Embed Size (px)
Citation preview

DiseñodeSistemasDistribuidosMásterenCienciayTecnologíaInformática
Curso2016-2017
AlejandroCalderónMateos &[email protected]@lab.inf.uc3m.es
Sistemasescalablesenentornosdistribuidos.IntroducciónaSpark

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s2
Contenidos
– Introducción– Hand-on– Benchmarking
http://Spark.apache.org

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s3
Arquitectura
https://www.mapr.com/sites/default/files/blogimages/Spark-core-stack-DB.jpg

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s4
Arquitectura
http://image.slidesharecdn.com/sparkwebinaroctober-141002152140-phpapp02/95/yarn-ready-apache-spark-4-638.jpg?cb=1412263553

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s5
Arquitectura
https://sigmoid.com/wp-content/uploads/2015/03/Apache_Spark1.png

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s6
Contenidos
– Introducción– Hand-on (1/3)– Benchmarking
http://Spark.apache.org

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s7
Spark:nodoautónomoPrerequisitos Instalación Uso básico
acaldero@h1:~$ sudo apt-get install ssh rsyncReading package lists... DoneBuilding dependency tree Reading state information... DoneThe following NEW packages will be installed:
rsync ssh…
acaldero@h1:~$ sudo apt-get install default-jdkReading package lists... DoneBuilding dependency tree Reading state information... DoneThe following extra packages will be installed:
libice-dev libpthread-stubs0-dev libsm-dev libx11-dev libx11-doclibxau-dev libxcb1-dev libxdmcp-dev libxt-dev openjdk-7-jdk
…

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s8
Spark:nodoautónomoPrerequisitos Instalación Uso básico
http://spark.apache.org/downloads.html

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s9
Spark:nodoautónomoPrerequisitos Instalación Uso básico
acaldero@h1:~$ wget http://d3kbcqa49mib13.cloudfront.net/spark-2.0.2-bin-hadoop2.7.tgz…2016-11-27 12:40:44 (6,02 MB/s) - “spark-2.0.2-bin-hadoop2.7.tgz” guardado [187426587/187426587]
acaldero@h1:~$ tar zxf spark-2.0.2-bin-hadoop2.7.tgzacaldero@h1:~$ ls -las spark-2.0.2-bin-hadoop2.7total 1124 drwxr-xr-x 12 acaldero acaldero 4096 nov 8 02:58 .4 drwxr-xr-x 3 acaldero acaldero 4096 nov 27 12:42 ..4 drwxr-xr-x 2 acaldero acaldero 4096 nov 8 02:58 bin4 drwxr-xr-x 2 acaldero acaldero 4096 nov 8 02:58 conf4 drwxr-xr-x 5 acaldero acaldero 4096 nov 8 02:58 data4 drwxr-xr-x 4 acaldero acaldero 4096 nov 8 02:58 examples
12 drwxr-xr-x 2 acaldero acaldero 12288 nov 8 02:58 jars20 -rw-r--r-- 1 acaldero acaldero 17811 nov 8 02:58 LICENSE4 drwxr-xr-x 2 acaldero acaldero 4096 nov 8 02:58 licenses
28 -rw-r--r-- 1 acaldero acaldero 24749 nov 8 02:58 NOTICE4 drwxr-xr-x 6 acaldero acaldero 4096 nov 8 02:58 python4 drwxr-xr-x 3 acaldero acaldero 4096 nov 8 02:58 R4 -rw-r--r-- 1 acaldero acaldero 3828 nov 8 02:58 README.md4 -rw-r--r-- 1 acaldero acaldero 120 nov 8 02:58 RELEASE4 drwxr-xr-x 2 acaldero acaldero 4096 nov 8 02:58 sbin4 drwxr-xr-x 2 acaldero acaldero 4096 nov 8 02:58 yarn

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s10
Spark:nodoautónomoPrerequisitos Instalación Uso básico
inactivo
my-launcher.sh
activo
Ctrl-C

