Embed Size (px)
Citation preview

Information Sciences 180 (2010) 3546–3561
Contents lists available at ScienceDirect
Information Sciences
journal homepage: www.elsevier .com/locate / ins
Distributed recommender for peer-to-peer knowledge sharing
Lu Zhen a,*, Zuhua Jiang a, Haitao Song b
a Department of Industrial Engineering, Shanghai Jiao Tong University, Shanghai, PR Chinab State Nuclear Power Engineering Corp., Ltd., Shanghai, PR China
a r t i c l e i n f o a b s t r a c t
Article history:Received 25 August 2009Received in revised form 13 May 2010Accepted 27 May 2010
Keywords:Knowledge managementKnowledge sharingRecommender systemsPeer-to-peerCollaborative filtering
0020-0255/$ - see front matter � 2010 Elsevier Incdoi:10.1016/j.ins.2010.05.036
* Corresponding author.E-mail address: [email protected] (L. Zhen).
A novel model of distributed knowledge recommender system is proposed to facilitateknowledge sharing among collaborative team members. Different from traditional recom-mender systems in the client–server architecture, our model is oriented to the peer-to-peer(P2P) environment without the centralized control. Among the P2P network of collabora-tive team members, each peer is deployed with one distributed knowledge recommender,which can supply proper knowledge resources to peers who may need them. This paperinvestigates the key techniques for implementing the distributed knowledge recommendermodel. Moreover, a series of simulation-based experiments are conducted by using thedata from a real-world collaborative team in an enterprise. The experimental results vali-date the efficiency of the proposed model. This research paves the way for developing plat-forms that can share and manage large-scale distributed knowledge resources. This studyalso provides a new framework for simulating and studying individual or organizationalbehaviors of knowledge sharing in a collaborative team.
� 2010 Elsevier Inc. All rights reserved.
1. Introduction
In a collaborative team, members constitute a community network. Each member is one node within the network. Knowl-edge is shared among members, just like knowledge flows within the community network. According to the architecture ofthe network, there are two modes of knowledge sharing: (a) Client–Server (C/S) based knowledge sharing, and (b) peer-to-peer (P2P) based knowledge sharing.
1.1. Client–Server based knowledge sharing
Client–Server (C/S) architecture based knowledge repository mode is the simplest way for knowledge sharing. All theknowledge resources are accumulated and stored in some centralized knowledge servers. Users can query and utilizeknowledge under some sort of centralized control. The centralized repositories facilitate the knowledge sharing and reus-ing among members. Furthermore, some intelligent modules in the centralized knowledge servers (e.g., recommenderagents) can proactively distribute knowledge to users according to their demands for knowledge [32]. It promotes the effi-ciency of knowledge sharing in an organization. This on-demand centralized knowledge distribution is an advanced modefor C/S based knowledge sharing [12]. The merits of the centralized knowledge sharing mode lie in: the high security forknowledge assets and intelligent capital in an organization; the easy management of knowledge resources in the uniformoperation and format; and the control of users’ access to knowledge resources. However, the limitations of the centralizedmode are also obvious:
. All rights reserved.

L. Zhen et al. / Information Sciences 180 (2010) 3546–3561 3547
(1) The C/S structured knowledge repository or the centralized knowledge distribution method is not suitable for theautonomous characteristics of knowledge sharing in a collaborative team [8]. For example, some members may notbe willing to store their knowledge in the centralized servers. In addition, they may not frequently update their knowl-edge or upload new knowledge in the centralized servers, which will reduce the effectiveness and efficiency of knowl-edge sharing. So each member should have their own knowledge bases to store and manage their own knowledgeresources.
(2) The business environment in an organization is not static. Both the team members’ knowledge demands and theteam’s organization structure are dynamically changing. The static knowledge sharing mode cannot automaticallychange the knowledge distribution routes among the team members. Thus the C/S mode is not adaptive to thedynamic characteristics of the knowledge sharing [11]. In addition, for the C/S structured knowledge repository mode,the potential risk of server crash also needs to be considered.
Therefore, how to solve the above autonomous and dynamic issues in knowledge sharing requires further researches. Itbrings out the P2P based knowledge sharing.
1.2. Peer-to-peer based knowledge sharing
The peer-to-peer (P2P) architecture is a network for data exchange among a large number of nodes. It can also beemployed as a basis for autonomous knowledge sharing in a collaborative team. In a P2P based knowledge sharing network,each member maintains their own knowledge repositories, from which the newly obtained knowledge can be shared withtheir colleagues in time. Moreover, the robust architecture of P2P can avoid sudden halt of resource accessing caused byserver crash.
For the P2P architecture, its excellent prospects in the applications on knowledge sharing are forecasted, and it has beendominating the C/S architecture. However, an increasing number of P2P users and knowledge resources incur a serious com-plexity for users querying and selecting their desired knowledge. For example, the most of P2P applications for knowledgesharing are that users input keywords and search their desired knowledge. It is usually a tedious work for users to browseand find out their really desired knowledge among numerous items provided by knowledge query systems. Moreover, forsome knowledge-intensive works, users may not exactly know or clearly describe what knowledge they need. To overcomethese difficulties, the P2P based knowledge sharing network should offer an intelligent capability (or function) that can pro-vide users with more convenient knowledge acquiring experiences. Knowledge recommenders under the P2P architecturewill be one of the solutions for the above target. To the best of our knowledge, few scholars have specially studied P2P basedknowledge recommenders for knowledge sharing in the collaborative team environment. This paper makes an exploratorystudy in this field, and investigates the key technical issues in designing and implementing a P2P based knowledge recom-mender. A series of simulation-based experiments are conducted to validate the efficiency of the proposed model.
2. P2P knowledge sharing based on distributed recommenders
From the view of knowledge flow among members, the P2P based knowledge sharing mode is a complex network topol-ogy, which is shown Fig. 1(2). Knowledge flows from one peer to others. Collaborative team members usually come fromdiverse disciplines, each with particular expertise and contribution in their relevant domains. Their demands for knowledgeare also different from each other. In order to deliver the right reference knowledge to the right members, we need develop adistributed knowledge recommender system to facilitate collaboration in knowledge sharing. With the distributed
Fig. 1. Two types of knowledge sharing.

3548 L. Zhen et al. / Information Sciences 180 (2010) 3546–3561
knowledge recommender engine equipped in each peer, proper knowledge resources could flow from the right source peersto the peers who need them.
An example of the P2P based knowledge sharing among collaborative team members is illustrated in Fig. 1(2). In thisexample, the team consists of eight members (peers). The lines with arrows represent knowledge flow among them. Somelines with two arrows on sides denote bidirectional knowledge flows. From the view of one peer (e.g., peer h), there are twopeer sets: source peers set and destination peers set. As the bidirectional flows exist, one peer can be both the source peerand the destination peer, such as the peer k in the example. By using the distributed knowledge recommender, the peer hobtains knowledge delivered from the peers f, c and k. After some certain processing or decision making, knowledge is deliv-ered to its destination peers, i.e., the peers a, b, and k.
In the above process, new knowledge resources may be produced by peers, and also be shared with their destinationpeers. Knowledge that flows out from one peer may be more abundant than the input. The total amount of knowledge flow-ing among all peers is not a constant, but is increasing all the time.
3. Distributed recommender in each peer
3.1. Distributed recommender model
The distributed recommender equipped in each peer is the core agent in the P2P based knowledge sharing mode. The dis-tributed recommender receives knowledge supplied from the source peers, and delivers knowledge to the destination peersafter some certain processing or decision making. These distributed recommenders are like ‘motors’ that drive the ‘knowl-edge transmission belt’ among the peers in a collaborative team. According to the above considerations, we propose the dis-tributed knowledge recommender model for the P2P environment. The architecture of the model is illustrated in Fig. 2.
