstock in Zwitserland, voor respectievelijk
1 / 3 en =0.4α α= . Omgerekend naar marginale productiviteit, ligt deze respectievelijk
ongeveer 33 en 12 keer hoger in Kameroen. Men zou dus verwachten dat er
kapitaalstromen op gang komen. De MPk in steady-state wordt gegeven door:
( ) /K
MP n g sδ α δ δ− = + + − (22)
Landen met een hogere spaarquote en lagere bevolkingsgroei zullen dus een lagere MP
hebben. In de realiteit vinden we echter weinig bewijs terug van kapitaalstromen van
arme naar rijke landen. Lucas (1990) geeft hiervoor een aantal mogelijke verklaringen.
Kapitaalmarktimperfecties vormen een eerste reden. Ook MRW halen dit aan. Lucas stelt
dat men kapitaalstromen kan beschouwen als leencontracten. Land C ontvangt kapitaal
van land D, verwacht wordt dan dat tegengestelde stromen, in de vorm van intresten en
winsten, op een later tijdstip plaats vinden. Een cruciale voorwaarde is afdwingbaarheid.
Afwezigheid hiervan impliceert dat land C, wanneer de periode van terugbetaling start,
de overeenkomst kan stilzetten. In zo een situatie zal land D, de acties van land C
anticiperend, niet lenen aan land C. Dit staat bekend als politiek risico. MRW wijzen op
een gelijkaardige impact van confiscatierisico. Verder stellen ze dat reële rente enkel
gelijk zal zijn aan MPk in perfecte kapitaalmarkten met optimaliserende economische
agenten. Budgetbeperkingen spelen hierin bijvoorbeeld een rol. Introductie van menselijk
kapitaal reduceert de verschillen in MPK sterk. Uitgaande van een uitgebreid Solow model
vindt Lucas dat de rate of return ratio tussen de Verenigde Staten en India daalt van 58
naar 5. Wanneer men een model beschouwt zoals in Lucas (1988) verdwijnen de
verschillen in MPk nagenoeg volledig. Dit model veronderstelt dat het technologieniveau
een functie is van het gemiddelde menselijk kapitaal tot een macht en introduceert dus
externaliteiten.
Een derde punt van kritiek betreft bepaalde assumpties. Het Solow model vertrekt van
een exogene technologie en spaarquote. Deze assumptie impliceert dat het Solow model
een belangrijke factor van groei niet verklaart: productiviteitsverschillen tussen landen.

17
Ten vierde veronderstel het Solow model dat beleidsacties geen impact hebben op de
groei. Via beleidsingrepen kan men wel het pad naar steady state beïnvloeden.
Empirische bevindingen spreken dit tegen. Bepaalde beleidsingrepen hebben wel degelijk
een impact op de groei.
Naast de theoretische kritiek, komt er ook uit een empirische hoek bewijs tegen het
neoklassieke model. Mankiw et al. vinden in hun onderzoek dat de variantie in de
productiefactoren voor een groot deel de variantie in groei verklaren. Ze baseren zich
hierbij op de R². Deze bedraagt 0.59 in het standaard en 0.78 in het uitgebreide Solow
model. Easterly en Levine (2001) vinden echter een ruim aantal studies terug die dit
tegenspreken. Iets anders dan factoraccumulatie verklaart dus de variantie in groei. Men
noemt dit “iets” totale factor productiviteit (TFP). TFP is een ruim begrip en kan op
verschillende manieren geïnterpreteerd worden: wijzigingen in technologie,
externaliteiten, introductie van productiefuncties met een lagere kost, wijzigingen in de
sectorsamenstelling van de productie, … Klenow en Rodriguez-Clare tonen via groei
accounting aan dat TFP belangrijke rol speelt. De resultaten blijken robuust voor de
invoering van menselijke kapitaal. De variatie in per capita groei wordt voor ongeveer
90% verklaard door verschillen in TFP voor een steekproef van 98 landen tussen 1960-
1992. Deze resultaten liggen in lijn van het onderzoek van Benhabib en Spiegel (1994).
Klenow en Rodriguez-Clare voeren ook argumenten aan die de bevindingen in Young
(1995) tegenspreken. Young vond dat factoraccumulatie de sleutel vormt voor de groei
van een aantal Oost Aziatische landen. Klenow en Rodriguez-Clare vinden dit enkel voor
Singapore terug. Mankiw (1997) bekritiseert hun bevindingen enigszins. Hij stelt dat de
resultaten gevoelig zijn voor de parameterkeuze. Verder bemerkt Mankiw dat de proxy
voor menselijk kapitaal te ruim is. In MRW werd secundaire scholing gebruikt. Klenow en
Rodriguez-Clare voegen hier primaire scholing en hogere scholing aan toe. Mankiw merkt
op dat de bijdrage aan menselijk kapitaal van primaire scholing vermoedelijk lager ligt
dan deze van secundaire scholing. Bovendien zullen externaliteiten meer optreden bij
secundaire dan primaire scholing. Deze argumenten ondersteunen het gebruik van
gewichten voor de verschillende niveaus van onderwijs. Naast groei accounting kan men
ook level accounting toepassen. Een schatting van (6), aangevuld met dummyvariabelen,
vormt hier een mogelijke empirische benadering. Eastly en Levine vinden een hogere
productiviteit terug voor OECD. Ook Temple (1998) vindt verschillen in productiviteit
terug.

18
1.4 Reacties op het neoklassieke model
De bovenstaande uiteenzetting wijst er dus op dat da arbeidselasticiteit te hoog ligt. Men
moet dus op zoek naar modellen die lagere waardes voor 1 α− rechtvaardigen. Hierdoor
zal de marginale productiviteit van kapitaal minder snel dalen. Mankiw et al. zochten
naar een oplossing binnen het neoklassieke kader. Het uitgebreide Solow model
introduceert menselijk kapitaal als bepalende determinant voor lange termijn groei.
Menselijke kapitaal verhoogt enerzijds de productiviteit van werknemers. Daarnaast kan
het ook een rol spelen in het absorptievermogen van technologie en een impact hebben
op bijvoorbeeld fertiliteit. Barro en Sala-i-Martin veronderstellen dat A(t) verschilt over
verschillende landen of staten. A(t) zal zich langzaam verspreiden en vloeien van landen
met een hoge A naar landen met een lage A. Tot slot zijn er de endogene groeimodellen.
In wat volgt gaan we dieper in op het uitgebreide Solow model en de endogene
groeitheorie
1.4.1 Uitgebreid Solow model
Door kapitaal in de ruime betekenis van het woord te interpreteren, kan men het hoge
kapitaalaandeel rechtvaardigen. Mankiw et al. voegen menselijk kapitaal toe aan het
standaard model. De afleiding verloopt zeer gelijkaardig. Men veronderstelt dat menselijk
kapitaal op gelijkaardige wijze evolueert als fysiek kapitaal. De productiefunctie is van de
vorm:
1( ) , + <1Y K H ALα β α β α β− −= (23)
waarin H menselijk kapitaal voorstelt. Menselijk en fysiek kapitaal groeien dan volgens:
ˆ ˆ ˆ ˆ( , ) ( )
ˆ ˆ ˆ ˆ( , ) ( ) ,
k
h
k s f k h n g k
h s f k h n g h
δ
δ
= − + +
= − + +
�
� (24)
Hierin is ˆ /h H AL= . Er kan zowel geïnvesteerd worden in menselijk als in fysiek kapitaal.
We vinden de steady states door ˆ ˆ 0k h= =� �
te stellen
1/(1 )1
*
1/(1 )1
*
ˆ
ˆ ,
k h
k h
s sk
n g
s sh
n g
α ββ β
α βα α
δ
δ
− −−
− −−
= + +
= + +
(25)

19
We substitueren (27) in (25) en schakelen over naar logaritmen:
t
k h
t
YA gt n g s s
L
α β α βδ
α β α β α β
+= + − + + + +
− − − − − − 0ln ln( ) ln( ) ln( ) ln( ),
1 1 1 (26)
De coëfficiënten voor n g δ+ +ln( ) zullen niet langer gelijk zijn aan deze voor de
investeringsquote van fysiek en menselijk kapitaal. Veronderstellen we α β= = 1 / 3 , dan
stijgt de coëfficiënt van k
sln( ) van 0.5 naar 0.1. De introductie van menselijk kapitaal
verhoogt met andere woorden de impact van menselijk kapitaal. De coëfficiënt
n g δ+ +ln( ) stijgt naar 2. Een hogere bevolkingsgroei leidt nu ook tot een daling van
menselijk per capita kapitaal. In (26) treed menselijk kapitaal op als een
stroomvariabele. In paragraaf 4.4 maken we echter gebruik van een stock variabele als
proxy voor menselijk kapitaal. Door de steady state vergelijking voor menselijk kapitaal
(25) te combineren met (26), bekomen we een uitdrukking in de stock van menselijk
kapitaal:
t
k
t
YA gt n g s h
L
α α βδ
α β α β α β
= + − + + + +
− − − − − −
*0ln ln( ) ln( ) ln( ) ln( ),
1 1 1 (27)
We bemerken dat deze vergelijking gelijkaardig is aan (6). (6) laat neemt h*ln( )niet op.
Dit kan leiden tot een omitted variable probleem. Substitutie van (27) in (15) levert de
dynamische groeivergelijking voor het uitgebreide model. Deze is identiek aan (18) op de
variabele h*ln( ) na. De convergentiesnelheid wordt gegeven door
n gλ α β δ= − − + +(1 )( ) . Dit impliceert een convergentiesnelheid van 0.2 wanneer we
dezelfde waarden gebruiken als voorheen.
Het uitgebreide model presteert duidelijk beter dan het standaardmodel in termen van
kapitaalelasticiteit en convergentiesnelheden. Voor een open economie echter verwacht
men convergentiesnelheden die hoger liggen dan de standaard 2%. Barro, Gregory en
Mankiw (1995), werken een model uit voor een open economie met gedeeltelijke
kapitaalmobiliteit. Ze laten toe fysiek kapitaal te gebruiken als onderpand om te lenen op
de internationale markt. Voor menselijk kapitaal daarentegen is dit niet mogelijk.
Menselijk kapitaal is immers meer persoonsgebonden en laat minder controle toe. Fysiek
kapitaal kan makkelijk wisselen van eigenaar. De schuld die een land kan aangaan is met
andere worden beperkt tot k. Deze beperking leidt tot een productiefunctie in menselijk
kapitaal met een kapitaal aandeel kleiner dan α β+ . Het open economie model met
kredietbeperking lijkt dus sterk op een gesloten economie model. De

20
convergentiesnelheid ligt nog steeds hoger dan in een gesloten economie, maar lager
dan de verwachte snelheden in een open economie. Wanneer men bovendien
veronderstelt dat men slechts een deel van het fysiek kapitaal als onderpand kan
gebruiken, daalt de convergentiesnelheid verder. Ze benadert dan deze van een gesloten
economie.
1.4.2 Endogene modellen
Endogene groeimodellen sluiten nauw aan bij empirisch onderzoek die een belangrijke rol
toeschrijven aan TFP als motor voor lange termijn groei. Romer (1990) en Howitt (2000)
baseren zich hierbij op technologische wijzigingen. Modellen zoals deze van Lucas (1988)
en Romer (1988) vertrekken van externaliteiten. Barro (1991) introduceert een publieke
sector in een groeimodel met constante schaaleffecten. De overheid financiert haar
uitgaven via een belasting op inkomen. Dit introduceert negatieve externaliteiten, leidt
tot suboptimale private spaarbeslissingen en dus ook tot een suboptimale groei. Indien
men een lump sum belasting invoert die de marginale productiviteit niet beïnvloedt
(bijvoorbeeld een consumptiebelasting), kan men wel de optimale groei bereiken. Rebelo
(1991) ontwikkelde een model zonder externaliteiten waarin private spaarbeslissingen en
groei Pareto-optimaal zijn.
Romer (1990) wijst op de specifieke kenmerken van publieke goederen zoals
bijvoorbeeld kennis. In tegenstelling tot traditionele goederen zijn deze niet rivaal en niet
uitsluitbaar. Niet uitsluitbaarheid betekent dat de eigenaar van een goed anderen het
gebruik van dat goed kan beletten. Dit kan omwille van technische redenen of omdat de
kost te hoog is ten opzichte van de waarde van het goed. Niet rivaliteit impliceert dat het
gebruik van een goed door persoon A, niet belet dat persoon B datzelfde goed
consumeert. Romer vermeldt als specifiek voorbeeld een design van een product. Kennis
in het algemeen is niet rivaal en niet uitsluitbaar. Deze eigenschappen vormen het
vertrekpunt van het model. Romer stelt verder dat er drie sectoren bestaan. De eerste
produceert finale goederen en gebruikt een continuüm van intermediaire goederen als
input. De intermediaire sector gebruikt kapitaal om intermediaire goederen te
produceren. Het aantal intermediaire goederen is een functie van het aantal designs.
Nieuwe designs ontstaan door een toename van de technologie. De groei van technologie
is hierbij een functie van menselijk kapitaal en een initiële stock van technologie. De
intermediaire sector is een monopolie die intermediaire goederen verkoopt en designs
koopt. De verdisconteerde waarde van alle toekomstige winsten van deze sector is gelijk
aan de prijs van een design. Een toename van de rente verlaagt de return van
onderzoek. Een toename van menselijk kapitaal tewerkgesteld in onderzoek, leidt tot een

21
toename van het aantal designs en dus tot een toename van intermediaire goederen. We
merken op dat de groei van technologie eveneens een functie is van de stock van
designs. In het model van Romer komt technologie tot stand als een beslissing van de
economisch, optimaliserende agent.
Endogene groei modellen leiden doorgaans tot divergentie. Het overweldigende
empirische bewijs in de literatuur ten gunste van convergentie leidde echter tot de
ontwikkeling van endogene groeimodellen met convergentie. Howitt (2000) vertrekt van
een standaard Schumpeteriaans groeimodel en voegt de idee van technologietransfers
toe. Deze idee vinden we al terug bij Baumol (1986). Spill-over effecten zullen optreden
van technologisch en innoverende leiders naar volgers. De volgers kunnen profiteren van
innovaties in het leidende land. Een stijging van internationale handel verhoogt de
competitie en dus ook de druk om innovaties over te nemen. Emigratie, toename van
communicatiemiddelen,… bevorderen dit proces. Het model van Howitt vertrekt van twee
sectoren. De eerste is een finale consumptie sector die uitgaat van perfecte concurrentie.
De productiefunctie is gelijkaardig aan deze in Romer (1990). Ze is een functie van een
continuüm intermediaire productiefactoren xi die de output vormen van een tweede,
monopolistische sector. Deze twee sector gebruikt kapitaal als input. Innovaties
introduceren een betere versie van een intermediair goed i. De innovator zal dan ook de
huidge monopolist uit de markt drijven. Tot dus ver lijkt het model dus sterk op dat van
Romer (1990). Het verschil zit hem in de definiëring van A� . Daar waar Romer deze
definieert als een functie van menselijk kapitaal en de stock van A, stelt Howitt:
max( ),i i
A A Aφ= −� (28)
met i i
φ κυ= . φ geeft een indicatie van de snelheid van adoptie van nieuwe technologieën
in elke sector. Hierin is κ een maatstaf voor de productiviteit van R&D. υ is gelijk aan de
R&D uitgaven per intermediair product gedeeld door maxi
A . Landen zullen dus telkens de
technologie van een leidend land overnemen. De productiviteitsparameter Ai wordt dan
vervangen door deze van het leidende land maxi
A De uitwerking van het model resulteert
in twee differentievergelijking. De eerste is analoog aan (4). De tweede geeft weer hoe
de productiviteitsgroei van technologie convergeert naar globale groei van productiviteit
als gevolg van technologietransfers. Het model werkt intuïtief als volgt. Stel dat men
afwijkt van het steady state niveau in vergelijking (). Kapitaal zal dan, geheel analoog
aan neoklassieke modellen, toenemen Deze toename leidt tot een stijging van
investeringen in R&D. Immers, de stijging van kapitaal verhoogt de opbrengst van
investeringen in R&D. Bovendien zal de rente dalen waardoor de verdisconteerde waarde

22
van toekomstige stromen stijgt. Hierdoor nemen de technologietransfers toe. Dit
impliceert een stijging van de productiviteit. In se vormt dit model dus een uitbreiding
van de neoklassieke modellen. Groei wordt niet enkel gedreven door verschillen in
productiefactoren. Ook verschillen in productiviteit spelen een belangrijke rol. De
groeisnelheid van technologie convergeert. Er bestaan wel verschillen in niveaus van
productiviteit, afhankelijk van de productiviteit en intensiteit van de R&D sector. Analoog
zal er convergentie optreden in de groei van per capita output. De steady state niveaus
zelf kunnen verschillen. Landen die niet investeren in de R&D sector kennen geen lange
termijn groei.
2 Empirische literatuur
Convergentie kan op verschillende manieren nagegaan worden. In wat volgt
concentreren we ons op cross sectie en panel data onderzoek. Andere methodes zijn
tijdreeks onderzoek en groei accounting. Deze laatste heeft echter als nadeel dat ze de
gevolgen van beleidsacties moeilijk kunnen nagaan. In deel 1 bespreken we een aantal
cross sectie studies. Vervolgens komt panel data aan bod. Tot slot overlopen we de
sterktes en zwaktes van beide.
2.1 Cross sectie benadering
Baumol (1986) maakt gebruik van Maddison’s dataset 1870-1979 en vindt een negatief
verband tussen GDP per gewerkt uur in 1870 en de groei over de periode 1870-1979
voor een groep van 16 landen. Baumol onderzoekt verder of convergentie voornamelijk
geldt voor een selecte groep van vrije markt economieën of eerder algemeen geldt.
Gebruik makende van de Summers-Heston data 1950-1980 vindt hij geen bewijs voor
convergentie in de volledige dataset. Wanneer men echter de dataset opdeelt in
verschillende groepen, blijken er verschillende zogenaamde convergentieclubs te
bestaan. Voor de 16 Maddison-landen bevestigt de Summers-Heston dataset de eerdere
conclusie. Bovendien blijkt dat een groep van centraal geplande economieën, hoewel
minder duidelijk dan de Maddison-landen, een convergentiegroep op zich vormen. Voor
een groep van ontwikkelingslanden, vindt Baumol daarentegen geen correlatie terug.
De bevindingen van Baumol oogstten kritiek van Romer (1986) en Delong (1988). Romer
(1994) stelt dat deze convergentie vooral plaatsvond na WOII. Gedurende de periode
1870-1950 divergeerde het inkomen per capita eerder. Delong (1988) bemerkt dat de
Maddison dataset enkel die landen omvat die succesvol industrialiseerden tegen 1979.
Dit zorgt voor een ex-post steekproef selectievertekening. Delong bemerkt bovendien dat
meetfouten in de inkomensniveaus van 1870 onvermijdelijk zijn. Hierdoor ontstaat er

23
een vertekening in de richting van het vinden van convergentie. Delong tracht beide
problemen te ontwijken. Hij schakelt over naar een groep van landen die ex-ante in 1870
een grote waarschijnlijkheid tot convergentie leken te hebben. Delong veronderstelt
verder dat de meetfout ε en de storingsterm van de te schatten vergelijking υ
ongecorreleerd zijn en de verhouding van de varianties van beide storingsterm een gelijk
is aan een constante ρ die hij laat variëren in zijn regressies. Hoe groter ρ , hoe groter
de meetfout. Onder deze assumpties kan men het model schatten. Enkel voor lage ρ
vindt Delong bewijs voor convergentie, de basissituatie 1ρ = levert bewijs voor
divergentie. Delong voert identieke regressies uit voor een dataset die start in 1913. De
meetfouten voor deze dataset liggen in se lager en de vertekening naar het vinden van
convergentie toe, zal dus minder sterk zijn. De regressieresultaten bevestigen dit. In een
reactie van Baumol en Wolff (1988), legt Baumol zich grotendeels neer bij kritiek van
Delong. Hij sluit zich echter niet aan bij zijn conclusies. Gebruik makende van nieuwe
datasets en rekening houdende met de problematiek van ex-post selectievertekeningen,
vindt Baumol resultaten die zijn oorspronkelijke bevindingen ondersteunen.
Mankiw et al. gaan een stap verder dan Baumol. In tegenstelling tot Baumol vertrekken
zij voor hun empirisch onderzoek van de eerder formeel afgeleide vergelijking. Hun
empirische vergelijking heeft een theoretische onderbouw. Dit laat toe om op basis van
de regressieresultaten conclusies te trekken over het neoklassieke model. Mankiw et al..
regresseren groei op een initieel inkomensniveau terwijl ze controleren voor een aantal
variabelen. Hierbij onderkennen ze dat het steady state niveau kan verschillen over
verschillende landen. Wil men convergentie testen, moet men controleren voor deze
verschillen. Dit staat ook bekend als conditionele convergentie. De regressie uitgevoerd
door Baumol meet onconditionele convergentie. Cross sectie onderzoek laat toe te
controleren voor s,n,g en δ . Eerder haalden we reeds aan dat Mankiw et al. in zekere
mate bewijs vinden voor het neoklassieke model. De regressies die niet controleren voor
steady state leveren een lage convergentiesnelheid op. Enkel voor de OECD groep komt
de convergentiesnelheid in de buurt van de theoretische voorspellingen: 1.67%. Dit wijst
erop dat OECD een homogene groep vormt met gelijkaardige steady state niveaus.
Introductie van investeringsratio’s en bevolkingsgroei ondersteunt conditionele
convergentie. De convergentiesnelheden voor zowel NONOIL als INTER blijven echter
laag. Na toevoeging van een proxy voor human capital, benadert de
convergentiesnelheid de theoretische voorspellingen. To do
Daar waar men het onderzoek van Mankiw et al. kan linken aan de neoklassieke
groeitheorie, moet men het onderzoek van Barro (1991) eerder beschouwen in de
context van de nieuwe groeimodellen. Barro concentreert zich in zijn onderzoek

24
voornamelijk op menselijk kapitaal. Deze spelen vaak een cruciale rol in endogene
groeimodellen (bijvoorbeeld Lucas (1988) en Romer (1990)). Zich baserend op de
Summers-Heston dataset, vindt Barro een correlatie van 0.09 terug tussen per capita
groei en initiële GDP per capita. Hij verwerpt dus de idee van onconditionele
convergentie. Vervolgens regresseert Barro groei op een initieel inkomensniveau en een
aantal proxys voor human capital. Hieruit blijkt dat, na controle voor een aantal
variabelen waaronder proxy’s voor human capital, initieel inkomensniveau significant
negatief is gecorreleerd met de groei.
Daarnaast gaat Barro het effect na van overheidsuitgaven, politieke instabiliteit,
marktverstoringen en een dummy variabele voor Afrikaanse en Latijns-Amerikaanse
landen op groei. Deze laatste kunnen we interpreteren als een proxy voor verschillen in
initiële efficiëntie. Overheidsuitgaven (exclusief onderwijs- en militaire uitgaven) blijken
een negatieve impact te hebben op groei. De intuïtie hierachter is, dat (niet productieve)
overheidsuitgaven geen directe impact hebben op productiviteit. Ze beïnvloeden echter
de groei en het sparen via een distortief effect op taxatie. Politieke instabiliteit wordt
gemeten via het aantal revoluties en staatsgrepen per jaar enerzijds en het aantal
politieke moorden per jaar per miljoen inwoners. Beide variabelen hebben een negatieve
impact op groei. De richting van de correlatie is echter niet geheel duidelijk. Mogelijks
leidt een hogere groei tot minder politieke instabiliteit. Prijsverstoringen blijken een
negatieve impact te hebben op groei. De dummy variabelen voor sub Sahara Afrika en
Latijns Amerika blijken significant te zijn. Dit wijst erop dat bepaalde variabelen
ontbreken om de groei in deze regio’s te verklaren. Barro wijst erop dat een slechte
proxy voor human capital mogelijks aan de basis ligt van deze resultaten. Anderzijds
kunnen deze dummyvariabelen wijzen op regionale spillover effecten.
Levine en Renelt (1992) voeren een gelijkaardige regressie uit en bekomen gelijkaardige
conclusies. Wanneer ze echter de verklarende variabelen uit Barro (1991) en Kormendi
en Meguire (1985) tezamen gebruiken in één regressie, blijken een groot aantal
variabelen niet langer significant te zijn. Enkel initieel inkomen per capita, de
investeringsratio en de regionale dummy’s blijven significant in beide regressies.
Barro en Sala-i-Martin (1992) onderzoeken convergentie voor de verschillende staten
van de Verenigde Staten. Ze vertrekken van een neoklassieke Cass-Koopmans model,
maar voegen een variabele toe die controleert voor sectoriele verschillen tussen de
staten. Hun resultaten ondersteunen onconditionele convergentie. Dit wijst erop dat de
verschillende staten over gelijkaardige steady states beschikken.