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s11
Spark:nodoautónomoPrerequisitos Instalación Uso básico
acaldero@h1:~$ ./bin/run-example SparkPi 5Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties16/11/27 13:22:34 INFO SparkContext: Running Spark version 2.0.216/11/27 13:22:34 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using
builtin-java classes where applicable16/11/27 13:22:34 WARN Utils: Your hostname, ws1 resolves to a loopback address: 127.0.1.1; using
10.0.2.15 instead (on interface eth0)16/11/27 13:22:34 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address16/11/27 13:22:34 INFO SecurityManager: Changing view acls to: acaldero16/11/27 13:22:34 INFO SecurityManager: Changing modify acls to: acaldero16/11/27 13:22:34 INFO SecurityManager: Changing view acls groups to: 16/11/27 13:22:34 INFO SecurityManager: Changing modify acls groups to: 16/11/27 13:22:34 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users
with view permissions: Set(acaldero); groups with view permissions: Set(); users with modify permissions: Set(acaldero); groups with modify permissions: Set()
16/11/27 13:22:35 INFO Utils: Successfully started service 'sparkDriver' on port 48004.16/11/27 13:22:35 INFO SparkEnv: Registering MapOutputTracker16/11/27 13:22:35 INFO SparkEnv: Registering BlockManagerMaster…

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s12
Spark:nodoautónomoPrerequisitos Instalación Uso básico
inactivo activo
Ctrl-C
./bin/spark-shell –master local[2]
./bin/pyspark –master local[2]
./bin/sparkR –master local[2]<monitoring>
<submit>

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s13
Spark:nodoautónomoPrerequisitos Instalación Uso básico
inactivo activo
Ctrl-C
./bin/spark-shell –master local[2]
./bin/pyspark –master local[2]
./bin/sparkR –master local[2]<monitoring>
<submit>
local ->1threadlocal[N] ->Nthreadslocal[*] ->asmanythreadsascoresare

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s14
Spark:nodoautónomoPrerequisitos Instalación Uso básico
acaldero@h1:~$ ./bin/pysparkPython 2.7.9 (default, Jun 29 2016, 13:08:31) [GCC 4.9.2] on linux2Type "help", "copyright", "credits" or "license" for more information.Using Spark's default log4j profile: org/apache/spark/log4j-defaults.propertiesSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel).16/11/27 13:53:36 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using
builtin-java classes where applicable16/11/27 13:53:36 WARN Utils: Your hostname, ws1 resolves to a loopback address: 127.0.1.1; using
10.0.2.15 instead (on interface eth0)16/11/27 13:53:36 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another addressWelcome to
____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//__ / .__/\_,_/_/ /_/\_\ version 2.0.2
/_/
Using Python version 2.7.9 (default, Jun 29 2016 13:08:31)SparkSession available as 'spark'.>>>

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s15
Spark:nodoautónomoPrerequisitos Instalación Uso básico
Using Python version 2.7.9 (default, Jun 29 2016 13:08:31)SparkSession available as 'spark'.>>> import sys>>> from random import random>>> from operator import add>>> from pyspark.sql import SparkSession>>> >>> partitions = 2>>> n = 100000 * partitions>>> def f(_):... x = random() * 2 - 1... y = random() * 2 - 1... return 1 if x ** 2 + y ** 2 < 1 else 0... >>> spark = SparkSession.builder.appName("PythonPi").getOrCreate()>>> count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)16/11/27 14:08:13 WARN TaskSetManager: Stage 0 contains a task of very large size (368 KB). The maximum
recommended task size is 100 KB.>>> print("Pi is roughly %f" % (4.0 * count / n))Pi is roughly 3.139500>>> spark.stop()>>>

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s16
Spark:nodoautónomoPrerequisitos Instalación Uso básico
inactivo activo
Ctrl-C
./bin/spark-shell –master local[2]
./bin/pyspark –master local[2]
./bin/sparkR –master local[2]<monitoring>
<submit>