The distributed knowledge recommender model mainly has six types of modules:
� Knowledge interfaces: The interfaces for delivering (or receiving) knowledge resources to (or from) other peers. They con-sist of two modules:– Knowledge fetcher: It fetches the knowledge resources from its source peers’ shared files. It is triggered by messages
from source peers that have some newly updated knowledge in their shared files. After fetching the knowledge fromits source peers, it filters out duplicated knowledge resources before recommending the received knowledge to theuser.
– Shared file: It stores the knowledge resources which will be fetched by its destination peers. When it has some newlyupdated knowledge resources, some messages will be sent to its destination peers and inform them to fetch theknowledge in the shared file.
Fig. 2. The distributed knowledge recommender model.

L. Zhen et al. / Information Sciences 180 (2010) 3546–3561 3549
� Profile information interfaces: The interfaces for communicating profile information with other peers. The profile informa-tion reflects the peer’s interest. They consist of two modules:– Profile fetcher: It fetches the profile information of other peers, so as to calculate the similarity with others and find
similar peers as its source peers.– Profile information file: It is the reflection of the peer’s favorite knowledge folder, and describes the peer’s interest in
multi-feature expressions way. The details are elaborated in Section 4.1.� Message interfaces: The interfaces for communicating messages with other peers, so as to trigger actions of knowledge
recommendation among peers. They consist of two modules:– Message receiver: It receives some messages from other peers and triggers corresponding reactions.– Message sender: It sends some messages to other peers for communication.� Data tables of peer sets: The data tables store the host peer’s source peers set and destination peers set. They consist of two
parts:– Source peers set table: It stores the source peers’ information that includes the peers’ names, addresses, and the sim-
ilarity values with the host peer.– Destination peer set table: It stores the information of the destination peers, which have selected the host peer as their
source peers.� Favorite knowledge folder: It preserves the favorite knowledge resources saved by the peer’s user. After a filtering pro-
cedure, the recommended knowledge from others will be browsed by the user, who will decide and save some poten-tially useful knowledge into this folder. It is connected with the profile information, which describes the peers’interest.� Source peers management module: It constructs the source peers set by selecting neighbor peers that are similar with the
peer, which is based on calculating similarity values between peers. Moreover, this module also re-formulates its sourcepeers set. Because the similarity values between peers are changing all the time, it needs to update its source peers set. Itshould guarantee that the peer connects with the top M most similar source peers at any time. Here M is the size of sourcepeers set.
3.2. The main flowchart
This section elaborates how the distributed knowledge recommender works in each peer. The overall procedure is shownin Fig. 2:
Step 1: The message receiver gets message from one of its source peers (e.g., peer m), who informs that new knowledgehas been ready. Then, the message receiver triggers the knowledge fetcher to get the knowledge from the shared file inthe peer m.Step 2: The knowledge fetcher gets all the knowledge resources in the shared file of the peer m, and stores them in a tem-porary queue. When the queue accumulates to a certain length (queue length, Q), the top-k correlative knowledgeresources are selected and recommended to the user. Here, k and Q are two parameters, and k < Q.Step 3: Among the recommended knowledge resources in the above step, some of them may already exist in the peer’sfavorite knowledge folder, which means these resources have ever been browsed by the user. Hence these duplicatedknowledge resources are filtered out.Step 4: The user browses the recommended knowledge resources, and some potentially useful knowledge will be savedinto the peer’s favorite knowledge folder, and also be saved into the shared file for its destination peers. It should be men-tioned that the user can also ‘invent’ and input new knowledge into the favorite knowledge folder. These newly inputknowledge resources may be self-invented or gotten from other channels. Any changes in the favorite knowledge folderwill trigger the following steps 5–7.Step 5: The resources changes (e.g., new items are added or removed) in peer’s favorite knowledge folder, will update theprofile information, which is the basis for calculating similarity among peers.Step 6: The message sender tells its destination peers that there are new knowledge resources updated in the shared file,and informs them to fetch the new knowledge.Step 7: The source peer management module is triggered to re-formulate the source peers set because the similarityamong peers may change. It should guarantee that the peer is connected with the top M most similar source peers allthe time (M: the size of source peers set). It has four sub-steps:Sub-step 7.1: The source peer management module determines the neighborhood search space, and the profile fetchergets the profile information of the peers in the search space.Sub-step 7.2: The module compares the host peer’s profile with the peers that are obtained in the above step, and thenselects the top M most similar peers as its source peers.Sub-step 7.3: The module writes these M similar peers into the source peers set.Sub-step 7.4: The message sender informs the above M peers, and asks them to involve the peer into their destinationpeers sets.

3550 L. Zhen et al. / Information Sciences 180 (2010) 3546–3561
4. The similarity measure between peers
How to define and calculate the similarity between two peers is crucial for implementing the distributed recommendermodel. The calculation of the similarity between two peers is based on the similarity of knowledge resources in the twopeers’ profile information. Thus how to define and represent a peer’s profile information is the first issue.
4.1. Profile information: multi-feature representation of knowledge resources
The profile information is a reflection of the knowledge resources stored in a peer’s favorite folder. In this study, we usethe multi-feature representation to model the profile information. More specifically, a knowledge resource can be describedas a set of features or attributes, fa1; a2; . . . ; aMg. Each feature, aij8i 2 f1; . . . ;Mg, may take on one out of a finite set of options,A�i � fa�i1; a�i2; . . . ; a�ini
g. That is, ai ¼:: a�ijj9a�ij 2 A�i , where j ¼ 1; . . . ;ni, denotes the jth option of ai.We define a peer’s profile as a set, P � fk1; k2; . . . ; kSg, where S denotes the total number of knowledge resources in the
peer’s favorite folder. As to one item in the above set, ks 2 pj9s 2 f1; . . . ; Sg, it can be described by a vector of certain optionsof these features. For example, a�s � fa�14; a
�21; . . . ; a�M3g, where a�14 refers to the fourth option of the feature a1 as described to
the knowledge resource ks, a�21 the first option of the feature a2, a�M3 and the third option of the feature aM . Hence the peer’sprofile is denoted by P � fk1; k2; . . . ; kSg � fa�1; a�2; . . . ; a�Sg.
4.2. Calculating similarity between different peers
By traversing all the elements in the profile information of two peers (e.g., h and n), the similarity between two knowl-edge resources are calculated one by one. Then the average value of the above results is obtained to measure the similaritybetween the two peers h and n:
SimNodeðh;nÞ ¼
Pa�
i2Fh ;a
�j2Fn
KSimða�i ; a�j Þ
jFhj � jFnj
where Fh denotes the profile information file in the peer h; Fn denotes the profile information file in the peer n; jFhj is thenumber of elements in the peer h’s profile information file; jFnj is the number of elements in the peer n’s profile informationfile. For how to calculate the similarity between two knowledge resources ðKSimða�i ; a�j ÞÞ, the details are given in the Appen-dix A of this paper.
5. Source peers set management
How to find source peers, and maintain the source peers set is another key issue for implementing the distributed rec-ommender system under the P2P architecture. The source peers set management module supports the above target, andhas two functions: (1) the initialization of source peers set; (2) the re-formulation of source peers set. The host peer’s sourcepeers set should contain the peers that have the similar profile information with the host peer. A peer cannot receive knowl-edge recommended from all other peers, otherwise it will incur information overload. Thus there should be a module tomanage the source peers set.