25
2.2 Panel data
De beschikbaarheid van panel data via de Summers-Heston dataset, leidde tot de bloei
van een nieuwe tak binnen het empirische onderzoek naar convergentie. Panel data
schattingen bieden een aantal interessante voordelen ten op zichte van cross sectie- en
tijdreeks schattingen. Door de grotere steekproefgrootte bevat panel data meer
informatie. De variantie van de variabelen neemt toe waardoor de efficiëntie stijgt.
Bovendien kan men in een panel data setting makkelijker rekening houden met de
vertekeningen als gevolg van endogeniteit en meetfouten. Panel data laat verder toe
rekening te houden met heterogeniteit in de productiefunctie over verschillende
individuen. Mankiw et al. controleren in hun cross sectie regressies voor verschillende
steady states. Cross sectie onderzoek laat echter niet toe te controleren voor verschillen
in het individuele landspecifieke effect A0. Dit resulteert in inconsistente schattingen. Via
panel data kan men wel rekening houden met dit effect. Hierin schuilt dan ongetwijfeld
ook de grootste kracht van panel data in de context van groei- en
convergentieonderzoek.
Beschouwen we een dynamische panel data vergelijking:
it i t it i t it
y y xγ κ µ η ν−
= + + + +, 1 , (29)
met
it i it i
E E Eν µ ν µ= = =( ) ( ) ( ) 0 voor i=1,...,N en t=2,...,T (30)
Hierin stelt i
µ een individueel, tijdsinvariant effect voor. Wanneer we teruggrijpen naar
vergelijking (18), komt dit overeen met A0. Deze vertegenwoordigt verschillen in de
productiefunctie tussen verschillende landen en omvat een breed spectrum aan factoren:
klimaat, instituties, … t
η is een tijddummy die de data trend stationair maakt.
Caselli, Esquivel en Lefort (1996) verduidelijken de implicaties van een individueel effect
in een dynamisch model. Een OLS schatting is consistent onder de assumptie dat de
verklarende variabelen geen correlatie vertonen met de storingsterm. In een dynamische
setting gaat deze assumptie echter niet op. Dit valt eenvoudig aan te tonen:
, 1 , 2 , 1 1 , 1[ ] [ ( )] 0,i i t i i t i t i t i t
E y E y xµ µ λ β µ η ν− − − − −
= + + + + ≠ (31)
Dit volgt direct uit 2[ ] 0i
E µ ≠ . Het individuele effect zal met andere woorden gecorreleerd
zijn met de vertraagde variabele. Omwille van het algemene karakter van A0, bestaat er
bovendien geen adequate proxy. Welke proxy men ook gebruikt, men zal er nooit in

26
slagen om A0 in zijn geheel te capteren. In de literatuur voert men soms regionale
dummy’s in als proxy voor het individuele effect. Onze schattingen in 4.4 indiceren dat
menselijk kapitaal eveneens een mogelijke proxy vormt. In cross sectie zal i
µ veelal deel
uitmaken van de storingsterm. Hierdoor ontstaat een zogenaamd omitted variable
probleem, waardoor een OLS schatting niet langer consistent en onvertekend is. Uit de
theorie kan men bovendien de richting van de vertekening afleiden. A0 bepaalt het
inkomensniveau waarnaar een land convergeert. Dit impliceert dat de correlatie tussen
iµ en het initiële inkomensniveau positief is2. Hierdoor ontstaat een opwaartse
vertekening van γ . De convergentiesnelheid zal dan een neerwaartse vertekening
vertonen. Intuïtief kan men dit als volgt interpreteren. Een hogere A0 zal leiden tot een
hoger steady state niveau. Als steady state niveaus verschillen zal een rijk land niet
noodzakelijker dichter bij zijn steady state niveau zitten dan een arm land. Dit impliceert
dat een rijk land niet noodzakelijk groeit aan een lagere snelheid.
Omwille van de ruime omschrijving van A0 kan men bovendien moeilijk stellen dat deze
niet zou gecorreleerd zijn met bijvoorbeeld de bevolkingsgroei of de besparingen. Ook de
schatting van deze coëfficiënten lijden dus mogelijkerwijs onder vertekeningen.
Door over te schakelen naar panel data kan men bovenstaande problematiek oplossen.
Panel data analyse biedt immers mogelijkheden om dit probleem te omzeilen. Bepaalde
schatters elimineren het individuele effect. Een LSDV schatter vermindert bijvoorbeeld de
variabelen met hun tijdsgemiddelden. Hierdoor wordt de vraag of er correlatie bestaat
tussen het individuele effect en de verklarende variabelen irrelevant. LSDV zal consistent
zijn voor zowel N→ ∞ , als voor T→ ∞ , op voorwaarde dat , 1( ) 0i t it
E γ ν−
=� � (met
, 1 , 1 , 11 1
= - = -T T
i t i t i t it it it
t t
enγ γ γ ν ν ν− − −
= =
∑ ∑� � ). In een dynamisch model gaat deze voorwaarde echter
niet op. De vertraagde verklarende variabele is dan gecorreleerd met het gemiddelde van
de storingsterm. Hierdoor krijgen we een neerwaartse vertekening van de LSDV schatter.
First difference GMM neemt de eerste verschillen om het individuele effect te verwijderen
en maakt vervolgens gebruik van een aantal momentvoorwaarden. System GMM vult de
first difference GMM aan met extra momentvoorwaarden. Beide GMM schatters zullen
consistent zijn, op voorwaarde dat de momentvoorwaarden correct gespecificeerd zijn. In
de volgende paragraaf gaan we dieper in op beide GMM schatters. Naast eliminatie van
het individuele effect, kan men ook trachten het individuele effect te definiëren. Een
voorbeeld hiervan is de Minimum Distance schatter (MD). Deze methode definiëert het
2 We vinden een correlatie terug van 0.7081 tussen de individuele effecten en het initiële inkomen. We
gebuiken daartoe de datagroep NONOIL met T=9. De individuele effecten werden berekend via LSDV. Een
bespreking van de data komt aan bod in 4.2

27
individuele effect en 0iy als een functie van 1,...i iTx x . Vervolgens herschrijft men voor
elke periode i
y in gereduceerde vorm. Deze kan geschat worden via OLS. De geschatte
parameters zijn dan een lineaire functie van een aantal onderliggende variabelen. Via
een minimering haalt men tot slot de onderliggende waarden uit de geschatte
parameters. Islam (1995) maakt gebruik van deze methode.
Empirisch onderzoek naar convergentie kende een sterke evolutie. Het startte bij Baumol
die onconditionele convergentie onderzocht. Mankiw et al. controleren voor steady state
in een cross sectie setting. Hierbij ging men nog steeds uit van homogeniteit van de
onderliggende productiefunctie. Islam (1995) gaat een stap verder en controleert voor
verschillen in initiële efficiëntie in een panel data setting. Minimum Distance en LSDV
In een laatste, logische stap laat men naast heterogeniteit in A0 ook heterogeniteit in g
toe Dit impliceert niet enkel verschillen in steady state, maar ook verschillen in, in steady
state groei. Lee, Pesaran en Smith (1997) stellen werken een stochastisch model op dat
dit toelaat. Lee et. al. wijzen erop dat negatie van heterogeniteit in een dynamisch model
leidt tot een inconsistente fixed effect en MD schatter in Islam (1995). Heterogeniteit
introduceert immers autocorrelatie in de storingstermen. De convergentiesnelheid stijgt
sterk naar 23%. Islam (1998) bemerkt echter dat het begrip convergentie steeds minder
waarde heeft naarmate men meer en meer voor verschillen in steady state controleert.
Wanneer men bovendien de assumptie van homogeniteit in g laat varen, kan men weinig
afleiden uit de convergentiesnelheid.
Caselli et al. stellen dat, hoewel hij rekening houdt met het individuele effect, de
resultaten van Islam (1995) toch vertekend zijn. De MD en LSDV schatter houdt immers
geen rekening met endogeniteit (zie infra). Caselli et al. gebruiken een GMM schatter met
vertraagde variabelen als instrumenten en vinden hoge convergentiesnelheden terug:
13.5% voor het standaard model en 6.79% voor het uitgebreide model. Dit komt
overeen met een halveringstijd van ongeveer 7 jaar en heeft tot gevolg dat een
economie zich continu in de buurt van steady state bevindt. Verschillen in per capita
inkomen moeten dan ook geïnterpreteerd worden als verschillen in steady state.
Technologieverschillen spelen hierin een belangrijke rol volgens Caselli et al. Deze hoge
convergentiesnelheden ondersteunen bovendien eerder het standaard Solow model
uitgebreid naar een open economie. Het uitgebreide Solow model voorspelt immers
lagere convergentiesnelheden, terwijl een uitbreiding naar een open economie hogere
snelheden impliceert. Het aandeel van menselijk kapitaal blijkt bovendien negatief te
zijn. Dit vormt een sterk bewijs tegen het uitgebreide Solow model. De schattingen voor
het aandeel van fysiek kapitaal liggen veel lager dan in Mankiw et al.: respectievelijk

28
0.104 en 0.757. Dit betekent dat de afnemende meeropbrengsten zich sneller moeten
inzetten.
Bond, Hoeffler en Temple (2001) breiden het onderzoek van Caselli et al. uit met een
system GMM schatter. Ze wijzen erop dat een first difference GMM schatter onderhevig is
aan kleine steekproef vertekeningen omwille van een zwak instrumentvariabelen
probleem (zie infra). Dit leidt tot een overschatting van de convergentiesnelheid. Men
kan dan ook stellen dat de resultaten van Caselli et al. niet zozeer een open economie
versie van het Solow model ondersteunen, maar eerder het gevolg zijn van een kleine
steekproefvertekening. Toepassing van de system GMM schatter resulteert in de
standaard bevindingen van 2% convergentiesnelheid.
Een interessante toepassing van de endogene en neoklassieke groeitheorie, bestaat eruit
de impact van vrijhandelszones op convergentie na te gaan. De Europese Unie vormt dan
een interessant voorbeeld. Cuaresma, Ritzberger-Grünwald en Silgoner (2008)
onderzoeken dit. Neoklassieke groeitheorie voorspellen een eenmalige impact. Integratie
zal geen langdurige impact hebben op groei. Endogene groeitheorieën voorspellen
daarentegen het tegenovergestelde. Naarmate de marktgrootte toeneemt, stijgen de
spill-over effecten en treden dus toenemende schaaleffecten op. Bovendien daalt de kost
van R&D wat leidt tot hogere rentes en een incentive tot investeren in R&D. Integratie
zal met andere woorden een permanente impact hebben op groei. Cuaresma et al.
vinden dat EU-lidmaatschap een positieve en asymmetrische impact heeft op de lange
termijn groei. Relatief armere landen profiteren hierbij het meest van integratie.
Cuaresma et al. tonen bovendien aan dat dit effect verschilt van de impact van
toegenomen handel op groei. Het positieve effect van lidmaatschap speelt voornamelijk
langs een toegenomen transmissie van technologie.
2.3 Kritiek
Zowel panel data, als cross sectie schattingen kampen met de nodige empirische en
economische problemen. Men moet dan ook oppassen met de interpretatie van de
resultaten. Eerder bespraken we de impact van het individuele effect en heterogeniteit.
Een aantal andere aandachtspunten zijn: robuustheid, de across-within spanning,
endogeniteit, evolutie naar steady state, business cycle effecten en kleine steekproef
prestaties van panel data schatters.
De empirische literatuur inzake groei is vrij uitgebreid. Men kan dan ook een groot aantal
variabelen in verband brengen met groei. Sala-i-Martin (1997) verzamelde meer dan 60

29
variabelen uit de literatuur die een significante correlatie vertonen met groei in ten
minste één regressie. Empirisch onderzoek vertrekt dan ook niet altijd van een
welomlijnd formeel afgeleide vergelijking. Men voert vaak cross sectie regressies uit met
economische groei als afhankelijke variabele en een aantal verklarende variabelen
waarvan men verwacht gecorreleerd te zijn met economische groei. Meestal bevatten
deze informele regressies de investeringsratio. Er bestaat immers een wijde consensus
dat deze een impact heeft op de groei. De overige opgenomen variabelen hangen sterk
af van de onderzoeksvraag. Over het algemeen zijn zulke specificaties dus vrij algemeen.
Enerzijds laat deze methode toe een breed spectrum aan politiek-economische
verklarende variabelen voor economische groei te introduceren, anderzijds heeft deze
methode weinig voeling met een formeel theoretische model. Hierdoor is het niet
duidelijk of een bepaalde variabele dan wel het inkomen per capita, de groei of beide
beïnvloedt. Bovendien geeft deze werkwijze weinig inzicht in de richting van de effecten.
Bovendien kunnen er endogeniteitsproblemen optreden. Temple (1999) stelt bijvoorbeeld
dat wanneer inflatie negatief gecorreleerd is met initiële efficiëntie, de coëfficiënt van
inflatie een negatief bezit, zelf wanneer er in werkelijkheid geen relatie tussen inflatie en
groei zou bestaan. Een derde probleem betreft robuustheid. We vinden beide punten van
kritiek terug in Solow (1994). Solow stelt daarnaast de robuustheid in vraag. Levine en
Renelt (1992) gaan hier dieper op in. Ze onderzoeken de robuustheid van een ruime set
verklarende variabelen via de extreme-bounds test van Leamer (1985). Levine en Renelt
concluderen dat het merendeel van de variabelen gevoelig zijn voor kleine veranderingen
in de samenstelling van verklarende variabelen in de regressie. De proportie van
investeringen tegenover GDP blijkt wel robuust gecorreleerd te zijn met de groei en het
aandeel van internationale handel tegenover GDP. Uit het onderzoek van Levine en
Renelt zou men dus kunnen concluderen dat men niet al te veel belang mag hechten aan
de resultaten van regressies gebaseerd op deze onderzoeksmethode. Weinig variabelen
blijken systematisch gecorreleerd te zijn met groei. Sala-i-Martin (1997) gaat dieper in
op het onderzoek van Levine en Renelt. Hij stelt dat de extreme-bounds test te sterk is.
Sala-i-Martin schakelt over op een test voor robuustheid die rekening houdt met de
volledige distributie van de parameters. Men berekent de gewogen, gemiddelde schatting
voor de parameterwaarden en het gewogen gemiddelde van de varianties. Het gewicht is
proportioneel t.o.v. de likelihoods. Vervolgens gaat Sala-i-Martin via een cumulatieve
functie de significantie na. Hij concludeert dat 22 van de 59 variabelen significant zijn en
deelt ze in, in 9 subgroepen: regionale, politieke en religieuze variabelen, variabelen die
marktverstoringen en marktprestaties meten, types van investeringen, productie in de
primaire sector, openheid, type van economische organisatie en een dummy voor
vroegere Spaanse kolonies. Temple (1999) relativeert de resultaten van Levine en Renelt
enigszins. Multicollineairiteit bijvoorbeeld impliceert dat de impact van bepaalde

30
variabelen op groei vooral werkt langs onderliggende processen. Hoge inflatie
bijvoorbeeld kan het resultaat zijn van een slecht macro economisch beleid. Wanneer
men, naast inflatie, variabelen opneemt die hiervoor een proxy zijn, verandert het
significiantieniveau van inflatie. Dit verklaart deels de fragiliteit van de schattingen. Het
al dan niet vinden van significantie, geeft dan ook niet altijd informatie over een mogelijk
verband met groei. Kennis van de onderliggende dynamiek is dan ook cruciaal.
Temple (1998) voert een aantal robuustheidtesten voor cross sectie schattingen van het
uitgebreide Solow model. Hij beschouwt daartoe de problematiek van omitted variable,
heterogeniteit en meetfouten. Deze impliceren dat bepaalde observaties niet
representatief zijn. Via een robuuste schatter kan men het meest coherente deel van de
dataset identificeren. Het laat bovendien toe na te gaan welke landen een afwijkende
groei vertonen. Lee maakt gebruik van een vereenvoudigde versie van de Reweighted
Least Squares (RWLS). Op OECD na, blijven de resultaten van Mankiw et al. min of meer
overeind na toepassing van robuuste schatters. Verwijdering van Portugal en Turijke uit
de OECD groep, zakt de verklaringskracht van het uitgebreide Solow model ter verklaring
van het inkomen per capita gevoelig van 0.32 naar 0.02. In schattingen van de
groeivergelijking blijkt de proxy voor menselijk kapitaal niet langer significant na het
verwijderen van extreme waarden en de introductie van regionale dummyvariabelen
(analoog aan Barro (1991)). Deze laatste vormen een proxy voor initiële efficiëntie A0.
Dit wijst erop dat de significantie van menselijk kapitaal in de regressies van MRW vooral
het gevolg is van extreme waarden en een correlatie tussen menselijk kapitaal en initiële
efficiëntie. Verder vindt Lee zowel in schattingen van de inkomens per capita als
groeivergelijkingen bewijs terug voor heterogeniteit in de onderliggende
technologieparameters. Hij splitst daartoe de steekproeven op in kwartielen van de 25%
armste tot 25% rijkste landen. Hierdoor wordt ook duidelijk dat de convergentiesnelheid
sterk verschilt over de kwartielen. Convergentie treed voornamelijk op in de armste
(9.2%) en rijkste groep (1.8%). De middengroepen tonen geen tendens tot
convergentie. Dit bevestigt de bevindingen van Quah (1996) dat er een zekere
polarisatie in de distributie van inkomen per capita optreed.
Temple concentreert zich verder op de impact van meetfouten. Delong (1988), Baumol
(1986) en Romer (1990) wijzen op de gevaren van meetfouten. Over het algemeen
houdt men in de literatuur echter weinig rekening met deze problematiek. Temple toont
nochtans aan dat meetfouten aanleiding geven tot ruime intervallen voor de waardes van
de technologieparameters. Bovendien leiden meetfouten in het initiële inkomen tot een
overschatting van de convergentiesnelheid. Extra complicaties treden op wanneer de
meetfout in het finale inkomen gecorreleerd is met deze in het initiële inkomen of indien
de overige verklarende variabelen eveneens onderhevig zijn aan meetfouten. In het

31
laatste geval wordt de richting van de vertekening van de convergentiesnelheid
onvoorspelbaar (zie (9)).
Een tweede aandachtspunt staat bekend als de Across-Within tension. Het model van
Solow stelt dat een land convergeert naar een zeker evenwichtsniveau en concentreert
zich dus op de dynamiek binnen een economie. Idealiter zou men dus gebruik moeten
maken van tijdsreeksen. Cross sectie onderzoek focust zich op de evoluties over
verschillende economieën heen. Hierdoor ontstaat een zekere spanning in de
interpretatie van λ . Daar waar λ in het theoretisch model de convergentiesnelheid naar
steady state geeft, interpreteert men λ in cross sectie onderzoek als de snelheid
waaraan arme landen de kloof dichten met rijkere landen. Deze tegenstelling, stelt zich
voornamelijk bij schatting van de formeel afgeleide neoklassieke groeivergelijking.
Informele schattingen, zoals deze van Baumol, geven dan wel geen informatie over de
structurele parameters, ze hebben als voordeel duidelijk interpreteerbaar te zijn.
Caselli et al. wijzen op twee problemen. De eerste betreft de eerder beschreven
problematiek rond het individuele effect. Verder vestigen Caselli et al. er de aandacht op
dat bepaalde verklarende variabelen mogelijks onderhevig zijn aan een
endogeniteitsprobleem. Door gebruik te maken van instrumentvariabelen kan men
endogeniteit omzeilen. Het blijkt echter moeilijk om variabelen te vinden die gecorreleerd
zijn met de endogene variabele, maar niet met groei. In een panel data context kan men
gebruik maken van de vertraagde endogene variabelen. Islam (1995) houdt geen
rekening met deze potentiële endogeniteit. Caselli et al. tonen nochtans aan dat
endogeniteit wel degelijk een rol speelt. De Hausman test verwerpt zowel voor een
restricted als unrestricted Solow model, als voor een meer algemene specificatie de
hypothese van strikte exogeniteit. De bevindingen van Caselli et al. verschillen sterk met
deze van Islam. Ook Barro (1991) gaat dieper in op endogeniteit tussen fertiliteit,
investeringen en per capita groei. Exogene wijzigingen in productiviteit kunnen
bijvoorbeeld zowel groei als de investeringsratio verhogen. Anderzijds zal een exogene
stijging van de productiviteit een negatieve impact hebben op fertiliteit. De
opportuniteitskost voor het opvoeden van een kind stijgt immers. De schattingen van
Barro bevestigen dat er een zekere graad van endogeniteit bestaat.
Cho en Graham (1996) vestigen de aandacht op een eigenaardige implicatie van
conditionele convergentie. Vertrekkende van de neoklassieke groeitheorie, verwacht men
dat arme landen hun steady state bereiken langs onder, terwijl rijke landen deze
bereiken langs boven. Gebruik makende van de MRW data tonen Cho en Graham echter
aan dat arme landen eerder van boven convergeren naar hun steady state

32
inkomensniveau. Van de 98 landen in de steekproef, bevinden 49 landen zich boven hun
steady state. Een opdeling in kwartielen verduidelijkt dat deze 49 landen zich
voornamelijk in de laagste twee kwartielen situeren. Deze bevinding impliceert bovendien
dat arme landen doorgaans een hogere kapitaal arbeid verhouding hebben dan in steady
state. De ratio zal dus dalen voor armere landen naarmate ze convergeren naar steady
state.
Wanneer men overschakelt naar panel data introduceert men naast de cross sectie
dimensie eveneens een tijdsdimensie. De aanwezigheid van een tijdsdimensie impliceert
dat de geschatte resultaten onderhevig zijn aan cyclische effecten. Dit kan leiden tot een
opwaartse vertekening van de convergentiesnelheid. In de literatuur schakelt men dan
ook vaak over naar 5 of 10 jaarlijkse intervallen. Dit heeft als nadeel dat de variatie in de
tijdsreeks daalt. Islam (1995) past deze methode toe en vergelijkt de cross sectie
resultaten van Mankiw et al. met een OLS schatting op panel data. De verschillen in de
resultaten zijn miniem. Men kan dus zonder problemen de data opdelen in intervallen.
Lee, Longmire, Matyas en Harris (1998) passen een dertigtal schatters toe op zowel
jaarlijkse als vijfjaarlijkse paneldata. De convergentiesnelheden gebaseerd op jaarlijkse
paneldata liggen merkelijk hoger dan deze voor de vijfjaarlijkse paneldata. Vooral de
schatters die zich baseren op het model in eerste verschillen vinden extreme
convergentiesnelheden terug die variëren tussen 17.37% en 158.26%.
Een laatste aandachtspunt betreft de eigenschappen van panel data schatters.
Theoretisch kan men bewijzen of de schatters al dan niet consistent zijn. Consistentie
zegt echter niets over de prestatie van de schatters in kleine steekproeven. De
eigenschappen van de verschillende schatters in kleine steekproeven is veelal onbekend
en hangt bovendien sterk af van het specifieke probleem dat men schat. Dit heeft tot
gevolg dat de verschillende schattingsmethodes, tot sterk uiteenlopende resultaten
kunnen leiden. Islam(2000) onderzocht dit voor een uiteenlopend aantal panel data
schatters. Via Monte Carlo experimenten toont Islam aan dat de theoretische,
asymptotische eigenschappen van schatters vaak afwijken van deze in kleine samples.
Verder volgt uit zijn onderzoek dat schatters die geen gebruik maken van vertraagde
variabelen als instrumentvariabelen over het algemeen beter presteren dan de
schattingsmethodes die dit wel doen. Eenvoudige schatters zoals LSDV en 2SLS blijken
ook beter te presteren dan meer gesofisticeerde schatters zoals GMM2. Deze laatste is
immers afhankelijk van de schatting van een optimale gewichtenmatrix (zie infra). Dit
kan extra storing introduceren in de schattingen. De goeie prestaties van de LSDV
schatter vormen een opvalland resultaat.