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s17
Spark:nodoautónomoPrerequisitos Instalación Uso básico
Using Python version 2.7.9 (default, Jun 29 2016 13:08:31)SparkSession available as 'spark'.>>> import sys>>> from random import random>>> from operator import add>>> from pyspark.sql import SparkSession>>> >>> partitions = 2>>> n = 100000 * partitions>>> def f(_):... x = random() * 2 - 1... y = random() * 2 - 1... return 1 if x ** 2 + y ** 2 < 1 else 0... >>> spark = SparkSession.builder.appName("PythonPi").getOrCreate()>>> count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)16/11/27 14:08:13 WARN TaskSetManager: Stage 0 contains a task of very large size (368 KB).
The maximum recommended task size is 100 KB.>>> print("Pi is roughly %f" % (4.0 * count / n))Pi is roughly 3.139500>>> spark.stop()>>>
http://spark.apache.org/docs/latest/monitoring.html
http://<ip>:4040
http://<ip>:4041
…

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s18
Spark:nodoautónomoPrerequisitos Instalación Uso básico

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s19
Spark:nodoautónomoPrerequisitos Instalación Uso básico

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s20
Spark:nodoautónomoPrerequisitos Instalación Uso básico

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s21
Contenidos
– Introducción– Hand-on (2/3)– Benchmarking
http://Spark.apache.org

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s22
Spark,AnacondayJupiterPrerequisitos Instalación Uso básico
acaldero@h1:~$ du –mh –s .2,8G .

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s23
Spark,AnacondayJupiterPrerequisitos Instalación Uso básico
https://www.continuum.io/downloads

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s24
Spark,AnacondayJupiterPrerequisitos Instalación Uso básico
acaldero@h1:~$ wget https://repo.continuum.io/archive/Anaconda2-4.2.0-Linux-x86_64.sh
…2016-11-27 15:12:23 (5,57 MB/s) - “Anaconda2-4.2.0-Linux-x86_64.sh” guardado [467689464/467689464]
acaldero@h1:~$ chmod a+x Anaconda2-4.2.0-Linux-x86_64.shacaldero@h1:~$ ./Anaconda2-4.2.0-Linux-x86_64.shWelcome to Anaconda2 4.2.0 (by Continuum Analytics, Inc.)
In order to continue the installation process, please review the licenseagreement.Please, press ENTER to continue>>> …
acaldero@h1:~$ bash acaldero@h1:~$ conda update --all Fetching package metadata .......Solving package specifications: ..........…
http://jupyter.readthedocs.io/en/latest/install.html#existing-python-new-jupyter

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s25
Spark,AnacondayJupiterPrerequisitos Instalación Uso básico
acaldero@h1:~$ conda install jupyterFetching package metadata .......Solving package specifications: ..........
# All requested packages already installed.# packages in environment at /home/acaldero/anaconda2:#jupyter 1.0.0 py27_3 …
acaldero@h1:~$ jupyter notebook[I 18:32:31.686 NotebookApp] [nb_conda_kernels] enabled, 2 kernels found[I 18:32:31.792 NotebookApp] ✓ nbpresent HTML export ENABLED[W 18:32:31.792 NotebookApp] ✗ nbpresent PDF export DISABLED: No module named nbbrowserpdf.exporters.pdf[I 18:32:31.796 NotebookApp] [nb_conda] enabled[I 18:32:32.336 NotebookApp] [nb_anacondacloud] enabled[I 18:32:32.338 NotebookApp] Serving notebooks from local directory: /home/acaldero[I 18:32:32.338 NotebookApp] 0 active kernels [I 18:32:32.338 NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/[I 18:32:32.338 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip
confirmation).…
http://www.ithinkcloud.com/tutorials/tutorial-on-how-to-install-apache-spark-on-windows/