5.1. Initialization of source peers set
When a new peer joins into the collaborative team’s knowledge sharing network, its source peers set is empty. The sourcepeers set management module selects the top M most similar peers to form its source peers set. Here M is the size of sourcepeers set. There are two strategies to initialize the source peers set.
5.1.1. Global searchIt means searching all other peers so as to select the top M most similar ones as its source peers. For example, in order to
initialize the source peers set of the peer h, it needs to calculate the similarity with all other peers n, SimNode(h,n), which isbased on calculating the similarity of two peers’ profile information. The calculation process may be time-consuming whenthe size of the network is huge.
5.1.2. Local searchIt means just searching some of other peers. As to one peer (e.g., peer h) who has newly joined into the P2P knowledge
sharing network, we initialize the searching space in its similar colleagues, who act the same role or task as the peer h. Forexample, h is a mechanical engineer and does some thermodynamics simulation work, those peers who are also acting asmechanical engineer or doing simulation works will be the candidates for the local search. It should be mentioned thatthe above members-roles-tasks information (e.g., peer h, mechanical engineer, simulation work) is available in the contextof collaborative team.

L. Zhen et al. / Information Sciences 180 (2010) 3546–3561 3551
5.2. Re-formulation of source peers set
The peers’ profile information reflects the characteristics of their favorite knowledge folders, in which the knowledgeresources may be added or removed at any time. Thus the profile information of peers is not fixed invariably, and the similaritybetween peers is dynamically changing all the time, which leads to updating and re-formulating the peer’s source peers set.
The core issue for re-formulating the source peers set is to search other peers again so as to find the top M most similarpeers in current states. The difference from the previously mentioned initialization procedure lies in: the re-formulation is tofind the new source peers set based on the current set.
For example, as to the peer h, the current source peers set is Sh ¼ fsh1; s
h2; . . . ; sh
j ; . . . ; shMg; sh
1 is the most similar peer, sh2 takes
the second place, and so on. M is the size of the source peers set. How to determine the search space for selecting sourcepeers is the key issue. There are some strategies to define the search space:
5.2.1. Equally expandingThe search space is constructed by expanding source peers of the h’s source peers. For example, in Fig. 3(1), for each peer
in the h’s source peers set shj 2 Sh, it extends to its source peers. In the same way, it expands to the level 2, level 3, and level N,
where the N is the fathoming depth in expanding the search space. The max number of peers in the search space is:M þM2 þ � � � þMN , which may contain some duplicated peers.
5.2.2. Unequally expandingThe search space is constructed by expanding source peers with different fathoming depths. The source peers with higher
similarity will be fathomed more deeply. There are plenty of different strategies for the above unequally expanding. Forexample, in Fig. 3(2), when M ¼ 5 and the deepest level N ¼ 5, for the peer sh
1, i.e., the most similar peer, its fathoming depthis 5; sh
2, i.e., the second place, its fathoming depth is 4, and so forth.We omit the duplicated peers in the above expanding process. Then we calculate the host peer h’s similarity with all peers
in the above search space, and select the top M most similar peers to form the new source peers set of peerh : Sh ¼ fsh
1; sh2; . . . ; sh
j ; . . . ; shMg. It should be mentioned that: the larger is the depth N, the better is the calculation result;
whereas it leads to time-consuming calculation. N should be determined according to the capacity of the PC in the peer.
5.3. Algorithm complexity analysis
For the traditional collaborative filtering (CF), its complexity for finding similar peers is OðP � IÞ, here P and I are the num-bers of peers and items, respectively; and its complexity for generating top-k recommendations is OðM � IÞ if only the top M
Fig. 3. Two expanding strategies for re-formulating source peers set.

3552 L. Zhen et al. / Information Sciences 180 (2010) 3546–3561
most similar peers are used. Thus the total complexity for the traditional CF is OðP � I þM � IÞ. If M � P, the complexity canbe regarded as OðP � IÞ.
For the proposed P2P model, there are two stages: the initialization of source peers set (neighbor peers set), and recom-mendation phase.
The initialization phase, as mentioned in Section 5.1, has two alternatives: the global search, its complexity is OðP � IÞ;and the local search, its complexity is OðC � IÞ, here C denotes the number of peers (similar colleagues) who act the samerole or task as the peer. Since C < P, the local search method is utilized in the following simulation experiments in this study.
The recommendation phase, it consists of two steps: generating top-k recommendations and re-formulating the sourcepeers set. The complexity of the former one is OðM � IÞ and the latter one is OðMN � IÞ. Hence the complexity of the recom-mendation phase is OðM � I þMN � IÞ � OðMN � IÞ.
When comparing the traditional CF and the proposed P2P model, their complexities are OðP � IÞ and OðMN � IÞ, where theinitialization phase in the P2P model is ignored. The reason lies in that the initialization only occurs for one time, when a peeris connected into the P2P network; whereas the recommendation phase occurs repeatedly. In each iteration for recommen-dations, there is no need to initialize the source peers set again; we just need to re-formulate the source peers set afterreceiving recommendations from others.
In a large-scale P2P network with very great P value, the proposed P2P model may outperform the traditional CF, if we assignproper values to M (i.e., the size of source peers set) and N (i.e., the fathoming depth) such that MN < P. In the following exper-iments, there are 19 iterations of recommendation phases are performed. The simulation results validate the above analysis.
6. Simulation-based experiments
6.1. Experiment design
We design a series of simulation experiments based on the realistic data from a large state-owned enterprise in China.The experiments use the source data that records 235 engineers’ knowledge browsing tracks in two months (40 workingdays). The enterprise has a normative management for its intellectual property, and holds a knowledge repository systemstoring various types of inner-enterprise knowledge resources. The knowledge repository stores more than 12,548 knowl-edge resources (e.g., patents, manuals, standards, articles). Every engineer queries and browses a lot of knowledge docu-ments each day from their knowledge portals. The data set in the experiments includes 101,617 transaction records thatreflect which knowledge documents has been browsed by which user in which date. All the knowledge resources havethe uniform description formats, i.e., the multi-features. These features include: knowledge type, creator, contributor, crea-tion date, and membership values to some certain domains (e.g., mechanic, mechatronics, electronic, computer aided design,software). That description information for knowledge documents has been maintained and kept integrated when they enterthe repository. The standard representations and management of these knowledge documents are the basis and precondi-tions for our experiments.
The main procedure of the simulation-based experiments is illustrated in Fig. 4.In Fig. 4, we see that the source data set is divided into two parts: a learning set and a testing set. The procedure of the
simulator in the experiments is explained as follows. Each step is marked in Fig. 4:
(1) The first part (the earlier 20 days) of records is used as the learning set to form the initial favorite knowledge folder ofeach peer.
(2) For the initial network topology, it mainly concerns how to determine the source peers set for each peer. We utilize thelocal search strategy (introduced in Section 5.1) based on the members-roles-tasks relevance table that describeswhich member acts as which roles or fulfills which tasks. For each peer, we select the top M most similar ones froma set of peers who act as the same roles or fulfill the same tasks as the peer.
(3) The first day’s data in the testing set, i.e., D_21 the 21th day, is utilized to simulate as the users actions of receivingsome knowledge and saving them into their favorite folders. These knowledge resources will be put in their sharedfiles and be waiting for their destination peers to fetch.
(4) Based on the network topology and the knowledge resources which the peers want to share with their destinationpeers, we could obtain the recommended knowledge resources for each peer. Then, the top k most correlative knowl-edge resources will be selected and recommended to each peer. The correlativeness is measured by the similaritybetween the recommended knowledge resources and the ones in the peer’s favorite folder.