33
3 Generalized Method of Moments (GMM)
In paragraaf 2 werd duidelijk dat een aantal empirische problemen optreden bij de
schatting van de neoklassieke groeivergelijking. Panel data bieden een aantal voordelen.
De keuze van een schatter is echter niet evident. Vaak verschaft de theorie weinig
informatie over de kleine steekproef eigenschappen niet. Deze hangen bovendien sterk af
van het specifieke onderzoeksprobleem. Via simulaties kan men meer informatie
verwerven over de prestaties in een kleine steekproef. Vooraleer we overgaan tot een
schatting van (18), willen we dan ook de eigenschappen van een aantal schatters
nagaan. We baseren ons daartoe op Islam (2000) en passen een Monte Carlo experiment
toe in paragraaf 4.1. Het onderzoek van Islam, hoewel zeer uitvoerig, bevat echter niet
de system GMM schatter. In de literatuur vinden we nochtans argumenten ten gunste
van het gebruik van een system GMM schatter. Sysem GMM zal bijvoorbeeld, in
tegenstelling tot de first difference GMM niet lijden onder het probleem van zwakke
instrumentvariabelen. Het loont dan ook de moeite dit verder te onderzoeken. In wat
volgt gaan we dieper in op de first difference en system GMM schatters en hun specifieke
theoretische eigenschappen. We starten met een bespreking van de first difference GMM
schatter. Vervolgens concentreren we ons op het zwakke instrumentvariabelen probleem.
In deel drie werken we de system GMM schatter. Deel vier focust op een aantal
problemen van de system GMM schatter. Deel 5 presenteert een oplossing voor deze
problemen in de vorm van een stacked GMM schatter. In het laatste deel komen tot slot
een aantal niet lineaire momentvoorwaarden aan bod.
3.1 First difference GMM schatter
First difference GMM verwijdert het individuele effect door de eerste verschillen te
nemen. Vermits i t i t
E y ν− −
≠, 1 , 1( ) 0 zal i t it
E y ν−
∆ ∆ ≠, 1( ) 0 . Er is dus niet voldaan aan de
noodzakelijke voorwaarde voor een consistente schatting. We moeten dus op zoek gaan
naar instrumentvariabelen die gecorreleerd zijn met i t
y−
∆ , 1 , maar niet met itν∆ Arellano
en Bond (1991) stellen voor de vertraagde variabelen in niveaus te gebruiken. Dit levert
de volgende 0.5(T-1)(T-2) momentvoorwaarden op:
i t s i t
E y ν−
∆ = ≥, ,( ) 0 voor t=3,...,T en s 2 (32)
We bemerken dat deze momentvoorwaarden niet opgaan indien de storingstermen
gecorreleerd zijn. Een tweede noodzakelijke voorwaarde is dus:

34
it is
E ν ν = ≠( ) 0 voor s t (33)
Bovendien moeten de initiële condities vooraf bepaald zijn. Dit levert een derde
voorwaarde:
i it
E y ν =1( ) 0 voor i=1,...,N en t=2,...,T (34)
(30), (33) en (34) zijn noodzakelijke voorwaarden voor (32) en laten toe de parameters
te schatten. Het aantal beschikbare instrumentvariabelen zal verschillen per periode. De
Z matrix met instrumentvariabelen ziet er als volgt uit:
i
i iGMM d
i
i i T
y
y yZ
y y−
=
� �
� �
� � � � � � �
� �
1
1 2( )
1 , 2
0 0 0 0
0 0 0,
0 0 0
Elke rij van deze matrix vertegenwoordigt een periode. Op de eerste rij staan
bijvoorbeeld de instrumentvariabelen voor T=3. Zi is een (T-2)xm matrix. Om tot de
volledige GMM dZ
( ) matrix te komen, worden de verschillende GMM d
iZ ( )
i onder elkaar
geplaatst om zo tot een N(T-2) x m matrix te komen.
Aangezien er meer condities dan te schatten parameters zijn, is het onmogelijk alle
condities gelijk te stellen aan nul, zoals bij een traditionele OLS schatting. GMM probeert
de condities zo dicht mogelijk bij nul te krijgen door de kwadratische functie
( ) ( )( ' ' )GMM d GMM d
NZ W Zν ν te minimaliseren. Hierin is WN een gewichtenmatrix. Sommige
momentvoorwaarden leveren immers meer informatie. De gewichtenmatrix speelt een rol
in de efficiëntie van de schatters. υ is een N(T-2) vector die gelijk aan 1( ,..., )'N
ν ν met
( ,3 ,( ,..., )i i i T
ν ν ν= ∆ ∆ en ( ) ( ) ( )1( ,... )'GMM d GMM d GMM d
NZ Z Z= Aangezien we werken met lineaire
condities, kunnen we het minimeringsprobleem analytisch oplossen door de eerste
afgeleide gelijk te stellen aan nul. Dit resulteert in:
' ( ) 1 ' ( ) ( )1 1 1 1( ' ) 'ˆ GMM d GMM d GMM d
N Na y Z W Z y y Z W Z y−
− − − −= (35)

35
De asymptotische variantie wordt gegeven door:
' ( ) ( )
1 1
' ( ) 2
1 1
ˆ 'avâr ,
( ' )
GMM d GMM d
N N N
GMM d
N
y Z W V W Z yN
y Z W Z y
− −
− −
= (36)
met GMM d GMM d
N i i i i
i
V N E Z Zν ν−= ∑1 ( )' ' ( )( ) de gemiddelde covariantie matrix van GMM d
i iZ ν( )' . Voor
de berekening van de variantie kunnen we een onderscheid maken tussen de een- en
twee-staps GMM schatter. De een-staps GMM schatter stelt
GMM d GMM d GMM d
N i i
i
W N Z H Z− −= ∑1 ( )' ( ) ( ) 11 ( ) Arellano en Bond (1991) stellen de volgende (T-2)x(T-
2) GMM dH
( ) matrix voor:
GMM dH
−
− − = −
�
�
�
� � � � �
�
( )
2 1 0 0
1 2 1 0
,0 1 2 0
0 0 0 2
Deze veronderstelt homoscedasticiteit en geen autocorrelatie. De twee-staps GMM
introduceert correcties voor heteroscedasticiteit en autocorrelatie. De optimale
gewichtenmatrix is dan N N
W V −= 12
ˆ( ) . Deze wordt berekend door de storingstermen te
schatten via een initiële schatting die gebruik maakt van een suboptimale
gewichtenmatrix N
W 1 . Indien geen autocorrelatie en geen heteroscedasticiteit aanwezig is
in de data zullen de één – en twee-staps GMM dezelfde schattingsresultaten geven. De
twee-staps GMM zal doorgaans efficiënter zijn. In de literatuur vinden we echter dat de
schattingen van de variantie op basis van een twee-staps GMM doorgaans een
neerwaartse vertekening vertonen van ongeveer 30%. Dit impliceert dat men de
nulhypotheses sneller verwerpt. De twee-staps GMM vereist een schatting van een
optimale gewichtenmatrix. Dit introduceert extra storing in het model en leidt tot de
vertekening. De één-staps GMM schatting van de variantie is dan ook betrouwbaarder.
Windmeijer (2000a) werken een correctie uit voor deze vertekening via een eerste order
Taylor expansie. In Monte Carlo simulaties blijken deze correcties goed te presteren.
3.2 Prestatie van first difference GMM in kleine samples
Voor N → ∞ (met T vast) levert GMM een consistente schatter op. Echter, voor een
beperkte N blijkt GMM minder sterk te presteren. Blundell en Bond (1998) tonen dit
zowel theoretisch als empirisch, via Monte Carlo experimenten, aan. De first difference

36
GMM blijkt te lijden onder het zwakke instrumentvariabelen probleem zoals besproken in
Nelsen en Startz (1990a en b)
In hun theoretische uitwerking beschouwen Blundell en Bond de situatie waarin T=3.
Door deze beperking op te leggen, herleid GMM zich tot een eenvoudige IV (instrument
variabel schatter). Zij tonen dan aan dat, wanneer de vertraagde variabele een zwak
instrument vormt voor de eerste verschillen variabelen, de IV schatter zwak presteert.
Naarmate N daalt, de variantie van het het individuele, tijdsonafhankelijke effect –
relatief ten opzichte van de variantie van de storingsterm - stijgt of alfa 1 nadert, krijgen
we zwakkere instrumentvariabelen. De Monte Carlo experimenten van BLundell en Bond
bevestigen dit. Naarmate observaties en T stijgen, verbetert de prestatie van de first
difference GMM. Dit is een belangrijke conclusie in het kader van empirisch onderzoek
naar convergentie. De variabele y is immers sterk persistent. Bovendien zal de variantie
van het individuele effect vermoedelijk toenemen naarmate men meer heterogene
groepen van landen gebruikt als panel data.
Bond, Hoeffler en Temple (2001) maken gebruik van een alternatieve methode om na te
gaan of er effectief een kleine sample vertekening aanwezig is. Beschouwen we
bijvoorbeeld een AR(1) proces met een specifiek individueel effect. Men schat dan eerst
het model met OLS en LSDV. OLS vertoont dan een opwaartse vertekening met
betrekking tot de parameter bij de autoregressieve component (Hsiao,1986). LSDV
daarentegen vertoont een neerwaartse vertekening (Nickell, 1981). Een consistente
schatting zal, logischerwijs, tussen de OLS en LSDV schattingen liggen. Dit vormt een
interessante werkwijze om na te gaan of GMM vertekend is. Wanneer de GMM schatting
dicht bij (of onder) de Within Groups waarde ligt, vormt dit een indicatie voor
vertekening. De empirische resultaten van Bond, Hoeffler en Temple bewijzen dat GMM
vertekend is. De schattingen van GMM met betrekking tot de autoregressieve component
liggen onder de Within Groups schattingen voor zowel het standaard, als het uitgebreide
Solow model.
3.3 System GMM
Hoe kunnen we dit probleem nu oplossen? GMM beschikt duidelijk over te weinig
informatie om de coëfficiënten correct te schatten. Door gebruik te maken van extra
momentvoorwaarden, kan men potentieel de performantie verbeteren. Arellano en Bover
(1995) stellen voor om de vertraagde verschillen te gebruiken als instrumenten voor het
model in niveaus (level GMM). Dit geeft aanleiding tot de volgende T-2 lineaire
momentvoorwaarden:

37
i it i t
E yµ ν−
+ ∆ =, 1(( ) ) 0 voor t=3,...,T (37)
Uitwerking leert ons dat deze momentvoorwaarden gelden indien de individuele effecten
niet gecorreleerd zijn met de vertraagde variabelen in eerste verschillen. De geldigheid
van deze momentenvoorwaarden berust op (30), (33) en (34).en de volgende
assumptie:
i i
E yµ ∆ =2( ) 0 voor i=1,...,N (38)
(39) is een noodzakelijke voorwaarde voor (38). We definiëren i
i iy
µν
γ= +
−1 11
. Substitutie
in (39) levert dan:
i i
E µν =1( ) 0, (39)
Het impliceert een beperking op het initiële condities generende proces voor i
y 1 .
Afwijkingen van de initiële condities i
ν 1 mogen niet gecorreleerd zijn met de initiële
conditie i
µ γ−/ (1 ) . In een stationair model gaat deze voorwaarde impliciet. Dit lijkt een
sterke assumptie in de context van groei en convergentie. Stationariteit vormt echter
geen noodzakelijke voorwaarde. De inclusie van tijddummy’s, zorgt ervoor dat (40) niet
wordt verbroken.
Wanneer men de moment voorwaarden van de level GMM en first-difference GMM
combineert, bekomt men de zogenaamde system GMM schatter. Een aantal
momentvoorwaarden van de level GMM zijn echter overbodig vermits deze al in de first
difference GMM begrepen zitten. De Z-matrix ziet er als volgt uit:
GMM d
i
i
sysGMM
i i
i T
Z
y
Z y
y−
∆ = ∆ ∆
�
�
�
� � � � �
�
( )
2
3
, 1
0 0 0
0 0 0
,0 0 0
0 0 0
De berekening van de parameterwaarden en varanties verloopt analoog aan deze van de
first difference GMM waarbij 1( ,..., )'sysGMM sysGMM sysGMM
NZ Z Z= en 1( ,..., )'sysGMM sysGMM sysGMM
Nv vν =

38
met ,3 ,( , ,..., )sysGMM
i i i i Tv vν ν= . Men kan opnieuw zowel een één- als twee-staps GMM
berekenen. De werkwijze is analoog. De H matrix verschilt echter enigszins door de
toevoeging van de level GMM momentvoorwaarden:
GMM d
sysGMM
N
H MH
M I
=
( )
,'
met
M
− = −
�
�
�
� � � � �
�
1 0 0 0
1 1 0 0
.0 1 1 0
0 0 0 1
3.4 Kleine steekproef eigenschappen system GMM schatter
In tegenstelling tot first difference GMM blijft system GMM informatief, zelf wanneer
γ → 1 . In hun Monte Carlo experimenten tonen Blundell en Bond (1998) aan dat system
GMM merkelijk beter presteert dan first difference GMM. Vooral wanneer de reeksen
persistent zijn en N klein, nemen we een sterke verbetering waar. Naarmate T stijgt en
de bijdrage van het individuele effect daalt, verbeteren de prestatie van first difference
GMM Naarmate Ook Bond et al. (2001) vinden bewijs dat system GMM beter presteert.
De schattingen voor system GMM liggen tussen de OLS en Within Groups schattingen. Dit
zowel voor het standaard, als het uitgebreide Solow model. Indien we de asymptotische
variantie beschouwen, presteert system GMM beter dan first difference GMM. Het
verschil in efficiëntie stijgt naarmate γ → 1 . System GMM blijkt dus een veelbelovende
schatter te zijn.
De conclusies die Blundell en Bond maken zijn echter gebaseerd op een aantal strikte
veronderstellingen. Zwakke instrumentvariabelen vormen bovendien slechts een deel van
de vertekening die we aantreffen in de first difference GMM. Een tweede bron van
vertekening, is het aantal instrumentenvariabelen relatief ten opzichte van de
steekproefgrootte. Bekker (1994) toonde aan dat 2SLS inconsistent is voor T → ∞ . Hahn
en Hausmann (2002) tonen aan dat de kleine steekproef afwijking monotoon stijgt met
het aantal instrumentvariabelen. Een zekere afweging is dus noodzakelijk. Toevoegen
van instrumentvariabelen zal enerzijds de efficiëntie verhogen. Anderzijds zal er een
vertekening optreden wanneer men te veel instrumentvariabelen gebruikt. Een system
GMM schatter gebruikt steeds meer momentvoorwaarden dan de standaard first

39
difference GMM. Het probleem van te veel instrumentvariabelen is dus sterker voor een
system GMM schatter.
Hayakawa (2007) toont theoretisch aan dat de vertekening van system GMM bestaat uit
een gewogen gemiddelde van de vertekening van de first difference GMM en de niveau
GMM. De first difference GMM vertoont een neerwaartse vertekening en de niveau
schatter een opwaartse. Beide vertekeningen heffen elkaar dus (gedeeltelijke) op. Dit
verklaart waarom de vertekening van de system GMM kleiner is. Twee factoren
beïnvloeden dit proces: de grootte van de vertekeningen van first difference – en niveau
GMM enerzijds, het gewicht anderzijds. De verhouding van de variantie van het
individuele de variantie van de storingsterm speelt een cruciale rol in de grootte van de
vertekening. Het gewicht bepaalt in welke mate de vertekeningen elkaar teniet doen.
Voor extreme waarden (0 of 1) zullen de vertekeningen van de first difference GMM en
niveau GMM elkaar niet opheffen. Hayakawa (2007) voert een aantal simulaties3 uit voor
verschillende νησ / σ2 2 en γ . Het gewicht voor de first difference GMM vertekening daalt
voor λ → 1 , ongeacht de verhouding van de varianties. De grootte van de vertekening
van first difference GMM stijgt dan echter, terwijl deze van de niveau GMM daalt. Dit is
niet geheel onverwacht. Naarmate λ → 1 stijgt, vergroot het probleem van zwakke
instrument voor first difference GMM, terwijl de kracht van de niveau schatter net dan
komt bovendrijven. Twee tegenstrijdige bewegingen zetten zich dus in wanneer γ
toeneemt. Het netto-effect varieert voor verschillende νησ / σ2 2 . Voor νη
σ / σ =2 2 1 vertoont
system GMM zeer kleine vertekeningen. Dit verklaart de goede prestaties van system
GMM in de Monte Carlo experimenten van Blundell en Bond(1998). Zij trokken i it
η ν en
immers uit een N(0,1) distributie. Wanneer νησ / σ =2 2 4 vindt Hayakawa een sterk
opwaartse bias. Deze schommelt rond 20 procent voor γ tussen 0.5 en 0.8. Voor γ = 0.9
bedraagt de vertekening 9.57 procent. Indien νησ / σ =2 2 0.25 vertoont system GMM een
neerwaartse vertekening van ongeveer 6 procent.
3.5 Stacked GMM
Het aantal instrumentvariabelen voor de first-difference GMM stijgt kwadratisch met het
aantal periodes. Ook de standaard first difference GMM zal dus onderhevig zijn aan het
probleem van te veel instrumentvariabelen. Alvarez en Arellano (2003) tonen theoretisch
3 Hayakawa (2007) berekent ook theoretisch de verschillende vertekeningen. Voor γ ≤ 0.5 benaderen zijn
berekeningen de simulaties vrij sterk. In de overige gevallen wijken de theoretische berekeningen echter af van
de simulaties.

40
aan dat, hoewel voor T → ∞ , het aantal momentvoorwaarden naar oneindig tendeert,
GMM toch consistent blijft. Voor een vaste T echter kunnen te veel instrumentvariabelen
problematisch zijn. Een tweede probleem treed op bij de schatting van de twee staps
GMM schatters. Deze vereisen een schatting van de optimale gewichtenmatrix. Het
aantal te schatten elementen in deze gewichtenmatrix is echter een functie van T tot de
vierde macht. Dit impliceert dat voor een hoge T en relatief kleine steekproeven, deze
gewichtenmatrix niet langer geschat kan worden. .We kunnen dit op twee manieren
oplossen. Enerzijds bestaat de mogelijkheid om het aantal momentvoorwaarden per
periode te beperken tot een vast aantal lags, anderzijds kunnen we lineaire combinaties
maken van momentvoorwaarden. Deze laatste methode staat ook wel bekend als
stacked GMM (Arellano, 2003). Stacked GMM zorgt ervoor dat het aantal
momentvoorwaarden constant blijft als T stijgt. Er bestaan verscheidene manieren om
momentvoorwaarden te combineren. We kunnen bijvoorbeeld alle first difference GMM
momentvoorwaarden per periode combineren. Dit resulteert in de volgende Z matrix:
i
i i
stacked
i i i i
i t i t i t i
y
y y
Z y y y
y y y y− − −
=
�
�
�
� � � �
�
,1
,2 ,1
,3 ,2 ,1
, 2 , 3 , 4 ,1
0 0 0
0 0
.0
0
3.6 Extra momentvoorwaarden
Ahn en Schmidt (1995) introduceren een aantal extra niet-lineaire momentvoorwaarden.
Wanneer de storingstermen homoscedastisch en niet gecorreleerd zijn, kunnen volgende
niet lineaire momentvoorwaarden gebruikt worden:
i t i t i t i t
E y v y v− − −
∆ − ∆ =, 2 , 1 , 1 ,( ) 0 voor t=4,...,T (40)
(30), (33) en (34) impliceren bovendien:
i it i it
E vµ ν µ+ ∆ + =(( ) ( )) 0 voor t=4,...,T (41)
Deze momentvoorwaarden verhogen de efficiëntie en leiden tot een daling van de
asymptotische variantie. Vooral wanneer γ → 1 en de variantie van het individuele
effectief relatief belangrijke wordt, zijn deze momentvoorwaarden sterk informatief. We
bemerken dat (40) overbodig wordt wanneer system GMM wordt toegepast.