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s26
Spark,AnacondayJupiterPrerequisitos Instalación Uso básico
acaldero@h1:~$ ln -s spark-2.0.2-bin-hadoop2.7 sparkacaldero@h1:~$ echo "export PATH=$PATH:/home/acaldero/spark/bin" >> .profileacaldero@h1:~$ echo "export PYSPARK_DRIVER_PYTHON=ipython" >> .profileacaldero@h1:~$ echo "export PYSPARK_DRIVER_PYTHON_OPTS='notebook' pyspark">> .profileacaldero@h1:~$ source .profile
acaldero@h1:~$ mkdir workacaldero@h1:~$ cd workacaldero@h1:~$ wget http://www.gutenberg.org/cache/epub/2000/pg2000.txt
acaldero@h1:~$ pyspark[TerminalIPythonApp]WARNING|Subcommand `ipython notebook`is deprecated andwill beremovedinfuture versions.[TerminalIPythonApp]WARNING|You likely want touse`jupyter notebook`inthe future[I18:48:14.980NotebookApp][nb_conda_kernels]enabled,2kernels found[I18:48:15.016NotebookApp]✓ nbpresent HTMLexport ENABLED[W18:48:15.016NotebookApp]✗ nbpresent PDFexport DISABLED:Nomodulenamed nbbrowserpdf.exporters.pdf[I18:48:15.018NotebookApp][nb_conda]enabled…
https://gist.github.com/tommycarpi/f5a67c66a8f2170e263c

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s27
Spark,AnacondayJupiterPrerequisitos Instalación Uso básico
acaldero@h1:~$ firefox http://localhost:8888/ps# sc + <shift + enter>
Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s28
Spark,AnacondayJupiterPrerequisitos Instalación Uso básico
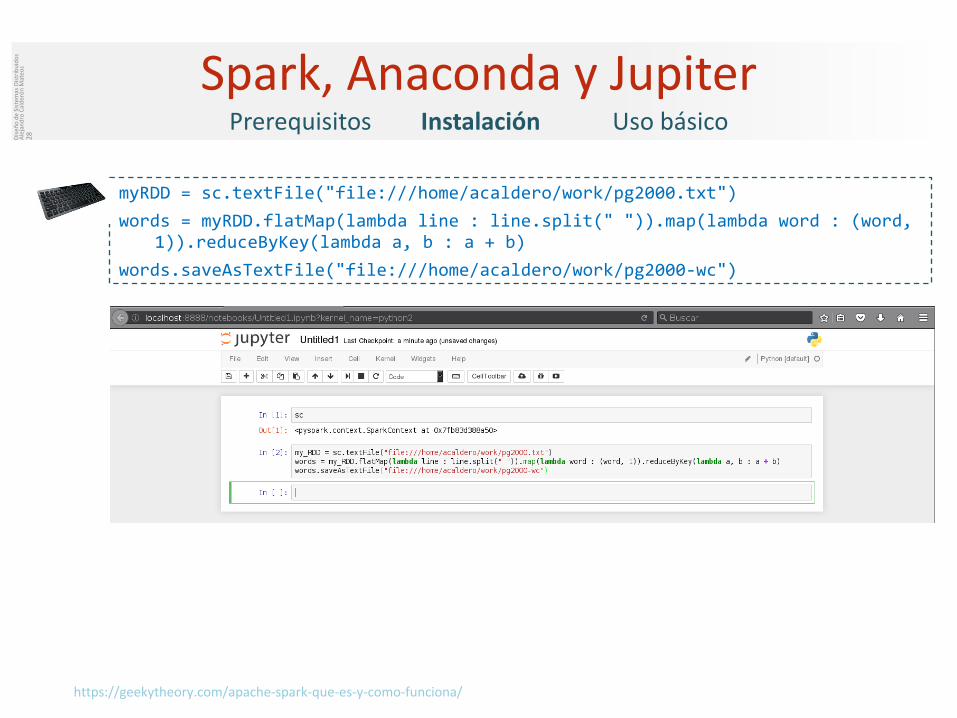
myRDD = sc.textFile("file:///home/acaldero/work/pg2000.txt")words = myRDD.flatMap(lambda line : line.split(" ")).map(lambda word : (word,
1)).reduceByKey(lambda a, b : a + b)words.saveAsTextFile("file:///home/acaldero/work/pg2000-wc")
https://geekytheory.com/apache-spark-que-es-y-como-funciona/

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s29
Spark,AnacondayJupiterPrerequisitos Instalación Uso básico
myRDD = sc.textFile("file:///home/acaldero/work/pg2000.txt")words = myRDD.flatMap(lambda line : line.split(" ")).map(lambda word : (word,
1)).reduceByKey(lambda a, b : a + b)words.takeOrdered(10, key=lambda x: -x[1])
http://stackoverflow.com/questions/24656696/spark-get-collection-sorted-by-value