(5) We compare the recommended knowledge resources with the ones that the users actually browse in the next day, i.e.,the D_22’s data from the testing set. And we can obtain the precision and recall values. The calculation of the similaritybetween knowledge resources is elaborated in the Appendix of this paper.
(6) Among the recommended knowledge resources, those with higher similarity are regarded as the knowledge that isaccepted by the user and saved into their favorite folders in this simulation.
(7) Based on the updated favorite knowledge folders of all peers, the simulator re-formulates the network topology again,which means updating source peers sets for all peers. In this process, both equally and unequally expanding strategies(introduced in Section 5.2) are tested.

Fig. 4. The main procedure of the simulation-based experiments.
L. Zhen et al. / Information Sciences 180 (2010) 3546–3561 3553
After the above process, the simulator conducts the next iteration from the D22’s data. In the same way, 19 iterations(from D21 to D39) would be conducted. In each iteration, the result is the average of precision and recall values for all peers.The final results are the average precision and recall values of the above 19 iterations.
6.2. Results and analysis
In the proposed P2P distributed knowledge recommender model and methods, there are some important parameters: (1)the size of source peers set (M), (2) k value in top-k filtering (k), which means the top k most correlative knowledge resourceswill be recommended to each user, (3) expanding strategies in the re-formulation of source peers set, i.e., equal or unequalstrategy, (4) fathoming depth (N) of expanding search space in the re-formulation of source peers set. These parameters havesome impacts on the quality of knowledge recommendation results.
Figs. 5–7 and Tables 1–3 illustrate the results with varying the above parameters. Here, the precision, recall, and responsetime are the performance measures in the experiments:
(1) The precision and recall are derived from the comparison between the recommended knowledge resources and theones in the testing sets. According to the similarity calculation between knowledge resources (introduced in Appen-dix), we regard one recommended knowledge resource (e.g., kr) ‘hits’ the testing set, if there exists another one (e.g.,kt) in the testing set, such that KSimðkr ; ktÞ > 0:9. Here, 0.9 is the threshold value, which can be set and adjusted as aparameter in advance. The precision value is: the number of recommended ones that hit the testing set, divided by thetotal number of recommended ones. The recall value is: the number of recommended ones that hit the testing set,divided by the total number of knowledge resources in the testing set.
(2) Let Ttotal be the time interval of the whole simulation process for handing all the source data. Recall that there are 19iterations and 245 peers, so we utilize ‘Ttotal=ð19� 245Þ’ as the response time measure in the following experiments. Itis an approximate way to reflect each peer’s handing time for an iteration of knowledge recommendation process.
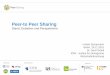
Experiment 1: Performances under different sizes of source peers set and k-values.We conduct the experiments with varying the size of source peers set from 5 to 30 (step by 5), and k-value equals to 4 and
8. For the re-formulation of source peers set, the equal expanding strategy is utilized, and the fathoming depth (N) is 2.From Fig. 5(1) and (2), we can see that the precision and recall values increase with the size of source peers set growing.
And the large k-value ðk ¼ 8Þ outperforms the small one ðk ¼ 4Þ. The higher is the k-value, the more knowledge can be rec-ommended to users, whereas it also increases the response time. From Fig. 5(3), we can see that the large k-value ðk ¼ 8Þleads to longer response time than the small one ðk ¼ 4Þ. With more knowledge recommended (larger k-value), the hit ratio
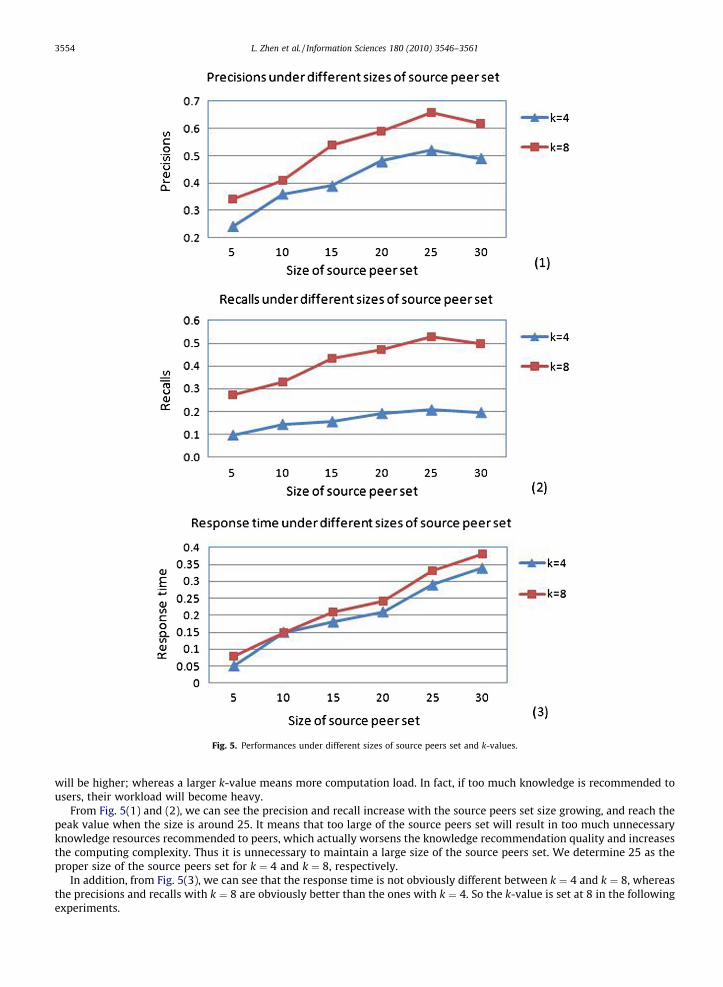
Fig. 5. Performances under different sizes of source peers set and k-values.
3554 L. Zhen et al. / Information Sciences 180 (2010) 3546–3561
will be higher; whereas a larger k-value means more computation load. In fact, if too much knowledge is recommended tousers, their workload will become heavy.
From Fig. 5(1) and (2), we can see the precision and recall increase with the source peers set size growing, and reach thepeak value when the size is around 25. It means that too large of the source peers set will result in too much unnecessaryknowledge resources recommended to peers, which actually worsens the knowledge recommendation quality and increasesthe computing complexity. Thus it is unnecessary to maintain a large size of the source peers set. We determine 25 as theproper size of the source peers set for k ¼ 4 and k ¼ 8, respectively.
In addition, from Fig. 5(3), we can see that the response time is not obviously different between k ¼ 4 and k ¼ 8, whereasthe precisions and recalls with k ¼ 8 are obviously better than the ones with k ¼ 4. So the k-value is set at 8 in the followingexperiments.