41
Wanneer een model exogene verklarende variabelen bevat, kunnen we deze gebruiken
om extra momentvoorwaarden op te leggen. Hoe deze er precies uitzien, hangt ervan of
deze variabelen strikt exogeen of deterministisch zijn. In het laatste geval geldt:
it isE x ν = ≥( ) 0 voor s t . Dit betekent dat
i t ix x
−, 1 1,..., geldige instrumentvariabelen zijn voor
de vergelijking in eerste verschillen in periode t. Wanneer we te maken hebben met strikt
exogene variabelen zijn i iT
x x1,..., geldige instrumenten voor de vergelijking in eerste
verschillen voor elke periode. Dit levert T(T-2) extra momentvoorwaarden op. De
problematiek van te veel instrumentvariabelen indachtig, gebruiken we daarom beter een
alternatief. Verbeek (2004) raadt aan de eerste verschillen van it
x te gebruiken als hun
eigen instrumentvariabele. Potentiële efficiëntiewinst van it
x s' die vertraagde endogene
variabelen helpen verklaren, wordt dan opgegeven. Dit geeft de volgende
momentvoorwaarden: it it
E x ν∆ ∆ =( ) 0 voor t=1,...,T . Ook endogene variabelen leveren
een aantal extra voorwaarden op. Deze voorwaarden zijn volledig analoog aan diegene
voor first difference- en system GMM.
Eerder vermeldden we het belang van meetfouten. GMM schatters laten toe rekening te
houden met meetfouten. Beschouwen we het probleem voor de first difference GMM.
Meetfouten introduceren seriële autocorrelatie in de storingsterm: it i t
E v v−
≠, 1( ) 0 . Dit
impliceert dat de momentvoorwaarden die gebruik maken van i t
y−, 2 niet langer gelden:
i t itE y ν
−∆ ≠, 2( ) 0 vermits
i t i tE y ν
− −≠, 2 , 1( ) 0 . Door gebruik te maken van vertraagde variabelen
voor t-3 en verder en t-2 te verwijderen lost men de vertekening als gevolg van
meetfouten op. De momentvoorwaarden voor system GMM kunnen op analoge wijze
aangepast worden.
4 Empirisch onderzoek: GMM versus system GMM4
Eerst geven we een overzicht van de werkwijze die we volgden in het opstellen van het
Monte Carlo experiment. Vervolgens volgt een korte bespreking van de gebruikte data,
gevolgd door een aantal Monte Carlo simulaties voor onder andere GMM en system GMM.
Tot slot selecteren we, op basis van de resultaten van onze Monte Carlo experimenten,
de meest adequate schatters. Deze gebruiken we dan voor de schatting van de
convergentievergelijking.
4 Alle berekeningen, op de schatting van de MA(1) processen na, werden uitgevoerd via MATLAB. De
verschillende programma’s zijn beschikbaar op cd-rom of via mail [email protected]

42
4.1 Methode
We starten met een definiëring van het model. Vervolgens bespreken we de schatting
van de populatieparameters. Tot slot volgt een korte bespreking van de schatters
waarvan we de kleine steekproef eigenschappen nagaan.
4.1.1 Model
De doelstelling van de Monte Carlo simulaties bestaat erin na te gaan welke panel data
schatter we het best gebruiken om (18) te schatten. We trachten dan ook de opstelling
van het experiment zo nauw aan te laten sluiten bij het specifieke probleem. De
conclusies die we trekken uit het experiment zullen immers meer waarde hebben
naarmate het data genererende proces, de data en het model sterker aanleunen bij het
effectieve probleem. Veronderstel bijvoorbeeld een experiment waarbij men de data
genereert op basis van normaal verdeelde storingstermen. Indien, louter hypothetisch,
de storingstermen het effectieve te schatten probleem autocorrelatie vertonen, zullen de
conclusies die men trekt uit het experiment minder relevant zijn voor het specifieke
probleem. De Monte Carlo resultaten hebben met andere woorden enkel betrekking op
de veronderstelde populatie. De definiëring van het model, de schatting van de
parameters en de selectie van de data zijn dan ook cruciaal.
We vertrekken voor ons Monte Carlo experiment van de eerder afgeleide klassieke
groeivergelijking (18) en leggen de volgende beperking op: κ κ= −1 2 . De vergelijking die we
gebruiken in het Monte Carlo experiment is dus (29) waarbij it
y de log van GDP per
capita op voorstelt, en it
x het verschil tussen de log van de investeringsquote en de log
van n+g+δ . Hierbij is g+δ =0.05. We vervolledigen het model door de datagenerende
processen voor i it
µ ν en nader specificeren. Aangezien het experiment zo nauw mogelijk
moet aansluiten bij het te schatten probleem, willen we een correlatie tussen het
individuele effect en xit tot uiting brengen. Islam opteert voor een methode voorgesteld
door Chamberlain, waarbij het individuele effect een lineaire functie is van de exogene
variabelen voor elke tijdsperiodes met variërende coëfficiënten. Dit proces kunnen we
vatten in de volgende vergelijking.
i i i T iT i
x x xµ λ λ λ λ ϖ= + + + + +0 1 0 2 1 ... , (42)
met i
N ϖϖ σ 2~ (0, ).

43
Islam (2000) beschouwt drie types datagenererende processen voor it
ν :
( )
( )
ν
ε
ε
ν σ
ν ε θ ε ε σ
ν ϕ ν ε ε σ
−
−
= +
= +
it
i,t it i,t 1 it
i,t i,t 1 i,t it
1. Geen autocorrelatie met ~ N(0, ²)
2. M A 1 proces : met ~ N(0, ²)
3. AR 1 proces : : met ~ N(0, ²),
(43)
We merken hierbij op dat de aanwezigheid van autocorrelatie belangrijke implicaties
heeft voor een aantal schatters. De momentvoorwaarden van de GMM schatters zullen
niet langer gelden. Autocorrelatie in de storingstermen zal bijvoorbeeld optreden bij
meetfouten, heterogeniteit in de groei van technologie, weglaten van verklarende
variabelen, …
4.1.2 Schatting van de “populatieparameters”
We starten met de bepaling van de ‘populatiewaarden’. Men zou arbitraire waarden
kunnen nemen en bijvoorbeeld γ laten variëren tussen 0.6 en 0.9 met constante
waarden voor de overige parameters. We willen echter dat de waarden zo goed mogelijk
het effectieve probleem beschrijven. Een schatting op basis van de Summers-Heston
dataset vormt dan ook de beste optie. Het eerder beschreven model vereist de schatting
van de volgende variabelen: γ κ; ;T
λ λ λ0 1, ,..., ; ϖ ν εσ σ σ θ ϕ; ; ; ; een aantal tijddummy’s t
η .
We wijken in onze methode enigszins af van Islam (2000). In een eerste stap schatten
we (29) via LSDV. Dit levert ons de waardes voor γ κ; en de tijddummy’s5. Vervolgens
passen we OLS toe op (42). De LSDV schatter laat ons toe het individuele effect te
berekenen. Vermits (42) een pure cross sectie schatting is, zal OLS niet vertekend zijn.
De schatting geeft ons de waarden voor de s ϖλ σ' en . Tot slot schatten we (43). (43.1)
volgt rechtstreeks uit de LSDV schatting. (43.2) schatten we via de methode van Durbin
(1956). Tabellen 1, 2, 5 en 6 bevatten de resultaten voor T=9 en T=6. We merken op
dat deze werkwijze resulteert in een lage waardes voor de AR en MA processen.
Bovendien vinden we in tabel 6 OECD een negatieve autocorrelatie van de
storingstermen terug. Dit in contrast met de resultaten van Islam. Deze vond een
positieve autocorrelatie terug voor zowel OECD, INTER en NONOIL.
Eerder vermeldden we echter dat LSDV een neerwaartse vertekening vertoont in een
dynamisch model. Deze benaderingswijze is dus niet optimaal. Nickell (1981) berekent
de theoretische vertekening van γ voor N → ∞ . De vertekening is een functie van T en
γ . Dit geeft echter weinig informatie over de vertekening in een kleine steekproef.
Bovendien kan κ ook vertekend zijn. Kiviet (1995) stelt een correctie voor, voor de
5 Omwille van multicollineariteit laten we de eerste tijdsdummy vallen.

44
vertekening van zowel γ als κ in een kleine steekproef. We berekenen een tweede set
van populatiewaarden die corrigeren voor de vertekening (LSDVcor). We maken daartoe
gebruik van de formule van Nickell (1981). Deze benadering is minder accuraat in
vergelijking met de Kiviet correcties en veronderstelt bovendien dat κ niet vertekend is6.
Dit laatste impliceert dat it
x strikt exogeen is. We willen echter voornamelijk de
robuustheid van de Monte Carlo resultaten nagaan en een soort bovengrens vastleggen7.
Een ruime benadering van de vertekening kadert in deze doelstelling. We houden
rekening met ruime vertekeningen: 10 en 15% voor respectievelijk T=6 en T=9. De
overige variabelen schatten we op analoge wijze. Tabellen 3, 4, 9 en 10 bevatten de
resultaten. Dit maal vinden we wel enige correlatie terug in de storingstermen voor T=9.
Voor T=6 verdwijnt de autocorrelatie echter in de INTER en NONOIL groepen.
Tot slot voegen we ook de resultaten van Islam (2000) toe in tabellen 5 en 6. Enerzijds
als robuustheidtest, anderzijds als vergelijkingspunt. Deze resultaten zijn enkel
beschikbaar voor T=6. De niet geschatte tijddummy’s en sλ ' werden gelijkgesteld aan
nul voor T=98. Islam vindt een zekere autocorrelatie patroon terug. Opvallend is dat onze
schattingen wijzen op een sterkere autocorrelatie binnen OECD ten opzichte van INTER
en NONOIL. Islam vindt de sterkste autocorrelatie terug voor NONOIL. De bevindingen
van Islam lijken logischer. Immers, NONOIL vormt een minder heterogene groep.
Bovendien zullen meetfouten met een grotere kans optreden in deze groep. Anderzijds
zou men kunnen stellen dat een er een variabele ontbreekt in (29) om OECD te schatten.
We denken hierbij bijvoorbeeld aan handelspatronen die potentieel sterker spelen binnen
de OECD landen. Deze kunnen ofwel een directe impact hebben. Indirect kunnen ze
bijvoorbeeld de diffusie van technologie faciliteren. Andere mogelijke verklaringen zijn
het niet opnemen van maatstaven voor ontwikkeling van financiële markten (deze
hebben een positieve impact op groei via sterker ontwikkelde kapitaalmarkten),
investeringen in infrastructuur, bepaalde politieke vrijheden (bijvoorbeeld ontwikkeling
eigendomsrecht, deze spelen een cruciale rol in kapitaalaccumulatie). (Temple (1999)).
7 OLS vormt een alternatieve manier om een bovengrens voor de populatiewaarden vast te leggen. Het Matlab
programma laat toe Monte Carlo uit te voeren op basis van OLS waarden. Deze simulaties geven dan een
beperkte opwaartse vertekening weer voor OLS. Dit wijst erop dat de correlatie tussen individuele effect en de
verklarende variabelen nihil is. Dit vormt mijns inziens dan ook geen interessante benaderingswijze. Bovendien
vinden we, in contrast met de resultaten van Islam, negatieve autocorrelatiepatronen terug voor T=6.
8 We namen geen tabellen op met de Islam parameterwaarden voor T=9 vermits deze geheel analoog zijn aan
de waarden voor T=6.

45
4.1.3 Monte Carlo simulaties
We voeren de Monte Carlo simulaties uit voor de drie verschillende schattingswijzen van
de populatieparameters, voor T=6 en T=9, 3 verschillende datageneratie processen voor
de storingstermen en 18 verschillende schatters. De schattingswijze van de
populatieparameters die berust op LSDV geeft een ondergrens. LSDVcor beschouwen we
als een bovengrens. De populatiewaarden van Islam (2000) vormen een referentiepunt.
Niet elk van de 18 schatters die we testen zijn in staat alle parameters in het model te
schatten. OLS laat bijvoorbeeld niet toe het individuele effect te schatten en bijgevolg
dus ook niet 0,..., Tλ λ . Daarom concentreren we ons op γ en κ . De aanwezigheid van
tijddummy’s compliceren de berekening enigszins. We kunnen echter op een eenvoudige
manier rekening houden met t
η We transformeren de data naar afwijkingen van cross
sectie gemiddelden. Het tijdseffect kan dan weggelaten worden uit de vergelijking. Om
de prestaties van de schatters te beoordelen maken we gebruik van twee criteria:
vertekening en mean square error (MSE). We berekenen de relatieve vertekening en de
relatieve grootte van de root mean squared error (RMSE). Tabellen 11 tot 16 en 17 tot
22 vatten de procentuele afwijking van γ κ en ten opzichte van de populatiewaarden
voor respectievelijk T=9 en T=6 samen. Tabellen 23 tot 28 en 29 tot 34 geven de RMSE
als percentage van de populatieparameter weer voor respectievelijk T=9 en T=69. De
resultaten zijn gebaseerd op 200 iteraties. Een hoger aantal iteraties leidde niet tot
substantiële wijzigingen in de resultaten. Stabilisatie van de distributie treedt dus vrij
snel op.
De volgende schatters komen aan bod in de Monte Carlo simulaties. We gebruiken de
notaties die voorkomen in de tabellen in bijlages B en C:
- OLS
- LSDV
- GMM(d)a: De first difference GMM schatter die eerder werd beschreven in
paragraaf 3.1. We merken op dat de twee-staps GMM niet geschat kan worden
voor T=9 in OECD. De twee-staps GMM schat immers een optimale
gewichtenmatrix. Het aantal te schatten waarden in deze gewichtenmatrix
stijgt met een macht tot de vierde in T. De steekproefgrootte van OECD is te
9 De volledige tabellen met de geschatte parameterwaarden, standaardafwijking van de parameterschattingen
en de verwachtingswaarde van de geschatte standaardafwijkingen werden, omwille van plaatsbesparende
redenen, niet opgenomen in de bijlage. Ze zijn echter beschikbaar op cd-rom of via mail:

46
klein om al deze waarden te schatten. We krijgen dan ook een singuliere
matrix. Dit betekent dat we de inverse van de matrix niet kunnen nemen.
- GMM(d)b en GMM(d)c: Deze first difference GMM schatters leggen een
beperking op aan het aantal momentvoorwaarden. door het aantal vertraagde
variabelen per periode die gebruikt worden als instrument te beperken tot,
respectievelijk 2 en 3. Deze schatter tracht enerzijds het probleem van te veel
instrumentvariabelen te ontwijken. Anderzijds laat het toe de twee-staps GMM
te berekenen voor OECD met T=9.
- SysGMMa: De system GMM schatter zoals eerder beschreven in paragraaf 3.3.
De twee-staps system GMM kan opnieuw niet geschat worden voor OECD T=9.
De reden is analoog aan deze voor GMM(d)a
- SysGMMb en SysGMMc: Net zoals GMM(d)b en GMM(d)c leggen deze schatters
beperkingen op aan het aantal vertraagde variabelen per periode die gebruikt
worden als instrument.
- Stacked: De stacked GMM schatter zoals eerder beschreven in 3.5. We
berekenen zowel de één, als twee-staps stacked GMM.
- AH(l): De Anderson en Hsiao (level) schatter is een instrumentvariabele
schatter die i t
y−, 2 gebruikt als instrument.
- AH(d): Deze schatter is gelijkaardig aan AH(l). In plaats van i t
y−, 2 , gebruikt
men echter i t
y−
∆ , 2 als instrument. De AH schatters behoren tot het type van de
stacked schatters.
Elk van de hierboven beschreven schatters veronderstellen een strikte exogene it
x . Deze
assumptie is geldig vermits we it
x deterministisch bepalen in de opstelling van ons Monte
Carlo experiment10. Voor de GMM(d), sysGMM, stacked en AH schatters gebruiken we
itx∆ dan ook als instrument voor zichzelf in de vergelijking in first differences. SysGMM
gebruikt in aanvulling it
x als instrument voor de vergelijking in levels.
De één-staps GMM schatters gebruiken de gewichtenmatrices voorgesteld in 3.1 en 3.2
en gaan dus uit van homoscedasticiteit. De twee-staps GMM type schatters introduceren
correcties voor heteroscedasticiteit. De schatting van de standaardafwijkingen van de
overige schatters werden gecorrigeerd voor heteroscedasticiteit via een White correctie.
10
We merken op dat deze assumptie afwijkt van het effectieve te schatten probleem. Endogeniteit van it
x
vormt immers een probleem in de schatting van (26). Caselli et al. tonen dit bijvoorbeeld aan.

47
4.2 Data
Een veelgebruikte dataset in het empirisch onderzoek naar convergentie, is de Summers-
Heston dataset. Mankiw et al. gebruikt de Penn World Tables (PWT) om drie panel
datasets op te stellen: NONOIL, INTER en OECD. Islam (1995, 2000) volgt –op twee
landen na- deze indeling. NONOIL omvat alle beschikbare landen (in de toenmalige
dataset) exclusief de olie producerende landen. Mankiw et al. stellen immers dat deze
landen voornamelijk bestaande voorraden ontginnen zonder extra toegevoegde waarde
te creëren. Men kan niet verwachten dat de economische groeitheorieën van toepassing
zijn op dit type landen. INTER verwijdert de landen die in de Summers-Heston dataset
het kwaliteitslabel D kregen. Hierdoor dalen de meetfouten tegenover de NONOIL groep.
De landen met een populatie lager dan 1 miljoen in 1960 gooien Mankiw et al. ook
overboord. Hun argumentatie luidt dat het inkomen van deze landen mogelijks
gedomineerd wordt door idiosyncratische effecten. OECD omvat de 22 OECD landen met
een populatie groter dan 1 miljoen. De grootte en homogeniteit van deze groep levert
een lagere variantie in de verklarende variabelen op. In econometrische termen zal deze
groep dus relatief minder informatie bevatten en over minder verklaringskracht
beschikken. In cross sectie onderzoek vormt de homogeniteit een voordeel, de variantie
in het landspecifieke effect zal immers lager liggen, waardoor de vertekeningen dalen.
Vermits we onze eigen resultaten enigszins willen vergelijken met deze van Islam
(2000), volgen ook wij deze indeling. Bovendien levert deze indeling een aantal
interessante empirische voordelen. NONOIL, INTER en OECD omvatten elk een
verschillend aantal landen. Eerder vermeldde ik dat GMM consistent is in de richting van
N. Deze onderverdeling van de data laat dan ook toe na te gaan hoe GMM en system
GMM presteren onder verschillende cross sectie groottes. De verschillende datasets
zullen vermoedelijk ook elk een verschillende graad van heterogeniteit vertonen. OECD
vormt een vrij homogene groep. INTER en NONOIL zullen meer heterogeen zijn. Dit zal
een effect hebben op de variantie van het individuele effect en dus op de prestaties van
GMM en system GMM (zie supra).
De prestatie van een schatter zal niet alleen in de richting van N variëren. De
vertekening van LSDV zal bijvoorbeeld dalen naarmate T stijgt. Daarom voeren we onze
Monte Carlo simulaties uit voor twee verschillende tijdsperiodes: 1960-1985 en 1960-
2000. We maken, net als Islam, gebruik van vijf jaarlijkse intervallen. Hierdoor filtert
men conjuncturele invloeden enigszins uit. Dit levert ons respectievelijk T=9 en T=6
periodes. Deze laatste komt overeen met Islam (2000).

48
In tegenstelling tot Mankiw et al., die zich baseren op de bevolking tussen 15 en 64 jaar,
berekenen we de GDP per capita op basis van de volledige bevolking. De variabele it
y
bevat telkens GDP per capita in het laatste jaar van elk interval. De investeringsratio en
de bevolkingsgroei werden berekend op basis van vijfjaarlijkse gemiddelden over de
intervallen. Deze werkwijze impliceert dat de steady state, bij assumptie, constant is
gedurende elk interval. Niet alle data was beschikbaar voor elk jaar en elk land. We
vormden dan ook onze data om naar een gebalanceerd panel data door trends door te
trekken en gemiddeldes te nemen over kleinere intervallen.
We merken op dat onze datasets niet volledig overeenstemmen met Mankiw et al. en
Islam. Voor T=6 vonden we geen, of onvoldoende, data terug voor Burma, Indonesië,
Ivoorkust, Burkina Fasso en Angola. T=6 bevat respectievelijk 22, 72 en 93 landen voor
OECD, INTER en NONOIL. In paragraaf 4.4 maken gebruiken we de T=9 data om het
standaard en uitgebreide Solow model te schatten. Deze laatste vereist een proxy voor
voor menselijk kapitaal. Daarom combineren we de Summers-Heston dataset met de
dataset van Barro en Lee (2001). Deze laatste omvat een vijfjaarlijkse proxy voor
menselijk over de periode 1960-1995 met een voorspelling voor 2000. In deze dataset
ontbreken echter een aantal landen die wel in de Summers-Heston dataset zitten. We
verwijderen dan ook Ethiopië, Madagaskar, Marokko, Nigeria, Tanzania, Burundi, Chad,
Somalië en Mauritanië11. Uiteindelijk bevatten de drie groepen OECD, INTER en NONOIL
voor T=9 respectievelijk 22, 67 en 84 observaties voor T=9. Dit betekent dat in onze
Monte Carlo simulaties N verschilt in INTER en NONOIL voor de twee tijdsperiodes. Dit
bemoeilijkt een vergelijking tussen de Monte Carlo resultaten voor T=6 en T=9 enigszins.
Een tweede bemerking betreft meetfouten. Eerder wezen we erop dat deze een
belangrijke impact kunnen hebben op de resultaten. Temple (1999) merkt op dat het
gebruik van de volledige populatie in plaats van de bevolking tussen 15 en 64 jaar,
meetfouten kan introduceren indien de participatiegraden sterk verschillen over de
landen. GDP per capita vormt dan een slechte proxy voor GDP per arbeider. Daarnaast
zal de aanwezigheid van een zwarte markt leiden tot een onderschatting van GDP. Dit
vormt vermoedelijk vooral een probleem in ontwikkelingslanden. Tot slot wijzen we op
een aantal problemen omtrent menselijk kapitaal. Een correcte proxy vinden blijkt geen
eenvoudige opgaven vermits menselijk kapitaal een ruim begrip is. Vaak concentreert
men zich op onderwijs. Menselijk kapitaal kan echter ook andere factoren omvatten zoals
bijvoorbeeld investeringen in gezondheid. In de literatuur duikt de inschrijvingsratio in
scholen vaak op. Het is echter niet geheel duidelijk of deze variabele dan wel een stroom
11
De data betreffende Duitsland voor 1990 werd opgedeeld in West- en Oost Duitsland. Hiervan werd een
gewogen gemiddelde genomen met als gewicht de verhouding van het bevolkingsaantal.