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s30
Contenidos
– Introducción– Hand-on (3/3)– Benchmarking
http://Spark.apache.org

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s31
Spark:cluster privadoPrerequisitos Instalación Uso básico
SparkWorker
SparkWorker
SparkWorker
SparkWorker
Driver Executors Executors Executors
SparkMaster
https://trongkhoanguyenblog.wordpress.com/2014/11/23/a-gentle-introduction-to-apache-spark/
Client
Submit App(mode=cluster)
Allocates resources(cores +memory)
Application
Spark

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s32
Spark:cluster privadoPrerequisitos Instalación Uso básico
SparkWorker
SparkWorker
SparkWorker
SparkWorker
Driver Executors Executors Executors
SparkMaster
Client
Submit App(mode=cluster)
Allocates resources(cores +memory)
Application
Spark
http://spark.apache.org/docs/latest/spark-standalone.html
acaldero@h1:~$ echo "127.0.0.1 master1" >> /etc/hostsacaldero@h1:~$ echo "127.0.0.1 slave1" >> /etc/hostsacaldero@h1:~$ echo "127.0.0.1 slave2" >> /etc/hosts

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s33
Spark:cluster privadoPrerequisitos Instalación Uso básico
SparkWorker
SparkWorker
SparkWorker
SparkWorker
Driver Executors Executors Executors
SparkMaster
Client
Submit App(mode=cluster)
Allocates resources(cores +memory)
Application
Spark
http://spark.apache.org/docs/latest/spark-standalone.html
acaldero@h1:~$ echo "node1" >> spark/conf/slavesacaldero@h1:~$ echo "node2" >> spark/conf/slaves
acaldero@h1:~$ : Spark en todos los nodos (si fuera necesario)acaldero@h1:~$ scp –r spark acaldero@node1:~/…

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s34
Spark:nodoautónomoPrerequisitos Instalación Uso básico
acaldero@h1:/home/acaldero$ ssh-keygen -t rsa -P ""Generating public/private rsa key pair.Enter file in which to save the key (/home/acaldero/.ssh/id_rsa): Created directory '/home/acaldero/.ssh'.Your identification has been saved in /home/acaldero/.ssh/id_rsa.Your public key has been saved in /home/acaldero/.ssh/id_rsa.pub.The key fingerprint is:f0:14:95:a1:0b:78:57:0b:c7:65:47:43:39:b2:2f:8a acaldero@ws1The key's randomart image is:+---[RSA 2048]----+| oo=+oo=. || . *oo..o. |…

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s35
Spark:nodoautónomoPrerequisitos Instalación Uso básico
acaldero@h1:/home/acaldero$ scp .ssh/id_rsa.pub acaldero@node1:~/.ssh/authorized_keysPassword:…
acaldero@h1:/home/acaldero$ ssh node1The authenticity of host 'localhost (::1)' can't be established.ECDSA key fingerprint is bb:85:4c:6a:ff:e4:34:f8:ac:82:bf:56:a6:79:d8:80.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
…
acaldero@node1:~$ exitlogout

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s36
Spark:cluster privadoPrerequisitos Instalación Uso básico
SparkWorker
SparkWorker
SparkWorker
SparkWorker
Driver Executors Executors Executors
SparkMaster
Client
Submit App(mode=cluster)
Allocates resources(cores +memory)
Application
Spark
http://spark.apache.org/docs/latest/spark-standalone.html
acaldero@h1:~$ : Ir al nodo masteracaldero@h1:~$ ssh acaldero@master1acaldero@master1:~$ ./spark/sbin/start-all.shlocalhost:starting org.apache.spark.deploy.worker.Worker,logging to/home/acaldero/spark/logs/spark-acaldero-org.apache.spark.deploy.worker.Worker-1-ws1.outlocalhost:starting org.apache.spark.deploy.worker.Worker,logging to/home/acaldero/spark/logs/spark-acaldero-org.apache.spark.deploy.worker.Worker-1-ws1.outlocalhost:starting org.apache.spark.deploy.worker.Worker,logging to/home/acaldero/spark/logs/spark-acaldero-org.apache.spark.deploy.worker.Worker-1-ws1.out…