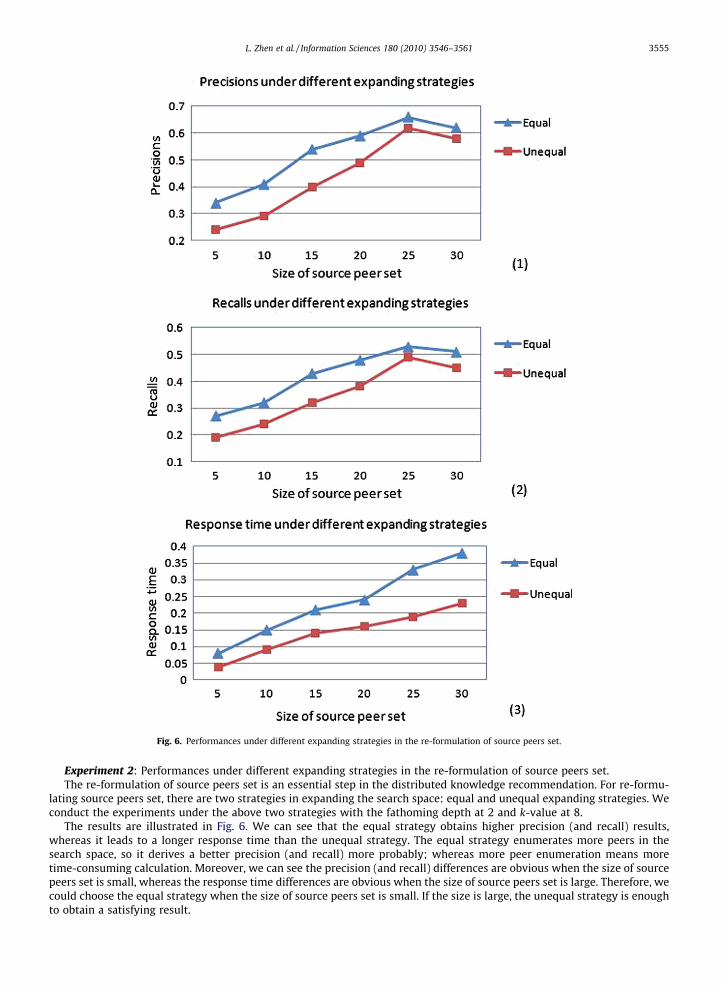
Fig. 6. Performances under different expanding strategies in the re-formulation of source peers set.
L. Zhen et al. / Information Sciences 180 (2010) 3546–3561 3555
Experiment 2: Performances under different expanding strategies in the re-formulation of source peers set.The re-formulation of source peers set is an essential step in the distributed knowledge recommendation. For re-formu-
lating source peers set, there are two strategies in expanding the search space: equal and unequal expanding strategies. Weconduct the experiments under the above two strategies with the fathoming depth at 2 and k-value at 8.
The results are illustrated in Fig. 6. We can see that the equal strategy obtains higher precision (and recall) results,whereas it leads to a longer response time than the unequal strategy. The equal strategy enumerates more peers in thesearch space, so it derives a better precision (and recall) more probably; whereas more peer enumeration means moretime-consuming calculation. Moreover, we can see the precision (and recall) differences are obvious when the size of sourcepeers set is small, whereas the response time differences are obvious when the size of source peers set is large. Therefore, wecould choose the equal strategy when the size of source peers set is small. If the size is large, the unequal strategy is enoughto obtain a satisfying result.
Fig. 7. Impact of peers’ willingness for sharing knowledge.
Table 1The performances under different fathoming depths (N) in source peers set re-formulation.
Precisions Recalls Response time (s)
Equal expanding N ¼ 2 0.34 0.27 0.08N ¼ 3 0.37 0.31 0.45N ¼ 4 0.36 0.28 1.19
Unequal expanding N ¼ 2 0.33 0.27 0.06N ¼ 3 0.35 0.28 0.31N ¼ 4 0.37 0.29 0.76
Notes:(1) The size of source peers set is set at 5;(2) The k is set at 8.
Table 2The comparisons with the traditional content-based filtering method.
P2P method CBF method Improvements (%)
Precisions k ¼ 4 0.52 0.31 67.7k ¼ 8 0.66 0.42 57.1
Recalls k ¼ 4 0.21 0.13 61.5k ¼ 8 0.53 0.34 55.9
Response time k ¼ 4 0.29 s 0.57 s 49.1k ¼ 8 0.33 s 0.62 s 46.8
Notes:(1) CBF is the traditional content-based filtering method;(2) Improvement of precision (or recall) = (P2P CBF)/CBF;(3) Improvement of response time = (CBFP2P)/CBF.
3556 L. Zhen et al. / Information Sciences 180 (2010) 3546–3561
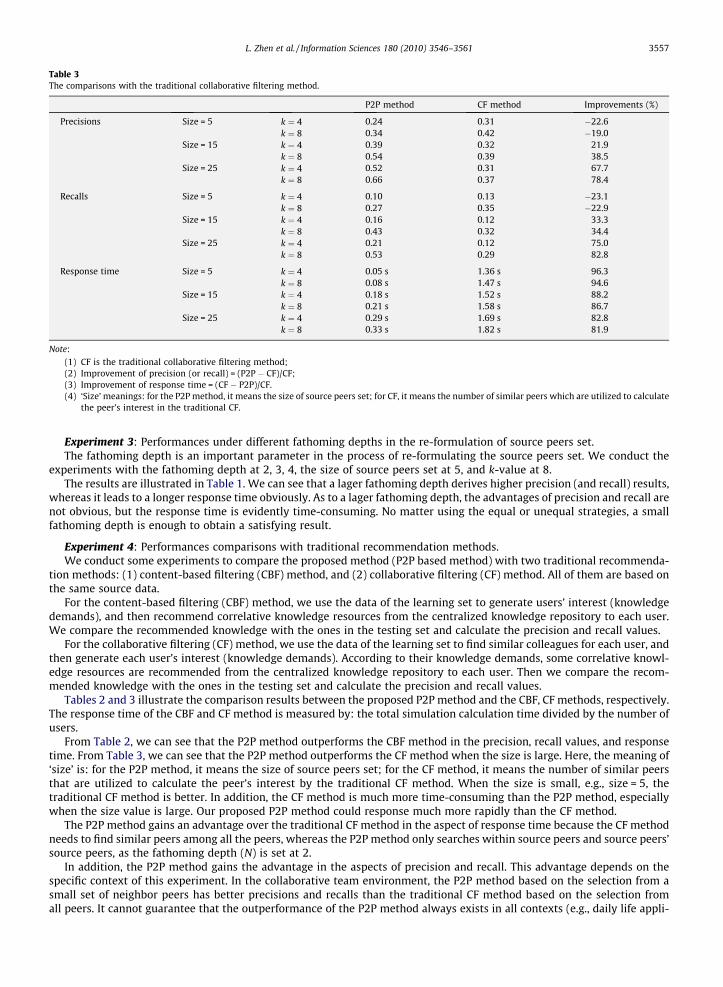
Table 3The comparisons with the traditional collaborative filtering method.
P2P method CF method Improvements (%)
Precisions Size = 5 k ¼ 4 0.24 0.31 22.6k ¼ 8 0.34 0.42 19.0
Size = 15 k ¼ 4 0.39 0.32 21.9k ¼ 8 0.54 0.39 38.5
Size = 25 k ¼ 4 0.52 0.31 67.7k ¼ 8 0.66 0.37 78.4
Recalls Size = 5 k ¼ 4 0.10 0.13 23.1k ¼ 8 0.27 0.35 22.9
Size = 15 k ¼ 4 0.16 0.12 33.3k ¼ 8 0.43 0.32 34.4
Size = 25 k ¼ 4 0.21 0.12 75.0k ¼ 8 0.53 0.29 82.8
Response time Size = 5 k ¼ 4 0.05 s 1.36 s 96.3k ¼ 8 0.08 s 1.47 s 94.6
Size = 15 k ¼ 4 0.18 s 1.52 s 88.2k ¼ 8 0.21 s 1.58 s 86.7
Size = 25 k ¼ 4 0.29 s 1.69 s 82.8k ¼ 8 0.33 s 1.82 s 81.9
Note:(1) CF is the traditional collaborative filtering method;(2) Improvement of precision (or recall) = (P2P CF)/CF;(3) Improvement of response time = (CF P2P)/CF.(4) ‘Size’ meanings: for the P2P method, it means the size of source peers set; for CF, it means the number of similar peers which are utilized to calculate
the peer’s interest in the traditional CF.