49
van investeringen of een stock van menselijk kapitaal vertegenwoordigen. Vergelijking
(26) en (27) wijzen erop dat beide interpretaties een verschillende te schatten
vergelijking hebben. Wij gebruiken, net als Islam (1995), het gemiddelde aantal jaren
scholing van de volledige bevolking ouder dan 25 jaar. Dit vormt een proxy voor de stock
van menselijk kapitaal.12 Deze data houdt echter geen rekening met de kwaliteit van
onderwijs Variabelen die de kwaliteit wel vatten zijn bijvoorbeeld de student-leerkracht
ratio (Barro (1991)) en scores van studenten op internationaal vergelijkbare testen.
Daarnaast vormt een groot deel van menselijk kapitaal de opportuniteitskost van
studeren, het misgelopen loon dat men had kunnen verdienen. Dit valt echter niet
eenvoudig te meten. Naarmate men over een hoger menselijk kapitaal beschikt zal de
opportuniteitskost immers stijgen. Verder zijn niet alle investeringen in menselijk
kapitaal even productief. Mankiw et al. stellen dat sommige investeringen in menselijk
kapitaal eerder de vorm van consumptie aannemen.
4.3 Monte Carlo simulaties
We merken op dat, voor nagenoeg alle schatters, de resultaten vrij robuust zijn voor de
verschillende DGP. Men verwacht nochtans dat de resultaten van de GMM schatters
zouden variëren in de aanwezigheid van autocorrelatie. De momentvoorwaarden gelden
dan immers niet langer. De resultaten voor MA(1) wijken soms sterk af, bijvoorbeeld in
tabel 13 voor de GMM schatters. Mogelijks ligt een incorrecte schatting van MA(1) aan de
basis. Het feit dat deze afwijkingen zich niet voordoen in de simulaties gebaseerd op de
parameterwaarden van Islam (2000) versterkt dit vermoeden. De schatting van MA
processen verloopt best via de maximum likelihood methode. De door ons toegepast
methode van Durbin is niet altijd even efficiënt. Enige voorzichtigheid in de interpretatie
van de vertekeningen voor MA(1) is dus geboden. Een verklaring voor deze robuustheid
ligt in de lage autocorrelatie in de populatiewaarden. In tabellen 2 en 8 liggen de
waarden voor ϕ bijvoorbeeld rond nul. De overige waarden variëren tussen 0.1 en 0.4.
Autocorrelatie lijkt dan ook geen al te groot probleem te vormen.
Wanneer we vervolgens de verschillende groepen OECD, INTER en NONOIL vergelijken
merken we sterke verschillen. Dit bevestigt dat de eigenschappen van de onderliggende
data sterk verschillen en dat dit een impact heeft op de schatters. Enkel voor de first
difference GMM vinden we een zekere robuustheid terug in de vertekeningen. Het is
echter moeilijk een specifiek patroon te ontwaren. Voor system GMM, T=9 liggen de
12 Barro en Lee (2001) wijzen erop dat meetfouten aanwezig zijn in deze variabele. Ze gebruiken immers data
van 1965 om de duur van elk onderwijstype te bepalen. Zodoende houden ze geen rekening met wijzigingen in
de duur van scholing per onderwijsniveau. In de afgelopen 30 jaar hebben 32 landen minstens één maal
veranderingen doorgebracht in de duur van onderwijs in primair en secundair onderwijs.

50
vertekeningen van γ telkens lager in INTER. Voor T=6 geldt het omgekeerde. De
vertekeningen van LSDV en OLS liggen, respectievelijk lager en hoger in OECD.
Ten derde vergelijken we de resultaten voor T=6 en T=9. We verwachten bijvoorbeeld
dat de prestatie van LSDV verbetert. Wanneer we tabel 21 met 15 en 19 met 13
vergelijken lijkt dit inderdaad het geval te zijn. Verder wijzen we erop dat de twee stap
GMMa niet langer berekend kunnen worden voor T=9 OECD. Het aantal
momentvoorwaarden stijgt immers sterk in T en de schatting van de optimale
gewichtenmatrix wordt onmogelijk. Een berperking van het aantal vertraagde variabelen
vormt een oplossing (GMMb en GMMc). Voor de overige schatters is de impact van een
toename van T niet eenzijdig, het leidt soms tot een verbetering, soms tot een
verslechtering van de prestaties.
Ten vierde beschouwen we de prestaties van OLS en LSDV. De OLS schattingen kennen,
zoals verwacht, een opwaartse vertekening voor γ . Deze vertekening is robuust voor
verschillen in T, DGP en de wijze van populatieparameter schatting. De vertekening
tendeert hoger te zijn voor OECD. De LSDV schatters lijden onder een neerwaartse
vertekening voor γ . Deze vertekeningen zijn opnieuw robuust over de verschillende DGP.
Ditmaal ligt de vertekening gemiddeld genomen lager binnen de OECD groep. Islam komt
tot gelijkaardige conclusies. De vertekening van LSDV in tabellen 13 en 19 ligt hoger in
vergelijking met de overige variabelen. De hogere populatiewaarden γ van LSDVcor ligt
aan de basis. Dit is in overeenstemming met de formule van Nickell.
De vertekening van de GMM(d)a schatter voor γ vertonen een robuuste neerwaartse
vertekening. In tegenstelling tot de verwachtingen blijft deze neerwaartse vertekening
zeer bescheiden. Op basis van de simulaties van Blundell en Bond (1998) en Windmeijer
(2000), anticiperen we een sterke vertekening. Wanneer we beperkingen opleggen aan
het aantal vertraagde variabelen (GMM(d)b en GMM(d)c) , bemerken we doorgaans een
lichte stijging in de vertekening (bijvoorbeeld tabel 11). De vertekeningen voor LSDVcor
liggen iets hoger. Dit ligt in lijn met de hogere populatiewaarden voor γ . Daarnaast zijn
de asymptotische varianties van GMM(d)b en GMM(d)c groter dan deze van GMM(d)a.
De system GMMa schatter vertoont een robuuste, opwaartse vertekening voor γ die
sterk varieert en waarden aanneemt tussen 0 en 47 procent. Wanneer we beperkingen
opleggen aan het aantal vertraagde variabelen, dalen de vertekeningen voor T=9. Dit
wijst erop dat er zich inderdaad een probleem van te veel instrumentvariabelen aanwezig
is. Voor T=6 verbeteren de prestaties niet. Dit is niet onlogisch vermits T al laag is, ligt
het aantal momentvoorwaarden laag. Bovendien verschilt voor T=6 de Z matrix zonder
beperkingen weinig van deze met beperking. Wat κ betreft, presteert system GMM het
slechts van alle schatters. De procentuele vertekening neemt extreem hoge waarden aan
in bijvoorbeeld tabellen 12 en 16 voor OECD.

51
De stacked GMM vertoont over het algemeen sterke neerwaartse vertekeningen voor
INTER en NONOIL. De resultaten voor OECD zijn minder vertekend. We bemerken
bovendien dat de varianties van de stacked GMM in een groot deel van de simulaties
gevoelig hoger ligt dan voor de andere schatters.
Opvallend zijn ook de prestaties van de AH schatters. Deze geven vrij hoge
asymptotische varianties. In een aantal simulaties vinden we zelf extreme waarden terug
voor de variantie. De vertekeningen van de schatters vertonen daarnaast geen duidelijk
patroon. Islam (2000) en Arellano en Bond (1991) vinden gelijkaardige, sterk
onregelmatige prestaties terug voor de AH schatters. In een model met exogene
variabelen bestaan er waarden voor γ en ρ (met , 1it i t itx xρ υ
−= + ), waarvoor , 1i t
y−
∆ niet
gecorreleerd is met , 2i ty
−∆ . Dit verklaart de teleurstellende prestaties van de AH klasse.
De vertekeningen van κ vertonen een minder duidelijk patroon. Opvallend is de sterke
vertekening van de system GMM klasse. Ook voor OLS vinden we doorgaans grote
vertekeningen. De vertekeningen voor GMM(d) liggen doorgaans lager.
Bekijken we tot slot RMSE relatief ten opzichte van de populatiewaarde. Voor γ vinden
we een robuust hoge waarde voor de OLS schattingen. GMM(d) presteert merkelijk beter,
de waarden zijn doorgaans vergelijkbaar met deze van LSDV en liggen in een aantal
simulaties lager. sysGMM presteert sterk in tabel 25. Voor tabel 29 liggen de RMSE
telkens boven deze van GMM(d). De AH klasse vertoont een aantal extreme waarde. Dit
bevestigt de onregelmatige prestaties van AH schatters. Wat betreft κ vinden we
opnieuw hoge waarden terug voor OLS. De overige schattingswijzen presteren echter
niet veel beter. We merken dat RMSE voor κ doorgaans hoger ligt voor OECD ten
opzichte van INTER en NONOIL.
De resultaten van het Monte Carlo experiment wijzen duidelijk in de richting van first
difference GMM als ideale schatter voor (18). System GMM overschat systematisch γ en
geeft sterke vertekeningen voor κ . LSDV scoort behoorlijk. De vertekeningen van first
difference GMM zijn echter robuuster over de verschillende schatters van de
populatiewaarden: LSDV, LSDVcor en Islam (2000). Bovendien kunnen GMM schatters
rekening houden met endogeniteit en meetfouten. De vertekeningen van LSDV nemen
ook toe naarmate γ toeneemt.(zie tabel 13 en 19 in vergelijking met tabel 11 en 17). De
AH schatters leveren te hoge varianties en de prestaties zijn te volatiel.
4.4 Schattingen
Tabellen 35 en 36 bevatten de respectievelijke schattingsresultaten voor het standaard
en uitgebreide Solow model. We schatten beide met OLS, LSDV, GMM(d) en system

52
GMM. De GMM schatters maken telkens gebruik van alle momentvoorwaarden en leggen
dus geen restrictie op aan het aantal vertraagde variabelen. Hierdoor kunnen we de
standaardafwijkingen in de twee-staps GMM’s niet berekenen voor OECD. We laten deze
resultaten dan ook achterwege. Verder schatten we zowel een model met en een model
zonder de restrictie 1 2κ κ= .
We starten met het standaard model. Het vertraagde per capita inkomen blijkt voor alle
schatters significant te verschillen van 0 op 5%. Ook κ is doorgaans significant op 5%.
In de schatting zonder restrictie vinden we voor een aantal schatters een verkeerd teken
terug voor ln( )n g δ+ + . De coëfficiënten zijn echter niet significant.
De GMM(d) resultaten van γ liggen voor zowel OECD, INTER als NONOIL onder de LSDV
waarden. Vermits de theorie een neerwaartse vertekening voor LSDV voorspelt, wijst dit
erop dat GMM(d) neerwaarts vertekend is. Deze neerwaartse vertekening vonden we
eveneens terug in de Monte Carlo simulaties. In de simulaties benaderde de vertekening
van GMM echter doorgaans deze van LSDV (in een aantal gevallen ligt de vertekening
zelf lager). De schattingsresultaten spreken dus enigszins de simulaties tegen. De system
GMM geeft schattingen voor γ die doorgaans in de buurt liggen van OLS. De LSDV
schatting van Islam (1995) resulteert in convergentiesnelheden rond 10% voor OECD en
4.5% voor INTER en NONOIL. Onze resultaten wijken licht iets lager. Voor OECD vinden
we via LSDV ongeveer 7.5% en voor INTER en NONOIL 4%. De OLS schatting geeft een
lage convergentiesnelheid voor NONOIL. De GMM(d) schattingen resulteren in hogere
convergentiesnelheden. Die varieren tussen 5% voor NONOIL en 10% voor OECD. Deze
waarden liggen lager dan deze die Caselli et al. en Bond et al. vinden via GMM(d). Deze
vinden λ terug boven 10%. Een verschil in tijdperiode ligt mogelijk aan de basis van
onze lagere convergentiesnelheid. Daar waar Caselli et al. en Bond et al. T=6 gebruiken,
schatten wij T=9. Naarmate T stijgt, daalt de neerwaartse vertekening van γ en daalt
dus ook de convergentiesnelheid. De system GMM schatter resulteert in snelheden die
iets hoger liggen dan de traditionele 2% voor OECD en INTER. In de groep NONOIL
vinden we zwakke convergentie en zelf divergentie voor sysGMM1.
Uit het gerestricteerde model halen we de waarden voor α . Deze variëren sterk tussen
0.1 en 0.8. Voorr GMM(d) en LSDV schommelen de waarden rond 1/3. OLS en sysGMM
vinden waarden die eerder in de buurt van 2/3 liggen. Over het algemeen vinden we
waarden terug die hoger liggen dan 1/3.
De schattingen van het uitgebreide Solow model wijzen opnieuw op de significantie van
het vertraagde inkomen per capita. Ook de investeringsratio van fysiek kapitaal is
doorgaans significant. De resultaten van Levine en Renelt (1992) indachtig, is dit niet

53
verwonderlijk. In het model zonder beperking vinden we opnieuw enkele positieve
waarden voor ln( )n g δ+ + . Deze zijn echter niet significant. De resultatenvoor het
uitgebreide model verschillen weinig van deze in het standaard model. We vinden sterk
gelijkaardige convergentiesnelheden terug. De conclusies omtrent de elasticiteit van
fysiek kapitaal zijn eveneens gelijkaardig. De toevoeging van menselijk kapitaal wijzigt
de resultaten dus weinig. Bovendien is menselijk kapitaal niet significant voor 16 van de
18 schattingen. Enkel voor sysGMM1 NONOIL en sysGMM2 INTER verschilt de coëfficiënt
significant van 0 op 5%. Hierbij geeft een GMM2 schatter een neerwaartse vertekening
voor de variantie. GMM2 tendeert dus de nulhypothese makkelijker te verwerpen. Verder
vinden we voor een aantal schatters een negatieve elasticiteit voor menselijk kapitaal.
Tot slot liggen de waarden van de coëfficiënten laag. Deze resultaten komen overeen met
deze van Islam (1995). Mankiw et al. vinden in tegenstelling wel een significante rol voor
menselijk kapitaal.
Kunnen we uit de resultaten nu concluderen dat menselijk kapitaal geen rol speelt in
groei? Islam (1995) wijst erop dat meetfouten of verkeerde specificaties van de
productiefunctie aan de basis kunnen liggen van de beperkte impact van menselijk
kapitaal. Het endogene groeimodel van Howitt wijst bijvoorbeeld op een complexere
impact van menselijk kapitaal op groei. Menselijk kapitaal kan bijvoorbeeld spelen via de
productiviteit van de R&D sector en zo de diffusie van technologie tussen landen
versnellen. De standaard productiefuncties zijn met andere woorden niet in staat de
impact van menselijk kapitaal volledig te capteren. Een andere verklaring vinden we
terug in de sterke correlatie tussen menselijk kapitaal en 0ln( )A . We berekenen 0ln( )A
via LSDV. Deze geeft immers impliciet een schatting voor de individuele effecten. We
vinden een correlatie terug van 0.8132.(Figuur 4). Dit verklaart eveneens waarom de
resultaten van Mankiw et al. sterk verbeteren na de inclusie van menselijk kapitaal.
Menselijk kapitaal lijkt immers een goede proxy te zijn voor de individuele effecten. De
vertekeningen die optreden als gevolg van het omitted variable probleem, dalen dan ook
sterk wanneer men menselijk kapitaal opneemt in een cross sectie onderzoek. De sterke
correlatie wijst er bovendien op dat menselijk kapitaal niet louter via de productiefunctie
werkt. De positieve impact die we terugvinden in cross sectie onderzoek, meet immers
de impact die menselijk kapitaal via ln(A0) uitoefent op groei. Wanneer men expliciet
rekening houdt met ln(A0), bijvoorbeeld via een panel data benadering, geeft de
coëfficiënt de directe impact van menselijk kapitaal op groei. Onze resultaten wijzen erop
dat deze directe impact nihil is. Menselijk kapitaal beïnvloedt de groei dan ook
vermoedelijk via ln(A0).

54
5 Conclusie
Empirisch onderzoek naar de convergentiesnelheid komt in de literatuur uitvoerig aan
bod. De resultaten ervan verschaffen ons niet alleen vanuit welvaartperspectief
interessante informatie, ze laten ook toe de geldigheid van verschillende groeitheorieën
na te gaan. De wisselwerking is echter niet eenzijdig. Onder impuls van het
overweldigende bewijs in de literatuur ten gunste van conditionele convergentie,
ontstaan ook endogene groeimodellen die convergentie voorspellen zoals Howitt (2000).
Empirisch onderzoek kende een sterke evolutie. Met elke nieuwe stap hield men rekening
met een extra element van heterogeniteit. Mankiw et al. geven het begrip conditionele
convergentie gestalte door de verschillen in steady state toe te voegen. Islam (1995)
introduceert individuele effecten door gebruik te maken van panel data. Lee et al. 1997
construeren, tot slot, een stochastisch model dat heterogeniteit in de groei van
technologie toelaat. De cros sectie schatting van groeivergelijkingen leiden onder het
probleem van omitted variables. Panel data kunnen dit probleem omzeilen Ze kunnen
bovendien omgaan met endogeniteit en meetfouten. De Panel data benadering wordt
echter eveneens geconfronteerd met een aantal beperkingen. Verschillende panel data
schatters leiden bijvoorbeeld tot sterk verschillende resultaten. Vaak kent men de kleine
steekproefeigenschappen van de panel data schatters niet. De theorie geeft wel een
indicatie, maar de specifieke vertekening zal sterk afhangen van het specifieke probleem.
Daarom voerden we dan ook een Monte Carlo experiment uit voor een uiteenlopend
aantal schatters. We focusten hierbij op first difference en system GMM. Uit de theorie
verwachtten we een neerwaartse vertekening voor first difference GMM en een weinig
vertekende system GMM. Onze simulaties wijzen echter uit dat system GMM een sterke
opwaartse vertekening vertoont, terwijl de neerwaartse vertekening voor first difference
GMM eerder beperkt is. De klasse van AH schatters lijken ons onbetrouwbaar. OLS en
LSDV gaven de verwachtte op-en neerwaartse vertekening.
Toepassing van OLS, LSDV, first difference GMM en system GMM op (18) leidt tot
conclusies die sterk overeenstemmen met deze van Islam (1995) en Bond et al. (2001).
Het vertraagde inkomen per capita is significant, net als de investeringsratio. Het
uitgebreide Solow model geeft gelijkaardige resultaten. Menselijk kapitaal is niet
significant. Bovendien kloppen in een aantal schattingen de tekens niet. Mogelijks ligt
een correlatie tussen menselijk kapitaal en het individuele effect aan de basis. De
geschatte convergentiesnelheden variëren sterk over de verschillende schatters. First
difference GMM en LSDV schattingen geven de hoogste convergentiesnelheden. De hoge
convergentiesnelheden die Caselli et al. (1996) bekomen, vinden we echter niet terug.

55
Referenties
Arellano, M., 2003, Panel Data Econometrics, Oxford University Press, Oxford.
Arellano, M. and S. Bond, 1991, Some Tests of Specifiation for Panel Data: Monte Carlo
Evidence and an Application to Employment Equations, The Review of Economic
Studies, Vol. 58, No. 2, 227-297.
Arellano, M. and O. Bover, 1995, Another Look at the Instrumental Variable Estimation of
Error-Components Models, Journal of Econometrics, Vol. 68, 29-51.
Barro, Robert J., 1991, Government Spending in a Simple Model of Endogenous Growth,
Journal of Political Economy, Vol. 98, No. 5, S103-S125.
Barro, Robert J., 1991, Economic Growth in a Cross Section of Countries, Quarterly
Journal of Economics, Vol. 106, No. 2, 407-443.
Barro, Robert J. and JW Lee, 2001, International Data on Educational Attainment:
Updates and Implications, Oxford Economic Papers, Vol. 3, 541-563.
Barro, Robert J. and X. Sala-i-Martin, 1992, Convergence, Journal of Political Economy,
Vol. 100, No. 2, 223-251.
Baumol, William .J., 1986, Productivity Growth, Convergence, and Welfare: What the
Long-Run Data Show, American Economic Review, Vol. 76, No. 5, 1072-1085.
Baumol, William .J. and Edward N. Wolff, 1988, Productivity Growth, Convergence, and
Welfare: Reply, American Economic Review, Vol. 78, No. , 1155-1159.
Blundell, R. and S. Bond, 1998, Initial Conditions and Moment Restrictions in Dynamic
Panel Data Models, Journal of Econometrics, Vol. 87, 115-143.
Blundell, R. and Bond, S. and F. Windmeijer, 2000, Estimation in dynamic panel data
models: improving on the performance of the standard GMM estimator, IFS
Working Papers, W00/12, Institute for Fiscal Studies
Bond, Stephen R., Hoeffler, A. and Jonathan R.W. Temple, 2001, GMM Estimation of
Empirical Growth Models, CEPR Discussion Paper No. 3048
Caselli, F., G. Esquivel and F. Lefort, 1996, Reopening the Convergence Debate: A New
Look at Cross-Country Growth Empirics, Journal of Economic Growth, Vol. 1, 363-
389.
Cho, D. and S. Graham, 1996, The Other Side of Conditional Convergence, Economic
Letters, Vol. 50, 285-290.
Cuaresma, Jesus C., D. Ritzberger-Grünwald and Maria.A. Silgoner, 2008, Growth,
Convergence and EU Membership, Applied Economics, Vol. 40, 643-656.
De Long, B., 1988, Productivity Growth, Convergence, and Welfare: Comment, American
Economic Review, Vol. 78, 1138-1154.
Eastly W. and R. Levine, 2001, It’s Not Factor Accumulation: Stylized Facts and Growth
Models, The World Bank Economic Review, Vol. 15, No. 2, 177-219.

56
Hamilton, James D., and J. Monteagudo , 1998, The augmented Solow Model and the
Productivity Slowdown, Journal of Monterary Economics, Vol. 42, No. 3, 495-509.
Hayakawa, K. 2007, Small Sample Bias Properties of the System GMM Estimator in
Dynamic Panel Data Models, Economic Letters, Vol. 95, 32-38.
Harris, Mark N., L. Matyas, 2004, A Comparative Analysis of Different IV and GMM
Estimators of Dynamic Panel Data Models, International Statistical Review, Vol.
72, 397-408.
Heston, A., R. Summers and B. Aten, 2006, Penn World Table Version 6.2, Center for
International Comparisons of Production, Income and Prices at the University of
Pennsylvania.
Howitt, P., 2000, Endogenous Growth and Cross-Country Income Differences, The
American Economic Review, Vol. 90, 829-846.
Kiviet, J.F., 1995, On bias, inconsistency, and efficiency of various estimators in dynamic
panel data models, Journal of Econometrics, Vol. 68, 53-78.
Klenow, Peter J. and Rodriguez-Clare, Andres, 1997, The Neoclassical Revival in Growth
Economics: Has It Gone Too Far? NBER Macroeconomics Annual, Vol. 12, 73-103.
Lee, K., M Hashem Pesaran and R. Smith, 1997, Growth and Convergence in a Multy-
Country Empirical Stochastic Solow Model, Journal of Applied Econometrics, Vol.
12, 357-392.
Lee, M., Longmire R, Matyas L. and M. Harris, 1998, Growth Convergence: Some Panel
Data Evidence, Applied Economics, Vol. 30, 907-912.
Levine, R. and D. Renelt, 1992, A Sensivity Analysis of Cross-Country Growth
Regressions, The American Economic Review, Vol. 82, No. 4, September 1992,
942-963.
Lucas, Robert E. Jr., 1988, On the Mechanics of Economic Development, Journal of
Monetary Economics, Vol. 22, 3-42.
Lucas, Robert E. Jr., 1990, Why Doesn’t Capital Flow from Rich to Poor Countries?
American Economic Review, Vol. 80, No. 2, 92-96.
Mankiw, N. Gregory, Romer, David and D. Weil, 1992, A contributution to the Empirics of
Economic Growth, Quarterly Journal of Economics, Vol. 107, No. , 407-437.
Mankiw, N. Gregory, 1997, The Neoclassical Revival in Growth Economics: Has It Gone
Too Far?: Comment, NBER Macroeconomics Annual, Vol. 12, 103-107.
Nazrul, I., 1995, Growth Empirics: A Panel Data Approach, The Quarterly Journal of
Economics, Vol. 110, No. 4, 1127-1170.
Nazrul, I., 1998, Growth Empirics: A Panel Data Approach – A Reply, The Quarterly
Journal of Economics, Vol. 113, No. 1, 325-329.