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s37
Spark:cluster privadoPrerequisitos Instalación Uso básico
SparkWorker
SparkWorker
SparkWorker
SparkWorker
Driver Executors Executors Executors
SparkMaster
Client
Submit App(mode=cluster)
Allocates resources(cores +memory)
Application
Spark
http://spark.apache.org/docs/latest/spark-standalone.html
acaldero@master1:~$ ./spark/sbin/stop-all.shacaldero@master1:~$ exitacaldero@h1:~$ : Regresar al clientelocalhost:stopping org.apache.spark.deploy.worker.Workerlocalhost:stopping org.apache.spark.deploy.worker.Workerlocalhost:stopping org.apache.spark.deploy.worker.Workerstopping org.apache.spark.deploy.master.Master

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s38
Spark:cluster privadoPrerequisitos Instalación Uso básico
inactivo activo
$SPARK_HOME/sbin/stop-all.sh
$SPARK_HOME/sbin/start-all.sh<monitoring>
<submit>

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s39
Spark:cluster privadoPrerequisitos Instalación Uso básico
SparkWorker
SparkWorker
SparkWorker
SparkWorker
Driver Executors Executors Executors
SparkMaster
Client
Submit App(mode=cluster)
Allocates resources(cores +memory)
Application
Spark
http://spark.apache.org/docs/latest/spark-standalone.html
acaldero@h1:~$ ./spark/bin/spark-shell --master spark://master1:7077Using Spark's default log4j profile: org/apache/spark/log4j-defaults.propertiesSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel).16/11/27 23:13:55 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform...
…scala> exit

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s40
Spark:cluster privadoPrerequisitos Instalación Uso básico
https://trongkhoanguyenblog.wordpress.com/2014/11/23/a-gentle-introduction-to-apache-spark/

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s41
Contenidos
– Introducción– Hand-on– Benchmarking
http://Spark.apache.org

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s42
Benchmarking
http://01org.github.io/sparkscore/about.html
• HiBench– https://github.com/intel-hadoop/HiBench
• Spark-perf– https://github.com/databricks/spark-perf

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s43
Benchmarking
https://www.oreilly.com/ideas/investigating-sparks-performance
• TeraSort– Elevadaentradaysalida,ycomunicaciónintermedia
• WordCount,PageRank– Contarreferenciasdepalabras,enlaces,etc.
• SQL– Scan,Join,Aggregate– …
• MachineLearning– Bayesian Classification– K-means clustering– …

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s44
TeraSort (2014)
https://gigaom.com/2014/10/10/databricks-demolishes-big-data-benchmark-to-prove-spark-is-fast-on-disk-too/

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s45
Bibliografía:tutoriales
• PáginaWeboficial:– http://spark.apache.org/
• IntroducciónacómofuncionaSpark:– http://spark.apache.org/docs/latest/quick-start.html
• TutorialdecómoinstalaryusarSpark:– http://spark.apache.org/docs/latest/index.html– http://spark.apache.org/docs/latest/configuration.html

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s46
Bibliografía:libro
• LearningSpark,AdvancedAnalyticswithSpark:– http://shop.oreilly.com/product/0636920028512.do– http://shop.oreilly.com/product/0636920035091.do
https://github.com/databricks/learning-spark

Diseño
deSistem
asDistrib
uido
sAlejandroCalderón
Mateo
s47
Agradecimientos
• Porúltimoperonoporellomenosimportante,agradeceralpersonaldelLaboratoriodelDepartamentodeInformáticatodosloscomentariosysugerenciasparaestapresentación.

DiseñodeSistemasDistribuidosMásterenCienciayTecnologíaInformática
Curso2016-2017
AlejandroCalderónMateos &[email protected]@lab.inf.uc3m.es
Sistemasescalablesenentornosdistribuidos.IntroducciónaSpark





