L. Zhen et al. / Information Sciences 180 (2010) 3546–3561 3557
Experiment 3: Performances under different fathoming depths in the re-formulation of source peers set.The fathoming depth is an important parameter in the process of re-formulating the source peers set. We conduct the
experiments with the fathoming depth at 2, 3, 4, the size of source peers set at 5, and k-value at 8.The results are illustrated in Table 1. We can see that a lager fathoming depth derives higher precision (and recall) results,
whereas it leads to a longer response time obviously. As to a lager fathoming depth, the advantages of precision and recall arenot obvious, but the response time is evidently time-consuming. No matter using the equal or unequal strategies, a smallfathoming depth is enough to obtain a satisfying result.
Experiment 4: Performances comparisons with traditional recommendation methods.We conduct some experiments to compare the proposed method (P2P based method) with two traditional recommenda-
tion methods: (1) content-based filtering (CBF) method, and (2) collaborative filtering (CF) method. All of them are based onthe same source data.
For the content-based filtering (CBF) method, we use the data of the learning set to generate users’ interest (knowledgedemands), and then recommend correlative knowledge resources from the centralized knowledge repository to each user.We compare the recommended knowledge with the ones in the testing set and calculate the precision and recall values.
For the collaborative filtering (CF) method, we use the data of the learning set to find similar colleagues for each user, andthen generate each user’s interest (knowledge demands). According to their knowledge demands, some correlative knowl-edge resources are recommended from the centralized knowledge repository to each user. Then we compare the recom-mended knowledge with the ones in the testing set and calculate the precision and recall values.
Tables 2 and 3 illustrate the comparison results between the proposed P2P method and the CBF, CF methods, respectively.The response time of the CBF and CF method is measured by: the total simulation calculation time divided by the number ofusers.
From Table 2, we can see that the P2P method outperforms the CBF method in the precision, recall values, and responsetime. From Table 3, we can see that the P2P method outperforms the CF method when the size is large. Here, the meaning of‘size’ is: for the P2P method, it means the size of source peers set; for the CF method, it means the number of similar peersthat are utilized to calculate the peer’s interest by the traditional CF method. When the size is small, e.g., size = 5, thetraditional CF method is better. In addition, the CF method is much more time-consuming than the P2P method, especiallywhen the size value is large. Our proposed P2P method could response much more rapidly than the CF method.
The P2P method gains an advantage over the traditional CF method in the aspect of response time because the CF methodneeds to find similar peers among all the peers, whereas the P2P method only searches within source peers and source peers’source peers, as the fathoming depth (N) is set at 2.
In addition, the P2P method gains the advantage in the aspects of precision and recall. This advantage depends on thespecific context of this experiment. In the collaborative team environment, the P2P method based on the selection from asmall set of neighbor peers has better precisions and recalls than the traditional CF method based on the selection fromall peers. It cannot guarantee that the outperformance of the P2P method always exists in all contexts (e.g., daily life appli-

3558 L. Zhen et al. / Information Sciences 180 (2010) 3546–3561
cation scenarios for recommending music, films, news, etc.). It is impossible to theoretically prove the advantage of P2Pmethod to the traditional CF method; each method has their relative merits in different application contexts.
In this experiment, we compare the proposed method with the traditional CBF and CF methods whose methodologies areuniversally acknowledged. So the traditional CBF and CF methods can be implemented under the context of this study. How-ever, in the fields of distributed recommenders, there is no universally acknowledged methodology. Other scholars proposedtheir models that are usually under specific architectures or application backgrounds. For example, Han et al. used distrib-uted hash table (DHT) [9,29], but it does not apply in this context; Rosaci et al. designed a distributed recommender whosearchitecture is based on community partitions [24]; the PocketLens system by Miller et al. [16] and the Vineyard system byOka et al. [19] run a set of independent recommenders each one dedicated to a specific domain. These distributed recom-menders have specific architectures or modules, and show good performances in their specific application contexts. If wecompare these models with ours, it is necessary to revise them to adapt to the context in this study. The comparison in thisway is unfair. Thus we have not compared our model with these existing distributed recommenders.
Experiment 5: Impact of peers’ willingness for sharing knowledge.The study on the impact of people’s willingness for sharing knowledge usually belongs to the research fields on
organization behavior that usually employ survey-based methods. Here we make an exploratory study on the impact ofpeers’ willingness for sharing knowledge by the means of simulation experiments.
In our proposed model, one peer receives recommended knowledge resources, and some correlative ones may be savedinto the favorite knowledge folder and these knowledge resources are also put into the shared files for the peer’s destinationpeers to fetch. In the above simulation experiments, we define a percentage (p) to denote: p% of the knowledge resourcesreceived in one peer will be delivered to its destination peers. As to the p% choosing process, we assume a random selectionin the simulation. We conduct the experiments with p at 40%, 60%, 80% and 100%. The results are shown in Fig. 7. The resultshows that the higher is the p value, the more precision and recall values will be obtained. This preliminary simulationexplains a simple phenomenon: if members have higher willingness for sharing, the proposed model will be more effectivefor knowledge sharing in a collaborative team.
7. Related works
For knowledge sharing, the agent based technologies and distributed knowledge management (KM) methods were widelyused [10,17,25,27]. In addition, game theory [3], cognitive theory [6], and some social science method [20] were alsoemployed to model knowledge sharing interactions among people. This paper mainly belongs to the area of knowledge shar-ing tools development. Petter summarized 10 types of tools for knowledge sharing [21]. Richards proposed a Wiki-styleknowledge sharing system [23]. Wang et al. developed a P2P knowledge sharing tool that enables members to voluntarilyshare and retrieve knowledge more effectively [28]. Qin et al. studied the query expressions along semantic paths for facil-itating P2P knowledge sharing [22]. Yang and Chen applied social network based system to support knowledge sharing overP2P network [30].
Knowledge recommenders, the theme of this paper, are related to the recommendation technology, which has become apromising and hot area in both academia and industries [1]. Tapestry [7] is one of the earliest recommender systems. In thepast decade, many recommender systems have been developed, e.g., a movie recommender developed by Konstan [15]; abook recommender by Mooney and Roy [18]; a recommender by Chen et al. based on product profitability in e-commerceweb sites for sellers [4]; a one-item recommender by Cornelis et al. based on fuzzy logic techniques [5]; AdROSA system byKazienko and Adamski for automatic web advertising [13]. In addition, the widely used collaborative filtering (CF) methodsare also studied for improving the efficiency of recommender systems. A CF method based on workflow space was proposedin [35]; based on it, a novel recommender is developed [36]. As to the cold-starting issue in CF methods, Ahn presented a newheuristic similarity measure when a small number of ratings are available [2]. Vozalis and Margaritis brought out a new CFmethod to increase accuracy in describing and predicting users’ profiles [26]. For large-scale P2P environment, Han et al. sug-gested a distributed CF algorithm by using DHT technology to construct a scalable distributed recommender system [9,29].Kim et al. proposed an image content recommender in P2P architecture [14]. Rosaci et al. designed a distributed recom-mender whose architecture is based on community partitions [24]. The PocketLens system by Miller et al. [16] and the Vine-yard system by Oka et al. [19] run a set of independent recommenders each one dedicated to a specific domain. As to theknowledge grid environment, some conceptual models of a proactive knowledge recommender system and a reactive knowl-edge query system were proposed in [33,34].