57
Nazrul, I., 2000, Small Sample Performance of Dynamic Panel Data Estimators: A Monte
Carlo Study on the Basis of Growth Data, Advances Ecoometrics, Vol. 15, 317-
339.
Nazrul, I, 2003, What Have We Learnt From the Convergence Debate?, Journal of
Economic Surveys, Vol. 17, No. 3, 309-362.
Nickell, S., 1981, Biases in Dynamic Models With Fixed Effects, Econometrica, Vol. 49,
No. 6, 1417-1426.
Nelson, Charles R. and R. Startz, 1990a, Some Further Results on the Exact Small
Sample Properties of the Instrumental Variable Estimator, Econometrica, Vol. 58,
No.4, 967-976.
Nelson, Charles R. and R; Startz, 1990b, The Distribution of the Instrumental Variables
Estimator and Its t-Ratio When the Instrument is a Poor One, The Journal of
Business, Vol. 63, No. 1, S125-S140.
Quah, Danny T., 1996, Empicirs for Economic Growth and Convergence, European
Economic Review, Vol. 40, 1353-1375.
Rebelo, S., 1991, Long-Run Policy Analysis and Long-Run Growth, Journal of Political
Economy, Vol. 99, No. 3, 500-521.
Romer, Paul M., 1990, Endogenous Technological Change, Journal of Political Economy,
Vol. 98, No. 5, S71- S102.
Romer, Paul M., 1994, The Origins of Endogenous Growth, Journal of Economic
Perspectives, Vol. 8, No. 1, 3-22.
Sala-i-Martin, X., 1996, The Classical Approach to Convergence Analysis, Economic
Journal, Vol. 106, No. 437, 1019-1036.
Sala-i-Martin, X., 1997, I Just Ran Two Million Regressions, American Economic Review,
Vol. 87, 178-183.
Seung, C. Ahn, 1995, Efficient estimation of models for dynamic panel data, Journal of
Econometrics, Vol. 68, 5-27.
Solow, Robert M., 1956, A Contribution to the Theory of Economic Growth, The Quarterly
Journal of Economics, Vol. 70, No. 1, 65-94.
Solow, Robert M., 1994, Perspectives on Growth Theory, Journal of Economic
Perspectives, Vol. 8, No. 1, 45-54.
Temple, Jonathan R.W., 1998, Robustness Tests of the Augmented Solow Model, Journal
of Applied Econometrics, Vol. 13, No. 4, 361-375.
Verbeek M., 2004, A Guide to Modern Econometrics, John Wiley and Sons Ltd.
Windmeijer, F., 2000. "A finite sample correction for the variance of linear two-step GMM
estimators," IFS Working Papers W00/19, Institute for Fiscal Studies.

58
6 Bijlagen
A Geschatte populatiewaarden
Tabel 1: Parameterwaarden LSDV (T=9)
Parameter OECD INTER NONOIL
γ 0,68591 0,79084 0,80589
κ 0,11165 0,16848 0,08498
λ0 2,06732 1,34419 1,25667
λ1 0,17652 0,10553 0,09765
λ2 -0,07058 -0,21464 -0,09965
λ3 -0,52987 0,07212 0,04146
λ4 0,68462 -0,09534 -0,13465
λ5 -0,09581 0,10554 0,04442
λ6 -0,08923 0,20687 0,10565
λ8 -0,29214 -0,15194 0,06447
λ8 0,47044 0,12414 0,10799
η70 0,20295 0,16578 0,15884
η75 0,37612 0,32563 0,30774
η80 0,54996 0,46509 0,45815
η85 0,53470 0,34179 0,31969
η90 0,62899 0,39104 0,33636
η95 0,60109 0,37784 0,29732
η00 0,69077 0,40751 0,36433
Tabel 2: Parameterwaarden LSDV (T=9)
Parameter OECD INTER NONOIL
SU
νσ 0,05558 0,10991 0,14715
ϖσ 0,06792 0,10322 0,12096
MA(1)
νσ 0,05558 0,10991 0,14715
ϖσ 0,06792 0,10322 0,12096
εσ 0,05100 0,09427 0,13717
θ -0,05457 0,00188 0,00320
AR(1)
νσ 0,05558 0,10991 0,14715
ϖσ 0,06792 0,10322 0,12096
εσ 0,04692 0,09357 0,12914
ϕ -0,02807 0,04566 0,03513
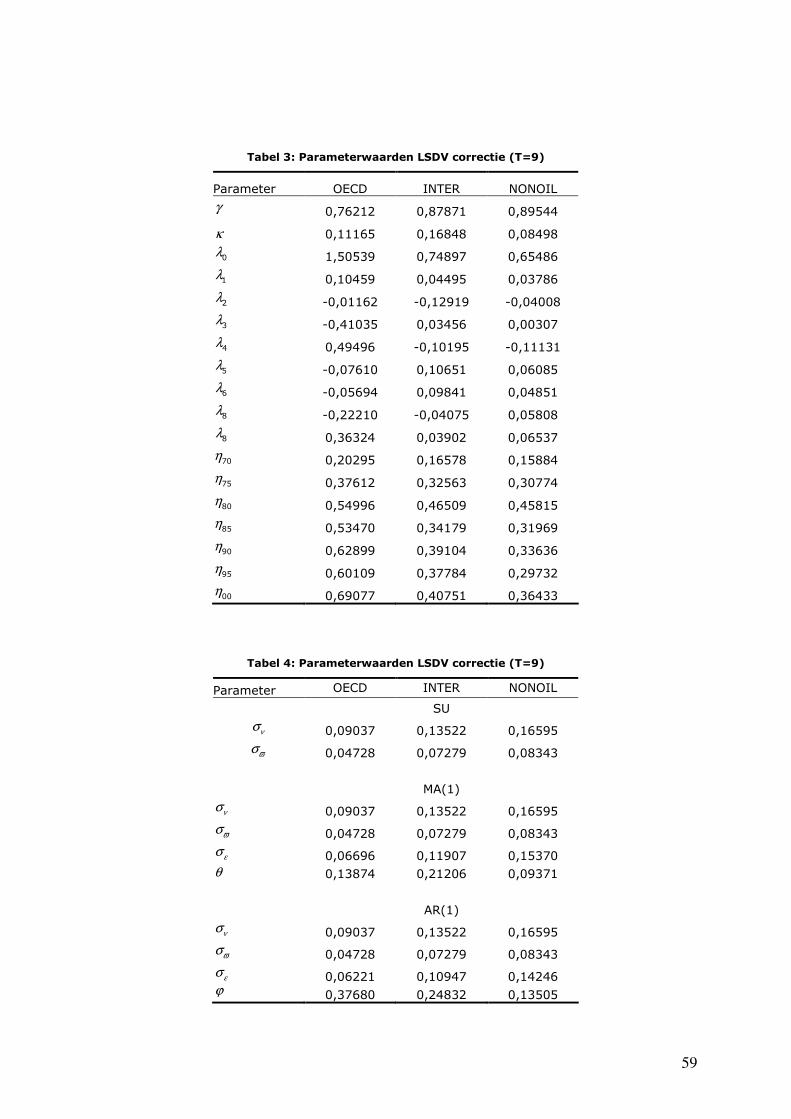
59
Tabel 3: Parameterwaarden LSDV correctie (T=9)
Parameter OECD INTER NONOIL
γ 0,76212 0,87871 0,89544
κ 0,11165 0,16848 0,08498
λ0 1,50539 0,74897 0,65486
λ1 0,10459 0,04495 0,03786
λ2 -0,01162 -0,12919 -0,04008
λ3 -0,41035 0,03456 0,00307
λ4 0,49496 -0,10195 -0,11131
λ5 -0,07610 0,10651 0,06085
λ6 -0,05694 0,09841 0,04851
λ8 -0,22210 -0,04075 0,05808
λ8 0,36324 0,03902 0,06537
η70 0,20295 0,16578 0,15884
η75 0,37612 0,32563 0,30774
η80 0,54996 0,46509 0,45815
η85 0,53470 0,34179 0,31969
η90 0,62899 0,39104 0,33636
η95 0,60109 0,37784 0,29732
η00 0,69077 0,40751 0,36433
Tabel 4: Parameterwaarden LSDV correctie (T=9)
Parameter OECD INTER NONOIL
SU
νσ 0,09037 0,13522 0,16595
ϖσ 0,04728 0,07279 0,08343
MA(1)
νσ 0,09037 0,13522 0,16595
ϖσ 0,04728 0,07279 0,08343
εσ 0,06696 0,11907 0,15370
θ 0,13874 0,21206 0,09371
AR(1)
νσ 0,09037 0,13522 0,16595
ϖσ 0,04728 0,07279 0,08343
εσ 0,06221 0,10947 0,14246 ϕ 0,37680 0,24832 0,13505
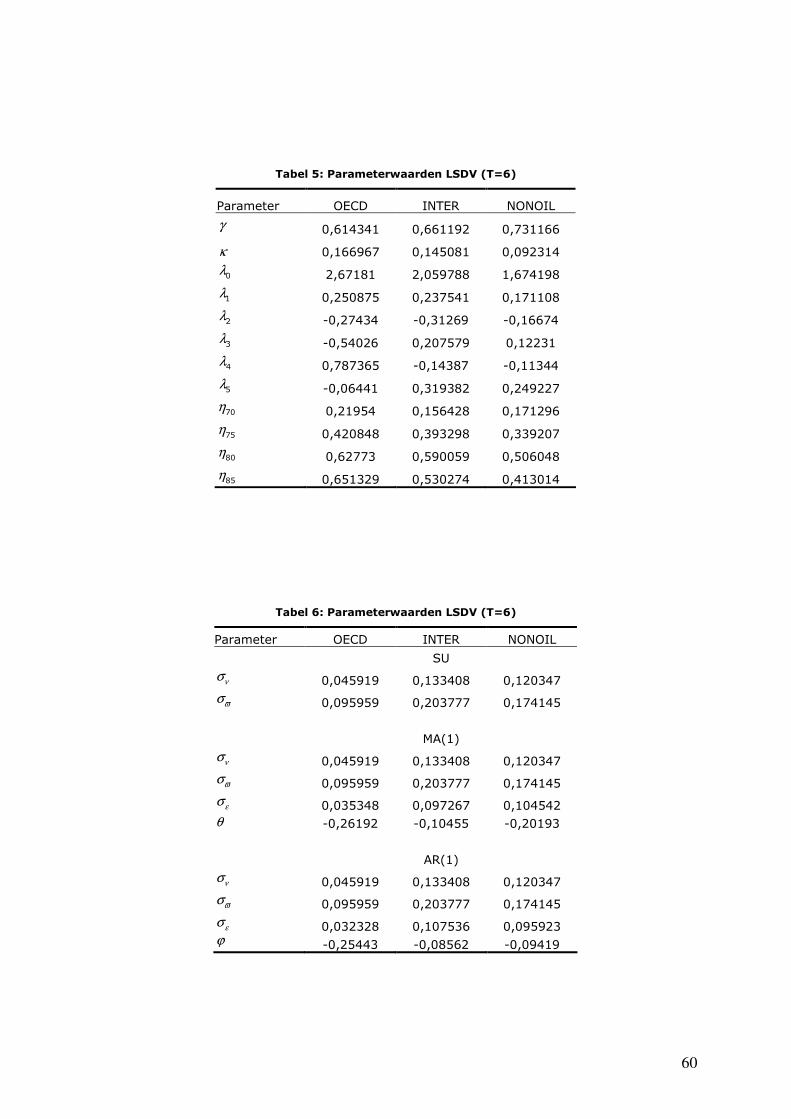
60
Tabel 5: Parameterwaarden LSDV (T=6)
Parameter OECD INTER NONOIL
γ 0,614341 0,661192 0,731166
κ 0,166967 0,145081 0,092314
λ0 2,67181 2,059788 1,674198
λ1 0,250875 0,237541 0,171108
λ2 -0,27434 -0,31269 -0,16674
λ3 -0,54026 0,207579 0,12231
λ4 0,787365 -0,14387 -0,11344
λ5 -0,06441 0,319382 0,249227
η70 0,21954 0,156428 0,171296
η75 0,420848 0,393298 0,339207
η80 0,62773 0,590059 0,506048
η85 0,651329 0,530274 0,413014
Tabel 6: Parameterwaarden LSDV (T=6)
Parameter OECD INTER NONOIL
SU
νσ 0,045919 0,133408 0,120347
ϖσ 0,095959 0,203777 0,174145
MA(1)
νσ 0,045919 0,133408 0,120347
ϖσ 0,095959 0,203777 0,174145
εσ 0,035348 0,097267 0,104542
θ -0,26192 -0,10455 -0,20193
AR(1)
νσ 0,045919 0,133408 0,120347
ϖσ 0,095959 0,203777 0,174145
εσ 0,032328 0,107536 0,095923 ϕ -0,25443 -0,08562 -0,09419

61
Tabel 7: Parameterwaarden LSDV correctie (T=6)
Parameter OECD INTER NONOIL
γ 0,72275 0,77787 0,86019
κ 0,16697 0,14508 0,09231
λ0 1,87574 1,32957 0,87329
λ1 0,10533 0,14809 0,08139
λ2 -0,14104 -0,21445 -0,08288
λ3 -0,35740 0,11998 0,03076
λ4 0,52327 -0,11435 -0,09410
λ5 -0,03518 0,24103 0,19640
η70 0,21954 0,15643 0,17130
η75 0,42085 0,39330 0,33921
η80 0,62773 0,59006 0,50605
η85 0,65133 0,53027 0,41301
Tabel 8: Parameterwaarden LSDV correctie (T=6)
Parameter OECD INTER NONOIL
SU
νσ 0,08677 0,15160 0,14443
ϖσ 0,06430 0,13676 0,10404
MA(1)
νσ 0,08677 0,15160 0,14443
ϖσ 0,06430 0,13676 0,10404
εσ 0,06840 0,11758 0,12855
θ 0,39918 -0,04113 -0,07207
AR(1)
νσ 0,08677 0,15160 0,14443
ϖσ 0,06430 0,13676 0,10404
εσ 0,05963 0,12291 0,11448
ϕ 0,35151 -0,02104 0,02194

62
Tabel 9: Parameterwaarden Islam (2000) (T=6)
Parameter OECD INTER NONOIL
γ 0,6294 0,7925 0,7884
κ 0,0954 0,1732 0,1641
λ0 2,8986 1,3588 1,3334
λ1 0,5863 0,1927 -0,0028
λ2 -0,6354 -0,1098 0,12
λ3 -0,0702 -0,1644 -0,1243
λ4 0,6355 0,1286 0,0267
λ5 -0,3484 0,1755 0,2277
η70 0,068 0,0093 0,0171
η75 0,0827 -0,0015 -0,0156
η80 0,1295 0,0218 -0,0067
η85 0,1238 -0,0523 -0,0669
Tabel 10: Parameterwaarden Islam (2000) (T=6)
Parameter OECD INTER NONOIL
SU
νσ 0,03 0,0872 0,1054
ϖσ 0,0762 0,0139 0,1281
MA(1)
νσ 0,0302 0,099 0,1179
ϖσ 0,0742 0,101 0,1225
εσ 0,03 0,098 0,1153
θ 0,1125 0,125 0,2037
AR(1)
νσ 0,0319 0,0943 0,1227
ϖσ 0,0742 0,0995 0,1183
εσ 0,0316 0,0927 0,1171
ϕ 0,1361 0,1787 0,2994
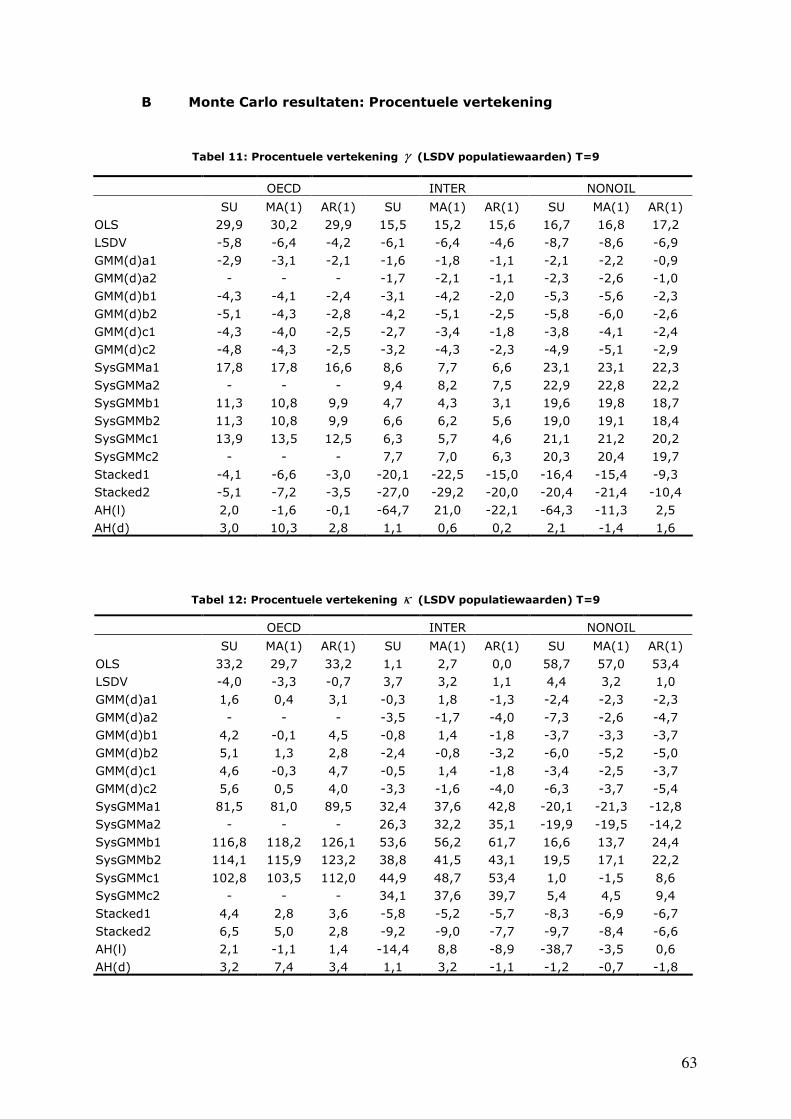
63
B Monte Carlo resultaten: Procentuele vertekening
Tabel 11: Procentuele vertekening γ (LSDV populatiewaarden) T=9
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 29,9 30,2 29,9 15,5 15,2 15,6 16,7 16,8 17,2
LSDV -5,8 -6,4 -4,2 -6,1 -6,4 -4,6 -8,7 -8,6 -6,9
GMM(d)a1 -2,9 -3,1 -2,1 -1,6 -1,8 -1,1 -2,1 -2,2 -0,9
GMM(d)a2 - - - -1,7 -2,1 -1,1 -2,3 -2,6 -1,0
GMM(d)b1 -4,3 -4,1 -2,4 -3,1 -4,2 -2,0 -5,3 -5,6 -2,3
GMM(d)b2 -5,1 -4,3 -2,8 -4,2 -5,1 -2,5 -5,8 -6,0 -2,6
GMM(d)c1 -4,3 -4,0 -2,5 -2,7 -3,4 -1,8 -3,8 -4,1 -2,4
GMM(d)c2 -4,8 -4,3 -2,5 -3,2 -4,3 -2,3 -4,9 -5,1 -2,9
SysGMMa1 17,8 17,8 16,6 8,6 7,7 6,6 23,1 23,1 22,3
SysGMMa2 - - - 9,4 8,2 7,5 22,9 22,8 22,2
SysGMMb1 11,3 10,8 9,9 4,7 4,3 3,1 19,6 19,8 18,7
SysGMMb2 11,3 10,8 9,9 6,6 6,2 5,6 19,0 19,1 18,4
SysGMMc1 13,9 13,5 12,5 6,3 5,7 4,6 21,1 21,2 20,2
SysGMMc2 - - - 7,7 7,0 6,3 20,3 20,4 19,7
Stacked1 -4,1 -6,6 -3,0 -20,1 -22,5 -15,0 -16,4 -15,4 -9,3
Stacked2 -5,1 -7,2 -3,5 -27,0 -29,2 -20,0 -20,4 -21,4 -10,4
AH(l) 2,0 -1,6 -0,1 -64,7 21,0 -22,1 -64,3 -11,3 2,5
AH(d) 3,0 10,3 2,8 1,1 0,6 0,2 2,1 -1,4 1,6
Tabel 12: Procentuele vertekening κ (LSDV populatiewaarden) T=9
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 33,2 29,7 33,2 1,1 2,7 0,0 58,7 57,0 53,4
LSDV -4,0 -3,3 -0,7 3,7 3,2 1,1 4,4 3,2 1,0
GMM(d)a1 1,6 0,4 3,1 -0,3 1,8 -1,3 -2,4 -2,3 -2,3
GMM(d)a2 - - - -3,5 -1,7 -4,0 -7,3 -2,6 -4,7
GMM(d)b1 4,2 -0,1 4,5 -0,8 1,4 -1,8 -3,7 -3,3 -3,7
GMM(d)b2 5,1 1,3 2,8 -2,4 -0,8 -3,2 -6,0 -5,2 -5,0
GMM(d)c1 4,6 -0,3 4,7 -0,5 1,4 -1,8 -3,4 -2,5 -3,7
GMM(d)c2 5,6 0,5 4,0 -3,3 -1,6 -4,0 -6,3 -3,7 -5,4
SysGMMa1 81,5 81,0 89,5 32,4 37,6 42,8 -20,1 -21,3 -12,8
SysGMMa2 - - - 26,3 32,2 35,1 -19,9 -19,5 -14,2
SysGMMb1 116,8 118,2 126,1 53,6 56,2 61,7 16,6 13,7 24,4
SysGMMb2 114,1 115,9 123,2 38,8 41,5 43,1 19,5 17,1 22,2
SysGMMc1 102,8 103,5 112,0 44,9 48,7 53,4 1,0 -1,5 8,6
SysGMMc2 - - - 34,1 37,6 39,7 5,4 4,5 9,4
Stacked1 4,4 2,8 3,6 -5,8 -5,2 -5,7 -8,3 -6,9 -6,7
Stacked2 6,5 5,0 2,8 -9,2 -9,0 -7,7 -9,7 -8,4 -6,6
AH(l) 2,1 -1,1 1,4 -14,4 8,8 -8,9 -38,7 -3,5 0,6
AH(d) 3,2 7,4 3,4 1,1 3,2 -1,1 -1,2 -0,7 -1,8

64
Tabel 13: Procentuele vertekening γ (LSDVcor populatiewaarden) T=9
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 16,3 17,3 16,8 6,2 6,6 6,3 7,4 7,7 7,6
LSDV -14,3 -11,4 -9,8 -11,0 -9,1 -8,4 -13,2 -12,0 -10,7
GMM(d)a1 -9,6 -10,0 -5,6 -3,9 -11,9 -2,5 -4,7 -9,1 -2,2
GMM(d)a2 - - - -4,3 -14,9 -2,8 -5,0 -10,7 -2,4
GMM(d)b1 -11,0 -11,4 -6,8 -11,2 -32,3 -6,5 -10,2 -20,4 -5,8
GMM(d)b2 -11,8 -11,9 -6,7 -13,6 -37,3 -7,4 -11,0 -23,4 -5,8
GMM(d)c1 -12,1 -13,2 -6,7 -7,6 -24,8 -4,8 -8,7 -17,3 -5,2
GMM(d)c2 -13,0 -13,3 -6,8 -8,9 -30,1 -5,7 -9,7 -19,8 -5,7
SysGMMa1 10,7 11,0 9,1 4,8 4,3 1,8 15,0 15,6 14,4
SysGMMa2 - - - 4,9 3,7 2,2 14,4 14,4 13,7
SysGMMb1 7,8 7,5 5,5 2,5 2,0 0,0 13,3 14,6 12,6
SysGMMb2 7,7 7,4 5,4 2,6 1,5 0,9 12,1 13,0 11,3
SysGMMc1 8,9 8,8 6,5 3,4 2,9 0,7 14,1 15,1 13,4
SysGMMc2 - - - 3,4 2,4 1,5 13,0 13,5 12,1
Stacked1 -7,0 -1,8 -5,9 -24,8 -32,2 -17,4 -8,7 -16,2 -5,9
Stacked2 -8,0 -1,3 -6,0 -31,1 -40,3 -22,1 -10,4 -19,4 -6,6
AH(l) 3,6 11,9 -1,2 -25,2 -35,6 71,8 5,2 0,0 1,5
AH(d) 84,7 -47,8 -1,0 4,0 -37,7 0,8 5,4 -26,2 3,0
Tabel 14: Procentuele vertekening κ (LSDVcor populatiewaarden) T=9
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 35,1 28,8 34,1 -9,0 -11,2 -10,0 38,1 33,2 34,5
LSDV -11,4 -7,9 -2,0 5,1 3,9 1,6 6,5 5,1 2,6
GMM(d)a1 7,5 18,9 8,2 -1,5 2,1 -2,6 -4,0 -3,5 -3,6
GMM(d)a2 - - - -5,4 -3,2 -5,6 -8,9 -4,3 -5,6
GMM(d)b1 14,3 26,0 11,8 -4,8 -7,1 -4,5 -6,6 -8,7 -6,3
GMM(d)b2 18,6 29,0 11,5 -7,5 -12,7 -6,1 -9,0 -10,4 -6,2
GMM(d)c1 15,9 25,6 11,6 -3,0 -4,1 -3,9 -6,3 -7,3 -5,9
GMM(d)c2 18,0 29,0 12,0 -6,6 -10,6 -7,0 -9,5 -8,9 -7,2
SysGMMa1 59,1 56,9 70,2 -2,5 -0,1 14,2 -54,1 -61,7 -48,9
SysGMMa2 - - - -4,5 2,4 10,4 -46,4 -48,6 -39,8
SysGMMb1 76,6 77,3 91,9 11,0 13,2 25,0 -34,3 -50,7 -27,4
SysGMMb2 74,9 76,3 89,8 8,2 14,4 17,0 -21,8 -32,4 -15,3
SysGMMc1 69,4 69,8 85,4 5,7 7,7 20,6 -43,8 -56,9 -36,9
SysGMMc2 - - - 3,6 9,6 14,2 -31,3 -38,2 -23,7
Stacked1 10,4 4,0 8,8 -10,5 -9,2 -8,9 -6,5 -7,0 -6,6
Stacked2 14,1 12,5 7,6 -13,6 -14,7 -11,0 -7,5 -7,6 -5,6
AH(l) 3,2 4,6 3,5 -8,4 -12,1 44,1 1,3 1,7 -2,2
AH(d) 83,7 -22,9 -10,8 2,6 -11,4 -1,4 -0,1 -8,6 -1,8

65
Tabel 15: Procentuele vertekening γ (Islam (2000) populatiewaarden) T=9
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 37,5 37,5 36,9 9,0 14,4 14,4 16,2 15,9 15,0
LSDV -1,6 -1,4 -2,0 -4,0 -3,7 -3,7 -3,5 -3,4 -4,8
GMM(d)a1 -0,5 -0,8 -0,8 -1,1 -2,5 -0,9 -0,7 -3,6 -0,7
GMM(d)a2 - - - -1,3 -2,9 -1,0 -0,8 -4,2 -0,9
GMM(d)b1 -0,7 -1,9 -0,7 -1,4 -8,2 -1,3 -0,8 -9,8 -1,0
GMM(d)b2 -1,1 -2,0 -0,8 -2,0 -9,0 -1,4 -0,7 -11,1 -0,9
GMM(d)c1 -0,8 -1,7 -0,9 -1,5 -5,8 -1,3 -0,8 -7,5 -1,4
GMM(d)c2 -1,0 -1,8 -0,9 -1,9 -6,8 -1,7 -1,1 -8,5 -1,7
SysGMMa1 20,4 19,9 19,6 4,3 10,3 10,5 18,6 18,1 18,0
SysGMMa2 - - - 5,3 10,6 11,1 18,5 17,9 18,1
SysGMMb1 10,7 10,2 9,8 3,4 6,2 6,2 14,4 14,4 13,8
SysGMMb2 10,8 10,2 9,8 4,9 7,5 8,2 14,4 14,3 14,1
SysGMMc1 14,6 14,1 13,6 3,6 7,9 8,1 16,3 16,0 15,5
SysGMMc2 - - - 5,0 8,6 9,4 16,1 15,6 15,5
Stacked1 -0,5 0,4 -1,1 -10,3 -13,1 -7,6 -1,2 -8,1 -1,7
Stacked2 -0,6 0,7 -1,6 -12,7 -14,2 -8,8 -1,2 -9,1 -1,8
AH(l) 1,0 1,4 -0,5 -2,0 -13,9 5,0 0,2 -7,5 0,2
AH(d) 0,7 -2,9 1,3 0,5 -9,2 0,3 0,3 -15,2 0,7
Tabel 16: Procentuele vertekening κ (Islam (2000) populatiewaarden) T=9
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 58,1 55,1 60,4 60,5 30,3 29,8 38,1 38,9 44,4
LSDV -2,0 -1,7 -0,4 -0,1 -0,4 -1,9 -2,0 -2,4 -3,9
GMM(d)a1 0,8 2,6 2,9 -0,9 2,0 -2,1 -1,9 -1,8 -2,5
GMM(d)a2 - - - -3,7 -1,7 -5,1 -4,5 -4,3 -4,6
GMM(d)b1 1,7 5,1 3,5 -0,9 -2,1 -2,4 -1,5 -5,4 -2,4
GMM(d)b2 1,6 4,8 0,8 -2,1 -4,7 -3,8 -2,4 -6,5 -2,9
GMM(d)c1 2,1 3,5 4,0 -0,9 -0,6 -2,5 -1,7 -3,7 -2,8
GMM(d)c2 2,6 3,4 3,2 -3,3 -4,3 -4,9 -3,4 -5,7 -4,5
SysGMMa1 121,6 122,2 126,7 84,5 46,8 44,6 14,3 16,5 17,3
SysGMMa2 - - - 77,5 42,1 38,6 11,6 15,1 14,2
SysGMMb1 172,4 172,9 178,8 90,2 71,3 70,2 40,8 39,7 43,5
SysGMMb2 169,5 169,7 176,0 79,3 59,0 53,7 35,2 35,8 37,1
SysGMMc1 152,2 152,5 158,4 89,0 61,2 58,9 28,9 29,9 33,2
SysGMMc2 - - - 79,4 52,8 47,4 24,9 28,0 29,2
Stacked1 2,5 0,6 2,4 -5,9 -5,8 -6,0 -1,7 -4,3 -2,6
Stacked2 4,3 1,8 1,9 -7,0 -6,8 -6,5 -1,9 -4,3 -2,4
AH(l) 1,4 0,8 1,6 0,3 -5,0 0,0 -0,6 -3,0 -1,0
AH(d) 1,5 0,5 3,1 0,9 -1,6 -1,1 -0,6 -6,7 -0,8

66
Tabel 17: Procentuele vertekening γ (LSDV populatiewaarden) T=6
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 36,8 37,4 38,6 34,1 33,9 34,7 22,0 21,4 22,1
LSDV -4,4 -6,4 -3,1 -9,5 -10,8 -6,6 -8,3 -9,2 -5,3
GMM(d)a1 -0,9 -1,2 -1,2 -1,4 -0,8 -0,6 -1,0 1,4 -0,2
GMM(d)a2 -1,1 -1,2 -0,9 -1,7 -0,7 -0,8 -1,0 1,5 -0,2
GMM(d)b1 -1,3 0,9 -1,1 -1,3 3,8 -0,2 -1,3 6,8 0,0
GMM(d)b2 -1,9 0,0 -1,2 -1,9 3,3 -0,6 -1,5 6,5 0,0
GMM(d)c1 -0,7 -0,2 -1,2 -1,6 0,7 -0,5 -1,2 3,3 -0,2
GMM(d)c2 -0,9 -0,4 -1,0 -1,9 0,9 -0,8 -1,3 3,5 -0,3
SysGMMa1 5,7 7,8 7,6 47,4 46,7 43,9 27,0 25,2 23,0
SysGMMa2 6,0 8,3 7,7 45,8 45,4 42,6 28,1 27,4 24,6
SysGMMb1 1,8 3,6 3,6 43,6 42,2 40,2 24,1 21,6 19,9
SysGMMb2 3,2 5,0 4,4 41,1 39,5 38,7 25,3 23,5 22,2
SysGMMc1 4,5 6,4 6,5 46,4 45,6 43,0 26,3 24,2 22,1
SysGMMc2 5,0 7,2 6,7 44,4 44,0 41,6 27,3 26,5 23,8
Stacked1 -3,0 -6,0 -1,9 -15,7 -17,4 -12,2 -9,3 -12,1 -3,4
Stacked2 -3,7 -5,8 -1,9 -15,9 -18,1 -15,4 -11,1 -8,8 -4,8
AH(l) -0,7 -2,8 3,4 19,2 -25,5 -14,1 6,7 -3,2 -18,8
AH(d) 2,4 12,6 0,1 2,3 12,0 0,7 0,2 14,6 1,0
Tabel 18: Procentuele vertekening κ (LSDV populatiewaarden) T=6
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 12,2 14,2 6,5 28,1 29,1 24,1 79,9 84,9 82,3
LSDV -6,8 -3,3 -3,8 -6,8 -5,6 -2,1 -1,4 -0,2 0,1
GMM(d)a1 -3,7 -0,1 -1,4 -1,8 1,2 0,9 -8,4 -10,1 -8,5
GMM(d)a2 -5,6 0,2 -1,1 -3,6 0,7 -0,6 -9,3 -13,1 -8,5
GMM(d)b1 -2,6 1,2 -1,7 -2,2 3,0 1,2 -8,5 -8,8 -8,5
GMM(d)b2 -2,7 1,3 -1,7 -3,8 2,3 1,0 -9,0 -11,0 -7,8
GMM(d)c1 -3,2 0,2 -1,6 -2,1 2,0 1,0 -8,6 -9,8 -8,5
GMM(d)c2 -4,3 0,2 -1,4 -4,0 1,5 -0,1 -9,1 -12,1 -8,2
SysGMMa1 89,9 88,4 82,8 -59,4 -56,5 -43,7 15,1 30,8 50,2
SysGMMa2 79,3 77,9 71,7 -47,3 -46,3 -33,7 5,5 13,6 32,7
SysGMMb1 101,3 101,0 94,7 -40,5 -34,5 -25,7 38,4 59,6 74,4
SysGMMb2 81,7 81,2 75,8 -23,2 -16,5 -14,1 26,3 43,2 51,1
SysGMMc1 93,5 92,9 86,2 -54,6 -50,9 -39,3 21,1 38,9 57,6
SysGMMc2 80,3 79,1 73,3 -39,8 -38,7 -28,3 11,4 20,9 38,6
Stacked1 -3,0 -2,0 -2,0 -7,6 -3,9 -2,2 -11,6 -11,3 -8,8
Stacked2 -5,2 -3,2 -1,4 -7,7 -4,7 -3,4 -13,0 -10,3 -8,6
AH(l) -0,7 0,4 2,8 10,9 -22,1 -14,4 -6,5 -11,3 -28,7
AH(d) 0,3 7,2 -0,8 -1,0 8,6 -0,2 -12,8 -3,2 -9,8

67
Tabel 19: Procentuele vertekening γ (LSDVcor populatiewaarden) T=6
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 17,1 19,3 18,5 15,3 15,2 15,7 7,1 6,8 7,3
LSDV -17,2 -12,0 -12,8 -15,7 -16,4 -11,3 -17,4 -17,7 -12,0
GMM(d)a1 -5,7 -12,9 -4,9 -3,1 -2,7 -1,4 -3,5 -0,2 -1,1
GMM(d)a2 -5,6 -14,2 -4,7 -3,7 -2,9 -1,7 -3,9 -0,2 -1,2
GMM(d)b1 -7,1 -17,6 -5,7 -4,0 0,0 -1,3 -5,6 1,4 -0,8
GMM(d)b2 -7,6 -20,1 -6,3 -4,8 -0,2 -1,7 -6,1 2,0 -0,7
GMM(d)c1 -5,8 -14,4 -5,2 -3,7 -1,8 -1,3 -4,3 0,9 -1,1
GMM(d)c2 -5,4 -15,9 -4,9 -4,2 -1,8 -1,6 -4,7 0,9 -1,3
SysGMMa1 1,5 2,3 0,4 22,2 21,0 15,5 11,0 10,0 4,8
SysGMMa2 1,7 2,5 0,9 21,3 20,0 16,1 11,5 11,1 7,4
SysGMMb1 0,4 -0,2 -1,5 19,1 17,7 12,4 9,4 8,4 3,0
SysGMMb2 0,6 0,1 -0,5 18,3 16,8 13,9 10,1 9,6 6,3
SysGMMc1 1,1 1,5 -0,2 21,3 20,0 14,5 10,5 9,5 4,1
SysGMMc2 1,3 1,8 0,4 20,2 19,0 15,5 11,0 10,6 7,0
Stacked1 -5,6 5,7 -6,1 -26,2 -22,6 -17,4 -25,8 -19,0 -10,4
Stacked2 -6,3 3,8 -5,0 -31,6 -26,5 -21,5 -30,9 -24,8 -14,8
AH(l) 1,1 20,7 0,0 -38,3 -53,3 -20,0 490,8 -53,4 9,6
AH(d) 13,5 -49,9 1,0 3,8 11,0 1,7 0,8 15,3 2,3
Tabel 20: Procentuele vertekening κ (LSDVcor populatiewaarden) T=6
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 8,5 5,8 4,2 22,8 23,2 19,7 54,5 57,1 55,6
LSDV -25,1 -14,5 -15,7 -12,5 -10,6 -5,7 -6,5 -4,2 -3,5
GMM(d)a1 -12,4 -11,1 -5,0 -3,2 0,8 0,4 -8,9 -9,3 -8,7
GMM(d)a2 -17,1 -10,4 -6,6 -5,4 0,2 -1,4 -10,4 -12,2 -9,1
GMM(d)b1 -8,3 -10,9 -3,9 -4,1 2,0 0,8 -10,1 -7,9 -8,8
GMM(d)b2 -9,9 -12,6 -4,6 -5,8 1,7 0,5 -10,6 -9,3 -8,3
GMM(d)c1 -10,9 -11,4 -4,6 -3,8 1,5 0,7 -9,5 -8,6 -8,7
GMM(d)c2 -13,8 -10,2 -5,4 -5,9 0,9 -0,8 -10,6 -11,0 -8,6
SysGMMa1 55,2 56,2 59,2 -27,0 -21,1 10,0 9,6 19,7 69,3
SysGMMa2 48,5 49,5 49,2 -18,7 -11,9 7,7 5,1 10,3 41,5
SysGMMb1 59,0 64,8 65,8 -9,3 -2,3 27,6 24,5 34,9 85,4
SysGMMb2 49,8 55,0 50,2 -2,3 5,1 19,1 16,7 23,1 51,2
SysGMMc1 56,6 59,0 61,3 -21,7 -15,3 15,4 14,1 25,0 75,4
SysGMMc2 48,9 51,6 49,3 -12,7 -6,6 11,4 8,7 14,7 45,1
Stacked1 -6,3 4,1 -3,2 -16,3 -7,0 -5,2 -17,2 -13,9 -10,4
Stacked2 -11,3 2,0 -2,4 -18,5 -9,0 -7,4 -20,3 -15,6 -11,2
AH(l) 0,0 9,8 2,0 -10,7 -51,8 -4,2 381,3 -25,0 -7,3
AH(d) 5,6 -36,5 2,7 -0,9 9,2 0,1 -12,5 -1,5 -9,4

68
Tabel 21: Procentuele vertekening γ (Islam (2000) populatiewaarden) T=6
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 28,2 28,9 29,0 8,0 12,9 12,5 12,5 12,3 11,3
LSDV -1,9 -1,9 -2,9 -6,8 -6,4 -6,7 -6,1 -5,5 -7,8
GMM(d)a1 -0,3 -0,7 -1,0 -1,0 -3,5 -0,8 -1,0 -4,6 -0,9
GMM(d)a2 -0,3 -0,8 -0,9 -1,1 -4,1 -0,8 -1,0 -5,2 -1,1
GMM(d)b1 -0,3 -1,2 -1,1 -0,9 -6,6 -0,7 -1,1 -9,5 -0,7
GMM(d)b2 -0,6 -1,6 -1,1 -0,6 -6,8 -0,6 -1,0 -9,8 -0,8
GMM(d)c1 -0,2 -0,7 -1,1 -1,1 -4,4 -0,7 -1,1 -6,0 -0,9
GMM(d)c2 -0,2 -0,9 -0,8 -1,1 -4,8 -0,7 -1,1 -6,4 -1,2
SysGMMa1 0,0 1,2 1,0 3,3 7,6 6,6 12,7 11,9 12,8
SysGMMa2 0,8 2,1 1,8 6,4 9,7 9,7 13,7 12,4 14,0
SysGMMb1 -2,7 -1,7 -2,1 3,0 5,6 4,5 10,3 10,1 10,8
SysGMMb2 -0,8 0,0 -0,2 6,3 8,7 8,8 12,1 11,2 12,7
SysGMMc1 -0,8 0,2 0,0 3,0 6,9 5,8 11,9 11,3 12,0
SysGMMc2 0,3 1,5 1,3 6,3 9,3 9,4 13,1 12,0 13,6
Stacked1 -0,4 0,0 -1,1 -4,0 -6,9 -3,2 -1,6 -5,2 -1,1
Stacked2 -0,5 -0,3 -0,5 -4,6 -8,4 -3,9 -1,8 -5,9 -1,9
AH(l) -0,2 0,7 -0,2 0,8 -3,5 0,0 -0,8 -5,0 0,2
AH(d) 1,4 -1,4 -0,5 0,9 -5,8 0,7 -0,3 -9,5 0,9
Tabel 22: Procentuele vertekening κ (Islam (2000) populatiewaarden) T=6
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 99,6 101,6 94,3 69,6 44,5 46,0 61,7 62,8 69,7
LSDV -7,9 -3,6 -8,6 -8,1 -6,6 -6,1 -2,9 -1,7 -3,9
GMM(d)a1 -4,7 0,0 -2,0 -1,9 -1,3 -0,3 -10,1 -12,5 -10,3
GMM(d)a2 -5,9 -1,8 -3,9 -3,1 -2,6 -1,2 -10,5 -13,3 -10,5
GMM(d)b1 -3,3 0,8 -1,6 -1,7 -4,5 0,1 -10,2 -16,0 -10,1
GMM(d)b2 -2,7 -0,8 -3,2 -2,0 -4,4 0,4 -9,9 -15,5 -9,8
GMM(d)c1 -4,0 0,2 -1,8 -2,0 -2,2 -0,1 -10,3 -13,5 -10,2
GMM(d)c2 -4,6 -2,1 -2,7 -3,0 -3,0 -0,7 -10,2 -14,1 -10,3
SysGMMa1 219,4 220,5 213,3 92,4 65,1 70,5 50,3 55,4 52,2
SysGMMa2 199,3 201,2 191,1 75,5 51,8 52,0 41,7 50,3 42,5
SysGMMb1 232,5 234,9 228,6 94,0 76,3 82,5 63,9 65,9 64,1
SysGMMb2 200,1 203,3 193,2 75,7 56,8 56,5 50,7 57,5 50,3
SysGMMc1 223,5 225,3 217,9 93,7 69,1 75,0 54,9 59,1 56,6
SysGMMc2 199,8 201,8 191,3 76,0 53,7 53,8 44,7 52,6 45,0
Stacked1 -2,6 0,3 -1,6 -4,3 -3,6 -2,0 -10,2 -12,1 -10,2
Stacked2 -4,0 -0,2 -2,1 -4,1 -4,8 -2,7 -9,7 -12,2 -10,4
AH(l) -1,3 0,2 0,0 0,0 -0,7 0,9 -9,3 -11,7 -9,5
AH(d) 0,4 -1,5 0,6 -0,5 -0,2 -0,2 -12,6 -14,5 -10,9

69
C Monte Carlo resultaten: RMSE als percentage van populatiewaarde
Tabel 23: RMSE γ (LSDV populatiewaarden) T=9
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 78,5 79,1 78,5 78,5 78,2 78,7 83,3 83,5 83,9
LSDV 7,5 7,7 5,8 6,5 6,8 5,0 9,0 9,0 7,2
GMM(d)a1 7,7 7,1 6,0 4,2 4,6 3,5 5,3 5,1 3,8
GMM(d)a2 - - - 4,7 5,1 3,9 5,9 6,0 4,3
GMM(d)b1 11,5 11,6 9,1 8,9 10,8 7,4 12,3 12,7 8,7
GMM(d)b2 11,7 11,6 9,4 10,6 12,3 8,4 13,8 13,8 9,8
GMM(d)c1 9,9 8,9 7,5 6,2 7,4 5,0 8,6 8,2 6,3
GMM(d)c2 10,6 9,3 7,7 7,7 8,8 5,7 10,0 9,5 7,3
SysGMMa1 19,6 19,4 18,5 9,8 9,0 8,0 23,5 23,5 22,6
SysGMMa2 - - - 10,4 9,5 8,7 23,3 23,2 22,5
SysGMMb1 13,9 13,2 12,3 6,2 6,2 5,2 20,1 20,3 19,2
SysGMMb2 13,9 13,2 12,4 7,7 7,7 6,9 19,4 19,6 18,7
SysGMMc1 16,2 15,5 14,7 7,7 7,2 6,4 21,6 21,7 20,7
SysGMMc2 - - - 8,8 8,4 7,6 20,8 20,8 20,1
Stacked1 18,3 19,2 15,5 43,0 44,4 32,4 33,8 31,7 24,1
Stacked2 20,1 21,8 17,3 51,8 59,4 38,1 42,7 40,6 25,9
AH(l) 19,6 20,2 16,7 752,4 485,3 402,0 733,6 121,4 81,3
AH(d) 25,8 31,7 18,4 11,5 13,2 8,7 18,0 18,0 12,6
Tabel 24: RMSE κ (LSDV populatiewaarden) T=9
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 49,2 44,6 47,0 13,2 13,5 11,9 62,4 61,0 57,1
LSDV 34,4 36,1 31,5 15,3 13,4 11,9 28,4 26,2 23,0
GMM(d)a1 49,4 50,0 42,0 20,8 21,2 19,0 41,0 42,3 33,0
GMM(d)a2 - - - 23,8 23,0 20,1 44,1 45,0 36,5
GMM(d)b1 51,8 51,1 44,5 20,8 21,3 19,3 41,3 41,5 33,7
GMM(d)b2 56,9 58,3 49,5 22,9 22,4 20,7 43,4 42,4 35,3
GMM(d)c1 52,5 49,9 43,6 20,8 21,0 19,4 41,4 41,3 33,4
GMM(d)c2 53,3 54,0 46,2 23,3 22,7 20,7 43,9 42,5 36,7
SysGMMa1 95,5 95,8 101,2 41,4 45,0 48,9 50,4 51,1 44,9
SysGMMa2 - - - 35,9 40,7 41,7 51,4 53,0 42,5
SysGMMb1 126,5 127,2 133,0 57,8 61,0 65,1 49,9 50,5 51,1
SysGMMb2 123,8 125,1 130,1 43,6 48,0 47,4 49,7 51,0 44,3
SysGMMc1 114,1 114,7 120,1 50,9 54,3 57,9 47,6 47,8 46,1
SysGMMc2 - - - 40,7 44,8 44,9 47,1 48,0 40,5
Stacked1 54,4 56,6 50,2 25,5 23,4 22,8 42,5 41,8 34,4
Stacked2 60,6 62,9 56,0 29,4 27,6 24,3 43,5 43,0 33,6
AH(l) 56,4 61,7 51,7 170,2 232,2 136,2 460,7 57,3 56,8
AH(d) 59,2 68,4 56,2 24,8 25,2 22,1 43,9 45,2 35,4