In all, knowledge sharing and recommendation technology are two well researched fields. However, to the best of ourknowledge, few scholars have specially studied P2P based knowledge recommender systems for knowledge sharing, espe-cially for the collaborative team environment. This paper makes an exploratory study in this field, and investigates thekey technical issues in designing and implementing a P2P based knowledge recommenders.
8. Summary
This paper proposes a P2P based recommender system that can supply knowledge to proper members in a collaborativeteam. By comparing with the studies of other scholars, the main contributions are listed as follows:

L. Zhen et al. / Information Sciences 180 (2010) 3546–3561 3559
(1) This paper proposes a comprehensive mechanism for recommending knowledge in the P2P environment. For imple-menting the proposed model, we investigate some key technical issues which include: how to coordinate informationexchanges and knowledge resources delivery among peers; how to measure the similarity between peers; and how tomaintain the source peers sets that are dynamically changing.
(2) The traditional CF method selects neighbors on the basis of users’ rating tables, but it is not applicable for knowledgesharing in a collaborative team. Moreover, the neighbors of peers are dynamically changing. This study proposes twoheuristics, i.e., equally and unequally expanding strategies that can update the neighbors for each peer efficiently.These strategies are oriented to the context of knowledge sharing in a collaborative team. In addition, for initializingneighbor sets of peers, we present a local search method based on members-roles-tasks information, which is espe-cially available in the context of collaborative team.
However, there still exist some drawbacks in the proposed model:
(1) The knowledge resources are stored in distributed peers rather than in a centralized repository. If a significant part ofsimilar users are not online, a peer will not receive much relevant knowledge. This P2P based recommender model isnot an ultimate solution for all situations. The combination of this model and the traditional C/S mode may be arational scheme in the realistic applications.
(2) Another assumption for this proposed model lies in that all peers are willing to share their knowledge with others. If alarge part of peers are more willing to receive recommendations from others than to share knowledge with others, thisP2P based knowledge sharing model will not work. Therefore, some incentive mechanisms need to be embedded intothe current model to improve its practicality.
(3) We only consider the similarity relationship among peers in this study. In the context of collaborative team, the rela-tionships between peers are very complex. We should take account of more semantic relationships between peers soas to build the knowledge sharing network at a more intelligent level [31].
In future, we will perform experiments by using the model in a large-scale collaborative team with more members andknowledge resources. In addition, users’ feedback for recommendation will be considered in experiments.
Acknowledgements
The authors thank the anonymous referees for their comments and suggestions which have helped to improve this paper.This research is supported by the National Natural Science Foundation of China (Grant No. 70971085).
Appendix A. The similarity measure between two knowledge resources
The similarity between knowledge resources is the basis for determining the similarity between peers. At first, we shoulddefine the distance between two knowledge resources.
A.1. The distance between two knowledge resources
In one peer’s profile information, each knowledge resource, i.e., a�s ¼ a�1s; a�2s; . . . ; a�qs; . . . ; a�Ms
n o, where 8a�qs � a�qr; 9a�qr 2
A�q; 8r ¼ f1; . . . ;nqg, may involve three types of attributes: numerical, binary, and nominal variables. For example, a�1s maybe a numerical value whilst a�2s may be a binary or a nominal value. We measure the similarity between two knowledgeresources by calculating the distance between them. The distance between two knowledge resources means the dissimilarityof them and thus is measured as a composite distance of three distance components corresponding to these three types ofattribute variables.
(1) Numerical attribute variables: a number of methods on distance measure have been proposed, e.g., Euclidean distance,Manhattan distance, Minkowski distance, and weighted Euclidean distance measures. In this study, we employ theweighted Euclidean distance. It is computed as follows:
dnumericalða�i ; a�j Þ ¼
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiXQ
q¼1
ðwqða�qi a�qjÞÞ2
vuut
where dnumericalða�i ; a�j Þ indicates the numerical distance between two knowledge resources, a�i and a�j ; 8a�i ; a�j 2 A�. wq
means the relative importance of the qth numerical attribute variable, aq 2 ANumerical # A; Q represents the total num-ber of numerical attribute variables ðQ 6 MÞ.
(2) Binary attribute variables: a binary variable assumes only two states: 0 or 1, where 0 means the variable is absent and1 means it is present. This paper uses a well-accepted coefficient for accessing the distance between symmetric binaryvariables, which is called by simple matching coefficient. It is calculated as follows:

3560 L. Zhen et al. / Information Sciences 180 (2010) 3546–3561
dbinaryða�i ; a�j Þ ¼a2 þ a3
a1 þ a2 þ a3 þ a4
where dbinaryða�i ; a�j Þ indicates the binary distance between two knowledge resources, a�i and a�j ; 8a�i ; a�j 2 A�. a1 is the
total number of binary attribute variables in A (i.e., aq 2 ABinary # AÞ that equal to 1 for both a�i and a�j ; a2 is the totalnumber of binary attribute variables that equal to 1 for a�i but 0 for a�j ; a3 is the total number of binary attribute vari-ables that equal to 0 for a�i but 1 for a�j ; and a4 is the total number of binary attribute variables that equal to 0 for botha�i and a�j .
(3) Nominal attribute variables: a nominal variable can be regarded as a generalization of a binary variable in that it cantake on more than two states. This type of variables cannot be expressed by numerical values but by qualitativeexpressions with more than one option. The above simple matching coefficient can also be used to measure the nom-inal distance between two knowledge resources that contain nominal attribute variables:
dnominalða�i ; a�j Þ ¼b c
b
where dnominalða�i ; a�j Þ indicates the nominal distance between two knowledge resources, a�i and a�j ; 8a�i ; a�j 2 A�. c means
the total number of nominal attribute variables in A (i.e., aq 2 ANominal # AÞ that assume the same states for both a�i anda�j , and b is the total number of nominal attribute variables among the total size-M attribute variables of knowledgeresources ðb 6 MÞ.
Given a set of attribute variables for describing knowledge resources, A � fa1; a2; . . . ; aMg, every knowledge resourceassumes a certain value for each attribute variable, and consists of a combination of numerical, binary, and/or nominal attri-bute values, i.e., ANumerical [ ABinary [ ANominal ¼ A. Hence, the overall distance between a�i and a�j comprises three components:the numerical, binary, and nominal distances. A composite distance can be calculated by the weighted sum:
dða�i ; a�j Þ ¼Wnumericaldnumericalða�i ; a�j Þ þWbinarydbinaryða�i ; a�j Þ þWnominaldnominalða�i ; a�j Þ
Here Wnumerical; Wbinary, and Wnominal refer to the relative importance of numerical, binary, and nominal distances, respectively,and Wnumerical þWbinary þWnominal ¼ 1.
A.2. The similarity between two knowledge resources
Before calculating the similarity based on the above distance measures, we should normalize the distance measuresbetween a�i and a�j .
We suppose a�i is one knowledge resource in peer h’s profile information file ðFhÞ, and a�j is one knowledge resource in peern’s profile information file ðFnÞ. That is, a�i 2 Fh; a�j 2 Fn. jFhj is the number of knowledge resources in peer h’s profile infor-mation file; jFnj is the number of knowledge resources in peer n’s profile information file. We define N dða�i ; a�j Þ 2 ½0;1 as thenormalized value of original distance dða�i ; a�j Þ. It can be calculated as follows:
N dða�i ; a�j Þ ¼dða�i ; a�j Þ min dða�x; a�yÞj8x ¼ 1; . . . ; jFhj;8y ¼ 1; . . . ; jFnj
n o
max dða�x; a�yÞj8x ¼ 1; . . . ; jFhj;8y ¼ 1; . . . ; jFnjn o
min dða�x; a�yÞj8x ¼ 1; . . . ; Fhj j;8y ¼ 1; . . . ; Fnj jn o
where dða�x; a�yÞ denotes the distance measure between any two knowledge resources contained in peer h’s profile informa-tion file ðFhÞ and peer n’s profile information file ðFnÞ, respectively.