70
Tabel 25: RMSE γ (LSDVcor populatiewaarden) T=9
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 80,4 81,3 80,5 82,6 83,0 82,8 86,9 87,4 87,3
LSDV 15,9 13,0 11,2 11,2 9,5 8,8 13,5 12,3 10,9
GMM(d)a1 16,0 15,1 10,4 7,1 14,2 5,5 8,2 11,4 5,3
GMM(d)a2 - - - 8,3 17,9 6,3 9,1 13,5 6,1
GMM(d)b1 21,6 20,8 15,7 18,4 34,7 13,6 16,4 24,3 12,6
GMM(d)b2 21,5 21,7 15,6 21,6 40,0 15,1 19,3 28,2 13,7
GMM(d)c1 19,9 19,3 13,1 12,4 27,1 9,0 13,6 19,8 9,5
GMM(d)c2 20,5 19,2 13,3 15,2 33,0 10,5 15,9 23,0 10,9
SysGMMa1 13,0 13,1 11,0 6,5 6,3 4,6 15,4 15,9 14,8
SysGMMa2 - - - 6,6 5,9 4,8 14,8 14,8 14,1
SysGMMb1 10,9 10,8 8,3 4,8 5,2 4,1 13,8 15,1 13,0
SysGMMb2 10,9 10,9 8,3 5,0 5,2 4,3 12,6 13,5 11,8
SysGMMc1 11,8 11,5 9,1 5,5 5,6 4,3 14,6 15,6 13,8
SysGMMc2 - - - 5,6 5,4 4,5 13,5 13,9 12,6
Stacked1 22,2 19,3 19,6 44,0 41,6 33,5 20,9 25,5 16,8
Stacked2 23,5 20,3 21,3 52,8 51,8 39,8 22,7 29,7 17,0
AH(l) 25,2 28,3 22,0 992,3 455,2 904,9 43,7 167,6 28,6
AH(d) 783,0 75,4 365,6 23,5 39,9 14,8 33,1 31,9 19,1
Tabel 26: RMSE κ (LSDVcor populatiewaarden) T=9
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 49,4 44,5 44,9 14,9 16,7 14,6 42,7 38,8 38,8
LSDV 58,7 66,0 48,0 18,9 17,8 14,3 32,3 30,5 26,1
GMM(d)a1 80,6 86,2 67,0 25,5 23,6 23,3 45,8 45,4 36,9
GMM(d)a2 - - - 29,4 25,4 24,9 49,0 48,4 41,5
GMM(d)b1 85,0 88,2 73,7 25,4 23,2 23,8 46,0 43,2 37,6
GMM(d)b2 92,0 97,1 82,5 28,4 25,5 25,6 48,6 44,9 40,3
GMM(d)c1 86,2 86,1 71,5 25,5 22,5 23,7 46,2 43,2 37,4
GMM(d)c2 88,3 89,9 76,5 28,6 25,6 25,8 48,8 45,4 41,7
SysGMMa1 76,9 78,4 80,4 27,1 28,3 28,1 67,5 73,5 61,7
SysGMMa2 - - - 26,6 28,6 26,0 63,0 65,0 53,5
SysGMMb1 92,3 95,3 99,6 26,9 32,0 33,9 54,7 67,6 48,1
SysGMMb2 91,0 95,1 97,7 26,0 32,8 28,4 48,9 55,8 39,5
SysGMMc1 86,1 89,3 93,6 26,7 30,0 31,7 61,2 71,1 54,3
SysGMMc2 - - - 25,9 30,5 27,5 54,1 58,5 43,2
Stacked1 88,3 89,5 77,5 31,2 26,2 28,1 47,4 44,1 38,0
Stacked2 98,4 99,2 86,4 34,6 30,5 29,8 47,5 44,5 37,6
AH(l) 92,4 98,5 78,8 460,2 189,1 585,1 57,9 87,0 40,0
AH(d) 645,5 92,8 389,7 32,4 25,8 27,4 51,0 44,3 40,1

71
Tabel 27: RMSE γ (Islam (2000) populatiewaarden) T=9
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 76,3 76,7 75,9 64,9 71,6 71,7 71,3 71,1 70,0
LSDV 3,2 2,9 3,4 4,3 4,1 4,1 3,8 3,9 5,1
GMM(d)a1 3,5 3,5 3,8 3,3 4,2 3,1 2,9 5,0 3,5
GMM(d)a2 - - - 3,8 4,8 3,4 3,2 5,7 4,0
GMM(d)b1 4,5 4,9 5,0 6,4 10,3 6,0 4,5 11,1 5,8
GMM(d)b2 4,7 5,0 5,2 7,1 11,5 6,6 5,0 12,5 6,2
GMM(d)c1 3,9 4,0 4,3 4,3 7,4 4,3 3,6 8,6 4,7
GMM(d)c2 4,2 4,3 4,5 5,1 8,6 4,8 4,0 9,7 5,5
SysGMMa1 22,0 21,7 21,3 4,5 10,9 11,2 18,8 18,4 18,3
SysGMMa2 - - - 5,6 11,2 11,7 18,7 18,1 18,3
SysGMMb1 13,3 12,8 12,2 3,6 7,1 7,3 14,6 14,7 14,1
SysGMMb2 13,2 12,8 12,1 5,2 8,4 9,0 14,7 14,6 14,3
SysGMMc1 16,6 16,3 15,6 3,8 8,7 9,0 16,5 16,3 15,8
SysGMMc2 - - - 5,2 9,3 10,2 16,4 15,9 15,7
Stacked1 7,8 8,6 8,9 26,9 23,5 19,7 6,8 12,4 9,9
Stacked2 9,2 10,1 10,6 27,7 26,3 21,9 6,8 13,3 8,9
AH(l) 8,6 9,3 9,7 94,8 76,5 93,4 8,7 13,4 13,0
AH(d) 8,4 8,5 9,7 7,3 11,4 7,0 5,9 16,5 7,8
Tabel 28: RMSE vertekening κ (Islam (2000) populatiewaarden) T=9
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 72,8 67,3 71,6 60,8 32,8 31,9 39,6 40,6 45,7
LSDV 21,5 24,2 24,7 11,5 12,0 11,8 10,8 11,9 11,7
GMM(d)a1 29,4 30,4 31,5 16,1 17,9 18,9 15,7 16,8 16,7
GMM(d)a2 - - - 18,9 19,5 20,2 17,6 18,6 19,3
GMM(d)b1 31,1 30,8 33,8 16,6 17,7 19,3 16,0 16,7 17,3
GMM(d)b2 33,2 34,8 36,9 18,0 19,3 20,7 17,1 17,8 18,8
GMM(d)c1 31,0 30,3 33,1 16,3 17,4 19,4 15,9 16,3 17,1
GMM(d)c2 32,3 32,5 34,7 18,4 19,6 20,8 17,2 18,0 19,5
SysGMMa1 133,4 134,1 136,9 85,0 51,8 50,0 22,5 24,2 24,3
SysGMMa2 - - - 78,2 47,1 44,5 21,5 23,6 22,4
SysGMMb1 179,8 180,1 184,5 90,6 74,4 73,1 44,7 43,8 46,8
SysGMMb2 176,7 177,0 181,7 80,0 62,5 57,5 39,6 40,4 40,6
SysGMMc1 161,2 161,4 165,4 89,4 64,9 62,7 34,2 35,2 37,5
SysGMMc2 - - - 80,1 56,8 52,0 31,0 33,4 33,6
Stacked1 33,9 33,5 39,9 24,3 20,9 22,9 16,4 17,1 18,0
Stacked2 37,6 37,0 44,1 24,1 22,6 23,8 16,7 17,1 17,9
AH(l) 35,3 36,1 41,3 60,5 49,4 55,4 17,0 17,2 18,5
AH(d) 36,4 37,3 44,3 19,2 19,4 21,7 16,7 17,5 18,2

72
Tabel 29: RMSE γ (LSDV populatiewaarden) T=6
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 70,1 69,5 71,7 72,1 71,8 72,9 77,4 76,7 77,1
LSDV 6,8 8,1 5,3 10,2 11,4 7,2 8,7 9,6 5,9
GMM(d)a1 7,4 7,2 6,2 7,4 7,4 6,1 4,8 4,8 4,3
GMM(d)a2 7,5 7,6 6,6 8,2 8,0 6,5 5,2 5,3 4,6
GMM(d)b1 7,8 8,8 6,9 12,2 14,6 8,1 7,3 10,7 5,9
GMM(d)b2 8,8 8,9 7,4 13,0 15,4 8,4 7,6 10,9 6,1
GMM(d)c1 7,4 7,0 6,3 8,3 8,7 6,5 5,6 6,3 4,6
GMM(d)c2 7,7 7,5 6,6 9,2 9,4 7,0 5,9 6,7 4,9
SysGMMa1 12,6 14,7 14,4 48,4 47,7 44,9 28,5 26,7 24,6
SysGMMa2 12,3 14,2 13,5 47,0 46,4 43,6 29,2 28,6 25,8
SysGMMb1 10,9 11,6 11,9 44,7 43,4 41,5 25,7 23,2 21,8
SysGMMb2 10,2 10,8 10,9 42,4 40,6 39,7 26,3 24,6 23,4
SysGMMc1 11,9 13,5 13,6 47,5 46,6 44,1 27,8 25,8 23,8
SysGMMc2 11,5 13,0 12,8 45,6 45,0 42,6 28,4 27,7 25,0
Stacked1 16,9 18,3 15,1 59,8 56,1 44,3 38,1 38,7 33,0
Stacked2 19,0 21,0 15,4 65,8 59,2 47,9 45,8 49,4 31,9
AH(l) 17,9 18,9 42,2 472,9 539,2 554,9 652,0 263,4 720,2
AH(d) 16,7 24,5 11,1 14,8 22,4 9,9 8,2 18,5 7,2
Tabel 30: RMSE κ (LSDV populatiewaarden) T=6
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 37,2 36,2 37,1 36,5 36,3 32,7 84,5 90,2 86,1
LSDV 35,5 35,6 27,9 26,2 25,9 21,0 28,0 25,7 22,0
GMM(d)a1 45,1 49,4 34,0 33,1 34,8 27,8 36,1 36,8 30,5
GMM(d)a2 47,3 53,0 37,6 35,2 35,7 28,7 36,4 38,7 31,1
GMM(d)b1 45,2 50,2 34,3 33,7 35,8 28,6 36,2 37,5 30,8
GMM(d)b2 48,7 54,4 38,7 35,9 36,9 28,8 37,0 38,3 30,6
GMM(d)c1 44,9 49,7 34,1 33,1 35,0 28,1 36,2 37,1 30,5
GMM(d)c2 48,0 53,1 37,8 35,5 36,1 29,1 36,7 38,5 30,7
SysGMMa1 100,9 100,9 95,7 77,5 73,9 64,4 72,6 74,5 84,8
SysGMMa2 90,1 89,8 84,0 72,9 67,5 56,6 61,7 63,4 65,8
SysGMMb1 110,4 111,1 105,7 65,9 59,6 56,1 78,7 88,0 100,4
SysGMMb2 91,0 91,0 87,1 57,9 48,4 45,8 61,5 69,5 74,4
SysGMMc1 103,8 104,4 98,7 74,6 70,2 62,2 73,4 78,0 89,1
SysGMMc2 90,8 90,1 85,5 68,1 63,0 53,1 61,1 63,7 67,9
Stacked1 46,5 50,5 34,9 42,1 45,1 33,9 40,7 37,5 33,4
Stacked2 49,4 55,5 37,7 43,9 48,5 33,9 41,8 38,5 33,4
AH(l) 48,2 52,0 54,9 339,6 518,5 250,7 237,0 91,6 368,0
AH(d) 52,0 58,6 36,9 39,1 46,3 33,5 40,9 44,8 33,6

73
Tabel 31: RMSE γ (LSDVcor populatiewaarden) T=6
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 75,3 75,9 76,2 77,2 77,1 77,8 83,4 83,2 83,3
LSDV 19,3 15,4 15,0 16,2 16,9 11,8 17,8 18,1 12,5
GMM(d)a1 15,6 21,1 13,0 9,8 10,0 7,6 8,9 8,4 7,0
GMM(d)a2 15,3 23,3 13,9 11,0 11,0 8,1 9,8 9,7 7,6
GMM(d)b1 18,1 25,5 15,7 17,9 20,3 11,2 15,2 17,1 11,2
GMM(d)b2 18,8 28,3 16,5 19,4 21,9 11,6 15,6 18,1 11,8
GMM(d)c1 16,0 22,3 13,6 11,6 11,8 8,5 10,8 10,0 7,9
GMM(d)c2 15,9 24,8 14,3 13,4 13,1 9,1 11,7 10,7 8,4
SysGMMa1 9,5 10,3 8,2 23,8 22,7 17,4 12,9 12,2 7,6
SysGMMa2 9,8 10,2 7,9 23,1 21,6 17,6 12,9 12,6 8,8
SysGMMb1 9,7 9,7 8,5 20,9 19,6 14,6 11,3 10,6 6,3
SysGMMb2 10,1 9,6 7,8 20,1 18,5 15,4 11,5 11,1 7,8
SysGMMc1 9,5 10,0 8,3 23,0 21,7 16,6 12,5 11,7 7,1
SysGMMc2 10,0 10,0 7,9 22,1 20,7 17,0 12,5 12,1 8,4
Stacked1 25,2 29,0 25,0 69,7 63,2 46,3 49,5 53,9 40,1
Stacked2 26,9 29,4 23,9 74,9 67,1 50,8 57,0 63,9 44,5
AH(l) 28,8 45,6 25,8 815,0 1022,1 450,5 5632,8 767,0 460,1
AH(d) 66,9 57,1 35,6 22,1 29,0 13,7 16,4 27,7 12,7
Tabel 32: RMSE κ (LSDVcor populatiewaarden) T=6
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 32,0 30,0 30,4 29,7 29,4 27,0 58,5 62,1 58,8
LSDV 71,2 72,4 54,4 31,2 31,0 24,2 33,4 31,7 25,6
GMM(d)a1 85,9 76,7 65,5 37,6 39,1 31,0 42,6 42,0 36,1
GMM(d)a2 89,7 77,9 69,2 40,0 39,9 32,0 42,8 44,5 37,1
GMM(d)b1 86,2 74,8 66,0 39,0 40,7 32,2 42,8 43,2 36,8
GMM(d)b2 93,2 76,8 70,2 41,5 42,0 32,5 43,4 44,1 37,2
GMM(d)c1 85,5 76,4 65,8 37,7 39,3 31,5 42,9 42,1 36,2
GMM(d)c2 91,0 78,7 69,8 40,4 40,2 32,6 43,5 44,0 36,9
SysGMMa1 69,6 72,5 71,1 57,9 51,9 46,5 60,6 65,0 87,0
SysGMMa2 64,6 67,1 62,6 55,3 46,5 39,4 51,7 54,2 59,6
SysGMMb1 72,8 78,9 76,7 51,0 45,8 52,0 62,0 68,5 98,6
SysGMMb2 66,5 70,6 64,1 48,0 42,9 41,0 52,4 55,8 65,5
SysGMMc1 70,8 74,5 72,9 55,8 49,8 48,0 61,0 66,5 91,4
SysGMMc2 65,2 68,4 63,2 52,4 45,6 39,6 51,7 54,5 61,6
Stacked1 89,2 76,3 66,5 59,6 56,7 36,5 51,4 45,2 41,1
Stacked2 93,0 83,7 73,7 64,1 57,9 36,9 53,1 49,0 42,6
AH(l) 93,9 82,2 69,1 442,6 1107,8 297,8 3998,5 287,6 197,0
AH(d) 111,8 84,6 76,9 45,2 52,2 38,2 48,7 52,8 39,5

74
Tabel 33: RMSE γ (Islam (2000) populatiewaarden) T=6
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 31,0 30,7 31,7 31,4 37,2 36,8 34,8 34,5 33,0
LSDV 0,1 0,1 0,1 0,4 0,4 0,4 0,3 0,3 0,5
GMM(d)a1 0,1 0,1 0,2 0,2 0,4 0,2 0,1 0,4 0,3
GMM(d)a2 0,1 0,1 0,2 0,3 0,5 0,3 0,2 0,4 0,3
GMM(d)b1 0,1 0,1 0,2 0,5 0,8 0,4 0,2 1,0 0,5
GMM(d)b2 0,1 0,2 0,2 0,5 0,9 0,5 0,2 1,0 0,6
GMM(d)c1 0,1 0,1 0,2 0,3 0,5 0,3 0,2 0,5 0,3
GMM(d)c2 0,1 0,1 0,2 0,3 0,5 0,3 0,2 0,5 0,4
SysGMMa1 0,4 0,4 0,4 0,1 0,6 0,5 1,4 1,3 1,4
SysGMMa2 0,3 0,4 0,3 0,4 0,9 0,8 1,6 1,3 1,7
SysGMMb1 0,4 0,3 0,3 0,1 0,4 0,3 1,0 0,9 1,0
SysGMMb2 0,3 0,2 0,2 0,4 0,7 0,7 1,2 1,1 1,4
SysGMMc1 0,4 0,4 0,4 0,1 0,5 0,4 1,3 1,1 1,3
SysGMMc2 0,3 0,3 0,3 0,4 0,8 0,8 1,5 1,2 1,6
Stacked1 0,3 0,3 0,5 2,1 2,8 2,6 1,2 1,3 1,6
Stacked2 0,4 0,4 0,5 2,6 3,1 2,5 1,1 1,3 1,7
AH(l) 0,4 0,4 0,6 4,3 6,7 4,6 1,7 2,3 2,0
AH(d) 0,5 0,4 0,6 0,5 0,8 0,5 0,2 1,0 0,6
Tabel 34: RMSE κ (Islam (2000) populatiewaarden) T=6
OECD INTER NONOIL
SU MA(1) AR(1) SU MA(1) AR(1) SU MA(1) AR(1)
OLS 112,0 112,5 107,0 69,8 46,1 47,8 63,1 64,6 70,8
LSDV 41,0 42,5 45,7 15,7 18,1 16,5 14,1 15,7 16,1
GMM(d)a1 52,2 51,0 54,1 18,6 21,8 19,8 20,3 21,9 23,7
GMM(d)a2 55,9 56,3 60,2 19,7 22,7 20,3 20,6 23,5 24,8
GMM(d)b1 52,6 50,6 54,2 19,3 22,2 21,1 20,4 24,2 24,0
GMM(d)b2 57,0 55,7 60,0 20,0 22,9 21,6 20,8 24,1 24,6
GMM(d)c1 52,1 51,2 54,0 18,7 21,8 20,4 20,5 22,4 23,9
GMM(d)c2 56,1 57,3 60,1 19,7 22,4 21,1 20,8 23,6 24,7
SysGMMa1 228,2 229,3 222,7 93,0 69,5 74,1 55,7 60,1 56,8
SysGMMa2 208,2 210,3 200,6 76,6 55,8 55,8 47,1 54,8 47,9
SysGMMb1 240,4 242,2 237,1 94,6 79,9 85,1 67,6 69,7 67,4
SysGMMb2 209,0 211,4 203,1 76,8 60,7 59,7 54,8 61,7 54,6
SysGMMc1 232,0 233,5 227,1 94,3 73,3 78,2 59,6 63,3 60,6
SysGMMc2 208,6 210,4 201,2 77,1 57,6 57,2 49,6 56,9 49,9
Stacked1 52,4 51,0 54,9 22,7 25,8 25,8 23,0 22,1 25,6
Stacked2 55,5 56,4 60,2 23,5 25,9 25,6 22,5 21,9 26,4
AH(l) 54,1 51,0 55,7 27,5 32,1 29,9 23,6 23,8 26,0
AH(d) 59,3 54,2 59,3 20,9 24,4 23,5 23,1 24,5 25,6

75
D Schattingsresultaten standaard en uitgebreid Solow model
Tabel 35: Schattingsresultaten standaard Solow model

76
Tabel 36: Schattingsresultaten uitgebreid Solow model

77
E Figuren
Figuur 1: Scatter plot: groei inkomen per capita (1960-2000) - Per capita inkomen (1960) (NONOIL)
0
1
2
3
4
5
6
7
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 1,1
Per capita inkomen relatief tov Zwitserland (1960)
Ge
mid
de
lde
ja
arl
ijk
se
gro
ei in
in
ko
me
n p
er
ca
pit
a (
19
60
-20
00
)
Figuur 2: Scatter plot: investeringsratio - per capita inkomen(1960) (NONOIL)
0
0,05
0,1
0,15
0,2
0,25
0,3
0,35
0,4
0,45
0 0,2 0,4 0,6 0,8 1 1,2
Per capita inkomen relatief tov Zwitserland (1960)
Aa
nd
ee
l v
an
in
ve
str
ing
en
in
GD
P

78
Figuur 3: Evolutie dispersie GDP per capita
0
0,1
0,2
0,3
0,4
0,5
0,6
1960 1965 1970 1975 1980 1985 1990 1995 2000
Sig
ma
lo
g(G
DP
pe
r c
ap
ita
)
OECD INTER NONOIL
Figuur 4: Scatter plot: ln(A0) – ln(H)
5
6
7
8
9
10
11
-0,5 0 0,5 1 1,5 2 2,5 3
ln(H)
ln(A
0)

79





