Then we derive KSimða�i ; a�j Þ, i.e., the similarity degree between two knowledge resources, from N dða�i ; a�j Þ, i.e., the normal-ized distance measure, according to the formula:
KSimða�i ; a�j Þ ¼ 1 N dða�i ; a�j Þ
Here we have 0 6 KSimða�i ; a�j Þ 6 1.
References
[1] G. Adomavicius, A. Tuzhilin, Toward the next generation of recommender systems: a survey of the state of the art and possible extensions, IEEETransactions on Knowledge and Data Engineering 17 (2005) 734–749.
[2] H.J. Ahn, A new similarity measure for collaborative filtering to alleviate the new user cold-starting problem, Information Sciences 178 (1) (2008) 37–51.
[3] S. Bandyopadhyay, P. Pathak, Knowledge sharing and cooperation in outsourcing projects – a game theoretic analysis, Decision Support Systems 43 (2)(2007) 349–358.
[4] L.S. Chen, F.H. Hsu, M.C. Chen, Y.C. Hsu, Developing recommender systems with the consideration of product profitability for sellers, InformationSciences 178 (4) (2008) 1032–1048.
[5] C. Cornelis, J. Lu, X. Guo, G. Zhang, One-and-only item recommendation with fuzzy logic techniques, Information Sciences 177 (22) (2007) 4906–4921.[6] C.M. Chiu, M.H. Hsu, E.T.G. Wang, Understanding knowledge sharing in virtual communities: an integration of social capital and social cognitive
theories, Decision Support Systems 42 (3) (2006) 1872–1888.[7] D. Goldberg, D. Nichols, B.M. Oki, D. Terry, Using collaborative filtering to weave an information tapestry, Communications of the ACM 35 (1992) 12–
13.

L. Zhen et al. / Information Sciences 180 (2010) 3546–3561 3561
[8] Z. Guo, J. Sheffield, A paradigmatic and methodological examination of knowledge management research, Decision Support Systems 44 (3) (2008) 673–688.
[9] P. Han, B. Xie, F. Yang, R. Shen, A scalable P2P recommender system based on distributed collaborative filtering, Expert Systems with Applications 27(2004) 203–210.
[10] L.C. Jain, N.T. Nguyen, Knowledge Processing and Decision Making in Agent-based Systems, Springer-Verlag, 2009.[11] J. Jung, I. Choi, M. Song, An integration architecture for knowledge management systems and business process management systems, Computers in
Industry 58 (1) (2007) 21–34.[12] J.J. Jung, Knowledge distribution via shared context between blog-based knowledge management systems: a case study of collaborative tagging, Expert
Systems with Applications 36 (7) (2009) 10627–10633.[13] P. Kazienko, M. Adamski, AdROSA—adaptive personalization of web advertising, Information Sciences 177 (11) (2007) 2269–2295.[14] J.K. Kim, H.K. Kim, Y.H. Cho, A user-oriented contents recommendation system in peer-to-peer architecture, Expert Systems with Applications 34 (1)
(2008) 00–312.[15] J. Konstan, B. Miller, D. Maltz, J. Herlocker, L. Gordon, J. Riedl, GroupLens: applying collaborative filtering to usenet news, Communications of the ACM
40 (3) (1997) 77–87.[16] B.N. Miller, J.A. Konstan, J. Riedl, PocketLens: toward a personal recommender system, ACM Transactions on Information Systems 22 (3) (2004) 437–
476.[17] R. Monclar, A. Tecla, J. Oliveira, J.M. de Souza, MEK: using spatial-temporal information to improve social network and knowledge dissemination,
Information Sciences 179 (15) (2009) 2524–2537.[18] R.J. Mooney, L. Roy, Content-based book recommending using learning for text categorization, in: Proceedings of the ACM International Conference on
Digital Libraries, San Antonia, Texas, USA, 2000, pp. 195–204.[19] T. Oka, H. Morikawa, T. Aoyama, Vineyard: a collaborative filtering service platform in distributed environment, in: Proceedings of International
Symposium on Applications and the Internet Workshops, 2004, pp. 575–581.[20] N. Panteli, S. Sockalingam, Trust and conflict within virtual inter-organizational alliances: a framework for facilitating knowledge sharing, Decision
Support Systems 39 (4) (2005) 599–617.[21] S. Petter, L. Mathiassen, V. Vaishnavi, Five keys to project knowledge sharing, IT Professional 9 (3) (2007) 42–46.[22] B.A. Qin, S. Wang, X.Y. Du, Q.M. Chen, Q.Y. Wang, Graph-based query rewriting for knowledge sharing between peer ontologies, Information Sciences
178 (18) (2008) 3525–3542.[23] D. Richards, A social software/Web 2.0 approach to collaborative engineering, Information Sciences 179 (15) (2009) 2515–2523.[24] D. Rosaci, G.M.L. Sarné, S. Garruzzo, MUADDIB: a distributed recommender system supporting device adaptively, ACM Transactions on Information
Systems 27 (4) (2009) 1–41. Article No. 24.[25] J. Vertommen, F. Janssens, B.D. Moor, J.R. Duflou, Multiple-vector user profile in supporting of knowledge sharing, Information Sciences 178 (17) (2008)
3333–3346.[26] M.G. Vozalis, K.G. Margartis, Using SVD and demographic data for the enhancement of generalized collaborative filtering, Information Sciences 177
(15) (2007) 3017–3037.[27] J. Wang, K. Gwebu, M. Shanker, M.D. Troutt, An application of agent-based simulation to knowledge sharing, Decision Support Systems 46 (2) (2009)
532–541.[28] C.Y. Wang, H.Y. Yang, S.C.T. Chou, Using peer-to-peer technology for knowledge sharing in communities of practices, Decision Support Systems 45 (3)
(2008) 528–540.[29] B. Xie, P. Han, F. Yang, R.M. Shen, H.J. Zeng, Z. Chen, DCFLA: a distributed collaborative filtering neighbor locating algorithm, Information Sciences 177
(6) (2007) 1349–1363.[30] S.J.H. Yang, I.Y.L. Chen, A social network-based system for supporting interactive collaboration in knowledge sharing over peer-to-peer network,
International Journal of Human–Computer Studies 66 (1) (2008) 35–50.[31] S.T. Yuan, Y.C. Chen, Semantic ideation learning for agent-based e-brainstorming, IEEE Transactions on Knowledge and Data Engineering 20 (2) (2008)
261–274.[32] L. Zhen, Z. Jiang, H. Song, C. Liu, J. Liang, Information supply: an approach based on demand modeling and information filtering, Proceedings of the
IMechE, Part B: Journal of Engineering Manufacture 222 (4) (2008) 541–557.[33] L. Zhen, Z. Jiang, Knowledge grid based knowledge supply model, IEICE Transactions on Information and Systems E91 (4) (2008) 1082–1090.[34] L. Zhen, Z. Jiang, Innovation-oriented knowledge query in knowledge grid, Journal of Information Science and Engineering 24 (2) (2008) 601–613.[35] L. Zhen, G.Q. Huang, Z. Jiang, Collaborative filtering based on workflow space, Expert Systems with Applications 36 (4) (2009) 7873–7881.[36] L. Zhen, G.Q. Huang, Z. Jiang, Recommender system based on workflow, Decision Support Systems 48 (1) (2009) 237–245.